有时有人说,操作系统在解决大多数空间管理问题时采用两种方法中的一种。第一种方法是将内存分割成大小可变的片段,就像我们在虚拟内存中看到的分段(segmentation)一样。不幸的是,这种解决方法存在固有的困难。特别是,当将空间划分为不同大小的块时,空间本身可能会变得碎片化(fragmented),因此随着时间的推移,分配变得更加困难。
因此,可能值得考虑第二种方法:将空间分割成固定大小的块。在虚拟内存中,我们称这种想法为分页(paging),它可以追溯到早期重要的系统Atlas [KE+62, L78]。不是将进程的地址空间分割成一些可变大小的逻辑段(例如,代码、堆、堆栈),而是将其分割成固定大小的单元,每个单元我们称之为页(page)。相应地,我们将物理内存视为一组固定大小的槽(称为页帧(page frames));每个帧都可以包含一个虚拟内存页面。我们面临的挑战:
关键的问题:如何用页面虚拟化内存 如何用页面来虚拟化内存,从而避免分段问题?基本技巧是什么?我们如何在最少的空间和时间开销下使这些技术发挥作用?
18.1 一个简单例子和概述 A Simple Example And Overview
为了使这种方法更清晰,让我们用一个简单的例子来说明它。图18.1展示了一个小地址空间的示例,总共只有64字节,有4个16字节的页(虚拟页0、1、2和3)。当然,实际地址空间要大得多,通常为32位,因此地址空间为4GB,甚至是64位;在书中,我们会经常使用一些小例子来让它们更容易理解。
64位地址空间是很难想象的,它是如此惊人的大。打个比方可能会有帮助:如果您将32位地址空间想象成一个网球场的大小,那么64位地址空间大约是欧洲的大小(!)

如图18.2所示,物理内存也由许多固定大小的槽组成,在本例中为8页帧(使得128字节的物理内存也小得离谱)。从图中可以看到,虚拟地址空间的页面被放置在整个物理内存的不同位置;该图还显示了操作系统为自己使用一些物理内存。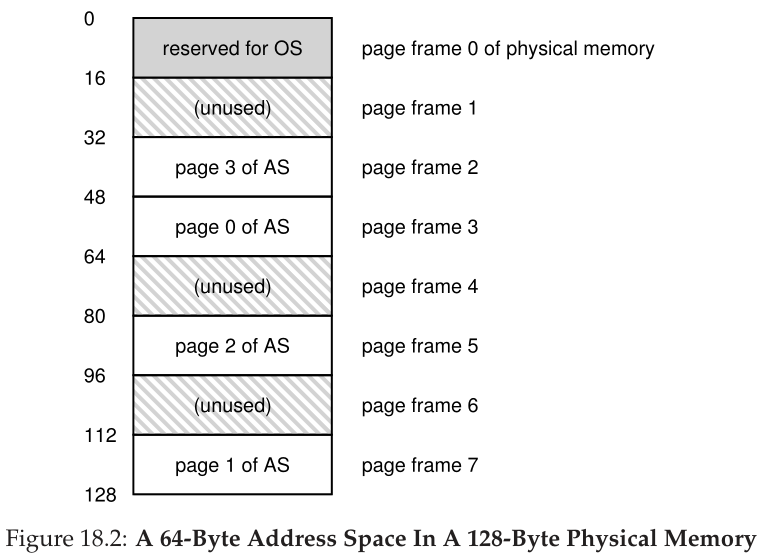
正如我们将看到的,分页与我们以前的方法相比有许多优点。最重要的改进可能是灵活性:通过完全开发的分页方法,系统将能够有效地支持地址空间的抽象,而不管进程如何使用地址空间;例如,我们不会假设堆和栈的增长方向以及它们的使用方式。
另一个优点是分页提供的空闲空间管理的简单性。例如,当操作系统希望将很小的64字节地址空间放入8页物理内存时,它只会找到4个空闲页;也许操作系统会为此保留一个包含所有空闲页面的空闲链表,并从这个链表中获取前四个空闲页面。在本例中,操作系统将AS虚拟页0放置在物理帧3中,将AS虚拟页1放置在物理帧7中,将页2放置在物理帧5中,将页3放置在物理帧2中。页帧1、4和6目前是空闲的。
为了记录地址空间的每个虚拟页在物理内存中的位置,操作系统通常保留一个称为页表(page table)的单进程(per-process)数据结构。页表的主要作用是存储地址空间中每个虚拟页的地址转换(address translations),从而让我们知道每个页在物理内存中的位置。对于我们的简单示例(图18.2),页表将有以下4个条目:(Virtual page 0 -> Physical Frame 3)、(VP1 -> PF 7)、(VP2 -> PF 5)和(VP3 -> PF 2)。
