如果你公司的产品数据反映出用户下单完成率很低、如果你公司年度目标是提升销售额、如果用户反映下单流程太复杂,…作为产品、设计、运营,你应该怎么做才能够为用户、为公司业务解决这些问题?你需要找到针对这些问题的优化点,并且做优化实验,通过数据的反馈来持续优化产品。
本文以 Keep 为例子,进行「提升用户关注率」的增长实验,出发点是为了长期促进平台用户的活跃程度和互动。
以下是本文大纲:
第一步:明确实验目标和类型
- 明确实验目标
明确实验类型
第二步:用数据支持实验假设从三类数据中寻找证据支持假设
- 最佳时间中的 Lift 模型
没有定量和定型数据,怎么做实验假设
第三步:提出实验假设实验假设的模板
针对 Keep 优化的几个实验假设
第四步:对实验假设进行优先级排序ICE模型打分法
用ICE模型为 Keep 的实验假设做优先级排序
第五步:设计一场实验确认实验假设
- 选择实验指标
- 确定实验受众
设计实验版本
第六步:根据数据分析和应用结果分析结果及评可信度
- 使用置信区间提高结果可信度
根据实验结果决定下一步
第一步:明确实验目标和类型
01 明确实验目标
出发点决定目标。我们在做每个优化方案的时候,都应该从实际的业务问题和用户反馈出发,而不是从自己的想法出发。
“我觉得用户需要这个功能”
