- 49.1 一个基础的分布式文件系统 A Basic Distributed File System
- 49.2 交出NFS On To NFS
- 49.3 关注点:简单快速的服务器崩溃恢复 Focus: Simple And Fast Server Crash Recovery
- 49.4 快速崩溃恢复的关键:无状态 Key To Fast Crash Recovery: Statelessness
- 49.5 NFSv2协议 The NFSv2 Protocol
- 49.6
- 49.7
- 49.8 改善性能:客户端缓存
- 49.9
- 49.10
- 49.11
- 49.12
- References
- Homework (Measurement)
分布式客户端/服务器计算的最初用途之一是在分布式文件系统领域。 在这样的环境中,有多台客户端机器和一台服务器(或几台); 服务器将数据存储在其磁盘上,客户端通过格式良好的协议消息请求数据。 图 49.1 描述了基本设置。<br />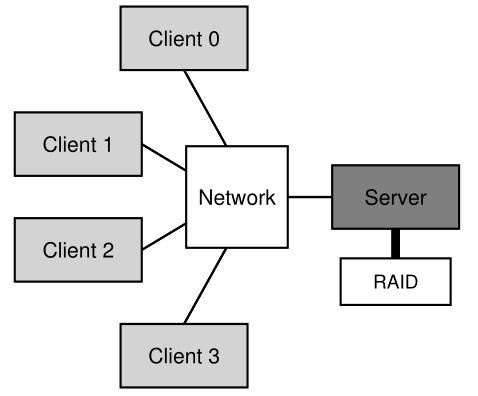<br />**Figure 49.1: A Generic Client/Server System**<br />从图中可以看出,服务器拥有磁盘,客户端通过网络发送消息以访问这些磁盘上的目录和文件。 我们为什么要为这样的安排而烦恼? (即,为什么我们不让客户端使用他们的本地磁盘?)嗯,主要是这种设置允许跨客户端轻松**共享(sharing)**数据。 因此,如果您访问一台机器(客户端 0)上的文件,然后再使用另一台机器(客户端 2),您将拥有相同的文件系统视图。 您的数据自然会在这些不同的机器之间共享。 第二个好处是**集中管理(centralized administration)**; 例如,备份文件可以从少数服务器机器而不是从众多客户端完成。 另一个优势可能是**安全性(security)**; 将所有服务器放在一个上锁的机房内可以防止出现某些类型的问题。
关键的问题:如何构建分布式文件系统 如何构建分布式文件系统? 需要考虑的关键方面是什么? 什么容易出错? 我们可以从现有系统中学到什么?
49.1 一个基础的分布式文件系统 A Basic Distributed File System
我们现在将研究简化的分布式文件系统的体系结构。 一个简单的客户端/服务器分布式文件系统比我们目前研究的文件系统具有更多的组件。 在客户端,有客户端应用程序通过客户端文件系统(client-side file system)访问文件和目录。 客户端应用程序向客户端文件系统发出系统调用(system calls)(例如 open()、read()、write()、close()、mkdir() 等)以访问存储在服务器上的文件。 因此,对于客户端应用程序,文件系统似乎与本地(基于磁盘的)文件系统没有任何不同,除了性能方面。 通过这种方式,分布式文件系统提供了对文件的透明(transparent)访问,这是一个明显的目标; 毕竟,谁会想要使用需要不同 API 集的文件系统,否则使用起来会很痛苦?
客户端文件系统的作用是执行为这些系统调用提供服务所需的操作。 例如,如果客户端发出 read() 请求,则客户端文件系统可能会向服务器端文件系统(server-side file system,或通常称为文件服务器(file server))发送消息以读取特定块; 然后文件服务器将从磁盘(或它自己的内存缓存)读取该块,并将带有请求数据的消息发送回客户端。 客户端文件系统然后将数据复制到提供给 read() 系统调用的用户缓冲区中,从而完成请求。 请注意,客户端上同一块的后续 read() 可能会缓存(cached)在客户端内存或客户端磁盘上; 在最好的情况下,不需要生成网络流量。
Figure 49.2: Distributed File System Architecture
从这个简单的概述中,您应该了解到客户端/服务器分布式文件系统中有两个重要的软件部分:客户端文件系统和文件服务器。 它们的行为共同决定了分布式文件系统的行为。 现在是研究一个特定系统的时候了:Sun 的网络文件系统 (Sun’s Network File System,NFS)。
Aside:为什么服务器会崩溃 在深入了解 NFSv2 协议的细节之前,您可能想知道:为什么服务器会崩溃? 好吧,正如您可能猜到的,有很多原因。 服务器可能只是遭受停电(power outage)(暂时); 只有恢复供电才能重新启动机器。服务器通常由数十万甚至数百万行代码组成; 因此,它们有bug(即使是好的软件每百或千行代码也会有几个bug),因此它们最终会触发导致它们崩溃的错误。 它们也有内存泄漏(memory leaks); 即使是很小的内存泄漏也会导致系统内存不足并崩溃。 最后,在分布式系统中,客户端和服务器之间有一个网络; 如果网络行为异常(例如,如果它被分区(partitioned)并且客户端和服务器正在工作但无法通信),它可能看起来好像远程机器已经崩溃,但实际上它只是当前无法通过网络访问。
49.2 交出NFS On To NFS
