在本节中,我们将仔细研究UDP,它是如何工作的,以及它的功能。我们鼓励您回顾一下2.1节,其中包括UDP服务模型的概述,以及2.7.1节,其中讨论了使用UDP进行套接字编程。<br />为了激发我们对UDP的讨论,假设您对设计一个简单的、基本的传输协议感兴趣。你会怎么做呢?您可能首先考虑使用一个空的传输协议(vacuous transport protocol)。特别是,在发送端,您可以考虑从应用程序进程获取报文,并将它们直接传递到网络层;在接收端,您可以考虑接收来自网络层的报文,并将它们直接传递给应用程序进程。但正如我们在前一节中所了解的,我们必须做一点事情,而不是什么都不做!至少,传输层必须提供多路复用/多路分解服务,以便在网络层和正确的应用程序级进程之间传递数据。<br />在[RFC 768]中定义的UDP只做传输协议所能做的事情。**除了多路复用/多路分解功能和一些轻微的错误检查,它没有增加IP**。事实上,**如果应用程序开发人员选择UDP而不是TCP,那么应用程序几乎是直接与IP对话**。**UDP从应用程序进程中获取报文,为多路复用/多路分解服务附加源端口号和目的端口号字段,增加另外两个小字段,并将产生的段传递到网络层。网络层将传输层段封装到IP数据报中,然后尽最大努力将段传递给接收主机**。如果段到达接收主机,UDP使用目的端口号将段的数据传递给正确的应用程序进程。**注意,使用UDP,发送和接收传输层实体之间在发送段之前没有握手。因此,UDP被认为是无连接的(connectionless)。**<br />DNS是使用UDP的应用层协议的一个典型例子。当主机中的DNS应用程序需要进行查询时,它构造DNS查询报文,并将报文传递给UDP。无需与目的端系统上运行的UDP实体进行任何握手,主机端UDP将报头字段添加到报文中,并将结果段传递到网络层。网络层将UDP段封装成数据报(datagram),并将数据报发送到域名服务器(name server)。然后,查询主机上的DNS应用程序等待对其查询的应答。如果它没有接收到应答(可能是因为底层网络丢失了查询或应答),它可能会尝试重新发送查询,尝试将查询发送到另一个域名服务器,或通知调用应用程序它无法获得应答。<br />现在您可能想知道为什么应用程序开发人员会选择在UDP而不是TCP上构建应用程序。既然TCP提供了可靠的数据传输服务,而UDP不提供,难道TCP不总是更好的吗?答案是否定的,因为一些应用程序更适合UDP,原因如下:
- 更精细的应用程序级控制发送什么数据以及何时发送(Finer application-level control over what data is sent, and when)。在UDP下,一旦应用程序将数据传递给UDP, UDP将把数据封装在UDP段中,并立即将该段传递到网络层。另一方面,TCP具有拥塞控制机制,当源主机和目标主机之间的一条或多条链路过度拥塞时,该机制会对传输层TCP发送方进行节流。TCP也将继续重新发送一个段,直到收到的段已被目的地确认,无论可靠的交付需要多长时间。由于实时应用程序通常要求最低发送速率,不希望过度延迟段传输,并能容忍一些数据丢失,TCP的服务模型并不能很好地满足这些应用程序的需求。正如下面所讨论的,这些应用程序可以使用UDP并实现作为应用程序的一部分的任何额外功能,这些功能需要UDP的无附加的分段交付服务。
- 没有连接建立(No connection establishment)。正如我们稍后将讨论的,TCP在开始传输数据之前使用三次握手。UDP只是在没有任何正式准备的情况下就开始了。因此,UDP在建立连接时不会引入任何延迟。这可能是DNS运行在UDP而不是TCP上的主要原因——如果DNS运行在TCP上,它会慢得多。HTTP使用TCP而不是UDP,因为可靠性对于带有文本的Web页面至关重要。但是,正如我们在第2.2节中简要讨论的那样,HTTP中的TCP连接建立延迟是与下载Web文档相关的延迟的一个重要因素。事实上,谷歌的Chrome浏览器中使用的QUIC协议(Quick UDP Internet Connection, [IETF QUIC 2020])使用UDP作为其底层传输协议,并在UDP之上的应用层协议中实现可靠性。我们将在第3.8节详细介绍QUIC。
