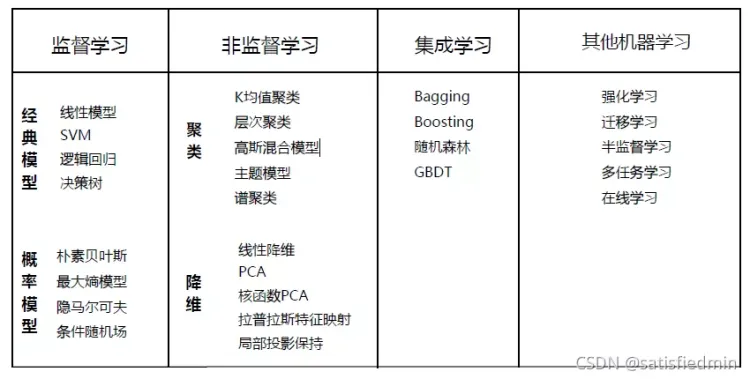
【监督学习】
1.SVM算法
SVM算法的实质是找出一个能够将某个值最大化的超平面,这个值就是超平面离所有训练样本的最小距离。这个最小距离用SVM术语来说叫做间隔(margin)。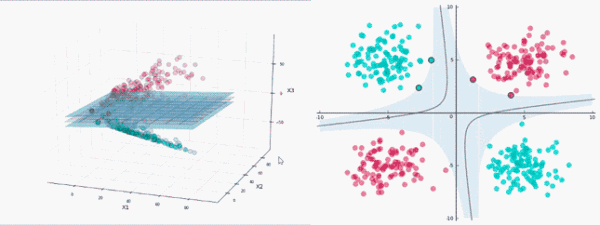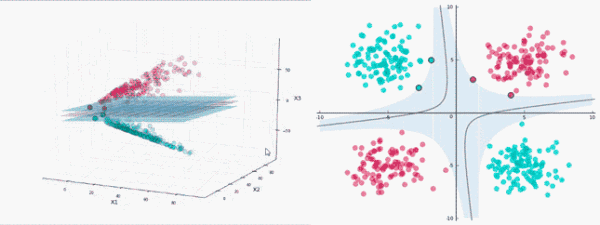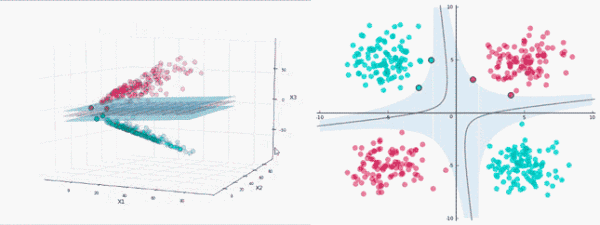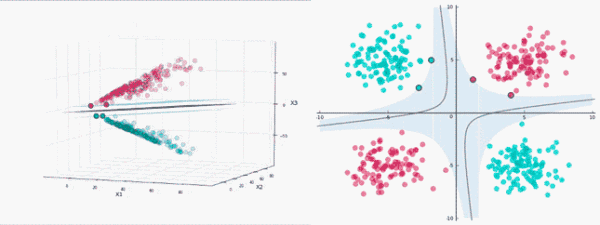
线性分类器的目标是要在n维的数据空间中找到一个超平面(hyper plane),将x的数据点分成两类,且超平面距离两边的数据的间隔最大。
参考:1.SVM原理详细图文教程来了!一行代码自动选择核函数,还有模型实用工具
【非监督学习】
【深度学习】
1.CNN
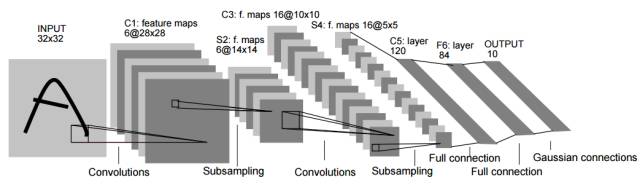
CNN(convolutional neural network)是一种前向人工神经网络模型,由Yann LeCun等人在1998年正式提出,其典型的网络结构包括卷积层、池化层和全连接层。下图(Figure 7)所示就是一种典型的CNN结构(LeNet-5),给定一张图片(一个训练样本)作为输入,通过多个卷积算子分别依次扫描输入图片,扫描结果经过激活函数激活得到特征图,然后再利用池化算子对特征图进行下采样,输出结果作为下一层的输入,经过所有的卷积和池化层之后,再利用全连接的神经网络进行进一步的运算,最终结果经输出层输出。
CNN模型强调的是中间的卷积过程,该过程通过权值共享大幅度降低了模型的参数数量,使得模型在不失威力条件下可以更为高效地得到训练。CNN模型是非常灵活的,其结构可以在合理的条件下任意设计,比如可以在多个卷积层之后加上池化层,正是由于这种灵活性,CNN被广泛地应用在各种任务中并且效果非常显著,比如后面将要介绍的AlexNet、GoogLeNet、VGGNet以及ResNet等。
当然,这种灵活性使得CNN的结构本身也成为了一种超参,这就难以保证针对特定任务所采用的模型是否是最优模型。在现实的应用中,CNN更多的用于处理一些网格数据,例如图片,对于这类数据CNN的卷积过程能发挥的作用相对更大。当然,CNN是可以完成多种类型的任务的,包括图片识别、自然语言处理、视频分析、药物挖掘以及游戏等。
2.RNN
