Andrew 文件系统于 1980 年代 [H+88] 在卡内基梅隆大学 (CMU) 推出。 在卡内基梅隆大学著名教授 M. Satyanarayanan(简称“Satya”)的带领下,该项目的主要目标很简单:**规模(scale)**。 具体来说,如何设计分布式文件系统,使服务器可以支持尽可能多的客户端?
虽然最初被称为“卡内基-梅隆大学(Carnegie-Mellon University)”,但 CMU 后来去掉了连字符,因此诞生了现代形式“卡内基梅隆大学(Carnegie Mellon University)”。 由于 AFS 源自 80 年代初的工作,我们以其原始的全连字符形式提到 CMU。 如果您真的很无聊,请参阅 https://www.quora.com/When-did-Carnegie-Mellon-University-remove-the-hyphen-in-the-university-name 了解更多详情。
有趣的是,设计和实现的许多方面都会影响可扩展性(scalability)。 最重要的是客户端和服务器之间协议(protocol)的设计。 例如,在 NFS 中,协议强制客户端定期检查服务器以确定缓存内容是否已更改; 因为每次检查都使用服务器资源(包括 CPU 和网络带宽),像这样频繁的检查将限制服务器可以响应的客户端数量,从而限制可扩展性。
AFS 与 NFS 的不同之处还在于,从一开始,合理的用户可见(user-visible)行为就是首要考虑的问题。 在 NFS 中,缓存一致性很难描述,因为它直接取决于低级实现细节,包括客户端缓存超时间隔。 在 AFS 中,缓存一致性很简单且易于理解:当文件打开时,客户端通常会从服务器接收最新的一致性副本。
50.1 AFS版本1 AFS Version 1
我们将讨论 AFS 的两个版本 [H+88, S+85]。 第一个版本(我们将其称为 AFSv1,但实际上原始系统称为 ITC 分布式文件系统(ITC distributed file system) [S+85])具有一些基本设计,但没有按预期扩展,这导致了重新设计和最终协议(我们将其称为 AFSv2,或简称为 AFS)[H+88]。 我们现在讨论第一个版本。
Figure 50.1: AFSv1 Protocol Highlights
所有 AFS 版本的基本原则之一是在访问文件的客户端计算机的本地磁盘(local disk)上缓存整个文件(whole-file caching)。 当您 open() 一个文件时,整个文件(如果存在)将从服务器获取并存储在本地磁盘上的文件中。 后续的应用程序 read() 和 write() 操作被重定向到存储文件的本地文件系统; 因此,这些操作不需要网络通信并且速度很快。 最后,在 close() 时,文件(如果它已被修改)被刷新回服务器。 请注意与 NFS 的明显对比,它缓存块(不是整个文件,尽管 NFS 当然可以缓存整个文件的每个块)并且在客户端内存(不是本地磁盘)中这样做。
让我们更深入地了解细节。 当客户端应用程序首次调用 open() 时,AFS 客户端代码(AFS 设计者称之为 Venus(译者注:维纳斯))将向服务器发送 Fetch 协议消息。 Fetch 协议消息会将所需文件的整个路径名(例如,/home/remzi/notes.txt)传递给文件服务器(他们称之为 Vice 的组),然后该服务器将遍历路径名,找到所需的文件,并将整个文件发送回客户端。 然后,客户端代码会将文件缓存在客户端的本地磁盘上(通过将其写入本地磁盘)。 正如我们上面所说,随后的 read() 和 write() 系统调用在 AFS 中是严格本地的(不发生与服务器的通信); 它们只是被重定向到文件的本地副本。因为 read() 和 write() 调用就像对本地文件系统的调用一样,所以一旦访问了一个块,它也可能被缓存在客户端内存中。 因此,AFS 还使用客户端内存来缓存它在其本地磁盘中的块副本。 最后,当完成时,AFS 客户端检查文件是否已被修改(即它已被打开用于写入); 如果是这样,它将使用 Store 协议消息将新版本刷新回服务器,将整个文件和路径名发送到服务器以进行永久存储。
