- 总结:
- 深度学习基本概念
- 第1章 课程介绍-选择Pytorch的理由
- 第2章 初识PyTorch框架与环境搭建
- 第3章 PyTorch入门基础串讲
- ———————————-
- ————————————
- ———————————
- —————————————
- ———————————————-
- ————————————-
- ————————————
- ———————————-
- ———————————————————
- ——————————————-
- ————————————-
- ———————————
- ——————————————
- 排序
- ——————————————————
- TopK 运算
- ——————————————————
- 第k个最小值的提取
- ————————————————————
- 有界与无界
- ——————————————
- ——————————————-
- ———————————-
- ———————————————
- —————————————————
- ———————————————
- ————————————————-
- —————————————————————————
- ——————————————————-
- torch.manual_seed(1)
- ————————————————-
- ———————————————————-
- ———————————————
- ———————————-
- 将数值 处理到 2-5 之间;
- ————————————-
- a>0.5,输出a, a<0.5,输出b
- torch.where
- ————————————————-
- torch.gather
- ————————————-
- b = torch.rand(4,4)
- ——————————————-
- ————————————-
- ————————
- ——————————-
- cat
- ————————————————————
- stack
- —————————————————————-
- gather
- ————————————————-
- ————————————————-
3-24 Pytorch与张量变形 (14:09)- 3-25 Pytorch与张量填充&傅里叶变换 (03:27)
- 3-26 Pytorch简单编程技巧 (11:33)
3-27 Pytorch与autograd-导数-方向导数-偏导数-梯度的概念 (10:02)- ">
- 3-28 Pytorch与autograd-梯度与机器学习最优解 (12:46)
3-29 Pytorch与autograd-Variable$tensor (02:57)- 3-30 Pytorch与autograd-如何计算梯度 (03:04)
3-31 Pytorch与autograd中的几个重要概念-variable-grad-grad_fn (10:32)
3-32 Pytorch与autograd中的几个重要概念-autograd例子 (14:15)- ">

- 3-33 Pytorch与autograd中的几个重要概念-function (08:18)
3-34 Pytorch与nn库 (19:46)- 3-35 Pytorch与visdom(调试工具)
- ">

3-36 Pytorch与tensorboardX (05:57)- ">
- 2.1首先建立一个文件夹log
- 3-37 Pytorch与torchvision
- 第4章 PyTorch搭建简单神经网络
- 第5章 计算机视觉与卷积神经网络基础串讲
5-7 激活层-BN层-FC层-损失层- 5-8 经典卷积神经网络结构
- ">

- 5-9 轻量型网络结构
- 5-10 多分支网络结构
- 5-11 attention的网络结构
- 5-12 学习率
- 5-13 优化器
- 5-14 卷积神经网添加正则化
- 第6章 PyTorch实战计算机视觉任务-Cifar10图像分类
- 6-1 图像分类网络模型框架解读(上)
6-2 图像分类网络模型框架解读(下)- 6-3 cifar10数据介绍-读取-处理(上)
- 6-4 cifar10数据介绍-读取-处理(下)
6-5 PyTorch自定义数据加载-加载Cifar10数据- 6-6 PyTorch搭建 VGGNet 实现Cifar10图像分类
6-7 PyTorch搭建cifar10训练脚本-tensorboard记录LOG(上)
6-8 PyTorch搭建cifar10训练脚本-tensorboard记录LOG(下- 6-9 PyTorch搭建cifar10训练脚本搭建-ResNet结构(上)
- 6-10 PyTorch搭建cifar10训练脚本搭建-ResNet结构(下)
- 6-11 PyTorch搭建cifar10训练脚本搭建-Mobilenetv1结构
- 6-12 PyTorch搭建cifar10训练脚本搭建-Inception结构(上)
- 6-13 PyTorch搭建cifar10训练脚本搭建-Inception结构(下)
- 6-14 PyTorch搭建cifar10训练脚本搭建-调用Pytorch标准网络ResNet18等
- 6-15 PyTorch搭建cifar10推理测试脚本搭建
- 6-16 分类问题优化思路
- 6-17 分类问题最新研究进展和方向
- 第7章 Pytorch实战计算机视觉任务-Pascal VOC目标检测问题
- 7-5 MMdetection框架使用说明
- 7-6 【讨论题】比较mmdetection与detectron
- 7-7 MMdetection训练Passcal VOC目标检测任务(上)
- 7-8 MMdetection训练Passcal VOC目标检测任务(中)
- 7-9 MMdetection训练Passcal VOC目标检测任务(下)
- 7-10 MMdetection Test脚本
- 7-11 MMdetection LOG分析
- 第8章 PyTorch实战计算机视觉任务-COCO目标分割问题
- 第9章 PyTorch搭建GAN网络实战图像风格迁移
- 第10章 循环神经网与NLP基础串讲
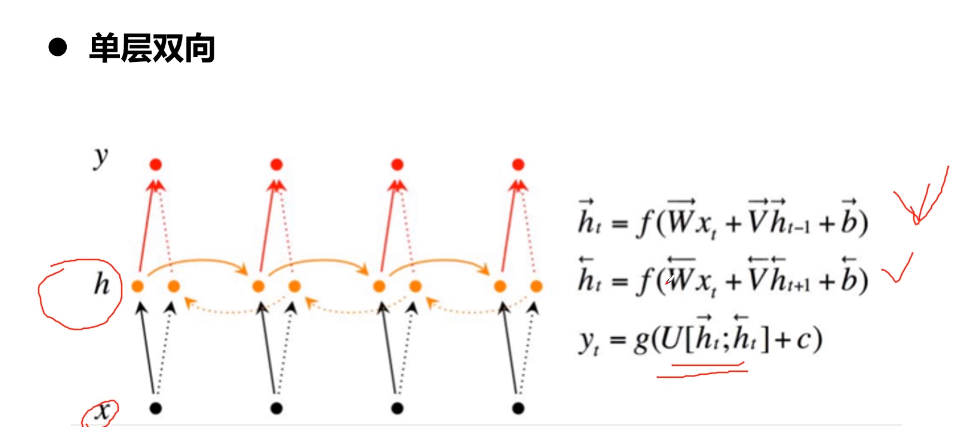
- 10-5 Attention结构
- ">
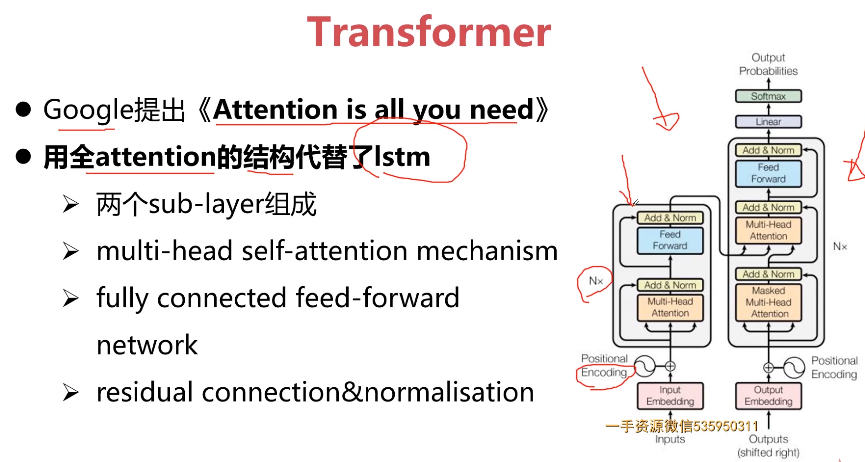
- 10-6 Transformer结构
- 10-7 BERT结构
- 10-8 NLP基础概念介绍
- 10-9 【讨论题】深入了解transformer在CV任务中的应用
- 第11章 PyTorch实战中文文本情感分类问题
- 第12章 PyTorch实战机器翻译问题
- 12-1 机器翻译相关方法-应用场景-评价方法
- 12-2 Seq2Seq-Attention编程实例数据准备-模型结构-相关函数
- 12-3 Seq2Seq-Attention编程实例-定义数据处理模块 (17:08)
- 12-4 Seq2Seq-Attention编程实例-定义模型结构模块(上) (13:10)
- 12-5 Seq2Seq-Attention编程实例-定义模型结构模块(下) (13:46)
- 12-6 Seq2Seq-Attention编程实例-定义train模块(上) (13:03)
- 12-7 Seq2Seq-Attention编程实例-定义train模块(下) (10:33)
- 12-8 Seq2Seq-Attention编程实例-定义train模块-loss function (20:10)
- 12-9 Seq2Seq-Attention编程实例-定义eval模块 (08:40)
- 12-10 【讨论题】深入了解Attention在CV任务中的应用前景?
- 13章 PyTorch工程应用介绍
- 第15章 课程总结与回顾1 节 | 12分钟
- 【工作篇】燕雀安知鸿鹄之志










参考:
1.https://github.com/kuangliu/pytorch-cifar (邦)
2.跟我一起学PyTorch(Pytorch机器学习从入门到实战)
Torch,torchvision:链接: https://pan.baidu.com/s/1eIXYYJzFztygaJJctRdDWg 提取码: 4njq
VOC:链接: https://pan.baidu.com/s/1u7cMfSFG6GkFsKoezPgjRQ 提取码: j9j7 复制这段内容后打开百度网盘手机App,操作更方便哦
CIFAR-10数据下载:链接: https://pan.baidu.com/s/1qz6BStCAnppsI6s6neyrQA 提取码: xheg
coco数据集:链接: https://pan.baidu.com/s/1G1e4X7g9AEGxYoWAaX2oCw 提取码: sqi7
CycleGAN训练数据:链接: https://pan.baidu.com/s/1G1e4X7g9AEGxYoWAaX2oCw 提取码: sqi7
CycleGAN: 训练模型链接: https://pan.baidu.com/s/1kzIM_Chic1Ebthv14GaU3w 提取码: fg9f
公众号:
1.随波竺流(入门系列) 2.花解语NLP(入门系列)
总结:
1.神经网络学习笔记 https://its203.com/article/qq_51682716/121272820
深度学习基本概念
1.深度学习 | 三个概念:Epoch, Batch, Iteration
2.神经网络训练的三个基本概念Epoch, Batch, Iteration
1.梯度下降更新参数的三种方法
1. 批量梯度下降(Batch Gradient Descent)
每一次迭代时使用整个训练集的数据计算Cost Function来进行梯度更新。
由于每一次参数更新都用到所有的训练集数据,当样本数量很大的时候,计算开销大,速度慢。
2.随机梯度下降(Stochastic Gradient Descent)
每一次迭代时,针对单个样本计算Loss Function,然后计算梯度更新参数。这种方法速度比较快,但是收敛性能不好,可能造成目标函数剧烈震荡,并且大数据集的相似样本会造成梯度的冗余计算。
3.小批量梯度下降(Mini-Batch Gradient Descent)
每次迭代时,采用一小批样本,一方面这样可以降低参数更新时的方差,收敛更加稳定,另一方面可以充分利用深度学习库中的高度优化的矩阵操作进行有效的梯度计算。
Mini-Batch Gradient Descent并不能保证很好的收敛性,Learning Rate 如果选择的太小,收敛速度会很慢;如果选择的太大,Loss Function可能在局部最优解附近不停地震荡甚至偏离。有一种措施是先设定大一点的学习率,当两次迭代之间的变化低于某个阈值后,就减小Learning Rate。
在大规模的神经网络训练中,一般采用小批量梯度下降的方式。 Batch Epoch Iteration 就是其中的重要的概念。
1.Batch
每次迭代时使用的一批样本就叫做一个Batch,样本的数量称为Batch Size。Batch大小是一个超参数,用于定义在更新内部模型参数之前要处理的样本数。深度学习每一次参数的更新的Loss Function并不是由一个样本得到的,而是由一个Batch的数据加权得到。
2. Iteration
使用Batch Size个样本训练一次的过程叫做一个Iteration。
3. Epoch
一个epoch就是使用训练集中的全部样本训练一次。通俗的讲,Epoch的值就是整个训练数据集被反复使用几次。
Epoch数是一个超参数,它定义了学习算法在整个训练数据集中的工作次数。一个Epoch意味着训练数据集中的每个样本都有机会更新内部模型参数。Epoch由一个或多个Batch组成。
4.loss
loss:在训练过程中,训练日志中会输出loss值。这个loss值是每一个Iteration得到的loss值,也就是一个batchsize个训练数据前向传播和反向传播后更新参数的过程之后得到的loss值。
第1章 课程介绍-选择Pytorch的理由
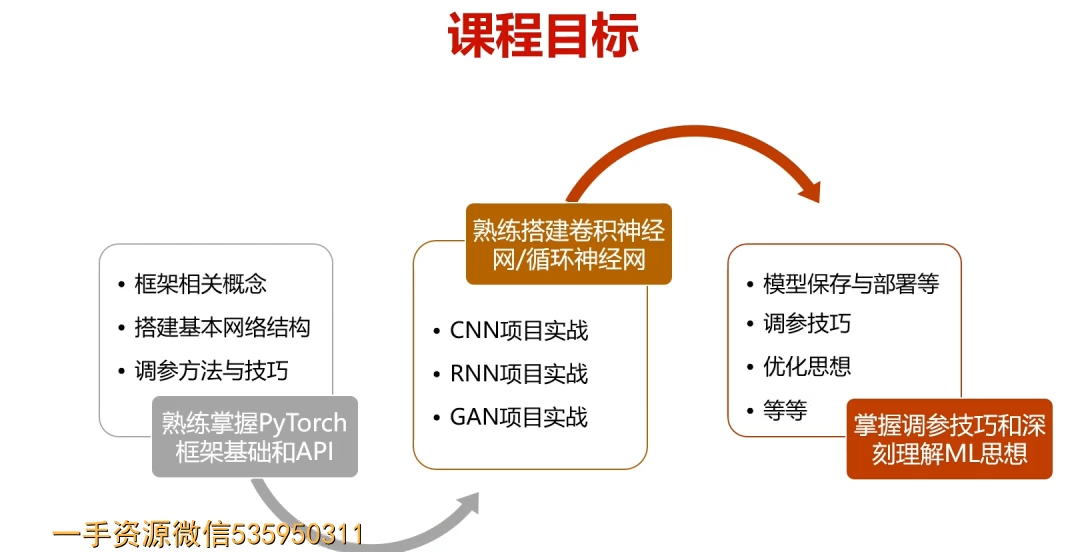
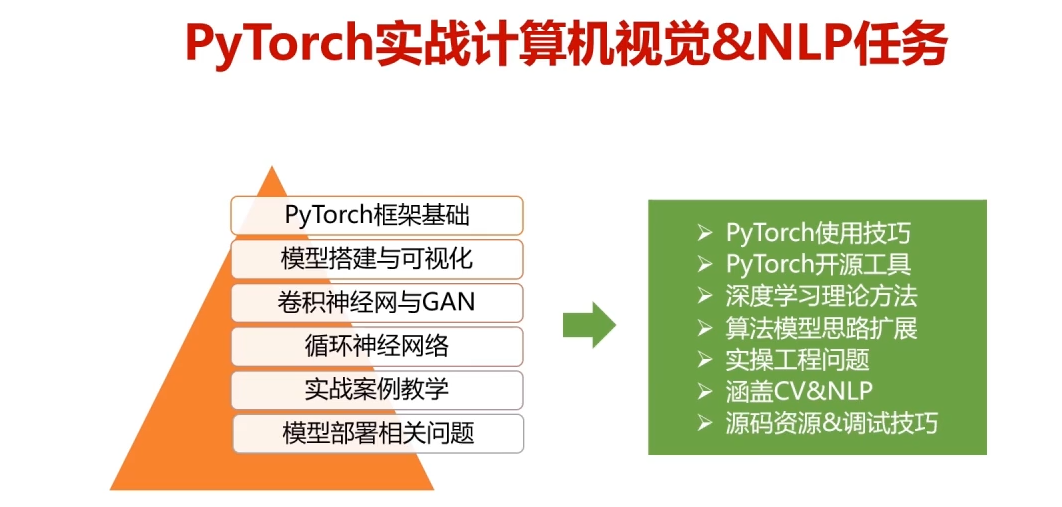
1.实战案例






第2章 初识PyTorch框架与环境搭建
PyTorch环境配置及安装
https://blog.csdn.net/weixin_43507693/article/details/109015177
# 安装conda install pytorch torchvision torchaudio cudatoolkit=10.2 -c pytorchimport torchprint(torch.__version__)print(torch.cuda.is_available())print(torch.cuda_version)#----------------------------------1.9.0True10.2
2-1 初识Pytorch基本框架



动态图 与 静态图

2-2 环境配置




第3章 PyTorch入门基础串讲
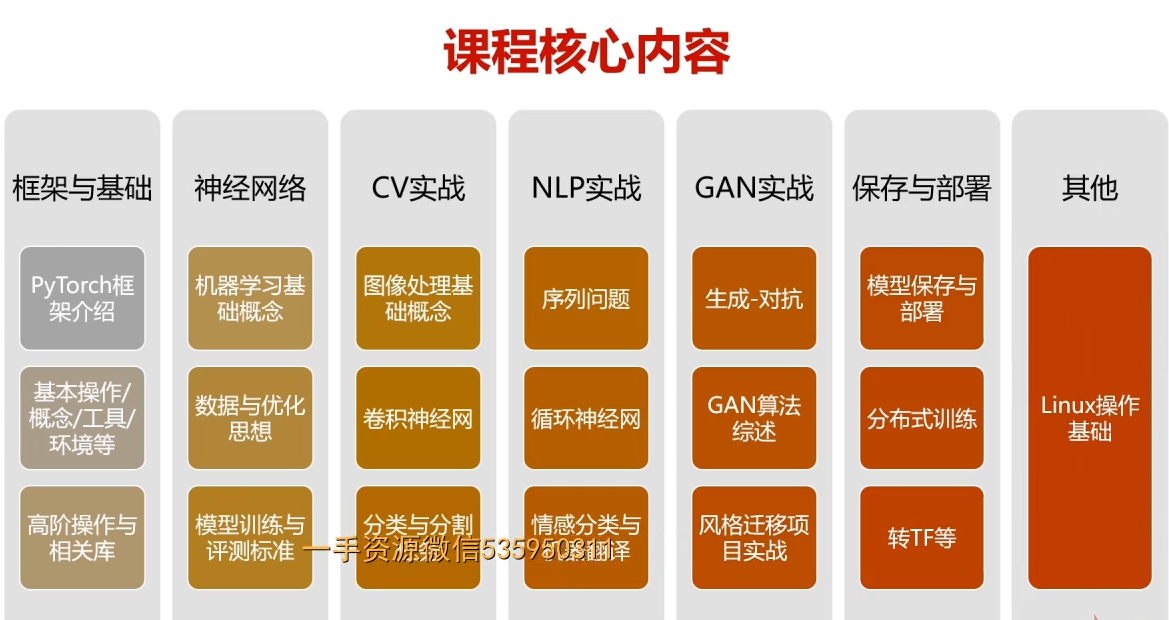
主要介绍PyTorch框架中涉及到的基础知识、核心概念以及API,
主要包括三个部分:
1)Tensor以及相关的函数,
2)Autograd机制以及相关函数,
3)Torch.nn库。在介绍过程中,结合实际的例子进行Tensor操作函数、AutoGrad自动求导以及神经网络相关函数的使用说明,同时介绍其中涉及到的数学基础(导数,方向导数,偏导数,梯度等…
3-1 机器学习中的分类与回归问题-机器学习基本构成元素 (11:15)
分类问题(离散值 预测)
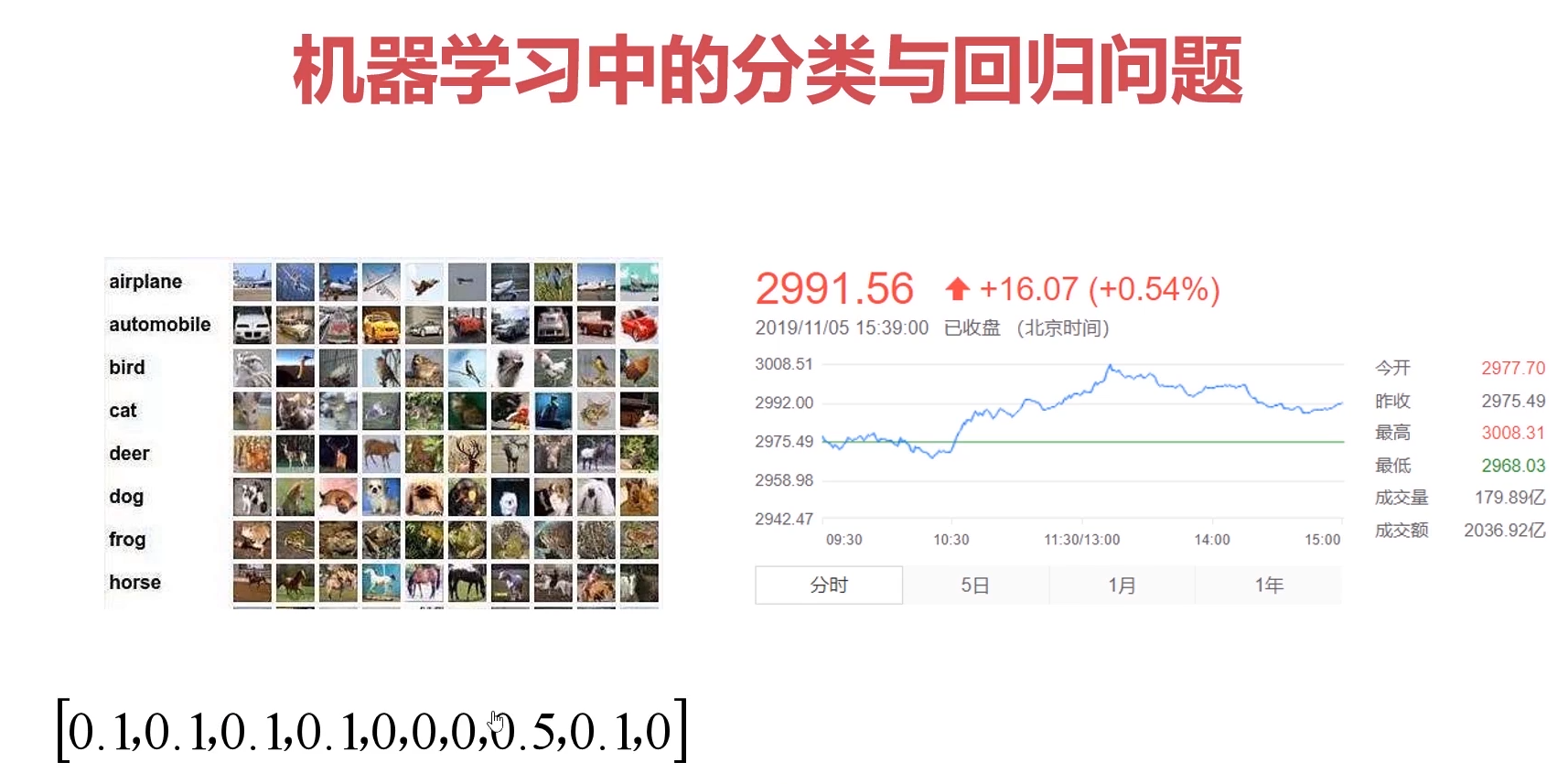
离散值的预测最大的就是 目标值
回归问题(连续值 预测)
机器学习问题的构成元素?

3-2 Tensor的基本定义
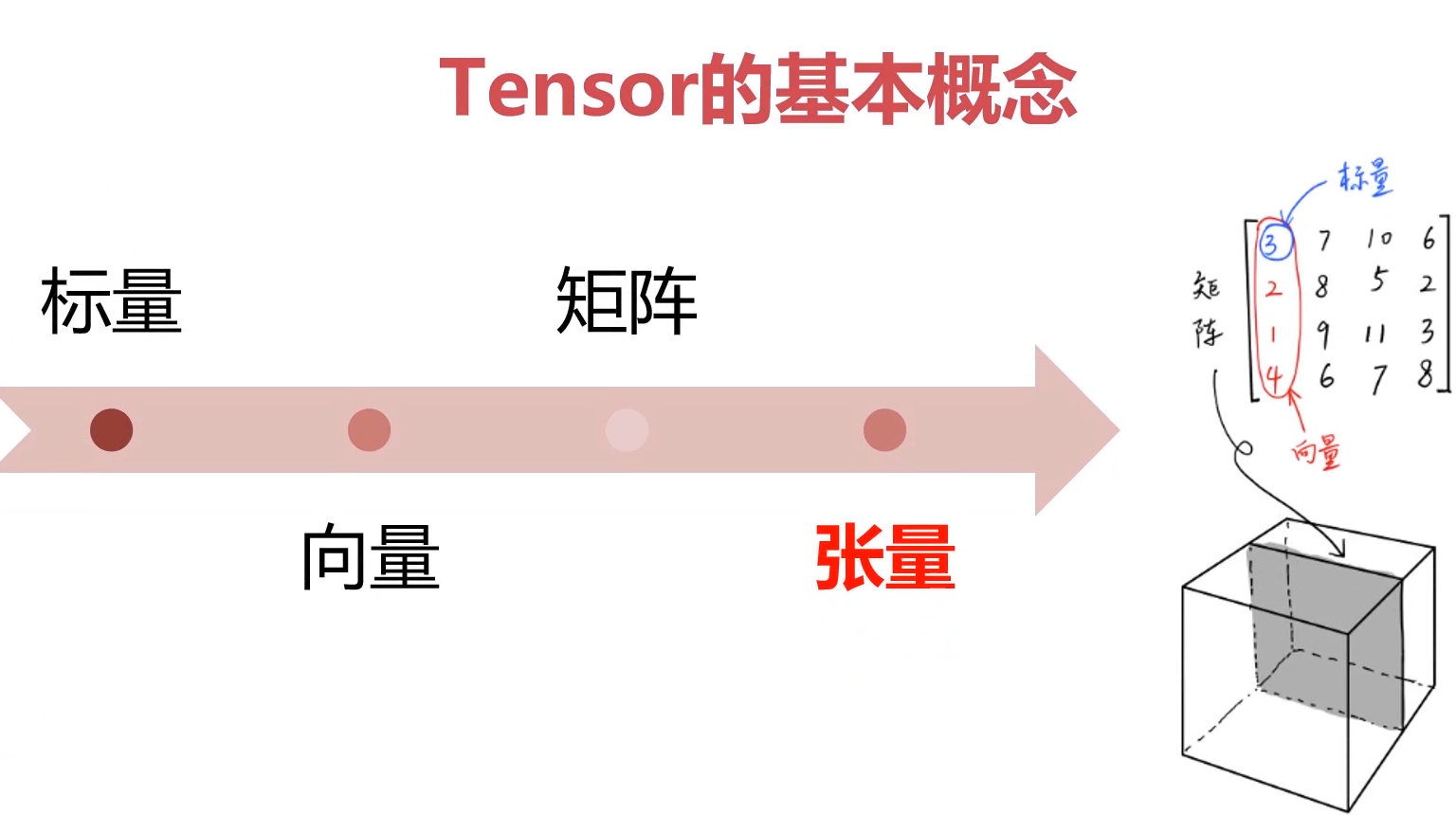
张量Tensor: 标量(0维)、向量(一维 )、矩阵(二维)
3-3 Tensor与机器学习的关系 (07:33)

Tensor 与 numpy的互换
`
`
# 在pytorch中判断一个数据结构x是否为tensor的语句为:torch.is_tensor(x)在pytorch中判断一个数据结构x存储是否为pytorch存储对象的语句为:torch.is_storage(x)import torchx = [1,2,3,4,5]print(torch.is_tensor(x))print(torch.is_storage(x))y = torch.randn(1,2,3,4,5)print(torch.is_tensor(y))print(torch.is_storage(y))print('the number of y is:',torch.numel(y))
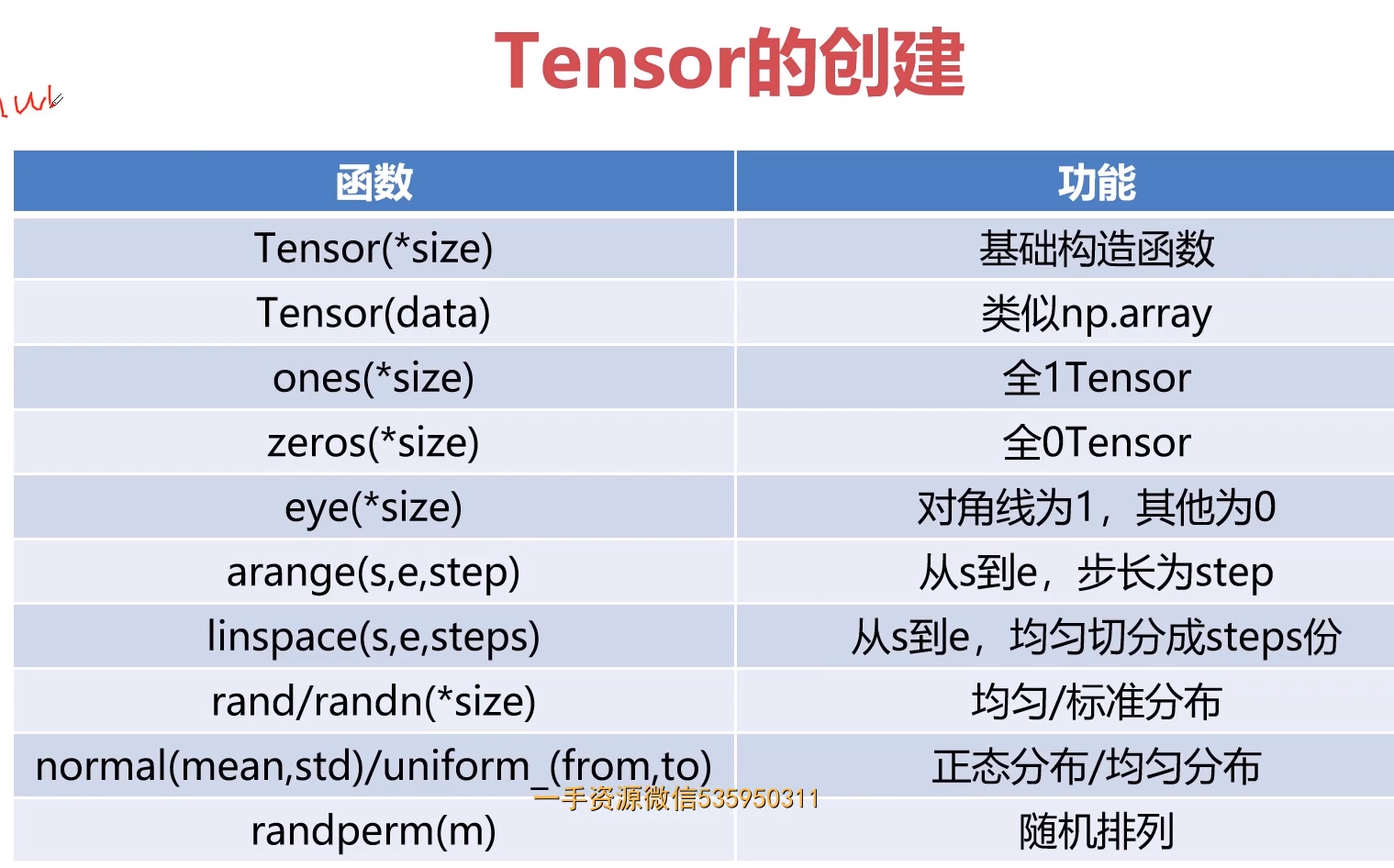
3-4 Tensor创建编程实例
1.几种特殊的Tensor
直接创建
import torcha = torch.Tensor([[1,2],[3,4]])print(a)print(a.shape)#--------------------tensor([[1., 2.],[3., 4.]])torch.Size([2, 2])
使用形状定义
#使用形状定义a = torch.Tensor(2,3)print(a)print(a.type())#----------------------------tensor([[1.3166e-08, 1.7155e-07, 5.2941e-08],[3.3428e+21, 2.6446e+20, 6.6824e-07]])
创建对角线全是1的tensor
print(torch.eye(2,2))
创建单位tensor
print(torch.ones(5,5))
创建和已有的tensor一样大的tensor
a = torch.Tensor(2,3)b = torch.zeros_like(a)c = torch.ones_like(a)print(a)print(b)print(c)#------------------------tensor([[0.0000e+00, 0.0000e+00, 1.7063e-07],[5.3175e-08, 1.3222e+22, 1.0524e+21]])tensor([[0., 0., 0.],[0., 0., 0.]])tensor([[1., 1., 1.],[1., 1., 1.]])
创建均匀分布的的tensor
a = torch.rand(2,2)print(a)#-------------------tensor([[0.6311, 0.8184],[0.5967, 0.8858]])
返回一个张量,包含了从指定均值means和标准差std的离散正态分布中抽取的一组随机数。标准差std是一个张量,包含每个输出元素相关的正态分布标准差
a = torch.normal(mean = torch.rand(5),std = torch.rand(5))print(a)a = torch.Tensor(2,2).uniform_(-1,1)print(a)#---------------------------tensor([ 1.3558, 0.7833, -0.3671, 1.0076, -0.3036])
产生序列
#序列a = torch.arange(0,10,3)print(a)#--------------------------------tensor([0, 3, 6, 9])
产生等间隔数
#等间隔n个数 # 前包后包a = torch.linspace(2,10,4)print(a)print(a.type())a = torch.randperm(10)print(a)#numpyimport numpy as npa = np.array([[1,2],[3,4]])print(a)
np 与 Tensor 具有非常大的相似性;
在pytorch中,tensor能够很好的跟numpy进行转换,这样上手就很方便。但是,装换时numpy类型需提前转换成array,对列表list这类数据转换成tensor会把报错。
实际操作:
import numpy as npx1 = np.array(x)x2 = torch.from_numpy(x1)#numpy转换成tensorx3 = x2.numpy()#tensor转换成numpyprint(x1)print(x2)print(x3)#----------------------[1 2 3 4 5]tensor([1, 2, 3, 4, 5], dtype=torch.int32)[1 2 3 4 5]
3-5 Tensor的属性 张量
张量是具有规则形状和相同数据类型的数字、向量、矩阵或多维数组。
类型:int、float

1.稀疏的张量device
稀疏和低质
稀疏:非0元素 (降低参数的数量,提高模型效率,减少内存开销)
低质:
3-6 Tensor的属性-稀疏的张量的编程实践
1.CPU与GPU
# cpu(默认)import torchdev = torch.device("cpu")a = torch.tensor([2,2],device = dev)print(a)#----------------------------------------tensor([2, 2])# GPUdev = torch.device("cuda:0")a = torch.tensor([2,2],dtype = torch.float32,device = dev)print(a)#--------------------------------tensor([2., 2.], device='cuda:0')
2.定义一个稀疏的张量
#定义一个稀疏的张量i = torch.tensor([[0,1,2],[0,1,2]])v = torch.tensor([1,2,3])a = torch.sparse_coo_tensor(i,v,(4,4),device = dev)print(a)#------------------------------------------------------tensor(indices=tensor([[0, 1, 2],[0, 1, 2]]),values=tensor([1, 2, 3]),device='cuda:0', size=(4, 4), nnz=3, layout=torch.sparse_coo)#转成稠密的张量a = a.to_dense()print(a)#资源的调度。。#---------------------------tensor([[1, 0, 0, 0],[0, 2, 0, 0],[0, 0, 3, 0],[0, 0, 0, 0]], device='cuda:0')
3-7 Tensor的算术运算 (08:12)

Tensor的算术运算——加法运算
其中,前三种一样,第四种是对 a 进行了修改。
c = a + bc = torch.add(a,b)a.add(b)a.add_(b) # 会对a修改#------------------------------------------a= torch.rand(2,3)b = torch.rand(2,3)print(a)print(b)print(a + b)print(a.add(b))print(torch.add(a,b))print(a.add_(b))print(a)#------------------------------------------tensor([[0.4610, 0.4274, 0.1595],[0.5649, 0.7950, 0.3734]])tensor([[0.2480, 0.5841, 0.7675],[0.1282, 0.2707, 0.5757]])tensor([[0.7090, 1.0115, 0.9270],[0.6931, 1.0657, 0.9491]])tensor([[0.7090, 1.0115, 0.9270],[0.6931, 1.0657, 0.9491]])tensor([[0.7090, 1.0115, 0.9270],[0.6931, 1.0657, 0.9491]])tensor([[0.7090, 1.0115, 0.9270],[0.6931, 1.0657, 0.9491]])tensor([[0.7090, 1.0115, 0.9270],[0.6931, 1.0657, 0.9491]])
Tensor的算术运算——减法运算
c = a - bc = torch.sub(a,b)a.sub(b)a.sub_(b)#-----------------------------##subprint(a -b)print(torch.sub(a ,b))print(a.sub(b))print(a.sub_(b))print(a)#-----------------------------tensor([[0.8213, 0.6452, 0.9052],[0.3017, 0.9604, 0.4588]])tensor([[0.6690, 0.5282, 0.9866],[0.4775, 0.4587, 0.6893]])tensor([[ 0.1523, 0.1169, -0.0814],[-0.1758, 0.5017, -0.2305]])tensor([[ 0.1523, 0.1169, -0.0814],[-0.1758, 0.5017, -0.2305]])tensor([[ 0.1523, 0.1169, -0.0814],[-0.1758, 0.5017, -0.2305]])tensor([[ 0.1523, 0.1169, -0.0814],[-0.1758, 0.5017, -0.2305]])tensor([[ 0.1523, 0.1169, -0.0814],[-0.1758, 0.5017, -0.2305]])
Tensor的算术运算——乘法运算
- 哈达玛积(element wise,对应元素相乘) ``` c = a * b c = torch.mul(a,b) a.mul(b) a.mul_(b)
print(a) print(b) print(a * b) print(torch.mul(a , b)) print(a.mul(b)) print(a.mul_(b)) print(a)
———————————-
tensor([[0.0473, 0.1081, 0.4513], [0.1399, 0.6380, 0.5727]]) tensor([[0.9497, 0.3675, 0.0536], [0.6467, 0.7527, 0.2862]]) tensor([[0.0449, 0.0397, 0.0242], [0.0905, 0.4802, 0.1639]]) tensor([[0.0449, 0.0397, 0.0242], [0.0905, 0.4802, 0.1639]]) tensor([[0.0449, 0.0397, 0.0242], [0.0905, 0.4802, 0.1639]]) tensor([[0.0449, 0.0397, 0.0242], [0.0905, 0.4802, 0.1639]]) tensor([[0.0449, 0.0397, 0.0242], [0.0905, 0.4802, 0.1639]])
<a name="mcVDU"></a>##<a name="jYOUa"></a>#### Tensor的算术运算——除法运算
c = a / b c = torch.div(a,b) a.div(b) a.div_(b)
print(a) print(b) print(a / b) print(torch.div(a,b)) print(a.div(b)) print(a.div_(b)) print(a)
————————————
tensor([[0.4673, 0.0171, 0.8596], [0.9005, 0.0510, 0.3394]]) tensor([[0.4493, 0.5639, 0.0891], [0.2864, 0.3972, 0.4697]]) tensor([[1.0402, 0.0303, 9.6496], [3.1445, 0.1285, 0.7226]]) tensor([[1.0402, 0.0303, 9.6496], [3.1445, 0.1285, 0.7226]]) tensor([[1.0402, 0.0303, 9.6496], [3.1445, 0.1285, 0.7226]]) tensor([[1.0402, 0.0303, 9.6496], [3.1445, 0.1285, 0.7226]]) tensor([[1.0402, 0.0303, 9.6496], [3.1445, 0.1285, 0.7226]])
<a name="HZGFf"></a>#### Tensor的算术运算——矩阵运算- 二维矩阵乘法运算操作包括torch.mm()、torch.matmul()、@
a = torch.ones(2,1) b = torch.ones(1,2) print(torch.mm(a,b)) print(torch.matmul(a,b)) print(a @ b) print(a.matmul(b)) print(a.mm(b))
———————————
a = torch.ones(2,1) b = torch.ones(1,2) print(torch.mm(a,b)) print(torch.matmul(a,b)) print(a @ b) print(a.matmul(b)) print(a.mm(b))
—————————————
tensor([[1., 1.], [1., 1.]]) tensor([[1., 1.], [1., 1.]]) tensor([[1., 1.], [1., 1.]]) tensor([[1., 1.], [1., 1.]]) tensor([[1., 1.], [1., 1.]])
- 对于高维的 Tensor (dim>2),定义其矩阵乘法仅在最后的两个维度上,要求前面的维度必须保持一致,就像矩阵的索引一样并且运算操作只有 torch.matmul()。
a = torch.ones(1,2,3,4) b = torch.ones(1,2,4,3) print(a.matmul(b)) print(torch.matmul(a,b))
———————————————-
tensor([[[[4., 4., 4.], [4., 4., 4.], [4., 4., 4.]],
[[4., 4., 4.],[4., 4., 4.],[4., 4., 4.]]]])
torch.Size([1, 2, 3, 3])
a = torch.ones(1,2,3,4) b = torch.ones(1,2,4,3) print(a.matmul(b)) print(torch.matmul(a,b))
<a name="ejsAR"></a>#### Tensor的算术运算——幂运算
a^2
print(torch.pow(a,2)) print(a.pow(2)) print(a ** 2) print(a.pow_(2))
a^e
print(torch.exp(a)) # e^n b = a.exp_()
————————————-
a = torch.tensor([1,2]) print(a) print(torch.pow(a,3)) print(a ** 3) print(a.pow_(3)) print(a)
————————————
tensor([1, 2]) tensor([1, 8]) tensor([1, 8]) tensor([1, 8]) tensor([1, 8])
a = torch.tensor([1,2],dtype = float) print(a.type())#long.tensor print(torch.exp(a)) print(torch.exp_(a))
print(a.exp()) print(a.exp())
———————————-
torch.DoubleTensor tensor([2.7183, 7.3891], dtype=torch.float64) tensor([2.7183, 7.3891], dtype=torch.float64) tensor([ 15.1543, 1618.1780], dtype=torch.float64) tensor([3814279.1048, inf], dtype=torch.float64)
<a name="w6Gor"></a>#### Tensor的算术运算——开方运算
print(a.sqrt()) print(a.sqrt_()) print(a)
a = torch.tensor([10,2],dtype = torch.float32) print(torch.sqrt(a)) print(torch.sqrt(a)) print(a.sqrt()) print(a.sqrt())
———————————————————
tensor([3.1623, 1.4142]) tensor([3.1623, 1.4142]) tensor([1.7783, 1.1892]) tensor([1.7783, 1.1892])
<a name="YOC4I"></a>#### Tensor的算术运算——对数运算
print(torch.log2(a)) print(torch.log10(a)) print(torch.log(a)) # 以 e 为底 print(torch.log_(a))
# a = torch.tensor([10,2],dtype = torch.float32) print(torch.log(a)) print(torch.log(a)) print(a.log()) print(a.log())
——————————————-
tensor([2.3026, 0.6931]) tensor([2.3026, 0.6931]) tensor([ 0.8340, -0.3665]) tensor([ 0.8340, -0.3665])
<a name="c7jBF"></a>### 3-8 Tensor的算术运算编程实例 (17:06)<a name="lswXj"></a>### <br />3-9 in-place的概念和广播机制 (09:58)<a name="IhfyL"></a>#### 1.in-place的概念<a name="LC43j"></a>#### 2.广播机制size不对齐,自动拓展对齐;<br /><a name="Asz7e"></a>###<a name="nKDpN"></a>###
import torch a = torch.rand(2,3) #右对齐 b = torch.rand(3) c = a + b print(a) print(b) print(c) print(c.shape)
————————————-
tensor([[0.8318, 0.1761, 0.9058], [0.5292, 0.1135, 0.7284]]) tensor([0.0350, 0.2060, 0.4145]) tensor([[0.8668, 0.3821, 1.3203], [0.5641, 0.3195, 1.1430]]) torch.Size([2, 3])
<a name="m3LuH"></a>###<a name="EGjsd"></a>### 3-10 取整-余 (03:49)
import torch a = torch.rand(2,2) a = a * 10 print(a) print(torch.floor(a)) print(torch.ceil(a)) print(torch.round(a)) print(torch.trunc(a)) print(a.frac()) print(a % 2)
———————————
tensor([[5.2226, 2.8359], [3.1016, 6.5535]]) tensor([[5., 2.], [3., 6.]]) tensor([[6., 3.], [4., 7.]]) tensor([[5., 3.], [3., 7.]]) tensor([[5., 2.], [3., 6.]]) tensor([[0.2226, 0.8359], [0.1016, 0.5535]]) tensor([[1.2226, 0.8359], [1.1016, 0.5535]])
<a name="odCXf"></a>### <br />3-11 比较运算-排序-topk-kthvalue-数据合法性校验 (18:28)<a name="jvcMs"></a>#### 1.比较运算<a name="wXIhW"></a>#### 2.排序<a name="gZuW1"></a>#### 3.有界与无界
import torch
a = torch.rand(2,3) b = torch.rand(2,3)
print(a) print(b)
print(torch.eq(a,b)) print(torch.equal(a,b))
print(torch.ge(a,b)) print(torch.gt(a,b)) print(torch.le(a,b)) print(torch.lt(a,b)) print(torch.ne(a,b))
——————————————
tensor([[0.1323, 0.5918, 0.8633], [0.4332, 0.9383, 0.5530]]) tensor([[0.0397, 0.2075, 0.8272], [0.1657, 0.1307, 0.6156]]) tensor([[False, False, False], [False, False, False]]) False tensor([[ True, True, True], [ True, True, False]]) tensor([[ True, True, True], [ True, True, False]]) tensor([[False, False, False], [False, False, True]]) tensor([[False, False, False], [False, False, True]]) tensor([[True, True, True], [True, True, True]])
排序
a = torch.tensor([[1,4,4,3,5], [1,4,4,10,5]]) print(a.shape) print(torch.sort(a)) print(torch.sort(a,descending = True)) print(torch.sort(a,dim=0, descending=True)) print(torch.sort(a,dim=1, descending=True))
——————————————————
torch.Size([2, 5]) torch.return_types.sort( values=tensor([[ 1, 3, 4, 4, 5], [ 1, 4, 4, 5, 10]]), indices=tensor([[0, 3, 1, 2, 4], [0, 1, 2, 4, 3]]))
torch.return_types.sort( values=tensor([[ 5, 4, 4, 3, 1], [10, 5, 4, 4, 1]]), indices=tensor([[4, 1, 2, 3, 0], [3, 4, 1, 2, 0]]))
torch.return_types.sort( values=tensor([[ 1, 4, 4, 10, 5], [ 1, 4, 4, 3, 5]]), indices=tensor([[0, 0, 0, 1, 0], [1, 1, 1, 0, 1]]))
torch.return_types.sort( values=tensor([[ 5, 4, 4, 3, 1], [10, 5, 4, 4, 1]]), indices=tensor([[4, 1, 2, 3, 0], [3, 4, 1, 2, 0]]))
TopK 运算
a = torch.tensor([[1,3,5,7,9], [2,4,6,8,10]]) print(torch.topk(a,k = 2, dim = 0)) print(torch.topk(a,k = 2, dim = 1))
——————————————————
torch.return_types.topk( values=tensor([[ 2, 4, 6, 8, 10], [ 1, 3, 5, 7, 9]]), indices=tensor([[1, 1, 1, 1, 1], [0, 0, 0, 0, 0]]))
torch.return_types.topk( values=tensor([[ 9, 7], [10, 8]]), indices=tensor([[4, 3], [4, 3]]))
第k个最小值的提取
print(torch.kthvalue(a,k = 2,dim = 0)) print(torch.kthvalue(a,k = 2,dim = 1))
————————————————————
tensor([[ 1, 3, 5, 7, 9], [ 2, 4, 6, 8, 10]]) torch.return_types.kthvalue( values=tensor([ 2, 4, 6, 8, 10]), indices=tensor([1, 1, 1, 1, 1])) torch.return_types.kthvalue( values=tensor([3, 4]), indices=tensor([1, 1]))
有界与无界
a = torch.rand(2,3) print(a) print(torch.isfinite(a))#有界的 print(torch.isfinite(a/0)) print(torch.isinf(a/0))#无界的 print(torch.isnan(a/0))
——————————————
tensor([[0.6125, 0.0574, 0.6154], [0.9098, 0.7073, 0.9240]]) tensor([[True, True, True], [True, True, True]]) tensor([[False, False, False], [False, False, False]]) tensor([[True, True, True], [True, True, True]]) tensor([[False, False, False], [False, False, False]])
import numpy as np a = torch.tensor([1,2,np.nan]) print(torch.isnan(a))
——————————————-
tensor([False, False, True])
<a name="dPA8H"></a>### <br />3-12 三角函数 (04:18)余弦用的多,相似性度量(余弦距离 欧式距离)<br />人脸识别常用的loss = am-soft<br />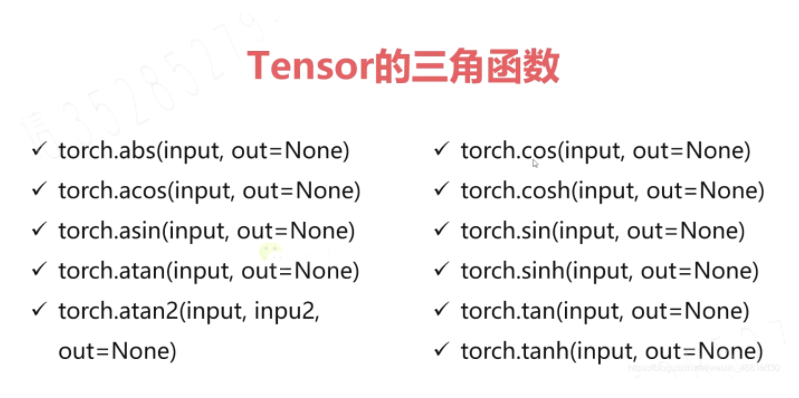<br />
import torch a = torch.rand(2,3) b = torch.cos(a) print(a) print(b)
———————————-
tensor([[0.5856, 0.6203, 0.2752], [0.2479, 0.1150, 0.6752]]) tensor([[0.8334, 0.8137, 0.9624], [0.9694, 0.9934, 0.7806]])
<a name="uuSra"></a>### <br />3-13 其他数学函数 (05:33)<br />**重点学习**<br />abs(绝对值函数)<br />l1loss<br />sigmoid()<br />sign(符号函数)<a name="ogjUS"></a>### 3-14 Pytorch与统计学方法 (14:55)<a name="ap63o"></a>#### 1.Tensor统计学相关函数<br />特征工程<br />特征(lbp gabor sift hog/纹理)
import torch
a = torch.rand(2,2)
print(a) print(torch.mean(a)) print(torch.sum(a)) print(torch.prod(a))#连乘
———————————————
tensor([[0.4105, 0.9479], [0.3493, 0.3481]]) tensor(0.5140) tensor(2.0558) tensor(0.0473)
print(a) print(torch.mean(a,dim=0)) print(torch.sum(a,dim=0)) print(torch.prod(a,dim=0))#连乘 print(torch.argmax(a,dim=0)) print(torch.argmin(a,dim=0))
—————————————————
tensor([[0.4105, 0.9479], [0.3493, 0.3481]]) tensor([0.3799, 0.6480]) tensor([0.7598, 1.2960]) tensor([0.1434, 0.3300]) tensor([0, 0]) tensor([1, 1])
print(torch.std(a)) print(torch.var(a))#方差
print(torch.median(a)) print(torch.mode(a))
———————————————
tensor(0.2908) tensor(0.0846) tensor(0.3493) torch.return_types.mode( values=tensor([0.4105, 0.3481]), indices=tensor([0, 1]))
a = torch.rand(2,2)*10 print(a) print(torch.histc(a,6,0,0))
————————————————-
tensor([[6.7650, 7.9510], [7.1968, 1.8218]]) tensor([1., 0., 0., 0., 1., 2.])
