- 22.1 缓存管理 Cache Management
- 22.2 最优替换策略 The Optimal Replacement Policy
- 22.3 一个简单的策略:FIFO先进先出 A Simple Policy: FIFO
- 22.4 另一个简单策略:随机 Another Simple Policy: Random
- 22.5 使用历史:LRU Using History: LRU
- 22.6 工作负载示例 Workload Examples
- 22.7 实现历史算法 Implementing Historical Algorithms
- 22.8 近似LRU Approximating LRU
- 22.9 考虑脏页 Considering Dirty Pages
- 22.10 其他虚拟内存策略 Other VM Policies
- 22.11 超负荷 Thrashing
- 22.12 总结 Summary
- References
- Homework (Simulation)
在虚拟内存管理器中,当您拥有大量空闲内存时,生活会很轻松。发生缺页错误,您在空闲页面列表中找到一个空闲页面,并将其分配给发生错误的页面。嘿,操作系统,恭喜!你又做了一次。
不幸的是,当内存很少时,事情就变得更有趣了。在这种情况下,这种内存压力(memory pressure)迫使操作系统开始移出页面(paging out pages),以便为活跃使用的页面腾出空间。决定要驱逐(evict)的页面(或页面)被封装在操作系统的替换策略(replacement policy)中;从历史上看,这是早期虚拟内存系统做出的最重要的决定之一,因为旧系统几乎没有物理内存。至少,这是一组有趣的政策,值得多了解一点。因此我们的问题是:
关键的问题:如何确定要驱逐哪一页? 操作系统如何决定从内存中删除哪些页面?这个决定是由系统的替换策略做出的,该策略通常遵循一些通用原则(下面将讨论),但也包括一些调整,以避免极端情况的行为。
22.1 缓存管理 Cache Management
在深入讨论策略之前,我们首先更详细地描述我们试图解决的问题。假定主内存包含系统中所有页面的一些子集,那么可以将它看作是系统中虚拟内存页面的缓存(cache)。因此,我们为这个缓存选择替换策略的目标是尽量减少缓存未命中(cache misses)的次数,也就是说,尽量减少从磁盘获取页面的次数。另一种情况是,我们的目标是最大化缓存命中(cache hits)的次数,即在内存中找到被访问页面的次数。
知道缓存命中和未命中的数量让我们可以计算程序的平均内存访问时间 (average memory access time,AMAT)(计算机架构师计算硬件缓存的度量标准 [HP06])。具体来说,给定这些值,我们可以计算程序的 AMAT 如下: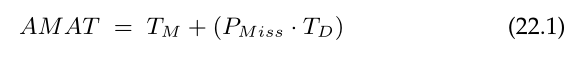
其中T__M表示访问内存的成本,TD表示访问磁盘的成本,PMiss表示在缓存中找不到数据的概率(a miss);PMiss从0.0到1.0不等,有时我们用百分率代替概率(例如,10%的未命中率意味着PMiss = 0.10)。请注意,您总是要为访问内存中的数据付出代价;然而,当您未命中时,您必须额外支付从磁盘获取数据的成本。
例如,让我们想象一台具有(很小的)地址空间的机器:4KB,具有256字节的页面。因此,一个虚拟地址有两个组成部分:4位的VPN(最高有效位)和8位偏移(最低有效位)。因此,本例中的进程总共可以访问24或16个虚拟页面。在这个例子中,进程生成以下内存引用(即虚拟地址):0x000, 0x100, 0x200, 0x300, 0x400, 0x500, 0x600, 0x700, 0x800, 0x900。这些虚拟地址指的是地址空间的前十页中的每一页的第一个字节(页码是每个虚拟地址的第一个十六进制数字)。
