在深入研究本书这一部分(关于持久性)的主要内容之前,我们首先介绍输入/输出(I/O,input/output device)设备的概念,并展示操作系统如何与这样的实体交互。当然,I/O 对计算机系统来说非常重要。想象一个没有任何输入的程序(它每次产生相同的结果);现在想象一个没有输出的程序(它运行的目的是什么?)。显然,要使计算机系统有趣,输入和输出都是必需的。因此,我们的一般问题是:
关键的问题:如何将I/O集成到系统中一般的机制是什么?我们怎样才能使它们更有效率呢?
36.1 系统架构 System Architecture
开始我们的讨论,让我们看看一个典型系统的经典图(图36.1)。该图显示了一个CPU通过某种内存总线(memory bus)或互连连接到系统的主内存上。一些设备通过一个通用的I/O总线(I/O bus)连接到系统,在许多现代系统中这将是PCI(或它的许多衍生物之一);图形和其他一些更高性能的I/O设备可能会在这里找到。最后,更低的是一个或多个外围总线(peripheral bus),如SCSI, SATA,或USB。它们将慢速设备连接到系统,包括磁盘、鼠标和键盘。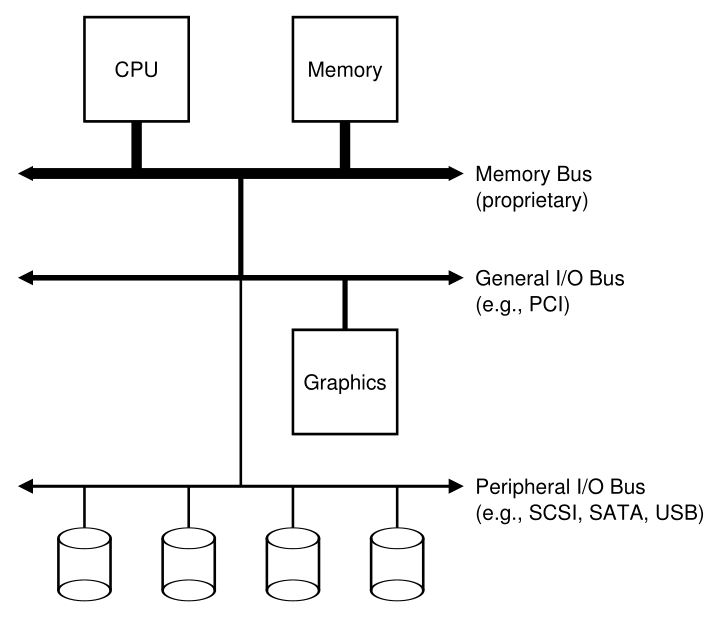
Figure 36.1: Prototypical System Architecture
你可能会问:为什么我们需要这样的等级结构?简单地说:物理和成本。总线越快,它一定越短;因此,高性能的内存总线没有太多的空间来插入设备等。此外,设计高性能的总线是相当昂贵的。因此,系统设计人员采用了这种分层方法,要求高性能的组件(如显卡)更接近CPU。性能较低的组件离得更远。将磁盘和其他慢速设备放在外围总线上的好处是多方面的;特别是,您可以在其中放置大量设备。
当然,现代系统越来越多地使用专用芯片组和更快的点对点互连来提高性能。图36.2显示了英特尔Z270芯片组[H17]的近似图。在顶部,CPU与内存系统连接最紧密,但也与显卡(以及显示器)有高性能连接,以支持游戏(哦,太可怕了!)和其他图形密集型应用程序。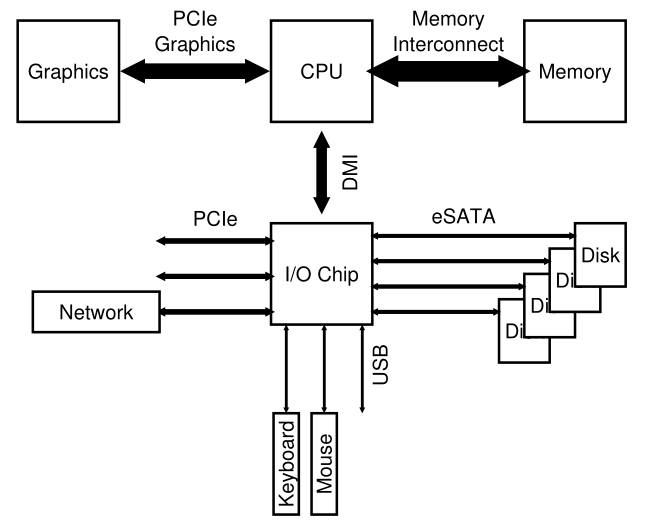
Figure 36.2: Modern System Architecture
CPU通过英特尔专有的DMI(Direct Media Interface,直接媒体接口)连接到一个I/O芯片,其余设备通过许多不同的互连连接到这个芯片。在右侧,一个或多个硬盘通过eSATA接口连接到系统;ATA (AT附件(Attachment),指提供与IBM PC AT的连接),然后是SATA(用于串行ATA(Serial ATA)),现在是eSATA(用于外部(external)SATA),代表了过去几十年存储接口的演变,每一步都在提高性能,以跟上现代存储设备的步伐。
在I/O芯片下面是一些USB(Universal Serial Bus,通用串行总线)连接,在这种描述中,可以将键盘和鼠标连接到计算机上。在许多现代系统中,USB被用于诸如此类的低性能设备。
