本章将介绍多处理器调度(multiprocessor scheduling)的基础知识。由于这个主题相对较高级,所以最好在详细研究并发性主题(即本书第二部分简单的内容)之后再讨论它。
在多年只存在于高端计算领域之后,多处理器(multiprocessor)系统越来越普遍,并在台式机、笔记本电脑甚至移动设备中找到了它们的方式。多核(multicore)处理器的兴起,将多个CPU核封装在一个芯片上,是这种扩散的根源;这些芯片已经变得流行,因为计算机架构师很难在不使用(方式)太多功率的情况下使单个CPU更快。因此我们现在都有一些可用的cpu,这是一件好事,对吧?
当然,随着不止一个CPU的到来,会出现许多困难。一个主要的原因是一个典型的应用程序(例如,你写的一些C程序)只使用一个CPU;添加更多的cpu并不会使单个应用程序运行得更快。为了解决这个问题,您必须重写应用程序以并行(parallel)运行,可能使用线程(threads)(本书第二部分详细讨论)。多线程应用程序可以将工作分散到多个CPU上,因此在获得更多CPU资源时运行得更快。
Aside:高级章节 高级章节需要从书中大量内容中获取材料才能真正理解,同时在逻辑上适合比上述先决条件材料更早的部分。例如,如果你先读了关于并发性的中间部分,那么关于多处理器调度的这一章就会更有意义;但是,它在逻辑上符合书中关于虚拟化(通常)和CPU调度(具体)的部分。因此,建议不按顺序介绍这些章节;在这种情况下,在书的第二部分之后。
除了应用程序之外,操作系统还出现了一个新问题(这并不奇怪!),即多处理器调度问题。到目前为止,我们已经讨论了单处理器调度背后的一些原则;我们如何将这些想法扩展到多个cpu上?我们必须克服哪些新问题?因此,我们的问题是:
关键的问题:怎样在多个CPU上调度作业(jobs) 操作系统如何在多个cpu上调度任务?出现了什么新问题?还是需要新的想法?
10.1 背景:多处理器架构
Background: Multiprocessor Architecture
为了理解围绕多处理器调度的新问题,我们必须理解单cpu硬件和多cpu硬件之间新的和基本的区别。这种差异主要体现在硬件缓存(caches)的使用上(如图10.1),以及数据是如何在多个处理器之间共享的。我们现在在高级别上进一步讨论这个问题。详情可从其他地方获得[CSG99],特别是在高级计算机体系结构课程或研究生计算机体系结构课程中。
在一个只有单个CPU的系统中,硬件缓存(hardware caches)的层次结构通常有助于处理器更快地运行程序。缓存是小型、快速的存储器,(通常)保存在系统主存储器中找到的常用数据的副本。相比之下,主内存保存所有数据,但访问这个更大内存的速度较慢。通过将经常访问的数据保存在缓存中,系统可以使大而慢的内存看起来是快速的。
例如,考虑一个程序,它发出一个显式的加载指令从内存中取值,一个只有一个CPU的简单系统;CPU有一个小的缓存(比如64kb)和一个大的主存。程序第一次发出这种加载时,数据驻留在主内存中,因此需要很长时间来获取数据(可能需要几十纳秒,甚至数百纳秒)。处理器期望数据可能被重用,将加载的数据的一个副本放入CPU缓存中。如果程序稍后再次获取相同的数据项,CPU首先在缓存中检查它;如果它在那里找到了它,那么获取数据的速度就快得多(比如,只有几纳秒),因此程序运行得更快。
