分布式系统已经改变了世界的面貌。 当您的网络浏览器连接到地球上其他地方的网络服务器时,它正在参与一种似乎是**客户端/服务器(client/server)**分布式系统的简单形式。 然而,当您联系 Google 或 Facebook 等现代网络服务时,您不仅仅是在与一台机器进行交互; 在幕后,这些复杂的服务是由大量(即数千台)机器构建的,每台机器都合作提供站点的特定服务。 因此,应该清楚是什么让研究分布式系统变得有趣。 确实,它值得一整堂课; 在这里,我们只介绍几个主要的话题。<br />构建分布式系统时会出现一些新的挑战。我们关注的主要问题是**失败(failure)**; 机器、磁盘、网络和软件都会不时出现故障,因为我们不知道(并且可能永远不会)知道如何构建“完美”的组件和系统。 但是,当我们构建现代 Web 服务时,我们希望它在客户面前看起来好像永远不会失败; 我们怎样才能完成这个任务?
关键的问题:如何构建组件失效时仍能工作的系统 我们如何用一直不能正常工作的部分构建一个工作系统? 基本问题应该让您想起我们在 RAID 存储阵列中讨论的一些主题; 然而,这里的问题往往更复杂,解决方案也是如此。
有趣的是,虽然失败是构建分布式系统的主要挑战,但它也代表了一个机会。 是的,机器出故障了; 但机器故障这一事实并不意味着整个系统都必须故障。 通过聚集一组机器,我们可以构建一个看起来很少发生故障的系统,尽管其组件经常发生故障。 这种现实是分布式系统的核心魅力和价值,也是为什么它们是您使用的几乎所有现代 Web 服务(包括 Google、Facebook 等)的基础。<br />还存在其他重要问题。 **系统性能(performance)**通常很关键; 通过将我们的分布式系统连接在一起的网络,系统设计人员必须经常仔细考虑如何完成给定的任务,尝试减少发送的消息数量并进一步使通信尽可能高效(低延迟、高带宽)。<br />最后,**安全(security)**也是一个必要的考虑因素。 当连接到远程站点时,确保远程方就是他们所说的那个人就成了一个核心问题。 此外,确保第三方无法监控或更改其他两个人之间正在进行的通信也是一个挑战。<br />在本介绍中,我们将介绍分布式系统中最基本的新方面:**通信(communication)**。 也就是说,分布式系统中的机器应该如何相互通信? 我们将从最基本的可用原语开始,消息(messages),并在它们之上构建一些更高级别的原语。 正如我们上面所说,失败将是一个中心焦点:通信层应该如何处理失败?
48.1 通信基础 Communication Basics
现代网络的核心原则是通信从根本上是不可靠的。 无论是在广域 Internet 中,还是在 Infiniband 等局域网高速网络中,数据包都会经常丢失、损坏或无法到达目的地。
导致数据包丢失或损坏(corruption)的原因有很多。 有时,在传输过程中,由于电气或其他类似问题,某些位会发生翻转。 有时,系统中的某个元素,例如网络链接或数据包路由器甚至远程主机,会以某种方式损坏或无法正常工作; 网络电缆确实会不小心被切断,至少有时是这样。
然而,更根本的是由于网络交换机、路由器或端点内缺乏缓冲而导致的数据包丢失。 具体来说,即使我们可以保证所有链路都正常工作,并且系统中的所有组件(交换机、路由器、终端主机)都按预期启动并运行,但仍然可能会丢失,原因如下。 想象一个数据包到达路由器; 对于要处理的数据包,它必须放置在路由器内某处的内存中。 如果许多这样的数据包同时到达,则路由器内的内存可能无法容纳所有数据包。此时路由器唯一的选择是丢弃(drop)一个或多个数据包。 同样的行为也发生在终端主机上; 当你向单台机器发送大量消息时,机器的资源很容易变得不堪重负,从而再次出现丢包。
因此,丢包是网络的基础。 那么问题就变成了:我们应该如何应对?
48.2 不可靠的通信层 Unreliable Communication Layers
一种简单的方法是:我们不处理它。 因为一些应用程序知道如何处理数据包丢失,有时让它们与一个基本的不可靠消息层进行通信很有用,这是一个经常听到的端到端原则(end-to-end argument )的例子(参见本章末尾的Aside)。 在当今几乎所有现代系统上可用的 UDP/IP 网络栈中都可以找到这种不可靠层的一个很好的例子。 要使用 UDP,进程使用套接字(sockets) API 来创建通信端点(communication endpoint); 其他机器(或同一台机器)上的进程将 UDP 数据报(datagrams)发送到原始进程(数据报是固定大小的报文,最大大小不超过某个最大大小)。
图 48.1 和 48.2 显示了一个建立在 UDP/IP 之上的简单客户端和服务器。 客户端可以向服务器发送消息,然后服务器以回复进行响应。 使用这少量代码,您就拥有了开始构建分布式系统所需的一切!
