在本章中,我们将讨论如何开发最著名的调度方法之一,即多级反馈队列(Multi-level Feed-back Queue,MLFQ)。多级反馈队列(MLFQ)调度程序最早是由Corbato等人在1962年[C+62]在一个称为兼容分时系统(CTSS)的系统中描述的,这项工作,连同后来在multitics上的工作,导致ACM授予Corbato其最高荣誉,图灵奖(Turing Award)。调度器随后经过多年的改进,最终实现了您将在一些现代系统中遇到的实现。
MLFQ试图解决的根本问题有两个方面。首先,它希望优化周转时间,正如我们在前面的笔记中看到的,这是通过先运行较短的作业来完成的;不幸的是,操作系统通常不知道作业将运行多长时间,而这正是SJF(或STCF)等算法所需要的知识。其次,MLFQ希望让系统对交互用户(即用户坐在那里,盯着屏幕,等待进程完成)做出响应,从而减少响应时间;不幸的是,像Round Robin这样的算法减少了响应时间,但在周转时间方面却很糟糕。因此,我们的问题是:如果我们通常不知道任何关于过程的事情,我们如何构建一个调度程序来实现这些目标?当系统运行时,调度器如何学习它所运行的作业的特征,从而做出更好的调度决策?
关键的问题:如何在没有完美知识的情况下进行计划 我们如何设计一个调度程序,既能最小化交互作业的响应时间,又能在没有作业长度先验知识的情况下最小化周转时间?
Tip:从历史中学习 多级反馈队列是一个很好的例子,它说明了从过去学习来预测未来的系统。这种方法在操作系统(以及计算机科学的许多其他领域,包括硬件分支预测器和缓存算法)中很常见。这种方法在工作有行为阶段时起作用,因此是可预测的;当然,人们必须小心使用这些技术,因为它们很容易出错,并导致系统做出比完全不知情更糟糕的决定。
8.1 MLFQ:基本规则 MLFQ: Basic Rules
为了构建这样一个调度程序,在本章中,我们将描述多级反馈队列背后的基本算法;尽管许多实现的MLFQs的细节不同[E95],但大多数方法是相似的。
在我们的处理中,MLFQ有许多不同的队列(queues),每个队列分配不同的优先级级别(priority level)。在任何给定时间,准备运行的作业都位于单个队列上。MLFQ使用优先级来决定在给定的时间应该运行哪个作业:选择一个具有较高优先级的作业(即处于较高队列中的作业)来运行。
当然,给定队列上可能有多个作业,因此具有相同的优先级。在本例中,我们将在这些作业中使用round-robin调度。
因此,我们得到了MLFQ的前两个基本规则:
- 规则1:如果Priority(A) > Priority(B),则A运行(B不运行)。
- 规则2:如果Priority(A) = Priority(B),那么A和B将在RR中运行。