下次访问文件时,AFSv1 的效率要高得多。 具体来说,客户端代码首先联系服务器(使用 TestAuth 协议消息)以确定文件是否已更改。 如果没有,客户端将使用本地缓存的副本,从而通过避免网络传输来提高性能。 上图显示了 AFSv1 中的一些协议消息。 请注意,该协议的早期版本仅缓存文件内容; 例如,目录只保存在服务器上。
Tip:先测量再建造(Patterson’s Law) 我们的一位顾问 David Patterson(以 RISC 和 RAID 闻名)过去总是鼓励我们在构建新系统以解决所述问题之前先测量系统并证明问题。 通过使用实验证据而不是直觉,您可以将系统构建过程转变为更科学的努力。 这样做还有一个附带好处,就是让您在开发改进版本之前考虑如何准确地测量系统。 当你最终开始构建新系统时,有两件事会变得更好:第一,你有证据表明你正在解决一个真正的问题; 其次,您现在有了一种方法来衡量您的新系统,以表明它实际上是在现有技术的基础上改进的。因此我们称之为帕特森定律。
50.2 版本1的问题 Problems with Version 1
第一个 AFS 版本的几个关键问题促使设计人员重新考虑他们的文件系统。 为了详细研究问题,AFS 的设计人员花了大量时间测量他们现有的原型,以找出问题所在。 这样的实验是一件好事,因为测量(measurement)是理解系统如何工作以及如何改进它们的关键; 因此,获得具体、良好的数据是系统建设的必要部分。 在他们的研究中,作者发现了 AFSv1 的两个主要问题:
- 路径遍历成本太高(Path-traversal costs are too high):在执行 Fetch 或 Store 协议请求时,客户端将整个路径名(例如,/home/remzi/notes.txt)传递给服务器。 服务器,为了访问文件,必须进行全路径遍历,首先在根目录中查找home,然后在home中找到remzi,依此类推,一直往下走,直到最后想要的文件被定位。由于许多客户端同时访问服务器,AFS 的设计者发现服务器花费大量 CPU 时间只是沿着目录路径走下去。
- 客户端发出过多的 TestAuth 协议消息(The client issues too many TestAuth protocol messages):与 NFS 及其过多的 GETATTR 协议消息非常相似,AFSv1 生成大量流量来检查本地文件(或其统计信息)是否对 TestAuth 协议消息有效。 因此,服务器花费大量时间来告诉客户端是否可以使用他们缓存的文件副本。 大多数情况下,答案是文件没有改变。
AFSv1 实际上还有另外两个问题:服务器之间的负载不平衡,服务器为每个客户端使用一个不同的进程,从而导致上下文切换和其他开销。 通过引入卷(volumes)解决了负载不平衡问题,管理员可以跨服务器移动以平衡负载; 通过使用线程而不是进程构建服务器,上下文切换问题在 AFSv2 中得到解决。 然而,由于篇幅原因,我们在此重点讨论上述限制系统规模的两个主要协议问题。
50.3 改进协议 Improving the Protocol
以上两个问题限制了AFS的可扩展性; 服务器 CPU 成为系统的瓶颈,每台服务器只能服务 20 个客户端而不会过载。 服务器接收了太多的 TestAuth 消息,当它们收到 Fetch 或 Store 消息时,花费了太多时间遍历目录层次结构。 因此,AFS 设计者面临一个问题:
关键的问题:如何设计可扩展的文件协议 应该如何重新设计协议以最小化服务器交互的数量,即他们如何减少 TestAuth 消息的数量? 此外,他们如何设计协议以使这些服务器交互有效? 通过解决这两个问题,新协议将产生更具可扩展性的 AFS 版本。
50.4 AFS版本2 AFS Version 2
