- 39.1 文件和目录 Files And Directories
- 39.2 文件系统接口 The File System Interface
- 39.3 创建文件 Creating Files
- 39.4 读和写文件 Reading And Writing Files
- 39.5 读和写,但不连续 Reading And Writing, But Not Sequentially
- 39.6 共享文件表项:fork()和dup() Shared File Table Entries: fork() And dup()
- 39.7 使用fsync()立即写入 Writing Immediately With fsync()
- 39.8 重命名文件 Renaming Files
- 39.9 获取文件信息 Getting Information About Files
- 39.10 删除文件 Removing Files
- 39.11 创建目录 Making Directories
- 39.12 读取目录 Reading Directories
- 39.13 删除目录 Deleting Directories
- 39.14 硬链接 Hard Links
- 39.15 符号链接 Symbolic Links
- 39.16 权限位和访问控制列表 Permission Bits And Access Control Lists
- 39.17 创建和挂载文件系统 Making And Mounting A File System
- 39.18 总结 Summary
- References
- Homework (Code)
到目前为止,我们已经看到了两个关键操作系统抽象的开发:进程(CPU的虚拟化)和地址空间(内存的虚拟化)。同时,这两个抽象允许程序像在自己私有的、孤立的世界中一样运行;就好像它有自己的处理器(或多个处理器);好像它有自己的内存。这种错觉使得系统编程变得更加容易,因此现在不仅在台式机和服务器上流行,而且越来越多地在所有可编程平台上流行,包括移动电话等。<br />在本节中,我们将为虚拟化难题添加一个更关键的部分:** 持久存储(persistent storage)**。持久存储设备,如经典的硬盘驱动器(hard disk drive)或更现代的**固态存储设备(solid-state storage device)**,永久地(或至少长时间地)存储信息。与内存不同,内存的内容在断电时就会丢失,持久化存储设备可以保存这些数据。因此,操作系统必须对这样的设备格外小心:这是用户保存他们真正关心的数据的地方。
关键的问题:如何管理持久设备 操作系统应该如何管理持久设备?API是什么?实施的重要方面是什么?
因此,在接下来的几章中,我们将探讨管理持久数据的关键技术,重点是提高性能和可靠性的方法。不过,我们首先概述一下API:您希望在与UNIX文件系统交互时看到的接口。
39.1 文件和目录 Files And Directories
随着时间的推移,存储虚拟化中出现了两个关键的抽象。首先是文件(file)。文件只是一个由字节组成的线性数组,每个字节都可以读或写。每个文件都有一些低级的名称(low-level name),通常是一些类型;通常,用户不知道这个名称(我们将看到)。由于历史原因,文件的低级名称通常称为其inode号(inode number)。我们将在以后的章节中学习更多关于inode的内容;现在,假设每个文件都有一个与之相关联的inode号。
在大多数系统中,操作系统并不知道文件的结构(例如,它是一个图片,还是一个文本文件,还是C代码);相反,文件系统的职责只是将这些数据持久地存储在磁盘上,并确保当您再次请求数据时,您能够得到您最初放在那里的数据。这么做并不像看起来那么简单!
第二个抽象是目录(directory)的抽象。 一个目录,像一个文件那样,也有一个低级名称(即一个 inode 编号),但它的内容非常具体:它包含一个(用户可读的名称,低级名称)配成对的列表。 例如,假设有一个低级名称为“10”的文件,它由用户可读的名称“foo”引用。 因此,“foo”所在的目录将有一个项(“foo”,“10”),将用户可读的名称映射到低级名称。 目录中的每个项都指的是文件或其他目录。 通过将目录放置在其他目录中,用户可以构建任意目录树(directory tree)(或目录层次结构(directory hierarchy)),所有文件和目录都存储在该目录树下。
目录层次结构从根目录(root directory)开始(在基于UNIX的系统中,根目录简单地称为/),并使用某种分隔符(separator)来命名后续的子目录(sub-directories),直到指定所需的文件或目录。例如,如果用户在根目录/中创建了一个目录foo,然后在目录foo中创建了一个文件bar.txt,我们可以通过它的绝对路径名来引用该文件,在本例中是/foo/bar.txt。图39.1是一个更复杂的目录树;示例中有效的目录是/,/foo, /bar, /bar/bar, /bar/foo,有效的文件是/foo/bar.txt和/bar/foo/bar.txt。目录和文件可以有相同的名称,只要它们位于文件系统树的不同位置(例如,在图中有两个名为bar.txt的文件,/foo/bar.txt和/bar/foo/bar.txt)。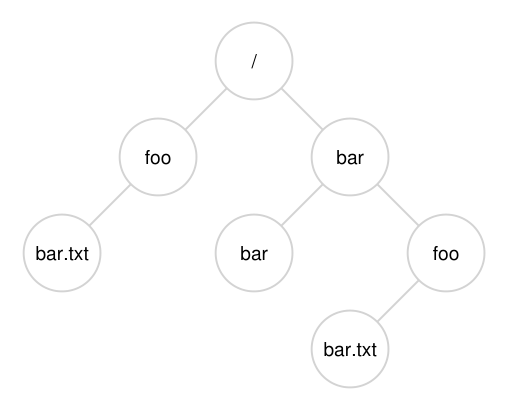
Figure 39.1: An Example Directory Tree
您可能还注意到,本例中的文件名通常由两个部分组成:bar和txt,用句点分隔。第一部分是一个任意的名称,而文件名的第二部分通常用来表示文件的类型(type),例如,它是C代码(例如。C),还是图像(例如。jpg),或者音乐文件(例如。mp3)。然而,这通常只是一种约定(convention):通常没有强制要求main.c文件中包含的数据确实是C源代码。
因此,我们可以看到文件系统提供的一个重要功能:一种方便的方式来命名(name)我们感兴趣的所有文件。名称在系统中很重要,因为访问任何资源的第一步是能够对其进行命名。因此,在UNIX系统中,文件系统提供了一种统一的方式来访问磁盘、u盘、CD-ROM、许多其他设备上的文件,实际上还有许多其他设备上的文件,这些都位于单一目录树下。
39.2 文件系统接口 The File System Interface
现在让我们更详细地讨论文件系统接口。我们将从创建、访问和删除文件的基础知识开始。您可能认为这很简单,但在此过程中,我们将发现用于删除文件的神秘调用unlink()。希望在本章结束时,这个谜题对你来说不再那么神秘了!
