在讨论锁之前,我们将首先描述如何在一些常见的数据结构中使用锁。向数据结构添加锁以使其可被线程使用,这将使结构**线程安全(thread safe)**。当然,如何添加这些锁决定了数据结构的正确性和性能。因此,我们的挑战是:
关键的问题:怎样为数据结构添加锁 当给定一个特定的数据结构时,我们应该如何给它添加锁,以使它正常工作?此外,我们如何添加锁以使数据结构产生高性能,使许多线程同时访问结构,即并发?
当然,我们很难涵盖所有添加并发性的数据结构或所有方法,因为这是一个已经研究了多年的主题,已经发表了数以千计的研究论文。因此,我们希望对所需的思维类型提供足够的介绍,并建议您参考一些好的资料来源,以便您自己进行进一步的调查。我们发现Moir和Shavit的调查是一个很好的信息来源[MS04]。
29.1 并发计数器 Concurrent Counters
最简单的数据结构之一是计数器。它是一种常用的结构,有一个简单的接口。我们在图29.1中定义了一个简单的非并发计数器(non-concurrent counter)。
简单但不可扩展 Simple But Not Scalable
如您所见,非同步计数器(non-synchronized counter)是一个简单的数据结构,只需要少量代码就可以实现。现在我们面临下一个挑战:如何使代码线程安全?图29.2显示了我们如何做到这一点。
这个并发计数器(concurrent counter)很简单,工作正常。事实上,它遵循最简单和最基本的并发数据结构的通用设计模式:它只是添加一个锁,该锁在调用操作数据结构的例程时获得,并在从调用返回时释放。在这种方式下,它类似于使用监视器(monitors)构建的数据结构[BH73],其中锁是在调用和从对象方法返回时自动获取和释放的。
此时,您就拥有了一个可工作的并发数据结构。您可能遇到的问题是性能。如果你的数据结构太慢,你需要做的不仅仅是添加一个锁;因此,如果需要,这样的优化就是本章其余部分的主题。注意,如果数据结构不是太慢,那么就完成了!如果简单的方法能奏效,就不需要做什么花哨的事情。
为了理解这种简单方法的性能代价,我们运行了一个基准测试(benchmark),其中每个线程对一个共享计数器进行固定次数的更新;然后我们改变线程的数量。图29.5显示了一个到四个线程活动时所花费的总时间;每个线程更新计数器一百万次。这个实验是在一台带有4个Intel 2.7 GHz i5 cpu的iMac上进行的;随着更多的cpu处于活动状态,我们希望在单位时间内完成更多的工作。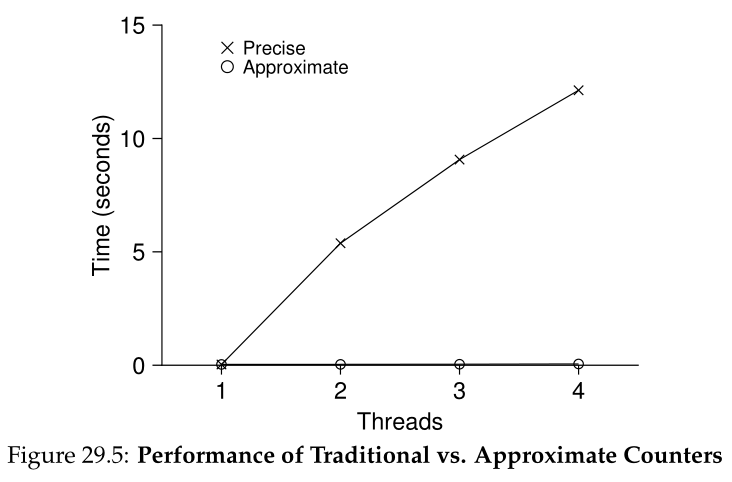
从图中的顶行(标有“Precise”),您可以看到同步计数器(synchronized counter)的性能扩展不佳。虽然单个线程可以在极短的时间内(大约 0.03 秒)完成百万次计数器更新,但有两个线程同时更新计数器一百万次会导致大幅减速(超过 5 秒!)。更多的线程只会变得更糟。
理想情况下,您希望看到线程在多个处理器上的完成速度与单个线程在一个处理器上的完成速度一样快。达到这一目的被称为完美扩展(perfect scaling);即使完成了更多的工作,它们也是并行完成的,因此完成任务所花的时间不会增加。
可扩展计数 Scalable Counting
令人惊讶的是,研究人员多年来一直在研究如何构建可扩展的计数器[MS04]。更令人惊讶的是,可扩展的计数器很重要,最近在操作系统性能分析方面的工作表明[B+10];如果没有可扩展的计数,在Linux上运行的一些工作负载在多核机器上会遇到严重的可扩展性问题。