// client codeint main(int argc, char *argv[]) {int sd = UDP_Open(20000);struct sockaddr_in addrSnd, addrRcv;int rc = UDP_FillSockAddr(&addrSnd, "cs.wisc.edu", 10000);char message[BUFFER_SIZE];sprintf(message, "hello world");rc = UDP_Write(sd, &addrSnd, message, BUFFER_SIZE);if (rc > 0)int rc = UDP_Read(sd, &addrRcv, message, BUFFER_SIZE);return 0;}// server codeint main(int argc, char *argv[]) {int sd = UDP_Open(10000);assert(sd > -1);while (1) {struct sockaddr_in addr;char message[BUFFER_SIZE];int rc = UDP_Read(sd, &addr, message, BUFFER_SIZE);if (rc > 0) {char reply[BUFFER_SIZE];sprintf(reply, "goodbye world");rc = UDP_Write(sd, &addr, reply, BUFFER_SIZE);}}return 0;}
Figure 48.1: Example UDP Code (client.c, server.c)
int UDP_Open(int port) {int sd;if ((sd = socket(AF_INET, SOCK_DGRAM, 0)) == -1)return -1;struct sockaddr_in myaddr;bzero(&myaddr, sizeof(myaddr));myaddr.sin_family = AF_INET;myaddr.sin_port = htons(port);myaddr.sin_addr.s_addr = INADDR_ANY;if (bind(sd, (struct sockaddr *) &myaddr, sizeof(myaddr)) == -1) {close(sd);return -1;}return sd;}int UDP_FillSockAddr(struct sockaddr_in *addr, char *hostname, int port) {bzero(addr, sizeof(struct sockaddr_in));addr->sin_family = AF_INET; // host byte orderaddr->sin_port = htons(port); // network byte orderstruct in_addr *in_addr;struct hostent *host_entry;if ((host_entry = gethostbyname(hostname)) == NULL)return -1;in_addr = (struct in_addr *) host_entry->h_addr;addr->sin_addr = *in_addr;return 0;}int UDP_Write(int sd, struct sockaddr_in *addr, char *buffer, int n) {int addr_len = sizeof(struct sockaddr_in);return sendto(sd, buffer, n, 0, (struct sockaddr *)addr, addr_len);}int UDP_Read(int sd, struct sockaddr_in *addr, char *buffer, int n) {int len = sizeof(struct sockaddr_in);return recvfrom(sd, buffer, n, 0, (struct sockaddr *)addr, (socklen_t *) &len);}
Figure 48.2: A Simple UDP Library (udp.c)
UDP 是不可靠通信层的一个很好的例子。 如果你使用它,你会遇到数据包丢失(丢弃)从而无法到达目的地的情况; 发送者从未因此被告知损失。 但是,这并不意味着 UDP 根本不预防任何故障。 例如,UDP 包含校验和(checksum)以检测某些形式的数据包损坏。
但是,由于许多应用程序只是想将数据发送到目的地而不必担心丢包,因此我们需要更多。 具体来说,我们需要在不可靠的网络之上进行可靠的通信。
Tip:用校验和来保证完整性 校验和是在现代系统中快速有效地检测损坏的常用方法。 一个简单的校验和是加法:将一个数据块的字节相加; 当然,已经创建了许多其他更复杂的校验和,包括基本的循环冗余码 (CRC)、Fletcher 彻校验和以及许多其他 [MK09]。 在网络中,校验和的使用如下。 在从一台机器向另一台机器发送消息之前,计算消息字节的校验和。 然后将消息和校验和发送到目的地。 在目的地,接收者也计算传入消息的校验和; 如果这个计算出的校验和与发送的校验和匹配,接收者可以确信数据在传输过程中可能没有被破坏。 校验和可以沿多个不同的轴进行评估。 有效性是一个主要考虑因素:数据的变化是否会导致校验和的变化? 校验和越强,数据的变化就越难被忽视。 性能是另一个重要标准:计算校验和的成本是多少? 不幸的是,有效性和性能通常是不一致的,这意味着高质量的校验和通常计算起来很昂贵。 再一次,生活并不完美。
48.3 可靠通信层 Reliable Communication Layers
为了构建可靠的通信层,我们需要一些新的机制和技术来处理数据包丢失。 让我们考虑一个简单的例子,其中客户端通过不可靠的连接向服务器发送消息。 我们必须回答的第一个问题是:发送方如何知道接收方实际收到了消息?