AFSv2 引入了回调(callback)的概念来减少客户端/服务器交互的数量。 回调只是从服务器到客户端的一个应答(promise),当客户端缓存的文件被修改时,服务器将通知客户端。 通过将此状态(state)添加到系统,客户端不再需要联系服务器来确定缓存文件是否仍然有效。 相反,它假定文件是有效的,直到服务器告诉它其他情况; 注意轮询(polling)与中断(interrupts)的类比。
AFSv2 还引入了文件标识符 (file identifier,FID)(类似于 NFS 文件句柄(file handle))而不是路径名的概念来指定客户端对哪个文件感兴趣。AFS 中的 FID 由卷标识符、文件标识符和“ uniquifier”(以便在删除文件时重新使用卷和文件 ID)。 因此,不是将整个路径名发送到服务器并让服务器遍历路径名以找到所需的文件,而是客户端将遍历路径名,一次一个,缓存结果,从而希望减少服务器上的负载。
例如,如果客户端访问文件 /home/remzi/notes.txt,并且 home 是挂载在 / 上的 AFS 目录(即 / 是本地根目录,但 home 及其子目录在 AFS 中),客户端将首先获取home目录下的内容,放入本地磁盘缓存,并在home上设置回调。 然后,客户端将获取目录remzi,将其放入本地磁盘缓存中,并在remzi 上设置回调。 最后,客户端会获取 notes.txt,将此常规文件缓存在本地磁盘中,设置回调,最后将文件描述符返回给调用应用程序。 有关摘要,请参见图 50.2。
Figure 50.2: Reading A File: Client-side And File Server Actions
然而,与 NFS 的主要区别在于,每次获取目录或文件时,AFS 客户端都会与服务器建立回调,从而确保服务器将其缓存状态的更改通知客户端。 好处是显而易见的:虽然第一次访问 /home/remzi/notes.txt 会生成许多客户端 - 服务器消息(client-server messages,如上所述),但它也为所有目录以及文件 notes.txt 建立了回调,因此后续 访问完全是本地的,根本不需要服务器交互。 因此,在文件缓存在客户端的常见情况下,AFS 的行为几乎与基于本地磁盘的文件系统相同。 如果多次访问一个文件,第二次访问应该和本地访问一个文件一样快。
Aside:缓存一致性不是灵丹妙药 在讨论分布式文件系统时,主要是文件系统提供的缓存一致性。然而,这种基准(baseline)一致性并不能解决从多个客户端访问文件的所有问题。例如,如果您正在构建一个代码存储库,多个客户端执行代码的签入和签出(check-ins and check-outs),则不能简单地依赖在底层文件系统上为您完成所有工作;相反,您必须使用显式文件级锁定(explicit file-level locking),以确保在发生此类并发访问时发生“正确”的事情。事实上,任何真正关心并发更新的应用程序都会添加额外的机制来处理冲突。本章和前一章中描述的基准一致性主要用于临时使用,即当用户登录到不同的客户端时,他们希望在那里显示一些合理版本的文件。对这些协议抱有更多期望,就是让自己为失败、失望和泪流满面的挫折做好准备。
50.5 缓存一致性 Cache Consistency
当我们讨论 NFS 时,我们考虑了缓存一致性的两个方面:更新可见性和缓存过时(update visibility and cache staleness)。 对于更新可见性,问题是:什么时候用新版本的文件更新服务器? 对于缓存过时,问题是:一旦服务器有了新版本,客户端多久才能看到新版本而不是旧的缓存副本?
由于回调和全文件缓存(callbacks and whole-file caching),AFS 提供的缓存一致性很容易描述和理解。 有两个重要的情况需要考虑:不同机器上进程之间的一致性,以及同一机器上进程之间的一致性。