已经开发了许多技术来解决这个问题。我们将描述一种称为近似计数器(approximate counter)的方法[C06]。
近似计数器的工作原理是通过多个局部物理计数器(每个CPU内核一个)来表示单个逻辑计数器,以及单个全局计数器。具体来说,在一台有四个cpu的机器上,有四个局部计数器和一个全局计数器。除了这些计数器外,还有锁:一个锁用于每个局部计数器,一个锁用于全局计数器。
我们需要局部锁,因为我们假设每个核上可能有多个线程。相反,如果每个内核上只运行一个线程,则不需要局部锁。
然而,为了保持全局计数器是最新的(在线程希望读取它的值的情况下),局部的值会定期被转移到全局计数器,方法是获取全局锁并按局部计数器的值增加;然后将局部计数器重置为零。
这种局部到全局的转移发生的频率是由阈值S决定的。S越小,计数器的行为就越像上面的不可扩展计数器;S越大,计数器的可扩展性就越大,但全局值可能离实际计数越远。可以简单地获取所有局部锁和全局锁(按照指定的顺序,以避免死锁)来获得准确的值,但这是不可扩展的。
为了说清楚这一点,让我们看一个示例(图29.3)。在这个例子中,阈值S被设置为5,四个cpu中的每个cpu上都有线程在更新它们的局部计数器L1…L4。跟踪中还显示了全局计数器值(G),随时间向下增加。在每个时间步,一个本地计数器可能会增加;如果本地值达到阈值S,则将本地值转移到全局计数器并重置本地计数器。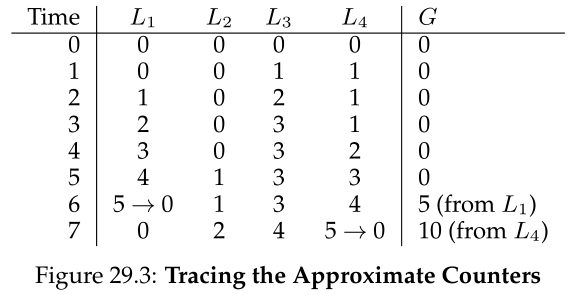
图29.5中的下一行(在标记为Approximate)显示了阈值S为1024的近似计数器的性能。性能很好;在4个处理器上更新计数器400万次所花费的时间并不比在1个处理器上更新计数器100万次所花费的时间高。
图 29.6 显示了阈值 S 的重要性,其中有四个线程,每个线程在四个 CPU 上将计数器递增 100 万次。如果 S 较低,则性能较差(但全局计数总是相当准确);如果 S 很高,则性能非常好,但全局计数滞后(最多为 CPU 数量乘以 S)。这种准确性/性能权衡是近似计数器所实现的。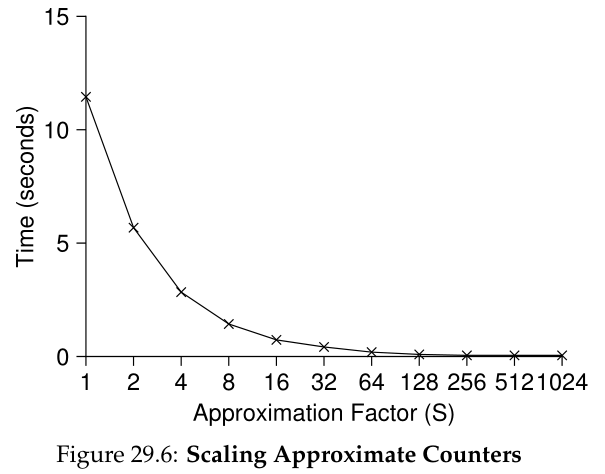
图29.4是一个近似计数器的粗略版本。请阅读它,或者更好的是自己在一些实验中运行它,以更好地理解它是如何工作的。
Tip:更多的并发并不一定会更快 如果您设计的方案增加了大量开销(例如,频繁地获取和释放锁,而不是一次),那么它更具有并发性这一事实可能就不重要了。简单的方案往往工作得很好,特别是当它们很少使用昂贵的例程时。增加更多的锁和复杂性可能是你的弱点。综上所述,有一种方法可以真正了解:构建两个备选方案(简单但更少并发,复杂但更并发)并衡量它们的表现。最后,你不能在表现上作弊;你的想法要么快,要么慢。
29.2 并发链表 Concurrent Linked Lists
我们接下来研究一个更复杂的结构,链表。让我们再次从基本方法开始。为简单起见,我们将省略此类列表将具有的一些明显例程,而仅关注并发插入;我们将留给读者考虑查找、删除等。图 29.7 显示了这个基本数据结构的代码。
正如您在代码中看到的,该代码只是在进入时在插入例程中获取一个锁,并在退出时释放它。如果malloc()碰巧失败(这是一种罕见的情况),就会出现一个棘手的小问题;在这种情况下,代码还必须在插入失败之前释放锁。
