《深度学习之Pytorch实战计算机视觉》阅读笔记 第4章:卷积神经网络
参考:
1.https://www.yuque.com/u1183174/wih4gs/wakxcf
1. 卷积神经网络基础
1. 卷积层
说卷积层,我们得先从卷积运算开始,卷积运算就是卷积核在输入信号(图像)上滑动, 相应位置上进行「乘加」。卷积核又称为滤过器,过滤器,可认为是某种模式,某种特征。
卷积过程类似于用一个模板去图像上寻找与它相似的区域, 与卷积核模式越相似, 激活值越高, 从而实现特征提取。好吧,估计依然懵逼,下面我们就看看 1d、2d、3d的卷积示意图,通过动图的方式看看卷积操作到底在干啥?
主要作用:对输入数据进行特征提取
- 卷积核:指定窗口大小的扫描器,扫描器通过一次又一次地扫描过输入的数据来提取数据中的特征
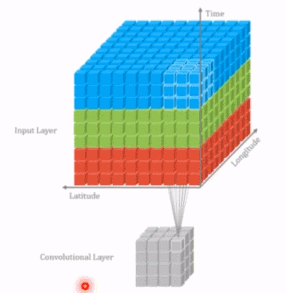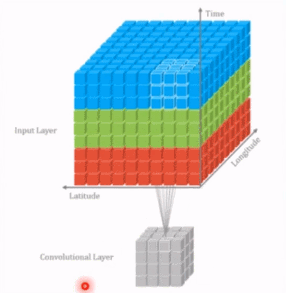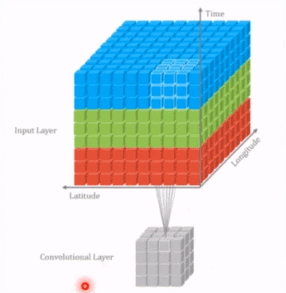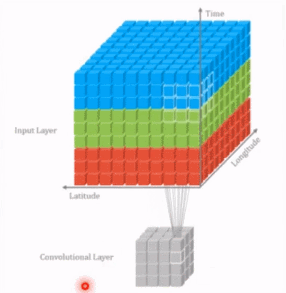
- 单色彩通道图像卷积
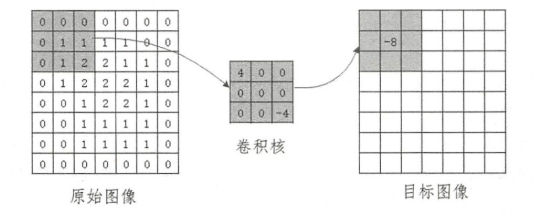
计算方式:对应位置数据相乘然后加和
步长(stride):卷积核窗口每次滑动经过图像上像素点的数量
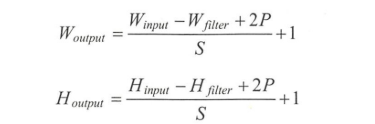
边界像素填充方式:1)Same,在边界加上指定层数的全为0的边界;2)Valid,不进行边界填充; - 卷积通用公式
P:边界填充像素层数,S:卷积核步长 - 三通道图像卷积
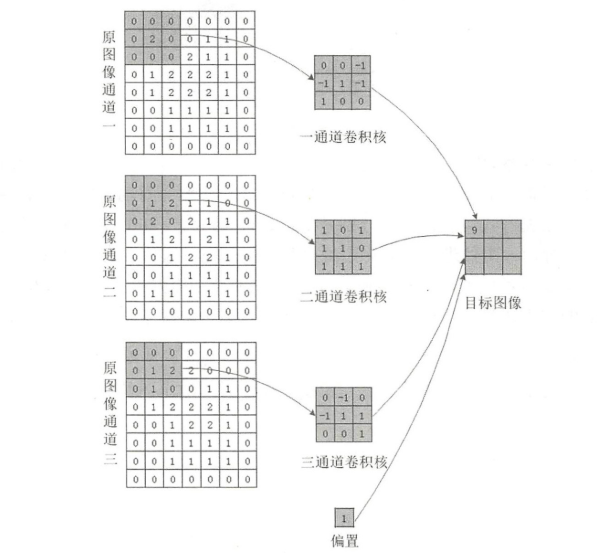
在三个通道进行独立的三次卷积,最后将对应位置的三个卷积结果进行相加。1.1 nn.Conv2d
nn.Conv2d: 对多个二维信号进行二维卷积
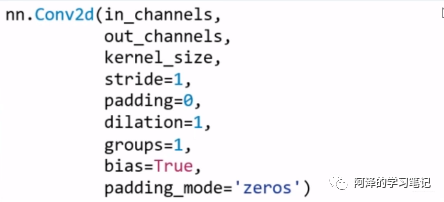
in_channels: 输入通道数
- out_channels: 输出通道数, 等价于卷积核个数
- kernel_size: 卷积核尺寸, 这个代表着卷积核的大小
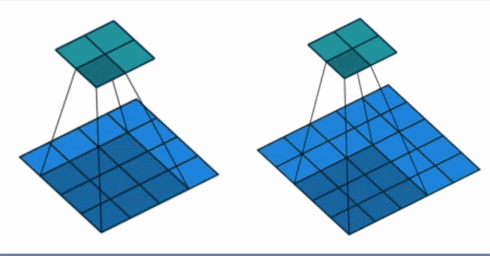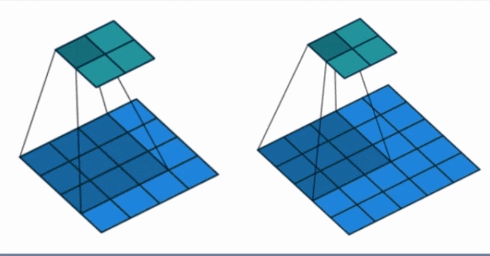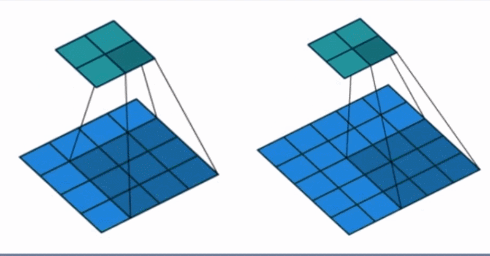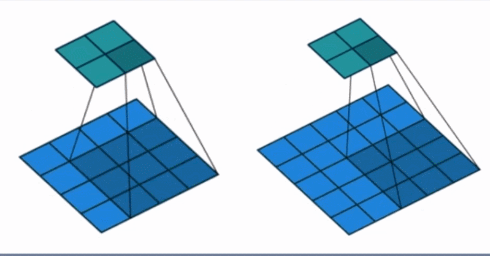
