在开发CPU虚拟化时,我们主要关注一种称为受限直接执行(limited direct execution, LDE)的通用机制。LDE背后的思想很简单:在大多数情况下,让程序直接在硬件上运行;然而,在某些关键的时间点(例如当进程发出系统调用,或计时器中断发生时),安排操作系统参与并确保“正确”的事情发生。因此,操作系统在硬件支持很少的情况下,尽量避开正在运行的程序,提供高效的虚拟化;然而,通过在这些关键时间点进行插入(interposing),操作系统确保它保持对硬件的控制。效率和控制一起是任何现代操作系统的两个主要目标。
Tip:插入是强大的 插入(Interposition)是一种通用的、功能强大的技术,在计算机系统中经常发挥重要作用。在虚拟化内存中,硬件将对每次内存访问进行干预,并将进程发出的每个虚拟地址转换为实际存储所需信息的物理地址。然而,插入的一般技术的适用范围要广泛得多;实际上,几乎任何定义良好的接口都可以被插入,以添加新的功能或改进系统的其他方面。这种方法通常的好处之一是透明度(transparency);插入操作通常不需要更改客户机的接口,因此不需要更改所述客户机。
在虚拟化内存方面,我们将采用类似的策略,在提供所需虚拟化的同时获得效率和控制。为了提高效率,我们必须使用硬件支持,一开始硬件支持是相当初级的(例如,只有几个寄存器),但是随着时间的推移会变得相当复杂(例如,TLBs、页表支持等等,您将看到)。控制意味着操作系统确保除了它自己的内存之外,不允许任何应用程序访问任何内存;因此,为了保护应用程序不受其他应用程序的侵害,保护操作系统不受应用程序的侵害,我们还需要硬件的帮助。最后,就灵活性而言,我们需要从VM(虚拟内存)系统中获得更多信息;具体来说,我们希望程序能够以任何他们想要的方式使用它们的地址空间,从而使系统更容易编程。这样我们就找到了精炼的关键问题:
关键的问题:如何高效灵活地虚拟化内存 我们如何构建高效的内存虚拟化?我们如何提供应用程序所需的灵活性?我们如何控制应用程序可以访问哪些内存位置,从而确保应用程序内存访问受到适当的限制?我们如何高效地完成这些?
我们将使用的通用技术(您可以将其视为对受限直接执行的通用方法的补充)称为基于硬件的地址转换(hardware-based address translation),或者简称为地址转换(address translation)。通过地址转换,硬件转换每次内存访问(例如,指令取、加载或存储),将指令提供的虚拟(virtual)地址更改为所需信息实际所在的物理(physical)地址。因此,在每个内存引用上,硬件执行一个地址转换,将应用程序内存引用重定向到它们在内存中的实际位置。
当然,硬件本身无法虚拟化内存,因为它只是提供了一种底层机制来有效地实现这一功能。操作系统必须在关键节点上参与设置硬件,以便进行正确的翻译;因此,它必须管理内存(manage memory),跟踪哪些位置是空闲的,哪些位置在使用中,并明智地干预以控制如何使用内存。
