《深度学习之Pytorch实战计算机视觉》阅读笔记 第10章:循环神经网络
1. 循环神经网络
- 主要用于处理序列相关问题
- 可以随意控制输入数据及输出数据的数量
- 简化模型
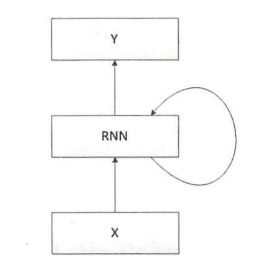
- 展开模型
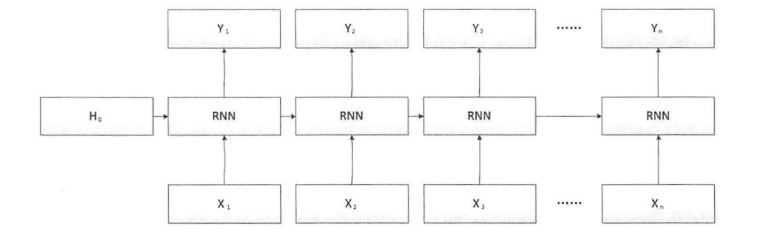
是最初输入的隐藏层,在一般情况下该隐藏层使用零进行初始化,即全部参数都是零
- RNN展开
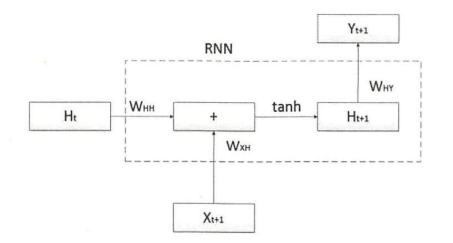
W表示权重参数,tanh是使用的激活函数
计算公式如下:%0A#card=math&code=H%7Bt%2B1%7D%3Dtanh%28H_t%5Ctimes%20W%7BHH%7D%2BX%7Bt%2B1%7D%5Ctimes%20W%7BXH%7D%29%0A&height=20&id=ujlY1)
则输出结果为:RNN能够很好的对输入的序列数据进行处理,但是不能长期记忆。如果近期输入的数据发生了变化,则会对当前的输出结果产生重大影响。
2. 手写数字识别
RNN模型 RNN定义中的一些参数:
class RNN(torch.nn.Module):def __init__(self):super(RNN,self).__init__()self.rnn=torch.nn.RNN(input_size=28,hidden_size=128,num_layers=1,batch_first=True)self.output=torch.nn.Linear(128,10)def forward(self,input):output,_=self.rnn(input,None)output=self.output(output[:,-1,:])return output
- input_size:用于指定输入数据的特征数
- hidden_size:指定最后隐藏层的输出特征数
- num_layers:RNN循环层的堆叠数量,default=1
- bias:偏置,default=True
- batch_fist:在RNN模型的输入层和输出层用到的数据默认维度是(seq,batch,feature),如果指定参数为True,输入层和输出层的数据维度对应为(batch,seq,feature)
数据加载
transform =transforms.Compose([transforms.ToTensor(),# 灰度图通道数是1transforms.Normalize([0.5],[0.5])])dataset_train=datasets.MNIST(root='../data',transform=transform,train=True,download=True)dataset_test=datasets.MNIST(root="../data",transform=transform,train=False)train_load=torch.utils.data.DataLoader(dataset=dataset_train,batch_size=64,shuffle=True)test_load=torch.utils.data.DataLoader(dataset=dataset_test,batch_size=64,shuffle=True)
训练
输出结果: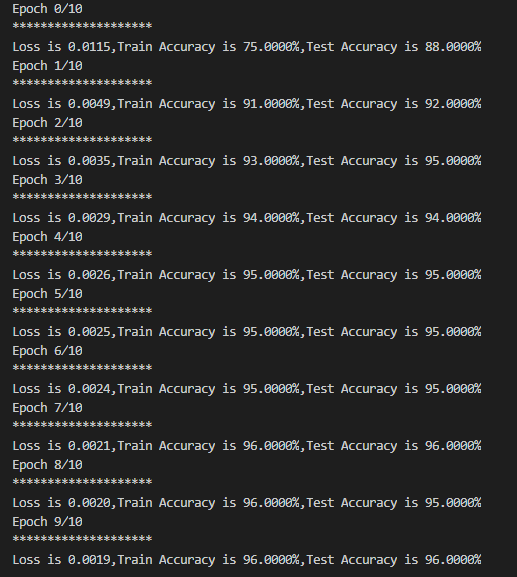
epoch_n=10for epoch in range(epoch_n):running_loss=0.0running_correct=0testing_correct=0print("Epoch {}/{}".format(epoch,epoch_n))print("*"*20)for data in train_load:x_train,y_train=datax_train=x_train.view(-1,28,28)x_train,y_train=Variable(x_train),Variable(y_train)y_pred=model(x_train)loss=loss_f(y_pred,y_train)_,pred=torch.max(y_pred.data,1)optimizer.zero_grad()loss.backward()optimizer.step()running_loss+=loss.item()running_correct+=torch.sum(pred==y_train.data)for data in test_load:x_test,y_test=datax_test=x_test.view(-1,28,28)x_test,y_test=Variable(x_test),Variable(y_test)outputs=model(x_test)_,pred=torch.max(outputs.data,1)testing_correct+=torch.sum(pred==y_test.data)print("Loss is {:.4f},Train Accuracy is {:.4f}%,Test Accuracy is {:.4f}%".\format(running_loss/len(dataset_train),100*running_correct/len(dataset_train),100*testing_correct/len(dataset_test)))

若有收获,就点个赞吧
0 人点赞