39.3 创建文件 Creating Files
我们将从最基本的操作开始:创建文件。这可以通过 open 系统调用来实现;通过调用open()并将O_CREAT标志传递给它,程序可以创建一个新文件。下面是一些在当前工作目录中创建一个名为“foo”的文件的示例代码:int fd = open("foo", O_CREAT|O_WRONLY|O_TRUNC, S_IRUSR|S_IWUSR);
Aside:CREAT()系统调用 旧的创建文件的方法是调用creat(),如下所示:
// option: add second flag to set permissionsint fd = creat("foo");您可以将 creat() 视为具有以下标志的 open():O_CREAT | O_WRONLY | O_TRUNC。 因为 open() 可以创建一个文件,所以 creat() 的用法有点失宠了(实际上,它可以作为对 open() 的库调用来实现); 然而,它确实在 UNIX 知识中占有特殊的地位。 具体来说,当 Ken Thompson 被问及如果他重新设计 UNIX 会有什么不同时,他回答说:“我会用 e 拼写 creat。(I’d spell creat with an e)”
例程open()有许多不同的标志(flags)。在本例中,第二个参数在文件不存在时创建文件(O_CREAT),确保文件只能被写入(O_WRONLY),如果文件已经存在,则将其截断为零字节,从而删除任何现有内容(O_TRUNC)。第三个参数指定权限,在本例中使文件的所有者可读和可写。<br />open() 的一个重要方面是它返回的内容:**文件描述符(file descriptor)**。 **文件描述符只是一个整数,每个进程是私有的,在 UNIX 系统中用于访问文件(译者注:实际上文件描述符是一个索引值,是内核为每个进程维护的该进程打开文件表的索引,这个进程级的打开文件表也可以称为文件描述符表,与系统级的打开文件表相区分)**; 因此,一旦打开文件,您就可以使用文件描述符来读取或写入文件,前提是您有权限这样做。 通过这种方式,文件描述符就是一种能力 [L84],即一个不透明的句柄,它赋予您执行某些操作的能力。**另一种理解文件描述符的方法是将其看作指向file类型对象的指针**; 一旦你有了这样的对象,你就可以调用其他“方法”来访问文件,比如 read() 和 write() (我们将在下面看到如何这样做)。 <br />如上所述,文件描述符由操作系统在每个进程的基础上进行管理。这意味着在UNIX系统上,某种简单的结构(例如数组)被保存在proc结构中。以下是来自xv6内核的相关片段[CK+08]:
struct proc {...struct file *ofile[NOFILE]; // Open files...};
**一个简单的数组(最大NOFILE个打开的文件)跟踪每个进程打开的文件(译者注:这个数组就是进程级的打开文件表,也就是文件描述符表,而文件描述符就是这个数组的索引)。数组的每个项实际上只是一个指向struct file的指针,它将用于跟踪正在读或写的文件的信息**;我们将在下面进一步讨论这个问题。
Tip:使用STRACE(和类似的工具) strace工具提供了一种非常棒的方式来查看程序正在做什么。通过运行它,您可以跟踪程序进行了哪些系统调用,查看参数和返回代码,并且通常可以很好地了解正在进行的操作。 该工具还接受一些非常有用的参数。例如,-f也跟在任何fork的子句之后;-t报告当天每次调用的时间;-e trace=open,close,read,write只跟踪对这些系统调用的调用,而忽略其他所有调用。还有许多其他的旗帜;请阅读手册页并了解如何利用这个奇妙的工具。
39.4 读和写文件 Reading And Writing Files
一旦我们有了一些文件,当然我们可能想要读取或写入它们。让我们从读取一个现有文件开始。如果在命令行中输入,则可以使用程序cat将文件的内容转储到屏幕上。
prompt> echo hello > fooprompt> cat foohelloprompt>
在此代码片段中,我们将程序 echo 的输出重定向到文件 foo,然后在其中包含单词“hello”。 然后我们使用 cat 来查看文件的内容。 但是 cat 程序是如何访问文件 foo 的呢?
为了弄清楚这一点,我们将使用一个非常有用的工具来跟踪程序发出的系统调用。在Linux上,这个工具叫做strace;其他系统也有类似的工具(参见Mac上的dtruss,或一些旧的UNIX变体上的truss)。strace所做的是跟踪程序在运行时发出的每个系统调用,并将跟踪信息转储到屏幕上供您查看。
下面是一个使用strace来确定cat正在做什么的例子(为了可读性,删除了一些调用):
prompt> strace cat foo...open("foo", O_RDONLY|O_LARGEFILE) = 3read(3, "hello\n", 4096) = 6write(1, "hello\n", 6) = 6helloread(3, "", 4096) = 0close(3) = 0...prompt>
cat所做的第一件事是打开文件进行读取。关于这一点,我们需要注意几点; 首先,该文件仅用于读取(而不是写入),由O_RDONLY标志表示; 第二,使用64位偏移量(O_LARGEFILE);第三,调用open()成功并返回一个文件描述符,该描述符的值为3。<br />为什么第一次调用open()返回3,而不是您所期望的0或1? 原因是,每个正在运行的进程已经默认打开了三个文件:标准输入(进程可以读取该文件以接收输入)、标准输出(进程可以写入该文件以将信息转储到屏幕)和标准错误(进程可以向该文件写入错误消息)。它们分别由文件描述符0、1和2表示。因此,当您第一次打开另一个文件(如上面的cat所做的)时,它几乎肯定是文件描述符3。<br />打开成功后,cat使用read()系统调用从文件中多次读取一定数量字节。read()的第一个参数是文件描述符,因此告诉文件系统要读哪个文件;当然,进程可以同时打开多个文件,因此,描述符使操作系统能够知道特定读操作指向的是哪个文件。第二个参数指向一个存放read()结果的缓冲区;在上面的系统调用跟踪中,**strace显示了在这个点(“hello”)读取的结果**。第三个参数是缓冲区的大小,在本例中是4 KB。对read()的调用也成功返回,这里返回它读取的字节数(6,其中5个用于单词“hello”中的字母,1个用于行结束标记)。<br />此时,您可以看到strace的另一个有趣的结果:对write()系统调用的单个调用,对文件描述符1。正如我们上面提到的,这个描述符被称为标准输出,因此用于将单词“hello”写入屏幕,就像程序cat要做的那样。但是它会直接调用write()吗?也许(如果它是高度优化的)。但如果不是,cat可能会调用库例程printf();在内部,printf()计算传递给它的所有格式化细节,并最终写入标准输出,将结果打印到屏幕上。<br />然后,cat程序尝试从文件中读取更多内容,但是由于文件中没有剩余字节,read()返回0,程序知道这意味着它已经读取了整个文件。因此,程序调用close()来表明它是通过文件“foo”完成的,并传入相应的文件描述符。这样文件就关闭了,读取也就完成了。<br />写文件是通过一组类似的步骤完成的。首先,打开文件进行写入操作,然后调用write()系统调用(对于较大的文件可能会多次调用),然后调用close()。使用strace跟踪对文件的写入,可能是您自己编写的程序,或者通过跟踪dd实用程序,例如,dd if=foo of=bar。
Aside:打开文件表 每个进程维护一个文件描述符数组,每个描述符引用系统范围的打开文件表(open file table)中的一个项。该表中的每个项跟踪描述符指向的底层文件、当前偏移量以及其他相关细节,如文件是可读还是可写。
39.5 读和写,但不连续 Reading And Writing, But Not Sequentially
到目前为止,我们已经讨论了如何读写文件,但所有的访问都是连续的(sequential); 也就是说,我们要么将文件从头读到尾,要么将文件从头写到尾。
然而,有时,能够读写文件中的特定偏移量是很有用的;例如,如果在文本文档上构建索引,并使用它查找特定的单词,那么最终可能会从文档中的一些随机偏移量(random offsets)中读取。为此,我们将使用lseek()系统调用。下面是函数原型:off_t lseek(int fildes, off_t offset, int whence);
第一个参数很熟悉(文件描述符)。 第二个参数是偏移量,它将文件偏移量(file offset)定位到文件中的特定位置。 第三个参数,由于历史原因而被称为 whence,它准确地确定了如何执行查找。 从手册页:
If whence is SEEK_SET, the offset is set to offset bytes.If whence is SEEK_CUR, the offset is set to its current location plus offset bytes.If whence is SEEK_END, the offset is set to the size of the file plus offset bytes.
