- 26.1 为什么使用线程? Why Use Threads?
- 26.2 一个示例:线程创建 An Example: Thread Creation
- 26.3 为什么会变糟:共享数据 Why It Gets Worse: Shared Data
- 26.4 问题的核心:不可控的调度 The Heart Of The Problem: Uncontrolled Scheduling
- 26.5 原子性的希望 The Wish For Atomicity
- 26.6 还有个问题:等到另一个 One More Problem: Waiting For Another
- 26.7 总结:为什么在操作系统课? Summary: Why in OS Class?
- References
- Homework (Simulation)
到目前为止,我们已经看到了操作系统执行的基本抽象的发展。我们已经看到了如何将一个物理CPU转换为多个**虚拟CPUs(virtual CPUs)**,从而实现多个程序同时运行的**假象(illusion)**。我们还看到了如何为每个进程创建一个大型私有**虚拟内存(virtual memory)**的假象;这种**地址空间(address space)**的抽象使每个程序的行为就像它拥有自己的内存一样,而实际上操作系统正在秘密地跨物理内存(有时是磁盘)多路复用地址空间。<br />在本文中,我们为单个运行的进程引入了一个新的抽象: **线程(thread)**的抽象。与我们传统的单执行点的观点不同,**多线程(multi-threaded)**程序有不止一个执行点(即,**多个PC(程序计数器),每个PC都在获取和执行指令**)。也许另一种思考方式是,**每个线程非常像一个独立的进程,除了一个不同点:它们共享相同的地址空间,因此可以访问相同的数据。**<br />因此,单个线程的状态非常类似于进程的状态。它有一个程序计数器(PC),用来跟踪程序从哪里获取指令。每个线程都有自己用于计算的一组私有寄存器;因此,如果在单个处理器上运行两个线程,当从运行一个(T1)切换到运行另一个(T2)时,必须进行**上下文切换(context switch)**。线程之间的上下文切换与进程之间的上下文切换非常相似,因为在运行T2之前,必须保存T1的寄存器状态,并恢复T2的寄存器状态。对于进程,我们将状态保存到**进程控制块(process control block,PCB)**;现在,我们需要一个或多个**线程控制块(thread control blocks,TCBs)**来存储进程中每个线程的状态。**但是,在线程之间执行的上下文切换与进程之间执行的上下文切换有一个主要区别: 地址空间保持不变(即,不需要切换我们正在使用的页表)。**<br />线程和进程之间的另一个主要区别在于栈。在经典进程(我们现在可以称之为**单线程进程(single-threaded process))**的地址空间的简单模型中,有一个栈,通常位于地址空间的底部(图26.1,左)。<br />然而,在多线程进程中,每个线程独立运行,当然可以调用各种例程来完成它正在做的任何工作。每个线程将有一个栈,而不是地址空间中的单个栈。假设我们有一个多线程进程,其中有两个线程;结果地址空间看起来不同(图 26.1,右)。<br />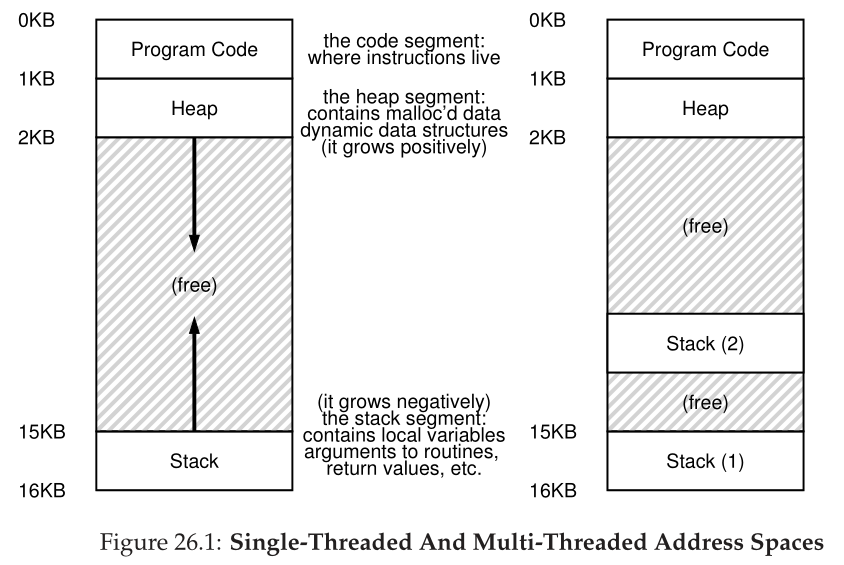<br />在该图中,您可以看到两个栈分布在进程的地址空间中。因此,任何栈分配的变量、参数、返回值和我们放在栈上的其他东西都将被放在有时称为**线程局部存储(thread-local storage)**的地方,即相关线程的栈。<br />您可能还注意到,这将如何破坏我们美丽的地址空间布局。以前,堆栈和堆可以独立增长,只有在地址空间中没有空间时才会出现问题。在这里,我们不再有这么好的情况。幸运的是,**这通常没问题,因为栈通常不必很大(在大量使用递归的程序中除外)**。
26.1 为什么使用线程? Why Use Threads?