记住这个页表是一个单进程数据结构(我们讨论的大多数页表结构都是单进程结构;我们将讨论的一个例外是反向页表(inverted page table))。如果在上面的示例中运行另一个进程,那么操作系统将不得不为它管理一个不同的页表,因为它的虚拟页显然映射到不同的物理页(不考虑正在进行的任何共享)。
现在,我们已经知道了足够的信息来执行一个地址转换示例。让我们想象一下,有这个小地址空间(64字节)的进程正在执行内存访问: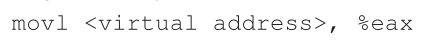
具体来说,让我们注意将数据从地址
要翻译进程生成的虚拟地址,我们必须首先将其分解为两个组件:虚拟页码(virtual page number,VPN)和页内的偏移量(offset)。对于本例,因为进程的虚拟地址空间是64字节,所以我们的虚拟地址总共需要6位(26 = 64)。因此,我们的虚拟地址可以概念化如下:
在这个图中,Va5是虚拟地址的最高阶位,Va0是最低阶位。因为我们知道页面大小(16字节),所以可以进一步划分虚拟地址,如下所示: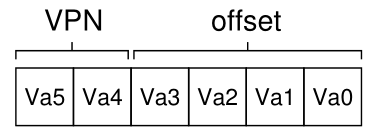
在64字节的地址空间中,页面大小为16字节;因此,我们需要能够选择4个页面,地址的前2位就是这样做的。因此,我们有一个2位的虚拟页码(VPN)。剩余的位告诉我们对页面的哪个字节感兴趣,在本例中是4位;我们称之为偏移量。
当一个进程生成一个虚拟地址时,操作系统和硬件必须结合起来把它转换成一个有意义的物理地址。例如,让我们假设上面的加载是虚拟地址21: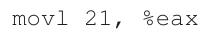
将“21”转换成二进制形式,我们得到“010101”,因此我们可以检查这个虚拟地址,看看它是如何分解为虚拟页码(VPN)和偏移量的: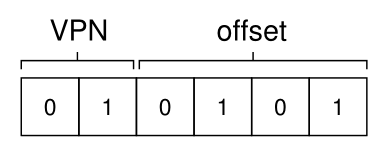
因此,虚拟地址“21”位于虚拟页“01”(或1)的第5个字节(“0101”th)。有了虚拟页码,我们现在可以索引页表,并找到虚拟页1所在的物理帧。在上面的页表中,物理帧号(physical frame number,PFN)(有时也称为物理页码physical page number或PPN)是7(二进制111)。因此,我们可以通过将VPN转换为PFN来转换这个虚拟地址,然后将加载发送到物理内存(图18.3)。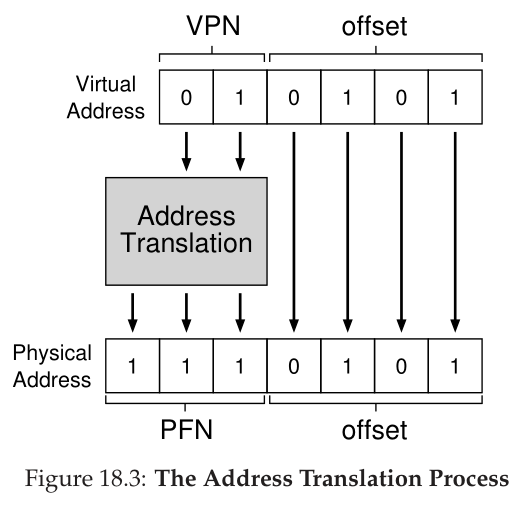
注意偏移量保持不变(即,它没有被转换),因为偏移量只是告诉我们想要页面中的哪个字节。我们最终的物理地址是1110101(十进制117),这正是我们希望加载从哪里获取数据(图18.2)。
有了这个基本的概述,我们现在可以问(希望回答)一些关于分页的基本问题。例如,这些页表存储在哪里?页面表的典型内容是什么?表有多大?分页是否使系统(太)缓慢?下面的文章至少部分地回答了这些和其他诱人的问题。继续读下去!