让我们进一步假设除了虚拟页面 3 之外的每个页面都已经在内存中。因此,我们的内存引用序列将遇到以下行为:hit、hit、hit、miss、hit、hit、hit、hit、hit、hit。我们可以计算命中率(hit rate)(内存中找到的引用百分比):90%,因为 10 个引用中有 9 个在内存中。因此,未命中率(miss rate)为 10% (PMiss = 0.1)。一般来说,PHit + PMiss = 1.0;命中率加上未命中率总和为 100%。
为了计算AMAT,我们需要知道访问内存的成本和访问磁盘的成本。假设访问内存的成本(T__M)约为100纳秒,访问磁盘的成本(TD)约为10毫秒,我们有以下AMAT: 100ns + 0.1 × 10ms,即100ns + 1ms,或1.0001 ms,或约1毫秒。如果我们的命中率是99.9% (PMiss = 0.001),结果就完全不同了:AMAT是10.1微秒,大约快了100倍。当命中率接近100%时,AMAT接近100纳秒。
不幸的是,正如您在此示例中所见,现代系统中磁盘访问的成本如此之高,以至于即使是很小的未命中率也会很快主导运行程序的整体 AMAT。显然,我们需要尽可能多地避免未命中,否则就会以磁盘速度缓慢运行。对此有帮助的一种方法是像我们现在所做的那样仔细制定明智的政策。
22.2 最优替换策略 The Optimal Replacement Policy
为了更好地理解特定的替换策略是如何工作的,最好将其与可能的最佳替换策略进行比较。其实,这种最优(optimal)策略是Belady多年前开发的B66。最优的替换策略导致了最少的失误次数。Belady展示了一种简单(但不幸的是,很难实现!)的方法,它可以替换将来访问次数最多的页面,这是最佳策略,从而导致可能的缓存丢失最少。
Tip:与最佳比较是有用的 虽然作为一个实际的策略,最优化不是非常实用,但作为仿真或其他研究的比较点,它是非常有用的。说你的新算法有80%的命中率是没有意义的;如果说最优方法能够达到82%的命中率(因此你的新方法非常接近最优方法),这便能够让结果变得更有意义,并提供相关背景。因此,在你进行的任何研究中,知道什么是最优,可以让你进行更好的比较,显示有多少改进仍有可能,以及何时可以停止使你的政策更好,因为它已经足够接近理想[AD03]。
有希望地,最优政策背后的直觉是有意义的。这样想:如果你必须扔掉某一页,为什么不扔掉离现在最远的那一页呢?通过这样做,您实际上是在说缓存中的所有其他页面都比最远的页面更重要。原因很简单:在引用最远的页面之前,您将引用其他页面。
让我们通过一个简单的示例来了解最优策略所做出的决策。假设一个程序访问以下虚拟页面流:0,1,2,0,1,3,0,3,1,2,1。图22.1显示了优化的行为,假设缓存适合三个页面。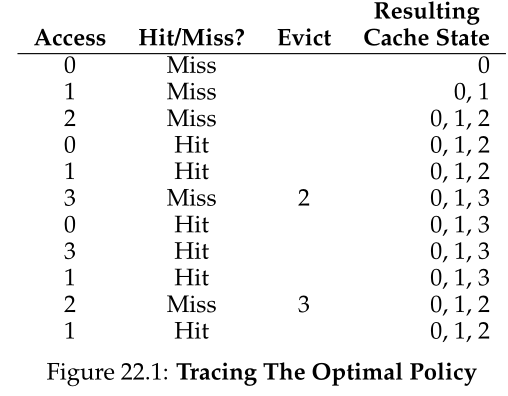
在图中,您可以看到以下操作。毫不奇怪,前三次访问都未命中,因为缓存开始时处于空状态;这种未命中有时被称为“冷启动未命中(cold-start miss)”(或“强制未命中(compulsory miss)”)。然后再次引用第0和1页,这两个页都在缓存中。最后,我们到达另一个miss(到第3页),但这一次缓存已满;必须替换!这就引出了一个问题:我们应该替换哪一页?使用最优策略,我们检查缓存中当前页面(0,1和2)的未来,看到0几乎是立即访问,1稍候访问,2是在未来访问最远的。
因此,最优策略有一个简单的选择:驱逐第2页,结果缓存中存在第0、1和3页。接下来的三个引用是命中,但是我们遇到了很久以前被驱逐的第 2 页,并再次未命中。这里的最优策略再次检查缓存中每个页面(0、1 和 3)的未来,并认为只要它不驱逐第 1 页(即将被访问)就可以。该示例显示第 3 页被驱逐,尽管 0 也是一个不错的选择。最后,我们遇到第 1 页,命中,跟踪完成。
我们还可以计算缓存的命中率:6次命中5次未命中,命中率是 ,即
,即 或54.5%。你也可以排除强制未命中计算命中率(例如,忽略给定页面的第一次未命中),结果是85.7%的命中率。