因此,MLFQ调度的关键在于调度器如何设置优先级。MLFQ不是给每个作业一个固定的优先级,而是根据观察到的行为来改变作业的优先级。例如,如果一个作业在等待键盘输入时反复放弃CPU,那么MLFQ将保持它的优先级高,因为这是交互进程的行为方式。相反,如果一个作业长时间密集地使用CPU, MLFQ将降低它的优先级。通过这种方式,MLFQ将尝试在流程运行时了解流程,从而使用作业的历史记录来预测其未来的行为。
如果我们要展示队列在给定时刻的样子,我们可能会看到如下所示的内容(图 8.1)。在图中,两个作业(A 和 B)处于最高优先级,而作业 C 处于中间,作业 D 处于最低优先级。鉴于我们目前对 MLFQ 工作原理的了解,调度程序只会在 A 和 B 之间交替时间片,因为它们是系统中优先级最高的作业;糟糕的工作 C 和 D 甚至永远无法运行——太愤怒了!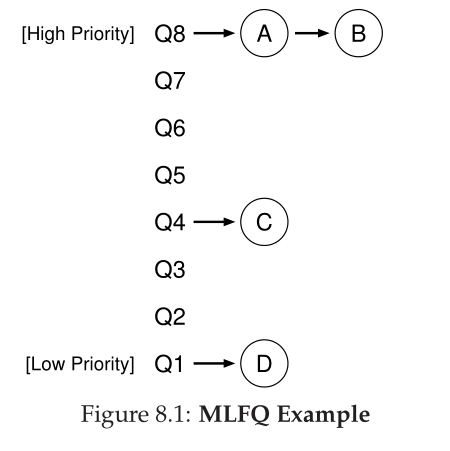
当然,仅仅显示一些队列的静态快照并不能真正让您了解MLFQ是如何工作的。我们需要的是了解工作优先级是如何随时间变化的。这正是我们接下来要做的,只有那些第一次读这本书的人会感到惊讶。
8.2 尝试1:怎样改变优先级 Attempt #1: How To Change Priority
现在,我们必须决定MLFQ将如何在作业的生命周期中更改作业的优先级(从而决定它在哪个队列中)。要做到这一点,我们必须记住我们的工作负载:短时间运行的交互式作业(可能经常放弃CPU)和一些长时间运行的CPU绑定作业的混合,这些作业需要大量CPU时间,但响应时间并不重要。这是我们对优先级调整算法的第一次尝试。
- 规则3:当一个作业进入系统时,它的优先级最高(最顶端的队列)。
- 规则4a:如果一个作业在运行时耗尽了整个时间片,那么它的优先级就会降低(也就是说,它会移动到一个队列下)。
- 规则4b:如果一个任务在时间片启动之前放弃CPU,它将保持在相同的优先级级别。
示例1:单个长时间运行的工作 Example 1: A Single Long-Running Job
让我们看一些例子。首先,我们将看看当系统中有一个长期运行的作业时会发生什么。图8.2显示了在一个三队列调度程序中该作业随时间的变化。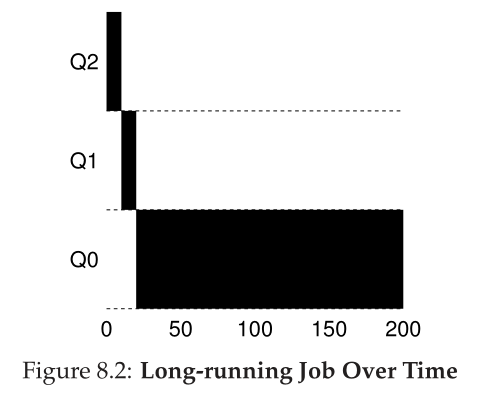
正如您在示例中所看到的,作业以最高优先级(Q2)进入。在一个10毫秒的时间片之后,调度器将作业的优先级降低1,因此该作业位于Q1。在Q1上运行一个时间片之后,作业最终被降低到系统中最低的优先级(Q0),它仍然在那里。很简单,不是吗?示例2:之后是一份短时间的工作 Example 2: Along Came A Short Job
现在让我们看一个更复杂的例子,希望看到MLFQ是如何尝试近似SJF的。在本例中,有两个作业:A是一个长时间运行的cpu密集型作业,B是一个短时间运行的交互式作业。假设A已经运行了一段时间,然后B到达。会发生什么呢?MLFQ是否接近B的SJF?
