《深度学习之Pytorch实战计算机视觉》阅读笔记 第3章:深度神经网络基础
1. 监督学习
监督学习:提供一组输入数据和其对应的标签数据,然后搭建一个模型,让模型在通过训练后准确地找到输入数据和标签数据之间的最优映射关系,在输入新的数据后,模型能够通过之前学习到的最优映射关系,快速地预测出这组新数据的标签。
- 回归问题
- 分类问题
2. 无监督学习
无监督学习:提供一组没有任何标签的输入数据,将其在搭建好的模型中进行训练,对整个训练过程不做任何干涉,最后得到一个能够发现数据之间隐藏特征的映射模型,使用这个映射模型能够实现对新数据的分类。 使用无监督学习实现的分类算法又叫做聚类。
3. 欠拟合
只捕获了数据的一部分特征,不能很好地对新数据进行准确预测。
解决过拟合问题:
- 增加特征项;
- 构造复杂的多项式;
- 减少正则化参数;
4. 过拟合
过度捕获原数据的特征,受原数据中的噪声数据影响十分严重。

解决过拟合问题:
- 增大训练的数据量;
- 采用正则化方法;
- Dropout方法(随即选取和丢弃指定层次之间的部分神经连接);
5. 后向传播
后向传播用于对模型中的参数进行微调,得到最优参数组合。其本质是复合函数的求导过程。

6. 损失
损失:度量模型得到的预测值和数据真实值之间的差距,也是衡量训练出来模型泛化能力好坏的重要指标。
- 均方误差函数(MSE):预测值和真实值之差的平方的期望值

- 均方根误差函数(RMSE):
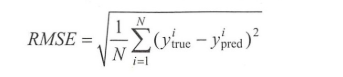
- 平均绝对误差函数(MAE):绝对误差的平均值
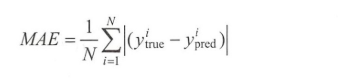
7. 优化函数
- 梯度:多元函数的各个参数求得的偏导数已向量的形式展示出来。
- 梯度下降(GD):
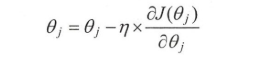
训练样本总数为 n,, 是需要优化的参数对象, 是学习速率, 是损失函数, 是根据损失函数计算  的梯度。<br /> 模型的训练依赖于整个数据集,增加了计算损失值的时间成本和模型训练过程中的复杂度。
- 批量梯度下降(BGD):
批量梯度下降就是将整个参与训练的数据集划分为若干个大小差不多的训练数据集,将其中一个训练数据集叫做一个批量,每次用一个批量的数据来对模型进行训练,并针对这个批量计算得到的损失函数为基准对模型中的全部参数进行梯度更新,默认每个批量只使用一次,直到所有的数据全部使用完毕。
- 随机梯度下降(SGD):
通过随机的方式从整个数据集中选取一部分进行训练。
- Adam(自适应时刻估计方法):
在模型训练优化的过程中通过让每一个参数获得自适应的学习来达到优化质量和速度的双重提升。
8. 激活函数
为模型带来非线性因素,处理更复杂的问题。
- Sigmoid
- 数学表达式:

- Sigmoid图形
- 数学表达式:
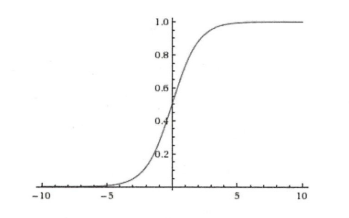
- 缺点:1)模型层次达到一定深度后,反向传播会导致梯度消失;2)Sigmoid函数的输出值恒大于0,模型在优化的过程中收敛速度变慢
- tanh
- 数学表达式:

- tanh图形
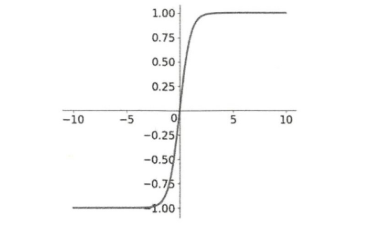
- 输出结果是零中心数据,解决了激活函数在模型优化过程中收敛速度变慢的问题。
- 缺点:tanh函数的导数取值区间是 $0 - 1$,在反向传播过程中任然可能出现梯度消失的情况
- ReLU(修正线性单元)
- 数学表达式:

ReLU图形
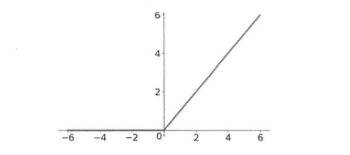
收敛速度非常快,计算效率高
- 缺点:ReLU的输出并不是零中心数据,某些神经元可能永远无法激活,对应参数也不能更新(模型在初始化过程中使用了全正或者全负的值,或者在后向传播过程中设置的学习速率太快)

若有收获,就点个赞吧
0 人点赞