a = torch.randint(0,10,[10])#只能1维[10,2]报错 print(a) print(torch.bincount(a))
—————————————————————————
tensor([6, 7, 1, 6, 8, 2, 5, 9, 7, 7]) tensor([0, 1, 1, 0, 0, 1, 2, 3, 1, 1])
tensor([4, 1, 0, 6, 5, 2, 2, 0, 1, 3]) tensor([2, 2, 2, 1, 1, 1, 1])
<a name="S0kiM"></a>### 3-15 Pytorch与分布函数 (04:56)<a name="TUUjk"></a>#### 分布概念的了解分布的操作简单了解就可以;**正太分布,Beta分布**<a name="KC4L8"></a>#### <a name="i8eFu"></a>####<a name="FOij1"></a>#### 得分函数与 pathwise derivative估计器<a name="rpTC4"></a>#### KL散度<a name="Xx2V4"></a>### <br />3-16 Pytorch与随机抽样 (05:15)<a name="GN6vh"></a>#### 随机抽样随机种子定义了 随机数生成序列 的起始值(默认值是变化的)<br />
import torch torch.manual_seed(1) mean = torch.rand(1,2) std = torch.rand(1,2) print(torch.normal(mean,std))
——————————————————-
tensor([[0.7825, 0.7358]]) # 保证随机结果一致;
import torch
torch.manual_seed(1)
mean = torch.rand(1,2) std = torch.rand(1,2) print(torch.normal(mean,std))
————————————————-
tensor([[0.7913, 0.0125]]) # 不一致
<a name="AQrV8"></a>### 3-17 Pytorch与线性代数运算 (09:18)<a name="DT4Mh"></a>#### 1.范数(距离,相似性)**范数**,是具有“长度”概念的函数。在[线性代数](https://baike.baidu.com/item/%E7%BA%BF%E6%80%A7%E4%BB%A3%E6%95%B0)、[泛函分析](https://baike.baidu.com/item/%E6%B3%9B%E5%87%BD%E5%88%86%E6%9E%90)及相关的数学领域,范数是一个函数,是[矢量空间](https://baike.baidu.com/item/%E7%9F%A2%E9%87%8F%E7%A9%BA%E9%97%B4)内的所有矢量赋予非零的正**长度**或**大小**。半范数可以为非零的矢量赋予零长度。<br />**一范数:计算张量之间的相似性(距离)**<br />**二范数**:欧氏距离<br />**核范数**:低秩问题的求解<br />计算机技术中有一种特点,图像有一种区域性,反应到数据上就是有相关性<br />**范数作用**:定义loss,参数约束
import torch a = torch.rand(1,1) b = torch.rand(1,1)
print(a,b)
print(torch.dist(a,b,p = 0)) print(torch.dist(a,b,p = 1)) print(torch.dist(a,b,p = 2)) print(torch.dist(a,b,p = 3))
———————————————————-
tensor([[0.9906]]) tensor([[0.2885]]) tensor(1.) tensor(0.7022) tensor(0.7022) tensor(0.7022)
print(torch.norm(a)) print(torch.norm(a,p = 0)) print(torch.norm(a,p = 1)) print(torch.norm(a,p = 2)) print(torch.norm(a,p = 3))
———————————————
tensor([[0.8750]]) tensor([[0.5059]]) tensor(0.8750) tensor(1.) tensor(0.8750) tensor(0.8750) tensor(0.8750)
<a name="nBalz"></a>### 3-18 Pytorch与矩阵分解-PCA (19:52)<a name="l9Zhq"></a>#### 1.常见的矩阵分解LU分解:<br />QR分解:<br />EVD:--------PCA算法<br />SVD:--------LDA算法(判别分析)(与特征工程相关)**矩阵分解**<br />要求A必须满秩!(非齐矩阵)<br />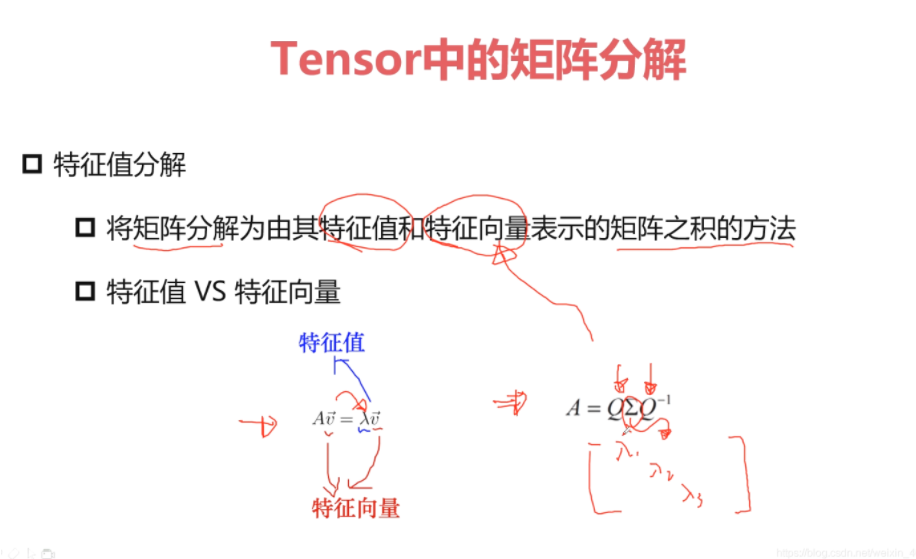**PCA特征分析**<br /><a name="Hh1Bz"></a>### <br />3-19 Pytorch与矩阵分解-SVD分解-LDA (13:09)<a name="AefIN"></a>#### 1.SVD分解-LDA 奇异值分解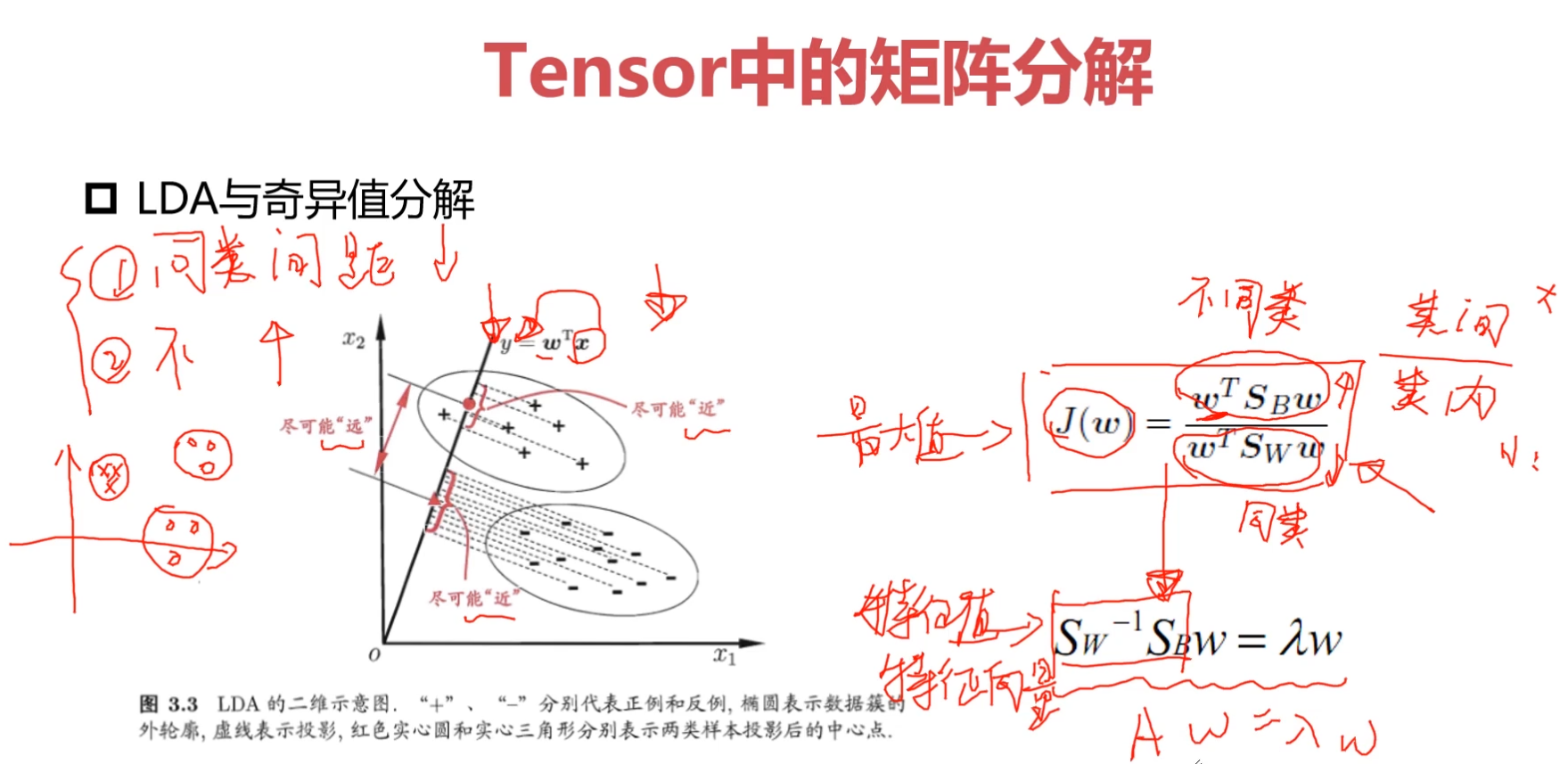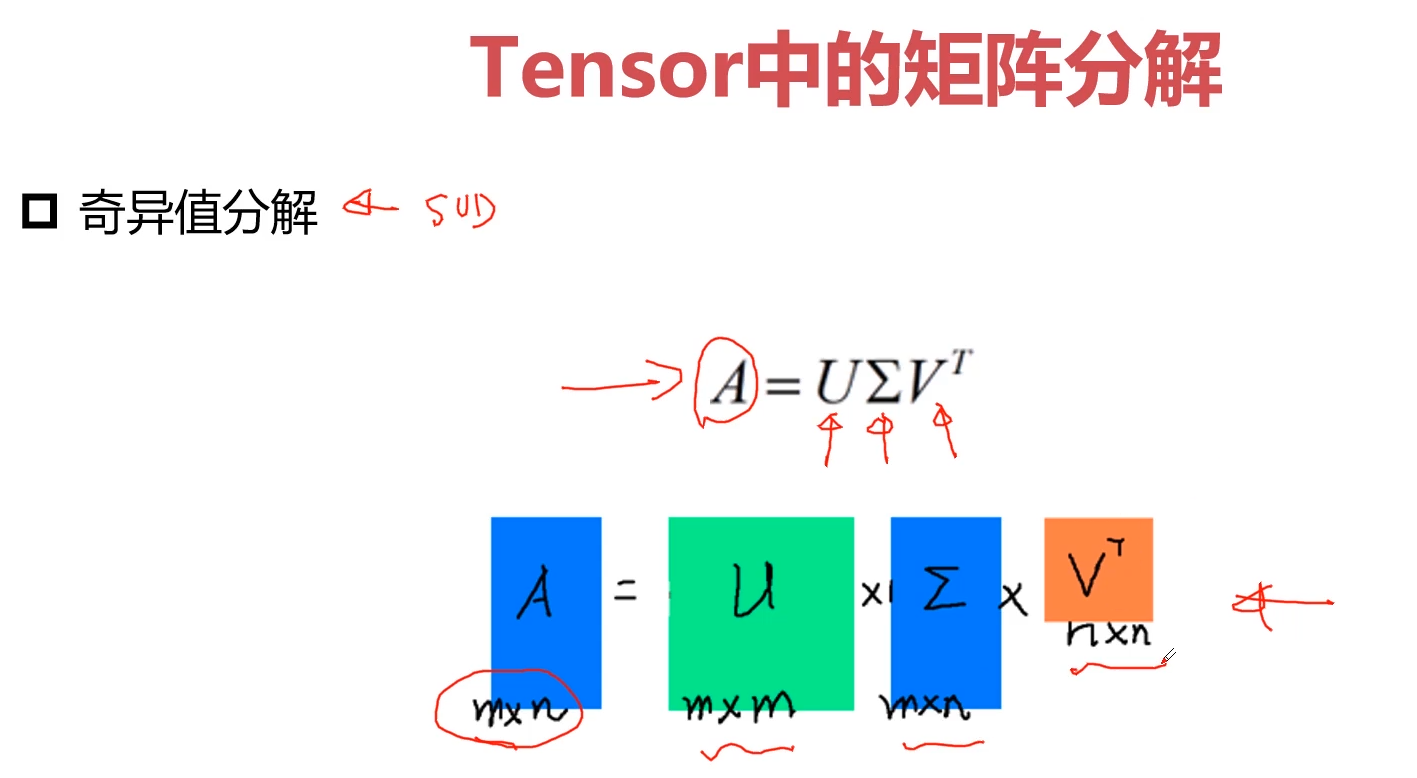<a name="tWIU5"></a>#### 矩阵分解特点矩阵分解与特征降维是不等价的<br />低质<br />稀疏<a name="OqrVN"></a>### <br />3-20 Pytorch与张量裁剪 (08:48)**网络训练的时候达到最优解**<br />约束tensor范围------------------->正则化/防止过拟合/解空间变小了/约束<br />loss解空间/约束<br />定点/量化<br />将数值 处理到 2-5 之间;
import torch a = torch.rand(5,5) * 10 print(a)
———————————-
tensor([[2.3659, 7.5701, 2.3459, 6.4705, 3.5562], [4.4518, 0.1931, 2.6161, 7.7132, 3.7846], [9.9802, 9.0079, 4.7659, 1.6626, 8.0448], [6.5518, 1.7679, 8.2477, 8.0355, 9.4345], [2.1972, 4.1770, 4.9031, 5.7303, 1.2054]])
将数值 处理到 2-5 之间;
a = a.clamp(2,5) print(a)
————————————-
tensor([[2.3659, 5.0000, 2.3459, 5.0000, 3.5562], [4.4518, 2.0000, 2.6161, 5.0000, 3.7846], [5.0000, 5.0000, 4.7659, 2.0000, 5.0000], [5.0000, 2.0000, 5.0000, 5.0000, 5.0000], [2.1972, 4.1770, 4.9031, 5.0000, 2.0000]])
<a name="uWyZd"></a>### 3-21 Pytorch与张量的索引与数据筛选 (27:08)<a name="rUCZy"></a>#### 1.Tensor的索引与数据筛选Tensor数据处理<br />dim:维度<br />input: tensor<br />mask: tensor<br /><a name="DcnKI"></a>#### tonser.where
a>0.5,输出a, a<0.5,输出b
import torch
torch.where
a = torch.rand(4,4) b = torch.rand(4,4) out = torch.where(a>0.5,a,b)
print(a) print(b) print(out)
————————————————-
tensor([[0.1452, 0.7720, 0.3828, 0.7442], [0.5285, 0.6642, 0.6099, 0.6818], [0.7479, 0.0369, 0.7517, 0.1484], [0.1227, 0.5304, 0.4148, 0.7937]]) tensor([[0.2104, 0.0555, 0.8639, 0.4259], [0.7812, 0.6607, 0.1251, 0.6004], [0.6201, 0.1652, 0.2628, 0.6705], [0.5896, 0.2873, 0.3486, 0.9579]]) tensor([[0.2104, 0.7720, 0.8639, 0.7442], [0.5285, 0.6642, 0.6099, 0.6818], [0.7479, 0.1652, 0.7517, 0.6705], [0.5896, 0.5304, 0.3486, 0.7937]])
<a name="BPkxr"></a>#### tonser.gather
torch.gather
a = torch.linspace(1,16,16).view(4,4)
print(a)
out = torch.gather(a, dim = 0, index = torch.tensor([[0,1,1,1], [0,1,2,2], [0,1,3,3]])) print(out) print(out.shape)
————————————-
tensor([[ 1., 2., 3., 4.], [ 5., 6., 7., 8.], [ 9., 10., 11., 12.], [13., 14., 15., 16.]]) tensor([[ 1., 6., 7., 8.], [ 1., 6., 11., 12.], [ 1., 6., 15., 16.]]) torch.Size([3, 4])
<a name="wiHHm"></a>#### tonser.index_select
a = torch.rand(4,4)
b = torch.rand(4,4)
print(a) print(torch.index_select(a,dim = 0,index=torch.tensor([0,3,2]))) print(torch.index_select(a,dim = 1,index=torch.tensor([0,3,2])))
——————————————-
tensor([[0.4075, 0.7819, 0.7165, 0.1768], [0.0748, 0.9799, 0.5261, 0.8427], [0.6036, 0.6608, 0.8735, 0.9741], [0.1682, 0.5625, 0.8731, 0.8622]]) tensor([[0.4075, 0.7819, 0.7165, 0.1768], [0.1682, 0.5625, 0.8731, 0.8622], [0.6036, 0.6608, 0.8735, 0.9741]]) tensor([[0.4075, 0.1768, 0.7165], [0.0748, 0.8427, 0.5261], [0.6036, 0.9741, 0.8735], [0.1682, 0.8622, 0.8731]])
<a name="KQ6Ob"></a>#### tonser.mask_select
a = torch.linspace(1,16,16).view(4,4) mask = torch.gt(a,8) print(a) print(mask) out = torch.masked_select(a, mask) print(out)
————————————-
tensor([[ 1., 2., 3., 4.], [ 5., 6., 7., 8.], [ 9., 10., 11., 12.], [13., 14., 15., 16.]]) tensor([[False, False, False, False], [False, False, False, False], [ True, True, True, True], [ True, True, True, True]]) tensor([ 9., 10., 11., 12., 13., 14., 15., 16.])
<a name="LnW7o"></a>#### tonser.take
a = torch.linspace(1,16,16).view(4,4) b = torch.take(a,index = torch.tensor([0,15,13,10])) print(b)
————————
tensor([ 1., 16., 14., 11.])
<a name="Nhi94"></a>#### tonser.nonzero
a = torch.tensor([[0,1,2,0],[2,3,0,1]]) out = torch.nonzero(a) print(a) print(out)
——————————-
tensor([[0, 1, 2, 0], [2, 3, 0, 1]]) tensor([[0, 1], [0, 2], [1, 0], [1, 1], [1, 3]])
<a name="x8g62"></a>### 3-22 Pytorch与张量组合与拼接 (11:34)<a name="PKwad"></a>#### 1.Tensor的组合与拼接
cat
import torch a = torch.zeros((2, 4)) b = torch.ones((2, 4))
out = torch.cat((a,b),dim = 0) print(out)
out = torch.cat((a,b),dim = 1) print(out)
————————————————————
tensor([[0., 0., 0., 0.], [0., 0., 0., 0.], [1., 1., 1., 1.], [1., 1., 1., 1.]]) tensor([[0., 0., 0., 0., 1., 1., 1., 1.], [0., 0., 0., 0., 1., 1., 1., 1.]])
stack
a = torch.linspace(1,6,6).view(2, 3) b = torch.linspace(7,12,6).view(2, 3) print(a) print(b) out = torch.stack((a,b),dim=0) print(out) print(out.shape) out = torch.stack((a,b),dim=1) print(out) print(out.shape)
—————————————————————-
tensor([[1., 2., 3.], [4., 5., 6.]]) tensor([[ 7., 8., 9.], [10., 11., 12.]]) tensor([[[ 1., 2., 3.], [ 4., 5., 6.]],
[[ 7., 8., 9.],[10., 11., 12.]]])
torch.Size([2, 2, 3]) tensor([[[ 1., 2., 3.], [ 7., 8., 9.]],
[[ 4., 5., 6.],[10., 11., 12.]]])
torch.Size([2, 2, 3])
gather
<a name="rPOO6"></a>### <br />3-23 Pytorch与张量切片 (07:37)
import torch a = torch.rand((10,4)) print(a) out = torch.chunk(a,2,dim = 0) print(out[0],out[0].shape) print(out[1],out[1].shape)
————————————————-
tensor([[0.8212, 0.9891, 0.1500, 0.6211], [0.1303, 0.9269, 0.3060, 0.8012], [0.5149, 0.4611, 0.4840, 0.5850], [0.7357, 0.5802, 0.6525, 0.0502], [0.8643, 0.9359, 0.9133, 0.8696], [0.1392, 0.3146, 0.9409, 0.1192], [0.9536, 0.1068, 0.1478, 0.7444], [0.1408, 0.3854, 0.8637, 0.8960], [0.9729, 0.3985, 0.1114, 0.9923], [0.3935, 0.2943, 0.6219, 0.1503]]) tensor([[0.8212, 0.9891, 0.1500, 0.6211], [0.1303, 0.9269, 0.3060, 0.8012], [0.5149, 0.4611, 0.4840, 0.5850], [0.7357, 0.5802, 0.6525, 0.0502], [0.8643, 0.9359, 0.9133, 0.8696]]) torch.Size([5, 4]) tensor([[0.1392, 0.3146, 0.9409, 0.1192], [0.9536, 0.1068, 0.1478, 0.7444], [0.1408, 0.3854, 0.8637, 0.8960], [0.9729, 0.3985, 0.1114, 0.9923], [0.3935, 0.2943, 0.6219, 0.1503]]) torch.Size([5, 4])
out = torch.chunk(a,2,dim = 1) print(out[0],out[0].shape) print(out[1],out[1].shape)
————————————————-
tensor([[0.8212, 0.9891], [0.1303, 0.9269], [0.5149, 0.4611], [0.7357, 0.5802], [0.8643, 0.9359], [0.1392, 0.3146], [0.9536, 0.1068], [0.1408, 0.3854], [0.9729, 0.3985], [0.3935, 0.2943]]) torch.Size([10, 2]) tensor([[0.1500, 0.6211], [0.3060, 0.8012], [0.4840, 0.5850], [0.6525, 0.0502], [0.9133, 0.8696], [0.9409, 0.1192], [0.1478, 0.7444], [0.8637, 0.8960], [0.1114, 0.9923], [0.6219, 0.1503]]) torch.Size([10, 2])
```out = torch.split(a,2,dim=0)print(out)#-----------------------------(tensor([[0.8212, 0.9891, 0.1500, 0.6211],[0.1303, 0.9269, 0.3060, 0.8012]]), tensor([[0.5149, 0.4611, 0.4840, 0.5850],[0.7357, 0.5802, 0.6525, 0.0502]]), tensor([[0.8643, 0.9359, 0.9133, 0.8696],[0.1392, 0.3146, 0.9409, 0.1192]]), tensor([[0.9536, 0.1068, 0.1478, 0.7444],[0.1408, 0.3854, 0.8637, 0.8960]]), tensor([[0.9729, 0.3985, 0.1114, 0.9923],[0.3935, 0.2943, 0.6219, 0.1503]]))out = torch.split(a,3,dim=0)print(out)print(len(out))#--------------------------(tensor([[0.8212, 0.9891, 0.1500, 0.6211],[0.1303, 0.9269, 0.3060, 0.8012],[0.5149, 0.4611, 0.4840, 0.5850]]), tensor([[0.7357, 0.5802, 0.6525, 0.0502],[0.8643, 0.9359, 0.9133, 0.8696],[0.1392, 0.3146, 0.9409, 0.1192]]), tensor([[0.9536, 0.1068, 0.1478, 0.7444],[0.1408, 0.3854, 0.8637, 0.8960],[0.9729, 0.3985, 0.1114, 0.9923]]), tensor([[0.3935, 0.2943, 0.6219, 0.1503]]))out = torch.split(a,[1,3,6],dim=0)for t in out:print(t,t.shape)#-----------------------------tensor([[0.8212, 0.9891, 0.1500, 0.6211]]) torch.Size([1, 4])tensor([[0.1303, 0.9269, 0.3060, 0.8012],[0.5149, 0.4611, 0.4840, 0.5850],[0.7357, 0.5802, 0.6525, 0.0502]]) torch.Size([3, 4])tensor([[0.8643, 0.9359, 0.9133, 0.8696],[0.1392, 0.3146, 0.9409, 0.1192],[0.9536, 0.1068, 0.1478, 0.7444],[0.1408, 0.3854, 0.8637, 0.8960],[0.9729, 0.3985, 0.1114, 0.9923],[0.3935, 0.2943, 0.6219, 0.1503]]) torch.Size([6, 4])
3-24 Pytorch与张量变形 (14:09)
1.常见的Tensor变形操作

import torcha = torch.rand((2,3))print(a)out = a.reshape(3,2)print(out)#---------------------------tensor([[0.8286, 0.8134, 0.1033],[0.0893, 0.4562, 0.7100]])tensor([[0.8286, 0.8134],[0.1033, 0.0893],[0.4562, 0.7100]])#转置print(torch.t(out))#----------------------tensor([[0.8286, 0.1033, 0.4562],[0.8134, 0.0893, 0.7100]])#指定交换维度print(torch.transpose(out,0,1))#--------------------------------------tensor([[0.9521, 0.1984, 0.3824],[0.0812, 0.2137, 0.9961]])a = torch.rand(1,2,3)out = torch.transpose(a,1,0)print(a)print(out)print(out.shape)#-----------------------------tensor([[[0.4855, 0.2465, 0.5114],[0.0300, 0.1466, 0.1672]]])tensor([[[0.4855, 0.2465, 0.5114]],[[0.0300, 0.1466, 0.1672]]])torch.Size([2, 1, 3])out = torch.squeeze(a)print(out)print(out.shape)out = torch.unsqueeze(a,-1)print(out.shape)#---------------------------------tensor([[0.4855, 0.2465, 0.5114],[0.0300, 0.1466, 0.1672]])torch.Size([2, 3])torch.Size([1, 2, 3, 1])out = torch.unbind(a,dim = 1)print(out)#----------------------------------(tensor([[0.4855, 0.2465, 0.5114]]), tensor([[0.0300, 0.1466, 0.1672]]))print(a)print(torch.flip(a,dims=[1,2]))#-------------------------------tensor([[[0.4855, 0.2465, 0.5114],[0.0300, 0.1466, 0.1672]]])tensor([[[0.1672, 0.1466, 0.0300],[0.5114, 0.2465, 0.4855]]])a = torch.rand((2,3))print(a)print(torch.rot90(a))#----------------------------tensor([[0.9118, 0.9408, 0.3302],[0.5224, 0.7230, 0.5599]])tensor([[0.3302, 0.5599],[0.9408, 0.7230],[0.9118, 0.5224]])print(torch.rot90(a,2))#默认逆时针#--------------------------------------tensor([[0.5599, 0.7230, 0.5224],[0.3302, 0.9408, 0.9118]])
3-25 Pytorch与张量填充&傅里叶变换 (03:27)
1.张量填充

import torcha = torch.full((2,3),10)print(a)#----------------------tensor([[10, 10, 10],[10, 10, 10]])
2.傅里叶变换

3-26 Pytorch简单编程技巧 (11:33)
1.模型的保存与加载

并行化操作
加快数据处理速度
分布式
CPU计算与GPU计算

2.实例
pip install -i https://pypi.douban.com/simple torch==1.5.0import torchimport numpy as npimport cv2# GPU计算data = cv2.imread('test.png')#print(data)cv2.imshow('test1',data)cv2.waitKey(0)out = torch.from_numpy(data) # out = torch.Tensor(data)out = out.to(torch.device("cuda"))print(out.is_cuda)# print(out) # Trueout = torch.flip(out,dims=[0])data = out.numpy()print(data)print(out)print(data)cv2.imshow('test2',data)cv2.waitKey(0)out = out.to(torch.device("cpu"))print(out.is_cuda)
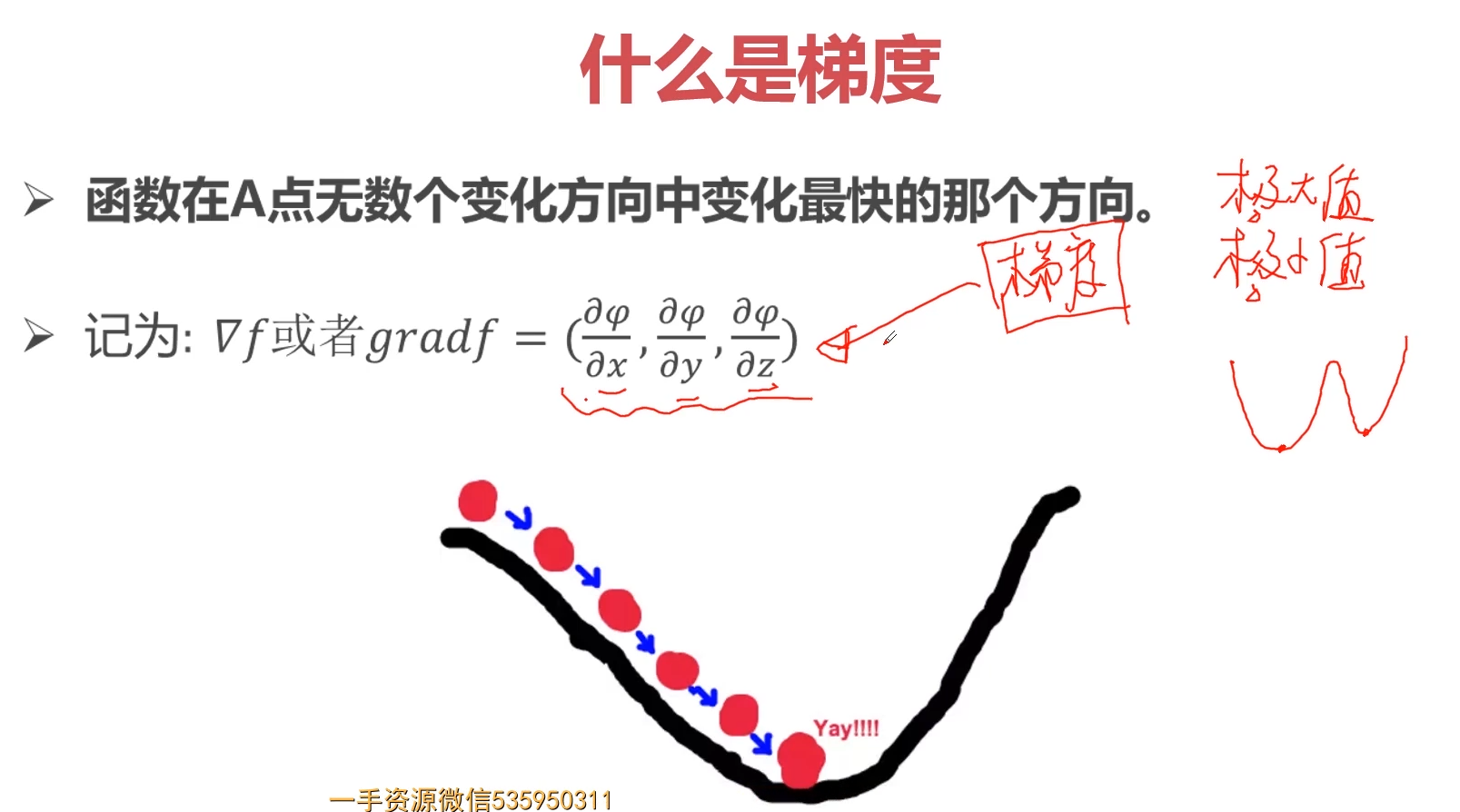
3-27 Pytorch与autograd-导数-方向导数-偏导数-梯度的概念 (10:02)
1.导数
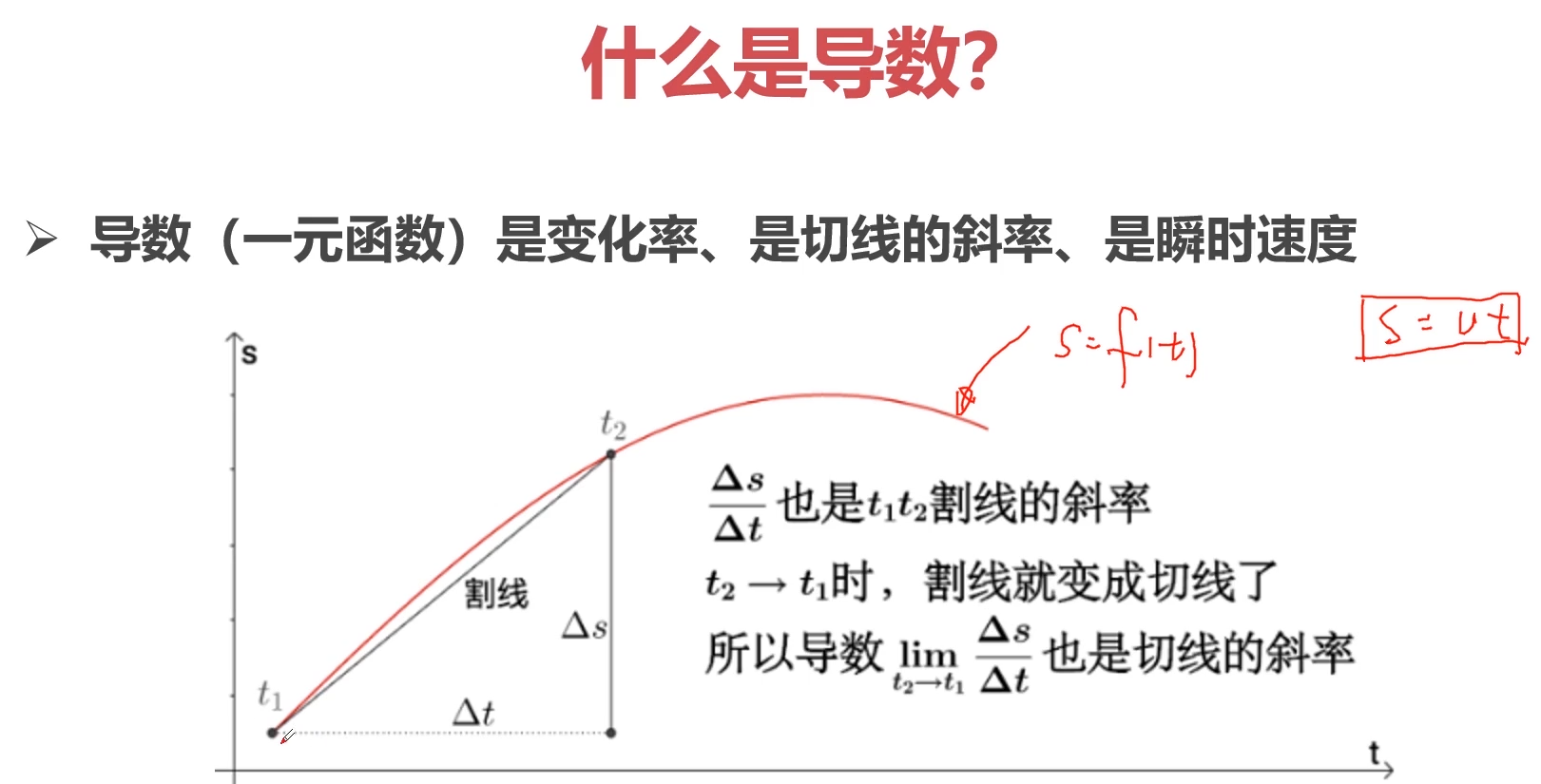
2.方向导数
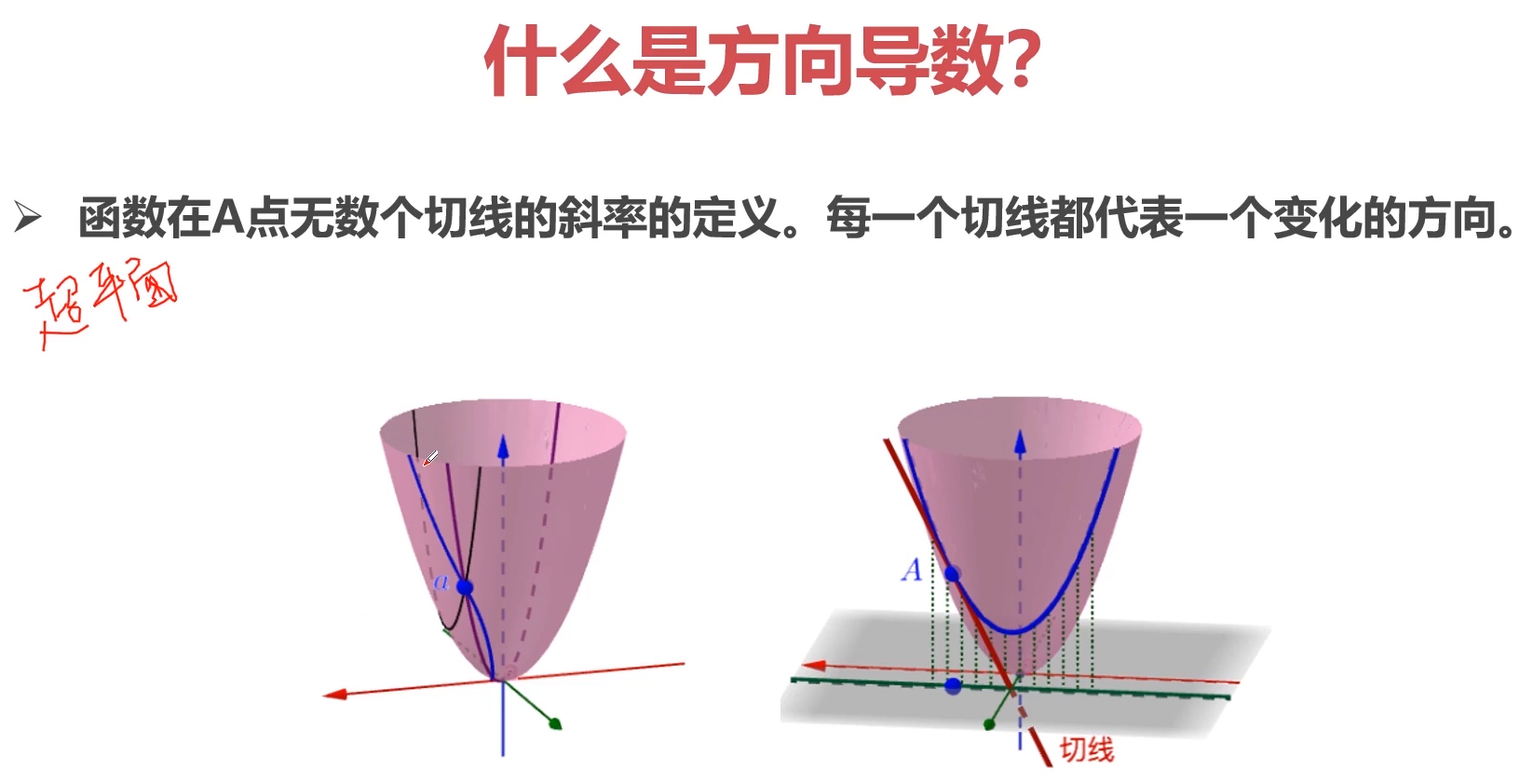
3.偏导数

4.梯度
5.各种函数的求导问题




3-28 Pytorch与autograd-梯度与机器学习最优解 (12:46)
1. 监督学习与无监督学习与半监督学习

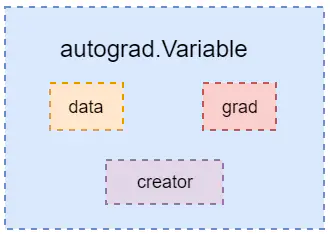
3-29 Pytorch与autograd-Variable$tensor (02:57)
Variable是PyTorch的另一个基本对象,可以把它理解为是对Tensor的一个封装。Variable用于放入计算图中进行前向传播、反向传播和自动求导,如下图所示。
在一个Variable中有三个重要属性:data、grad和creator。其中,
data表示包含的Tensor数据部分;grad表示传播方向的梯度,这个属性是延迟分配的,而且仅允许进行一次;creator表示创建这个Variable的Function的引用,该引用用户回溯整个创建链路。如果是用户创建的Variable,其creator为None,同时这种Variable称为Leaf Variable,autograd只会给Leaf Variable分配梯度。
from torch.autograd import variableimport torchx = torch.rand(4)x = variable(x, requires_grad = True)y = x * 3grad_variables = torch.FloatTensor([1,2,3,4])y.backward(grad_variables)x.grad#-------------------------------tensor([ 3., 6., 9., 12.])
对于y.backward(grad_variables),grad_variables就是y求导时的梯度参数,由于autograd仅用于标量,因此当y不是标量而且在声明时使用了requires_grad = True时,必须指定grad_variables参数,然后将结果保存至Variable的grad中。grad_variables的长度要与y的长度一致。在深度学习中求导与梯度有关,因此grad_variables一般会定义类似为[1, 0.1, 0.01, 0.001],表示梯度的方向,求较小的值不会对求导效率有影响。
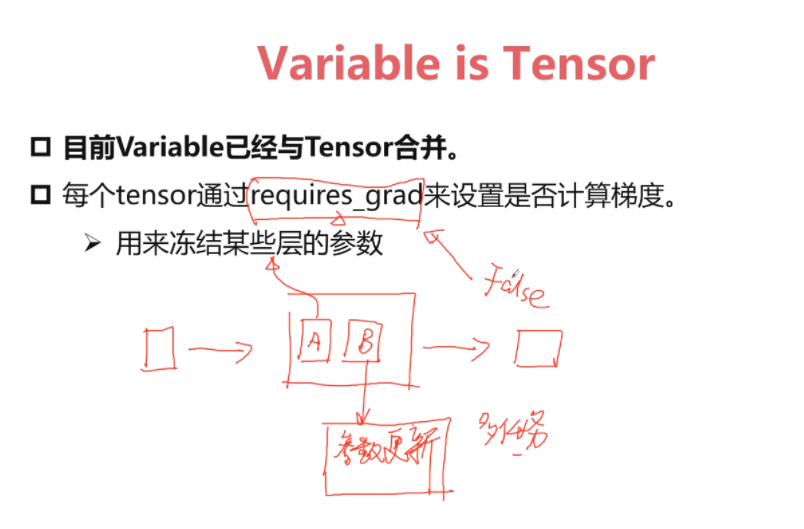
Variable与Tensor类(合并)
3-30 Pytorch与autograd-如何计算梯度 (03:04)
1.如何计算梯度

3-31 Pytorch与autograd中的几个重要概念-variable-grad-grad_fn (10:32)
只有叶子张量才有梯度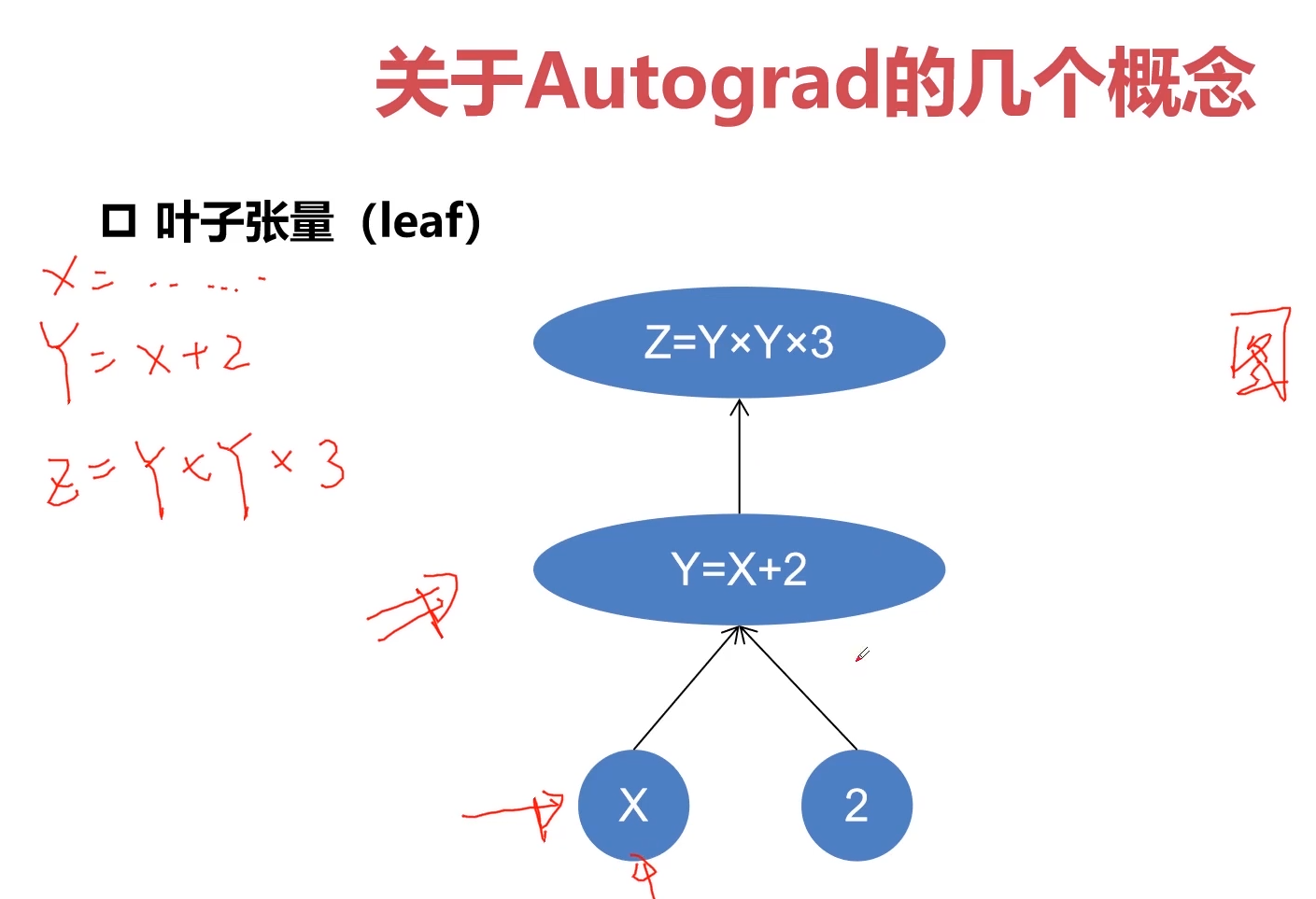
grad VS frad fn

backward函数


torch.autograd.grad()函数

torch.autograd()

torch.autograd.Function

import torchclass line(torch.autograd.Function):@staticmethoddef forward(ctx,w,x,b):#y = w*x + bctx.save_for_backward(w,x,b)return w * x + b@staticmethoddef backward(ctx,grad_out):w,x,b = ctx.saved_tensorsgrad_w = grad_out * xgrad_x = grad_out * wgrad_b = grad_outreturn grad_w,grad_x,grad_bw = torch.rand(2,2,requires_grad=True)x = torch.rand(2,2,requires_grad=True)b = torch.rand(2,2,requires_grad=True)out = line.apply(w,x,b)out.backward(torch.ones(2,2))print(w,x,b)print(w.grad,x.grad,b.grad)#————————————————tensor([[0.9371, 0.2165],[0.9892, 0.6237]], requires_grad=True) tensor([[0.1679, 0.7737],[0.1267, 0.9620]], requires_grad=True) tensor([[0.1786, 0.6414],[0.6523, 0.6189]], requires_grad=True)tensor([[0.1679, 0.7737],[0.1267, 0.9620]]) tensor([[0.9371, 0.2165],[0.9892, 0.6237]]) tensor([[1., 1.],[1., 1.]])
3-32 Pytorch与autograd中的几个重要概念-autograd例子 (14:15)
1.叶子张量
只有叶子张量才有梯度
2.grad VS grad_fn
3.backwward函数


4.torch.autograd.grad()函数

5.torch.autograd包中的其他函数

6.torch.autograd.Function

import torchclass line(torch.autograd.Function):@staticmethoddef forward(ctx,w,x,b):#y = w*x + bctx.save_for_backward(w,x,b)return w * x + b@staticmethoddef backward(ctx,grad_out):w,x,b = ctx.saved_tensorsgrad_w = grad_out * xgrad_x = grad_out * wgrad_b = grad_outreturn grad_w,grad_x,grad_bw = torch.rand(2,2,requires_grad=True)x = torch.rand(2,2,requires_grad=True)b = torch.rand(2,2,requires_grad=True)out = line.apply(w,x,b)out.backward(torch.ones(2,2))print(w,x,b)print(w.grad,x.grad,b.grad) # x.的导数;#--------------------------------------tensor([[0.1788, 0.5433],[0.1255, 0.3669]], requires_grad=True) tensor([[0.0218, 0.6001],[0.9676, 0.0454]], requires_grad=True) tensor([[0.2679, 0.1733],[0.4605, 0.2411]], requires_grad=True)tensor([[0.0218, 0.6001],[0.9676, 0.0454]]) tensor([[0.1788, 0.5433],[0.1255, 0.3669]]) tensor([[1., 1.],[1., 1.]])