最后,在左边,其他性能更高的设备可以通过PCIe (Peripheral Component Interconnect Express)连接到系统。在这个图中,一个网络接口连接到这里的系统;更高性能的存储设备(如NVMe持久存储设备)经常连接在这里。
36.2 一个典型的设备 A Canonical Device
现在让我们看看一个典型的设备(不是真正的设备),并使用这个设备来推动我们理解使设备交互高效所需的一些机制。从图 36.3 中,我们可以看到设备有两个重要组件。第一个是它呈现给系统其余部分的硬件接口(interface)。就像一个软件一样,硬件也必须提供某种接口,允许系统软件控制其操作。因此,所有设备都有一些用于典型交互的特定接口和协议。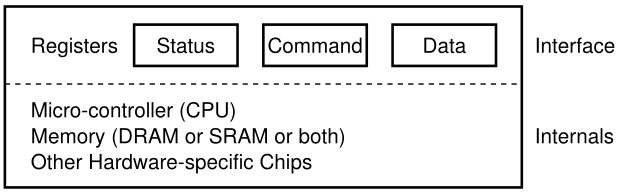
Figure 36.3: A Canonical Device
任何设备的第二部分是它的内部结构(internal structure)。设备的这一部分是特定实现的,负责实现设备呈现给系统的抽象。非常简单的设备将有一个或几个硬件芯片来实现其功能;更复杂的设备将包括一个简单的CPU、一些通用内存和其他设备特定的芯片来完成它们的工作。例如,现代RAID控制器可能包含几十万行固件(firmware)(即硬件设备中的软件)来实现其功能。
36.3
典型的协议 The Canonical Protocol
在上图中,(简化的)设备接口由三个寄存器组成:一个状态(status)寄存器,可以读取设备的当前状态;命令(command)寄存器,告诉设备执行某一任务;和数据(data)寄存器,用于将数据传递给设备,或从设备获取数据。通过读写这些寄存器,操作系统可以控制设备的行为。
现在让我们描述一个典型的交互,为了让设备代表操作系统做一些事情,操作系统可能会与设备进行交互。协议如下:
While (STATUS == BUSY); // wait until device is not busyWrite data to DATA registerWrite command to COMMAND register(starts the device and executes the command)While (STATUS == BUSY); // wait until device is done with your request
**该协议有四个步骤**。首先,操作系统通过反复读取状态寄存器等待设备准备好接收命令;我们称之为**轮询(polling)**设备(基本上,只是询问它发生了什么)。其次,操作系统将一些数据向下发送到数据寄存器;可以想象,如果这是一个磁盘,例如,需要进行多次写入才能将磁盘块(例如 4KB)传输到设备。当主 CPU 参与数据移动(如本示例协议中)时,我们将其称为**可编程 I/O (programmed I/O,PIO)**。