在前几节中,我们研究了在丢包时用于提供可靠数据传输服务的一般原则和特定TCP机制。我们前面提到过,在实践中,**这种损失通常是由于网络拥塞时路由器缓冲区溢出造成的**。因此,包重传处理的是网络拥塞的症状(丢失特定的传输层段),但不处理网络拥塞的原因——太多的源试图以过高的速率发送数据。为了处理网络拥塞的原因,需要在网络拥塞时限制发送方的机制。<br />在本节中,我们将在一般的上下文中考虑拥塞控制问题,试图理解拥塞为什么是一件坏事,网络拥塞如何体现在上层应用程序收到的性能中,以及可以采取的各种方法来避免或应对网络拥塞。对拥塞控制进行更普遍的研究是合适的,因为和可靠的数据传输一样,它在我们的“十大”网络中最重要的问题中名列前茅。以下部分包含TCP拥塞控制算法的详细研究。
3.6.1 拥塞的成因和损失 The Causes and the Costs of Congestion
让我们通过检查发生拥塞的三个日益复杂的场景来开始我们对拥塞控制的一般研究。在每一种情况下,我们将了解为什么首先会发生拥塞,以及以拥塞为代价(即资源没有得到充分利用和终端系统接收到的性能较差)。我们(还)不会关注如何应对或避免拥塞,而是关注更简单的问题,即当主机增加传输速率和网络拥塞时发生了什么。
场景1:两个发送者,一个无限缓冲区的路由器 Scenario 1: Two Senders, a Router with Infinite Buffers
我们首先考虑可能的最简单的拥塞场景:两台主机(A和B)各自有一个连接,在源和目的地之间共享一个hop,如图3.43所示。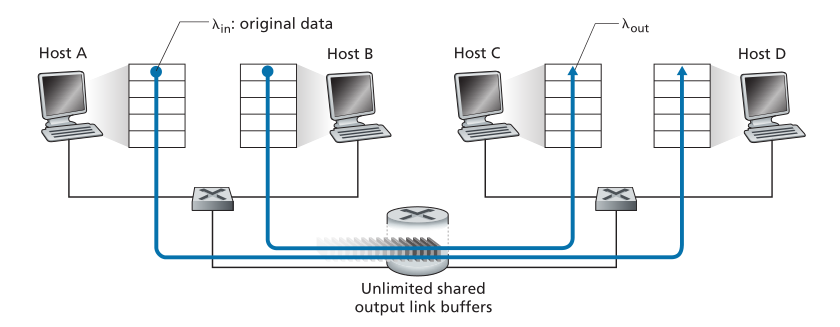
Figure 3.43 ♦ Congestion scenario 1: Two connections sharing a single hop with infinite buffers
图3.43♦拥塞场景1:两个连接共享一个hop,并且有无限缓冲区
让我们假设主机A中的应用程序以每秒 字节的平均速率向连接发送数据(例如,通过套接字将数据传递到传输层协议)。这些数据是原始的,因为每个数据单元只被发送到套接字一次。底层传输层协议很简单。数据被封装并发送;不执行错误恢复(例如,重传)、流量控制或拥塞控制。忽略由于添加传输和下层首部信息而产生的额外开销,在第一种情况下,主机A向路由器提供流量的速率因此是
字节的平均速率向连接发送数据(例如,通过套接字将数据传递到传输层协议)。这些数据是原始的,因为每个数据单元只被发送到套接字一次。底层传输层协议很简单。数据被封装并发送;不执行错误恢复(例如,重传)、流量控制或拥塞控制。忽略由于添加传输和下层首部信息而产生的额外开销,在第一种情况下,主机A向路由器提供流量的速率因此是 字节/秒。主机B以类似的方式运行,为了简单起见,我们假设它也以每秒
字节/秒。主机B以类似的方式运行,为了简单起见,我们假设它也以每秒 字节的速率发送。来自主机A和主机B的数据包经过一个路由器,并经过一个容量为R的共享的出站链路。路由器有缓冲区,当包到达速率超过出站链路的容量时,允许它存储入站的数据包。在第一个场景中,我们假设路由器有无限的缓冲区空间。