3-33 Pytorch与autograd中的几个重要概念-function (08:18)
3-34 Pytorch与nn库 (19:46)
1.nn库

2.nn.Parameter参数

3.nn.ParameterList
4.nn.Linear&nn.conv2d

nn.Linear
线性连接层又叫做全连接层(fully connected layer),指的是通过矩阵乘法将前一层的矩阵变换为下一层的矩阵:fc = nn.Linear(input_size, output_size)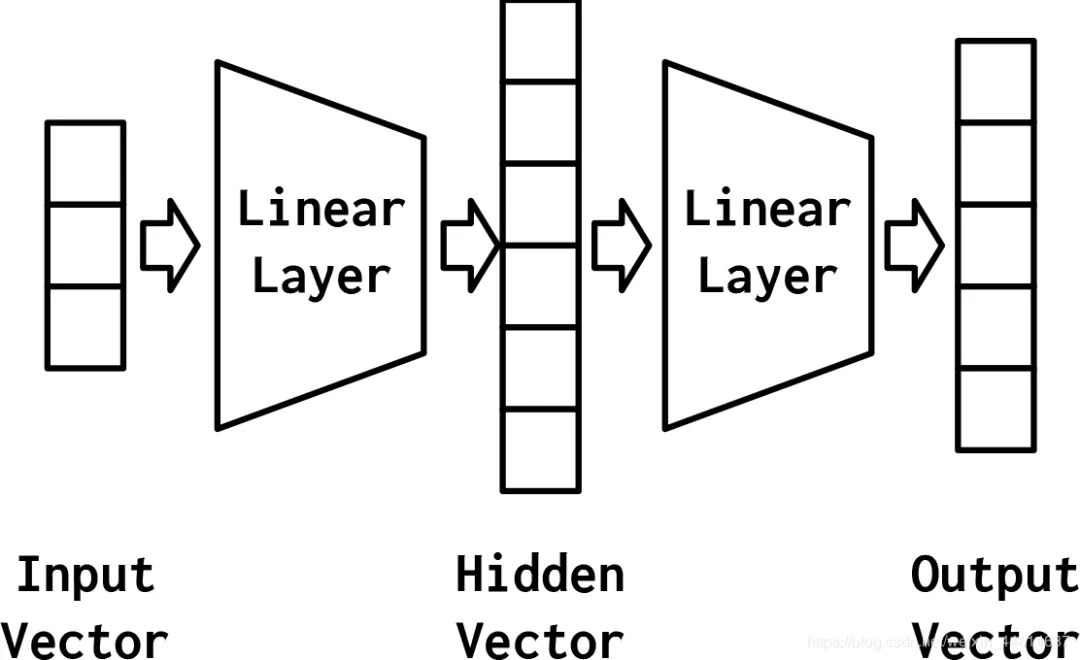
可见若干层全连接层相连,最终可以化简为一个全连接层,因此 MLP 的性能非常有限。为了解决这个问题,激活函数(activation function)出现了。
nn.Conv2d
参考:1.Pytorch的nn.Conv2d()详解
Pytroch中的Conv2D是构建卷积神经网络常用的函数,支持的输入数据是四维的tensor对象,格式为NCHW,其中N表示样本数目、C表示通道数目彩色图像为3,灰度图像为1、H跟W分别表示图像高与宽。它们的计算方法可以图示如下: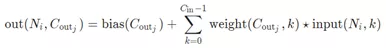
# 前三个参数是必须手动提供的,后面的有默认值torch.nn.Conv2d(in_channels, // 输入通道数out_channels, // 输出通道数kernel_size, // 卷积核大小()stride=1, // 步长padding=0, // 图像填充:padding = 1为例,若原始图像大小为32x32-》34x34dilation=1, // 空洞卷积支持groups=1, // 分组卷积支持bias=True, // 偏置padding_mode='zeros' // 填0)torch.nn.functional.conv2d(input, // 输入数据weight, // 卷积核bias=None, // 偏置stride=1, // 步长padding=0, // 填充dilation=1, // 空洞groups=1 // 分组)
其中torch.nn.Conv2d主要是在各种组合的t.nn.Sequential中使用,构建CNN模型。torch.nn.functional.conv2d更多是在各种自定义中使用,需要明确指出输入与权重filters参数。
5.nn.functional


6.nn.Sequential
一个有序的容器,神经网络模块将按照在传入构造器的顺序依次被添加到计算图中执行,同时以神经网络模块为元素的有序字典也可以作为传入参数。

7.nn.ModuleList
8.nn.ModuleDict

9.nn.Module




归一化层方法
参考:1. PyTorch学习之归一化层 https://blog.csdn.net/shanglianlm/article/details/85075706
归一化层,目前主要有这几个方法,Batch Normalization(2015年)、Layer Normalization(2016年)、Instance Normalization(2017年)、Group Normalization(2018年)、Switchable Normalization(2019年);
将输入的图像shape记为[N, C, H, W],这几个方法主要的区别就是在,
- batchNorm是在batch上,对NHW做归一化,对小batchsize效果不好;
- layerNorm在通道方向上,对CHW归一化,主要对RNN作用明显;
- instanceNorm在图像像素上,对HW做归一化,用在风格化迁移;
- GroupNorm将channel分组,然后再做归一化;
- SwitchableNorm是将BN、LN、IN结合,赋予权重,让网络自己去学习归一化层应该使用什么方法。
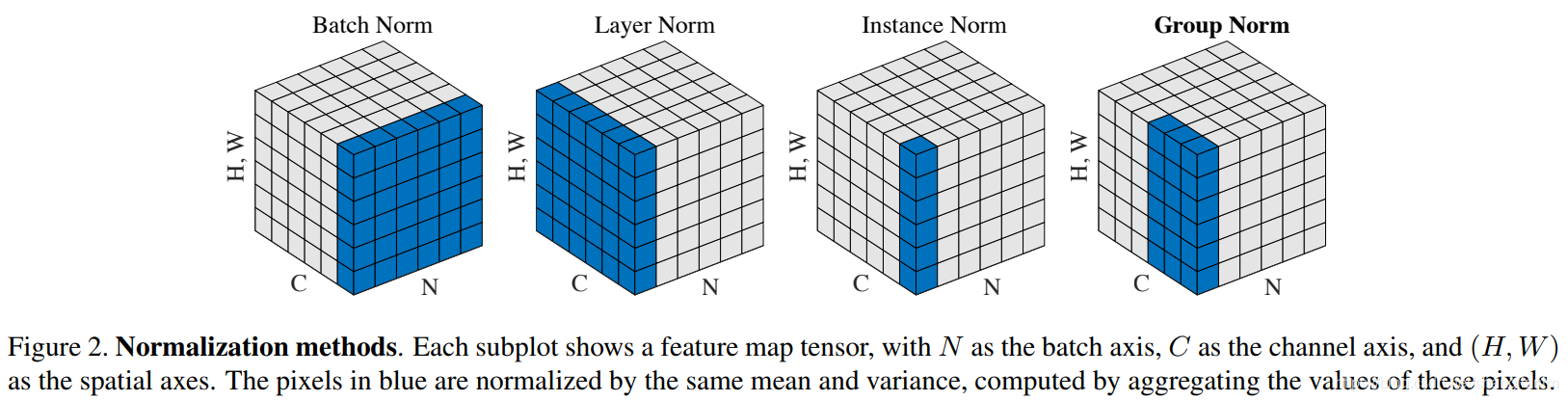
BN,LN,IN,GN从学术化上解释差异:
BatchNorm:batch方向做归一化,算NHW的均值,对小batchsize效果不好;BN主要缺点是对batchsize的大小比较敏感,由于每次计算均值和方差是在一个batch上,所以如果batchsize太小,则计算的均值、方差不足以代表整个数据分布
LayerNorm:channel方向做归一化,算CHW的均值,主要对RNN作用明显;
InstanceNorm:一个channel内做归一化,算HW的均值,用在风格化迁移;因为在图像风格化中,生成结果主要依赖于某个图像实例,所以对整个batch归一化不适合图像风格化中,因而对HW做归一化。可以加速模型收敛,并且保持每个图像实例之间的独立。
GroupNorm:将channel方向分group,然后每个group内做归一化,算(C//G)HW的均值;这样与batchsize无关,不受其约束。
S*witchableNorm是将BN、LN、IN结合,赋予权重,让网络自己去学习归一化层应该使用什么方法。
[
](https://blog.csdn.net/shanglianlm/article/details/85075706)
1.InstanceNorm
torch.nn.InstanceNorm1d(num_features, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)num_features: 来自期望输入的特征数,该期望输入的大小为’batch_size x num_features [x width]’eps: 为保证数值稳定性(分母不能趋近或取0),给分母加上的值。默认为1e-5。momentum: 动态均值和动态方差所使用的动量。默认为0.1。affine: 布尔值,当设为true,给该层添加可学习的仿射变换参数。track_running_stats:布尔值,当设为true,记录训练过程中的均值和方差;
2.BatchNorm
torch.nn.BatchNorm1d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)num_features: 来自期望输入的特征数,该期望输入的大小为’batch_size x num_features [x width]’eps: 为保证数值稳定性(分母不能趋近或取0),给分母加上的值。默认为1e-5。momentum: 动态均值和动态方差所使用的动量。默认为0.1。affine: 布尔值,当设为true,给该层添加可学习的仿射变换参数。track_running_stats:布尔值,当设为true,记录训练过程中的均值和方差;
激活函数
参考:1.美!最常用的10个激活函数!
2.深度学习领域最常用的10个激活函数,一文详解数学原理及优缺点;
激活函数(Activation Function)是一种添加到人工神经网络中的函数,旨在帮助网络学习数据中的复杂模式。类似于人类大脑中基于神经元的模型,激活函数最终决定了要发射给下一个神经元的内容。
在人工神经网络中,一个节点的激活函数定义了该节点在给定的输入或输入集合下的输出。标准的计算机芯片电路可以看作是根据输入得到开(1)或关(0)输出的数字电路激活函数。因此,激活函数是确定神经网络输出的数学方程式,本文概述了深度学习中常见的十种激活函数及其优缺点。
激活函数就是非线性连接层,通过非线性函数将一层变为另一层。常用的激活函数有 sigmoid,tanh,relu 及其变种。虽然 torch.nn 有激活函数层,因为激活函数比较轻量级,使用 torch.nn.functional 里的函数功能就足够了。通常我们将 torch.nn.functional 写成 F: import torch.nn.functional as F
ReLU
参考:1.原来ReLU这么好用!一文带你深度了解ReLU激活函数!
ReLU 是一个分段线性函数,如果输入为正,它将直接输出,否则,它将输出为零。它已经成为许多类型神经网络的默认激活函数,因为使用它的模型更容易训练,并且通常能够获得更好的性能。
Rectified Linear Unit(relu) 缓解了上述两个激活函数容易产生梯度消失的问题。它实际上是一个分段函数:
relu 的优点在于求导非常方便,而且非常稳定:
if input > 0:return inputelse:return 0
F.sigmoid
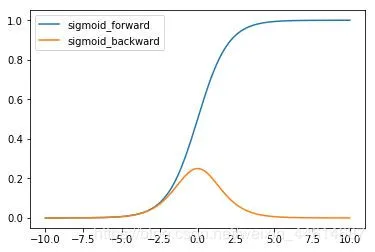
sigmoid 函数的特点为:
- 函数的值在0,1 之间,符合概率分布;
- 导数的值域为0,0.25 ,容易造成梯度消失;
- 输出为非对称正值,破坏数据分布。
F.tanh
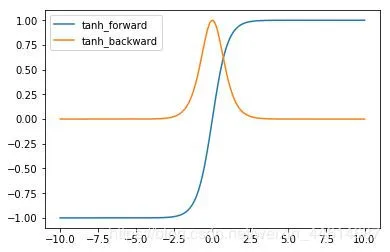
导数的值域为 (0,1)。tanh 的特点为:
- 函数值域为(0,1) ,对称分布;
- 导数值域为(0,1) ,容易造成梯度消失。
3-35 Pytorch与visdom(调试工具)
1.Visdom介绍

2.Visdom 安装:

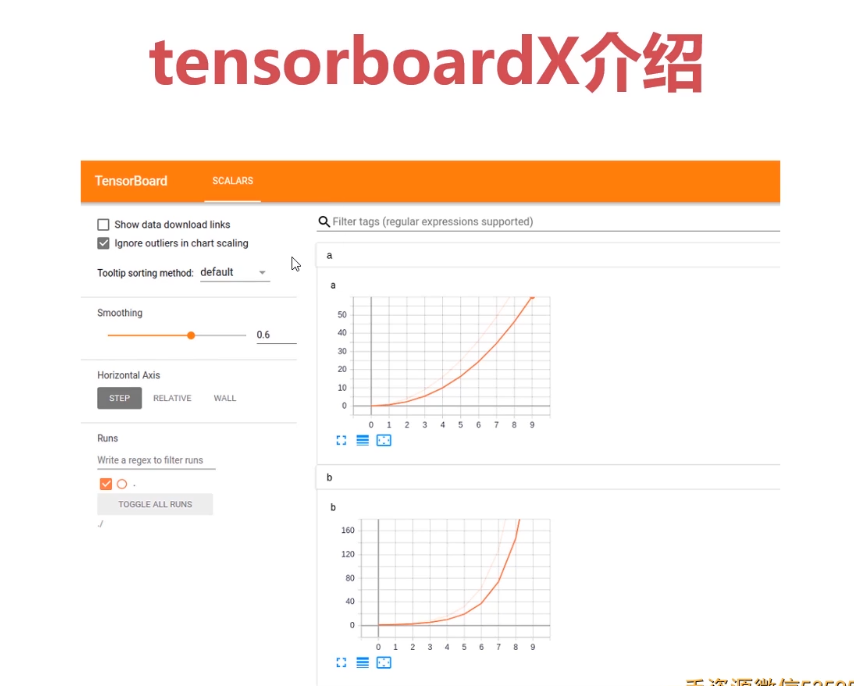
3-36 Pytorch与tensorboardX (05:57)
1.tensorboardX 介绍

安装
执行命令如下。不能用conda命令安装,别问我为啥,反正我没用conda安装成功。
pip install tensorflow
pip install tensorflow -i https://pypi.douban.com/simple
pip install tensorboardX
https://zhuanlan.zhihu.com/p/97585876
2.1首先建立一个文件夹log
运行一下脚本
from tensorboardX import SummaryWriterwriter = SummaryWriter("log")for i in range(100):writer.add_scalar("a",i,global_step = i)writer.add_scalar("b",i ** 2,global_step = i)writer.close()
在终端输入如下命令
(pytorch_gpu) E:\pytorch>cd log系统找不到指定的路径。(pytorch_gpu) E:\pytorch>cd 003(pytorch_gpu) E:\pytorch\003>cd log(pytorch_gpu) E:\pytorch\003\log>tensorboard --logdir ./2021-01-28 23:28:35.357052: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfullyopened dynamic library cudart64_101.dllServing TensorBoard on localhost; to expose to the network, use a proxy or pass --bind_allTensorBoard 2.2.2 at http://localhost:6006/ (Press CTRL+C to quit)http://localhost:6006/#scalars
http://localhost:6006/#scalars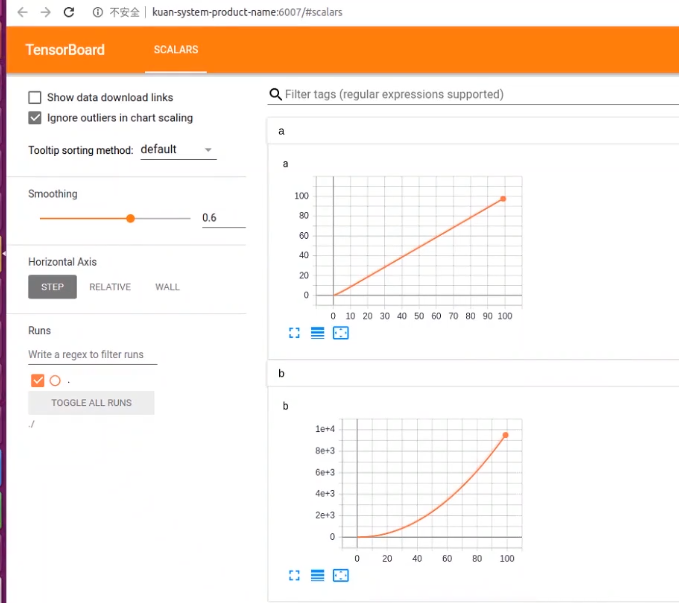
3-37 Pytorch与torchvision
1.torchvision介绍

第4章 PyTorch搭建简单神经网络
主要介绍机器学习建模思维、神经网络基本概念以及PyTorch解决机器学习问题时搭建模型的基本组成模块,并使用PyTorch搭建简单的神经网络结构,完成手写数字识别和波士顿房价预测,两种不同问题(分类和回归)的数据处理、模型搭建、模型训练等不同过程。通过这个过程帮助大家梳理PyTorch搭建神经网络的基本流程,为后续解决…
4-1 机器学习和神经网络的基本概念1
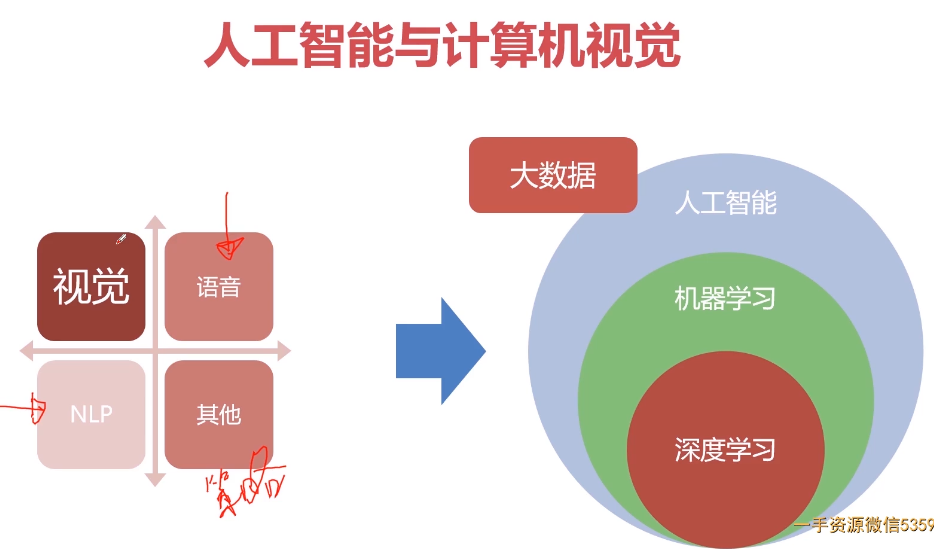
人工智能、机器学习、深度学习之间的关系
总结:机器学习是人工智能一个子领域,神经网络和深度学习是机器学习的子领域。深度学习源自于人工神经网络的研究,神经网络构成了深度学习算法的支柱,但是并不完全等于深度学习。
人工智能即为机器赋予人的智能,机器学习是人工智能的一种实现方式,也是最重要的实现方式,机器学习的方法也被大量的应用于解决人工智能的问题。
神经网络是机器学习众多算法中的一种,设计的时候就是模仿人脑的处理方式,希望其可以按人类大脑的逻辑运行,尽管目前来说对人脑的研究仍不够透彻。
深度学习是机器学习研究中一个新的但特别重要的领域,其动机在于建立、模拟人脑进行分析和学习的神经网络,它模仿人脑的机制来解释数据,例如图像、声音和文本。
神经网络和深度学习并不等价。深度学习可以采用神经网络模型,也可以采用其他模型(比如深度信念网络是一种概率图模型)。但是,由于神经网络模型可以比较容易地解决贡献度分配问题,因此神经网络模型成为深度学习中主要采用的模型。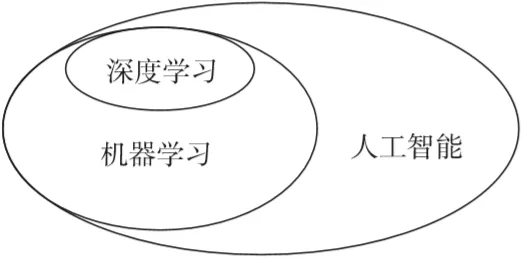
1.神经网络
神经网络是机器学习中的一个重要算法,也是深度学习发展的基础算法,它的思想影响了深度学习,使得深度学习成为了人工智能中极为重要的技术之一。
神经网络作为一种常用的方法,是一种通过模仿生物的神经网络结构和功能的数学模型,也是一种自适应的计算模型。它通过感知外部信息的变化来改变系统的内部结构。神经网络由许多的神经元组成,神经元之间相互联系构成处理信息的庞大网络。神经网络模型一般比较复杂,从输入到输出的信息传递路径一般比较长,所以复杂神经网络的学习可以看成是一种深度的机器学习即深度学习。
神经网络的优势在于它是一个能够通过现有数据进行自我学习、总结、归纳的系统,能够推理产生一个智能识别系统,从而成为人工智能技术中的重要基石。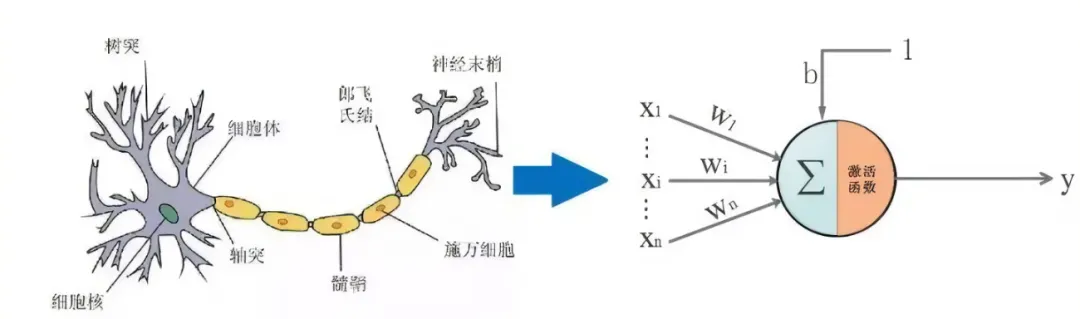
参考:
神经网络原来这么简单,机器学习入门贴送给你 | 干货
神经网络浅讲:从神经元到深度学习
连接是神经元中最重要的东西。每一个连接上都有一个权重。
一个神经网络的训练算法就是让权重的值调整到最佳,以使得整个网络的预测效果最好。
神经网络是多层网络结构构造的结果
神经网络的运算是逐层运算的结果、
参数的求解过程:w, b
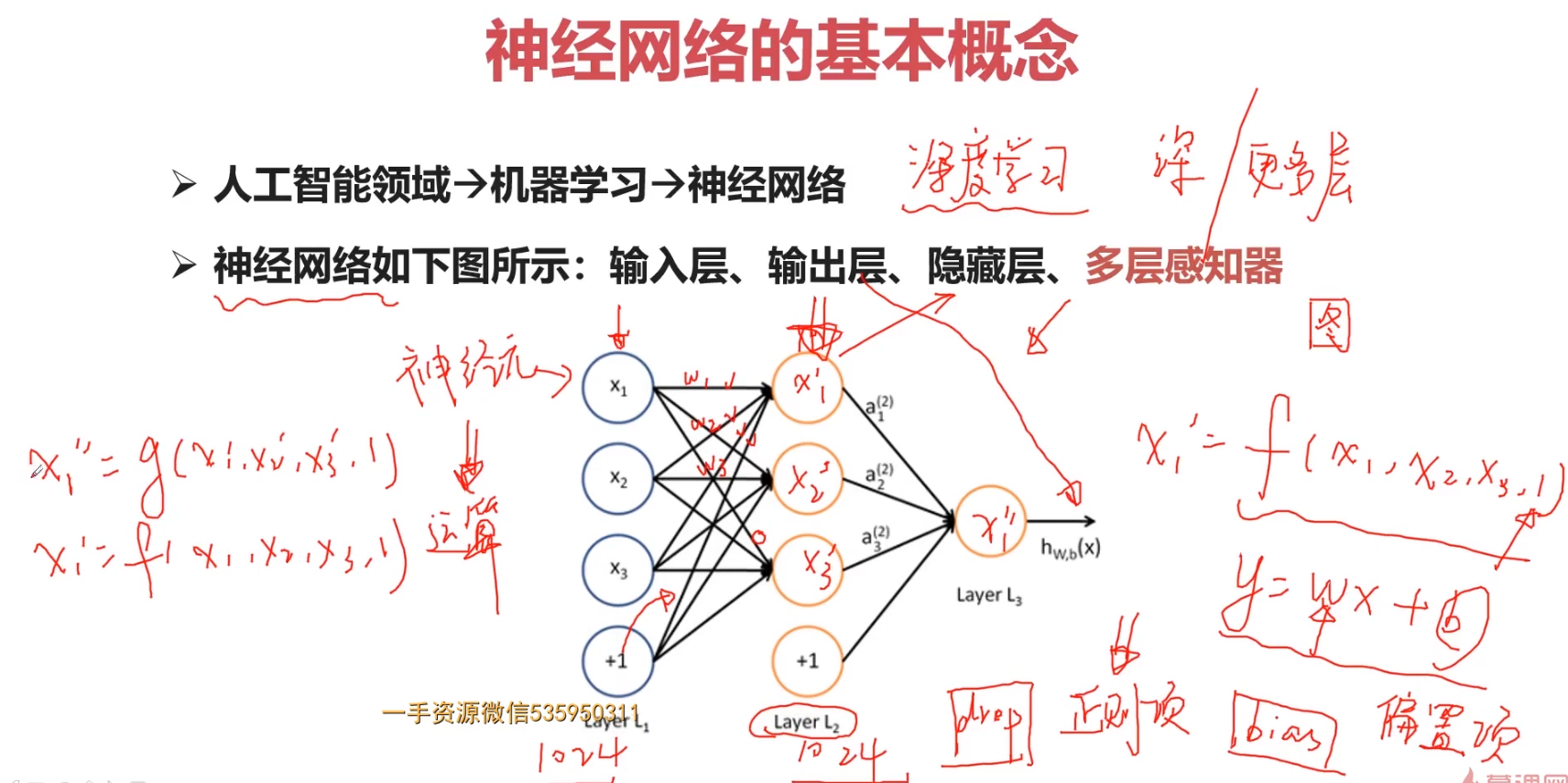
神经元模型的使用可以这样理解:
我们有一个数据,称之为样本。样本有四个属性,其中三个属性已知,一个属性未知。我们需要做的就是通过三个已知属性预测未知属性。
具体办法就是使用神经元的公式进行计算。三个已知属性的值是a1,a2,a3,未知属性的值是z。z可以通过公式计算出来。
这里,已知的属性称之为特征,未知的属性称之为目标。假设特征与目标之间确实是线性关系,并且我们已经得到表示这个关系的权值w1,w2,w3。那么,我们就可以通过神经元模型预测新样本的目标。
2.感知器的基本概念
在原来MP模型的“输入”位置添加神经元节点,标志其为“输入单元”。其余不变
在“感知器”中,有两个层次。分别是输入层和输出层。输入层里的“输入单元”只负责传输数据,不做计算。输出层里的“输出单元”则需要对前面一层的输入进行计算。假如我们要预测的目标不再是一个值,而是一个向量,例如[2,3]。那么可以在输出层再增加一个“输出单元”。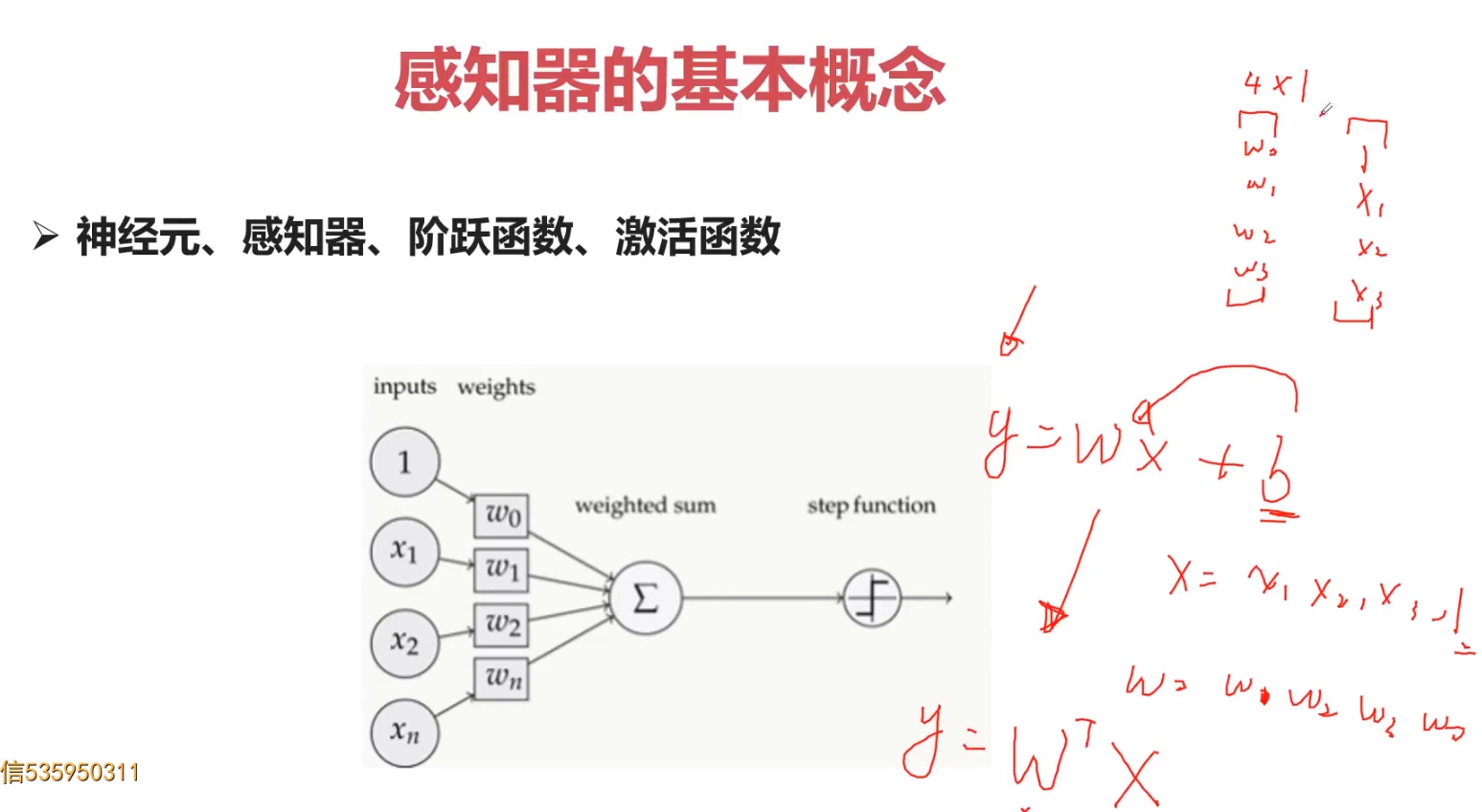
与神经元模型不同,感知器中的权值是通过训练得到的。因此,根据以前的知识我们知道,感知器类似一个逻辑回归模型,做线性分类任务。
单层网络只能做线性分类任务。而两层神经网络中的后一层也是线性分类层,应该只能做线性分类任务。为什么两个线性分类任务结合就可以做非线性分类任务?
3.神经网络与深度学习
深度学习:隐藏层之间更丰富的结构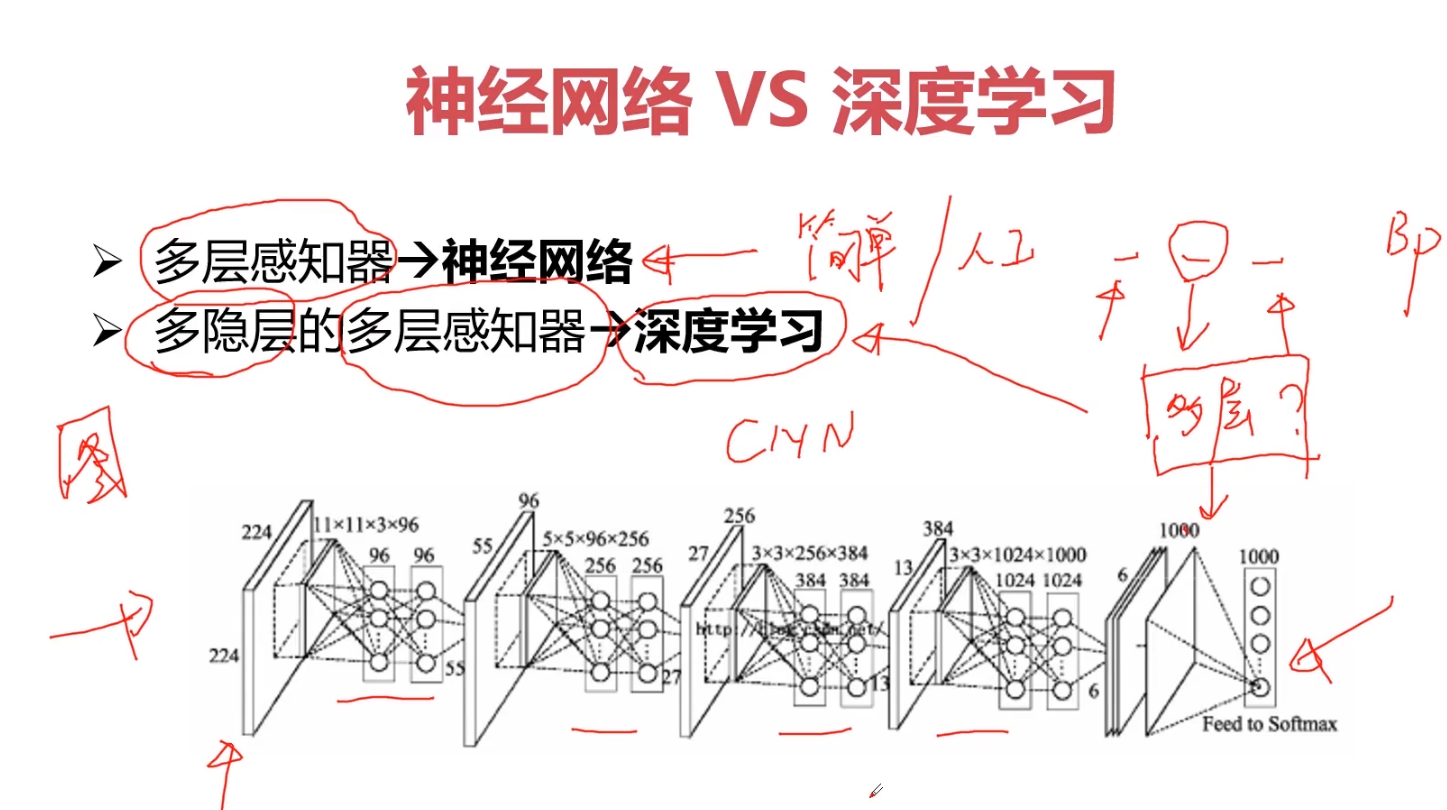
4.前向传播
卷积层、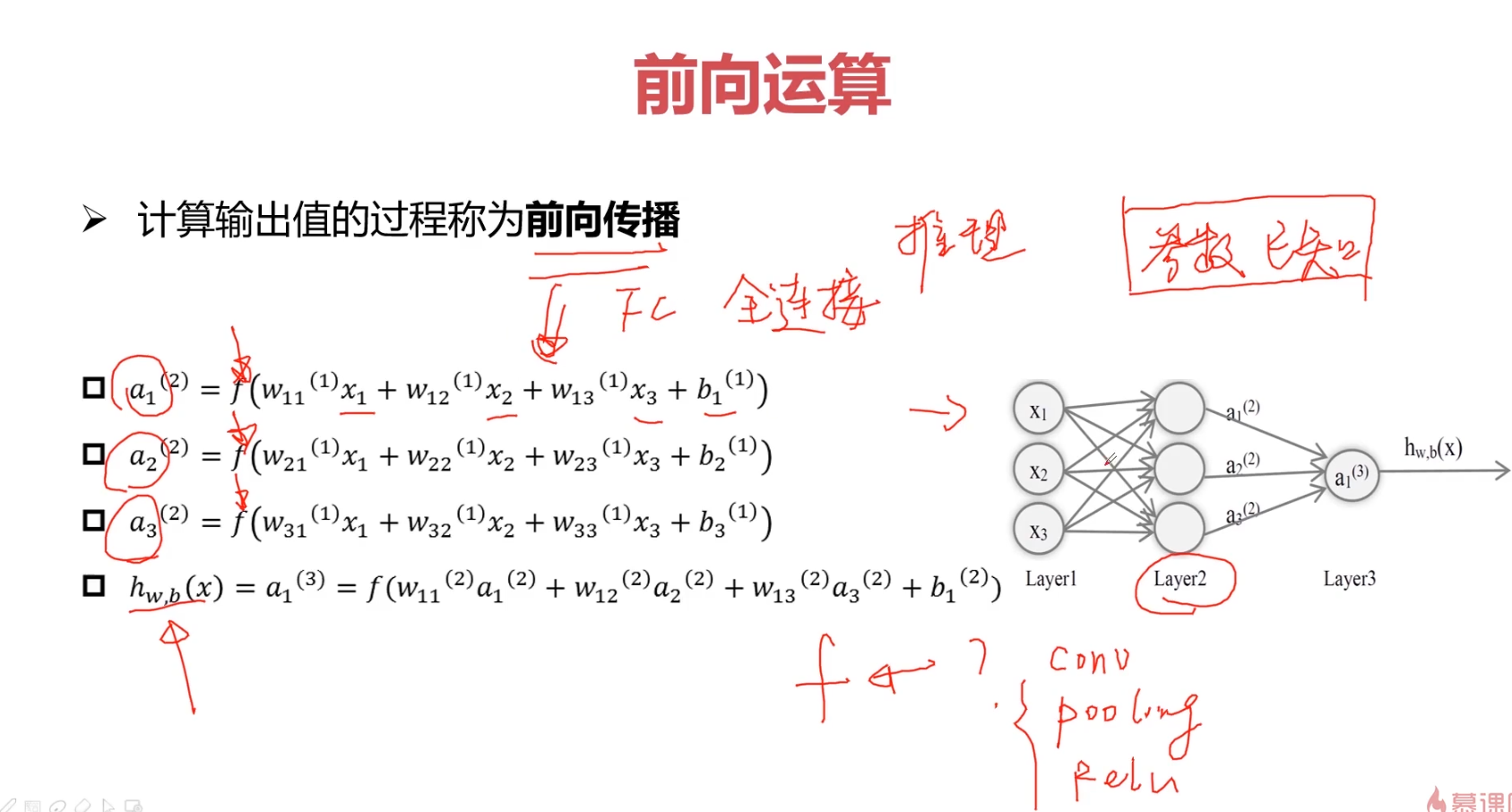
5.反向传播
此时这个问题就被转化为一个优化问题。一个常用方法就是高等数学中的求导,但是这里的问题由于参数不止一个,求导后计算导数等于0的运算量很大,所以一般来说解决这个优化问题使用的是梯度下降算法。梯度下降算法每次计算参数在当前的梯度,然后让参数向着梯度的反方向前进一段距离,不断重复,直到梯度接近零时截止。一般这个时候,所有的参数恰好达到使损失函数达到一个最低值的状态。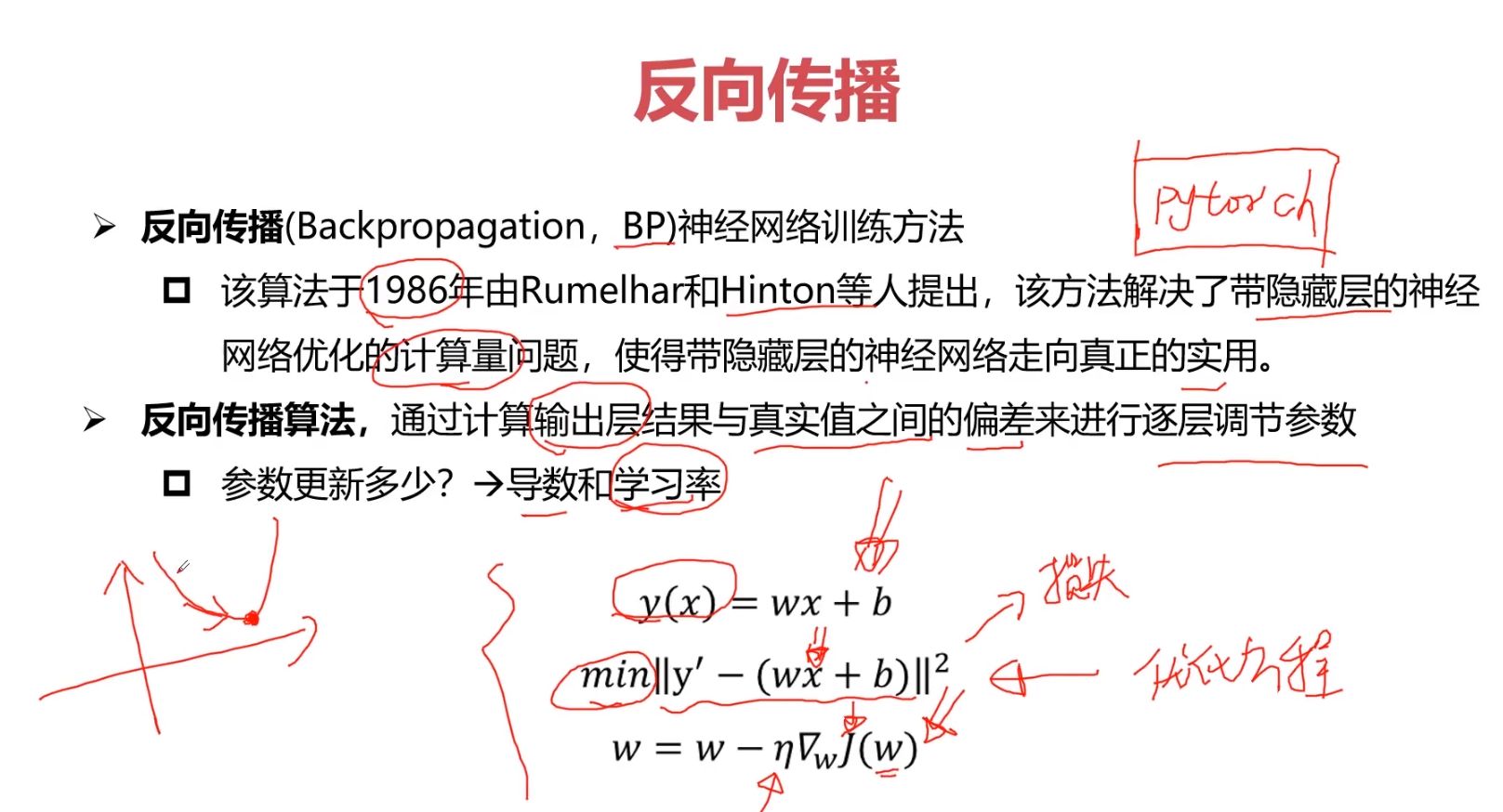
导数的求导公式

4-2 机器学习和神经网络的基本概念2
4-3 利用神经网络解决分类和回归问题1
1.分类和回归问题
分类模型和回归模型本质一样,
分类模型可将回归模型的输出离散化,
回归模型也可将分类模型的输出连续化
分类: 图像识别;
回归:目标检测;
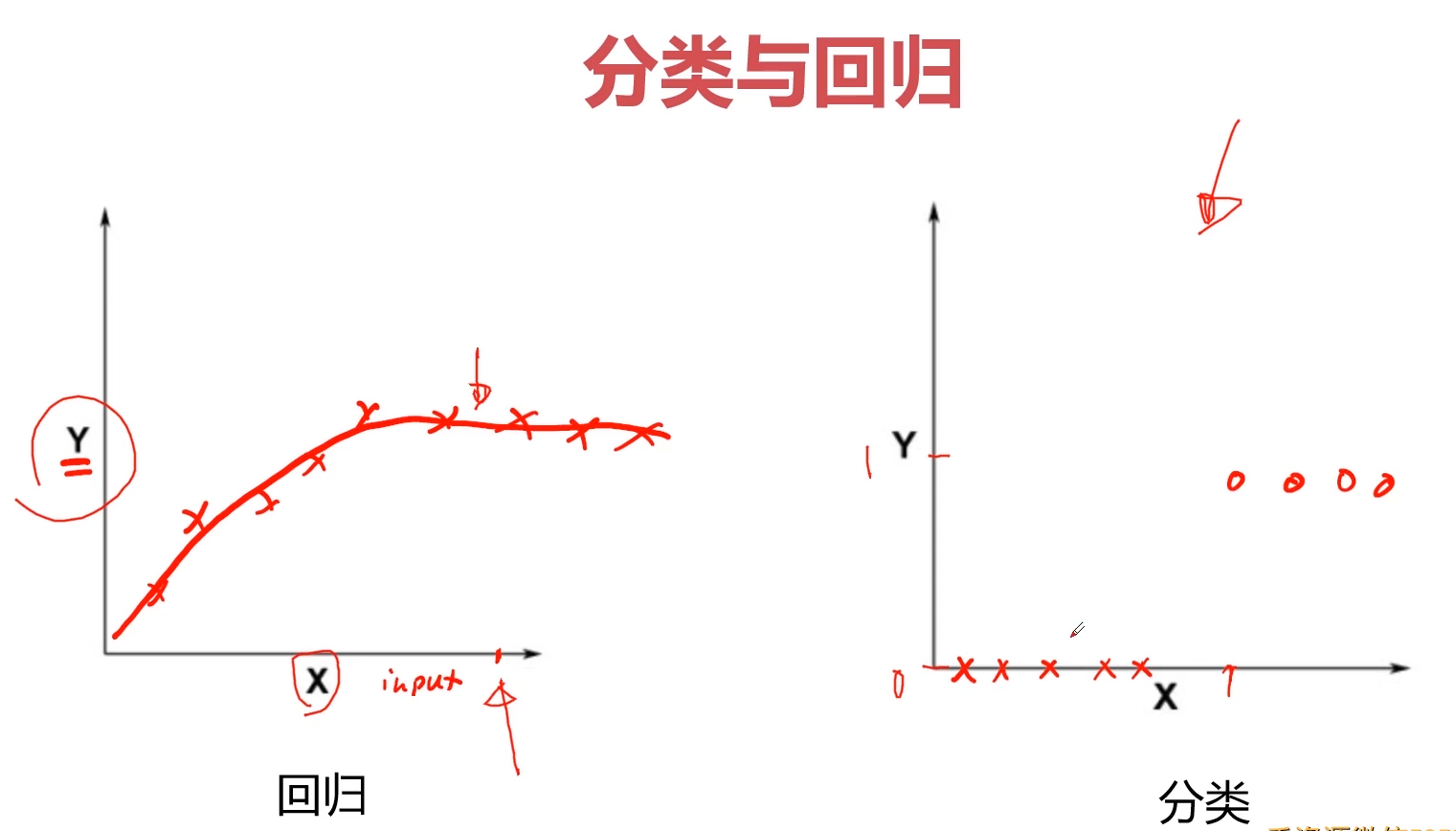
2.过拟合与欠拟合(回归)
参考:1.机器学习过拟合与欠拟合!
过拟合指的是在训练数据集上表现良好,而在未知数据上表现差。如图所示:
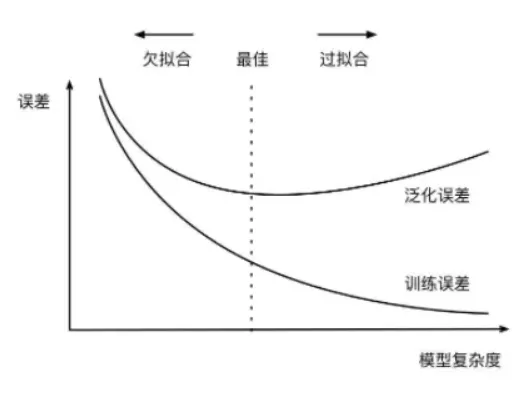
欠拟合指的是模型没有很好地学习到数据特征,不能够很好地拟合数据,在训练数据和未知数据上表现都很差。
过拟合的原因在于:
- 参数太多,模型复杂度过高;
- 建模样本选取有误,导致选取的样本数据不足以代表预定的分类规则;
- 样本噪音干扰过大,使得机器将部分噪音认为是特征从而扰乱了预设的分类规则;
- 假设的模型无法合理存在,或者说是假设成立的条件实际并不成立。
欠拟合的原因在于:
- 特征量过少;
- 模型复杂度过低。
3.如何防止过拟合?
过拟合(重点)
a) 减少特征的数量:
-人工的选择保留哪些特征;
-模型选择算法
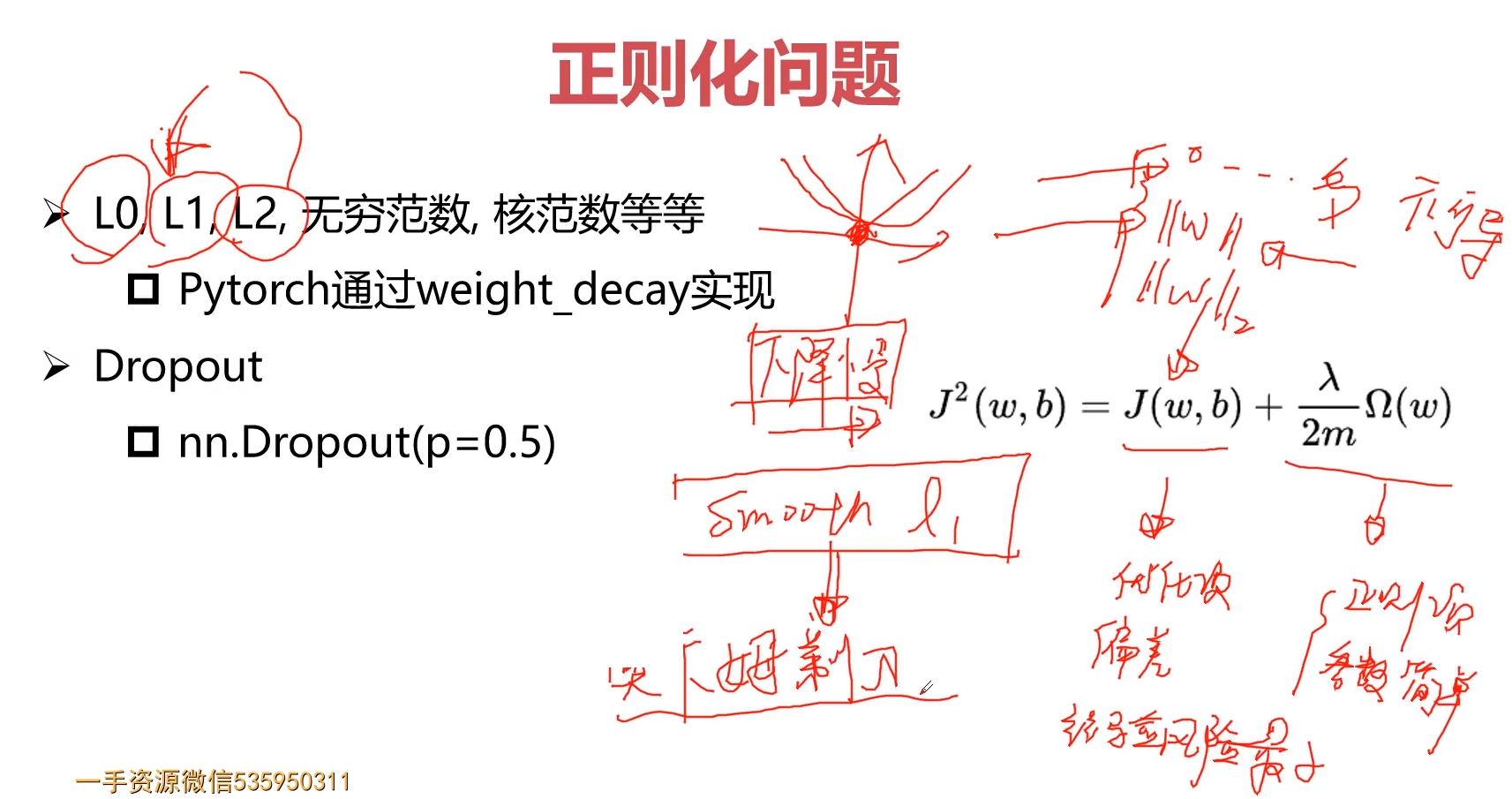
4.正则化问题
参考:机器学习中的正则化到底是什么意思?