我们将使用的技术称为确认(acknowledgment),或简称为 ack。 想法很简单:发送者向接收者发送一条消息; 然后接收者发回一条短消息以确认其收到。 图 48.3 描述了这个过程。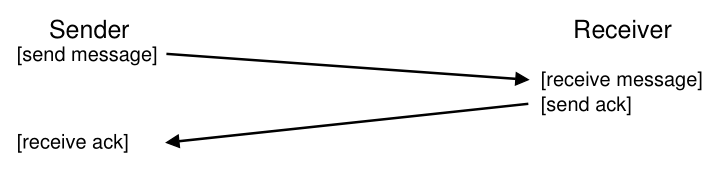
Figure 48.3: Message Plus Acknowledgment
当发送方收到对消息的确认时,它就可以确信接收方确实收到了原始消息。 但是,如果发送方没有收到确认,它应该怎么做?
为了处理这种情况,我们需要一个额外的机制,称为超时(timeout)。 当发件人发送消息时,发件人现在设置一个计时器,在一段时间后关闭。 如果在那段时间内没有收到确认,则发送方得出消息已丢失的结论。 然后发送方简单地重传(retry)发送,再次发送相同的消息,希望这次能够通过。 为了使这种方法起作用,发件人必须保留一份消息的副本,以防它需要再次发送。 超时和重传的结合导致了一些调用超时/重传的方法(timeout/retry); 相当聪明的一群人,那些网络类型,不是吗? 图 48.4 显示了一个示例。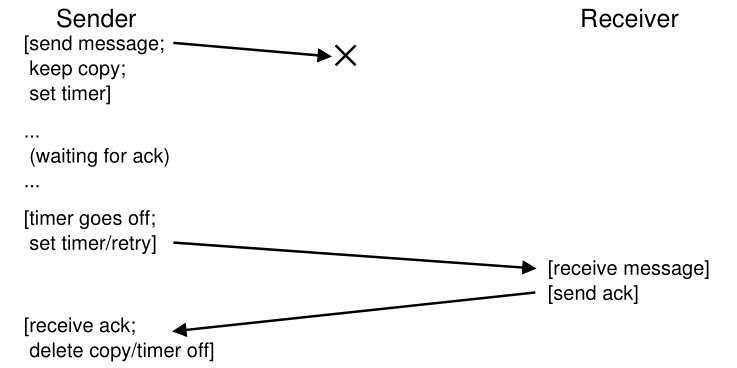
Figure 48.4: Message Plus Acknowledgment: Dropped Request
不幸的是,这种形式的超时/重传还不够。 图 48.5 显示了可能导致故障的数据包丢失示例。 在这个例子中,丢失的不是原始消息,而是确认。 从发送者的角度来看,情况似乎是一样的:没有收到 ack,因此超时和重传是有序的。 但是从接收者的角度来看,就大不相同了:现在同一个消息已经收到了两次! 虽然在某些情况下这是可以的,但通常情况并非如此; 想象一下当你下载一个文件并且在下载中重复额外的数据包时会发生什么。 因此,当我们以可靠的消息层为目标时,我们通常还希望保证每个消息都被接收者恰好接收一次(is received exactly once)。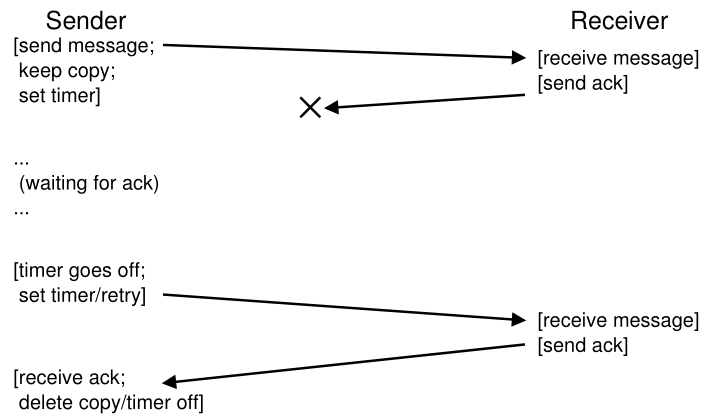
Figure 48.5: Message Plus Acknowledgment: Dropped Reply
为了使接收者能够检测重复的消息传输,发送者必须以某种独特的方式识别每条消息,而接收者需要某种方式来跟踪它之前是否已经看过每条消息。 当接收者看到重复传输时,它只是确认消息,但(关键)不会将消息传递给接收数据的应用程序。 因此,发送方收到 ack 但消息没有收到两次,保留了上面提到的恰好一次(exactly-once)语义。
有无数种方法可以检测重复消息。 例如,发送者可以为每条消息生成一个唯一的 ID; 接收者可以跟踪它见过的每个 ID。 这种方法可行,但成本高得令人望而却步,需要无限内存来跟踪所有 ID。
需要很少内存的更简单的方法解决了这个问题,该机制称为序列计数器(sequence counter)。 使用序列计数器,发送方和接收方就双方将维护的计数器的起始值(例如,1)达成一致。 每当发送消息时,计数器的当前值与消息一起发送; 此计数器值 (N) 用作消息的 ID。 发送消息后,发送方将值递增(至 N + 1)。