图8.3描绘了这个场景的结果。一个(黑色显示)正在最低优先级队列中运行(任何长时间运行的cpu密集型作业也是如此);B(以灰色表示)到达时间为T = 100,因此被插入到最高队列;由于它的运行时间很短(只有20毫秒),B在到达底部队列之前完成,在两个时间片中;然后A继续运行(优先级较低)。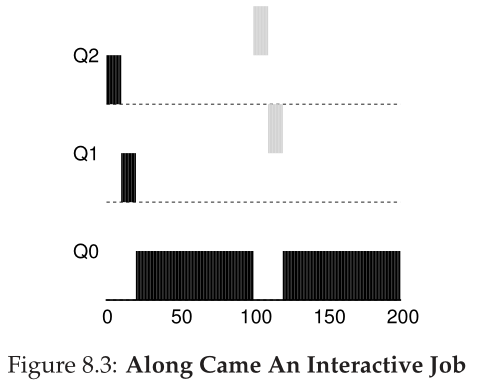
从这个示例中,您有望理解该算法的主要目标之一:因为它不知道一个任务是短期任务还是长期运行的任务,所以它首先假定它可能是短期任务,从而赋予该任务高优先级。如果它实际上是一个短期的工作,它将快速运行和完成;如果它不是一个短期的工作,它将缓慢地沿着队列移动,因此很快证明自己是一个更像批处理的长时间运行的过程。这样,MLFQ近似于SJF。示例3:I/O怎么样 Example 3: What About I/O
现在让我们看一个带有一些I/O的示例。正如上面的规则4b所述,如果一个进程在耗尽它的时间片之前放弃了处理器,我们将它保持在相同的优先级级别。这条规则的目的很简单:例如,如果一个交互任务正在执行大量I/O(比如等待用户键盘或鼠标的输入),它将在其时间片完成之前放弃CPU;在这种情况下,我们不希望对该工作进行处罚,而只是保持在原来的水平。
图8.4展示了这个过程的一个示例,一个交互式作业B(灰色显示)在执行I/O与一个长时间运行的批处理作业a(黑色显示)竞争CPU之前只需要占用CPU 1毫秒。MLFQ方法保持B的最高优先级,因为B不断释放CPU;如果B是一个交互作业,MLFQ进一步实现了快速运行交互作业的目标。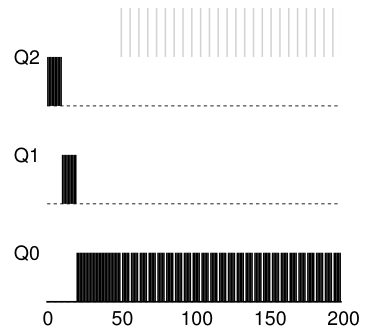
我们当前MLFQ的问题 Problems With Our Current MLFQ
这样我们就有了一个基本的MLFQ。它似乎做得相当不错,在长时间运行的作业之间公平地共享CPU,并允许短的或 I/O 密集型交互作业快速运行。不幸的是,我们迄今所开发的方法存在严重的缺陷。你能想到吗?
(这时你会停下来,尽可能迂回地思考)
首先,有一个饿死(starvation)的问题:如果系统中有太多的交互作业,它们将合并起来消耗所有的CPU时间,因此长时间运行的作业将永远不会获得任何CPU时间(它们饿死(starve))。我们希望即使在这种情况下,这些工作也能取得一些进展。
其次,聪明的用户可以重写他们的程序来对付调度程序。欺骗调度器通常指的是做一些狡猾的事情来欺骗调度器给你更多的资源份额。我们描述的算法容易受到以下攻击:在时间片结束之前,发出一个I/O操作(对一些你不关心的文件),从而放弃CPU;这样做可以让您保持在相同的队列中,从而获得更高的CPU时间百分比。如果操作正确(例如,在放弃CPU之前运行99%的时间片),一个作业几乎可以垄断CPU。
