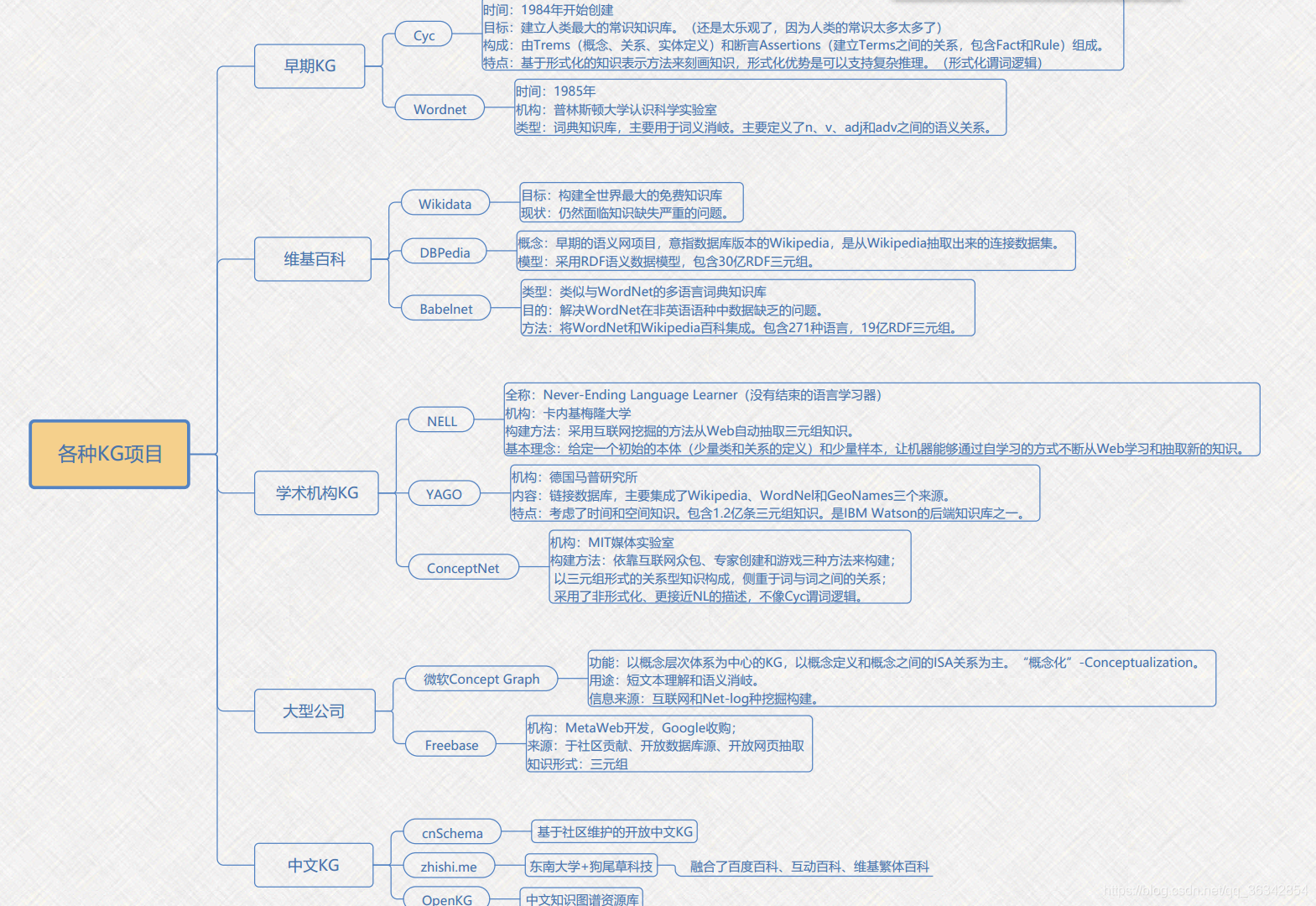
- 第1章 弱人工智能 VS 强人工智能
- 第2章 Cypher之核心语法
- 第3章 Cypher之进阶操作
- name>2的;
- 单个数定义
- 多个参数定义
- // 这样会删除目标元素u1的其它属性
- 设置标签
- // 更新关系
- 李四认识了几个朋友CDE
- 连接数据库
- 删除所有实体 match (n) detach delete n
- 创建实体
- 构建关系
- 创建另一个实体
- 实体追加数据
- 调用neo4j模式匹配进行查询(返回的是游标类型),类似SQL
- 方式1 match(不灵活:了解就行)
- 方式2 run(重点掌握) 节点本质:字典
- 找到存储过程,都是db开头
- 调用数据库内置存储过程db.labels() 并且计算数据库中的总标签数
- 调用过程并过滤结果,contains 可以包括子集
- 返回标签的所有属性
- 计算数据库中保护每个属性键的节点数量
- 查看自定义函数;
- ——————————————-
- 调用自定义函数;
- csv文件movies.csv
- ———————————
- csv文件movies2.csv
- csv文件movies2.csv
- 数据部分
- 忽略坏的节点;
- 忽略重复的节点
- H:\neo4j-community-3.5.28\conf\neo4j.conf
- Bolt connector 0.0.0.0
- dbms.connector.bolt.tls_level=OPTIONAL
- HTTP Connector. There can be zero or one HTTP connectors.
- 创建节点
- 创建关系;
- 数据下载
- 数据导入
- 查询大洋洲的鱼的分布
- 查询各州鱼类的分布;
- 查询亚洲和大洋洲中都生存的鱼类;
- 给csv文件的index取名为no
- 修改省会数据
- relation.insert(relation.shape[1], ‘’,’属于’)

课程地址:https://edu.51cto.com/course/29375.html
开放知识图谱社区:http://www.openkg.cn/tool
公众号:
- 网安杂谈 _(_1.知识图谱系列:Task 1 知识图谱介绍)
第1章 弱人工智能 VS 强人工智能
1-1-课程介绍与资源下载
1-2-勤奋的AI与会推理的AI
知识图谱
知识图谱与大数据、深度学习,这三大“秘密武器”已经成为推动互联网和人工智能发展的核心驱动力之一。
知识图谱是由一些相互连接的实体和他们的属性构成的。换句话说,知识图谱是由一条条知识组成,每条知识表示为一个 SPO 三元组 (Subject-Predicate-Object)。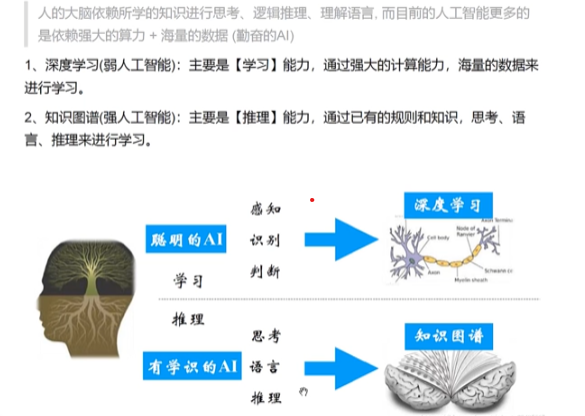
应用场景和图谱分类
知识图谱的典型应用
知识图谱的典型应用包括语义搜索、智能问答以及可视化决策支持三种。
1-3-图谱概念、分类、技术架构
知识图谱概念

知识图谱示意图主要包含有三种节点:实体、概念、属性。
实体指的是具有可区别性且独立存在的某种事物。如某一个人、某一座城市、某一种植物、某一件商品等等。世界万物由具体事物组成,此指实体。实体是知识图谱中的最基本元素,不同的实体间存在不同的关系。
概念指的是具有同种特性的实体构成的集合,如国家、民族、书籍、电脑等。
属性则用于区分概念的特征,不同概念具有不同的属性。不同的属性值类型对应于不同类型属性的边。如果属性值对应的是概念或实体,则属性描述两个实体之间的关系,称为对象属性;如果属性值是具体的数值,则称为数据属性;
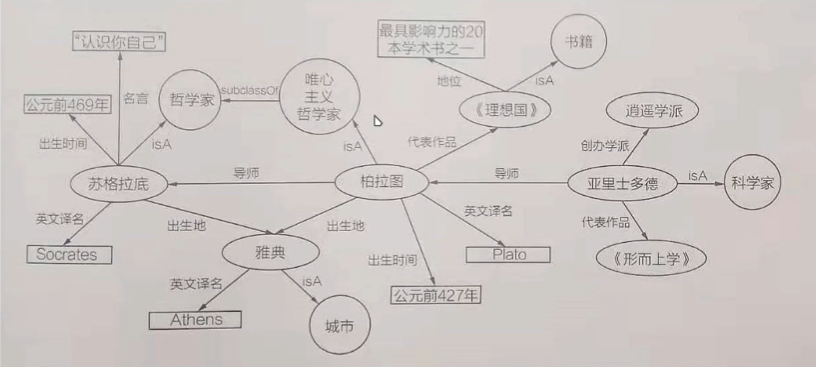
箭头是边,除了边之外的统统都是点(矩形,圆,椭圆等都是点);
节点可以是实体和属性;
边可以分为属性和关系;
三元组:A、B和他们之间的关系;
不同视角下的知识图谱
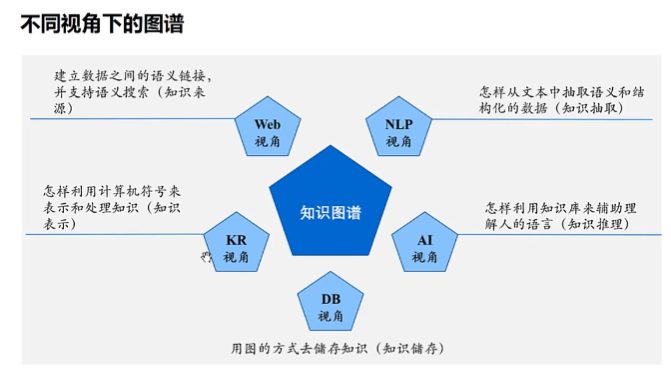
Web项目主要用来展示数据和获取数据;
图谱分类
知识图谱的分类方式很多,例如可以通过知识种类、构建方法等划分。
从领域上来说,知识图谱通常分为两种:通用知识图谱、特定领域知识图谱。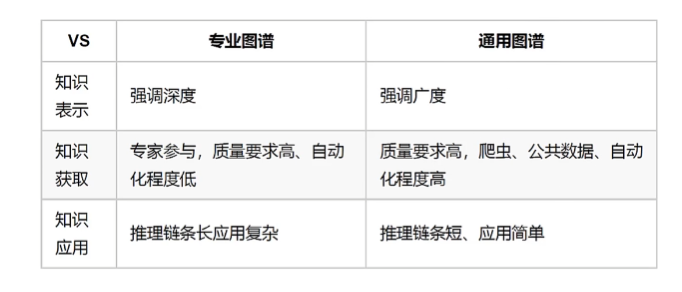
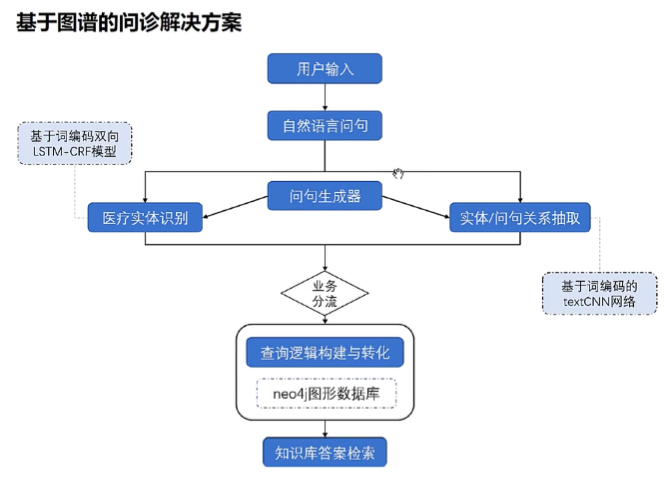
基于图谱的问诊解决方案
1-4-Neo4j安装与图谱构建
参考:1.图数据库Neo4j学习笔记系列
https://neo4j.com/
http://localhost:7474/browser/
1.neo4j的安装和启动
1、下载,建议从官网下载社区版本
ftp://neo4j.55555.io/neo4j/3.5.12/neo4j-community-3.5.28-windows.zip
2、预安装,确保java已安装
执行java –version命令,检查java是否已安装
3、安装步骤,很简单,不必赘述
4、安装后的环境变量配置
SET NEO4J_HOME=c:\neo4j
SET PATH=% NEO4J_HOME %\BIN
5、以管理员身份在命令窗口执行neo4j.bat console
C:\Users\dell\Desktop$ neo4jUsage: neo4j { console | start | stop | restart | status | install-service | uninstall-service | update-service } < -Verbose ># 注册服务C:\Users\dell\Desktop$ neo4j install-serviceNeo4j service installedC:\Users\dell\Desktop$ neo4j console2022-02-13 15:59:58.086+0000 WARN The version of the Java runtime you are using does not include some important security features. Please use a JRE of version 8u121 or higher.2022-02-13 15:59:58.093+0000 INFO ======== Neo4j 3.5.28 ========2022-02-13 15:59:58.100+0000 INFO Starting...2022-02-13 16:00:01.261+0000 INFO Bolt enabled on 127.0.0.1:7687.2022-02-13 16:00:02.312+0000 INFO Started.2022-02-13 16:00:03.015+0000 INFO Remote interface available at http://localhost:7474/
注册服务:将程序注册到服务中,便于启动;
服务启动
match(m:Movie) where m.released > 1990 and m.released<2000 return m

第2章 Cypher之核心语法
2-1-要复杂、先简单(CQL增、删、查、改操作)
https://www.w3cschool.cn/neo4j/
RETURN
我们不能单独使用RETURN子句。我们应该使用MATCH或CREATE命令。
增
#neo4j代码CREATE (p:Person { name: "Emil", age:23, from:"Sweden", klout: 99 }) return p
查询
MATCH
match (p:Person) return p#------------------------------------╒═══════════════════════════════════════════════════╕│"p" │╞═══════════════════════════════════════════════════╡│{"name":"Emil","from":"Sweden","klout":99} │├───────────────────────────────────────────────────┤│{"name":"Emil","from":"Sweden","klout":99,"age":23}│├───────────────────────────────────────────────────┤│{"name":"Emil","from":"Sweden","klout":99,"age":23}│└───────────────────────────────────────────────────┘