接收方使用其计数器值作为来自该发送方的传入消息 ID 的预期值。 如果接收到的消息的 ID (N) 与接收者的计数器(也是 N)匹配,则确认消息并将其传递给应用程序; 在这种情况下,接收者得出结论,这是第一次收到此消息。 然后接收器增加它的计数器(到 N + 1),并等待下一条消息。
如果 ack 丢失,发送方将超时并重新发送消息 N。 这次,接收方的计数器更高(N +1),因此接收方知道它已经收到了这条消息。 因此,它确认消息但不将其传递给应用程序。 以这种简单的方式,可以使用序列计数器来避免重复。
最常用的可靠通信层称为 TCP/IP,或简称为 TCP。 TCP 比我们上面描述的要复杂得多,包括处理网络拥塞的机制 [VJ88]、多个未完成的请求以及数百个其他小的调整和优化。 如果您好奇,请阅读更多相关信息; 更好的是,参加网络课程并很好地学习该材料。
Tip:设置超时值时要小心 从讨论中你大概可以猜到,正确设置超时值是使用超时重传消息发送的一个重要方面。如果超时太小,发送方会不必要地重新发送消息,从而浪费发送方的 CPU 时间和网络资源。 如果超时过大,则发送方等待重新发送的时间过长,从而降低了发送方的感官性能。 因此,从单个客户端和服务器的角度来看,“正确”值是等待足够长的时间来检测数据包丢失,但不再等待。 然而,在分布式系统中,通常不止一个客户端和服务器,我们将在后面的章节中看到。 在许多客户端发送到单个服务器的情况下,服务器的数据包丢失可能表明服务器过载。 如果为 true,客户端可能会以不同的自适应方式重传; 例如,在第一次超时后,客户端可能会将其超时值增加到更高的值,可能是原始值的两倍。 这种在早期 Aloha 网络中首创并在早期以太网 [A70] 中采用的指数回退(exponential back-off)方案避免了资源因过度重新发送而过载的情况。 健壮的系统努力避免这种性质的过载。
48.4 通信抽象 Communication Abstractions
给定一个基本的消息传递层,我们现在处理本章中的下一个问题:在构建分布式系统时,我们应该使用什么样的通信抽象?
多年来,系统社区开发了许多方法。 一项工作采用了操作系统抽象并将其扩展为在分布式环境中运行。 例如,分布式共享内存 (distributed shared memory,DSM) 系统使不同机器上的进程能够共享大型虚拟地址空间 [LH89]。 这种抽象将分布式计算变成了一个看起来像多线程(multi-threaded)应用程序的东西; 唯一的区别是这些线程运行在不同的机器上,而不是同一台机器内的不同处理器上。
大多数 DSM 系统的工作方式是借助操作系统的虚拟内存系统。 在一台机器上访问页面时,可能会发生两种情况。 在第一种(最佳)情况下,页面已经在机器本地,因此可以快速获取数据。 在第二种情况下,页面当前在其他机器上。 发生页面错误,页面错误处理程序向其他机器发送消息以获取页面,将其安装到请求进程的页表中,然后继续执行。
由于多种原因,这种方法今天并未广泛使用。 DSM 最大的问题是它如何处理故障。 想象一下,例如,如果一台机器出现故障; 那台机器上的页面会发生什么? 如果分布式计算的数据结构分布在整个地址空间呢? 在这种情况下,这些数据结构的一部分会突然变得不可用。 当部分地址空间丢失时处理故障是很困难的; 想象一个链表,其中“下一个(next)”指针指向已消失的地址空间部分。 哎呀!