或54.5%。你也可以排除强制未命中计算命中率(例如,忽略给定页面的第一次未命中),结果是85.7%的命中率。
不幸的是,正如我们之前在调度策略的开发中所看到的,未来通常是未知的;您无法为通用操作系统构建最优策略注释1。因此,在开发一个真实的、可部署的策略时,我们将重点关注找到其他方法来决定删除哪个页面的方法。因此,最优政策只能作为一个比较点,以了解我们离“完美”有多近。
注释1:如果可以,请告诉我们!我们可以一起致富。或者,像“发现”冷聚变的科学家一样,被广泛地嘲笑和嘲笑[FP89]。
22.3 一个简单的策略:FIFO先进先出 A Simple Policy: FIFO
许多早期系统避免了试图接近最优的复杂性,并采用了非常简单的替换策略。例如,一些系统使用FIFO(first-in, first-out,先进先出)替换,页面在进入系统时简单地放在队列中;当发生替换时,队列尾部的页面(“first-in”页面)将被移除。FIFO有一个很大的优点:它很容易实现。
让我们来看看 FIFO 在我们的示例引用流上的表现(图 22.2)。我们再次以三个强制未命中第 0、1 和 2 页开始我们的跟踪,然后命中 0 和 1。接下来,引用第 3 页,导致未命中;使用 FIFO ,很容易做出替换决定:选择页面中的“第一个”(图中的缓存状态按 FIFO 顺序保存,先进页面在左侧),即第 0 页。不幸的是,我们的下一次访问是访问第 0 页,这会导致再次未命中和替换(第 1 页)。然后我们命中了第 3 页,但未命中 1 和 2,最后命中了 3。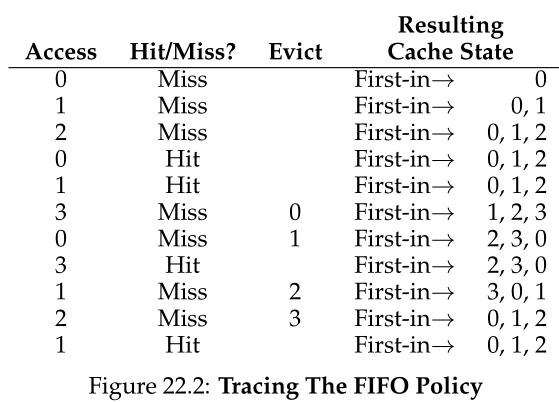
比较先进先出和最优,先进先出做得明显更差:36.4%的命中率(或57.1%排除强制性未命中)。FIFO根本不能确定块的重要性:即使第0页已经被访问了很多次,FIFO仍然会把它踢出内存,这仅仅是因为它是第一个进入内存的页面。
Aside:Belady的异常 Belady(最优策略)和同事发现了一个有趣的引用流,它的行为有点出乎意料[BNS69]。内存引用流:1,2,3,4,1,2,5,1,2,3,4,5。他们研究的替代政策是先进先出。有趣的部分:当缓存大小从3页变到4页时,缓存命中率如何变化。 通常,当缓存变大时,缓存命中率会增加(变得更好)。但是在这种情况下,使用FIFO,情况会变得更糟!计算一下你自己的命中数。这种奇怪的行为通常被称为Belady的异常(Belady’s Anomaly)(令他的合著者懊恼)。 其他一些政策,比如LRU(Least Recently Used,最近最少使用),就没有这个问题。你能猜到为什么吗?事实证明,LRU具有所谓的栈属性(stack property)[M+70]。对于具有此属性的算法,大小为N + 1的缓存自然包含大小为N的缓存的内容。因此,当增加缓存大小时,命中率要么保持不变,要么提高。FIFO和Random(以及其他)显然不服从栈属性,因此容易受到异常行为的影响。
22.4 另一个简单策略:随机 Another Simple Policy: Random
另一个类似的替换策略是Random(随机),它只是在内存压力下随机选择要替换的页面。Random具有类似FIFO的性质;它实现起来很简单,但是在选择要清除哪些块时,它并不是很聪明。让我们看看Random在我们著名的示例引用流上是如何做的(参见图22.3)。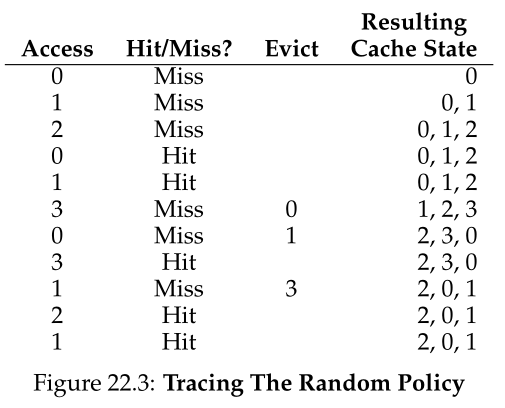
当然,Random的做法完全取决于随机的选择有多幸运(或多不幸)。在上面的例子中,Random做得比FIFO好一点,但比optimal差一点。事实上,我们可以进行数千次随机实验,并确定它的一般情况。图22.4显示了Random在10,000次尝试中获得的命中次数,每次尝试都带有不同的随机种子。正如你所看到的,有时候(超过40%的时间),Random和optimal一样优秀,在示例追踪中实现6次命中;有时它做得更糟,达到2次或更少。Random的表现取决于抽签的运气。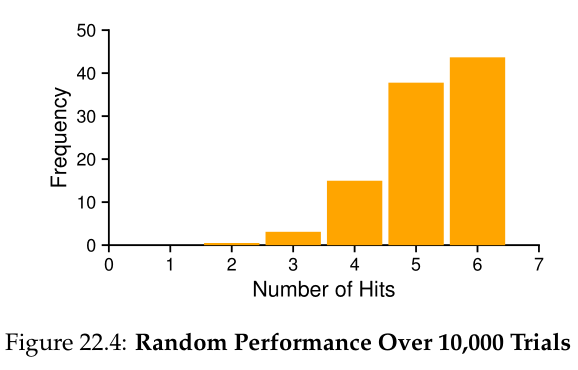
