在本节中,我们将在一般情况下考虑可靠数据传输的问题。 **这是合适的,因为实现可靠数据传输的问题不仅发生在传输层,还发生在链路层和应用层。** 因此,一般问题对联网至关重要。 确实,如果必须确定所有网络中根本重要问题的“前十名”列表,那么这将是领导该列表的候选人。 在下一节中,我们将检查 TCP 并特别说明 TCP 利用了我们将要描述的许多原理。<br />图3.8说明了我们研究可靠数据传输的框架。提供给上层实体的服务抽象是数据传输的可靠通道。有了可靠的信道,传输的数据位不会损坏(从0翻转到1,反之亦然)或丢失,所有数据都按照发送的顺序传递。这正是TCP为调用它的Internet应用程序提供的服务模型。<br />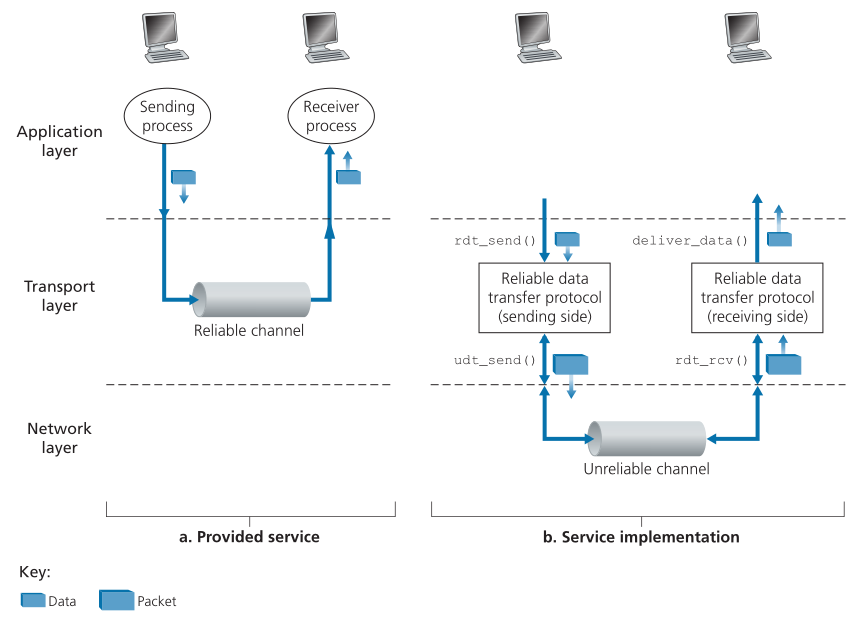<br />**Figure 3.8 ♦ Reliable data transfer: Service model and service implementation**<br />**图3.8♦可靠的数据传输:服务模型和服务实现**<br />**可靠的数据传输协议(reliable data transfer protocol)**负责实现这个服务抽象。由于可靠数据传输协议下面的层可能是不可靠的,使得这项任务变得困难。例如,TCP是一个可靠的数据传输协议,它是在一个不可靠的(IP)端到端网络层之上实现的。**更一般地,两个可靠通信端点下面的层可能由单个物理链路(如在链路级数据传输协议中)或全球互联网络(如在传输级协议中)组成**。然而,就我们的目的而言,我们可以将这个较低的层简单地视为一个不可靠的点对点通道。<br />在本节中,考虑到越来越复杂的底层通道模型,我们将逐步开发可靠数据传输协议的发送方和接收方。例如,当底层通道可能损坏位或丢失整个数据包时,我们将考虑需要哪些协议机制。我们将在这里的整个讨论中采用的一个假设是,**数据包将按照发送的顺序进行交付,其中一些数据包可能会丢失;也就是说,底层通道不会重新排序数据包。**图 3.8(b) 说明了我们的数据传输协议的接口。数据传输协议的发送端将通过调用 rdt_send() 从上面调用。它会将要下发的数据传递给接收端的上层。 (这里 rdt 代表可靠数据传输协议,_send 表示正在调用 rdt 的发送方。开发任何协议的第一步都是选择一个好名字!)在接收方,rdt_rcv() 将在数据包从信道的接收端到达。当 rdt 协议想要向上层传递数据时,它会通过调用 delivery_data() 来实现。在下文中,我们使用术语“数据包(packet)”而不是传输层“段(segment)”。由于本节中开发的理论一般适用于计算机网络,而不仅仅是 Internet 传输层,因此通用术语“数据包”在这里可能更合适。<br />在本节中,我们只考虑**单向数据传输(unidirectional data transfer)**的情况,即从发送端到接收端的数据传输。可靠的**双向(bidirectional)(即全双工(full-duplex))数据传输**从概念上讲并不困难,但解释起来却相当繁琐。尽管我们只考虑单向数据传输,但需要注意的是,协议的发送方和接收方仍然需要在两个方向上传输数据包,如图3.8所示。我们很快就会看到,除了交换包含要传输的数据的包外,rdt的发送端和接收端还需要来回交换控制包(control packets)。rdt的发送端和接收端都通过调用udt_send()(其中udt表示不可靠的数据传输)向另一端发送数据包。
3.4.1 建立可靠数据传输协议 Building a Reliable Data Transfer Protocol
我们现在一步一步地通过一系列协议,每一个都变得更加复杂,最终达成一个完美、可靠的数据传输协议。
完全可靠的信道上的可靠数据传输:rdt1.0 Reliable Data Transfer over a Perfectly Reliable Channel: rdt1.0
我们首先考虑最简单的情况,即底层通道是完全可靠的。协议本身(我们称之为rdt1.0)很简单。有限状态机(finite-state machine,FSM)与rdt1.0的发送方和接收方之间的相互作用如图3.9所示。图3.9(a)中的FSM定义了发送方的操作,图3.9(b)中的FSM定义了接收方的操作。重要的是要注意,发送方和接收方有独立的FSMs。图3.9中的发送方和接收方FSMs都只有一个状态。FSM描述中的箭头表示协议从一种状态过渡到另一种状态。(由于图3.9中的每个FSM只有一个状态,所以必须从一个状态转换回它自己;稍后我们将看到更复杂的状态图。)导致转换的事件显示在标记该转换的水平线上方,当事件发生时所采取的操作显示在水平线下方。当没有对某个事件执行操作时,或者没有事件发生而执行了某个操作时,我们将分别在水平线的下方或上方使用符号Λ来明确表示缺少操作或事件。FSM的初始状态用虚线箭头表示。虽然图3.9中的FSM只有一个状态,但是我们很快就会看到FSM有多个状态,所以识别每个FSM的初始状态是很重要的。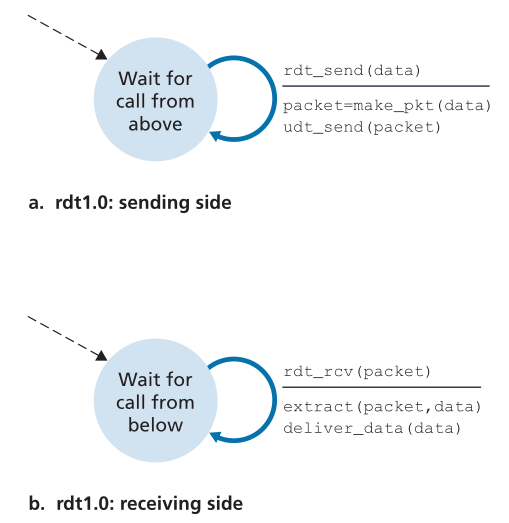
Figure 3.9 ♦ rdt1.0—A protocol for a completely reliable channel
图3.9♦用于完全可靠信道的rdt1.0-A协议
rdt的发送端只是通过rdt_send(data)事件从上层接收数据(data),创建一个包含数据的数据包(packet)(通过动作make_pkt(data))并将包发送到通道。实际上,rdt_send(data)事件是由上层应用程序的进程调用(例如,对rdt_send())产生的。
在接收端,rdt通过rdt_rcv(packet)事件从底层通道接收一个数据包,从包中删除数据(通过动作extract(packet, data)),并将数据传递到上层(通过动作deliver_data(data))。实际上,rdt_rcv(packet)事件是由底层协议的进程调用(例如,对rdt_rcv())引起的。
在这个简单的协议中,一单位数据(a unit of data)和一个数据包之间没有区别。而且,所有数据包流都是从发送方到接收方;有了一个完全可靠的通道,接收方就不需要向发送方提供任何反馈,因为没有什么会出错!注意,我们还假设接收方接收数据的速度与发送方发送数据的速度一样快。因此,接收者没有必要要求发送者放慢速度!