- stride: 步长, 这个指的卷积核滑动的时候,每一次滑动几个像素。下面看个动图来理解步长的概念:左边那个的步长是 1, 每一次滑动 1 个像素,而右边的步长是 2,会发现每一次滑动 2个像素。
- padding: 填充个数,通常用来保持输入和输出图像的一个尺寸的匹配,依然是一个动图展示,看左边那个图,这个是没有 padding 的卷积,输入图像是 4 4,经过卷积之后,输出图像就变成了 2 2 的了,这样分辨率会遍变低,并且我们会发现这种情况卷积的时候边缘部分的像素参与计算的机会比较少。所以加入考虑 padding 的填充方式,这个也比较简单,就是在原输入周围加入像素,这样就可以保证输出的图像尺寸分辨率和输入的一样,并且边缘部分的像素也受到同等的关注了。
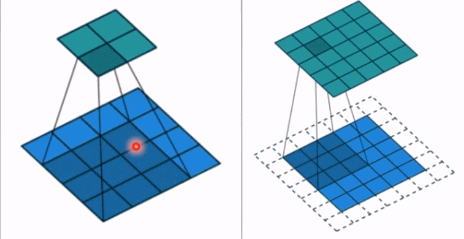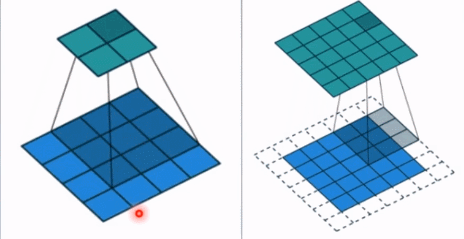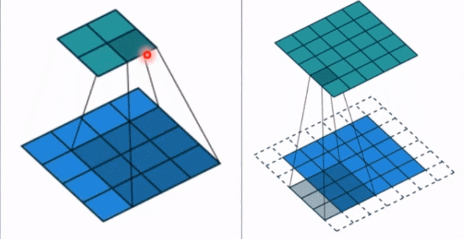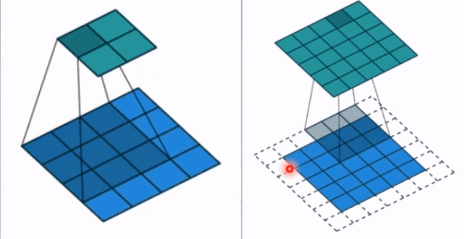
- dilation: 孔洞卷积大小,下面依然是一个动图:
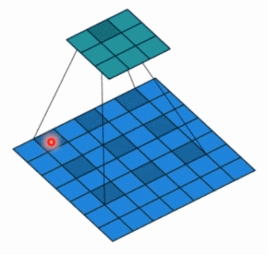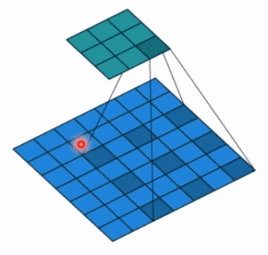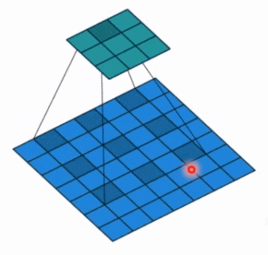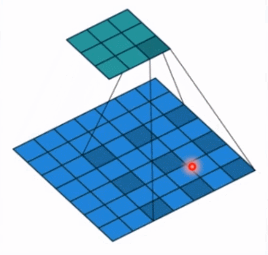
- 孔洞卷积就可以理解成一个带孔的卷积核,常用于图像分割任务,主要功能就是提高感受野。也就是输出图像的一个参数,能看到前面图像更大的一个区域。
- groups: 分组卷积设置,分组卷积常用于模型的轻量化。我们之前的 AlexNet 其实就可以看到分组的身影, 两组卷积分别进行提取,最后合并;
- bias: 偏置
下面是尺寸计算的方式:
- 没有 padding:
- 如果有 padding 的话:
- 如果再加上孔洞卷积的话:
下面我们用代码看看卷积核是怎么提取特征的,毕竟有图才有真相:
2. 池化层
池化运算:对信号进行“「收集」”并“「总结」”, 类似水池收集水资源, 因而美其名曰池化层。
收集:多变少,图像的尺寸由大变小