22.5 使用历史:LRU Using History: LRU
不幸的是,任何像FIFO或Random这样简单的策略都可能有一个共同的问题:它可能驱逐一个将要再次引用的重要页面。FIFO将第一次引入的页面驱逐; 就算这恰好是一个包含重要代码或数据结构的页面,它无论如何都会被驱逐,即使它很快就会被重新调入。因此,FIFO、Random和类似策略不太可能接近最佳;需要更聪明的东西。
就像我们在调度策略上所做的那样,为了改进我们对未来的猜测,我们再次依靠过去,并使用历史作为我们的指南。例如,如果一个程序在不久前访问了某个页面,那么它很可能在不久的将来再次访问该页面。
页面替换策略可以使用的一种历史信息是频率(frequency);如果一个页面被访问了很多次,可能不应该替换它,因为它显然有一些价值。页面更常用的属性是最近访问(recency of access);页面被访问的时间越晚,再次访问的可能性就越大。
这一系列策略是基于人们所说的局部性原则(principle of locality)[D70],它基本上只是对程序及其行为的观察。这个原则说的很简单,就是程序倾向于非常频繁地访问某些代码序列(例如,在循环中)和数据结构(例如,由循环访问的数组);因此,我们应该尝试使用历史来确定哪些页面是重要的,并在涉及驱逐时间时将这些页面保留在内存中。
因此,一组简单的基于历史(historically-based)的算法诞生了。当必须发生驱逐时,最不常用页面(Least-Frequently-Used,LFU)策略将替换最不常用页面。类似地,最近最少使用 (Least-Recently-Used,LRU) 策略替换最近最少使用页面。这些算法很容易记住:一旦你知道名字,你就会确切地知道它的作用,这是名字的一个很好的属性。
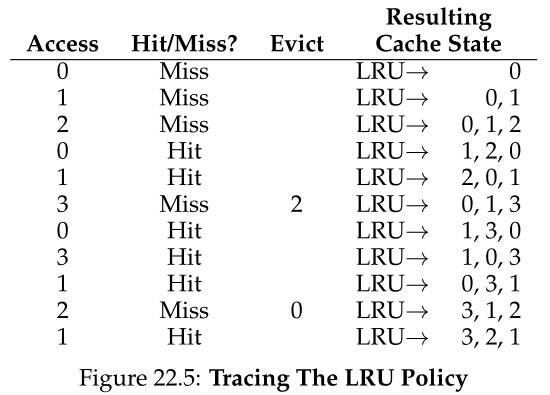
为了更好地理解LRU,让我们检查一下LRU在示例引用流上是如何工作的。图22.5显示了结果。从图中,您可以看到LRU如何使用历史记录来比无状态策略(如Random或FIFO)做得更好。在本例中,当LRU首先必须替换页面时,它将驱逐页面2,因为0和1最近被访问过。然后它会替换第0页,因为1和3最近被访问过。在这两种情况下,LRU基于历史的决定被证明是正确的,因此下一个引用是命中的。因此,在我们的例子中,LRU做得尽可能好,在性能上匹配最优。
好的,我们煮熟了结果。但有时需要烹饪来证明一个观点。(OK, we cooked the results. But sometimes cooking is necessary to prove a point.)
我们还应该注意到,这些算法的对立面也存在:最常使用(Most-Frequently-Used,MFU)和最近使用(Most-Recently-Used,MRU)。在大多数情况下(不是全部!),这些策略效果不佳,因为它们忽略了大多数程序所表现出的局部性,而不是接受它。
Aside:局部性的类型 程序倾向于显示两种类型的局部性。第一个称为空间局部性(spatial locality),即如果页面P被访问,它周围的页面(比如P - 1或P + 1)也很可能被访问。第二种是时间局部性(temporal locality),即最近访问过的页面很可能在不久的将来再次访问。这些类型的局部性存在的假设在硬件系统的缓存层次结构中发挥着重要作用,硬件系统部署了许多级别的指令、数据和地址转换缓存,以帮助程序在存在此类局部性时快速运行。 当然,通常所说的局域性原则(principle of locality)并不是所有程序都必须遵守的硬性规则。事实上,一些程序以相当随机的方式访问内存(或磁盘),并且在它们的访问流中不显示太多或任何局部。因此,尽管在设计任何类型的缓存(硬件或软件)时都要记住局部性,但它不能保证成功。相反,它是一种启发式,在计算机系统的设计中经常被证明是有用的。
22.6 工作负载示例 Workload Examples