有位错误的信道上的可靠数据传输: rdt2.0 Reliable Data Transfer over a Channel with Bit Errors: rdt2.0
一个更真实的底层通道模型是数据包中的比特可能被破坏。当数据包被传输、传播或缓冲时,这种位错误通常发生在网络的物理组件中。我们将继续假设所有发送的数据包都按照发送的顺序被接收(尽管它们的位可能已经损坏)。
在开发用于在此类通道上进行可靠通信的协议之前,首先考虑人们可能如何处理这种情况。考虑一下你自己如何在电话中口述长信息。在一个典型的场景中,信息接收者可能会在听到、理解和记录每句话后说“OK”。如果收信人听到了一个混淆的句子,你就会被要求重复这个混淆的句子。此报文听写协议同时使用正面确认(positive acknowledgments)(“OK”)和负面确认(negative acknowledgments)(“Please repeat that.”)。这些控制报文允许接收方让发送方知道哪些是正确接收的,哪些是错误接收的,因此需要重复。在计算机网络设置中,基于这种重传(retransmission)的可靠数据传输协议称为ARQ(Automatic Repeat reQuest,自动重复请求)协议。
基本上,ARQ协议需要三个额外的协议功能来处理位错误的存在:
- 错误检测(Error detection)。首先,需要一种机制来允许接收方在发生比特错误时进行检测。回想一下,在上一节中,UDP使用Internet校验和字段正是出于这个目的。在第6章,我们将更详细地检查错误检测和修正技术;这些技术允许接收端检测并可能纠正数据包的比特错误。现在,我们只需要知道,这些技术要求从发送方向接收方发送额外的位(超出要传输的原始数据位);这些位将被收集到rdt2.0数据包的数据包校验和字段中。
- 接收反馈(Receiver feedback)。由于发送方和接收方通常是执行在不同的终端系统,可能相隔数千英里,发送者了解接收端的世界的唯一途径(在这种情况下,接收报文是否正确)是接收方提供显式反馈给发送方。消息口述场景中的正(ACK)和负(NAK)确认应答(positive (ACK) and negative (NAK) acknowledgment replies)就是这种反馈的例子。我们的rdt2.0协议将类似地将ACK和NAK包从接收端发送回发送端。原则上,这些包只需要一个比特长;例如,0值可能表示NAK, 1值可能表示ACK。
- 重传(Retransmission)。在接收方错误接收到的数据包将由发送方重新发送。
图3.10显示了rdt2.0的FSM表示,rdt2.0是一个使用错误检测、正确认和负确认的数据传输协议。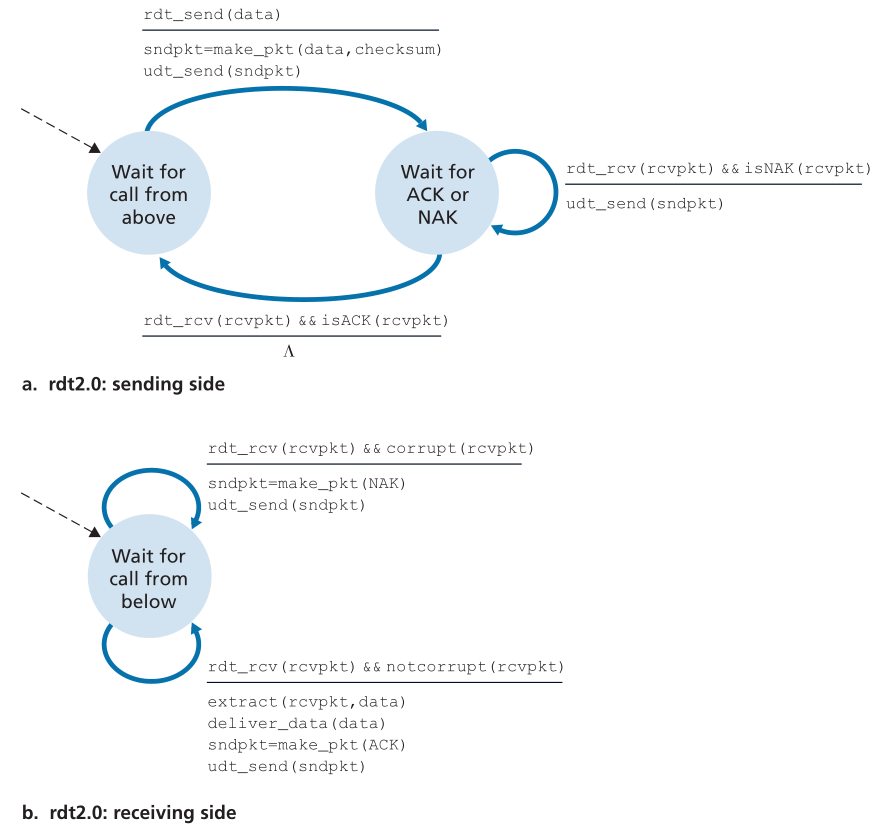
Figure 3.10 ♦ rdt2.0—A protocol for a channel with bit errors
图3.10♦针对位错误信道的rdt2.0-A协议
rdt2.0的发送端有两种状态。在最左边的状态下,发送端协议正在等待从上层传来的数据。当rdt_send(data)事件发生时,发送方将创建一个包(sndpkt),其中包含要发送的数据,以及一个包的校验和(例如,在3.3.2节中讨论的UDP段),然后通过udt_send(sndpkt)操作发送这个包。在最右边的状态中,发送方协议正在等待接收方的ACK或NAK包。如果收到一个ACK包(图3.10中的符号rdt_rcv(rcvpkt) && isACK(rcvpkt)对应于这个事件),发送方知道最近发送的包已经被正确接收,因此协议返回到等待上层数据的状态。如果接收到NAK,协议将重传最后一个数据包,并等待接收端返回ACK或NAK作为对重传数据包的响应。需要注意的是,当发送方处于等待ACK或NAK状态(wait-for-ACK-or-NAK)时,它不能从上层获取更多数据;也就是说,rdt_send()事件不能发生;只有在发送方收到ACK并离开此状态后才会发生。因此,发送方在确定接收方已正确接收到当前数据包之前,不会发送新的数据。由于这种行为,像rdt2.0这样的协议被称为停止-等待(stop-and-wait )协议。
rdt2.0的接收端FSM仍然只有一个状态。在数据包到达时,接收端以ACK或NAK应答,这取决于接收到的数据包是否损坏。在图3.10中,符号rdt_rcv(rcvpkt) && corrupt(rcvpkt)对应于接收到数据包并发现出错的事件。
协议rdt2.0看起来好像可以工作,但不幸的是,它有一个致命的缺陷。特别是,我们还没有考虑到ACK或NAK包可能被破坏的可能性!(在继续之前,您应该考虑如何解决这个问题。)不幸的是,我们的轻微疏忽并不像看起来那样无害。最低限度地,我们将需要添加校验和位到ACK/NAK包,以检测此类错误。更困难的问题是协议应该如何从ACK或NAK包中的错误中恢复。这里的困难在于,如果ACK或NAK损坏,发送方无法知道接收方是否正确地接收了最后一段传输的数据。
考虑三种处理损坏的ACK或NAK的可能性:
- 对于第一种可能性,请考虑在消息口述场景中人类可能会做什么。如果说话人听不懂对方的“OK”或“Please repeat that”的回答,他可能会问:“你说了什么?”(因此在我们的协议中引入了一种新的发送方到接收方的包)。然后收信人会重复回答。 但是说话者的“你说什么?” 是否已损坏? 接收者不知道混乱的句子(garbled sentence)是口述的一部分还是要求重复上次答复的一部分,然后可能会回答“你说什么?” 然后,当然,该响应可能是乱码。 显然,我们正走在一条艰难的道路上。
- 第二种选择是添加足够的校验和位,以便发送方不仅能检测到位错误,而且还能从位错误中恢复。这解决了信道可能损坏数据包但不会丢失数据包的直接问题。
- 第三种方法是发送方在收到错误的ACK或NAK包时简单地重新发送当前数据包。然而,这种方法在发送方到接收方通道中引入了重复的数据包。重复数据包的基本困难在于,接收方不知道上次发送的ACK或NAK是否被发送方正确接收。因此,它不能预先知道一个到达的包是否包含新数据或是一个重传!
