谷歌(Google)、微软(Microsoft)、亚马逊(Amazon)和阿里巴巴(Alibaba)等互联网公司已经建立了大规模的数据中心,每个中心都有数万到数十万台主机。正如第1.2节的侧栏中简要讨论的那样,数据中心不仅连接到Internet,而且在内部还包括复杂的计算机网络,称为数据中心网络(data center networks),这些网络互连其内部主机。在本节中,我们将简要介绍云应用的数据中心网络。
一般说来,数据中心有三个目的。首先,它们向用户提供网页、搜索结果、电子邮件或流视频等内容。其次,它们充当特定数据处理任务的大规模并行计算基础设施,例如搜索引擎的分布式索引计算。第三,他们为其他公司提供云计算。事实上,今天计算的一个主要趋势是公司使用云提供商(如Amazon Web Services、Microsoft Azure和阿里巴巴云)来处理基本上所有的IT需求。
6.6.1 数据中心架构 Data Center Architectures
数据中心设计严格保守公司机密,因为它们通常会为领先的云计算公司提供关键的竞争优势。大型数据中心的成本是巨大的,2009年100,000个主机数据中心的成本超过每月1200万美元[Greenberg 2009a]。在这些成本中,约45%来自主机本身(每3-4年需要更换一次);25%用于基础设施,包括变压器、不间断电源(UPS)系统、用于长期停机的发电机和冷却系统;15%用于电力供应;15%用于网络成本,包括网络设备(交换机、路由器和负载均衡器)、外部链路和运输流量成本。(在这些百分比中,设备成本已摊销,以便对一次性采购和持续费用(如电力)应用通用成本衡量标准。)。虽然联网不是最大的成本,但联网创新是降低总体成本和最大化性能的关键[Greenberg 2009a]。
数据中心的工蜂(worker bees)是主机。数据中心中的主机称为刀片(blades),类似于披萨盒,通常是包括CPU、内存和磁盘存储的商用主机。主机堆叠在机架中,每个机架通常有20到40个刀片。每个机架的顶部都有一台交换机,恰如其分地命名为架顶式(Top of Rack,TOR)交换机,它将机架中的主机彼此互连,并与数据中心中的其他交换机互连。具体地说,机架中的每台主机都有一个连接到其TOR交换机的网络接口,并且每台TOR交换机都有可以连接到其他交换机的附加端口。如今,主机通常有40 Gbps或100 Gbps以太网连接到其ToR交换机[FB 2019;Greenberg 2015;Roy 2015;Singh 2015]。每台主机还分配有自己的数据中心内部IP地址。
数据中心网络支持两种类型的流量:外部客户端和内部主机之间的流量和内部主机之间的流量。为了处理外部客户端和内部主机之间的流量,数据中心网络包括一个或多个将数据中心网络连接到公共互联网的边界路由器(border routers)。因此,数据中心网络将机架彼此互连,并将机架连接到边界路由器。图6.30显示了数据中心网络的示例。数据中心网络设计(Data center network design)是设计互连网络和协议的艺术,这些互连网络和协议将机架彼此连接起来,并与边界路由器相连,近年来已成为计算机网络研究的一个重要分支。(请参阅本节中的参考资料。)
负载均衡 Load Balancing