18.2 页表存储在哪里? Where Are Page Tables Stored?
页表可能会变得非常大,比我们前面讨论的小段表或基/边界对大得多。例如,想象一个典型的32位地址空间,有4KB的页。这个虚拟地址分成20位VPN和12位偏移量(回想一下,1KB的页面大小需要10位,再加2位就可以达到4KB)。
一个20位的VPN意味着操作系统必须为每个进程管理220种翻译(大约是100万);假设我们需要每个页表项(page table entry,PTE) 4个字节来保存物理转换和其他有用的东西,那么每个页表需要巨大的4MB内存!这是相当大的。现在,假设有100个进程在运行:这意味着操作系统需要400MB的内存来进行所有这些地址转换!即使在现代时代,机器有十亿字节的内存,把一大块内存用于翻译似乎有点疯狂,不是吗?我们甚至不会考虑这样一个页表对于64位地址空间会有多大;那太可怕了,可能会把你完全吓跑。
Aside:数据结构——页表 在现代操作系统的内存管理子系统中,页表(page table)是最重要的数据结构之一。通常,页表存储虚拟到物理的地址转换(virtual-to-physical address translations),从而让系统知道地址空间的每个页实际驻留在物理内存中的位置。因为每个地址空间都需要这样的转换,所以通常系统中每个进程都有一个页表。页表的确切结构要么由硬件(旧系统)决定,要么由操作系统(现代系统)更灵活地管理。
因为页表太大了,我们没有在MMU(内存管理单元)中保留任何特殊的片上硬件来存储当前运行进程的页表。相反,我们将每个进程的页表存储在内存中的某个位置。现在让我们假设页表位于操作系统管理的物理内存中;稍后我们将看到,许多操作系统内存本身可以虚拟化,因此页表可以存储在操作系统虚拟内存中(甚至交换到磁盘),但现在这太令人困惑了,所以我们将忽略它。图18.4是OS内存中页表的图片;看到那一小部分转换了吗?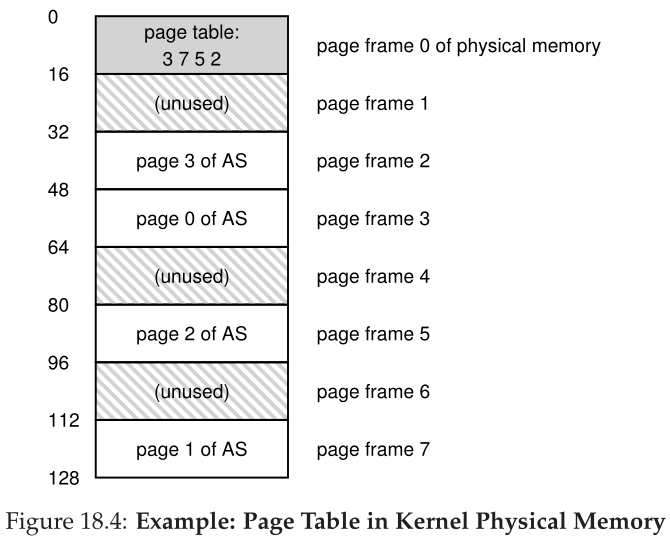
18.3 页表中到底有什么? What’s Actually In The Page Table?