在不同的机器之间,AFS 使更新在服务器上可见,并在同一时间使缓存的副本无效,也就是在关闭更新的文件时。 客户端打开一个文件,然后写入(可能重复)。 当它最终关闭时,新文件被刷新到服务器(因此可见)。 此时,服务器会“打断(breaks)”任何具有缓存副本的客户端的回调; 打断(the break)是通过联系每个客户端并通知它它对文件的回调不再有效来完成的。 此步骤可确保客户端不再读取文件的过时副本; 随后在这些客户端上打开将需要从服务器重新获取文件的新版本(并且还将用于重新建立对文件新版本的回调)。
AFS 对同一台机器上的进程之间的这种简单模型提出了一个例外。 在这种情况下,对文件的写入对其他本地进程立即可见(即,进程不必等到文件关闭才能查看其最新更新)。 这使得使用一台机器的行为完全符合您的预期,因为这种行为基于典型的 UNIX 语义。 只有当切换到不同的机器时,您才能检测到更通用的 AFS 一致性机制。
有一个有趣的跨机案例值得进一步讨论。 具体来说,在不同机器上的进程同时修改文件的极少数情况下,AFS 自然会采用所谓的最后写入者获胜(last writer wins)方法(或许应该称为最后关闭者获胜(last closer wins))。 具体来说,无论哪个客户端最后调用 close() 都会最后更新服务器上的整个文件,因此将是“获胜”文件,即保留在服务器上供其他人查看的文件。结果是一个由一个客户端或另一个客户端完整生成的文件。请注意与 NFS 等基于块的协议的区别:在 NFS 中,在每个客户端更新文件时,单个块的写入可能会被刷新到服务器,因此服务器上的最终文件可能是来自两个客户端的更新的混合。在许多情况下,这种混合文件输出没有多大意义,即想象一个 JPEG 图像被两个客户端分块修改; 由此产生的写入混合不太可能构成有效的 JPEG。
在图 50.3 中可以看到显示其中一些不同场景的时间线。 这些列显示了 Client1 上的两个进程(P1 和 P2)及其缓存状态、Client2 上的一个进程 (P3) 及其缓存状态以及服务器 (Server) 的行为,所有这些都在一个名为 F 的文件上运行 . 对于服务器来说,图中只是简单的展示了左边的操作完成后的文件内容。 通读它,看看你是否能理解为什么每次读取都会返回它所做的结果。 如果您遇到困难,右侧的注释栏将为您提供帮助。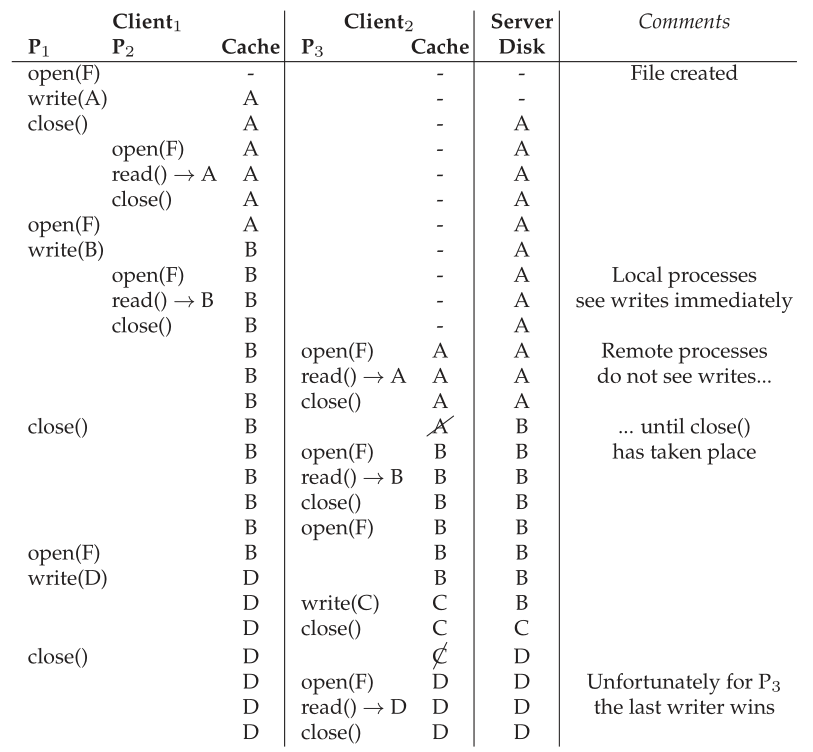
Figure 50.3: Cache Consistency Timeline
50.6 崩溃恢复 Crash Recovery
从上面的描述中,您可能会感觉到崩溃恢复比 NFS 更复杂。 你会是对的。 例如,假设在短时间内服务器 (S) 无法联系客户端 (C1),例如,当客户端 C1 重新启动时。 当 C1 不可用时,S 可能试图向它发送一条或多条回调召回(recall)消息; 例如,假设 C1 将文件 F 缓存在其本地磁盘上,然后 C2(另一个客户端)更新 F,从而导致 S 向所有缓存该文件的客户端发送消息,以将其从其本地缓存中删除。 由于 C1 在重新启动时可能会错过那些关键消息,因此在重新加入系统时,C1 应将其所有缓存内容视为可疑内容。 因此,在下次访问文件 F 时,C1 应首先询问服务器(使用 TestAuth 协议消息)其缓存的文件 F 副本是否仍然有效; 如果是这样,C1 可以使用它; 如果没有,C1 应该从服务器获取更新的版本。
崩溃后的服务器恢复也更加复杂。 出现的问题是回调保存在内存中; 因此,当服务器重新启动时,它不知道哪台客户端机器有哪些文件。 因此,在服务器重新启动时,服务器的每个客户端都必须意识到服务器已崩溃并将其所有缓存内容视为可疑内容,并且(如上所述)在使用文件之前重新建立文件的有效性。因此,服务器崩溃是一件大事,因为必须确保每个客户端都及时知道崩溃,否则客户端会冒着访问过时文件的风险。 有很多方法可以实现这种恢复; 例如,当服务器再次启动并运行时,让服务器向每个客户端发送一条消息(说“不要相信你的缓存内容!”),或者让客户端定期检查服务器是否处于活动状态(使用心跳(heartbeat)消息,顾名思义)。 如您所见,构建更具可扩展性和合理性的缓存模型需要付出代价; 使用 NFS,客户端几乎不会注意到服务器崩溃。