云数据中心(例如由Google、Microsoft、Amazon和阿里巴巴运营的云数据中心)同时提供许多应用程序,例如搜索、电子邮件和视频应用程序。为了支持来自外部客户端的请求,每个应用程序都与一个公开可见的IP地址相关联,客户端将其请求发送到该地址,并从该地址接收响应。在数据中心内部,外部请求首先被定向到负载均衡器(load balancer),该负载均衡器的工作是将请求分发到主机,根据主机的当前负载来平衡主机间的负载[Patel 2013;Eisenbud 2016]。大型数据中心通常会有多个负载均衡器,每个负载均衡器专用于一组特定的云应用。这种负载均衡器有时被称为“第四层交换机”,因为它根据数据包中的目的端口号(第四层)以及目的IP地址做出决定。在接收到对特定应用程序的请求时,负载均衡器将其转发给处理该应用程序的主机之一。(然后,主机可以调用其他主机的服务来帮助处理该请求。)。负载均衡器不仅平衡主机间的工作负载,还提供类似NAT的功能,将公共外部IP地址转换为相应主机的内部IP地址,然后将反向传输的数据包转换回客户端。这可防止客户端直接联系主机,从而具有隐藏内部网络结构和防止客户端直接与主机交互的安全优势。
分层架构 Hierarchical Architecture
对于仅容纳几千台主机的小型数据中心,由一台边界路由器、一个负载均衡器和几十个机架组成的简单网络(全部由一台以太网交换机互连)可能就足够了。但是,为了扩展到数万到数十万台主机,数据中心通常采用路由器和交换机的层次结构,如图6.30所示的拓扑。在层次结构的顶部,边界路由器连接到接入路由器(图6.30中只显示了两个,但还可以有更多)。每台接入路由器下面有三层交换机。每个接入路由器连接到一个顶级交换机,每个顶级交换机连接到多个第二层交换机和一个负载均衡器。每个第二层交换机依次通过机架的ToR交换机(第三层交换机)连接到多个机架。所有链路通常使用以太网作为其链路层和物理层协议,并混合使用铜缆和光纤布线。使用这种分层设计,可以将数据中心扩展到数十万台主机。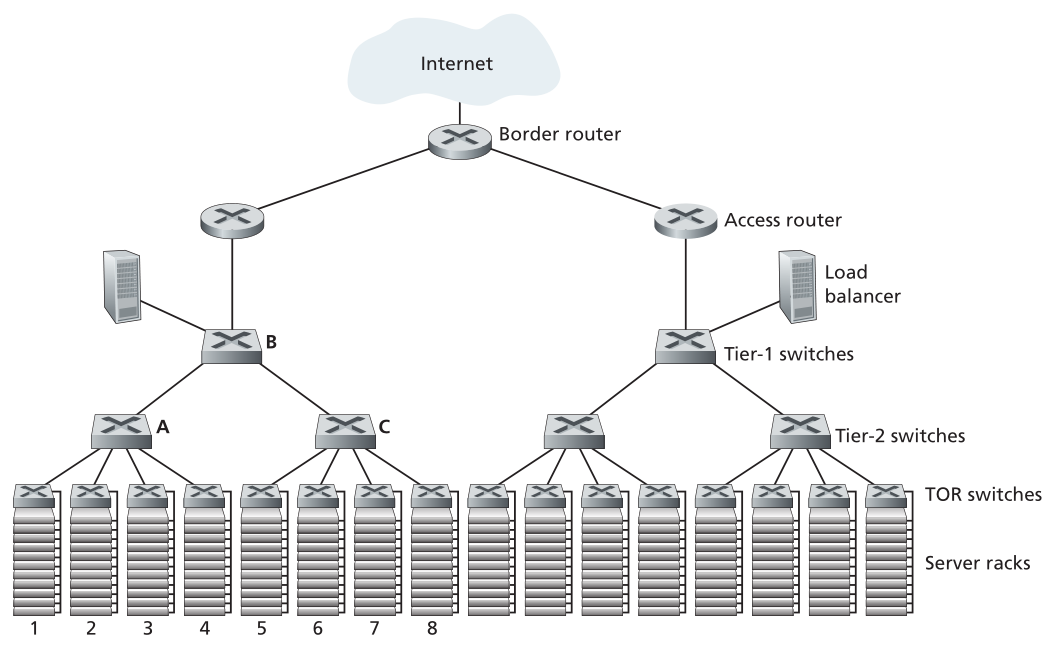
Figure 6.30 ♦ A data center network with a hierarchical topology
图6.30♦具有分层拓扑的数据中心网络
由于云应用提供商持续为应用提供高可用性至关重要,因此数据中心在其设计中还包括冗余网络设备和冗余链路(图6.30中未显示)。例如,每个ToR交换机可以连接到两个第2层交换机,并且每个接入路由器、第1层交换机和第2层交换机都可以复制并集成到设计中[Cisco 2012;Greenberg 2009b]。在图6.30的分层设计中,可以看到每台接入路由器下方的主机形成了单个子网。为了使ARP广播流量本地化,这些子网中的每个进一步划分为较小的VLAN子网,每个子网包含数百台主机[Greenberg 2009a]。
虽然上述传统的分层体系结构解决了规模问题,但它受到主机到主机容量的限制(Greenberg 2009b)。要理解此限制,请再次参考图6.30,假设每台主机通过10 Gbps链路连接到其TOR交换机,而交换机之间的链路是100 Gbps以太网链路。同一机架中的两台主机可以始终以10 Gbps的速度通信,仅受主机网络接口控制器速率的限制。但是,如果数据中心网络中有许多并发流量,则不同机架中的两台主机之间的最大速率可能会小得多。要深入了解此问题,请考虑一种流量模式,该模式由不同机架中的40对主机之间的40个并发流量组成。