第三,OS向命令寄存器写入命令;这样做隐式地让设备知道数据存在并且它应该开始处理命令。最后,操作系统通过在循环中再次轮询设备来等待设备完成,等待查看它是否完成(然后它可能会收到一个错误代码来指示成功或失败)。<br />这个基本协议的积极方面是简单和有效。然而,也存在一些效率低下和不便之处。在该协议中,您可能会注意到的第一个问题是轮询似乎效率低下;特别是,它浪费了大量的CPU时间,只是等待(可能很慢的)设备完成其活动,而不是切换到另一个就绪进程,从而更好地利用CPU。
关键的问题:操作系统如何在不频繁轮询的情况下检查设备状态,从而降低管理设备所需的CPU开销?
36.4
通过中断降低CPU开销 Lowering CPU Overhead With Interrupts
许多工程师多年前发明了一种改进这种交互的方法我们已经看到了:中断(interrupt)。与重复轮询设备不同,操作系统可以发出一个请求,让调用进程休眠,然后上下文切换到另一个任务。当设备最终完成操作时,它将引发一个硬件中断,导致CPU以预定的中断服务程序(interrupt service
routine,ISR)或更简单的中断处理程序(interrupt handler)跳转到操作系统。处理程序只是一段操作系统代码,它将完成请求(例如,通过从设备读取数据和可能的错误代码)并唤醒等待I/O的进程,然后可以按预期进行。
因此,中断允许计算和I/O的重叠(overlap),这是提高利用率的关键。这个时间线显示了问题:
在图中,进程1在CPU上运行了一段时间(由CPU行上重复的1表示),然后向磁盘发出I/O请求来读取一些数据。没有中断,系统只是自旋,重复轮询设备的状态,直到I/O完成(由p表示)。磁盘服务请求,最后进程1可以再次运行。
如果我们使用中断并允许重叠,操作系统可以在等待磁盘时做其他事情:
本例中,操作系统运行进程2,而磁盘服务运行进程1。当磁盘请求完成后,发生中断,系统唤醒进程1并重新运行。因此,CPU和磁盘在中间时间段都得到了适当的利用。
请注意,使用中断并不总是最好的解决方案。例如,假设一个设备执行它的任务非常快:第一个轮询通常发现该设备与任务。在这种情况下,使用中断实际上会减慢系统的运行速度:切换到另一个进程、处理中断、再切换回发出中断的进程的开销是很大的。因此,如果设备速度快,最好进行轮询;如果它是慢的,中断,允许重叠,是最好的。如果不知道设备的速度,或者有时快有时慢,最好使用一种混合方法,先轮询一段时间,然后如果设备还没有完成,就使用中断。这种分两阶段的方法可能达到两个领域的最佳效果。
另一个不使用中断的原因出现在网络中[MR96]。当大量传入的数据包产生一个中断时,操作系统可能会成为活锁(livelock),也就是说,发现自己只处理中断,而不允许用户级进程运行并实际服务请求。例如,想象一个网络服务器因为它成为黑客新闻[H18]的头号条目而经历了负载激增。在这种情况下,最好偶尔使用轮询来更好地控制系统中正在发生的事情,并允许web服务器在返回设备检查更多到达的数据包之前为一些请求提供服务。