另一个问题是性能。 人们通常认为,在编写代码时,访问内存的成本很低。 在 DSM 系统中,一些访问成本低廉,但其他访问会导致缺页错误并从远程机器上进行昂贵的获取。 因此,此类 DSM 系统的程序员必须非常小心地组织计算,以致几乎不发生任何通信,这在很大程度上违背了这种方法的要点。 尽管在这个领域进行了大量研究,但实际影响很小。 今天没有人使用 DSM 构建可靠的分布式系统。
48.5 远程程序调用 Remote Procedure Call (RPC)
虽然 OS 抽象被证明是构建分布式系统的糟糕选择,但编程语言 (programming language,PL) 抽象更有意义。 最主要的抽象是基于远程程序调用(remote procedure call)的思想,或简称为 RPC [BN84]。
在现代编程语言中,我们可能会说远程方法调用(remote method invocation,RMI),但无论如何谁喜欢这些语言,以及它们所有花哨的对象?
远程程序调用包(packages)都有一个简单的目标:使在远程机器上执行代码的程序像调用本地函数一样简单直接。 因此,对客户端进行程序调用,一段时间后返回结果。 服务器只是定义了一些它希望输出的例程。 其余的魔法由 RPC 系统处理,它通常有两部分:**stub 生成器(stub generator,有时称为协议编译器(protocol compiler))和运行时库(run-time library)**。现在,我们将更详细地了解这些部分中的每一个。
Stub生成器 Stub Generator
stub生成器的工作很简单:通过自动化来消除将函数参数和结果打包到消息中的一些痛苦。 产生了许多好处:通过设计避免了手工编写此类代码时出现的简单错误; 此外,stub编译器或许可以优化此类代码,从而提高性能。
这种编译器的输入只是服务器希望导出到客户端的一组调用。 从概念上讲,它可能像这样简单:
interface {int func1(int arg1);int func2(int arg1, int arg2);};
stub生成器采用这样的接口并生成一些不同的代码段。 对于客户端,生成一个**客户端stub(client stub)**,其中包含接口中指定的每个函数; 希望使用此 RPC 服务的客户端程序将与此客户端 stub 链接并调用它以生成 RPC。<br />在内部,客户端stub中的这些函数中的每一个都完成执行远程程序调用所需的所有工作。 对于客户端,代码只是作为一个函数调用出现(例如,客户端调用 func1(x)); 在内部,func1() 的客户端 stub 中的代码执行以下操作:
- 创建消息缓冲区(Create a message buffer)。 消息缓冲区通常只是具有某个大小的连续字节数组。
- 将所需的信息打包到消息缓冲区中(Pack the needed information into the message buffer)。 此信息包括要调用的函数的某种标识符,以及该函数需要的所有参数(例如,在我们上面的示例中,func1 的一个整数)。 将所有这些信息放入单个连续缓冲区的过程有时称为参数的封送处理(marshaling)或消息的序列化(serialization)。
- 将消息发送到目标 RPC 服务器(Send the message to the destination RPC server)。 与 RPC 服务器的通信以及使其正确运行所需的所有细节都由 RPC 运行时库处理,如下所述。
- 等待回复(Wait for the reply)。因为函数调用通常是同步的,所以调用将等待其完成。
- 解压返回码和其他参数(Unpack return code and other arguments)。 如果函数只返回一个返回码,这个过程很简单; 然而,更复杂的函数可能会返回更复杂的结果(例如,一个列表),因此 stub 可能也需要解压这些结果。 此步骤也称为解封送处理(unmarshaling)或反序列化(deserialization)。
- 返回给调用者(Return to the caller)。最后,从客户端 stub 返回到客户端代码。
对于服务器,还会生成代码。 在服务器上采取的步骤如下:
- 解包消息(Unpack the message)。 这一步称为解封送处理(unmarshaling)或反序列化(deserialization),从传入的消息中取出信息。 提取函数标识符和参数。
- 调用实际函数(Call into the actual function)。 最后! 我们已经到了真正执行远程函数的地步。 RPC 运行时调用由 ID 指定的函数并传入所需的参数。