WHERE
# 推荐使用wherematch (p:Person) where p.age=23 return p# 字典属性;match (p:Person{age:23}) return p
更新
match (p:Person) where p.age=23 set p.address="shanghai" return pmatch (p:Person) where p.age=23 set p.address="shanghai",p.age=18 return p
2-2-豪厘之差,将致千里(ID属性与正则匹配)
ID查询
match (p:Person) where id(p)=20 return p
DELETE
Neo4j使用CQL DELETE子句
- 删除节点。
删除节点及相关节点和关系。
match (p:Person) where id(p)=20 delete
REMOVE
Neo4j CQL DELETE和REMOVE命令之间的主要区别
DELETE操作用于删除节点和关联关系。
- REMOVE操作用于删除标签和属性。
Neo4j CQL DELETE和REMOVE命令之间的相似性
- 这两个命令不应单独使用。
- 两个命令都应该与MATCH命令一起使用。
# remove 删除78的age属性match (p:Person) where id(p)=20 remove p.age
标签
# p属于AA、BB标签,具有属性name=abccreate (p:AA:BB{name:'abc'}) return p# 移除p的name=abc 的标签AAmatch (p) where p.name='abc' remove p:AA# 创建标签合并match (p) where p.name='abc' remove p:AA
正则表达式
正则前面的 (?i) (?s) (?m) (?is) (?im)
(?i) 表示所在位置右侧的表达式开启忽略大小写模式
(?s) 表示所在位置右侧的表达式开启单行模式
(?m) 表示所在位置右侧的表示式开启指定多行模式
(?is) 更改句点字符 (.) 的含义,以使它与每个字符(而不是除 \n 之外的所有字符)匹配
(?im) 更改 ^ 和 $ 的含义,以使它们分别与任何行的开头和结尾匹配,而不只是与整个字符串的开头和结尾匹配
注意:(?s)通常在匹配有换行的文本时使用
注意:(?m)只有在正则表达式中涉及到多行的“^”和“$”的匹配时,才使用Multiline模式,上面的匹配模式可以组合使用,比如(?is),(?im)
另外,还可以用(?i:exp)或者(?i)exp(?-i)来指定匹配的有效范围
附:
.表示除\n之外的任意字符
*表示匹配0-无穷
+表示匹配1-无穷
# 不区分大小写匹配 name属性=abc的pmatch (p:Person) where p.name=~'(?i)abc' return p# 不区分大小写匹配 name属性=a..的pmatch (p:Person) where p.name=~'(?i)a..' return p
2-3-藕断丝连(关系创建与删除)
关系的创建
创建的时候一定要有箭头方向;查询可以不需要;
# a,b 关系创建MATCH (a:Person {name:'Liz'}), (b:Person {name:'Mike'}) MERGE (a)-[f:FRIENDS]->(b) return f;# 设置关系属性 关系创建(从2001建立朋友关系)MATCH (a:Person {name:'Shawn'}), (b:Person {name:'Sally'}) MERGE (a)-[:FRIENDS {since:2001}]->(b);MATCH (a:Person {name:'Shawn'}), (b:Person {name:'John'}) MERGE (a)-[:FRIENDS {since:2012}]->(b);MATCH (a:Person {name:'Mike'}), (b:Person {name:'Shawn'}) MERGE (a)-[:FRIENDS {since:2006}]->(b);MATCH (a:Person {name:'Sally'}), (b:Person {name:'Steve'}) MERGE (a)-[:FRIENDS {since:2006}]->(b);MATCH (a:Person {name:'Liz'}), (b:Person {name:'John'}) MERGE (a)-[:MARRIED {since:1998}]->(b);#创建关系MATCH (a:Person {name:'John'}), (b:Location {city:'Boston'}) MERGE (a)-[:BORN_IN {year:1978}]->(b);MATCH (a:Person {name:'Liz'}), (b:Location {city:'Boston'}) MERGE (a)-[:BORN_IN {year:1981}]->(b);MATCH (a:Person {name:'Mike'}), (b:Location {city:'San Francisco'}) MERGE (a)-[:BORN_IN {year:1960}]->(b);MATCH (a:Person {name:'Shawn'}), (b:Location {city:'Miami'}) MERGE (a)-[:BORN_IN {year:1960}]->(b);MATCH (a:Person {name:'Steve'}), (b:Location {city:'Lynn'}) MERGE (a)-[:BORN_IN {year:1970}]->(b);
relationship 有6个,2种类型 friends,married;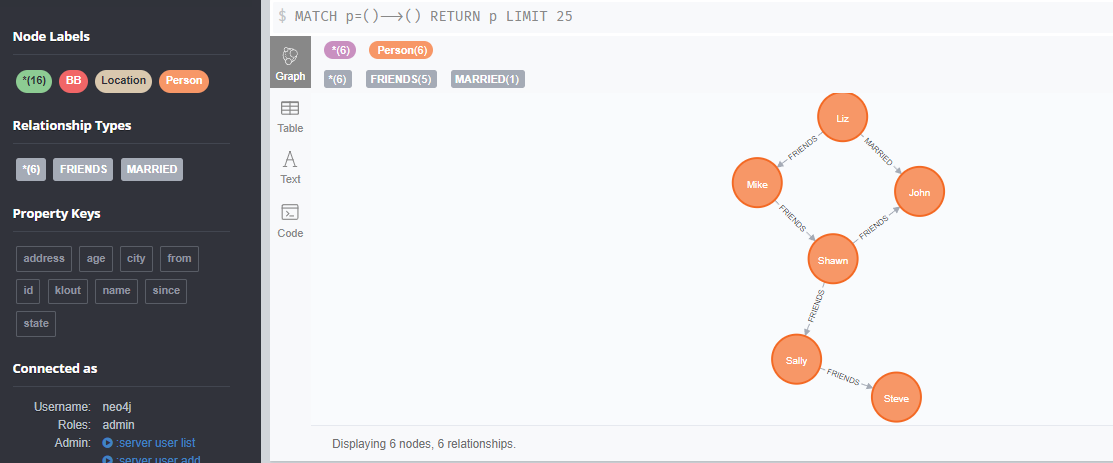
节点的查询
# 查询对外的所有结点;match (a)-->() return a
关系的删除
# 查询单个关系match (a:Person{name:'Mike'})-[r1:BORN_IN]-(x) return a,r1,x# 删除关系match (a:Person{name:'Mike'})-[r1:BORN_IN]-(x) delete r1# 删除所有关系(级联删除)match (n) detach delete n# 朋友关系查询:查找mike的朋友match (a:Person{name:'Mike'})-[r1:FRIENDS]-(p2)-[r2:FRIENDS]-(ff) return ff.name as ffName
2-4-Movie 电影查询
这个案例的本质就是把电影、导演、演员时之间的复杂网状关系作为蓝本,创建三者之间的结构。
Movie:released (发布时间),tagline (宣传词)、title (标题) | 关系:ACTED_IN 参演 DIRECTED 导演 PRODUCED 制片商 WROTE 编导
根据条件查询节点信息 :
1:查询演员Tom Hanks
2:随机查找多个演员
3:查找名为 Cloud Atlas 的电影
match (a:Person{name:"Tom Hanks"}) return amatch (a:Person) return a limit 5match (a:Movie) where a.title='Cloud Atlas' return a
根据条件查询关系
# 1:查找Tom Hanks参演过的电影match (tom:Person{name:"Tom Hanks"})-[:ACTED_IN]->(m:Movie) return tom,m# 2:查找谁导演了电影 Cloud Atlasmatch (m:Movie{title:"Cloud Atlas"})<-[:DIRECTED]-(p:Person) return p.name# 3:查找与Tom Hanks同出演过电影的人match (tom:Person{name:"Tom Hanks"})-[:ACTED_IN]->(m:Movie)<-[:ACTED_IN]-(p:Person) return p.namematch (tom:Person{name:"Tom Hanks"})-[:ACTED_IN]->(m:Movie)<-[:ACTED_IN]-(p:Person) return tom,m,p# 4:查找与电影Cloud Atlas 相关的所有人match (p:Person)-[r]->(m:Movie{title:"Cloud Atlas"}) return p,type(r),m,r# 5:查找Kevin Bacon 存在的长度为3及内2,1关系的任何相关节点(演员和电影)match (kevin:Person{name:'Kevin Bacon'})-[*1..3]-(other) return distinct other,kevin# 6度空间理论,也就是世界上任何两个人,他们之间最多通过6条关系就能联系到彼此 (可以实现人脉查询了)# 7:查找Kevin Bacon和Meg Ryan两者之间最短路径:match (kevin:Person{name:'Kevin Bacon'})-[*]-(meg:Person{name:'Meg Ryan'}) return meg,kevin# 最短函数(推荐使用)match p=shortestPath((kevin:Person{name:'Kevin Bacon'})-[*]-(meg:Person{name:'Meg Ryan'})) return p
第3章 Cypher之进阶操作
