隐马尔可夫模型
介绍隐马尔可夫模型之前,首先需要明白马尔可夫链。
马尔可夫链
假设随机过程中各个 的概率分布,只与它之前的状态
的概率分布,只与它之前的状态 有关,即
有关,即 。比如硬性规定今天的气温只跟昨天有关,跟前天或之前的天气无关。这种假设未必适用所有的应用,但是至少对以前很多不好解决的问题给出了近似解。这个假设后来被命名为马尔可夫假设,而符合这个假设的随机过程则称为马尔可夫过程,也称为马尔可夫链。
。比如硬性规定今天的气温只跟昨天有关,跟前天或之前的天气无关。这种假设未必适用所有的应用,但是至少对以前很多不好解决的问题给出了近似解。这个假设后来被命名为马尔可夫假设,而符合这个假设的随机过程则称为马尔可夫过程,也称为马尔可夫链。
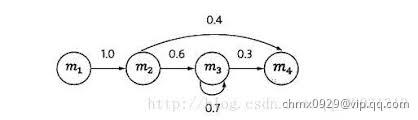
上图中,四个圈表示四个状态,每条边表示一个可能的状态转换,边上的权值为转移概率。例如,状态 到状态
到状态 之间只有一条边,且边上的权重为
之间只有一条边,且边上的权重为 。这表示从状态
。这表示从状态 只可能转换到状态
只可能转换到状态 ,转移概率为
,转移概率为 。从
。从 出发的有两条边:到
出发的有两条边:到 和到
和到 。其中权值
。其中权值 表示:如果某个时刻
表示:如果某个时刻 的状态
的状态 是
是 ,则下一个时刻的状态
,则下一个时刻的状态 的概率是
的概率是 。如果用数学符号表示是
。如果用数学符号表示是 。类似的,有
。类似的,有 。随机选择一个状态作为初始状态,随后按照上述规则随机选择后续状态。这样运行一段时间
。随机选择一个状态作为初始状态,随后按照上述规则随机选择后续状态。这样运行一段时间 后,就会产生一个状态序列:
后,就会产生一个状态序列: 。
。
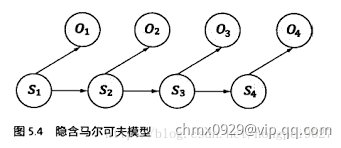
隐马尔可夫模型
隐马尔可夫模型是马尔可夫链的一个扩展:任一时刻 的状态
的状态 是不可见的。观察者没法通过观察到一个状态序列
是不可见的。观察者没法通过观察到一个状态序列 来推测转移概率等参数。但是,隐马尔可夫模型在每个时刻
来推测转移概率等参数。但是,隐马尔可夫模型在每个时刻 会输出一个符号
会输出一个符号 ,而且
,而且 跟
跟 相关且仅跟
相关且仅跟 相关。即,我们观测不到状态变化,只能观测到输出符号。
相关。即,我们观测不到状态变化,只能观测到输出符号。
基于马尔可夫假设和独立输出假设,我们可以计算出某个特定的状态序列 产生输出符号
产生输出符号 的概率
的概率

除了结构信息,想要确定一个隐马尔可夫模型还需要以下三组参数:
1、状态转移概率:模型在各个状态间转换的概率,通常记为矩阵 其中
其中

表示在任意时刻 ,若状态为
,若状态为 ,则下一时刻状态为
,则下一时刻状态为 的概率
的概率
2、输出观测概率:模型根据当前状态获得各个观测值的概率,记矩阵 其中
其中