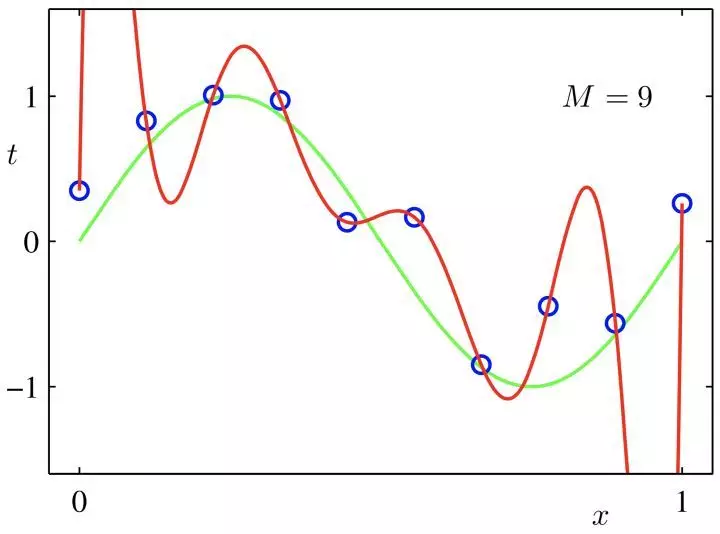
使用正则化的目的就是为了是为了防止过拟合。红色这条想象力过于丰富上下横跳的曲线就是过拟合情形,叫规则化。
正则化有另外一个名字:惩罚项。
试想:如果某一个东西超过了一些限制,我们需要用一些手段来进行制约。
什么是规则?比如明星再红也不能违法,这就是规则,一个限制。同理,规划化就是给需要训练的目标函数加上一些规则(限制),让它们不要自我膨胀,不要过于上下无规则的横跳,不能无法无天
那添加L1和L2正则化有什么用?
L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择
L2正则化可以防止模型过拟合(overfitting)。当然,一定程度上,L1也可以防止过拟合
b) 正则化
-保留所有的特征,但是降低参数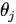 的量/值;
的量/值;
-正则化的好处是当特征很多时,每一个特征都会对预测y贡献一份合适的力量;
4-4 利用神经网络解决分类和回归问题2
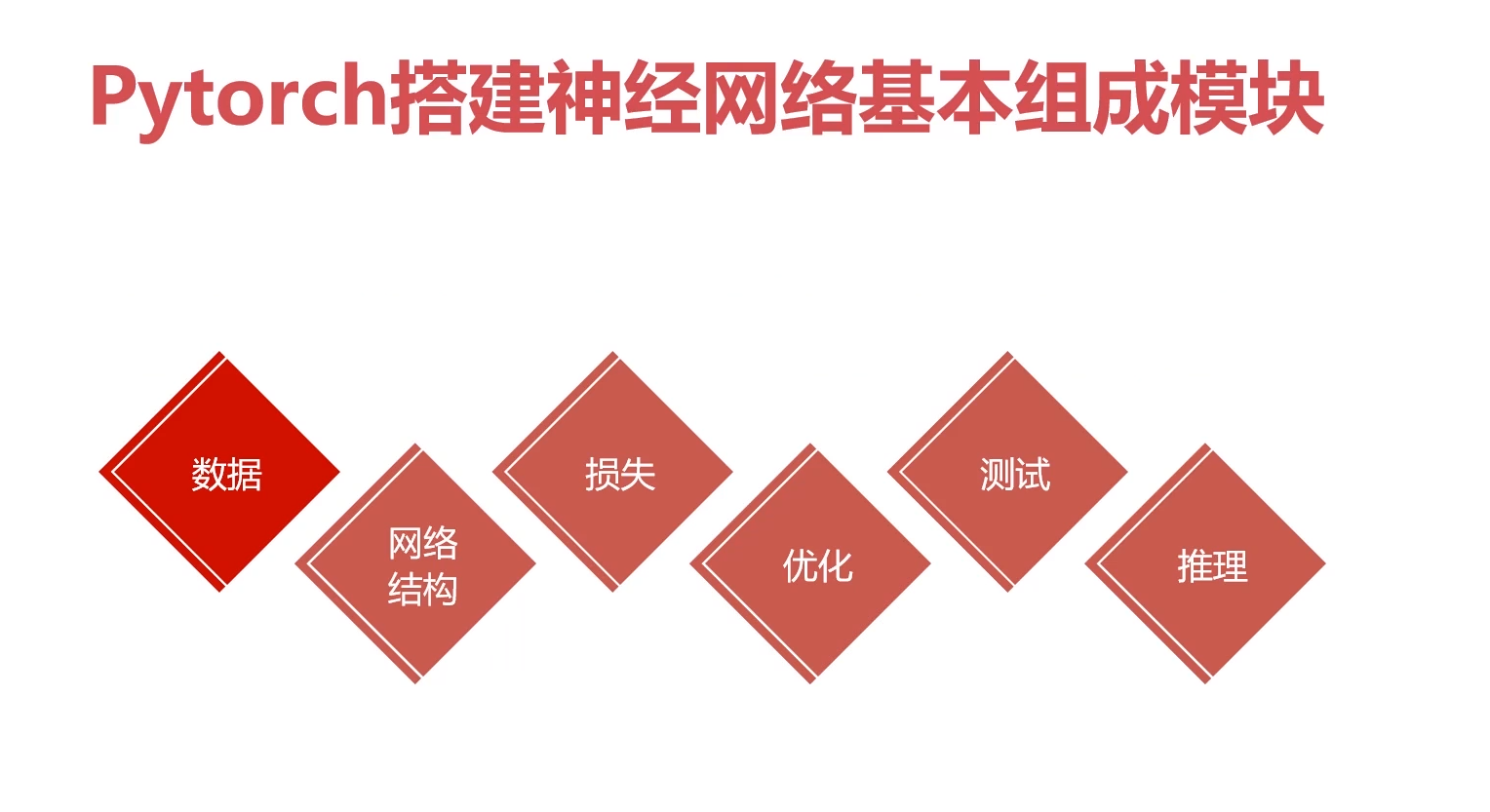
1.Pytorch搭建神经网络基本组成模块
2.波士顿房价预测模型搭建(损失函数)
回归问题 采用 损失函数MSE-LOSS
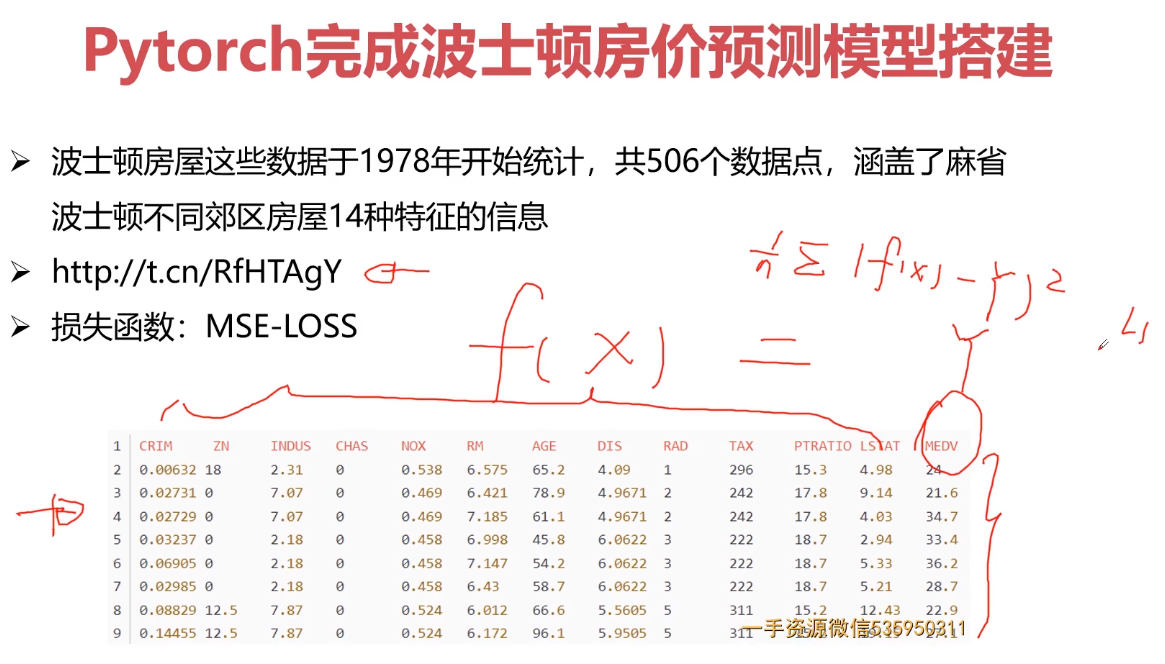
# 训练demoimport torch# dataimport numpy as npimport reff = open("housing.data").readlines()data = []for item in ff:out = re.sub(r"\s{2,}", " ", item).strip() # 多个空格合并为 一个空格# print(out)data.append(out.split(" "))data = np.array(data).astype(np.float) # 初始化转换为浮点型;print(data.shape) # 506 14Y = data[:, -1]X = data[:, 0:-1]# 训练集和测试集X_train = X[0:496, :]Y_train = Y[0:496]X_test = X[496:, :]Y_test = Y[496:]print(X_train.shape)print(Y_train.shape)print(X_test.shape)print(Y_test.shape)# netclass Net(torch.nn.Module):def __init__(self, n_feature, n_output):super(Net, self).__init__()self.hidden = torch.nn.Linear(n_feature, 100)self.predict = torch.nn.Linear(100, n_output)def forward(self, x):out = self.hidden(x) # 一个隐藏层out = torch.relu(out)out = self.predict(out)return out# 输入13,输出1net = Net(13, 1)# lossloss_func = torch.nn.MSELoss()# optimiter 优化器# optimizer = torch.optim.SGD(net.parameters(),lr = 0.0001)optimizer = torch.optim.Adam(net.parameters(), lr=0.001)# trainingfor i in range(10000):x_data = torch.tensor(X_train, dtype=torch.float32)y_data = torch.tensor(Y_train, dtype=torch.float32)pred = net.forward(x_data) # 定义前向运算;pred = torch.squeeze(pred)loss = loss_func(pred, y_data) * 0.001# print(pred.shape)# print(y_data.shape)optimizer.zero_grad()loss.backward()optimizer.step()print("ite:{},loss_train:{}".format(i, loss))print(pred[0:10])print(y_data[0:10])# testx_data = torch.tensor(X_test, dtype=torch.float32)y_data = torch.tensor(Y_test, dtype=torch.float32)pred = net.forward(x_data)pred = torch.squeeze(pred)loss_test = loss_func(pred, y_data) * 0.001print("ite:{}, loss_test:{}".format(i, loss_test))torch.save(net, "model/model.pkl")# torch.load("")# torch.save(net.state_dict(),"params.pkl")# net.load_state_dict("")
#demo_regimport torch# dataimport numpy as npimport reclass Net(torch.nn.Module):def __init__(self, n_feature, n_output):super(Net, self).__init__()self.hidden = torch.nn.Linear(n_feature, 100)self.predict = torch.nn.Linear(100, n_output)def forward(self, x):out = self.hidden(x) # 一个隐藏层out = torch.relu(out)out = self.predict(out)return outff = open("housing.data").readlines()data = []for item in ff:out = re.sub(r"\s{2,}", " ", item).strip() # 多个空格合并为 一个空格# print(out)data.append(out.split(" "))data = np.array(data).astype(np.float) # 初始化转换为浮点型;print(data.shape) # 506 14Y = data[:, -1]X = data[:, 0:-1]# 训练集和测试集X_train = X[0:496, :]Y_train = Y[0:496]X_test = X[496:, :]Y_test = Y[496:]print(X_train.shape)print(Y_train.shape)print(X_test.shape)print(Y_test.shape)# netnet = torch.load("model/model.pkl")# lossloss_func = torch.nn.MSELoss()# testx_data = torch.tensor(X_test, dtype=torch.float32)y_data = torch.tensor(Y_test, dtype=torch.float32)pred = net.forward(x_data)pred = torch.squeeze(pred)loss_test = loss_func(pred, y_data) * 0.001print("ite:test loss_test:{}".format(loss_test))
3.手写数字分类模型搭建(交叉熵)
分类问题 采用交叉熵损失函数CrossEntropyLoss
交叉熵损失函数:不确定越大,熵越大;
demo_cls.py 训练

4.模型的性能评价——交叉验证
参考:图解机器学习中的 12 种交叉验证技术
第一种是简单交叉验证
首先,随机的将样本数据分为两部分(比如:70%的训练集,30%的测试集),然后用训练集来训练模型,在测试集上验证模型及参数。接着再把样本打乱,重新选择训练集和测试集,继续训练数据和检验模型。最后选择损失函数评估最优的模型和参数。
第二种是K折交叉验证(K-Fold Cross Validation)
和第一种方法不同, K折交叉验证会把样本数据随机的分成 K 份,每次随机的选择 K-1 份作为训练集,剩下的1份做测试集。当这一轮完成后,重新随机选择 K-1 份来训练数据。若干轮(小于 K )之后,选择损失函数评估最优的模型和参数。
第三种是留一交叉验证(Leave-one-out Cross Validation)
它是第二种情况的特例,此时 K 等于样本数 N,这样对于 N 个样本,每次选择 N-1 个样本来训练数据,留一个样本来验证模型预测的好坏。此方法主要用于样本量非常少的情况,比如对于普通适中问题,N 小于50时,一般采用留一交叉验证。
4-5 利用神经网络解决分类和回归问题3
房价预测
import torch#dataimport numpy as npimport reff = open("housing.data").readlines()data = []for item in ff:out = re.sub(r"\s{2,}"," ",item).strip() # 多个空格合并为 一个空格#print(out)data.append(out.split(" "))data = np.array(data).astype(np.float)print(data.shape)Y = data[:, -1]X = data[:, 0:-1]X_train = X[0:496, :]Y_train = Y[0:496]X_test = X[496:, :]Y_test = Y[496:]print(X_train.shape)print(Y_train.shape)print(X_test.shape)print(Y_test.shape)#netclass Net(torch.nn.Module):def __init__(self,n_feature,n_output):super(Net,self).__init__()self.hidden = torch.nn.Linear(n_feature,100)self.predict = torch.nn.Linear(100,n_output)def forward(self,x):out = self.hidden(x)out = torch.relu(out)out = self.predict(out)return out#输入13,输出1net = Net(13,1)#lossloss_func = torch.nn.MSELoss()#optimiter#optimizer = torch.optim.SGD(net.parameters(),lr = 0.0001)optimizer = torch.optim.Adam(net.parameters(), lr = 0.001)#trainingfor i in range(10000):x_data = torch.tensor(X_train, dtype=torch.float32)y_data = torch.tensor(Y_train, dtype=torch.float32)pred = net.forward(x_data)pred = torch.squeeze(pred)loss = loss_func(pred, y_data) * 0.001# print(pred.shape)# print(y_data.shape)optimizer.zero_grad()loss.backward()optimizer.step()print("ite:{},loss_train:{}".format(i,loss))print(pred[0:10])print(y_data[0:10])# testx_data = torch.tensor(X_test, dtype=torch.float32)y_data = torch.tensor(Y_test, dtype=torch.float32)pred = net.forward(x_data)pred = torch.squeeze(pred)loss_test = loss_func(pred, y_data) * 0.001print("ite:{}, loss_test:{}".format(i, loss_test))torch.save(net, "model/model.pkl")# torch.load("")# torch.save(net.state_dict(),"params.pkl")# net.load_state_dict("")
# demo_reg_inference.pyimport torchimport numpy as npimport re#netclass Net(torch.nn.Module):def __init__(self,n_feature,n_output):super(Net,self).__init__()self.hidden = torch.nn.Linear(n_feature,100)self.predict = torch.nn.Linear(100,n_output)def forward(self,x):out = self.hidden(x)out = torch.relu(out)out = self.predict(out)return outff = open("housing.data").readlines()data = []for item in ff:out = re.sub(r"\s{2,}"," ",item).strip()#print(out)data.append(out.split(" "))data = np.array(data).astype(np.float)#print(data)#print(data.shape)Y = data[:, -1]X = data[:, 0:-1]X_train = X[0:496, ...]Y_train = Y[0:496, ...]X_test = X[496:, ...]Y_test = Y[496:, ...]net = torch.load("model/model.pkl")#lossloss_func = torch.nn.MSELoss()# testx_data = torch.tensor(X_test, dtype=torch.float32)y_data = torch.tensor(Y_test, dtype=torch.float32)pred = net.forward(x_data)pred = torch.squeeze(pred)loss_test = loss_func(pred, y_data) * 0.001print("loss_test:{}".format(loss_test))
手写数字识别
深度学习综合案例:手写数字识别;
手写数字识别;‘
定义CNN网络
import torchimport torchvision.datasets as dataset#加载数据import torchvision.transforms as transformsimport torch.utils.data as data_utilsclass CNN(torch.nn.Module):def __init__(self):super(CNN, self).__init__()self.conv =torch.nn.Sequential(torch.nn.Conv2d(1, 32, kernel_size=5, padding=2),torch.nn.BatchNorm2d(32),torch.nn.ReLU(),torch.nn.MaxPool2d(2))self.fc = torch.nn.Linear(14 * 14 * 32, 10)def forward(self, x):out = self.conv(x)out = out.view(out.size()[0], -1)out = self.fc(out)return out#datatrain_data = dataset.MNIST(root="mnist",train=True,transform=transforms.ToTensor(),download=True)test_data = dataset.MNIST(root="mnist",train=False,transform=transforms.ToTensor(),download=False)
batchsize
import torchimport torchvision.datasets as dataset#加载数据import torchvision.transforms as transformsimport torch.utils.data as data_utilsclass CNN(torch.nn.Module):def __init__(self):super(CNN, self).__init__()# 卷积操作;self.conv =torch.nn.Sequential(torch.nn.Conv2d(1, 32, kernel_size=5, padding=2),torch.nn.BatchNorm2d(32),torch.nn.ReLU(),torch.nn.MaxPool2d(2))# 线性操作self.fc = torch.nn.Linear(14 * 14 * 32, 10) # 10维度;def forward(self, x):out = self.conv(x) # 卷积传入xout = out.view(out.size()[0], -1)out = self.fc(out) #return out#datatrain_data = dataset.MNIST(root="mnist",train=True,transform=transforms.ToTensor(),download=True)test_data = dataset.MNIST(root="mnist",train=False,transform=transforms.ToTensor(),download=False)#batchsize data_utils# 数据的读取与加载train_loader = data_utils.DataLoader(dataset=train_data,batch_size=64, # 一般不会太小;shuffle=True)test_loader = data_utils.DataLoader(dataset=test_data,batch_size=64,shuffle=True)# net 网络结构cnn = CNN()cnn = cnn.cuda()#lossloss_func = torch.nn.CrossEntropyLoss()#optimizer 优化器optimizer = torch.optim.Adam(cnn.parameters(), lr=0.01)#training 训练过程;for epoch in range(10):for i, (images, labels) in enumerate(train_loader):images = images.cuda()labels = labels.cuda()outputs = cnn(images)loss = loss_func(outputs, labels)optimizer.zero_grad() # 反向传播;loss.backward()optimizer.step()print("epoch is {}, ite i s ""{}/{}, loss is {}".format(epoch+1, i,len(train_data) // 64,loss.item()))# 保存模型torch.save(cnn, "model/CNN.pkl")print("保存模型完毕")#-----------------------------------------------epoch is 1, ite i s 937/937, loss is 0.0066219354048371315epoch is 2, ite i s 937/937, loss is 0.023710286244750023epoch is 3, ite i s 937/937, loss is 0.36938509345054626epoch is 4, ite i s 937/937, loss is 0.00893715862184763epoch is 5, ite i s 937/937, loss is 0.0017298912862315774epoch is 6, ite i s 937/937, loss is 0.00033515063114464283epoch is 7, ite i s 937/937, loss is 0.19212040305137634epoch is 8, ite i s 937/937, loss is 0.001334078493528068epoch is 9, ite i s 937/937, loss is 0.0009439224377274513epoch is 10, ite i s 937/937, loss is 0.022724593058228493保存模型完毕
#eval/test# loss_test = 0# accuracy = 0# for i, (images, labels) in enumerate(test_loader):# images = images.cuda()# labels = labels.cuda()# outputs = cnn(images)# #[batchsize]# #outputs = batchsize * cls_num# loss_test += loss_func(outputs, labels)# _, pred = outputs.max(1)# accuracy += (pred == labels).sum().item()## accuracy = accuracy / len(test_data)# loss_test = loss_test / (len(test_data) // 64)## print("epoch is {}, accuracy is {}, "# "loss test is {}".format(epoch + 1,# accuracy,# loss_test.item()))
使用测试数据集,并且使用训练好的网络CNN
把cnn放在cuda上
#nettest_data = dataset.MNIST(root="mnist",train=False,transform=transforms.ToTensor(),download=False)test_loader = data_utils.DataLoader(dataset=test_data,batch_size=64,shuffle=True)cnn = torch.load("model/CNN.pkl")cnn = cnn.cuda()#loss#eval/testloss_test = 0accuracy = 0
#pip install opencv-python -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.comfor i, (images, labels) in enumerate(test_loader):images = images.cuda()labels = labels.cuda()outputs = cnn(images)_, pred = outputs.max(1)accuracy += (pred == labels).sum().item()images = images.cpu().numpy()labels = labels.cpu().numpy()pred = pred.cpu().numpy()#batchsize * 1 * 28 *28for idx in range(images.shape[0]):im_data = images[idx]im_label = labels[idx]im_pred = pred[idx]im_data = im_data.transpose(1, 2, 0)print("labe1",im_label)print("pred",im_pred)# cv2.imshow("imdata",im_data)# cv2.waitKey(0)accuracy = accuracy / len(test_data)print(accuracy)————————————————版权声明:本文为CSDN博主「摩诃摩瑜」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。原文链接:https://blog.csdn.net/weixin_46815330/article/details/113446757
4-6 利用神经网络解决分类和回归问题4
4-7 利用神经网络解决分类和回归问题5
第5章 计算机视觉与卷积神经网络基础串讲
主要介绍计算机视觉的基本概念,涉及到图像数据表示,颜色空间,亮度对比度,边缘提取,滤波与锐化等基础概念,然后引入深度学习的基本概念(前向运算、反向传播等)、并详细介绍了基本网络单元(卷积层、池化层、激活层、Dropout层、BN层、FC层、损失层等)、感受野、参数量计算量评估等
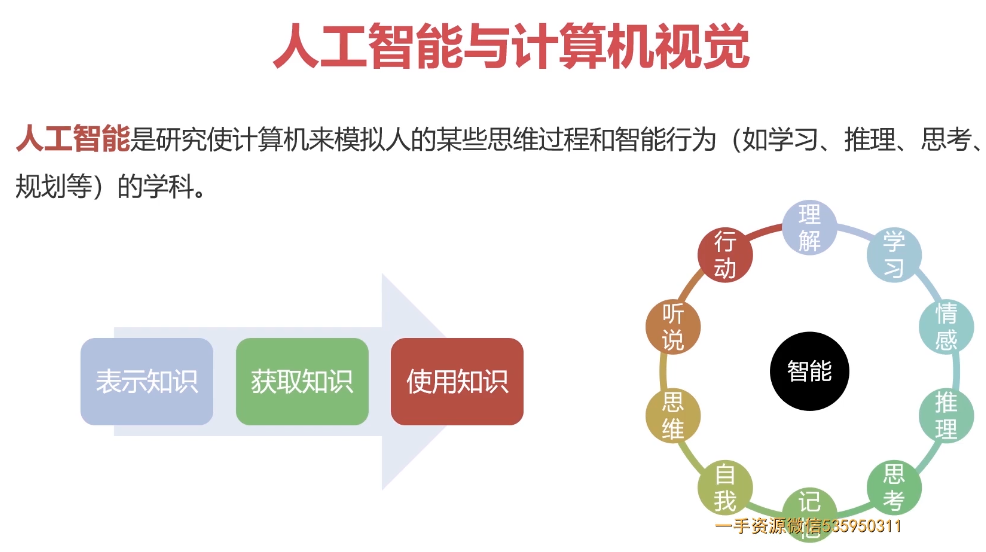
5-1 计算机视觉基本概念
人工智能与计算机视觉
计算机视觉
这也是计算机视觉系统需要的技能。简单来说,计算机视觉解决的主要问题是:
给出一张二维图像,计算机视觉系统必须识别出图像中的对象及其特征,如形状、纹理、颜色、大小、空间排列等,从而尽可能完整地描述该图像。
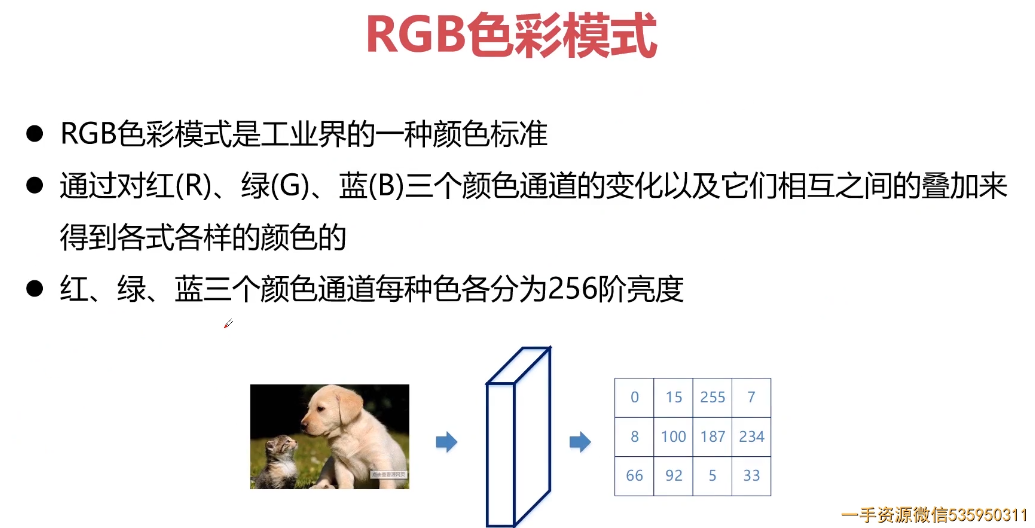
颜色空间

RGB
RGB(0,0,0)——三盏灯都不开,就是黑色。
RGB(255,0,0)——红灯开到最亮,绿灯、蓝灯均不开,所以是红色。
RGB(255,255,0)——红灯、绿灯开到最亮,蓝灯不开,所以是黄色。
RGB(255,255,255)——三盏灯均开到最亮,所以是白色。
当三盏灯开的亮度值一致时,就会产生消色,即黑白灰。
RGB(20,20,20)——三盏灯相同的低亮度,即深灰色。
RGB(200,200,200)——三盏灯相同的高亮度,即浅灰色。
HSV色彩模式
HSV 模式对应的媒介是人眼,在选择色彩这件事上,HSB 使用了更贴近人类感官直觉的方式来描述色彩,它把颜色分为色相、饱和度、明度三个因素(将我们人脑的“深浅”概念扩展为饱和度和明度)。
H—色相/色调:颜色的相貌,颜色的调性,在标准色轮上,色相是按位置度量的,取值在 0—360 度之间(黑色与白色无色相)。
S—表示饱和度/纯度:颜色的纯度,取值在 0—100 之间,饱和度高色彩较艳丽。饱和度低色彩就接近灰色。
V—表示明度/亮度:颜色的明暗程度。取值也是在 0—100 之间。亮度高色彩明亮,亮度低色彩暗淡,亮度最高得到纯白,最低得到纯黑。
灰度图
参考:什么是灰度图(csdn)
灰度是指黑白图像中的颜色深度,范围一般0-255,白色为255,黑色为0,故黑白图片也称为灰度图像;
若是彩色图像的灰度其实是在转化为黑白图像后的像素值(是一种广义的提法),转化的方法看应用领域而定,一般按加权的方法转换,R,G,B的一般比例为3: 6:1。
任何颜色都有红、绿、蓝三原色组成,假如原来某点的颜色为RGB(R,G,B),那么,我们可以通过下面几种方法,将其转换为灰度:
1.浮点算法:Gray = R0.3 + G0.59 + B0.11
2.整数方法:Gray = (R30+G59+B11)/100
3.移位方法:Gray =(R28+G151+B77)>> 8
4.平均值法:Gray = (R+G+B)/3
5.仅取绿色:Gray = G
*注意:若是utf8(0-255), float(0-1)
通过以上任何一种方法求得Gray后,将原来的RGB(r,g,b)中的r,g,b统一用Gray替换,形成新的颜色RGB(Gray,Gray,Gray),用它替换原来的RGB(r,g,b)就是灰度图了。
[
](https://blog.csdn.net/qq_43141726/article/details/113759352)
5-2 图像处理常见概念

亮度、对比度、饱和度
亮度(Intensity):对应成像亮度和图像灰度,是颜色的明亮程度。
对比度 指的是一幅图像中明暗区域最亮的白和最暗的黑之间不同亮度层级的测量,差异范围越大代表对比越大,差异范围越小代表对比越小。一般来说对比度越大,图像越清晰醒目,色彩也越鲜明艳丽;而对比度小,则会让整个画面都灰蒙蒙的。
饱和度 是指色彩的鲜艳程度,也称色彩的纯度。饱和度高,颜色则深而艳。
图像的平滑与降噪
有时我们也会把图像平滑处理称为图像滤波
图像平滑处理的基本原理是,将噪声所在像素点的像素值处理为其周围临近像素点的值的近似值。可能是噪声29,需要将该点的值调整为周围像素值的近似值(145-150。该点的像素值由29变为148,。
取近似值的方式很多,本章主要介绍:
均值滤波

图像锐化/增强

边缘提取
图像边缘(Edlge)是指图像局部特性的不连续性,例如,灰度级的突变,颜色的突变,纹理结构的突变等。边缘广泛存在于目标与目标、物体与背景、区域与区域(含不同色彩)之间,它是图像分割所依赖的重要特征。
求梯度有三种卷积核(robert,prewitt,sobel算子),每种卷积核有两个,对图像分别做两次卷积,一个代表水平梯度,一个代表垂直梯度。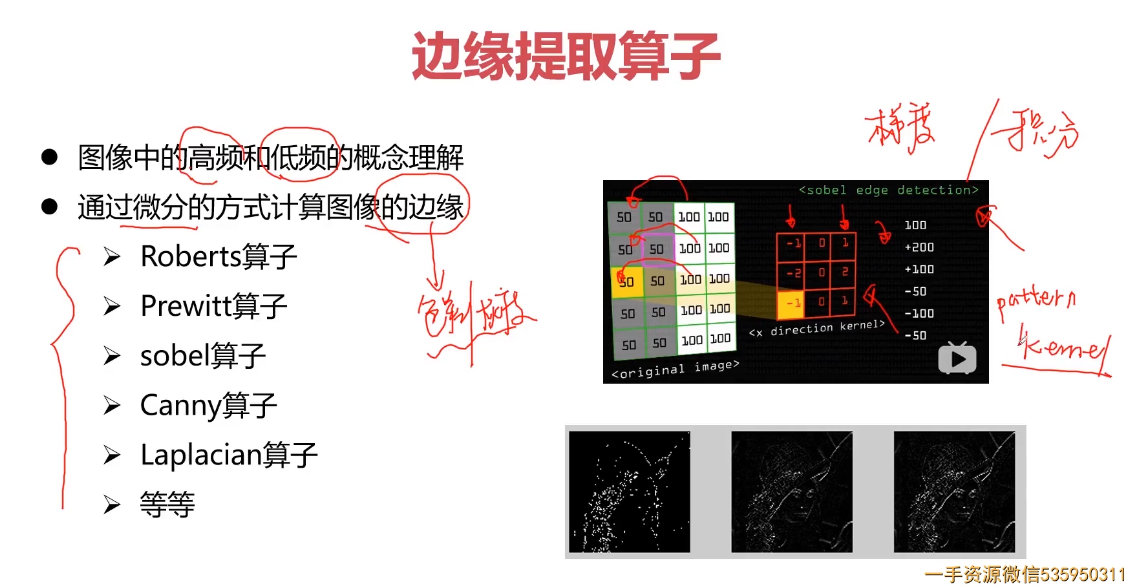
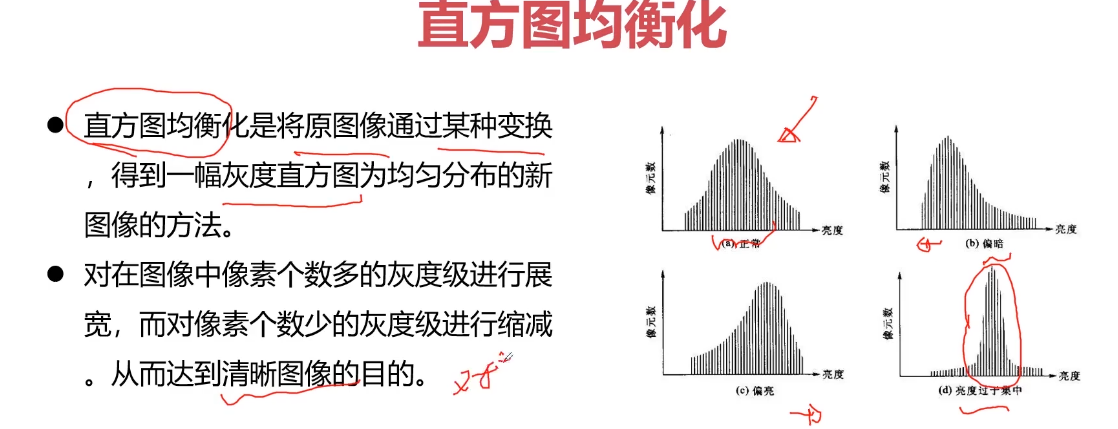
直方图均衡化
直方图均衡化是图像处理领域中利用图像直方图对对比度进行调整的方法。
基本思想:把原始图的直方图变换为均匀分 布的形式,这样就增加了像素灰度值的动态 范围,从而达到增强图像整体对比度的效果。
直方图均衡化的三种情况,分别是:
- 灰度图像直方图均衡化
- 彩色图像直方图均衡化
- YUV 直方图均衡化
图像滤波

形态学运算

Opencv及其常用库函数介绍

5-3 特征工程
特征工程 是这样一个过程:将数据转化为能更好地表示潜在问题的特征,从而提高机器学习性能。
划重点,表示潜在问题、提高机器学习性能,所以但凡能实现这个目标的,我们都可以称其为特征工程方法的一种。
另外有一种“特征调不好,调参调到老”的说法,因此学好特征工程绝对对你的算法性能有很大提升,甚至让你的模型有四两拨千斤的作用。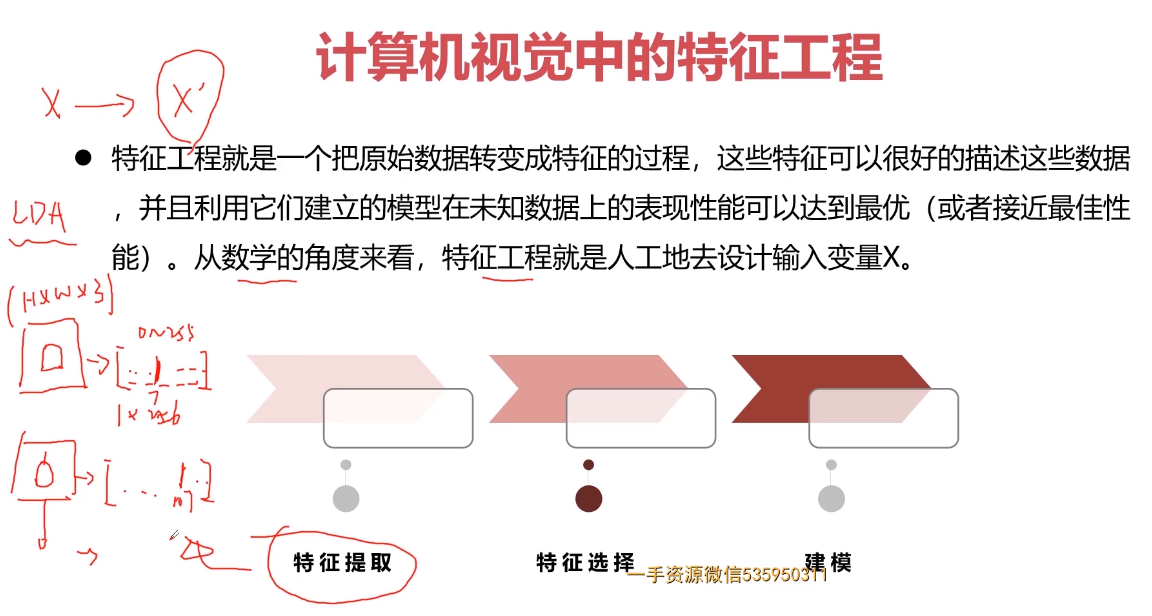
图像的分类、检测、分割、匹配、跟踪
匹配:图像的相似性匹配
跟踪:单目标跟踪 与 多目标跟踪
基于检测的跟踪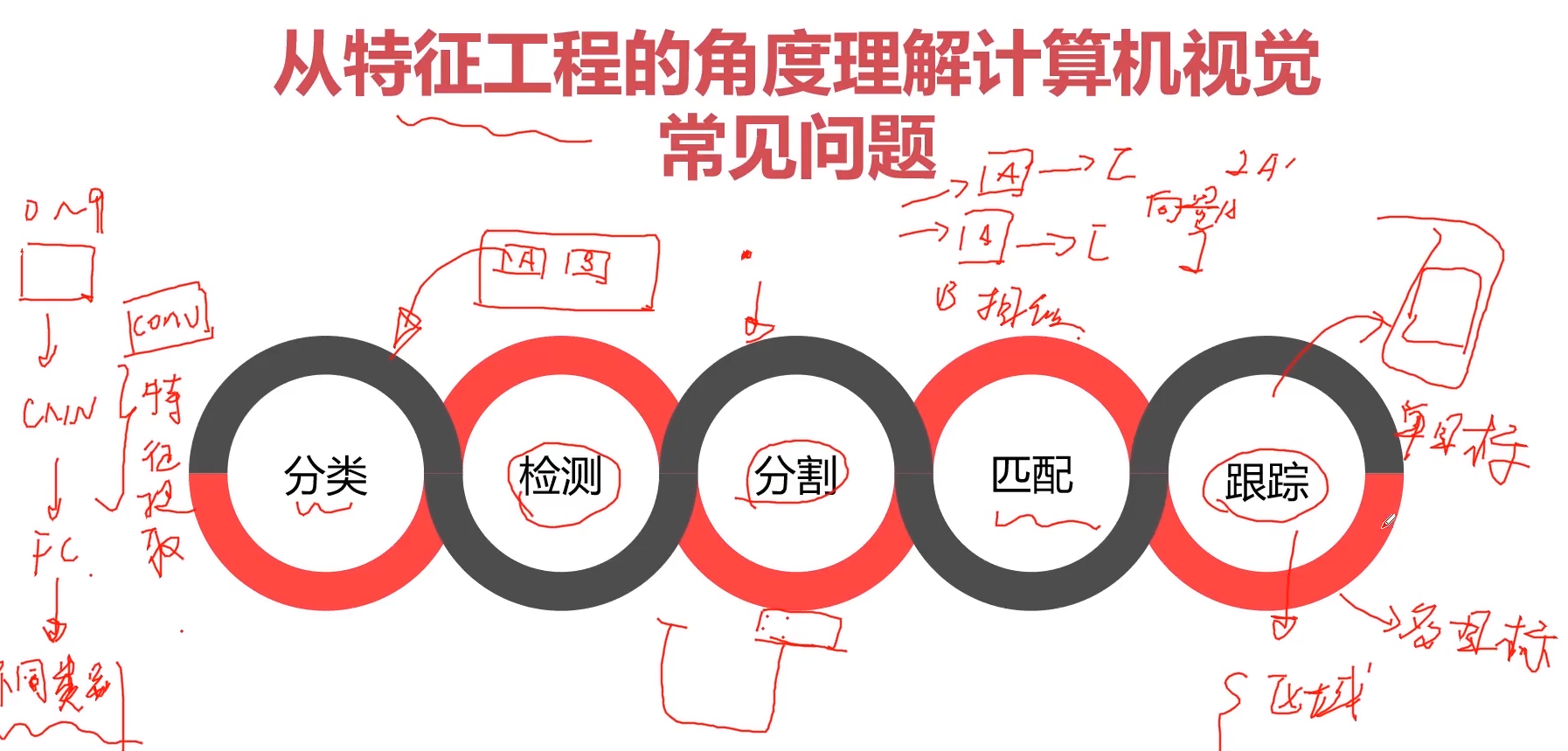
5-4 卷积神经网CNN
参考:
1.卷积神经网络(CNN)概念解释
2.跟我一起学PyTorch-06:卷积神经网络CNN
全连接层:前一层的神经单元与下一层的所有神经 单元都有箭头连接,这样的层构造称为全连接层(fully connected layer)。
在图像处理中,图像是一个或者多个二维矩阵,如前面提到的MNIST手写体图片是一个28x28的二维矩阵。传统的神经网络都是采用全连接的方式,即输入层到隐含层的神经元都是全连接的,这样导致参数量巨大,使得网络训练耗时甚至难以训练,并且容易过拟合,而卷积神经网络则通过局部连接、权值共享等方法避免这一困难。如下图所示。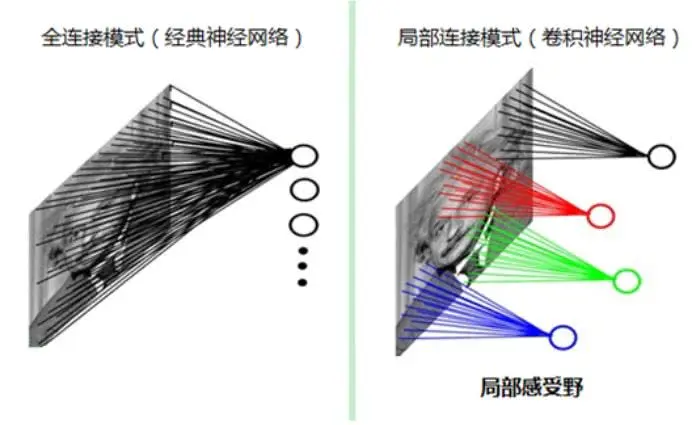
对于一个200x200的输入图像而言,如果下一个隐含层的神经元数目为10000个,采用全连接则有200x200
x10000=400000000个权值参数,如此巨大的参数几乎难以训练;而采用局部连接,隐含层的每个神经元仅与图像中4x4的局部图像相连接,那么此时的权值参数个数为4x4x10000=160000,大大减少了参数的个数。
传统对象识别-模式识别
传统的模式识别神经网络(NN)算法基于梯度下降,基于输入的大量样本特征数据学习有能力识别与分类不同的目标样本。这些传统模式识别方法包括KNN、SVM、NN等方法、他们有一个无法避免的问题,就是必须手工设计算法实现从输入图像到提取特征,而在特征提取过程中要考虑各种不变性问题、最常见的需要考虑旋转不变性、光照不变性、尺度不变性、通过计算图像梯度与角度来实现旋转不变性、通过归一化来避免光照影响,构建尺度金字塔实现尺度不变性,这其中SIFT与SURF是其这类特征的典型代表、此外还可以基于轮廓HOG特征、LBP特征等,然后把特征数据作为输入,选择适合的机器学习方法如KNN、SVM等方法实现分类或者识别。这些方法的一个最大的弊端就是特征提取设计过程完全依赖于人、人的因素太多,没有发挥出机器主动学习、提取特征的能力。好处就是人可以完全控制特征提取的每个细节、每个特征数据。图示如下: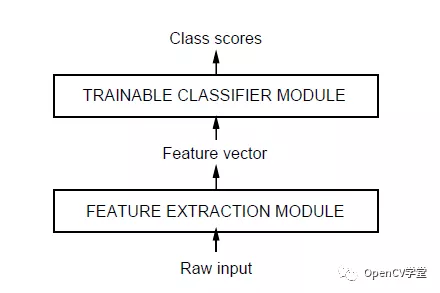
卷积神经网络(CNN)
以卷积神经网络(CNN)为代表的深度学习方法实现对象识别与分类,则是把特征提取完全交给机器、整个特征提取的过程无需手工设计、全部由机器自动完成。通过不同filter的卷积实现特征提取,这样就可以对畸变与光照保持一定程度的不变性、通过最大池化层采样实现尺度不变性,在保持传统特征数据三个不变性的同时,在特征提取方法上尽量减少人工设计细节,通过监督学习把计算机的计算能力发挥出来,主动寻找合适的特征数据。完成了特征提取算法有传统的白盒机制到以机器为主导的黑盒机制,实现了识别分类结果的最优化求解。最早的卷积神经网络模型出现在1998年,主要是用来实现OCR(英文字母识别),它的名称叫做LeNet-5网络,其结构如下: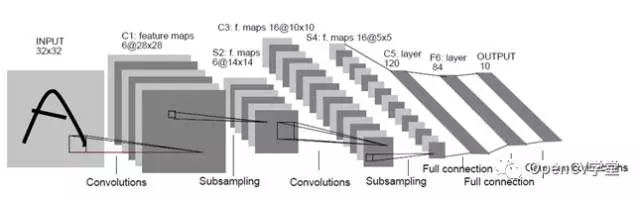
包含以下各层:
- 输入层(Input Layer)表示输入数据(图像)
- 卷积层(Convolution Layer)通过5x5的卷积核实现特征提取,然 后通过2x大小最大池化,降采样。上图有两个卷积层
- 池化层:池化层的神经网络不会改变三维矩阵的深度,但是它将缩小矩阵的大小。池化层将分辨率较高的图片转换为分辨率较低的图片。
- 全连接层FC(Full connection Layer),经过多轮的卷积层和池化层处理后,卷积神经网络一般会接1到2层全连接层来给出最后的分类结果。传统神经网络的多层感知器 (MLP)。上图有两个全连接层
- 输出层(Output Layer)

卷积层
参考:如何理解卷积神经网络(CNN)中的卷积和池化?
我愿称之为最强!卷积自提出以来,凭借其优异的提取特征的能力,已逐渐成为现代CNN网络中必不可少的组成部分,并引发了基于深度学习的方法研究计算机视觉的浪潮!,
卷积层由一组滤波器组成,滤波器可以视为二维数字矩阵,卷积层操作是对图像和滤波矩阵做内积(每个元素相乘再求和)。可称之为卷积核(kernel)或滤波器(filter);
PyTorch文档中将这个结构称为卷积核,因此这里我们也统称为卷积核。如图所示,卷积核将当前层神经网络上的一个子节点矩阵转换为下一层神经网络上的一个节点矩阵。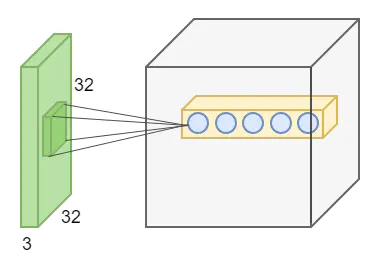
卷积层是卷积神经网络最重要的部分,也是卷积神经网络得名的缘由。卷积层中每一个节点的输入是上一层神经网络中的一小块,卷积层试图将神经网络中的每一小块进行更加深入的分析,从而得到抽象程度更高的特征。
这是一个示例3x3滤波器: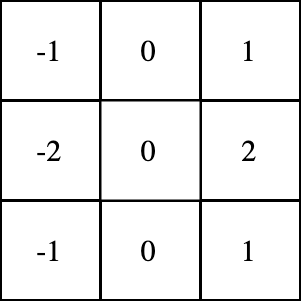
我们可以将滤波器与输入图像进行卷积来产生输出图像,那么什么是卷积操作呢?具体的步骤如下:
- 在图像的某个位置上覆盖滤波器;
- 将滤波器中的值与图像中的对应像素的值相乘;
- 把上面的乘积加起来,得到的和是输出图像中目标像素的值;
- 对图像的所有位置重复此操作。

在PyTorch中,类nn.Conv2d()是卷积核模块。卷积核及其调用的例子如下:
nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0,dilation=1,groups=1,bias=True)
在nn.Conv2d()中,in_channels表示输入数据体的深度,out_channels表示输出数据体的深度,kernel_size表示卷积核的大小,stride表示滑动步长,padding表示0边界填充个数,dilation表示数据体的空间间隔,groups表示输入数据体和输出数据体在深度上的关联,bias表示偏置。
# 方形卷积核和等长的步长m = nn.Conv2d(16,33,3,stride=2)# 非方形卷积核,非等长的步长和边界填充m = nn.Conv2d(16,33,(3,5),stride=(2,1),padding=(4,2))# 非方形卷积核,非等长的步长,边界填充和空间间隔m = nn.Conv2d(16,33,(3,5),stride=(2,1),padding=(4,2),dilation=(3,1))input = autograd.Variable(torch.randn(20,16,50,100))output = m(input)
常见的卷积操作
参考:盘点CNN中形形色色的卷积操作
分组卷积(group参数)
分组卷积最早是为了解决显存不够的问题,将网络分布在两张显卡上训练,能够减少训练参数,不容易出现过拟合。
后来出现在shuffleNet等轻量化的网络中用于减少网络参数,提高在ARM等嵌入式部署神经网络时的运算速度。
空洞卷积(dilation参数)
空洞卷积的目的就在于扩大感受野,以提升模型的性能。空洞卷积的运行原理跟卷积非常类似,唯一不同之处在于空洞卷积引入了一个扩张率(dilated rate)的概念,可以认为,普通卷积是空洞卷积的一种情形,普通卷积的扩张率默认为1。
以下分别是dilated rate=1、dilated rate=6、dilated rate=24的空洞卷积案例: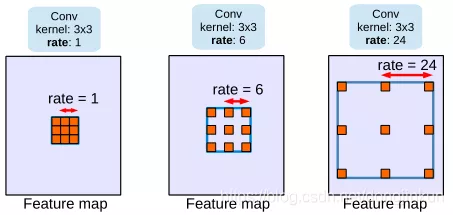
深度可分离卷积(分组卷积+1*1卷积)
反卷积(torch.nn.ConvTranspose2d)
可变性卷积
卷积中的其他概念
感受野(receptive-field)
卷积核大小 Convolution filter
卷积核大小定义了卷积的视图。根据卷积核的大小,常见的卷积尺寸有1×1卷积、3×3 卷积、5×5卷积、7×7卷积等。
填充(padding)
表示卷积核对边缘的处理方式,常见的填充方式有两种:same与valid,其中same表示根据卷积核大小填充ksize/2 。当卷积核为3x3时,填充1个像素;5x5时,填充两个像素,依此类推。Valid表示不填充。
如何理解卷积层的参数量与计算量?