这种异常控制流已经被证明是非常容易出错的;Linux内核补丁的最近的一项研究发现, 在这种很少采用的代码路径上发现了很大一部分错误(近 40%)(事实上,这一观察激发了我们自己的一些研究,其中我们从 Linux 文件系统中删除了所有内存失败的路径,从而产生了一个更健壮的系统 [S+11]。)。
因此,有一个挑战:我们是否可以重写插入和查找例程,以在并发插入时保持正确,但避免出现故障路径也需要我们添加调用来解锁的情况?
在这种情况下,答案是肯定的。具体来说,我们可以稍微重新排列代码,以便锁定和释放仅围绕插入代码中的实际临界区,并且在查找代码中使用公共退出路径。前者有效,因为插入中的部分代码实际上不需要锁定;假设 malloc() 本身是线程安全的,每个线程都可以调用它而不必担心竞争条件或其他并发错误。只有在更新共享链表时才需要持有锁。有关这些修改的详细信息,请参见图 29.8。
至于查找例程,它是一个简单的代码转换,从主搜索循环跳转到单个返回路径。再次这样做可以减少代码中锁获取/释放点的数量,从而减少意外引入错误(例如在返回之前忘记解锁)的机会。
可扩展链表 Scaling Linked Lists
虽然我们又有了一个基本的并发链表,但是我们又一次遇到了它不能很好地扩展的情况。研究人员已经探索了一种技术,可以在链表中实现更多的并发性,这种技术被称为“hand-over-hand locking(连锁式加锁)”(也称为lock coupling锁耦合)[MS04]。
这个想法很简单。不是为整个列表添加一个锁,而是为列表的每个节点添加一个锁。当遍历列表时,代码首先获取下一个节点的锁,然后释放当前节点的锁(这激发了名称hand-over-hand)。(译者注:妙啊!)
Tip:注意锁和控制流 一个通用的设计技巧(在并发代码和其他地方都有用)是警惕导致函数返回、退出的控制流更改或其他类似的错误条件,这些错误条件会停止函数的执行。因为许多函数都是从获取锁、分配内存或执行其他类似的有状态操作开始的,当出现错误时,代码必须在返回之前撤销所有状态,这很容易出错。因此,最好对代码进行结构化,以最小化这种模式。
从概念上讲,一个hand-over-hand的链表是有道理的。它在链表操作中实现了高度的并发性。然而,在实践中,很难使这种结构比简单的单锁方法更快,因为为链表遍历的每个节点获取和释放锁的开销令人望而却步。即使有非常大的链表和大量线程,通过允许多个持续遍历实现的并发性也不可能比简单地获取单个锁、执行操作并释放它更快。也许某种混合(每隔一定数量节点就获取一个新锁)值得研究。
29.3 并发队列 Concurrent Queues
正如您现在所知道的,总是有一个标准的方法来创建并发数据结构:添加一个大锁。对于队列,我们将跳过这种方法,假设您能够理解它。
相反,我们将看一看Michael和Scott设计的稍微多一点并发的队列[MS98]。这个队列使用的数据结构和代码可以在下面的图29.9中找到。
如果仔细研究这段代码,您会注意到有两个锁,一个用于队列的头部,一个用于队列的尾部。这两个锁的目标是支持入队和出队操作的并发性。在常见的情况下,enqueue例程只访问尾锁,而dequeue仅从队列中取出头锁。
Michael和Scott使用的一个技巧是添加一个虚拟(dummy)节点(在队列初始化代码中分配);这个dummy可以分离头部和尾部的操作。研究代码,或者更好的是,输入代码,运行它,并度量它,以深入理解它是如何工作的。
队列通常用于多线程应用程序。然而,这里使用的队列类型(仅使用锁)通常不能完全满足此类程序的需要。在条件变量的下一章中,我们将深入研究一个更完善的有界队列,它使线程能够在队列空或过满时等待。注意它!