让我们再看几个例子,以便更好地理解其中一些策略的行为。在这里,我们将检查更复杂的工作负载,而不是小的跟踪。然而,即使是这些工作负载也被大大简化了;更好的研究将包括应用程序跟踪。
我们的第一个工作负载没有局部性,这意味着每个引用都指向一组被访问的页面中的随机页面。在这个简单的示例中,工作负载随时间访问100个不同的页面,随机选择下一个页面进行引用;总共访问了 10,000 页。在实验中,我们将缓存大小从非常小(1 页)变化到足以容纳所有不同页面(100 页),以查看每个策略在缓存大小范围内的行为。
图22.6绘制了最优(OPT)、LRU、Random和FIFO的实验结果。图中的y轴为每个策略的命中率;x轴根据上面的描述改变缓存大小。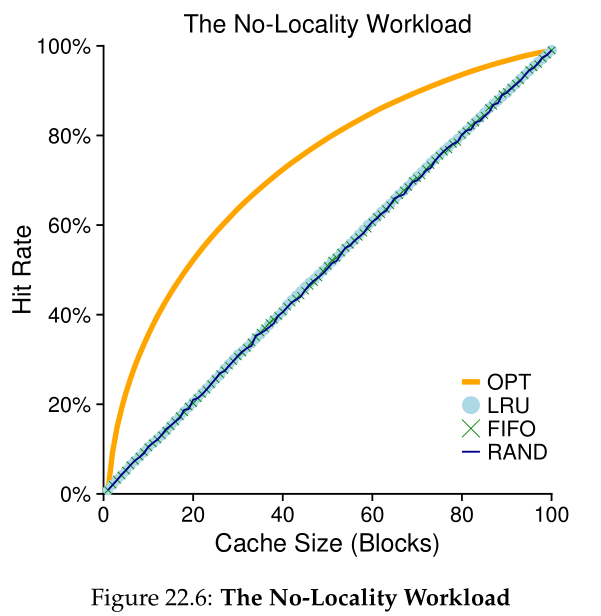
我们可以从图中得出一些结论。首先,当工作负载没有局部性时,您使用哪种现实策略并不重要;LRU、FIFO 和 Random 都执行相同的操作,命中率完全由缓存的大小决定。其次,当缓存足够大以适应整个工作负载时,使用哪种策略也无关紧要;当所有引用的块都适合缓存时,所有策略(甚至 Random)都会收敛到 100% 的命中率。最后,您可以看到最优策略的性能明显优于现实策略;展望未来,如果可能的话,最优策略在替换方面做得更好。
我们研究的下一个工作负载称为80-20工作负载,它显示了局域性:80%的引用都指向20%的页面(热点页面);剩下的20%的参考是剩下的80%的页面(冷页面)。在我们的工作负载中,总共又有100个独特的页面;因此,大多数情况下引用的是热页,其余情况下引用的是冷页。图22.7(第10页)显示了策略如何在此工作负载下执行。
我们研究的下一个工作负载称为“80-20”工作负载,它展示了局部性:80%的引用都指向20%的页面(“热门”页面);剩下的20%的引用是对剩下的80%的页面(“冷”页面)的引用。在我们的工作负载中,总共又有100个不同的页面;因此,“热”页在大多数情况下是引用的,而“冷”页则是剩下的。图22.7显示了策略如何在此工作负载下执行。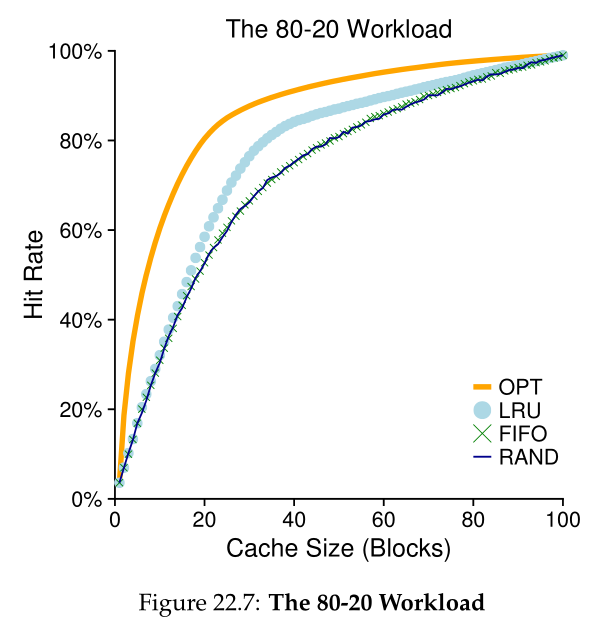
从图中可以看出,虽然 random 和 FIFO 都做得相当好,但 LRU 做得更好,因为它更有可能保留热页;由于这些页面过去经常被引用,它们很可能在不久的将来再次被引用。Optimal 再次做得更好,说明 LRU 的历史信息并不完美。
你现在可能会想:LRU对Random和FIFO的改进真的有那么重要吗?和往常一样,答案是“视情况而定”。如果每次未命中都是非常昂贵的(很常见),那么即使是命中率的小幅提高(未命中率的降低)也会对性能产生巨大的影响。如果未命中的代价不是那么高,那么LRU可能带来的好处当然就不那么重要了。
让我们看看最后一个工作负载。我们称它为“循环序列”工作负载,在它中,我们按顺序引用50页,从0开始,然后是1,…,直到第49页,然后循环,重复这些访问,总共10,000次访问50个不同的页面。图22.8中的最后一个图显示了该工作负载下策略的行为。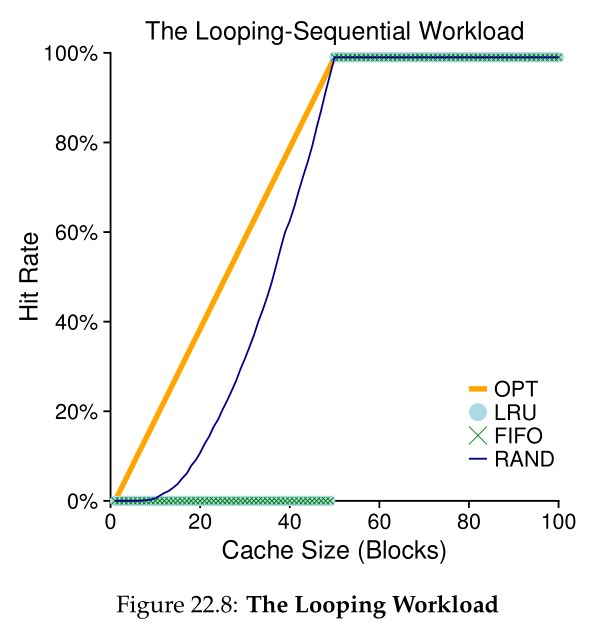
这种工作负载在许多应用程序(包括重要的商业应用程序,如数据库[CD85])中很常见,对LRU和FIFO来说都是最坏的情况。在循环顺序工作负载下,这些算法会删除旧页面;不幸的是,由于工作负载的循环特性,这些较旧的页面将比策略希望保存在缓存中的页面更快地被访问。事实上,即使缓存大小为 49,50 页的循环顺序工作负载也会导致 0% 的命中率。有趣的是,Random的表现明显更好,虽然不是最优的,但至少达到了非零命中率。结果表明,随机有一些很好的性质;其中一个属性是没有奇怪的极端情况行为。
22.7 实现历史算法 Implementing Historical Algorithms
如您所见,LRU这样的算法通常比FIFO或Random这样的简单策略做得更好,因为后者可能丢弃重要的页面。不幸的是,历史策略给我们提出了一个新的挑战:我们如何实施它们?
