数据预处理主要任务
数据清洗(Data cleaning):填充空值、平滑噪声、移出异常…
数据整合(Data integration):整合多个数据库、数据立方或者文件等
数据缩减(Data reduction):降维、数量缩减、数据压缩
数据转化(Data transformation):数据标准化、层级划分
数据清洗
- 不完整数据:例如数据缺属性值等,4种常规方法:
- 给一个新值类别,比如”unknown”
- 给这个属性的均值、众数或其他统计指标
- 样本聚类,给这一类样本中这个属性的均值、众数或其他统计指标
- 用贝叶斯或者决策树等去推测此属性可能的
- 噪声:例如薪水为
 元,4种常规方法:
元,4种常规方法:- 分桶(平滑)
- 回归(平滑)
- 聚类(检测与移除)
- 机器计算结合人工打标(检测与移除)
- 矛盾数据:例如年龄为
 岁,但生日在
岁,但生日在 年。
年。- 写规则整理数据
- 非合理数据:例如每个人的生日数据都是1月1日。
- 进一步研究或写规则整理数据
分桶

数据整合
由于数据从不同源头来,可能出现很多问题比如格式不一或冗余等,比如:鞋号,EU 42和UK 8.0及JP 260其实是表示同样大小鞋子;一个数据来源包含鞋盒长宽数据,另一数据源含鞋盒底面积。
冗余数据可用 correlation analysis 和 covariance analysis来检测
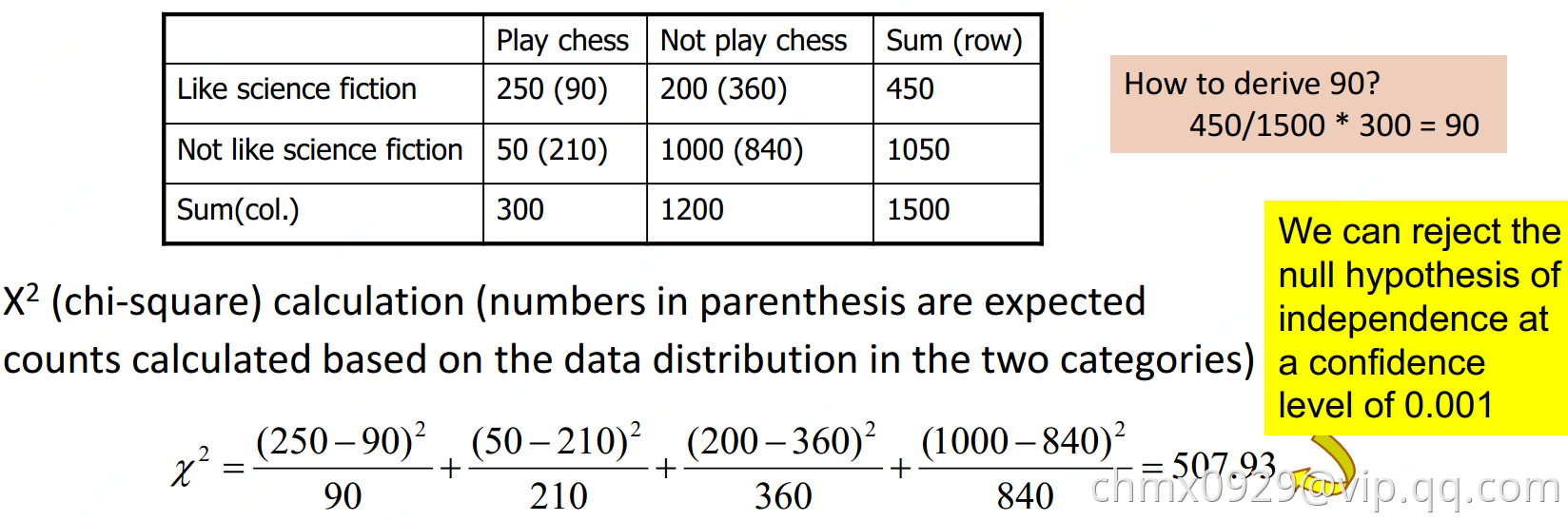
Correlation analysis(针对分类型数据)
 检测:
检测: ,
, 为观测值
为观测值 为期望值
为期望值
方差Variance)

协方差Covariance)

