现在我们已经介绍了可靠数据传输的基本原则,让我们转向TCP——Internet的传输层、面向连接的可靠传输协议。在这一节中,我们将看到为了提供可靠的数据传输,TCP依赖于上一节中讨论的许多底层原则,包括错误检测、重传、累积确认、计时器以及用于序列和确认号的首部字段。TCP定义在RFC 793、RFC 1122、RFC 2018、RFC 5681和RFC 7323中。
3.5.1 TCP连接 The TCP Connection
TCP被认为是面向连接的(Connection-Oriented),因为在一个应用程序进程开始向另一个进程发送数据之前,两个进程必须首先“握手”,也就是说,它们必须相互发送一些初步的段,以建立后续数据传输的参数。作为TCP连接建立的一部分,连接的双方将初始化与TCP连接相关的许多TCP状态变量(其中许多将在本节和3.7节中讨论)。
TCP“连接(connection)”不是电路交换网络中的端到端TDM或FDM电路。相反,“连接”是一个逻辑连接,公共状态仅驻留在两个通信端系统的TCP中。回想一下,因为TCP协议只在终端系统中运行,而不在中间网络元素(路由器和链路层交换机)中运行,所以中间网络元素并不维护TCP连接状态。事实上,中间路由器完全不知道TCP连接;他们看到的是数据报(datagrams),而不是连接(connections)。
TCP连接提供全双工服务(full-duplex service):如果一台主机上的进程 A 和另一台主机上的进程 B 之间存在 TCP 连接,那么应用层数据可以与应用层同时从进程 A 流向进程 B 数据从进程 B 流向进程 A。 TCP 连接也始终是点对点的(point-to-point),即在单个发送方和单个接收方之间。 所谓的“多播(multicasting)”(参见本文的在线补充材料)——在一次发送操作中将数据从一个发送方传输到多个接收方——用 TCP 是不可能的。 使用 TCP,两台主机是同伴,三台主机是人群!
现在让我们看看TCP连接是如何建立的。假设一个主机上运行的进程想要启动与另一个主机上的另一个进程的连接。回想一下,发起连接的进程称为客户端进程,而另一个进程称为服务器进程。客户端应用程序进程首先通知客户端传输层,它想要建立到服务器中的进程的连接。回想一下2.7.2节,Python客户端程序通过发出命令来实现这一点
clientSocket.connect((serverName,serverPort))
其中serverName是服务器的名称,serverPort标识服务器上的进程。然后,客户端中的TCP继续与服务器中的TCP建立TCP连接。在本节的最后,我们将详细讨论建立连接的过程。现在只要知道客户端首先发送一个特殊的TCP段就足够了;服务器响应第二个特殊的TCP段;最后,客户端再次响应第三个特殊段。前两段不携带有效负载(payload),即不携带应用层数据;第三段可携带有效负载。因为在两台主机之间要发送三个段,所以这个建立连接的过程通常被称为**三次握手(three-way handshake)**。<br />一旦建立TCP连接,两个应用程序进程就可以互相发送数据。让我们考虑将数据从客户端进程发送到服务器进程。客户端进程通过套接字(进程的门)传递数据流,如2.7节所述。一旦数据通过了门,数据就在客户端中运行的TCP手中。如图3.28所示,**TCP将这些数据定向到连接的发送缓冲区(send buffer),这是在最初的三次握手期间预留的缓冲区之一**。**有时,TCP会从发送缓冲区抓取数据块,并将数据传递到网络层**。有趣的是,TCP规范[RFC 793]在指定TCP应该在什么时候实际发送缓存数据方面非常宽松,声明TCP应该“根据自己方便以段的形式发送数据”。**可以抓取和放置在一个段中的最大数据量受最大段大小(maximum segment size,MSS)的限制**。MSS通常是通过首先确定本地发送主机可以发送的最大链路层帧(largest link-layer frame)的长度来设置的(所谓的**maximum transmission unit,最大传输单元,MTU**),**然后设置MSS以确保TCP段(封装在IP数据报中)加上TCP/IP首部长度(通常为40字节)将适合于单个链路层帧。以太网和PPP链路层协议的MTU都是1500字节。因此,MSS的典型值是1460字节**。还提出了发现路径MTU(从源到目的的所有链路上可以发送的最大链路层帧)的方法,以及基于路径MTU值设置MSS的方法。注意,**MSS是应用程序层数据在段中的最大数量,而不是TCP段(包括头)的最大大小**。(这个术语令人困惑,但我们不得不接受它,因为它根深蒂固。)<br />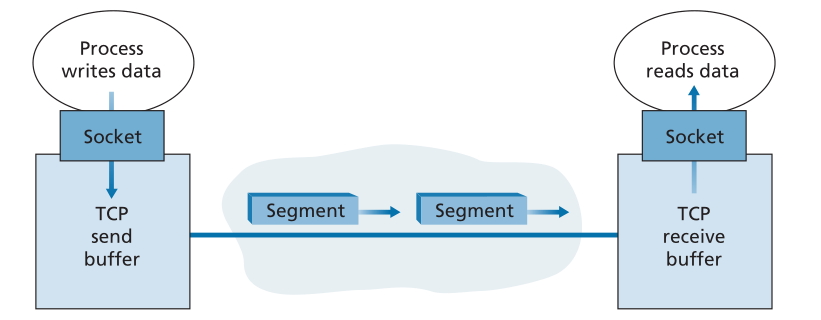<br />**Figure 3.28 ♦ TCP send and receive buffers**<br />**图3.28 ♦ TCP发送和接收缓冲区**<br />TCP将每个客户端数据块与TCP首部配对,从而形成TCP段(segments)。这些段向下传递到网络层,在那里它们被分别封装在网络层IP数据报(datagrams)中。然后IP数据报被发送到网络中。当TCP接收到另一端的一个网段时,该网段的数据被放入TCP连接的接收缓冲区中,如图3.28所示。应用程序从这个缓冲区读取数据流。连接的每一方都有自己的发送缓冲区和接收缓冲区。(您可以在[http://www.awl.com/kurose-ross](http://www.awl.com/kurose-ross)上看到在线流量控制交互动画,它提供了发送和接收缓冲区的动画。)<br />从本文的讨论中我们可以看出,**TCP连接由缓冲区、变量和一个连接到一个主机上的进程的套接字连接,以及另一组缓冲区、变量和连接到另一个主机上进程的套接字连接组成**。如前所述,**主机之间的网络元素(路由器、交换机和中继器)中的连接没有分配缓冲区或变量。**
CASE HISTORY 历史案例 VINTON CERF, ROBERT KAHN, AND TCP/IP 文顿瑟夫,罗伯特卡恩,和TCP/IP 在20世纪70年代早期,数据包交换网络开始激增,而阿帕网(ARPAnet,internet的前身)只是众多网络中的一个。每个网络都有自己的协议。文顿·瑟夫(Vinton Cerf)和罗伯特·卡恩(Robert Kahn)两位研究人员认识到互连这些网络的重要性,并发明了一种名为TCP/IP的跨网络协议,即传输控制协议/互联网协议。虽然Cerf和Kahn开始将协议视为一个单一的实体,但后来它被分成了TCP和IP两部分,分别运行。Cerf和Kahn于1974年5月在IEEE通信技术汇刊上发表了一篇关于TCP/IP的论文[Cerf 1974]。 TCP/IP协议是今天互联网的主要支柱,在个人电脑、工作站、智能手机和平板电脑出现之前,在以太网、电缆、DSL、WiFi和其他接入网络技术出现之前,在网络、社交媒体和流媒体出现之前,TCP/IP协议就被设计出来了。Cerf和Kahn看到了对网络协议的需求,一方面,它为尚未定义的应用程序提供广泛支持,另一方面,它允许任意主机和链路层协议进行互操作。 2004年,Cerf和Kahn获得了ACM的图灵奖,该奖被认为是“计算领域的诺贝尔奖”,因为他们“在互联网络方面的开创性工作,包括设计和实现了互联网络的基本通信协议,TCP/IP,以及在网络领域的杰出领导能力”。
3.5.2 TCP段结构 TCP Segment Structure