这个新问题的一个简单解决方案(几乎所有现有的数据传输协议,包括TCP)是在数据包中添加一个新的字段,并让发送方通过在该字段中放入序列号(sequence number)来为其数据包编号。然后,接收方只需要检查这个序列号就可以确定接收到的数据包是否为重传。对于这个简单的stop-and-wait协议,一个1位的序列号就足够了,因为它将允许接收方知道发送方是否重新发送先前发送的包(收到的包的序列号与最近接收的包的序列号相同)或一个新的包(序列号改变,在模-2算法中“向前移动”(moving “forward” in modulo-2 arithmetic))。由于我们目前假设一个通道不会丢失数据包,因此ACK和NAK数据包本身不需要指明它们所确认的数据包的序列号。发送方知道接收到的ACK或NAK包(无论是否被篡改)是对其最近传输的数据包的响应。
图3.11和3.12显示了rdt2.0的修订版本(fixed version)rdt2.1的FSM描述。rdt2.1发送端和接收端FSMs现在的状态数都是以前的两倍。这是因为协议状态现在必须反映当前(由发送方)发送的包或预期(在接收方)的包的序列号是否应该为0或1。注意,在那些0编号的包正在发送或预期的状态下的动作是那些1编号的包正在发送或预期的状态的镜像;唯一的区别在于对序列号的处理。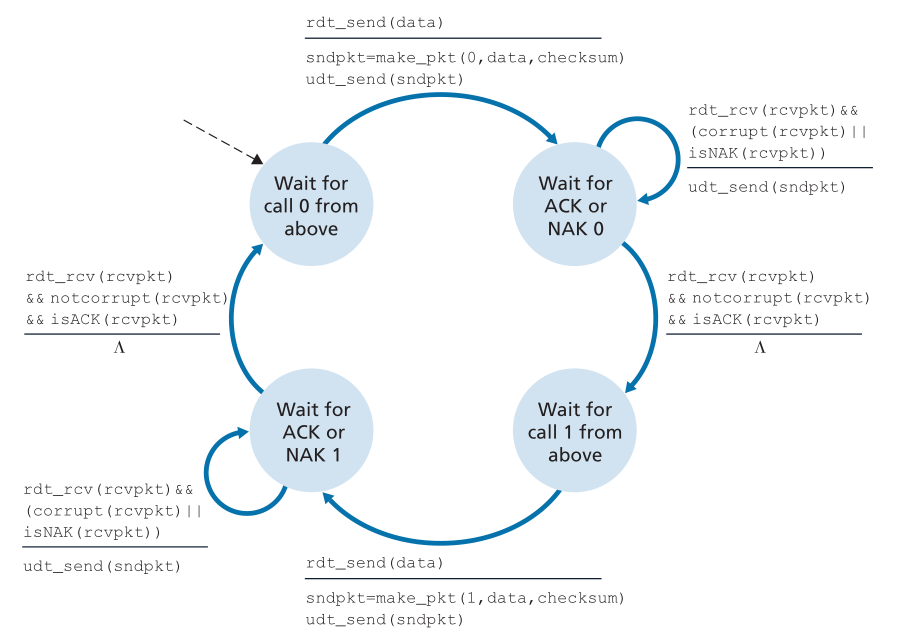
Figure 3.11 ♦ rdt2.1 sender
图 3.11 ♦ rdt2.1 发送方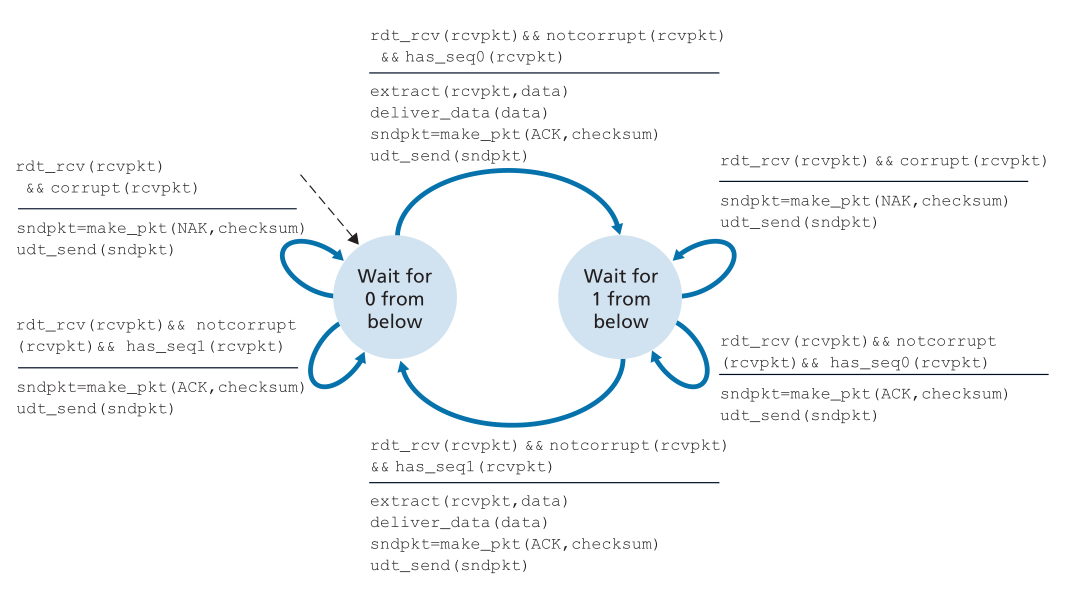
Figure 3.12 ♦ rdt2.1 receiver
图 3.12 ♦ rdt2.1 接收方
协议rdt2.1使用了从接收方到发送方的正确认和负确认。当接收到一个乱序的包时,接收方对它接收到的包发送一个肯定的确认。当接收到损坏的数据包时,接收方发送一个否定的确认。我们可以实现与NAK相同的效果,如果我们不发送NAK,而是对上一个正确接收的包发送ACK。接收同一个数据包(即接收重复ACK(duplicate ACK))的两个 ACK 的发送方知道接收方没有正确地接收跟随正在进行两次 ACK 的数据包。我们的NAK-free(无NAK)可靠数据传输协议是rdt2.2,如图3.13和3.14所示。rdt2.1和rdt2.2之间的一个微妙的变化是,接收方现在必须包含被ACK报文确认的数据包的序列号(这是通过在接收方的FSM中包含make_pkt()中的ACK, 0或ACK, 1参数来完成的),发送方现在必须检查接收到的ACK消息所确认的数据包的序列号(这是通过在发送方的FSM中包含isACK()中的0或1参数来完成的)。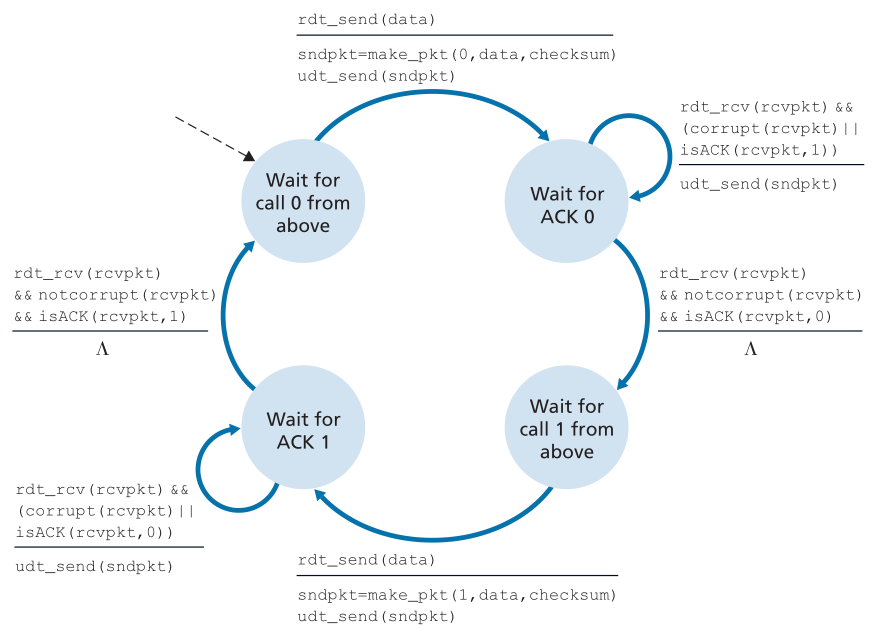
Figure 3.13 ♦ rdt2.2 sender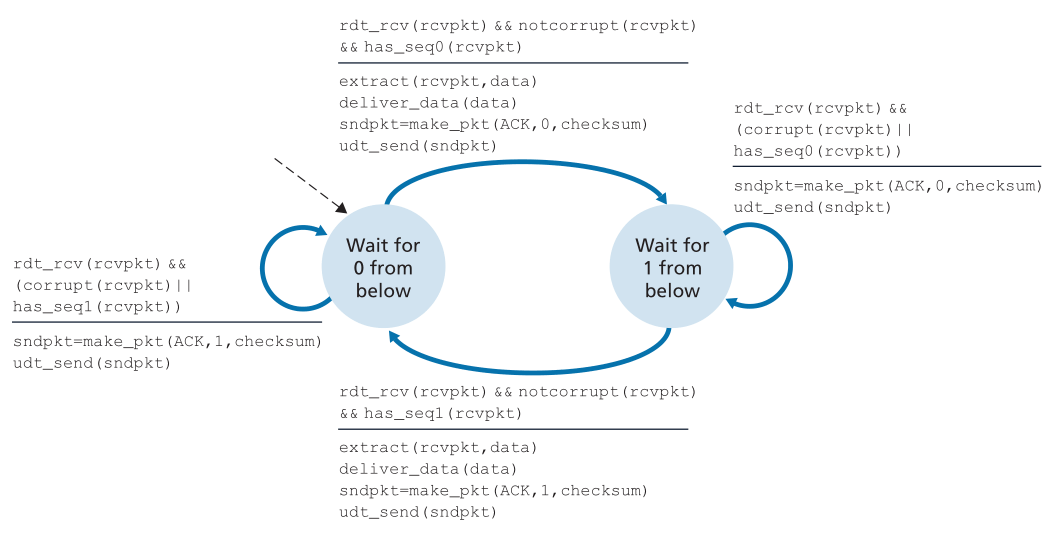
Figure 3.14 ♦ rdt2.2 receiver
译者注:来自知乎Panyang的回答,关于rdt2.1,他描述的非常好: rdt2.1属于等停协议,就是说要按顺序传送数据包,上一个分组确认传达后才会开始下一个数据包。假设接收端收到了正确的数据包并向发送端发出了确认信息,但是当发送端接收到错误的接收端的确认信息(即不是ACK也不是NAK)时候,发送端不知道接收端是否得到正确的数据包,发送端会在当前状态(1或0)下重新发送数据包,而此时接收端已经进入下一个状态(0或1),发送端与接收端当前处于不同的状态,当前接受端的状态是期望得到下一个数据包,而发送端发送的是上一个数据包,这时候接收端就会通过两端不同的状态明白发送端发送的是上一个数据包,跟着会丢弃这个数据包,并且发送ACK给发送端, 让发送端进入下一个状态。一个状态可以表示两种情况:1.发送端收到接收端ACK,发下一数据包。 2.发送端收到接收端NAK,重发。而两个状态可以表示第三种情况:3.发送端不知道接受端收到的是否正确,重发。