在深入讨论线程的细节以及编写多线程程序时可能遇到的一些问题之前,让我们先回答一个更简单的问题。为什么要使用线程呢?
事实证明,应该使用线程至少有两个主要原因。第一个很简单:并行性(parallelism)。假设您正在编写一个程序,该程序在非常大的数组上执行操作,例如,将两个大数组相加,或将数组中每个元素的值增加一定数量。如果您只在单个处理器上运行,那么任务很简单:只需执行每个操作并完成即可。但是,如果您在一个有多个处理器的系统上执行程序,那么通过使用每个处理器执行部分工作,就有可能大大提高这个进程的速度。将标准单线程(single-threaded)程序转换为在多个 CPU 上执行此类工作的程序的任务称为并行化(parallelization),使用每个 CPU 一个线程来完成这项工作是使程序在现代硬件上运行得更快的自然而典型的方法.
第二个原因更微妙:避免由于缓慢的I/O而阻塞程序进程。假设您正在编写一个执行不同类型I/O的程序:等待发送或接收消息,等待显式磁盘I/O完成,甚至(隐式)等待缺页错误完成。与其等待,您的程序可能希望做一些其他的事情,包括利用CPU执行计算,甚至进一步发出I/O请求。使用线程是避免卡住的自然方法;当你的程序中的一个线程等待(即,阻塞等待I/O)时,CPU调度程序可以切换到其他线程,这些线程已经准备好运行并做一些有用的事情。线程化使I/O与单个程序内的其他活动重叠(overlap),很像多程序(multiprogramming)处理跨程序的进程;因此,许多现代基于服务器的应用程序(web服务器、数据库管理系统等)在其实现中使用了线程。
当然,在上面提到的任何一种情况下,都可以使用多个进程而不是线程。然而,线程共享一个地址空间,从而使共享数据变得容易,因此在构造这些类型的程序时是一个自然的选择。对于逻辑上独立的任务,如果不需要共享内存中的数据结构,则进程是更合理的选择。
当然,在上面提到的任何一种情况下,都可以使用多个进程而不是线程。然而,线程共享一个地址空间,从而使共享数据变得容易,因此在构造这些类型的程序时是一个自然的选择。对于逻辑上独立的任务,如果不需要共享内存中的数据结构,则进程是更合理的选择。
26.2 一个示例:线程创建 An Example: Thread Creation
让我们进入一些细节。假设我们想运行一个创建两个线程的程序,每个线程都做一些独立的工作,在本例中打印“A”或“B”。代码如图26.2(第4页)所示。
主程序创建两个线程,每个线程将运行mythread()函数,尽管参数不同(字符串A或B)。一旦创建了一个线程,它可能会立即开始运行(取决于调度程序的想法);另一种情况是,它可能处于“就绪”但不是“运行”状态,因此还没有运行。当然,在多处理器上,线程甚至可以同时运行,但现在还不需要担心这种可能性。
在创建两个线程(让我们称它们为T1和T2)之后,主线程调用pthread_join(),该方法等待特定线程完成。它这样做了两次,从而确保T1和T2将在最终允许主线程再次运行之前运行并完成;当它这样做时,它将打印“main: end”并退出。总的来说,在此运行期间使用了三个线程:主线程、T1和T2。