Cypher与模式介绍
一种声明式图数据库查询语言,具有丰富的表现力,能够高效的查询和更新图数据。声明式的查询语言,它具有丰富的表现力,能高效的查询和更新图数据。对于初学者而言Cypher相对简单,相比命令式的Java要简单的多,但是由于Cypher目前处于不断的更新和维护中,其本身的语言也会发生变化。
Neo4j模式 (Pattern)
模式和模式匹配是Cypher的核心,使用模式来描述所需数据的形状,通常使用小括号()表示节点,[] 表示关系和关系的类型,箭头表示关系的方向
- 标签模式:(u:User:Admin)
- 属性模式: (u:User{name:’tom’})
- 关系模式:
-- // 不带类型,不带方向-[role]-> // 关系名称-[:ACTIVE_IN]-> // 关系类型-[role:ACTIVE_IN]-> // 名称、类型、方向-[role:ACTIVE_IN{key:value}]-> // 名称、类型、方向、属性-[role:ACTIVE_IN*start..end]-> // 可变长关系
3-1-where高级查询_上
包括 标签过滤、方向的过滤、关系的过滤和属性的过滤数据准备
``` merge (n:User{name:’李四’}); merge (n:User{name:’王五’}); merge (n:User{name:’二麻子’}); merge (n:User{name:’孙七’}); merge (n:User{name:’张三’});
match(u1:User{name:’张三’}),(u2:User{name:’李四’}) create(u1)-[f:Friend]->(u2); match(u1:User{name:’张三’}),(u2:User{name:’王五’}) create(u1)-[f:Friend]->(u2); match(u1:User{name:’孙七’}),(u2:User{name:’王五’}) create(u1)<-[f:Friend]-(u2); match(u1:User{name:’二麻子’}),(u2:User{name:’李四’}) create(u1)<-[f:Friend]-(u2);
match(u1:User{name:’张三’}),(u2:User{name:’李四’})create(u1)-[c:Colleague]->(u2); match(u1:User{name:’李四’}),(u2:User{name:’孙七’})create(u1)-[c:Colleague]->(u2);
<a name="bOE31"></a>#### 几个重要的函数id:返回关系或者节点系统生成的 id (唯一)<br />labels: 返回一个节点的所有标签(非唯一)<br />type: 返回关系类型(唯一)
name>2的;
match(n)-[r]-(m) where length(n.name) >2 return n,id(n),type(r),labels(n)
<a name="AWJTc"></a>#### 约束查询者与被查询者1. 与SQL一样,Neo4j CQL提供了一个IN运算符,以便为CQL命令提供值的集合:IN[]1. where不是独立语句,而是match,with的一部分,用于给模式添加约束或者过滤传递给with的中间结果
// 修改 -[]-> 试试 match (u:User)-[:Friend]-(f:User) where u.name in [‘李四’,’张三’,’王五’,’孙七’,’二麻子’] and f.name=~’王.*’ return u.name,f.name;
<a name="RBD1M"></a>#### 查询二度人脉1. 变长关系、| 都不能用于Create语句,因为关系在创建时只能有一个类型1. extract: 可以从节点或者关系列表中返回单个属性,它将遍历整个列表 (variable in list | expression )***2代表节点的长度2**
match (u1)-[f:Friend|Colleague2]->(u2) return u1.name,u2.name,f // f返回的是list不能用type match (u1)-[f:Friend|Colleague2]->(u2) return distinct u1.name,u2.name match (u1)-[f:Friend|Colleague*2]->(u2) return u1.name,u2.name,extract(n in f | type(n))
<a name="Qj0Sq"></a>### 3-2-where高级查询_下<a name="YPCu9"></a>#### 关系的类型进行过滤(关系过滤)所有的部分都可以在where后做相同的操作;
match (u:User{name:’李四’})-[friend]-(f) where type(friend)=~’Fri.*’ return u,type(friend),f
<a name="FLFIX"></a>#### 在where中使用路径方向过滤(方向过滤)1. 模式是返回一个路径表示,模式的局限性只能使用单条路径表达它,不能像MATCH语句中那样使用逗号分隔多条路径。但是可以直接通过AND,1. 注意是:and not (u)<--(other) 则代表取反
match (u:User{name:’李四’}),(other) where other.name in [‘张三’,’二麻子’] and (u)<—(other) return u,other
1<a name="BQOvD"></a>#### 属性存在性检查(属性的过滤)1. DELETE操作用于删除节点和关联关系、REMOVE操作用于删除标签和属性、添加或更新属性值(设置为NULL则为删除属性)
match (n:User) where n.name=~’张.*’ set n.age = 23; match (n) where exists(n.age) return n match (u:User) where u.age is not null return u match (u1:User{name:’张三’}) set u1.age = null // set除了新增和更新属性之外还可以赋值null为删除属性
<a name="D6xwL"></a>#### where传入参数(参数)合法的参数是字母、数字以及两者的组合。参数语法采用json方式提供,可以通过:help param 来获取参数设置语法<br />参数会一直存在
单个数定义
:param n1=>’张三’;
match (n) where n.name=$n1 return n;
多个参数定义
:param obj=>({props:{n1:’王五’,n2:’李四’}}); match (n) where n.name=$n1 or n.name=$n2 return n;
<a name="GV10p"></a>### 3-3-with、foreach、merge<a name="i8XxC"></a>#### Merge VS Create1. Create:用于创建图元素,节点与关系1. Merge: 可以确保图数据库中存在某个特定的模式。如果该模式不存在,则创建它(要么整个模式匹配到, 要么整个模式被创建)