另一种基于中断的优化是合并(coalescing)。在这样的设置中,需要触发中断的设备在将中断发送给CPU之前先等待一段时间。在等待时,其他请求可能很快就会完成,因此多个中断可以合并为一个中断交付,从而降低中断处理的开销。当然,等待太长将增加请求的延迟,这是系统中常见的折衷。见Ahmad等人[A+11]的精彩总结。
Tip:中断并不总比PIO好 虽然中断允许计算和I/O重叠,但它们只对慢设备有意义。否则,中断处理和上下文切换的成本可能会超过中断提供的好处。也有这样的情况,大量中断可能会使系统超载,导致系统活锁[MR96];在这种情况下,轮询为操作系统的调度提供了更多的控制,因此也是有用的。
36.5
使用 DMA 更高效的数据移动 More Efficient Data Movement With DMA
不幸的是,我们的典型协议还有另一个方面需要我们注意。特别是,当使用编程I/O (PIO)将一大块数据传输到设备时,CPU再次因为一项相当琐碎的任务而不堪重负,因此浪费了大量的时间和精力,而这些时间和精力本可以用在运行其他进程上。这个时间线说明了这个问题:
在时间线上,进程1正在运行,然后希望将一些数据写入磁盘。然后它开始I/O,它必须显式地将数据从内存复制到设备,每次一个字(在图中标记为c)。当复制完成时,I/O开始在磁盘上进行,CPU最终可以用于其他事情。
关键的问题:如何降低PIO开销 使用PIO时,CPU要花费大量的时间手动地将数据从设备移动到设备。我们如何才能卸载这些工作,从而更有效地利用CPU ?
这个问题的解决方案就是我们所说的直接内存访问(Direct Memory Access,DMA)。DMA引擎本质上是系统中的一个非常独特的设备,它可以在不需要太多CPU干预的情况下协调设备和主内存之间的传输。
DMA的工作原理如下。例如,要将数据传输到设备,操作系统将通过告诉 DMA 引擎数据在内存中的位置、要复制的数据量以及将其发送到哪个设备来对 DMA 引擎进行安排(program)。此时,操作系统已经完成了传输,可以继续进行其他工作。当DMA完成时,DMA控制器引发一个中断,这样操作系统就知道传输已经完成。修改后的时间线: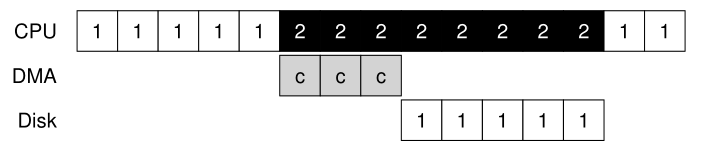
从时间线可以看到,数据的复制现在由DMA控制器处理。因为CPU在这段时间内是空闲的,所以操作系统可以做其他事情,这里选择运行进程2。因此,进程2将在进程1再次运行之前使用更多的CPU。
36.6 设备交互方法 Methods Of Device Interaction
现在,我们已经对执行I/O所涉及的效率问题有了一些认识,为了将设备集成到现代系统中,我们还需要处理一些其他问题。到目前为止,你可能已经注意到一个问题:我们还没有真正说过操作系统实际上是如何与设备通信的!因此,存在的问题:
关键的问题:如何与设备通信 硬件应该如何与设备通信?应该有明确的指示吗?或者还有其他方法吗?
