《深度学习之Pytorch实战计算机视觉》阅读笔记
第7章:迁移学习
1. 迁移学习
- 通过对一个训练好的模型进行细微调整,将其应用到相似的问题中取得很好的效果
- 迁移学习也能有效解决原始数据较少的问题
- 在使用迁移学习的过程中,有时会导致迁移模型出现负迁移
2. 数据及处理
数据集:Kaggle Dogs vs Cats
其Test测试集中图片无需混杂,没有对应的标签,所以从Train训练集中抽出部分数据代替
os.path
- os.path.dirname:返回一个目录的目录名
- os.path.exists:测试输入参数指定的文件是否存在
- os.path.isdir:测试输入的参数是否是目录名
- os.path.isfile:用于测试输入参数是否是一个文件
- os.path.samefile:用于测试两个输入的路径参数是否指向同一个文件
- os.path.split:返回输入参数中目录的分割元组,目录名+文件名
数据集目录
# datasets.ImageFolder函数# ImageFolder加载图片目录的一般形式为 root/分类标签/分类文件--- train--- cat--- ***.jpg--- ...--- dog--- ***.jpg--- ...--- test--- cat--- ***.jpg--- ...--- dog--- ***.jpg--- ...
加载数据
data_dir = "./data/DogsAndCats"data_transform = {x: transforms.Compose([transforms.Resize([64, 64]),transforms.ToTensor()])for x in ["train", "test"]}image_datasets = {x: datasets.ImageFolder(root=os.path.join(data_dir, x),transform=data_transform[x])for x in ["train", "test"]}print(image_datasets)dataloader = {x: torch.utils.data.DataLoader(dataset=image_datasets[x],batch_size=16,shuffle=True)for x in ["train", "test"]}
DataLoader
{'train': Dataset ImageFolderNumber of datapoints: 25000Root location: ./data/DogsAndCats/train,'test': Dataset ImageFolderNumber of datapoints: 25000Root location: ./data/DogsAndCats/test}
3. 自定义网络
网络模型
class Model(torch.nn.Module):def __init__(self):super(Model, self).__init__()self.Conv = torch.nn.Sequential(torch.nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1),torch.nn.ReLU(),torch.nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1),torch.nn.ReLU(),torch.nn.MaxPool2d(kernel_size=2, stride=2),torch.nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1),torch.nn.ReLU(),torch.nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=1),torch.nn.ReLU(),torch.nn.MaxPool2d(kernel_size=2, stride=2),torch.nn.Conv2d(128, 256, kernel_size=3, stride=1, padding=1),torch.nn.ReLU(),torch.nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1),torch.nn.ReLU(),torch.nn.MaxPool2d(kernel_size=2, stride=2),torch.nn.Conv2d(256, 512, kernel_size=3, stride=1, padding=1),torch.nn.ReLU(),torch.nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),torch.nn.ReLU(),torch.nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),torch.nn.ReLU(),torch.nn.MaxPool2d(kernel_size=2, stride=2))self.Classes = torch.nn.Sequential(torch.nn.Linear(4 * 4 * 512, 1024),torch.nn.ReLU(),torch.nn.Dropout(p=0.5),torch.nn.Linear(1024, 1024),torch.nn.ReLU(),torch.nn.Dropout(p=0.5),torch.nn.Linear(1024, 2))def forward(self, input):x = self.Conv(input)x = x.view(-1, 4 * 4 * 512)x = self.Classes(x)return x
损失函数
loss_f = torch.nn.CrossEntropyLoss()- 优化函数
optimizer = torch.optim.Adam(model.parameters(), lr=0.00001) 改为GPU计算
# 迁移模型if (cuda):model = model.cuda()# 迁移变量if (cuda):x, y = Variable(x.cuda()), Variable(y.cuda())else:x, y = Variable(x), Variable(y)
训练结果
识别准确率大概是76%
4. 迁移到VGG16网络