create (u1:User),(u2:User) return u1,u2; // 一次性创建多个节点 create (u:User{name:’A’})-[r:Friend{name:u.name + ‘<->’ + u2.name}]->(u2:User{name:’B’}); // 一次性创建节点与关系 merge (u:User{name:’A’})-[r:Friend{name:u.name + ‘<=>’ + u2.name}]->(u2:User{name:’B’}); // 会重新创建节点与关系 match (u1:User{name:’A’}),(u2:User{name:’B’}) merge (u1)-[:Friend{type:’good’}]->(u2); // 不会创建节点,仅仅会创建关系 match (u1:User{name:’A’})-[r]-(u2:User{name:’B’}) delete u1,u2,r
<a name="ruyEr"></a>#### 节点与关系的赋值1. **with 语句**将分段的查询部分连接在一起,查询结果从一部分以管道的形式传递给另外一部分作为开始点1. delete用于删除图元素(节点、关系、路径),删除属性和标签参考Remove
// 这样会删除目标元素u1的其它属性
match (u1:User{name:’A’,age=34}),(u2:User{name:’B’,address=’深圳’}) set u1 = u2
设置标签
match (n:User{name:’二麻子’})-[r1]-(n2:User{name:’李四’})-[r2]-(n3:User{name:’孙七’}) set r2.born=2021,r1.born=2020
// 更新关系
match (n2:User{name:’李四’})-[r2]->(n3:User{name:’孙七’}) merge (n2)-[r3:Friend]->(n3) with r2 delete r2
<a name="tVe4n"></a>#### FOREACH标记节点1. 可以使用FOREACH来更新其中的数据,括号中的变量是与外部分开的,这意味着FOREACH中创建的变量不能用于该语句之外1. 注意match后面不能直接更**extract函数(可以查看异常提示),它用于return关键字**,f**oreach语法格式与extract相同**1. 在管道的右边可以执行任何的**更新**命令,包括CREATE、DELETE、FOREACH
李四认识了几个朋友CDE
MATCH (n:User{name:’李四’}) foreach (p in [‘C’,’D’,’E’] | create (n)-[:Friend]->(new:User{name:p}))
<a name="siL5d"></a>#### return1. return语句有三个子语句,分别为**skip,limit,order by**1. return * 代表返回所有
MATCH (n) return n order by n.name desc skip 1 limit 2 MATCH (n)—(m) return * // 显示所有带关系节点 MATCH (n) return n //显示所有的节点
<a name="ck4j0"></a>### 3-4国家队与地方军(List推导式、集合 系统函数)<a name="QK5Fp"></a>#### list与list推导式1. List:在查询时多个节点或者关系返回的都有可能是List1. List推导式:本质是基于List列表创建一个语法结构支持映射和过滤函数
return range(1,10,2); return range(1,10,2)[-1]; return range(1,10)[1..2]; // 类似切片,半闭半开区间 return range(1,10)[..2]; return [i in range(0,10,2) where i%2=0 | i+1] as result // where实现过滤,表达式执行映射 match (u1)-[f:Friend|Colleague*2]->(u2) return u1.name,u2.name,[t in f where type(t)= ‘Colleague’ | type(t)] as abc
<a name="Zkx94"></a>#### 计算函数1. count用于计算行的数量count(*) 用于计算匹配的行数,而count(expr)用于计算非空值的数量1. 使用聚合函数类似sql中的group by,聚合函数通常有多个输入值,然后基于它们计算初一个聚合值1. return n,count(*), 前者n不是一个聚合函数, 是一个分组键(类似group by n),根据不同的分组键匹配的子图将被分为不同的组
MATCH (n:User) return count(n),count(n.age),sum(n.age),avg(n.age),max(n.age),min(n.age) MATCH (n:User)-[r]->(m:User) return type(r),count(r)
<a name="NzdIM"></a>#### 字符串函数1. 下面的函数都是针对字符串表达式,如果用于其它值,将会返回错误
return replace(‘hello’,’l’,’w’),substring(‘hello’,2,4),lower(rtrim(ltrim(‘ Hello ‘))),split(‘h e l l o’,’ ‘),size(split(‘h e l l o’,’ ‘)) as size,reverse(‘hello world’)
<a name="CBV5O"></a>#### 类型转化函数1. 可以采用toInt、toFloat、toString来进行类型的转化,如果转化失败返回为null
return toInt(‘3.14’),toInt(‘hello’),toFloat(‘300’),toString(3.14)
<a name="uLw46"></a>### 3-5唯有自律方得自由(构建索引、与约束
match (n) detach delete n
<a name="mKAyh"></a>#### keys1. 字符串**列表**的形式返回一个节点、关系或者map的所有属性的名称
match (n:User) return keys(n)
<a name="YSvVJ"></a>#### union all 将两个查询结果组合在一起1. Union语句用于将多个查询结果组合起来,由于是追加结果集因此要保证记录集列名数量相同(列的别名必须一致)1. union all 包含重复行,而union不包含重复行
match (n:Person) return n.name as name,n.born as born union match (m:Movie) return m.name as name,m.released as born
<a name="cXKO7"></a>#### 索引1. 数据库的索引本质都是为了使得检索数据更高效而引入的冗余信息。它的代价是需要额外存储空间1. 在Neo4j中索引一旦创建,将自己管理并当图发生变化时自动更新。一旦索引创建并生效后,Neo4j将自动使用索引
create index on :Person(name); drop index on :Person(name); // 通常不需要指定在查询中使用哪个索引,Cypher自己会决定 match (p:Person) where p.name=’Tom Cruise’ return p
<a name="fXhBe"></a>#### 约束1. Neo4j通过约束来保证数据的完整性。它可以用于给节点或者关系指定属性的唯一性1. 添加一个约束同时Neo4j也自动为该属性添加了一个索引(查询高效)
create constraint on (book:Book) assert book.name is unique; create (book:Book{name:’B’}); // 重复创建则抛出异常
11<a name="wzuyV"></a>## 第4章 Python与Java操作Neo4j<a name="FTHxZ"></a>### 4-1-Python操作neo4j<a name="LqzwQ"></a>#### 安装Py2neo
pip install py2neo
pip show py2neo Name: py2neo Version: 2021.1.5 Summary: Python client library and toolkit for Neo4j Home-page: https://py2neo.org/