FLOPS: 注意全大写,是floating point operations per second的缩写,意指每秒浮点运算次数,理解为计算速度。是一个衡量硬件性能的指标。
计算公式:
对卷积层:(K_h K_w C_in C_out) (H_out W_out)
对全连接层:C_in C_out
FLOPs: 注意s小写,是floating point operations的缩写(s表复数),意指浮点运算数,理解为计算量。可以用来衡量算法/模型的复杂度
MAC:内存访问成本;
如何压缩卷积层参数和计算量?

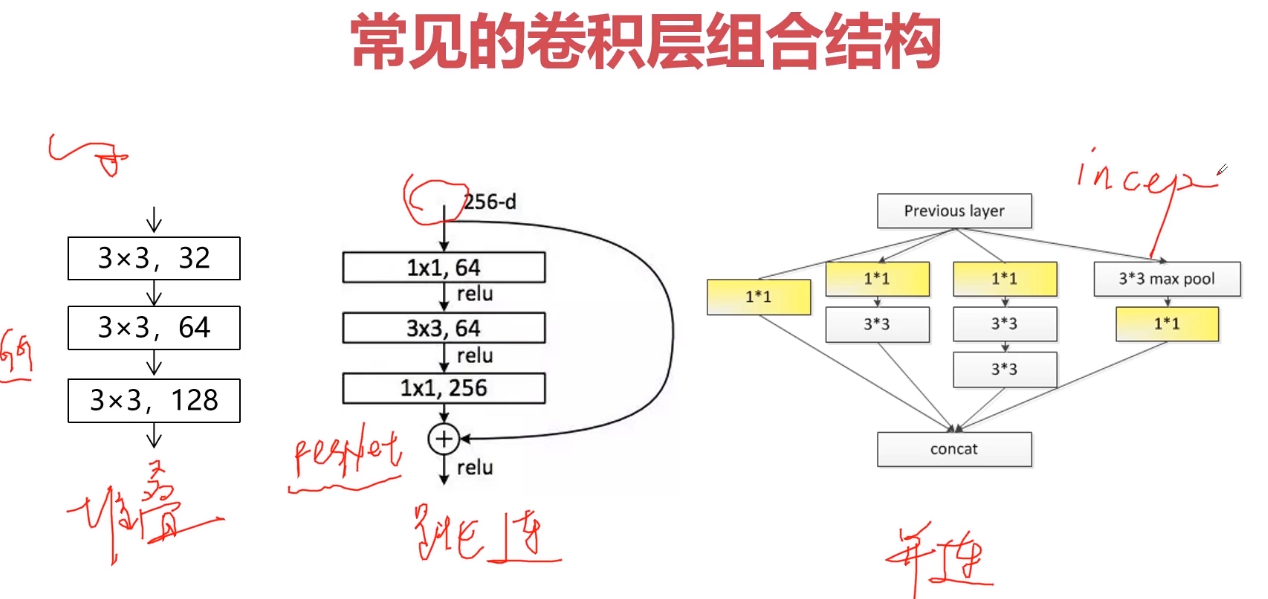
常见的卷积层组合结构?
5-6 pooling层
池化层
池化层是指由池化运算构成的连接层,也称为汇聚层,夹在连续的卷积层中间压缩数据和参数的规模,主要功能是进行特征选择,实现数据的下采样(Down-sampling)操作,进一步避免过拟合现象。池化层也具有局部连接的特点,但与卷积层不同的是池化层没有权重系数,无需通过训练来优化运算结果。
卷积层指包含卷积运算的隐藏层,以其局部连接、权重共享的显著特点区别于全连接层。卷积层中的局部连接是指相邻两层中后一层的每个神经元只和前一层卷积窗口内的神经元连接,而不像全连接层中后一层的神经元要和前一层的全部神经元都建立联系,这种特点也被称为稀疏交互(sparse interactions)。权重共享也称参数共享,是指卷积核的系数对同层所有的神经元都适用,不像全连接层每条连接的权重系数各不相同。局部连接和权重共享一方面可以显著降低网络中连接的数量从而减小网络规模、避免过拟合,另一方面可以提取图像的内在本质特征,不同的卷积核提取不同的特征,组合在一起形成数据的特征图。
卷积层和池化层经常组合在一起使用,二者共同决定了模型局部感受野的大小。局部感受野在卷积神经网络中定义为输出特征图上每个像素点在原始输入图像上映射的区域,它的值越大表明网络运算接触到的原始图像范围就越大,提取特征的语义层次更高更抽象;相反它的值越小表示网络运算接触到的原始图像范围就越小,提取的特征趋向于局部和细节,抽象程度较低。一般而言,随着卷积层和池化层的不断叠加,模型的层数越来越深,局部感受野的区域越来越大,提取的特征也越发抽象,更有利于目标类型的准确识别。
池化层操作
池化层用于缩小特征图尺寸,常用池化操作有最大值池化(Max pool)、均值池化(Average pool)等,和卷积操作类似,池化也是在特征图上按照一定的stride进行从左到右,从上到下的滑窗操作。
传统上,池化的主要好处是创建了比原始版本小得多的表征,从而减少了计算需求,并支持创建更大、更深层次的网络架构。
下采样的池化方法
- Average Pooling:区域平均值。
- Max Pooling:区域最大值。
- Stochastic Pooling:它使用一个核区域内激活的概率加权抽样。
- Mix Pooling:基于最大池化和平均池化的混合池化。
- Power average Pooling:基于平均和最大化的结合,幂平均(Lp)池化利用一个学习参数p来确定这两种方法的相对重要性;当p=1时,使用局部求和,而p为无穷大时,对应max-pooling。
最大值池化(Max pool):
选取池化区域内的最大值作为池化后特征图对应位置的像素点,如下示意图(2x2 stride=2):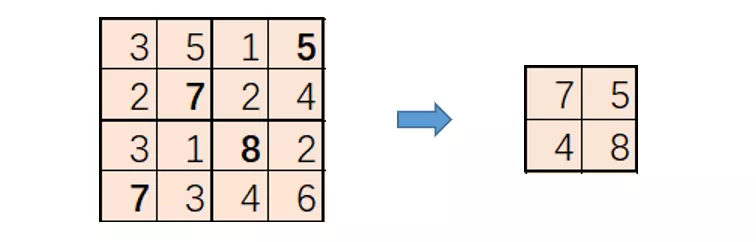
均值池化(Average pool):
选取池化区域内的像素点均值作为池化后特征图对应位置的像素点,如下示意图(2x2 stride=2):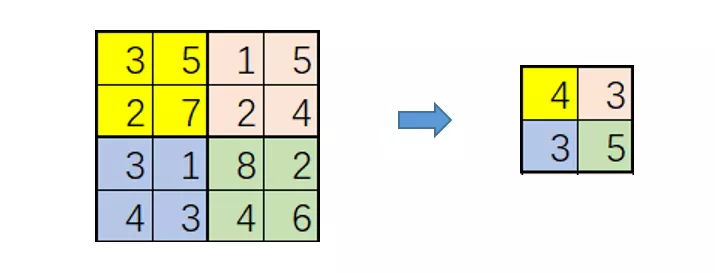
池化层的特点
- 没有需要学习的参数
- 计算是按通道独立进行的,输入数据和输出数据的通道数不会发生变化
池化层实操函数nn.MaxPool2d
在nn.MaxPool2d中,kernel_size,stride,padding,dilation参数在nn.Conv2d中已经解释过,return_indices表示是否返回最大值所处的下标,ceil_mode表示使用方格代替层结构。
nn.MaxPool2d(kernel_size,stride=None,padding=0,dilation=1,return_indices=False,ceil_mode=False)
# 方形窗口尺寸为3,等长滑动步长为2m = nn.MaxPool2d(3,stride=2)# 非方形窗口,非等长滑动步长m = nn.MaxPool2d((3,2),stride=(2,1))input = autograd.Variable(torch.randn(20,16,50,32))output = m(input)
上采样层

下采样层
下采样层也叫池化层,其具体操作与卷基层的操作基本相同,只不过下采样的卷积核为只取对应位置的最大值、平均值等(最大池化、平均池化),并且不经过反向传播的修改。
5-7 激活层-BN层-FC层-损失层
BP算法
BP反向传播
先将训练集沿正向传播走一遍,保存下各种中间变量,先计算出最后一层的误差;用误差更新最后一层的权重;计算前一层的误差;更新前一层的权重;再计算前一层的误差;更新权重,直到所有权重更新完成;
激活层(激活函数)
激活层的作用可以理解为把卷积层的结果做非线性映射。增加非线性表达能力

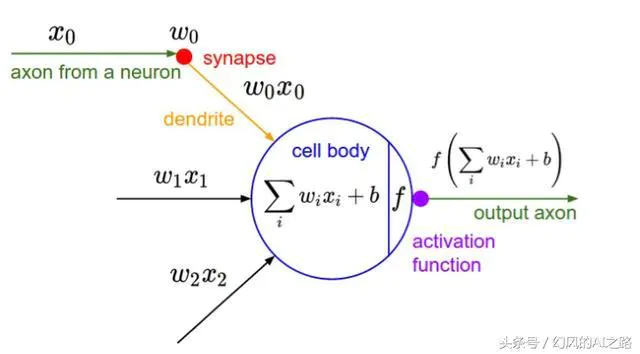
上图中的f表示激励函数,常用的激励函数几下几种:
ReLU激活函数
增加非线性表达能力
Leaky ReLU激活函数:不会饱和或者挂掉,计算也很快,但是计算量比较大;
从卷积层、激活层、池化层到全连接层深度解析卷积神经网络的原理
Leaky ReLU激活函数
一些激励函数的使用技巧:一般不要用sigmoid,首先试RELU,因为快,但要小心点,如果RELU失效,请用Leaky ReLU,某些情况下tanh倒是有不错的结果。
softmax函数
softmax用于多分类过程中,它将多个神经元的输出,映射到(0,1)区间内,可以看成概率来理解,从而来进行多分类!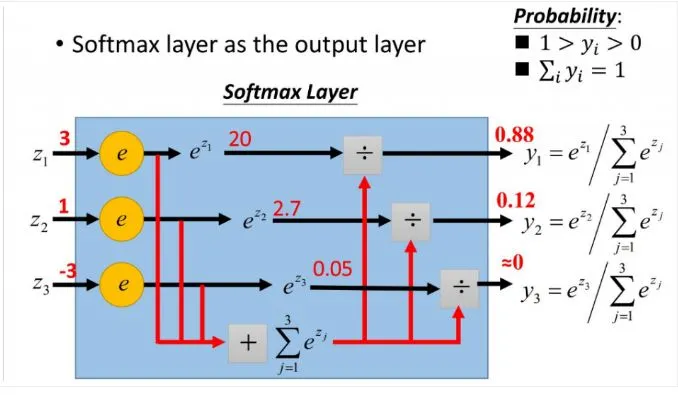
softmax直白来说就是将原来输出是3,1,-3通过softmax函数一作用,就映射成为(0,1)的值,而这些值的累和为1(满足概率的性质),那么我们就可以将它理解成概率,在最后选取输出结点的时候,我们就可以选取概率最大(也就是值对应最大的)结点,作为我们的预测目标!
BatchNorm 归一化层
参考:1.Batchnorm原理详解
Batchnorm是归一化的一种手段,极限来说,这种方式会减小图像之间的绝对差异,突出相对差异,加快训练速度。所以说,并不是在深度学习的所有领域都可以使用,下文会写到其不适用的情况。
全连接层(fully connected layers,FC)
参考:1.全连接层的作用是什么? 2. CNN 入门讲解:什么是全连接层
全连接层(fully connected layers,FC)在整个卷积神经网络中起到“分类器”的作用。如果说卷积层、池化层和激活函数层等操作是将原始数据映射到隐层特征空间的话(全连接层之前的作用是提取特征,全连接层的作用是分类:判断是不是猫),全连接层则起到将学到的“分布式特征表示”映射到样本标记空间的作用。在实际使用中,全连接层可由卷积操作实现:对前层是全连接的全连接层可以转化为卷积核为1x1的卷积;而前层是卷积层的全连接层可以转化为卷积核为hxw的全局卷积,h和w分别为前层卷积结果的高和宽
喵在哪我不管,我只要猫,于是我让filter去把这个喵找到,实际就是把feature map 整合成一个值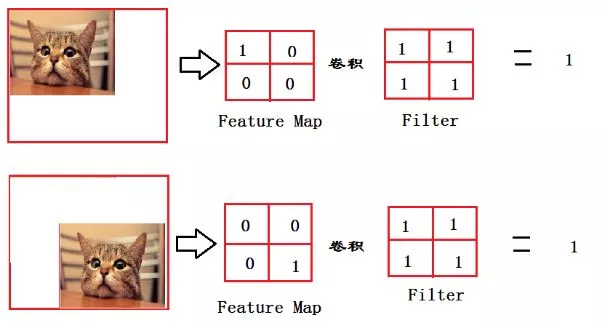
因为空间结构特性被忽略了,所以全连接层不适合用于在方位上找Pattern的任务,比如segmentation
Dropout层
一般情况,dropout rate 设为0.3-0.5即可,配合FC层使用;
损失层

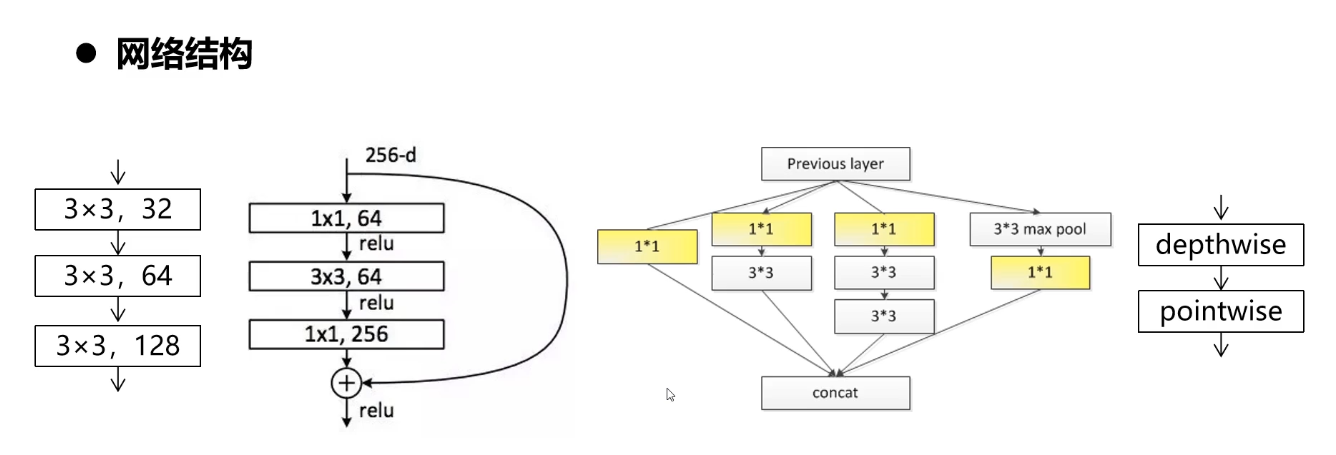
5-8 经典卷积神经网络结构
参考:1.【深度学习基础】经典卷积神经网络
卷积神经网络(Convolutional Neural Networks, CNN)是一类包含卷积计算且具有深度结构的前馈神经网络(Feedforward Neural Networks),是深度学习(deep learning)的代表算法之一。经典的神经网络结构,分别是LeNet-5、AlexNet和VGGNet。本问对经典卷积神经网络进行讲解。
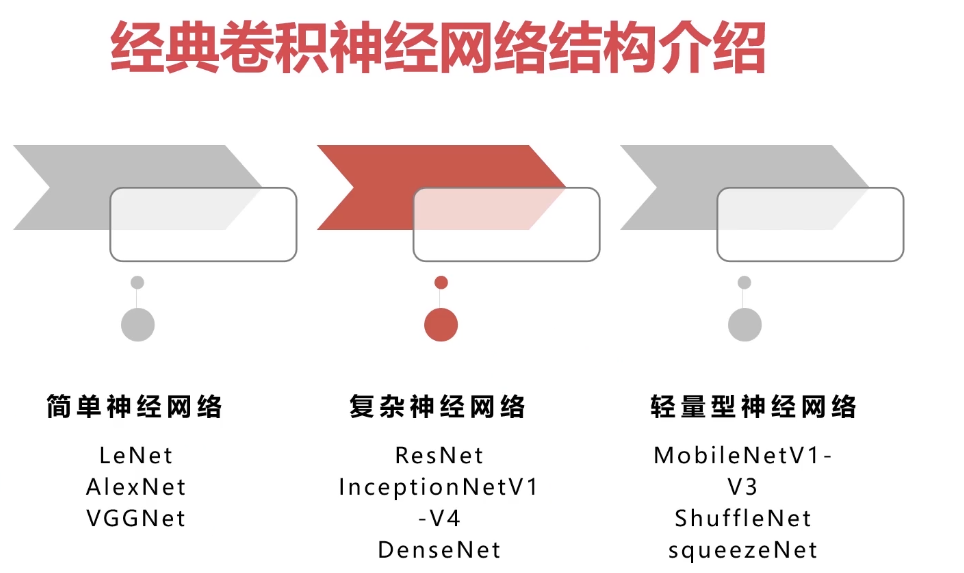
串联结构的典型代表

跳连结构的典型代表 — 残差网络(ResNet)
并行结构的典型代表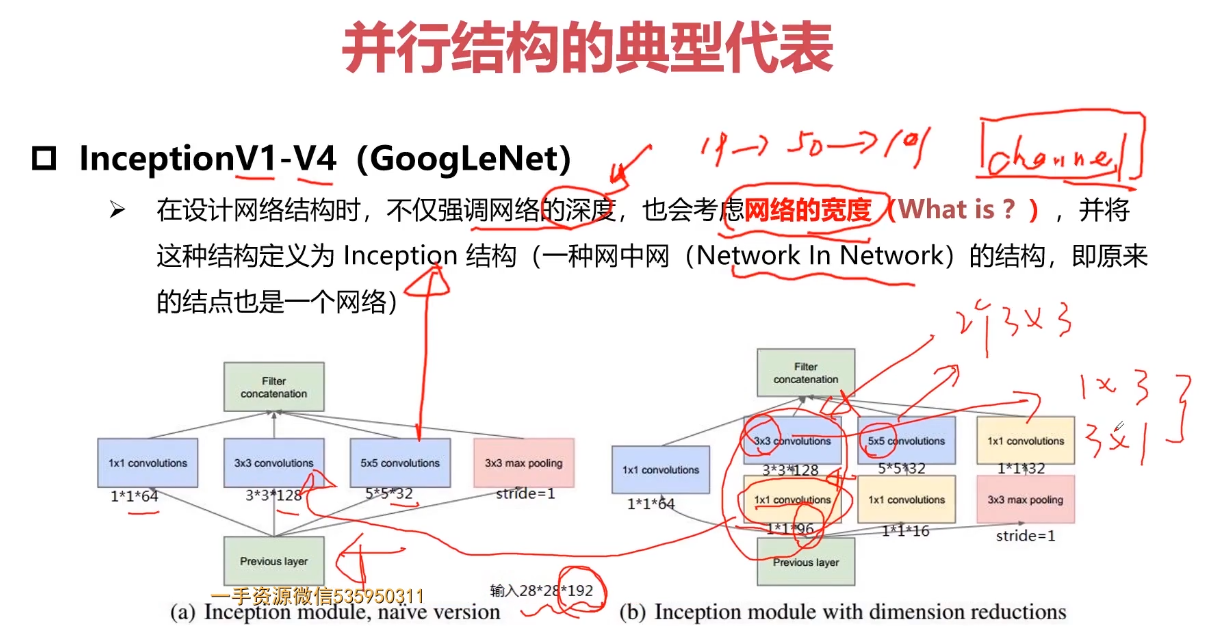
5-9 轻量型网络结构
参考:1.【综述专栏】网络模型加速——轻量化网络
除了一些模型压缩的方法,研究人员更加重视手工设计轻量高效的卷积神经网络架构,能有效保证模型精度的同时大大减少参数,一直是在嵌入式平台和移动端应用最为广泛的一种方法。近几年来也逐渐提出了很多优秀的轻量化网络。
MobileNetv1
MobileNetv1将常规卷积替换为深度可分离卷积,包含了深度卷积(depth-wise)和点态卷积(point-wise),假设采用的是3x3的卷积核,一般可达到8-9倍的加速,而精度不会损失太多。
MobileNetv1采用的是类似VGG的简单堆叠的方式,更为先进的方法是加入ResNet的shortcut的链接方式,MobileNetv2就借鉴了这种思想,应用了invered residual block,与Residual block相比,有如下的区别:1)、通道数:两边窄中间宽;2、3x3卷积改成了Depthwise Conv;3、去掉了最后的ReLU(ReLU会使得一些神经元失活,而高维的ReLU可以保留低维特征的完整信息,同时又不失非线性。所以采用中间宽+ReLU的方式来保留低维输入的信息)。MobileNetv3采用了网络结构搜索(NAS)的方法,得到一个高效的网络结构,先通用NAS算法,优化每一个block,得到大体的网络结构,然后使用NetAdapt 算法来确定每个filter的channel的数量,此外并结合一些必要的trick,包含
1)、引入SE(squeeze and excitation)结构,并将SE结构放在了depthwise之后;
2)、对网络结构的尾部部分进行了简化修改;
3)、修改了channels;
4)、非线性激活的改变,使用h-swish替换swish。

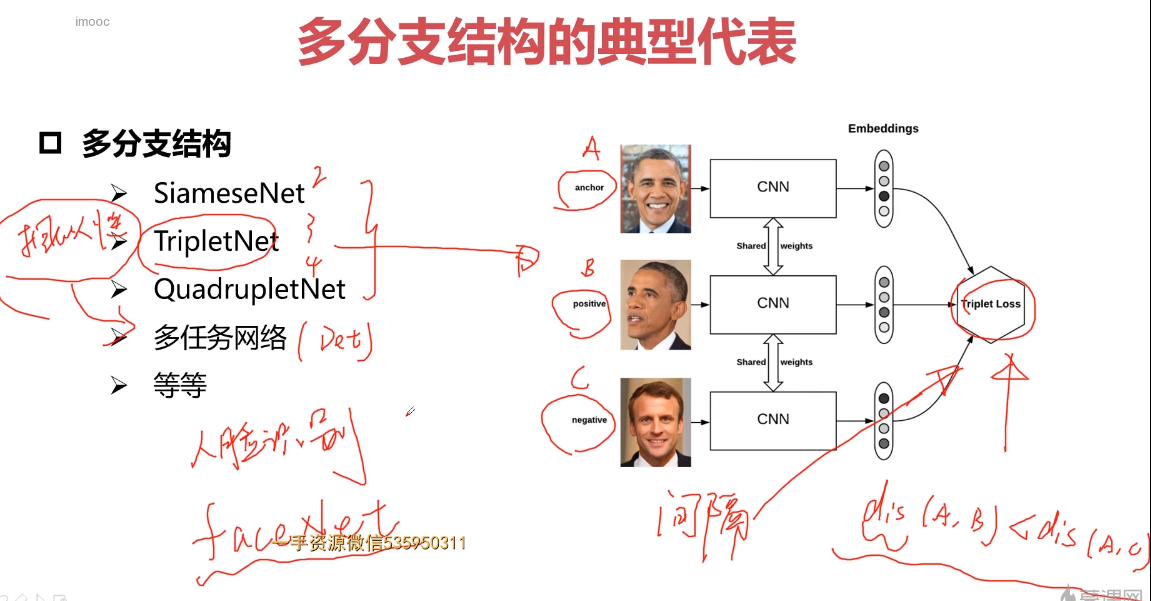
5-10 多分支网络结构
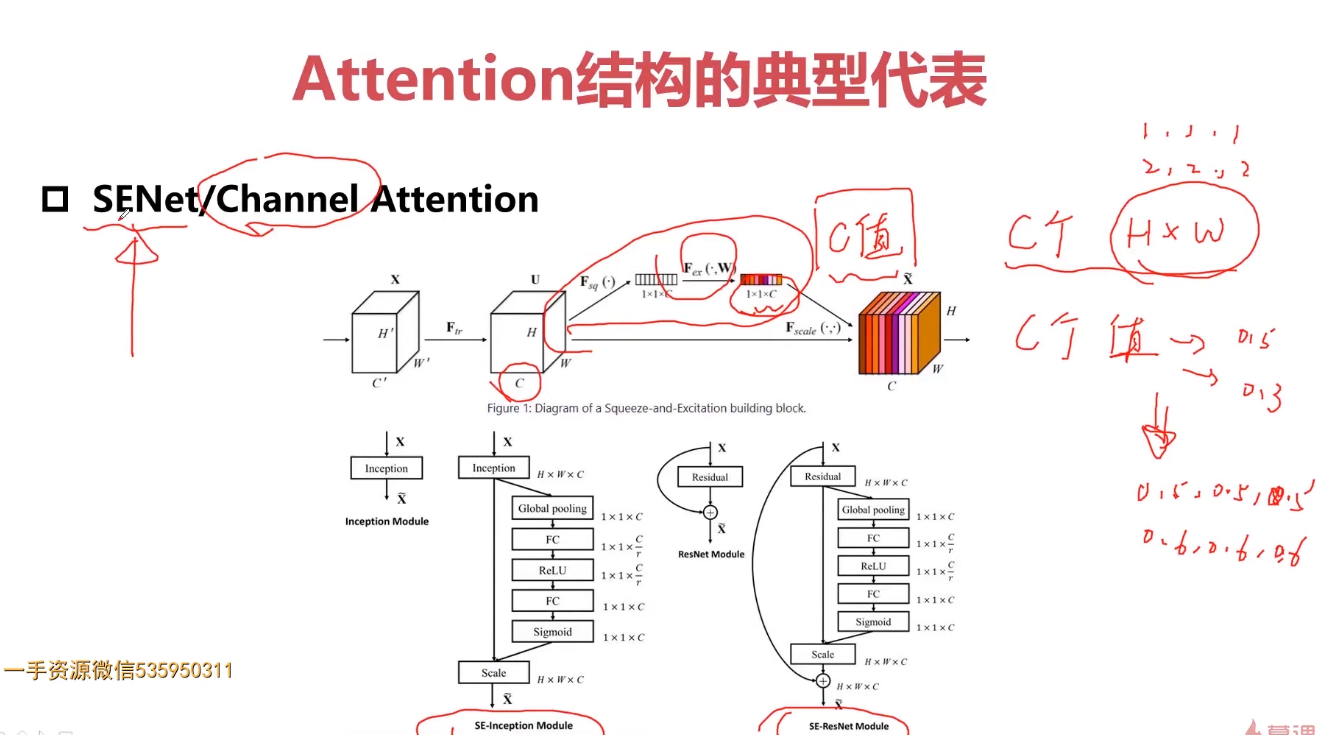
5-11 attention的网络结构
Attention机制的本质
attention机制的本质是从人类视觉注意力机制中获得灵感(可以说很‘以人为本’了)。大致是我们视觉在感知东西的时候,一般不会是一个场景从到头看到尾每次全部都看,而往往是根据需求观察注意特定的一部分。而且当我们发现一个场景经常在某部分出现自己想观察的东西时,我们就会进行学习在将来再出现类似场景时把注意力放到该部分上。这可以说就是注意力机制的本质内容了。至于它本身包含的‘自上而下’和‘自下而上’方式就不在过多的讨论。
Attention机制的理解
Attention机制其实就是一系列注意力分配系数,也就是一系列权重参数罢了。
优点:
一步到位的全局联系捕捉
上文说了一些,attention机制可以灵活的捕捉全局和局部的联系,而且是一步到位的。另一方面从attention函数就可以看出来,它先是进行序列的每一个元素与其他元素的对比,在这个过程中每一个元素间的距离都是一,因此它比时间序列RNNs的一步步递推得到长期依赖关系好的多,越长的序列RNNs捕捉长期依赖关系就越弱。并行计算减少模型训练时间
Attention机制每一步计算不依赖于上一步的计算结果,因此可以和CNN一样并行处理。但是CNN也只是每次捕捉局部信息,通过层叠来获取全局的联系增强视野。模型复杂度小,参数少
模型复杂度是与CNN和RNN同条件下相比较的。缺点:
缺点很明显,attention机制不是一个”distance-aware”的,它不能捕捉语序顺序(这里是语序哦,就是元素的顺序)。这在NLP中是比较糟糕的,自然语言的语序是包含太多的信息。如果确实了这方面的信息,结果往往会是打折扣的。说到底,attention机制就是一个精致的”词袋”模型。所以有时候我就在想,在NLP任务中,我把分词向量化后计算一波TF-IDF是不是会和这种attention机制取得一样的效果呢? 当然这个缺点也好搞定,我在添加位置信息就好了。所以就有了 position-embedding(位置向量)的概念了,这里就不细说了。
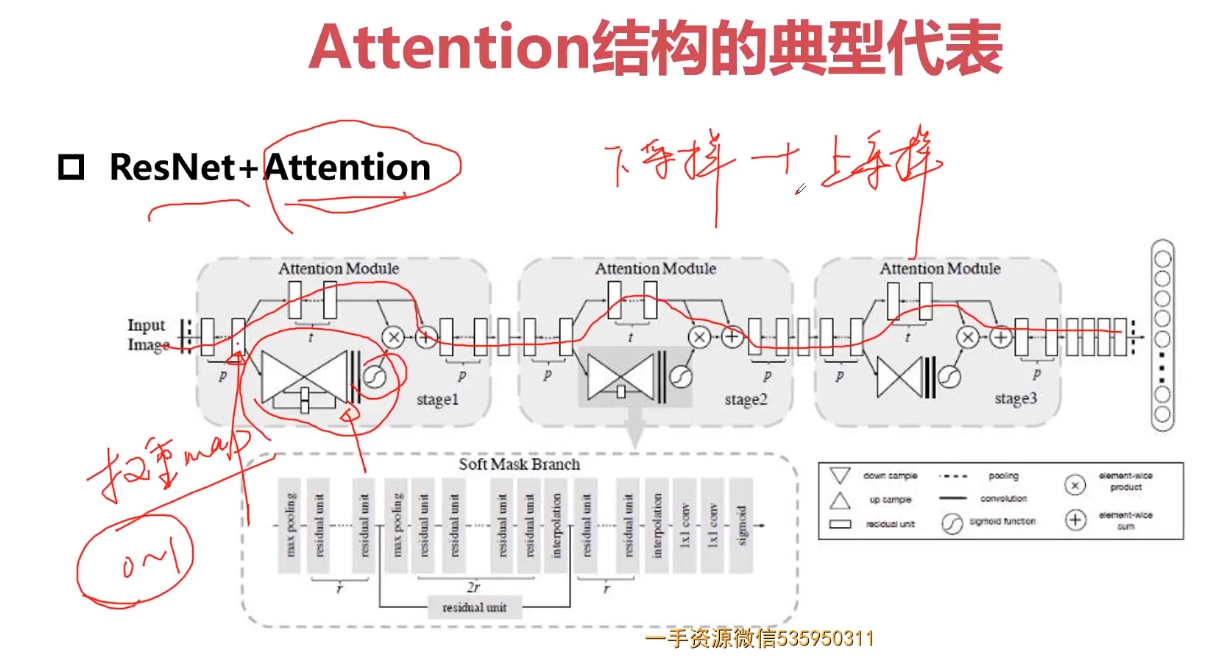
5-12 学习率
学习率
学习率是一个超参数,控制我们要多大程度调整网络的权重,以符合梯度损失。 值越低,沿着梯度下降越慢。 虽然使用较小学习率可能是一个 好主意,以确保我们不会错过任何局部最低点,但也可能意味着我们将花费很长的时间来收敛——特别是当我们卡在平稳区域(plateau region)的时候。
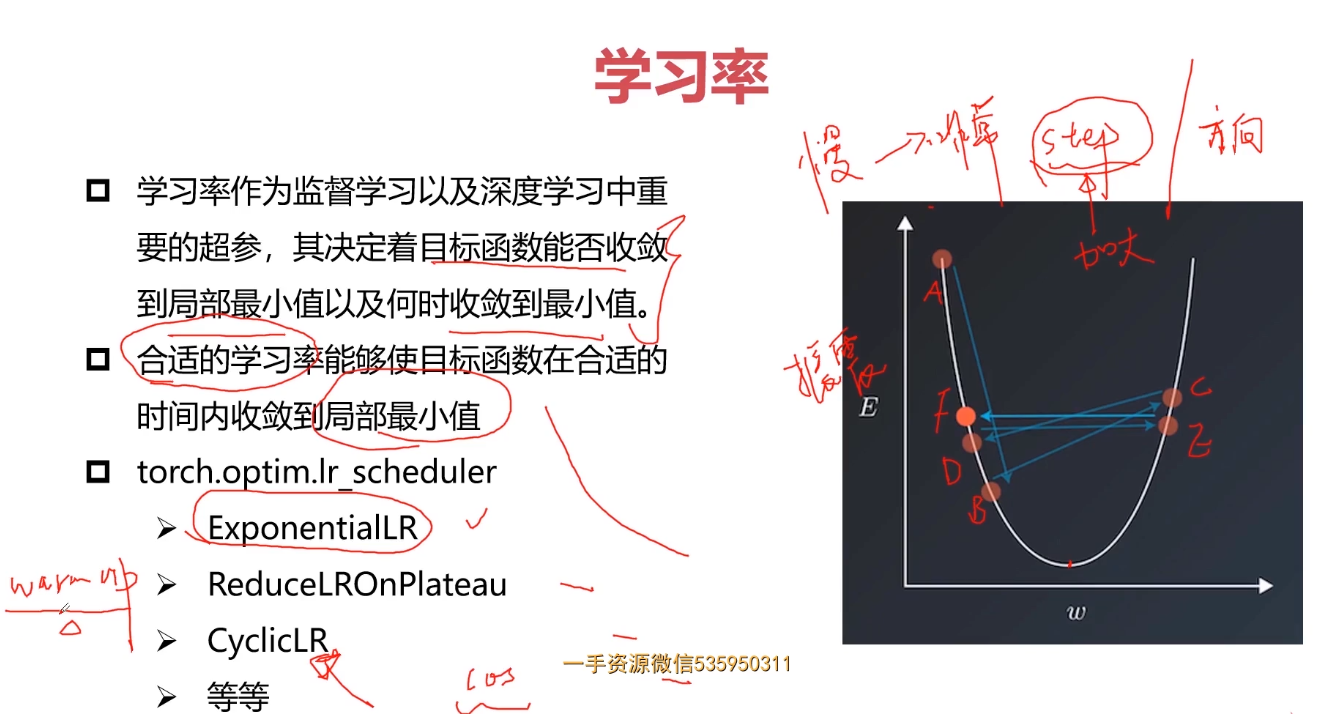
通常,学习率是由用户随意配置的。 用户最多也只能通过之前的经验来配置最佳的学习率。
scheduler = torch.optim.lr_scheduler.StepLR(optimizer,step_size=1,gamma=0.9)
5-13 优化器
参考:1.基础学习系列 | 深度学习优化器使用详解
深度学习算法的本质是优化,实现的途径就是通过调整参数,使得损失尽可能的小。优化器就是实现优化的手段,它沿着损失函数导数的反方向调整参数,使得损失函数取值尽可能的小,从而达到优化的目的。
常见的优化器算法是随机梯度下降(Stochastic Gradient Descent,SGD)算法,以及在随机梯度下降算法基础上改进而来的自适应算法。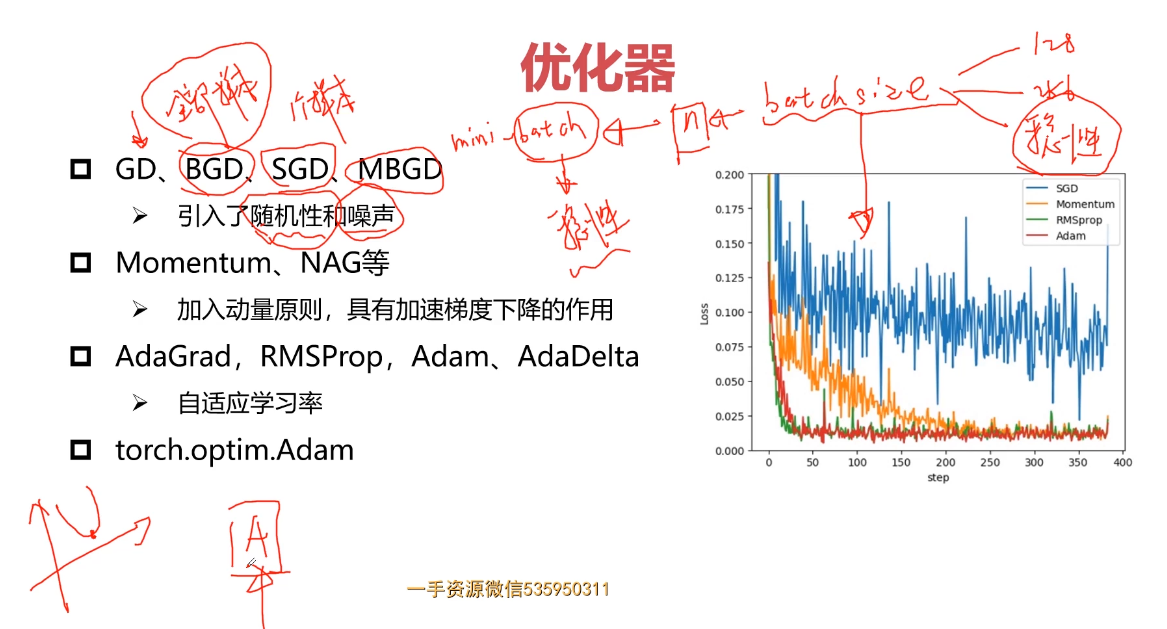
自适应算法
早期,优化器学习率的设置多采用指数衰减法。当初始学习率和衰减率都是已知的情况下,指数衰减法的每个训练步骤的学习率也是固定的,所以,指数衰减法有可能出现学习率衰减过快、或者学习率衰减过慢的问题。衰减过快是指,模型的参数距离最优解依然很远,但是,此时的学习率已经很小、导致模型需要很长的时间才能拟合;衰减过慢是指,模型已经接近最优解,但是,此时学习率依然很大、模型越过最优解来回震荡,同样会导致模型难以拟合,或者说模型训练困难。
针对以上不足,现代的优化器多采用自适应算法,能在优化过程中动态的调整学习率。比如,引入动量(Momentum)概念,判断本次更新的梯度方向与上一次方向是否一致,如果一致,说明距离最优解很远,就在本次优化的幅度上叠加上一次的优化幅度;如果方向不一致,说明已经越过最优解,就将本地的优化服务减去上一次的优化幅度、降低优化步幅。除了动量之外,有的算法还能各个参数梯度的大小,给不同参数设置不同的学习率,加速模型拟合。
自适应算法能够大幅度提高模型的拟合速度,广泛的应用在深度学习的各个场景中。
1.SGD
最常见的优化器是随机下降优化器。在默认的情况下,它的出示学习率会设置为0.01,动量的系数设置为0.0(不采用动量技术)。
2.Adam
Adam是最简单、易用的优化器,可以适用于各种常见场景。如果您不知道该选择哪一个优化器,那么,Adam优化器就是您最佳选择。从它的构造函数不难理解这一点,在模型情况下,它的初始学习率设置为很小的0.001、同时设置了动量系统0.9和0.999,再结合自适应优化算法Adam在多个常见的业务场景中都能有出色表现。
optimizer = optim.Adam(model_text_cls.parameters(), lr=cfg.learn_rate)
5-14 卷积神经网添加正则化

正则化内容
正则化有另外一个名字:惩罚项。
试想:如果某一个东西超过了一些限制,我们需要用一些手段来进行制约
上文的 λG(x) 有两种写入方式(原式的参数是a)
L1: MSE(a) + 所有权重的平均绝对值 * λ
L1可以让一部分特征的系数缩小到0,从而间接实现特征选择(稀疏矩阵指的是很多元素为0,只有少数元素是非零值的矩阵,即得到的线性回归模型的大部分系数都是0)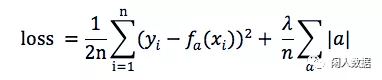
L2: MSE(a) + 所有权重平方和的平均值 * λ / 2
通过限制系数的大小实现了对模型的限制, 在一定程度上避免了过拟合
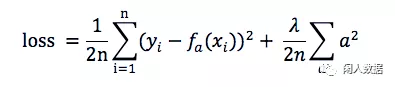
目标是在惩罚项的约束下,求出损失函数最小的解
L1正则可以使少数权值较大,多数权值为0,得到稀疏的权值;
L2正则会使权值都趋近于0但非零,得到平滑的权值
结构最小化
风险最小化
第6章 PyTorch实战计算机视觉任务-Cifar10图像分类
6-1 图像分类网络模型框架解读(上)
1.分类网络的基本结构
包括三个重要的模块:
如基于卷积神经网络来训练数据(求解参数:离线)
推理过程
对数据进行预处理、增强,
这个时候,我们会将数据丢到卷积神经网络里面,进行卷积特征的提取,
将提取的特征转化为N维的向量,N维向量就是表示的N个类别的概率分布;
利用loss函数来计算当前损失,利用当前的损失来进行反向传播;对网络参数进行调整;
利用优化器对网络参数进行调整-BP算法;
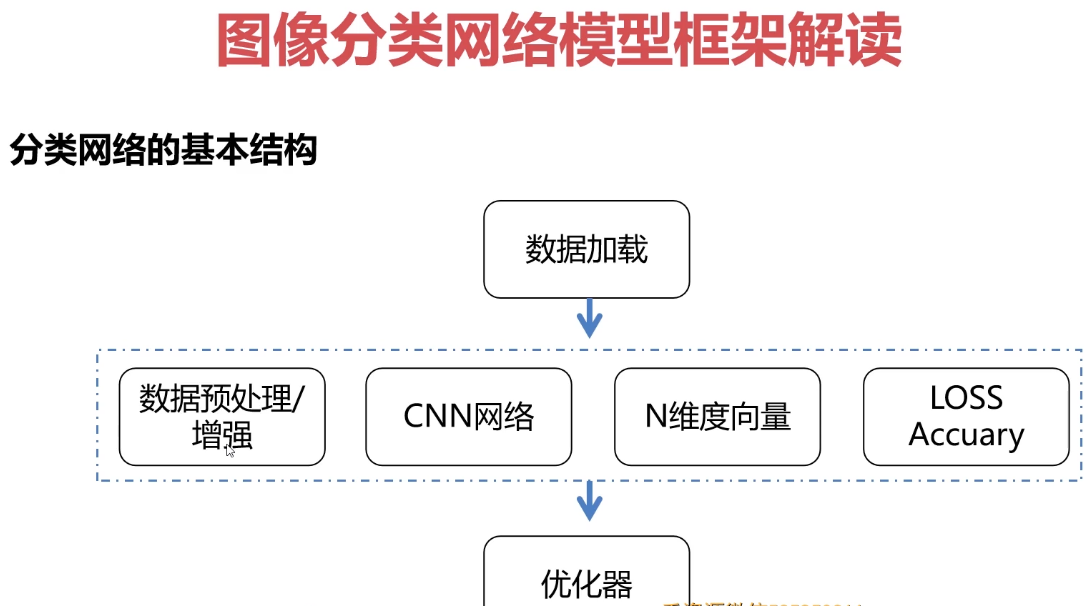
1.1数据加载

1.2数据增强

1.3网络结构
1.4类别概率分布
可以采用FC、卷积conv、pool(无参的)来完成概率分布的转换Softmax(N维向量的转换);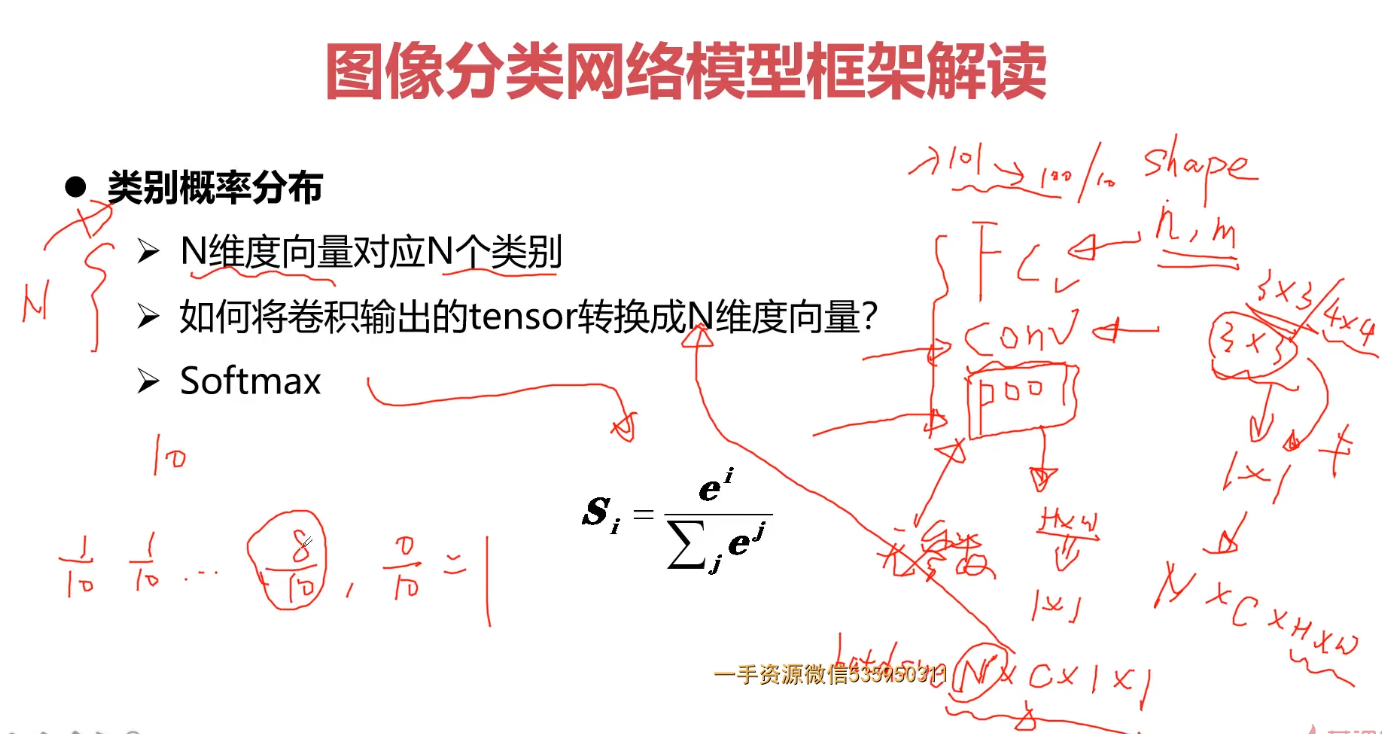
6-2 图像分类网络模型框架解读(下)
1.5 LOSS

1.6 分类问题常用评价指标
TP/TN 正确的值
PR曲线 VS ROC曲线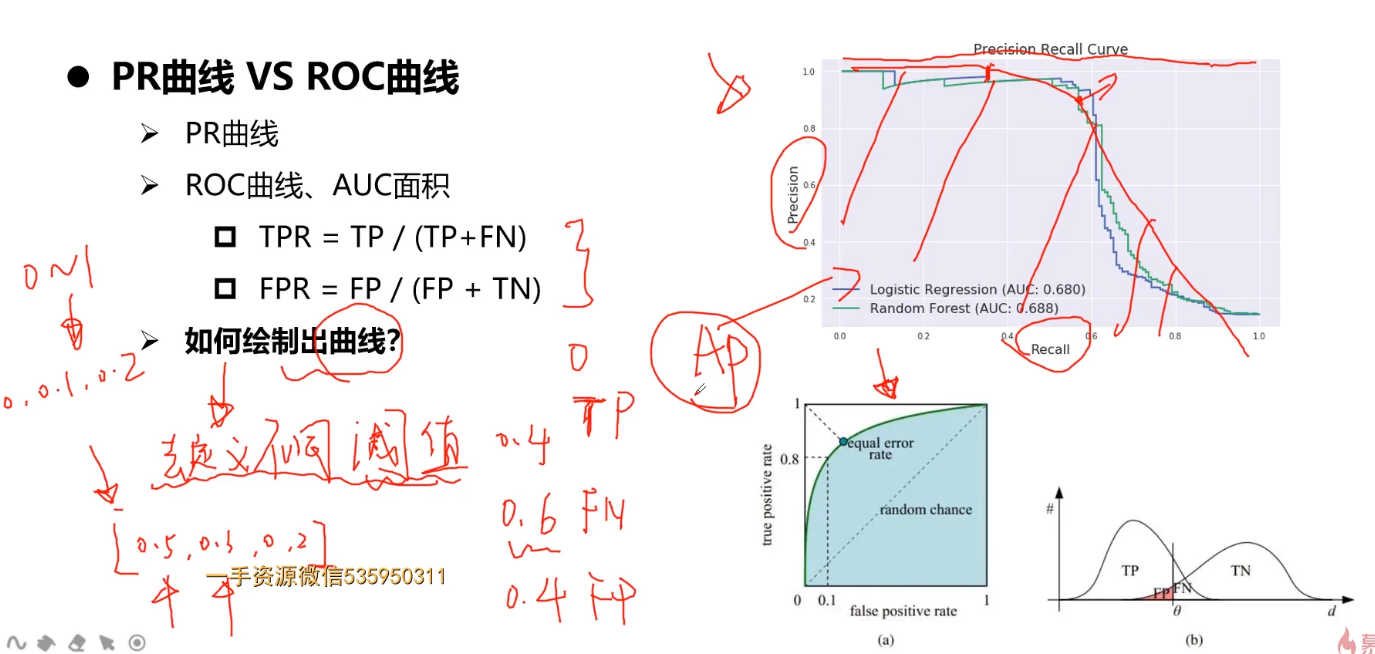
1.7优化器选择

6-3 cifar10数据介绍-读取-处理(上)
CIFAR-10/100
针对 MNIST 数据集和 CIFAR10 数据集,最大的不同:就是 MNIST 是单通道的,CIFAR10 是三通道的,因此在构建 LeNet-5 网络的时候,C1层需要做不同的设置。至于输入图片尺寸不一样,我们可以使用 transforms.Resize 方法统一缩放到 32x32 的尺寸大小。
https://www.cs.toronto.edu/~kriz/cifar.html
CIFAR-10是一个用于识别普适物体的小型经典数据集,包含10个类别的RGB彩色图片,分别是’airplane’, ‘automobile’, ‘bird’, ‘cat’, ‘deer’, ‘dog’, ‘frog’, ‘horse’, ‘ship’, ‘truck’。可以在官网(http://www.cs.toronto.edu/~kriz/cifar.html)下载到该数据集。本案例使用CIFAR-10数据集进行图片分类任务。
训练集5000,测试集1000 图片32*32
数据读取
glob是一个功能强大的python包,可以进行路径的读取。这里的代表读取cifar10目录下的所有路径,并整理在一个列表images中。通过代码可以展示该目录下文件的个数和前面5个路径的名称。输出结果显示cifar10目录下有60,000个文件,都是png格式的图片。同时,文件的命名有一定规律,都是“种类_序号.png”的方式,后续将利用这种命名方式实现自动分类。
batch_size=128
input: torch.Size([128, 3, 32, 32])
*labels: torch.Size([128])
import pickledef unpickle(file):with open(file, 'rb') as fo:dict = pickle.load(fo, encoding='bytes')return dictlabel_name = ["airplane","automobile","bird","cat","deer","dog","frog","horse","ship","truck"]import globimport numpy as npimport cv2import ostrain_list = glob.glob("/home/kuan/dataset/CIFAR10/test_batch*")print(train_list)save_path = "/home/kuan/dataset/CIFAR10/TEST"for l in train_list:print(l)l_dict = unpickle(l)# print(l_dict)print(l_dict.keys())for im_idx, im_data in enumerate(l_dict[b'data']):im_label = l_dict[b'labels'][im_idx]im_name = l_dict[b'filenames'][im_idx]print(im_label, im_name, im_data)im_label_name = label_name[im_label]im_data = np.reshape(im_data, [3, 32, 32])im_data = np.transpose(im_data, (1, 2, 0))# cv2.imshow("im_data",cv2.resize(im_data, (200, 200)))# cv2.waitKey(0)if not os.path.exists("{}/{}".format(save_path,im_label_name)):os.mkdir("{}/{}".format(save_path, im_label_name))cv2.imwrite("{}/{}/{}".format(save_path,im_label_name,im_name.decode("utf-8")), im_data)# data_list = glob.glob("/home/kuan/dataset/"# "cifar-11-batches-py/data_batch*")# for path in data_list:# data = unpickle(path)# for i in range(len(data[b"labels"])):## im_data = np.reshape(data[b"data"][i], (3, 32, 32))# im_data = np.transpose(im_data, (1, 2, 0))# im_name = data[b'filenames'][i].decode("utf-8")# im_label = label_name[data[b"labels"][i]]## if not os.path.exists("/home/kuan/dataset/cifar-11-batches-py/train/{}"# .format(im_label)):# os.mkdir("/home/kuan/dataset/cifar-11-batches-py/train/{}"# .format(im_label))## cv2.imwrite("/home/kuan/dataset/cifar-11-batches-py/train/{}/{}"# .format(im_label, im_name), im_data)
6-4 cifar10数据介绍-读取-处理(下)
数据存贮到文件夹
import pickledef unpickle(file):with open(file, 'rb') as fo:dict = pickle.load(fo, encoding='bytes')return dictlabel_name = ["airplane","automobile","bird","cat","deer","dog","frog","horse","ship","truck"]import globimport numpy as npimport cv2import os# test测试训练集生成train_list = glob.glob("F:/Projects/imooc/Pytorch/Cifar/Cifar10/test_batch*")print(train_list)save_path = "F:/Projects/imooc/Pytorch/Cifar/Cifar10/TEST"#for l in train_list:print(l)l_dict = unpickle(l)# print(l_dict)print(l_dict.keys())#for im_idx, im_data in enumerate(l_dict[b'data']):im_label = l_dict[b'labels'][im_idx]im_name = l_dict[b'filenames'][im_idx]print(im_label, im_name, im_data)im_label_name = label_name[im_label]im_data = np.reshape(im_data, [3, 32, 32]) # 将数据转换为 3*32*32im_data = np.transpose(im_data, (1, 2, 0)) # 维度转换# # 查看图片# cv2.imshow("im_data",cv2.resize(im_data, (200, 200)))# cv2.waitKey(0)#if not os.path.exists("{}/{}".format(save_path,im_label_name)):os.mkdir("{}/{}".format(save_path, im_label_name))#cv2.imwrite("{}/{}/{}".format(save_path,im_label_name,im_name.decode("utf-8")), im_data)# data_list = glob.glob("/home/kuan/dataset/"# "cifar-11-batches-py/data_batch*")# for path in data_list:# data = unpickle(path)# for i in range(len(data[b"labels"])):## im_data = np.reshape(data[b"data"][i], (3, 32, 32))# im_data = np.transpose(im_data, (1, 2, 0))# im_name = data[b'filenames'][i].decode("utf-8")# im_label = label_name[data[b"labels"][i]]## if not os.path.exists("/home/kuan/dataset/cifar-11-batches-py/train/{}"# .format(im_label)):# os.mkdir("/home/kuan/dataset/cifar-11-batches-py/train/{}"# .format(im_label))## cv2.imwrite("/home/kuan/dataset/cifar-11-batches-py/train/{}/{}"# .format(im_label, im_name), im_data)
6-5 PyTorch自定义数据加载-加载Cifar10数据
基于Pytorch中的torch.utils.data.Dataset类实现自定义的FaceLandmarksDataset类,主要是重写了getitem这个方法。
实现了自定义的Dataset类之后,就可以通过自定义的Dataset来构建一个DataLoader对象实现数据的加载跟批次处理,对自定义的dataset完成测试。
Batch Size
直观的理解:
Batch Size定义:一次训练所选取的样本数。
Batch Size的大小影响模型的优化程度和速度。同时其直接影响到GPU内存的使用情况,假如你GPU内存不大,该数值最好设置小一点。
Batch Size从小到大的变化对网络影响
1、没有Batch Size,梯度准确,只适用于小样本数据库
2、Batch Size=1,梯度变来变去,非常不准确,网络很难收敛。
3、Batch Size增大,梯度变准确,
4、Batch Size增大,梯度已经非常准确,再增加Batch Size也没有用
原文链接:https://blog.csdn.net/qq_34886403/article/details/82558399
batch_size=128
input: torch.Size([128, 3, 32, 32])
labels: torch.Size([128])
from torchvision import transformsfrom torch.utils.data import DataLoader, Datasetimport osfrom PIL import Imageimport numpy as np # 数据存储import globlabel_name = ["airplane", "automobile", "bird","cat", "deer", "dog","frog", "horse", "ship", "truck"]label_dict = {}for idx, name in enumerate(label_name):label_dict[name] = idxdef default_loader(path):return Image.open(path).convert("RGB")# train_transform = transforms.Compose([# transforms.RandomCrop(28),# transforms.RandomHorizontalFlip(),# transforms.ToTensor(),# ])train_transform = transforms.Compose([transforms.RandomHorizontalFlip(),transforms.RandomVerticalFlip(),# transforms.RandomRotation(90),# transforms.ColorJitter(brightness=0.2, contrast=0.2, hue=0.2),# transforms.RandomGrayscale(0.2),# transforms.RandomCrop(28),transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465),(0.2023, 0.1994, 0.2010)),])# 数据增强# test_transform = transforms.Compose([# transforms.CenterCrop((32, 32)),# transforms.ToTensor(),# transforms.Normalize((0.4914, 0.4822, 0.4465),# (0.2023, 0.1994, 0.2010)),# ])train_transform = transforms.Compose([transforms.RandomCrop(28),transforms.RandomHorizontalFlip(),transforms.RandomVerticalFlip(),# transforms.RandomRotation(90),transforms.ColorJitter(0.1, 0.1, 0.1, 0.1),transforms.RandomGrayscale(0.2),transforms.ToTensor()])#test_transform = transforms.Compose([transforms.Resize((28, 28)),transforms.ToTensor()])class MyDataset(Dataset):def __init__(self, im_list, transform=None, loader=default_loader):super(MyDataset, self).__init__()imgs = []for im_item in im_list:#"/home/kuan/dataset/CIFAR10/TRAIN/" \#"airplane/aeroplane_s_000021.png"im_label_name = im_item.split("\\")[-2] # win10 \\ 与 linux /imgs.append([im_item, label_dict[im_label_name]])self.imgs = imgsself.transform = transformself.loader = loaderdef __getitem__(self, index): # 读取图片数据中的元素;im_path, im_label = self.imgs[index] # 图片路径和labelim_data = self.loader(im_path)if self.transform is not None:im_data = self.transform(im_data)return im_data, im_labeldef __len__(self): # 返回样本的数量lenreturn len(self.imgs)im_train_list = glob.glob("F:\\Projects\\imooc\\Pytorch\\Cifar\\Cifar10\\TRAIN\\*\\*.png")im_test_list = glob.glob("F:\\Projects\\imooc\\Pytorch\\Cifar\\Cifar10\\TEST\\*\\*.png")train_dataset = MyDataset(im_train_list, transform=train_transform)test_dataset = MyDataset(im_test_list, transform=test_transform)train_loader = DataLoader(dataset=train_dataset,batch_size=128, # 6shuffle=True,num_workers=4)test_loader = DataLoader(dataset=test_dataset,batch_size=128,shuffle=False,num_workers=4)print("num_of_train", len(train_dataset))print("num_of_test", len(test_dataset))