让我们检查一下这个小程序可能的执行顺序。在执行图(图26.3)中,时间是向下增加的,每一列都显示正在运行的不同线程(主线程,或者线程1,或者线程2)。
但是,请注意,这种排序不是唯一可能的排序。事实上,给定一个指令序列,有相当多的指令,这取决于调度程序在给定点决定运行哪个线程。例如,一旦创建了一个线程,它可能会立即运行,这将导致如图26.4所示的执行。
我们甚至可以看到“B”打印在“A”之前,如果调度程序决定先运行线程2,即使线程1更早创建;没有理由假设先创建的线程会先运行。图26.5显示了最后的执行顺序,线程2在线程1之前开始执行。
您可能会看到,考虑线程创建的一种方式是它有点像进行函数调用;然而,系统不是首先执行函数然后返回给调用者,而是为被调用的例程创建一个新的执行线程,它独立于调用者运行,可能在从创建返回之前,但也可能是更晚的时间。接下来运行什么由操作系统调度程序(scheduler)决定,尽管调度程序可能实现了一些合理的算法,但很难知道在任何给定的时刻将运行什么。
从这个示例中您可能也可以看出,线程使生活变得复杂:已经很难判断什么时候运行!如果没有并发性,计算机就很难理解。不幸的是,对于并发性(concurrency),它只会变得更糟。更糟。
26.3 为什么会变糟:共享数据 Why It Gets Worse: Shared Data
我们上面展示的简单线程示例有助于说明线程是如何创建的,以及它们如何根据调度程序决定运行它们的方式以不同的顺序运行。但是,它没有向您展示的是线程在访问共享数据时如何交互。
让我们想象一个简单的示例,其中两个线程希望更新一个全局共享变量。我们将研究的代码见图26.6。
这里有一些关于代码的注释。首先,正如 Stevens 所建议的 [SR05],我们包装 thread creation 和 join routines,以便在失败时简单地退出;对于像这样简单的程序,我们希望至少注意到发生了错误(如果发生了),但不要对其做任何非常明智的事情(例如,退出)。因此,Pthread_create() 只是调用 Pthread_create() 并确保返回码为 0;如果不是,Pthread_create() 只打印一条消息并退出。
其次,我们不为工作线程使用两个单独的函数体,而是只使用一段代码,并向线程传递一个参数(在本例中是一个字符串),这样我们就可以让每个线程在其消息之前打印不同的字母。
最后,也是最重要的,我们现在可以看看每个worker正在尝试做什么:向共享变量计数器加一,并在一个循环中这样做1000万次(1e7)。因此,期望的最终结果是:2000万。
现在我们编译并运行程序,看看它的行为。有些时候,一切都按照我们的预期运行:
不幸的是,当我们运行这段代码时,即使是在单个处理器上,我们也不一定会得到期望的结果。有时,我们得到:
让我们再试一次,看看我们是不是疯了。毕竟,计算机不应该产生确定性(deterministic)的结果吗?也许你的教授们一直在骗你?(喘气)。
不仅每次运行都是错误的,而且还会产生不同的结果!一个大问题仍然存在:为什么会发生这种情况?