最早且相当成功的分布式系统之一是由 Sun Microsystems 开发的,它被称为 Sun 网络文件系统(或 NFS)[S86]。 在定义 NFS 时,Sun 采取了一种不同寻常的方法:Sun 没有构建专有的封闭系统,而是开发了一种开放协议(open protocol),该协议简单地指定了客户端和服务器用于通信的确切消息格式。 不同的团体可以开发自己的 NFS 服务器,从而在保持互操作性的同时在 NFS 市场中展开竞争。 它奏效了:今天有许多公司销售 NFS 服务器(包括 Oracle/Sun、NetApp [HLM94]、EMC、IBM 等),NFS 的广泛成功很可能归功于这种“开放市场”方法。
49.3 关注点:简单快速的服务器崩溃恢复 Focus: Simple And Fast Server Crash Recovery
在本章中,我们将讨论经典的 NFS 协议(第 2 版,又名 NFSv2),这是多年来的标准; 迁移到 NFSv3 时进行了小的更改,迁移到 NFSv4 时进行了更大规模的协议更改。 然而,NFSv2 既精彩又令人沮丧,因此成为我们关注的焦点。
在 NFSv2 中,协议设计的主要目标是简单快速的服务器崩溃恢复。 在多客户端、单服务器环境中,这个目标很有意义; 服务器停机(或不可用)的任何一分钟都会使所有客户端计算机(及其用户)不高兴且效率低下。 因此,随着服务器的运行,整个系统也会运行。
49.4 快速崩溃恢复的关键:无状态 Key To Fast Crash Recovery: Statelessness
这个简单的目标在 NFSv2 中通过设计我们所说的无状态协议(stateless protocol)来实现。 按照设计,服务器不会跟踪有关每个客户端发生的事情的任何信息。 例如,服务器不知道哪些客户端缓存了哪些块,或者每个客户端当前打开了哪些文件,或者文件的当前文件指针位置等。简单地说,服务器不跟踪客户端正在做的任何事情;相反,协议被设计为在每个协议请求中交付完成请求所需的所有信息。如果现在还没有,那么这种无状态方法将更有意义,因为我们将在下面更详细地讨论该协议。
对于有状态(stateful,不是无状态(not stateless))协议的示例,请考虑 open() 系统调用。 给定一个路径名,open() 返回一个文件描述符(一个整数)。 此描述符用于后续 read() 或 write() 请求以访问各种文件块,如在此应用程序代码中一样(请注意,由于空间原因,省略了对系统调用的正确错误检查):
char buffer[MAX];int fd = open("foo", O_RDONLY); // get descriptor "fd"read(fd, buffer, MAX); // read MAX from foo via "fd"read(fd, buffer, MAX); // read MAX again...read(fd, buffer, MAX); // read MAX againclose(fd); // close file
Figure 49.3: Client Code: Reading From A File
现在想象一下,客户端文件系统通过向服务器发送一个协议消息来打开文件,说“打开文件‘foo’并给我一个描述符”。 然后文件服务器在其本地打开文件并将描述符发送回客户端。 在后续读取中,客户端应用程序使用该描述符来调用 read() 系统调用; 然后客户端文件系统将描述符在消息中传递给文件服务器,说“从我在这里传递给你的描述符所引用的文件中读取一些字节”。
在这个例子中,文件描述符是客户端和服务器之间的一段共享状态(shared state,Ousterhout 将此称为分布式状态(distributed state) [O91])。正如我们上面暗示的那样,共享状态使崩溃恢复变得复杂。 想象一下,服务器在第一次读取完成后崩溃,但在客户端发出第二次读取之前。 在服务器再次启动并运行后,客户端然后发出第二次读取。 不幸的是,服务器不知道 fd 指的是哪个文件; 该信息是短暂的(即在内存中),因此在服务器崩溃时丢失。 为了处理这种情况,客户端和服务器必须采用某种恢复协议(recovery protocol),客户端将确保在其内存中保留足够的信息,以便能够告诉服务器它需要知道什么(在这种情况下,该文件描述符 fd 指的是文件 foo)。
当您考虑到有状态服务器必须处理客户端崩溃的事实时,情况会变得更糟。 例如,想象一下打开文件然后崩溃的客户端。 open() 使用了服务器上的文件描述符; 服务器如何知道可以关闭给定的文件? 在正常操作中,客户端最终会调用 close() 并因此通知服务器应该关闭文件。 但是,当客户端崩溃时,服务器永远不会收到 close(),因此必须注意到客户端崩溃才能关闭文件。
由于这些原因,NFS 的设计者决定采用无状态方法:每个客户端操作都包含完成请求所需的所有信息。 不需要花哨的崩溃恢复; 服务器只是再次开始运行,而客户端,在最坏的情况下,可能不得不重试请求(retry a request)。
49.5 NFSv2协议 The NFSv2 Protocol
因此,我们得出了 NFSv2 协议定义。 我们的问题陈述很简单:
关键的问题:如何定义无状态文件协议 我们如何定义网络协议以实现无状态操作?显然,像 open() 这样的有状态调用不能成为讨论的一部分(因为它需要服务器跟踪打开的文件); 但是,客户端应用程序需要调用 open()、read()、write()、close() 和其他标准 API 调用来访问文件和目录。 因此,作为一个精炼的问题,我们如何定义协议既是无状态的又支持 POSIX 文件系统 API?