有位错误的有损信道上的可靠数据传输: rdt3.0 Reliable Data Transfer over a Lossy Channel with Bit Errors: rdt3.0
现在假设除了损坏比特之外,底层通道还可能丢失数据包,这在当今的计算机网络(包括Internet)中是很常见的事件。协议现在必须解决两个额外的问题:如何检测包丢失以及发生包丢失时应该做什么。使用校验和、序列号、ACK包和重传(rdt2.2中已经开发的技术)将使我们能够回答后一个问题。处理第一个问题需要添加一个新的协议机制。
有许多可能的处理丢包的方法(本章末尾的练习中还探讨了更多的方法)。在这里,我们将把检测和从丢失的包中恢复的负担交给发送方。假设发送方发送了一个数据包,而该数据包或接收方对该数据包的ACK丢失了。在这两种情况下,发送方没有收到来自接收方的回复。如果发送方愿意等待足够长的时间以确定数据包已经丢失,它可以简单地重新发送数据包。你应该说服自己这个协议确实有效。
但是发送方要等多久才能确定丢失了什么东西呢?显然,发送方必须至少等待发送方和接收方之间的往返延迟(可能包括中间路由器的缓冲)加上接收方处理数据包所需的时间。在许多网络中,这种最坏情况下的最大延迟甚至很难估计,更不用说确定地知道了。此外,在理想情况下,协议应该尽快从丢包中恢复;等待最坏情况的延迟可能意味着在启动错误恢复之前要等待很长时间。因此,在实践中采用的方法是,发送方明智地选择一个时间值,使丢包虽然不能保证,但仍有可能发生。如果在此时间内没有收到ACK,数据包将被重传。请注意,如果一个包经历了特别大的延迟,即使数据包和ACK都没有丢失,发送方也可以重新发送该包。这就引入了在发送端到接收端通道中存在重复数据包(duplicate data packets)的可能性。值得高兴的是,协议rdt2.2已经有足够的功能(即序列号)来处理重复包的情况。
从发送者的角度来看,重新发送是一种灵丹妙药。发送方不知道数据包是否丢失,ACK是否丢失,或者数据包或ACK是否只是过度延迟。在所有情况下,操作都是相同的:重传(retransmit)。实现基于时间的重传机制需要一个倒计时计时器(countdown timer),该计时器可以在给定的时间过期后中断发送方。因此,发送方需要能够(1)在每次发送包(第一次包或重传)时启动计时器,(2)响应计时器中断(采取适当的行动),以及(3)停止计时器。
图3.15显示了rdt3.0的发送方FSM, rdt3.0是一种可靠地在可能损坏或丢失数据包的通道上传输数据的协议;在作业问题中,你会被要求提供rdt3.0的接收方FSM。图3.16显示了协议在没有丢失或延迟包的情况下如何操作,以及它如何处理丢失的数据包。在图3.16中,时间从图的顶部向图的底部移动;注意,由于传输和传播延迟,包的接收时间必然要晚于包的发送时间。在图3.16(b) - (d)中,发送端括号表示设置计时器的时间以及之后超时的时间。本章末尾的练习将探讨该协议的几个更微妙的方面。因为包序列号在0和1之间交替,协议rdt3.0有时被称为交替位协议(alternating-bit protocol)。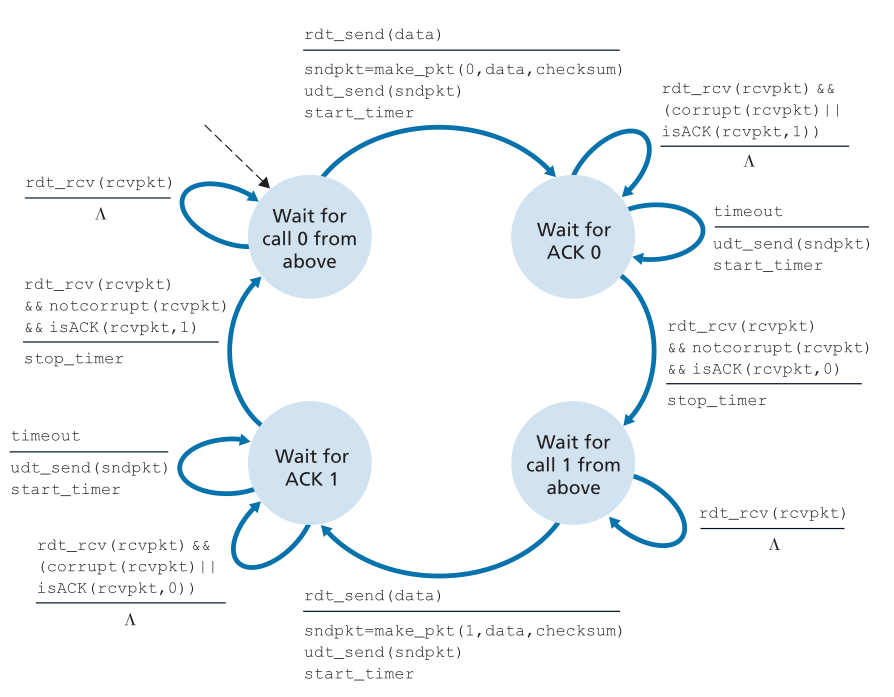
Figure 3.15 ♦ rdt3.0 sender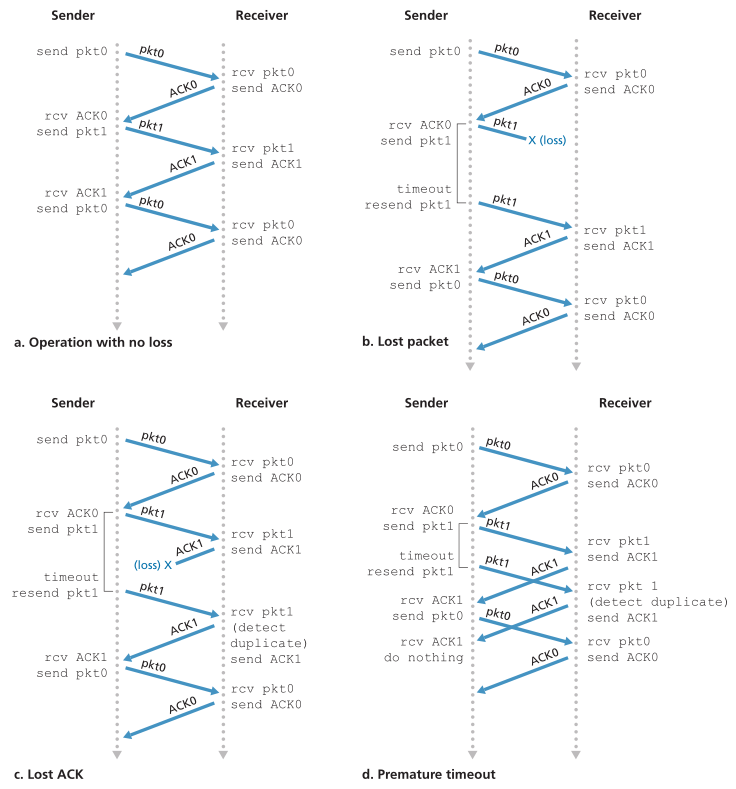
Figure 3.16 ♦ Operation of rdt3.0, the alternating-bit protocol
图3.16♦交互位协议rdt3.0的操作
我们现在已经收集了数据传输协议的关键要素。校验和、序列号、计时器和正负确认数据包(Checksums, sequence numbers, timers, and positive and negative acknowledgment packets)在协议的操作中都起着至关重要和必要的作用。我们现在有一个工作可靠的数据传输协议!