50.7 AFSv2的扩展性和性能 Scale And Performance Of AFSv2
新协议就位后,AFSv2 被测量并发现比原始版本更具可扩展性。 事实上,每个服务器可以支持大约 50 个客户端(而不是仅仅 20 个)。 另一个好处是客户端性能通常非常接近本地性能,因为在常见情况下,所有文件访问都是本地的; 文件读取通常进入本地磁盘缓存(也可能是本地内存)。 仅当客户端创建新文件或写入现有文件时,才需要向服务器发送 Store 消息,从而使用新内容更新文件。
通过将常见的文件系统访问场景与 NFS 进行比较,我们还可以对 AFS 性能有所了解。 图 50.4显示了我们定性比较的结果。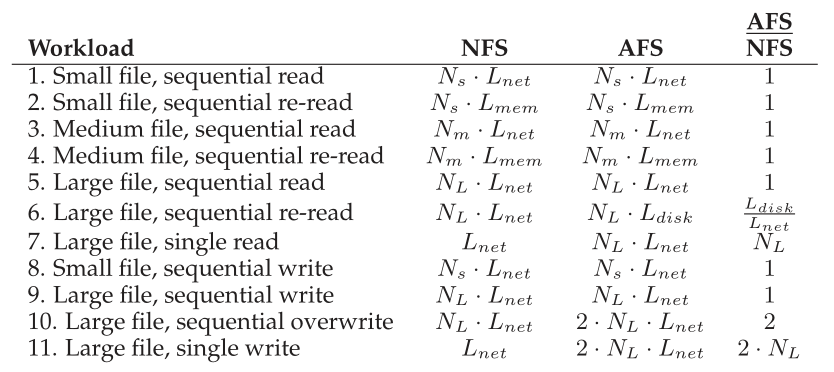
Figure 50.4: Comparison: AFS vs. NFS
在图中,我们分析了不同大小文件的典型读写模式。 小文件中有  个块; 中等文件有
个块; 中等文件有  个块; 大文件有
个块; 大文件有  块。 我们假设小型和中型文件适合客户端的内存; 大文件适合本地磁盘但不适合客户端内存。
块。 我们假设小型和中型文件适合客户端的内存; 大文件适合本地磁盘但不适合客户端内存。
为了便于分析,我们还假设通过网络访问远程服务器的文件块需要  时间单位。 访问本地内存需要
时间单位。 访问本地内存需要  ,访问本地磁盘需要
,访问本地磁盘需要  。 一般假设是
。 一般假设是  %22%20aria-hidden%3D%22true%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-4C%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3Cg%20transform%3D%22translate(681%2C-150)%22%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-6E%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-65%22%20x%3D%22600%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-74%22%20x%3D%221067%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3C%2Fsvg%3E#card=math&code=L%7Bnet%7D&id=F53FB) >  >
%22%20aria-hidden%3D%22true%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-4C%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3Cg%20transform%3D%22translate(681%2C-150)%22%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-6E%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-65%22%20x%3D%22600%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-74%22%20x%3D%221067%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3C%2Fsvg%3E#card=math&code=L%7Bnet%7D&id=F53FB) >  >  。
。