总结:最大值/平均值
主要作用:提取输入数据的核心特征;对原始数据进行压缩;减少参与模型计算的参数;
池化层 可以起到保留主要特征,减少下一层的参数量和计算量的作用,从而防止过拟合风险。
- 最大池化
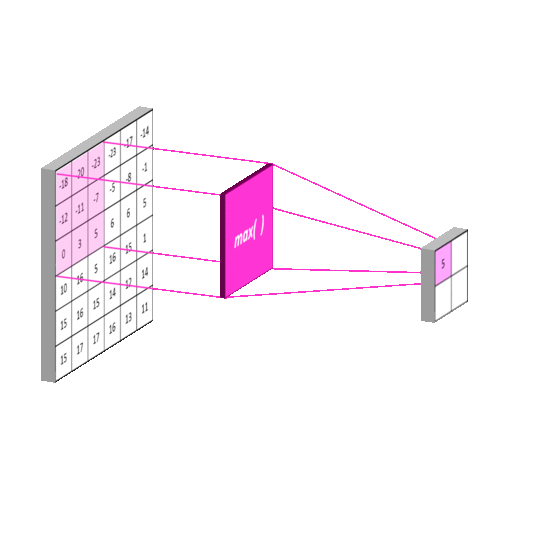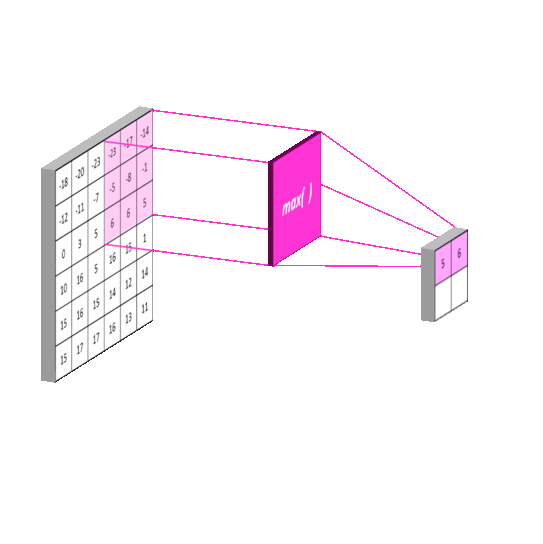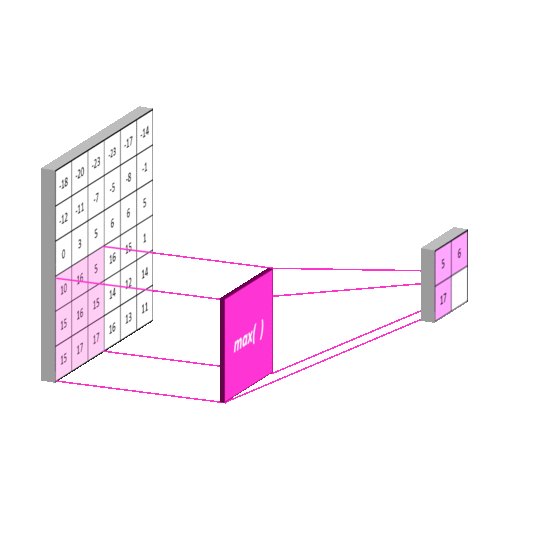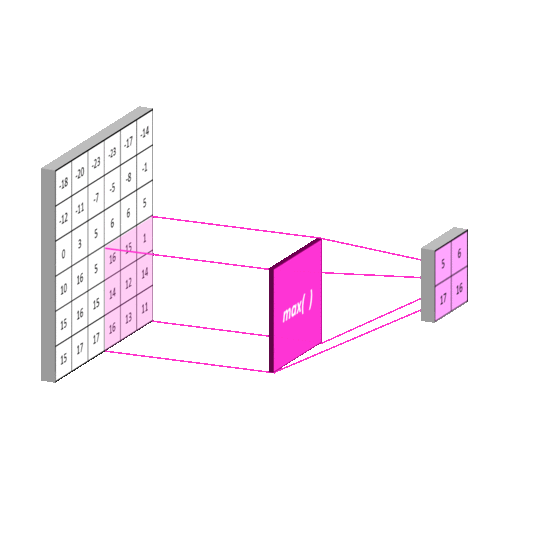
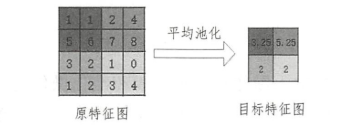
- 平均池化
-
2.1 nn.MaxPool2d

kernel_size: 池化核尺寸
- stride: 步长
- padding: 填充个数
- dilation: 池化核间隔大小
- ceil_mode: 尺寸向上取整
- return_indices: 记录池化像素索引

前四个参数和卷积的其实类似,最后一个参数常在最大值反池化的时候使用,那什么叫最大值反池化呢?看下图: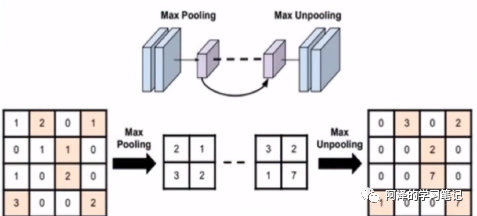
反池化就是将尺寸较小的图片通过上采样得到尺寸较大的图片,看右边那个,那是这些元素放到什么位置呢? 这时候就需要当时最大值池化记录的索引了。用来记录最大值池化时候元素的位置,然后在最大值反池化的时候把元素放回去。
2.2 nn.AvgPool2d
nn.AvgPool2d: 对二维信号(图像)进行平均值池化
- count_include_pad: 填充值用于计算
- divisor_override: 除法因子, 这个是求平均的时候那个分母,默认是有几个数相加就除以几,当然也可以自己通过这个参数设定
3. 全连接层FC(是猫)
线性层又称为全连接层,其每个神经元与上一层所有神经元相连实现对前一层的「线性组合,线性变换」
主要作用:将图像经过卷积和池化操作提取的特征进行压缩,并根据压缩的特征进行模型分类;
一般用于分类网络最后面,起到类似于“分类器”的作用,将数据的特征映射到样本标记特征,相比卷积层的某一位置的输出仅与上一层中相邻位置有关,全连接层中每一个神经元都会与前一层的所有神经元有关,因此全连接层的层数量也是很大的。

3.1 nn.Linear
nn.Linear(in_features, out_features, bias=True) : 对一维信号(向量)进行线性组合