3.4.2 流水线可靠数据传输协议 Pipelined Reliable Data Transfer Protocols
协议rdt3.0在功能上是正确的,但是任何人都不可能对它的性能感到满意,特别是在今天的高速网络中。rdt3.0性能问题的核心在于它是一个“停止-等待”协议。
为了了解这种停止-等待行为对性能的影响,考虑两个主机的理想化情况,一个位于美国西海岸,另一个位于东海岸,如图3.17所示。这两个端系统之间的光速往返传播延迟,RTT,大约是30毫秒。假设它们通过一个传输速率为1 Gbps(109位每秒)的信道连接。如果包大小L为每个包1,000字节(8,000位),包括首部字段和数据,则实际将包传输到1Gbps链路所需的时间为
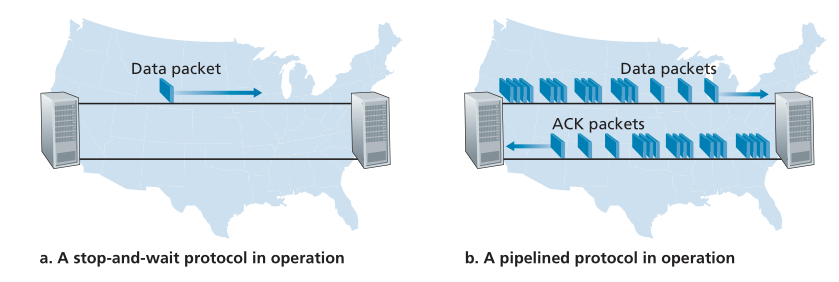
Figure 3.17 ♦ Stop-and-wait versus pipelined protocol
图3.17♦停止-等待与流水线协议的比较
图3.18(a)显示了使用我们的stop-and-wait协议,如果发送方在t=0时开始发送数据包,那么在t=L/R=8微秒时,最后一位进入发送方端的通道。然后包进行15毫秒的全国旅行,包的最后一个比特在t=RTT/2+L/R = 15.008毫秒时出现在接收端。为了简单,假设ACK包非常小(这样我们就可以忽略它们的传输时间),并且接收端只要收到数据包的最后一位就可以发送ACK,那么ACK就会在t=RTT+L/R=30.008 msec返回给发送端。此时,发送方可以传送下一条报文。因此,在30.008毫秒内,发送方只发送了0.008毫秒。如果我们将发送方(或信道)的利用率(utilization)定义为发送方实际忙着向信道发送比特的时间比例,图3.18(a)中的分析显示,停止-等待协议的发送方利用率相当低,Usender为
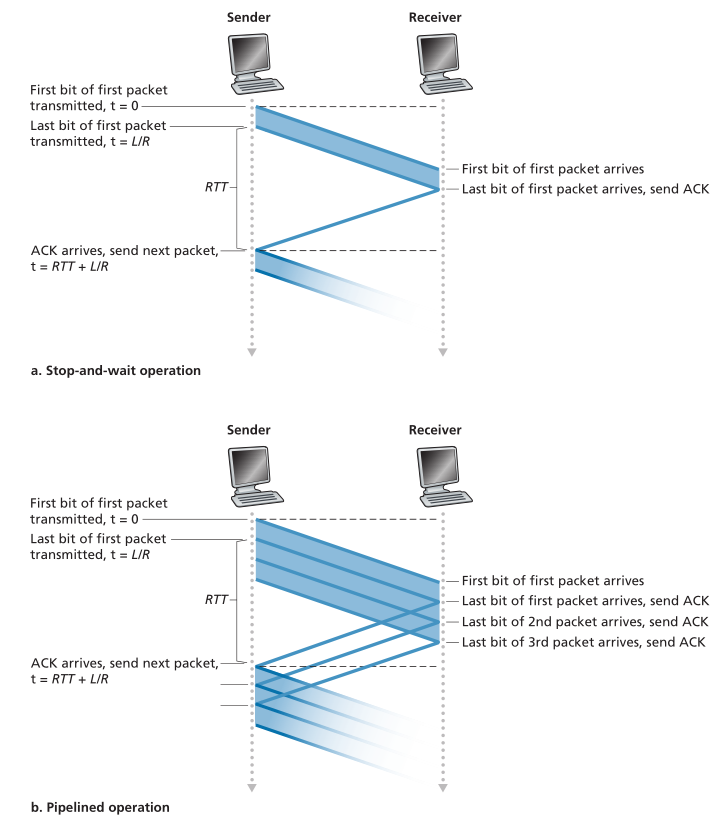
Figure 3.18 ♦ Stop-and-wait and pipelined sending
图3.18♦停止等待和流水线发送
也就是说,发送方只有百分之2.7的时间是忙碌的!从另一个角度来看,发送方能够在30.008毫秒内发送1000字节,有效吞吐量只有267 kbps——即使有1 Gbps的链路可用!想象一下,一个不高兴的网络经理刚刚花了一大笔钱买了一条千兆字节的链路,却设法得到了每秒267千比特的吞吐量!这是一个生动的示例,说明了网络协议如何限制底层网络硬件提供的功能。此外,我们忽略了在发送方和接收方的底层协议处理时间,以及在发送方和接收方之间的任何中间路由器上可能发生的处理和排队延迟。将这些影响包括在内只会进一步增加延迟,并进一步加重糟糕的表现。
这个特殊性能问题的解决方案很简单:发送方不需要等待确认就可以发送多个数据包,而不是以停止-等待的方式操作,如图3.17(b)所示。图3.18(b)显示,如果允许发送方在等待确认之前发送三个包,则发送方的利用率实质上是原来的三倍。由于许多传输中的发送方到接收方数据包可视化为填充一个流水线,因此这种技术称为流水线(pipelining)。流水线对于可靠的数据传输协议有以下结果:
- 序列号(sequence numbers)的范围必须增加,因为每个在传输中的包(不包括重传输)必须有一个唯一的序列号,并且可能有多个在传输中的未确认的包。
- 协议的发送方和接收方可能必须缓冲(buffer)一个以上的包。最低限度地,发送方必须缓冲已经传输但尚未确认的数据包。在接收端也可能需要对正确接收的数据包进行缓冲,如下所述。
所需序列号的范围和缓冲要求将取决于数据传输协议对丢失、损坏和过度延迟的数据包的响应方式。管道错误恢复的两种基本方法是Go-Back-N和选择性重复(selective repeat)。
3.4.3 Go-Back-N (GBN)
在Go-Back-N (GBN)协议中,发送方被允许在不等待确认的情况下发送多个包(当可用时),但被限制在流水线中未确认包的最大允许数量不超过N。我们将在这一节详细描述GBN协议。但是在继续阅读之前,我们鼓励您在相关网站上播放GBN动画(一种很棒的交互式动画)。
图3.19显示了发送方对GBN协议中序列号范围的视图。如果将base定义为最旧的未确认数据包的序列号,将nextseqnum定义为最小的未使用的序列号(即下一个要发送的数据包的序列号),则可以在序列号范围内识别出四个区间。区间为[0,base-1]的序列号对应的是已经发送和确认的数据包。interval [base,nextseqnum-1]对应的是已经发送但还没有被确认的数据包。如果数据从上层到达,则可以使用区间为[nextseqnum,base+N-1]的序列号来立即发送数据包。最后,大于或等于base+N的序列号不能被使用,直到当前流水线中未确认的包(具体来说,具有序列号base的包)被确认。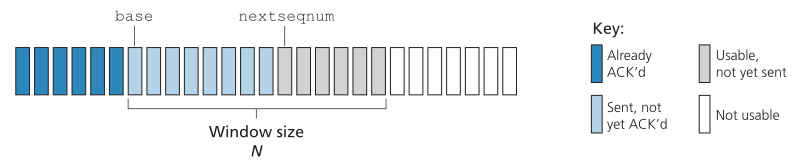
Figure 3.19 ♦ Sender’s view of sequence numbers in Go-Back-N
图3.19 Go-Back-N中发送方对序列号的看法
如图3.19所示,对于已发送但尚未确认的数据包,允许的序列号范围可以看作是序列号范围内的一个大小为N的窗口。当协议运行时,该窗口向前滑动到序列号空间。由于这个原因,N通常被称为窗口大小(window size),而GBN协议本身被称为滑动窗口协议(sliding-window protocol)。您可能想知道,为什么我们要把未确认的未处理数据包的数量限制在N。为什么不允许无限数量的这样的数据包呢?我们将在第3.5节中看到,流控制是对发送方施加限制的原因之一。在第3.7节学习TCP拥塞控制时,我们将研究这样做的另一个原因。