让我们以LRU为例。为了完美地实施它,我们需要做很多工作。具体来说,在每次页面访问(即每次内存访问,无论是指令获取、加载还是存储)时,我们必须更新一些数据结构,将页面移到列表的前面(即MRU端)。与此形成对比的是FIFO,在FIFO中,只有当页面被逐出(通过删除先进的页)或将新页面添加到列表(到后进端)时,才会访问页面的FIFO列表。为了跟踪哪些页面使用得最少和最近,系统必须对每个内存引用做一些统计工作。显然,如果不多加小心,这样的统计可能会大大降低性能。
一种可以帮助加快速度的方法是添加一点硬件支持。例如,机器可以在每次访问页面时更新内存中的时间字段(例如,这可以在每个进程的页表中,或者只是在内存中的某个单独的数组中,系统的每个物理页面有一个条目)。因此,当一个页面被访问时,时间字段将被硬件设置为当前时间。然后,当替换一个页面时,操作系统可以简单地扫描系统中的所有时间字段,以找到最近使用次数最少的页面。
不幸的是,随着系统中页面数量的增加,为了找到最近使用最少(least-recently-used)的页面而花大量的时间扫描是非常昂贵的。想象一下,一台拥有4GB内存的现代机器被分割成4KB的页面。这台机器有100万个页面,因此查找LRU页面将花费很长时间,即使在现代CPU速度下也是如此。这就引出了一个问题:我们真的需要找到最老(oldest)的页面来替换吗?我们能不能用近似来代替?
关键的问题:如何实现LRU替换策略 考虑到实现完美的LRU代价高昂,我们能否以某种方式近似它,同时仍能获得期望的行为?
22.8 近似LRU Approximating LRU
事实证明,答案是肯定的:从计算开销的角度来看,近似LRU是更可行的,而且这确实是许多现代系统所做的。这个想法需要一些硬件支持,以使用位(use bit)(有时称为引用位(reference bit))的形式,第一个使用位是在第一个分页系统中实现的,Atlas一级存储[KE+62]。系统的每页有一个使用位,并且使用位存在内存中的某个地方(例如,它们可能在每个进程的页表中,或者只是在某个地方的数组中)。每当页面被引用(即读取或写入)时,使用位由硬件设置为 1。硬件永远不会清除该位(即,将其设置为 0);这是操作系统的责任。
操作系统如何使用use位来近似LRU?嗯,可能有很多方法,但是时钟算法(clock algorithm)[C69]提出了一个简单的方法。假设系统的所有页面都排列在一个循环列表中。时钟指针(clock hand)指向某个特定的页面开始(这并不重要)。当必须发生替换时,操作系统检查当前指向的页 P 的使用位是否为 1 或 0。如果为 1,这意味着页 P 最近被使用过,因此不是替换的好候选者。因此,P 的使用位设置为 0(清零),并且时钟指针递增到下一页 (P + 1)。该算法一直继续,直到找到设置为 0 的使用位,这意味着该页面最近未被使用(或者,在最坏的情况下,所有页面都已被使用,我们现在已经搜索了整个页面集,清除所有的位)。
注意,这种方法并不是使用使用位来近似LRU的唯一方法。实际上,任何定期清除使用位,然后区分哪些页面使用位是1还是0来决定替换哪个页面的方法都是好的。Corbato的时钟算法只是早期的一种取得了一些成功的方法,并且具有不重复扫描所有内存以寻找未使用页面的良好特性。
时钟算法变体的行为如图22.9所示。这种变体在进行替换时随机扫描页面;当它对一个引用位设置为1的页面进行计数时,它清除该位(即,将其设置为0);当它发现一个引用位设置为0的页面时,它选择该页面作为其“受害者”。正如您所看到的,尽管它不如完美的LRU,但它比完全不考虑历史的方法做得更好。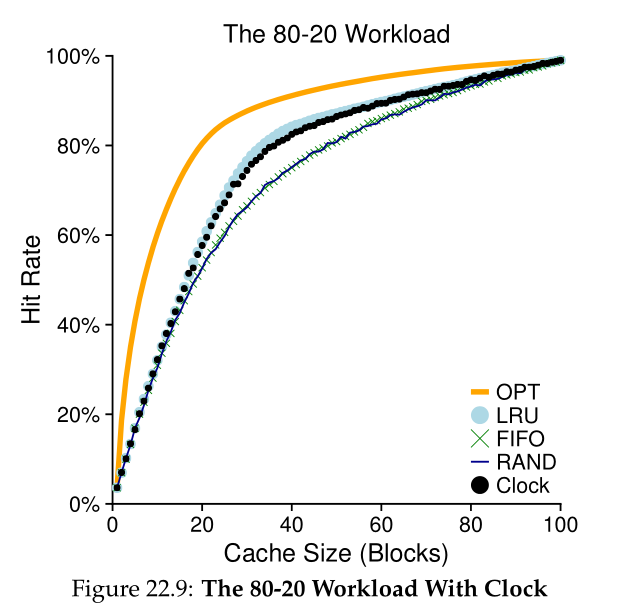
22.9 考虑脏页 Considering Dirty Pages
对时钟算法(最初也是由Corbato [C69]建议的)的一个小修改通常是额外考虑页面在内存中是否被修改。这样做的原因是:如果一个页面被修改了(modified),因此是脏的(dirty),那么就必须将它写回磁盘以逐出它,这是非常昂贵的。如果它没有被修改(因此是干净的(clean)),驱逐是自由的;物理帧可以简单地用于其他目的而无需额外的I/O。因此,一些 VM 系统更喜欢驱逐脏页而不是清除干净页。
为了支持这种行为,硬件应该包含一个修改过的位(modified bit)(也就是脏位(dirty bit))。这个位是在任何时候写入页面时设置的,因此可以合并到页面替换算法中。例如,时钟算法可以更改为扫描未使用和干净的页面,然后首先驱逐;如果找不到那些,然后是脏的未使用页面,等等。
22.10 其他虚拟内存策略 Other VM Policies
页面替换不是VM子系统使用的唯一策略(尽管它可能是最重要的策略)。例如,操作系统还必须决定何时将页面放入内存。这个策略有时被称为页面选择策略(page selection)(正如Denning [D70]所称),为操作系统提供了一些不同的选项。