最后,程序可能会随着时间的推移而改变其行为;cpu限制可能会过渡到交互阶段。按照我们目前的方法,这样的任务将会很不幸,不会像系统中的其他交互式任务一样被对待。Tip:必须确保调度免受攻击 您可能会认为调度策略,无论是在操作系统本身内部(如本文所讨论的),还是在更广泛的上下文中(例如,在分布式存储系统的I/O请求处理[Y+18]),都不是一个安全(security)问题,但在越来越多的情况下,它确实是一个安全问题。考虑一下现代数据中心,来自世界各地的用户共享cpu、内存、网络和存储系统;如果在政策设计和执行方面不谨慎,一个用户就可能对他人造成不利的伤害,并为自己获得好处。因此,调度策略是系统安全性的重要组成部分,需要谨慎构建。
8.3 尝试2:优先级提升 Attempt #2: The Priority Boost
让我们试着改变规则,看看我们是否可以避免饥饿的问题。我们可以做些什么来保证受 CPU 限制的作业会取得一些进展(即使进展不大?)。
这里的简单思想是定期提高系统中所有作业的优先级。有很多方法可以实现这一点,但让我们做一些简单的事情:把它们都扔到最顶端的队列中;因此,有了新规则:
- 规则5:在一段时间后,将系统中的所有作业移到最顶端的队列。
我们的新规则同时解决了两个问题。首先,保证进程不会饿死:通过坐在最顶端的队列中,一个作业将以循环的方式与其他高优先级的作业共享CPU,从而最终获得服务。其次,如果cpu绑定的作业变成交互式的,调度程序会在它收到优先级提升后适当地处理它。
让我们看一个例子。在这个场景中,我们只展示了一个长时间运行的作业在与两个短期运行的交互式作业竞争 CPU 时的行为。图 8.5(第 6 页)显示了两个图形。在左边,没有优先级提升,因此一旦两个短作业到达,长时间运行的作业就会饿死;在右边,每 50 ms 有一个优先级提升(这可能是一个太小的值,但在示例中使用),因此我们至少可以保证长期运行的工作会取得一些进展,得到提升每 50 毫秒设置一次最高优先级,从而定期运行。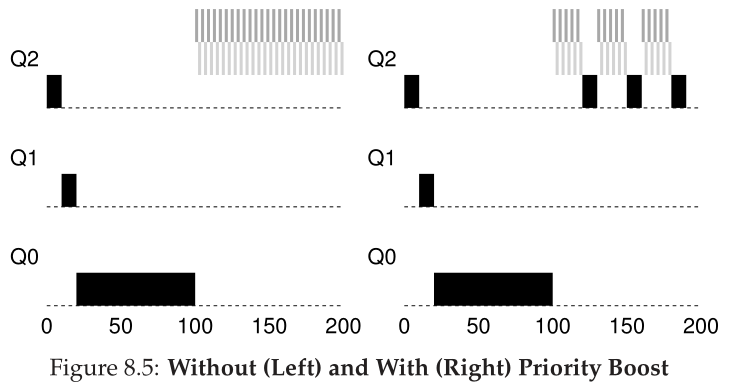
当然,时间周期S的加入会导致一个显而易见的问题:S应该被设为什么?John Ousterhout,一位著名的系统研究者[O11],曾经在系统中称这些值为巫术常量(voo-doo constants),因为它们似乎需要某种形式的黑魔法来正确地设置它们。不幸的是,S有这种味道。如果设定过高,长时间运行的工作可能会饿死;太低,交互作业可能得不到适当的CPU共享。
8.4 尝试3:更好的核算 Attempt #3: Better Accounting
现在我们还有一个问题要解决:如何防止调度程序的游戏?这里真正的罪魁祸首(您可能已经猜到了)是规则4a和4b,它们通过在时间片到期之前放弃CPU来让作业保持其优先级。那么我们该怎么办呢?