“领导说了,就用这种交互方式”
“这个界面太难看了,要改”
当听到这种自主代入用户而产生的想法时,应该思考:「公司现在的目标是什么?当前支撑这个目标最应该实现的功能是什么?」「什么交互方式才适用于用户,在相同业务逻辑和用户使用场景下,有没有原理支撑和数据论证?数据从哪来?」「界面难看,是个人感官还是用户使用过程中产生了困难而提出反馈?」
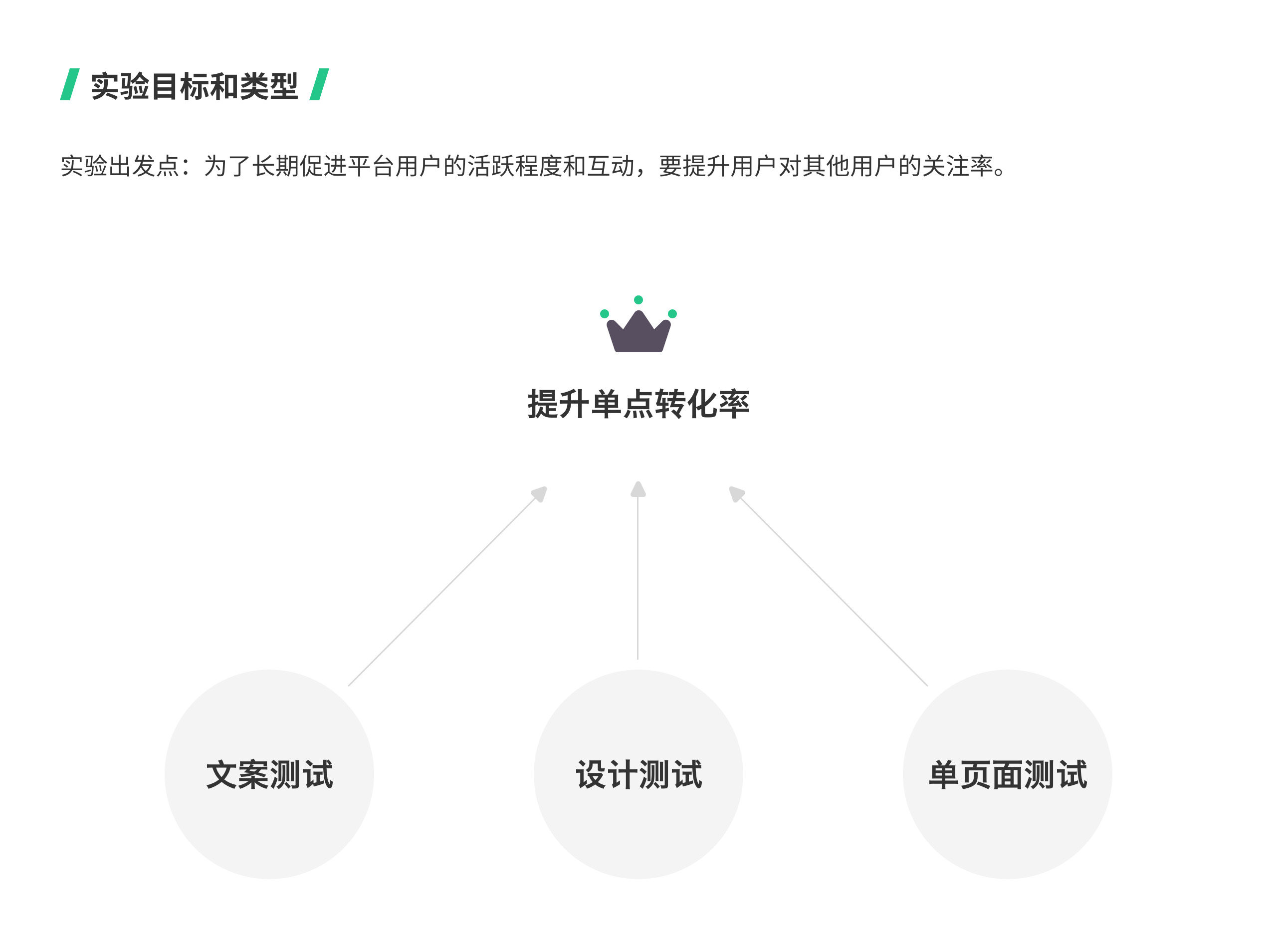
以 Keep 作为例子来说,这次优化是从业务角度出发,目的是长期促进平台用户的活跃程度和互动。所以实验目标是提升用户的关注率,即提升单点转化率。
常见的产品优化目标有:提升单点转化率、提升全漏斗转化率、对比新旧版本的指标、新功能探索、提升留存率、个人化等等。
02 明确实验类型
上述提到的常见优化目标可以划分为两个类型:简单实验和复杂实验。
- 提升单点转化率和全漏斗转化率都属于简单实验,用文案测试、设计测试、单页面测试、路径测试等方法就可以实现。
- 对比新旧版本指标和新功能探索、提升留存率等,则属于复杂实验,需要新版本上线或者使用算法来进行。
第二步:用数据支持实验假设**
01 从三类数据中寻找证据支持假设
这三类数据分别是「定量数据」、「定性数据」、「最佳实践」。定量数据可以帮助我们发现问题;定性数据可以帮助我们了解这个问题是怎么发生的;最佳实践告诉我们怎么改比较好。
