我们现在解决分页引入的第二个问题:页表太大,因此消耗太多内存。让我们从一个线性页表开始。您可能还记得注释1,线性页表变得非常大。再次假设一个 32 位地址空间(232 字节),具有 4KB(212 字节)页和一个 4 字节页表项。因此,一个地址空间中大约有 100 万个虚拟页面( );乘以页表项大小,您会看到我们的页表大小为 4MB。还记得:我们通常为系统中的每个进程都有一个页表!有一百个活动进程(在现代系统中并不少见),我们将为页表分配数百兆字节的内存!因此,我们正在寻找一些技术来减轻这种沉重的负担。他们有很多,所以让我们开始吧。但不是在我们列出关键问题之前:
);乘以页表项大小,您会看到我们的页表大小为 4MB。还记得:我们通常为系统中的每个进程都有一个页表!有一百个活动进程(在现代系统中并不少见),我们将为页表分配数百兆字节的内存!因此,我们正在寻找一些技术来减轻这种沉重的负担。他们有很多,所以让我们开始吧。但不是在我们列出关键问题之前:
关键的问题:如何使页表更小 简单的基于数组的页表(通常称为线性页表)太大了,在典型系统中占用了太多的内存。如何使页表更小?关键思想是什么?这些新的数据结构会导致哪些效率低下?
注释1:或者确实,您可能不会;这个分页事情失控了,不是吗?也就是说,在着手解决问题之前,请务必确保您了解正在解决的问题;确实,如果您了解问题,通常可以自己推导出解决方案。在这里,问题应该很清楚了:简单的线性(基于数组)页表太大了。
20.1 简单的解决办法:更大的页 Simple Solution: Bigger Pages
我们可以用一种简单的方法减小页表的大小:使用更大的页。再次使用我们的32位地址空间,但这次假设页面为16KB。这样我们就有了一个18位的VPN加上一个14位的偏移量。假设每个PTE(页表项)的大小相同(4字节),我们现在有218项在线性页表,因此每个页表1 MB的总大小,减少4倍大小的页表(毫不奇怪,减少确切地反映了4倍增加页面大小)。
然而,这种方法的主要问题是,大页面会导致每个页面内的浪费,这个问题称为内部碎片(internal fragmentation)(因为浪费是分配单元内部(internal)的)。因此,应用程序最终分配页面,但每个页面只使用很少的位和片段,内存很快就会被这些过大的页面填满。因此,大多数系统在常见情况下使用相对较小的页面大小:4KB(如x86)或8KB(如SPARCv9)。唉,我们的问题不会这么简单地解决。
Aside:多种页面大小 顺便说一句,请注意许多架构(例如MIPS、SPARC、x86-64)现在支持多种页面大小。通常使用较小的页面大小(4KB或8KB)。然而,如果智能应用程序请求它,单个大页面(例如,4MB大小)可以用于地址空间的特定部分,使此类应用程序能够将经常使用的(和大的)数据结构放在这样的空间中,而只消耗单个TLB项。这种类型的大页面使用在数据库管理系统和其他高端商业应用程序中很常见。但是,多种页大小的主要原因不是为了节省页表空间;它是为了减少对TLB的压力,使程序能够访问更多的地址空间,而不会遇到太多的TLB未命中。然而,正如研究人员所表明的 [N+02],使用多个页面大小会使操作系统虚拟内存管理器变得更加复杂,因此有时只需将新接口导出到应用程序以直接请求大页面,就可以最轻松地使用大页面。
20.2 混合方法:分页和分段 Hybrid Approach: Paging and Segments
每当你对生活中的某件事有两种合理但不同的方法时,你应该总是检查两者的结合,看看你是否可以两全其美。我们称这种组合为混合体(hybrid)。例如,为什么只吃巧克力或普通花生酱,而您可以将两者混合在一个可爱的混合物中,称为里斯花生酱杯 [M28]?