29.4 并发哈希表 Concurrent Hash Table
我们以一个简单且广泛适用的并发数据结构——哈希表结束讨论。我们将关注一个不调整大小的简单哈希表;需要更多的工作来处理调整大小,我们把它留给读者作为练习(抱歉!)
这个并发哈希表(图29.10)很简单,是使用我们前面开发的并发链表构建的,并且工作得非常好。它具有良好性能的原因是,它不是为整个结构使用一个锁,而是为每个散列桶使用一个锁(每个散列桶由一个链表表示)。这样做可以发生许多并发操作。
图29.11显示了在并发更新下哈希表的性能(在带有4个cpu的同一个iMac上,从4个线程每个线程并发更新10,000到50,000个)。为了便于比较,本文还展示了链表(只有一个锁)的性能。从图中可以看出,这个简单的并发哈希表扩展性非常好;而链表则相反。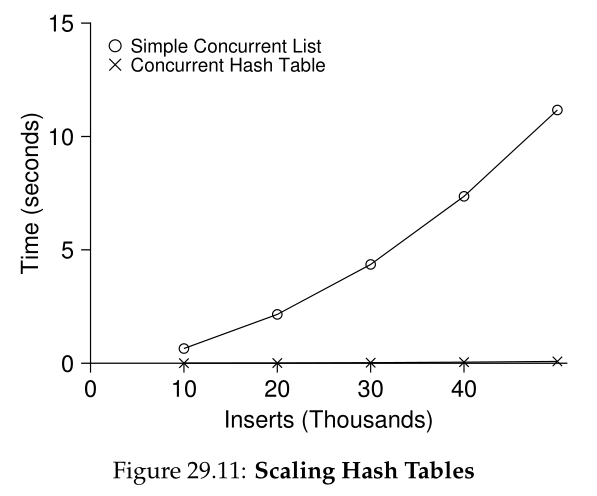
29.5 总结 Summary
我们介绍了并发数据结构的一个示例,从计数器到列表和队列,最后到无处不在和大量使用的哈希表。在此过程中,我们学到了一些重要的教训:在控制流更改周围的锁的获取和释放时要小心;启用更多并发不一定会提高性能;性能问题只有在它们存在后才应该被修复。避免过早优化(premature optimization)的最后一点是任何注重性能的开发人员的核心。如果这样做不会提高应用程序的整体性能,那么做更快的事情就没有任何价值。
当然,我们只是触及了高性能结构的表面。更多信息请参阅Moir和Shavit的优秀调查,以及其他来源的链接[MS04]。特别是,您可能对其他结构(如b -树)感兴趣;对于这方面的知识,数据库类是最好的选择。您可能还会对完全不使用传统锁的技术感到好奇;这种非阻塞数据结构(non-blocking data structures)是我们将在常见并发错误一章中体验到的东西,但坦白地说,这个主题是一个完整的知识领域,需要更多的学习,而不是在这本简陋的书中。如果你想了解更多的话(一如既往!)
