在本节中,我们将回到我们对 TCP 的研究。 正如我们在 3.5 节中了解到的,TCP 在运行在不同主机上的两个进程之间提供了可靠的传输服务。 TCP 的另一个关键组件是它的拥塞控制机制。 如上一节所述,我们可能称之为“经典”TCP(在 [RFC 2581] 和最近的 [RFC 5681] 中标准化的 TCP 版本)使用端到端拥塞控制而不是网络辅助拥塞控制,因为 IP 层没有向终端系统提供关于网络拥塞的明确反馈。 我们将首先在第 7.3.1 节中深入介绍这个“经典”版本的 TCP。 在第 7.3.2 节中,我们将查看使用网络层提供的显式拥塞指示的 TCP 的新版本,或者在几种不同方式中的任何一种与“经典”TCP 略有不同。 然后,我们将介绍在必须共享拥塞链路的传输层流之间提供公平性的挑战。
3.7.1 经典TCP拥塞控制 Classic TCP Congestion Control
TCP采用的方法是让每个发送方限制其将流量发送到其连接的速率,作为感知到的网络拥塞的函数。如果TCP发送方察觉到自己和目的地之间的路径上没有什么拥塞,那么TCP发送方就会增加它的发送速率;如果发送方察觉到沿路径存在拥塞,则发送方降低其发送速率。但这种方法提出了三个问题。首先,TCP发送方如何限制其将流量发送到其连接的速率?第二,TCP发送者如何感知在自己和目的地之间的路径上存在拥塞?第三,在感知到端到端拥塞的情况下,发送方应该使用什么算法来改变其发送速率?
让我们首先研究TCP发送方如何限制其将流量发送到其连接的速率。在3.5节中,我们看到TCP连接的每一端都由一个接收缓冲区、一个发送缓冲区和几个变量(LastByteRead、rwnd等)组成。在发送端运行的TCP拥塞控制机制会跟踪一个额外的变量,拥塞窗口(congestion window)。拥塞窗口(用cwnd表示)限制了TCP发送者向网络发送流量的速率。具体来说,发送方未确认的数据量不能超过cwnd和rwnd的最小值,即:
为了关注拥塞控制(而不是流量控制),让我们假设TCP接收缓冲区非常大,接收窗口限制可以忽略;因此,发送方未确认的数据量仅受cwnd的限制。我们还将假设发送方总是有数据要发送,也就是说,拥塞窗口中的所有段都被发送了。
上述约束限制了发送方未确认数据的数量,因此间接限制了发送方的发送速率。要理解这一点,请考虑一个可以忽略丢失和包传输延迟的连接。然后,粗略地说,在每个RTT开始时,约束允许发送方将cwnd字节的数据发送到连接中;在RTT结束时,发送方接收到对数据的确认。因此发送方的发送速率大致为cwnd/RTT字节/秒。因此,通过调整cwnd的值,发送方可以调整将数据发送到其连接的速率。
接下来让我们考虑 TCP 发送方如何感知其与目的地之间的路径上存在拥塞。 让我们将 TCP 发送方的“丢失事件”定义为超时的发生或从接收方收到三个重复的 ACK。 (回想一下我们在图 3.33 中超时事件的第 3.5.4 节中的讨论以及随后的修改,包括在收到三个重复的 ACK 时进行快速重传。)当拥塞过多时,路径上的一个(或多个)路由器缓冲区会溢出 ,导致数据报(包含 TCP 段)被丢弃。 丢弃的数据报反过来会导致发送方发生丢失事件——超时或收到三个重复的 ACK——发送方将其视为发送方到接收方路径拥塞的指示。
考虑了如何检测拥塞之后,让我们接下来考虑网络无拥塞时更乐观的情况,即不发生丢失事件时。在这种情况下,TCP 发送方将收到对先前未确认段的确认。正如我们将看到的,TCP 将这些确认的到达作为一切正常的指示——传输到网络的段正在成功地传送到目的地——并将使用确认来增加其拥塞窗口大小(因此其传输速率)。请注意,如果确认以相对较慢的速率到达(例如,如果端到端路径具有高延迟或包含低带宽链路),则拥塞窗口将以相对较慢的速率增加。另一方面,如果确认以高速率到达,那么拥塞窗口将增加得更快。由于 TCP 使用确认来触发(或计时)其拥塞窗口大小的增加,因此 TCP 被称为自计时(self-clocking)。