字节的速率发送。来自主机A和主机B的数据包经过一个路由器,并经过一个容量为R的共享的出站链路。路由器有缓冲区,当包到达速率超过出站链路的容量时,允许它存储入站的数据包。在第一个场景中,我们假设路由器有无限的缓冲区空间。
图3.44描绘了主机A在第一种情况下的连接性能。左边的图描绘了每个连接的吞吐量(接收端每秒的字节数)作为连接发送速率的函数。对于0和R/2之间的发送速率,接收端吞吐量等于发送端发送速率——发送端发送的所有内容都在接收端以有限延迟接收。当发送速率高于R/2时,吞吐量仅为R/2。这个吞吐量上限是两个连接之间共享链路容量造成的。链路不能以超过R/2的稳定速率将数据包发送给接收者。无论主机A和主机B设置了多高的发送速率,它们都不会看到吞吐量高于R/2。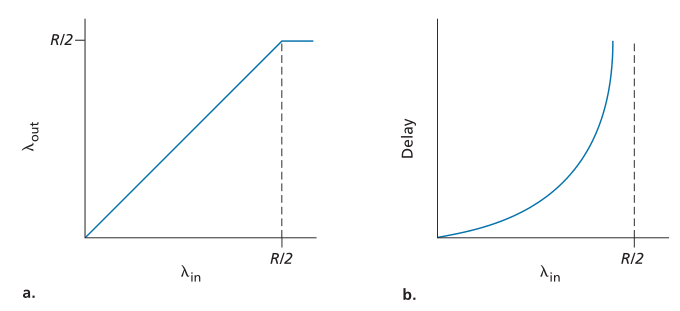
Figure 3.44 ♦ Congestion scenario 1: Throughput and delay as a function of host sending rate
图3.44♦拥塞场景1:吞吐量和延迟作为主机发送速率的函数
实现每个连接的吞吐量R/2实际上可能是一件好事,因为在将数据包发送到目的地时,链路被充分利用了。然而,图3.44的右图显示了接近链路容量运行的结果。当发送速率接近R/2时(从左边开始),平均延迟变得越来越大。当发送速率超过 R/2 时,路由器中排队数据包的平均数量是无限的,源和目的地之间的平均延迟变得无限(假设连接以这些发送速率运行无限时间,并且有无限量的可用缓冲)。因此,虽然从吞吐量的角度来看,以接近 R 的总吞吐量运行可能是理想的,但从延迟的角度来看,它远非理想。即使在这种(极其)理想化的场景中,我们也已经发现了拥塞网络的一个成本——当数据包到达速率接近链路容量(link capacity)时,会经历大的排队延迟(large queuing delays are experienced as the packet-arrival rate nears the link capacity)。
场景2:两个发送者和有限缓冲区的路由器 Scenario 2: Two Senders and a Router with Finite Buffers
现在,让我们用以下两种方式对场景1稍加修改(参见图3.45)。首先,假定路由器缓冲的数量是有限的。这种现实假设的结果是,当数据包到达一个已经满了的缓冲区时,它将被丢弃。其次,我们假设每个连接都是可靠的。如果一个包含传输层段的包在路由器上被丢弃,发送方最终将重新发送它。因为数据包可以被重新传输,所以我们现在必须更加小心地使用“发送速率(sending rate)”这个术语。具体来说,让我们再次用 表示应用程序将原始数据发送到套接字的速率,单位是字节/秒。传输层将段(包含原始数据和重传数据)发送到网络的速率将表示为