Tip:避免过早优化(knuth定律) 在构建并发数据结构时,从最基本的方法开始,即添加一个大锁来提供同步访问。通过这样做,您可能会构建一个正确的锁;如果您随后发现它存在性能问题,您可以对它进行优化,从而只在需要时使其变快。正如Knuth所言:“过早优化是万恶之源。” 许多操作系统在第一次过渡到多处理器时使用单一锁,包括Sun OS和Linux。在后者中,这种锁甚至有一个名称,即大内核锁(big kernel lock,BKL)。多年来,这种简单的方法一直是一种很好的方法,但是当多cpu系统成为规范时,一次只允许内核中有一个活动线程就成了性能瓶颈。因此,终于到了将改进的并发性优化添加到这些系统的时候了。在Linux中,采用了更直接的方法:将一个锁替换为多个锁。在Sun内部,做出了一个更激进的决定:构建一个全新的操作系统,称为Solaris,从第一天起就从根本上集成了并发性。阅读Linux和Solaris内核书籍以获得更多关于这些迷人系统的信息[BC05, MM00]。
References
[B+10] “An Analysis of Linux Scalability to Many Cores” by Silas Boyd-Wickizer, Austin T.
Clements, Yandong Mao, Aleksey Pesterev, M. Frans Kaashoek, Robert Morris, Nickolai Zel-
dovich . OSDI ’10, Vancouver, Canada, October 2010. A great study of how Linux performs on
multicore machines, as well as some simple solutions. Includes a neat sloppy counter to solve one form
of the scalable counting problem.
[BH73] “Operating System Principles” by Per Brinch Hansen. Prentice-Hall, 1973. Available:
http://portal.acm.org/citation.cfm?id=540365. One of the first books on operating
systems; certainly ahead of its time. Introduced monitors as a concurrency primitive.
[BC05] “Understanding the Linux Kernel (Third Edition)” by Daniel P. Bovet and Marco Cesati.
O’Reilly Media, November 2005. The classic book on the Linux kernel. You should read it.
[C06] “The Search For Fast, Scalable Counters” by Jonathan Corbet. February 1, 2006. Avail-
able: https://lwn.net/Articles/170003. LWN has many wonderful articles about the latest
in Linux This article is a short description of scalable approximate counting; read it, and others, to learn
more about the latest in Linux.
[L+13] “A Study of Linux File System Evolution” by Lanyue Lu, Andrea C. Arpaci-Dusseau,
Remzi H. Arpaci-Dusseau, Shan Lu. FAST ’13, San Jose, CA, February 2013. Our paper that
studies every patch to Linux file systems over nearly a decade. Lots of fun findings in there; read it to
see! The work was painful to do though; the poor graduate student, Lanyue Lu, had to look through
every single patch by hand in order to understand what they did.
[MS98] “Nonblocking Algorithms and Preemption-safe Locking on by Multiprogrammed Shared-
memory Multiprocessors. ” M. Michael, M. Scott. Journal of Parallel and Distributed Com-
puting, Vol. 51, No. 1, 1998 Professor Scott and his students have been at the forefront of concurrent
algorithms and data structures for many years; check out his web page, numerous papers, or books to
find out more.
[MS04] “Concurrent Data Structures” by Mark Moir and Nir Shavit. In Handbook of Data
Structures and Applications (Editors D. Metha and S.Sahni). Chapman and Hall/CRC Press,
2004. Available: www.cs.tau.ac.il/˜shanir/concurrent-data-structures.pdf.
A short but relatively comprehensive reference on concurrent data structures. Though it is missing
some of the latest works in the area (due to its age), it remains an incredibly useful reference.
[MM00] “Solaris Internals: Core Kernel Architecture” by Jim Mauro and Richard McDougall.
Prentice Hall, October 2000. The Solaris book. You should also read this, if you want to learn about
something other than Linux.
[S+11] “Making the Common Case the Only Case with Anticipatory Memory Allocation” by
Swaminathan Sundararaman, Yupu Zhang, Sriram Subramanian, Andrea C. Arpaci-Dusseau,
Remzi H. Arpaci-Dusseau . FAST ’11, San Jose, CA, February 2011. Our work on removing
possibly-failing allocation calls from kernel code paths. By allocating all potentially needed memory
before doing any work, we avoid failure deep down in the storage stack.