同样,所有这些工作的目标是创建一个美丽的假象(illusion):程序有它自己的私有内存,它自己的代码和数据驻留在那里。在虚拟现实的背后隐藏着一个丑陋的物理事实:当CPU(或多个CPU)在运行一个程序和下一个程序之间切换时,许多程序实际上同时共享内存。通过虚拟化,操作系统(在硬件的帮助下)将丑陋的机器现实变成了有用的、强大的、易于使用的抽象。
15.1 假设 Assumptions
我们对内存虚拟化的第一次尝试是非常简单的,几乎是可笑的。去吧,想笑就笑吧;很快,当您试图理解TLBs、多级页表和其他技术奇迹的来由时,操作系统就会嘲笑您。不喜欢操作系统嘲笑你的想法?好吧,那你可就倒霉了;这就是操作系统的运行方式。
具体来说,我们现在假设用户的地址空间必须连续地放置在物理内存中。为了简单起见,我们还假设地址空间的大小不是太大;具体来说,它小于物理内存的大小。最后,我们还假设每个地址空间的大小完全相同。如果这些假设听起来不现实,不要担心;我们将在进行过程中放松它们,从而实现现实的内存虚拟化。
15.2 一个例子 An Example
为了更好地理解实现地址转换需要做什么,以及为什么需要这样的机制,让我们看一个简单的示例。假设有一个进程,其地址空间如图15.1所示。我们在这里要检查的是一个简短的代码序列,它从内存中加载一个值,将其加3,然后将该值存储回内存中。你可以想象这段代码的c语言表示是这样的: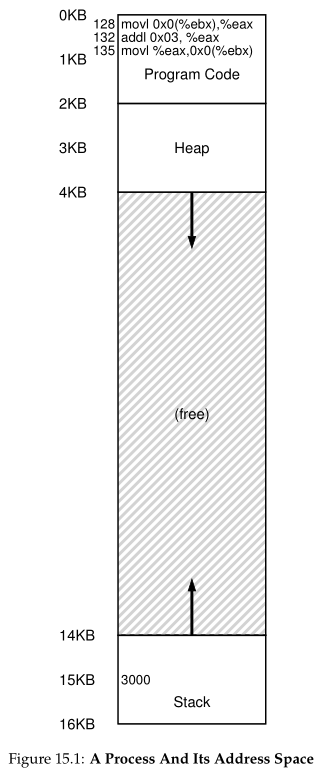

编译器将这行代码转换为汇编代码,它可能看起来像这样(在x86汇编中)。在Linux上使用objdump或在Mac上使用otool来分解它: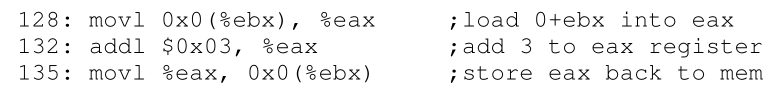
这段代码相对简单;它假定x的地址已经放在寄存器ebx中,然后使用movl指令(用于“长字”移动)将该地址处的值加载到通用寄存器eax中。下一条指令给eax加3,最后一条指令将eax中的值存储回同一位置的内存中。
在图15.1中,观察代码和数据是如何在进程的地址空间中布局的;三指令代码序列位于地址128(靠近顶部的代码段),变量x的值位于地址15 KB(靠近底部的堆栈)。在图中,x的初始值是3000,如其在堆栈中的位置所示。
从进程的角度来看,当这些指令运行时,将发生以下内存访问。
- 取地址为128的指令
- 执行此指令(从地址15kb加载)
- 获取地址132的指令
- 执行此指令(没有内存引用)
- 获取地址135的指令
- 执行此指令(存储到15kb)
从程序的角度来看,它的地址空间从地址0开始,并增长到最大16 KB;它生成的所有内存引用都应该在这些范围内。然而,为了虚拟化内存,操作系统希望将进程放置在物理内存中的其他位置,而不一定是地址0。因此,我们有一个问题:如何以一种对进程透明的方式在内存中重新部署这个进程?我们如何提供虚拟地址空间从0开始的假象,而实际上地址空间位于其他物理地址?