**随着时间的推移,出现了两种主要的设备通信方法**。**第一种,也是最古老的方法(IBM大型机使用了很多年)是使用显式I/O指令(explicit I/O instructions)**。这些指令指定了操作系统将数据发送到特定设备寄存器的方法,从而允许构建上述协议。<br />例如,在x86上,输入(in)和输出(out)指令可以用来与设备通信。例如,要将数据发送到设备,调用者指定一个包含数据的寄存器,以及命名设备的特定端口。 执行指令会导致所需的行为。 <br />这样的指示通常是有**特权的(privileged)**。操作系统控制设备,因此操作系统是唯一允许与设备直接通信的实体。想象一下,如果任何程序都可以读取或写入磁盘,例如:完全混乱(一如既往),因为任何用户程序都可以使用这样的漏洞来获得对机器的完全控制。<br />与设备交互的第二种方法称为**内存映射I/O(memory-mapped I/O)**。通过这种方法,硬件使设备寄存器可用,就像它们是内存位置一样。为了访问一个特定的寄存器,操作系统发出一个加载load(读取)或存储store(写入)地址;然后硬件将加载/存储路由到设备而不是主存储器。
36.7
适应操作系统:设备驱动程序 Fitting Into The OS: The Device Driver 我们将讨论的最后一个问题是:如何将设备(每个设备都有非常具体的接口)适配到操作系统中,我们希望尽可能保持通用。例如,考虑一个文件系统。我们希望构建一个在 SCSI 磁盘、IDE 磁盘、USB 钥匙串驱动器等之上工作的文件系统,并且我们希望文件系统相对忽略如何向这些不同类型的驱动器发出读或写请求的所有细节 。 因此,我们的问题:
关键的问题:如何构建设备中立的操作系统 我们如何保持大多数操作系统与设备无关,从而对主要操作系统子系统隐藏设备交互的细节?
这个问题是通过古老的**抽象(abstraction)**技术解决的。在最低层次上,操作系统中的一个软件必须详细了解设备是如何工作的。我们称这个软件为**设备驱动程序(device driver)**,设备交互的任何细节都被封装在其中。<br />让我们通过研究Linux文件系统软件栈来了解这种抽象如何帮助操作系统设计和实现。图36.4是Linux软件组织的大致描述。从图中可以看出,文件系统(当然还有上面的应用程序)完全不知道它使用的是哪个磁盘类;它只是向通用块层(generic block layer)发出块读和写请求,通用块层将它们路由到适当的设备驱动程序,后者处理发出特定请求的细节。虽然简化了,但该图显示了如何对大多数操作系统隐藏这些细节。<br />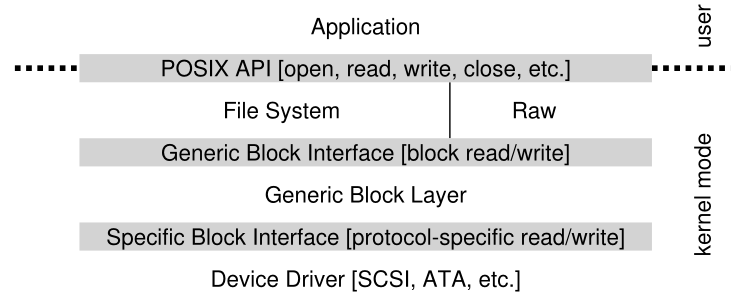<br />**Figure 36.4: The File System Stack**<br />该图还显示了设备的**原始接口(raw interface)**,它使特殊应用程序(如稍后介绍的**文件系统检查程序(file-system checker)**[AD14],或**磁盘碎片整理(disk defragmentation)**工具)能够直接读写块,而不使用文件抽象。大多数系统提供这种类型的接口来支持这些低级存储管理应用程序。<br />**注意,上面看到的封装也有它的缺点**。**例如,如果有一个设备具有许多特殊功能,但必须向内核的其他部分提供通用接口,那么这些特殊功能将不被使用**。例如,在带有 SCSI 设备的 Linux 中会出现这种情况,这些设备具有非常丰富的错误报告; 因为其他块设备(例如 ATA/IDE)有更简单的错误处理,所以更高级别的软件接收到的只是通用 EIO(通用 IO 错误)错误代码; 因此,SCSI 可能提供的任何额外细节都将丢失到文件系统 [G08] 中。 <br />有趣的是,因为您可能插入系统的任何设备都需要设备驱动程序,所以随着时间的推移,它们已经占据了内核代码的很大一部分。 **对 Linux 内核的研究表明,超过 70% 的 OS 代码位于设备驱动程序中** [C01]; 对于基于 Windows 的系统,它也可能相当高。 因此,当人们告诉您操作系统有数百万行代码时,他们真正说的是操作系统有数百万行设备驱动程序代码。 当然,对于任何给定的安装,大部分代码可能不是活动的(即,一次只有少数设备连接到系统)。 **也许更令人沮丧的是,由于驱动程序通常是由业余爱好者(而不是全职内核开发人员)编写的,他们往往有更多的错误,因此是导致内核崩溃的主要因素** [S03]。
36.8
案例研究:一个简单的IDE磁盘驱动程序 Case Study: A Simple IDE Disk Driver 为了更深入地挖掘,让我们快速查看一个实际设备:IDE磁盘驱动器[L94]。我们总结了本参考文献[W10]中描述的协议;我们还将查看xv6源代码,以获得一个简单的IDE驱动程序示例[CK+08]。