Tip:了解并使用你的工具 你应该总是学习新的工具来帮助你编写、调试和理解计算机系统。在这里,我们使用了一个叫做反汇编器(disassembler)的简洁工具。当您在可执行文件上运行反汇编程序时,它会向您显示构成程序的汇编指令。例如,如果我们希望了解更新计数器的低级代码(如我们的示例中所示),我们运行 objdump (Linux) 以查看汇编代码:
prompt> objdump -d main这样做会产生一长串程序中所有指令的清单,这些清单被整齐地标记(特别是如果您使用-g标志进行编译),其中包括程序中的符号信息。objdump程序只是你应该学习如何使用的众多工具之一;像gdb这样的调试器,像valgrind或purify这样的内存分析器,当然还有编译器本身,您应该花时间了解更多;你越擅长使用你的工具,你就能构建更好的系统。
26.4 问题的核心:不可控的调度 The Heart Of The Problem: Uncontrolled Scheduling
要理解为什么会发生这种情况,我们必须理解编译器为 counter 更新生成的代码序列。在本例中,我们希望简单地向 counter 加一个数字(1)。因此,执行此操作的代码序列可能如下所示(在x86中);
本例假设变量 counter 位于地址0x8049a1c。在这三个指令序列中,x86 mov指令首先被用于获取地址处的内存值,并将其放入寄存器eax中。然后,执行add,在eax寄存器的内容中添加1 (0x1),最后,eax的内容被存储回相同地址的内存中。
让我们假设两个线程中的一个(线程1)进入了这个代码区域,因此要将 counter 加1。它将counter的值加载到它的寄存器eax中(假设counter的值是50)。因此,线程1的eax=50。然后将1加到寄存器中;因此eax = 51。现在,不幸的事情发生了:定时器中断;因此,操作系统将当前运行线程的状态(它的PC,它的寄存器,包括eax,等等)保存到线程的TCB(线程控制块)。
现在更糟糕的事情发生了:线程2被选择运行,它进入了相同的代码段。它还执行第一个指令,获取counter的值并将其放入它的eax中(记住:每个线程在运行时都有自己的私有寄存器;保存和恢复寄存器的上下文切换代码虚拟化(virtualized)了寄存器)。此时counter的值仍然是50,因此线程2的eax=50。然后让我们假设线程2执行接下来的两条指令,将eax加1(因此eax=51),然后将eax的内容保存到counter中(地址0x8049a1c)。因此,全局变量计数器现在的值是51。
最后,发生另一个上下文切换,线程1继续运行。回想一下,它刚刚执行了mov和add,现在要执行最后的mov指令。回想一下eax=51。因此,最后一条mov指令执行,并将值保存到内存中;计数器再次设置为51。
简单地说,所发生的事情是这样的:递增counter的代码已经运行了两次,但是counter,从50开始,现在只等于51。这个程序的正确版本应该使变量counter等于52。
让我们看一下详细的执行跟踪,以便更好地理解问题。假设,在这个例子中,上面的代码被加载在内存的地址100,就像下面的序列(注意那些习惯于类似risc的指令集的人:x86有可变长度的指令;这个mov指令占用5字节的内存,而add指令只占用3字节的内存):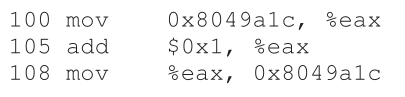
有了这些假设,图26.7显示了发生的情况。假设计数器的起始值为50,然后跟踪这个示例,以确保您理解发生了什么。
我们在这里演示的被称为竞争条件(race condition)(或者更具体地说,数据竞争(data race)):结果取决于代码执行的时序。如果运气不好(即在执行中不合时宜的点发生上下文切换),我们会得到错误的结果。事实上,我们每次都可能得到不同的结果;因此,我们将这个结果称为不确定的(indeterminate),而不是一个很好的确定性(deterministic)计算(这是我们在计算机中使用的),因为它不知道输出是什么,并且它确实可能在运行中有所不同。