其中, ,
, ,其实就是期望与加权均值一致。如果
,其实就是期望与加权均值一致。如果 与
与 相互独立,则
相互独立,则 。
。
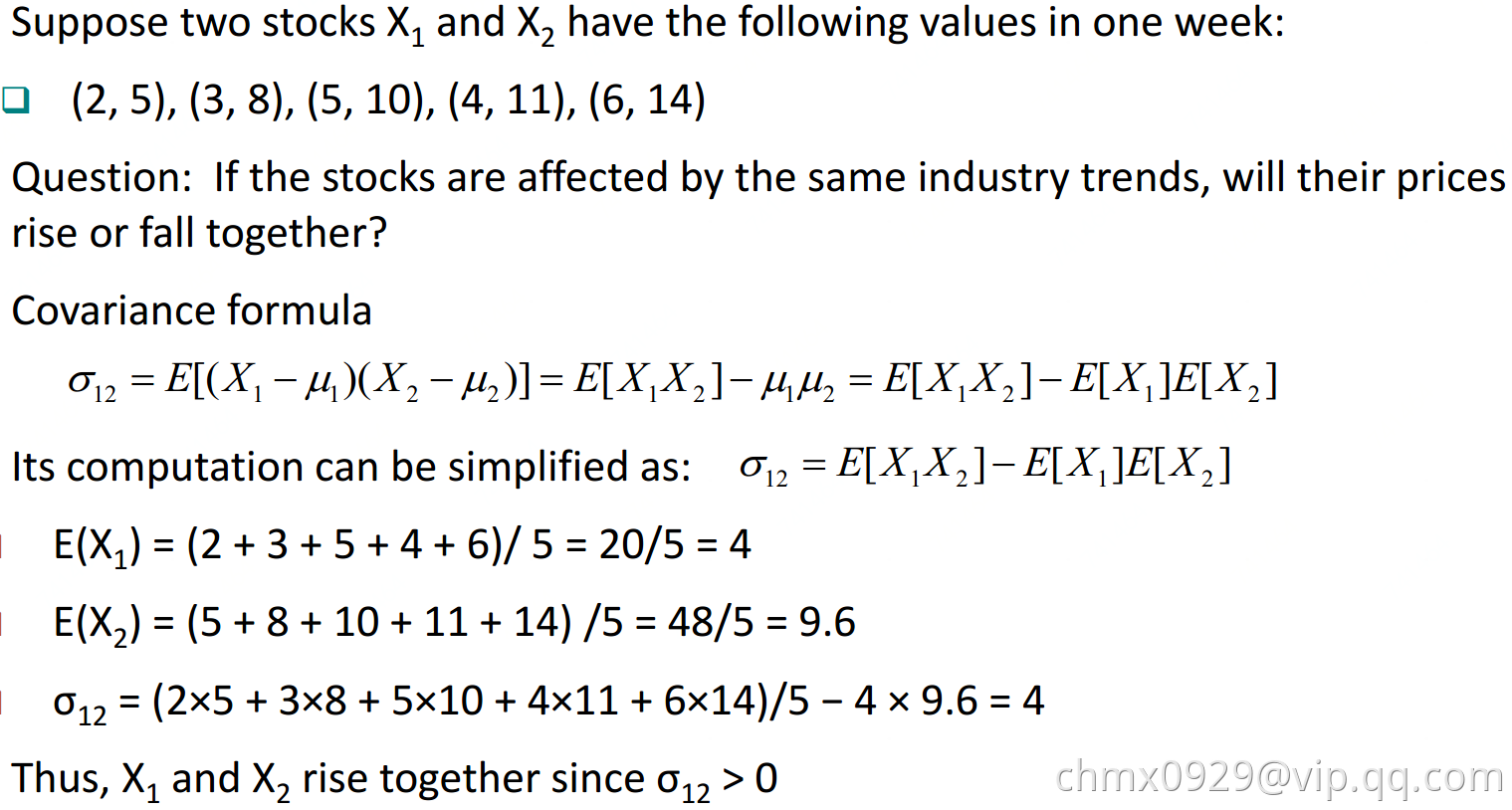
协方差矩阵[Covariance matrix]
由数据集中两两变量的协方差组成。矩阵的第 个元素是数据集中第
个元素是数据集中第 和
和 个元素的协方差。例如,三维数据的协方差矩阵如下:
个元素的协方差。例如,三维数据的协方差矩阵如下:


Correlation Analysis(针对数值型数据)
 与
与 的相关性通过协方差与他们的标准差获得:
的相关性通过协方差与他们的标准差获得:
如果 则两者正相关,反之负相关,为0则两者独立。
则两者正相关,反之负相关,为0则两者独立。
数据缩减
目的:1、降维;2、数值减少;3、数据压缩
方法:
- Regression and Log-Linear Models
- Histograms, clustering, sampling
- Data cube aggregation
- Data compression
数据转化
目的:1、标准化 2、概念层次生成
- 平滑:将噪声从数据中移除
- 属性/特征构造:从旧特征构造新特征,比如由长宽数据构造面积数据
- 整合:概要(比如各种统计指标均值,方差…),数据立方构造
- 标准化:min-max、z-score、十进制缩放、softmax…
- 离散化:分箱、直方图分析、聚类分析、决策树分析、相关性分析
标准化
min-max 标准化:
z-score 标准化:
十进制缩放标准化: ,这里
,这里 是满足
是满足 的最小整数
的最小整数
softmax:
数据标准化又叫作数据归一化,是数据挖掘过程中常用的数据预处理方式。当我们使用真实世界中的数据进行分析时,会遇到两个问题:
- 特征变量之间的量纲单位不同
- 特征变量之间的变化尺度(scale)不同
特征变量的尺度不同导致参数尺度规模也不同,带来的最大问题就是在优化阶段,梯度变化会产生震荡,减慢收敛速度。经标准化的数据,各个特征变量对梯度的影响变得统一,梯度的变化会更加稳定,如下图

总结起来,数据标准化有以下三个优点:
- 数据标准化能够是数值变化更稳定,从而使梯度的数量级不会变化过大。
- 在某些算法中,标准化后的数据允许使用更大的步长,以提高收敛地速度。
- 数据标准化可以提高被特征尺度影响较大的算法的精度,比如k-means、kNN、带有正则的线性回归。
Source
https://github.com/chmx0929/UIUCclasses/blob/master/412DataMining/PDF/03Preprocessing.pdf

若有收获,就点个赞吧
0 人点赞
