信息论是应用数学的一个分支,主要研究的是对一个信号包含信息的多少进行量化。信息论的基本想法是一个不太可能发生的事件居然发生了,要比一个非常可能发生的事件发生,能提供更多的信息。消息说“今天早上太阳升起”,信息量是如此之少,但一条消息说“今天早上有日食”,信息量就很丰富了。我们想通过这种基本想法来量化信息
- 非常可能发生的事件信息量比较少,并且极端情况下,确保能够发生的事件应该没有信息量
- 较不可能发生的事件具有更高的信息量
- 独立事件应具有增量的信息。如扔硬币两次正面朝上传递的信息量,应是投掷一次正面朝上的信息量的两倍
信息熵
如果 是一个离散型随机变量,取值空间为
是一个离散型随机变量,取值空间为 ,其概率分布为
,其概率分布为 ,那么熵:
,那么熵:

熵又称为自信息,可以视为描述一个随机变量的不确定性的数量。它表示信号源 每发一个符号所提供的的平均信息量。一个随机变量的熵越大,它的不确定性越大,那么正确估计其值的可能性就越小。越不确定的随机变量越需要大的信息量用以确定其值。
每发一个符号所提供的的平均信息量。一个随机变量的熵越大,它的不确定性越大,那么正确估计其值的可能性就越小。越不确定的随机变量越需要大的信息量用以确定其值。
在只掌握关于未知分布的部分知识的情况下,符合已知知识的概率分布可能有多个,但使熵值最大的概率分布最真实地反映了事件的分布情况,因为熵定义了随机变量的不确定性,当熵最大时,随机变量最不确定,最难准确地预测其行为。也就是说,在已知部分知识的前提下,关于未知分布最合理的推断应该是符合已知知识最不确定或最大随机的推断。最大熵概念被广泛地应用于自然语言处理中,通常的做法是,根据已知样本设计特征函数,假设存在 个特征函数
个特征函数 ,它们都在建模过程中对输出有影响,那么,所建立的模型应满足所有这些特征的约束,即所建立的模型
,它们都在建模过程中对输出有影响,那么,所建立的模型应满足所有这些特征的约束,即所建立的模型 应该属于这
应该属于这 个特征函数约束下所产生的所有模型的集合
个特征函数约束下所产生的所有模型的集合 。使熵
。使熵 值最大的模型用来推断某种语言现象存在的可能性,或者作为进行某种处理操作的可靠性依据,即:
值最大的模型用来推断某种语言现象存在的可能性,或者作为进行某种处理操作的可靠性依据,即:

Example
例子1:设a,b,c,d,e,f这6个字符在某一语言中随机出现,出现概率为1/8,1/4,1/8,1/4,1/8,1/8。每个字符的熵为

这个结果表明,我们可以设计一种编码,传输一个字符平均只需要2.5个比特。
例子2:我面试时遇到这样一道题,1000杯水中只有1杯有毒,问需要最少几只小白鼠能找到有毒的那杯。
解答即
10只就可以。实际操作方案就是1000可用10位2进制(到1024)表示,看哪几只小白鼠挂掉就可以找到对应编号水
例子3:例2进阶版,为防止爱鼠人士表示谴责,我们改为可爱的猪。1000桶水,其中一桶有毒,猪喝毒水后会在15分钟内死去,想用1个小时找到这桶毒水,至少需要几头猪?
有了前面简化的版本(例子2)的理解,我们容易得知“1000桶水其中有一桶有毒”的信息熵为

而对于猪的状态就不太一样了,我们可以想象一下,一只猪在一个小时内会有几种状态?
- 在第0分钟的时候喝了一桶水以后,第15分钟死去
- 第15分钟依然活着,喝了一桶水后,第30分钟死去
- 第30分钟依然活着,喝了一桶水后,第45分钟死去
- 第45分钟依然活着,喝了一桶水后,第60分钟死去
- 第45分钟依然活着,喝了一桶水后,第60分钟依然活着
可见,1只可爱的猪猪在有5种状态,“1只猪1个小时后的状态”的信息熵为

 只猪1小时后有
只猪1小时后有 种状态,即“
种状态,即“ 只猪1个小时后的状态”的信息墒为
只猪1个小时后的状态”的信息墒为

所以,按照题目要求 头猪能够找到这桶毒水,那么信息墒
头猪能够找到这桶毒水,那么信息墒 必须要大于信息墒
必须要大于信息墒 ,也就是
,也就是
 ,即
,即 ,其
,其
条件熵
给定随机变量 的情况下,随机变量
的情况下,随机变量 的条件熵定义为:
的条件熵定义为:



联合熵
如果 ,
, 是一对离散型随机变量
是一对离散型随机变量 ,
, ,
, 的联合熵
的联合熵 定义为
定义为

联合熵实际上就是描述一对随机变量平均所需要的信息量。将上式中的联合概率 展开可得:
展开可得:






我们称 为熵的连锁规则。推广到一般情况,有
为熵的连锁规则。推广到一般情况,有

Example
假设某种语言的字符有元音和辅音两类,其中,元音随机变量 ,辅音随机变量
,辅音随机变量 。如果该语言的所有单词都由辅音-元音音节序列组成,其联合概率分布
。如果该语言的所有单词都由辅音-元音音节序列组成,其联合概率分布 如下
如下
| 元/辅 | p | t | k |
|---|---|---|---|
| a | 1/16 | 3/8 | 1/16 |
| i | 1/16 | 3/16 | 0 |
| u | 0 | 3/16 | 1/16 |
我们不难算出p,t,k,a,i,u这6个字符的边缘概率(就是单词中含有这个音的概率)分别为: , 3/4, 1/8, 1/2, 1/4, 1/4。但需要注意的是,这些边缘概率是基于音节的,每个字符的概率是基于音节的边缘概率的
, 3/4, 1/8, 1/2, 1/4, 1/4。但需要注意的是,这些边缘概率是基于音节的,每个字符的概率是基于音节的边缘概率的 (即若选中t,前提是先选中辅音音节,又元-辅概率为
(即若选中t,前提是先选中辅音音节,又元-辅概率为 ),因此每个字符的概率值实际为:1/16, 3/8, 1/16, 1/4, 1/8, 1/8。现求联合熵:
),因此每个字符的概率值实际为:1/16, 3/8, 1/16, 1/4, 1/8, 1/8。现求联合熵:
方法一(套公式):

方法二(连锁规则):



互信息
根据熵的连锁规则,有

因此,

这个差叫做 和
和 的互信息(Mutual Information, MI),记作
的互信息(Mutual Information, MI),记作 。或者定义为:如果
。或者定义为:如果 ,则
,则 之间的互信息
之间的互信息
 反映的是在知道了
反映的是在知道了 的值以后
的值以后 的不确定性的减少量。可以理解为
的不确定性的减少量。可以理解为 的值透露了多少关于
的值透露了多少关于 的信息量。
的信息量。
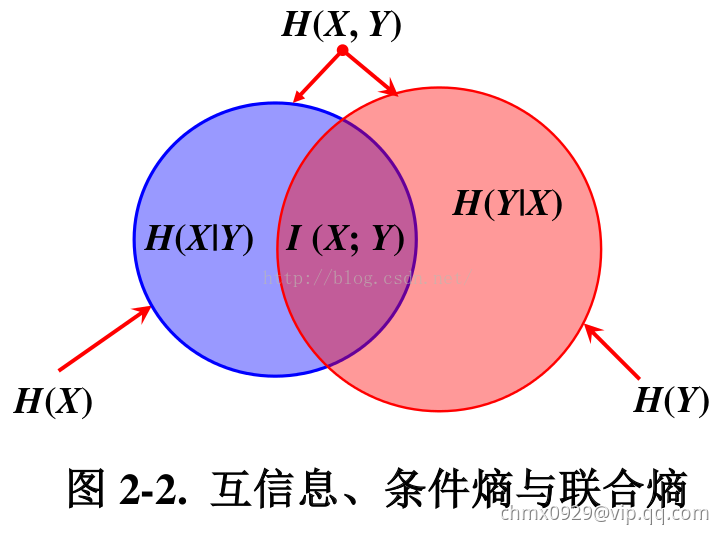
互信息度量的是两个随机变量之间的统计相关性,是从随机变量整体角度,在平均的意义上观察问题,因此通常称之为平均互信息。平均互信息是非负的额,即 。在自然语言处理中通常利用这一测度判断两个对象之间的关系,如根据主题类别和词之间互信息大小进行特征词提取。互信息在词汇聚类、汉语自动分词、词义消歧、文本分类和聚类等问题研究中有重要通途。
。在自然语言处理中通常利用这一测度判断两个对象之间的关系,如根据主题类别和词之间互信息大小进行特征词提取。互信息在词汇聚类、汉语自动分词、词义消歧、文本分类和聚类等问题研究中有重要通途。
相对熵
相对熵又称KL散度,衡量相同事件空间里两个概率分布相对差距。两个概率分布 和
和 的相对熵定义为
的相对熵定义为

该定义中约定 。表示成期望为:
。表示成期望为:

当两个随机分布完全相同时,即 ,其相对熵为
,其相对熵为 。当两个随机分布的差别增大时,其相对熵期望值也增大。
。当两个随机分布的差别增大时,其相对熵期望值也增大。
互信息实际上就是衡量一个联合分布与独立性差距多大的测度:





交叉熵
根据熵的定义,知道熵是一个不确定性的测度,也就是说,我们对于某件事情知道得越多,那么,熵就越小,因而对于试验的结果我们越不感到意外。交叉熵的概念就是用来衡量估计模型与真实概率分布之间差异情况的。
如果一个随机变量 ,
, 为用于近似
为用于近似 的概率分布,那随机变量
的概率分布,那随机变量 和模型
和模型 之间的交叉熵定义为:
之间的交叉熵定义为:


若有收获,就点个赞吧
0 人点赞