理解 NFS 协议设计的关键之一是理解**文件句柄(file handle)**。 **文件句柄用来唯一地描述一个特定操作将要操作的文件或目录**;因此,许多协议请求都包含一个文件句柄。<br />您可以将文件句柄视为具有三个重要组成部分:**卷标识符、inode 编号和代编号(a volume identifier, an inode number, and a generation number)**; 这三项共同构成了客户端希望访问的文件或目录的唯一标识符。 卷标识符通知服务器请求所指的文件系统(一个NFS服务器可以输出多个文件系统); inode 编号告诉服务器请求正在访问该分区中的哪个文件。 **最后,重用一个inode号时需要代编号; 通过在重复使用 inode 编号时增加它,服务器确保具有旧文件句柄的客户端不会意外访问新分配的文件。**<br />以下是协议的一些重要部分的摘要; 完整的协议可在其他地方获得(有关 NFS [C00] 的出色而详细的概述,请参阅 Callaghan 的书)。
NFSPROC GETATTR file handlereturns: attributesNFSPROC SETATTR file handle, attributesreturns: –NFSPROC LOOKUP directory file handle, name of file/dir to look upreturns: file handleNFSPROC READ file handle, offset, countdata, attributesNFSPROC WRITE file handle, offset, count, dataattributesNFSPROC CREATE directory file handle, name of file, attributes–NFSPROC REMOVE directory file handle, name of file to be removed–NFSPROC MKDIR directory file handle, name of directory, attributesfile handleNFSPROC RMDIR directory file handle, name of directory to be removed–NFSPROC READDIR directory handle, count of bytes to read, cookiereturns: directory entries, cookie (to get more entries)
Figure 49.4: The NFS Protocol: Examples
我们简要强调了协议的重要组成部分。 首先,LOOKUP 协议消息用于获取文件句柄,然后用于访问文件数据。 客户端传递要查找的目录文件句柄和文件名,该文件(或目录)的句柄及其属性(attributes)从服务器传回客户端。
例如,假设客户端已经有一个文件系统根目录的目录文件句柄(/)(实际上,这将通过 NFS 挂载协议(mount protocol)获得,这是客户端和服务器首先连接在一起的方式;为简洁起见,我们不在此讨论挂载协议)。 如果客户端上运行的应用程序打开文件 /foo.txt,则客户端文件系统向服务器发送查找请求,将根文件句柄和名称 foo.txt 传递给它; 如果成功,将返回 foo.txt 的文件句柄(和属性)。
一旦文件句柄可用,客户端就可以在文件上发出 READ 和 WRITE 协议消息以分别读取或写入文件。 READ 协议消息要求协议传递文件的文件句柄以及文件内的偏移量和要读取的字节数。然后服务器将能够发出读取(毕竟,句柄告诉服务器从哪个卷和哪个inode读取,偏移量和计数告诉服务器读取文件的哪个字节)并将数据返回给客户端 (或者如果失败则是错误)。 WRITE 的处理方式类似,只是数据从客户端传递到服务器,并且只返回一个成功码。
最后一个有趣的协议消息是 GETATTR 请求; 给定一个文件句柄,它只是获取该文件的属性,包括文件的最后修改时间。 当我们在下面讨论缓存时,我们将看到为什么这个协议请求在 NFSv2 中很重要(你能猜到为什么吗?)。
49.6
从协议到分布式文件系统 From Protocol To Distributed File System
希望您现在对如何将此协议转变为跨客户端文件系统和文件服务器的文件系统有所了解。 客户端文件系统跟踪打开的文件,并通常将应用程序请求转换为相关的协议消息集(set of protocol messages)。 服务器简单地响应协议消息,每个协议消息都包含完成请求所需的所有信息。
例如,让我们考虑一个读取文件的简单应用程序。在图中(图 49.5),我们显示了应用程序进行了哪些系统调用,以及客户端文件系统和文件服务器在响应此类调用时所做的工作。
Figure 49.5: Reading A File: Client-side And File Server Actions
关于图有一些注释。 首先,注意客户端如何跟踪文件访问的所有相关状态(state),包括整数文件描述符到 NFS 文件句柄的映射以及当前文件指针。 这使客户端能够将每个读取请求(您可能已经注意到没有明确指定要读取的偏移量)转换为格式正确的读取协议消息,该消息告诉服务器确切地从文件中读取哪些字节。 成功读取后,客户端更新当前文件位置; 后续读取使用相同的文件句柄但不同的偏移量发出。
其次,您可能会注意到服务器交互发生的位置。 当文件第一次打开时,客户端文件系统发送一个 LOOKUP 请求消息。 事实上,如果必须遍历一个长路径名(例如,/home/remzi/foo.txt),客户端将发送三个 LOOKUP:一个在目录 / 中查找 home,一个在 home 中查找 remzi,最后一个 在 remzi 中查找 foo.txt。
第三,您可能会注意到每个服务器请求如何拥有完整完成请求所需的所有信息。 这个设计点对于能够从服务器故障中优雅地恢复至关重要,我们现在将更详细地讨论; 它确保服务器不需要状态即可响应请求。
Tip:幂等性是强大的 在构建可靠系统时,幂等性(Idempotency)是一个有用的属性。 当一个操作可以多次发出时,处理操作失败就容易多了; 你可以重试一下。 如果操作不是幂等的,生活就会变得更加困难。
49.7
使用幂等操作处理服务器故障 Handling Server Failure With Idempotent Operations
当客户端向服务器发送消息时,有时不会收到响应。 这种未能响应的可能原因有很多。 在某些情况下,消息可能会被网络丢弃; 网络确实会丢失消息,因此请求或回复都可能丢失,因此客户端永远不会收到响应。
服务器也可能崩溃,因此当前没有响应消息。 稍后,服务器将重新启动并重新开始运行,但同时所有请求都已丢失。 在所有这些情况下,客户端都面临一个问题:当服务器没有及时回复时,他们应该怎么做?