让我们来谈谈页表的结构。页表只是一种数据结构,用于将虚拟地址(或实际的虚拟页码)映射到物理地址(物理帧号)。因此,任何数据结构都可以工作。最简单的形式称为线性页表(linear page table),它只是一个数组。OS通过虚拟页号(VPN)索引数组,并在该索引处查找页表项(PTE),以找到所需的物理帧号(PFN)。现在,我们假设这个简单的线性结构;在后面的章节中,我们将使用更高级的数据结构来帮助解决分页的一些问题。
对于每一个PTE的内容,我们有许多不同的bits,在某种程度上值得理解。有效位(valid bit)通常用于指示特定转换是否有效;例如,当一个程序开始运行时,它的地址空间的一端是代码和堆,另一端是栈。所有未使用的中间空间将被标记为无效(invalid),如果进程试图访问这些内存,它将向操作系统生成一个trap,可能会终止进程。因此,有效位是支持稀疏地址空间的关键;通过简单地将地址空间中所有未使用的页标记为无效,我们无需为这些页分配物理帧,从而节省大量内存。
我们还可能有保护位(protection bits),指示是否可以从该页读取、写入或执行。同样,以这些位不允许的方式访问页面会向操作系统生成一个trap。
还有一些很重要的东西,但我们现在不会讲太多。当前位(present bit)指示该页是在物理内存中还是在磁盘上(即,它已被交换出来(swapped out))。当我们学习如何将部分地址空间交换到磁盘以支持比物理内存大的地址空间时,我们将进一步理解这种机制;交换允许操作系统通过将很少使用的页移动到磁盘来释放物理内存。脏位(dirty bit)也很常见,它指示页面在进入内存后是否被修改过。
引用位(reference bit)(也称为访问位accessed bit)有时用于跟踪某个页面是否已被访问,并有助于确定哪些页面是常用的,因此应该保留在内存中;这些知识在页面替换(page replacement)过程中是至关重要的,我们将在后续章节中详细研究这个主题。
图18.5显示了来自x86体系结构[I09]的一个示例页表项。它包含一个当前位(P);一个读写位(R/W),决定是否允许对该页进行写入;一个用户/管理器位(U/S),决定用户模式进程是否可以访问页面;几个位(PWT、PCD、PAT和G)决定这些页面的硬件缓存如何工作;一个访问位(A)和一个脏位(D);最后是页面帧号(PFN)本身。
有关x86分页支持的更多细节,请阅读英特尔架构手册[I09]。警告,然而;阅读这样的手册,虽然信息量很大(对于编写代码在操作系统中使用这样的页表的人来说,这当然是必要的),但一开始会很有挑战性。需要一点耐心,再加上大量的欲望。
Aside:为什么没有有效位 您可能会注意到,在因特尔示例中,没有单独的有效位和当前位,而只有一个当前位(P)。如果设置了该位(P=1),则意味着该页既存在又有效。如果不是(P=0),则意味着页面可能不在内存中(但是有效的),或者是无效的。对P=0的页面的访问将触发对操作系统的trap;然后,操作系统必须使用它保留的附加结构来确定页面是否有效(因此可能应该交换回)或无效(因此程序试图非法访问内存)。这种明智的做法在硬件中很常见,通常只提供操作系统能够构建完整服务的最小特性集。