定量数据是指转化率计算、用户分群、点击热图、路径分析、场景细查、漏斗分析等。> 定性数据是指用户可用性研究、用户问卷或访谈、录屏和点击录像、实时聊天和产品内弹窗等。> 最佳实践是指Lift模型、用户心理学、文案写作最佳实践、UX和设计最佳实践、路径设计最佳实践。
02 最佳实践中的 Lift 模型 #模型术语
Lift 模型的原理就是基于数据认识的基础,在营销信息中找出问题,设计有关解决这些问题的假设来提高产品效益,得出改进问题的结果,从而提升转换率。 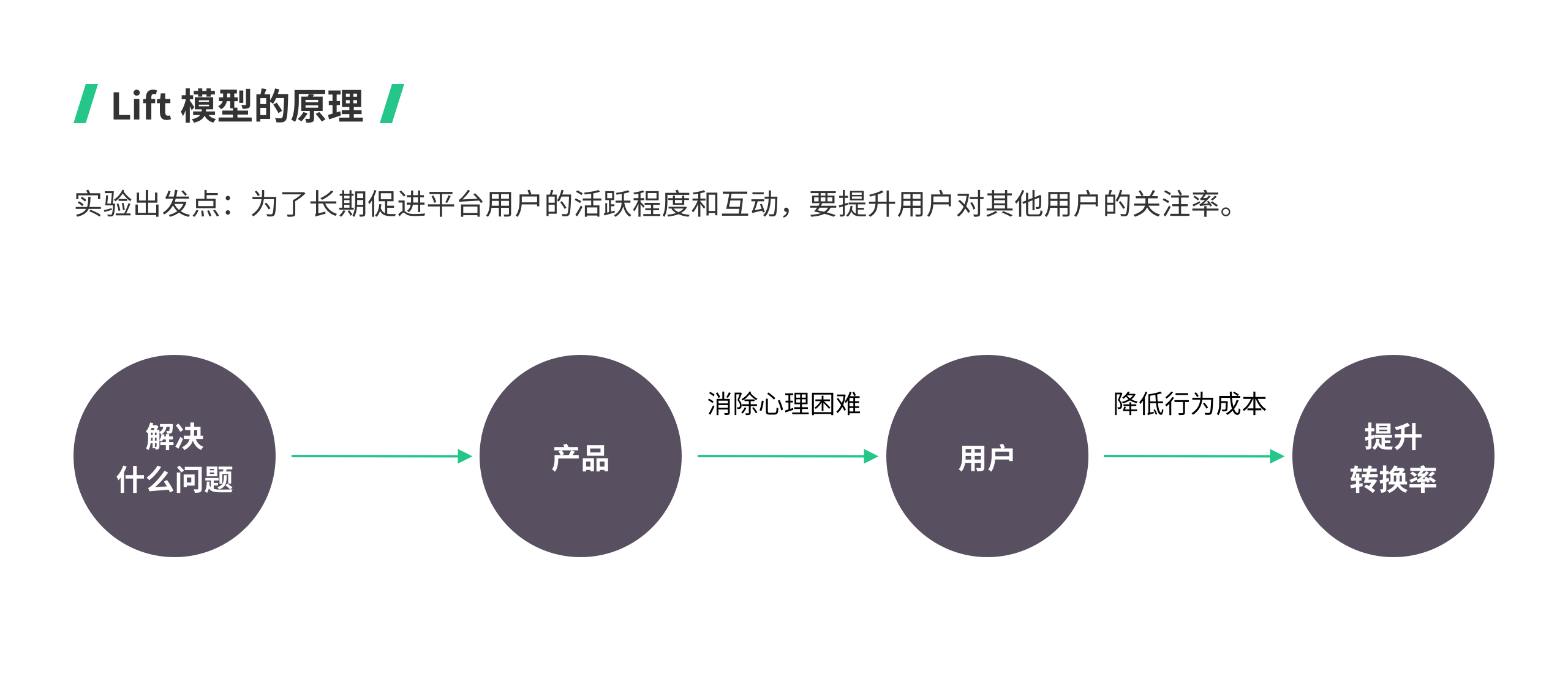
影响Lift模型的6个因素分别是价值主张、相关性、清晰度、紧迫性、焦虑性、注意力分散。
价值主张是载体;相关性、清晰度、紧迫性是推动因素;焦虑性和注意力分散是阻碍因素。下面这张图会帮助你了解这六个因素的关系: 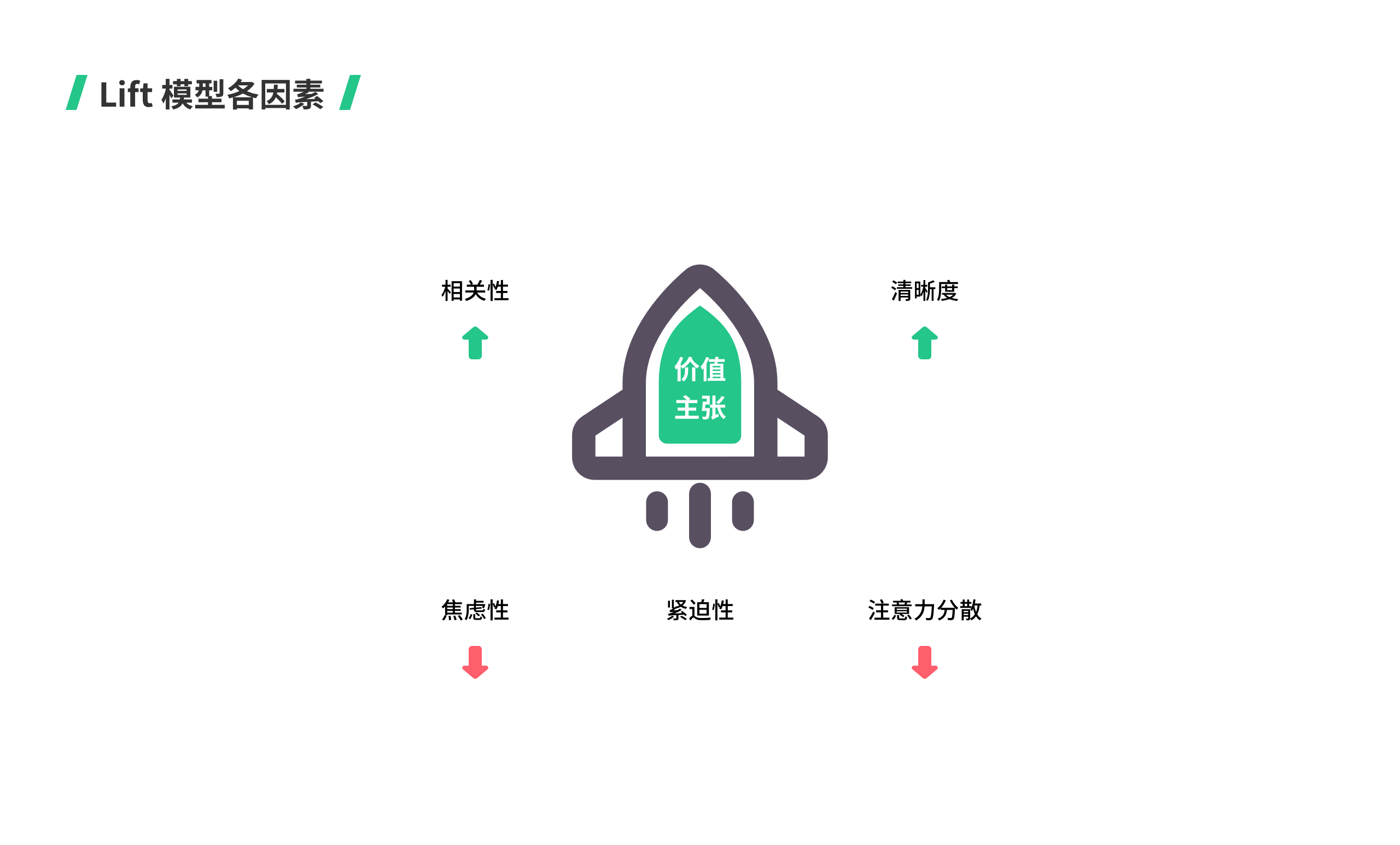
要达到目的,我们应该加强推动因素的强度,降低阻碍因素的影响:
强化价值主张
明确有力的营销口号,用户可以精准感知到自己能获得怎样的好处
放大相关性
落地页、转化页符合用户预期,与你的价值主张紧密关联
提升清晰度