RNN(Recurrent neural network)是一类用于处理序列数据的神经网络模型。典型的RNN模型通常是由三类神经元组成,分别是输入、隐藏和输出,其中输入单元只与隐藏单元相连,隐藏单元则与输出、上一个隐藏单元以及下一个隐藏单元相连,输出单元只接受隐藏单元的输入。在RNN训练过程中,一般需要学习优化三种类参数,即输入映射到隐层的权重、隐层单元之间转换权重以及隐层映射到输出的权重。
3.Adam优化算法的公式,和普通SGD有什么区别?
1.为什么LSTM的结构能达成长期记忆?
链接:https://www.zhihu.com/question/313870027/answer/610658122
推导forget gate,input gate,cell state,hidden information等的变化;因为LSTM有进有出且当前的cell information是通过input gate控制之后叠加的,RNN是叠乘,因此LSTM可以防止梯度消失或爆炸。
LSTM实现长期记忆不仅仅是依靠门控,还有cell状态。
在前向传播中,如果将输入的一串序列当做一部戏剧,那么LSTM的cell就是记录下的主线,而遗忘门,输入门都用于给主线增加一些元素(比如新的角色,关键性的转机)。通过训练,遗忘门能够针对性地对主线进行修改,选择“保留”或是“遗忘”过去主线中出现的内容,输入门用于判断是否要输入新的内容,并且输入内容。输出门则用于整合cell状态,判断需要把什么内容提取出来传递给下一层神经元。而RNN只是每一层接受上一幕的情景以及对以前情景越来越模糊的记忆,进行下一步传递,虽然运算很快,写法简单,但是无法处理长时间依赖的数据.
LSTM和RNN一样都会有梯度爆炸(千万记住),都需要进行梯度裁剪,防止Inf和NaN的出现。
之所以LSTM能比RNN更好地应对梯度消失,原因要从反向传播的过程中去找。
一般情况下我们用RNN的时候,使用的激励函数是tanh,tanh的导数范围在[0,1]之间,且在自变量为0的时候导数为1,这就直接导致了在不断往反向传播的过程中,反复乘以小于1的数,不需要经过几个time step,梯度就会变得非常非常小,出现梯度消失。
而LSTM的神经元中与输入数据有关的有三个sigmoid和一个tanh。sigmoid的导数范围在[0,0.25]之间,且在自变量为0的时候导数取最大值0.25。那么在不考虑权重等等影响条件下,三个sigmoid和一个tanh控制的门在反向传播中都要接受上一层的梯度,并且在这一层进行整合,在最好的情况下,几乎等同于乘以3*0.25+1,显然是大于1的(所以如果参数设置不太好的话,每次都乘大于1的数,会梯度爆炸),不过介于每一个time step不一定都是这种情况,所以要乘以的数值的分布基本上很均匀,有小于1和大于1的,一定程度上可以缓解梯度消失。

若有收获,就点个赞吧
0 人点赞