对于大多数页面,操作系统仅使用按需分页(demand paging),这意味着操作系统在访问页面时将页面放入内存中,就像“按需”一样。当然,操作系统可以猜测一个页面即将被使用,从而提前将其引入;这种行为被称为预取(prefetching),只有在有合理的成功机会时才应该这样做。例如,一些系统会假设如果代码页 P 被带入内存,那么该代码页 P +1 很可能很快就会被访问,因此也应该被带入内存。
另一种策略决定了操作系统如何将页面写入磁盘。当然,它们可以简单地一次写一个;但是,许多系统会在内存中收集大量挂起(pending)的写操作,然后以一次(更有效的)写操作将它们写入磁盘。这种行为通常称为聚集(clustering)或简单的写分组(grouping),由于磁盘驱动器的特性,这种行为非常有效,它执行单个大的写操作比许多小的写操作更有效。
22.11 超负荷 Thrashing
在关闭之前,我们要解决最后一个问题:当内存完全超额请求,并且一组正在运行的进程的内存需求超过了可用的物理内存时,操作系统应该怎么做?在这种情况下,系统将不断进行分页(paging),这种情况有时称为超负荷(thrashing )[D70]。
一些早期的操作系统有一套相当复杂的机制来检测和处理发生的超负荷。例如,给定一组进程,系统可以决定不运行一部分进程的子集,并希望减少了的进程工作集(working sets)(它们正在积极使用的页面)能够装入内存,从而能够取得进展。这种通常被称为准入控制(admission control)的方法表明,有时把少部分工作做好,总比一下子把所有事情都做得很差要好,这是我们在现实生活和现代计算机系统中经常遇到的情况(很遗憾)。
当前的一些系统对内存过载采取了更为严厉的方法。例如,某些版本的 Linux 在内存超额请求时运行超出内存杀手(out-of-memory killer);这个守护进程(daemon)选择一个内存密集型进程并杀死它,从而以一种不太精妙的方式减少内存。虽然成功地降低了内存压力,但这种方法可能会出现问题,例如,如果它杀死 X 服务器,从而使需要显示的任何应用程序无法使用。
22.12 总结 Summary
我们已经看到了许多页面替换(和其他)策略的引入,它们是所有现代操作系统VM子系统的一部分。现代系统添加了一些简单的LRU近似,如时钟;例如,扫描抵抗(scan resistance)是许多现代算法的重要组成部分,如ARC [MM03]。抗扫描算法通常与LRU类似,但也试图避免LRU的最坏情况行为,这是我们在循环顺序工作负载(looping-sequential workload)中看到的。因此,页面替换算法的发展仍在继续。
然而,在许多情况下,由于内存访问和磁盘访问时间之间的差异增加,上述算法的重要性已经降低。由于到磁盘的分页非常昂贵,因此频繁分页的成本令人望而却步。因此,过度分页的最佳解决方案通常很简单(如果在智力上不令人满意):购买更多内存。
References
[AD03] “Run-Time Adaptation in River” by Remzi H. Arpaci-Dusseau. ACM TOCS, 21:1,
February 2003. A summary of one of the authors’ dissertation work on a system named River, where
he learned that comparison against the ideal is an important technique for system designers.
[B66] “A Study of Replacement Algorithms for Virtual-Storage Computer” by Laszlo A. Be-
lady. IBM Systems Journal 5(2): 78-101, 1966. The paper that introduces the simple way to compute
the optimal behavior of a policy (the MIN algorithm).
[BNS69] “An Anomaly in Space-time Characteristics of Certain Programs Running in a Paging
Machine” by L. A. Belady, R. A. Nelson, G. S. Shedler. Communications of the ACM, 12:6, June
1969. Introduction of the little sequence of memory references known as Belady’s Anomaly. How do
Nelson and Shedler feel about this name, we wonder?