体验流程清晰流畅,用户清晰知道下一步应该做什么,怎么操作
降低焦虑性
做减法,不要给用户过多选择,不要做不符合用户预期、习惯的事
降低注意力分散
减少视觉干扰、信息噪音,只为一个核心目的服务
制作紧迫性
营造饥饿感促使用户决策,善于利用禀赋效应、损失厌恶等用户心理
03 没有定量和定性数据,怎么做实验假设
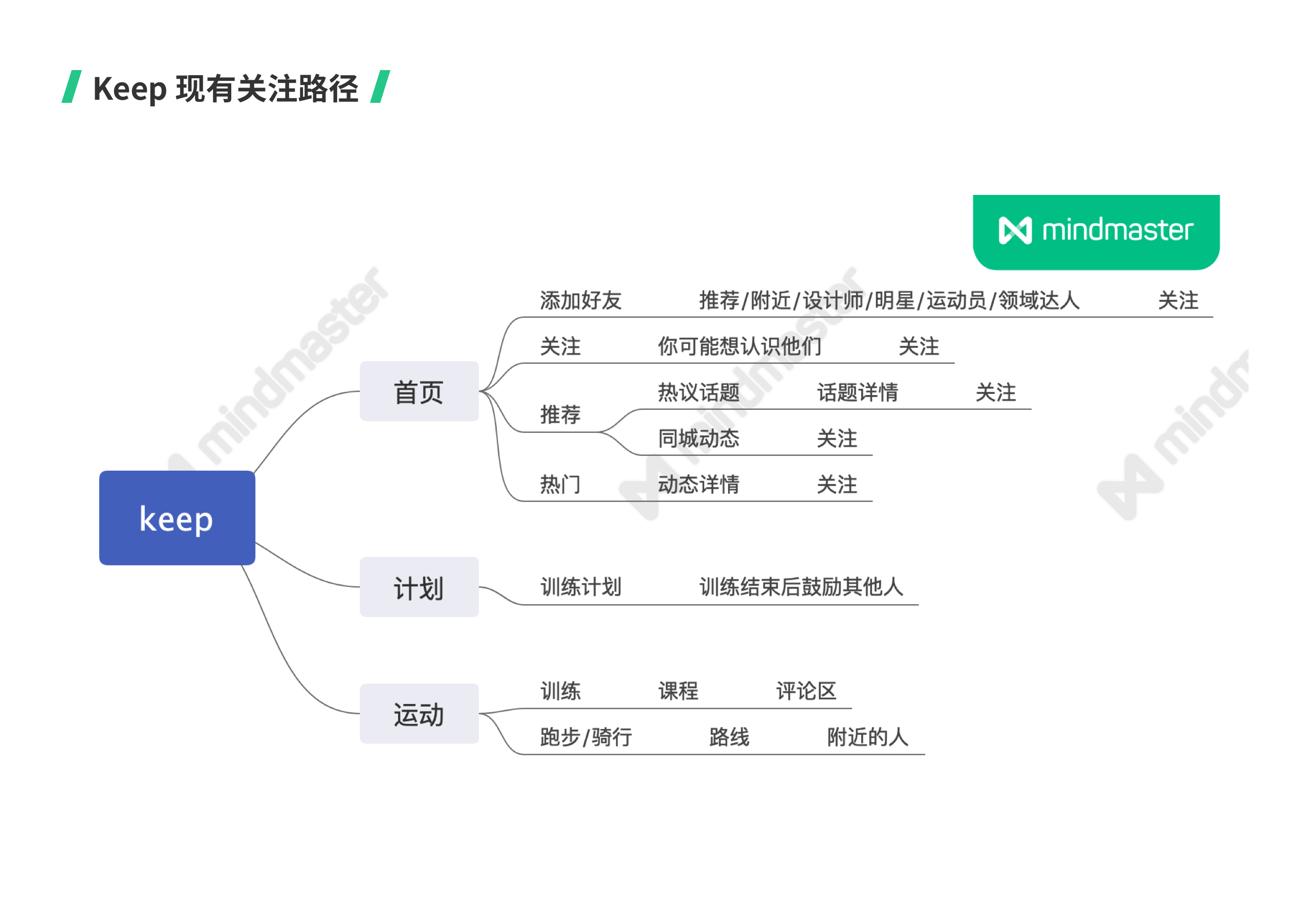
如果有定量和定性数据,实验会更准确。但是目前我缺乏 Keep 的这些数据,所以采用了其他方法去做实验假设。
- 梳理 Keep 的产品结构,找到现有的关注路径有哪些;
- 按照关注行为倒推关键触点,并分析用户在什么场景下会关注其他用户;
- 从关键行为归纳引起关注行为的种类,找出可干涉的修改点。
对于可干涉的修改点,在其他产品中找相应的参考。
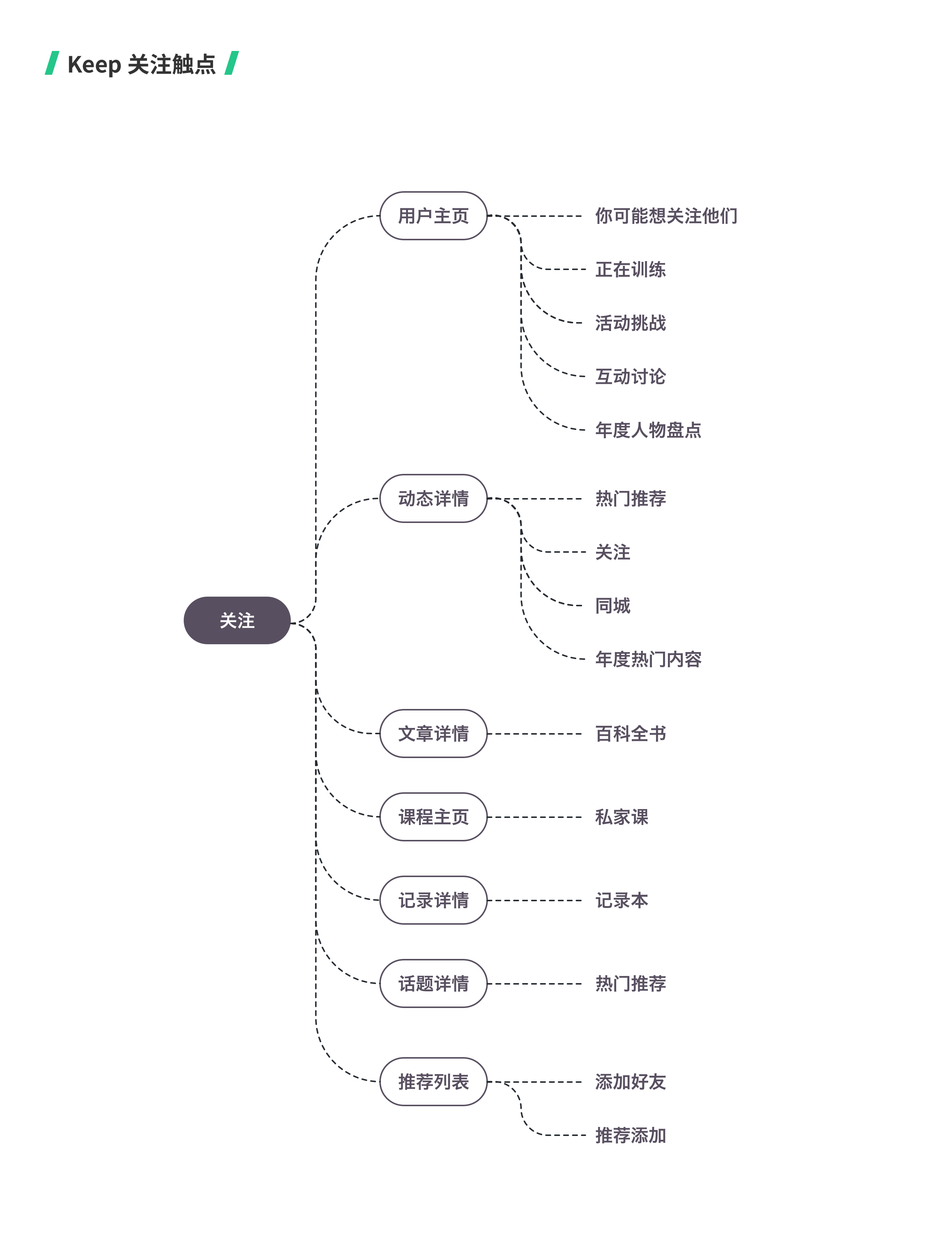
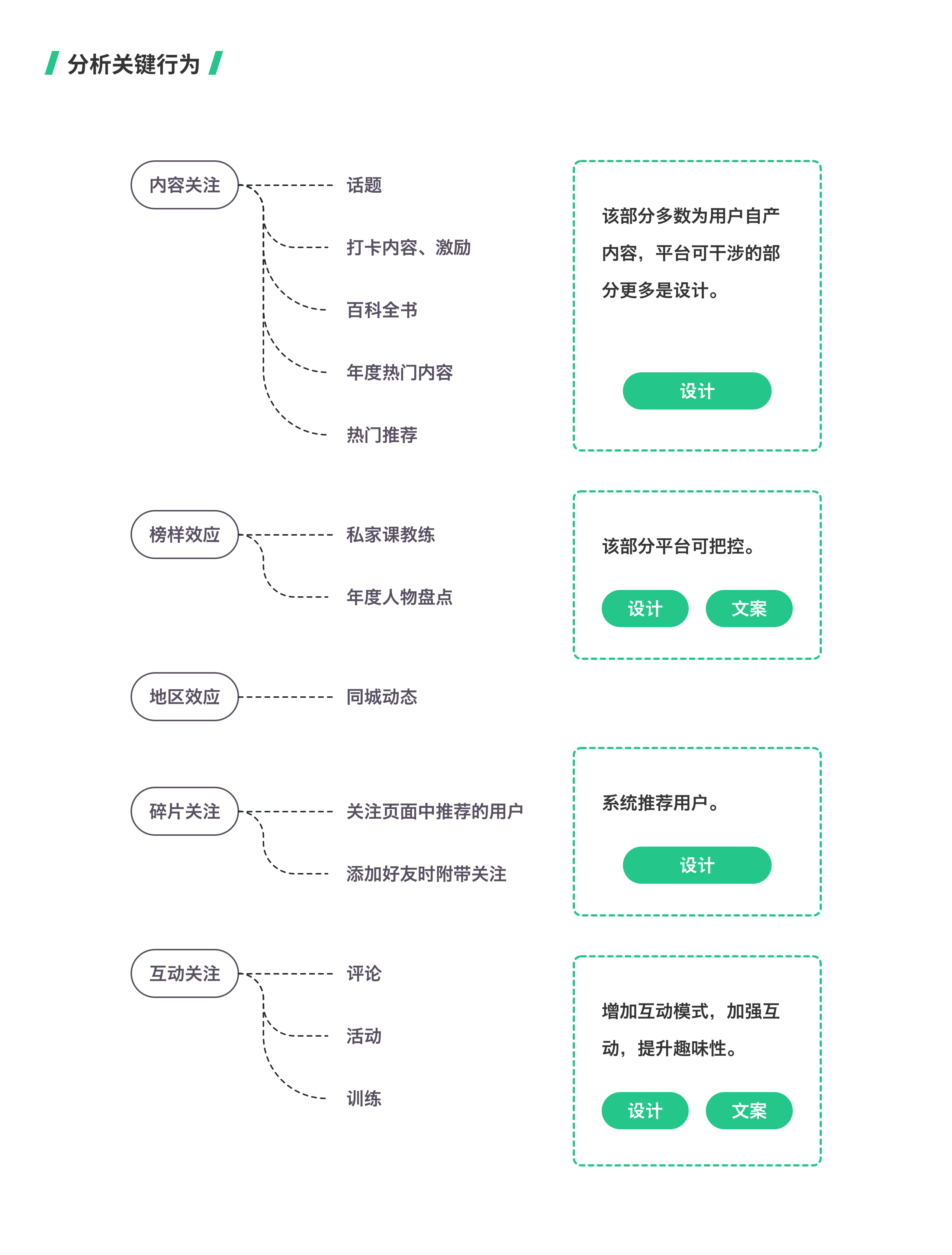


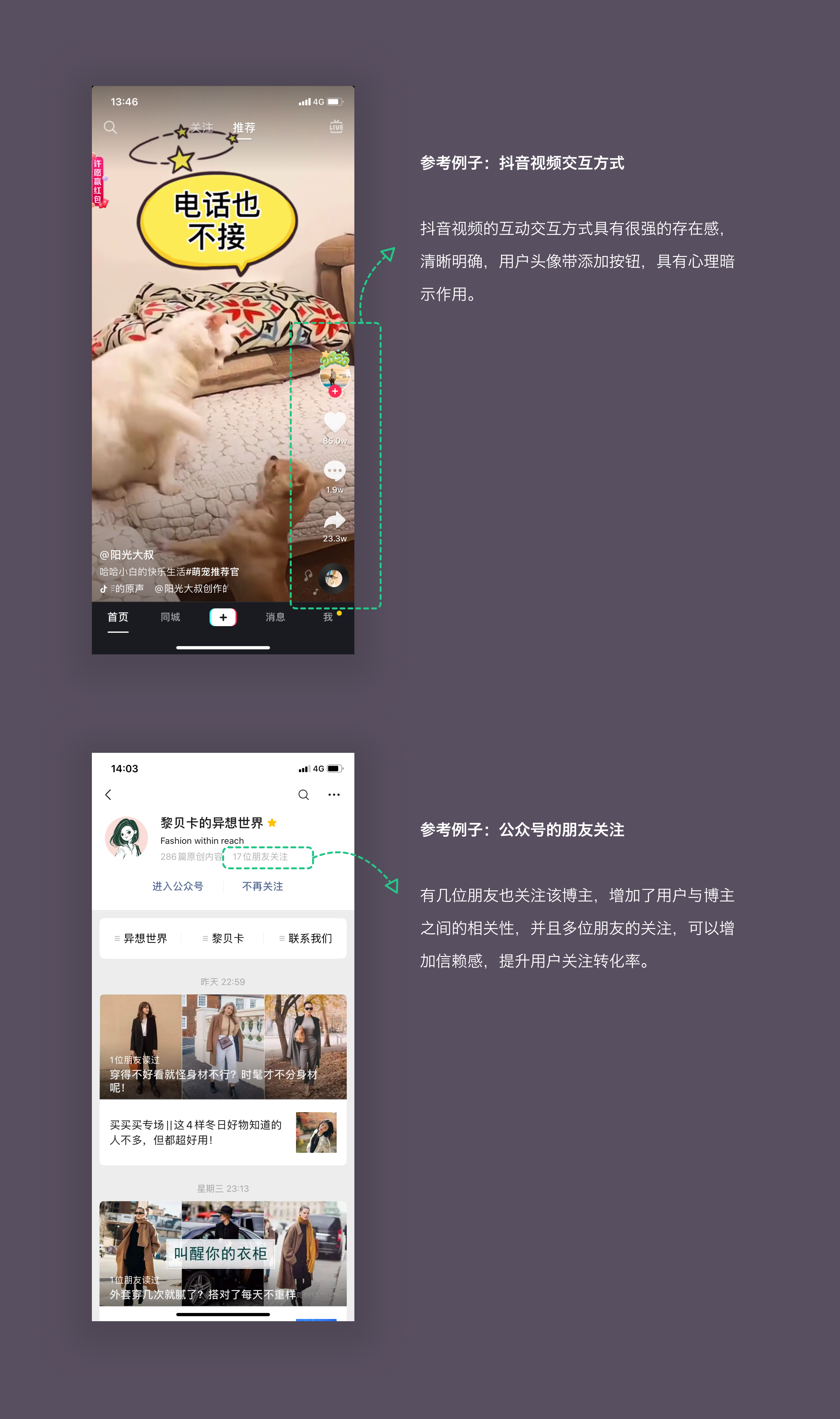
第三步:提出实验假设
01 实验假设的模板
经过分析和参考,此刻你应该产生了好几种假设。为了能够清晰描述实验假设,你的假设必须包含明确的指标和时间限制,要解析背后的原因,并且可以被证伪。这是一个常见的假设模板:如果具体的改动,预计某指标可以提升x%,因为深层的原因——有数据支持的假设。