因为执行此代码的多个线程可能会导致竞争条件,所以我们称此代码为临界区(critical section)。临界区是访问共享变量(或者更普遍地说,访问共享资源)的一段代码,并且不能由多个线程并发执行。
我们真正想要的是所谓的互斥(mutual exclusion)。这个属性保证,如果一个线程在临界区内执行,其他线程将无法执行。
事实上,所有这些术语,都是由Edsger Dijkstra创造的,他是这一领域的先驱,也因此获得了图灵奖;参见他1968年的论文“Cooperating Sequential Processes”[D68],对这个问题的描述非常清晰。在本书的这一部分,我们将听到更多关于Dijkstra的内容。
Tip:使用原子操作(atomic operation) 原子操作是构建计算机系统中最强大的底层技术之一,从计算机体系结构到并发代码(我们在这里要学习的),再到文件系统(我们很快就会学习),数据库管理系统,甚至分布式系统[L+93]。 将一系列操作原子化(atomic)的想法简单地用短语“all or nothing”来表达;它应该看起来好像您希望组合在一起的所有操作都发生了,或者它们都没有发生,没有可见的中间状态。有时,将许多操作组合成单个原子操作称为事务(transaction),这是在数据库和事务处理领域中非常详细地发展起来的一种想法 [GR92]。 在探索并发性的主题中,我们将使用同步原语(synchronization primitives)将简短的指令序列转换为执行的原子块,但正如我们将看到的,原子性的概念远不止于此。例如,文件系统使用诸如日志记录或写时复制等技术,以原子方式转换其磁盘上的状态,这对于在面临系统故障时正确操作至关重要。如果这还说不通,别担心——在以后的章节里会明白的。
26.5 原子性的希望 The Wish For Atomicity
解决这个问题的一种方法是使用更强大的指令,在一个步骤中,完成我们需要完成的任何事情,从而消除了不及时中断的可能性。例如,如果我们有一个像这样的超级指令: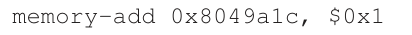
假设这条指令向内存位置加一个值,并且硬件保证它以原子方式执行;当指令执行时,它会根据需要执行更新。不能在指令中途中断,因为这正是我们从硬件得到的保证:当发生中断时,要么指令根本没有运行,要么已经运行完成;没有中间状态。硬件可以是一件美丽的事情,不是吗?
在这里,原子的意思是“作为一个单元”,有时我们认为是“all or none”。我们想要的是原子地执行三个指令序列:
就像我们说的,如果我们有一条指令来做这件事,我们就可以发出指令,然后完成。但一般情况下,我们不会有这样的指令。假设我们正在构建一个并发的b-树,并且希望更新它;我们真的希望硬件支持“b-树的原子更新”指令吗?可能不会,至少在一个正常的指令集中是这样。
因此,我们要做的是向硬件请求一些有用的指令,在这些指令的基础上,我们可以构建一组我们称为同步原语(synchronization primitives)的通用集合。通过使用这种硬件支持,并结合操作系统的一些帮助,我们将能够构建多线程代码,以同步和控制(ynchronized and controlled)的方式访问关键部分,从而可靠地产生正确的结果,尽管并发执行具有挑战性。非常棒,不是吗?
这是我们将在本书这一部分研究的问题。这是一个奇妙而又困难的问题,应该会使你的思想受到(一点)伤害。如果它没有,那么你就不明白!一直工作到你头疼为止;这样你就知道你走的方向是对的。这时,休息一下;我们不想让你的头太疼。
关键的问题:如何支持同步 为了构建有用的同步原语(synchronization primitives),我们需要硬件提供什么支持?我们需要从操作系统得到什么支持?如何正确高效地构建这些原语?程序如何使用它们来获得预期的结果?