[CD85] “An Evaluation of Buffer Management Strategies for Relational Database Systems”
by Hong-Tai Chou, David J. DeWitt. VLDB ’85, Stockholm, Sweden, August 1985. A famous
database paper on the different buffering strategies you should use under a number of common database
access patterns. The more general lesson: if you know something about a workload, you can tailor
policies to do better than the general-purpose ones usually found in the OS.
[C69] “A Paging Experiment with the Multics System” by F.J. Corbato. Included in a Festschrift
published in honor of Prof. P.M. Morse. MIT Press, Cambridge, MA, 1969. The original (and
hard to find!) reference to the clock algorithm, though not the first usage of a use bit. Thanks to H.
Balakrishnan of MIT for digging up this paper for us.
[D70] “Virtual Memory” by Peter J. Denning. Computing Surveys, Vol. 2, No. 3, September
1970. Denning’s early and famous survey on virtual memory systems.
[EF78] “Cold-start vs. Warm-start Miss Ratios” by Malcolm C. Easton, Ronald Fagin. Commu-
nications of the ACM, 21:10, October 1978. A good discussion of cold- vs. warm-start misses.
[FP89] “Electrochemically Induced Nuclear Fusion of Deuterium” by Martin Fleischmann,
Stanley Pons. Journal of Electroanalytical Chemistry, Volume 26, Number 2, Part 1, April,
1989. The famous paper that would have revolutionized the world in providing an easy way to generate
nearly-infinite power from jars of water with a little metal in them. Unfortunately, the results pub-
lished (and widely publicized) by Pons and Fleischmann were impossible to reproduce, and thus these
two well-meaning scientists were discredited (and certainly, mocked). The only guy really happy about
this result was Marvin Hawkins, whose name was left off this paper even though he participated in the
work, thus avoiding association with one of the biggest scientific goofs of the 20th century.
[HP06] “Computer Architecture: A Quantitative Approach” by John Hennessy and David
Patterson. Morgan-Kaufmann, 2006. A marvelous book about computer architecture. Read it!
[H87] “Aspects of Cache Memory and Instruction Buffer Performance” by Mark D. Hill. Ph.D.
Dissertation, U.C. Berkeley, 1987. Mark Hill, in his dissertation work, introduced the Three C’s,
which later gained wide popularity with its inclusion in H&P [HP06]. The quote from therein: “I have
found it useful to partition misses … into three components intuitively based on the cause of the misses
(page 49).”
[KE+62] “One-level Storage System” by T. Kilburn, D.B.G. Edwards, M.J. Lanigan, F.H. Sum-
ner. IRE Trans. EC-11:2, 1962. Although Atlas had a use bit, it only had a very small number of pages,
and thus the scanning of the use bits in large memories was not a problem the authors solved.
[M+70] “Evaluation Techniques for Storage Hierarchies” by R. L. Mattson, J. Gecsei, D. R.
Slutz, I. L. Traiger. IBM Systems Journal, Volume 9:2, 1970. A paper that is mostly about how to
simulate cache hierarchies efficiently; certainly a classic in that regard, as well for its excellent discussion
of some of the properties of various replacement algorithms. Can you figure out why the stack property
might be useful for simulating a lot of different-sized caches at once?
[MM03] “ARC: A Self-Tuning, Low Overhead Replacement Cache” by Nimrod Megiddo and
Dharmendra S. Modha. FAST 2003, February 2003, San Jose, California. An excellent modern
paper about replacement algorithms, which includes a new policy, ARC, that is now used in some
systems. Recognized in 2014 as a “Test of Time” award winner by the storage systems community at
the FAST ’14 conference.
Homework (Simulation)
这个名为pag-policy.py的模拟器允许您使用不同的页面替换策略。有关详细信息,请参阅README。
Questions
- 使用以下参数生成随机地址:-s 0 -n 10、-s 1 -n 10 和 -s 2 -n 10。将策略从 FIFO 更改为 LRU,再到 OPT。计算所述地址跟踪中的每次访问是命中还是未命中。
- 对于大小为5的缓存,为以下策略生成最坏情况的地址引用流:FIFO, LRU和MRU(最坏情况的引用流导致最大未命中可能性)。对于最坏情况下的引用流,需要多大的缓存才能显著提高性能并接近OPT?
- 生成一个随机轨迹(内存引用流)(使用python或perl)。您希望不同的策略如何执行这样的轨迹?
- 现在生成带有局部性的轨迹。如何生成这样的轨迹?LRU在上面表现如何?LRU比RAND好多少?CLOCK是怎么做的?那么时钟比特数不同的时钟呢?
- 使用像valgrind这样的程序来测试一个真实的应用程序并生成一个虚拟的页面引用流。例如,运行valgrind —tool=lackey —trace-mem=yes ls将输出由程序ls所做的每条指令和数据引用的几乎完整的引用跟踪。为了使这对上面的模拟器有用,您必须首先将每个虚拟内存引用转换为虚拟页码引用(通过屏蔽偏移量并向下移动结果的位来实现)。为了满足大部分请求,应用程序跟踪需要多大的缓存?绘制当缓存大小增加时其工作集的图。

若有收获,就点个赞吧
0 人点赞