从这个描述中可以看出,对于进程打开的每个文件,操作系统跟踪一个“当前(current)”偏移量,该偏移量决定了下一个读或写将从文件中的什么地方开始读或写。因此,**对打开的文件进行抽象的一部分是它有一个当前偏移量,该偏移量以两种方式之一更新。第一个是当发生N个字节的读或写时,将N加到当前偏移量上;因此,每次读或写都隐式地(implicitly)更新偏移量。第二种方法是显式地(explicitly)使用lseek,它会像上面指定的那样改变偏移量。**<br />正如您可能已经猜到的那样,偏移量保存在我们之前看到的那个 struct file 中,从 struct proc 中引用。以下是该结构的(简化的)xv6定义:
struct file {int ref;char readable;char writable;struct inode *ip;uint off;};
Aside:调用lseek()不会执行磁盘寻道 名字很差的系统调用lseek()使许多试图理解磁盘及其上的文件系统如何工作的学生感到困惑。不要混淆这两者! lseek()调用只是简单地更改操作系统内存中的一个变量,该变量用于跟踪某个特定进程的下一个读或写开始时的偏移量。当发往磁盘的读或写与最后一次读或写不在同一磁道上时,就会发生磁盘寻道,因此需要磁头移动。更令人困惑的是,调用 lseek() 来读取/写入文件的随机部分,然后读取/写入这些随机部分,确实会导致更多的磁盘寻道。 因此,调用 lseek() 可以导致在即将进行的读取或写入中进行寻道,但绝对不会导致任何磁盘 I/O 本身发生。
正如您在结构中看到的,操作系统可以使用它来确定打开的文件是可读的还是可写的(或两者都是),它引用的是哪个底层文件(由结构inode指针ip指向),以及当前偏移量(off)。还有一个引用计数(ref),我们将在下面进一步讨论。<br />**这些文件结构表示系统中当前打开的所有文件**;它们有时被称为**打开文件表(open file table)**。xv6内核也将这些保存为一个数组,每个项有一个锁,如下所示:
struct {struct spinlock lock;struct file file[NFILE];} ftable;
让我们通过几个例子来更清楚地说明这一点。 首先,让我们跟踪一个打开文件(大小为 300 字节)并通过多次调用 read() 系统调用读取它,每次读取 100 字节。 以下是相关系统调用的跟踪,以及每个系统调用返回的值,以及用于此文件访问的打开文件表中的当前偏移值: <br /><br />跟踪中有几个有趣的项目需要注意。首先,**您可以看到打开文件时当前偏移量是如何初始化为零的**。接下来,您可以看到它是如何随着进程的每次read()而递增的;这使得进程很容易一直调用read()来获取文件的下一个块。最后,您可以看到,在最后,尝试的read()超过文件的末尾返回0,从而向进程表明它已经完整地读取了文件。<br />其次,让我们跟踪一个进程,该进程打开相同的文件两次,并向每个文件发出读取。<br /><br />在这个例子中,分配了两个文件描述符(3和4),每个都指向**打开文件表(open file table)**中的不同项(在这个例子中,项10和11,如表标题所示; OFT代表打开文件表(Open File Table))。如果跟踪发生了什么,可以看到每个当前偏移量是如何独立更新的。<br />在最后一个例子中,进程使用lseek()在读取之前重新定位当前偏移量;在本例中,只需要一个打开文件表项(与第一个示例一样)。<br /><br />在这里,lseek()调用首先将当前偏移量设置为200。随后的read()读取接下来的50个字节,并相应地更新当前偏移量。
39.6 共享文件表项:fork()和dup() Shared File Table Entries: fork() And dup()
在许多情况下(如上面所示的示例),文件描述符到打开文件表中的项的映射是一对一的映射。例如,当一个进程运行时,它可能决定打开一个文件,读取它,然后关闭它;在这个例子中,文件在打开文件表中有一个唯一的项。即使其他进程同时读取同一个文件,每个进程在打开文件表中都有自己的项。这样,文件的每次逻辑读或写都是独立的,并且每次访问给定文件时都有自己的当前偏移量。
但是,在一些有趣的情况下,打开文件表中的项是共享的(shared)。其中一种情况发生在父进程使用fork()创建子进程时。图39.2显示了一个小代码片段,其中父进程创建了子进程,然后等待子进程完成。子进程通过调用lseek()调整当前偏移量,然后退出。最后,父节点在等待子节点之后,检查当前偏移量并打印出它的值。
int main(int argc, char *argv[]) {int fd = open("file.txt", O_RDONLY);assert(fd >= 0);int rc = fork();if (rc == 0) {rc = lseek(fd, 10, SEEK_SET);printf("child: offset %d\n", rc);} else if (rc > 0) {(void) wait(NULL);printf("parent: offset %d\n",(int) lseek(fd, 0, SEEK_CUR));}return 0;}
Figure 39.2: Shared Parent/Child File Table Entries (fork-seek.c)
当我们运行这个程序时,我们看到如下输出:
prompt> ./fork-seekchild: offset 10parent: offset 10prompt>
图39.3显示了连接每个进程的私有描述符数组、共享打开文件表项以及从它到底层文件系统inode的引用的关系。注意,我们最后在这里使用了**引用计数(reference count)**。**当一个文件表项被共享时,它的引用计数增加; 只有当两个进程都关闭(或退出)文件时,项才会被删除。**<br />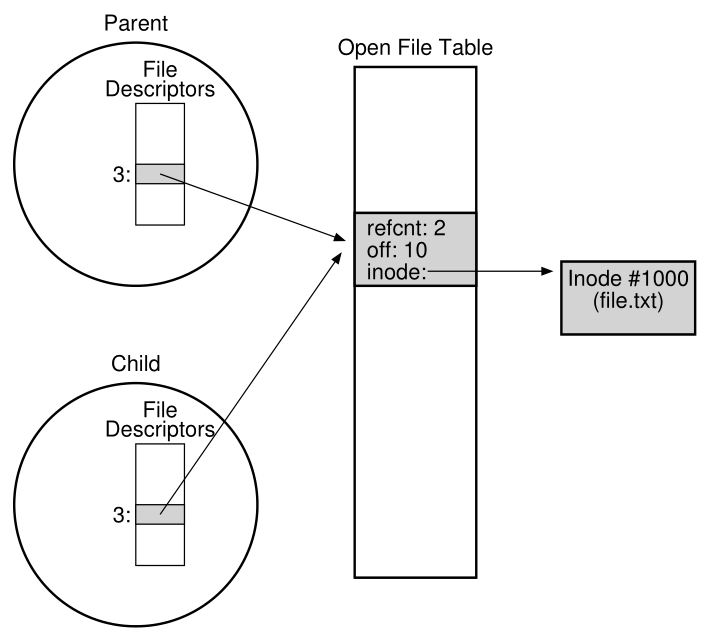<br />**Figure 39.3: Processes Sharing An Open File Table Entry**<br />**跨父节点和子节点共享打开文件表项有时是有用的**。例如,如果您创建了许多协同工作的进程,它们可以写入相同的输出文件,而不需要任何额外的协调。有关调用fork()时进程共享的内容的更多信息,请参阅手册页(man pages)。<br />**另一种有趣的、可能更有用的共享情况发生在dup()系统调用(及其表亲dup2()和dup3())中**。<br />dup() 调用允许进程创建一个新的文件描述符,该描述符引用与现有描述符相同的底层打开的文件。 图 39.4 显示了一个小代码片段,展示了如何使用 dup()。
int main(int argc, char *argv[]) {int fd = open("README", O_RDONLY);assert(fd >= 0);int fd2 = dup(fd);// now fd and fd2 can be used interchangeablyreturn 0;}
Figure 39.4: Shared File Table Entry With dup() (dup.c)
dup()调用(尤其是dup2())在编写UNIX shell和执行输出重定向等操作时非常有用;花点时间想想为什么!现在,你在想:为什么在我做shell项目的时候,他们不告诉我这些?好吧,你不可能把所有东西都按正确的顺序排列,即使是在一本关于操作系统的令人难以置信的书里。对不起!