给出了调整cwnd值以控制发送速率的机制,关键问题仍然存在:TCP发送方如何确定它应该发送的速率?如果TCP发送者集体发送太快,他们会导致网络拥塞,导致如图3.48所示的拥塞崩溃(congestion collapse)。事实上,我们即将研究的TCP版本是为了响应早期TCP版本下观察到的互联网拥塞崩溃(Jacobson 1988)而开发的。但是,如果TCP发送方过于谨慎,发送速度过慢,可能无法充分利用网络的带宽;也就是说,TCP发送者可以在不阻塞网络的情况下以更高的速率发送。那么,TCP发送者如何确定他们的发送速率,以确保他们不会阻塞网络,但同时利用所有可用的带宽?TCP发送者是否明确协调,或者是否存在一种分布式方法,TCP发送者可以仅基于本地信息设置其发送速率?TCP使用以下指导原则回答这些问题:
- 丢失的段意味着拥塞,因此,TCP发送方的速率应该在段丢失时降低(A lost segment implies congestion, and hence, the TCP sender’s rate should be decreased when a segment is lost)。回想一下我们在 3.5.4 节中的讨论,超时事件或对给定段的四个确认的接收(一个原始 ACK,然后是三个重复的 ACK)被解释为隐含的“丢失事件”指示,即在四重 ACK 段之后的段,触发丢失段的重传。 从拥塞控制的角度来看,问题是 TCP 发送方应该如何减小其拥塞窗口大小,从而减少其发送速率,以响应这种推断的丢失事件。
- 一个确认的段表明网络正在将发送方的段发送给接收方,因此,当针对先前未确认的段的ACK到达时,发送方的速率可以增加(An acknowledged segment indicates that the network is delivering the sender’s segments to the receiver, and hence, the sender’s rate can be increased when an ACK arrives for a previously unacknowledged segment)。确认的到来被视为一种隐式的指示,表明所有的段都是良好的——从发送方成功地传递到接收方,因此网络没有拥塞。因此,拥塞窗口大小可以增加。
- 带宽探测(Bandwidth probing)。给定表示无拥塞的源到目的地路径的 ACK 和表示拥塞路径的丢失事件,TCP 调整其传输速率的策略是增加其速率以响应到达的 ACK,直到发生丢失事件,此时,降低传输速率。 因此,TCP 发送方增加其传输速率以探测拥塞开始的速率,从该速率回退,然后再次开始探测以查看拥塞发生速率是否已改变。 TCP 发送方的行为可能类似于孩子请求(并获得)越来越多的好东西,直到最后他/她最终被告知“不!”,退后一点,但不久之后又开始提出请求。 请注意,网络没有明确的拥塞状态信号(ACK 和丢失事件作为隐式信号),并且每个 TCP 发送方都与其他 TCP 发送方异步处理本地信息。
鉴于TCP拥塞控制的概述,我们现在可以考虑著名的TCP拥塞控制算法(TCP congestion-control algorithm)的细节,该算法在[Jacobson 1988]中首次描述,并在[RFC 5681]中标准化。该算法有三个主要组成部分:(1)慢启动(slow start),(2)拥塞避免(congestion avoidance),(3)快速恢复(fast recovery)。慢启动和拥塞避免是 TCP 的强制性组件,不同之处在于它们如何增加 cwnd 的大小以响应收到的 ACK。 我们很快就会看到慢启动比拥塞避免更快地增加 cwnd 的大小(尽管它的名字!)。 对于 TCP 发送方,建议快速恢复,但不是必需的。
慢启动 Slow Start
当TCP连接开始时,cwnd的值通常被初始化为1 MSS [RFC 3390],导致初始发送速率大致为MSS/ RTT。例如,如果MSS = 500字节和RTT = 200 msec,产生的初始发送速率只有大约20 kbps。由于TCP发送方的可用带宽可能比MSS/RTT大得多,TCP发送方希望快速找到可用带宽的数量。因此,在慢启动状态(slow-start state)下,cwnd的值从1 MSS开始,并在每次发送段第一次确认时增加1 MSS。在图3.50的示例中,TCP将第一个段发送到网络并等待确认。当此确认到达时,TCP发送方将拥塞窗口增加一个MSS,并发送两个最大长度的段。然后对这些段进行确认,发送方为每个确认的段增加1个MSS的拥塞窗口,给出一个4个MSS的拥塞窗口,以此类推。这个过程导致发送速率每增加一倍。因此,TCP发送速率开始较慢,但在慢启动阶段呈指数增长。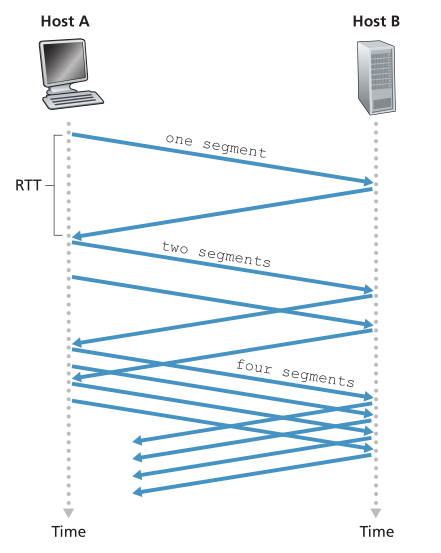