缓存基于局部性的概念,有两种类型:时间局部性和空间局部性。时间局部性背后的思想是,当一个数据被访问时,它很可能在不久的将来再次被访问;想象变量甚至指令本身在一个循环中被一次又一次地访问。空间局部性背后的思想是,如果程序访问地址x的数据项,它很可能也访问地址x附近的数据项;这里,想象一个程序通过一个数组流动,或者指令一个接一个地执行。因为在许多程序中都存在这些类型的局部性,硬件系统可以很好地猜测应该将哪些数据放入缓存中,从而工作得很好。
现在来看看棘手的部分:当您在一个系统中使用一个共享主内存有多个处理器时,如图10.2所示,会发生什么情况?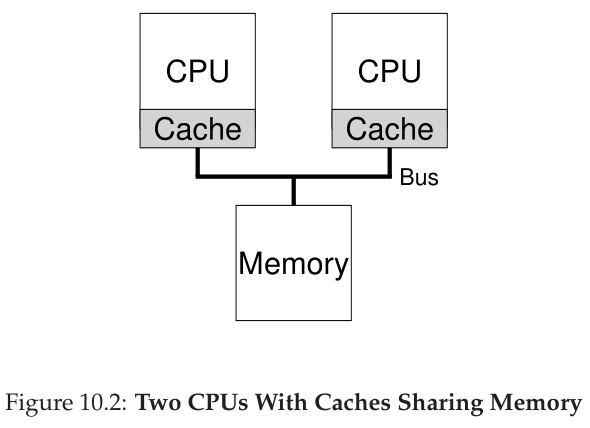
事实证明,使用多个cpu进行缓存要复杂得多。例如,假设一个在CPU 1上运行的程序在地址A上读取一个数据项(值为D);因为数据不在CPU 1的缓存中,所以系统从主存中取出数据,得到值D。然后程序修改地址A的值,用新的值D ‘更新缓存;将数据一直写到主存是很慢的,所以系统(通常)稍后会这样做。然后假设操作系统决定停止运行该程序,并将其移动到CPU 2。然后程序重新读取地址A的值;CPU 2的缓存中没有这样的数据,因此系统从主存中取值,得到旧的值D而不是正确的值D ‘。哦!
这个普遍的问题被称为缓存一致性(cache coherence)问题,有大量的研究文献描述了解决这个问题的许多不同的微妙之处[SHW11]。在这里,我们将跳过所有的细微差别,并提出一些主要观点;参加计算机架构课程(或三门)学习更多知识。
基本的解决方案是由硬件提供的:通过监控内存访问,硬件可以确保基本的“正确的事情”发生,并且单个共享内存的视图被保留。在基于总线的系统上实现这一点的一种方法(如上所述)是使用一种古老的技术,称为总线侦听(bus snooping)[G83];每个高速缓存通过观察连接它们到主存的总线来关注内存更新。当CPU看到缓存中数据项的更新时,它会注意到这个变化,并使它的拷贝失效(invalidate)(即从自己的缓存中移除数据项)或更新(update)数据(即也将新值放入缓存中)。回写缓存,如上所述,使这变得更加复杂(因为到主存的写入直到稍后才可见),但是您可以想象基本方案是如何工作的。
10.2
不要忘记同步 Don’t Forget Synchronization
既然缓存做了所有这些工作来提供一致性,那么程序(或操作系统本身)在访问共享数据时还需要担心什么吗?不幸的是,答案是肯定的,在本书关于并发主题的第二部分有详细的记录。虽然这里我们不会详细讨论,但我们将在这里概述/回顾一些基本思想(假设您熟悉并发性)。
当访问(特别是更新)跨cpu的共享数据项或结构时,应该使用互斥原语(比如锁)来保证正确性(其他方法,比如构建无锁(lock-free)的数据结构,是复杂的,只在偶然情况下使用;有关详细信息,请参阅关于并发的那篇文章中关于死锁的章节)。例如,假设我们有一个共享队列正在多个cpu上并发访问。如果没有锁,并发地从队列中添加或删除元素将无法正常工作,即使使用底层的一致性协议;我们需要锁来原子地将数据结构更新到新的状态。
为了更具体,想象一下这个代码序列,它用于从共享链表中删除一个元素,如图10.3所示。想象一下,如果两个cpu上的线程同时进入这个例程。如果线程1执行第一行,它的当前head值将存储在它的tmp变量中;如果线程2也执行第一行,它也将有相同的head值存储在它自己的私有tmp变量中(tmp是在栈上分配的,因此每个线程将有自己的私有存储)。因此,不是每个线程从链表的头部删除一个元素,而是每个线程将尝试删除相同的头部元素,导致各种问题(例如尝试在第 10 行对头部元素进行双重释放,以及因为可能两次返回相同的数据值)。