具体地说,假设图6.30中的机架1中的10台主机中的每台都向机架5中的相应主机发送流。同样,机架2和6中的主机对之间有10个同时流,机架3和7之间有10个同时流,机架4和8之间有10个同时流。如果每个流与通过该链路的其他流平均共享一条链路的容量,则通过100 Gbps A到B链路(以及100 Gbps B到C链路)的40个流将各自仅接收100 Gbps / 40 = 2.5 Gbps,这明显低于10Gbps的网络接口速率。对于需要在层次结构中向上传输的主机之间的流量,这个问题变得更加严重。
此问题有几种可能的解决方案:
- 解决此限制的一个可能的解决方案是部署更高速率的交换机和路由器。但这将显著增加数据中心的成本,因为端口速度高的交换机和路由器非常昂贵。
- 此问题的第二个解决方案(可在任何可能的情况下采用)是将相关服务和数据尽可能靠近地放在一起(例如,在同一机架中或在附近的机架中)[Roy 2015;Singh 2015],以便最大限度地减少通过第2层或第1层交换机进行的机架间通信。但这只能到此为止,因为数据中心的一个关键要求是计算和服务放置的灵活性[Greenberg 2009b;Farrington 2010]。例如,大型互联网搜索引擎可能在分布在多个机架上的数千台主机上运行,所有主机对之间的带宽要求很高。类似地,云计算服务(诸如亚马逊网络服务或微软Azure)可能希望将构成客户服务的多个虚拟机放置在具有最大容量的物理主机上,而不管它们在数据中心中的位置。如果这些物理主机分布在多个机架上,如上所述的网络瓶颈可能会导致性能下降。
- 该解决方案的最后一部分是在ToR交换机和第2层交换机之间以及第2层交换机和第1层交换机之间提供更高的连接性。例如,如图6.31所示,每个TOR交换机可以连接到两个第2层交换机,然后在机架之间提供多条链路和交换机不相交的路径。在图6.31中,第一个第2层交换机和第二个第2层交换机之间有四条不同的路径,前两个第2层交换机之间的总容量为400 Gbps。提高层之间的连接度有两个显著的好处:既增加了交换机之间的容量,又提高了可靠性(由于路径多样性)。在Facebook的数据中心[FB 2014;FB 2019],每个ToR连接到四个不同的二级交换机,每个二级交换机连接到四个不同的一级交换机。
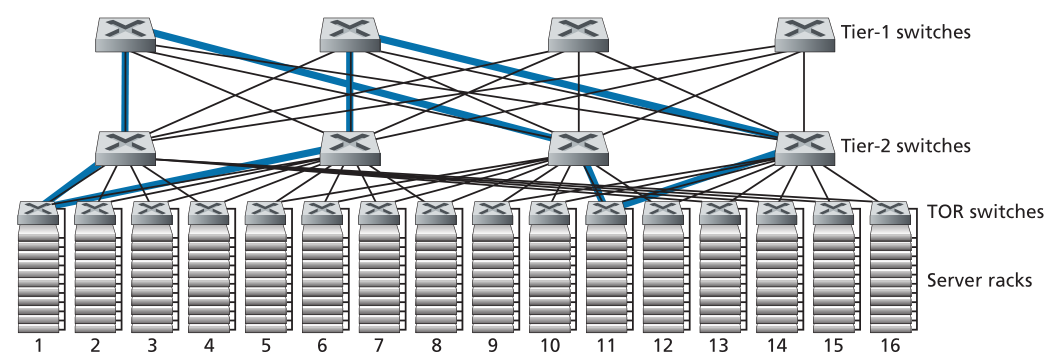
Figure 6.31 ♦ Highly interconnected data network topology
图6.31♦高度互联数据网络拓扑
数据中心网络中各层之间连接性增强的一个直接后果是,多路径路由可以成为这些网络中的一等公民。默认情况下,流是多路径流。实现多路径路由的一个非常简单的方案是等成本多路径(ECMP)[RFC 2992],它沿源和目的地之间的交换机执行随机化的下一跳选择。还提出了使用更细粒度负载平衡的高级方案[Alizadeh 2014;Noormohammadour 2018]。虽然这些方案在流级别执行多路径路由,但也有在多条路径之间路由一个流中的单个数据包的设计[He 2015;Raiciu 2010]。
6.6.2 数据中心网络的发展趋势 Trends in Data Center Networking
数据中心网络发展迅速,其趋势受成本降低、虚拟化、物理约束、模块化和定制化的推动。
降低成本 Cost Reduction