39.7 使用fsync()立即写入 Writing Immediately With fsync()
大多数时候,当程序调用write()时,它只是告诉文件系统: 请在将来的某个时候将该数据写入持久存储。出于性能原因,文件系统将在内存中缓冲这样的写操作一段时间(比如5秒,或者30秒);在稍后的时间点,写将被实际发送到存储设备。从调用应用程序的角度来看,写入似乎很快就完成了,而且只有在极少数情况下(例如,机器在write()调用之后但在写入磁盘之前崩溃)数据会丢失。
但是,某些应用程序需要的不仅仅是这个最终保证。 例如,在数据库管理系统(DBMS)中,开发正确的恢复协议需要不时强制写入磁盘的能力。
为了支持这些类型的应用程序,大多数文件系统提供了一些额外的控制 API。 在 UNIX 世界中,提供给应用程序的接口称为 fsync(int fd)。 当进程为特定文件描述符调用 fsync() 时,文件系统通过强制所有脏(dirty,即尚未写入)数据到磁盘来响应指定文件描述符引用的文件。 一旦所有这些写入完成, fsync() 例程就会返回。
下面是一个如何使用fsync()的简单示例。该代码打开文件foo,向其写入单个数据块,然后调用fsync()以确保立即强制写入磁盘。一旦fsync()返回,应用程序就可以安全地继续运行,因为它知道数据已经被持久化了(如果fsync()正确实现的话)。
int fd = open("foo", O_CREAT|O_WRONLY|O_TRUNC,S_IRUSR|S_IWUSR);assert(fd > -1);int rc = write(fd, buffer, size);assert(rc == size);rc = fsync(fd);assert(rc == 0);
**有趣的是,这个顺序并不能保证您所期望的一切; 在某些情况下,您还需要 fsync() 包含文件 foo 的目录。 添加此步骤不仅可以确保文件本身在磁盘上,而且可以确保该文件(如果是新创建的)也是目录的持久组成部分。 毫不奇怪,这种类型的细节经常被忽视,导致许多应用程序级错误 [P+13,P+14]。 **
39.8 重命名文件 Renaming Files
一旦我们有了一个文件,有时能够给一个文件一个不同的名字是很有用的。当在命令行输入时,这是通过mv命令完成的;在这个例子中,文件foo被重命名为bar:prompt> mv foo bar
通过使用strace,我们可以看到mv使用了系统调用rename(char old, char new),它接受两个参数:文件的原始名称(old)和新名称(new)。
rename() 调用提供的一个有趣保证是,它(通常)被实现为针对系统崩溃的原子(atomic)调用; 如果系统在重命名期间崩溃,文件将被命名为旧名称或新名称,并且不会出现奇怪的中间状态。 因此,rename() 对于支持某些需要对文件状态进行原子更新的应用程序至关重要。
让我们在这里更具体一点。假设您正在使用一个文件编辑器(例如,emacs),并且在文件中间插入一行。例如,文件的名称是foo.txt。编辑器更新文件以确保新文件包含原始内容和插入的行,方法如下(为了简单起见,忽略错误检查):
int fd = open("foo.txt.tmp", O_WRONLY|O_CREAT|O_TRUNC,S_IRUSR|S_IWUSR);write(fd, buffer, size); // write out new version of filefsync(fd);close(fd);rename("foo.txt.tmp", "foo.txt");
**在这个例子中编辑器所做的很简单:以临时名称 (foo.txt.tmp) 写出文件的新版本,使用 fsync() 将其强制写入磁盘,然后,当应用程序确定新文件时 元数据和内容在磁盘上,将临时文件重命名为原始文件的名称。 最后一步原子地将新文件交换到位,同时删除文件的旧版本,从而实现原子文件更新。 **
Aside:MMAP()和持久内存(Terence Kelly客串) 内存映射(Memory mapping)是访问文件中持久数据的另一种方法。mmap()系统调用在文件中的字节偏移量和调用进程中的虚拟地址之间创建对应关系;前者称为后台文件(backing file),后者称为内存中的映像(in-memory image)。然后,进程可以使用CPU指令(即,加载和存储)访问内存映像的后台文件。 通过将文件的持久性与内存的访问语义结合起来,文件支持的内存映射支持一种称为持久内存(persistent memory)的软件抽象。持久内存风格的编程可以通过消除内存和存储的不同数据格式之间的转换来简化应用程序[K19]。
p = mmap(NULL, file_size, PROT_READ|PROT_WRITE,MAP_SHARED, fd, 0);assert(p != MAP_FAILED);for (int i = 1; i < argc; i++)if (strcmp(argv[i], "pop") == 0) { // popif (p->n > 0) // stack not emptyprintf("%d\n", p->stack[--p->n]);} else { // pushif (sizeof(pstack_t) + (1 + p->n) * sizeof(int) <= file_size) // stack not fullp->stack[p->n++] = atoi(argv[i]);}
程序 pstack.c(包含在 OSTEP 代码 github 存储库中,上面显示了一个片段)在文件 ps.img 中存储了一个持久栈,它以一组零的形式开始,例如,通过truncate或dd实用程序在命令行中创建。 该文件包含栈大小的计数和保存栈内容的整数数组。 在对后台文件进行 mmap() 处理后,我们可以使用指向内存中映像的 C 指针访问栈,例如,p->n 访问栈上的项目数,而 p->stack 访问整数数组。 由于栈是持久的,因此一次 pstack 调用 push 的数据可以在下一次调用时 pop。 崩溃,例如,在增加和push的赋值之间,可能会使持久栈处于不一致的状态。应用程序通过使用针对故障自动更新持久内存的机制来防止这种损害[K20]。
39.9 获取文件信息 Getting Information About Files
除了文件访问之外,我们希望文件系统保留有关它所存储的每个文件的大量信息。 我们通常将此类数据称为文件元数据(metadata)。 要查看某个文件的元数据,我们可以使用 stat() 或 fstat() 系统调用。 这些调用获取文件的路径名(或文件描述符)并填充 stat 结构,如图 39.5 所示。
struct stat {dev_t st_dev; // ID of device containing fileino_t st_ino; // inode numbermode_t st_mode; // protectionnlink_t st_nlink; // number of hard linksuid_t st_uid; // user ID of ownergid_t st_gid; // group ID of ownerdev_t st_rdev; // device ID (if special file)off_t st_size; // total size, in bytesblksize_t st_blksize; // blocksize for filesystem I/Oblkcnt_t st_blocks; // number of blocks allocatedtime_t st_atime; // time of last accesstime_t st_mtime; // time of last modificationtime_t st_ctime; // time of last status change};
Figure 39.5: The stat structure.