多年前,Multics的创建者(特别是Jack Dennis)在构建Multics虚拟内存系统[M07]时偶然发现了这样一个想法。具体来说,Dennis的想法是将分页和分段结合起来,以减少页表的内存开销。我们可以通过更详细地检查一个典型的线性页表来了解为什么这样做是可行的。假设我们有一个地址空间,其中堆和栈的使用部分很小。例如,我们使用16KB的地址空间和1KB的页面(图20.1);这个地址空间的页表如图20.2所示。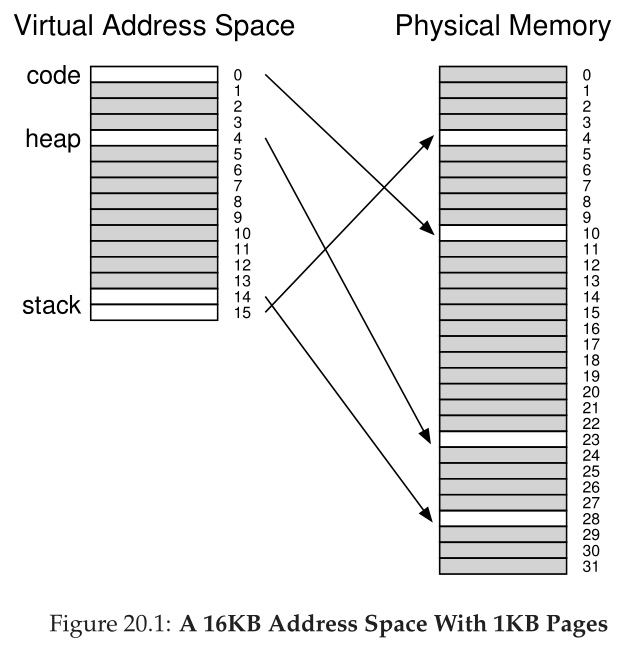

这个例子假定单个代码页(VPN 0)映射到物理页10,单个堆(VPN 4)物理页23页,和另一端的两个栈页的地址空间(VPNs 14和15)分别被映射到物理页28和4。从图中可以看到,页表的大部分都是未使用的,满是无效的项。真是浪费!这是一个很小的16KB地址空间。想象一下32位地址空间的页表和其中所有潜在的浪费空间!其实,不要想这样的事;这太可怕了。
因此,我们的混合方法:与其为整个进程的地址空间使用一个页表,为什么不为每个逻辑段使用一个页表呢?在本例中,我们可能有三个页表,其中一个用于地址空间的代码、堆和栈部分。
记住,对于分段,我们有一个基寄存器告诉我们每个段在物理内存中的位置,还有一个边界寄存器告诉我们段的大小。在我们的混合模型中,MMU中仍然有这些结构;在这里,我们使用基不是指向段本身,而是保存该段的页表的物理地址。边界寄存器用于指示页表的结束(即,它有多少有效页)。
让我们举一个简单的例子来说明。假设一个32位的虚拟地址空间有4KB的页面,一个地址空间分成4个段。在这个示例中,我们只使用三个段:一个用于代码,一个用于堆,一个用于栈。
为了确定一个地址指向哪个段,我们将使用地址空间的前两位。我们假设00是未使用的段,01是代码段,10是堆段,11是栈段。因此,一个虚拟地址看起来像这样:
在硬件中,假设有三个基/边界对(base/bounds pairs),分别代表代码、堆和栈。当进程运行时,每个段的基寄存器包含该段的线性页表的物理地址;因此,系统中的每个进程现在都有三个与其相关联的页表。在上下文切换时,必须更改这些寄存器以反映新运行进程的页表的位置。
在TLB未命中(假设是硬件管理的TLB,即硬件负责处理TLB未命中)上,硬件使用段位(SN)来决定使用哪个基和边界对。然后硬件获取其中的物理地址,并将其与VPN结合,如下所示,形成页表项 (PTE)的地址:
这个序列看起来应该很熟悉;它实际上与我们之前看到的线性页表相同。当然,唯一的区别是使用三个段基寄存器中的一个而不是单页表基寄存器。
Tip:使用混合 当您有两个看似相反的好想法时,您应该始终查看是否可以将它们组合成一个混合体,从而实现两全其美。例如,众所周知,杂交玉米品种比任何天然品种都更健壮。当然,并非所有混合动力车都是好主意。参见 Zeedonk(或 Zonkey),它是斑马和驴的杂交。如果您不相信这样的生物存在,请查一查,并准备好大吃一惊。
我们的混合方案的关键区别是每个段都有一个边界寄存器;每个边界寄存器保存段中最大有效页的值。例如,如果代码段使用它的前三个页(0、1和2),那么代码段页表将只有三个项分配给它,边界寄存器将被设置为3;超出段末端的内存访问将产生异常,并可能导致进程终止。通过这种方式,与线性页表相比,我们的混合方法实现了显著的内存节省;栈和堆之间未分配的页不再占用页表中的空间(只需要将它们标记为无效)。