实际上,数据包的序列号是在数据包首部的固定长度字段中携带的。如果k是包序列号字段中的位数,则序列号的范围为[0,2k-1]。对于有限范围的数列,所有涉及数列的算术必须使用模2k算法来完成。(也就是说,序列号空间可以被认为是一个大小为2k的环,其中序列号2k-1紧跟着序列号0。)回想一下,rdt3.0有一个1位的序列号和一个[0,1]的序列号范围。本章末尾的几个问题探讨了有限范围的序列号的结果。在第3.5节中,我们将看到TCP有一个32位序列号字段,其中TCP序列号计数字节流中的字节而不是包。
图3.20和3.21给出了ACK-base、NAK-free、GBN协议的发送方和接收方的扩展的FSM描述。我们将这种FSM描述称为扩展的(extended)FSM,因为我们为base和nextseqnum添加了变量(类似于编程语言的变量),并添加了对这些变量的操作和涉及这些变量的条件操作。注意,扩展的FSM规范现在看起来有点像编程语言规范。[Bochman 1984]提供了对FSM技术的额外扩展以及用于指定协议的其他基于编程语言的技术的出色调查。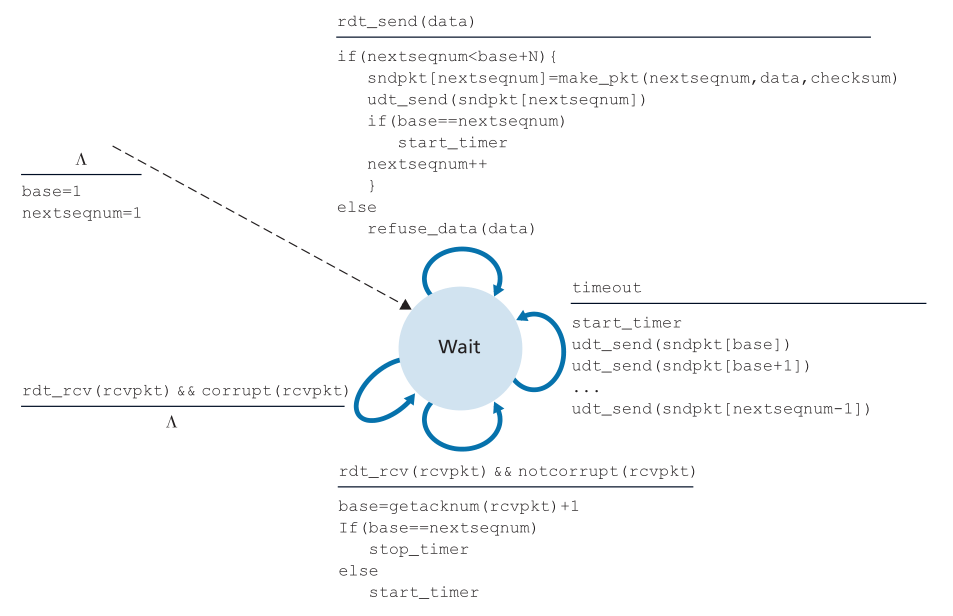
Figure 3.20 ♦ Extended FSM description of the GBN sender
图3.20♦GBN发送方的FSM扩展描述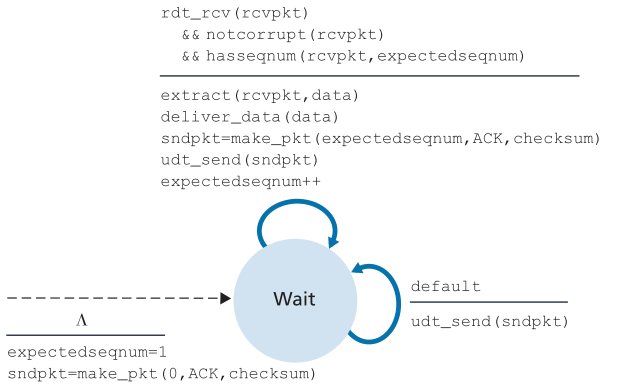
Figure 3.21 ♦ Extended FSM description of the GBN receiver
图3.21♦GBN接收方扩展FSM描述
GBN发送者必须响应三种类型的事件:从上面调用(Invocation from above)。当上面调用rdt_send()时,发送方首先检查窗口是否已满,也就是说,是否有N个未被确认的数据包。如果窗口未满,则创建并发送一个包,并适当地更新变量。如果窗口已满,发送方只需将数据返回到上层,这是窗口已满的隐式指示。上层可能不得不稍后再试一次。在实际的实现中,发送方很可能已经缓冲(但不是立即发送)了这些数据,或者有一个同步机制(例如,一个信号量或一个标志) ,允许上层仅在窗口未满时调用 rdt_send()。
- 收到一个ACK(Receipt of an ACK)。在我们的GBN协议中,对序列号为n的信息包的确认将被视为累积确认(cumulative acknowledgment),表明接收者已正确地接收到所有序列号为n的数据包。当我们检查GBN的接收端时,我们很快会回来讨论这个问题。
- 一个超时事件(A timeout event)。该协议的名称“Go-Back-N”源自发送方在丢失或过度延迟包时的行为。如同在停止-等待协议中一样,将再次使用计时器来从丢失的数据或确认包中恢复。如果超时,发送方将重新发送之前发送过但尚未确认的所有包。在图3.20中,我们的发送方只使用一个定时器,它可以被认为是最老的传输但尚未确认的数据包的定时器。如果收到ACK,但仍有额外的报文发送,但尚未确认,则重启定时器。如果没有未处理的、未确认的报文,定时器就会停止。
接收者在GBN中的操作也很简单。如果接收到一个数据包序列号n正确且有序(也就是说,最后送到上层的数据来自一个数据包序列号n - 1),接收方就会发送一个对数据包 n 的回传,并将数据包的数据部分传递到上层。在所有其他情况下,接收方丢弃数据包,并为最近收到的有序数据包重新发送ACK。需要注意的是,由于数据包是一次一个发送到上层的,如果数据包k已经被接收和发送,那么所有序号低于k的数据包也已经被发送。因此,使用累积确认是GBN的自然选择。
在我们的 GBN 协议中,接收方丢弃无序的数据包。尽管丢弃正确接收(但无序)的数据包似乎很愚蠢和浪费,但这样做是有一定道理的。回想一下,接收者必须按顺序向上层传递数据。现在假设数据包 n 是预期的,但数据包 n+1 到达。由于数据必须按顺序传递,接收方可以缓冲(保存)数据包 n+1,然后在接收并传递数据包 n 后将该数据包传递给上层。但是,如果数据包 n 丢失,由于发送方的 GBN 重传规则,它和数据包 n+1 最终都会被重传。因此,接收器可以简单地丢弃数据包 n+1。这种方法的优点是接收器缓冲的简单性——接收器不需要缓冲任何无序数据包。因此,虽然发送方必须维护其窗口的上下边界以及该窗口内 nextseqnum 的位置,但接收方需要维护的唯一信息是下一个有序数据包的序列号。该值保存在变量 expectedseqnum 中,如图 3.21 中的接收器 FSM 所示。当然,丢弃正确接收的数据包的缺点是该数据包的后续重传可能会丢失或出现乱码,因此将需要更多的重传。
图3.22显示了窗口大小为4个包时GBN协议的操作。由于这个窗口大小的限制,发送方发送0到3的数据包,但是在继续之前必须等待一个或多个数据包被确认。当每个后续的ACK(例如ACK0和ACK1)被接收时,窗口向前滑动,发送方可以发送一个新的包(分别是pkt4和pkt5)。在接收端,数据包2丢失,因此发现数据包3、4、5顺序错误而丢弃。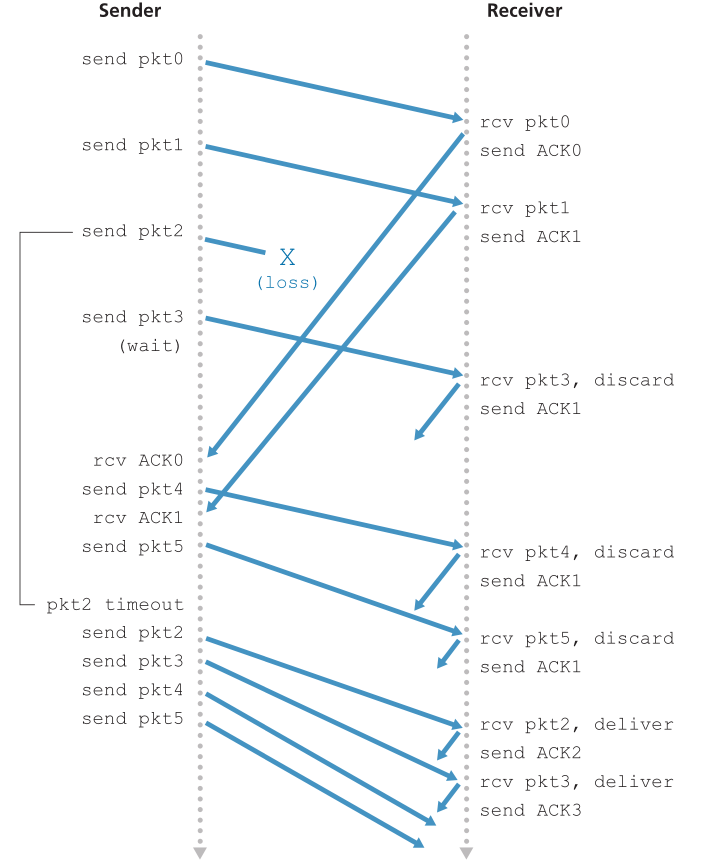
Figure 3.22 ♦ Go-Back-N in operation
图3.22♦Go-Back-N操作