Figure 3.50 ♦ TCP slow start
图3.50♦TCP慢启动
但这种指数级增长何时结束呢?“慢启动”为这个问题提供了几个答案。首先,如果有一个由超时指示的丢失事件(即拥塞),TCP发送者将cwnd的值设置为1,并重新开始慢启动进程。它还将第二个状态变量ssthresh(“慢启动阈值”的缩写)的值设置为cwnd/2 -检测到拥塞时拥塞窗口值的一半。慢启动结束的第二种方式直接与ssthresh值相关联。由于ssthresh是上次检测拥塞时cwnd值的一半,所以当cwnd达到或超过ssthresh值时,继续使cwnd加倍可能有点鲁莽。因此,当cwnd的值等于ssthresh时,慢速启动结束,TCP进入拥塞避免模式。正如我们将看到的,TCP在避免拥塞模式下会更谨慎地增加cwnd。慢启动结束的最后一种方式是检测到三个重复的ack,在这种情况下,TCP执行快速重传(参见3.5.4节)并进入快速恢复状态,如下所述。TCP的慢启动行为在图3.51中TCP拥塞控制的FSM描述中进行了总结。慢启动算法可以追溯到[Jacobson 1988];[Jain 1986]也单独提出了一种类似于慢启动的方法。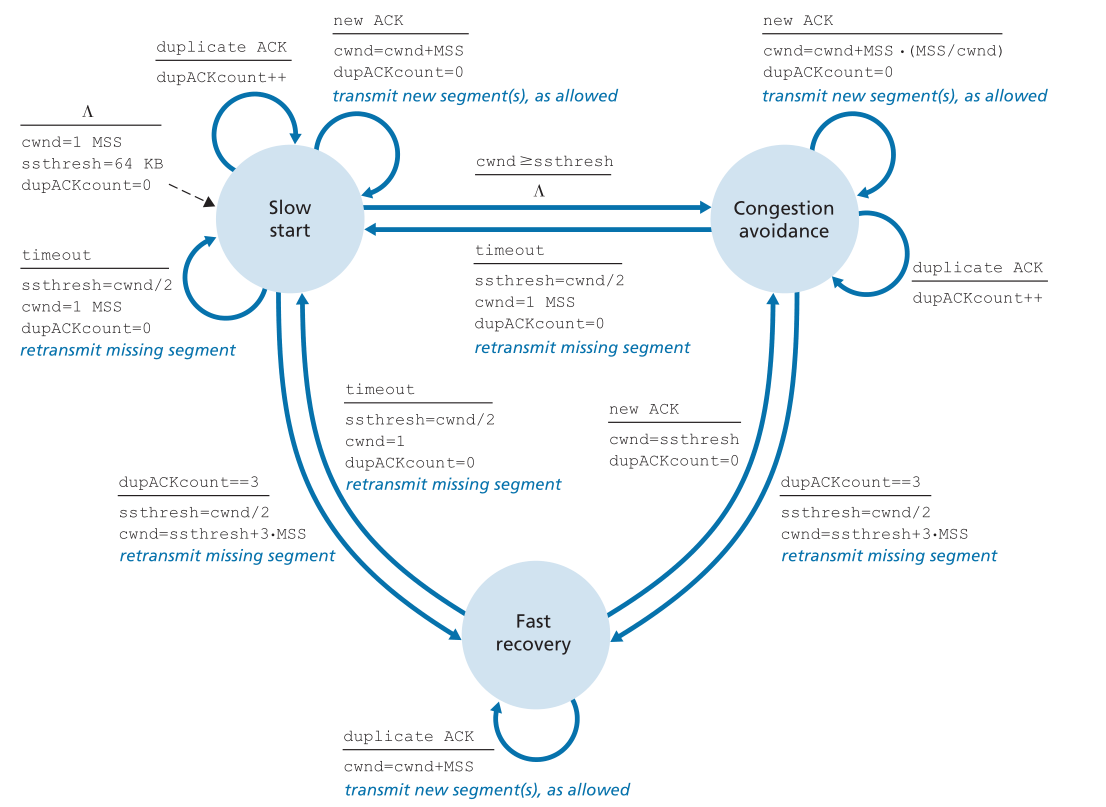
Figure 3.51 ♦ FSM description of TCP congestion control
图3.51 ♦ TCP拥塞控制的FSM描述
拥塞避免 Congestion Avoidance
在进入拥塞避免状态时,cwnd的值大约是上次遇到拥塞时值的一半——拥塞可能很快就会到来!因此,TCP并没有将cwnd的值在每一次RTT中增加一倍,而是采用了一种更为保守的方法,在每一次RTT中只增加一个MSS [RFC 5681]。这可以通过几种方式实现。一种常见的方法是TCP发送方在收到新的确认信息时增加MSS字节(MSS/cwnd)。例如,如果MSS是1460字节,cwnd是14600字节,那么在一个RTT中有10个段正在发送。每一个到达的ACK(假设每个段一个ACK)都会使拥塞窗口的大小增加1/10 MSS,因此,当所有10个段都收到ACK后,拥塞窗口的值将增加一个MSS。
但是拥塞避免的线性增加(每RTT一个MSS)何时结束?TCP的拥塞避免算法在发生超时和慢启动时的行为相同:将cwnd的值设置为1 MSS,当发生丢失事件时,将ssthresh的值更新为cwnd值的一半。但是,请回忆一下,丢失事件也可以由三重重复ACK事件触发。
在这种情况下,网络会继续从发送方到接收方传递一些数据段(如收到重复 ACK 所示)。 因此,TCP 对此类丢失事件的行为应该没有超时指示丢失那么剧烈:TCP 将 cwnd 的值减半(添加 3 MSS 以很好地衡量收到的三重重复 ACK)并记录 ssthresh 的值,当收到三重重复 ACK 时,它是 cwnd 值的一半。 然后进入快速恢复状态。
快速恢复 Fast Recovery
在快速恢复中,对于导致 TCP 进入快速恢复状态的丢失段收到的每个重复 ACK,cwnd 的值增加 1 MSS。 最终,当丢失的数据段的 ACK 到达时,TCP 在降低 cwnd 后进入拥塞避免状态。 如果发生超时事件,快速恢复在执行与慢启动和拥塞避免相同的操作后转换到慢启动状态: cwnd 的值设置为 1 MSS,ssthresh 的值设置为丢失事件发生时 cwnd 值的一半。
快速恢复是 TCP [RFC 5681] 的推荐组件,但不是必需的。 有趣的是,早期版本的 TCP,称为 TCP Tahoe,无条件地将其拥塞窗口减少到 1 MSS,并在超时指示或三重重复 ACK 指示丢失事件后进入慢启动阶段。 TCP 的较新版本 TCP Reno 包含快速恢复功能。