在 NFSv2 中,客户端以单一、统一且优雅的方式处理所有这些故障:它只是重试(retries)请求。 具体来说,客户端发送请求后,设置一个定时器,在指定的时间段后关闭。 如果在计时器关闭之前收到回复,则取消计时器,一切正常。 但是,如果计时器在收到任何回复之前就关闭了,则客户端假定请求尚未处理并重新发送。 如果服务器回复,一切都很好,客户端已经巧妙地处理了问题。
客户端能够简单地重试请求(不管是什么导致失败)是由于大多数 NFS 请求的一个重要属性:它们是幂等的(idempotent)。 当多次执行该操作的效果与执行该操作一次的效果相同时,该操作称为幂等的。 例如,如果将一个值存储到内存位置三次,则与存储一次相同; 因此“将值存储到内存”是一种幂等操作。 但是,如果您将计数器递增 3 次,则会产生与仅递增一次不同的数量; 因此,“增量计数器”不是幂等的。 更一般地说,任何只读取数据的操作显然都是幂等的; 必须更仔细地考虑更新数据的操作,以确定它是否具有此属性。
NFS 中崩溃恢复设计的核心是大多数常见操作的幂等性。 LOOKUP 和 READ 请求是微幂等的,因为它们只从文件服务器读取信息而不更新它。 更有趣的是,WRITE 请求也是幂等的。 例如,如果 WRITE 失败,客户端可以简单地重试。 WRITE 消息包含数据、计数和(重要的)写入数据的确切偏移量。 因此,它可以在知道多次写入的结果与单个写入的结果相同的情况下重复。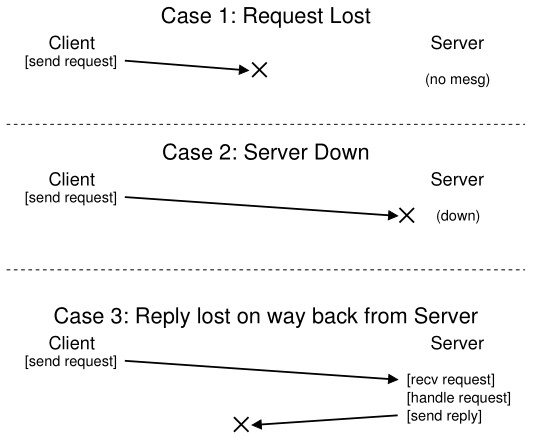
Figure 49.6: The Three Types Of Loss
这样,客户端就可以统一处理所有超时。 如果 WRITE 请求只是丢失了(上面的情况 1),客户端将重试它,服务器将执行写入,一切都会好起来的。 如果服务器在请求发送时碰巧关闭,但会在发送第二个请求时备份并运行,并且一切都按预期工作(情况 2),也会发生同样的情况。 最后,服务器实际上可能会收到 WRITE 请求,向其磁盘发出写入,并发送应答。 这个应答可能会丢失(情况 3),再次导致客户端重新发送请求。 当服务器再次收到请求时,它只会做完全相同的事情:将数据写入磁盘并回复它已经这样做了。 如果客户端这次收到应答,则一切正常,因此客户端以统一的方式处理了消息丢失和服务器故障。 优雅!