为了降低数据中心的成本,同时提高其延迟和吞吐量性能,以及易于扩展和部署,互联网云巨头不断部署新的数据中心网络设计。虽然其中一些设计是专有的,但其他设计(例如,[FB 2019])在公开文献中是明确开放或描述的(例如,[Greenberg,2009b;Singh 2015])。因此,可以确定许多重要的趋势。
图6.31说明了数据中心网络中最重要的趋势之一-互连数据中心主机的层次分层网络的出现。此层次结构在概念上与我们在第4.2.2节中研究的单个(非常、非常!)大型交叉交换机的用途相同,它允许数据中心中的任何主机与任何其他主机通信。但正如我们已经看到的,这种分层互连网络与概念性交叉交换机相比具有许多优势,包括从源到目的地的多条路径,以及容量(由于多路径路由)和可靠性(由于任意两台主机之间的多条交换机和链路不相交的路径)。
数据中心互联网络由大量小型交换机组成。例如,在Google的Jupiter数据中心结构中,一种配置在ToR交换机及其下面的服务器之间有48条链路,连接多达8台二级交换机;一台二级交换机连接到256台ToR交换机,链接多达16台一级交换机[Singh 2015]。在Facebook的数据中心架构中,每台ToR交换机最多连接四台不同的二级交换机(每台交换机都在不同的“样条平面(spline plane)”内),每台二级交换机在其样条平面内连接48台一级交换机中的最多四台;共有四个样条平面。第1层和第2层交换机分别连接到更多可扩展的第2层或ToR交换机(低于[FB 2019])。对于一些最大的数据中心运营商来说,这些交换机是由商品、现成的商用芯片在内部构建的 [Greenberg 2009b; Roy 2015; Singh 2015] 而不是从交换机供应商处购买。
多交换机分层(分层、多级)互连网络(multi-switch layered (tiered, multistage) interconnection network),如图6.31中所示,并在上面讨论的数据中心架构中实施,称为Clos网络,以Charles Clos命名,他在电话交换的背景下研究了此类网络[Clos 1953]。从那时起,Clos网络发展了丰富的理论,在数据中心网络和多处理器互连网络中发现了更多的用途。
SDN集中控制与管理 Centralized SDN Control and Management
由于数据中心由单个组织管理,因此许多最大的数据中心运营商(包括Google、Microsoft和Facebook)自然会接受类似SDN的逻辑集中控制概念。它们的架构还反映了数据平面(由相对简单的商用交换机组成)和基于软件的控制平面的明确分离,如我们在第5.5节中所见。由于其数据中心的巨大规模,我们在第5.7节中遇到的自动化配置和操作状态管理也至关重要。
虚拟化 Virtualization
虚拟化一直是云计算和更广泛的数据中心网络增长的主要推动力。虚拟机(VM)将运行应用程序的软件与物理硬件分离。这种分离还允许在可能位于不同机架上的物理服务器之间无缝迁移虚拟机。标准以太网和IP协议在跨服务器保持活动网络连接的同时支持VM移动方面存在限制。由于所有数据中心网络都由单个管理机构管理,因此将整个数据中心网络视为单一、扁平的第2层网络是该问题的完美解决方案。回想一下,在典型的以太网络中,ARP协议维护接口上的IP地址和硬件(MAC)地址之间的绑定。为了模拟将所有主机连接到一个“单个”交换机的效果,ARP机制被修改为使用DNS式查询系统而不是广播,并且目录维护分配给VM的IP地址和VM当前连接到数据中心网络中的哪个物理交换机的映射。[Mysore 2009;Greenberg 2009b]中提出了实现这一基本设计的可扩展方案,并已成功部署在现代数据中心。