然而,您可能会注意到,这种方法并非没有问题。首先,它仍然需要我们使用分段;正如我们之前讨论过的,分段并不像我们希望的那样灵活,因为它假定了地址空间的某种使用模式;例如,如果我们有一个大的但很少使用的堆,我们仍然会产生大量的页表浪费。其次,这种混合导致外部碎片再次出现。虽然大部分内存以页大小为单位进行管理,但页表现在可以是任意大小(PTE 的倍数)。因此,在内存中为它们寻找空闲空间更加复杂。由于这些原因,人们继续寻找更好的方法来实现更小的页表。
20.3 多级页表 Multi-level Page Tables
另一种方法不依赖于分段,但解决相同的问题:如何摆脱页表中的所有无效区域,而不是将它们全部保存在内存中?我们称这种方法为多级页表(multi-level page table),因为它将线性页表变成了类似树的东西。这种方法非常有效,以至于许多现代系统都采用了它(例如,x86 [BOH10])。现在我们详细描述这种方法。
多级页表背后的基本思想很简单。首先,将页表切成页大小的单位;然后,如果整个页表项 (PTE) 无效,则根本不要分配页表的该页。要跟踪页表的一个页是否有效(如果有效,则跟踪它在内存中的位置),请使用一个新结构,称为页目录(page directory)。因此,页目录可用于告诉您页表的页在哪里,或者页表的整个页都不包含有效页。
图20.3显示了一个示例。图的左边是经典的线性页表;即使地址空间的大部分中间区域都是无效的,我们仍然需要为这些区域分配页表空间(即页表的中间两个页面)。右边是一个多级页面表。页目录只将页表的两个页标记为有效的(第一个和最后一个);因此,只有页表的这两个页驻留在内存中。因此,您可以看到一种可视化多级表的方法:它只是使线性页表的部分消失(释放那些框架用于其他用途),并跟踪页表的哪些页是由页目录分配的。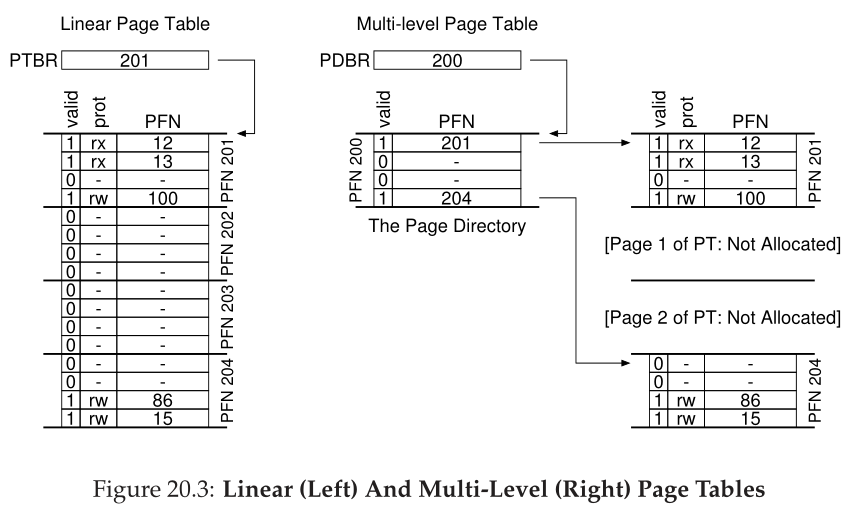
页面目录在一个简单的两级表中,每页包含一个项。它由许多页目录项(page directory entries,PDE)组成。PDE(最低限度)有一个有效位(valid bit)和一个页帧号(page frame number,PFN),类似于PTE。但是,如上所述,这个有效位的含义略有不同:如果 PDE 有效,则意味着该入口(通过 PFN)指向的页表中至少有一个页是有效的,即,在该 PDE 指向的页面上的至少一个 PTE 中,该 PTE 中的有效位设置为 1。如果 PDE 无效(即等于零),则 PDE 的其余部分未定义。
与我们目前看到的方法相比,多级页表有一些明显的优势。首先,也许是最明显的,多级表仅根据您使用的地址空间量按比例分配页表空间;因此它通常是紧凑的并且支持稀疏地址空间。
其次,如果精心构造,页表的每一部分都可以整齐地放在一个页面中,从而更容易管理内存;当操作系统需要分配或增长页表时,它可以简单地抓取下一个空闲页。将此与简单(非分页)线性页表进行对比,后者只是由 VPN 索引的 PTE 数组;使用这样的结构,整个线性页表必须连续驻留在物理内存中。对于一个大页表(比如 4MB),找到这么大块未使用的连续空闲物理内存可能是一个很大的挑战。使用多级结构,我们通过使用页目录添加一个间接层(level of indirection),它指向页表的各个部分;这种间接性允许我们将页表页面放置在物理内存中我们想要的任何位置。
我们在这里做了一些假设,即,所有页表全部驻留在物理内存中(即,它们没有交换到磁盘);我们将很快放宽这一假设。