- 打包结果(Package the results)。 返回参数被编组回单个应答缓冲区(reply buffer)。
- 发送应答(Send the reply)。 应答最终发送给调用者。
在 stub 编译器中还有一些其他重要问题需要考虑。 第一个是复杂参数,即一个复杂的数据结构如何打包和发送? 例如,当调用 write() 系统调用时,会传入三个参数:整数文件描述符、指向缓冲区的指针和指示要写入的字节数(从指针开始)的大小。 如果 RPC 包被传递一个指针,它需要能够弄清楚如何解释该指针,并执行正确的操作。 通常这是通过众所周知的类型(例如,用于传递给定大小的数据块的 buffer_t,RPC 编译器理解),或者通过使用更多信息注释数据结构,使编译器知道哪些字节需要序列化。
另一个重要问题是关于并发性的服务器结构。一个简单的服务器只是在一个简单的循环中等待请求,并且一次处理一个请求。然而,正如您可能已经猜到的,这可能非常低效;如果一个 RPC 调用阻塞(例如,在 I/O 上),就会浪费服务器资源。因此,大多数服务器都是以某种并发方式构建的。一个常见的结构是线程池(thread pool)。在这种结构中,服务器启动时会创建一组有限的线程;当消息到达时,它被分派到这些工作线程之一,然后执行 RPC 调用的工作,最终应答;在此期间,主线程不断接收其他请求,并可能将它们分派给其他工作线程。这样的结构可以在服务器内实现并发执行,从而提高其利用率;标准成本也出现了,主要是在编程复杂性方面,因为 RPC 调用现在可能需要使用锁和其他同步原语来确保它们的正确操作。
运行时库 Run-Time Library
运行时库处理 RPC 系统中的大部分繁重工作; 大多数性能和可靠性问题都在这里处理。 我们现在将讨论构建这样一个运行时层的一些主要挑战。
我们必须克服的首要挑战之一是如何定位远程服务。 这个命名(naming)问题在分布式系统中很常见,在某种意义上超出了我们当前讨论的范围。 最简单的方法建立在现有的命名系统上,例如,当前互联网协议提供的主机名和端口号(hostnames and port numbers)。 在这样的系统中,客户端必须知道运行所需 RPC 服务的机器的主机名或 IP 地址,以及它正在使用的端口号(端口号只是识别机器上发生的特定通信活动的一种方式,允许同时使用多个通信通道)。然后,协议套件(protocol suite)必须提供一种机制,将数据包从系统中的任何其他机器路由到特定地址。 为了更好地讨论命名,你必须到别处去看看,例如,在互联网上阅读 DNS 和名称解析,或者更好的是阅读 Saltzer 和 Kashoek 的书 [SK09] 中的精彩章节。
一旦客户端知道它应该与哪个服务器通信以获取特定的远程服务,下一个问题是 RPC 应该建立在哪个传输层级协议(transport-level protocol)上。 具体来说,RPC 系统应该使用可靠的协议,如 TCP/IP,还是建立在不可靠的通信层,如 UDP/IP?
天真的选择似乎很容易:显然我们希望将请求可靠地传递到远程服务器,并且显然我们希望可靠地接收回复。 因此我们应该选择可靠的传输协议,例如TCP,对吗?
不幸的是,在可靠的通信层之上构建 RPC 会导致性能严重低下。 回想一下上面的讨论,可靠的通信层是如何工作的:使用确认加上超时/重传。 因此,当客户端向服务器发送 RPC 请求时,服务器会以确认响应,以便调用者知道已收到请求。 类似地,当服务器向客户端发送应答时,客户端会对其进行确认,以便服务器知道它已收到。 通过在可靠通信层之上构建请求/响应协议(例如 RPC),会发送两条“额外”消息。
出于这个原因,许多 RPC 包建立在不可靠的通信层之上,例如 UDP。 这样做可以实现更高效的 RPC 层,但确实增加了为 RPC 系统提供可靠性的责任。 RPC 层通过使用超时/重传和确认来实现所需的责任级别,就像我们上面描述的一样。 通过使用某种形式的序列编号,通信层可以保证每个 RPC 只发生一次(在没有失败的情况下) ,或至多一次(在出现故障的情况下)。
其他问题 Other Issues
RPC 运行时还必须处理一些其他问题。 例如,当远程调用需要很长时间才能完成时会发生什么? 鉴于我们的超时机制,长时间运行的远程调用可能对客户端显示为失败,从而触发重传,因此这里需要注意。 一种解决方案是在没有立即生成应答时使用显式确认(从接收方到发送方); 这让客户端知道服务器收到了请求。 然后,经过一段时间后,客户端可以定期询问服务器是否仍在处理请求; 如果服务器一直说“是”,客户端应该很高兴并继续等待(毕竟,有时程序调用可能需要很长时间才能完成)。