- in_features: 输入节点数
- out_features: 输出节点数
- bias: 是否需要偏置
定义fc nn.Linear(in_features, out_features) 的in和out实际上是w(weight)和b(bias)的维度
import torchm = torch.nn.Linear(20, 30)input = torch.randn(128, 20)#输入数据的维度(128,20)output = m(input)print(m.weight.shape)print(m.bias.shape)print(output.size())#--------------------------------------torch.Size([30, 20])torch.Size([30])torch.Size([128, 30])
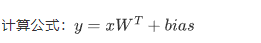
4. 归一化层
参考:1.Pytorch学习笔记(七):F.softmax()和F.log_softmax函数详解
归一化层包括了BatchNorm, LayerNorm, InstanceNorm, GroupNorm等方法;
BatchNorm
BatchNorm在batch的维度上进行归一化,使得深度网络中间卷积的结果也满足正态分布,整个训练过程更快,网络更容易收敛。
F.softmax
F.softmax作用:
按照行或者列来做归一化的
- x指的是输入矩阵。
- dim指的是归一化的方式,如果为0是对列做归一化,1是对行做归一化。
F.softmax函数语言格式:
# 0是对列做归一化,1是对行做归一化F.softmax(x,dim=1) 或者 F.softmax(x,dim=0)
F.log_softmax
F.log_softmax作用:
在softmax的结果上再做多一次log运算
F.log_softmax函数语言格式:
F.log_softmax(x,dim=1) 或者 F.log_softmax(x,dim=0)
2.PyTorch构建神经网络
2.1 参数初始化
参数初始化:每个层的权重和偏置参数被初始化为张量变量。张量是PyTorch的基本数据结构,用于建立不同类型的神经网络。可以将它们当作是数组和矩阵的推广,换句话说,张量是N维矩阵。
在参数初始化完成之后,可以通过以下四个关键步骤来定义和训练神经网络:
- 前向传播