表示任意时刻 ,若状态为
,若状态为 ,则观测值
,则观测值 被获取的概率
被获取的概率
3、初始状态概率:模型在初始时刻各状态出现的概率,记为 其中
其中

表示模型的初始状态为 的概率
的概率
通过指定状态空间 、观测空间
、观测空间 和上面三组参数,就能确定一个隐马尔可夫模型,通常用其参数
和上面三组参数,就能确定一个隐马尔可夫模型,通常用其参数 来指代。给定隐马尔可夫模型
来指代。给定隐马尔可夫模型 ,它按如下过程产生观测序列
,它按如下过程产生观测序列 :
:
- 设置
 ,并根据初始状态概率
,并根据初始状态概率 选择初始状态
选择初始状态
- 根据状态
 和输出观测概率
和输出观测概率 选择观测变量取值
选择观测变量取值
- 根据状态
 和状态转移矩阵
和状态转移矩阵 转移模型状态,即确定
转移模型状态,即确定
- 若
 设置
设置 ,并转到第2.步,否则停止
,并转到第2.步,否则停止
其中 和
和 分别为第
分别为第 时刻的状态和观测值
时刻的状态和观测值
举例如下:假设有4个盒子,每个盒子里都装有红白两种颜色的球
| 盒子 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| 红球 | 5 | 3 | 6 | 8 |
| 白球 | 5 | 7 | 4 | 2 |
按照下面的方法抽球,产生一个球的颜色的观测序列:
开始,从4个盒子里以等概率随机选取1个盒子,从这个盒子里随机抽出1个球,记录颜色后,放回;然后,从当前盒子随机转移到下一个盒子,规则是:如果当前是盒子1,那么下一个盒子一定是盒子2,如果当前是盒子2或3,那么分别以概率0.4,0.6转移到左边或右边的盒子,如果当前是盒子4,那么各以0.5的概率停留在盒子4或转移到盒子3;确定转移的盒子后,再从这个盒子里随机抽取1个球,记录颜色,放回;如此下去,重复5次,得到一个球的颜色的观测序列:

在这个过程中,观察者只能观测到球颜色的序列,观测不到球从哪个盒子取出,即观测不到盒子的序列。
在这个例子中有两个随机序列,一个是盒子的序列(状态序列),一个是球的颜色的观测序列(观测序列)。前者是隐藏的,只有后者是可观测的。这是一个隐马尔可夫模型的例子,根据所给条件,可以明确状态集合、观测集合、序列长度及模型的三要素
状态集合:
观测集合:
状态序列和观测序列长度:
初始状态概率分布为:
状态转移概率分布为:
观测概率分布为:
隐马尔可夫模型的训练
围绕着隐马尔可夫模型有三个基本问题:
- 给定一个模型,如何计算某个特定的输出序列的概率
- 给定一个模型和某个特定的输出序列,如何找到最能产生这个输出序列的状态序列
- 给定足够量的观测数据,如何估计隐马尔可夫模型的参数
三大问题
给定模型,计算特定的输出序列的概率
使用前向与后向(Forward-Backward)算法。现实任务中,许多任务需要根据以往的观测序列来推测当前时刻最有可能的观测值,这显然可转化为这个计算特定输出序列的概率的问题。
前向算法
给定隐马尔可夫模型 ,定义到时刻
,定义到时刻 部分观测序列为
部分观测序列为 且状态为
且状态为 的概率为前向概率,记作:
的概率为前向概率,记作: 可以递推地求得前向概率
可以递推地求得前向概率 及观测序列概率
及观测序列概率
输入:隐马尔可夫模型 ,观测序列
,观测序列
输出:观测序列概率
(1)初值:
(2)递推:对

(3)终止:
递推部分就是上个状态转移到当前状态的所有可能乘上当前状态出现对应观测的概率;终止部分即把所有可能出现这种观测的可能加起来,即
举例如下
考虑盒子和球模型 ,状态集合
,状态集合 ,观测集合
,观测集合 ,
,
 ,
, ,
,
设 ,
, ,用前向算法计算
,用前向算法计算
(1)初值:


(2)迭代:





(3)终止:
后向算法
给定隐马尔可夫模型 ,定义在时刻
,定义在时刻 状态为
状态为 的条件下,从
的条件下,从 到
到 的部分观测序列为
的部分观测序列为 的概率为后向概率,记作:
的概率为后向概率,记作: 可以用递推地方法求得后向概率
可以用递推地方法求得后向概率 及观测序列概率
及观测序列概率
输入:隐马尔可夫模型 ,观测序列
,观测序列
输出:观测序列概率
(1)
(2)对