将进程的地址空间放入内存后,物理内存可能是什么样子的示例如图 15.2 所示。在图中,您可以看到操作系统为自己使用了第一个物理内存插槽,并且它已将上述示例中的进程重新定位到从物理内存地址 32 KB 开始的插槽中。另外两个插槽是空闲的(16 KB-32 KB 和 48 KB-64 KB)。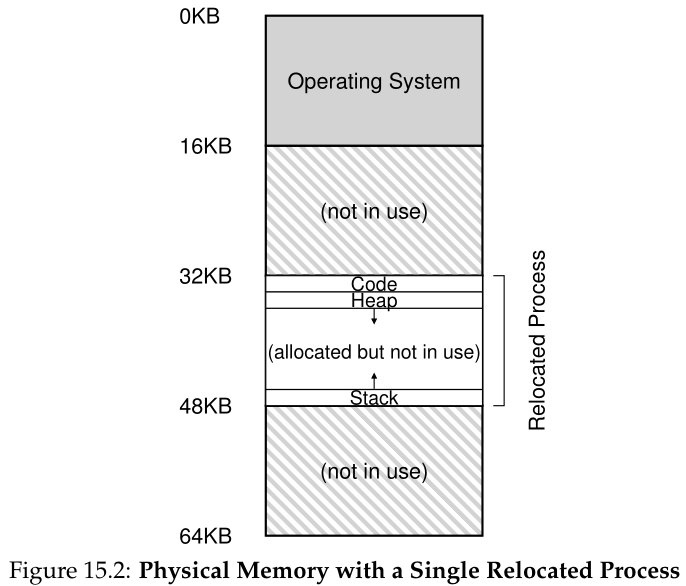
15.3 动态重定位(基于硬件) Dynamic (Hardware-based) Relocation
为了更好地理解基于硬件的地址转换,我们将首先讨论它的第一次出现。在20世纪50年代末第一台分时机器中引入的是一个简单的概念,称为基础和界限(base and bounds);这种技术也被称为动态重定位(dynamic relocation);我们将交替使用这两个术语[SS74]。
具体来说,我们需要在每个CPU中使用两个硬件寄存器:一个称为基(base)寄存器,另一个称为边界(bounds)寄存器(有时称为界限(limit)寄存器)。这个base-and-bounds对允许我们将地址空间放置在物理内存中的任何位置,同时确保进程只能访问它自己的地址空间。
Aside:基于软件的重定位 在早期,在硬件支持出现之前,一些系统纯粹通过软件方法执行一种粗糙的重新定位形式。基本的技术被称为静态重定位(static relocation),在这种情况下,被称为加载器(loader)的软件接受一个即将运行的可执行文件,并将其地址重写到物理内存中预期的偏移量。 例如,如果一条指令是从地址 1000 加载到寄存器(例如,movl 1000,%eax),并且程序的地址空间从地址 3000(而不是程序认为的 0)开始加载,则加载程序将重写指令以将每个地址偏移 3000(例如,movl 4000,%eax)。这样就实现了进程地址空间的简单静态重定位。 然而,静态重定位有许多问题。首先也是最重要的是,它不提供保护,因为进程会产生坏地址,从而非法访问其他进程甚至是操作系统的内存;一般来说,真正的保护可能需要硬件支持[WL+93]。另一个缺点是,一旦放置,以后很难将地址空间迁移到另一个位置[M65]。
在这个设置中,每个程序被编写和编译,就像它在地址0加载一样。然而,当程序开始运行时,操作系统决定应该在物理内存中的什么位置加载它,并将基寄存器设置为该值。在上面的例子中,操作系统决定在物理地址32kb上加载进程,因此将基寄存器设置为这个值。
当进程运行时,有趣的事情开始发生。现在,当进程生成任何内存引用时,处理器按照以下方式对其进行翻译(translated):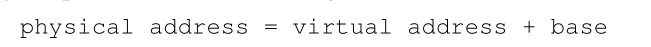
进程生成的每个内存引用都是一个虚拟地址(virtual address);硬件依次将基寄存器的内容添加到这个地址,结果就是一个可以发布到内存系统的物理地址(physical address)。
为了更好地理解这一点,让我们跟踪当单个指令执行时发生了什么。具体来说,让我们看看前面序列中的一条指令: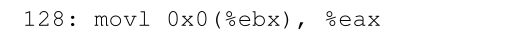
程序计数器(PC)设置为128;当硬件需要获取该指令时,它首先将该值加32kb的基寄存器值(32768),以获得物理地址32896;然后,硬件从该物理地址获取指令。接下来,处理器开始执行指令。在某个时刻,该进程然后从虚拟地址 15 KB 发出load,处理器将其取出并再次添加基址寄存器 (32 KB),从而获得 47 KB 的最终物理地址,从而获得所需的内容。
Tip:基于硬件的动态重定位 使用动态重定位,少量的硬件就能走很长的路。也就是说,基(base)寄存器用于将虚拟地址(由程序生成)转换为物理地址。边界(bounds)(或限制limit)寄存器确保这些地址在地址空间的限制内。它们一起提供了简单而高效的内存虚拟化。