在简要了解了TCP连接之后,让我们研究一下TCP段结构。TCP段由首部字段和数据字段组成。数据字段包含应用程序数据块。如上所述,MSS限制了段数据字段的最大大小。当TCP发送一个大文件(如作为Web页面一部分的图像)时,它通常将文件分成大小为MSS的块(chunks)(最后一个块除外,它通常小于MSS)。然而,交互式应用程序经常传输比MSS更小的数据块;例如,对于Telnet和ssh等远程登录应用程序,TCP段中的数据字段通常只有一个字节。因为TCP首部(header)通常是20字节(比UDP报头多12字节),通过Telnet和ssh发送的段长度可能只有21字节。
图3.29给出了TCP段的结构。与UDP一样,首部包括源端口号和目的端口号,它们用于从上层应用程序多路复用/多路分解数据。同样,与UDP一样,首部包含校验和字段。TCP段首部还包含以下字段:
- 32位序列号字段(sequence number field)和32位确认号字段(acknowledgment number field)被TCP发送方和接收方用于实现可靠的数据传输服务,如下所述。
- 16位接收窗口字段(receive window field)用于流量控制。我们很快就会看到它被用来表示接收方愿意接受的字节数。
- 4位首部长度字段(header length field)以 32 位字指定TCP首部长度。由于TCP选项(options)字段,TCP首部可以是可变长度的。(通常,options字段为空,因此典型TCP首部的长度为20字节。)
- 可选和可变长度选项字段(options field)用于发送方和接收方协商最大段大小(MSS)或作为高速网络中使用的窗口缩放因子。还定义了一个时间戳选项。更多细节请参阅RFC 854和RFC 1323。
- 标志字段(flag field)包含 6 位。 ACK位用于指示确认字段中携带的值有效;也就是说,该段包含对已成功接收的段的确认。 RST、SYN 和 FIN 位用于连接建立和拆除,我们将在本节末尾讨论。 CWR 和 ECE 位用于显式拥塞通知,如第 3.7.2 节所述。设置 PSH 位表示接收器应立即将数据传递给上层。最后,URG位用于指示该段中有发送端上层实体标记为“紧急(urgent)”的数据。该紧急数据的最后一个字节的位置由 16 位紧急数据指针字段(urgent data pointer field)指示。当有紧急数据存在时,TCP 必须通知接收方上层实体,并传递一个指向紧急数据末尾的指针。 (实际上,不使用 PSH、URG 和紧急数据指针。但是,为了完整起见,我们提到了这些字段。)
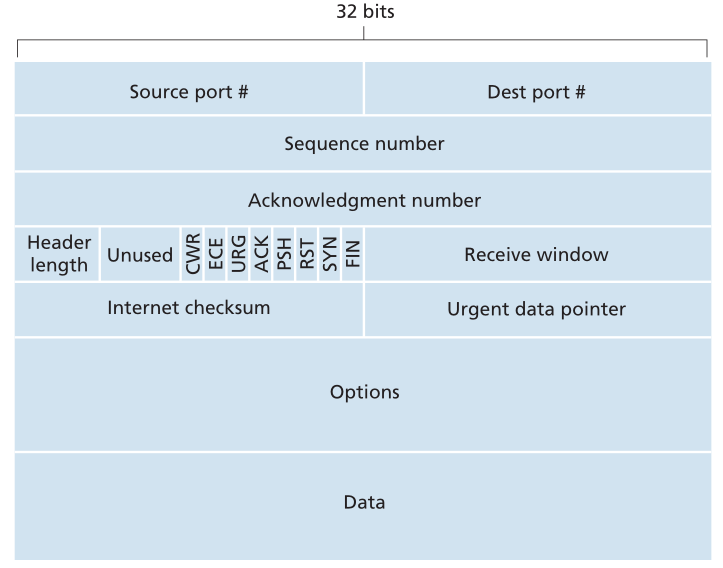
Figure 3.29 ♦ TCP segment structure
图3.29 ♦ TCP段结构
作为老师,我们的经验是,我们的学生有时会发现关于包格式的讨论相当枯燥,可能还有点无聊。想要了解TCP报头字段的有趣和有趣的内容,特别是如果你像我们一样喜欢乐高™,请参见[Pomeranz 2010]。
序列号和确认号 Sequence Numbers and Acknowledgment Numbers
TCP段首部中最重要的两个字段是序列号字段和确认号字段。这些字段是TCP可靠数据传输服务的关键部分。但是在讨论如何使用这些字段来提供可靠的数据传输之前,让我们首先解释一下TCP在这些字段中放入了什么。
TCP 将数据视为非结构化但有序的字节流。 TCP 对序列号的使用反映了这种观点,因为序列号在传输的字节流(stream of transmitted bytes)上而不是在一系列传输的段(transmitted segments)上。因此,段的序列号是段中第一个字节的字节流编号。让我们看一个例子。假设主机 A 中的进程想要通过 TCP 连接向主机 B 中的进程发送数据流。主机 A 中的 TCP 将隐式编号数据流中的每个字节。假设数据流由一个500,000字节的文件组成,MSS为1,000字节,数据流的第一个字节编号为0。如图3.30所示,TCP从数据流中构造出500个段。第一个段被分配序列号 0,第二个段被分配序列号 1,000,第三个段被分配序列号 2,000,依此类推。每个序列号都插入到相应 TCP 段的首部中的序列号字段中。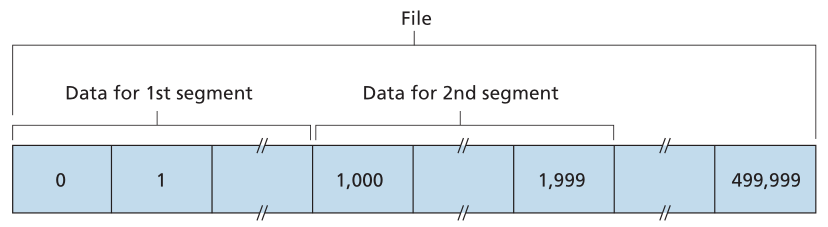
Figure 3.30 ♦ Dividing file data into TCP segments
图3.30♦将文件数据划分为TCP段
现在让我们考虑确认号。 这些比序列号要棘手一些。 回想一下 TCP 是全双工的,因此主机 A 可能正在从主机 B 接收数据,同时向主机 B 发送数据(作为同一 TCP 连接的一部分)。 从主机 B 到达的每个段都有一个从 B 到 A 的数据流的序列号。 看几个例子来了解这里发生了什么是很好的。 假设主机 A 已从 B 接收到编号为 0 到 535 的所有字节,并假设它即将向主机 B 发送一个段。主机 A 正在等待字节 536 和主机 B 数据流中的所有后续字节。 所以主机 A 将 536 放在它发送给 B 的段的确认号字段中。
另一个例子是,假设主机A从主机B接收到一个包含0到535字节的段,以及另一个包含900到1000字节的段。由于某些原因,主机A还没有收到字节536到899。在这个例子中,主机A仍然在等待字节536(以及以上),以便重新创建B的数据流。因此,A到B的下一个段将在确认号码字段中包含536。因为TCP只承认流中第一个丢失的字节之前的字节,所以TCP提供了累积确认(cumulative acknowledgments)。
最后一个例子也提出了一个重要但微妙的问题。 主机 A 在接收第二个段(字节 536 到 899)之前接收到第三个段(字节 900 到 1,000)。 因此,第三段出现乱序。 微妙的问题是:当主机在 TCP 连接中接收到乱序段时,它会做什么? 有趣的是,TCP RFC 并没有在这里强加任何规则,而是由实现 TCP 实现的程序员来决定。 基本上有两种选择:(1) 接收方立即丢弃乱序段(正如我们之前讨论的,可以简化接收方的设计),或者 (2) 接收方保留乱序字节并等待用于填补空白的缺失字节。 显然,后一种选择在网络带宽方面更有效,并且是实践中采用的方法。
在图 3.30 中,我们假设初始序列号为零。 事实上,TCP 连接的双方随机选择一个初始序列号。 这样做是为了最大限度地减少网络中仍然存在的段的可能性,该段来自两台主机之间较早的、已经终止的连接,被误认为是这两个相同主机之间的稍后连接中的有效段(也碰巧正在使用与旧连接相同的端口号)[Sunshine 1978]。
Telnet:序列和确认号的一个案例研究 Telnet: A Case Study for Sequence and Acknowledgment Numbers
在RFC 854中定义的Telnet是用于远程登录的一种流行的应用层协议。它在TCP上运行,并被设计为在任何一对主机之间工作。与第2章中讨论的批量数据传输应用程序不同,Telnet是一个交互式应用程序。我们在这里讨论一个Telnet示例,因为它很好地说明了TCP序列和确认号。我们注意到许多用户现在更喜欢使用SSH协议而不是Telnet,因为在Telnet连接中发送的数据(包括密码!)是不加密的,这使得Telnet容易受到窃听攻击(如8.7节所讨论的)。