需要注意的是,多级表是有成本的;在 TLB 未命中时,需要从内存中加载两次才能从页表中获取正确的转换信息(一次用于页目录,另一次用于 PTE 本身),与仅一次加载线性页表不同。因此,多级表是时间空间权衡(time-space trade-off)的一个小例子。我们想要更小的表(并得到了它们),但不是免费的;尽管在常见情况下(TLB 命中),性能显然是相同的,但使用这个较小的表,TLB 未命中会导致更高的成本。
另一个明显的负面因素是复杂性。无论是硬件还是操作系统处理页表查找(在TLB未命中时),这样做无疑比简单的线性页表查找更复杂。我们经常愿意增加复杂性,以提高性能或减少开销;在多级表的情况下,为了节省宝贵的内存,我们使页表查找更加复杂。
一个详细的多级页表例子 A Detailed Multi-Level Example
为了更好地理解多级页表背后的思想,让我们举个例子。想象一下大小为 16KB 的小地址空间,具有 64 字节的页面。因此,我们有一个 14 位的虚拟地址空间,其中 8 位用于 VPN,6 位用于偏移。一个线性页表将有 28 (256) 个项,即使只有一小部分地址空间在使用。图 20.4展示了这种地址空间的一个示例。
在本例中,虚拟页0和1用于代码,虚拟页4和5用于堆,虚拟页254和255用于栈;地址空间的其余页面是未使用的。
为了为这个地址空间构建一个两级页表,我们从完整的线性页表开始,并将其分解为页大小的单元。回想一下我们的全表(在这个例子中)有 256 个条目;假设每个 PTE 的大小为 4 个字节。因此,我们的页表大小为 1KB(256 × 4 字节)。假设我们有 64 字节的页面,那么 1KB 的页表可以分为 16 个 64 字节的页面;每个页面可以容纳 16 个 PTE。
我们现在需要了解的是,如何使用VPN首先索引到页目录,然后索引到页表的页。记住,每个元素都是一个数组;因此,我们需要弄清楚的是如何为每个VPN片段构建索引。
让我们首先在页目录中建立索引。本例中的页表很小:256个条目,分布在16个页面上。页目录需要页表的每一页一个条目;因此,它有16个元素。因此,我们需要VPN的四个bits来索引目录;我们使用VPN的前四位,如下所示: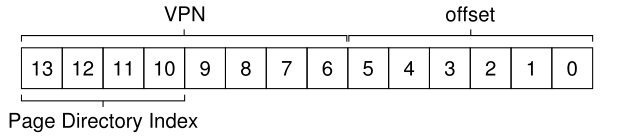
一旦我们从 VPN 中提取了页目录索引(page-directory index)(简称 PDIndex),我们就可以使用它通过简单的计算找到页面目项(PDE)的地址:PDEAddr = PageDirBase + (PDIndex sizeof(PDE))。这就产生了我们的页面目录,我们现在对它进行检查,以便在转换中取得进一步的进展。
如果页目录项被标记为无效,我们就知道访问是无效的,并因此引发异常。但是,如果PDE是有效的,我们就有更多的工作要做。具体地说,我们现在必须从这个页目录项(PDE)所指向的页表的页中获取页表项(PTE)。为了找到这个PTE,我们必须使用VPN的剩余位索引到页表的部分: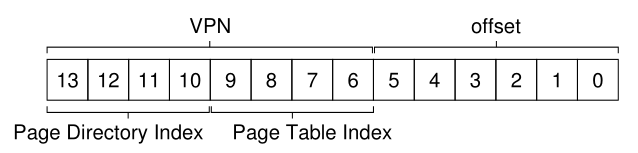
然后可以使用这个页表索引(page-table index)(简称PTIndex)来索引页表本身,从而得到PTE的地址: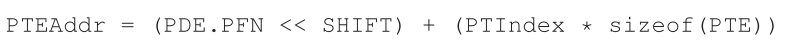
注意,*从页目录项获得的页帧号(PFN)必须左移到合适的位置,然后将它与页表索引结合起来,形成PTE的地址。
为了看看这一切是否有意义,我们现在将用一些实际值填充一个多级页表,并转换一个虚拟地址。让我们从这个示例的页目录开始(图20.5的左侧)。