[demo.py](https://www.yuque.com/attachments/yuque/0/2022/py/12996376/1644896443214-1fc4357c-9087-4c0c-b63f-d903f4f5333d.py?_lake_card=%7B%22src%22%3A%22https%3A%2F%2Fwww.yuque.com%2Fattachments%2Fyuque%2F0%2F2022%2Fpy%2F12996376%2F1644896443214-1fc4357c-9087-4c0c-b63f-d903f4f5333d.py%22%2C%22name%22%3A%22demo.py%22%2C%22size%22%3A12479%2C%22type%22%3A%22%22%2C%22ext%22%3A%22py%22%2C%22status%22%3A%22done%22%2C%22taskId%22%3A%22u21980994-b302-4c5c-8500-8fbb1c6fde5%22%2C%22taskType%22%3A%22upload%22%2C%22id%22%3A%22u9bc86932%22%2C%22card%22%3A%22file%22%7D)
from py2neo import Graph, Node, Relationship, Record
连接数据库
graph = Graph(“http://localhost:7474“, user=”neo4j”, password=’ ‘)
删除所有实体 match (n) detach delete n
graph.delete_all()
创建实体
p1 = Node(“Person”, name=’小明’) p2 = Node(“Person”, name=’小红’) graph.create(p1) graph.create(p2)
构建关系
p1_r_p2 = Relationship(p1, “喜欢”, p2, year=”初中”) p2_r_p1 = Relationship(p2, “讨厌”, p1, year=”高中”) graph.create(p1_r_p2) graph.create(p2_r_p1)
创建另一个实体
p3 = Node(“Person”, name=’小刚’) graph.create(p3) p2_r_p3 = Relationship(p2, ‘喜欢’, p3) graph.create(p2_r_p3)
实体追加数据
p2[‘age’] = 20 graph.push(p2) p1_r_p2[‘程度’] = ‘非常’ graph.push(p1_r_p2)
调用neo4j模式匹配进行查询(返回的是游标类型),类似SQL
方式1 match(不灵活:了解就行)
print(list(graph.match(r_type=’喜欢’)))
方式2 run(重点掌握) 节点本质:字典
res = graph.run(“MATCH (p:Person) return p”) print(res, type(res)) for v in res: print(v, type(v), v[0], type(v[0])) for val in v[0].items(): print(val, end=’ ‘) print(‘-‘ * 10)
<a name="HEgav"></a>### 4-2-Java操作neo4j<a name="W1wLm"></a>### 4-3奇变偶不变,符号看象限(调用存储过程与自定义函数)<a name="iQICY"></a>#### 调用存储VS函数函数与存储过程区别:<br />1.函数定义采用@UserFunction, 而存储过程采用:@Procedure;<br />2.返回多个值采用存储过程,返回一个值,采用函数;<br />3. 存储过程一般完成特定的数据操作(CRUD),而函数实现非数据的业务逻辑常见存储过程调用;
找到存储过程,都是db开头
call dbms.procedures()
call db.labels() # 返回标签;
<a name="LAEQA"></a>#### 调用过程并过滤结果call语句用于调用数据库中的存储过程,返回的结果可以采用yield引入一个where 字<br />句来过滤结果 (with ... where ...)
调用数据库内置存储过程db.labels() 并且计算数据库中的总标签数
call db.labels() yield label return count(label) as num
调用过程并过滤结果,contains 可以包括子集
call db.labels() yield label where label contains ‘Per’ return count(label) as a
返回标签的所有属性
call db.propertyKeys()
计算数据库中保护每个属性键的节点数量
call db.propertyKeys() yield propertyKey as prop match (n) where n[prop] is n[prop] is not null return prop,count(n)
<a name="b8RFv"></a>#### 自定义函数<a name="bhF1s"></a>#### 调用自定义函数
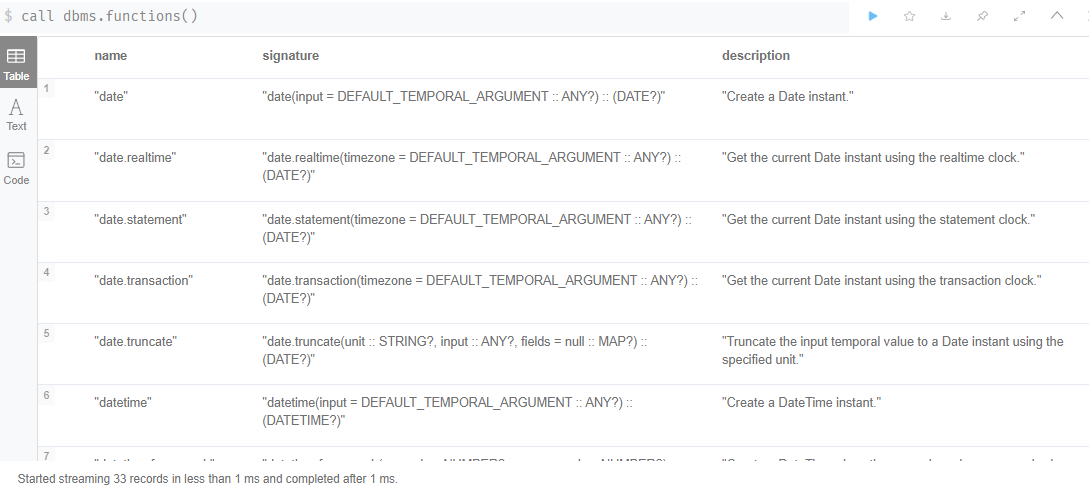
查看自定义函数;
call dbms.functions()
——————————————-
调用自定义函数;
return my.greet(‘neo4j’)
<a name="al3xC"></a>### 4-4-neo4j导入CSV文件_上<a name="B9kJ4"></a>#### 如何导入CSV文件格式从Neo4j 2.2版本开始,系统就自带了一个大数据导入工具:neo4j-import,可支持并<br />行、可扩展的大规模数据导入。它每次导入必须要创建一个新数据库,并且要为节点<br />个关系提供不同的CSV文件。
—into:指明了到日Neo4j数据库名称; —mode: 知名节点CSV文件; —relationship:指明了关系CSV文件; —id-type:生成节点和关系的主键类型为string类型;
<a name="q8VND"></a>#### 注意事项-. 目前在neo4j 3.x 也只能每次启动读取到一个数据库。可以通过conf文件夹指定: <br />dbms.active_database=neo4j.db ;<br />-. 对于node文件,name:field_type 如果没有指定类型默认为string,除了一般属性之外 <br />还要包括ID和Lable标签 ;<br />-. database=neo4j.db 数据库的名称必须要有db后缀,启动时conf配置中的 <br />dbms.active_database=neo4j.db(启动时访问的数据库) 必须和创建的数据库名称相同 <br />-. nodes与relationships依赖的必须是绝对路径;<a name="fhgZj"></a>##### 导入demo
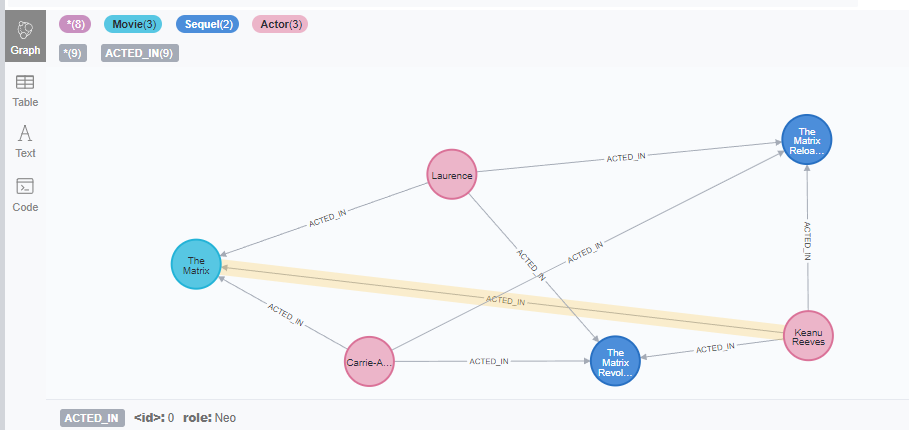
csv文件movies.csv
movieId:ID,title,year:int,:LABEL tt0133093,”The Matrix”,1999,Movie tt0234215,”The Matrix Reloaded”,2003,Movie;Sequel tt0242653,”The Matrix Revolutions”,2003,Movie;Sequel
neo4j-admin import —database=neo4j.db —nodes=C:\Users\dell\Desktop\neo4j\movies.csv —nodes=C:\Users\dell\Desktop\neo4j\actors.csv —relationships=C:\Users\dell\Desktop\neo4j\roles.csv
———————————
IMPORT DONE in 1s 591ms. Imported: 6 nodes 9 relationships 24 properties Peak memory usage: 1.00 GB