图 3.52 说明了 Reno 和 Tahoe 的 TCP 拥塞窗口的演变。 在该图中,阈值最初等于 8 MSS。 在前八轮传输中,Tahoe 和 Reno 采取相同的行动。 拥塞窗口在慢启动期间呈指数级快速攀升,并在第四轮传输时达到阈值。 然后拥塞窗口线性上升,直到发生三重重复 ACK 事件,就在第 8 轮传输之后。请注意,当此丢失事件发生时,拥塞窗口是 12 × MSS。 然后将 ssthresh 的值设置为 0.5 × cwnd = 6 × MSS。 在 TCP Reno 下,拥塞窗口设置为 cwnd = 9 × MSS 然后线性增长。 在 TCP Tahoe 下,拥塞窗口设置为 1 MSS 并呈指数增长,直到达到 ssthresh 的值,此时它会线性增长。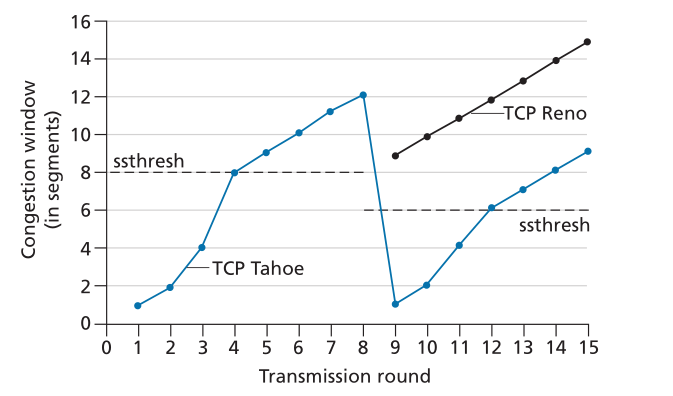
Figure 3.52 ♦ Evolution of TCP’s congestion window (Tahoe and Reno)
图3.52 ♦ TCP拥塞窗口的演进(Tahoe和Reno)
图3.51给出了TCP拥塞控制算法慢启动、拥塞避免和快速恢复的完整FSM描述。该图还显示了新段或重传段的传输可能发生的位置。虽然区分TCP错误控制/重传和TCP拥塞控制很重要,但是理解TCP的这两个方面是如何不可分割地联系在一起的也很重要。
PRINCIPLES IN PRACTICE 实践原则 TCP SPLITTING: OPTIMIZING THE PERFORMANCE OF CLOUD SERVICES TCP拆分:优化云服务性能 对于像搜索、电子邮件和社交网络这样的云服务,提供高水平的响应是很有必要的,理想情况下给用户一种服务在他们自己的终端系统(包括他们的智能手机)中运行的错觉。这可能是一个主要的挑战,因为用户通常位于远离负责提供与云服务相关的动态内容的数据中心的地方。实际上,如果终端系统距离数据中心很远,那么RTT就会很大,可能会由于TCP启动缓慢而导致响应时间性能较差。 作为一个案例研究,考虑接收搜索查询响应的延迟。通常,服务器在慢速启动时需要三个TCP窗口来传递响应[Pathak 2010]。因此从当系统启动TCP连接,直到时间结束接收到的最后一个数据包响应时,大约是4 × RTT (RTT设置TCP连接+ 3 RTT的三个窗口数据)+数据中心的处理时间。对于很大一部分查询,这些RTT延迟会导致返回搜索结果的明显延迟。此外,在接入网络中可能会有大量的包丢失,导致TCP重传甚至更大的延迟。 缓解这个问题并提高用户感知性能的一种方法是:(1)将前端服务器部署到离用户更近的地方,(2)通过断开前端服务器上的TCP连接来利用TCP拆分。通过TCP拆分(TCP splitting),客户端与附近的前端建立TCP连接,而前端与数据中心保持一个持久的TCP连接,并有一个非常大的TCP拥塞窗口[Tariq 2008, Pathak 2010, Chen 2011]。使用这种方法,响应时间大致变成4×RTTFE+RTTBE+处理时间,其中RTTFE是客户端和前端服务器之间的往返时间,RTTBE是前端服务器和数据中心(后端服务器)之间的往返时间。如果前端服务器接近客户端,那么这个响应时间近似为RTT加上处理时间,因为RTTFE很小,而RTTBE近似为RTT。总之,TCP拆分可以将网络延迟从4×RTT降低到RTT,显著提高用户感知的性能,特别是对于远离最近数据中心的用户。TCP拆分也有助于减少由于接入网络丢失而导致的TCP重传延迟。谷歌和Akamai在接入网络中广泛使用了他们的CDN服务器(回顾我们在第2.6节的讨论),为他们支持的云服务执行TCP拆分[Chen 2011]。
TCP拥塞控制:回顾 TCP Congestion Control: Retrospective
在深入研究了慢启动、拥塞避免和快速恢复的细节之后,现在退后一步,从树上看森林是值得的。忽略连接开始时的初始慢启动期,并假设丢失由三重重复 ACK 而不是超时指示,TCP 的拥塞控制包括每个 RTT 1 MSS 的 cwnd 线性(加性)增加,然后减半(乘性减少) cwnd 在三重重复 ACK 事件上。为此,TCP 拥塞控制通常被称为拥塞控制的加法增加乘法减少 (additive-increase, multiplicative-decrease,AIMD) 形式。 AIMD 拥塞控制产生了如图 3.53 所示的“锯齿”行为,这也很好地说明了我们早期对 TCP“探测”带宽的直觉——TCP 线性增加其拥塞窗口大小(因此它的传输速率)直到三重重复-ACK 事件发生。然后它将其拥塞窗口大小减少两倍,但随后又开始线性增加它,探查是否有额外的可用带宽。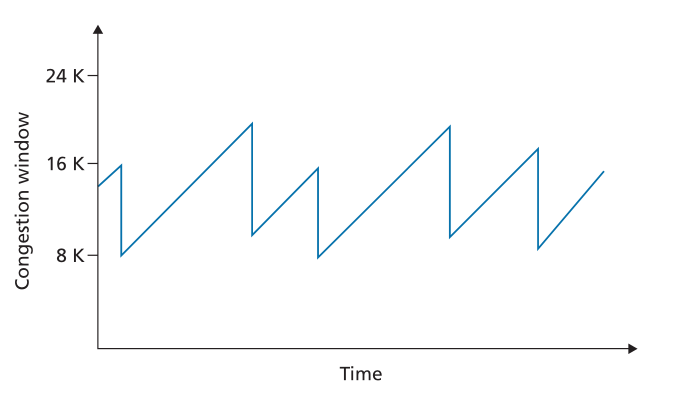