将虚拟地址转换为物理地址就是我们所说的地址转换(address translation)技术;也就是说,硬件获取进程认为它正在引用的虚拟地址,并将其转换为数据实际驻留的物理地址。因为这种地址重定位是在运行时发生的,而且我们甚至可以在进程开始运行后移动地址空间,所以这种技术通常被称为动态重定位(dynamic relocation)[M65]。
现在你可能会问:边界寄存器发生了什么?毕竟,这不是base and bounds方法吗?事实上,它是。正如您可能已经猜到的,边界寄存器是用来帮助进行保护的。具体来说,处理器将首先检查内存引用是否在边界内,以确保它是合法的;在上面的简单示例中,边界寄存器总是设置为16 KB。如果进程生成的虚拟地址大于边界,或者是负数,CPU将引发异常,进程很可能被终止。边界的要点是确保由进程生成的所有地址都是合法的,并且在进程的“边界”之内。
我们应该注意到基寄存器和边界寄存器是存储在芯片上的硬件结构(每个CPU一对)。有时人们把处理器中帮助进行地址转换的部分称为内存管理单元(memory-management unit,MMU);随着我们开发更复杂的内存管理技术,我们将为MMU增加更多的电路。
关于边界寄存器的一小段旁白,它可以用两种方式之一来定义。以一种方式(如上所述),它保存地址空间的大小,因此硬件在添加基之前首先根据它检查虚拟地址。第二种方法是,它保存地址空间末端的物理地址,因此硬件首先添加基址,然后确保地址在边界内。这两种方法在逻辑上是等价的;为简单起见,我们通常采用前一种方法。
翻译的例子 Example Translations
为了更详细地理解通过基和边界的地址转换,让我们看一个示例。设想一个地址空间大小为4kb(是的,非常小)的进程在物理地址为16kb时被加载。以下是一些地址翻译的结果:
从示例中可以看到,简单地将基址添加到虚拟地址(可以将其视为地址空间的偏移量)就可以得到最终的物理地址。只有当虚拟地址“太大”或为负数时,结果才会是错误,从而引发异常。
15.4 硬件支持:一个总结 Hardware Support: A Summary
现在让我们总结一下我们需要从硬件获得的支持(参见图15.3)。首先,正如在CPU虚拟化一章中讨论的那样,我们需要两种不同的CPU模式。操作系统运行在特权模式(或内核模式)中,它可以访问整个机器;应用程序在用户模式下运行,在用户模式下它们所能做的事情是有限的。一个单bit,可能存储在某种处理器状态字(processor status word)中,指示CPU当前运行的模式;在某些特殊情况下(例如,系统调用或其他类型的异常或中断),CPU切换模式。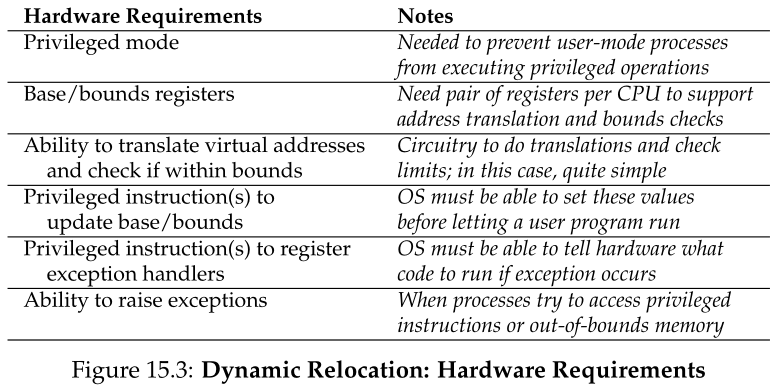
硬件本身也必须提供基寄存器和边界寄存器(base and bounds registers);因此,每个CPU都有一对额外的寄存器,这是CPU的内存管理单元(memory management unit,MMU)的一部分。当用户程序运行时,硬件将通过将基值加到用户程序生成的虚拟地址中来转换每个地址。硬件还必须能够检查地址是否有效,这是通过使用边界寄存器和CPU中的一些电路来实现的。
硬件应该提供特殊的指令来修改基寄存器和边界寄存器,允许操作系统在不同进程运行时更改它们。这些指令是有特权的;只有在内核(或特权)模式下才能修改寄存器。想象一下,如果用户进程可以在运行时任意更改基本寄存器,那么它会造成多大的破坏(Imagine the havoc a user process could wreak if it could arbitrarily change the base register while running.)。想象一下吧!然后迅速把这些阴暗的想法从你的头脑中清除出去,因为它们是构成噩梦的可怕的东西。