在图中,可以看到每个页目录项(PDE)描述了地址空间的页表中的页。在这个例子中,我们在地址空间中有两个有效的区域(在开始和结束处),以及一些无效的映射。
在物理页 100(页表第 0 页的物理帧号)中,我们有地址空间中前 16 个 VPN 的 16 个页表项的第一页。页表这部分的内容见图20.5(中间部分)。
页表的这一页包含前16个VPNs的映射;在我们的示例中,VPN 0和1(代码段)是有效的,4和5(堆段)也是有效的。因此,表中有每个页面的映射信息。其余的条目被标记为无效。
页表的另一个有效页在PFN101中找到。该页包含地址空间的最后16个VPN的映射;详见图20.5(右)。
在该示例中,VPN 254 和 255(堆栈)具有有效映射。希望我们可以从这个例子中看到多级索引结构可以节省多少空间。在这个例子中,我们没有为线性页表分配完整的 16 个页面,而是只分配了三个:一个用于页目录,两个用于具有有效映射的页表块。大型(32 位或 64 位)地址空间的节省显然要大得多。
最后,让我们使用这些信息来执行转换。下面是一个地址,它指的是VPN 254: 0x3F80的第0个字节,或者11 1111 1000 0000。
回想一下,我们将使用VPN的前4位来索引页目录。因此,1111将选择上面页面目录的最后一项(如果从第0项开始,则是第15项)。这将指向页表中地址101的一个有效页。然后我们使用 VPN (1110) 的下 4 位索引到页表的该页并找到所需的 PTE。1110 是页面上倒数第二(第 14 个)条目,它告诉我们虚拟地址空间的第 254 页映射到物理页 55。通过将 PFN=55(或十六进制 0x37)与 offset=000000 连接起来,我们因此可以形成我们想要的物理地址并向内存系统发出请求:PhysAddr = (PTE.PFN << SHIFT) + offset = 00 1101 1100 0000 = 0x0DC0。
现在,您应该对如何使用指向页表的页目录来构造两级页表有了一些了解。然而,不幸的是,我们的工作还没有完成。正如我们现在将要讨论的,有时两级页表是不够的!
Tip:警惕复杂性 系统设计人员应该谨慎给他们的系统增加复杂性。一个好的系统构建者所做的就是实现最简单的系统来完成手头的任务。例如,如果磁盘空间充足,您不应该设计一个努力使用尽可能少字节的文件系统;同样,如果处理器速度很快,那么最好在操作系统中编写一个干净且易于理解的模块,而不是针对手头任务的 CPU 优化程度最高的手工组装代码。警惕不必要的复杂性,过早优化的代码或其他形式;这种方法使系统更难理解、维护和调试。正如安托万·德·圣埃克苏佩里 (Antoine de Saint-Exupery) 的名言:“最终达到完美的时候,不是不再有什么可添加的,而是不再有什么可带走的。”他没有写的是:“说完美比实际实现要容易得多。”
超过两级页表 More Than Two Levels
到目前为止,在我们的示例中,我们假设多级页表只有两个级别:一个页目录和页表的各个部分。在某些情况下,更深层的树是可能的(实际上是需要的)。
让我们举一个简单的例子来说明为什么更深层次的多级表是有用的。在本例中,假设我们有一个30位的虚拟地址空间和一个小的(512字节)页。因此,我们的虚拟地址有一个21位的虚拟页码组件和一个9位的偏移量。
记住我们构建多级页表的目标:使页表的每一部分适合于单个页面。到目前为止,我们只考虑了页表本身;但是,如果页面目录变得太大怎么办?