顺便说一句:有些操作很难实现幂等。 例如,当您尝试创建一个已经存在的目录时,您会被告知 mkdir 请求失败。因此,在NFS中,如果文件服务器接收到MKDIR协议消息并成功执行,但应答丢失,客户端可能会重复它并遇到失败,而实际上操作最初是成功的,然后只是在重试时失败。
因此,生活是不完美的。
Tip:完美是优秀的敌人(Voltaire’s Law) 即使您设计了一个漂亮的系统,有时所有的极端情况也不会完全按照您的意愿运行。 以上面的 mkdir 为例; 可以重新设计 mkdir 以使其具有不同的语义,从而使其具有幂等性(请考虑如何这样做); 然而,何必呢? NFS 设计理念涵盖了大部分重要情况,总体而言,系统设计在失败方面变得简洁明了。因此,接受生活并不完美并仍在构建系统是良好工程的标志。显然, 这种智慧归功于伏尔泰,因为他说“……一个聪明的意大利人说最好的就是善的敌人”[V72],因此我们称之为伏尔泰定律。
49.8 改善性能:客户端缓存
Improving Performance: Client-side Caching
分布式文件系统的好处有很多,但是通过网络发送所有读写请求会导致一个很大的性能问题:网络通常没有那么快,尤其是与本地内存或磁盘相比。 因此,另一个问题是:我们如何提高分布式文件系统的性能?
正如您通过阅读上面副标题中的粗体字可能猜到的那样,答案是客户端缓存(client-side caching)。 NFS 客户端文件系统将从服务器读取的文件数据(和元数据)缓存在客户端内存中。 因此,虽然第一次访问代价高昂(即,它需要网络通信),但后续访问会很快从客户端内存中得到服务。
缓存还用作写入的临时缓冲区。 当客户端应用程序第一次写入文件时,客户端会在将数据写出到服务器之前缓冲客户端内存中的数据(与它从文件服务器读取的数据在同一个缓存中)。 这种写缓冲(write buffering)很有用,因为它将应用程序 write() 延迟与实际写性能分离,即应用程序对 write() 的调用立即成功(并且只是将数据放入客户端文件系统的缓存中); 只有稍后数据才会被写出到文件服务器。
因此,NFS 客户端缓存数据和性能通常很好,我们就完成了,对吧? 不幸的是,不完全是。 将缓存添加到具有多个客户端缓存的任何类型的系统中都会带来一个巨大而有趣的挑战,我们将其称为缓存一致性问题(cache consistency problem)。
49.9
缓存一致性问题 The Cache Consistency Problem
缓存一致性问题最好用两个客户端和一个服务器来说明。 假设客户端 C1 读取文件 F,并在其本地缓存中保留该文件的副本。 现在想象一个不同的客户端 C2 覆盖了文件 F,从而改变了它的内容; 让我们将文件的新版本称为 F(版本 2),或者 F[v2] 和旧版本 F[v1],这样我们就可以保持两者不同(当然,文件具有相同的名称,只是内容不同)。 最后,还有第三个客户端 C3,它尚未访问文件 F。
您可能会看到即将出现的问题(图 49.7)。 实际上,有两个子问题。 第一个子问题是客户端 C2 可能会在其缓存中缓冲一段时间,然后再将它们传播到服务器; 在这种情况下,虽然 F[v2] 位于 C2 的内存中,但从另一个客户端(比如 C3)对 F 的任何访问都将获取文件的旧版本(F[v1])。 因此,通过在客户端缓冲写入,其他客户端可能会获得文件的旧版本,这可能是不可取的; 确实,想象一下这样的情况,您登录机器 C2,更新 F,然后登录 C3 并尝试读取文件,结果却得到了旧副本! 当然,这可能令人沮丧。 因此,让我们将缓存一致性问题的这一方面称为更新可见性(update visibility); 来自一个客户端的更新何时在其他客户端可见?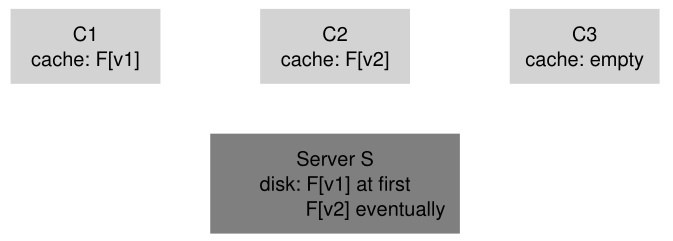
Figure 49.7: The Cache Consistency Problem
缓存一致性的第二个子问题是过时(stale)缓存; 在这种情况下,C2 最终将其写入刷新到文件服务器,因此服务器具有最新版本 (F[v2])。 但是,C1 的缓存中仍然有 F[v1]; 如果在 C1 上运行的程序读取文件 F,它将获得一个陈旧的版本 (F[v1]) 而不是最新的副本 (F[v2]),这(通常)是不可取的。
NFSv2 实现以两种方式解决这些缓存一致性问题。 首先,为了解决更新可见性,客户端实现了有时称为关闭时刷新(flush-on-close,也称为关闭到打开(close-to-open))的一致性语义; 具体来说,当一个文件被写入并随后被客户端应用程序关闭时,客户端会将所有更新(即缓存中的脏页)刷新到服务器。 通过关闭时刷新一致性,NFS 确保从另一个节点随后打开将看到最新的文件版本。
其次,为了解决过时缓存问题,NFSv2 客户端在使用其缓存内容之前首先检查文件是否已更改。 具体来说,在使用缓存块之前,客户端文件系统将向服务器发出 GETATTR 请求以获取文件的属性。 重要的是,属性包括有关文件上次在服务器上修改时间的信息; 如果修改时间比文件被提取到客户端缓存的时间更近,则客户端会使文件无效,从而将其从客户端缓存中删除并确保后续读取将转到服务器并检索最新的文件的版本。 另一方面,如果客户端看到它拥有最新版本的文件,它将继续使用缓存的内容,从而提高性能。