typedef struct __Node_t {int value;struct __Node_t *next;} Node_t;int List_Pop() {Node_t *tmp = head; // remember old head ...int value = head->value; // ... and its valuehead = head->next; // advance head to next pointerfree(tmp); // free old headreturn value; // return value at head}
Figure 10.3: Simple List Delete Code
当然,解决方案是通过锁定使这些例程正确。在这种情况下,分配一个简单的互斥锁(例如,pthread_mutex_t m;),然后在例程的开头添加一个lock(&m)和一个在结尾的unlock(&m)将解决问题,确保代码将执行为想要的。不幸的是,正如我们将看到的,这种方法并非没有问题,尤其是在性能方面。具体来说,随着 CPU 数量的增加,对同步共享数据结构的访问变得非常缓慢。
10.3
最后一个问题:缓存相关性 One Final Issue: Cache Affinity 最后一个问题出现在构建多处理器缓存调度器时,称为缓存相关性(cache affinity)[TTG95]。这个概念很简单:进程在特定CPU上运行时,会在CPU的缓存(和tlb)中构建相当多的状态。当进程下一次运行时,在同一个CPU上运行它通常是有利的,因为如果它的某些状态已经存在于该CPU的缓存中,那么它将运行得更快。相反,如果一个进程每次在不同的CPU上运行,进程的性能将会更差,因为它每次运行都必须重新加载状态(注意,由于硬件的缓存一致性协议,它将在不同的CPU上正确运行)。因此,多处理器调度器在做出调度决策时应该考虑缓存相关性,如果可能的话,可能会选择将一个进程保留在同一个CPU上。
10.4 单队列调度
Single-Queue Scheduling
有了这些背景知识,我们现在讨论如何为多处理器系统构建调度器。最基本的方法是简单地重用用于单处理器调度的基本框架,将所有需要调度的作业放到一个队列中;我们称之为单队列多处理器调度(single-
queue multiprocessor scheduling)或简称SQMS。这种方法的优点是简单;它不需要做很多工作,就可以采用现有的策略来选择接下来运行的最佳作业,并将其调整到一个以上的CPU上(例如,如果有两个CPU,它可以选择最好的两个作业运行)。
然而,SQMS也有明显的缺点。第一个问题是缺乏可扩展性。为了确保调度器在多个cpu上正确工作,开发人员将在代码中插入某种形式的锁定,如上所述。锁确保当SQMS代码访问单个队列(例如,查找要运行的下一个作业)时,会产生正确的结果。
不幸的是,锁会极大地降低性能,特别是当系统中的cpu数量增加时[A91]。随着对这样一个锁的争用的增加,系统在锁开销上花费的时间越来越多,而在做系统应该做的工作上花费的时间越来越少(注意: 有一天在这里包含一个真正的测量结果会很棒)。
SQMS的第二个主要问题是缓存相关性。例如,假设我们有5个要运行的作业(A、B、C、D、E)和4个处理器。我们的调度队列是这样的:
随着时间的推移,假设每个作业在一个时间片上运行,然后选择了另一个作业,下面是可能的跨cpu的作业调度: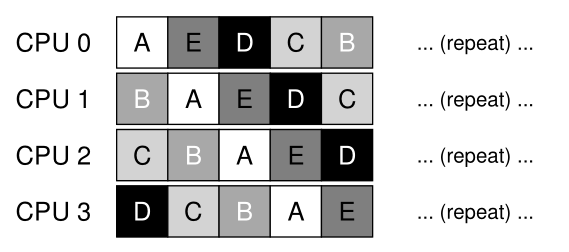