运行时还必须处理带有大参数的程序调用,大于单个数据包所能容纳的参数。 一些较低级别的网络协议提供了这样的发送方分段(fragmentation)(将较大的数据包分成一组较小的分组)和接收方重组(将较小的部分组成一个更大的逻辑整体); 如果没有,RPC 运行时可能必须自己实现此类功能。 有关详细信息,请参阅 Birrell 和 Nelson 的论文 [BN84]。
许多系统处理的一个问题是字节顺序(byte ordering)。 您可能知道,一些机器以所谓的大端(big endian)顺序存储值,而其他机器使用小端(little endian)顺序。 大端存储从字节的最高有效位到最低有效位(例如,一个整数),很像阿拉伯数字; 小端正好相反。两者都是同样有效的存储数字信息的方式; 这里的问题是如何在不同字节序的机器之间进行通信。
RPC 包通常通过在其消息格式中提供明确定义的字节序来处理此问题。 在 Sun 的 RPC 包中,XDR(eXternal Data Representation)层提供了这个功能。 如果发送或接收消息的机器与 XDR 的字节序匹配,则消息只是按预期发送和接收。 但是,如果通信的机器具有不同的字节序,则必须转换消息中的每条信息。 因此,字节序的差异可以带来很小的性能成本。
最后一个问题是是否将通信的异步特性暴露给客户端,从而实现一些性能优化。 具体来说,典型的 RPC 是同步(synchronously)进行的,即当客户端发出程序调用时,它必须等待程序调用返回才能继续 。 由于此等待时间可能很长,而且客户端可能还有其他工作要做,因此某些 RPC 包使您能够异步(asynchronously)调用 RPC。 当发出异步RPC时,RPC包发送请求并立即返回; 然后客户端可以自由地做其他工作,例如调用其他 RPC 或其他有用的计算。 客户端有时会想要查看异步 RPC 的结果; 因此它回调到 RPC 层,告诉它等待未完成的 RPC 完成,此时可以访问返回参数。
Aide:端到端原则 端到端原则表明,系统中的最高层级,即通常是“最后”的应用程序,最终是分层系统中可以真正实现某些功能的唯一场所。 在他们具有里程碑意义的论文 [SRC84] 中,Saltzer 等人。 通过一个很好的例子来论证这一点:两台机器之间的可靠文件传输。 如果您想将文件从机器 A 传输到机器 B,并确保在 B 上结束的字节与在 A 上开始的字节完全相同,您必须对此进行“端到端”检查 ; 较低级别的可靠机器(例如,在网络或磁盘中)不提供此类保证。 对比(contrast)是一种尝试通过为系统的较低层增加可靠性来解决可靠文件传输问题的方法。例如,假设我们构建了一个可靠的通信协议并使用它来构建我们可靠的文件传输。通信协议保证发送方发送的每个字节都会被接收方按顺序接收,比如使用超时/重传、确认和序列号。不幸的是,使用这样的协议并不是可靠的文件传输;想象一下,在通信发生之前,发送方内存中的字节已损坏,或者在接收方将数据写入磁盘时发生了一些不好的事情。在这些情况下,即使字节可靠地通过网络传输,我们的文件传输最终也不可靠。为了建立可靠的文件传输,必须包括端到端的可靠性检查,例如,在整个传输完成后,读回接收器磁盘上的文件,计算校验和,并将校验和与发送方的校验和进行比较。 这个准则的推论是,有时让较低的层提供额外的功能确实可以提高系统性能,或者优化系统。因此,您不应该排除在系统的较低层级上拥有这样的机制;相反,您应该仔细考虑这种机制的效用,因为它最终会在整个系统或应用程序中使用。
48.6 总结 Summary
我们已经看到了一个新主题分布式系统的引入,以及它的主要问题:如何处理故障,这现在是一个司空见惯的事件。正如谷歌内部所说,当你只有台式机时,故障很少见; 当您在拥有数千台机器的数据中心时,故障一直在发生。 任何分布式系统的关键在于您如何处理该故障。
我们还看到,通信构成了任何分布式系统的核心。 在远程程序调用 (RPC) 中可以找到该通信的常见抽象,它使客户端能够在服务器上进行远程调用; RPC 包处理所有繁琐的细节,包括超时/重传和确认,以便提供密切反映本地程序调用的服务。
真正理解 RPC 包的最好方法当然是自己使用。 Sun 的 RPC 系统,使用 stub 编译器 rpcgen,是一个较旧的系统; 谷歌的 gRPC 和 Apache Thrift 是现代的。 试一试,看看有什么大惊小怪的。
References
[A70] “The ALOHA System — Another Alternative for Computer Communications” by Norman Abramson. The 1970 Fall Joint Computer Conference.
