《深度学习之Pytorch实战计算机视觉》阅读笔记 第9章:多模型融合
1. 结果融合法
通过多模型融合来提高输出结果的预测准确率,则各个模型的相关度越低,融合的效果会更好。也就是说各个模型的输出结果差异性越高,多模型融合的效果就会更好。
结果多数表决
假设我们现在已经拥有三个优化好的模型,而且它们能够独立完成对新输入数据的预测,现在我们向这三个模
型分别输入10个同样的新数据,然后统计模型的预测结果。如果模型预测的结果和真实的结果是一样的 , 那么我们将层次预测结果记录为True,否 则将其记录为 False。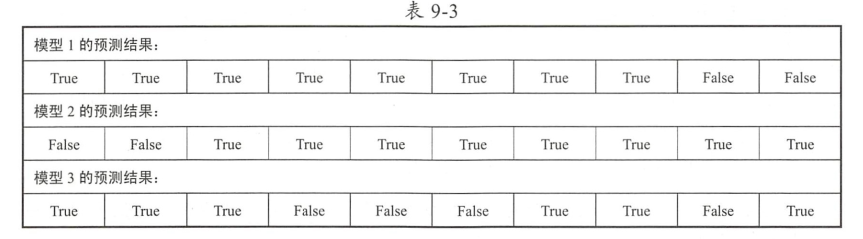
三个模型预测结果的准确率是80%、80%、60%,计算多模型融合之后的预测结果:
此时模型融合之后的预测结果准确率已经提升到了90%结果直接平均
结果直接平均追求的是融合各个模型的平均预测水平,已提升模型整体的预测能力,能在一定程度上弥补个别模型的明显劣势。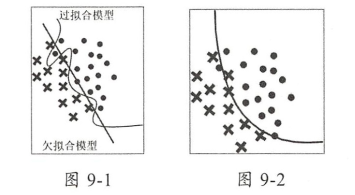
图9-1中,一个模型出现了过拟合现象,另一个模型出现了欠拟合现象。对两个模型进行融合之后,一定程度上弥补了各个模型的不足,拥有了更好的泛化能力。
对于另一个例子: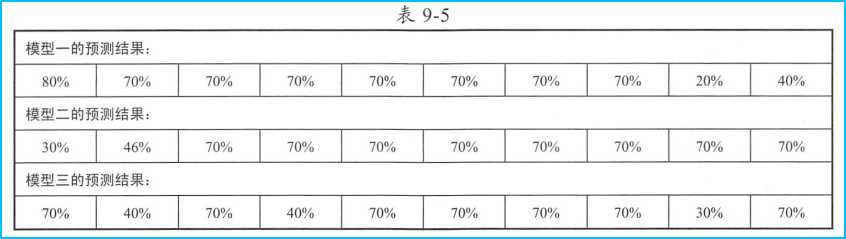
三个模型预测结果的准确率是80%、80%、60%,计算多模型融合之后的预测结果:
此时得到融合模型的预测结果准确率为90%。另外可以看出,融合模型在单个数据的预测能力上并不会完胜其他三个模型。结果加权平均
在结果直接平均方法的基础上加入一个权重参数,这个权重参数控制各个模型对融合结果的影响程度。
两个模型预测结果的准确率都是80%,设置模型一的权重参数是0.8,模型二的权重参数是0.2,融合模型的计算结果为:
使用结果加权平均的方法融合的模型的预测准确率是90% ,且在所有新的预测结果中低于50%的只有一个,单个预测值表现良好。
不过,结果加权平均方法对于合理权重的依赖度较高,需要尝试不同的权重组合,以达到融合的最优解决方案。
例如,在模型一和模型二交换权重之后
融合模型的预测准确率下降为80%
2. 多模型融合实战
基本思路是首先构建两个卷积神经网络模型,然后使用我们的训练数据集分别对这两个模型进行训练和对参数进行优化,使用优化后的模型对验证集进行预测,并将各模型的预测结果进行加权平均以作为最后的输出结果,通过对输出结果和真实结果的对比,来完成对融合模型准确率的计算。
加载数据集
data_path='../data/DogsAndCats'data_transform={x:transforms.Compose([transforms.Resize([224,224]),transforms.ToTensor(),transforms.Normalize(mean=[0.5,0.5,0.5],std=[0.5,0.5,0.5])])for x in ["train","test"]}image_dataset={x:datasets.ImageFolder(root=os.path.join(data_path,x),transform=data_transform[x])for x in ["train","test"]}dataloader={x:torch.utils.data.DataLoader(dataset=image_dataset[x],batch_size=16,shuffle=True)for x in ["train","test"]}
搭建网络模型 ```python model_1=models.vgg16(pretrained=True) for param in model_1.parameters(): param.requires_grad=False model_1.classifier=torch.nn.Sequential( torch.nn.Linear(25088,4096), torch.nn.RReLU(), torch.nn.Dropout(p=0.5), torch.nn.Linear(4096,4096), torch.nn.ReLU(), torch.nn.Dropout(p=0.5), torch.nn.Linear(4096,2) )
model_2=models.resnet50(pretrained=True) for param in model_2.parameters(): param.requires_grad=False model_2.fc=torch.nn.Linear(2048,2)