表示应用程序将原始数据发送到套接字的速率,单位是字节/秒。传输层将段(包含原始数据和重传数据)发送到网络的速率将表示为 ,单位为字节/秒。
,单位为字节/秒。 有时被称为网络输入负载(offered load)。
有时被称为网络输入负载(offered load)。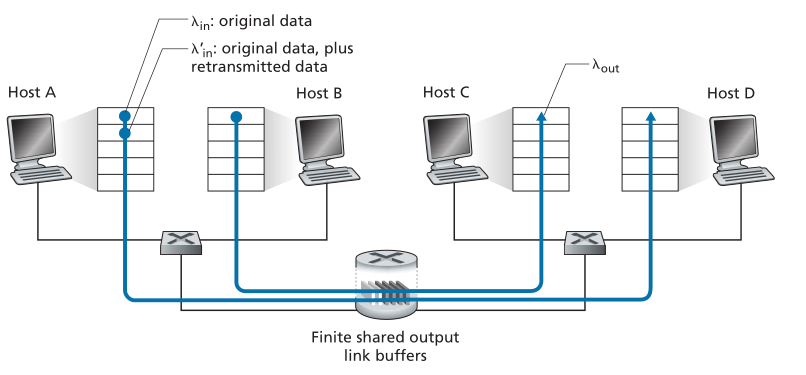
Figure 3.45 ♦ Scenario 2: Two hosts (with retransmissions) and a router with finite buffers
图3.45♦场景2:两台主机(带重传)和一台有限缓冲区的路由器
场景2中实现的性能现在很大程度上取决于如何执行重传输。首先,考虑一个不现实的情况,主机A能够以某种方式(神奇地!)确定路由器中的缓冲区是否空闲,因此只在缓冲区空闲时发送一个包。在这种情况下,不会发生损失, 等于
等于 ,连接的吞吐量等于
,连接的吞吐量等于 。这种情况如图3.46(a)所示。从吞吐量的角度来看,性能是理想的——发送的所有内容都会被接收到。请注意,在这种情况下,平均主机发送速率不能超过R/2,因为假定丢包永远不会发生。
。这种情况如图3.46(a)所示。从吞吐量的角度来看,性能是理想的——发送的所有内容都会被接收到。请注意,在这种情况下,平均主机发送速率不能超过R/2,因为假定丢包永远不会发生。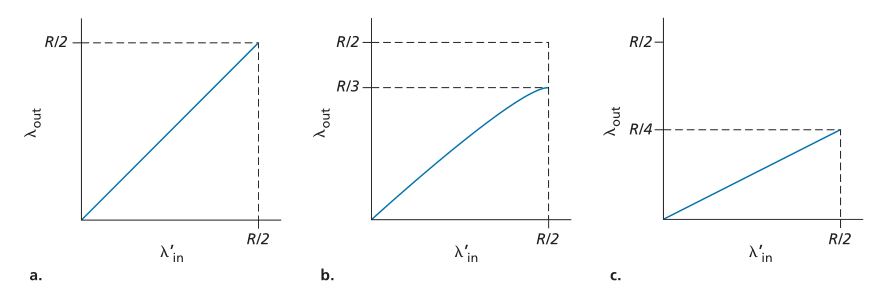
Figure 3.46 ♦ Scenario 2 performance with finite buffers
图3.46♦有限缓冲区场景2性能分析
接下来考虑稍微更现实一点的情况,即发送方仅在知道某个包确实已丢失时才重新传输。(同样,这个假设有点牵强。但是,发送主机可能会将其超时设置得足够大,以确保没有被确认的包已经丢失。)在本例中,性能可能如图3.46(b)所示。为了理解这里发生的情况,考虑以下情况:所提供的负载 (原始数据传输加上重传输的速率)等于R/2。根据图3.46(b),在提供的负载的这个值下,数据发送到接收应用程序的速率为R/3。因此,在传输的0.5R单位数据中,0.333R字节/秒(平均)是原始数据,0.166R字节/秒(平均)是重传输数据。我们在这里看到拥塞网络的另一个代价——发送方必须执行重传以补偿由于缓冲区溢出而丢失的包(the sender must perform retransmissions in order to compensate for dropped (lost) packets due to buffer overflow)。
(原始数据传输加上重传输的速率)等于R/2。根据图3.46(b),在提供的负载的这个值下,数据发送到接收应用程序的速率为R/3。因此,在传输的0.5R单位数据中,0.333R字节/秒(平均)是原始数据,0.166R字节/秒(平均)是重传输数据。我们在这里看到拥塞网络的另一个代价——发送方必须执行重传以补偿由于缓冲区溢出而丢失的包(the sender must perform retransmissions in order to compensate for dropped (lost) packets due to buffer overflow)。