这里的解决方案是在MLFQ的每个级别上更好地计算(accounting)CPU时间。调度程序应该跟踪进程在给定级别上使用了多少时间片,而不是忘记;一旦进程使用了它的分配,它就降级到下一个优先级队列。它是在一个长脉冲中使用时间片还是在许多小脉冲中使用时间片并不重要。因此,我们将规则4a和4b改写为以下单一规则:
- 规则4:一旦一个任务在给定的级别上耗尽了它的时间分配(不管它放弃了CPU多少次),它的优先级就会降低(也就是说,它会向下移动一个队列)。
让我们来看一个例子。图8.6(第7页)显示了当工作负载试图用旧规则4a和4b(左边)以及新的反游戏规则4与调度程序博弈时的结果。在没有任何防止游戏的保护的情况下,进程可以在时间片结束之前发出I/O,从而支配CPU时间。有了这样的保护,不管进程的I/O行为如何,它都会缓慢地沿着队列移动,因此不会获得不公平的CPU份额。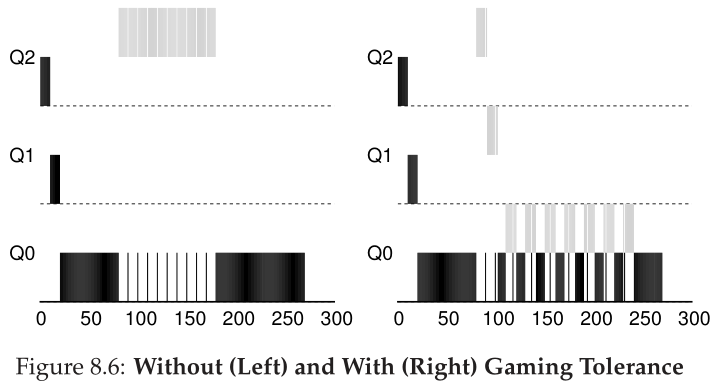
8.5 调整MLFQ和其他问题 Tuning MLFQ And Other Issues
在MLFQ调度中还出现了其他一些问题。一个大问题是如何参数化(parameterize)这样的调度器。例如,应该有多少队列?每个队列的时间片应该有多大?为了避免饥饿和核算(starvation and account)行为的变化,应该多长时间提高优先级?这些问题没有简单的答案,因此只有一些工作负载方面的经验和调度器的后续调优才能达到令人满意的平衡。
Tip:避免巫术常数 只要可能,避免巫术常量(voo-doo constants)是一个好主意。不幸的是,就像上面的例子一样,这通常是困难的。人们可以尝试让系统学习到一个好的值,但这也不是简单的。常见的结果是:配置文件中充满了默认参数值,经验丰富的管理员可以在某些东西不能正常工作时调整这些值。可以想象,这些通常都没有修改,因此我们只能希望默认值在该领域能够正常工作。这个提示是由我们的老操作系统教授约翰·奥斯特胡特带来的,因此我们称之为奥斯特胡特定律(Ousterhout’s Law)。
例如,大多数MLFQ变体允许在不同队列之间改变时间片长度。高优先级队列通常分配较短的时间片;毕竟,它们是由交互式作业组成的,因此在它们之间快速切换是有意义的(例如,10毫秒或更少的毫秒)。相比之下,低优先级队列包含受cpu限制的长时间运行的作业;因此,较长的时间片可以很好地工作(例如,100毫秒)。图8.7(第8页)显示了一个示例,其中两个作业在最高队列上运行20毫秒(时间片为10毫秒),在中间队列运行40毫秒(时间片为20毫秒),在最低队列运行40毫秒。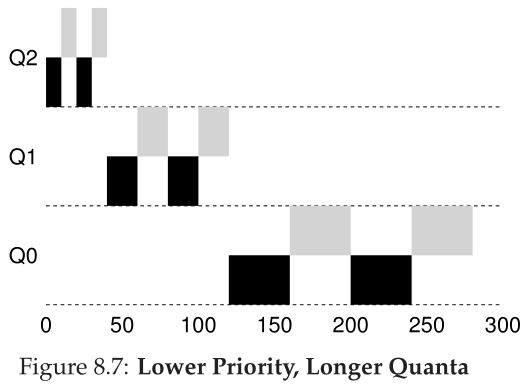
Solaris MLFQ实现分时调度类(TS)特别容易配置;它提供了一组表,这些表精确地确定了进程的优先级在整个生命周期中是如何改变的,每个时间片有多长,以及提高作业的优先级的频率[AD00];管理员可以对该表进行修改,以使调度程序以不同的方式运行。该表的默认值是60个队列,时间片长度从20毫秒(最高优先级)缓慢增加到几百毫秒(最低优先级),优先级大约每1秒提高一次。
其他MLFQ调度程序不使用本章描述的表或确切规则;相反,他们使用数学公式调整优先级。例如,FreeBSD调度器(4.3版)使用一个公式来计算任务的当前优先级,基于进程使用了多少CPU [LM+89];此外,使用量会随着时间的推移而下降,以一种与本文所描述的不同的方式提供所需的优先级提升。请参阅Epema的论文,了解这种衰减使用(decay-usage)算法及其特性的优秀概述[E95]。