假设主机A与主机B发起Telnet会话。因为主机A发起会话,所以它被标记为客户端,主机B被标记为服务器。用户(在客户端)输入的每个字符都将被发送到远程主机;远程主机将发送回每个字符的副本,该副本将显示在Telnet用户的屏幕上。此“回显(echo back)”用于确保Telnet用户看到的字符已经在远程站点接收和处理。因此,从用户按下按键到字符显示在用户显示器上的时间,每个字符都要穿过网络两次。
现在假设用户输入一个字母“C”,然后拿起一杯咖啡。让我们检查一下在客户端和服务器之间发送的TCP段。如图3.31所示,我们假设客户端和服务器的起始序列号分别为42和79。回想一下,段的序列号是数据字段中第一个字节的序列号。因此,从客户端发送的第一个段的序列号为42;从服务器发送的第一个段的序列号为79。回想一下,确认号是主机正在等待的下一个数据字节的序列号。TCP连接建立后,在发送任何数据之前,客户端等待第79字节,服务器等待第42字节。
如图3.31所示,发送了三个段。第一个段从客户端发送到服务器端,它的数据字段包含字母“C”的1字节ASCII表示。第一个段的序列号字段也有42,正如我们刚才描述的。而且,因为客户端还没有从服务器接收到任何数据,所以第一个段的确认号字段中有79。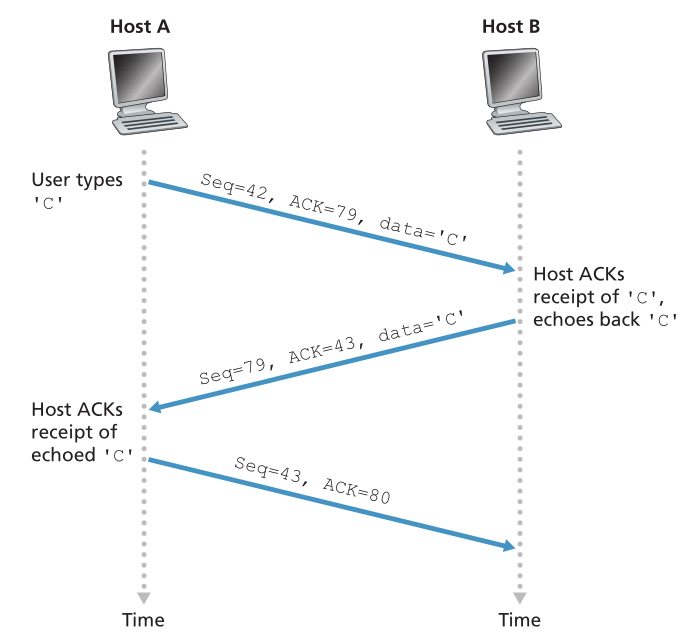
Figure 3.31 ♦ Sequence and acknowledgment numbers for a simple Telnet application over TCP
图3.31♦通过TCP的简单Telnet应用程序的序列和确认号码
第二段从服务器发送到客户端。 它有双重目的。 首先,它提供对服务器已收到数据的确认。 通过将 43 放在确认字段中,服务器告诉客户端它已成功接收到字节 42 之前的所有内容,现在正在等待字节 43。 该段的第二个目的是回显字母“C”。因此,第二个段在其数据字段中具有“C”的 ASCII 表示。 第二段的序列号为 79,这是此 TCP 连接的服务器到客户端数据流的初始序列号,因为这是服务器发送的数据的第一个字节。 注意client-to-server数据的确认是在承载server-to-client数据的段中携带的; 据说这个确认被搭载(piggybacked)在服务器到客户端的数据段上。
第三段从客户端发送到服务器。 它的唯一目的是确认它从服务器收到的数据。 (回想一下,第二段包含数据——字母‘C’——从服务器到客户端。)这个段有一个空的数据字段(也就是说,确认没有被任何客户端到服务器的数据捎带)。 该段在确认号字段中有 80,因为客户端已经接收到字节序列号为 79 的字节流,现在正在等待字节 80。 由于该段不包含任何数据,因此您可能认为该段还有一个序列号很奇怪。 但是因为 TCP 有一个序列号字段,所以该段需要有一些序列号。
3.5.3 往返时间估计和超时 Round-Trip Time Estimation and Timeout
TCP,就像我们在 3.4 节中的 rdt 协议一样,使用超时/重传机制从丢失的段中恢复。 尽管这在概念上很简单,但当我们在实际协议(如 TCP)中实现超时/重传机制时,会出现许多微妙的问题。 也许最明显的问题是超时间隔的长度(the length of the timeout intervals)。 显然,超时应该大于连接的往返时间 (RTT),即从发送段到确认的时间。 否则,将发送不必要的重传。 但是大多少? 首先应该如何估计 RTT? 计时器是否应该与每个未确认的段相关联? 这么多的问题! 我们在本节中的讨论基于 [Jacobson 1988] 中的 TCP 工作和当前 IETF 管理 TCP 计时器的建议 [RFC 6298]。
估计往返时间 Estimating the Round-Trip Time
让我们通过考虑TCP如何估计发送方和接收方之间的往返时间来开始对TCP计时器管理的研究。这是通过以下方式完成的。段的样本RTT,表示为SampleRTT,是段发送(即传递给IP)到段收到确认的时间。大多数TCP实现一次只进行一个SampleRTT测量,而不是为每个传输段测量SampleRTT。也就是说,在任何时间点,仅对一个传输的但目前未确认的段估计SampleRTT,导致大约每RTT一次SampleRTT的新值。此外,TCP从不计算已重传的段的SampleRTT;它只测量一次传输的片段的SampleRTT [Karn 1987]。(本章末尾有个问题让你思考原因。)
显然,由于路由器的拥塞和终端系统负载的变化,SampleRTT值会在段与段之间波动。由于这种波动,任何给定的SampleRTT值都可能是非典型的(atypical)。因此,为了估计一个典型的RTT,对SampleRTT值取某种平均值是很自然的。TCP维护SampleRTT值的平均值,称为EstimatedRTT。在获得一个新的SampleRTT时,TCP根据以下公式更新EstimatedRTT:
上面的公式是以编程语言语句的形式写出来的——EstimatedRTT的新值是EstimatedRTT之前的值和SampleRTT的新值的加权组合。α的推荐值为α = 0.125(即1/8)[RFC 6298],此时式为:
注意EstimatedRTT是SampleRTT值的加权平均值。正如本章末尾的一个家庭作业问题中所讨论的,加权平均对近期样本的权重大于对旧样本的权重。这是很自然的,因为最近的样本更好地反映了当前网络的拥塞。在统计学中,这样的平均被称为指数加权移动平均(exponential weighted moving average,EWMA)。“指数”一词出现在EWMA中,因为给定SampleRTT的权重随着更新的进行呈指数级快速衰减。在作业问题中,你们会被要求在EstimatedRTT中推导指数项。
图 3.32 显示了 gaia.cs.umass.edu(位于马萨诸塞州阿默斯特)与 fantasia.eurecom.fr(位于法国南部)之间的 TCP 连接的 SampleRTT 值和 EstimatedRTT 值,α = 1/8。 显然,SampleRTT 的变化在 EstimatedRTT 的计算中被平滑了。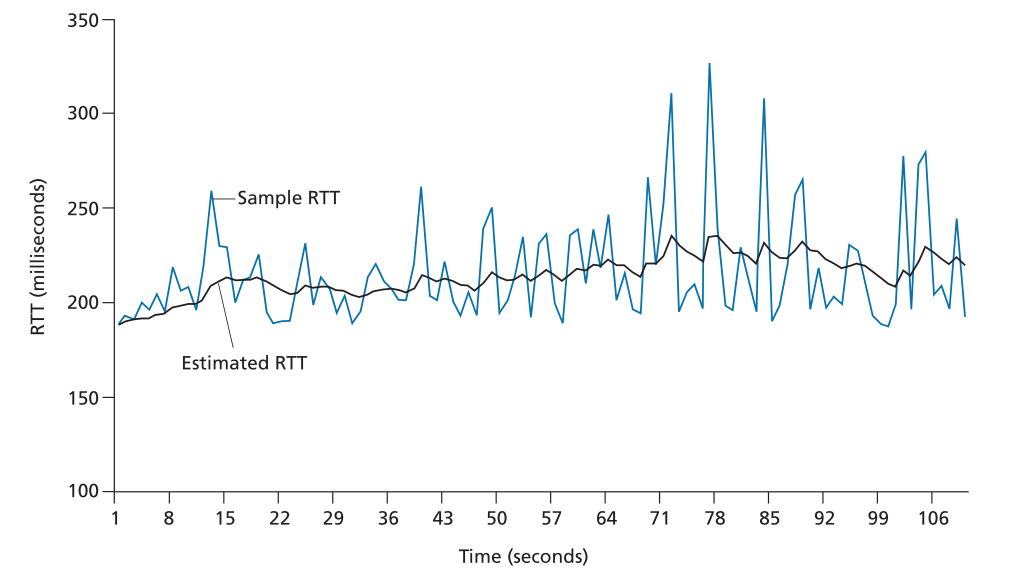
Figure 3.32 ♦ RTT samples and RTT estimates
图3.32♦RTT样本和RTT估计
除了对RTT进行估计外,对RTT的可变性进行测量也是很有价值的。[RFC 6298]定义了RTT变异,DevRTT,作为SampleRTT通常偏离EstimatedRTT多少的估计:
注意,DevRTT是SampleRTT和EstimatedRTT之间的差值的EWMA。如果SampleRTT值波动较小,则DevRTT较小;另一方面,如果有很大的波动,DevRTT将会很大。β的推荐值为0.25。
PRINCIPLES IN PRACTICE 实践中的原则 TCP通过使用正确认和计时器来提供可靠的数据传输,这与我们在3.4节中学习的方法非常相似。TCP对已正确接收的数据进行确认,然后在认为段或其相应的确认丢失或损坏时重新传输段。某些版本的TCP也有一种隐式NAK机制——使用TCP的快速重传机制(fast retransmit mechanism),对于给定的段接收到三个重复的ACK将作为下一个段的隐式NAK,在超时前触发该段的重传。TCP使用序列号来允许接收方识别丢失或重复的段。就像我们的可靠数据传输协议rdt3.0一样,TCP本身不能确定一个段或它的ACK是否丢失、损坏或过度延迟。在发送方,TCP的响应将是相同的:重新发送有问题的段。 TCP还使用流水线(pipelining),允许发送方在任何给定时间有多个已传输但尚未确认的段未完成。我们在前面看到,当段大小与往返延迟的比例很小时,流水线可以极大地提高会话的吞吐量。发送方可以拥有的未被确认的段的具体数量是由TCP的流控制和拥塞控制机制决定的。本节的最后将讨论TCP流量控制;TCP拥塞控制将在第3.7节中讨论。目前,我们必须简单地意识到TCP发送方使用流水线。