6-6 PyTorch搭建 VGGNet 实现Cifar10图像分类
参考:1.【长文详解】卷积神经网络常见架构AlexNet、ZFNet、VGGNet、GoogleNet和ResNet模型的理论与实践
总结:
- LeNet是第一个成功应用于手写字体识别的卷积神经网络 ALexNet展示了卷积神经网络的强大性能,开创了卷积神经网络空前的高潮
- ZFNet通过可视化展示了卷积神经网络各层的功能和作用
- VGG采用堆积的小卷积核替代采用大的卷积核,堆叠的小卷积核的卷积层等同于单个的大卷积核的卷积层,不仅能够增加决策函数的判别性还能减少参数量
- GoogleNet增加了卷积神经网络的宽度,在多个不同尺寸的卷积核上进行卷积后再聚合,并使用1*1卷积降维减少参数量
- ResNet解决了网络模型的退化问题,允许神经网络更深
搭载一个类似VGNet 的串联网络结构来处理cifar10分类任务
VGNet
VGGNet 是由牛津大学视觉几何小组(Visual Geometry Group, VGG)提出的一种深层卷积网络结构,他们以 7.32% 的错误率赢得了 2014 年 ILSVRC 分类任务的亚军(冠军由 GoogLeNet 以 6.65% 的错误率夺得)和 25.32% 的错误率夺得定位任务(Localization)的第一名(GoogLeNet 错误率为 26.44%)
VGGNet可以看成是加深版本的AlexNet,都是由卷积层、全连接层两大部分构成。
eg:
- 预处理过程:图片每个像素中减去在训练集上的图片计算 RGB 均值
- 所有隐藏层都配备了 ReLU 激活
- 全局使用 3×3 小卷积,可以有效的减少参数,2 个 3×3 卷积可以替代一个 5×5 卷积,参数量变成 5×5 卷积的 (2×3×3)/(5×5)=0.72 倍,3 个 3×3 卷积可以替换 1 个 7×7 卷积,参数量是 7×7 卷积的 (3×3×3)/(7×7)=0.6 倍。这样的连接方式使得网络参数量更小,而且多层的激活函数令网络对特征的学习能力更强。多个 3*3 的卷积核比一个较大尺寸的卷积核有更多层的非线性函数,增加了非线性表达,使判决函数更具有判决性。
- 结合 1×1 卷积层是增加决策函数非线性而不影响卷积层感受野的一种方式。
- 训练设置:批量大小设为 256,动量为 0.9。训练通过权重衰减(L2 惩罚乘子设定为 5×10^−4)进行正则化,前两个全连接层采取 dropout 正则化(dropout 比率设定为 0.5)。学习率初始设定为 10−2,然后当验证集准确率停止改善时,学习率以 10 倍的比率进行减小。学习率总共降低 3 次,学习在 37 万次迭代后停止(74 个 epochs)。
- 为了进一步增强训练集,裁剪图像经过了随机水平翻转和随机 RGB 颜色偏移
- 全连接转卷积(测试阶段),使用不同的尺度进行测试
1、输入224x224x3的图片,经64个3x3的卷积核作两次卷积+ReLU,卷积后的尺寸变为224x224x64
2、作max pooling(最大化池化),池化单元尺寸为2x2(效果为图像尺寸减半),池化后的尺寸变为112x112x64
3、经128个3x3的卷积核作两次卷积+ReLU,尺寸变为112x112x128
4、作2x2的max pooling池化,尺寸变为56x56x128
5、经256个3x3的卷积核作三次卷积+ReLU,尺寸变为56x56x256
6、作2x2的max pooling池化,尺寸变为28x28x256
7、经512个3x3的卷积核作三次卷积+ReLU,尺寸变为28x28x512
8、作2x2的max pooling池化,尺寸变为14x14x512
9、经512个3x3的卷积核作三次卷积+ReLU,尺寸变为14x14x512
10、作2x2的max pooling池化,尺寸变为7x7x512
11、与两层1x1x4096,一层1x1x1000进行全连接+ReLU(共三层)
12、通过softmax输出1000个预测结果
load_cifar10.py
train.py
定义VGNet网络结构
import torchimport torch.nn as nnimport torch.nn.functional as Fclass VGGbase(nn.Module):def __init__(self):super(VGGbase, self).__init__()# 3 * 28 * 28 (crop-->32, 28)self.conv1 = nn.Sequential(nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(64),nn.ReLU())self.max_pooling1 = nn.MaxPool2d(kernel_size=2, stride=2)# 14 * 14self.conv2_1 = nn.Sequential(nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(128),nn.ReLU())self.conv2_2 = nn.Sequential(nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(128),nn.ReLU())self.max_pooling2 = nn.MaxPool2d(kernel_size=2, stride=2)# 7 * 7self.conv3_1 = nn.Sequential(nn.Conv2d(128, 256, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(256),nn.ReLU())self.conv3_2 = nn.Sequential(nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(256),nn.ReLU())self.max_pooling3 = nn.MaxPool2d(kernel_size=2,stride=2,padding=1)# 4 * 4self.conv4_1 = nn.Sequential(nn.Conv2d(256, 512, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(512),nn.ReLU())self.conv4_2 = nn.Sequential(nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(512),nn.ReLU())self.max_pooling4 = nn.MaxPool2d(kernel_size=2,stride=2)# batchsize * 512 * 2 *2 --> batchsize * (512 * 4)# 定义fcself.fc = nn.Linear(512 * 4, 10) # 特征图大小*channel 输出:10维度def forward(self, x):batchsize = x.size(0)out = self.conv1(x)out = self.max_pooling1(out) # 卷积1out = self.conv2_1(out)out = self.conv2_2(out)out = self.max_pooling2(out)# 卷积2out = self.conv3_1(out)out = self.conv3_2(out)out = self.max_pooling3(out)# 卷积3out = self.conv4_1(out)out = self.conv4_2(out)out = self.max_pooling4(out)# 定义fc层之前将tenser展平,# 也就是 batchsize * c * h * w --> batchsize * nout = out.view(batchsize, -1)# 定义fc层out = self.fc(out) # batchsize * 11out = F.log_softmax(out, dim=1) # softmaxreturn outdef VGGNet():return VGGbase()
6-7 PyTorch搭建cifar10训练脚本-tensorboard记录LOG(上)
tensorboard --logdir H:\project\Pytorch\06\logs# cifar10import torchimport torch.nn as nnimport torchvisionfrom vggnet import VGGNetfrom resnet import ResNet18from load_cifar10 import train_loader, test_loaderimport osimport tensorboardX#是否使用GPUdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")epoch_num = 200 # 遍历样本200次lr = 0.1 # 学习率batch_size = 128net = VGGNet().to(device)#loss 交叉熵loss_func = nn.CrossEntropyLoss()#optimizer 优化器optimizer = torch.optim.Adam(net.parameters(), lr=lr)# optimizer = torch.optim.SGD(net.parameters(), lr = lr,# momentum=0.9, weight_decay=5e-4)# 学习率调整:指数衰减 每进行5个epoch,学习率变成以前的0.9scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.9)model_path = "models"log_path = "logs"if not os.path.exists(log_path):os.makedirs(log_path)if not os.path.exists(model_path):os.makedirs(model_path)writer = tensorboardX.SummaryWriter(log_path)step_n = 0# 开始训练;for epoch in range(epoch_num):print("epoch is ", epoch)net.train() # train BN dropoutfor i, data in enumerate(train_loader):inputs, labels = datainputs, labels = inputs.to(device), labels.to(device)outputs = net(inputs)loss = loss_func(outputs, labels)optimizer.zero_grad() # 优化器梯度为0loss.backward() # 反向传播optimizer.step()_, pred = torch.max(outputs.data, dim=1)correct = pred.eq(labels.data).cpu().sum()# print("epoch is ", epoch)# print("train lr is ", optimizer.state_dict()["param_groups"][0]["lr"])# print("train step", i, "loss is:", loss.item(),# "mini-batch correct is:", 100.0 * correct / batch_size)writer.add_scalar("train loss", loss.item(), global_step=step_n)writer.add_scalar("train correct",100.0 * correct.item() / batch_size, global_step=step_n)# 图像数据拼接im = torchvision.utils.make_grid(inputs)writer.add_image("train im", im, global_step=step_n)step_n += 1torch.save(net.state_dict(), "{}/{}.pth".format(model_path, epoch+1))scheduler.step()# test测试集sum_loss = 0sum_correct = 0for i, data in enumerate(test_loader):net.eval()inputs, labels = datainputs, labels = inputs.to(device), labels.to(device)outputs = net(inputs)# test 没有反向传播;loss = loss_func(outputs, labels)_, pred = torch.max(outputs.data, dim=1)correct = pred.eq(labels.data).cpu().sum()sum_loss += loss.item()sum_correct += correct.item()im = torchvision.utils.make_grid(inputs)writer.add_image("test im", im, global_step=step_n)test_loss = sum_loss * 1.0 / len(test_loader)test_correct = sum_correct * 100.0 / len(test_loader) / batch_sizewriter.add_scalar("test loss", test_loss, global_step=epoch + 1)writer.add_scalar("test correct",test_correct, global_step=epoch + 1)print("epoch is", epoch + 1, "loss is:", test_loss,"test correct is:", test_correct)writer.close()
6-8 PyTorch搭建cifar10训练脚本-tensorboard记录LOG(下
6-9 PyTorch搭建cifar10训练脚本搭建-ResNet结构(上)
基本结构 卷积、BN、ReLU
'''ResNet-18 Image classfication for cifar-11 with PyTorchAuthor 'Sun-qian'.'''import torchimport torch.nn as nnimport torch.nn.functional as Fclass ResidualBlock(nn.Module):def __init__(self, inchannel, outchannel, stride=1):super(ResidualBlock, self).__init__()self.left = nn.Sequential(nn.Conv2d(inchannel, outchannel, kernel_size=3, stride=stride, padding=1, bias=False),nn.BatchNorm2d(outchannel),nn.ReLU(inplace=True),nn.Conv2d(outchannel, outchannel, kernel_size=3, stride=1, padding=1, bias=False),nn.BatchNorm2d(outchannel))self.shortcut = nn.Sequential() # 跳连分支if stride != 1 or inchannel != outchannel:self.shortcut = nn.Sequential(nn.Conv2d(inchannel, outchannel, kernel_size=1, stride=stride, bias=False),nn.BatchNorm2d(outchannel))def forward(self, x):out = self.left(x)out += self.shortcut(x)out = F.relu(out)return outclass ResNet(nn.Module): # 分类网络def __init__(self, ResidualBlock, num_classes=10):super(ResNet, self).__init__()self.inchannel = 32self.conv1 = nn.Sequential(nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1, bias=False),nn.BatchNorm2d(32),nn.ReLU(),)self.layer1 = self.make_layer(ResidualBlock, 64, 2, stride=2)self.layer2 = self.make_layer(ResidualBlock, 128, 2, stride=2)self.layer3 = self.make_layer(ResidualBlock, 256, 2, stride=2)self.layer4 = self.make_layer(ResidualBlock, 512, 2, stride=2)self.fc = nn.Linear(512, num_classes)def make_layer(self, block, channels, num_blocks, stride):strides = [stride] + [1] * (num_blocks - 1) #strides=[1,1]layers = []for stride in strides:layers.append(block(self.inchannel, channels, stride))self.inchannel = channelsreturn nn.Sequential(*layers)def forward(self, x):out = self.conv1(x)out = self.layer1(out)out = self.layer2(out)out = self.layer3(out)out = self.layer4(out)out = F.avg_pool2d(out, 2)out = out.view(out.size(0), -1) # 去掉特征图的两个维度;out = self.fc(out) #return outdef ResNet18():return ResNet(ResidualBlock)
优化方案:
1.加大channel (32 64),stride参数加大, self.make_layer(ResidualBlock, 64, 2, stride=2)
2.对ResBlock结构进行调整; 如:outchannel//4
import torchimport torch.nn as nnimport torch.nn.functional as Fclass ResidualBlock(nn.Module):def __init__(self, inchannel, outchannel, stride=1):super(ResidualBlock, self).__init__()self.left = nn.Sequential(nn.Conv2d(inchannel, outchannel//4, kernel_size=3, stride=stride, padding=1, bias=False),nn.BatchNorm2d(outchannel),nn.ReLU(inplace=True),nn.Conv2d(outchannel, outchannel//4, kernel_size=3, stride=1, padding=1, bias=False),nn.BatchNorm2d(outchannel))self.shortcut = nn.Sequential() # 跳连分支if stride != 1 or inchannel != outchannel:self.shortcut = nn.Sequential(nn.Conv2d(inchannel, outchannel, kernel_size=1, stride=stride, bias=False),nn.BatchNorm2d(outchannel))def forward(self, x):out = self.left(x)out += self.shortcut(x)out = F.relu(out)return out
6-10 PyTorch搭建cifar10训练脚本搭建-ResNet结构(下)
6-11 PyTorch搭建cifar10训练脚本搭建-Mobilenetv1结构
MobileNet
mobilenetv1.py
MobileNet基于深度可分离卷积构建了非常轻量且延迟小的模型,并且可以通过两个超参数来进一步控制模型的大小,该模型能够应用到终端设备中,具有很重要的实践意义。
MobileNet系列很重要的轻量级网络家族,出自谷歌,MobileNetV1使用深度可分离卷积来构建轻量级网络,MobileNetV2提出创新的inverted residual with linear bottleneck单元,虽然层数变多了,但是整体网络准确率和速度都有提升,MobileNetV3则结合AutoML技术以及人工微调进行更轻量级的网络构建
import torchimport torch.nn as nnimport torch.nn.functional as Fclass mobilenet(nn.Module):def conv_dw(self, in_channel, out_channel, stride):return nn.Sequential(# # 深度分组卷积nn.Conv2d(in_channel, in_channel,kernel_size=3, stride=stride, padding=1,groups=in_channel, bias=False),nn.BatchNorm2d(in_channel),nn.ReLU(),# # 点卷积1*1nn.Conv2d(in_channel, out_channel,kernel_size=1, stride=1, padding=0,bias=False),nn.BatchNorm2d(out_channel),nn.ReLU(),)def __init__(self):super(mobilenet, self).__init__()self.conv1 = nn.Sequential(nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(32),nn.ReLU())self.conv_dw2 = self.conv_dw(32, 32, 1)self.conv_dw3 = self.conv_dw(32, 64, 2)self.conv_dw4 = self.conv_dw(64, 64, 1)self.conv_dw5 = self.conv_dw(64, 128, 2)self.conv_dw6 = self.conv_dw(128, 128, 1)self.conv_dw7 = self.conv_dw(128, 256, 2)self.conv_dw8 = self.conv_dw(256, 256, 1)self.conv_dw9 = self.conv_dw(256, 512, 2)self.fc = nn.Linear(512, 10)def forward(self, x):out = self.conv1(x)out = self.conv_dw2(out)out = self.conv_dw3(out)out = self.conv_dw4(out)out = self.conv_dw5(out)out = self.conv_dw6(out)out = self.conv_dw7(out)out = self.conv_dw8(out)out = self.conv_dw9(out)out = F.avg_pool2d(out, 2) # 下采样;out = out.view(-1, 512)out = self.fc(out)return outdef mobilenetv1_small():return mobilenet()
6-12 PyTorch搭建cifar10训练脚本搭建-Inception结构(上)
参考:1.经典神经网络 | 从Inception v1到Inception v4全解析
Inception 网络是CNN分类器发展史上一个重要的里程碑。在 Inception 出现之前,大部分流行 CNN 仅仅是把卷积层堆叠得越来越多,使网络越来越深,以此希望能够得到更好的性能。
例如AlexNet,GoogleNet、 VGG-Net、ResNet等都是通过加深网络的层次和深度来提高准确率。
GoogLeNet 最大的特点就是使用了 Inception 模块,它的目的是设计一种具有优良局部拓扑结构的网络,即对输入图像并行地执行多个卷积运算或池化操作,并将所有输出结果拼接为一个非常深的特征图。因为 11、33 或 5*5 等不同的卷积运算与池化操作可以获得输入图像的不同信息,并行处理这些运算并结合所有结果将获得更好的图像表征。
Inception常见的版本有:
- Inception v1
- Inception v2 和 Inception v3
- Inception v4 和 Inception-ResNet
每个版本都是前一个版本的迭代进化。了解 Inception 网络的升级可以帮助我们构建自定义分类器,优化速度和准确率。
Inception v1
Inception v1的主要特点:一是挖掘了1 1卷积核的作用,减少了参数,提升了效果;*二是让模型自己来决定用多大的的卷积核。
6-13 PyTorch搭建cifar10训练脚本搭建-Inception结构(下)
import torchimport torch.nn as nn'''input: AresnetV2: B = g(A) + f(A)Inception:B1 = f1(A)B2 = f2(A)B3 = f3(A)B4 = f4(A)concat([B1, B2, B3, B4])'''# 算子def ConvBNRelu(in_channel, out_channel, kernel_size):return nn.Sequential(nn.Conv2d(in_channel, out_channel,kernel_size=kernel_size,stride=1,padding=kernel_size // 2),nn.BatchNorm2d(out_channel),nn.ReLU())class BaseInception(nn.Module):def __init__(self,in_channel,out_channel_list,reduce_channel_list):super(BaseInception, self).__init__()self.branch1_conv = ConvBNRelu(in_channel,out_channel_list[0],1)self.branch2_conv1 = ConvBNRelu(in_channel,reduce_channel_list[0],1)self.branch2_conv2 = ConvBNRelu(reduce_channel_list[0],out_channel_list[1],3)self.branch3_conv1 = ConvBNRelu(in_channel,reduce_channel_list[1],1)self.branch3_conv2 = ConvBNRelu(reduce_channel_list[1],out_channel_list[2],5)# 不进行下采样;self.branch4_pool = nn.MaxPool2d(kernel_size=3,stride=1,padding=1)self.branch4_conv = ConvBNRelu(in_channel,out_channel_list[3],3)def forward(self, x):out1 = self.branch1_conv(x)out2 = self.branch2_conv1(x)out2 = self.branch2_conv2(out2)out3 = self.branch3_conv1(x)out3 = self.branch3_conv2(out3)out4 = self.branch4_pool(x)out4 = self.branch4_conv(out4)out = torch.cat([out1, out2, out3, out4], dim=1)return outclass InceptionNet(nn.Module):def __init__(self):super(InceptionNet, self).__init__()self.block1 = nn.Sequential(nn.Conv2d(3, 64,kernel_size=7,stride=2,padding=1),nn.BatchNorm2d(64),nn.ReLU())self.block2 = nn.Sequential(nn.Conv2d(64, 128,kernel_size=3,stride=2,padding=1),nn.BatchNorm2d(128),nn.ReLU(),)self.block3 = nn.Sequential(BaseInception(in_channel=128,out_channel_list=[64, 64,64, 64],reduce_channel_list=[16, 16]),nn.MaxPool2d(kernel_size=3, stride=2, padding=1))self.block4 = nn.Sequential(BaseInception(in_channel=256,out_channel_list=[96, 96,96, 96],reduce_channel_list=[32, 32]),nn.MaxPool2d(kernel_size=3, stride=2, padding=1))self.fc = nn.Linear(384, 10)def forward(self, x):out = self.block1(x)out = self.block2(out)out = self.block3(out)out = self.block4(out)out = torch.nn.functional.avg_pool2d(out, 2)out = out.view(out.size(0), -1)out = self.fc(out)return outdef InceptionNetSmall():return InceptionNet()