除了“havoc”,还有什么可以“wreaked”的吗?[W17]
Aside:空闲链表 操作系统必须跟踪哪些空闲内存没有被使用,以便能够将内存分配给进程。当然,许多不同的数据结构可以用于这样的任务;最简单的(我们在这里假设)是一个空闲链表(free list),它只是一个当前未使用的物理内存范围的链表。
最后,CPU必须能够在用户程序试图非法访问内存的情况下生成异常(exceptions)(地址是“out of bounds”);在这种情况下,CPU应该停止执行用户程序,并安排操作系统“out-of-bounds”异常处理程序(exception handler)运行。然后,操作系统处理程序可以确定如何作出反应,在这种情况下可能会终止进程。类似地,如果一个用户程序试图改变(特权的)基寄存器和边界寄存器的值,CPU应该引发一个异常并运行“在用户模式下尝试执行特权操作”处理程序。CPU还必须提供一个方法来告知这些处理程序的位置;因此需要一些更特殊的指令。
15.5 操作系统问题 Operating System Issues
就像硬件提供了支持动态重定位的新特性一样,操作系统现在也有新的问题需要处理;硬件支持和操作系统管理的结合导致了一个简单的虚拟内存的实现。具体来说,有几个关键时刻OS必须参与实现base-and-bounds版本的虚拟内存。
首先,当一个进程被创建时,操作系统必须采取行动,在内存中为它的地址空间寻找空间。幸运的是,假设每个地址空间(a)小于物理内存的大小,(b)相同大小,这对操作系统来说很容易;它可以简单地将物理内存看作插槽的数组,并跟踪每个插槽是空闲的还是正在使用中。当一个新进程被创建时,操作系统将不得不搜索一个数据结构(通常称为空闲链表(free list))来为新地址空间找到空间,然后将其标记为已使用。使用可变大小的地址空间,情况会更加复杂,但我们将把这个问题留给以后的章节。
让我们来看一个例子。在图15.2中,可以看到操作系统为自己使用物理内存的第一个插槽,并且它将进程从上面的示例重新定位到物理内存地址为32 KB的插槽中。另外两个插槽是空闲的(16kb - 32kb和48kb - 64kb);因此,空闲链表表应该由这两个条目组成。
第二,当一个进程被终止时(即,当它正常退出时,或者由于它的错误行为而被强制终止时),操作系统必须做一些工作,回收它的所有内存以供其他进程或操作系统使用。当进程终止时,操作系统将其内存放回空闲列表,并根据需要清理任何相关的数据结构。
第三,当发生上下文切换时,操作系统还必须执行一些额外的步骤。毕竟,每个CPU上只有一个基寄存器和边界寄存器对,它们的值对于每个运行的程序是不同的,因为每个程序加载在内存中的不同物理地址。因此,当操作系统在进程之间切换时,必须保存和恢复base-and-bounds对。具体来说,当操作系统决定停止运行一个进程时,它必须将基寄存器和边界寄存器的值保存到内存,在某些单进程结构(per-process structure)中,例如进程结构(process structure)或进程控制块(process control block,PCB)。类似地,当操作系统恢复一个正在运行的进程(或第一次运行它)时,它必须将CPU上的基值和边界值设置为该进程的正确值。
我们应该注意到,当一个进程停止(即不运行)时,操作系统可以很容易地将一个地址空间从内存中的一个位置移动到另一个位置。为了移动进程的地址空间,操作系统首先取消调度该进程;然后,操作系统将地址空间从当前位置复制到新位置;最后,操作系统更新(在进程结构中)保存的基寄存器以指向新的位置。当进程被恢复时,它的(新的)基寄存器被恢复,它再次开始运行,不知道它的指令和数据现在在内存中一个全新的位置。