(3)
给定模型和特定的输出序列,找到最能产生这个输出序列的状态序列
使用维特比(Viterbi Algorithm)算法。在语音识别等任务中,观测值为语音信号,隐藏状态为文字,目标就是根据观测信号来推断最有可能的状态序列(即对应的文字)。
维特比算法是一种动态规划方法,核心思想是:如果最终的最优路径经过某个 ,那么从初始节点到
,那么从初始节点到 点的路径必然也是一个最优路径,因为每一个节点
点的路径必然也是一个最优路径,因为每一个节点 只会影响前后两个
只会影响前后两个 和
和
维特比算法实际上是用动态规划解隐马尔可夫模型预测问题,即用动态规划求概率最大路径。这时一条路径对应着一个状态序列。根据动态规划原理,最优路径具有这样的特性:如果最优路径在时刻 通过结点
通过结点 ,那么这一路径从结点
,那么这一路径从结点 到终点
到终点 的部分路径,对于从
的部分路径,对于从 到
到 的所有可能的部分路径来说,必须是最优的。因为假如不是这样,那么从
的所有可能的部分路径来说,必须是最优的。因为假如不是这样,那么从 到
到 就有另一条更好的部分路径存在,如果把它和从
就有另一条更好的部分路径存在,如果把它和从 到
到 的部分路径连接起来,就会形成一条比原来的路径更优的路径,这是矛盾的。依据这一原理,我们只需从时刻
的部分路径连接起来,就会形成一条比原来的路径更优的路径,这是矛盾的。依据这一原理,我们只需从时刻 开始,递推地计算在时刻
开始,递推地计算在时刻 状态为
状态为 的各条部分路径的最大概率,直至得到时刻
的各条部分路径的最大概率,直至得到时刻 状态为
状态为 的各条路径的最大概率。
的各条路径的最大概率。
输入:模型 和观测
和观测
输出:最优路径
(1)初始化:
(2)递推:对


(3)终止:
(4)最优路径回溯:对

举例如下
考虑盒子和球模型 ,状态集合
,状态集合 ,观测集合
,观测集合 ,
,
 ,
, ,
,
已知观测序列 ,求最优状态序列,即最优路径
,求最优状态序列,即最优路径
(1)初始化。在 时,对每一个状态
时,对每一个状态 ,求状态
,求状态 观测
观测 为红的概率,记此概率为
为红的概率,记此概率为 ,则
,则

代入实际数据

记
(2)在 时,对每个状态
时,对每个状态 ,求在
,求在 时状态为
时状态为 观测为红并在
观测为红并在 时状态为
时状态为 观测
观测 为白的路径的最大概率,记此最大概率为
为白的路径的最大概率,记此最大概率为 ,则
,则

同时,对每个状态 ,记录概率最大路径的前一个状态
,记录概率最大路径的前一个状态

计算:


同样,在 时,
时,



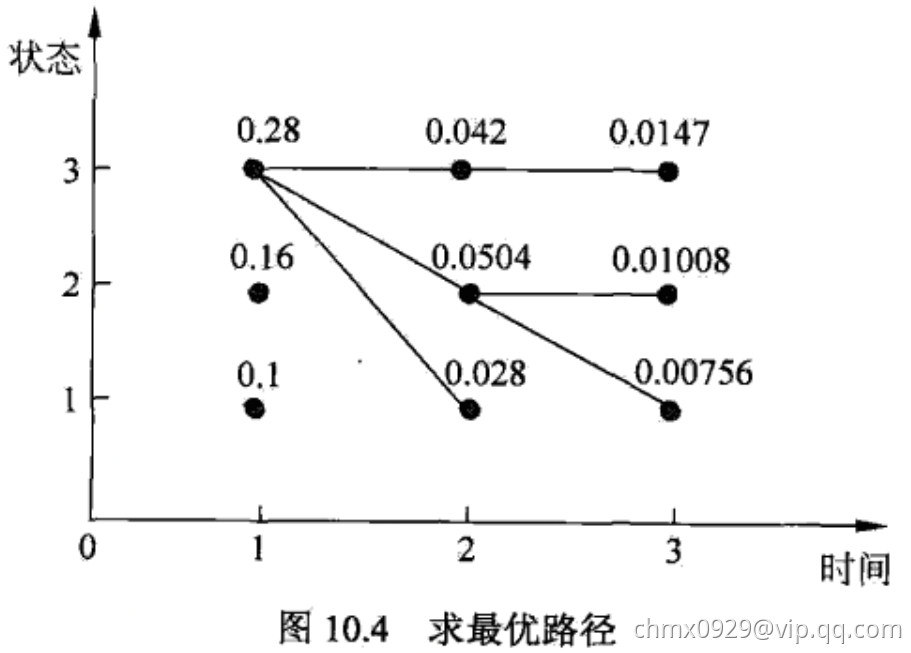
(3)以 表示最优路径的概率,则
表示最优路径的概率,则

最优路径的终点是

(4)由最优路径的终点 ,逆向找到
,逆向找到 ,
,
在 时,
时,
在 时,
时,
于是求得最优路径,即最优状态序列
给定足够量的观测数据,估计隐马尔可夫模型的参数
使用鲍姆-韦尔奇(Baum-Welch)算法,也就是EM算法。在大多数现实应用中,人工指定模型参数已变得越来越不可行,如何根据训练样本学得最优的模型参数,正好就是本问题。
在利用隐马尔可夫模型解决实际问题中,需要先知道每个状态 产生相应输出符号
产生相应输出符号 的概率
的概率 ,也称为生成概率;和转移概率,即从前一个状态
,也称为生成概率;和转移概率,即从前一个状态 进入当前状态
进入当前状态 的概率
的概率 。这些概率被称为马尔可夫模型的参数,而计算或者估计这些参数的过程称为模型的训练。
。这些概率被称为马尔可夫模型的参数,而计算或者估计这些参数的过程称为模型的训练。
我们从条件概率的定义出发,知道:


对于上面第一个概率公式(生成概率),状态输出概率,如果有足够多人工标记的数据,知道经过状态 有多少次
有多少次 ,每经过这个状态时,分别产生的输出
,每经过这个状态时,分别产生的输出 是什么,而且分别有多少次
是什么,而且分别有多少次 就可以算出(比如语音识别中,符号即每个词对应声波;中英翻译中,中文字为状态,英文字为输出符号)。上述第二个概率公式(转移概率),与前文提到的训练统计语言模型的条件概率完全相同,因此可以依照统计语言模型的训练方法,即数一下出现前一个词后出现这个词的次数(同上文例子,出现“联想”这个词后,出现“公司”的概率是多少,即数一下“联想”的次数,数一下“联想公司”的次数)
就可以算出(比如语音识别中,符号即每个词对应声波;中英翻译中,中文字为状态,英文字为输出符号)。上述第二个概率公式(转移概率),与前文提到的训练统计语言模型的条件概率完全相同,因此可以依照统计语言模型的训练方法,即数一下出现前一个词后出现这个词的次数(同上文例子,出现“联想”这个词后,出现“公司”的概率是多少,即数一下“联想”的次数,数一下“联想公司”的次数)