Figure 3.53 ♦ Additive-increase, multiplicative-decrease congestion control
图3.53♦加增乘减拥塞控制
TCP的AIMD算法是基于大量的工程洞察力和操作网络拥塞控制实验而开发的。TCP发展十年后,理论分析表明,TCP的拥塞控制算法作为一种分布式异步优化算法(distributed asynchronous-optimization algorithm),使得用户和网络性能的几个重要方面同时得到优化[Kelly 1998]。此后发展了丰富的拥塞控制理论[Srikant 2012]。
TCP Cubic
鉴于TCP Reno采用加增乘减的方法来控制拥塞,人们自然会想,这是否是“探测”数据包发送速率低于触发数据包丢失阈值的最佳方法。实际上,将发送速率减半(甚至更糟,将发送速率削减到每个RTT一个包,就像TCP的早期版本称为TCP Tahoe),然后随着时间的推移缓慢增加可能过于谨慎。如果发生丢包的拥塞链路的状态没有发生太大变化,那么可能最好更快地提高发送速率,使其接近丢包前的发送速率,然后再谨慎地探测带宽。这种见解是TCP CUBIC的核心[Ha 2008, RFC 8312]。
TCP CUBIC与TCP Reno仅略有不同。同样,拥塞窗口仅在ACK接收时增加,慢启动和快速恢复阶段保持不变。CUBIC只改变了拥塞避免阶段,如下所示:
- 设Wmax为上次检测到丢包时TCP拥塞控制窗口的大小,设K为TCP CUBIC窗口大小再次达到Wmax的未来时间点,假设没有丢包。几个可调的CUBIC参数决定了K值,即协议的拥塞窗口大小将以多快的速度达到Wmax。
- CUBIC 将拥塞窗口增加为当前时间 t 和 K 之间距离的立方的函数。因此,当 t 远离 K 时,拥塞窗口大小的增加比 t 接近 K 时要大得多。 也就是说,CUBIC 迅速提高 TCP 的发送速率以接近丢失前速率 Wmax,然后才在接近 Wmax 时谨慎地探测带宽。
- 当 t 大于 K 时,立方规则意味着当 t 仍然接近 K 时,CUBIC 的拥塞窗口增加很小(如果导致丢失的链路的拥塞水平没有太大变化,这很好),但随后随着 t 迅速增加并超过 K(如果导致丢失的链路拥塞水平发生显着变化,则允许 CUBIC 更快地找到新的工作点)。
在这些规则下,TCP Reno 和 TCP CUBIC 的理想化性能在图 3.54 中进行了比较,改编自 [Huston 2017]。 我们看到慢启动阶段在 t0 结束。 然后,当拥塞丢失发生在 t1、t2 和 t3 时,CUBIC 会更快地上升到 Wmax 附近(从而获得比 TCP Reno 更多的总吞吐量)。 我们可以图形化地看到 TCP CUBIC 如何尽可能长时间地将流量保持在(发送方未知的)拥塞阈值之下。 请注意,在 t3 时,拥塞级别可能已明显降低,从而允许 TCP Reno 和 TCP CUBIC 实现高于 Wmax 的发送速率。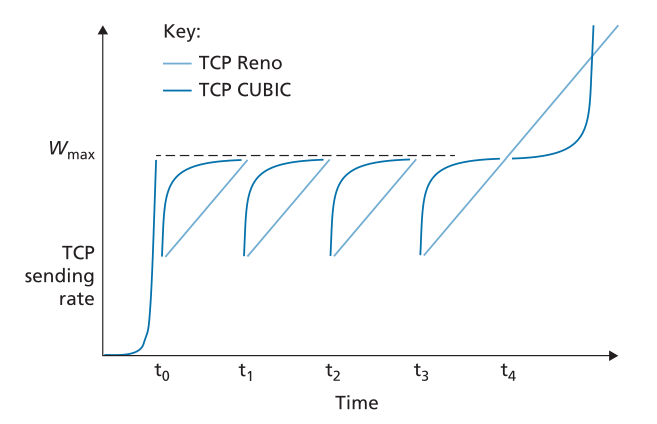
Figure 3.54 ♦ TCP congestion avoidance sending rates: TCP Reno and TCP CUBIC
图3.54♦TCP拥塞避免发送速率:TCP Reno和TCP CUBIC
TCP CUBIC最近得到了广泛的部署。虽然在2000年左右对流行Web服务器进行的测量显示,几乎所有服务器都在运行TCP Reno的某个版本[Padhye 2001],但最近对5000个最流行的Web服务器进行的测量显示,近50%的服务器在运行TCP CUBIC的某个版本[Yang 2014],这也是Linux操作系统中使用的TCP的默认版本。
TCP Reno 吞吐量的宏观描述 Macroscopic Description of TCP Reno Throughput