要确定多级表中需要多少层才能使页面表的所有部分适合于一个页面,我们首先要确定页面中适合于多少页表条目。给定页面大小为512字节,并假设PTE大小为4字节,您应该可以看到在单个页面上可以容纳128个PTE。当我们索引到页表的一个页时,我们可以得出这样的结论:我们需要VPN的最低有效位(log2128)作为索引: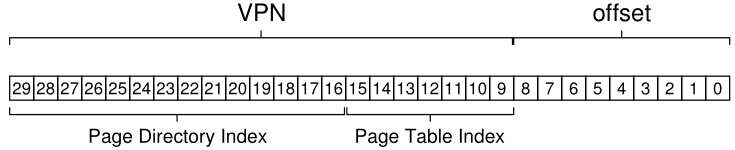
您还可能从上图中注意到(大)页目录中还剩下多少位:14。如果我们的页目录有214个条目,那么它跨越的就不是一个页面,而是128个页面,因此我们让多级页表的每一部分都适合于一个页面的目标就不存在了。
为了解决这个问题,我们构建了更深层次的树,方法是将页目录本身分割为多个页面,然后在此基础上添加另一个页目录,以指向页面目录的页面。因此,我们可以将虚拟地址拆分如下: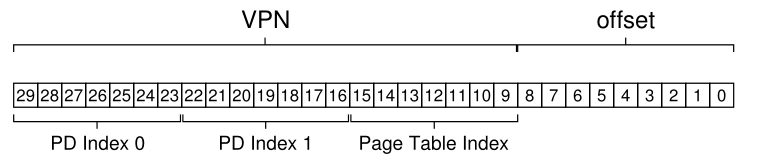
现在,当索引上层页目录时,我们使用虚拟地址的最顶端位(图中PD Index 0);此索引可用于从顶级页目录获取页目录项。如果有效,则通过组合来自顶级 PDE 的物理帧号和 VPN 的下一部分(PD 索引 1)来查询页目录的第二级。最后,如果有效,则可以使用页表索引与来自第二级 PDE 的地址组合形成 PTE 地址。哇!这是很多工作。而这一切只是为了在多级表中查找内容。
转换过程:记住TLB The Translation Process: Remember the TLB
为了使用两层页表总结地址转换的整个过程,我们再次以算法的形式展示了控制流(图20.6)。该图显示了每次内存引用在硬件(假设硬件管理的TLB)中发生的情况。
从图中可以看出,在进行任何复杂的多级页表访问之前,硬件首先检查TLB;一旦命中,物理地址就直接形成,完全不需要访问页表,就像以前一样。只有在TLB失败时,硬件才需要执行完整的多级查找。在这条路径上,您可以看到传统的两级页表的成本:查找有效转换所需的两次额外内存访问。
20.4
反向页表 Inverted Page Tables
在页表世界中,使用反向页表(inverted page tables)可以节省更多的空间。在这里,我们没有使用许多页表(系统的每个进程一个),而是保留一个页表,该页表为系统的每个物理页都有一个项。该项告诉我们哪个进程正在使用该页面,以及该进程的哪个虚拟页面映射到该物理页面。
现在,要找到正确的项,只需搜索整个数据结构。线性扫描开销很大,因此经常在基本结构上构建哈希表以加快查找速度。PowerPC就是这种架构的一个例子[JM98]。
更一般地说,反向页表说明了我们从一开始就说过的内容:页表只是数据结构。你可以用数据结构做很多疯狂的事情,让它们变得更小或更大,让它们变得更慢或更快。多层和反向页表只是人们可以做的许多事情的两个例子。
20.5
将页表交换到磁盘 Swapping the Page Tables to Disk 最后,我们讨论放宽最终假设。到目前为止,我们假设页表驻留在内核拥有的物理内存中。即使我们使用了许多减少页表大小的技巧,但是它们仍然可能太大而无法一次性全部放入内存。因此,一些系统将这样的页表放在内核虚拟内存中,从而允许系统在内存压力有点紧张时将这些页表中的一些交换到磁盘。一旦我们更详细地了解如何将页面移入和移出内存,我们将在以后的章节(即 VAX/VMS 的案例研究)中详细讨论这一点。
20.6
总结 Summary
现在我们已经了解了如何构建真正的页面表;不一定是线性数组,而是更复杂的数据结构。这样的表在时间和空间上的权衡是,表越大,处理TLB miss的速度就越快,反之亦然,因此结构的正确选择很大程度上取决于给定环境的约束。
在内存受限的系统中(像许多老系统一样),小的结构是有意义的;在具有合理内存量和主动使用大量页面的工作负载的系统中,加速 TLB 未命中的更大表可能是正确的选择。使用软件管理的 TLB,整个数据结构空间都为操作系统创新者带来了乐趣(提示:这就是你)。你能想出什么新结构?他们解决什么问题?在您入睡时思考这些问题,并梦想只有操作系统开发人员才能梦想的大梦想。
References
[BOH10] “Computer Systems: A Programmer’s Perspective” by Randal E. Bryant and David
R. O’Hallaron. Addison-Wesley, 2010. We have yet to find a good first reference to the multi-level
page table. However, this great textbook by Bryant and O’Hallaron dives into the details of x86, which
at least is an early system that used such structures. It’s also just a great book to have.