最后,我们假设对文件的第一次访问没有命中任何缓存。 如果相关缓存有足够的容量来保存文件,我们假设后续文件访问(即“重新读取”)将命中缓存。
图中的列显示了特定操作(例如,小文件连续读取(a small file sequential read))在 NFS 或 AFS 上大致花费的时间。 最右侧的列显示 AFS 与 NFS 的比率。
我们作出以下观察。 首先,在很多情况下,每个系统的性能大致相当。 例如,当第一次读取文件(例如,工作负载 1、3、5)时,从远程服务器获取文件的时间占主导地位,并且在两个系统上都是相似的。 您可能认为 AFS 在这种情况下会更慢,因为它必须将文件写入本地磁盘; 然而,这些写入由本地(客户端)文件系统缓存缓冲,因此所述成本可能是隐藏的。 同样,您可能认为 AFS 从本地缓存副本读取会更慢,这也是因为 AFS 将缓存副本存储在磁盘上。 然而,AFS 再次受益于本地文件系统缓存; AFS 上的读取可能会命中客户端内存缓存,并且性能将类似于 NFS。
其次,在大文件连续重读(工作负载 6)期间出现了一个有趣的差异。 因为 AFS 有一个很大的本地磁盘缓存,当再次访问文件时,它会从那里访问文件。 相反,NFS 只能在客户端内存中缓存块; 因此,如果重新读取大文件(即大于本地内存的文件),NFS 客户端将不得不从远程服务器重新获取整个文件。 因此,在这种情况下,AFS 比 NFS 快  ,假设远程访问确实比本地磁盘慢。 我们还注意到,在这种情况下,NFS 会增加服务器负载,这也会对可扩展性产生影响。
,假设远程访问确实比本地磁盘慢。 我们还注意到,在这种情况下,NFS 会增加服务器负载,这也会对可扩展性产生影响。
第三,我们注意到(新文件的)连续写入在两个系统(工作负载 8、9)上的表现应该相似。 在这种情况下,AFS 会将文件写入本地缓存副本; 当文件关闭时,AFS 客户端将根据协议强制写入服务器。 NFS 会缓冲客户端内存中的写入,可能会由于客户端内存压力而强制将一些块写入服务器,但在文件关闭时肯定会将它们写入服务器,以保持 NFS 关闭时刷新的一致性。 您可能认为 AFS 在这里会更慢,因为它将所有数据写入本地磁盘。 但是,意识到它正在写入本地文件系统; 这些写入首先提交到页面缓存,然后才(在后台)提交到磁盘,因此 AFS 获得客户端操作系统内存缓存基础结构的好处来提高性能。
第四,我们注意到 AFS 在连续文件覆盖(工作负载 10)上的表现更差。 到目前为止,我们假设写入的工作负载也在创建一个新文件; 在这种情况下,文件存在,然后被覆盖。 覆盖对于 AFS 来说可能是一个特别糟糕的情况,因为客户端首先获取整个旧文件,然后才覆盖它。 相反,NFS 将简单地覆盖块,从而避免初始(无用)读取。
我们在这里假设 NFS 写入是块大小和块对齐的; 如果不是,NFS 客户端也必须首先读取该块。 我们还假设文件没有用 O_TRUNC 标志打开; 如果是这样,AFS 中的初始打开将不会获取即将被截断的文件的内容。(译者注:O_TRUNC,若文件存在并且以可写的方式打开时, 此标志会令文件长度清为0, 而原来存于该文件的数据也会消失)
**最后,访问大文件中一小部分数据的工作负载在 NFS 上的性能比 AFS 好得多(工作负载 7、11)。 在这些情况下,AFS 协议会在打开文件时获取整个文件; 不幸的是,只执行了少量的读取或写入。 更糟糕的是,如果文件被修改,整个文件被写回服务器,性能影响加倍。 NFS 作为基于块的协议,执行与读取或写入大小成正比的 I/O。**<br />总的来说,我们看到 NFS 和 AFS 做出了不同的假设,因此实现了不同的性能结果也就不足为奇了。 与往常一样,这些差异是否重要是工作负载的问题。
Aide:工作负载的重要性 评估任何系统的一个挑战是工作负载的选择。 由于计算机系统的使用方式多种多样,因此有多种工作负载可供选择。 存储系统设计人员应该如何确定哪些工作负载是重要的,以便做出合理的设计决策? AFS 的设计者根据他们在测量文件系统使用方式方面的经验,做出了某些工作负载假设; 特别是,他们假设大多数文件不经常共享,而是连续访问整个文件。 