在结束我们对GBN的讨论之前,值得注意的是,在协议栈中实现该协议可能具有与图3.20中扩展的FSM类似的结构。实现还可能采用各种过程的形式,这些过程实现了对可能发生的各种事件作出响应的操作。在这种基于事件的编程(event-based programming)中,各种过程要么由协议栈中的其他过程调用(调用),要么作为中断的结果。在发送端,这些事件将是(1)上层实体调用rdt_send(),(2)定时器中断,(3)当一个包到达时,下层实体调用rdt_rcv()。本章末尾的编程练习将给你一个机会在一个模拟的,但现实的网络设置中实际实现这些例程。
我们在这里注意到GBN协议几乎包含了我们在3.5节中研究TCP的可靠数据传输组件时将会遇到的所有技术。这些技术包括使用序列号、累积确认、校验和和超时/重传操作(sequence numbers, cumulative acknowledgments, checksums, and a timeout/retransmit operation)。
3.4.4 选择性重传 Selective Repeat (SR)
GBN协议允许发送方潜在地用包“填充流水线”,如图3.17所示,从而避免了我们在停止-等待协议中注意到的通道利用问题。然而,在某些情况下,GBN本身也会遇到性能问题。特别是,当窗口大小和带宽延迟乘积(window size and bandwidth-delay product)都很大时,许多包可能在流水线中。因此,单个数据包错误会导致GBN重传大量数据包,其中很多是不必要的。随着信道错误概率的增加,流水线可能会充满这些不必要的重传。想象一下,在我们的消息口述场景中,如果每一次一个单词被混淆,就必须重复周围的1000个单词(例如,一个窗口大小为1000个单词)。口述会因为重复的单词而变慢。
顾名思义,选择性重传协议(selective-repeat protocols)通过让发送方只重传那些它怀疑在接收方错误接收(即丢失或损坏)的包来避免不必要的重传。根据需要,这个单独的重传将要求接收方单独确认正确接收的数据包。 N 的窗口大小将再次用于限制管道中未完成的、未确认的数据包的数量。 但是,与 GBN 不同的是,发送方已经收到了窗口中某些数据包的 ACK。 图 3.23 显示了 SR 发送者对序列号空间的视角。 图 3.24 详细说明了 SR 发送者采取的各种行动。 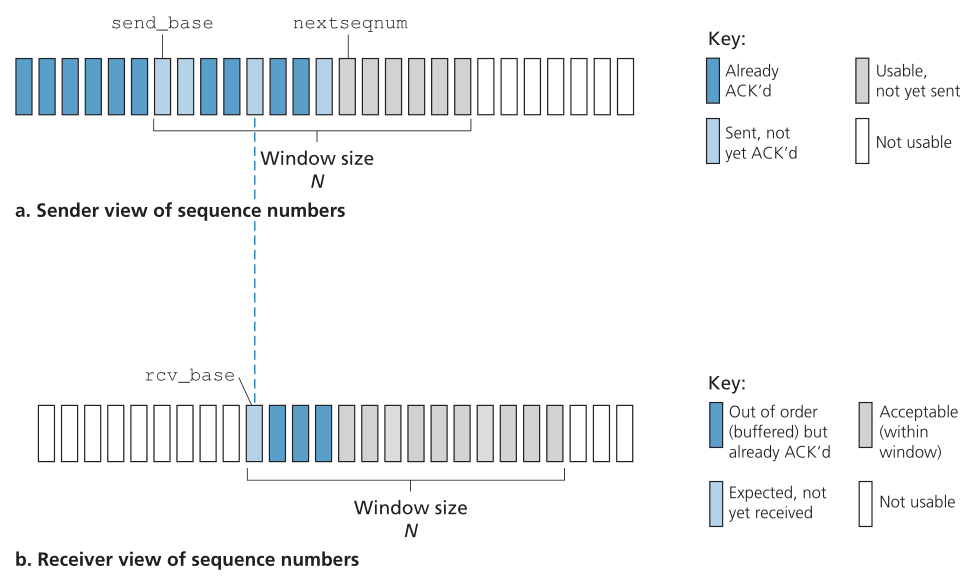
Figure 3.23 ♦ Selective-repeat (SR) sender and receiver views of sequence-number space
图3.23序列号空间的选择性重传(SR)发送方和接收方视角
- 从上面收到数据(Data received from above)。当从上面接收数据时,SR发送者检查数据包的下一个可用序列号。如果序列号在发送方的窗口内,则数据被打包并发送;否则它将被缓冲或返回到上层以供稍后传输,如GBN。
- 超时(Timeout)。计时器也被用来防止数据包丢失。然而,每个包现在必须有自己的逻辑计时器,因为只有一个包会在超时时传输。单个硬件定时器可以用来模拟多个逻辑定时器的操作[Varghese 1997]。
- ACK。如果收到ACK, SR发送者将该包标记为已收到,前提是它在窗口中。如果报文的序列号等于send_base,则窗口base将向前移动到序列号最小的未确认报文。如果窗口移动了,并且有序列号在窗口内的未传输数据包,这些数据包将被传输。
Figure 3.24 ♦ SR sender events and actions
图3.24♦SR发送方事件和动作
SR接收方将确认正确接收的数据包是否有序。无序的包被缓冲,直到接收到任何丢失的包(即序列号较低的包),然后可以按顺序将一批包发送到上层。图3.25详细列出了SR接收方所采取的各种行动。图3.26给出了丢包情况下的SR操作示例。注意,在图3.26中,接收发首先将报文3、4、5进行缓冲,并在最终接收到报文2时将其与报文2一起发送到上层。
- 序列号在 [rcv_base, rcv_base + N-1] 中的数据包被正确接收。在这种情况下,接收到的数据包落在接收方的窗口内,并且选择性的 ACK 数据包被返回给发送方。 如果先前未收到该数据包,则对其进行缓冲。 如果此数据包的序列号等于接收窗口的base(图 3.22 中的 rcv_base),则此数据包以及任何先前缓冲并连续编号(以 rcv_base 开始)的数据包将被传送到上层。 然后接收窗口向前移动传送到上层的数据包数量。 例如,请考虑图 3.26。 当接收到一个序列号为rcv_base=2的数据包时,它和数据包3、4、5可以被传递给上层。
- 正确接收序列号为[rcv_base-N, rcv_base-1]的数据包。在这种情况下,必须生成一个ACK,即使这是一个接收方先前已经确认的包。
- 其他。忽略包。
Figure 3.25 ♦ SR receiver events and actions
图3.25 ♦ SR 接收方事件及动作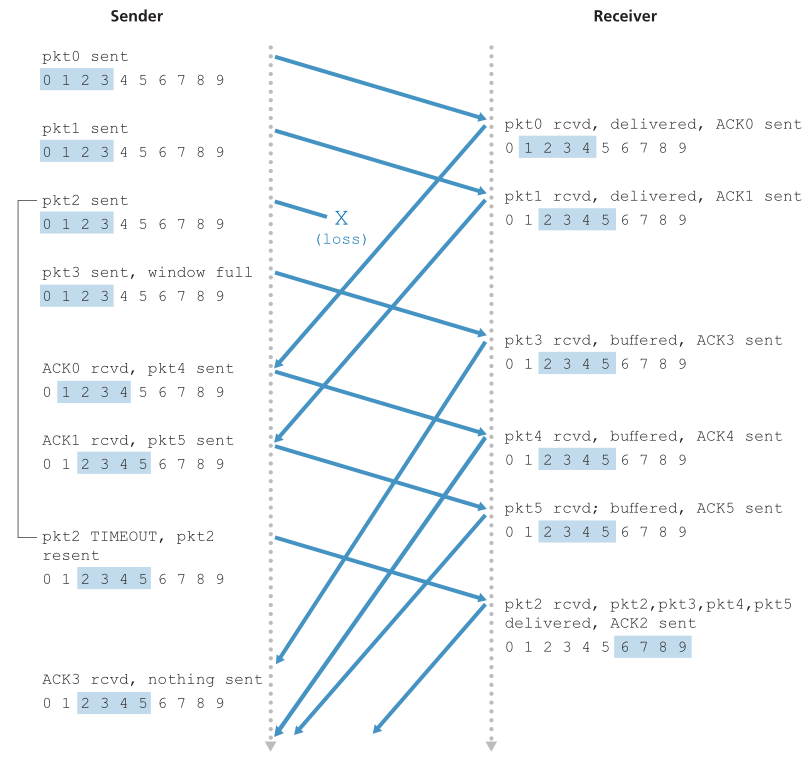
Figure 3.26 ♦ SR operation
图3.26♦SR行动