ALOHA网络开创了网络的一些基本概念,包括指数回退和重传,多年来形成了共享总线以太网通信的基础。
[BN84] “Implementing Remote Procedure Calls” by Andrew D. Birrell, Bruce Jay Nelson. ACM TOCS, Volume 2:1, February 1984.
所有其他人建立的基础 RPC 系统。是的,我们在 Xerox PARC 的朋友的另一项开创性努力。
[MK09] “The Effectiveness of Checksums for Embedded Control Networks” by Theresa C. Maxino and Philip J. Koopman. IEEE Transactions on Dependable and Secure Computing, 6:1, January ’09.
对基本校验和机制以及它们之间的一些性能和健壮性比较进行了很好的概述。
[LH89] “Memory Coherence in Shared Virtual Memory Systems” by Kai Li and Paul Hudak. ACM TOCS, 7:4, November 1989.
通过虚拟内存引入基于软件的共享内存。这肯定是一个有趣的想法,但最终不是一个持久的或好的想法。
[SK09] “Principles of Computer System Design” by Jerome H. Saltzer and M. Frans Kaashoek. Morgan-Kaufmann, 2009.
一本关于系统的优秀书籍,是每个书架的必读书籍。这是我们所见过的为数不多的关于命名(naming)的精彩讨论之一。
[SRC84] “End-To-End Arguments in System Design” by Jerome H. Saltzer, David P. Reed, David D. Clark. ACM TOCS, 2:4, November 1984.
关于分层、抽象以及功能最终必须驻留在计算机系统中的位置的精彩讨论。
[VJ88] “Congestion Avoidance and Control” by Van Jacobson. SIGCOMM ’88 .
关于客户应如何适应感知到的网络拥塞的开创性论文; 绝对是互联网背后的关键技术之一,对于任何认真对待系统的人以及 Van Jacobson 的亲戚来说,都必须阅读,因为好的亲戚应该阅读您的所有论文。
Homework (Code)
在本节中,我们将编写一些简单的通信代码,使您熟悉这样做的任务。玩得开心!
Questions
- 使用本章提供的代码,构建一个简单的基于 UDP 的服务器和客户端。服务器应该接收来自客户端的消息,并回复一个确认。 在第一次尝试中,不要添加任何重传或健壮性(假设通信工作正常)。 在一台机器上运行它进行测试; 稍后,在两台不同的机器上运行它。
- 将您的代码变成一个通信库(communication library)。 具体来说,根据需要使用发送和接收调用以及其他 API 调用来制作您自己的 API。 重写您的客户端和服务器以使用您的库而不是原始套接字调用。
- 以超时/重传(timeout/retry)的形式将可靠的通信添加到您新兴的通信库中。 具体来说,您的库应该复制它要发送的任何消息。 发送时,它应该启动一个计时器,以便它可以跟踪自消息发送以来已经过去了多长时间。 在接收方,库应该确认(acknowledge)收到的消息。 客户端发送时应该阻塞(block),即它应该等到消息被确认后再返回。 它也应该愿意无限期地重传发送。 最大消息大小应该是您可以使用 UDP 发送的最大单个消息的大小。 最后,确保通过让调用者休眠直到 ack 到达或传输超时来有效地执行超时/重传; 不要旋转并浪费CPU!
- 使您的库更高效,功能更丰富。 首先,添加超大消息传输。 具体来说,虽然网络限制了最大消息大小,但您的库应该接收任意大小的消息并将其从客户端传输到服务器。 客户端应该将这些大消息分段传输给服务器; 服务器端库代码应该将接收到的片段组装成连续的整体,并将单个大缓冲区传递给等待的服务器代码。
- 再次执行上述操作,但性能要高。 您应该快速发送多个片段,而不是一次发送一个片段,从而使网络得到更高的利用率。 为此,请仔细标记传输的每个部分,以便接收方的重新组装不会扰乱消息。
- 最后一个实现挑战:按顺序发送异步消息。 也就是说,客户端应该能够重复调用 send 来发送一条又一条消息; 接收者应该调用receive并可靠地按顺序获取每条消息; 来自发送者的许多消息应该能够同时传输。 还添加一个发送方调用,使客户端能够等待所有未完成的消息得到确认。
- 现在,还有一个痛点:测量。 测量每种方法的带宽; 您可以在两台不同的机器之间以什么速率传输多少数据? 还要测量延迟:对于单个数据包发送和确认,它完成的速度有多快? 最后,你的数字看起来合理吗? 你期待什么? 您如何更好地设定您的期望以便知道是否存在问题,或者您的代码是否运行良好?

若有收获,就点个赞吧
0 人点赞