26.6 还有个问题:等到另一个 One More Problem: Waiting For Another
本章讨论了并发问题,就好像线程之间只有一种交互,即访问共享变量(accessing shared variables)和支持临界区原子性(support atomicity for critical sections)的需求。结果是,出现了另一种常见的交互,其中一个线程必须等待另一个线程完成某些操作后才能继续。例如,当进程执行磁盘I/O并进入睡眠状态时,就会出现这种交互;当I/O完成时,需要将进程从休眠状态唤醒,以便继续执行。
因此,在接下来的章节中,我们不仅将学习如何构建对同步原语的支持以支持原子性,还将学习支持这种在多线程程序中常见的睡眠/唤醒交互(sleeping/waking interaction)的机制。如果这现在还说不通,那也没关系!当你读条件变量(condition variables)那一章时,很快就会明白了。如果到那时还没有,那就没那么好了,你应该一遍又一遍地读那一章,直到它变得有意义为止。
Aside:关键的并发术语(临界区域critical section,竞争条件race condition,不确定indeterminate,互斥mutual exclusion) 这四个术语对于并发代码非常重要,我们认为值得明确地列出它们。有关更多详细信息,请参阅 Dijkstra 的一些早期工作 [D65,D68]。
- 临界区域(critical section)是访问共享资源(通常是变量或数据结构)的一段代码。
- 如果多个执行线程大致在同一时间进入临界区,就会出现竞争条件(race condition)(或数据竞争(data race)[NM92]);两者都试图更新共享的数据结构,结果令人惊讶(也许是不希望的)。
- 不确定(indeterminate)程序由一个或多个竞争条件组成;程序的输出因运行而异,具体取决于哪个线程何时运行。因此,结果不是确定性(deterministic)的,这是我们通常对计算机系统的期望。
- 为了避免这些问题,线程应该使用某种互斥原语(mutual exclusion primitives);这样做可以保证只有一个线程进入临界区,从而避免竞争,并导致确定的程序输出。
26.7 总结:为什么在操作系统课? Summary: Why in OS Class?
在结束之前,你们可能会有一个问题:为什么我们要在操作系统课上学习这个?答案是“历史”;操作系统是第一个并发程序,许多技术被创造出来在操作系统中使用。后来,在多线程进程中,应用程序程序员也不得不考虑这些事情。
例如,假设有两个进程在运行。假设它们都调用write()来写入文件,并且都希望将数据追加到文件中(即,将数据添加到文件的末尾,从而增加文件的长度)。为此,两者都必须分配一个新块,记录在该块所在的文件的inode中,并更改文件的大小以反映新的更大的大小(以及其他事情;我们将在本书的第三部分学习更多关于文件的知识)。由于中断可能在任何时候发生,更新这些共享结构的代码(例如,分配的位图或文件的inode)是临界区域;因此,从引入中断的一开始,操作系统设计者就不得不担心操作系统如何更新内部结构。不合时宜的中断会导致上述所有问题。毫不奇怪,页表、进程列表、文件系统结构和几乎每个内核数据结构都必须使用适当的同步原语小心地访问,才能正常工作。
References
[D65] “Solution of a problem in concurrent programming control” by E. W. Dijkstra. Communications of the ACM, 8(9):569, September 1965.
Pointed to as the first paper of Dijkstra’s where he outlines the mutual exclusion problem and a solution. The solution, however, is not widely used; advanced hardware and OS support is needed, as we will see in the coming chapters.
[D68] “Cooperating sequential processes” by Edsger W. Dijkstra. 1968. Available at this site: http://www.cs.utexas.edu/users/EWD/ewd01xx/EWD123.PDF.
Dijkstra has an amazing number of his old papers, notes, and thoughts recorded (for posterity) on this website at the last place he worked, the University of Texas. Much of his foundational work, however, was done years earlier while he was at the Technische Hochshule of Eindhoven (THE), including this famous paper on “cooperating sequential processes”, which basically outlines all of the thinking that has to go into writing multi-threaded programs. Dijkstra discovered much of this while working on an operating system named after his school: the “THE” operating system (said “T”, “H”, “E”, and not like the word “the”).
[GR92] “Transaction Processing: Concepts and Techniques” by Jim Gray and Andreas Reuter. Morgan Kaufmann, September 1992.
This book is the bible of transaction processing, written by one of the legends of the field, Jim Gray. It is, for this reason, also considered Jim Gray’s “brain dump”, in which he wrote down everything he knows about how database management systems work. Sadly, Gray passed away tragically a few years back, and many of us lost a friend and great mentor, including the co-authors of said book, who were lucky enough to interact with Gray during their graduate school years.
[L+93] “Atomic Transactions” by Nancy Lynch, Michael Merritt, William Weihl, Alan Fekete. Morgan Kaufmann, August 1993.