需要注意的是,在图 3.25 的步骤 2 中,接收方重新确认(而不是忽略)已经接收到的具有低于当前窗口base的特定序列号的数据包。 您应该说服自己确实需要这种重新确认。 给定图 3.23 中的发送方和接收方序列号空间,例如,如果从接收方传输到发送方的数据包 send_base 没有 ACK,发送方最终将重传数据包 send_base,即使很清楚(对我们来说,不是发送者!)接收者已经收到该数据包。 如果接收方不确认这个数据包,发送方的窗口将永远不会向前移动! 此示例说明了 SR 协议(以及许多其他协议)的一个重要方面。 发送方和接收方对于正确接收的内容和未正确接收的内容并不总是有相同的看法。 对于 SR 协议,这意味着发送方和接收方窗口并不总是一致。
当我们面临序列号范围有限的现实时,发送方和接收方窗口之间缺乏同步会产生重要后果。 考虑可能发生的情况,例如,在有限范围的四个数据包序列号 0、1、2、3 和窗口大小为 3 的情况下会发生什么。 假设数据包 0 到 2 被发送并在接收方正确接收和确认。 此时,接收方的窗口在第四、第五和第六个数据包上,它们的序列号分别为 3、0 和 1。 现在考虑两种情况。 在第一种情况下,如图 3.27(a) 所示,前三个数据包的 ACK 丢失,发送方重新传输这些数据包。 因此,接收方接下来会收到一个序列号为 0 的数据包——发送的第一个数据包的副本。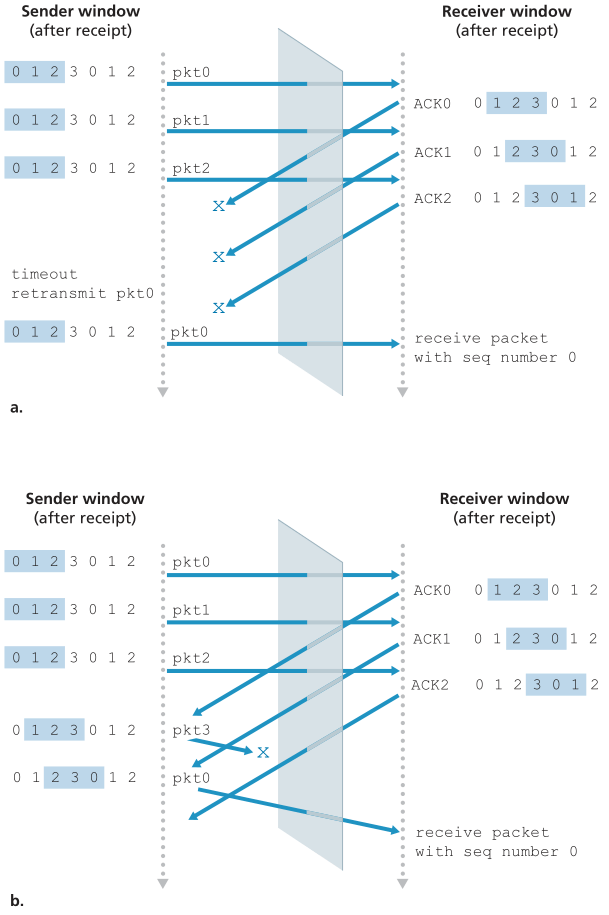
Figure 3.27 ♦ SR receiver dilemma with too-large windows: A new packet or a retransmission?
图3.27♦SR接收端窗口过大的困境:是新包还是重传?
在第二个场景中,如图3.27(b)所示,前三个包的ACK都正确发送。因此,发送方将其窗口向前移动并发送序号分别为3、0和1的第4、5和6个包。序列号为3的包丢失,但序列号为0的包到达——一个包含新数据的包。
现在考虑图3.27中接收者的观点,它在发送者和接收者之间有一个象征性的帘子,因为接收者不能“看到”发送者所采取的行动。接收方所观察到的是它从信道接收到并发送到信道的报文序列。就我们所知,图3.27中的两个场景是相同的。没有办法区分第一个包的重传和第五个包的原始传输。显然,小于序列号空间大小1的窗口大小是不起作用的。但是窗口必须有多小呢?本章末尾的一个问题要求您证明窗口大小必须小于或等于SR协议序列号空间大小的一半。
在配套的Web站点上,您将找到一个演示SR协议操作的动画。尝试执行与GBN动画相同的实验。结果与你所期望的一致吗?
这完成了我们对可靠数据传输协议的讨论。 我们已经涵盖了很多领域并引入了许多共同提供可靠数据传输的机制。 表 3.1 总结了这些机制。 既然我们已经看到所有这些机制在运作并且可以看到“大局”,我们鼓励您再次查看本节以了解如何逐步添加这些机制以涵盖连接越来越复杂(和现实)的渠道模型的发送方和接收方,或提高协议的性能。
| 机制 | Use, Comments |
|---|---|
| 校验和(Checksum) | 用于检测发送的报文中的位错误(bit errors)。 |
| 定时器(Timer) | 用于超时/重传(timeout/retransmit)数据包,可能是因为数据包(或其ACK)在通道中丢失(lost)。由于超时可能发生在包被延迟但未丢失(过早超时)的情况下,或者当接收方接收到包但接收方到发送方的ACK已经丢失时,接收方可能会接收到包的副本。 |
| 序列号(Sequence number) | 用于对从发送方流向接收方的数据包进行顺序编号(sequential numbering)。接收到的数据包序列号的空缺允许接收方检测到丢失的数据包。具有重复序列号的数据包允许接收者检测数据包的重复副本(duplicate copies)。 |
| 确认(Acknowledgment) | 接收者使用它来告诉发送者一个数据包或一组数据包已被正确接收。 确认通常会携带一个或多个被确认的数据包的序列号。 确认可以是单独的或累积的,具体取决于协议。 |
| 负确认(Negative acknowledgment) | 接收方用来告诉发送方数据包没有被正确接收。负确认通常会携带没有正确接收到的数据包的序列号。 |
| 窗口,流水线(Window, pipelining) | 发送方可能被限制为仅发送序列号在给定范围内的数据包。 通过允许传输多个数据包但尚未确认,可以通过停止等待操作模式提高发送方利用率。 我们很快就会看到,窗口大小可以根据接收者接收和缓冲消息的能力,或者网络中的拥塞程度,或者两者来设置。 |
Table 3.1 ♦ Summary of reliable data transfer mechanisms and their use
表3.1 ♦ 对可靠数据传输机制及其使用的概述
让我们通过考虑底层信道模型中剩下的一个假设来结束对可靠数据传输协议的讨论。回想一下,我们已经假设包不能在发送方和接收方之间的通道中重新排序。当发送方和接收方通过一条物理线连接时,这通常是一个合理的假设。然而,当连接两者的“通道”是一个网络时,包可能发生重排序。包重排序的一种表现是,即使发送方和接收方的窗口都不包含x,序列或确认号为x的包的旧副本也会出现。该通道可以被认为是缓冲数据包,并在未来的任何时刻自发地发出这些数据包。因为序列号可能被重复使用,所以必须小心防止这种重复的包。在实践中采用的方法是确保一个序列号不会被重复使用,直到发送方“确定”先前发送的带有序列号x的数据包已经不在网络中。这是通过假设一个数据包在网络中“存活”的时间不能超过某个固定的最长时间来实现的。在高速网络的TCP扩展[RFC 7323]中,假定最大数据包生存时间大约为3分钟。[Sunshine 1978]描述了一种使用序列号的方法,这样可以完全避免重新排序问题。

若有收获,就点个赞吧
0 人点赞