设置和管理重传超时时间 Setting and Managing the Retransmission Timeout Interval
给定EstimatedRTT和DevRTT的值,TCP的超时时间应该使用什么值?显然,间隔应该大于或等于EstimatedRTT,否则将发送不必要的重传。但是超时时间不应该比EstimatedRTT大太多;否则,当段丢失时,TCP无法快速重传段,导致数据传输延迟较大。因此,我们希望将超时设置为EstimatedRTT加上一些余量(margin)。当SampleRTT值波动较大时,余量应较大;当波动小的时候,应该是小的。因此,DevRTT的价值应该在这里发挥作用。TCP的重传超时时间的确定方法考虑了所有这些因素:
建议TimeoutInterval的初始值为1秒[RFC 6298]。此外,当超时发生时,TimeoutInterval的值将增加一倍,以避免即将被确认的后续段过早超时。然而,一旦收到一个段并且EstimatedRTT被更新,TimeoutInterval就会再次使用上面的公式计算。
3.5.4 可靠数据传输 Reliable Data Transfer
回想一下 Internet 的网络层服务(IP 服务)是不可靠的。 IP 不保证数据报的传递,不保证数据报的有序传递,也不保证数据报中数据的完整性。 对于 IP 服务,数据报可能会溢出路由器缓冲区而永远无法到达目的地,数据报可能会乱序到达,并且数据报中的位可能会被破坏(从 0 翻转到 1,反之亦然)。 因为传输层段是由 IP 数据报在网络上传送的,所以传输层段也会遇到这些问题。
TCP 在 IP 不可靠的尽力服务之上创建了可靠的数据传输服务(reliable data transfer service)。 TCP可靠的数据传输服务,保证进程从其TCP接收缓冲区中读出的数据流是完整、无间隙、无重复、有序的; 也就是说,字节流与连接另一端的终端系统发送的字节流完全相同。 TCP 如何提供可靠的数据传输涉及我们在 3.4 节中研究的许多原则。
在我们早期可靠数据传输技术的开发中,在概念上最容易假设一个单独的定时器与每个已传输但尚未确认的段相关联。虽然这在理论上很好,但计时器管理可能需要相当大的开销。因此,推荐的TCP定时器管理程序[rfc6298]只使用一个重传定时器,即使有多个已传输但尚未确认的段。本节描述的TCP协议遵循这个单定时器建议。
我们将讨论 TCP 如何以两个增量步骤(incremental steps)提供可靠的数据传输。 我们首先对 TCP 发送方进行高度简化的描述,该发送方仅使用超时从丢失的段中恢复; 然后我们提供一个更完整的描述,除了超时之外,还使用重复确认。 在接下来的讨论中,我们假设数据仅在一个方向上发送,从主机 A 到主机 B,并且主机 A 正在发送一个大文件。
图 3.33 给出了对 TCP 发送方的高度简化的描述。 我们看到 TCP 发送端与数据传输和重传相关的三个主要事件: 从上面的应用程序接收到的数据; 定时器超时; 和 ACK 收据(receipt)。 当第一个重大事件发生时,TCP 从应用程序接收数据,将数据封装在一个段中,并将该段传递给 IP。 请注意,每个段都包含一个序列号,它是段中第一个数据字节的字节流编号,如第 3.5.2 节所述。 还要注意,如果计时器已经没有为某个其他段运行,则当该段传递给 IP 时,TCP 会启动计时器。 (将计时器视为与最旧的未确认段相关联是有帮助的。)此计时器的到期间隔是 TimeoutInterval,它是根据 EstimatedRTT 和 DevRTT 计算得出的,如第 3.5.3 节所述。
/* Assume sender is not constrained by TCP flow or congestion control, that data from above is lessthan MSS in size, and that data transfer is in one direction only. */NextSeqNum=InitialSeqNumberSendBase=InitialSeqNumberloop (forever) {switch(event)event: data received from application abovecreate TCP segment with sequence number NextSeqNumif (timer currently not running)start timerpass segment to IPNextSeqNum=NextSeqNum+length(data)break;event: timer timeoutretransmit not-yet-acknowledged segment withsmallest sequence numberstart timerbreak;event: ACK received, with ACK field value of yif (y > SendBase) {SendBase=yif (there are currently any not-yet-acknowledged segments)start timer}break;} /* end of loop forever */
Figure 3.33 ♦ Simplified TCP sender
图3.33 ♦ 简化的TCP发送方
第二个主要事件是超时。TCP通过重传导致超时的段来响应超时事件。然后TCP重新启动定时器。
TCP发送方必须处理的第三个主要事件是来自接收方的确认段(ACK)的到达(更具体地说,一个包含有效ACK字段值的段)。在发生此事件时,TCP将ACK值y与它的变量SendBase进行比较。TCP状态变量SendBase是最老的未确认字节的序列号。(因此SendBase-1是已知已正确接收的最后一个字节的序列号,并且在接收端按顺序接收。)如前所述,TCP使用累积确认,因此y确认在字节号y之前的所有字节的接收。如果y > SendBase,则ACK确认一个或多个先前未确认的段。因此发送方更新它的SendBase变量;如果当前有任何尚未确认的段,它也会重新启动计时器。
一些有趣的场景 A Few Interesting Scenarios
我们刚刚描述了 TCP 如何提供可靠数据传输的高度简化版本。 但即使是这个高度简化的版本也有许多微妙之处。 为了更好地了解该协议的工作原理,现在让我们来看看几个简单的场景。 图 3.34 描述了第一种情况,其中主机 A 向主机 B 发送一个段。假设该段的序列号为 92,包含 8 个字节的数据。 发送此段后,主机 A 等待来自 B 的确认编号为 100 的段。尽管 B 收到了来自 A 的段,但从 B 到 A 的确认丢失了。 在这种情况下,超时事件发生,主机 A 重传同一段。 当然,当Host B收到重传时,它从序列号中观察到该段包含已经接收到的数据。 因此,主机 B 中的 TCP 将丢弃重传段中的字节。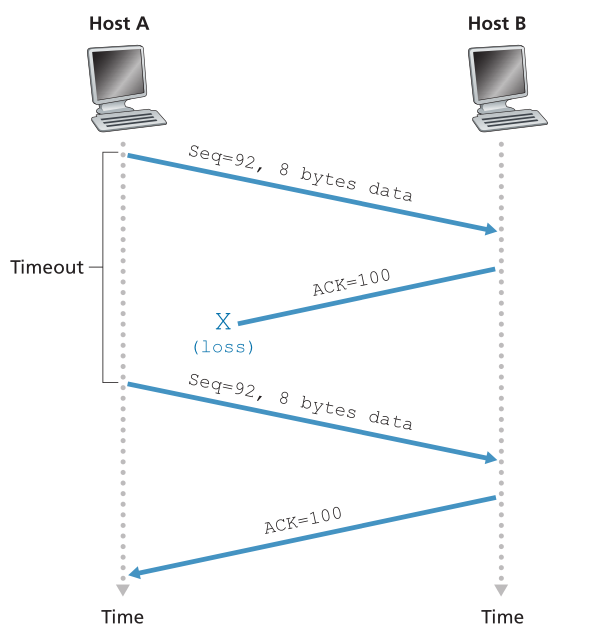
