在本节中,我们将讨论传输层多路复用和多路分解(transport-layer multiplexing and demultiplexing),即将网络层提供的主机到主机传输服务扩展为在主机上运行的应用程序的进程到进程传输服务。为了使讨论更加具体,我们将在Internet的上下文中讨论这个基本的传输层服务。然而,**我们强调,多路复用/多路分解(multiplexing/demultiplexing)服务对于所有的计算机网络都是需要的。**<br />在目标主机上,传输层接收来自下面的网络层的段(segments)。传输层负责将这些段中的数据传送到主机中运行的适当的应用程序进程。让我们来看一个例子。假设您坐在计算机前面,正在下载Web页面,同时运行一个FTP会话(session)和两个Telnet会话。因此,您有四个网络应用程序进程在运行——两个Telnet进程、一个FTP进程和一个HTTP进程。当您的计算机中的传输层从下面的网络层接收数据时,它需要将接收到的数据定向到这四个进程中的一个。现在让我们来看看这是如何做到的。<br />首先回想一下2.7节,**一个进程(作为网络应用程序的一部分)可以有一个或多个套接字**,也就是数据从网络传递到进程和数据从进程传递到网络的门。因此,如图3.2所示,接收主机中的传输层实际上并不直接将数据传递给进程,而是传递给中介套接字(intermediary socket)。因为在任何给定的时间,接收主机中都可能有多个套接字,所以每个套接字都有一个唯一的标识符。标识符的格式取决于套接字是UDP还是TCP套接字,稍后我们将对此进行讨论。<br /><br />**Figure 3.2 ♦ Transport-layer multiplexing and demultiplexing**<br />**图3.2♦传输层复用和分解原理**<br />现在让我们考虑接收主机如何将传入的传输层段引导到适当的套接字。**每个传输层段在段中都有一组用于此目的的字段**。**在接收端,传输层检查这些字段以识别接收套接字,然后将段定向到该套接字。将传输层段中的数据传送到正确的套接字的这项工作称为多路分解。在源主机上从不同的套接字收集数据块(chunk),用首部(header)信息(稍后将在多路复用中使用)封装每个数据块来创建段,并将段传递到网络层的工作称为多路复用。**需要注意的是,图3.2中间主机中的传输层必须将从下面网络层到达P1或P2进程的段进行多路复用;这是通过将到达的段的数据定向到相应进程的套接字来实现的。中间主机中的传输层也必须从这些套接字收集传出的数据,形成传输层段,并将这些段向下传递到网络层。尽管我们已经在Internet传输协议的内容中介绍了多路复用和多路分解,但重要的是要认识到,**当一层(在传输层或其他地方)上的单个协议被下一层的多个协议使用时,它们(多路复用和多路分解)就是需要考虑的问题。**<br />为了说明多路复用工作,请回忆上一节中的家庭类比。每个孩子都有他或她的名字。当比尔从邮递员那里收到一批邮件时,他通过观察信件的地址来执行多路复用操作,然后将邮件交给他的兄弟姐妹。当安从她的兄弟姐妹那里收集信件并把收集的信件交给邮递员时,她进行了多路复用操作。<br />现在我们了解了传输层多路复用和多路分解的作用,让我们检查一下它在主机中实际上是如何完成的。从上面的讨论中,我们知道**传输层多路复用需要(1)套接字有唯一的标识符,(2)每个段都有特殊的字段来指示段要交付给哪个套接字**。如图3.3所示,**这些特殊字段是源端口号字段和目的端口号字段(source port number field and the destination port number field)**。(UDP和TCP段也有其他字段,将在本章的后续章节中讨论。)**每个端口号为16位数字,取值范围为0 ~ 65535**。**0 ~ 1023之间的端口号称为知名端口号(well-known port numbers)**,是受限制的端口号,即HTTP(端口号为80)、FTP(端口号为21)等知名应用协议使用这些端口号。