因为每个CPU只是从全局共享队列中选择下一个运行的作业,所以每个作业最终会在CPU和CPU之间来回跳转,这与缓存相关性的意义完全相反。
为了解决这个问题,大多数 SQMS 调度程序都包含某种关联机制,以尽可能地使进程更有可能继续在同一 CPU 上运行。具体来说,可能会为某些工作提供关联性,但移动其他工作以平衡负载。例如,假设同样安排了五个作业,如下所示: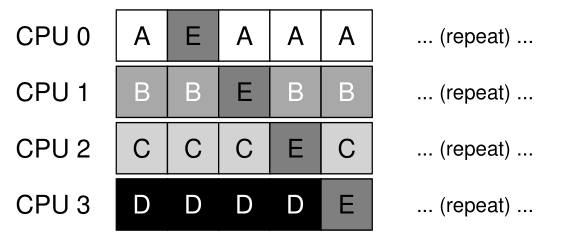
在这种安排下,作业 A 到 D 不会跨处理器移动,只有作业 E 从 CPU 迁移(migrating)到另一个 CPU,从而为大多数保留了关联性。然后,您可以决定下一次迁移不同的工作,从而也实现某种关联性公平。然而,实施这样的方案可能很复杂。
因此,我们可以看到SQMS方法有其优点和缺点。给定一个现有的单cpu调度器(根据定义,它只有一个队列),实现它很简单。但是,它不能很好地扩展(由于同步开销),而且它不能很容易地保持缓存相关性。
10.5
多队列调度 Multi-Queue Scheduling
由于单队列调度器带来的问题,一些系统选择多个队列,例如每个 CPU 一个。我们称这种方法为多队列多处理器调度(multi-queue multiprocessor scheduling,MQMS)。
在 MQMS 中,我们的基本调度框架由多个调度队列组成。每个队列都可能遵循特定的调度规则,例如轮询(round robin),当然可以使用任何算法。当一项作业进入系统时,它会根据某种启发式(例如,随机,或选择一个作业比其他作业少的作业)精准地放在一个调度队列中。那么它基本上是独立调度的,从而避免了单队列方法中存在的信息共享和同步问题。
例如,假设我们有一个系统,其中只有两个CPU(标记为CPU 0和CPU 1),并且有一些作业进入系统:例如A、B、C和D。假设每个CPU现在都有一个调度队列,操作系统必须决定将每个作业放到哪个队列中。它可能是这样的: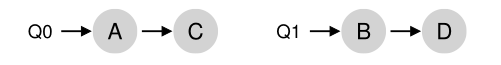
根据队列调度策略,每个 CPU 现在在决定应该运行什么时有两个作业可供选择。例如,对于轮询(round robin),系统可能会生成如下所示的时间表:
MQMS 具有 SQMS 的独特优势,因为它本质上应该更具可扩展性。随着 CPU 数量的增加,队列数量也在增加,因此锁和缓存争用不应成为核心问题。此外,MQMS 本质上提供了缓存相关性;作业保留在同一个 CPU 上,从而获得重用其中缓存内容的优势。
但是,如果您一直在关注,您可能会发现我们遇到了一个新问题,这是基于多队列的方法的基础:负载不平衡(load
imbalance)。让我们假设我们有与上面相同的设置(四个作业,两个 CPU),但是其中一个作业(比如 C)完成了。我们现在有以下调度队列:
如果我们然后在系统的每个队列上运行我们的轮询策略,我们将看到这个结果调度:
从此图中可以看出,A 获得的 CPU 是 B 和 D 的两倍,这不是您想要的结果。更糟糕的是,假设 A 和 C 都完成了,系统中只剩下作业 B 和 D。两个调度队列和产生的时间线将如下所示: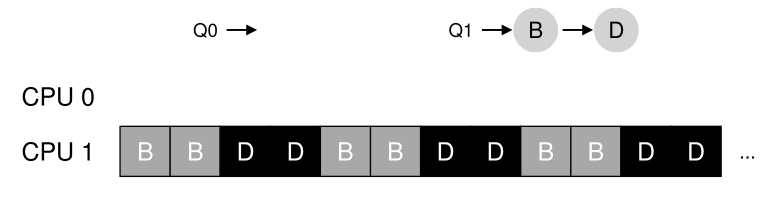
多么可怕- CPU 0是空闲的!因此,我们的CPU使用时间轴看起来相当糟糕。
那么一个糟糕的多队列多处理器调度器应该怎么做呢?我们如何克服负载不平衡的阴险问题并击败…霸天虎的邪恶势力?我们如何停止问与这本精彩的书几乎不相关的问题?