Figure 3.34 ♦ Retransmission due to a lost acknowledgment
图3.34♦由于丢失的确认信息而导致的重传
在第二种情况下,如图 3.35 所示,主机 A 连续发送两个段。 第一段具有序号 92 和 8 个字节的数据,第二段具有序号 100 和 20 个字节的数据。 假设两个段都完好无损地到达 B,并且 B 为这些段中的每一个发送了两个单独的确认。 这些确认中的第一个确认编号为 100; 第二个确认编号为 120。假设现在没有一个确认在超时之前到达主机 A。 当超时事件发生时,主机 A 重新发送序列号为 92 的第一个段并重新启动计时器。 只要第二个段的 ACK 在新的超时时间之前到达,就不会重传第二个段。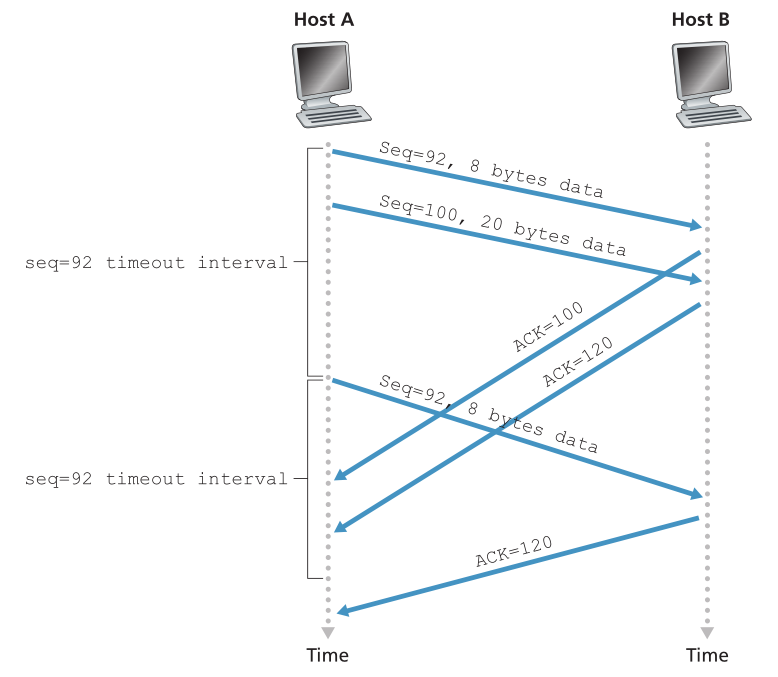
Figure 3.35 ♦ Segment 100 not retransmitted
图3.35 ♦ 100段未重传
在第三个也是最后一个场景中,假设主机 A 发送了两个段,与第二个示例完全相同。 第一段的确认在网络中丢失,但就在超时事件之前,主机 A 收到确认编号为 120 的确认。因此,主机 A 知道主机 B 已经收到了直到字节 119 的所有内容; 所以主机 A 不会重新发送两个段中的任何一个。 这种情况如图 3.36 所示。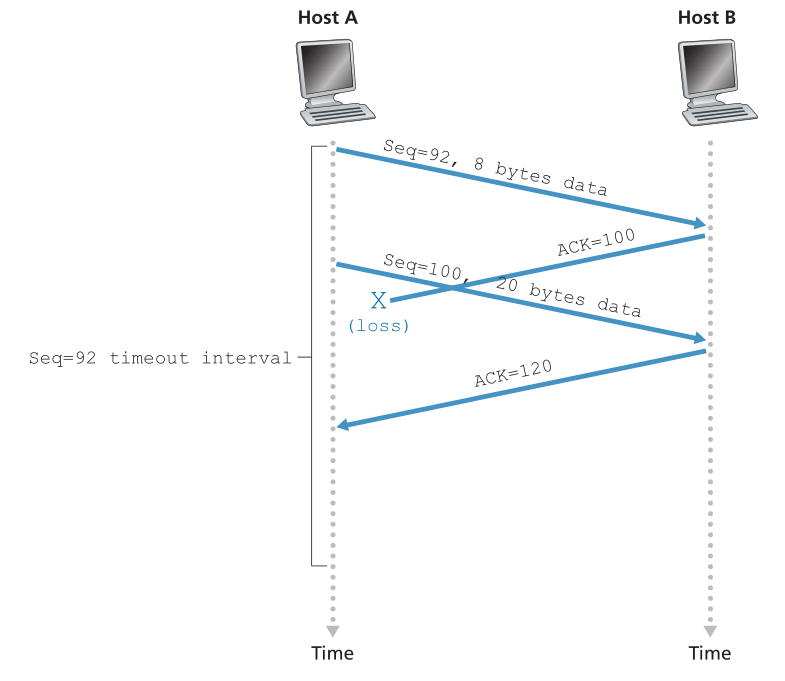
Figure 3.36 ♦ A cumulative acknowledgment avoids retransmission of the first segment
图3.36♦累积的确认避免了第一部分的重传
超时间隔加倍 Doubling the Timeout Interval
我们现在讨论大多数 TCP 实现采用的一些修改。第一个涉及计时器到期后超时间隔的长度。在此修改中,每当超时事件发生时,TCP 将重传具有最小序列号的尚未确认的段,如上所述。但是每次 TCP 重传时,它都会将下一个超时间隔设置为前一个值的两倍,而不是从最后一个 EstimatedRTT 和 DevRTT(如第 3.5.3 节中所述)推导出来。例如,假设与最旧的尚未确认的段相关联的 TimeoutInterval 在计时器第一次到期时为 0.75 秒。然后 TCP 将重新传输该段并将新的到期时间设置为 1.5 秒。如果定时器在 1.5 秒后再次到期,TCP 将再次重传该段,现在将到期时间设置为 3.0 秒。因此,间隔在每次重传后呈指数增长。但是,无论何时在其他两个事件(即从上面的应用程序接收到的数据和收到的 ACK)之后启动计时器时,TimeoutInterval 都是从 EstimatedRTT 和 DevRTT 的最新值派生出来的。
这种修改提供了一种有限形式的拥塞控制。(更全面的TCP拥塞控制形式将在第3.7节中研究。)定时器超时很可能是由于网络拥塞造成的,即太多的包到达源和目的路径上的一个(或多个)路由器队列,导致包被丢弃和/或长时间的排队延迟。在拥塞时,如果源持续重传数据包,拥塞可能会加剧。相反,TCP的行为更加礼貌,每个发送方在越来越长的间隔后重新发送。当我们在第6章学习CSMA/CD时,我们将看到以太网使用了类似的思想。
快速重传 Fast Retransmit
超时触发重传的问题之一是超时时间可能相对较长。当一个段丢失时,这个长超时时间迫使发送方延迟重新发送丢失的数据包,从而增加端到端延迟。幸运的是,发送方通常可以通过注意到所谓的重复 ACK (duplicate ACK)在超时事件发生之前很好地检测到数据包丢失。重复 ACK 是重新确认发送方已经收到较早确认的段的 ACK。要了解发送方对重复 ACK 的响应,我们必须首先了解接收方发送重复 ACK 的原因。表 3.2 总结了 TCP 接收方的 ACK 生成策略 [RFC 5681]。当 TCP 接收方接收到一个序列号大于下一个预期的有序序列号的数据段时,它会检测到数据流中的间隙,即丢失的数据段。这种差距可能是由于网络中的段丢失或重新排序造成的。由于 TCP 不使用否定确认,因此接收方无法向发送方发送明确的否定确认。相反,它只是重新确认(即,为其生成重复的 ACK)它已接收到的最后一个有序字节的数据。 (请注意,表 3.2 允许接收方不丢弃乱序段的情况。)
| 事件 | TCP接收方动作 |
|---|---|
| 有预期序列号的有序段到达。所有符合预期序列号的数据已确认。 | 延迟ACK确认。 等待 500 毫秒以等待另一个有序段的到达。 如果下一个有序段未在此间隔内到达,则发送 ACK。 |
| 有预期序列号的有序段到达。另一个按顺序等待ACK传输的段。 | 立即发送单个累积 ACK,确认两个有序段。 |
| 序列号高于预期的乱序段到达。 检测到间隙。 | 立即发送重复的ACK,指示下一个预期字节的序列号(即间隙的低端)。 |
| 部分或全部填补接收数据空白的段的到达。 | 立即发送 ACK,前提是该段从间隙的低端开始。 |
Table 3.2 ♦ TCP ACK Generation Recommendation [RFC 5681]
表3.2 ♦ TCP ACK生成建议[RFC 5681]
因为发送方经常会连续发送大量的segment,如果一个segment丢失了,很可能会有很多连续的重复ACK。 如果 TCP 发送方针对相同的数据收到三个重复的 ACK,则将其视为已被 ACK 三次的段之后的段已丢失的指示。 (在作业问题中,我们考虑了为什么发送方要等待三个重复的 ACK,而不只是一个重复的 ACK 的问题。)在收到三个重复的 ACK 的情况下,TCP 发送方执行快速重传(fast retransmit) [RFC 5681] ,在该段的计时器到期之前重新传输丢失的段。 这如图 3.37 所示,其中第二个段丢失,然后在其计时器到期之前重新传输。 对于具有快速重传的 TCP,以下代码片段替换了图 3.33 中的 ACK 接收事件:
event: ACK received, with ACK field value of yif (y > SendBase) {SendBase=yif (there are currently any not yetacknowledged segments)start timer}else {/* a duplicate ACK for already ACKedsegment */increment number of duplicate ACKsreceived for yif (number of duplicate ACKS receivedfor y==3)/* TCP fast retransmit */resend segment with sequence number y}break;
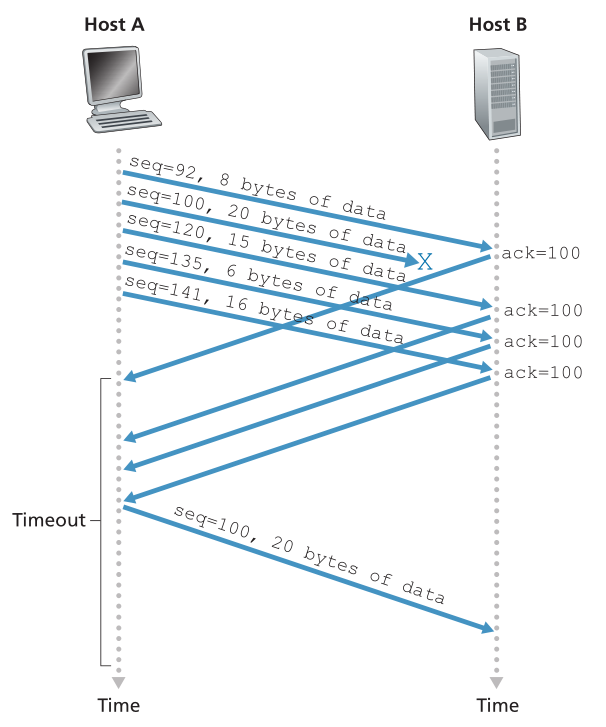
Figure 3.37 ♦ Fast retransmit: retransmitting the missing segment before the segment’s timer expires
图3.37♦快速重传:在段的定时器过期之前重传丢失的段
我们前面注意到,当在实际协议(如TCP)中实现超时/重传机制时,会出现许多微妙的问题。上面的过程是30多年使用TCP计时器的经验的结果,应该会使您相信这确实是这样的!