引入VGG16网络
from torchvision import datasets, models, transforms# 已经具备最有参数model = models.vgg16(pretrained=True)
冻结卷积神经网络中的参数
VGG16网络已自带最优参数,无需进行梯度更新。for param in model.parameters():param.requires_grad = False
VGG16的全连接层(分类器)
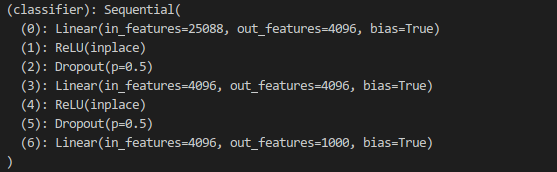
VGG16分类器输出结果有1000个参数,对于实际分类结果来看只需要两个参数,因此必须更换全连接层。
更换分类器
model.classifier = torch.nn.Sequential(torch.nn.Linear(25088,4096),torch.nn.ReLU(),torch.nn.Dropout(p=0.5),torch.nn.Linear(4096, 4096),torch.nn.ReLU(),torch.nn.Dropout(p=0.5),torch.nn.Linear(4096, 2))
此时分类器中的参数**require_grad**默认重置为**True**,即只更新全连接层的梯度
参数优化:optimizer = torch.optim.Adam(model.classifier.parameters(), lr=0.00001)训练结果
识别准确率大概在91%
5. 迁移到ResNet网络
- 类似VGG16引入过程,以及冻结参数、参数优化
- ResNet网络的全连接层

ResNet全连接层输出结果有1000个参数 - 更换全连接层
model.fc=torch.nn.Linear(2048,2) - 训练结果
识别准确率大概在97%
在加载数据时,一定要进行正则化操作,不然识别准确率大概只有75%
6. ResNet迁移完整代码
import torchimport torchvisionfrom torchvision import datasets, models, transformsimport osfrom torch.autograd import Variableimport timedata_dir = "./data/DogsAndCats"data_transform = {x: transforms.Compose([transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize(mean=[0.5,0.5,0.5],std=[0.5,0.5,0.5])])for x in ["train", "test"]}image_datasets = {x: datasets.ImageFolder(root=os.path.join(data_dir, x),transform=data_transform[x])for x in ["train", "test"]}dataloader = {x: torch.utils.data.DataLoader(dataset=image_datasets[x],batch_size=16,shuffle=True)for x in ["train", "test"]}model = models.resnet50(pretrained=True)print(model)for param in model.parameters():param.requires_grad = Falsemodel.fc=torch.nn.Linear(2048,2)loss_f = torch.nn.CrossEntropyLoss()optimizer = torch.optim.Adam(model.fc.parameters(), lr=0.00001)epoch_n = 5time_open = time.time()cuda = torch.cuda.is_available()if (cuda):model = model.cuda()for epoch in range(epoch_n):print("Epoch {}/{}".format(epoch, epoch_n - 1))print("-" * 10)for phase in ["train", "test"]:if phase == "train":print("Training...")model.train(True)else:print("Testing")model.train(False)running_loss = 0.0running_corrects = 0for batch, data in enumerate(dataloader[phase], 1):x, y = dataif (cuda):x, y = Variable(x.cuda()), Variable(y.cuda())else:x, y = Variable(x), Variable(y)y_pred = model(x)_, pred = torch.max(y_pred.data, 1)optimizer.zero_grad()loss = loss_f(y_pred, y)if phase == "train":loss.backward()optimizer.step()running_loss += loss.item()running_corrects += torch.sum(pred == y.data)if batch & 500 == 0 and phase == "train":print("Batch {},Train Loss:{:.4f},Train Acc{:.4f}".format(batch, running_loss / batch,100 * running_corrects / (16 * batch)))epoch_loss = running_loss * 16 / len(image_datasets[phase])epoch_acc = 100 * running_corrects / len(image_datasets[phase])print("{} Loss:{:.4f} Acc:{:.4f}%".format(phase, epoch_loss,epoch_acc))time_end = time.time() - time_openprint(time_end)

若有收获,就点个赞吧
0 人点赞