鲜为人知的事实是,塞伯坦的母星被糟糕的 CPU 调度决策摧毁了。现在让它成为本书中第一次也是最后一次提及变形金刚,我们对此深表歉意。
关键的问题:如何处理负载不均衡 多队列多处理器调度器应该如何处理负载不均衡,以便更好地实现其预期的调度目标?
这个问题的明显答案是移动工作,我们(再次)将这种技术称为**迁移(migration)**。通过将作业从一个 CPU 迁移到另一个 CPU,可以实现真正的负载平衡。<br />让我们看几个例子来让你更明白。再一次,我们遇到了一个 CPU 空闲而另一个有一些工作的情况。<br /><br />在这种情况下,所需的迁移很容易理解:操作系统应该简单地将 B 或 D 之一移动到 CPU 0。这种单一作业迁移的结果是负载均衡,每个人都很高兴。<br />在我们之前的示例中出现了一个更棘手的情况,其中 A 单独留在 CPU 0 上,B 和 D 在 CPU 1 上交替:<br /><br />在这种情况下,单次迁移并不能解决问题。在这种情况下你会怎么做?唉,**答案是一项或多项工作的持续迁移**。一种可能的解决方案是不断更换工作,如下面的时间表所示。图中,首先A单独在CPU 0上,B和D交替在CPU 1上。经过几个时间片后,B被移动到CPU 0上与A竞争,而D在CPU 1上单独享受几个时间片。因此负载是平衡的:<br /><br />当然,还存在许多其他可能的迁移模式。但现在是棘手的部分:系统应该如何决定制定这样的迁移?<br />一种基本方法是使用一种称为**工作窃取(work stealing)** [FLR98] 的技术。使用工作窃取方法,作业较少的(源)队列偶尔会偷看另一个(目标)队列,以查看它有多满。如果目标队列(显著的)比源队列更满,则源将从目标“窃取”一个或多个作业以帮助平衡负载。<br />当然,这种方法存在一种天然的紧张局势。如果你经常环顾其他队列,你将遭受高开销和扩展性问题,但这就是实现多队列调度的首要目的!另一方面,如果您不经常查看其他队列,您就有遭受严重负载不平衡的危险。正如系统策略设计中常见的那样,找到正确的阈值仍然是一门黑艺术。
10.6
Linux多处理器调度器 Linux Multiprocessor Schedulers 有趣的是,在 Linux 社区中,还没有通用的解决方案来构建多处理器调度程序。随着时间的推移,出现了三种不同的调度器:O(1) 调度器、完全公平调度器 (CFS) 和 BF 调度器 (BFS)。参见 Meehean 的论文,对上述调度器的优点和缺点进行了很好的概述 [M11];在这里,我们只总结了一些基础知识。
自己查一下BF代表什么;预先警告,它不适合胆小的人。
O(1) 和 CFS 都使用多个队列,而 BFS 使用单个队列,表明这两种方法都可以成功。当然,还有许多其他细节将这些调度程序分开。例如,O(1) 调度器是一个基于优先级的调度器(类似于前面讨论的 MLFQ),随着时间的推移改变进程的优先级,然后调度那些优先级最高的,以满足各种调度目标;交互性是一个特别的焦点。相比之下,CFS 是一种确定性的比例共享方法(更像前面讨论的**跨步调度(Stride scheduling)**)。BFS 是三者中唯一的单队列方法,也是比例共享,但基于更复杂的方案,称为最早合格虚拟截止日期优先(Earliest Eligible Virtual Deadline First,EEVDF)[SA96]。自己阅读有关这些现代算法的更多信息;您现在应该能够理解它们的工作原理了!
10.7
总结 Summary 我们已经看到了多处理器调度的各种方法。单队列方法 (SQMS) 在构建和平衡负载方面相当简单,但本质上难以扩展到多个处理器和缓存相关性。多队列方法 (MQMS) 可扩展性更好并能很好地处理缓存关联,但在负载不平衡方面存在问题并且更复杂。无论您采用哪种方法,都没有简单的答案:构建通用调度程序仍然是一项艰巨的任务,因为小的代码更改可能会导致巨大的行为差异。仅当您确切地知道自己在做什么,或者至少获得了大量资金来这样做时,才进行这样的练习。
References
[A90] “The Performance of Spin Lock Alternatives for Shared-Memory Multiprocessors” by
Thomas E. Anderson. IEEE TPDS Volume 1:1, January 1990.