- 损失计算
- 反向传播
- 更新参数
2.2 前向传播
前向传播:在这个步骤中,每个层都使用以下两个公式计算激活流。这些激活流从输入层流向输出层,以生成最终输出。
2.3 损失计算
损失计算:这一步在输出层中计算误差 (也称为损失)。一个简单的损失函数可以用来衡量实际值和预测值之间的差异。稍后,我们将查看PyTorch中可用的不同类型的损失函数。
loss = y - output
2.4 反向传播
反向传播:这一步的目的是通过对偏差和权重进行边际变化,从而将输出层的误差降到最低,边际变化是利用误差项的导数计算出来的。
根据链规则的微积分原理,将增量变化返回到隐藏层,并对其权重和偏差进行相应的修正。通过对权重和偏差的调整,使得误差最小化。
2.5 更新参数
更新参数:最后一步,利用从上述反向传播中接收到的增量变化来对权重和偏差进行更新;
当使用大量训练示例对多个历元执行这些步骤时,损失将降至最小值。得到最终的权重和偏差值之后,用它对未知数据进行预测。
3.常见卷积神经网络结构
网络结构总结
- LeNet是第一个成功应用于手写字体识别的卷积神经网络 ALexNet展示了卷积神经网络的强大性能,开创了卷积神经网络空前的高潮
- ZFNet通过可视化展示了卷积神经网络各层的功能和作用
- VGG采用堆积的小卷积核替代采用大的卷积核,堆叠的小卷积核的卷积层等同于单个的大卷积核的卷积层,不仅能够增加决策函数的判别性还能减少参数量
- GoogleNet增加了卷积神经网络的宽度,在多个不同尺寸的卷积核上进行卷积后再聚合,并使用1*1卷积降维减少参数量
- ResNet解决了网络模型的退化问题,允许神经网络更深
AlexNet,GoogleNet、 VGG-Net、ResNet等都是通过加深网络的层次和深度来提高准确率
Inception 网络的升级可以帮助我们构建自定义分类器,优化速度和准确率
LeNet
- LeNet-5网络

- Input:32*32的单通道图像
- 卷积层C1
Filter:551,步长为:1,Padding:0,进行6次同样的卷积操作
输出特征图:28286 - 下采样层S2
最大池化层,滑动窗口226,步长为2 - 卷积层C3
- 下采样层S4
- 卷积层C5
- 全连接层F6
输入:11120特征图
权重参数:120*84 - Output:
将184的数据压缩成110的数据
权重参数:84*10
Softmax激活函数
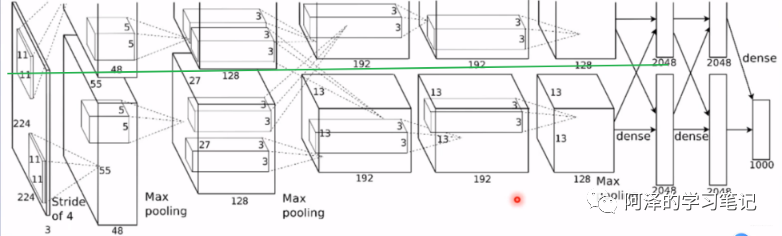
