- 28.1 锁:基本思想 Locks: The Basic Idea
- 28.2 线程锁 Pthread Locks
- 28.3 构建一个锁 Building A Lock
- 28.4 评估锁 Evaluating Locks
- 28.5 控制中断 Controlling Interrupts
- 28.6 一次失败的尝试:只使用加载和存储 A Failed Attempt: Just Using Loads/Stores
- 28.7 用测试并设置构建可用的自旋锁 Building Working Spin Locks with Test-And-Set
- 28.8 评估自旋锁 Evaluating Spin Locks
- 28.9 比较并交换 Compare-And-Swap
- 28.10 加载链接和存储条件 Load-Linked and Store-Conditional
- 28.11
- 28.12 自旋太多:现在呢? Too Much Spinning: What Now?
- 28.13
- 28.14 使用队列:睡眠而不是自旋 Using Queues: Sleeping Instead Of Spinning
- 28.15
- 28.16
- 28.17
- References
- Homework (Simulation)
从并发性的介绍中,我们看到了并发编程中的一个基本问题:我们希望以原子方式执行一系列指令,但由于单个处理器(或多个线程在多个处理器上并发执行)上存在中断,我们不能这样做。在本章中,我们通过引入锁(lock)来直接解决这个问题。程序员用锁标记源代码,把它们放在临界区周围,从而确保任何这样的临界区都像单个原子指令(atomic instruction)一样执行。
28.1 锁:基本思想 Locks: The Basic Idea
例如,假设我们的临界区域是这样的,一个共享变量的典型更新: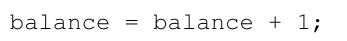
当然,其他临界区域也是可能的,比如向链表中添加元素,或者对共享结构进行其他更复杂的更新,但我们现在只讨论这个简单的示例。为了使用锁,我们在临界区周围添加一些代码,如下所示:
锁只是一个变量,因此要使用它,必须声明某种类型的锁变量(lock variable)(比如上面的互斥锁(mutex))。这个锁变量(或者简称为“锁”)保存着锁在任何时刻的状态。它要么是可用的(available)(或未锁定的或空闲的(unlocked or free)),因此没有线程持有锁,要么是获得的(acquired)(或锁定的或持有的(locked or held)),因此只有一个线程持有锁,并且假定处于临界区。我们也可以在数据类型中存储其他信息,比如哪个线程持有锁,或者获取锁的顺序队列,但是这样的信息对锁的用户是隐藏的。
lock()和unlock()例程的语义很简单。调用例程lock()试图获取锁;如果没有其他线程持有锁(即,它是空闲的),线程将获得锁并进入临界区;这个线程有时被称为锁的所有者。如果另一个线程随后对同一个锁变量(本例中为互斥锁)调用lock(),当锁被另一个线程持有时,lock()将不会返回;这样,当持有锁的第一个线程在临界区时,其他线程就不能进入临界区。
一旦锁的所有者调用unlock(),锁就可以再次使用(释放)了。如果没有其他线程在等待锁(即,没有其他线程调用lock()并被困在其中),锁的状态就简单地更改为释放。如果有等待的线程(卡在lock()中),其中一个将(最终)注意到(或被告知)锁状态的变化,获取锁,并进入临界区。
锁为程序员提供了对调度的最小控制。通常,我们将线程视为由程序员创建但由操作系统调度的实体,以操作系统选择的任何方式执行。锁将部分控制交还给程序员;通过将一段代码锁起来,程序员可以保证在该代码中不超过一个线程处于活动状态。因此,锁有助于将传统操作系统调度的混乱转变为更受控制的活动。
28.2 线程锁 Pthread Locks
POSIX 库用于锁的名称是互斥锁(mutex),因为它用于提供线程之间的互斥(mutual exclusion),即,如果一个线程处于临界区,则在完成该部分之前,它会阻止其他线程进入。因此,当您看到以下 POSIX 线程代码时,您应该明白它正在做与上面相同的事情(我们再次使用我们的封装在锁定和解锁时检查错误):
您可能还注意到,POSIX版本传递了一个变量来锁定和解锁,因为我们可能使用不同的锁来保护不同的变量。这样做可以提高并发性:而不是任何时候访问任何临界区时都使用一个大锁(一种粗粒度的(coarse-grained)锁定策略),人们通常会用不同的锁保护不同的数据和数据结构,从而允许更多的线程同时处于锁定代码中(一种更细粒度的(fine-grained)方法)。
28.3 构建一个锁 Building A Lock
到目前为止,您应该已经从程序员的角度对锁的工作原理有了一些了解。但是我们该怎么构建锁呢?需要哪些硬件支持?操作系统支持什么?这就是我们在本章剩下的部分要解决的问题。
关键的问题:如何建立一个锁 我们如何构建一个有效的锁?高效的锁以较低的代价提供互斥,还可能获得下面讨论的其他一些属性。需要哪些硬件支持?操作系统支持什么?