关于不同锁定替代方案如何扩展和不扩展的经典论文。作者:Tom Anderson,系统和网络领域的著名研究员。我们必须说,这是一本非常优秀的操作系统教科书的作者。
[B+10] “An Analysis of Linux Scalability to Many Cores Abstract” by Silas Boyd-Wickizer,
Austin T. Clements, Yandong Mao, Aleksey Pesterev, M. Frans Kaashoek, Robert Morris, Nickolai Zeldovich. OSDI ’10, Vancouver, Canada, October 2010.
一篇关于将 Linux 扩展到多核的困难的极好的现代论文。
[CSG99] “Parallel Computer Architecture: A Hardware/Software Approach” by David E.
Culler, Jaswinder Pal Singh, and Anoop Gupta. Morgan Kaufmann, 1999.
一个充满关于并行机和算法细节的宝藏。正如马克希尔在封面上幽默地观察到的那样,这本书包含的信息比大多数研究论文都要多。
[FLR98] “The Implementation of the Cilk-5 Multithreaded Language” by Matteo Frigo, Charles
E. Leiserson, Keith Randall.
PLDI ’98, Montreal, Canada, June 1998.
Cilk 是一种用于编写并行程序的轻量级语言和运行时,也是工作窃取范式的一个很好的例子。
[G83] “Using Cache Memory To Reduce Processor-Memory Traffic” by James R. Goodman.
ISCA ’83, Stockholm, Sweden, June 1983.
关于如何使用总线监听(即关注您在总线上看到的请求)来构建缓存一致性协议的开创性论文。古德曼在威斯康星州多年的研究充满智慧,这只是一个例子。
[M11] “Towards Transparent CPU Scheduling” by Joseph T. Meehean. Doctoral Dissertation
at University of Wisconsin—Madison, 2011.
一篇论文,涵盖了现代 Linux 多处理器调度如何工作的许多细节。非常棒!但是,作为 Joe’s 的顾问,我们在这里可能有点偏见。
[SHW11] “A Primer on Memory Consistency and Cache Coherence” by Daniel J. Sorin, Mark
D. Hill, and David A. Wood. Synthesis Lectures in Computer Architecture. Morgan and Claypool Publishers, May 2011.
内存一致性和多处理器缓存的权威概述。任何喜欢对给定主题了解太多的人的必读读物。
[SA96] “Earliest Eligible Virtual Deadline First: A Flexible and Accurate Mechanism for Proportional Share Resource Allocation” by Ion Stoica and Hussein Abdel-Wahab. Technical Report TR-95-22, Old Dominion University, 1996.
关于这个很酷的调度想法的技术报告,来自 Ion Stoica,现在是加州大学的教授。伯克利和网络、分布式系统和许多其他方面的世界专家。
[TTG95] “Evaluating the Performance of Cache-Affinity Scheduling in Shared-Memory Multiprocessors” by Josep Torrellas, Andrew Tucker, Anoop Gupta. Journal of Parallel and Distributed Computing, Volume 24:2, February 1995.