知名端口号的列表在RFC 1700中给出,并在[http://www.iana.org](http://www.iana.org) [RFC 3232]进行更新。**当我们开发一个新的应用程序时(比如在2.7节中开发的简单应用程序),我们必须给这个应用程序分配一个端口号。**<br />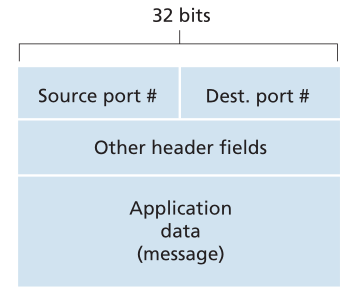<br />**Figure 3.3 ♦ Source and destination port-number fields in a transport-layer segment**<br />**图3.3传输层段中的源端口号和目的端口号字段**<br />现在应该清楚传输层如何实现多路分解服务:每个套接字在主机可以分配一个端口号,当一个段(segment)到达主机,传输层段检查目的端口号和定向段对应的套接字。段的数据然后通过套接字传递到相应的进程。正如我们将看到的,这基本上是UDP如何做到的。然而,我们也将看到TCP中的多路复用/多路分解更加微妙。
无连接多路复用和多路分解 Connectionless Multiplexing and Demultiplexing
回想一下第2.7.1节,在主机中运行的Python程序可以用这一行创建UDP套接字
clientSocket = socket(AF_INET, SOCK_DGRAM)
当以这种方式创建UDP套接字时,传输层会自动分配一个端口号(port number)给套接字。特别是,传输层分配一个1024到65535的端口号,该端口号目前没有被主机中的任何其他UDP端口使用。或者,在创建套接字后,可以通过套接字 bind()方法在Python程序中添加一行代码,将特定的端口号(比如,19157)关联到这个UDP套接字:
clientSocket.bind(('', 19157))
如果编写代码的应用程序开发人员正在实现“众所周知的协议(well-known protocol)”的服务器端,那么开发人员将必须分配相应的知名端口号。通常,应用程序的客户端让传输层自动(透明地)分配端口号,而应用程序的服务器端分配特定的端口号。<br />通过分配给 UDP 套接字的端口号,我们现在可以准确地描述 UDP 多路复用/多路分解。假设主机 A 中的进程使用 UDP 端口 19157,想要将应用程序数据块发送到主机 B 中使用 UDP 端口 46428 的进程。主机 A 中的传输层创建一个传输层段,其中包含应用程序数据,源端口号 (19157)、目标端口号 (46428) 和其他两个值(稍后将讨论,但对当前讨论不重要)。然后传输层将结果段(resulting segment)传递给网络层。网络层将段封装在 IP 数据报中,并尽最大努力(best-effort)将段传送到接收主机。如果该段到达接收主机 B,则接收主机的传输层会检查该段中的目标端口号 (46428) 并将该段传送到其由端口 46428 标识的套接字。 请注意,主机 B 可能正在运行多个进程,每个都有自己的 UDP 套接字和关联的端口号。**当 UDP 段从网络到达时,主机 B 通过检查段的目标端口号将每个段定向(多路分解)到适当的套接字。**<br />值得注意的是,**UDP套接字完全由一个由目的IP地址和目的端口号组成的二元组(two-tuple)来标识。**因此,如果两个UDP段有不同的源IP地址和/或源端口号,但有相同的目的IP地址和目的端口号,那么这两个段将通过相同的目的套接字被定向到相同的目的进程。<br />您现在可能想知道,源端口号的用途是什么?如图3.4所示,在A-to-B网段中,源端口号作为“返回地址”的一部分——当B要将一个段发送回A时,B-to-A段中的目的端口的值将取自A-to-B网段的源端口值。(完整的返回地址是A的IP地址和源端口号。)以2.7节中研究的UDP服务器程序为例。在UDPServer.py中,服务器使用recvfrom()方法从从客户端接收到的段中提取客户端(源)端口号;然后它将一个新的段发送给客户端,将提取的源端口号作为这个新段中的目的端口号。<br />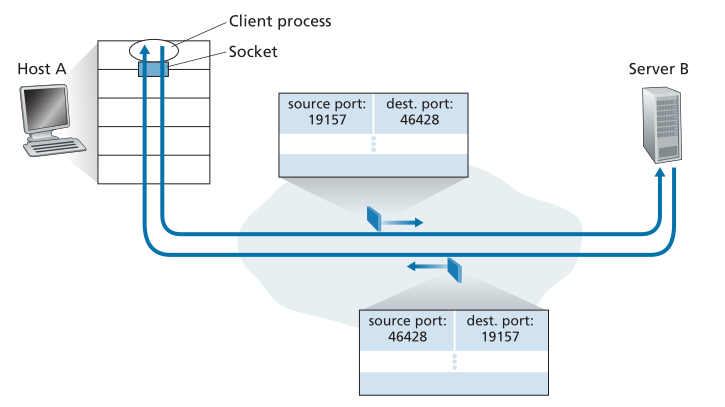<br />**Figure 3.4 ♦ The inversion of source and destination port numbers**<br />**图3.4♦源端口号和目的端口号的转换**