您可以看到保存了关于每个文件的大量信息,包括它的大小(以字节为单位)、它的低级名称(即inode编号)、一些所有权信息以及关于文件何时被访问或修改的一些信息等。要查看这些信息,你可以使用命令行工具stat。在这个例子中,我们首先创建一个文件(称为file),然后使用stat命令行工具来了解关于文件的一些事情。
下面是Linux上的输出:
prompt> echo hello > fileprompt> stat fileFile: ‘file’Size: 6 Blocks: 8 IO Block: 4096 regular fileDevice: 811h/2065d Inode: 67158084 Links: 1Access: (0640/-rw-r-----) Uid: (30686/remzi) Gid: (30686/remzi)Access: 2011-05-03 15:50:20.157594748 -0500Modify: 2011-05-03 15:50:20.157594748 -0500Change: 2011-05-03 15:50:20.157594748 -0500
每个文件系统通常将这种类型的信息保存在一个称为inode的结构中。在讨论文件系统实现时,我们将学习更多关于 inode 的内容。现在,您应该将 inode 视为由文件系统保存的持久数据结构,其中包含如上所示的信息。**所有 inode 驻留在磁盘上; 活动 inodes 的副本通常缓存在内存中以加快访问速度。**
一些文件系统将这些结构称为类似但略有不同的名称,例如dnodes;然而,基本思想是相似的。
39.10 删除文件 Removing Files
至此,我们知道了如何创建文件并访问它们(连续或不连续)。但是如何删除文件呢?如果你用过UNIX,你可能认为你知道:只要运行rm程序。但是rm使用什么系统调用来删除文件呢?
让我们再次利用我们的老朋友 strace 来找出答案吧。在这里,我们删除了那个讨厌的文件foo:
prompt> strace rm foo...unlink("foo") = 0...
我们从跟踪的输出中删除了一堆不相关的垃圾,只留下对神秘命名的系统调用 unlink() 的一次调用。 如您所见, unlink() 仅获取要删除的文件的名称,成功时返回零。 但这给我们带来了一个很大的难题:为什么这个系统调用名为 unlink? 为什么不是 remove 或 delete ? 要了解这个难题的答案,我们首先必须了解的不仅仅是文件,还要了解目录。
39.11 创建目录 Making Directories
除了文件之外,还有一组与目录相关的系统调用,使您能够创建、读取和删除目录。注意,您永远不能直接写入目录。因为目录的格式被认为是文件系统元数据,所以文件系统认为自己对目录数据的完整性负责;因此,您只能通过在目录中创建文件、目录或其他对象类型来间接地更新目录。通过这种方式,文件系统确保目录内容符合预期。
要创建目录,可以使用一个系统调用mkdir()。可以使用同名的mkdir程序创建这样的目录。让我们看看运行mkdir程序创建一个简单的目录foo时会发生什么:
prompt> strace mkdir foo...mkdir("foo", 0777) = 0...prompt>
创建这样的目录时,它被认为是“空的(empty)”,尽管它确实只有最少的内容。 具体来说,**一个空目录有两个条目:一个条目引用它自己,一个条目引用它的父目录。 前者称为“.”(点)目录,后者为“..”(点-点)**。 您可以通过将标志 (-a) 传递给程序 ls 来查看这些目录:
prompt> ls -a./../prompt> ls -altotal 8drwxr-x--- 2 remzi remzi 6 Apr 30 16:17 ./drwxr-x--- 26 remzi remzi 4096 Apr 30 16:17 ../
Tip:要警惕强大的命令 rm程序为我们提供了一个强大命令的很好的例子,说明有时候过于强大可能是一件坏事。例如,要一次删除一堆文件,你可以输入如下内容:
prompt> rm *其中将匹配当前目录中的所有文件。但有时你也想删除目录,实际上是它们的所有内容。你可以通过告诉rm递归地进入每个目录,并删除其中的内容来做到这一点: `prompt> rm -rf ` 当您不小心从文件系统的根目录发出命令时,就会遇到这个小字符串的麻烦,从而从中删除每个文件和目录。 哎呀! 因此,记住有力的命令这把双刃剑;虽然它们让您能够用少量的键入来完成大量的工作,但它们也可以快速而容易地造成很大的伤害。
39.12 读取目录 Reading Directories
现在我们已经创建了一个目录,我们可能也希望读取一个。 事实上,这正是程序 ls 所做的。 让我们编写我们自己的像 ls 这样的小工具,看看它是如何完成的。
我们不是像打开一个文件一样打开一个目录,而是使用一组新的调用。 下面是一个打印目录内容的示例程序。 该程序使用三个调用 opendir()、readdir() 和 closedir() 来完成工作,您可以看到接口是多么简单; 我们只是使用一个简单的循环一次读取一个目录条目,并打印出目录中每个文件的名称和 inode 编号。
int main(int argc, char *argv[]) {DIR *dp = opendir(".");assert(dp != NULL);struct dirent *d;while ((d = readdir(dp)) != NULL) {printf("%lu %s\n", (unsigned long) d->d_ino, d->d_name);}closedir(dp);return 0;}
下面的声明显示了 struct dirent 数据结构中每个目录条目中可用的信息:
struct dirent {char d_name[256]; // filenameino_t d_ino; // inode numberoff_t d_off; // offset to the next direntunsigned short d_reclen; // length of this recordunsigned char d_type; // type of file};
因为目录的信息很少(基本上,只是将名称映射到 inode 编号,以及其他一些细节),程序可能希望对每个文件调用 stat() 以获取有关每个文件的更多信息,例如它的长度或其他详细信息。 实际上,这正是 ls 在您传递 -l 标志时所做的; 在带有和不带有该标志的 ls 上尝试 strace 以亲自查看。
39.13 删除目录 Deleting Directories
最后,您可以通过调用 rmdir()(由同名程序 rmdir 使用)来删除目录。 然而,与文件删除不同的是,删除目录更危险,因为您可能会使用单个命令删除大量数据。 因此,rmdir() 要求目录在删除之前为空(即,只有“.”和“..”条目)。 如果您尝试删除非空目录,则对 rmdir() 的调用将失败。
39.14 硬链接 Hard Links
我们现在回到为什么要通过 unlink() 执行删除文件的神秘面纱,通过理解一种通过称为 link() 的系统调用在文件系统树中创建条目的新方法。 link() 系统调用有两个参数,一个旧的路径名和一个新的; 当您将新文件名“链接(link)”到旧文件名时,您实际上是在创建另一种方式来引用同一文件。 命令行程序 ln 用于执行此操作,如我们在此示例中看到的:
prompt> echo hello > fileprompt> cat filehelloprompt> ln file file2prompt> cat file2hello
在这里,我们创建了一个包含单词“hello”的文件,并将该文件称为file。然后使用ln程序创建到该文件的硬链接。在此之后,我们可以通过打开file或file2来检查文件。
再次注意这本书的作者是多么有创造力。我们也曾经有一只猫叫“猫(Cat)”(真实故事)。然而,她死了,我们现在有了一只叫“哈米(Hammy)”的仓鼠。更新:哈米现在也死了。宠物的尸体越来越多。
**link() 的工作方式是,它只是在您创建链接的目录中创建另一个名称,并将其引用到与原始文件相同的 inode 编号(即低级名称)。 不会以任何方式复制文件;** 相反,您现在只有两个人类可读的名称(file 和 file2),它们都指向同一个文件。 我们甚至可以通过打印出每个文件的 inode 编号在目录本身中看到这一点:
prompt> ls -i file file267158084 file67158084 file2prompt>
**通过将 -i 标志传递给 ls,它会打印出每个文件的 inode 编号(以及文件名)**。 因此,您可以看到链接真正做了什么:只是对相同的 inode 编号(在本例中为 67158084)进行新引用。 <br />现在您可能开始明白为什么 unlink() 被称为 unlink()。 **创建文件时,您实际上是在做两件事。 首先,您正在创建一个结构(inode),它将跟踪有关文件的几乎所有相关信息,包括其大小、其块在磁盘上的位置等。 其次,您将一个人类可读的名称链接到该文件,并将该链接放入一个目录中。 **<br />在创建到文件、到文件系统的硬链接之后,原文件名(file)和新创建的文件名(file2)没有区别; 实际上,它们都只是指向有关文件的底层元数据的链接,该元数据位于 inode 编号 67158084 中。 <br />因此,要从文件系统中删除一个文件,可以调用 unlink() 。在上面的例子中,我们可以删除名为 file 的文件,但仍然可以轻松访问该文件:
prompt> rm fileremoved ‘file’prompt> cat file2hello
这样做的原因是,当文件系统断开文件链接时,它会检查 inode 号中的**引用计数(reference count)**。**这个引用计数(有时称为链接计数(link count))允许文件系统跟踪有多少不同的文件名链接到这个特定的 inode **。**当调用 unlink() 时,它会删除人类可读的名称(被删除的文件)与给定 inode 号之间的“链接”,并减少引用计数;只有当引用计数达到零时,文件系统才会释放 inode 和相关的数据块,从而真正“删除”文件。**<br />当然,您可以使用 stat() 查看文件的引用计数。 让我们看看当我们创建和删除文件的硬链接时是什么。 在此示例中,我们将创建指向同一文件的三个链接,然后将其删除。 看链接计数!