6-14 PyTorch搭建cifar10训练脚本搭建-调用Pytorch标准网络ResNet18等
ResNet18
从图中可以看到红色框内八个比较特别的块,这些块就是该网络的特色:残差结构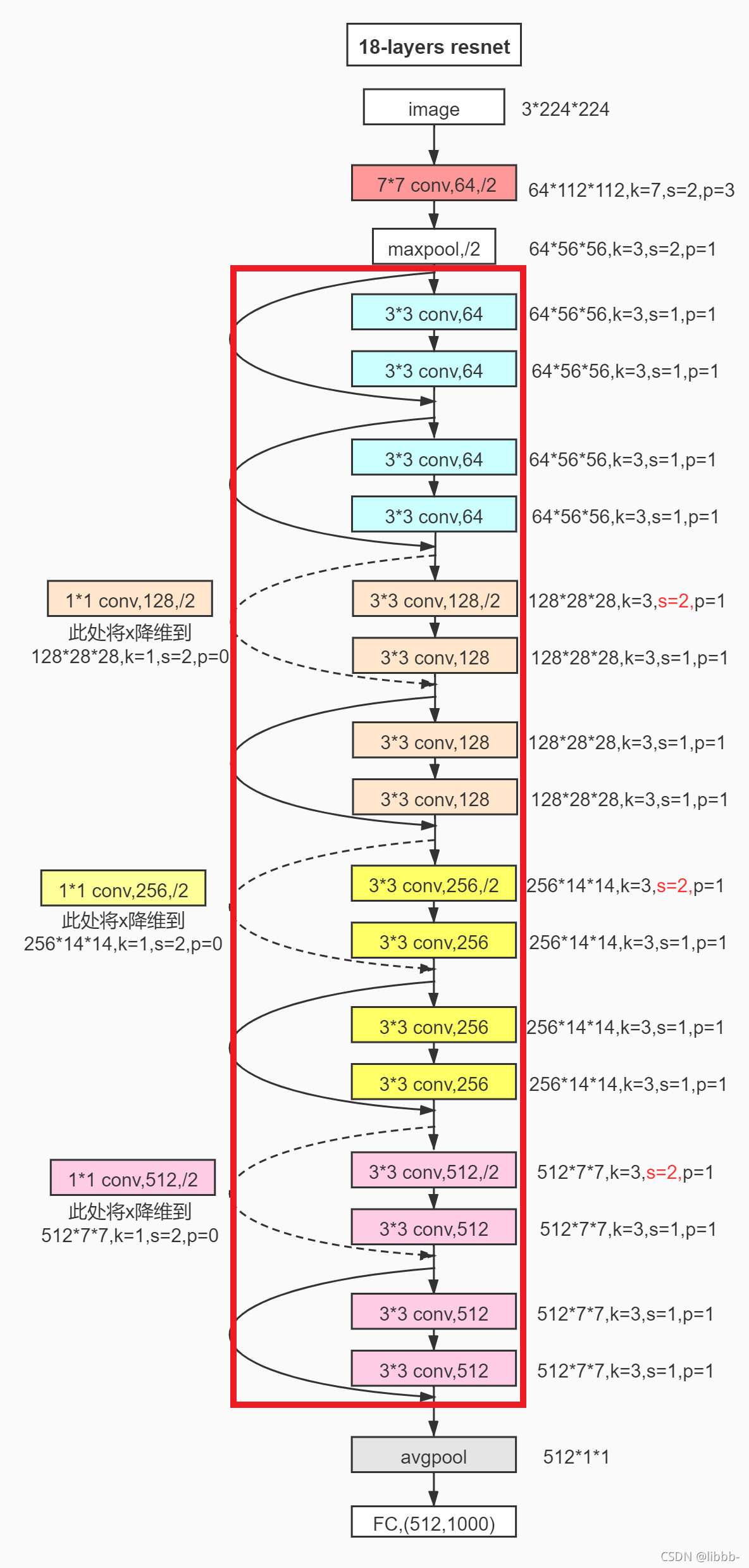
从刚刚的网络整体结构图我们可以看到红色框内的块不完全相同,有两类:Identity Block和Conv Block。
两者的结构如下图,左边的主干部分两者是相同的:两次 [卷积,标准化,激活函数] 和一次 [卷积,标准化]。
不同的是在右侧的残差边,Identity Block直接将 原始输入 与左侧结果相连,而Conv Block则 对原始输入进行了一次 [卷积,标准化] 后再与左侧结果相连。
[
](https://blog.csdn.net/m0_55938287/article/details/120900264)
残差结构
如图,可以看出最终的输出包括两个部分:经过处理后的F(x)和原始输入x
Pytorch调用标准的网络结构
pytorch的标准模型都放在torchvision中
# pre_resnet.pyimport torch.nn as nnfrom torchvision import modelsclass resnet18(nn.Module):def __init__(self):super(resnet18, self).__init__()self.model = models.resnet18(pretrained=True)self.num_features = self.model.fc.in_featuresself.model.fc = nn.Linear(self.num_features, 10)def forward(self, x):out = self.model(x)return outdef pytorch_resnet18():return resnet18()
6-15 PyTorch搭建cifar10推理测试脚本搭建
# test.pyimport torchimport globimport cv2from PIL import Imagefrom torchvision import transformsimport numpy as npfrom base_resnet import resnetdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")net = resnet()net.load_state_dict(torch.load("H:\\project\\Pytorch\\06\\models\\137.pth"))im_list = glob.glob("H:\\project\\Pytorch\\Cifar\\Cifar10\\TEST\\*\\*")np.random.shuffle(im_list)net.to(device)label_name = ["airplane", "automobile", "bird","cat", "deer", "dog","frog", "horse", "ship", "truck"]test_transform = transforms.Compose([transforms.CenterCrop((28, 28)),transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465),(0.2023, 0.1994, 0.2010)),])for im_path in im_list:net.eval()im_data = Image.open(im_path)inputs = test_transform(im_data)inputs = torch.unsqueeze(inputs, dim=0)inputs = inputs.to(device)outputs = net.forward(inputs) #前向运算_, pred = torch.max(outputs.data, dim=1)print(label_name[pred.cpu().numpy()[0]])img = np.asarray(im_data)img = img[:, :, [1, 2, 0]] # 格式转换;img = cv2.resize(img, (300, 300))cv2.imshow("im", img)cv2.waitKey()
6-16 分类问题优化思路
调参技巧
卷积神经网络优化主要还是 如何去优化模型的计算量;
1.backbone
backbone这个单词原意指的是人的脊梁骨,后来引申为支柱,核心的意思。
在神经网络中,尤其是CV领域,一般先对图像进行特征提取(常见的有vggnet,resnet,谷歌的inception),这一部分是整个CV任务的根基,因为后续的下游任务都是基于提取出来的图像特征去做文章(比如分类,生成等等)。
2.过拟合
http://www.imooc.com/article/305024
3.学习率调整
4.优化函数
5.数据增强
数据对模型的影响是非常重要的;
数据增强:翻转,旋转,裁剪,变形,缩放等各类操作; 颜色变换类
6-17 分类问题最新研究进展和方向
1.Backbone方面

2.小样本&0样本问题
3.数据增强
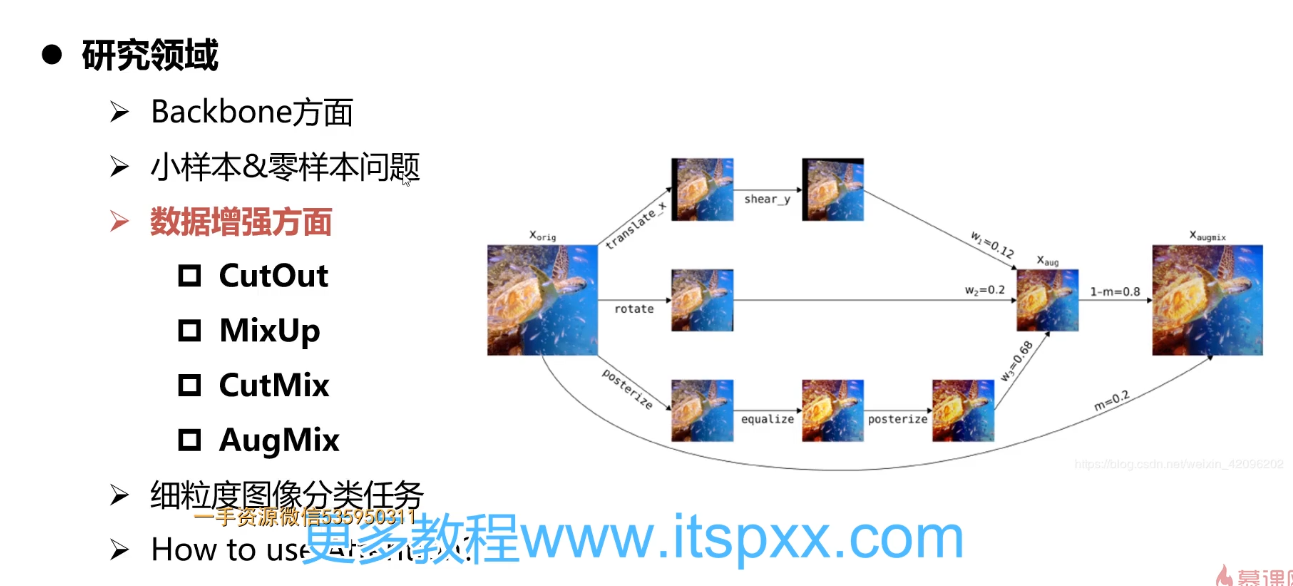
4.细粒度图像分类问题
给鸟进行分类:注意力机制

第7章 Pytorch实战计算机视觉任务-Pascal VOC目标检测问题
主要介绍使用Pytorch完成Pascal VOC目标检测问题,具体包括了目标检测算法综述,检测问题建模,Pascal VOC数据集介绍、Pascal VOC数据下载、数据处理,开源工具MMDetection介绍,使用MMDetection完成检测任务配置,使用MMDetection完成模型训练和结果分析。通过具体Passcal VOC目标检测任务来帮助大家了解如何使用MMDec…
7-1 目标检测问题介绍(上)
1.目标检测:包括 分类、定位、分割、目标检测

目标检测问题介绍
把定位和分类任务结合起来,我们就需要同时进行一张图片中的多个目标的检测和分类。目标检测问题就是定位和分类一张图像中的多个物体。与定位最重要的差别就是“变量”部分。与分类任务只输出一个类别信息不同的是,目标检测的输出的个数是不定的,因为一张图片中检测到的目标数量是不定的;

2.目标检测问题方法
3.目标检测两大算法Anchor-free和Anchor-based
参考:1. 11种Anchor-free目标检测综述 — Keypoint-based篇
Anchor-based
Anchor-based的检测:主要分为一阶段one-stage和两阶段two-stage两大类,但是不管是one-stage还是two-stage的,都是首先在图像上预设一些anchors,然后再预测目标物体的类别并refine这些anchor(一次或多次),并最终把这些refined anchors作为最终的检测结果。
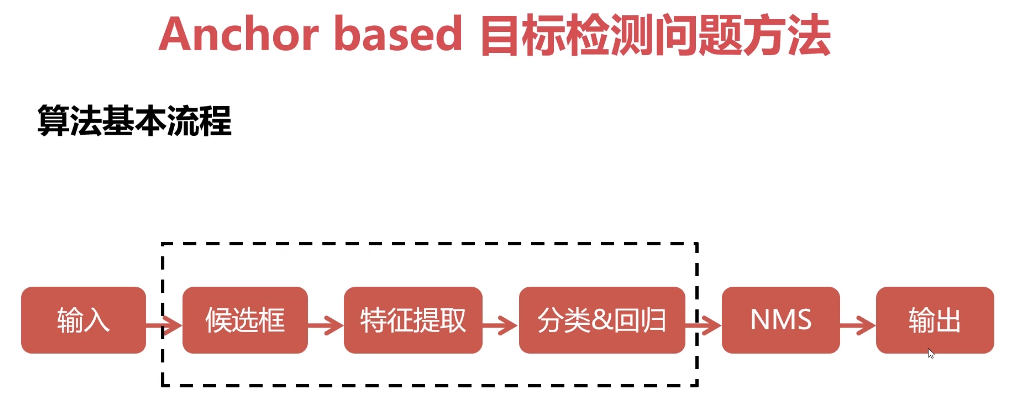
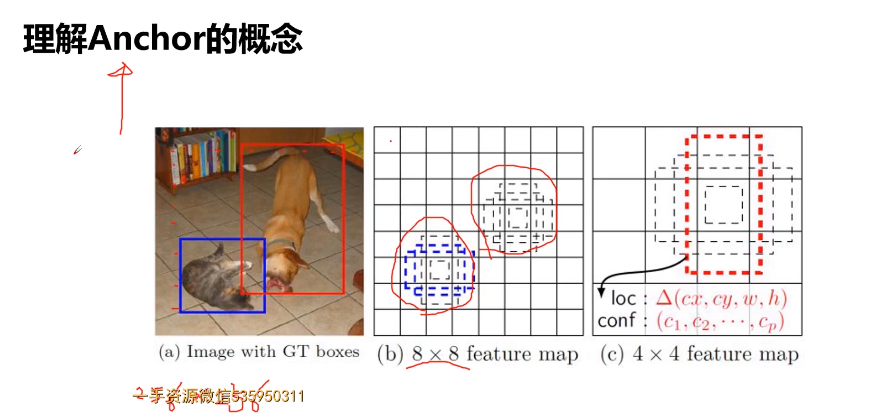
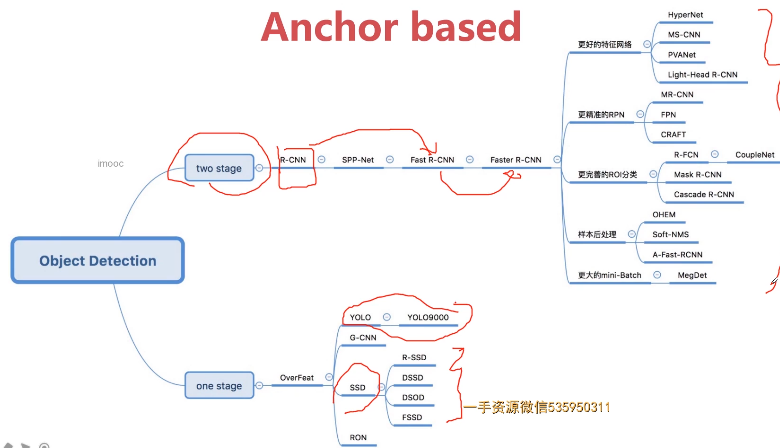
AnchorBased 存在的问题
Anchor-free
Anchor-free的检测:可以首先找到几个预定义或自学习的关键点,然后限制目标对象的空间范围。或者使用目标对象的中心点或区域定义正样本,然后预测从正样本到对象边界的四个距离。在各种Anchor-Free的算法中,根据其表征一个物体的方法,大体可以分为以下几类:
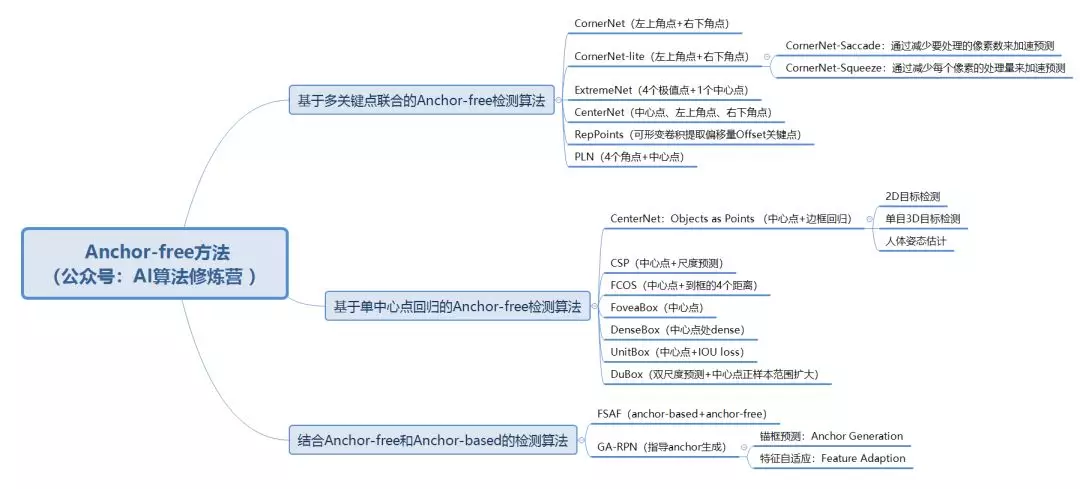
4.目标检测问题评价指标

5.目标检测问题难点
7-2 目标检测问题介绍(下)
7-3 Pascal VOC-COCO数据集介绍
Pascal VOC数据集

PASCAL VOC为图像识别和分类提供了一整套标准化的数据集,用来构建和评估用于图像分类(Classification),目标检测(Object Detection)和分割(Segmentation)的算法,我们耳熟能详的计算机视觉模型,如R-CNN系列、SSD和YOLO等等都是基于PASCAL VOC数据集上推出的
目前最完整的数据集是PASCAL VOC 2012数据集,而大多数研究者普遍使用的是PASCAL VOC 2007和PASCAL VOC 2012这2个数据集,它们二者是互斥的,不相容的。PASCAL VOC 2012总共包括了20类物体,train和val中有11530张图片,共有27450个目标检测标签和6929个分割标签
数据集的组织结构
数据集下载后解压,文件结构是这样的
├── Annotations 标签文件,xml格式
├── ImageSets 存放数据集的分割文件
├── JPEGImages 图片文件,jpg格式
├── SegmentationClass 存放按照class类别分割的图片
└── SegmentationObject 存放按照object目标分割的图片
其中Annotations文件夹
├── 000001.xml
├── 000002.xml
├── 000003.xml
…
一个典型的xml标签文件如下
各个字段的含义分别是
- folder:所属文件夹
- filename:文件名
- database:数据库名
- annotation:标记文件格式
- size:图像尺寸,width宽、height高,depth通道数目
- segmented:分割
- object: 表示一个目标,name标签名、pose拍摄角度right,有front、rear、left、right和unspecified、truncated是否被截断也就是图片中是否包含完整目标、difficult检测难易程度,1表示是、0表示否
- bndbox:目标所在的位置,用xmin、ymin、xmax、ymax来表示
ImageSets文件夹,存放数据集的分割文件,包含三个子文件夹Action、Layout、Main和Segmentation,其中Action文件夹存放用于动作识别文件,Main文件夹存放的是用于分类和检测的数据集分割文件,Layout文件夹用于person layout任务,Segmentation用于分割任务
COCO数据集介绍

7-4 MMdetection框架介绍-安装说明
参考:1.Multipass使用教程 http://www.manongjc.com/detail/21-gtzvxvzjtoaxswf.html
1.MMDetection介绍
香港中文大学-商汤科技联合实验室(MMLab)推出了OpenMMLab计划。OpenMMLab是一个用于多个重要研究领域的开源的代码库,力求在代码的质量和整体架构比别的代码库更具有优势,其目标是做到”Open-Source, Unified, Reproducible”。
众所周知,目标检测算法比较复杂,细节比较多,难以复现,而我们推出的 MMDetection 开源框架则希望解决上述问题。目前 MMdetection 已经复现了大部分主流和前沿模型,例如 Faster R-CNN 系列、Mask R-CNN 系列、YOLO 系列和比较新的 DETR 等等,模型库非常丰富,star 接近 13k,在学术研究和工业落地中应用非常广泛。
GitHub 链接:https://github.com/open-mmlab/mmdetection 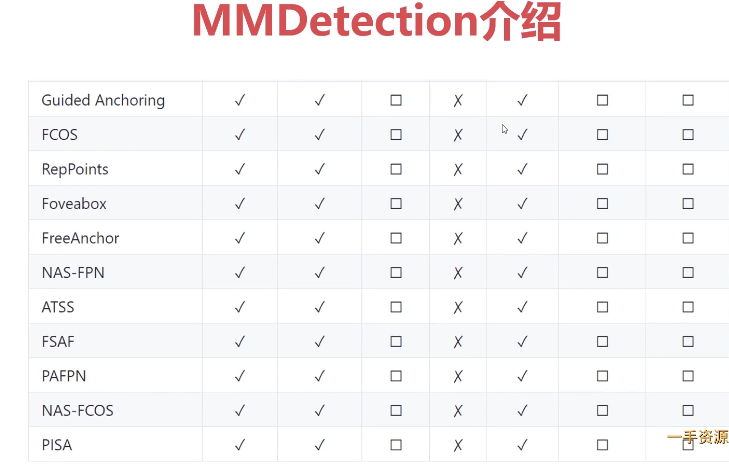
在mmdetection中,模型组件基本上分为4种类型:
backbone:通常是FCN网络,用于提取功能图,例如ResNet。
neck:骨干和头部之间的部分,例如FPN,ASPP。
head:用于特定任务的部分,例如bbox预测和mask预测。
roi extractor:用于从 feature maps中提取feature的部分,例如RoI Align
1.代码结构

2.mmcv

3.MMDetection安装




7-5 MMdetection框架使用说明
1.MMdetection框架使用说明

2.训练



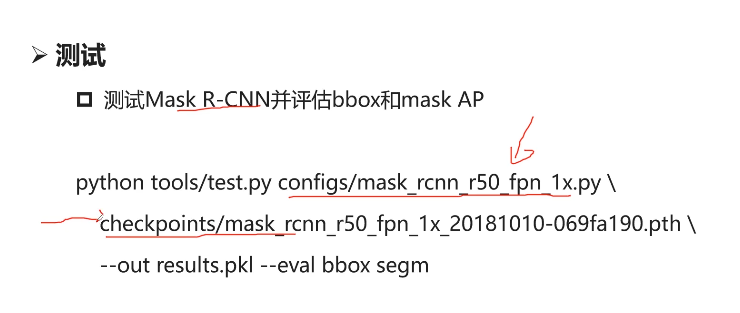


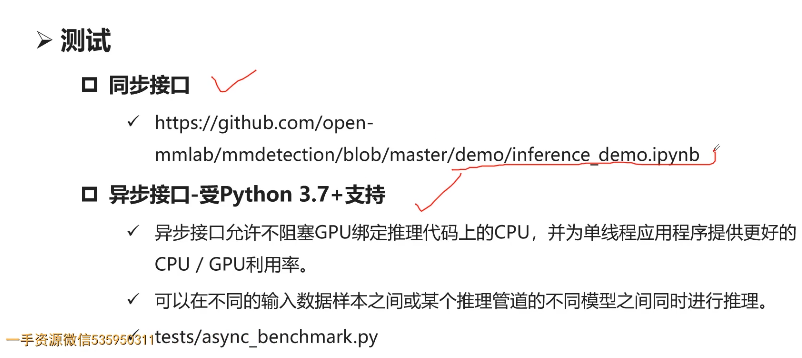







7-6 【讨论题】比较mmdetection与detectron
7-7 MMdetection训练Passcal VOC目标检测任务(上)
安装
https://github.com/open-mmlab/mmdetection/blob/master/docs/en/get_started.md
# 项目下载;git clone https://github.com/open-mmlab/mmdetection.git
Prepare environment
conda create -n openmmlab python=3.7 -yconda activate openmmlabconda install pytorch torchvision -c pytorchpip install Cython
网络配置文件
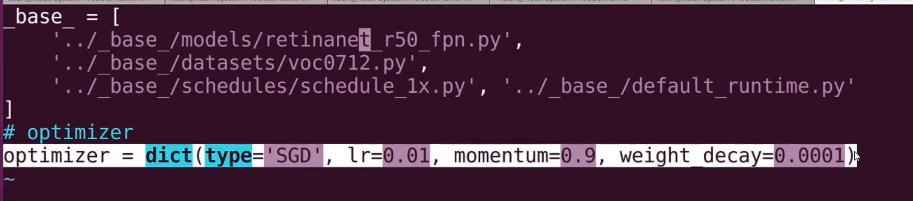
7-8 MMdetection训练Passcal VOC目标检测任务(中)
7-9 MMdetection训练Passcal VOC目标检测任务(下)
7-10 MMdetection Test脚本
7-11 MMdetection LOG分析
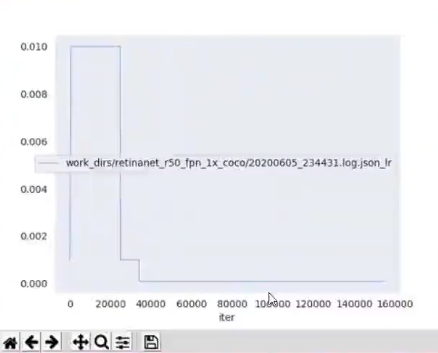
第8章 PyTorch实战计算机视觉任务-COCO目标分割问题
主要介绍使用Pytorch完成COCO数据集目标分割问题,具体包括了目标分割算法综述(语义分割、实例分割、全景分割),目标分割问题建模,COCO数据集介绍、COCO数据下载、数据处理,开源工具detectron介绍,使用detectron完成实例分割模型MASK-RCNN任务配置,使用detectron完成模型训练和结果分析。通过具体COCO目标分割任务来…
8-1 图像分割基本概念 (10:37)
1.图像分割(image segmentation)技术
图像分割是指将图像分成若干具有相似性质的区域的过程,从数学角度来看,图像分割是将图像划分成互不相交的区域的过程。


2.图像分割三大类

2.1语义分割
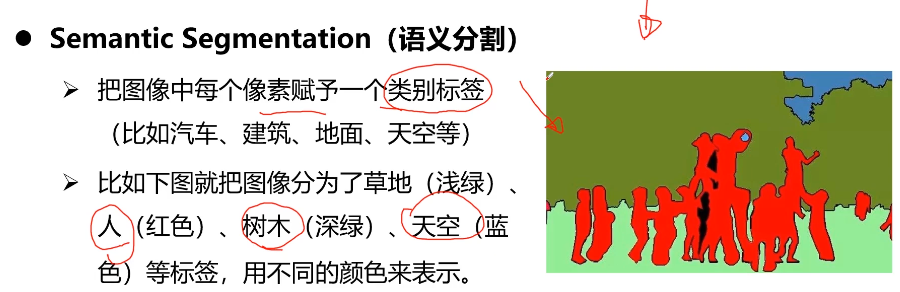
2.2实例分割
每个目标都是一个实例,需要把每一个人都识别出来;
2.3全景分割


8-2 图像分割方法介绍 (19:02)
图像分割模型的基本架构包括编码器与解码器。编码器通过卷积核提取图像特征。解码器负责输出包含物体轮廓的分割蒙版。
下采样减少计算量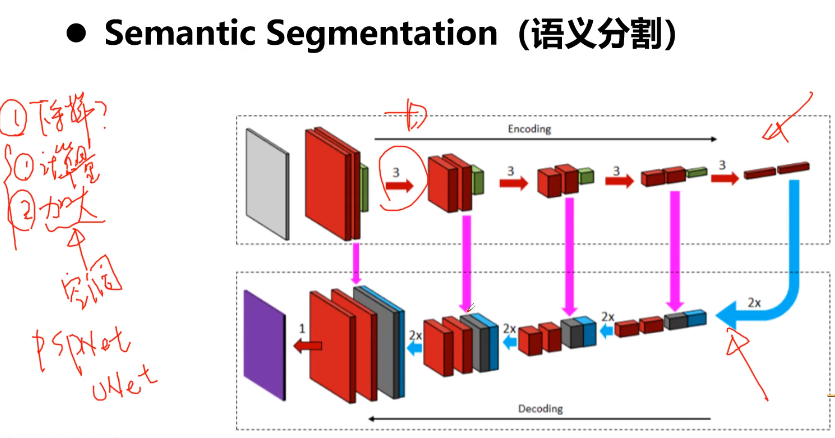
语义分割网络

实例分割网络
检测+分割的模型(检测+分割的模块):two-stage,single-stage
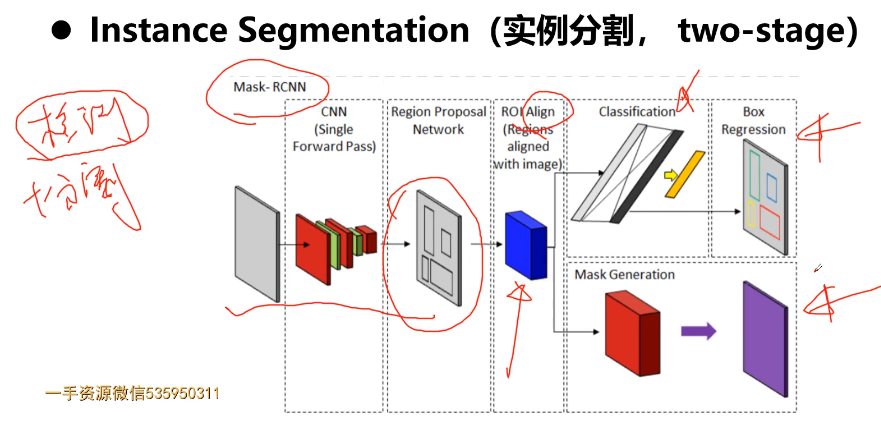
single-stage:
solo框架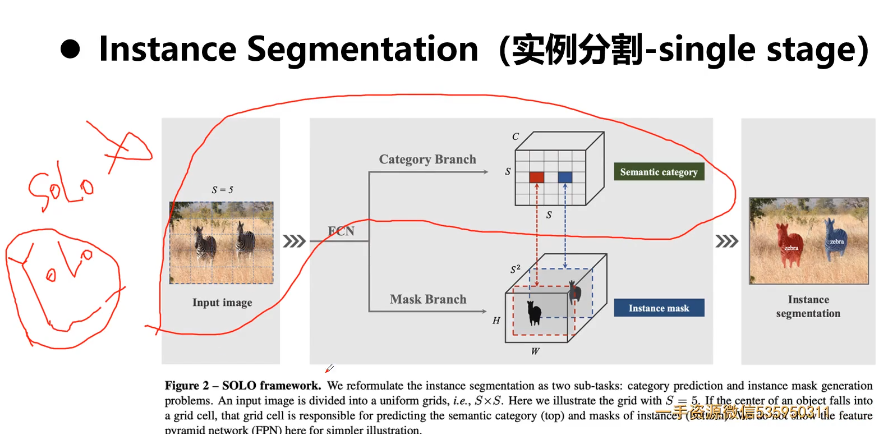
全景分割网络
输入的图像经过卷积网络,卷积网络处理的结果在经过实例分割的模块和语义分割的模块处理,拿到两个分割模块的结果结合 拿到全景网络的结果;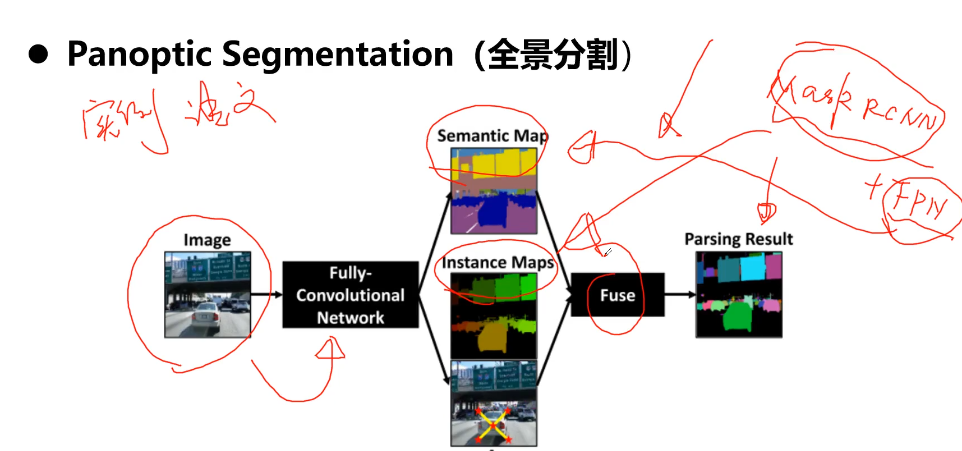

8-3 图像分割评价指标及目前面临的挑战 (09:51)
算法性能的评价指标

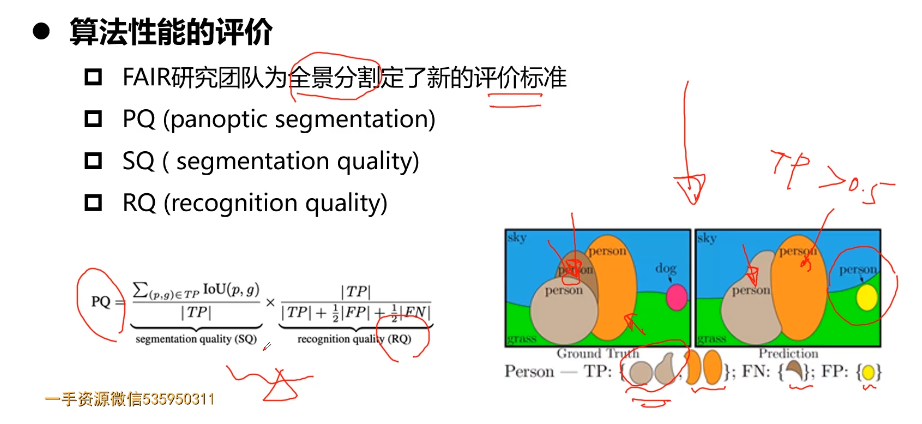
图像分割问题的难点

8-4 COCO数据集介绍 (04:20)
1.COCO数据集介绍

2.COCO数据集格式

8-5 detectron框架介绍和使用简单说明 (10:09)

1.Detectron 框架
Facebook 终于开源了 Detectron,Detectron 开源项目使用 caffe2 和 python 接口。实现了 10 多篇计算机视觉最新的成果。
2.Detectron 框架结构
3.Detectron 框架安装
Detectron 安装,参照 https://github.com/facebookresearch/Detectron/blob/master/INSTALL.md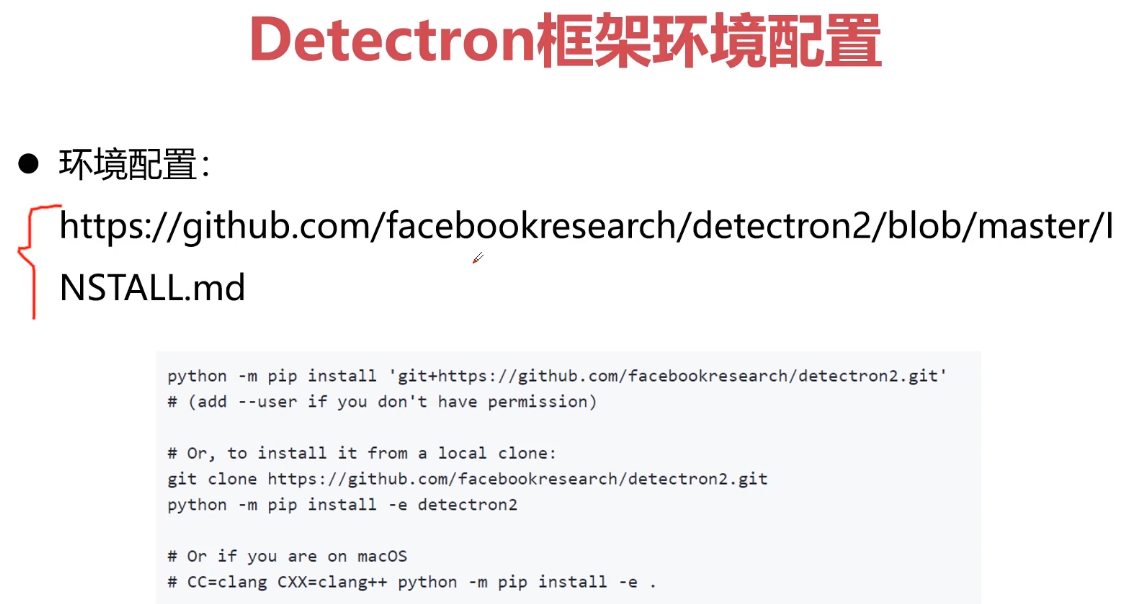
4.训练

8-6 coco数据集标注文件解析 (07:52)
read_coco.py #标注人的图片
from pycocotools.coco import COCOfrom skimage import iofrom matplotlib import pyplot as pltanno_file = "/home/kuan/MUKE-SOURCES/DATA/coco/annotations/instances_val2017.json"coco = COCO(anno_file)# 拿到personId找到对应的图片;catIds = coco.getCatIds(catNms=['person'])print(catIds)imgIds = coco.getImgIds(catIds=catIds)print(imgIds)# 可视化:单张图片读取for i in range(len(imgIds)):image = coco.loadImgs(imgIds[i])[0]I = io.imread(image["coco_url"])plt.imshow(I)anno_id = coco.getAnnIds(imgIds=image["id"], catIds=catIds, iscrowd=None)annotation = coco.loadAnns(anno_id)coco.showAnns(annotation)plt.show()
8-7 detectron源码解读和模型训练-demo测试 (37:29)
参照 https://github.com/facebookresearch/Detectron/blob/master/INSTALL.md
8-8 【讨论题】比较全景分割,语义分割和实例分割不同任务
第9章 PyTorch搭建GAN网络实战图像风格迁移
主要介绍生成对抗模型,GAN网络的基础概念,以及GAN网络在各种不同计算机视觉任务中的应用。并重点介绍GAN网络的典型网络结构,其中包括了:GAN、CycleGAN、Pixel to Pixel等网络结构。帮助大家梳理GAN网络的基本理论、核心概念和框架结构,为后续模型的搭建提供理论基础。并通过使用Pytorch完成GAN网络搭建,并解决图像…
9-1 GAN的基础概念和典型模型介绍(上) (15:03)
参考:1.GAN(1) GAN介绍: 基本概念及逻辑 https://www.jianshu.com/p/59980c56336c
生成式对抗网络(GAN)
GAN由Ian Goodfellow于2014年提出,并迅速成为了非常火热的研究话题,GAN的变种更是有上千种,深度学习先驱之一的Yann LeCun就曾说, “GAN及其变种是数十年来机器学习领域最有趣的 idea”。
生成式对抗网络(GAN, Generative Adversarial Networks )是一种深度学习模型,是近年来复杂分布上无监督学习最具前景的方法之一。模型通过(至少)两个模块:生成模型(Generative Model)和判别模型(Discriminative Model)的零和博弈进行学习,即通过两个网络的互相对抗来达到最好的生成效果。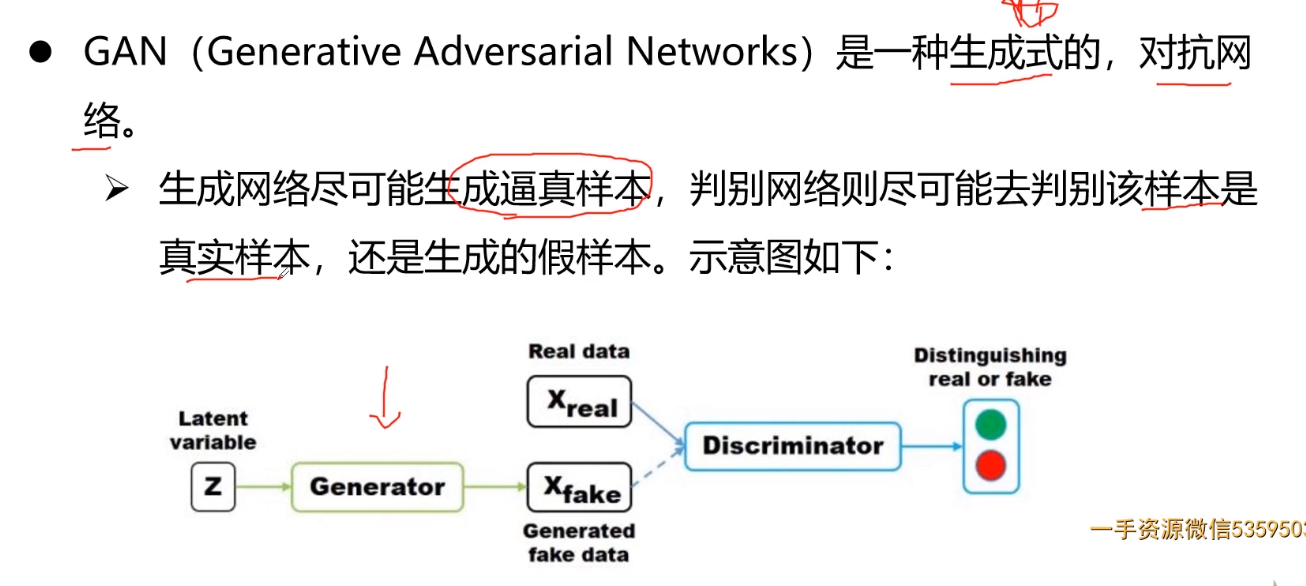
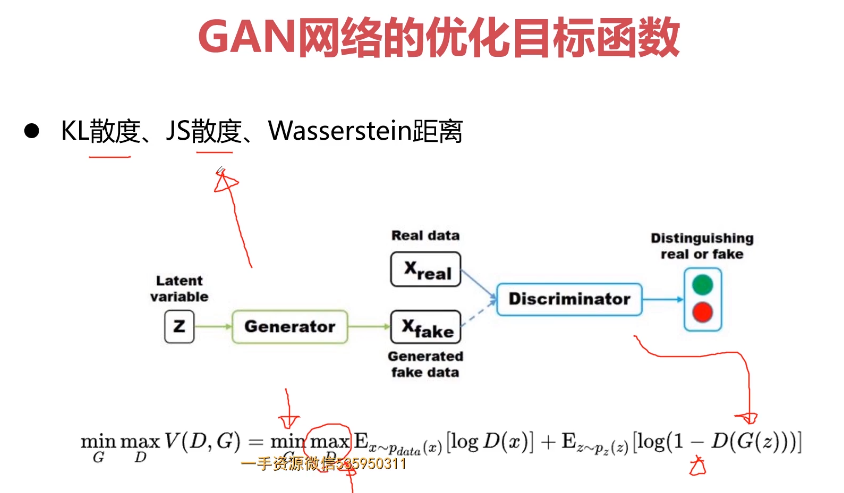
生成模型G
生成模型G是指能够随机生成观测数据的模型,尤其是在给定某些隐含参数的条件下。在GAN中,可以理解为输入一个vector,生成一个图片、语音、文本等有结构的输出。

判别模型D
判别模型D是一种对未知数据与已知数据之间关系进行建模的方法,在GAN中,可以理解为判别器建立了训练数据与生成器输出的数据的关系,按训练数据的标准为生成的数据打分。
以图像的生成为例:
- G负责生成图片。接收一个随机的噪声z,通过z生成图片G(z);
- D负责判别一张图片是不是“真实的”。输入是一张图片x,输出D(x)表示x为真实图片的概率,如果为1,代表是真实图片的概率为100%,而输出为0,代表不可能是真实的图片。
9-2 GAN的基础概念和典型模型介绍(下)
常见的GAN网络结构

DCGAN
条件GAN网络pixel2pixel
CycleGAN

styleGAN
BigGAN
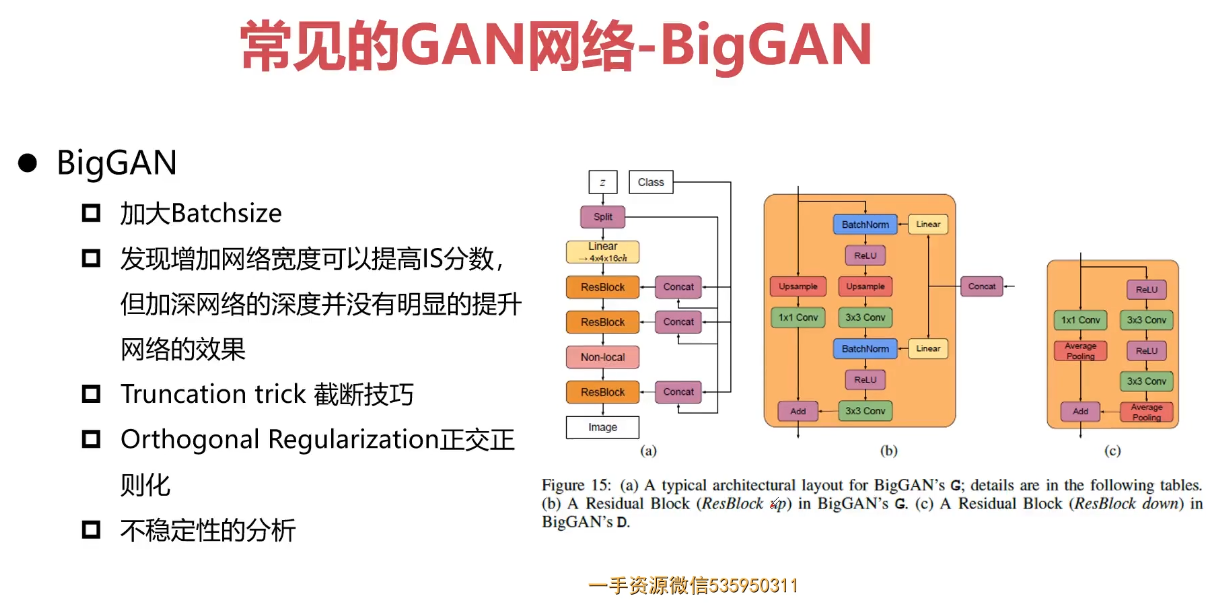
GAN优缺点
如何训练GAN网络

GAN网络应用

9-3 图像风格转换数据下载与自定义dataset类 (11:14)
风格迁移
风格迁移又称风格转换,直观点的类比就是给输入的图像加个滤镜,但是又不同于传统滤镜。风格迁移基于人工智能,每个风格都是由真正的艺术家作品训练、创作而成。只需要给定原始图片,并选择艺术家的风格图片,就能把原始图片转化成具有相应艺术家风格的图片。
数据处理
import globimport randomfrom torch.utils.data import Datasetfrom PIL import Imageimport osimport torchvision.transforms as trFormsclass ImageDataset(Dataset):def __init__(self, root="", transform=None, model="train"):self.transform = trForms.Compose(transform)self.pathA = os.path.join(root, model, "A/*")self.pathB = os.path.join(root, model, "B/*")self.list_A = glob.glob(self.pathA)self.list_B = glob.glob(self.pathB)def __getitem__(self, index):im_pathA = self.list_A[index % len(self.list_A)]im_pathB = random.choice(self.list_B)im_A = Image.open(im_pathA)im_B = Image.open(im_pathB)item_A = self.transform(im_A)item_B = self.transform(im_B)return {"A": item_A, "B": item_B}def __len__(self):return max(len(self.list_A), len(self.list_B))if __name__ == '__main__':from torch.utils.data import DataLoaderroot = "apple2orange"transform_ = [trForms.Resize(256, Image.BILINEAR), trForms.ToTensor()]dataloader = DataLoader(ImageDataset(root, transform_,"train"),batch_size=1,shuffle=True,num_workers=1)for i, batch in enumerate(dataloader):print(i)print(batch)
nn.ReflectionPad2d
torch.nn.ReflectionPad2d(padding)这个函数简单来说就是:利用输入边界的反射来填充输入张量。
nn.ReflectionPad2d((1, 1, 2, 0))中,这几个数字表示左右上下分别要填充的层数。我们画图表示更清楚,如下:
9-5 cycleGAN模型搭建-train(上) (18:02)
datasets.pymodels.pytest.pytrain.pyutils.py
9-6 cycleGAN模型搭建-train(下) (18:28)
9-7 cycleGAN模型搭建-test (06:40)
第10章 循环神经网与NLP基础串讲
主要介绍循环神经网络与NLP理论基础,涉及到语音&NLP数据表示,语言模型,词向量等基础概念,然后介绍循环神经网络的基本网络单元(RNN层、BiRNN层、LSTM、GRU、Attention、Seq2seq、Transformer等)等,
另外,课程中帮助大家梳理了循环神经网络发展的主要脉络以及目前工业届和学术界在解决NLP时的主要问题,主流模型和网络…
10-1 RNN网络基础
参考:1.一文详解 RNN 股票预测实战(Python代码)
2.【算法】循环神经网络RNN
3.深度学习 RNN基础
循环神经网络RNN
参考:1.探索LSTM:基本概念到内部结构
如果是一幕海滩的场景,我们应该在后续帧中强化海滩相关的标记:如果有人在水中,大概可以标记为游泳;而闭眼的场景,可能是在晒太阳。
我们想做的事情,是让模型追踪世界的状态。
- 看到每个图像后,模型输出一个标签,并更新其对世界的知识。例如,模型能学会自动发现和追踪信息,例如位置、时间和电影进度等。重要的是,模型应该能自动发现有用的信息。
- 对于给定的新图像,模型应该融合收集而来的知识,从而更好的工作
循环神经网络(RNN)是基于序列数据(如语言、语音、时间序列)的递归性质而设计的,是一种反馈类型的神经网络,其结构包含环和自重复,因此被称为“循环”。它专门用于处理序列数据,如逐字生成文本或预测时间序列数据(例如股票价格)。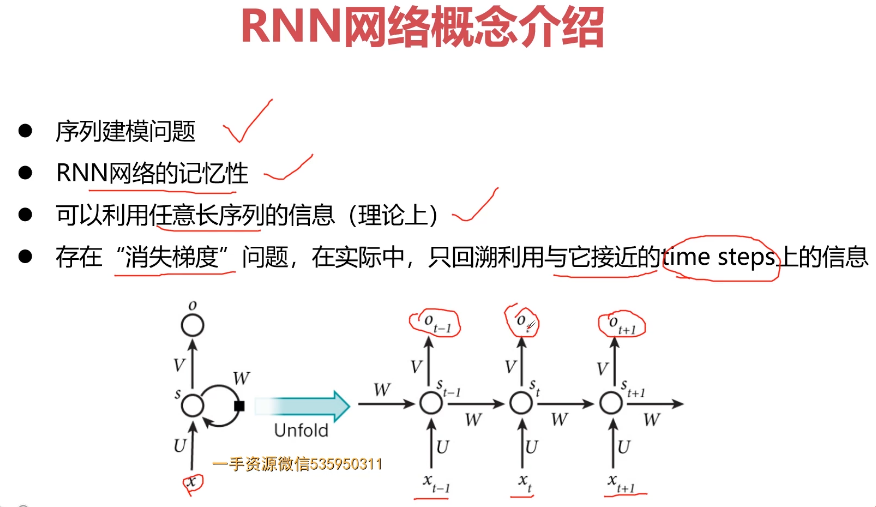
研究一下模型的输入和输出。以输入句子为例,输入的句子中第t个单词进行Embedding之后的向量表达作为网络t时刻的输入,而输入层神经元个数和Embedding的向量长度相符。每个时刻的输出是一个概率分布向量,其中最大值的下标决定了输出哪个词。如果输入的序列中有4个单词,那么,横向展开网络后将有四个神经网络,一个网络对应一个单词,即RNN是在time_step上进行拓展。
RNN-CNN差异
| 类别 | 特点描述 |
|---|---|
| 相同点 | 1、传统神经网络的扩展。2、前向计算产生结果,反向计算模型更新。3、每层神经网络横向可以多个神经元共存,纵向可以有多层神经网络连接 |
| 不同点 | 1、CNN空间扩展,神经元与特征卷积;RNN时间扩展,神经元与多个时间输出计算 2、RNN可以用于描述时间上连续状态的输出,有记忆功能,CNN用于静态输出 |

RNN网络应用场景

10-2 RNN常见网络结构-simple RNN网络 (10:56)
Simple-RNN
参考:1.深度学习之RNN、LSTM及正向反向传播原理
先介绍RNN最简单的循环神经网络,称为Simple-RNN,它是后面LSTM的基础。从网络架构上,Simple-RNN与BP神经网络一脉相承,两个网络都有前馈层和反馈层,但Simple-RNN引入的基于时间的循环机制,因此而发展了BP网络。下面从整体上考察Simple-RNN的架构和训练运行。
这些循环使得RNN可以被看做同一个网络在不同时间步的多次循环,每个神经元会把更新的结果传递到下一个时间步,为了更清楚的说明,将这个循环展开,放大该神经网络A,看一下网络细节:
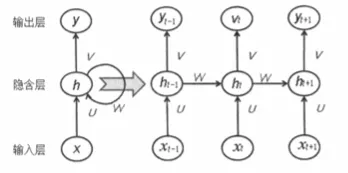
递归网络的输入是一整个序列,也就是x=[ x_0, … , x_t-1, x_t, x_t+1, x_T ],对于语言模型来说,每一个x_t将代表一个词向量,一整个序列就代表一句话。h_t代表时刻t的隐含状态,y_t代表时刻t的输出。
其中:
U:输入层到隐藏层直接的权重
W:隐藏层到隐藏层的权重
V: 隐藏层到输出层的权重
1.正向传播
首先在t=0的时刻,U、V、W都被随机初始化好了,h_0通常初始化为0,然后进行如下计算: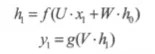
其中,f ,g 是激活函数,g通常是Softmax。
注:RNN有记忆能力,正是因为这个 W,记录了以往的输入状态,作为下次的输出。这个可以简单的理解为:
全局误差为: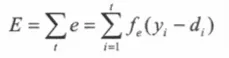
E是全局误差,e_i是第i个时间步的误差,y是输出层预测结果,d是实际结果。误差函数f_e可以为交叉熵( Cross Entropy ) ,也可以是平方误差项等。
2.反向传播
就是利用输出层的误差e( Cost Function ) ,求解各个权重derta_V、darta_U、derta_W,然后梯度下降更新各个权重。
各个权重的更新的递归公式: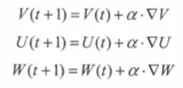
现在的问题是如何求解各个权重的梯度,即: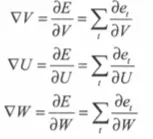
求解的顺序分为如下两步,首先我们知道
对于任何代价函数,直接求取每一时刻的 。得到derta_V,由于它不依赖之前的状态,可以直接求导获得。然后简单相加即可:
。得到derta_V,由于它不依赖之前的状态,可以直接求导获得。然后简单相加即可:
但是derta_U、derta_W依赖于之前的状态,不能直接求导,需要定义中间变量:
依次类推,知道输出层: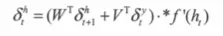
这里的*表示点乘。通过下面的计算出derta_U,derta_W: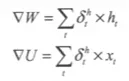
到这里,Simple-RNN原理也就讲解完了。但是实际应用中并不多,因为:
a:如果出入越长的话,展开的网络就越深,对于“深度”网络训练的困难最常见的是“梯度爆炸( Gradient Explode )” 和 “梯度消失( Gradient Vanish )” 的问题。
b:Simple-RNN善于基于先前的词预测下一个词,但在一些更加复杂的场景中,例如,“我出生在法国……我能将一口流利的法语。” “法国”和“法语”则需要更长时间的预测,而随着上下文之间的间隔不断增大时,Simple-RNN会丧失学习到连接如此远的信息的能力。
10-3 Bi-RNN网络
biLSTM是双向循环神经网络,简单的理解就是LSTM正向走一遍,又反向走了一遍而已。而对于立场检测这个实验,在这里我借用此论文的图片
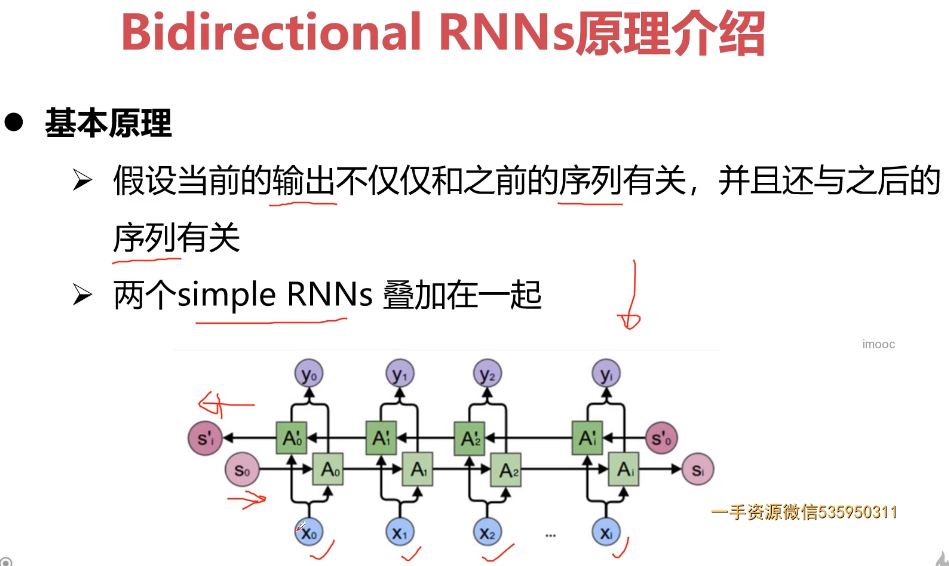
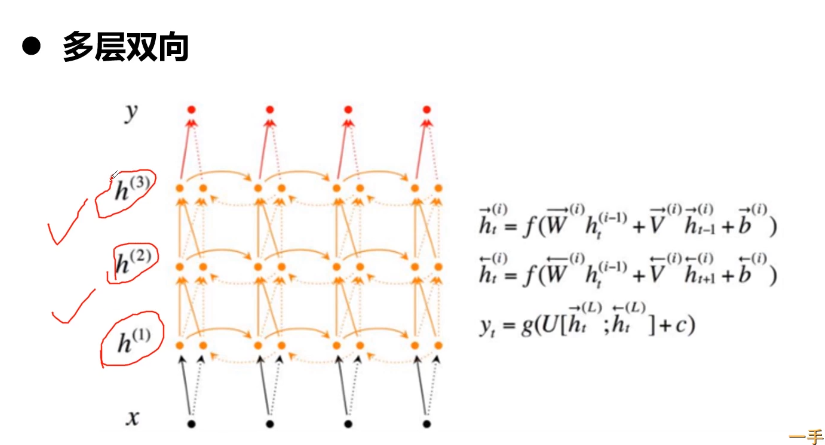