鉴于这些假设,AFS 设计非常有意义。 然而,这些假设并不总是正确的。 例如,假设有一个应用程序定期将信息附加到日志中。 这些向现有大文件中添加少量数据的小日志写入对于 AFS 来说是相当有问题的。 还存在许多其他困难的工作负载,例如,事务数据库中的随机更新。 通过已经进行的各种研究,可以获得关于常见工作负载类型的一些信息。有关工作负载分析的良好示例,请参阅这些研究中的任何一项 [B+91、H+11、R+00、V99], 包括 AFS 回顾 [H+88]。
50.8 AFS:其他改进 AFS: Other Improvements
正如我们在 Berkeley FFS(添加符号链接和许多其他功能)的引入中看到的那样,AFS 的设计者在构建他们的系统时利用这个机会添加了许多使系统更易于使用和管理的功能。 例如,AFS 为客户端提供了一个真正的全局命名空间(global namespace),从而确保所有文件在所有客户端机器上都以相同的方式命名。 相反,NFS 允许每个客户端以他们喜欢的任何方式挂载 NFS 服务器,因此只有通过约定(和大量的管理工作)才能在客户端之间以类似的方式命名文件。
AFS 还非常重视安全性,并结合了对用户进行身份验证的机制,并确保如果用户需要,可以将一组文件保密。 相比之下,NFS 多年来一直对安全性提供相当原始的支持。
AFS 还包括用于灵活的用户管理访问控制(user-managed access control)的工具。因此,在使用 AFS 时,用户对谁可以访问哪些文件有很大的控制权。 与大多数 UNIX 文件系统一样,NFS 对此类共享的支持要少得多。
最后,如前所述,AFS 添加了工具,以便系统管理员能够更简单地管理服务器。 在考虑系统管理方面,AFS 领先于该领域数光年。
50.9
总结 Summary
AFS 向我们展示了如何构建与我们在 NFS 中看到的完全不同的分布式文件系统。 AFS的协议设计尤为重要; 通过最小化服务器交互(通过全文件缓存和回调),每个服务器可以支持多个客户端,从而减少管理特定站点所需的服务器数量。 许多其他特性,包括统一命名空间、安全性和访问控制列表,使 AFS 非常好用。 AFS 提供的一致性模型易于理解和推理,并且不会导致偶尔在 NFS 中观察到的奇怪行为。
也许不幸的是,AFS 可能会衰退。 由于 NFS 成为一种开放标准,许多不同的供应商都支持它,并且与 CIFS(基于 Windows 的分布式文件系统协议)一起,NFS 在市场上占据主导地位。尽管人们仍然不时看到 AFS 的安装(例如在各种教育机构,包括威斯康星州),但唯一持久的影响可能来自 AFS 的想法而不是实际系统本身。 事实上,NFSv4 现在添加了服务器状态(例如,“开放”协议消息),因此与基本 AFS 协议越来越相似。
References
[B+91] “Measurements of a Distributed File System” by Mary Baker, John Hartman, Martin
Kupfer, Ken Shirriff, John Ousterhout. SOSP ’91, Pacific Grove, California, October 1991.
一篇衡量人们如何使用分布式文件系统的早期论文。 与 AFS 中的大部分直觉相匹配。
[H+11] “A File is Not a File: Understanding the I/O Behavior of Apple Desktop Applications” by Tyler Harter, Chris Dragga, Michael Vaughn, Andrea C. Arpaci-Dusseau, Remzi H. Arpaci-
Dusseau. SOSP ’11, New York, New York, October 2011.