物理约束 Physical Constraints
与广域互联网(wide area Internet)不同,数据中心网络的运行环境不仅容量非常高(40 Gbps和100 Gbps链路现在很常见),而且延迟极低(微秒)。因此,缓冲区大小很小,拥塞控制协议(如TCP及其变体)在数据中心中不能很好地扩展。在数据中心,拥塞控制协议必须做出快速反应,并在极低的损耗状态下运行,因为丢失恢复和超时可能导致极低的效率。已经提出并部署了几种解决此问题的方法,从特定于数据中心的TCP变体[Alizadeh 2010]到在标准以太网上实施远程直接内存访问(Remote Direct Memory Access,RDMA)技术[Zhu 2015; Moshref 2016; Guo 2016]。调度理论还被应用于开发将流量调度与速率控制分离的机制,从而实现非常简单的拥塞控制协议,同时保持链路的高利用率[Alizadeh 2013;Hong 2012]。
硬件模块化和定制化 Hardware Modularity and Customization
另一个主要趋势是采用基于集装箱的模块化数据中心(modular data centers,MDC)[YouTube 2009;Waldrop 2007]。在MDC中,工厂在一个标准的12米长的装运集装箱内建造一个“迷你数据中心”,并将集装箱装运到数据中心位置。每个集装箱最多有几千台主机,堆叠在几十个机架上,紧密地堆放在一起。在数据中心位置,多个集装箱彼此互连,也与互联网互连。在数据中心部署预制容器后,通常很难对其进行维护。因此,每个容器都是针对正常的性能降级而设计的:当组件(服务器和交换机)随着时间的推移发生故障时,容器将继续运行,但性能会下降。当许多组件发生故障且性能降至阈值以下时,整个容器将被移除,并替换为新的容器。
使用容器构建数据中心会带来新的网络挑战。对于MDC,有两种类型的网络:容器-每个容器内的内部网络和连接每个容器的核心网络[Guo 2009;Farrington 2010]。在每个容器内,在多达数千台主机的规模内,可以使用廉价的商用千兆以太网交换机构建完全连接的网络。然而,核心网络的设计仍然是一个具有挑战性的问题,即在为典型工作负载提供跨容器的高主机到主机带宽的同时,将数百到数千个容器互连起来。在[Farrington 2010]中描述了一种用于互连集装箱的混合电/光交换体系结构(hybrid electrical/optical switch architecture)。
另一个重要趋势是,大型云提供商越来越多地构建或定制其数据中心中的几乎所有内容,包括网络适配器、交换机路由器、ToR、软件和网络协议[Greenberg 2015;Singh 2015]。亚马逊倡导的另一种趋势是通过“可用区(availability zones)”提高可靠性,“可用区”本质上是在附近不同建筑中复制不同的数据中心。通过将建筑物放在附近(相距几公里),事务数据可以跨同一可用区的数据中心进行同步,同时提供容错能力[Amazon 2014]。数据中心设计方面的更多创新可能会继续出现。

若有收获,就点个赞吧
0 人点赞