Go-Back-N还是选择性重传? Go-Back-N or Selective Repeat?
让我们通过考虑以下问题来结束对 TCP 错误恢复机制的研究:TCP 是 GBN 协议还是 SR 协议?回想一下,TCP 确认是累积的并被正确接收,但接收方不会单独确认乱序段。因此,如图 3.33(另请参见图 3.19)所示,TCP 发送方只需维护已传输但未确认字节的最小序列号 (SendBase) 和要发送的下一个字节的序列号 (NextSeqNum)。从这个意义上说,TCP 看起来很像 GBN 风格的协议。但是 TCP 和 Go-Back-N 之间存在一些显着差异。许多 TCP 实现会缓冲正确接收但乱序的段 [Stevens 1994]。还要考虑当发送方发送段 1, 2, … , N的序列,并且所有的段都按顺序到达接收方,并且没有错误时,会发生什么?进一步假设数据包 n < N 的确认丢失,但剩余的 N-1 个确认在它们各自的超时之前到达发送方。在这个例子中,GBN 不仅会重传数据包 n,还会重传所有后续的数据包 n+1,n+2,… ,N。另一方面,TCP 将最多重传一个段,即段 n。此外,如果第 n+1 段的确认在第 n 段超时之前到达,TCP 甚至不会重传第 n 段。
对 TCP 的提议修改,即所谓的选择性确认(selective acknowledgment) [RFC 2018],允许 TCP 接收器选择性地确认乱序段,而不是仅仅累积确认最后一个正确接收的有序段。 当与选择性重传(跳过已被接收方选择性确认的段的重传)结合使用时,TCP 看起来很像我们的通用 SR 协议。 因此,TCP 的错误恢复机制可能最好归类为 GBN 和 SR 协议的混合。
3.5.5 流量控制 Flow Control
回想一下,TCP连接两端的主机都为该连接预留了一个接收缓冲区。当TCP连接按照正确的顺序接收字节时,它将数据放入接收缓冲区。关联的应用程序进程将从该缓冲区读取数据,但不一定在数据到达时读取。实际上,接收应用程序可能正忙于其他任务,甚至可能在数据到达很久之后才尝试读取数据。如果应用程序读取数据的速度相对较慢,则发送方很容易因过快发送过多数据而溢出连接的接收缓冲区。
TCP 为其应用程序提供流量控制服务(flow-control service),以消除发送方溢出接收方缓冲区的可能性。因此,流量控制是一种速度匹配服务(speed-matching service)——将发送方发送的速率与接收应用程序读取的速率进行匹配。如前所述,TCP 发送方也可能因 IP 网络内的拥塞而受到限制;这种形式的发送方控制称为拥塞控制(congestion control),我们将在 3.6 和 3.7 节中详细探讨该主题。尽管流量控制和拥塞控制采取的行动是相似的(发送方的节流),但它们显然是出于非常不同的原因而采取的。不幸的是,许多作者交替使用这些术语,精明的读者最好区分它们。现在让我们讨论 TCP 如何提供其流量控制服务。为了透过一棵树看森林,我们在本节中假设 TCP 实现是这样的:TCP 接收方丢弃无序段。
TCP通过让发送方维护一个叫做接收窗口(receive window)的变量来提供流量控制。非正式地,接收窗口用于给发送方一个关于接收方有多少可用缓冲区空间的概念。因为TCP是全双工的,所以连接两端的发送方都维护一个不同的接收窗口。让我们研究一下文件传输上下文中的接收窗口。假设主机A通过TCP连接向主机B发送一个大文件。主机B分配一个接收缓冲区给这个连接;用RcvBuffer表示它的大小。主机B中的应用程序进程有时会从缓冲区中读取数据。定义以下变量:
- LastByteRead: B中的应用程序进程从缓冲区中读取的数据流中最后一个字节的编号。
- LastByteRcvd: 从网络到达的数据流中最后一个字节的编号,并且已经放在B的接收缓冲区中。
因为TCP不允许溢出已分配的缓冲区,所以我们必须有
接收窗口(rwnd表示)设置为缓冲区中的空闲空间数量:
因为空闲空间随时间变化,rwind是动态的。变量rwnd如图3.38所示。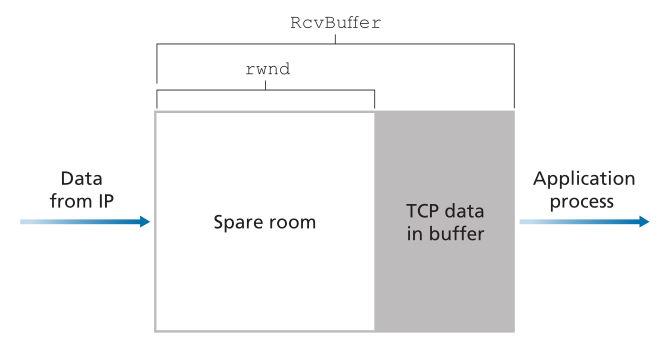
Figure 3.38 ♦ The receive window (rwnd) and the receive buffer (RcvBuffer)
图3.38♦接收窗口(rwnd)和接收缓冲区(RcvBuffer)
主机A依次跟踪两个变量,LastByteSent和LastByteAcked,这两个变量有明显的含义。注意,这两个变量之间的差LastByteSent - LastByteAcked是A已经发送到连接中的未确认数据的数量。通过保持未确认数据的数量小于rwnd的值,主机A可以确保它不会溢出主机B的接收缓冲区。因此,主机A确保在连接的整个生命周期内
这个方案有一个小的技术问题。为了看到这一点,假设主机B的接收缓冲区已满,因此rwnd = 0。在向主机A通告rwnd = 0之后,还假设B没有任何东西要发送给主机A。现在考虑发生了什么。当B的应用程序进程清空缓冲区时,TCP不会向主机A发送带有新rwnd值的新段;实际上,TCP只有在有数据要发送或有确认要发送的情况下才向主机A发送一个段。因此,主机A永远不会被告知主机B的接收缓冲区中有一些空间被开放了——主机A被阻塞了,不能传输更多的数据!为了解决这个问题,TCP规范要求主机A在B的接收窗口为零时继续发送一个数据字节的段。这些段将由接收方确认。最后,缓冲区将开始为空,确认将包含一个非零rwnd值。
在线站点为这本书提供了一个交互式动画,说明了TCP接收窗口的操作。
在描述了 TCP 的流量控制服务之后,我们在这里简要提到 UDP 不提供流量控制,因此,由于缓冲区溢出,接收方可能会丢失数据段。 例如,考虑从主机 A 上的进程向主机 B 上的进程发送一系列 UDP 段。对于典型的 UDP 实现,UDP 会将这些段添加到“precedes”相应套接字(即 ,进程的门)的有限大小缓冲区中。 该进程一次从缓冲区读取一个完整的段。 如果进程没有足够快地从缓冲区读取段,缓冲区将溢出并且段将被丢弃。
3.5.6 TCP连接管理 TCP Connection Management