prompt> echo hello > fileprompt> stat file... Inode: 67158084 Links: 1 ...prompt> ln file file2prompt> stat file... Inode: 67158084 Links: 2 ...prompt> stat file2... Inode: 67158084 Links: 2 ...prompt> ln file2 file3prompt> stat file... Inode: 67158084 Links: 3 ...prompt> rm fileprompt> stat file2... Inode: 67158084 Links: 2 ...prompt> rm file2prompt> stat file3... Inode: 67158084 Links: 1 ...prompt> rm file3
39.15 符号链接 Symbolic Links
还有另一种类型的链接非常有用,它被称为符号链接(symbolic link),有时也称为软链接(soft link)。硬链接有一定的限制:您不能创建一个到目录的硬链接(因为担心您将在目录树中创建一个循环);您不能硬链接到其他磁盘分区中的文件(因为inode号仅在特定的文件系统中是唯一的,而不是跨文件系统);等。因此,创建了一种名为符号链接的新类型链接[MJLF84]。
要创建这样的链接,您可以使用相同的程序 ln,但是带有 -s 标志。下面是一个例子:
prompt> echo hello > fileprompt> ln -s file file2prompt> cat file2hello
如您所见,创建软链接看起来大致相同,现在可以通过文件名 file 以及符号链接名 file2 访问原始文件。 <br />然而,除了表面的相似之外,符号链接实际上与硬链接有很大的不同。第一个区别是,符号链接实际上是一个不同类型的文件本身。我们已经讨论了常规文件和目录;符号链接是文件系统知道的第三种类型。符号链接上的 stat 揭示了一切:
prompt> stat file... regular file ...prompt> stat file2... symbolic link ...
运行ls也揭示了这个事实。如果仔细查看ls输出的长格式的第一个字符,可以看到最左列中的第一个字符是一个 - 表示普通文件,d表示目录,l表示软链接。您还可以看到符号链接的大小(在本例中为4字节)以及链接指向什么(名为file的文件)。
prompt> ls -aldrwxr-x--- 2 remzi remzi 29 May 3 19:10 ./drwxr-x--- 27 remzi remzi 4096 May 3 15:14 ../-rw-r----- 1 remzi remzi 6 May 3 19:10 filelrwxrwxrwx 1 remzi remzi 4 May 3 19:10 file2 -> file
**file2之所以是4字节是因为符号链接的形成方式是将链接到的文件的路径名作为链接文件的数据**。因为我们已经链接到一个名为file的文件,所以我们的链接文件file2很小(4字节)。如果我们链接到一个更长的路径名,我们的链接文件将会更大:
prompt> echo hello > alongerfilenameprompt> ln -s alongerfilename file3prompt> ls -al alongerfilename file3-rw-r----- 1 remzi remzi 6 May 3 19:17 alongerfilenamelrwxrwxrwx 1 remzi remzi 15 May 3 19:17 file3 -> alongerfilename
最后,由于符号链接的创建方式,它们可能会出现所谓的**悬空引用(dangling reference)**:
prompt> echo hello > fileprompt> ln -s file file2prompt> cat file2helloprompt> rm fileprompt> cat file2cat: file2: No such file or directory
正如您在本例中所看到的,与硬链接完全不同,删除名为file的原始文件会导致链接指向一个不再存在的路径名。
39.16 权限位和访问控制列表 Permission Bits And Access Control Lists
进程的抽象提供了两个核心虚拟化:CPU 和内存。 每一个都给人一种进程的假象,即它拥有自己的私有 CPU 和自己的私有内存; 实际上,底层操作系统使用各种技术以安全可靠的方式在竞争实体之间共享有限的物理资源。
文件系统还提供了磁盘的虚拟视图,将它从一堆原始块转换成用户友好的文件和目录,如本章所述。然而,这种抽象与CPU和内存的抽象明显不同,因为文件通常在不同用户和进程之间共享,而不是(总是)私有的。因此,文件系统中通常有一组更全面的机制来启用不同程度的共享。
这种机制的第一种形式是经典的UNIX权限位(permission bits)。要查看foo.txt文件的权限,只需输入:
prompt> ls -l foo.txt-rw-r--r-- 1 remzi wheel 0 Aug 24 16:29 foo.txt
我们只关注输出的第一部分,即 -rw-r--r--。这里的第一个字符只是显示了文件的类型: - 表示普通文件(foo.txt就是),d表示目录,l表示符号链接,等等;这(大部分)与权限无关,所以我们暂时忽略它。<br />我们对权限位感兴趣,它由接下来的九个字符 (rw-r--r--) 表示。 对于每个常规文件、目录和其他实体,这些位确定谁可以访问它以及如何访问它。 <br />权限由三组组成: 文件的**所有者(owner)**可以对文件做什么,**组(group)**中的某个人可以对文件做什么,最后是任何人(有时称为**其他人(other)**)可以对文件做什么。**所有者、组成员或其他人(owner, group member, or others)**可以拥有的能力包括**读取、写入或执行文件(read the file, write it, or execute it)**的能力。<br />在上面的例子中,ls 输出的前三个字符表明文件对所有者(rw-)可读和可写,并且只能由组 wheel 的成员以及系统中的任何其他人读取(r-- 后跟 r--)。 <br />文件的所有者可以很容易地更改这些权限,例如使用 **chmod 命令(更改文件模式(change the file mode))**。要删除除所有者以外的任何人访问该文件的能力,可以输入:<br />`prompt> chmod 600 foo.txt`<br />此命令为所有者启用可读位 (4) 和可写位 (2)(将它们组合在一起产生上面的 6),但将组和其他权限位分别设置为 0 和 0,从而将权限设置为 rw-------.
Aside:文件系统的超级用户 哪个用户被允许执行特权操作来帮助管理文件系统?例如,如果需要删除不活跃用户的文件以节省空间,谁有权限这样做? 在本地文件系统上,通常的默认情况是存在某种类型的超级用户(superuser,即root),他们可以访问所有文件,而不管权限如何。在AFS(具有访问控制列表)等分布式文件系统中,一个名为 system:administrators 的组包含可信的用户。在这两种情况下,这些受信任的用户都代表着固有的安全风险;如果攻击者能够以某种方式模拟这样的用户,那么攻击者就可以访问系统中的所有信息,从而违反了预期的隐私和保护保障。
执行位特别有趣。 对于常规文件,它的存在决定了程序是否可以运行。 例如,如果我们有一个名为 hello.csh 的简单 shell 脚本,我们可能希望通过键入以下内容来运行它:
prompt> ./hello.cshhello, from shell world.