最后,让我们考虑发送方可能会提前超时并重新传输队列中已延迟但尚未丢失的数据包的情况。在这种情况下,原始数据包和重传都可能到达接收方。当然,接收方只需要该数据包的一个副本,并将丢弃重传。在这种情况下,路由器在转发原始数据包的重传副本时所做的工作被浪费了,因为接收者已经收到了该数据包的原始副本。路由器最好使用链路传输容量来发送不同的数据包。这是拥塞网络的另一个成本——发送方在面对大延迟时不必要的重传可能会导致路由器使用其链路带宽来转发不需要的数据包副本(unneeded retransmissions by the sender in the face of large delays may cause a router to use its link bandwidth to forward unneeded copies of a packet)。图 3.46 (c) 显示了当假设每个数据包被路由器转发(平均)两次时的吞吐量与提供的负载。由于每个数据包被转发两次,当提供的负载接近 R/2 时,吞吐量将具有 R/4 的渐近值。
场景3:四个发送者,有限缓冲区的路由器,多hop路径 Scenario 3: Four Senders, Routers with Finite Buffers, and Multihop Paths
在我们最后的拥塞场景中,四个主机传输数据包,每个数据包都在重叠的两hop路径上,如图3.47所示。我们再次假设每个主机使用超时/重传机制来实现可靠的数据传输服务,所有主机都有相同的 值,所有路由器链路的容量为R字节/秒。
值,所有路由器链路的容量为R字节/秒。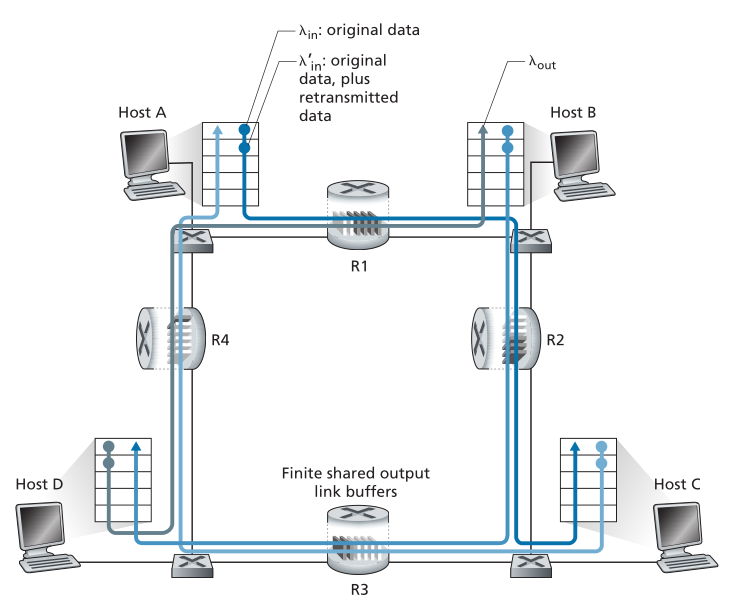
Figure 3.47 ♦ Four senders, routers with finite buffers, and multihop paths
图3.47♦四个发送者、有限缓冲区的路由器和多hop路径
让我们考虑从主机A到主机C的连接,经过路由器R1和R2。A-C和D-B共用R1路由器,B-D共用R2路由器。对于极小的 值,很少出现缓冲区溢出(如在拥塞场景1和2中),而且吞吐量大约等于所提供的负载。对于稍大的
值,很少出现缓冲区溢出(如在拥塞场景1和2中),而且吞吐量大约等于所提供的负载。对于稍大的 值,相应的吞吐量也会更大,因为更多的原始数据被传输到网络并传递到目的地,溢出的情况仍然很少。因此,对于较小的
值,相应的吞吐量也会更大,因为更多的原始数据被传输到网络并传递到目的地,溢出的情况仍然很少。因此,对于较小的 值,
值, 的增加导致
的增加导致 的增加。
的增加。
考虑过非常低的流量情况后,让我们接下来检查一下 (以及
(以及 )非常大的情况。考虑路由器R2。A-C流量到达R2(从R1转发后到达R2)时,无论