- 没有连接状态(No connection state)。TCP在终端系统中维护连接状态。这种连接状态包括接收和发送缓冲区、拥塞控制参数、序列和确认号参数(send buffers, congestion-control parameters, and sequence and acknowledgment number parameters)。我们将在3.5节中看到,这个状态信息是实现TCP的可靠数据传输服务和提供拥塞控制所需要的。另一方面,UDP不维护连接状态,也不跟踪这些参数。由于这个原因,当应用程序运行于UDP而不是TCP时,专用于特定应用程序的服务器通常可以支持更多的活动客户端。
- 小数据包首部开销(Small packet header overhead)。TCP段在每个段中有20字节的首部开销,而UDP只有8字节的开销。
图3.6列出了流行的Internet应用程序及其使用的传输协议。如我们所料,电子邮件、远程终端访问和文件传输都是通过TCP运行的——所有这些应用程序都需要TCP的可靠数据传输服务。我们在第二章中了解到,早期版本的HTTP运行在TCP上,但最新版本的HTTP运行在UDP上,在应用层提供自己的错误控制和拥塞控制(以及其他服务)。然而,许多重要的应用程序运行于UDP而不是TCP。例如,UDP用于承载网络管理(carry network management)(SNMP;见5.7节)数据。在这种情况下,UDP优于TCP,因为网络管理应用程序必须经常在网络处于紧张状态时运行——确切地说,当可靠的、拥塞控制的数据传输难以实现时。此外,正如我们前面提到的,DNS运行于UDP之上,因此避免了TCP的连接建立延迟。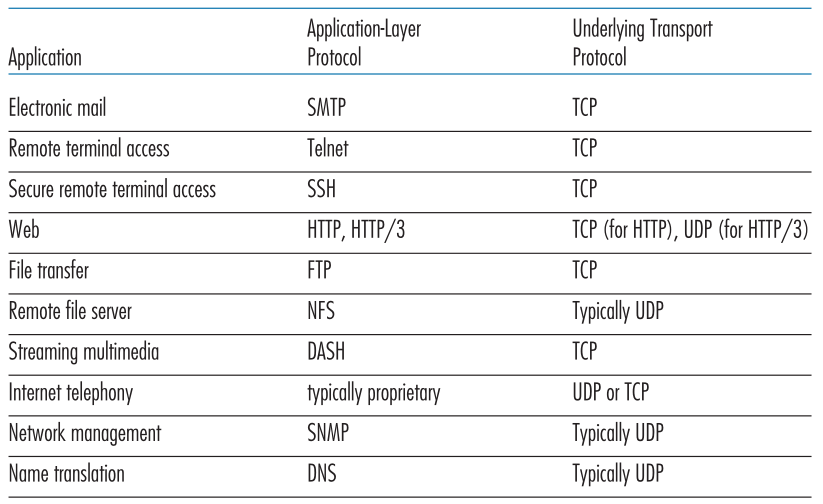
Figure 3.6 ♦ Popular Internet applications and their underlying transport protocols
图3.6流行的互联网应用及其基础传输协议
如图3.6所示,UDP和TCP有时被用于多媒体应用程序,如互联网电话、实时视频会议和存储的音频和视频流。我们刚才提到,所有这些应用程序都可以容忍少量的丢包,因此可靠的数据传输对应用程序的成功并非绝对关键。此外,实时应用程序,如互联网电话和视频会议,对TCP的拥塞控制反应非常差。由于这些原因,多媒体应用程序的开发人员可能会选择在UDP而不是TCP上运行他们的应用程序。当丢包率较低时,由于一些组织出于安全原因阻塞UDP流量(见第8章),TCP成为流媒体传输越来越有吸引力的协议。
虽然在今天这样做很常见,但是在UDP上运行多媒体应用程序需要小心。正如我们上面提到的,UDP没有拥塞控制。但是拥塞控制是需要的,以防止网络进入拥塞状态,在这种状态下几乎没有做什么有用的工作。如果每个人都开始流高比特率的视频而不使用任何拥塞控制,将有如此多的包溢出路由器,很少UDP包将成功地通过源到目的路径。此外,由不受控制的UDP发送方引起的高丢包率将导致TCP发送方(正如我们将看到的,在面对拥塞时确实降低了它们的发送率)大幅降低它们的速率。因此,UDP缺乏拥塞控制可能导致UDP发送方和接收方之间的高丢包率,并挤出TCP会话。许多研究人员提出了新的机制来强制所有的源,包括UDP源,执行自适应拥塞控制(adaptive congestion control)[Mahdavi 1997;Floyd 2000年;Kohler 2006: rfc4340]。
在讨论UDP段结构之前,我们提到当使用UDP时,应用程序有可能有可靠的数据传输。如果应用程序本身内置了可靠性,就可以做到这一点(例如,通过添加确认和重传(acknowledgment and retransmission)机制,我们将在下一节中研究这些机制)。我们在前面提到QUIC协议在UDP之上的应用层协议中实现了可靠性。但是,这是一项非常重要的任务,将使应用程序开发人员在很长一段时间内忙于调试。然而,将可靠性直接构建到应用程序中可以让应用程序“鱼与熊掌兼得”。也就是说,应用程序进程可以可靠地通信,而不受TCP拥塞控制机制施加的传输速率限制。