当 Sun 的原始团队针对过时缓存问题实施此解决方案时,他们意识到了一个新问题; 突然,NFS 服务器被 GETATTR 请求淹没。 要遵循的一个好的工程原则是针对常见情况(common case)进行设计,并使其运行良好; 在这里,虽然常见的情况是文件只能从单个客户端访问(可能是重复访问),但客户端总是必须向服务器发送 GETATTR 请求以确保没有其他人更改了该文件。 因此,客户端轰炸服务器,不断询问“有人更改过这个文件吗?”,而大多数时候没有人更改过。
为了补救这种情况(在某种程度上),为每个客户端添加了一个属性缓存(attribute cache)。 客户端在访问文件之前仍会对其进行验证,但大多数情况下只会查看属性缓存以获取属性。特定文件的属性在第一次访问文件时放置在缓存中,然后在一段时间后超时(比如 3 秒)。 因此,在这三秒钟内,所有文件访问都将确定可以使用缓存文件,因此无需与服务器进行网络通信。
49.10
评估NFS缓存一致性 Assessing NFS Cache Consistency
关于 NFS 缓存一致性的最后几句话。 关闭时刷新行为被添加到“有意义”,但引入了一定的性能问题。 具体来说,如果在客户端上创建了一个临时或短期文件,然后很快被删除,它仍然会被强制发送到服务器。 一个更理想的实现可能会在内存中保留这些短期文件,直到它们被删除,从而完全删除服务器交互,可能会提高性能。
更重要的是,在 NFS 中添加一个属性缓存使得很难理解或推断一个文件的确切版本。 有时你会得到最新版本; 有时您会得到一个旧版本,因为您的属性缓存尚未超时,因此客户端很乐意为您提供客户端内存中的内容。 尽管这在大多数情况下都很好,但它会(现在仍然如此!)偶尔会导致奇怪的行为。
因此,我们已经描述了 NFS 客户端缓存的奇怪之处。 它是一个有趣的例子,其中实现的细节用于定义用户可观察的语义,而不是反过来。
49.11
服务器端写缓冲的隐含意义 Implications On Server-Side Write Buffering
到目前为止,我们的重点一直放在客户端缓存上,这也是大多数有趣问题出现的地方。 然而,NFS 服务器往往也是配备大量内存的设备精良的机器,因此它们也有缓存问题。当从磁盘读取数据(和元数据)时,NFS 服务器会将其保存在内存中,随后读取所述数据(和元数据)不会进入磁盘,这是性能的潜在(小)提升。
更有趣的是写缓冲的情况。 NFS 服务器绝对不会在 WRITE 协议请求上返回成功,直到写入已被强制写入稳定存储(例如,写入磁盘或某些其他持久设备)。虽然他们可以将数据的副本放在服务器内存中,但在 WRITE 协议请求上向客户端返回成功可能会导致不正确的行为; 你能弄清楚为什么吗?
答案在于我们对客户端如何处理服务器故障的假设。 想象一下客户端发出的以下写入序列:
write(fd, a_buffer, size); // fill 1st block with a’swrite(fd, b_buffer, size); // fill 2nd block with b’swrite(fd, c_buffer, size); // fill 3rd block with c’s
这些写入会用 a 块、b 块和 c 块覆盖文件的三个块。 因此,如果文件最初如下所示:<br /><br />我们可能期望这些写入后的最终结果是这样的,x、y 和 z 将分别被 a、b 和 c 覆盖。<br /><br />现在让我们假设这三个客户端写入作为三个不同的 WRITE 协议消息发送到服务器。 假设第一个 WRITE 消息由服务器接收并发布到磁盘,并且客户端获知其成功。 现在假设第二次写入只是缓存在内存中,并且服务器也在强制写入磁盘之前向客户端报告它成功; 不幸的是,服务器在将其写入磁盘之前崩溃了。 服务器迅速重启,收到第三次写请求,也成功。<br /><br />哎呀! 因为服务器在将其提交到磁盘之前告诉客户端第二次写入成功,所以文件中会留下一个旧块,这取决于应用程序,这可能是灾难性的。<br />为了避免这个问题,NFS 服务器必须在通知客户端成功之前将每次写入提交到稳定(持久)存储; 这样做使客户端能够在写入期间检测到服务器故障,从而重试直到最终成功。 这样做可以确保我们永远不会像上面的例子那样混合文件内容。<br />这个要求在 NFS 服务器实现中引起的问题是写入性能,如果不小心,可能是主要的性能瓶颈。 事实上,一些公司(例如 Network Appliance)成立时的简单目标是构建一个可以快速执行写入的 NFS 服务器; 他们使用的一个技巧是首先将写操作放在电池支持的内存中,这样就可以快速应答写请求,而不用担心丢失数据,也不用马上写入磁盘;第二个技巧是使用专门设计用于在最终需要时快速写入磁盘的文件系统设计[HLM94, RO91]。