考虑到 TCP Reno 的锯齿状行为,很自然地要考虑长期 TCP Reno 连接的平均吞吐量(即平均速率)可能是多少。 在此分析中,我们将忽略超时事件后发生的慢启动阶段。 (这些阶段通常非常短,因为发送方以指数方式快速退出阶段。)在特定的往返间隔期间,TCP 发送数据的速率是拥塞窗口和当前 RTT 的函数。 当窗口大小为 w 字节,当前往返时间为 RTT 秒时,那么 TCP 的传输速率大致为 w/RTT。 然后,TCP 通过每个 RTT 将 w 增加 1 MSS 来探测额外的带宽,直到发生丢失事件。 用 W 表示丢失事件发生时 w 的值。 假设 RTT 和 W 在连接期间大致恒定,则 TCP 传输速率范围从 W/(2·RTT) 到 W/RTT。
这些假设导致了一个高度简化的TCP稳态行为的宏观模型。当速率增加到W/RTT时,网络从连接丢弃一个数据包;然后速率减半,然后每一次RTT增加MSS/RTT,直到再次达到W/RTT。这个过程一遍又一遍地重复。因为TCP的吞吐量(即速率)在两个极值之间呈线性增长,所以我们有
使用这个高度理想化的TCP稳态动态学(steady-state dynamics)模型,我们还可以推导出一个有趣的表达式,将连接的丢失率与其可用带宽联系起来[Mathis 1997]。这个推导过程在家庭作业中有概述。一个更复杂的模型已经被发现与实测数据一致[Padhye 2000]。
3.7.2 网络辅助显式拥塞通知和基于延迟的拥塞控制 Network-Assisted Explicit Congestion Notification and Delayed-based Congestion Control
自从 1980 年代后期 [RFC 1122] 对慢启动和拥塞避免进行初始标准化以来,TCP 已经实现了我们在第 3.7.1 节中研究的端到端拥塞控制的形式:TCP 发送方没有从网络层接收到明确的拥塞指示,而是通过观察到的数据包丢失来推断拥塞。 最近,IP 和 TCP [RFC 3168] 的扩展已经被提出、实施和部署,允许网络向 TCP 发送方和接收方明确地发出拥塞信号。 此外,已经提出了许多 TCP 拥塞控制协议的变体,它们使用测量数据包延迟来推断拥塞。 在本节中,我们将看看网络辅助和基于延迟的拥塞控制。
显式拥塞通知 Explicit Congestion Notification
显式拥塞通知(ECN)[RFC 3168]是一种在互联网上执行的网络辅助拥塞控制形式。如图3.55所示,涉及到TCP和IP。在网络层,ECN使用IP数据报首部(我们将在4.3节中讨论)的服务类型字段中的两个比特(总共有四个可能的值)。
路由器使用 ECN 位的一种设置来指示它(路由器)正在经历拥塞。 这个拥塞指示然后在标记的 IP 数据报中携带到目标主机,然后通知发送主机,如图 3.55 所示。 RFC 3168 没有提供路由器何时拥塞的定义; 该决定是由路由器供应商做出的配置选择,并由网络运营商决定。 然而,直觉是拥塞指示位可以设置为以在实际发生丢失之前向发送端发出拥塞开始的信号。 发送主机使用 ECN 位的第二个设置来通知路由器发送者和接收者具有 ECN 能力,因此能够对 ECN 指示的网络拥塞做出响应。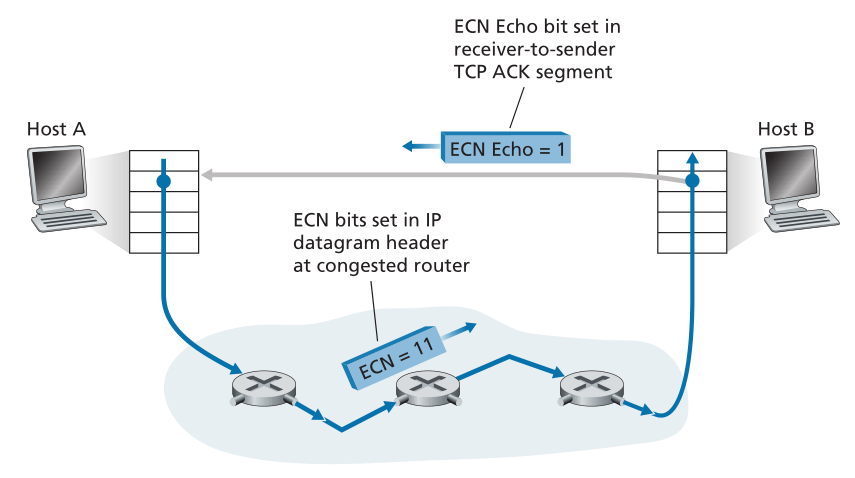
Figure 3.55 ♦ Explicit Congestion Notification: network-assisted congestion control
图3.55♦显式拥塞通知:网络辅助拥塞控制
如图3.55所示,当接收主机中的TCP通过接收到的数据报收到ECN拥塞指示时,接收主机中的 TCP 通过设置接收方到发送方 TCP ACK 段中的 ECE(Explicit Congestion Notification Echo)位(见图 3.29),将拥塞指示通知发送主机中的 TCP。 反过来,TCP 发送方通过将拥塞窗口减半来对带有拥塞指示的 ACK 作出反应,因为它会使用快速重传对丢失的段作出反应,并在下一个传输的 TCP 发送方到接收方段的首部中设置 CWR(减少拥塞窗口)位。