比如“在新浪微博的首页投放广告可以引流用户到天猫旗舰店”这个假设应该写成:「在新浪微博首页投放关于该产品的广告,可以在投放后的三周内为品牌的天猫旗舰店引流 500 位用户,因为这个广告清晰介绍了产品的功效。」
02 针对 Keep 优化的几个实验假设
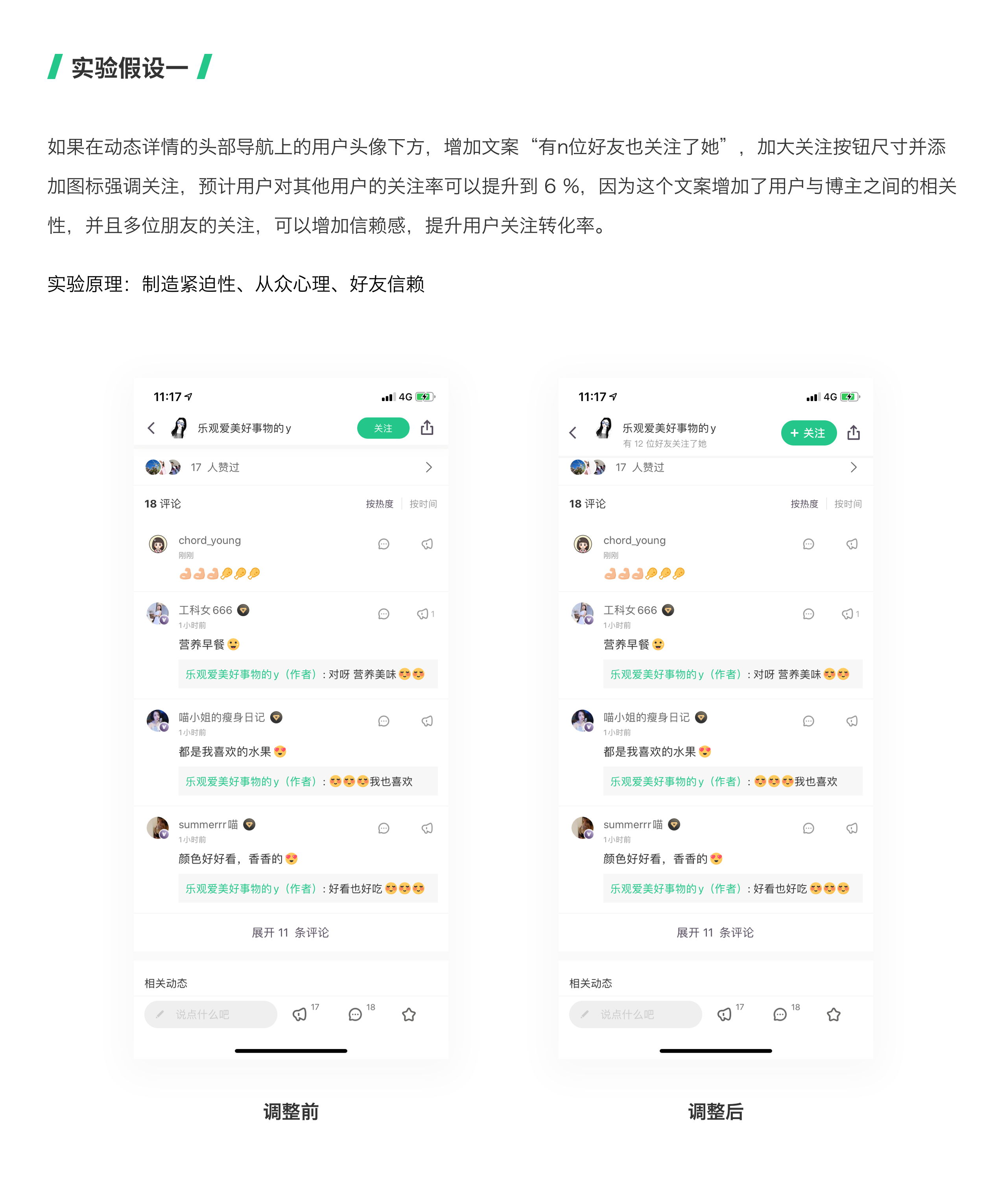
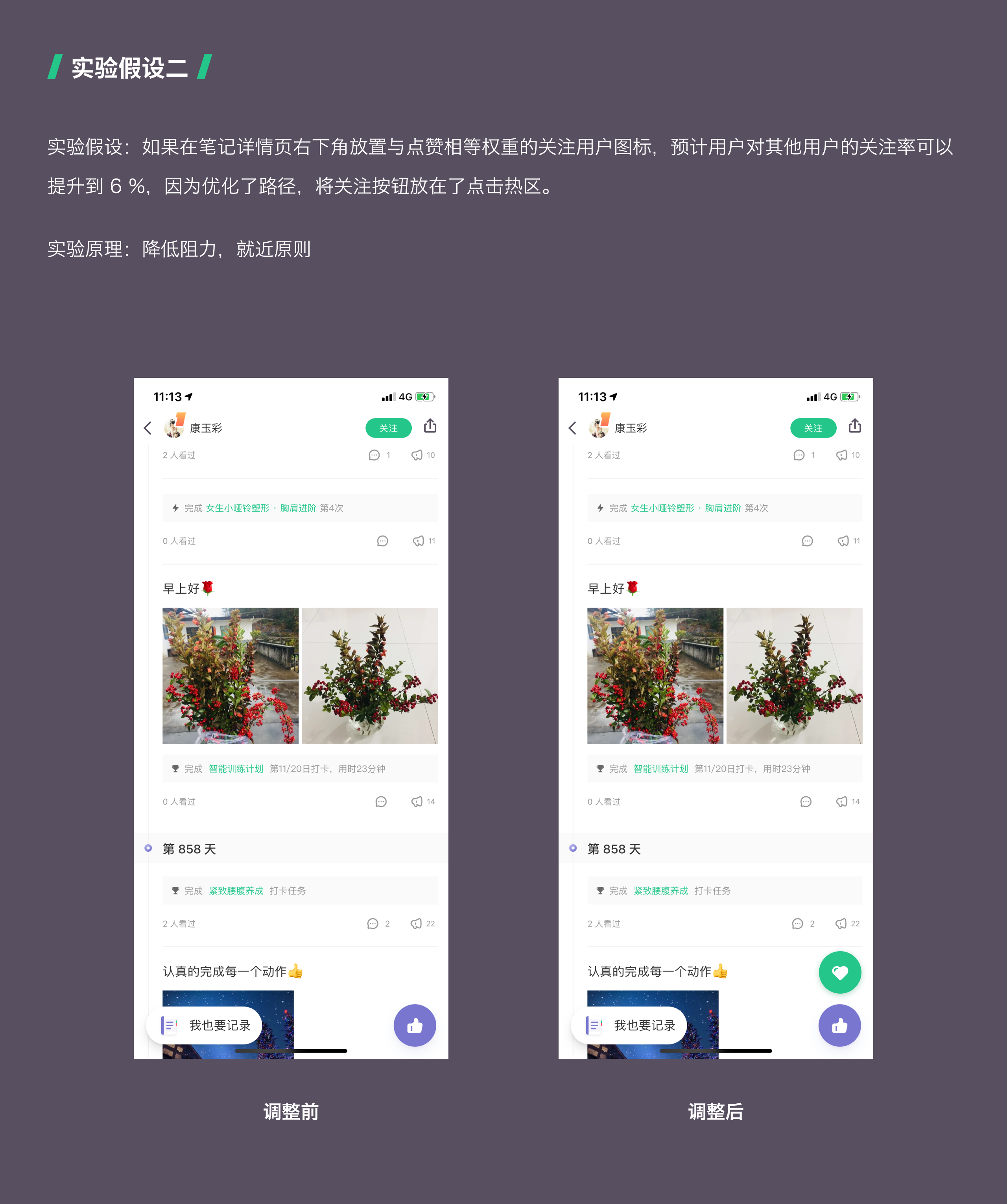

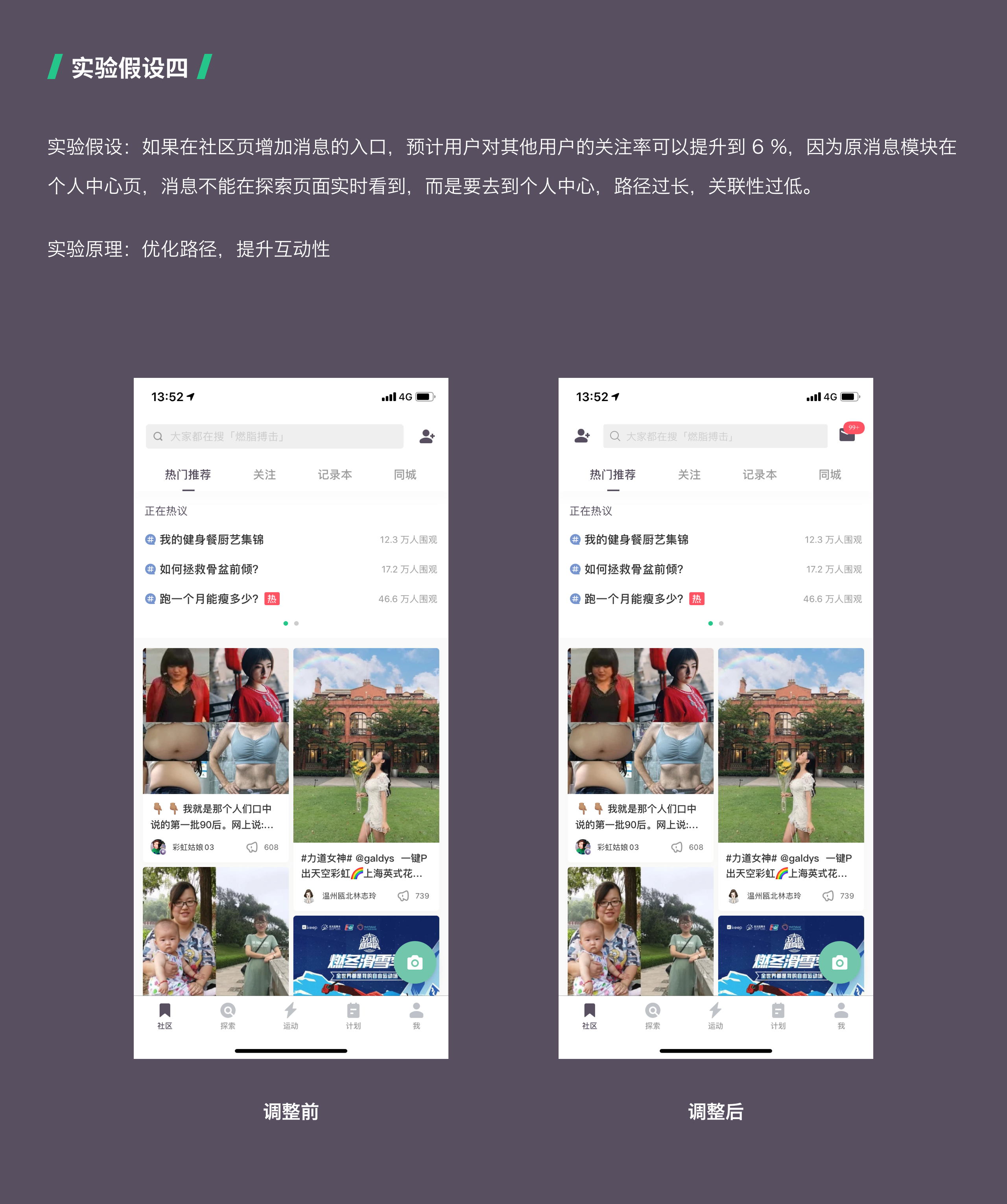
第四步:对实验假设进行优先级排序
01 ICE模型打分法
使用 ICE 模型打分法,可以直观看到实验假设的优先级排序。ICE 模型是一个从预期影响(Impact)、成功概率(Confidence)、容易程度(Ease)三个方面为实验设想打分的模型。预期影响指的是实验能够覆盖的用户数和实验的成功后能够提升多少指标;成功概率指的是能否在数据中找到足够有力的洞察支持;容易程度是指实现这个假设需要多少成本。综合三个方面的打分,评分最高的则优先级最高。
02 用ICE模型为KEEP的实验假设做优先级排序

第五步:设计一场实验