AlexNet模型

VGGNet
80%
GoogleNet模型
- GoogleNet网络
- Naive Inception单元
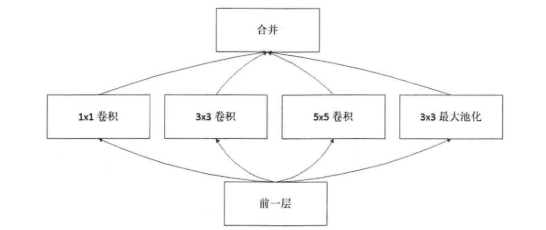
- 前一层( Previous Layer)是 Naive Inception 单元的数据输入层,之后被分成了 4 个部分,这 4 个部分分别对应滑动窗口的高度和宽度为 1 × 1 的卷积层、 3 × 3 的卷积层 、 5 ×5 的卷积层和 3 ×3 的最大池化层,然后将各层计算的结果汇聚至合并层 (Filter Concatenation ),在完成合并后将结果输出。
- 缺点:1)卷积层中计算量很大;2)最后合并时,总的输出特征图深度只会增加,增加了后续网络结构的计算量;
- GoogleNet Inception单元
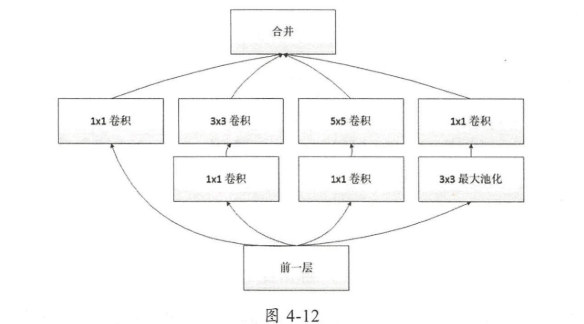
- 1*1卷积:完成特征图通道的聚合和发散
比如将一个 32 × 32 × 10 的特征图输入 3 × 3 的卷积层中 , 要求最后输出的特征图深度为 20 , 那么在这个过程中需 要用到的卷积参数为 1800 个,即 1800=10 × 3 × 3 × 20 ,如果将 32 × 32 × 10 的特征图先输入 1 × 1 的卷积层中,使其变成 32 × 32 × 5 的特征图,再将其输入 3 x 3 的卷积层中,那么在这个过程 中需要用到的卷积参数减少至 950 个,即 950 =1 x 1 x 10 x 5 + 5 x 20 x 3 x 3 。 使用 1 × 1 的卷积层使卷积参数几乎减少了一半,极大提升了模型的性能。
ResNet模型
- 残差网络(Residual Network)避免网络层次加深带来的模型性能退化问题
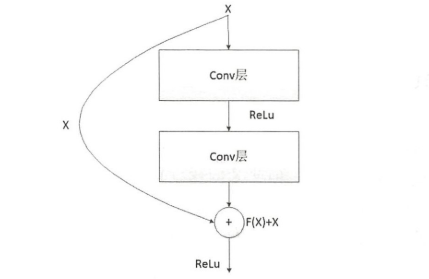
- 输出结果 = F(x) + 输入数据的恒等映射
- 不会增加额外的参数和计算量;提升模型训练速度和训练效果
- 残差模块的输入数据若和输出结果的维度一致,则直接相加;若维度不一致,则先进行线性投影;

MobileNet
参考:1.https://www.yuque.com/yahei/hey-yahei/mobilenetv1
2.轻量化CNN网络MobileNet系列详解
简单来说,MobileNet v1就是将常规卷积替换为深度可分离卷积的VGG网络。下图分别是VGG和MobileNet v1 一个卷积块所包含的网络层。