在本小节中,我们将进一步了解TCP连接是如何建立和拆除的。尽管这个主题似乎不是特别令人兴奋,但它很重要,因为TCP连接的建立可能会显著增加可感知的延迟(例如,在浏览Web时)。而且,许多最常见的网络攻击——包括非常流行的SYN flood攻击(参见关于SYN flood攻击的侧栏)——都利用了TCP连接管理中的漏洞。让我们首先看看TCP连接是如何建立的。假设一个运行在一个主机(客户端)上的进程想要发起与另一个主机(服务器)上的另一个进程的连接。客户端应用程序进程首先通知客户端TCP,它想要建立到服务器中的进程的连接。客户端TCP与服务器端TCP建立连接的方式如下:
- 步骤1。客户端TCP首先向服务器端TCP发送一个特殊的TCP段。这个特殊的段不包含应用层数据。但是段头中的一个标志位(参见图3.29),SYN位被设置为1。由于这个原因,这个特殊的段被称为SYN段。此外,客户端随机选择一个初始序列号(client_isn),并将这个数字放在初始TCP SYN段的序列号字段中。这个段封装在一个IP数据报中并发送到服务器。为了避免某些安全攻击,对client_isn的选择进行适当的随机化已经引起了相当大的兴趣[CERT 2001-09;RFC 4987)。
- 步骤2。一旦包含TCP SYN段的IP数据报到达服务器主机(假设它真的到达了!),服务器从数据报中提取TCP SYN段,分配TCP缓冲区和变量给连接,并发送一个连接授予的段(connection-granted segment)给客户端TCP。(我们将在第8章中看到,在完成三次握手的第三步之前,这些缓冲区和变量的分配使得TCP容易受到被称为SYN泛洪的拒绝服务攻击。)这个被授予连接的段也不包含应用层数据。然而,它在段头中包含了三个重要的信息。首先,SYN位设置为1。第二,TCP段首部的确认字段设置为client_isn+1。最后,服务器选择自己的初始序列号(server_isn),并将这个值放入TCP段首部的序列号字段。这个授予连接的段实际上是在说,“我收到了您的SYN包,它使用您的初始序列号client_isn来启动一个连接。我同意建立这种联系。我自己的初始序列号是server_isn。”被授予连接的段称为SYNACK段。
- 步骤3。在接收到SYNACK段后,客户端也会分配缓冲区和变量给连接。然后,客户端主机再向服务器发送另一个段;最后一个段确认服务器的连接授权段(客户端通过在TCP段报头的确认字段中放入值server_isn+1来实现)。SYN位被设置为0,因为连接已经建立。三次握手的第三阶段可以在段有效负载中携带客户端到服务器的数据。
一旦这三个步骤完成,客户机和服务器主机就可以相互发送包含数据的段。在每一个将来的段中,SYN位将被设置为零。请注意,为了建立连接,在两台主机之间发送三个包,如图3.39所示。由于这个原因,这个连接建立过程通常被称为三次握手(three-way handshake)。作业问题中探讨了TCP三次握手的几个方面(为什么需要初始序列号?为什么需要三向握手,而不是双向握手?)有趣的是,攀岩者和保护者(驻扎在攀岩者下方,负责处理攀岩者的安全绳)使用与 TCP 相同的三向握手通信协议,以确保双方在攀岩者开始攀登之前准备好。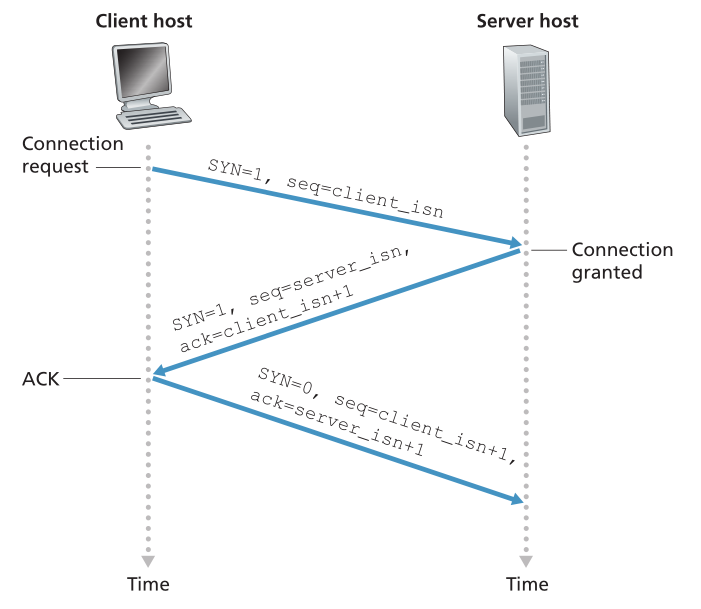
Figure 3.39 ♦ TCP three-way handshake: segment exchange
图3.39 TCP三次握手:段交换
天下无不散之筵席,TCP连接也是如此。参与TCP连接的两个进程中的任何一个都可以终止该连接。当连接结束时,主机中的“资源”(即缓冲区和变量)被释放。例如,假设客户端决定关闭连接,如图3.40所示。客户端应用程序进程发出关闭命令(close command)。这导致客户端TCP向服务器进程发送一个特殊的TCP段。这个特殊的段在段的首部有一个标志位,FIN位(见图3.29),设置为1。当服务器接收到这个段时,它返回给客户端一个确认段。然后服务器发送自己的shutdown段,其中FIN位设置为1。最后,客户端确认服务器的关闭段(shutdown segment)。此时,两个主机中的所有资源都被释放了。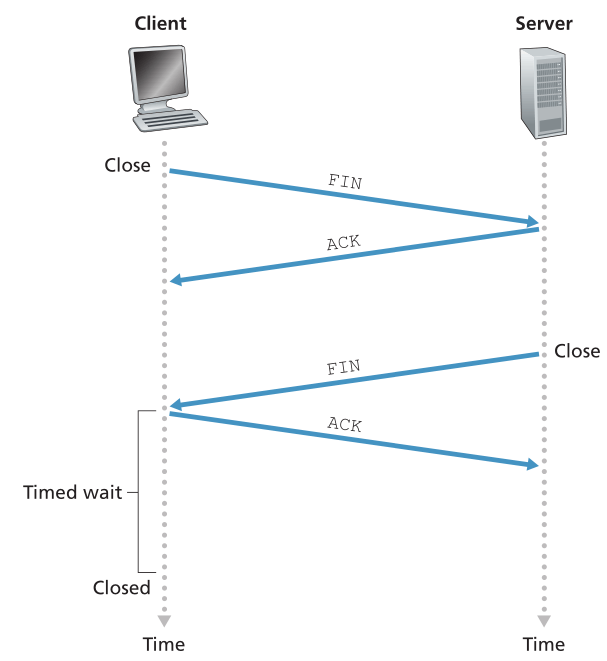
Figure 3.40 ♦ Closing a TCP connection
图3.40♦关闭TCP连接
在TCP连接的生命周期中,运行在每个主机上的TCP协议通过各种TCP状态(TCP states)进行转换。图3.41显示了客户端TCP访问的TCP状态的一个典型序列。客户端TCP以CLOSED状态开始。客户端应用程序发起一个新的TCP连接(通过在第2章的Python示例中创建一个Socket对象)。这会导致客户端中的TCP向服务器中的TCP发送一个SYN段。发送完SYN段后,客户端TCP进入SYNSENT状态。当处于SYN_SENT状态时,客户端TCP等待来自服务器TCP的一个段,该段包含对客户端前一个段的确认,并且SYN位设置为1。客户端TCP接收到这样一个段后,进入ESTABLISHED状态。在ESTABLISHED状态下,TCP客户端可以发送和接收包含有效负载(即应用程序生成的)数据的TCP段。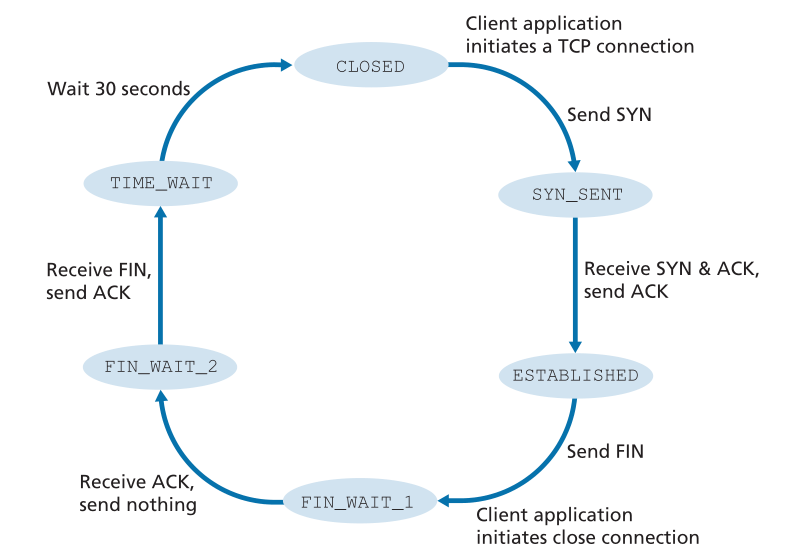
Figure 3.41 ♦ A typical sequence of TCP states visited by a client TCP
图3.41♦客户端TCP访问的TCP状态的典型序列
假设客户端应用程序决定要关闭连接。(注意,服务器也可以选择关闭连接。)这导致客户端TCP发送一个FIN位为1的TCP段并进入FIN_WAIT_1状态。当处于FIN_WAIT_1状态时,客户端TCP等待来自服务器的TCP段的确认。当客户端TCP接收到该报文段时,进入FIN_WAIT_2状态。当处于FIN_WAIT_2状态时,客户端等待来自服务器的另一个FIN位设为1的段;客户端TCP接收到该段后,确认服务器的段并进入TIME_WAIT状态。**TIME WAIT状态允许TCP客户端在ACK丢失的情况下重新发送最后的确认(客户端的最后ACK丢失,服务端的FIN会触发超时重传,然后客户端收到FIN后重新发送ACK,TIME_WAIT保证了一定可以不断将ACK发送到服务端,直到服务端收到,服务端到了超时时间还没发送FIN就代表服务端收到了ACK)。花在TIME_WAIT状态上的时间取决于实现,但典型值是30秒、1分钟和2分钟。等待之后,连接正式关闭,客户端上的所有资源(包括端口号)被释放。