最后,许多调度程序还有一些您可能会遇到的其他特性。例如,一些调度程序为操作系统工作保留最高的优先级级别;因此,典型的用户作业永远无法在系统中获得最高级别的优先级。一些系统还允许一些用户建议(advice)来帮助确定优先级;例如,通过使用命令行实用程序nice,您可以(在一定程度上)提高或降低作业的优先级,从而提高或降低作业在任何给定时间运行的机会。有关更多信息,请参阅手册页(man page)。
Tip:在可能的情况下使用建议 由于操作系统很少知道对系统的每个进程来说什么是最好的,所以提供允许用户或管理员向操作系统提供一些提示(hints)的接口通常是有用的。我们经常称这些提示为建议(advice),因为操作系统不一定要注意它,而是可能会考虑这些建议,以便做出更好的决定。这种提示在操作系统的许多部分都很有用,包括调度程序(例如nice)、内存管理器(例如madvise)和文件系统(例如知情预取和缓存[P+95])。
8.6 MLFQ:总结 MLFQ: Summary
我们已经描述了一种调度方法,称为多级反馈队列(MLFQ)。希望您现在能够明白为什么这样称呼它:它有多个级别的队列,并使用反馈来确定给定作业的优先级。历史是它的指南:注意随着时间的推移,工作表现如何,并相应地对待它们。
详细的MLFQ规则集,遍布整个章节,为了您的观感在这里重新列出:
- 规则1:如果Priority(A) > Priority(B),则A运行(B不运行)。
- 规则2:如果Priority(A) = Priority(B),那么A和B将使用给定队列的时间片(量子长度quantum length)进行轮询。
- 规则3:当一个作业进入系统时,它的优先级最高(最顶端的队列)。
- 规则4:一旦一个任务在给定的级别上用完它的时间分配(不管它放弃了CPU多少次),它的优先级就会降低(也就是说,它会移到一个队列下面)。
- 规则5:在一段时间后,将系统中的所有作业移到最顶端的队列。
MLFQ之所以有趣,原因如下:它不是要求对作业性质的先验知识,而是观察作业的执行情况,并相应地对其进行优先级排序。通过这种方式,它设法实现了两方面的最佳效果:它可以为短时间运行的交互式作业提供出色的总体性能(类似于SJF/STCF),并且对于长时间运行的cpu密集型工作负载是公平的,并取得了进步。因此,许多系统,包括BSD UNIX衍生物[LM+89, B86]、Solaris [M06]、Windows NT和后续的Windows操作系统[CS97],都使用一种形式的MLFQ作为基本调度器。
References
[AD00] “Multilevel Feedback Queue Scheduling in Solaris” by Andrea Arpaci-Dusseau. Avail-able: http://www.ostep.org/Citations/notes-solaris.pdf. A great short set of notes by one of the
authors on the details of the Solaris scheduler. OK, we are probably biased in this description, but the
notes are pretty darn good.
[B86] “The Design of the UNIX Operating System” by M.J. Bach. Prentice-Hall, 1986. One of the
classic old books on how a real UNIX operating system is built; a definite must-read for kernel hackers.