除了TCP之外,其他传输层协议也可以使用网络层信号ECN。数据报拥塞控制协议(Datagram Congestion Control Protocol,DCCP) [RFC 4340]提供了一种低开销、拥塞控制、类似UDP的不可靠服务,它利用ECN。专门为数据中心网络设计的DCTCP (Data Center TCP) [Alizadeh 2010, RFC 8257]和DCQCN (Data Center Quantized Congestion Notification)[Zhu 2015]也利用了ECN。最近的互联网测量显示,在流行服务器以及通往这些服务器的路径上的路由器上,ECN能力的部署正在增加[Kühlewind 2013]。
基于延迟的拥塞控制 Delay-based Congestion Control
回想一下我们在上面的ECN讨论,拥塞路由器可以设置拥塞指示位,在满缓冲区导致包在该路由器上被丢弃之前,向发送方发送拥塞开始的信号。这允许发送方更早地降低发送速率,希望是在丢包之前,从而避免昂贵的丢包和重传。第二种避免拥塞的方法采用基于延迟的方法,也可以在丢包之前主动检测拥塞发生。
在TCP Vegas [Brakmo 1995]中,发送方测量所有确认报文的源到目的路径的RTT。设RTT**min为发送端这些测量值的最小值;当路径没有拥塞且包的排队延迟最小时,就会发生这种情况。如果TCP Vegas的拥塞窗口大小为cwnd,则无拥塞吞吐量速率为cwnd/RTTmin**。TCP Vegas背后的直觉是,如果实际发送者测量的吞吐量接近这个值,TCP发送速率可以增加,因为(根据定义和测量)路径还没有拥塞。然而,如果发送方测量的实际吞吐量明显小于非拥塞吞吐量率,则路径拥塞,Vegas TCP发送方将降低其发送速率。详情见[Brakmo 1995]。
TCP Vegas的操作直觉是,TCP发送者应该“保持管道刚好满,但不满”[Kleinrock 2018]。“保持管道满”意味着链路(特别是限制连接吞吐量的瓶颈链路)一直忙于传输,做有用的工作;“但是不填满”意味着如果允许在管道被填满的情况下建立大队列,那么就不会有任何收获(除了增加延迟!)。
BBR拥塞控制协议[Cardwell 2017]建立在TCP Vegas的思想之上,并合并了允许它与TCP非BBR发送方公平竞争的机制(见章节3.7.3)。[Cardwell 2017]报告称,2016年,谷歌开始在其私有B4网络上使用BBR处理所有TCP流量[Jain 2013],该网络连接谷歌数据中心,取代CUBIC。它也被部署在谷歌和YouTube Web服务器上。其他基于延迟的TCP拥塞控制协议包括用于数据中心网络的TIMELY [Mittal 2015],用于高速和长途网络的复合TCP (CTPC) [Tan 2006]和FAST [Wei 2006]。
3.7.3 公平 Fairness
考虑K个TCP连接,每个连接都有不同的端到端路径,但都要通过一个传输速率为R bps的瓶颈链接。(瓶颈链路是指对于每条链路,该链路所在路径上的所有其他链路都不发生拥塞,且与瓶颈链路的传输能力相比,传输能力较强。)假设每个连接都在传输一个大文件,并且没有UDP流量通过瓶颈链接。如果每个连接的平均传输速率近似为R/K,则拥塞控制机制是公平的;也就是说,每个连接获得相同的链路带宽。
TCP的AIMD算法是否公平,特别是考虑到不同的TCP连接可能在不同的时间开始,因此在给定的时间点可能有不同的窗口大小?[Chiu 1989]提供了一个优雅而直观的解释,解释了为什么TCP拥塞控制会收敛,在竞争的TCP连接中提供同等份额的瓶颈链路带宽。
让我们考虑一个简单的情况,两个TCP连接共享一个传输速率为R的链路,如图3.56所示。假设这两个连接有相同的MSS和RTT(因此,如果它们有相同的拥塞窗口大小,那么它们有相同的吞吐量),它们有大量的数据要发送,并且没有其他TCP连接或UDP数据报穿越这条共享链路。另外,忽略TCP的慢启动阶段,假设TCP连接一直在CA模式(AIMD)下运行。
Figure 3.56 ♦ Two TCP connections sharing a single bottleneck link
图3.56♦两个TCP连接共享一个瓶颈链路