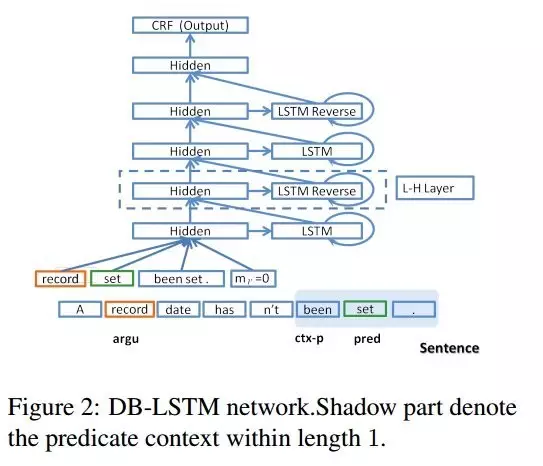
10-4 LSTM网络基础
参考:1.http://blog.echen.me/2017/05/30/exploring-lstms/
模型如何更新对世界的认知?到目前为止,还没有任何规则限制,所以模型的认知可能非常混乱。这一帧模型认为人物身处美国,下一帧如果出现了寿司,模型可能认为人物身处日本……
这种混乱的背后,是信息的快速变换和消失,模型难以保持长期记忆。所以我们需要让网络学习如何更新信息。方法如下:
- 增加遗忘机制。例如当一个场景结束是,模型应该重置场景的相关信息,例如位置、时间等。而一个角色死亡,模型也应该记住这一点。所以,我们希望模型学会一个独立的忘记/记忆机制,当有新的输入时,模型应该知道哪些信息应该丢掉。
- 增加保存机制。当模型看到一副新图的时候,需要学会其中是否有值得使用和保存的信息。
- 所以当有一个新的输入时,模型首先忘掉哪些用不上的长期记忆信息,然后学习新输入有什么值得使用的信息,然后存入长期记忆中。
- 把长期记忆聚焦到工作记忆中。最后,模型需要学会长期记忆的哪些部分立即能派上用场。不要一直使用完整的长期记忆,而要知道哪些部分是重点。
这样就成了一个长短期记忆网络(LSTM)。
RNN会以相当不受控制的方式在每个时间步长内重写自己的记忆。
LSTM则会以非常精确的方式改变记忆,应用专门的学习机制来记住、更新、聚焦于信息。这有助于在更长的时期内跟踪信息。
LSTM原理
参考:1.深度学习之RNN、LSTM及正向反向传播原理
LSTM通过对循环层的刻意设计来避免长期依赖和梯度消失,爆炸等问题。长期信息的记忆在LSTM中是默认行为,而无需付出代价就能获得此能力。
从网络主题上来看,RNN和LSTM是相似的,都具有一种循环神经网络的链式形式。在标准的RNN中,这个循环节点只有一个非常简单的结构,如一个tanh层。LSTM的内部要复杂得多,在循环的阶段内部拥有更多的复杂的结构,即4个不同的层来控制来控制信息的交互。
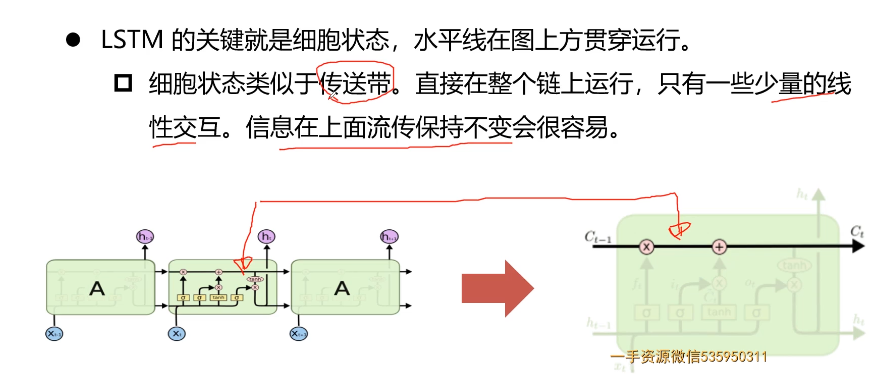
门结构
一个门,包含一个Sigmoid网络层和一个Pointwise乘法操作。LSTM拥有三个门,来保护和控制细胞状态。0代表“不允许任何量通过”,1代表“允许任何量通过”。
遗忘门:首先,决定从细胞状态中丢弃什么信息。这个决策是通过一个称为“遗忘门”的层来完成的。该门会读取 h_t-1 和 x_t,使用sigmoid函数输出一个在0-1之间的数值,输出给在状态C_t-1中每个细胞的数值。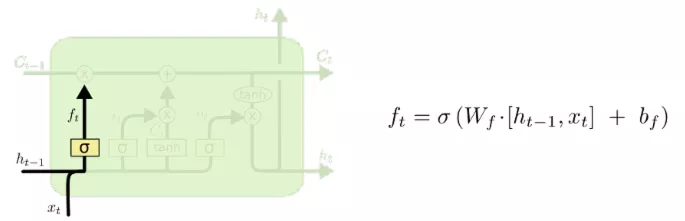
输入和更新 然后确定什么样的新信息被存放在细胞状态中。这里包含两部分:
一部分是Sigmoid层,称为“输入门”,它决定我们将要更新什么值;
另一部分是tanh层,创建一个新的候选值向量~C_t,它会被加入到状态中。
这样,就能用这两个信息产生对状态的更新。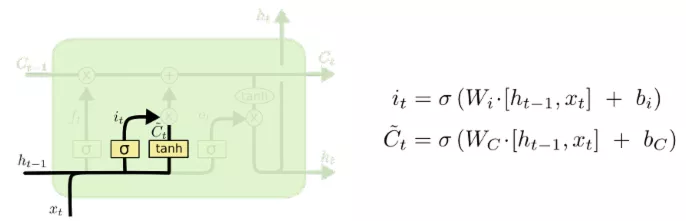
更新细胞状态 现在是更新旧细胞状态的时间了,C_t-1 更新为 C_t 。前面的步骤已经决定了将会做什么,现在就是实际去完成。把旧状态与 f_t 相乘,丢弃掉我们确定需要丢掉的信息,接着加上i_t*~C_t。这就是新的候选值,根据更新每个状态的程度进行变化;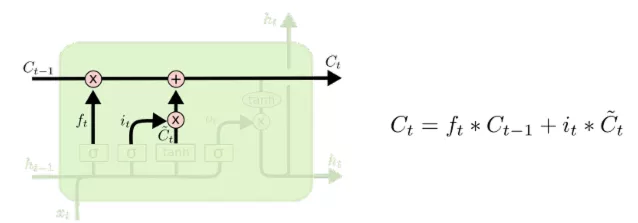
输出信息 最终需要确定输出什么值。这个输出将会基于细胞状态,但也是一个过滤后的版本。首先,运行一个Sigmoid层来确定细胞状态的哪个部分将输出出去。接着,把细胞状态通过tanh进行处理( 得到一个在 -1~1 之间的值 ) 并将它和Sigmoid门相乘,最终仅仅会输出我们确定输出的那部分。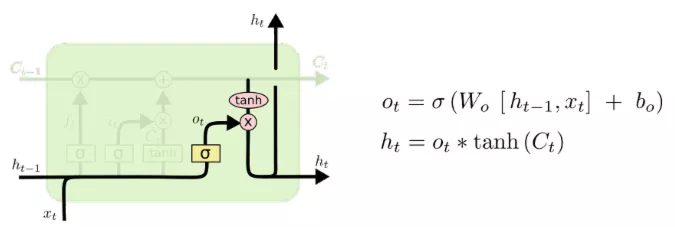
LSTM其他结构

10-5 Attention结构
参考:1.关于Attention的总结
2.Attention注意力机制的前世今身
Attention机制也叫注意力机制,之所以在图像分类中起作用,主要是模拟人类看图片的逻辑,当我们看一张图片的时候,其实并没有看清图片的全部内容,而是将注意力集中在了图片的焦点上;
如果把高的注意力用数学方式表达,就是赋予高的权重,低的注意力赋予低的权重,那么可以认为,Attention 的本质是权重的分配问题,可以理解成一种对输入进行重新加权分配的问题。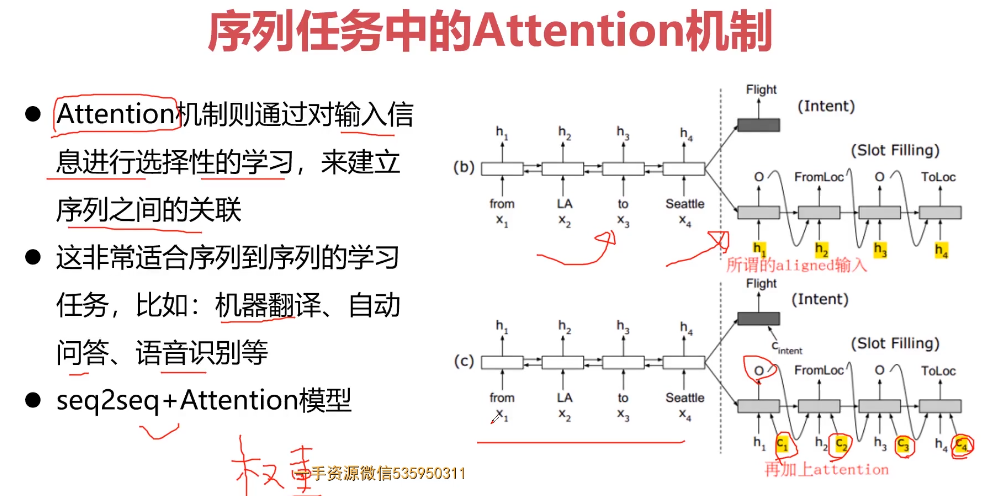
先引入 seq2seq 框架,由编码器和解码器组成,广泛用于机器翻译、自动文摘等任务。
由编码器对原始输入进行编码,压缩为固定长度的上下文向量;
编码器最后的一个隐藏层状态送入解码器,进行解码输出。
可以解决变长的输入与输出,用于不同语言、不同长短的输入与输出。常用的网络结构为 RNN,具体为 LSTM 或 GRU。
Seq2Seq模型
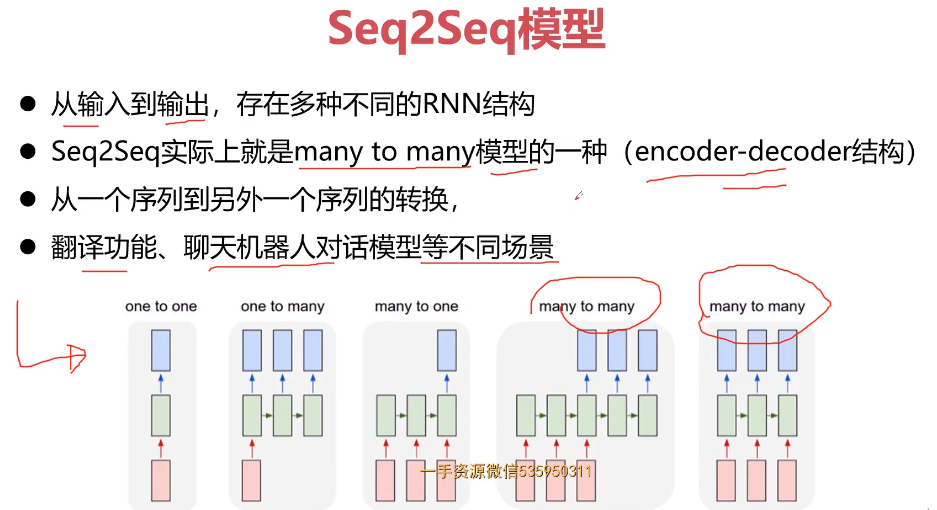
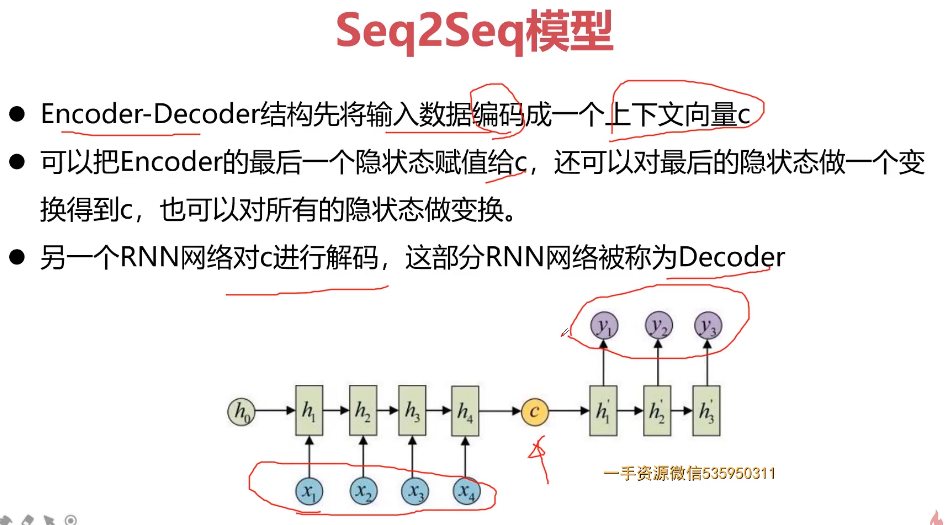
Seq2Seq+Attention应用领域

Attention使其每一步的计算不依赖于上一步的计算,达到和CNN一样的并行处理效果。
并且由于Attention只关注部分的信息,所以它的参数较少,速度就会快
10-6 Transformer结构
1.Transformer结构
Transformer的结构和Attention模型一样,Transformer模型中也采用了 encoer-decoder 架构。但其结构相比于Attention更加复杂,论文中encoder层由6个encoder堆叠在一起,decoder层也一样。
Attention机制
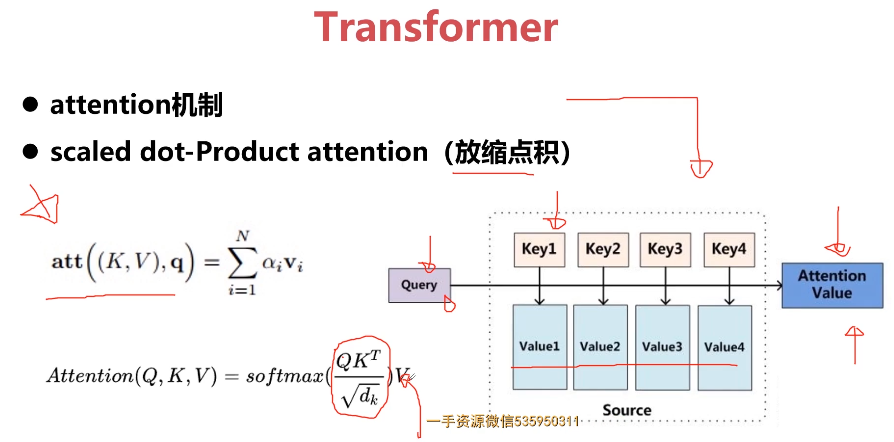

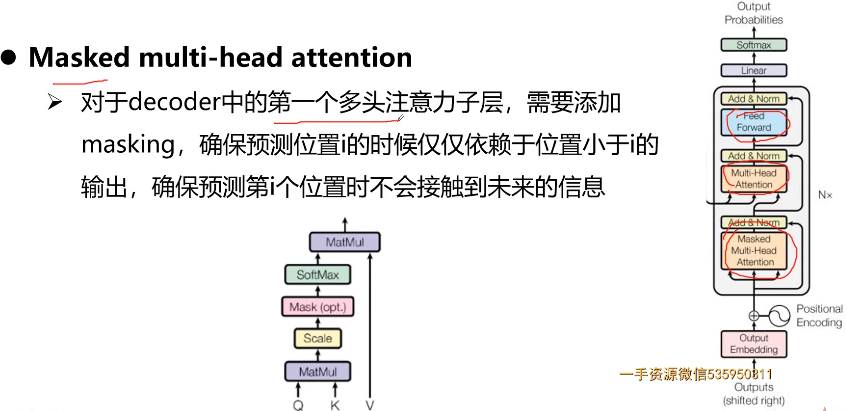

Transformer优点和缺点


10-7 BERT结构
参考:1.为什么BERT成为了最好用的NLP模型?NVIDIA算法大牛一文深度讲解【附课件下载】;
2.BERT 核心原理与实战(课程)
BERT 的优秀之处主要在于以下三点:
第一:使用大量数据预训练
第二:可以处理文字语意
第三:开源
MLM
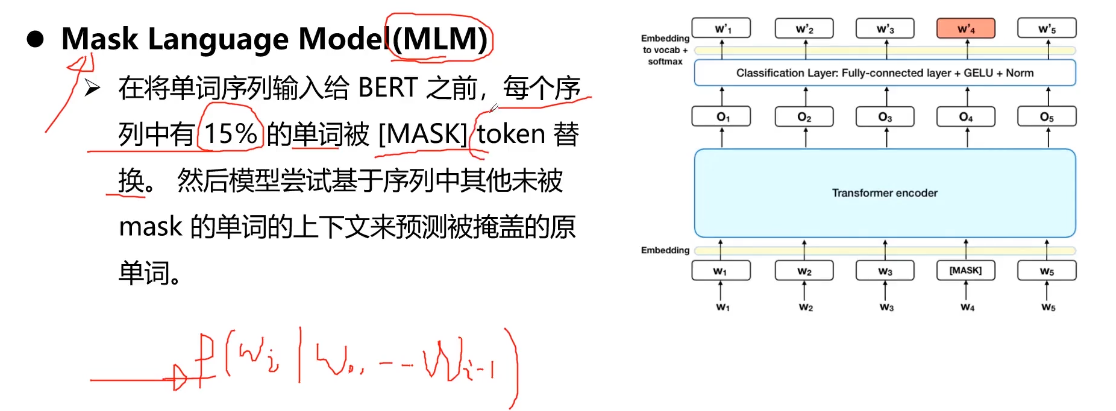
NSP
MLM+NSP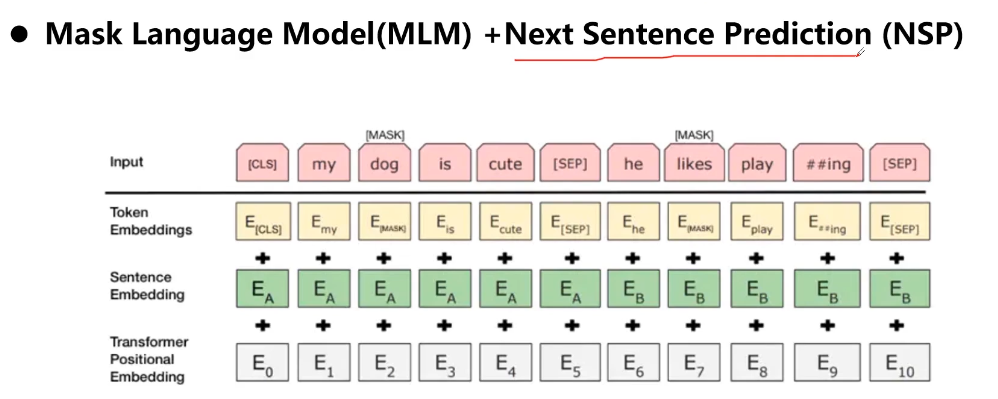
10-8 NLP基础概念介绍
自然语言处理(Natural Language Processing,以下简称NLP),
首先介绍一下自然语言处理常见的应用方向,
第一类是序列标注,比如命名实体的识别、语义标注、词性标注,循环智能也是用了序列标注。
第二类是分类任务,如文本分类和情感分析,这个方向目前在量化金融领域,尤其是对冲基金上应用性很强,尤其是情感分析。我记得3、4年前,有一条新闻说斯坦福大学的一个硕士生,暑期在他的宿舍里用几块GPU卡,自己搭建了一个小的超级计算机,他把Twitter上的信息全部录下来,每天更新。他使用了BERT进行情感分析,把每天每个人的信息分成三类:positive积极、neutral中性、negative消极。他把三类情感的量化信息和当天纳斯达克股票的升跌情况汇总,进行了统计分析,发现如果Twitter上的信息大部分都是积极的,那么股票就有很大的概率会上涨。我们现在把这类数据叫做情感分析因子,它在股票分析上是一个特别重要的推进方向,能让模型越发准确。
第三类NLP应用方向就是对句子关系的判断,如自然语言的推理、问答系统,还有文本语义相似性的判断。
最后一类,是生成式任务,如机器翻译、文本摘要,还有创造型的任务比如机器写诗、造句等。
1.NLP语言模型
参考:1.自然语言处理科普系列(一)N-gram语言模型
语言模型的主要用途有两个
第一个是基于已有的单词序列预测下一个词是什么,举例如下:
今天 小明 去 超市 …
模型从所有词汇中选出最有可能的一个,例如模型预测“买”是下一个词,而“早饭”不是。
第二,语言模型可以给一个完整的句子计算一个概率,假设有两个句子A和B:
句A 今天小明去超市买了一盒牛奶
句B 今天去一盒小明买了超市牛奶
语言模型可以预测A的概率要大于B的概率,从而说明A比B要更加像一条句子;
任何技术都要有其应用价值才值得去研究,语言模型有着丰富的应用案例,包括语音识别中纠正声学模型的结果、搜索引擎中拼写纠正或语法错误纠正、机器翻译中提供结果的精度和语法性等,同时语言模型也是很多其它NLP技术的重要基础。
N-gram
N-gram即N元语法,应该是大家遇到的第一个NLP术语,我这里援引维基百科对它的定义:“指文本中连续出现的n个语词。N元语法模型是基于马尔科夫链的一种概率语言模型,通过n个语词出现的概率来推断语句的结构。
当n分别为1、2、3时,又分别称为一元语法(unigram)、二元语法(bigram)和三元语法(trigram)。”
先忽略这里面的马尔科夫链,我一会儿介绍,简单来说,N-gram就是N个词语的序列,例如“今天 小明”就是一个二元bigram,而“小明 去 超市”是一个三元trigram,根据gram的不同定义,又可以分为单词序列、字符序列等,一般NLP中主要以单词为基本单位。

注意到这里的就是之前讲到的bigram二元词序列,所以这样乘积形式的马尔科夫链就是天然的bigram语言模型,相比统计一个很长的词序列出现的次数,明显对bigram进行计数更靠谱些。同时我们也可以将问题泛化,如果当前词仅依赖于前n-1个词,那么我们只需研究N-gram出现次数就行了。至此我们将N-gram与语言模型做了一个结合,下面我们仍以小明的例子来具体说明bigram语言模型的过程:
句A 今天小明去超市买了一盒牛奶
句B 今天去一盒小明买了超市牛奶
其中表示句子开始标志,用于给第一个词提供context即公式中的
假设我们已经从足够大的语料集中得到了如下统计信息:
所以,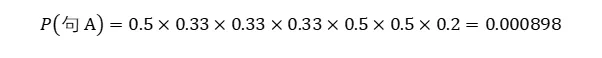
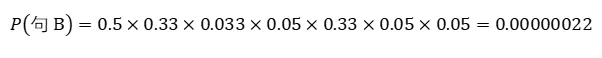
明显P(句A)>P(句B)符合我们的认知。往往我们会用log概率替换概率,以防止概率过小导致underflow现象。
基于前馈神经网络的模型
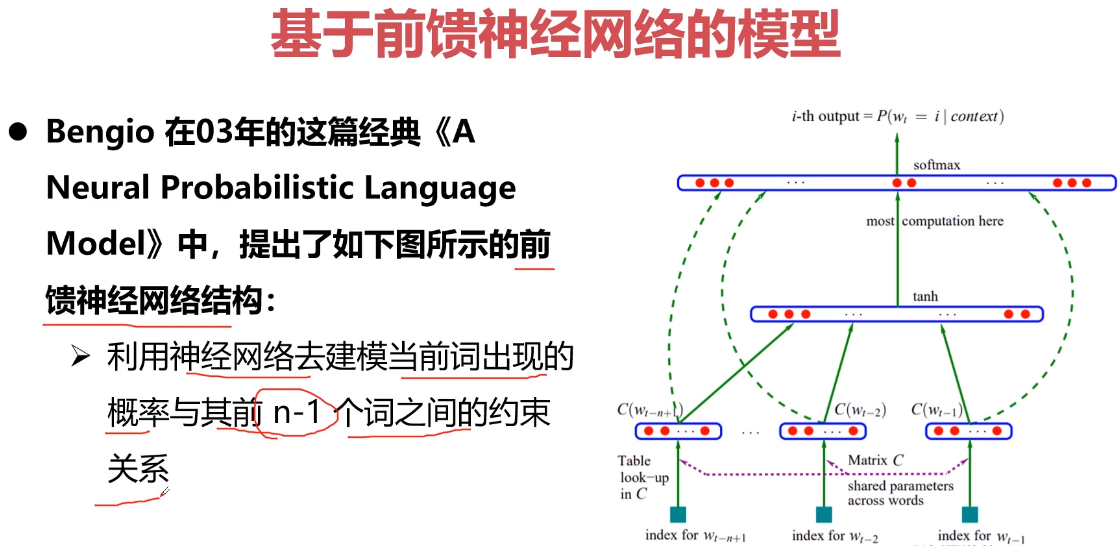
基于循环神经网络的模型
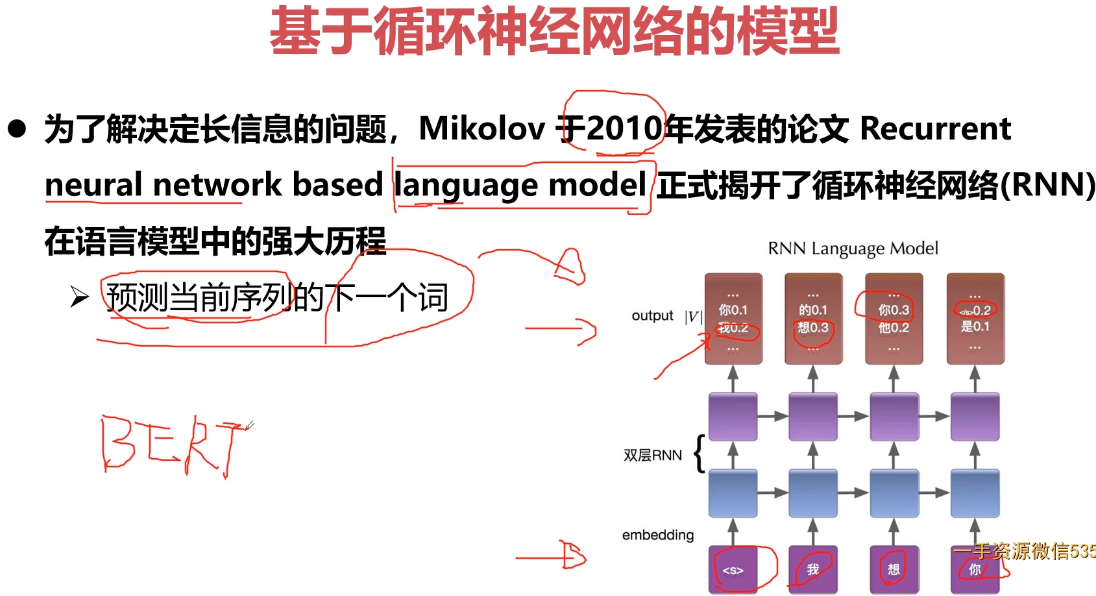
语言模型评价

其他基础概念

NLP主要研究方向

10-9 【讨论题】深入了解transformer在CV任务中的应用
第11章 PyTorch实战中文文本情感分类问题
主要介绍使用Pytorch搭建循环神经网络,并用来解决中文文本情感分类问题,具体包括了、数据集介绍和下载、数据处理,循环神经网络模型搭建,模型训练和结果分析。通过PyTorch+LSTM模型来帮助大家了解如何使用PyTorch解决自然语言处理问题中的基础任务——中文文本情感分类问题
11-1 文本情感分析-情感分类概念介绍
机器理解人类情感是一个多模态的感知过程,通过表情、行为、语言来理解情感[1]。而语言通常以文本的形式存在,本文将从文本的角度讨论情感分析的研究。
1.情感分析介绍
情感分析(Sentiment Analysis)是自然语言处理(NLP)领域的一类任务,又称倾向性分析,意见抽取(Opinion Extraction),意见挖掘(Opinion Mining),情感挖掘(Sentiment Mining),主观分析(Subjectivity Analysis)等,它是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程[2],如从电影评论中分析用户对电影的评价(positive、negative),从商品评论文本中分析用户对商品的“价格、大小、重量、易用性”等属性的情感倾向。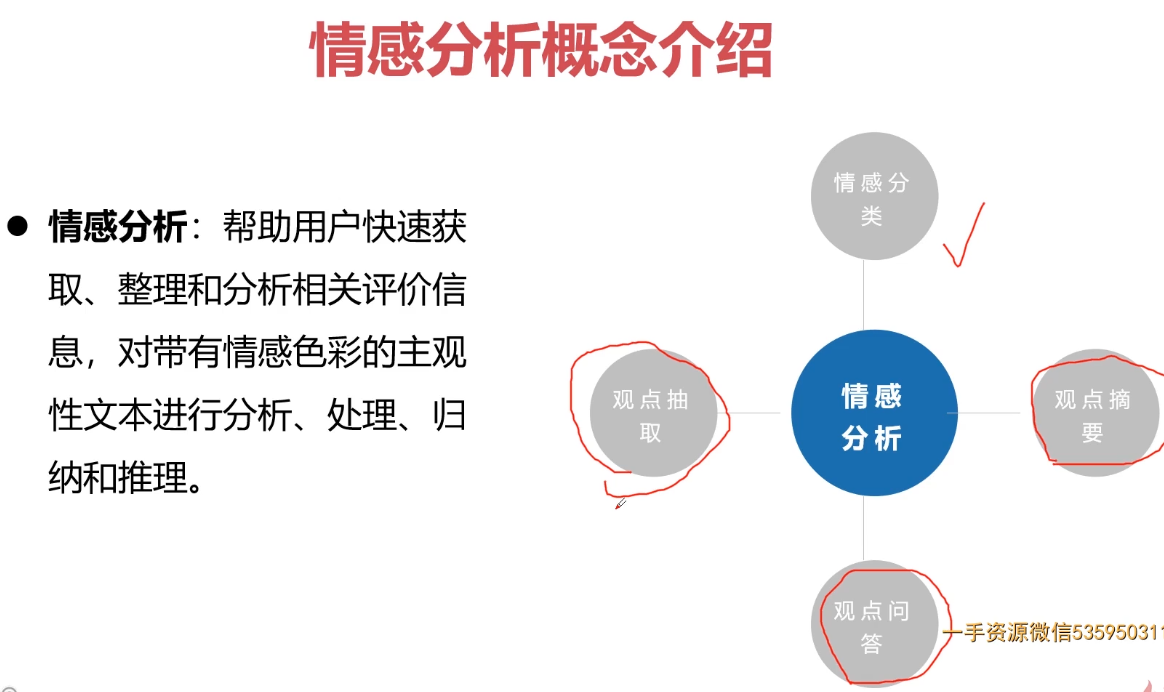

11-2 文本情感分类关键流程介绍
1.情感分类关键流程
文本转化为向量进行业务分析;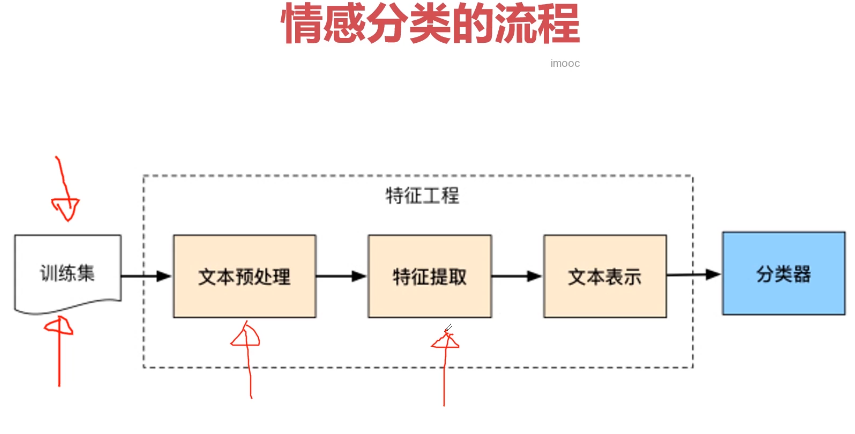
11-3 文本情感分类之文本预处理
1.文本预处理


常见方法:
- 删除标签:我们的文本经常包含不必要的内容,如HTML标签,分析文本的时候这不会增加多少价值。BeautifulSoup库可以帮我们做很多必须的工作。
- 删除重音字符:在任何文本语料库中,特别是在处理英语时,通常可能要处理重音字符/字母。因此,我们需要确保将这些字符转换并标准化为ASCII字符。一个简单的例子是将é转换为e。
- 扩展缩略语:在英语中,缩略语基本上是单词或音节的缩写形式。这些现有单词或短语的缩略形式是通过删除特定的字母和声音来创建的。例如,do not变为don ‘t以及I would 变为I ‘d 。将每个缩略语转换为其扩展的原始形式通常有助于文本标准化。
- 删除特殊字符:非字母数字字符的特殊字符和符号通常会增加非结构化文本中的额外噪音。通常,可以使用简单正则表达式(regexes)来实现这一点。
- 词根提取和词形还原:词干通常是可能的单词的基本形式,可以通过在词干上附加词缀,如前缀和后缀来创建新单词。这就是所谓的拐点。获取单词基本形式的反向过程称为“词根提取”。一个简单的例子是单词WATCHES, WATCHING,和WATCHED。它们以词根WATCH作为基本形式。词形还原与词根提取非常相似,在词根提取中,我们去掉词缀以得到单词的基本形式。然而,在这种情况下,基本形式被称为根词,而不是词根。不同之处在于,词根总是一个词典上正确的单词(存在于字典中),但根词的词干可能不是这样。
- 删除停止词:在从文本中构造有意义的特征时,意义不大或者没有意义的词被称为停止词或停止词。如果你在语料库中做一个简单的词或词的频率,这些词的频率通常是最高的。像a、an、the、and等词被认为是停止词。没有一个通用的停止词列表,但是我们使用了一个来自“nltk”的标准英语停止词列表。你还可以根据需要添加自己的域特定的停止词。
11-4 文本情感分类之特征提取与文本表示
1.文本特征提取
文本特征提取是文本挖掘中非常重要的一个环节,无论是聚类、分类还是相似度任务,都需要提取出较好的文本特征,如此才能取得较好的结果。
2.文本表示
1.词袋模型
- 词集模型:单词构成的集合,集合自然每个元素都只有一个,也即词集中的每个单词都只有一个。
- 词袋模型:在词集的基础上如果一个单词在文档中出现不止一次,统计其出现的次数(频数)。

2.TF-IDF
TF-IDF实际上是:TF * IDF。TF表示词条在文档d中出现的频率。IDF(inverse document frequency,逆向文件频率)的主要思想是:如果包含词条t的文档越少,也就是n越小,IDF越大,则说明词条t具有很好的类别区分能力。如果某一类文档C中包含词条t的文档数为m,而其他类包含t的文档总数为k,显然所有包含t的文档数n=m+k,当m大的时候,n也大,按照IDF公式得到的IDF的值会小,就说明该词条t类别区分能力不强。
但是实际上,如果一个词条在一个类的文档中频繁出现,则说明该词条能够很好代表这个类的文本的特征,这样的词条应该给它们赋予较高的权重,并选来作为该类文本的特征词以区别与其他类文档。
在Scikit-Learn中实现了TF-IDF算法,
3.语言模型
参考:1.语言模型及Word2vec与Bert简析
语言模型可以对一段文本的合理性概率进行估计,对信息检索,机器翻译,语音识别等任务有着重要的作用。
神经语言模型可直接用于NLP任务,随着深度学习的快速发展,语言模型也更多的应用于NLP模型的预训练,常用的预训练模型有:
- Word2vec (Google)
- Glove (Facebook)
- ELMO (AllenNLP艾伦人工智能研究所)
- GPT (OpenAI)
- BERT (Google)
- RoBERTa (FaceBook)
- AlBert (Google)
- MT-DNN (微软)
11-5 文本情感分类之深度学习模型
深度学习模型

FastText

TextCNN
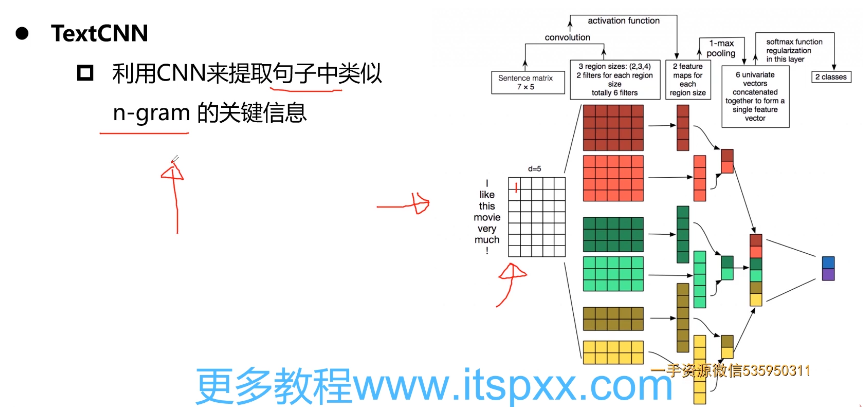
TextRNN
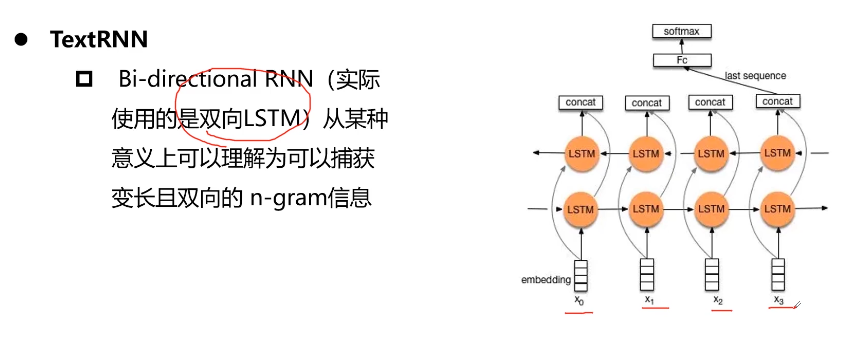
TextRCNN (TextRNN+TextCNN)
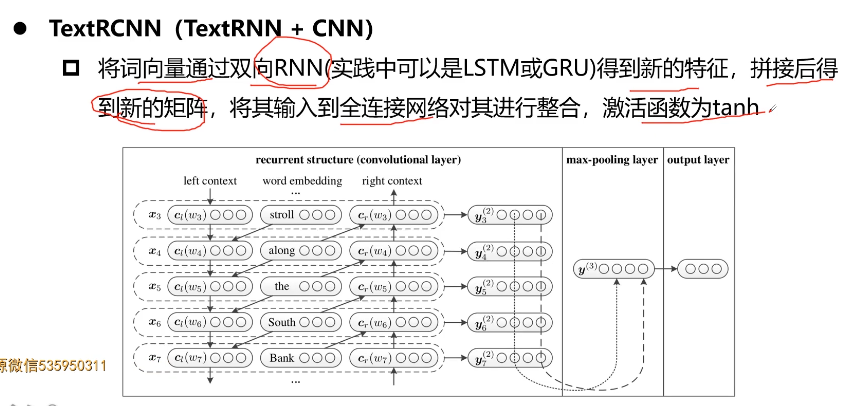
TextRNN+Attention(HAN)
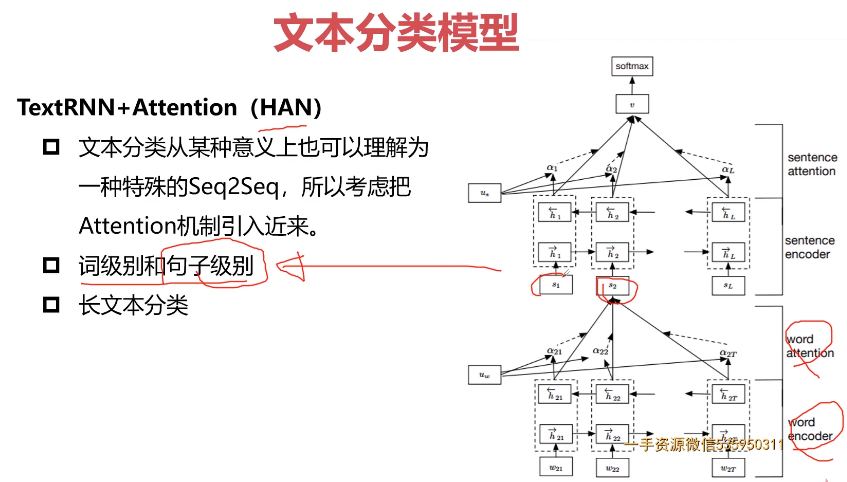
11-6 文本情感分类-数据准备
https://github.com/SophonPlus/ChineseNlpCorpus/blob/master/datasets/weibo_senti_100k/intro.ipynb
data_processing.py
11-7 文本情感分类-dataset类定义
# datasets.pyfrom torch.utils.data import Dataset, DataLoaderimport jiebaimport numpy as npdef read_dict(voc_dict_path):voc_dict = {}dict_list = open(voc_dict_path, 'r', encoding='utf8').readlines()for item in dict_list:item = item.split(",")voc_dict[item[0]] = int(item[1].strip())return voc_dictdef load_data(data_path,data_stop_path):data_list = open(data_path, 'r', encoding='utf8').readlines()[1:]stops_word = open(data_stop_path, 'r', encoding='utf8').readlines()stops_word = [line.strip() for line in stops_word]stops_word.append(" ")stops_word.append("\n")voc_dict = {}data = []max_len_seq = 0np.random.shuffle(data_list)for item in data_list[:1000]:label = item[0]content = item[2:].strip()seg_list = jieba.cut(content, cut_all=False)seg_res = []for seg_item in seg_list:if seg_item in stops_word:continueseg_res.append(seg_item)if seg_item in voc_dict.keys():voc_dict[seg_item] = voc_dict[seg_item] + 1else:voc_dict[seg_item] = 1if len(seg_res) > max_len_seq:max_len_seq = len(seg_res)data.append([label, seg_res])return data, max_len_seqclass text_ClS(Dataset):def __init__(self, voc_dict_path, data_path, data_stop_path, max_len_seq=None):self.data_path = data_pathself.data_stop_path = data_stop_pathself.voc_dict = read_dict(voc_dict_path)self.data, self.max_seq_len = \load_data(self.data_path, self.data_stop_path)# if max_len_seq is not None:# self.max_seq_len = max_len_seqnp.random.shuffle(self.data)def __len__(self):return len(self.data)def __getitem__(self, item):data = self.data[item]label = int(data[0])word_list = data[1]input_idx = []for word in word_list:if word in self.voc_dict.keys():input_idx.append(self.voc_dict[word])else:input_idx.append(self.voc_dict["<UNK>"])if len(input_idx) < self.max_seq_len:input_idx += [self.voc_dict["<PAD>"]for _ in range(self.max_seq_len - len(input_idx))]data = np.array(input_idx)return label, datadef data_loader(data_path, data_stop_path, dict_path):dataset = text_ClS(dict_path, data_path, data_stop_path)return DataLoader(dataset, batch_size=10, shuffle=True)# return DataLoader(dataset, batch_size=config.batch_size, shuffle=config.is_shuffle)if __name__ == "__main__":data_path = "sources/weibo_senti_100k.csv"data_stop_path = "sources/hit_stopword"dict_path = "sources/dict"train_dataloader = data_loader(data_path, data_stop_path, dict_path)for i, batch in enumerate(train_dataloader):print(batch[1].size())
11-8 文本情感分类-model类定义
11-9 文本情感分类-train脚本定义
11-10 文本情感分类-test脚本定义
第12章 PyTorch实战机器翻译问题
主要介绍使用Pytorch搭建Attention-Seq2seq网络,并用来解决机器翻译问题
具体包括了:数据集介绍和下载、数据处理,循环神经网络模型搭建,模型训练和结果分析。通过PyTorch+Attention+Seq2Seq模型来帮助大家了解如何使用PyTorch解决自然语言处理问题中的基础任务——机器翻译(序列到序列)。
12-1 机器翻译相关方法-应用场景-评价方法
参考:1.机器翻译的原理你知道多少?
现有的机器翻译系统按照其基本工作原理,可以分为基于规则的(Rule-Based)机器翻译,基于实例的(Example-Based)机器翻译和统计型的(Statistical)机器翻译这三种基本类型。
基于规则的(Example-Based Machine Translation,EBMT)机器翻译
基于规则的机器翻译系统(Rule-Based Machine Translation, RBMT):其基本工作原理基于一个假设,即语言无限的句子可以由有限的规则推导出来。基于这个假设的机器翻译方法又可以分为三类:直接翻译法(Direct Translation),中间语言法(Interlingual Approach),和转换法(Transfer Approach)。它们都需要用到大规模的双语词典,需要用到源语言推导规则,语言转换规则和目标语言生成规则;其不同点在于对语言进行的分析深度不同。如直译法几乎不需要进行语言分析,中间语言法和转换法需要对源语言和目标语言进行某种程度的语言分析。
基于实例的(Rule-Based)机器翻译
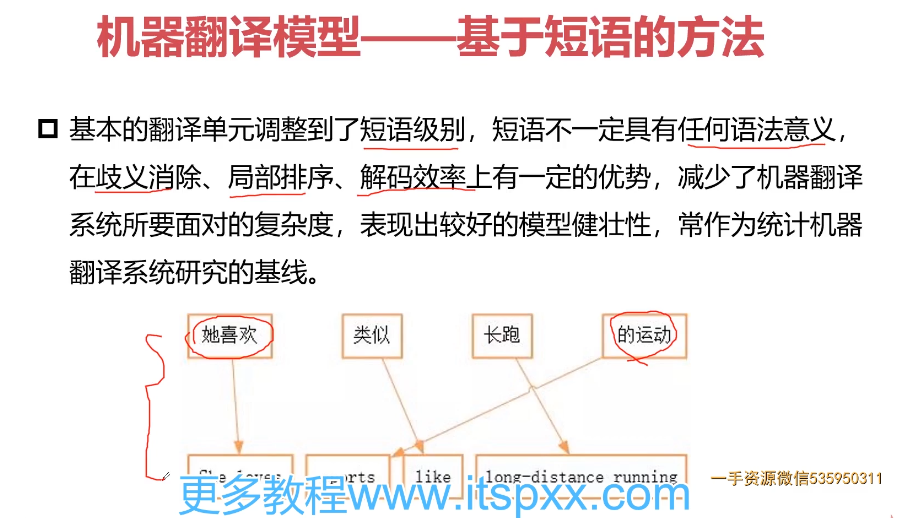
基于实例的机器翻译(Example-Based Machine Translation,EBMT):其基本工作原理是基于类比(Analogy)的原则,从实例库中匹配出与源文字片段最相似的文字片段,取出实例文字片段对应的目标语言翻译结果,进行适当的改造,最终得出完整的翻译结果。基于实例的机器翻译其核心思想最早由Mako Nagao 提出[2],他提出:人们在翻译简单句子时并不作深层语言分析,而是翻译。首先把源句子分解成若干片段,然后将这些片段译为目标语言,每个片段的翻译都是通过与例句做匹配以类比的原则得到的,最后将这些译后句子组合成一个长句子。
基于统计型机器翻译系统(Statistical MT)
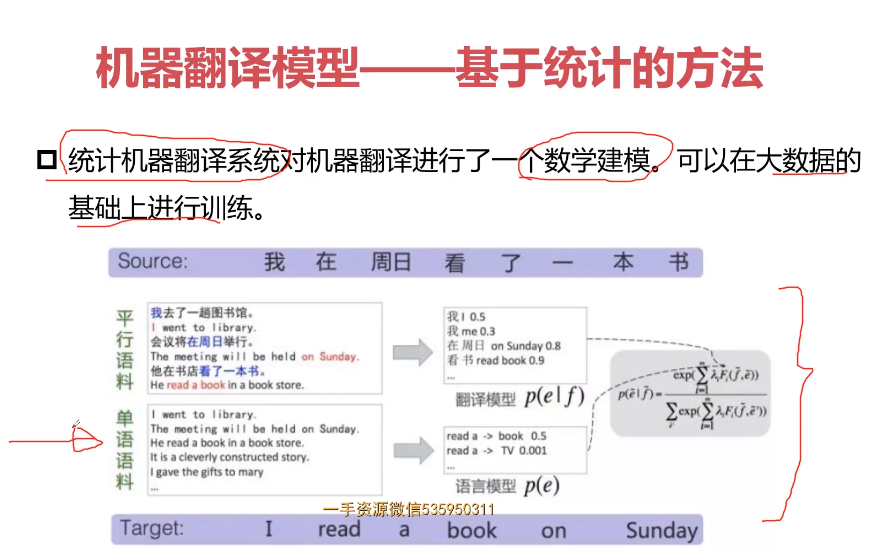
[
](https://mp.weixin.qq.com/s?src=3×tamp=1644630291&ver=1&signature=2EUzbnDj3UmUNkW8-bUVRBXs3cTX0D6XDUJgV*hIF2JhRhhpsfDhn3MVjKstPa88l8jHgtu0L8MJuqxitQkLEHQmHbTg1Y5dtvwMGRQKE10AAEBRpju-XE4nYgE9GDGs*7TgBDm10CNHbLsAL4y3Yw==#:~:text=1.3.%20%E7%BB%9F%E8%AE%A1%E5%9E%8B,%E6%A8%A1%E5%9E%8B%E7%94%A8%E4%BA%8E%E7%BF%BB%E8%AF%91%E3%80%82)
其基本思想是:把机器翻译问题看成是一个噪声信道问题,然后用信道模型来进行解码。翻译过程被看作是一个解码的过程,进而变成寻求最优翻译结果的过程。基于这种思想的机器翻译重点是定义最合适的语言概率模型和翻译概率模型,然后对语言模型和翻译模型的概率参数进行估计。语言模型的参数估计需要大量的单语语料,翻译模型的参数估计需要大量平行双语语料。统计机器翻译的质量很大程度上取决于语言模型和翻译模型的性能,
基于神经网络的机器翻译
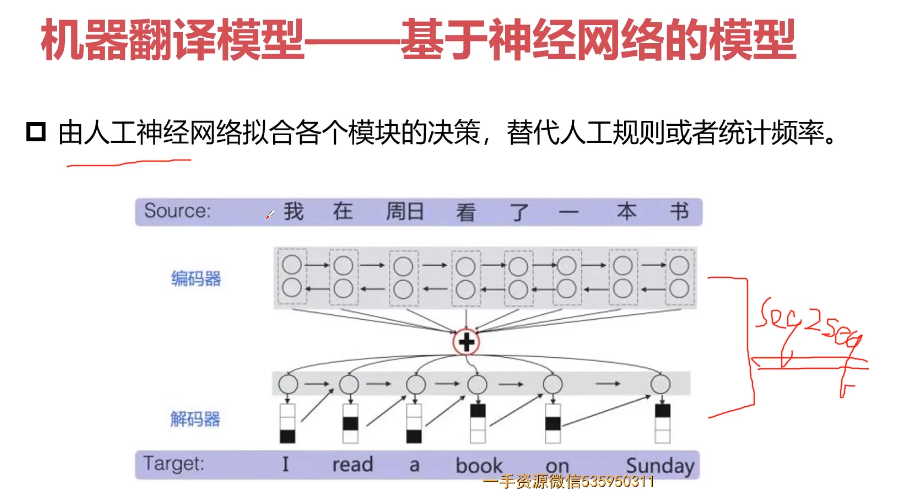
机器翻译应用场景
评价指标


12-2 Seq2Seq-Attention编程实例数据准备-模型结构-相关函数
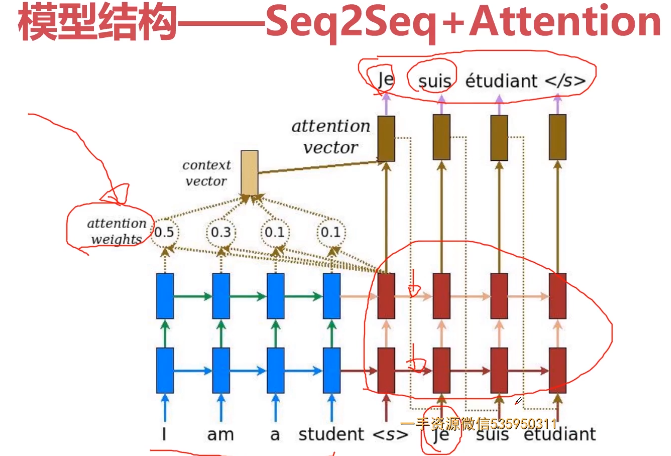
12-3 Seq2Seq-Attention编程实例-定义数据处理模块 (17:08)
http://www.manythings.org/anki/
Seq2Seq+Attention

12-4 Seq2Seq-Attention编程实例-定义模型结构模块(上) (13:10)
12-5 Seq2Seq-Attention编程实例-定义模型结构模块(下) (13:46)
12-6 Seq2Seq-Attention编程实例-定义train模块(上) (13:03)
12-7 Seq2Seq-Attention编程实例-定义train模块(下) (10:33)
12-8 Seq2Seq-Attention编程实例-定义train模块-loss function (20:10)
12-9 Seq2Seq-Attention编程实例-定义eval模块 (08:40)
12-10 【讨论题】深入了解Attention在CV任务中的应用前景?
13章 PyTorch工程应用介绍
主要介绍如何在工程应用中进行模型选择、模型优化、模型存储、模型部署、分布式训练等问题,帮助大家了解如何将算法模型实际应用于工程项目中,并提供稳定的服务;
13-1 PyTorch模型开发与部署基础平台介绍
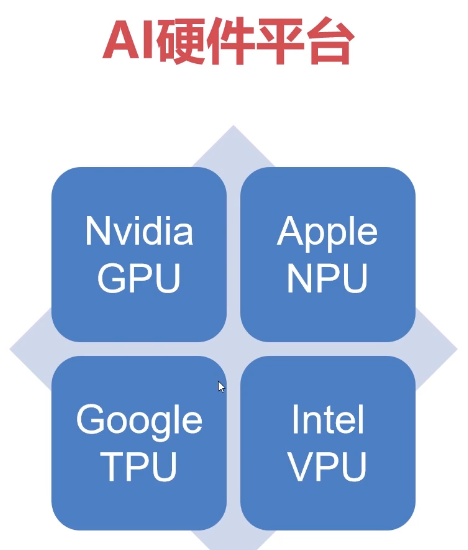



服务端运行

13-2 PyTorch工程化基础—Torchscript
Torchscript


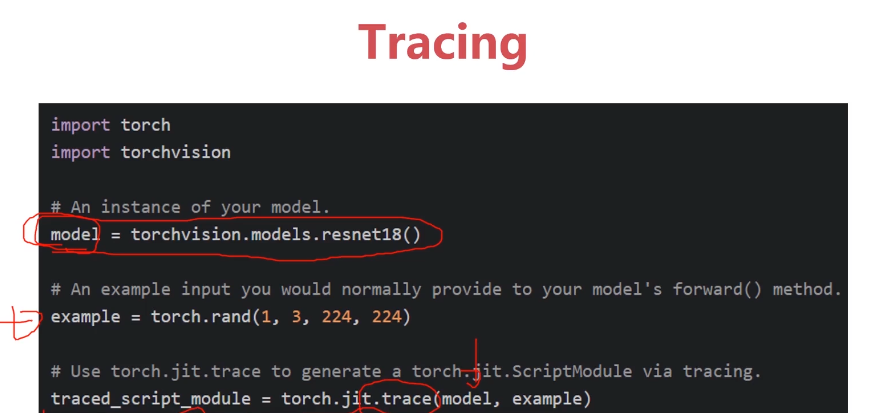



13-3 PyTorch服务端发布平台—Torchserver
Torchserver
参考:1.PyTorch 1.5 发布,与 AWS 合作 TorchServe;
TorchServe 旨在为大规模部署 PyTorch 模型推理,提供一个干净、兼容性好的工业级路径。
而 TorchElastic Kubernetes 控制器,可让开发人员快速使用 Kubernetes 集群,在 PyTorch 中创建容错分布式训练作业。
这似乎是 Facebook 联手亚马逊,在针对大型性能 AI 模型框架上,宣战 TensorFlow 的一个举措。
TorchServe 的测试版本现已可用,其特点包括:
- 原生态 API:支持用于预测的推理 API,和用于管理模型服务器的管理 API。
- 安全部署:包括对安全部署的 HTTPS 支持。
- 强大的模型管理功能:允许通过命令行接口、配置文件或运行时 API 对模型、版本和单个工作线程进行完整配置。
- 模型归档:提供执行「模型归档」的工具,这是一个将模型、参数和支持文件打包到单个持久工件的过程。使用一个简单的命令行界面,可以打包和导出为单个「 .mar」文件,其中包含提供 PyTorch 模型所需的一切。该 .mar 文件可以共享和重用。
- 内置的模型处理程序:支持涵盖最常见用例,如图像分类、对象检测、文本分类、图像分割的模型处理程序。TorchServe 还支持自定义处理程序。
- 日志记录和指标:支持可靠的日志记录和实时指标,以监视推理服务和端点、性能、资源利用率和错误。还可以生成自定义日志并定义自定义指标。
- 模型管理:支持同时管理多个模型或同一模型的多个版本。你可以使用模型版本回到早期版本,或者将流量路由到不同的版本进行 A/B 测试。
- 预构建的图像:准备就绪后,可以在基于 CPU 和 NVIDIA GPU 的环境中,部署T orchServe 的 Dockerfile 和 Docker 镜像。最新的 Dockerfiles 和图像可以在这里找到。

13-4 PyTorch终端推理基础—ONNX
开放式神经网络交换(ONNX)是迈向开放式生态系统的第一步,使AI开发人员能够随着项目发展而选择正确的工具。 ONNX为AI模型提供了一个开源格式。 它定义了一个可扩展的计算图模型,以及内置运算符和标准数据类型的定义。 最初专注于推理(评估)所需的功能。
ONNX
ONNX有两个分类:基础的ONNX主要用于描述神经网络、ONNX-ML是对基础ONNX的扩展,增加了神经网络之外的其他机器学习算法的支持。本文不会涉及ONNX-ML,接下来的文字以一个简单的ONNX模型为例,介绍一下 ONNX是如何来描述一个计算网络的。该模型可以在ONNX的Github上下载(https://github.com/onnx/models/blob/master/vision/classification/mobilenet/model/mobilenetv2-7.onnx).
Pytorch转化为ONNX

第15章 课程总结与回顾1 节 | 12分钟
主要对之前内容进行总结和回顾,并针对大家在学习中的一些问题和后续的算法职业发展提供一些建议,最后对后续的课程规划进行展望
15-1 课程总结 (11:14)

课程核心知识点

课程模型效果

课程技术难点

学习经验分享与建议

推荐读物

AI技术后续课程
【工作篇】燕雀安知鸿鹄之志
1 转行AI,老师傅的建议 (07:42)
AI公司推荐


知识储备
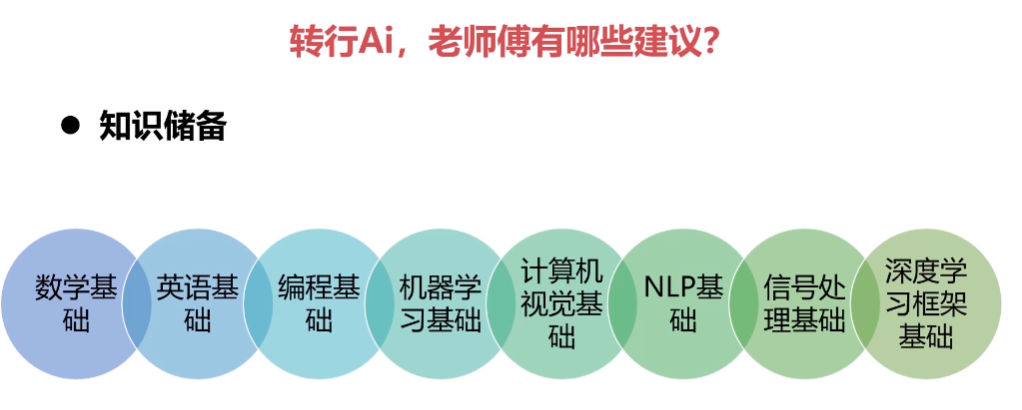

面试准备
重点突出论文和你的项目经历;尽可能细致的描述你做的东西;细致的做一个方向的东西;
巩固基础
1.轻量型卷积神经网络有哪些?
2.卷积模型的压缩有哪些方法吗?
3.1*1的卷积有什么用?
刷比赛榜

职业技能
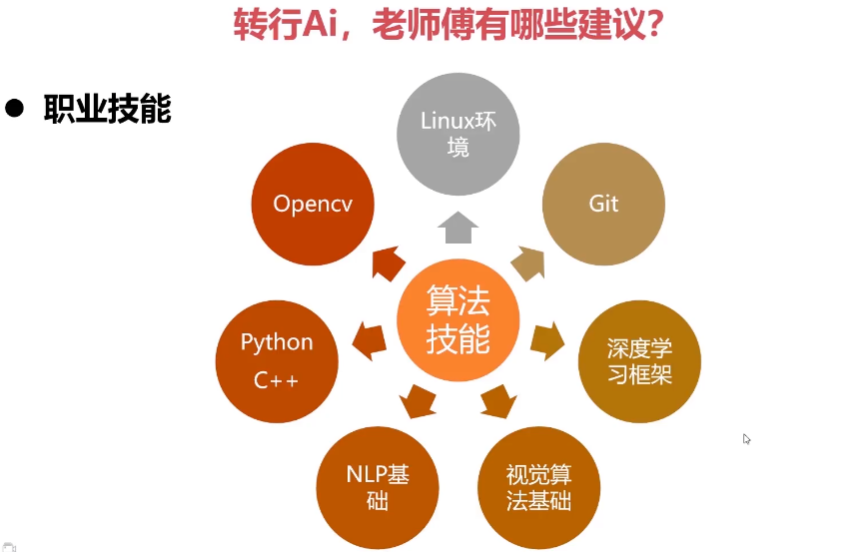
一些疑问
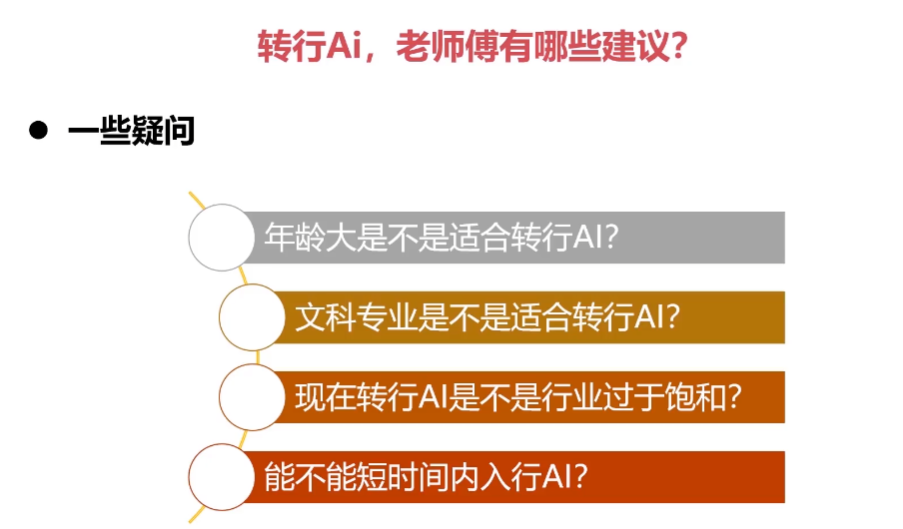
行业饱和问题;
转行成功的关键:花费大量的时间来了解行业知识;多去做;
工作中如何提高自己的职业素养和能力?
学如逆水行舟不进则退;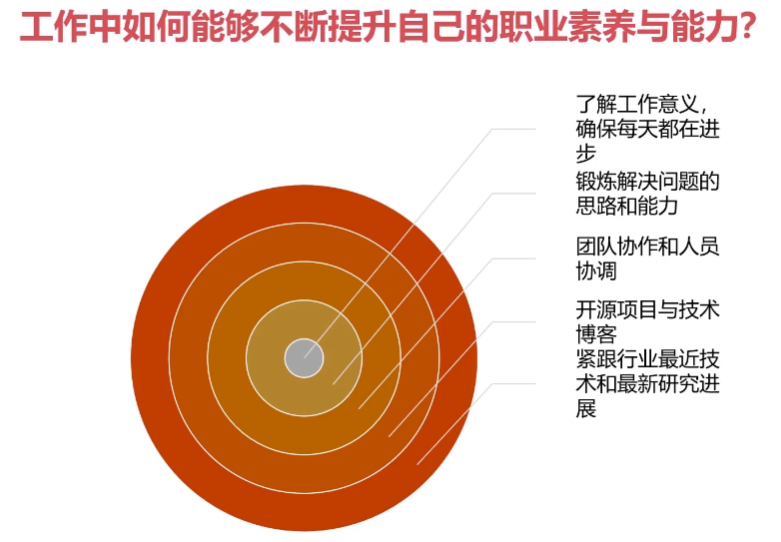


若有收获,就点个赞吧
0 人点赞