面向连接的多路复用和多路分解 Connection-Oriented Multiplexing and Demultiplexing
为了理解TCP多路分解,我们必须仔细看看TCP套接字和TCP连接建立。TCP套接字和UDP套接字之间的一个细微区别是TCP套接字由四个元组标识:(源IP地址、源端口号、目的IP地址、目的端口号)。因此,当一个TCP段从网络到达主机时,主机使用所有四个值将该段定向(多路分解)到适当的套接字。特别地,与UDP相反,两个到达的具有不同源IP地址或源端口号的TCP段(携带原始连接建立请求的TCP段除外)将被定向到两个不同的套接字。为了进一步了解,让我们重新考虑第2.7.2节中的TCP客户机-服务器编程示例:
- TCP服务器应用程序有一个“欢迎套接字(welcoming socket)”,它等待TCP客户端在端口号12000上的建立连接请求(参见图2.29)。
TCP客户端创建一个套接字并发送一个连接建立请求段:
clientSocket = socket(AF_INET, SOCK_STREAM)clientSocket.connect((serverName,12000))
一个连接建立请求只不过是一个目的端口号为12000的TCP段,在TCP首部(header)中设置了一个特殊的连接建立位(connection-establishment bit)(在章节3.5中讨论)。段还包括客户端选择的源端口号。
当运行服务器进程的计算机的主机操作系统接收到目的端口为12000的传入连接请求段时,它在端口号为12000上定位到正在等待接受连接的服务器进程。然后,服务器进程创建一个新的套接字:
connectionSocket, addr = serverSocket.accept()
此外,服务器的传输层在连接请求段(connection-request segment)中注意以下四个值:(1)段中的源端口号,(2)源主机的IP地址,(3)段中的目的端口号,(4)它自己的IP地址。新创建的连接套接字由这四个值标识;所有源端口、源IP地址、目的端口和目的IP地址匹配这四个值的后续到达段将被多路分解到这个套接字。现在有了TCP连接,客户机和服务器就可以互相发送数据了。
服务器主机可以同时支持多个TCP连接套接字,每个套接字连接到一个进程,并且每个套接字由它自己的四元组标识。当一个TCP段到达主机时,所有四个字段(源IP地址、源端口、目的IP地址、目的端口)都被用来将该段定向(多路分解)到适当的套接字。
FOCUS ON SECURITY 关注安全 PORT SCANNING 端口扫描 我们已经看到,服务器进程耐心地等待一个开放的端口,以便与远程客户机进行联系。一些端口为知名应用程序保留(如Web、FTP、DNS和SMTP服务器);其他端口由流行的应用程序使用(例如,Microsoft Windows SQL服务器侦听UDP端口1434上的请求)。因此,如果我们确定主机上的端口是打开的,那么我们就可以将该端口映射到主机上运行的特定应用程序。这对于系统管理员来说非常有用,因为他们经常想知道哪些网络应用程序在他们的网络中的主机上运行。但是,攻击者为了“探查连接处(case the joint)”,还想知道目标主机上的哪些端口是开放的。如果找到主机运行应用程序与一个已知的安全漏洞(例如,监听端口1434的SQL服务器容易发生缓冲区溢出,允许远程用户在脆弱的主机上执行任意代码,这是Slammer蠕虫病毒所利用的缺陷(CERT 2003 - 04)),那么主机攻击的时机已经成熟。 