18.4 分页:还是太慢 Paging: Also Too Slow
由于页表在内存中,我们已经知道它们可能太大了。事实证明,它们也能减慢速度。以我们的简单说明为例: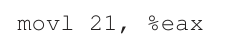
同样,我们只检查对地址 21的显式引用,而不用担心指令获取。在本例中,我们假设硬件为我们执行翻译。为了获取所需的数据,系统必须首先将虚拟地址(21)转换为正确的物理地址(117)。因此,在从地址117获取数据之前,系统必须首先从进程的页表中获取适当的页表项,执行转换,然后从物理内存加载数据。
为此,硬件必须知道当前运行的进程的页表在哪里。现在让我们假设一个页表基寄存器(page-table base register)包含页表起始位置的物理地址。为了找到所需PTE(页表项)的位置,硬件将执行以下功能:
在我们的示例中,VPN_MASK将被设置为0x30(十六进制30,或二进制110000),它从完整的虚拟地址中挑选出VPN(虚拟页码)位;SHIFT设置为4(偏移量中的位数),这样我们就可以向右移动VPN位来形成正确的整数虚拟页码。例如,使用虚拟地址21(010101),屏蔽(masking)将此值转换为010000;这一转换将其转换为01,即虚拟页1。然后使用这个值作为页表基寄存器所指向的PTEs(页表项)数组的索引。
一旦知道这个物理地址,硬件就可以从内存中取出 PTE,提取 PFN(物理帧号),并将它与虚拟地址的偏移量连接起来,形成所需的物理地址。具体来说,你可以认为PFN被SHIFT左移,然后与偏移量按位逻辑或,形成最终地址,如下所示:
最后,硬件可以从存储器中取出所需的数据,并将其放入寄存器eax中。程序现在已经成功地从内存中加载了一个值!
总结一下,我们现在描述在每个内存引用上发生的初始协议。图18.6显示了这种方法。对于每一个内存引用(无论是指令获取还是显式加载或存储),分页都需要我们执行一次额外的内存引用,以便首先从页表中获取地址转换。工作量真大!额外的内存引用是昂贵的,在这种情况下,可能会使进程减慢两个或更多倍。
18.5 一次内存跟踪 A Memory Trace
在关闭之前,我们现在跟踪一个简单的内存访问示例,以演示在使用分页时发生的所有最终内存访问。我们感兴趣的代码片段(用C语言,在一个名为array.c的文件中)如下:
我们编译array.c并使用以下命令运行它:
当然,要真正理解访问这个代码段(它只是初始化一个数组)的内存会产生什么,我们必须知道(或假设)更多的事情。首先,我们必须对生成的二进制文件进行反汇编(disassemble)(在Linux上使用objdump,或者在Mac上使用otool),以查看在循环中使用了哪些汇编指令来初始化数组。下面是生成的程序集代码:
这里我们有点作弊,假设每条指令的大小为4个字节;实际上,x86指令的大小是可变的。