Control Register:Address 0x3F6 = 0x08 (0000 1RE0): R=reset,E=0 means "enable interrupt"Command Block Registers:Address 0x1F0 = Data PortAddress 0x1F1 = ErrorAddress 0x1F2 = Sector CountAddress 0x1F3 = LBA low byteAddress 0x1F4 = LBA mid byteAddress 0x1F5 = LBA hi byteAddress 0x1F6 = 1B1D TOP4LBA: B=LBA, D=driveAddress 0x1F7 = Command/statusStatus Register (Address 0x1F7):7 6 5 4 3 2 1 0BUSY READY FAULT SEEK DRQ CORR IDDEX ERRORError Register (Address 0x1F1): (check when ERROR==1)7 6 5 4 3 2 1 0BBK UNC MC IDNF MCR ABRT T0NF AMNFBBK = Bad BlockUNC = Uncorrectable data errorMC = Media ChangedIDNF = ID mark Not FoundMCR = Media Change RequestedABRT = Command abortedT0NF = Track 0 Not FoundAMNF = Address Mark Not Found
IDE 磁盘为系统提供了一个简单的接口,由四种类型的寄存器组成:控制、命令块、状态和错误。 通过使用(在 x86 上)输入(in)和输出(out) I/O 指令读取或写入特定的“I/O 地址”(例如下面的 0x3F6),可以使用这些寄存器。
与设备交互的基本协议如下,假设它已经初始化。
- 等待驱动做好准备Wait for drive to be ready。读取状态寄存器(0x1F7),直到驱动器是READY而不是BUSY。
- 将参数写入命令寄存器Write parameters to command registers。将扇区数量、要访问扇区的逻辑块地址(logical block address,LBA)和驱动器号(主驱动器=0x00或从驱动器=0x10,因为IDE只允许两个驱动器)写入命令寄存器(0x1F2-0x1F6)。
- 开始的I/O Start the I/O。通过向命令寄存器发出读/写指令。写READ-WRITE命令到命令寄存器(0x1F7)。
- 数据传输(写)Data transfer (for writes):等待磁盘状态为READY和DRQ(磁盘请求数据(drive request for data));将数据写入数据端口。
- 处理中断Handle interrupts。在最简单的情况下,为每个扇区处理一个中断;更复杂的方法允许批处理,因此在整个传输完成后会有一个最后的中断。
- 错误处理Error handling。每次操作后,读取状态寄存器。如果ERROR位是打开的,请读取错误寄存器的详细信息。
该协议的大部分内容都可以在 xv6 IDE 驱动程序中找到(图 36.6),它(初始化后)通过四个主要功能工作。第一个是 ide_rw(),它将请求排队(如果还有其他待处理的请求),或者直接将其发送到磁盘(通过 ide_start_request());在任何一种情况下,例程都会等待请求完成并且调用进程进入睡眠状态。第二个是ide_start_request(),用于向磁盘发送请求(可能还有数据,在写的情况下);分别调用 in 和 out x86 指令来读取和写入设备寄存器。启动请求例程使用第三个函数 ide_wait_ready() 来确保驱动器在向其发出请求之前已准备就绪。最后,ide_intr() 在发生中断时被调用;它从设备读取数据(如果请求是读,而不是写),唤醒等待 I/O 完成的进程,并且(如果 I/O 队列中有更多请求),通过 ide_start_request() 启动下一个 I /O 。