01 确认实验假设
如果用户在某个文章或动态上停留5秒以上,“关注”按钮变亮变大,提示用户可以关注此博主,预计某指标可以提升到 6 %,因为该改变突出了关注按钮,能吸引用户的注意力。
02 选择实验指标
实验指标分为核心指标、辅助指标和反向指标。 核心指标,一般选取一个,是决定实验成败的关键指标。找核心指标的时候,你需要思考这些问题:实验的最终目标是什么?你最想要影响的指标是什么?哪个指标能够告诉你实验组的改动是成功的? 辅助指标,一般选取不超过十个,它是监测其他实验可能影响到的重要指标,帮助你全面了解实验结果。常见的辅助指标是漏斗细分步骤转化率、重要的下游指标和其他关键用户指标。 反向指标,一般是一至两个,作用是提示实验可能的负面影响。常见的反向指标有NPS、邮件退订率、页面退出率、其他按钮点击率、应用删除率、Push退订率、订单取消率、其他页面访问率等。 
03 确定实验受众
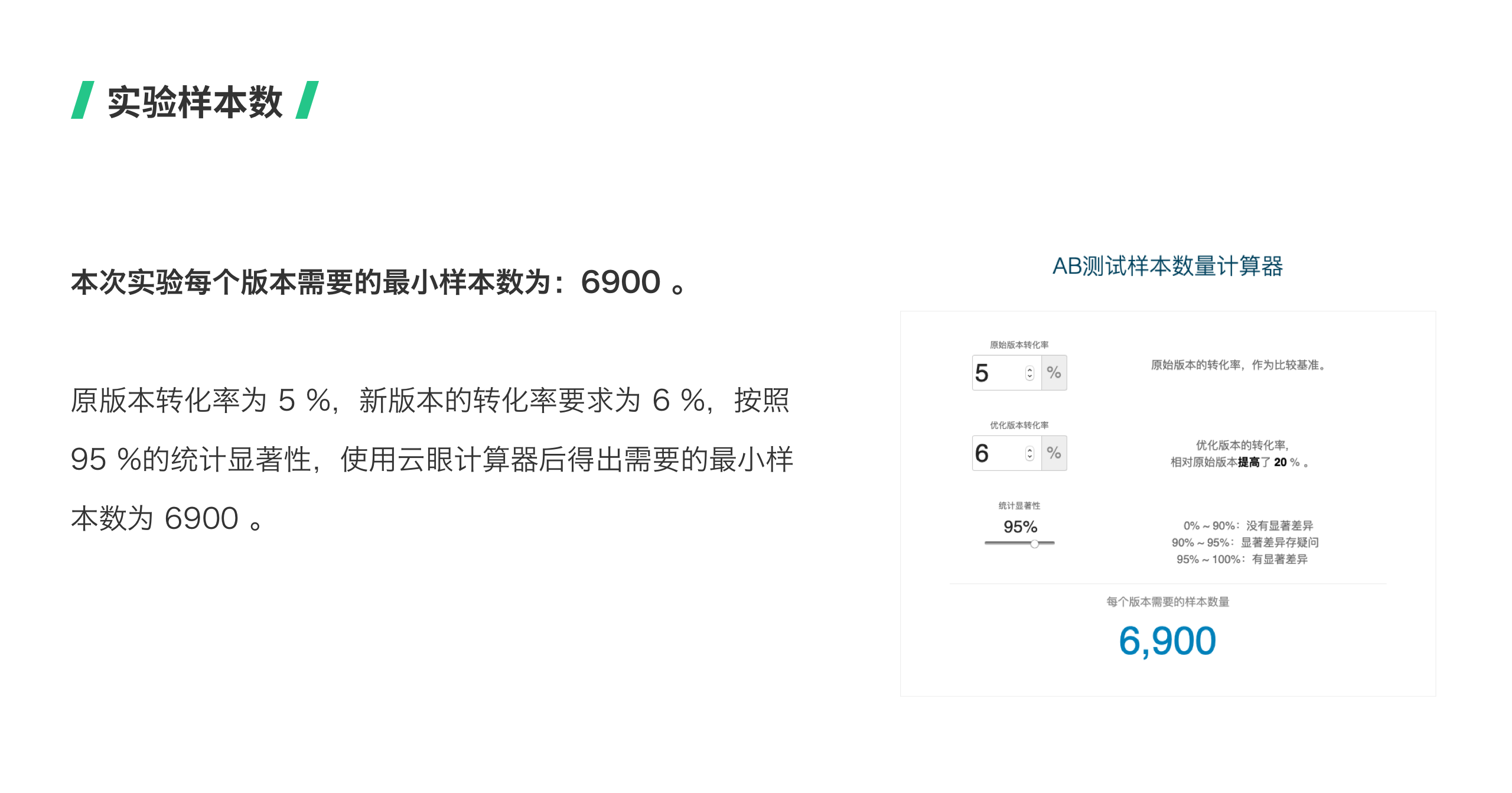
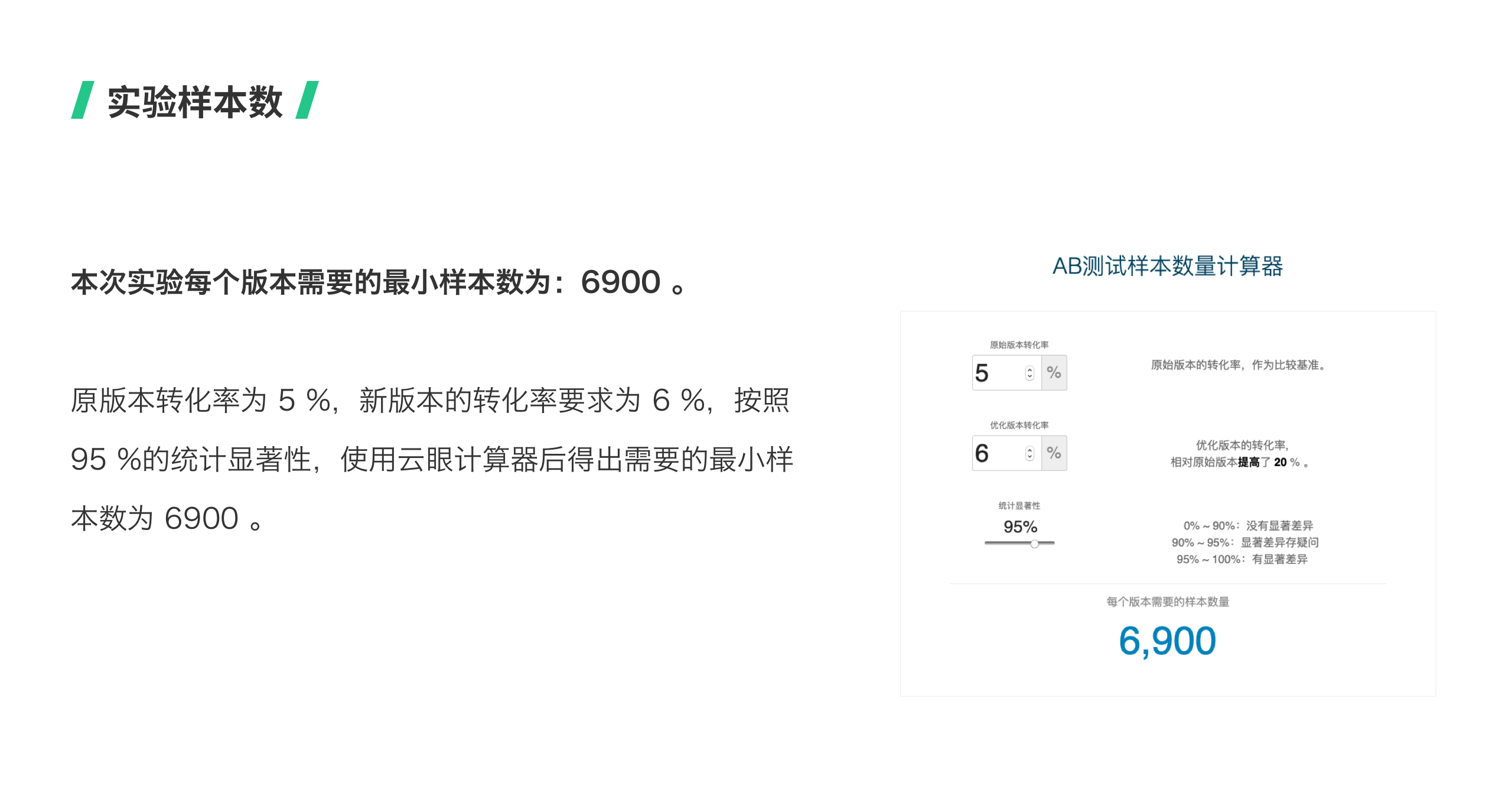