<a name="O8HJo"></a>### 4-5-neo4j导入CSV文件_中说明书:[https://neo4j.com/docs/operations-manual/current/tutorial/neo4j-admin-import/](https://neo4j.com/docs/operations-manual/current/tutorial/neo4j-admin-import/)<br />常见**导入形式对比**| | CREATE语句 | LOAD CSV语句 | Batch Inserter | Batch Import | Neo4j-import || --- | --- | --- | --- | --- | --- || 适用场景 | 1 ~ 1w nodes | 1w ~ 10 w nodes | 千万以上 nodes | 千万以上 nodes | 千万以上 nodes || 速度 | 很慢 (1000 nodes/s) | 一般 (5000 nodes/s) | 非常快 (数万 nodes/s) | 非常快 (数万 nodes/s) | 非常快 (数万 nodes/s) || 优点 | 使用方便,可实时插入。 | 使用方便,可以加载本地/远程CSV;可实时插入。 | 速度相比于前两个,有数量级的提升 | 基于Batch Inserter,可以直接运行编译好的jar包;可以在已存在的数据库中导入数据 | 官方出品,比Batch Import占用更少的资源 || 缺点 | 速度慢 | 需要将数据转换成CSV | 需要转成CSV;只能在JAVA中使用;且插入时必须停止neo4j | 需要转成CSV;必须停止neo4j | 需要转成CSV;必须停止neo4j;只能生成新的数据库,而不能在已存在的数据库中插入数据。 |<a name="NabmX"></a>#### 设置路径变量
set import=C:\Users\dell\Desktop\neo4j\ set import=H:\neo4j-community-3.5.28\import\ echo %import%
<a name="WEFQJ"></a>####<a name="uDoCG"></a>####<a name="W3Gl5"></a>#### 2.CSV文件分隔符非默认如果您的数据不符合默认格式,您可以自定义导入工具使用的配置选项(请参阅选项)。<br />以下 CSV 文件具有:<br />--delimiter=";"<br />--array-delimiter="|"<br />--quote="'"
csv文件movies2.csv
movieId:ID;title;year:int;:LABEL tt0133093;’The Matrix’;1999;Movie tt0234215;’The Matrix Reloaded’;2003;Movie|Sequel tt0242653;’The Matrix Revolutions’;2003;Movie|Sequel
neo4j-admin import —database=neo4j.db —nodes=C:\Users\dell\Desktop\neo4j\movies2.csv —nodes=C:\Users\dell\Desktop\neo4j\actors2.csv —relationships=C:\Users\dell\Desktop\neo4j\roles2.csv —delimiter=”;” —array-delimiter=”|” —quote=”‘“
<a name="KqK25"></a>#### 3.使用单独的头文件导入在处理非常大的 CSV 文件时,将标头放在单独的文件中会更方便。这样可以更轻松地编辑标题,因为您不必打开一个巨大的数据文件来更改它。必须在每个文件组中的其余文件之前指定头文件。<br />导入工具还可以处理单文件压缩档案,例如:- --nodes=import/nodes.csv.gz- --relationships=import/relationships.zip
csv文件movies2.csv
bin/neo4j-admin import —database=neo4j —nodes=import/movies3-header.csv,import/movies3.csv —nodes=import/actors3-header.csv,import/actors3.csv —relationships=import/roles3-header.csv,import/roles3.csv
<a name="sGTTA"></a>#### 4.多个文件导入除了使用单独的头文件之外,您还可以提供多个节点或关系文件。此类输入组中的文件可以用多个匹配字符串指定,由 分隔,,其中每个匹配字符串可以是确切的文件名,也可以是匹配一个或多个文件的正则表达式。多个匹配的文件将根据其字符及其自然数排序顺序对包含数字的文件名进行排序。
数据部分
movies4-header.csv movies4-part1.csv movies4-part2.csv
neo4j-admin import —database=neo4j.db —nodes=%import%\movies4-header.csv,%import%\movies4-part. —nodes=”%import%/actors4-header.csv, %import%/actors4-part.“ —relationships=”%import%/roles4-header.csv, %import%/roles4-part.*”
<a name="E4k1U"></a>#### 5. 对每个节点使用相同的标签如果您想为节点文件中的每个节点使用相同的节点标签,您可以通过将适当的值指定为neo4j-admin import. 这样就不需要:LABEL在头文件中指定列,并且每一行(节点)都将应用命令行选项中指定的标签。**_示例 2. 指定节点标签选项_**<br />--nodes=LabelOne:LabelTwo=import/example-header.csv,import/example-data1.csv
neo4j-admin import —database=neo4j.db —nodes:Movie=%import%\movies5a.csv —nodes:Movie:Sequel=”%import%/sequels5a.csv” —nodes:Actor=%import%/actors5a.csv —relationships=”%import%/roles5a.csv”
<a name="Xc5Nf"></a>#### 6. 对每个关系使用相同的关系类型如果您想对关系文件中的每个关系使用相同的关系类型,可以通过将适当的值指定为neo4j-admin import.<br />**_示例 3. 指定关系类型选项_**<br />--relationships=TYPE=import/example-header.csv,import/example-data1.csv
neo4j-admin import —database=neo4j.db —nodes=%import%\movies6.csv —nodes=%import%/actors6.csv —relationships=”%import%/roles6.csv”
neo4j-admin import —database=neo4j.db —nodes=%import%\fish.csv —nodes=%import%/place.csv —relationships=”%import%/fishplacerelationship.csv”
<a name="JbyEo"></a>#### 8.忽略错误导入导入工具不能容忍不良实体(关系或节点),并且会在第一个不良实体上导入失败。您可以明确指定您希望它忽略包含错误实体的行。<br />有两种不同类型的错误输入:1. 关系不好。1. 坏节点。引用缺失节点 ID 的关系,:START_ID或者:END_ID被认为是不良关系。是否跳过此类关系由标志控制,--skip-bad-relationships标志可以有值true或false没有值,这意味着true. 默认值为false,这意味着任何不良关系都将被视为错误并且将导致导入失败。有关详细信息,请参阅-**-ignore-missing-node**s。
忽略坏的节点;
—ignore-missing-nodes
忽略重复的节点
—ignore-duplicate-nodes
neo4j-admin import —database=neo4j.db —ignore-missing-nodes —nodes=%import%/movies8a.csv —nodes=%import%/actors8a.csv —relationships=%import%/roles8a.csv