但是,如果我们没有正确地设置这个文件的执行位,会发生以下情况:
prompt> chmod 600 hello.cshprompt> ./hello.csh./hello.csh: Permission denied.
**对于目录,执行位的行为略有不同。具体来说,它允许用户(或组,或所有人)在给定的目录中更改目录(即cd),并结合可写位在其中创建文件。最好的学习方法是:自己动手玩!别担心,你(可能)不会把事情搞得太糟的。**<br />除了权限位之外,一些文件系统,如称为AFS的分布式文件系统(将在后面的章节中讨论),还包括更复杂的控制。例如,AFS以每个目录的**访问控制列表(access control list,ACL)**的形式做到这一点。访问控制列表是一种更通用、更强大的方法,可以准确地表示谁可以访问给定的资源。**在文件系统中,这使用户能够创建一个非常具体的列表,列出哪些人可以读取和不可以读取一组文件,这与上述有限的所有者/组/每个人权限位模型形成对比。** <br />例如,以下是一个作者AFS帐户的私有目录的访问控制,如 fs listacl 命令所示:
prompt> fs listacl privateAccess list for private isNormal rights:system:administrators rlidwkaremzi rlidwka
清单显示,系统管理员和用户remzi都可以查找、插入、删除和管理该目录中的文件,以及读取、写入和锁定这些文件。
要允许某人(在本例中是另一个作者)访问这个目录,用户remzi只需输入以下命令。prompt> fs setacl private/ andrea rl
remzi 的隐私消失了! 但是现在您已经学到了更重要的一课:在良好的婚姻中没有秘密,即使在文件系统中也是如此。
如果你想知道的话,他们从1996年就幸福地结婚了。我们知道,你不是。
39.17 创建和挂载文件系统 Making And Mounting A File System
我们现在已经介绍了访问文件、目录和特定类型的特殊链接的基本接口。但是还有一个我们应该讨论的主题:如何从许多底层文件系统组装一个完整的目录树。这个任务是通过首先创建文件系统,然后挂载它们以使其内容可访问来完成的。
为了创建文件系统,大多数文件系统都提供了一个工具,通常称为 mkfs(发音为“make fs”),可以完全执行此任务。 思路如下:将工具作为输入,提供一个设备(例如磁盘分区,例如/dev/sda1)和一个文件系统类型(例如ext3),然后它就简单地将一个空的文件系统,从根目录开始,写入该磁盘分区。mkfs说,要有一个文件系统!
但是,一旦创建了这样的文件系统,就需要在统一的文件系统树中访问它。这个任务是通过挂载程序完成的(它让底层系统调用mount()来完成实际工作)。挂载所做的工作非常简单,就是将一个现有目录作为目标挂载点(mount point),并在此时将一个新的文件系统粘贴到目录树中。
这里有个例子可能会有用。假设我们有一个未挂载的ext3文件系统,存储在设备分区/dev/sda1中,它有以下内容:根目录包含两个子目录a和b,每个子目录依次保存一个名为foo的文件。假设我们希望在挂载点/home/users上挂载这个文件系统我们会输入这样的内容:prompt> mount -t ext3 /dev/sda1 /home/users
如果成功,则挂载将使这个新文件系统可用。但是,请注意现在如何访问新文件系统。要查看根目录的内容,我们可以像这样使用ls:
prompt> ls /home/users/a b
可以看到,路径名 /home/users/ 现在是新挂载目录的根目录。类似地,我们可以使用路径名 /home/users/a 和 /home/users/b 访问目录 a 和 b 。最后,可以通过 /home/users/a/foo 和 /home/users/b/foo 访问名为 foo 的文件。 这就是挂载的美妙之处:挂载将所有文件系统统一到一棵树中,而不是拥有多个单独的文件系统,从而使命名统一且方便。
要查看系统上挂载了什么以及在什么位置,只需运行 mount 程序。你会看到像这样的东西:
/dev/sda1 on / type ext3 (rw)proc on /proc type proc (rw)sysfs on /sys type sysfs (rw)/dev/sda5 on /tmp type ext3 (rw)/dev/sda7 on /var/vice/cache type ext3 (rw)tmpfs on /dev/shm type tmpfs (rw)AFS on /afs type afs (rw)
这种疯狂的混合显示了大量不同的文件系统,包括 ext3(一种标准的基于磁盘的文件系统)、proc 文件系统(一种用于访问有关当前进程的信息的文件系统)、tmpfs(一种仅用于临时文件的文件系统) 和 AFS(一种分布式文件系统)都粘在这台机器的文件系统树上。
Tip:小心TOCTTOU 1974 年,麦克菲(McPhee)注意到计算机系统中的一个问题。 具体而言,McPhee 指出“……如果在有效性检查和与该有效性检查相关的操作之间存在时间间隔,[并且,]通过多任务处理,可以在此时间间隔内有意更改有效性检查变量 ,导致控制程序执行无效操作。” 我们今天称其为使用检查时间 (Time Of Check To Time Of Use,TOCTTOU) 问题,唉,它仍然可能发生。 正如 Bishop 和 Dilger [BD96] 所描述的,一个简单的例子展示了用户如何欺骗更受信任的服务从而造成麻烦。 例如,想象一下邮件服务以 root 身份运行(因此有权访问系统上的所有文件)。 此服务将传入消息附加到用户的收件箱文件中,如下所示。 首先,它调用 lstat() 来获取有关文件的信息,特别是确保它实际上只是目标用户拥有的常规文件,而不是指向邮件服务器不应更新的另一个文件的链接。 然后,在检查成功后,服务器用新消息更新文件。 不幸的是,检查和更新之间的差距导致了一个问题:攻击者(在这种情况下,是接收邮件的用户,因此有权访问收件箱)切换收件箱文件(通过调用 rename( )) 指向敏感文件,例如 /etc/passwd(保存有关用户及其密码的信息)。 如果此切换发生在正确的时间(在检查和访问之间),服务器将使用邮件内容轻松更新敏感文件。 攻击者现在可以通过发送电子邮件(权限升级)来写入敏感文件; 通过更新 /etc/passwd,攻击者可以添加具有 root 权限的帐户,从而获得对系统的控制。 TOCTTOU 问题 [T+08] 没有任何简单而伟大的解决方案。 一种方法是减少需要 root 权限才能运行的服务数量,这很有帮助。 O_NOFOLLOW 标志使得如果目标是符号链接,open() 将失败,从而避免需要所述链接的攻击。 更激进的方法,例如使用事务文件系统 [H+18],可以解决这个问题,广泛部署的事务文件系统(transactional file systems)并不多。 因此,通常的(蹩脚的)建议:编写以高权限运行的代码时要小心!