实验受众包含两个内容,一是实验对象,二是实验样本数。 实验对象可以选择所有用户都进入试验,或只有符合特定条件的用户才能进入试验。如果选择特定用户群体进行实验,会帮助生成更精细的产品优化方案。通常会通过第三方A/B测试的工具来进行设置。 实验样本数是指确认结果统计显著性所需要的最小样本数。统计显著性是指对照组和实验组之间的转化率有多大可能是真实存在而不是随机误差引起的。一般建议至少要求95%的统计显著。在这里推荐一个估算所需样本数的工具:云眼。https://www.eyeofcloud.com 那么,怎么决定实验的时长呢?实验时长=所需总样本数/实验页面每天的访问数。



04 设计实验版本
实验版本取决于实验假设的数量,只选择高质量的实验假设能够减少实验成本。不同的实验类型也会影响到版本数。如果是优化实验,每个版本只改变单一的变量,可以明确改动的影响。如果是探索实验,则可以同时改变多个变量,设计全新的版本。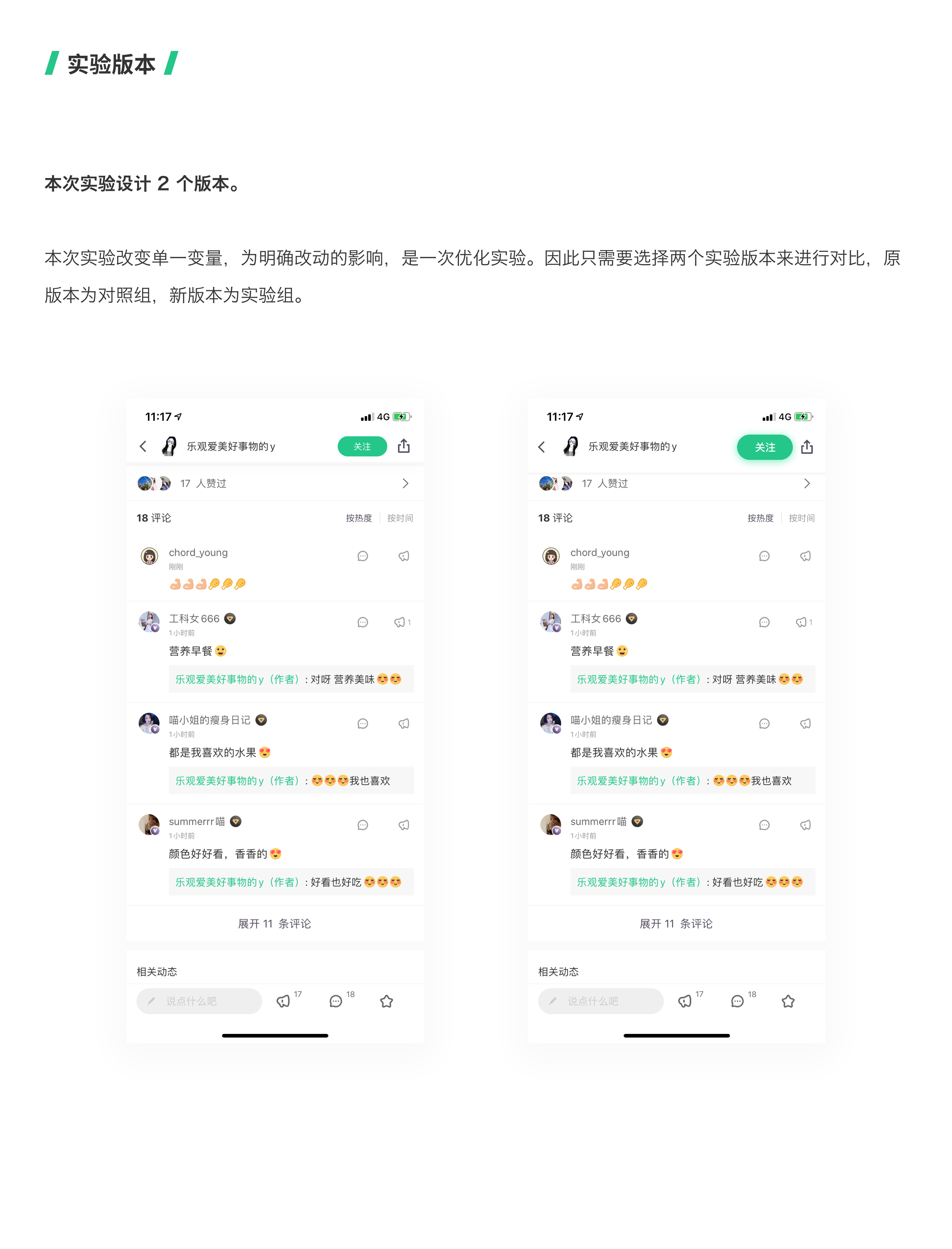
第六步:根据数据分析和应用结果**
01 分析结果及评估可信度
以下是实验在3天和14天时的数据情况。根据这些数据,从样本分流是否均匀、核心指标是否达到统计显著、辅助指标是否和核心指标趋势一致、反向指标是否有异常等角度来分析结果的可信度。 我的判断是两个数据都不可信。其实14天的数据情况,有人判断结果是可信的。这个没有绝对的对错,只有对数据的要求是不是十分严谨。我判断不可信的原因是,我认为分流的样本误差达到4%,不够严谨。 