3.3.1 UDP段结构 UDP Segment Structure
UDP段结构在 RFC 768 中定义,如图3.7所示。应用数据占用UDP段的数据字段。例如,对于DNS,数据字段包含查询消息或响应消息。对于音频流应用程序,音频示例填充数据字段。UDP首部只有四个字段,每个字段由两个字节组成。正如前一节所讨论的,端口号允许目标主机将应用程序数据传递给在目标端系统上运行的正确进程(即执行多路复用功能)。length字段指定UDP段(首部加数据)的字节数。一个显式的长度值是需要的,因为数据字段的大小可能不同于一个UDP段到下一个。接收主机使用校验和(checksum)检查段中是否引入了错误。事实上,除了UDP段,校验和也在IP首部中的一些字段上计算。但我们忽略了这个细节,以便透过树木看到森林。我们将在下面讨论校验和计算。错误检测的基本原理见第6.2节。length字段指定UDP段的长度,包括首部(header),单位为字节。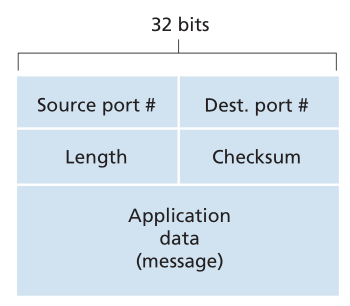
Figure 3.7 ♦ UDP segment structure
图3.7 UDP段结构
3.3.2 UDP校验和 UDP Checksum
UDP校验和提供错误检测(error detection)。也就是说,校验和用于确定UDP段内的比特是否已经被改变(例如,由于链路中的噪声或存储在路由器中),因为它从源移动到目的地。
UDP在发送端执行在段中所有16位字的和的1补码,忽略在和被封装期间遇到任何溢出。这个结果放在UDP段的校验和字段中。这里我们给出一个校验和计算的简单例子。你可以在RFC 1071中找到关于计算的有效实现和在真实数据上的性能的细节[Stone 1998;Stone 2000]。例如,假设我们有以下三个16位的字:
前两个16位字的和是
在上面的总和上加上第三个字
注意,最后一个添加项有溢出,它被环绕起来了。通过将所有的0都转换为1,再将所有的1都转换为0,得到1的补码。因此,和0100101011000001的1s补码是1011010100111110,它成为校验和。在接收端,包括校验和在内的四个16位字都被加上。如果数据包中没有引入错误,那么接收端的和显然是1111111111111111。如果其中一位是0,那么我们就知道错误已经被引入包中。
您可能想知道为什么UDP首先提供校验和,因为许多链路层协议(包括流行的以太网协议)也提供错误检查。原因是不能保证源和目标之间的所有链路都提供错误检查;也就是说,其中一个链路可能使用不提供错误检查的链路层协议。此外,即使段在链路上正确传输,当段存储在路由器的内存中时,也有可能引入比特错误。由于链路对链路的可靠性和内存的错误检测都不能保证,UDP必须在传输层提供错误检测,如果终端数据传输服务要提供错误检测,UDP 必须在传输层提供终端(end-end)基础上的错误检测。这是系统设计中著名的终端原则(end-end principle)的一个例子[ saltzer 1984] ,该原则指出,由于某些功能(在本例中是错误检测)必须在终端基础上实现:“与在较高层级提供这些功能的成本相比,放在较低层级的功能可能是多余的或价值不大
”。
因为 IP 应该运行在几乎任何第 2 层协议上,所以传输层提供错误检查作为一种安全措施是有用的。 尽管 UDP 提供了错误检查,但它不会从错误中恢复。 UDP 的一些实现只是简单地丢弃损坏的段; 其他一些则将损坏的段传递给应用程序并发出警告。
以上就是我们对UDP的讨论。我们很快就会看到TCP为它的应用程序提供可靠的数据传输,以及UDP不能提供的其他服务。当然,TCP也比UDP更复杂。然而,在讨论TCP之前,先退一步,首先讨论可靠数据传输的基本原则是有用的。

若有收获,就点个赞吧
0 人点赞