static int ide_wait_ready() {while (((int r = inb(0x1f7)) & IDE_BSY) || !(r & IDE_DRDY)); // loop until drive isn’t busy}static void ide_start_request(struct buf *b) {ide_wait_ready();outb(0x3f6, 0); // generate interruptoutb(0x1f2, 1); // how many sectors?outb(0x1f3, b->sector & 0xff); // LBA goes here ...outb(0x1f4, (b->sector >> 8) & 0xff); // ... and hereoutb(0x1f5, (b->sector >> 16) & 0xff); // ... and here!outb(0x1f6, 0xe0 | ((b->dev&1)<<4) | ((b->sector>>24)&0x0f));if(b->flags & B_DIRTY){outb(0x1f7, IDE_CMD_WRITE); // this is a WRITEoutsl(0x1f0, b->data, 512/4); // transfer data too!} else {outb(0x1f7, IDE_CMD_READ); // this is a READ (no data)}}void ide_rw(struct buf *b) {acquire(&ide_lock);for (struct buf **pp = &ide_queue; *pp; pp=&(*pp)->qnext); // walk queue*pp = b; // add request to endif (ide_queue == b) // if q is emptyide_start_request(b); // send req to diskwhile ((b->flags & (B_VALID|B_DIRTY)) != B_VALID)sleep(b, &ide_lock); // wait for completionrelease(&ide_lock);}void ide_intr() {struct buf *b;acquire(&ide_lock);if (!(b->flags & B_DIRTY) && ide_wait_ready() >= 0)insl(0x1f0, b->data, 512/4); // if READ: get datab->flags |= B_VALID;b->flags &= ˜B_DIRTY;wakeup(b); // wake waiting processif ((ide_queue = b->qnext) != 0) // start next requestide_start_request(ide_queue); // (if one exists)release(&ide_lock);}
Figure 36.6: The xv6 IDE Disk Driver (Simplified)
36.9
历史记录 Historical Notes
在结束之前,我们简要地回顾一下这些基本思想的起源。如果你有兴趣了解更多,请阅读Smotherman的精彩总结[S08]。
中断是一个古老的概念,存在于最早的机器中。例如,20世纪50年代早期的UNIVAC有某种形式的中断矢量,尽管还不清楚这一功能在哪一年可用[S08]。遗憾的是,即使在它的婴儿期,我们也开始失去计算历史的起源。
至于是哪台机器首先引入了DMA的概念,也存在一些争论。例如,Knuth和其他人提到了DYSEAC(一种移动机器,在当时意味着它可以用拖车拖拽),而其他人认为IBM SAGE可能是第一个[S08]。无论哪种方式,在50年代中期,带有I/O设备的系统直接与内存通信,并在完成时中断CPU。
这里的历史很难追溯,因为这些发明与真实的、有时晦涩难懂的机器有关。例如,有人认为林肯实验室的TX-2机器是第一个带有矢量中断的机器[S08],但这并不清楚。
因为这些想法是相对明显的——当一个缓慢的I/O正在等待时,不需要爱因斯坦式的飞跃来提出让CPU做其他事情的想法——也许我们的重点是谁先?是被误导了。有一点很清楚:当人们构建这些早期的机器时,很明显需要I/O支持。中断、DMA和相关思想都是快速cpu和慢速设备的直接结果;如果你当时在场,你可能会有类似的想法。
36.10
总结 Summary 现在,您应该对操作系统如何与设备交互有了非常基本的了解。两种技术,中断和直接存储器访问(DMA),已经被介绍来帮助设备效率,并描述了两种访问设备寄存器的方法,显式I/O指令和内存映射I/O。最后,提出了设备驱动程序的概念,展示了操作系统本身如何封装底层细节,从而更容易以设备无关的方式构建操作系统的其余部分。
References
[A+11] “vIC: Interrupt Coalescing for Virtual Machine Storage Device IO” by Irfan Ahmad,
Ajay Gulati, Ali Mashtizadeh. USENIX ’11.