确定哪个应用程序正在侦听哪个端口是一项相对简单的任务。事实上,有许多公共领域的程序,称为端口扫描器(port scanners),就是这样做的。其中最广泛使用的可能是nmap,它可以在http://nmap.org上免费获得,并且包含在大多数Linux发行版中。对于TCP, nmap顺序扫描端口,寻找正在接受TCP连接的端口。对于UDP, nmap再次顺序扫描端口,寻找响应传输UDP段的UDP端口。在这两种情况下,nmap都会返回一个打开、关闭或不可达端口的列表。运行nmap的主机可以尝试扫描Internet上任何位置的任何目标主机。在第3.5.6节讨论TCP连接管理时,我们将重新讨论nmap。
如图3.5所示,主机C向服务器B发起两个HTTP会话,主机A向服务器B发起一个HTTP会话。主机A、主机C和服务器B都有各自的唯一IP地址——A、C和B。主机C为它的两个HTTP连接分配两个不同的源端口号(26145和7532)。因为主机A选择的源端口号独立于C,所以它也可能将源端口26145分配给它的HTTP连接。**但这不是一个问题,服务器B仍然能够正确地将两个具有相同源端口号的连接多路分解,因为这两个连接具有不同的源IP地址。**<br />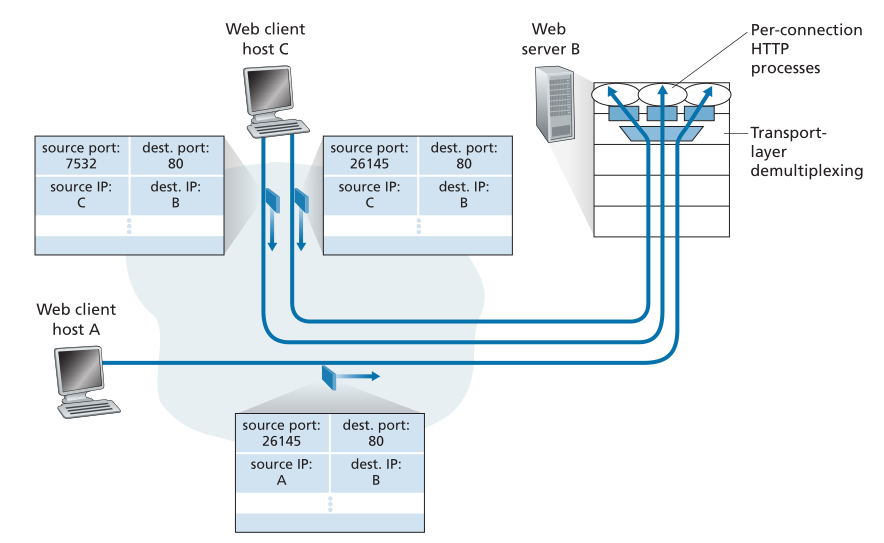<br />**Figure 3.5 ♦ Two clients, using the same destination port number (80) to communicate with the same Web server application**<br />**图3.5♦两个客户端使用相同的目的端口号(80)与同一个Web服务器应用程序通信**
Web服务器和TCP Web Servers and TCP
在结束讨论之前,对Web服务器及其如何使用端口号进行一些补充说明是有益的。考虑在端口80上运行Web服务器(如Apache Web服务器)的主机。当客户端(例如,浏览器)向服务器发送段时,所有段的目标端口都是80。特别是,初始连接建立段(initial connection-establishment segments)和携带HTTP请求报文的段(the segments carrying HTTP request messages)的目标端口都是80。正如我们刚才所描述的,服务器使用源IP地址和源端口号来区分不同的客户端段。
图3.5显示了为每个连接生成新进程(spawns a new process)的Web服务器。如图3.5所示,每个进程都有自己的连接套接字,HTTP请求通过该套接字到达并发送HTTP响应。但是,我们提到,连接套接字和进程之间并不总是一对一的对应关系。事实上,现在的高性能Web服务器通常只使用一个进程,并为每个新客户机连接创建一个带有新连接套接字的新线程。(线程可以看作是轻量级的子进程。)如果您在第2章中完成了第一个编程任务,那么您构建的Web服务器就是这样做的。对于这样的服务器,在任何时候都可能有许多连接套接字(具有不同的标识符)连接到同一个进程。
如果客户机和服务器使用持久HTTP,那么在持久连接的整个过程中,客户机和服务器通过相同的服务器套接字交换HTTP报文。但是,如果客户端和服务器使用非持久HTTP,则会创建一个新的TCP连接,并为每个请求/响应关闭该连接,因此会创建一个新的套接字,然后为每个请求/响应关闭该套接字。频繁地创建和关闭套接字可能会严重影响繁忙的Web服务器的性能(尽管可以使用许多操作系统技巧来缓解这个问题)。对持久和非持久HTTP的操作系统问题感兴趣的读者可以去看看[Nielsen 1997; Nahum 2002]。
既然我们已经讨论了传输层多路复用和多路分解,现在让我们继续讨论Internet的传输协议之一UDP。在下一节中,我们将看到UDP只增加了多路复用/多路分解服务。

若有收获,就点个赞吧
0 人点赞