要构建一个可用的锁,我们需要老朋友硬件以及我们的好朋友操作系统的帮助。多年来,许多不同的硬件原语被添加到各种计算机体系结构的指令集中;虽然我们不会研究这些指令是如何实现的(毕竟这是计算机体系结构课程的主题),但我们将研究如何使用它们来构建像锁这样的互斥原语。我们还将研究操作系统如何参与其中,以完成整个过程,并使我们能够构建一个**复杂的锁库(sophisticated locking library)**。
28.4 评估锁 Evaluating Locks
在构建任何锁之前,我们应该首先了解我们的目标是什么,然后询问如何评估特定锁实现的有效性。为了评估锁是否工作(并且工作良好),我们应该建立一些基本标准。第一个问题是锁是否完成了它的基本任务,即提供互斥(mutual exclusion)。从根本上说,锁是否有效阻止多个线程进入临界区?
其次是公平(fairness)。一旦它是空闲的,每个争锁的线程是否都有公平的机会获得它?另一种方法是检查更极端的情况:是否有线程在争用锁时饿死(starve),因此永远得不到锁?
最后一个标准是性能(performance),特别是使用锁所增加的时间开销。这里有几个不同的案例值得考虑。一是没有竞争(contention)的情况;当单个线程运行并获取和释放锁时,这样做的开销是什么?另一种情况是多个线程在单个CPU上争夺锁;在这种情况下,是否存在性能问题?最后,当涉及多个cpu,并且每个cpu上的线程都在争用锁时,锁如何执行?通过比较这些不同的场景,我们可以更好地理解使用各种锁定技术对性能的影响,如下所述。
28.5 控制中断 Controlling Interrupts
最早用于提供互斥的解决方案之一是禁用临界区域的中断;这个解决方案是为单处理器系统而发明的。代码看起来像这样:
假设我们运行在这样一个单处理器系统上。通过在进入临界区之前关闭中断(使用某种特殊的硬件指令),我们可以确保临界区中的代码不会被中断,从而像原子一样执行。当我们完成时,我们重新启用中断(再次,通过硬件结构),因此程序照常进行。
这种方法的主要优点是简单。你当然不需要绞尽脑汁去弄清楚为什么这是可行的。在没有中断的情况下,线程可以确保它执行的代码将会执行,并且没有其他线程会干涉它。
不幸的是,负面因素很多。首先,这种方法要求我们允许任何调用线程执行特权操作(打开和关闭中断),因此相信这个功能不会被滥用。正如你已经知道的,任何时候我们被要求信任一个任意的程序,我们都可能陷入麻烦。在这里,问题以多种方式表现出来:贪婪的程序可能在开始执行时调用lock(),从而垄断处理器;更糟糕的是,一个错误的或恶意的程序可能调用lock()并进入一个无限循环。在后一种情况下,操作系统永远不会重新获得对系统的控制,只有一个补救办法:重新启动系统。使用中断禁用作为一个通用的同步解决方案需要对应用程序太多的信任。
第二,这种方法在多处理器上不起作用。如果多个线程在不同的cpu上运行,并且每个线程都试图进入相同的临界区,那么是否禁用中断并不重要;线程将能够在其他处理器上运行,因此可以进入临界区。由于多处理器现在很普遍,我们的通用解决方案必须做得更好。
第三,长时间关闭中断可能导致中断丢失(interrupts becoming lost),从而导致严重的系统问题。例如,假设CPU没有注意到磁盘设备已经完成了一个读请求。操作系统如何知道唤醒等待读取的进程?
最后,可能也是最不重要的一点是,这种方法可能效率低下。与普通指令执行相比,现代cpu执行屏蔽或取消屏蔽中断的代码往往很慢。
由于这些原因,关闭中断只在有限的上下文中作为互斥原语(mutual-exclusion primitive)使用。例如,在某些情况下,操作系统本身将使用中断屏蔽来在访问其自己的数据结构时保证原子性,或者至少防止出现某些混乱的中断处理情况。这种用法是有意义的,因为信任问题在操作系统内部消失了,它总是相信自己无论如何都会执行特权操作。
28.6 一次失败的尝试:只使用加载和存储 A Failed Attempt: Just Using Loads/Stores
为了超越基于中断的技术,我们将不得不依赖CPU硬件和它提供给我们的指令来构建一个合适的锁。让我们首先尝试使用一个标志变量来构建一个简单的锁。在这次失败的尝试中,我们将了解构建锁所需的一些基本思想,并(希望)了解为什么仅仅使用一个变量并通过正常的加载和存储访问它是不够的。
在第一次尝试中(图28.1),其思想非常简单:使用简单变量(标志)来指示某个线程是否拥有锁。进入临界区段的第一个线程将调用lock(),它将测试标志是否等于1(在本例中,它不等于),然后将标志设置为1以表明线程现在持有锁。当完成临界区时,线程调用unlock()并清除标志,从而表明锁不再被持有。
如果另一个线程碰巧在第一个线程处于临界区时调用lock(),它将在while循环中自旋等待(spin-wait)该线程调用unlock()并清除标志。一旦第一个线程这样做了,等待的线程将退出while循环,将自己的标志设置为1,并继续进入临界区。