Homework (Code)
在本作业中,您将获得编写并发代码和测量其性能的一些经验。学习构建性能良好的代码是一项关键技能,因此在这方面获得一点经验是非常值得的。
Questions
- 我们将在本章中重新进行度量。使用gettimeofday()调用来度量程序中的时间。这个计时器有多精确?它能测量的最小间隔是多少?在它的工作中获得信心,因为我们在接下来的所有问题中都需要它。您还可以查看其他计时器,例如通过rdtsc指令在x86上可用的周期计数器。
解答:https://blog.csdn.net/russell_tao/article/details/7185588
- 现在,构建一个简单的并发计数器,并测量随着线程数量的增加,多次增加计数器所需的时间。您正在使用的系统上有多少cpu可用?这个数字对你的测量有影响吗?
- 接下来,构建一个版本的粗糙计数器(sloppy counter)。同样,在线程数量变化时度量它的性能,以及阈值。这些数字和你在这一章看到的相符吗?
- 构建一个链表的版本,它使用了在本章中引用的hand-over-hand locking [MS04]。您应该先阅读论文以了解其工作原理,然后再实施。衡量其性能。什么时候hand-over-hand locking链表比本章所示的标准链表更有效?
```c
//linkList.h
include “Pthread.h”
define SUCCESS 0
define ERROR -1
typedef struct node_t { int key; struct node_t *next; pthread_mutex_t lock; } node_t;
typedef struct { node_t *head; pthread_mutex_t lock; } list_t;
void list_init(list_t *list);
int list_insert(list_t *list, int key);
int lookup(list_t *list, int key);
void free_list(list_t *list);
```c//Pthread.h#include <pthread.h>#include <assert.h>#include <stdlib.h>#define Pthread_mutex_init(mutex, attr) assert(pthread_mutex_init(mutex, attr) == 0)#define Pthread_mutex_lock(m) assert(pthread_mutex_lock(m) == 0)#define Pthread_mutex_unlock(m) assert(pthread_mutex_unlock(m) == 0);#define Pthread_cond_init(cond, attr) assert(pthread_cond_init(cond, attr) == 0)#define Pthread_cond_wait(cond, mutex) assert(pthread_cond_wait(cond, mutex) == 0)#define Pthread_cond_signal(cond) assert(pthread_cond_signal(cond) == 0)#define Pthread_create(thread, attr,start_routine, arg) assert(pthread_create(thread, attr, start_routine, arg) == 0)#define Pthread_join(thread, value_ptr) assert(pthread_join(thread, value_ptr) == 0)
//linkList.c#include <stdio.h>#include "linkList.h"void list_init(list_t *list) {list->head = NULL;Pthread_mutex_init(&list->lock, NULL);};int list_insert(list_t *list, int key) {node_t *node = (node_t *) malloc(sizeof(node_t));if (node == NULL) {perror("malloc");return ERROR;}Pthread_mutex_init(&node->lock, NULL);node->key = key;Pthread_mutex_lock(&list->lock);node->next = list->head;list->head = node;Pthread_mutex_unlock(&list->lock);return SUCCESS;}int lookup(list_t *list, int key) {int rv = -1;//获取head节点后释放,防止刚获取头节点就切出去的情况Pthread_mutex_lock(&list->lock);node_t *curr = list->head;Pthread_mutex_lock(&curr->lock);Pthread_mutex_unlock(&list->lock);while (curr) {if (curr->key == key) {rv = 0;break;}Pthread_mutex_lock(&curr->next->lock);Pthread_mutex_unlock(&curr->lock);curr = curr->next;}Pthread_mutex_unlock(&curr->lock);return rv;}void free_list(list_t *list) {Pthread_mutex_lock(&list->lock);node_t *curr = list->head;node_t *next = list->head->next;while (curr) {free(curr);curr = next;if (next) {next = next->next;}}Pthread_mutex_unlock(&list->lock);}
- 选择您最喜欢的数据结构,例如B-tree或其他稍微更有趣的结构。实现它,并从简单的锁定策略(如单个锁定)开始。随着并发线程数量的增加,度量它的性能。
- 最后,为您最喜欢的数据结构考虑一种更有趣的锁定策略。实现它,并衡量它的性能。它与直接的锁定方法相比如何?

若有收获,就点个赞吧
0 人点赞