如果您了解一点x86,那么代码实际上非常容易理解。第一条指令将值0(显示为$0x0)移动到数组所在位置的虚拟内存地址中;这个地址是通过将%edi的内容加上%eax乘以4来计算的。因此,%edi保存数组的基址,而%eax保存数组的索引(i);乘以4是因为数组是一个整数数组,每个整数大小为4个字节。
第二条指令增加%eax中的数组索引,第三条指令将该寄存器的内容与十六进制值0x03e8或十进制1000进行比较。如果比较显示两个值还不相等(这是jne指令所测试的),则第四个指令跳转回循环的顶部(地址1024处)。
为了理解这个指令序列访问哪些内存(在虚拟和物理级别),我们必须假设在虚拟内存中找到代码段和数组的位置,以及页表的内容和位置。
对于本例,我们假设虚拟地址空间大小为64KB(小得不现实)。我们还假设页面大小为1KB。
我们现在只需要知道页表的内容,以及它在物理内存中的位置。让我们假设我们有一个线性(基于数组的)页表,它位于物理地址1KB(1024)。
至于它的内容,我们只需要为这个示例映射几个虚拟页面。首先是代码所在的虚拟页面。由于页面大小为1KB,虚拟地址1024驻留在虚拟地址空间的第二个页面(VPN=1,因为VPN=0是第一个页面)。让我们假设这个虚拟页面映射到物理帧4 (VPN 1 -> PFN 4)。
接下来是数组本身。它的大小是4000字节(1000个整数),我们假设它驻留在虚拟地址40000到44000(不包括最后一个字节)。这个十进制范围的虚拟页是VPN=39…VPN = 42。因此,我们需要这些页面的映射。让我们为示例假设这些虚拟到物理的映射:(VPN 39 -> PFN 7)、(VPN 40 -> PFN 8)、(VPN 41 -> PFN 9)、(VPN 42 -> PFN 10)。
现在我们可以跟踪程序的内存引用了。当它运行时,每次取指令都会产生两个内存引用:一个是对页表的引用,用来查找指令所在的物理帧,另一个是对指令本身的引用,用来将指令取到CPU进行处理。此外,在mov指令的形式中有一个显式内存引用;这将首先添加另一个页表访问(将数组虚拟地址转换为正确的物理地址),然后再访问数组本身。
图18.7描述了前五个循环迭代的整个过程。最下面的图用黑色表示y轴上的指令内存引用(左边是虚拟地址,右边是实际物理地址);中间的图以深灰色显示数组访问(同样左边是virtual,右边是physical);最后,最上面的图显示了浅灰色的页表内存访问(只是物理的,因为本例中的页表驻留在物理内存中)。整个跟踪的x轴显示了循环前5次迭代的内存访问;每个循环有10次内存访问,包括4次指令获取,一次显式的内存更新,以及5次页表访问来转换这4次获取和一次显式更新。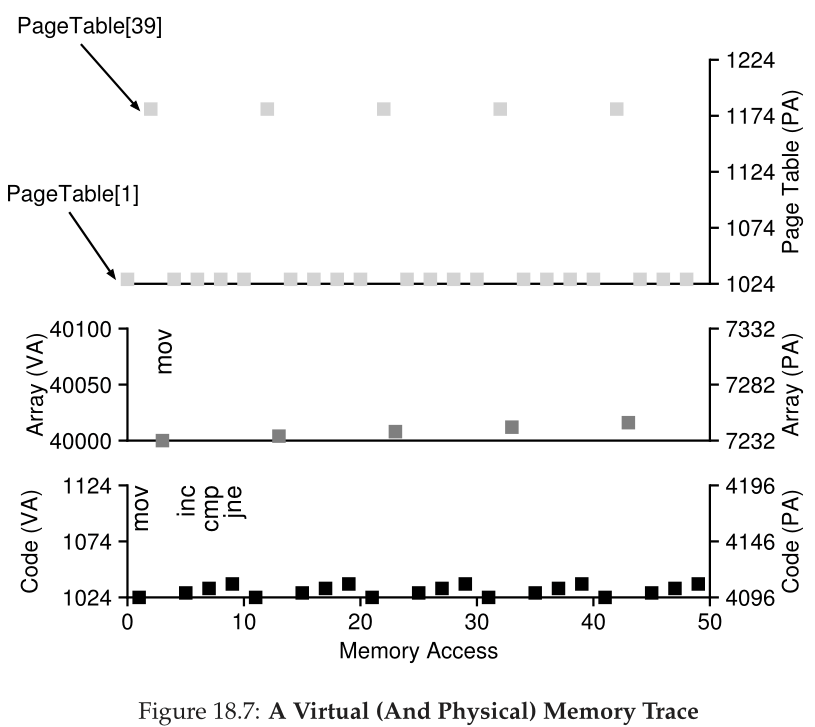
看看你是否能理解这个可视化中出现的模式。特别是,当循环继续运行超过前五次迭代时会发生什么变化?哪些新的内存位置将被访问?你能弄清楚吗?
这只是最简单的示例(只有几行C代码),但您可能已经能够感受到理解实际应用程序的实际内存行为的复杂性。不要担心:它肯定会变得更糟,因为我们将要引入的机制只会使这个已经很复杂的机制更加复杂。对不起!