这不是关于该主题的第一篇论文,但它引用了早期工作,并且比一些早期的基于队列的分析论文更具可读性和实用性。
Homework (Simulation)
在本作业中,我们将使用 multi.py 来模拟多处理器 CPU 调度程序,并了解其一些细节。阅读相关的自述文件以获取有关模拟器及其选项的更多信息。
Questions
- 首先,让我们学习如何使用模拟器来研究如何构建有效的多处理器调度程序。第一次模拟将只运行一个作业,其运行时间为 30,工作集大小为 200。在一个模拟 CPU 上运行此作业(此处称为作业 ‘a’),如下所示:./multi.py-n 1 -L a:30:200。需要多长时间才能完成?打开 -c 标志以查看最终答案,打开 -t 标志以查看作业的逐笔跟踪以及它是如何安排的。
- 现在增加缓存大小,使作业的工作集(大小=200)适合缓存(默认情况下,大小=100);例如,运行 ./multi.py -n 1 -L a:30:200 -M 300。您能预测作业装入缓存后的运行速度吗?(提示:记住warm_rate 的关键参数,它由 -r 标志设置)通过在启用解决标志 (-c) 的情况下运行来检查您的答案。
- multi.py 的一件很酷的事情是你可以看到更多关于不同跟踪标志发生了什么的细节。运行与上面相同的模拟,但这次启用了 time_left 跟踪 (-T)。此标志显示在每个时间步在 CPU 上调度的作业,以及在每个时钟运行后该作业剩余的运行时间。你注意到第二列是如何减少的?
- 现在再添加一点跟踪,用 -C 标志显示每个作业的每个 CPU 缓存的状态。对于每个作业,每个缓存将显示一个空格(如果该作业的缓存是冷的)或一个“w”(如果该作业的缓存是热的)。在这个简单的例子中,缓存在什么时候对作业 ‘a’ 变得温暖?当您将预热时间参数 (-w) 更改为低于或高于默认值时会发生什么?
- 在这一点上,您应该很好地了解模拟器如何为在单个 CPU 上运行的单个作业工作。但是,嘿,这不是多处理器CPU调度章节吗?哦耶!因此,让我们开始处理多个作业。具体来说,让我们在一个双 CPU 系统上运行以下三个作业(即键入 ./multi.py -n 2 -L a:100:100,b:100:50,c:100:50)你能给定循环集中式调度程序,预测这将需要多长时间?使用 -c 查看您是否正确,然后使用 -t 深入了解详细信息以查看分步,然后使用 -C 查看缓存是否为这些作业有效预热。你注意到什么?
- 现在我们将应用一些显式控制来研究缓存关联,如本章所述。为此,您需要 -A 标志。此标志可用于限制调度程序可以将特定作业放置在哪些 CPU 上。在这种情况下,让我们用它来放置作业 ‘b’ 和 ‘c’CPU 1,同时将 ‘a’ 限制为 CPU 0。这个魔法是通过输入这个 ./multi.py -n 2 -L a:100:100,b:100:50, c:100:50 -A a 来实现的:0,b:1,c:1 ;不要忘记打开各种跟踪选项,看看到底发生了什么!你能预测这个版本的运行速度吗?为什么效果更好?’a’、’b’ 和 ‘c’ 在两个处理器上的其他组合会运行得更快还是更慢?
- 缓存多处理器的一个有趣方面是,与在单个处理器上运行作业相比,当使用多个 CPU(及其缓存)时,有机会获得比预期更好的作业加速。具体来说,当你在 N 个 CPU 上运行时,有时你可以加速超过 N 倍,这种情况称为超线性加速(super-linear speedup)。要对此进行试验,请使用此处的作业描述 (-L a:100:100,b:100:100,c:100:100) 和小缓存 (-M 50) 创建三个作业。在具有 1、2 和 3 个 CPU(-n 1、-n 2、-n 3)的系统上运行它。现在,执行相同的操作,但每个 CPU 的缓存更大,大小为 100。随着 CPU 数量的增加,您对性能有什么看法?使用 -c 来确认您的猜测,并使用其他跟踪标志进行更深入的探索。
- 模拟器的另一个值得研究的方面是 per-CPU 调度选项,-p 标志。再次使用两个 CPU 运行,这三个作业配置(-L a:100:100,b:100:50,c:100:50)。与您在上面设置的手动控制的亲和力限制相比,此选项有何作用?当您将“查看间隔”(-P)更改为更低或更高的值时,性能如何变化?随着 CPU 数量的增加,这种 per-CPU 方法如何工作?
- 最后,随意生成随机工作负载,看看是否可以预测它们在不同数量的处理器、缓存大小和调度选项上的性能。如果你这样做,你很快就会成为一个多处理器调度大师,这是一件非常棒的事情。祝你好运!

若有收获,就点个赞吧
0 人点赞