对传统和虚拟环境中的中断合并进行了极好的调查。
[AD14] “Operating Systems: Three Easy Pieces” (Chapters: Crash Consistency: FSCK and
Journaling and Log-Structured File Systems) by Remzi Arpaci-Dusseau and Andrea Arpaci-
Dusseau. Arpaci-Dusseau Books, 2014.
文件系统检查程序及其工作方式的描述,它要求对通常不由文件系统直接提供的磁盘设备进行低级访问。
[C01] “An Empirical Study of Operating System Errors” by Andy Chou, Junfeng Yang, Benjamin Chelf, Seth Hallem, Dawson Engler. SOSP ’01.
最早系统地探讨现代操作系统中有多少缺陷的论文之一。在其他整洁的发现中,作者表明,设备驱动程序的bug大约是主线内核代码的7倍。
[CK+08] “The xv6 Operating System” by Russ Cox, Frans Kaashoek, Robert Morris, Nickolai
Zeldovich.
有关IDE设备驱动程序,请参阅IDE .c,并在其中提供更多细节。https://pdos.csail.mit.edu/6.828/2008/index.html
[D07] “What Every Programmer Should Know About Memory” by Ulrich Drepper. November, 2007.
这是一本关于现代内存系统的精彩读物,从DRAM开始,一直到虚拟化和缓存优化算法。
[G08] “EIO: Error-handling is Occasionally Correct” by Haryadi Gunawi, Cindy Rubio-Gonzalez,
Andrea Arpaci-Dusseau, Remzi Arpaci-Dusseau, Ben Liblit. FAST ’08, San Jose, CA, February
2008.
我们自己的工作是构建一个工具来查找Linux文件系统中不能正确处理错误返回的代码。我们发现了成百上千的漏洞,其中很多已经被修复了。
[H17] “Intel Core i7-7700K review: Kaby Lake Debuts for Desktop” by Joel Hruska. January 3,
深入回顾了最近的英特尔芯片组,包括cpu和 I/O子系统。
[H18] “Hacker News” by Many contributors. Available: https://news.ycombinator.com.
技术相关内容的更好聚合器之一。早在 2014 年,这本书就成为排名靠前的条目,仅一天之内就获得了 100 万章的下载量!遗憾的是,我们还没有经历过这样的高潮。
[L94] “AT Attachment Interface for Disk Drives” by Lawrence J. Lamers. Reference number: ANSI X3.221, 1994.
一个相当枯燥的关于设备接口的文档。你自己去读吧。
[MR96] “Eliminating Receive Livelock in an Interrupt-driven Kernel” by Jeffrey Mogul, K. K. Ramakrishnan. USENIX ’96, San Diego, CA, January 1996.
Mogul和他的同事在web服务器网络性能方面做了大量开创性的工作。这篇论文只是一个例子。
[S08] “Interrupts” by Mark Smotherman. July ’08.
关于中断历史、DMA和计算中相关的早期思想的信息宝库。
[S03] “Improving the Reliability of Commodity Operating Systems” by Michael M. Swift, Brian N. Bershad, Henry M. Levy. SOSP ’03.
Swift 的工作重新激发了人们对更类似于微内核的操作系统方法的兴趣;至少,它最终给出了一些基于地址空间的保护在现代操作系统中有用的充分理由。
[W10] “Hard Disk Driver” by Washington State Course Homepage.
一个简单的IDE磁盘驱动器接口的漂亮总结,以及如何为它构建一个设备驱动程序。

若有收获,就点个赞吧
0 人点赞