[JM98] “Virtual Memory: Issues of Implementation” by Bruce Jacob, Trevor Mudge. IEEE
Computer, June 1998. An excellent survey of a number of different systems and their approach to
virtualizing memory. Plenty of details on x86, PowerPC, MIPS, and other architectures.
[LL82] “Virtual Memory Management in the VAX/VMS Operating System” by Hank Levy, P.
Lipman. IEEE Computer, Vol. 15, No. 3, March 1982. A terrific paper about a real virtual memory
manager in a classic operating system, VMS. So terrific, in fact, that we’ll use it to review everything
we’ve learned about virtual memory thus far a few chapters from now.
[M28] “Reese’s Peanut Butter Cups” by Mars Candy Corporation. Published at stores near
you. Apparently these fine confections were invented in 1928 by Harry Burnett Reese, a former dairy
farmer and shipping foreman for one Milton S. Hershey. At least, that is what it says on Wikipedia. If
true, Hershey and Reese probably hate each other’s guts, as any two chocolate barons should.
[N+02] “Practical, Transparent Operating System Support for Superpages” by Juan Navarro,
Sitaram Iyer, Peter Druschel, Alan Cox. OSDI ’02, Boston, Massachusetts, October 2002. A nice
paper showing all the details you have to get right to incorporate large pages, or superpages, into a
modern OS. Not as easy as you might think, alas.
[M07] “Multics: History” Available: http://www.multicians.org/history.html. This
amazing web site provides a huge amount of history on the Multics system, certainly one of the most
influential systems in OS history. The quote from therein: “Jack Dennis of MIT contributed influential
architectural ideas to the beginning of Multics, especially the idea of combining paging and segmenta-
tion.” (from Section 1.2.1)
Homework (Simulation)
这个有趣的小作业测试您是否理解多级页表的工作原理。是的,关于前一句中“有趣”一词的使用存在一些争议。程序被调用,也许并不令人意外:pagination-multilevel-translate.py;详细信息请参见README。
Questions
- 对于线性页表,您需要一个寄存器来定位页表,假设硬件在 TLB 未命中时进行查找。定位一个两级页表需要多少个寄存器?三层表呢?
- 使用模拟器执行给定的随机种子0、1和2的转换,并使用-c标记检查您的答案。执行每次查找需要多少内存引用?
- 鉴于您对缓存内存工作原理的理解,您认为对页表的内存引用在缓存中会如何表现?它们是否会导致大量缓存命中(从而导致快速访问?)或者是大量的未命中(因此缓慢的访问)?

若有收获,就点个赞吧
0 人点赞