<a name="MyLWI"></a>## 第5章 从零构建新冠图谱<a name="oJphL"></a>### 5-1-关系数据图谱化(neo4j导入Excel文件)导入精灵标准格式:[微云.xlsx](https://www.yuque.com/attachments/yuque/0/2022/xlsx/12996376/1644979517623-3f8a098b-a5a7-4d08-bab1-a16b6f03332c.xlsx?_lake_card=%7B%22src%22%3A%22https%3A%2F%2Fwww.yuque.com%2Fattachments%2Fyuque%2F0%2F2022%2Fxlsx%2F12996376%2F1644979517623-3f8a098b-a5a7-4d08-bab1-a16b6f03332c.xlsx%22%2C%22name%22%3A%22%E5%BE%AE%E4%BA%91.xlsx%22%2C%22size%22%3A19590%2C%22type%22%3A%22application%2Fvnd.openxmlformats-officedocument.spreadsheetml.sheet%22%2C%22ext%22%3A%22xlsx%22%2C%22status%22%3A%22done%22%2C%22taskId%22%3A%22uae112c4d-af3a-485f-b053-d90bb6b4c15%22%2C%22taskType%22%3A%22upload%22%2C%22id%22%3A%22ucb3d53b9%22%2C%22card%22%3A%22file%22%7D)<a name="nTyMI"></a>#### neo4j导入Excel数据导入精灵下载地址:[https://we-yun.com/doc/neo4j-guide/toNeo4j/](https://we-yun.com/doc/neo4j-guide/toNeo4j/)<a name="eJ3hq"></a>##### 配置远程连接
H:\neo4j-community-3.5.28\conf\neo4j.conf
Bolt connector 0.0.0.0
dbms.connector.bolt.enabled=true
dbms.connector.bolt.tls_level=OPTIONAL
dbms.connector.bolt.listen_address=0.0.0.0:7687
HTTP Connector. There can be zero or one HTTP connectors.
dbms.connector.http.enabled=true dbms.connector.http.listen_address=0.0.0.0:7474
<a name="pn5mI"></a>##### 取消安全验证
dbms.security.auth_enabled=false
和前面的neo4j-admin不同,导入精灵生成的是Cypher语句,因此可以在非空库执行 <br />导入操作<a name="BLYip"></a>##### Excel映射规则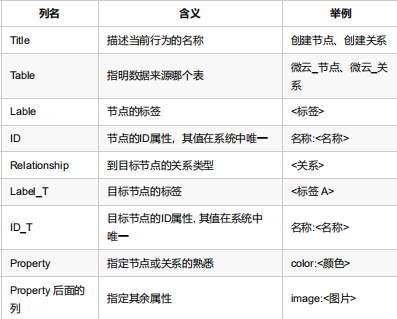<br /><a name="UREYp"></a>##### 节点规则映射图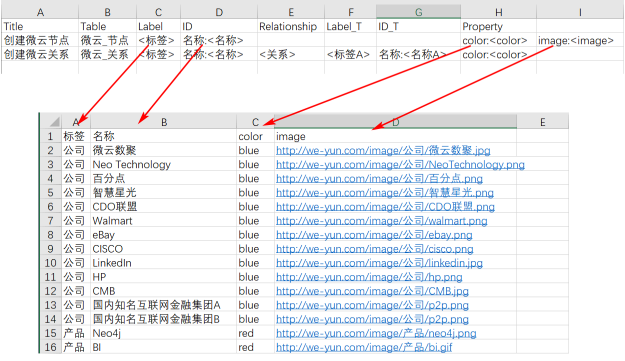<a name="xXxpB"></a>##### 关系规则映射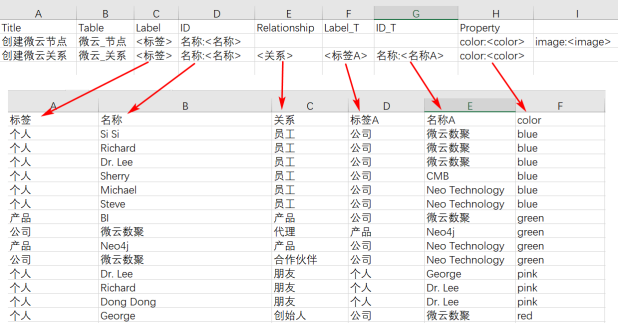
创建节点
MERGE (n:<标签> {名称:<名称>})
CREATE CONSTRAINT ON (n:公司) ASSERT n.名称 IS UNIQUE
MERGE (n:公司 {名称:’微云数聚’}) SET n.color=’blue’,n.image=’http://we-yun.com/image/公司/微云数聚.jpg‘
创建关系;
MATCH (n:<标签> {名称:<名称>}), (m:<标签A> {名称:<名称A>}) MERGE (n)-[r:<关系>]->(m)
MATCH (n:个人 {名称:’Si Si’}), (m:公司 {名称:’微云数聚’}) MERGE (n)-[r:员工]->(m) SET r.color=’blue’
<a name="vLm5E"></a>### 5-2-关系数据图谱化(neo4j导入SQL数据)<a name="Hlwv0"></a>#### neo4j导入SQL数据[微云.sql](https://www.yuque.com/attachments/yuque/0/2022/sql/12996376/1644980875849-6ed8d59c-4e3f-4967-8b6b-ee3f6c45b0eb.sql?_lake_card=%7B%22src%22%3A%22https%3A%2F%2Fwww.yuque.com%2Fattachments%2Fyuque%2F0%2F2022%2Fsql%2F12996376%2F1644980875849-6ed8d59c-4e3f-4967-8b6b-ee3f6c45b0eb.sql%22%2C%22name%22%3A%22%E5%BE%AE%E4%BA%91.sql%22%2C%22size%22%3A7297%2C%22type%22%3A%22%22%2C%22ext%22%3A%22sql%22%2C%22status%22%3A%22done%22%2C%22taskId%22%3A%22ue4799052-833b-4d66-bc9e-2e7d4532cef%22%2C%22taskType%22%3A%22upload%22%2C%22id%22%3A%22u96ded4e3%22%2C%22card%22%3A%22file%22%7D)<a name="R7yAJ"></a>#### neo4j导入cql数据(速度最快)新建demo.cql文件<br />复制粘贴 movies的示例语句<br />直接导入<a name="mGW6b"></a>### 5-3-海洋百科图谱构建<a name="vLjLu"></a>#### 图谱数据获取[http://www.openkg.cn/dataset/ocean](http://www.openkg.cn/dataset/ocean)<br />
数据下载
数据导入
neo4j-admin import —database=neo4j.db —nodes=%import%\fish.csv —nodes=%import%/place.csv —relationships=”%import%/fishplacerelationship.csv”
neo4j console
查询大洋洲的鱼的分布
match p=(:鱼)-[:分布]->(:区域{name:’大洋洲’}) return p
查询各州鱼类的分布;
match p=(f:鱼)-[r:分布]->(a:区域) where a.name=~’.*洲’ return a, count(f) limit 25
查询亚洲和大洋洲中都生存的鱼类;
match p=(:区域{name:’亚洲’})-[r:分布]-(:鱼)-[:分布]->(:区域{name:’大洋洲’}) return p limit 25
<a name="DogFJ"></a>### 5-4-新冠图谱应用场景及数据获取<a name="I3dgp"></a>#### DataV数据可视化DataV数据可视化是使用可视化应用的方式来分析并展示庞杂数据的产品。DataV旨让更多的人看到数据可视化的魅力,帮助非专业的工程师通过图形化的界面轻松搭建专业水准的可视化应用,满足您会议展览、业务监控、风险预警、地理信息分析等多种业务的展示需求[https://baijiahao.baidu.com/s?id=1660201581810583762](https://baijiahao.baidu.com/s?id=1660201581810583762)<a name="syDnj"></a>#### 图谱案例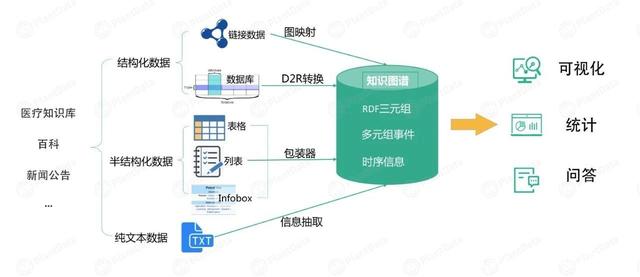<a name="FUDa6"></a>#### RDF与JSON-LDRDF(Resource Description Framework,资源描述框架)是一种资源描述语言,它<br />受到元数据标准、框架系统、面向对象语言等多方面的影响,被用来描述各种网络资<br />源,其出现为人们在Web上发布结构化数据提供一个标准的数据描述框架。<br />1. 源实体 - 关系 - 目标实体 <br />2. 实体 - 属性 - 属性值 <br />3. 节点:存储"实体" 和 属性值 <br />4. 边:存储关系、属性 <br />5. RDF格式验证:https://www.w3.org/RDF/Validator/ <br />6. 官方RDF导入文档(neo4j 3.x vs neo4j 4.x): https://neo4j.com/labs/neosemantics/4.0/introduction/<a name="Q0InT"></a>####<a name="dFHVs"></a>#### 新冠专题时间维度知识图谱:AbutionGraph<a name="Er2fn"></a>##### 1.数据获取途径1. 政府平台 [https://opendata.sz.gov.cn/data/dataSet/toDataDetails/29200_01503670](https://opendata.sz.gov.cn/data/dataSet/toDataDetails/29200_01503670)<br />2. 专业医疗机构数据[https://github.com/eAzure/COVID-19-Data](https://github.com/eAzure/COVID-19-Data) <br />3. 众筹平台 [http://www.openkg.cn/](http://www.openkg.cn/)<br />4. 第三方数据 [https://download.csdn.net/download/CSDNhijack/12594029](https://download.csdn.net/download/CSDNhijack/12594029)<a name="kM3uy"></a>##### 2.数据处理