图3.42说明了服务器端TCP通常访问的一系列状态,假设客户端开始断开连接。这些转换不言自明。在这两个状态转换图中,我们只展示了TCP连接通常是如何建立和关闭的。我们没有描述在某些病态情况下会发生什么,例如,当连接的双方想同时启动或关闭。如果您有兴趣了解关于TCP的这方面和其他高级问题,请参阅Stevens的综合著作[Stevens 1994]。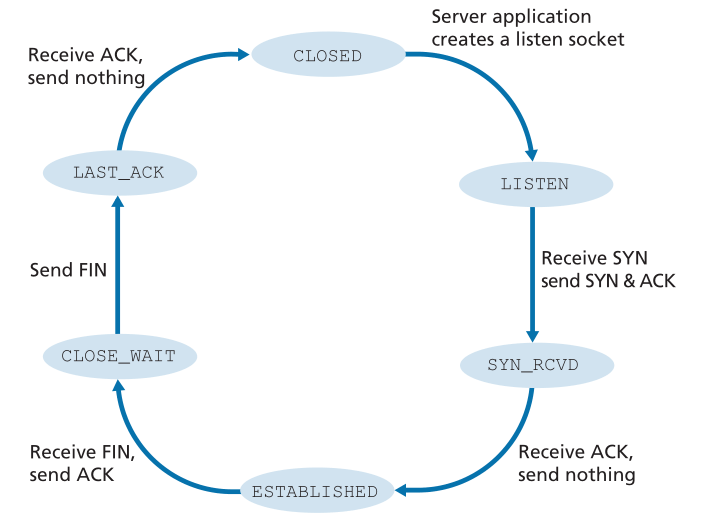
Figure 3.42 ♦ A typical sequence of TCP states visited by a server-side TCP
图3.42♦服务器端TCP访问TCP状态的典型序列
我们上面的讨论假设客户端和服务器都准备进行通信,也就是说,服务器正在侦听(listening)客户端发送SYN段的端口。让我们考虑一下,当主机接收到端口号或源IP地址与主机中任何正在进行的套接字不匹配的TCP段时会发生什么。例如,假设一台主机接收一个目的端口为80的TCP SYN包,但是该主机没有在端口80上接受连接(也就是说,它没有在端口80上运行Web服务器)。然后,主机将向源发送一个特殊的重置段(reset segment)。这个TCP段的RST标志位(参见3.5.2节)设置为1。因此,当主机发送一个重置段时,它是在告诉源“我没有该段的套接字。请不要重新发送这个片段。”当主机接收到一个UDP包,其目的端口号与正在进行的UDP套接字不匹配,主机发送一个特殊的ICMP数据报(datagram)**,如第五章所述。
现在我们已经很好地理解了TCP连接管理,让我们重新访问nmap端口扫描工具,并更仔细地研究它是如何工作的。为了探索目标主机上的特定TCP端口,比如端口6789,nmap将向该主机发送一个目标端口6789的TCP SYN段。有三种可能的结果:
- 源主机从目标主机接收TCP SYNACK段(The source host receives a TCP SYNACK segment from the target host)。因为这意味着应用程序在目标post上使用TCP端口6789运行,所以nmap返回“open”。
- 源主机从目标主机接收TCP RST段(The source host receives a TCP RST segment from the target host)。这意味着SYN段到达目标主机,但目标主机没有运行TCP端口6789的应用程序。但是攻击者至少知道发送到端口6789的主机的段没有被源主机和目标主机之间的路径上的任何防火墙阻止。(防火墙在第8章中讨论。)
- 源没有接收到任何东西(The source receives nothing)。这可能意味着SYN段被中间的防火墙阻止了,并且从未到达目标主机。
Nmap是一个强大的工具,它不仅可以用于开放的TCP端口,还可以用于开放的UDP端口,用于防火墙及其配置,甚至用于应用程序和操作系统的版本。这大部分是通过操作TCP连接管理段(TCP connection-management segments)完成的。你可以从www.nmap.org下载nmap。
这就完成了我们对TCP中的错误控制和流量控制的介绍。在第3.7节中,我们将回到TCP并深入了解TCP拥塞控制。然而,在这样做之前,我们首先后退一步,在更广泛的背景下检查拥塞控制问题。
FOCUS ON SECURITY 关注安全 THE SYN FLOOD ATTACK SYN泛洪攻击 我们已经在讨论TCP的三次握手中看到,服务器分配并初始化连接变量和缓冲区来响应接收到的SYN,然后服务器发送一个SYNACK作为响应,并等待客户端的ACK段。如果客户端没有发送ACK来完成这个三次握手的第三步,最终(通常在一分钟或更长时间后)服务器将终止半开的连接并回收分配的资源。 此 TCP 连接管理协议为经典的拒绝服务 (Denial of Service,DoS) 攻击(称为 SYN 泛洪攻击)奠定了基础。 在这次攻击中,攻击者发送了大量 TCP SYN 段,而没有完成第三个握手步骤。 随着 SYN 段的大量涌入,服务器的连接资源在为半开连接分配(但从未使用!)时会耗尽; 然后拒绝合法客户服务。 这种 SYN 泛洪攻击是最早记录在案的 DoS 攻击之一 [CERT SYN 1996]。 幸运的是,一种称为 SYN cookie [RFC 4987] 的有效防御现已部署在大多数主要操作系统中。 SYN cookie 的工作原理如下:
- 当服务器收到 SYN 段时,它不知道该段是来自合法用户还是属于 SYN 泛洪攻击的一部分。 因此,服务器不是为此 SYN 创建半开 TCP 连接,而是创建初始 TCP 序列号,该序列号是 SYN 段的源和目标 IP 地址和端口号,以及只有服务器知道的秘密号码的复杂函数(散列函数)。 这个精心制作的初始序列号就是所谓的“cookie”。 然后服务器向客户端发送一个带有这个特殊初始序列号的 SYNACK 数据包。 重要的是,服务器不会记住与 SYN 对应的 cookie 或任何其他状态信息。
- 合法的客户端将返回一个 ACK 段。 当服务器收到这个 ACK 时,它必须验证 ACK 是否对应于之前发送的某个 SYN。 但是如果服务器不维护关于 SYN 段的内存,这是如何完成的呢? 正如您可能已经猜到的那样,它是通过 cookie 完成的。 回想一下,对于合法的 ACK,确认字段中的值等于 SYNACK 中的初始序列号(本例中的 cookie 值)加一(见图 3.39)。 然后,服务器可以使用 SYNACK 中的源和目标 IP 地址和端口号(与原始 SYN 中的相同)和秘密号运行相同的散列函数。 如果函数的结果加一与客户端 SYNACK 中的确认 (cookie) 值相同,则服务器推断 ACK 对应于较早的 SYN 段,因此是有效的。 然后服务器创建一个完全开放的连接和一个套接字。
- 另一方面,如果客户端没有返回 ACK 段,那么原始 SYN 对服务器没有任何伤害,因为服务器尚未分配任何资源来响应原始虚假 SYN。

若有收获,就点个赞吧
0 人点赞