)非常大的情况。考虑路由器R2。A-C流量到达R2(从R1转发后到达R2)时,无论 值如何,到达R2的速率最多为R,即R1到R2链路的容量。如果所有连接(包括B-D连接)的
值如何,到达R2的速率最多为R,即R1到R2链路的容量。如果所有连接(包括B-D连接)的 都非常大,则B-D流量在R2的到达速率可能会比A-C流量的到达速率大得多。因为 A-C 和 B-D 流量必须在路由器 R2 竞争有限的缓冲区空间,所以成功通过 R2 的 A-C 流量(即不会因缓冲区溢出而丢失)变得越来越小,并且随着 B-D 提供的负载越来越大,它越来越小。在极限情况下,当提供的负载接近无穷大时,R2 处的空缓冲区立即被 B-D 数据包填充,R2 处 A-C 连接的吞吐量变为零。反过来,这意味着 A-C 端到端吞吐量在繁忙流量的限制下变为零。这些考虑导致了提供的负载与吞吐量的权衡,如图 3.48 所示。
都非常大,则B-D流量在R2的到达速率可能会比A-C流量的到达速率大得多。因为 A-C 和 B-D 流量必须在路由器 R2 竞争有限的缓冲区空间,所以成功通过 R2 的 A-C 流量(即不会因缓冲区溢出而丢失)变得越来越小,并且随着 B-D 提供的负载越来越大,它越来越小。在极限情况下,当提供的负载接近无穷大时,R2 处的空缓冲区立即被 B-D 数据包填充,R2 处 A-C 连接的吞吐量变为零。反过来,这意味着 A-C 端到端吞吐量在繁忙流量的限制下变为零。这些考虑导致了提供的负载与吞吐量的权衡,如图 3.48 所示。 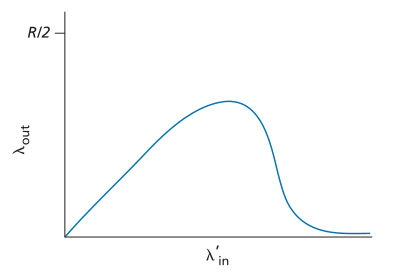
Figure 3.48 ♦ Scenario 3 performance with finite buffers and multihop paths
图3.48♦有限缓冲区和多hop路径场景3的性能
考虑到网络浪费的工作量,吞吐量随着提供负载的增加而最终下降的原因是显而易见的。在上面概述的高流量场景中,每当数据包在第二hop路由器上丢弃时,第一hop路由器在将数据包转发到第二hop路由器时所做的工作最终都会“浪费”。如果第一个路由器只是简单地丢弃该数据包并保持空闲状态,网络将同样好(更准确地说,同样糟糕)。更重要的是,第一个路由器用于将数据包转发到第二个路由器的传输容量本可以更有利地用于传输不同的数据包。 (例如,在选择要传输的数据包时,路由器最好优先考虑已经通过一定数量的上游路由器的数据包。)因此,在这里我们看到由于拥塞而丢弃数据包的另一个成本——当一个数据包沿着一条路径被丢弃,在每个上游链路上用于将该数据包转发到它被丢弃的点的传输容量最终被浪费了(when a packet is dropped along a path, the transmission capacity that was used at each of the upstream links to forward that packet to the point at which it is dropped ends up having been wasted)。