import pandas as pd
给csv文件的index取名为no
df = pd.read_csv(“./data/china_data_2020_02_08.csv”, index_col=”no”)
city = df.drop([‘province’], axis=1) # 删除第一列 city.drop_duplicates(subset=[‘city’], keep=’first’, inplace=True) city.to_csv(“./data/city.csv”, index=False, index_label=None)
province = df[[‘province’]] province.drop_duplicates(keep=’first’, inplace=True) province.to_csv(“./data/province.csv”, index=False, index_label=None)
relation = df[[‘city’, ‘province’]]
修改省会数据
relation.insert(relation.shape[1], ‘’,’属于’)
def find_province_capital(city_name):
# 23 个省, 5 个自治区province_capital = ['呼和浩特', '乌鲁木齐', '拉萨', '银川', '南宁', '哈尔滨', '长春', '沈阳', '石家庄', '太原', '西宁', '济南', '郑州', '南京', '杭州','合肥', '福州', '南昌', '长沙', '武汉', '广州', '台北', '海口', '兰州', '西安', '成都', '贵阳', '昆明']if city_name in province_capital:return '省会'else:return '隶属'
relation[‘:TYPE’] = relation[‘city’].map(find_province_capital) relation.drop(index=relation.loc[(relation[‘city’] == ‘地区待确认’)].index, inplace=True) relation.to_csv(“./data/relation.csv”, index=False, index_label=None, header=[‘:START_ID’, ‘:END_ID’, ‘:TYPE’])
<a name="JV0sX"></a>##### 3.导入数据[city.csv](https://www.yuque.com/attachments/yuque/0/2022/xls/12996376/1645015436285-d1db21cd-4766-41d4-934f-c1f3e8a9d6a7.xls?_lake_card=%7B%22src%22%3A%22https%3A%2F%2Fwww.yuque.com%2Fattachments%2Fyuque%2F0%2F2022%2Fxls%2F12996376%2F1645015436285-d1db21cd-4766-41d4-934f-c1f3e8a9d6a7.xls%22%2C%22name%22%3A%22city.csv%22%2C%22size%22%3A11038%2C%22type%22%3A%22application%2Fvnd.ms-excel%22%2C%22ext%22%3A%22xls%22%2C%22status%22%3A%22done%22%2C%22taskId%22%3A%22u58ab976e-672b-4b9b-b99e-0a3157205ed%22%2C%22taskType%22%3A%22upload%22%2C%22id%22%3A%22uded23a43%22%2C%22card%22%3A%22file%22%7D)[province.csv](https://www.yuque.com/attachments/yuque/0/2022/xls/12996376/1645015440144-6b0f969f-8646-48ee-9d54-448ccf350bc9.xls?_lake_card=%7B%22src%22%3A%22https%3A%2F%2Fwww.yuque.com%2Fattachments%2Fyuque%2F0%2F2022%2Fxls%2F12996376%2F1645015440144-6b0f969f-8646-48ee-9d54-448ccf350bc9.xls%22%2C%22name%22%3A%22province.csv%22%2C%22size%22%3A291%2C%22type%22%3A%22application%2Fvnd.ms-excel%22%2C%22ext%22%3A%22xls%22%2C%22status%22%3A%22done%22%2C%22taskId%22%3A%22u408528d9-fba4-43df-95c2-8cf4f7ff418%22%2C%22taskType%22%3A%22upload%22%2C%22id%22%3A%22u66ba8628%22%2C%22card%22%3A%22file%22%7D)[relation.csv](https://www.yuque.com/attachments/yuque/0/2022/xls/12996376/1645015443007-84163226-04e0-431e-96a4-2928f191e94e.xls?_lake_card=%7B%22src%22%3A%22https%3A%2F%2Fwww.yuque.com%2Fattachments%2Fyuque%2F0%2F2022%2Fxls%2F12996376%2F1645015443007-84163226-04e0-431e-96a4-2928f191e94e.xls%22%2C%22name%22%3A%22relation.csv%22%2C%22size%22%3A9762%2C%22type%22%3A%22application%2Fvnd.ms-excel%22%2C%22ext%22%3A%22xls%22%2C%22status%22%3A%22done%22%2C%22taskId%22%3A%22ue3739b8b-c384-4d4a-acde-b2404cf6453%22%2C%22taskType%22%3A%22upload%22%2C%22id%22%3A%22uf972a390%22%2C%22card%22%3A%22file%22%7D)
neo4j-admin import —database=neo4j.db —nodes=%import%\province.csv —nodes=%import%/city.csv —relationships=”%import%/relation.csv”
IMPORT DONE in 1s 494ms Imported: 451 nodes 416 relationships 3787 properties Peak memory usage: 1.00 GB
```
5-5-AI战疫情(构建并展示疫情数据
5-6-温故而知新,后会有期(课程总复习)
1.通过NLP对人类的语音和文字进行切割和匹配;能够和数据库中的三元组做很好的匹配;
2.脑机接口:图形图像的语义识别;
下一课:人机聊天的对话模型

若有收获,就点个赞吧
0 人点赞

{kind=link}