深度可分离卷积是在11卷积基础上的一种创新。主要包括两个部分:**深度卷积和点卷积11卷积**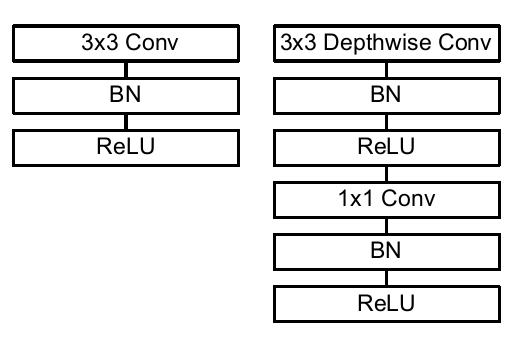
可以看到,VGG的卷积块就是一个常规33卷积和一个BN、一个ReLU激活层。MobileNet v1则是一个33深度可分离卷积和一个1*1卷积,后面分别跟着一个BN和ReLU层。MobileNet v1的ReLU指的是ReLU6,区别于ReLU的是对激活输出做了一个clip,使得最大最输出值不超过6,这么做的目的是为了防止过大的激活输出值带来较大的精度损失。
Inception
Inception 网络是CNN分类器发展史上一个重要的里程碑。在 Inception 出现之前,大部分流行 CNN 仅仅是把卷积层堆叠得越来越多,使网络越来越深,以此希望能够得到更好的性能。
例如AlexNet,GoogleNet、 VGG-Net、ResNet等都是通过加深网络的层次和深度来提高准确率。
了解 Inception 网络的升级可以帮助我们构建自定义分类器,优化速度和准确率。
代替人工来确定卷积层中的过滤器类型,或者确定是否需要创建卷积层或池化层
基本思想是Inception网络不需要认为决定使用哪个过滤器,或是否需要池化,而是由网络自行确定这些参数,可以给网络添加这些参数的所有可能的值,然后把这些输出连接起来,让网络自己学习它需要什么样的参数,采用哪些过滤器组合
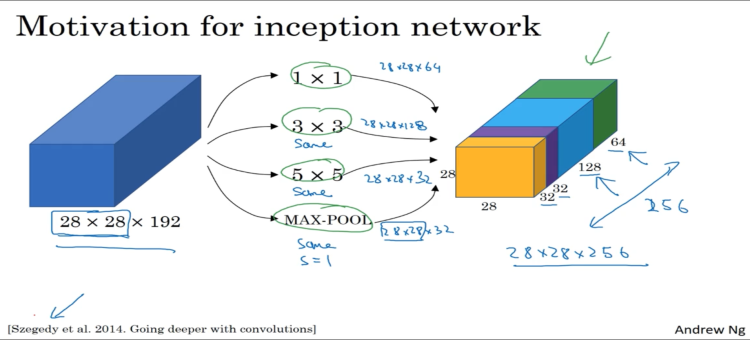
Inception v1
Inception v1的主要特点:一是挖掘了1 1卷积核的作用,减少了参数,提升了效果;*二是让模型自己来决定用多大的的卷积核。
4.优化模型方法
数据增强

1.backbone
backbone这个单词原意指的是人的脊梁骨,后来引申为支柱,核心的意思。
在神经网络中,尤其是CV领域,一般先对图像进行特征提取(常见的有vggnet,resnet,谷歌的inception),这一部分是整个CV任务的根基,因为后续的下游任务都是基于提取出来的图像特征去做文章(比如分类,生成等等)。
2.过拟合
http://www.imooc.com/article/305024
3.学习率调整
4.优化函数
5.数据增强
数据对模型的影响是非常重要的;
数据增强:翻转,旋转,裁剪,变形,缩放等各类操作; 颜色变换类

若有收获,就点个赞吧
0 人点赞