- Training```pythonfor epoch in range(epoch_n):print("Epoch {}/{}".format(epoch,epoch_n-1))print("-"*10)for phase in ["train","test"]:if phase=="train":print("Train..................")model_1.train(True)model_2.train(True)else:print("Test...................")model_1.train(False)model_2.train(False)running_loss1=0.0running_corrects1=0running_loss2=0.0running_corrects2=0blend_running_corrects=0for batch,data in enumerate(dataloader[phase],1):x,y=dataif torch.cuda.is_available():x,y=Variable(x.cuda()),Variable(y.cuda())else:x,y=Variable(x),Variable(y)y_pred1=model_1(x)y_pred2=model_2(x)blend_y_pred=y_pred1*weight_1+y_pred2*weight_2_,pred1=torch.max(y_pred1.data,1)_,pred2=torch.max(y_pred2.data,1)_,blend_pred=torch.max(blend_y_pred.data,1)optimizer1.zero_grad()optimizer2.zero_grad()loss1=loss_fun1(y_pred1,y)loss2=loss_fun2(y_pred2,y)if phase=="train":loss1.backward()loss2.backward()optimizer1.step()optimizer2.step()running_loss1+=loss1.item()running_corrects1+=torch.sum(pred1==y.data)running_loss2+=loss2.item()running_corrects2+=torch.sum(pred2==y.data)blend_running_corrects+=torch.sum(blend_pred==y.data)if batch%500==0 and phase=="train":print("Batch {},Model1 Train Loss:{:.4f},Model1 train ACC:{:.4f}".format(batch,running_loss1/batch,100*running_corrects1/(16*batch)))print("Model2 Train Loss:{:.4f},Model2 train ACC:{:.4f}".format(running_loss1/batch,100*running_corrects1/(16*batch)))print("BlendModel train ACC:{:.4f}".format(100*blend_running_corrects/(16*batch)))epoch_loss1=running_loss1*16/len(image_dataset[phase])epoch_acc1=100*running_corrects1*16/len(image_dataset[phase])epoch_loss2=running_loss2*16/len(image_dataset[phase])epoch_acc2=100*running_corrects2*16/len(image_dataset[phase])epoch_blend_acc=100*blend_running_corrects/len(image_dataset[phase])print("Epoch {},Model1 Loss:{:.4f},Model1 Acc:{:.4f}%".format(epoch,epoch_loss1,epoch_acc1))print("Model2 Loss:{:.4f},Model2 Acc:{:.4f}%".format(epoch_loss2,epoch_acc2))print("BlendModel Acc:{:.4f}".format(epoch_blend_acc))
- 训练结果
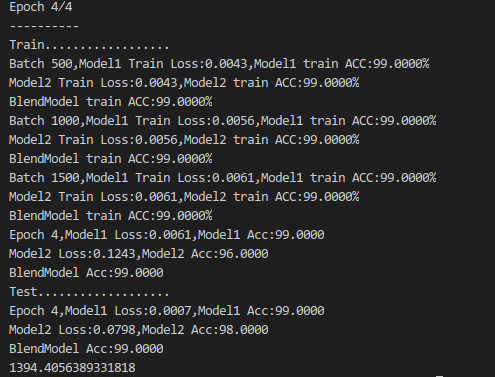
通过结果加权平权得到的融合模型在预测结果的预测结果准确率稍优于VGG16和ResNet50模型。

若有收获,就点个赞吧
0 人点赞