3.6.2 拥塞控制方法 Approaches to Congestion Control
在第3.7节中,我们将详细研究TCP的拥塞控制方法。在这里,我们确定了在实践中采用的两种广泛的拥塞控制方法,并讨论了具体的网络架构和包含这些方法的拥塞控制协议。
在最高层次上,我们可以通过网络层是否为传输层提供明显的拥塞控制帮助来区分拥塞控制方法:
- 端到端拥塞控制(End-to-end congestion control)。 在拥塞控制的端到端方法中,网络层没有为传输层提供明确的拥塞控制支持。 甚至网络拥塞的存在也必须由终端系统仅根据观察到的网络行为(例如,数据包丢失和延迟)来推断。 我们将在 3.7.1 节中很快看到 TCP 采用这种端到端的方法来控制拥塞,因为 IP 层不需要向主机提供有关网络拥塞的反馈。 TCP 段丢失(由超时或收到三个重复确认表示)被视为网络拥塞的指示,并且 TCP 相应地减小其窗口大小。 我们还将看到最近的 TCP 拥塞控制提案,该提案使用增加的往返段延迟作为网络拥塞增加的指标。
- 网络辅助拥塞控制(Network-assisted congestion control)。 通过网络辅助拥塞控制,路由器向发送方和/或接收方提供有关网络拥塞状态的明确反馈。 这种反馈可能就像一个指示链路拥塞的单个比特一样简单——这是早期 IBM SNA [Schwartz 1982]、DEC DECnet [Jain 1989; Ramakrishnan 1990] 架构和 ATM [Black 1995] 网络架构。 更复杂的反馈也是可能的。 例如,在 ATM 可用比特率 (ATM Available Bite Rate,ABR) 拥塞控制中,路由器会通知发送方它(路由器)在传出链路上可以支持的最大主机发送速率。 如上所述,IP 和 TCP 的 Internet 默认版本采用端到端的方法来控制拥塞。 然而,我们将在 3.7.2 节中看到,最近,IP 和 TCP 也可以选择性地实现网络辅助拥塞控制。
对于网络辅助拥塞控制,拥塞信息通常通过两种方式从网络反馈给发送方,如图3.49所示。直接反馈(Direct feedback)可以从网络路由器发送到发送方。这种形式的通知通常采用阻塞包(choke packet)的形式(本质上说,“我拥塞了!”)。当路由器标记/更新(marks/updates)从发送方流向接收方的数据包中的字段以指示拥塞时,会出现第二种也是更常见的通知形式。 在收到标记的数据包后,接收方将拥塞指示通知发送方。 后一种通知形式需要完整的往返时间。 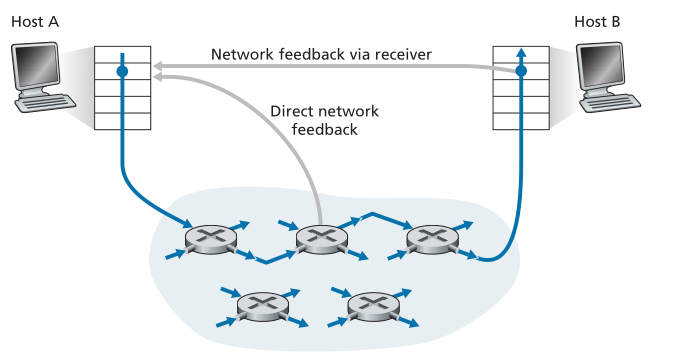
Figure 3.49 ♦ Two feedback pathways for network-indicated congestion information
图3.49♦网络拥塞信息的两条反馈路径

若有收获,就点个赞吧
0 人点赞