A nice text on some of the theory and practice of atomic transactions for distributed systems. Perhaps a bit formal for some, but lots of good material is found herein.
[NM92] “What Are Race Conditions? Some Issues and Formalizations” by Robert H. B. Netzer and Barton P. Miller. ACM Letters on Programming Languages and Systems, Volume 1:1, March 1992.
An excellent discussion of the different types of races found in concurrent programs. In this chapter (and the next few), we focus on data races, but later we will broaden to discuss general races as well.
[SR05] “Advanced Programming in the UNIX Environment” by W. Richard Stevens and Stephen A. Rago. Addison-Wesley, 2005.
As we’ve said many times, buy this book, and read it, in little chunks, preferably before going to bed. This way, you will actually fall asleep more quickly; more importantly, you learn a little more about how to become a serious UNIX programmer.
Homework (Simulation)
这个程序x86.py允许您查看不同的线程交错是如何导致或避免竞争条件的。有关程序如何工作的详细信息,请参阅README,然后回答下面的问题。
Questions
- 让我们研究一个简单的程序“loop.s”。首先,阅读和理解它。然后,使用以下参数运行它(./x86.py -p loop.s -t 1 -i 100 -R dx)指定一个线程,每100条指令中断一次,并跟踪寄存器%dx。在运行期间%dx是什么?使用-c标志来检查你的答案;左边的答案显示了在右边的指令运行后寄存器的值(或内存值)。
- 相同的代码,不同的标志: (./x86.py -p loop.s -t 2 -i 100 -a dx=3,dx=3 -R dx) 这指定了两个线程,并将每个 %dx 初始化为 3。%dx 会看到什么值?使用 -c 运行以进行检查。多线程的存在是否会影响您的计算?这段代码中有竞争吗?
- 运行这个: ./x86.py -p loop.s -t 2 -i 3 -r -a dx=3,dx=3 -R dx 这使得中断间隔小/随机;使用不同的种子 (-s) 来查看不同的交错。中断频率会改变什么吗?
- 现在,一个不同的程序,looping-race-nolock.s,访问地址为2000的共享变量;我们称这个变量为value。./x86.py -p loop-race-nolock.s -t 1 -M 2000在整个运行过程中的值(即内存地址2000)是多少?使用-c进行检查。
- 使用多个迭代/线程运行: ./x86.py -p looping-race-nolock.s -t 2 -a bx=3 -M 2000 为什么每个线程循环 3 次?什么是value的最终值?
- 用不同的种子(-s 1, -s 2, etc.)以随机中断间隔运行: ./x86.py -p looping-race-nolock.s -t 2 -M 2000 -i 4 -r -s 0,您可以通过查看交织的线程来判断 value 的最终值是多少?中断的时间重要吗?哪里可以安全发生?哪里不行?换句话说,临界区究竟在哪里?
- 现在检查固定中断间隔: ./x86.py -p looping-race-nolock.s -a bx=1 -t 2 -M 2000 -i 1 共享变量value的最终值是多少?当您更改 -i 2、-i 3 等时呢?对于哪些中断间隔,程序给出了“正确”的答案?
- 对于更多的循环运行相同的程序(例如,set -a bx=100)。什么中断间隔(-i)会导致正确的结果?哪些间隔是令人惊讶的?
- 最后一个程序:wait-for-me.s.运行:./x86.py -p wait-for-me.s -a ax=1,ax=0 -R ax -M 2000 这会将 %ax 寄存器设置为线程 0 的 1,线程 1 的 0,以及观察 %ax 和内存位置 2000。代码应该如何表现?线程如何使用位置 2000 处的值?它的最终值是多少?
- 现在切换输入: ./x86.py -p wait-for-me.s -a ax=0,ax=1 -R ax -M 2000 线程的行为如何?线程 0 在做什么?更改中断间隔(例如,-i 1000,或者可能使用随机间隔)将如何更改跟踪结果?程序是否有效地使用了 CPU?

若有收获,就点个赞吧
0 人点赞