然而,像语音识别等这种应用大量人工标注不现实,所以这个方法只适用于一部分应用。因此,训练隐马尔可夫模型更实用的方法是仅仅通过大量观测到的信号 就能推算模型参数的
就能推算模型参数的 和
和 的方法,主要是使用鲍姆-韦尔奇算法。
的方法,主要是使用鲍姆-韦尔奇算法。
两个不同的隐马尔可夫模型可以产生同样的输出信号,因此,仅仅通过观察到的输出信号来倒推它的隐马尔可夫模型可能会得到多个合适的模型,但总会有一个模型 比其他的
比其他的 更有可能产生观测到的输出,其中
更有可能产生观测到的输出,其中 是隐马尔科夫模型的参数(可理解为最大似然)。鲍姆-韦尔奇算法就是来寻找这个最可能的模型
是隐马尔科夫模型的参数(可理解为最大似然)。鲍姆-韦尔奇算法就是来寻找这个最可能的模型
鲍姆-韦尔奇算法思想:
鲍姆-韦尔奇算法使用的就是EM算法原理。首先找到一组能够产生输出序列 的模型参数(显然它们是一定存在的,因为转移概率
的模型参数(显然它们是一定存在的,因为转移概率 和输出概率
和输出概率 为均匀分布时,模型可以产生任何输出,当然包括我们观测到的输出
为均匀分布时,模型可以产生任何输出,当然包括我们观测到的输出 )现在,有了这样一个初始模型
)现在,有了这样一个初始模型 ,根据上文提到的
,根据上文提到的 和
和 公式计算出一组新的模型参数
公式计算出一组新的模型参数 ,为一次迭代,可以证明
,为一次迭代,可以证明 。经过不断迭代
。经过不断迭代 轮,直到模型的质量不再有显著提高,得到的
轮,直到模型的质量不再有显著提高,得到的 即我们所求参数。
即我们所求参数。
马尔可夫随机场
马尔可夫随机场(Markov Random Field)包含两层意思。
马尔可夫性质:它指的是一个随机变量序列按时间先后关系依次排开的时候,第 时刻的分布特性,与
时刻的分布特性,与 时刻以前的随机变量的取值无关。拿天气来打个比方。如果我们假定天气是马尔可夫的,其意思就是我们假设今天的天气仅仅与昨天的天气存在概率上的关联,而与前天及前天以前的天气没有关系。其它如传染病和谣言的传播规律,就是马尔可夫的。
时刻以前的随机变量的取值无关。拿天气来打个比方。如果我们假定天气是马尔可夫的,其意思就是我们假设今天的天气仅仅与昨天的天气存在概率上的关联,而与前天及前天以前的天气没有关系。其它如传染病和谣言的传播规律,就是马尔可夫的。
随机场:当给每一个位置中按照某种分布随机赋予相空间的一个值之后,其全体就叫做随机场。我们不妨拿种地来打个比方。其中有两个概念:位置(site),相空间(phase space)。“位置”好比是一亩亩农田;“相空间”好比是种的各种庄稼。我们可以给不同的地种上不同的庄稼,这就好比给随机场的每个“位置”,赋予相空间里不同的值。所以,俗气点说,随机场就是在哪块地里种什么庄稼的事情。
马尔可夫随机场:马尔科夫随机场是具有马尔科夫特性的随机拿种地打比方,如果任何一块地里种的庄稼的种类仅仅与它邻近的地里种的庄稼的种类有关,与其它地方的庄稼的种类无关,那么这些地里种的庄稼的集合,就是一个马尔可夫随机场。
模型定义
概率图模型是由图表示概率分布。设有联合概率分布 ,
, 是一组随机变量。由无向图
是一组随机变量。由无向图 表示概率分布
表示概率分布 ,即在图
,即在图 中,结点
中,结点 表示一个随机变量
表示一个随机变量 ,
, ;边
;边 表示随机变量之间的概率依赖关系。
表示随机变量之间的概率依赖关系。
给定一个联合概率分布 和表示它的无向图
和表示它的无向图 。首先定义无向图表示的随机变量之间存在的成对马尔可夫性、局部马尔可夫性和全局马尔可夫性。
。首先定义无向图表示的随机变量之间存在的成对马尔可夫性、局部马尔可夫性和全局马尔可夫性。
成对马尔可夫性:设 和
和 是无向图
是无向图 中任意两个没有边连接的结点,结点
中任意两个没有边连接的结点,结点 和
和 分别对应随机变量
分别对应随机变量 和
和 。其他所有结点为
。其他所有结点为 ,对应的随机变量组是
,对应的随机变量组是 。成对马尔可夫性是指给定随机变量组
。成对马尔可夫性是指给定随机变量组 的条件下随机变量
的条件下随机变量 和
和 是条件独立的,即
是条件独立的,即

局部马尔可夫性:设 是无向图
是无向图 中任意一个结点,
中任意一个结点, 是与
是与 有边连接的所有结点,
有边连接的所有结点, 是
是 ,
, 以外的其他所有结点。
以外的其他所有结点。 表示的随机变量是
表示的随机变量是 ,
, 表示的随机变量组是
表示的随机变量组是 ,
, 表示的随机变量是
表示的随机变量是 。局部马尔可夫性是指在给定随机变量组
。局部马尔可夫性是指在给定随机变量组 的条件下随机变量
的条件下随机变量 和
和 是独立的,即
是独立的,即

全局马尔可夫性:设结点集合 ,
, 是在无向图
是在无向图 中被结点组合
中被结点组合 分开的任意结点集合。结点集合
分开的任意结点集合。结点集合 ,
, ,
, 所对应的随机变量组分别是
所对应的随机变量组分别是 ,
, ,
, 。全局马尔可夫性是指给定随机变量组
。全局马尔可夫性是指给定随机变量组 条件下随机变量
条件下随机变量 和
和 是条件独立的,即
是条件独立的,即