Aside:创新孕育创新 与许多开创性技术一样,将 NFS 引入世界还需要其他基础创新才能使其成功。 可能最持久的是虚拟文件系统 (VFS) / 虚拟节点 (vnode) 接口(Virtual File System (VFS) / Virtual Node (vnode)),由 Sun 引入以允许不同的文件系统轻松插入操作系统 [K86]。 VFS 层包括对整个文件系统执行的操作,例如挂载和卸载、获取文件系统范围的统计信息以及强制所有脏数据(尚未写入)写入磁盘。 vnode 层包含可以对文件执行的所有操作,例如打开、关闭、读取、写入等。 要构建一个新的文件系统,只需定义这些“方法”; 然后框架处理其余部分,将系统调用连接到特定的文件系统实现,以集中方式执行所有文件系统通用的通用功能(例如,缓存),从而为多个文件系统实现提供了一种在同一个系统中同时操作的方法。 尽管一些细节发生了变化,但许多现代系统都有某种形式的 VFS/vnode 层,包括 Linux、BSD 变体、macOS,甚至 Windows(以可安装文件系统(Installable File System)的形式)。 即使 NFS 与世界的相关性降低,其下的一些必要基础仍将继续存在。
49.12
总结 Summary
我们已经看到了 NFS 分布式文件系统的介绍。 NFS 以面对服务器故障时简单快速恢复的思想为中心,并通过精心的协议设计来实现这一目标。 操作的幂等性是必不可少的; 因为客户端可以安全地重传失败的操作,所以无论服务器是否执行了请求,都可以这样做。
我们还看到了将缓存引入多客户端、单服务器系统如何使事情复杂化。 尤其是系统必须解决缓存一致性问题才能合理运行; 然而,NFS 以一种稍微特别的方式这样做,这有时会导致可观察到的奇怪行为。 最后,我们看到了服务器缓存是如何棘手的:在返回成功之前必须强制写入服务器到稳定存储(否则数据可能会丢失)。
我们还没有讨论其他肯定相关的问题,特别是安全性。 早期 NFS 实现的安全性非常松懈; 客户端上的任何用户都可以很容易地伪装成其他用户,从而获得对几乎任何文件的访问权限。 随后与更严格的身份验证服务(例如 Kerberos [NT94])的集成解决了这些明显的缺陷。
Aside:关键NFS术语
- 在 NFS 中实现快速简单的崩溃恢复主要目标的关键在于无状态(stateless)协议的设计。 崩溃后,服务器可以快速重启并重新开始服务请求; 客户端只是重试(retry)请求,直到他们成功。
- 使请求幂等(idempotent)是 NFS 协议的一个核心方面。当一个操作执行多次的效果相当于执行一次时,它就是幂等的。 在 NFS 中,幂等性使客户端可以放心重试,并统一了客户端丢失消息重传和客户端如何处理服务器崩溃。
- 性能问题决定了客户端缓存(caching)和写入缓冲(write buffering)的需要,但引入了缓存一致性问题(cache consistency problem)。
- NFS 实现提供了一种通过多种方式缓存一致性的工程解决方案:flush-on-close(close-to-open)方法确保当文件关闭时,其内容被强制发送到服务器,使其他客户端能够观察到它更新。 属性缓存(attribute cache)减少了与服务器检查文件是否已更改的频率(通过 GETATTR 请求)。
- NFS 服务器必须在返回成功之前提交写入持久性媒体; 否则,可能会发生数据丢失。
- 为了支持将 NFS 集成到操作系统中,Sun 引入了 VFS/Vnode 接口,使多个文件系统实现能够在同一操作系统中共存。
References
[AKW88] “The AWK Programming Language” by Alfred V. Aho, Brian W. Kernighan, Peter
J. Weinberger. Pearson, 1988 (1st edition).
一本关于 awk 的简洁而精彩的书。 我们曾经有幸见到 Peter Weinberger; 当他自我介绍时,他说:“我是 Peter Weinberger,你知道吗,awk 中的‘W’?” 作为 awk 的忠实粉丝,这是一个值得细细品味的时刻。 然后我们中的一个人(Remzi)说:“我喜欢 awk! 我特别喜欢这本书,它让一切都变得如此清晰。” Weinberger 回答(垂头丧气):“哦,Kernighan 写了这本书。”
[C00] “NFS Illustrated” by Brent Callaghan. Addison-Wesley Professional Computing Series,
一个很好的 NFS 参考; 根据协议本身,令人难以置信的彻底和详细。
[ES03] “New NFS Tracing Tools and Techniques for System Analysis” by Daniel Ellard and Margo Seltzer. LISA ’03, San Diego, California.