39.18 总结 Summary
UNIX系统中的文件系统接口(事实上,在任何系统中都是如此)看起来都是相当初级的,但是如果您想掌握它,还有很多东西需要了解。当然,没有什么比简单地(大量地)使用它更好了。所以请这么做吧!当然,多读书;一如既往,Stevens [SR05]是我们的起点。
Aside:关键文件系统术语
- 文件(file)是一个可创建、可读、可写和可删除的字节数组。它有一个唯一引用它的低级名称(即一个数字)。底层的名字通常被称为i-number。
- 目录(directory)是元组的集合,每个元组包含一个人类可读的名称和它所映射到的低级名称。每个条目都指向另一个目录或一个文件。每个目录本身也有一个低级名称(i-number)。 目录总是有两个特殊条目: . 条目,它指的是它自己,而 .. 条目,它指的是它的父项。
- 目录树(directory tree)或目录层次结构(directory hierarchy)将所有文件和目录组织成一个大的树,从根(root)开始。
- 要访问文件,进程必须使用系统调用(通常是open())向操作系统请求权限。如果授予了权限,操作系统返回一个文件描述符(file descriptor),该描述符可以用于读或写访问,因为权限和意图允许。
- 每个文件描述符都是私有的、每个进程的实体,它引用打开文件表(open file table)中的一个条目。其中的条目跟踪这次访问所指的文件、文件的当前偏移量(current offset,即,下一次读或写将访问文件的哪一部分)以及其他相关信息。
- 调用read()和write()会自然更新当前偏移量; 另外,进程可以使用lseek()来更改当前偏移量的值,从而允许对文件的不同部分进行随机访问。
- 要强制对持久媒体进行更新,进程必须使用fsync()或相关调用。然而,在保持高性能的同时正确地这样做是具有挑战性的[P+14],所以在这样做时要仔细考虑。
- 要让文件系统中的多个人类可读的名称引用同一个底层文件,请使用硬链接(hard links)或符号链接(symbolic links)。每种方法在不同的情况下都有用,所以在使用前要考虑它们的优缺点。请记住,删除文件只是从目录层次结构中执行最后一个unlink()。
- 大多数文件系统都有启用和禁用共享的机制。这种控制的基本形式是由权限位(permissions bits)提供的;更复杂的访问控制列表(access control lists)允许更精确地控制谁可以访问和操作信息。
References
[BD96] “Checking for Race Conditions in File Accesses” by Matt Bishop, Michael Dilger. Computing Systems 9:2, 1996.
详细描述了TOCTTOU问题及其在文件系统中的存在。
[CK+08] “The xv6 Operating System” by Russ Cox, Frans Kaashoek, Robert Morris, Nickolai Zeldovich.
如前所述,这是一个很酷且简单的Unix实现。我们一直在使用一个较旧的版本(2012-01-30-1-g1c41342),因此本书中的一些示例可能与源代码中的最新示例不匹配。https://github.com/mit-pdos/xv6-public
[H+18] “TxFS: Leveraging File-System Crash Consistency to Provide ACID Transactions” by Y. Hu, Z. Zhu, I. Neal, Y. Kwon, T. Cheng, V. Chidambaram, E. Witchel. USENIX ATC ’18, June 2018.
这是USENIX ATC’18上最好的论文,也是最近开始学习事务性文件系统的好地方。
[K19] “Persistent Memory Programming on Conventional Hardware” by Terence Kelly. ACM Queue, 17:4, July/August 2019.
持久内存编程的伟大概述; 查看一下!
[K20] “Is Persistent Memory Persistent?” by Terence Kelly. Communications of the ACM, 63:9, September 2020.
一篇关于如何在低成本的情况下测试系统硬件故障的迷人的文章;谁知道摔东西会这么好玩?
[K84] “Processes as Files” by Tom J. Killian. USENIX, June 1984.
这篇文章介绍了/proc文件系统,其中每个进程都可以被视为伪文件系统中的一个文件。在现代UNIX系统中仍然可以看到这种聪明的想法。
[L84] “Capability-Based Computer Systems” by Henry M. Levy. Digital Press, 1984. http://ebook.pldworld.com/-huihoo-/book/pdf/capability-based-computer-systems/Preface.pdf
对早期基于功能的系统的出色概述。
[MJLF84] “A Fast File System for UNIX” by Marshall K. McKusick, William N. Joy, Sam J. Leffler, Robert S. Fabry. ACM TOCS, 2:3, August 1984.
稍后我们将明确地讨论快速文件系统(FFS)。在这里,我们提到它是因为它引入了其他一些随机有趣的东西,比如长文件名和符号链接。有时候,当你建立一个系统来改善一件事情时,你也同时改善了很多其他事情。
[P+13] “Towards Efficient, Portable Application-Level Consistency” by Thanumalayan S. Pil- lai, Vijay Chidambaram, Joo-Young Hwang, Andrea C. Arpaci-Dusseau, and Remzi H. Arpaci- Dusseau. HotDep 13, November 2013.
我们自己的工作显示了应用程序在将数据提交到磁盘时很容易出错;特别是,关于文件系统的假设会渗透到应用程序中,因此只有当应用程序运行在特定的文件系统上时,它们才能正常工作。
[P+14] “All File Systems Are Not Created Equal: On the Complexity of Crafting Crash-Consistent Applications” by Thanumalayan S. Pillai, Vijay Chidambaram, Ramnatthan Alagappan, Samer Al-Kiswany, Andrea C. Arpaci-Dusseau, and Remzi H. Arpaci-Dusseau. OSDI 14, Broom-field, Colorado, October 2014.
关于这个主题的完整会议论文比上面的第一篇研讨会论文有更多的细节和有趣的花边新闻。
[SK09] “Principles of Computer System Design” by Jerome H. Saltzer and M. Frans Kaashoek. Morgan-Kaufmann, 2009.
这本系统杰作是任何对该领域感兴趣的人的必读书籍。这就是麻省理工学院的教学方法。先读一遍,然后再多读几遍,让你完全融入其中。
[SR05] “Advanced Programming in the UNIX Environment” by W. Richard Stevens and Stephen A. Rago. Addison-Wesley, 2005.
我们可能已经引用这本书几十万次了。如果您想成为一名出色的系统程序员,那么它对您是非常有用的。
[T+08] “Portably Solving File TOCTTOU Races with Hardness Amplification” by D. Tsafrir, T. Hertz, D. Wagner, D. Da Silva. FAST ’08, San Jose, California, 2008.
不是介绍TOCTTOU的那篇论文,而是一篇最近做得很好的关于问题的描述,以及一种以可移植的方式解决问题的方法。
Homework (Code)
在这个作业中,我们将熟悉本章中描述的API是如何工作的。为此,您只需编写几个不同的程序,这些程序大多基于各种UNIX实用程序。
Questions
- Stat: 编写您自己的命令行程序 stat 版本,它只对给定的文件或目录调用 stat() 系统调用。 打印出文件大小、分配的块数、引用(链接)计数等。 随着目录中条目数的变化,目录的链接数是多少? 有用的接口:stat(),自然。
- List Files:编写一个程序,列出给定目录中的文件。 当不带任何参数调用时,程序应该只打印文件名。 当使用 -l 标志调用时,程序应该打印出有关每个文件的信息,例如所有者、组、权限以及从 stat() 系统调用获得的其他信息。 该程序应该采用一个额外的参数,即要读取的目录,例如 myls -l 目录。 如果没有给出目录,程序应该只使用当前的工作目录。 有用的接口:stat()、opendir()、readdir()、getcwd()。
- Tail:编写一个程序,打印出文件的最后几行。 程序应该是高效的,因为它试图接近文件的末尾,读入一个数据块,然后向后返回,直到找到所需的行数; 此时,它应该从文件的开头到结尾打印出这些行。 要调用该程序,应键入: mytail -n file,其中 n 是要打印的文件末尾的行数。 有用的接口:stat()、lseek()、open()、read()、close()。
- Recursive Search:编写一个程序,从树中的给定点开始,打印出文件系统树中每个文件和目录的名称。 例如,当不带参数运行时,程序应该从当前工作目录开始并打印其内容以及任何子目录的内容等,直到打印整个树,CWD 的根目录。 如果给定一个参数(目录名称),则使用它作为树的根。 使用更多有趣的选项优化您的递归搜索,类似于强大的 find 命令行工具。 有用的接口:弄清楚。

若有收获,就点个赞吧
0 人点赞