我们自己的论文研究了 Apple 桌面工作负载的行为; 事实证明,它们与系统研究社区通常关注的许多基于服务器的工作负载略有不同。 也是一个很好的最近参考,它指向了很多相关的工作。
[H+88] “Scale and Performance in a Distributed File System” by John H. Howard, Michael
L. Kazar, Sherri G. Menees, David A. Nichols, M. Satyanarayanan, Robert N. Sidebotham,
Michael J. West. ACM Transactions on Computing Systems (ACM TOCS), Volume 6:1, February 1988.
大名鼎鼎的AFS系统的长日志版本,至今仍在全球多个地方使用,也可能是最早清晰思考如何构建分布式文件系统的版本。 测量科学与原理工程的完美结合。
[R+00] “A Comparison of File System Workloads” by Drew Roselli, Jacob R. Lorch, Thomas E.
Anderson. USENIX ’00, San Diego, California, June 2000.
与 Baker 论文 [B+91] 相比的一组更新的跟踪,有一些有趣的曲折。
[S+85] “The ITC Distributed File System: Principles and Design” by M. Satyanarayanan, J.H.
Howard, D.A. Nichols, R.N. Sidebotham, A. Spector, M.J. West. SOSP ’85, Orcas Island, Washington, December 1985.
关于分布式文件系统的旧论文。 AFS 的大部分基本设计都在这个旧系统中就位,但没有对规模进行改进。 更名为“安德鲁”是为了向两位名叫安德鲁、安德鲁卡内基和安德鲁梅隆的人致敬。 这两个有钱人分别创办了卡内基理工学院和梅隆工业研究所,最终合并为现在的卡内基梅隆大学。
[V99] “File system usage in Windows NT 4.0” by Werner Vogels. SOSP ’99, Kiawah Island
Resort, South Carolina, December 1999.
对 Windows 工作负载的一项很酷的研究,这与之前所做的许多基于 UNIX 的研究本质上是不同的。
Homework (Simulation)
本节介绍 afs.py,这是一个简单的 AFS 模拟器,可用于巩固您对 Andrew 文件系统工作原理的了解。 阅读 README 文件以获取更多详细信息。
Questions
- 运行一些简单的案例以确保您可以预测客户端将读取哪些值。 改变随机种子标志 (-s),看看您是否可以跟踪和预测存储在文件中的中间值和最终值。 还可以改变文件数量 (-f)、客户端数量 (-C) 和读取比率 (-r,从 0 到 1),使其更具挑战性。 您可能还希望生成稍长的跟踪以进行更有趣的交互,例如 (-n 2 或更高)。
- 现在做同样的事情,看看是否可以预测 AFS 服务器启动的每个回调。 尝试不同的随机种子,并确保使用高级别的详细反馈(例如,-d 3)来查看当您让程序为您计算答案时(使用 -c)何时发生回调。 你能准确猜出每次回调发生的时间吗?一个回调发生的确切条件是什么?
- 与上面类似,使用一些不同的随机种子运行,看看是否可以预测每一步的确切缓存状态。 可以通过运行 -c 和 -d 7 来观察缓存状态。
- 现在让我们构建一些特定的工作负载。 使用 -A oa1:w1:c1,oa1:r1:c1 标志运行模拟。 当使用随机调度程序运行时,客户端 1 在读取文件 a 时观察到的不同可能值是什么? (尝试不同的随机种子以查看不同的结果)? 在两个客户端操作的所有可能的调度交错中,有多少导致客户端 1 读取值 1,有多少导致客户端读取值 0?
- 现在让我们构建一些特定的时间表。 当使用 -A oa1:w1:c1,oa1:r1:c1 标志运行时,还要使用以下计划运行:-S 01、-S 100011、-S 011100 以及您可以想到的其他计划。 客户端 1 将读取什么值?
- 现在运行此工作负载:-A oa1:w1:c1,oa1:w1:c1,并按上述方式改变计划。 使用 -S 011100 运行时会发生什么? 当你使用 -S 010011 运行时呢? 在确定文件的最终价值时,什么是重要的?

若有收获,就点个赞吧
0 人点赞

{kind=link}