图3.57描绘了两个TCP连接实现的吞吐量。如果TCP在两个连接之间平均共享链路带宽,那么实现的吞吐量应该沿着从原点发出的45度箭头(平均带宽共享)下降。理想情况下,这两个吞吐量的总和应该等于R(当然,每个接收相等但为零的链路容量共享不是一个理想的情况!)因此,目标应该是使达到的吞吐量落在图3.57中等带宽共享线和全带宽利用率线的交点附近。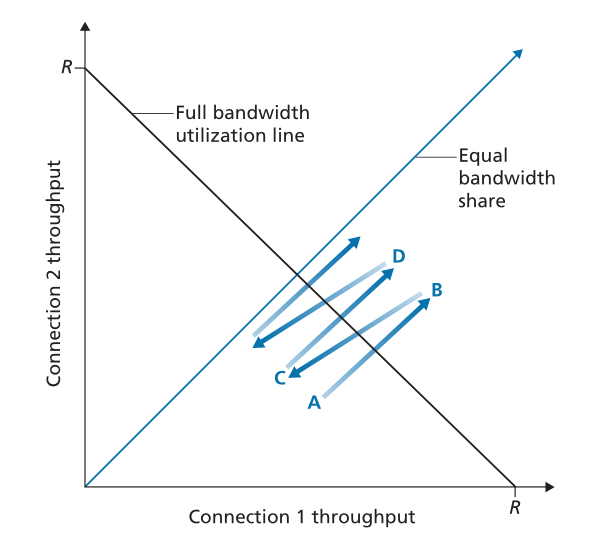
Figure 3.57 ♦ Throughput realized by TCP connections 1 and 2
图3.57 ♦ TCP连接1和2实现的吞吐量
假设 TCP 窗口大小使得在给定的时间点,连接 1 和 2 实现了图 3.56 中点 A 所示的吞吐量。因为两个连接共同消耗的链路带宽量小于R,所以不会发生丢失,并且由于TCP的拥塞避免算法,两个连接每个RTT都会将它们的窗口增加1 MSS。因此,两个连接的联合吞吐量从 A 点开始沿 45 度线(两个连接增加相等)进行。最终,两个连接共同消耗的链路带宽将大于 R,最终丢包发生。假设连接 1 和 2 在实现点 B 指示的吞吐量时遇到数据包丢失。连接 1 和 2 然后将它们的窗口减小两倍。因此,实现的最终吞吐量位于 C 点,沿着从 B 开始并在原点结束的向量的中间。因为在 C 点的联合带宽使用小于 R,两个连接再次沿着从 C 开始的 45 度线增加它们的吞吐量。最终,将再次发生丢失,例如在 D 点,两个连接再次减少它们的窗口大小为一半,依此类推。您应该说服自己,两个连接实现的带宽最终会沿着相等的带宽共享线波动。您还应该说服自己,无论它们在二维空间中的哪个位置,这两个连接都会收敛到这种行为!尽管该场景背后存在许多理想化的假设,但它仍然为 TCP 导致连接之间平等共享带宽的原因提供了一种直观的感觉。
在我们的理想场景中,我们假设只有TCP连接穿越瓶颈链路,这些连接具有相同的RTT值,并且只有一个TCP连接与一个主机-目的地对相关联。在实践中,这些条件通常得不到满足,因此客户机-服务器应用程序获得的链路带宽非常不平等。特别是,当多个连接共享一个共同的瓶颈时,那些具有较小RTT的会话能够在该链路空闲时更快地获取可用带宽(即,更快地打开拥塞窗口),因此将比那些使用更大RTT的连接享有更高的吞吐量[Lakshman 1997]。
公平和UDP Fairness and UDP
我们刚刚看到了TCP拥塞控制如何通过拥塞窗口机制来调节应用程序的传输速率。许多多媒体应用程序,如互联网电话和视频会议,常常因为这个原因而不运行TCP——它们不希望自己的传输速率被限制,即使网络非常拥挤。相反,这些应用程序更喜欢在UDP上运行,因为UDP没有内置拥塞控制。当运行UDP时,应用程序可以以恒定的速率将音频和视频输入网络,偶尔会丢失数据包,而不是在拥塞时将它们的速率降低到“公平”水平,而不会丢失任何数据包。从TCP的角度来看,在UDP上运行的多媒体应用程序是不公平的——它们不与其他连接协作,也不适当地调整传输速率。由于TCP拥塞控制会在拥塞(丢失)增加的情况下降低其传输速率,而UDP源不需要,因此UDP源有可能排挤TCP流量。一些拥塞控制机制已经被提议用于互联网,以防止UDP流量使互联网的吞吐量停止[Floyd 1999;弗洛伊德2000年;科勒2006;RFC 4340)。
公平和并行TCP连接 Fairness and Parallel TCP Connections
但即使我们可以强制 UDP 流量公平地表现,公平性问题仍然无法完全解决。这是因为没有什么可以阻止基于 TCP 的应用程序使用多个并行连接。例如,Web 浏览器经常使用多个并行 TCP 连接来传输一个网页中的多个对象。 (多个连接的确切数量在大多数浏览器中是可配置的。)当应用程序使用多个并行连接时,它会从拥塞的链接中获得更大的带宽。例如,考虑支持九个正在进行的客户端-服务器应用程序的速率为 R 的链路,其中每个应用程序使用一个 TCP 连接。如果一个新应用程序出现并且也使用一个 TCP 连接,那么每个应用程序将获得大约相同的 R/10 传输速率。但是,如果这个新应用程序改为使用 11 个并行 TCP 连接,那么新应用程序将获得超过 R/2 的不公平分配。由于 Web 流量在 Internet 中如此普遍,多个并行连接并不少见。

若有收获,就点个赞吧
0 人点赞