[C+62] “An Experimental Time-Sharing System” by F. J. Corbato, M. M. Daggett, R. C. Daley.
IFIPS 1962. A bit hard to read, but the source of many of the first ideas in multi-level feedback schedul-
ing. Much of this later went into Multics, which one could argue was the most influential operating
system of all time.
[CS97] “Inside Windows NT” by Helen Custer and David A. Solomon. Microsoft Press, 1997.
The NT book, if you want to learn about something other than UNIX. Of course, why would you? OK,
we’re kidding; you might actually work for Microsoft some day you know.
[E95] “An Analysis of Decay-Usage Scheduling in Multiprocessors” by D.H.J. Epema. SIG-
METRICS ’95. A nice paper on the state of the art of scheduling back in the mid 1990s, including a
good overview of the basic approach behind decay-usage schedulers.
[LM+89] “The Design and Implementation of the 4.3BSD UNIX Operating System” by S.J. Lef-
fler, M.K. McKusick, M.J. Karels, J.S. Quarterman. Addison-Wesley, 1989. Another OS classic,
written by four of the main people behind BSD. The later versions of this book, while more up to date,
don’t quite match the beauty of this one.
[M06] “Solaris Internals: Solaris 10 and OpenSolaris Kernel Architecture” by Richard Mc-
Dougall. Prentice-Hall, 2006. A good book about Solaris and how it works.
[O11] “John Ousterhout’s Home Page” by John Ousterhout. www.stanford.edu/˜ouster/.
The home page of the famous Professor Ousterhout. The two co-authors of this book had the pleasure of
taking graduate operating systems from Ousterhout while in graduate school; indeed, this is where the
two co-authors got to know each other, eventually leading to marriage, kids, and even this book. Thus,
you really can blame Ousterhout for this entire mess you’re in.
[P+95] “Informed Prefetching and Caching” by R.H. Patterson, G.A. Gibson, E. Ginting, D.
Stodolsky, J. Zelenka. SOSP ’95, Copper Mountain, Colorado, October 1995. A fun paper about
some very cool ideas in file systems, including how applications can give the OS advice about what files
it is accessing and how it plans to access them.
[Y+18] “Principled Schedulability Analysis for Distributed Storage Systems using Thread Ar-
chitecture Models” by Suli Yang, Jing Liu, Andrea C. Arpaci-Dusseau, Remzi H. Arpaci-
Dusseau. OSDI ’18, San Diego, California. A recent work of our group that demonstrates the
difficulty of scheduling I/O requests within modern distributed storage systems such as Hive/HDFS,
Cassandra, MongoDB, and Riak. Without care, a single user might be able to monopolize system re-
sources.
Homework (Simulation)
这个程序,mlfq.py,允许你查看本章中呈现的MLFQ调度器的行为。有关详细信息,请参阅README。
Questions
- 使用两个作业和两个队列运行一些随机生成的问题;计算每一个的MLFQ执行跟踪。通过限制每个作业的长度和关闭I/O来简化您的工作。
- 您将如何运行调度程序来重现本章中的每个示例?
- 如何配置调度器参数,使其行为类似于round-robin调度器?
- 使用两个作业和调度器参数创建一个工作负载,这样一个作业就可以利用旧的规则4a和4b(使用-S标志打开)来操纵调度器,并在特定的时间间隔内获得99%的CPU。
- 给定一个系统在其最高队列中的量子长度(时间片)为 10 毫秒,您必须多久将作业提升回最高优先级(使用 -B 标志)以保证单个长时间运行(和潜在-饿死)作业至少获得 5% 的 CPU?
- 在调度中出现的一个问题是,在队列的哪个末端添加一个刚刚完成I/O的作业;-I标志改变这个调度模拟器的行为。尝试一些工作负载,看看是否可以看到这个标志的效果。

若有收获,就点个赞吧
0 人点赞