18.6
总结 Summary
我们引入了分页(paging)的概念,作为虚拟化内存挑战的解决方案。分页比以前的方法(如分段)有许多优点。首先,它不会导致外部碎片,因为分页(按照设计)将内存划分为固定大小的单元。其次,它非常灵活,允许稀疏地使用虚拟地址空间。
然而,不加注意地实现分页支持将导致机器速度变慢(访问页表需要大量额外的内存访问)以及内存浪费(内存中填充的是页表而不是有用的应用程序数据)。因此,我们必须更加努力地思考,才能设计出一个不仅能工作,而且工作良好的分页系统。幸运的是,接下来的两章将向我们展示如何做到这一点。
References
[KE+62] “One-level Storage System” by T. Kilburn, D.B.G. Edwards, M.J. Lanigan, F.H. Sum-
ner. IRE Trans. EC-11, 2, 1962. Reprinted in Bell and Newell, “Computer Structures: Readings
and Examples”. McGraw-Hill, New York, 1971. The Atlas pioneered the idea of dividing memory
into fixed-sized pages and in many senses was an early form of the memory-management ideas we see
in modern computer systems.
[I09] “Intel 64 and IA-32 Architectures Software Developer’s Manuals” Intel, 2009. Available:
http://www.intel.com/products/processor/manuals. In particular, pay attention to “Volume
3A: System Programming Guide Part 1” and “Volume 3B: System Programming Guide Part 2”.
[L78] “The Manchester Mark I and Atlas: A Historical Perspective” by S. H. Lavington. Com-
munications of the ACM, Volume 21:1, January 1978. This paper is a great retrospective of some of
the history of the development of some important computer systems. As we sometimes forget in the US,
many of these new ideas came from overseas.
Homework (Simulation)
在本作业中,您将使用一个简单的程序,它被称为paging-linear-translate.py,来看看您是否理解简单的虚拟到物理地址转换如何使用线性页表。有关详细信息,请参阅README。
Questions
- 在进行任何转换之前,让我们使用模拟器来研究线性页表如何在给定不同参数的情况下改变大小。当不同参数发生变化时,计算线性页表的大小。一些建议的投入如下;通过使用-v flag,您可以看到填充了多少页表项。首先,要理解线性页表大小如何随着地址空间的增长而变化,请使用这些标志运行:
-P 1k -a 1m -p 512m -v -n 0-P 1k -a 2m -p 512m -v -n 0-P 1k -a 4m -p 512m -v -n 0
然后,要理解线性页表大小如何随着页大小的增长而变化:-P 1k -a 1m -p 512m -v -n 0-P 2k -a 1m -p 512m -v -n 0-P 4k -a 4m -p 512m -v -n 0
在运行这些之前,试着想想预期的趋势。页表大小如何随着地址空间的增长而变化?随着页面大小的增长?为什么一般不使用大页面呢?
- 现在让我们做一些翻译。从一些小示例开始,使用-u标志更改分配给地址空间的页面数。例如:
-P 1k -a 16k -p 32k -v -u 0
-P 1k -a 16k -p 32k -v -u 25
-P 1k -a 16k -p 32k -v -u 50
-P 1k -a 16k -p 32k -v -u 75
-P 1k -a 16k -p 32k -v -u 100
当您增加每个地址空间中位于同一位置的页面的百分比时,会发生什么?
- 现在让我们尝试一些不同的随机种子和一些不同的(有时相当疯狂的)地址空间参数,以获得多样性
-P 8
-a 32
-p 1024 -v -s 1
-P 8k -a 32k
-p 1m
-v -s 2
-P 1m -a 256m -p 512m -v -s 3
哪些参数组合是不现实的?为什么?
- 用这个程序来尝试一些其他的问题。你能找到程序不再工作的极限吗?例如,如果地址空间大小大于物理内存,会发生什么?

若有收获,就点个赞吧
0 人点赞