通过被动跟踪对NFS进行的复杂、仔细的分析。通过简单地监控网络流量,作者展示了如何获得大量的文件系统理解。
[HLM94] “File System Design for an NFS File Server Appliance” by Dave Hitz, James Lau, Michael Malcolm. USENIX Winter 1994. San Francisco, California, 1994.
希茨等人。 受以前在日志结构文件系统上的工作影响很大。
[K86] “Vnodes: An Architecture for Multiple File System Types in Sun UNIX” by Steve R. Kleiman. USENIX Summer ’86, Atlanta, Georgia.
本文展示了如何将灵活的文件系统架构构建到操作系统中,使多个不同的文件系统实现能够共存。 现在几乎以某种形式在每个现代操作系统中使用。
[NT94] “Kerberos: An Authentication Service for Computer Networks” by B. Clifford Neuman, Theodore Ts’o. IEEE Communications, 32(9):33-38, September 1994.
Kerberos 是一种早期且极具影响力的身份验证服务。 我们可能应该在某个时候写一本书关于它的章节……
[O91] “The Role of Distributed State” by John K. Ousterhout. 1991.
一个很少被引用的关于分布式状态的讨论; 对问题和挑战有更广阔的视野。
[P+94] “NFS Version 3: Design and Implementation” by Brian Pawlowski, Chet Juszczak, Peter Staubach, Carl Smith, Diane Lebel, Dave Hitz. USENIX Summer 1994, pages 137-152.
NFS版本3下的小修改。
[P+00] “The NFS version 4 protocol” by Brian Pawlowski, David Noveck, David Robinson, Robert Thurlow. 2nd International System Administration and Networking Conference (SANE 2000).
毫无疑问,这是有史以来关于 NFS 的最具文学性的论文。
[RO91] “The Design and Implementation of the Log-structured File System” by Mendel Rosen- blum, John Ousterhout. Symposium on Operating Systems Principles (SOSP), 1991.
再次 LFS。不,您永远无法获得足够的 LFS。
[S86] “The Sun Network File System: Design, Implementation and Experience” by Russel Sandberg. USENIX Summer 1986.
NFS论文原件;虽然读起来有点挑战性,但还是值得一看这些奇妙想法的来源。
[Sun89] “NFS: Network File System Protocol Specification” by Sun Microsystems, Inc. Request for Comments: 1094, March 1989.
可怕的规范;如果你必须读它,也就是说,你是拿钱来读它的。希望你付了很多钱。 钱钱!
[V72] “La Begueule” by Francois-Marie Arouet a.k.a. Voltaire. Published in 1772.
伏尔泰说了很多聪明的话,这只是一个例子。 例如,伏尔泰还说:“如果你的土地上有两种宗教,两者就会互相割喉; 但如果你有三十种宗教,它们就会和平共处。” 民主党人和共和党人,你对此有什么看法?Homework (Measurement)
在本作业中,您将使用真实跟踪进行一些 NFS 跟踪分析。 这些跟踪的来源是 Ellard 和 Seltzer 的努力 [ES03]。在开始之前,请务必阅读相关的 README 并从 OSTEP 作业页面(像往常一样)下载相关的 tarball。Questions
- 跟踪分析的第一个问题:使用第一列中找到的时间戳,确定跟踪的时间段。 周期是多久? 那是哪天/周/月/年? (这是否与文件名中给出的提示匹配?) 提示:使用工具 head -1 和 tail -1 提取文件的第一行和最后一行,并进行计算。
- 现在,让我们做一些操作计数。 跟踪中每种类型的操作发生了多少次? 按频率对这些进行排序; 哪个操作最频繁? NFS 不辜负它的声誉吗?
- 现在让我们更详细地看一些特定的操作。 例如,GETATTR 请求会返回许多有关文件的信息,包括针对哪个用户 ID 执行请求、文件的大小等。 对跟踪中访问的文件大小进行分布; 平均文件大小是多少? 此外,有多少不同的用户访问跟踪中的文件? 是少数用户主导流量,还是分布更广? 在 GETATTR 回复中还发现了哪些其他有趣的信息?
- 您还可以查看对给定文件的请求并确定文件的访问方式。 例如,给定的文件是按顺序读取还是写入? 还是随机的? 查看 READ 和 WRITE 请求/回复的详细信息以计算答案。
- 流量来自多台机器并流向一台服务器(在此跟踪中)。 计算流量矩阵,该矩阵显示跟踪中有多少个不同的客户端,以及每个客户端有多少请求/回复。 是几台机器占主导地位,还是比较均衡?
- 计时信息和每个请求/回复的唯一 ID 应该允许您计算给定请求的延迟。 计算所有请求/回复对的延迟,并将它们绘制为分布。平均值是多少? 最大值? 最低限度?
- 有时会重试请求,因为请求或其回复可能会丢失或丢弃。 您能在跟踪样本中找到任何此类重试的证据吗?
- 还有很多其他问题可以通过更多的分析来回答。您认为哪些问题很重要?向我们提出建议,也许我们会在这里添加它们!

若有收获,就点个赞吧
0 人点赞