第四,如前所述,操作系统必须提供异常处理程序(exception handlers)或要调用的函数;操作系统在启动(boot)时安装这些处理程序(通过特权指令)。例如,如果一个进程试图访问其边界之外的内存,CPU将引发异常;当出现此类异常时,操作系统必须准备好采取行动。操作系统的普遍反应将是一种敌意:它可能会终止冒犯的进程。操作系统应该高度保护它正在运行的机器,因此它不会友好地接受一个进程试图访问内存或执行它不应该执行的指令。再见,行为不端的过程;很高兴认识你。
图15.5和15.6在时间轴上展示了大部分硬件/操作系统交互。第一个图显示了操作系统在启动时为机器准备使用所做的工作,第二个图显示了进程(进程a)开始运行时所发生的事情;请注意它的内存转换是如何由硬件在没有操作系统干预的情况下处理的。在某个点(第二个图中间),定时器中断发生,操作系统切换到进程B,进程B执行一个“坏load”(到一个非法的内存地址);此时,操作系统必须参与进来,终止进程,并通过释放B的内存并从进程表中删除它的条目来进行清理。从数据中可以看出,我们仍然遵循受限直接执行(limited direct execution)的基本方法。在大多数情况下,操作系统只是适当地设置硬件,并让进程直接在CPU上运行;只有当进程行为异常时,操作系统才需要介入。

15.6 总结 Summary
在本章中,我们使用虚拟内存中使用的特定机制(称为地址转换)扩展了受限直接执行的概念。通过地址转换(address translation),操作系统可以控制进程的每一次内存访问,确保访问保持在地址空间的范围内。这种技术效率的关键是硬件支持,它为每次访问快速执行转换,将虚拟地址(进程的内存视图)转换为物理地址(实际视图)。所有这些都以对已重新定位的进程透明的方式执行;该进程不知道它的内存引用正在被翻译,从而产生一种美妙的假象(illusion)。
我们还看到了虚拟化的一种特殊形式,称为base and bounds或动态(dynamic)重定位。基和边界虚拟化非常有效,因为只需要稍微多一点硬件逻辑就可以向虚拟地址添加一个基寄存器,并检查进程生成的地址是否在边界内。Base-and-bounds也提供了保护;操作系统和硬件的结合,以确保没有进程可以在它自己的地址空间之外生成内存引用。保护当然是操作系统最重要的目标之一;没有它,操作系统就无法控制机器(如果进程可以自由地覆盖内存,它们可以很容易地做一些令人讨厌的事情,比如覆盖trap表并接管系统)。
不幸的是,这种简单的动态重新定位技术确实有其低效之处。例如,如图15.2所示,重新定位的进程使用的物理内存从32 KB到48 KB;但是,由于进程栈和堆不是太大,两者之间的所有空间都被浪费了。这种类型的浪费通常被称为内部碎片(internal fragmentation),因为分配的单元内部的空间没有被全部使用(即碎片化),因此被浪费了。在我们当前的方法中,尽管可能有足够的物理内存来容纳更多的进程,但我们目前被限制在一个固定大小的插槽中放置地址空间,因此可能会出现内部碎片。因此,我们需要更复杂的机制来更好地利用物理内存并避免内部碎片。我们的第一个尝试是对基和边界的稍微一般化,也就是我们接下来要讨论的分段(segmentation)。
另一种解决方案可能会在地址空间中放置一个固定大小的栈(就在代码区域的下方),并在其下方放置一个不断增长的堆。然而,这限制了灵活性,因为递归和深度嵌套函数调用具有挑战性,因此是我们希望避免的。
References
[M65] “On Dynamic Program Relocation” by W.C. McGee. IBM Systems Journal, Volume 4:3,
1965, pages 184–199. This paper is a nice summary of early work on dynamic relocation, as well as
some basics on static relocation.