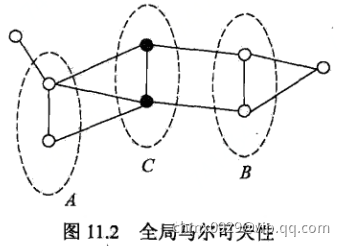
设有联合分布 ,由无向图
,由无向图 表示,在图
表示,在图 中,结点表示随机变量,边表示随机变量之间的依赖关系。如果联合概率分布
中,结点表示随机变量,边表示随机变量之间的依赖关系。如果联合概率分布 满足成对、局部或全局马尔可夫性,就称此联合概率分布为概率无向图模型,或马尔可夫随机场。
满足成对、局部或全局马尔可夫性,就称此联合概率分布为概率无向图模型,或马尔可夫随机场。
模型的因子分解
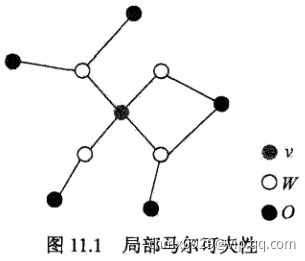
马尔科夫随机场(Markov Random Field, MRF)是典型的马尔可夫网,这是一种著名的无向图模型。图中每个结点表示一个或一组变量,结点之间的边表示两个变量之间的依赖关系。马尔科夫随机场有一组势函数,又称为“因子”,这是定义在变量子集上的非负实函数,主要用于定义概率分布函数。
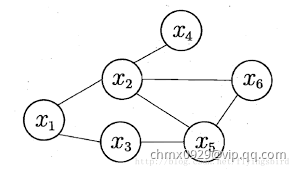
上图就是一个简单的马尔科夫随机场。对于图中结点的一个子集,若其中任意两结点间都有边连接,则称该结点子集为一个“团”(clique)。若在一个团中加入另外任何一个结点都不再形成团,则称该团为“极大团”;换言之,极大团就是不能被其他团所包含的团。例如上图 ,
, ,
, ,
, ,
, ,
, ,
, ,
, 都是团,并且除了
都是团,并且除了 ,
, ,
, 之外都是极大团。显然,每个结点至少出现在一个极大团中。
之外都是极大团。显然,每个结点至少出现在一个极大团中。
将概率无向图模型的联合概率分布表示为其最大团上的随机变量的函数的乘积形式的操作,称为概率无向图模型的因子分解。给定概率无向图模型,设其无向图为 ,
, 为
为 上的最大团,
上的最大团, 表示
表示 对应的随机变量。那么概率无向图模型的联合概率分布
对应的随机变量。那么概率无向图模型的联合概率分布 可写作图中所有最大团
可写作图中所有最大团 上的函数
上的函数 的乘积形式,即
的乘积形式,即

其中, 是规范化因子,由下式得出
是规范化因子,由下式得出

规范化因子保证 构成一个概率分布。函数
构成一个概率分布。函数 称为势函数。这里要求势函数是严格正的,通常定义为指数函数:
称为势函数。这里要求势函数是严格正的,通常定义为指数函数:

概率无向图模型的因子分解由Hammersley-Clifford定理来保证


其中, 是无向图的最大团,
是无向图的最大团, 是
是 的结点对应的随机变量,
的结点对应的随机变量, 是
是 上定义的严格正函数,乘积是在无向图所有的最大团上进行的。
上定义的严格正函数,乘积是在无向图所有的最大团上进行的。
Code实现
import numpy as npclass HiddenMarkov:def forward(self, Q, V, A, B, O, PI): # 使用前向算法N = len(Q) # 状态序列的大小M = len(O) # 观测序列的大小alphas = np.zeros((N, M)) # alpha值T = M # 有几个时刻,有几个观测序列,就有几个时刻for t in range(T): # 遍历每一时刻,算出alpha值indexOfO = V.index(O[t]) # 找出序列对应的索引for i in range(N):if t == 0: # 计算初值alphas[i][t] = PI[t][i] * B[i][indexOfO] # P176(10.15)print('alpha1(%d)=p%db%db(o1)=%f' % (i, i, i, alphas[i][t]))else:alphas[i][t] = np.dot([alpha[t - 1] for alpha in alphas], [a[i] for a in A]) * B[i][indexOfO] # 对应P176(10.16)print('alpha%d(%d)=[sigma alpha%d(i)ai%d]b%d(o%d)=%f' % (t, i, t - 1, i, i, t, alphas[i][t]))# print(alphas)P = np.sum([alpha[M - 1] for alpha in alphas]) # P176(10.17)# alpha11 = pi[0][0] * B[0][0] #代表a1(1)# alpha12 = pi[0][1] * B[1][0] #代表a1(2)# alpha13 = pi[0][2] * B[2][0] #代表a1(3)def backward(self, Q, V, A, B, O, PI): # 后向算法N = len(Q) # 状态序列的大小M = len(O) # 观测序列的大小betas = np.ones((N, M)) # betafor i in range(N):print('beta%d(%d)=1' % (M, i))for t in range(M - 2, -1, -1):indexOfO = V.index(O[t + 1]) # 找出序列对应的索引for i in range(N):betas[i][t] = np.dot(np.multiply(A[i], [b[indexOfO] for b in B]), [beta[t + 1] for beta in betas])realT = t + 1realI = i + 1print('beta%d(%d)=[sigma a%djbj(o%d)]beta%d(j)=(' % (realT, realI, realI, realT + 1, realT + 1),end='')for j in range(N):print("%.2f*%.2f*%.2f+" % (A[i][j], B[j][indexOfO], betas[j][t + 1]), end='')print("0)=%.3f" % betas[i][t])# print(betas)indexOfO = V.index(O[0])P = np.dot(np.multiply(PI, [b[indexOfO] for b in B]), [beta[0] for beta in betas])print("P(O|lambda)=", end="")for i in range(N):print("%.1f*%.1f*%.5f+" % (PI[0][i], B[i][indexOfO], betas[i][0]), end="")print("0=%f" % P)def viterbi(self, Q, V, A, B, O, PI):N = len(Q) # 状态序列的大小M = len(O) # 观测序列的大小deltas = np.zeros((N, M))psis = np.zeros((N, M))I = np.zeros((1, M))for t in range(M):realT = t+1indexOfO = V.index(O[t]) # 找出序列对应的索引for i in range(N):realI = i+1if t == 0:deltas[i][t] = PI[0][i] * B[i][indexOfO]psis[i][t] = 0print('delta1(%d)=pi%d * b%d(o1)=%.2f * %.2f=%.2f'%(realI, realI, realI, PI[0][i], B[i][indexOfO], deltas[i][t]))print('psis1(%d)=0' % (realI))else:deltas[i][t] = np.max(np.multiply([delta[t-1] for delta in deltas], [a[i] for a in A])) * B[i][indexOfO]print('delta%d(%d)=max[delta%d(j)aj%d]b%d(o%d)=%.2f*%.2f=%.5f'%(realT, realI, realT-1, realI, realI, realT, np.max(np.multiply([delta[t-1] for delta in deltas], [a[i] for a in A])), B[i][indexOfO], deltas[i][t]))psis[i][t] = np.argmax(np.multiply([delta[t-1] for delta in deltas], [a[i] for a in A]))print('psis%d(%d)=argmax[delta%d(j)aj%d]=%d' % (realT, realI, realT-1, realI, psis[i][t]))print(deltas)print(psis)I[0][M-1] = np.argmax([delta[M-1] for delta in deltas])print('i%d=argmax[deltaT(i)]=%d' % (M, I[0][M-1]+1))for t in range(M-2, -1, -1):I[0][t] = psis[int(I[0][t+1])][t+1]print('i%d=psis%d(i%d)=%d' % (t+1, t+2, t+2, I[0][t]+1))print(I)#测试数据Q = [1, 2, 3]V = ['红', '白']A = [[0.5, 0.2, 0.3], [0.3, 0.5, 0.2], [0.2, 0.3, 0.5]]B = [[0.5, 0.5], [0.4, 0.6], [0.7, 0.3]]# O = ['红', '白', '红', '红', '白', '红', '白', '白']O = ['红', '白', '红', '白']PI = [[0.2, 0.4, 0.4]]HMM = HiddenMarkov()# HMM.forward(Q, V, A, B, O, PI)# HMM.backward(Q, V, A, B, O, PI)HMM.viterbi(Q, V, A, B, O, PI)
Source

若有收获,就点个赞吧
0 人点赞