02 使用置信区间提高结果可信度
置信区间是指由样本统计量所构造的总体参数的估计区间。在统计学里面,一个概率样本的置信区间是对这个样本的某个总体参数的区间估计。利用置信区间的计算,可以提高实验结果的可信度。刘津老师的 UGD lab 制作了一个置信区间计算的微信小程序,感兴趣可以搜索小程序的名字:A/B测试计算器。 假设 14 天时的数据为样本分流均匀后的结果,验证时间足够,反向指标数据逐渐趋同,在实验结果可信的情况下,可以增加置信区间计算,再次确认结果是否可信。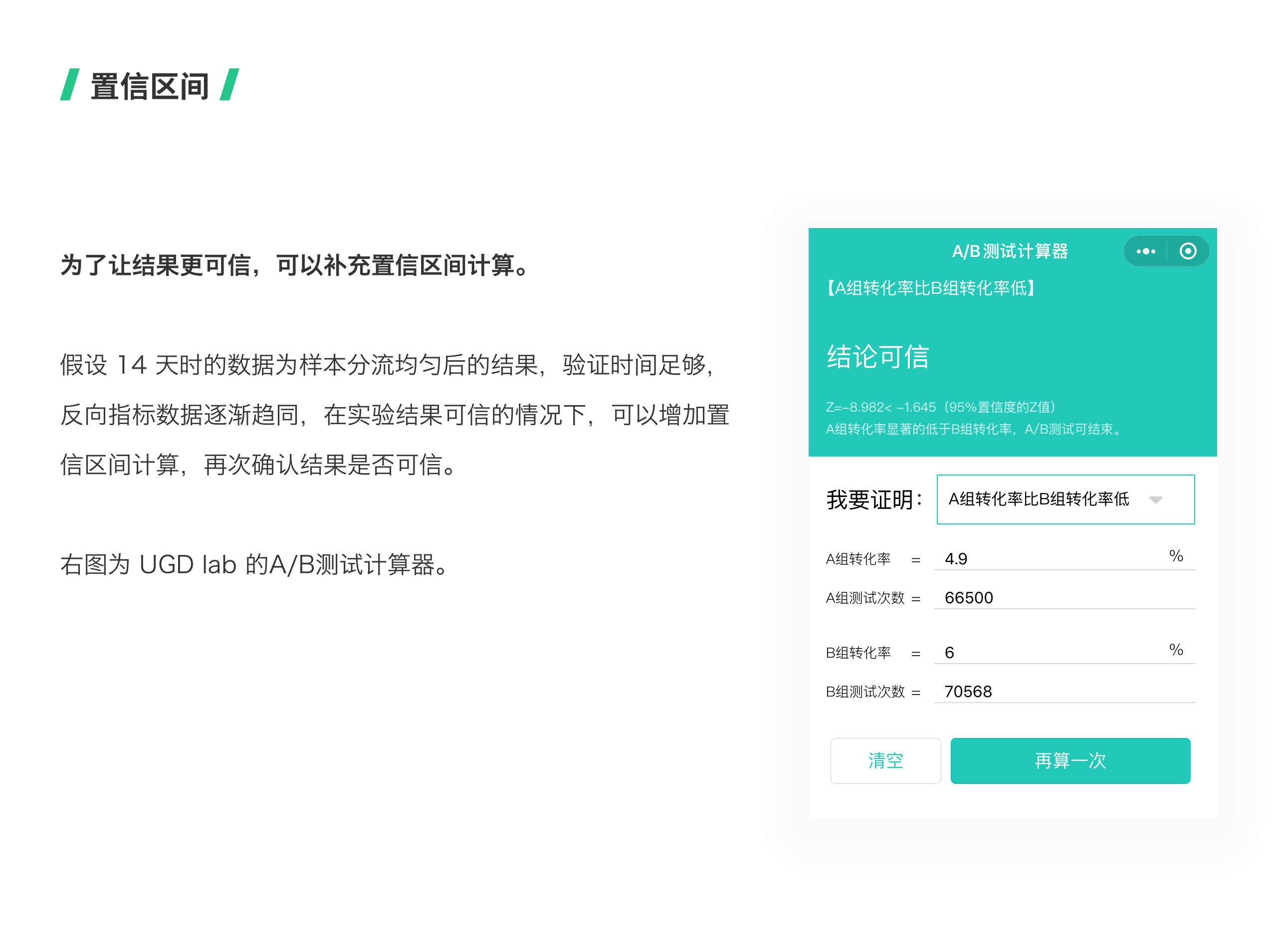
03 根据实验结果决定下一步
判断实验是否成功,要注意指标判断的标准、两种观测周期的变化外以及产生的四种状态:统计显著的指标大幅度或小幅度提升,则实验组胜;统计显著的指标下降或无差别,则对照组胜。 如果实验成功,应该将实验产品化,放大实验的影响。如果实验失败,则考虑放弃还是继续迭代。
备注:本文中所有与 keep 相关的界面,均为 keep 软件的截图,其中为了展示实验的效果而做了部分界面的调整。实验中的数据均为虚构,如有雷同,实属巧合。本文的重点在于如何科学地做好一场 A/B 测试,请勿过分解读数据。

若有收获,就点个赞吧
0 人点赞