[P90] “Relocating loader for MS-DOS .EXE executable files” by Kenneth D. A. Pillay. Micro-
processors & Microsystems archive, Volume 14:7 (September 1990). An example of a relocating
loader for MS-DOS. Not the first one, but just a relatively modern example of how such a system works.
[SS74] “The Protection of Information in Computer Systems” by J. Saltzer and M. Schroeder.
CACM, July 1974. From this paper: “The concepts of base-and-bound register and hardware-interpreted
descriptors appeared, apparently independently, between 1957 and 1959 on three projects with diverse
goals. At M.I.T., McCarthy suggested the base-and-bound idea as part of the memory protection system
necessary to make time-sharing feasible. IBM independently developed the base-and-bound register as a
mechanism to permit reliable multiprogramming of the Stretch (7030) computer system. At Burroughs,
R. Barton suggested that hardware-interpreted descriptors would provide direct support for the naming
scope rules of higher level languages in the B5000 computer system.” We found this quote on Mark
Smotherman’s cool history pages [S04]; see them for more information.
[S04] “System Call Support” by Mark Smotherman. May 2004. people.cs.clemson.edu/
˜mark/syscall.html. A neat history of system call support. Smotherman has also collected some
early history on items like interrupts and other fun aspects of computing history. See his web pages for
more details.
[WL+93] “Efficient Software-based Fault Isolation” by Robert Wahbe, Steven Lucco, Thomas
E. Anderson, Susan L. Graham. SOSP ’93. A terrific paper about how you can use compiler support
to bound memory references from a program, without hardware support. The paper sparked renewed
interest in software techniques for isolation of memory references.
[W17] Answer to footnote: “Is there anything other than havoc that can be wreaked?” by
Waciuma Wanjohi. October 2017. Amazingly, this enterprising reader found the answer via google’s
Ngram viewing tool (available at the following URL: http://books.google.com/ngrams)..)
The answer, thanks to Mr. Wanjohi: “It’s only since about 1970 that ’wreak havoc’ has been more
popular than ’wreak vengeance’. In the 1800s, the word wreak was almost always followed by ’his/their
vengeance’.” Apparently, when you wreak, you are up to no good, but at least wreakers have some
options now.
Homework (Simulation)
relocation.py程序允许你查看地址转换是如何在带有基寄存器和边界寄存器的系统中执行的。有关详细信息,请参阅README。
Questions
- 使用种子1、2和3运行,计算进程生成的每个虚拟地址是在边界内还是在边界外。如果在边界内,计算偏移。
- 使用这些标志运行:-s 0 -n 10。您将-l(边界寄存器)设置为什么值,以确保所有生成的虚拟地址都在边界内?
- 运行这些标志:-s 1 -n 10 -l 100。base可以设置的最大值是多少,以使地址空间仍然适合于整个物理内存?
- 运行上面的一些相同的问题,但是使用更大的地址空间(-a)和物理内存(-p)。
- 作为边界寄存器值的函数,有多少随机生成的虚拟地址是有效的?使用不同的随机种子运行生成图形,限制值范围从 0 到地址空间的最大大小。

若有收获,就点个赞吧
0 人点赞