不幸的是,代码有两个问题:一个是正确性问题,另一个是性能问题。一旦您习惯了并发编程,正确性问题就很容易理解了。想象一下图28.2中的代码交错;假设flag=0开始。
正如您可以从这种交错中看到的,通过及时(不及时?)中断,我们可以很容易地产生这样一种情况:两个线程都将标志设置为1,因此两个线程都能够进入临界区。这种行为就是专业人士所说的“bad”,我们显然没有提供最基本的要求:提供互斥。
性能问题(我们将在后面详细讨论)是线程等待获取已经持有的锁的方式:它无休止地检查flag的值,这种技术称为自旋等待(spin-waiting)。自旋等待浪费了等待另一个线程释放锁的时间。单处理器上的浪费是非常高的,在单处理器上,等待者所等待的线程甚至不能运行(至少,直到发生上下文切换)!因此,当我们向前推进并开发出更复杂的解决方案时,我们也应该考虑避免这类浪费的方法。
28.7 用测试并设置构建可用的自旋锁 Building Working Spin Locks with Test-And-Set
由于禁用中断在多处理器上不起作用,而且由于使用加载和存储(如上所示)的简单方法不起作用,系统设计人员开始发明对锁定的硬件支持。最早的多处理器系统,如20世纪60年代早期的Burroughs B5000 [M82],就有这样的支持;今天,所有系统都提供这种类型的支持,甚至对单个CPU系统也是如此。
需要理解的最简单的硬件支持是test-and-set(或atomic exchange)指令。下面的C代码段定义了test-and-set指令的作用:
每个支持test-and-set的体系结构都以不同的名称调用它。在SPARC上,它被称为加载/存储无符号字节指令(ldstub);在x86上,它是原子交换(xchg)的锁定版本。
Aside:戴克和彼得森的算法 20世纪60年代,Dijkstra向他的朋友提出了并发问题,其中一位数学家Theodorus Jozef Dekker提出了一个解决方案[D68]。不像我们在这里讨论的解决方案,使用特殊的硬件指令甚至操作系统支持,Dekker的算法(Dekker’s algorithm)只使用加载和存储(假设它们相互之间是原子的,这在早期的硬件上是正确的)。 Dekker的方法后来被Peterson改进了[P81]。同样,只使用加载和存储,其思想是确保两个线程永远不会同时进入临界区。这是Peterson的算法(Peterson’s algorithm)(用于两个线程);看看你能不能理解代码。flags和turn变量的用途是什么?
由于某些原因,开发不需要特殊硬件支持的锁风靡一时,给理论类型带来了许多问题。当然,当人们意识到提供一点硬件支持更容易时(事实上,这种支持早在早期的多处理时代就已经存在了),这一行工作就变得非常无用了。此外,如上所述的算法不能在现代硬件上工作(由于放松的内存一致性模型(relaxed memory consistency models)),从而使它们比以前更没用。然而,更多的研究被扔进了历史的垃圾箱……
测试和设置指令的作用如下所示。它返回old_ptr指向的旧值,并同时将该值更新为new。当然,关键是这个操作序列是以原子方式执行的。它被称为“测试并设置”的原因是,它使您能够“测试”旧的值(这是返回的),同时“设置”内存位置为一个新值;事实证明,这条稍微强大一点的指令足以构建一个简单的旋转锁,如图28.3所示。或者更好的做法是:先自己想清楚!<br />先弄清楚为什么这个锁管用。首先想象这样一种情况:一个线程调用lock(),而当前没有其他线程持有锁;因此,flag应该是0。当线程调用TestAndSet(flag, 1)时,例程将返回flag的旧值,即0;因此,正在测试flag值的调用线程将不会在while循环中被捕获,并将获得锁。线程还将原子地将该值设置为1,从而表示锁现在被持有。当线程完成它的临界区时,它调用unlock()将标志设置回0。<br />我们可以想象的第二种情况是,当一个线程已经持有了锁(即,flag是1)。在这种情况下,这个线程将调用lock(),然后也调用TestAndSet(flag,1)。这一次,TestAndSet()将返回旧的flag值,即1(因为锁被持有),同时再次将其设置为1。只要锁被另一个线程持有,TestAndSet()就会重复返回1,因此这个线程会不停地自旋,直到锁最终被释放。当其他线程最终将该标志设置为0时,该线程将再次调用TestAndSet(),该函数现在将返回0,同时原子地将值设置为1,从而获得锁并进入临界区。<br />通过将(旧锁值的)测试和(新锁值的)设置为单个原子操作,我们确保只有一个线程获得锁。这就是如何构建一个有效的**互斥原语(mutual exclusion primitive)**!<br />您现在也可以理解为什么这种类型的锁通常被称为**自旋锁(spin lock)**。它是要构建的最简单的锁类型,只是使用CPU周期自旋,直到锁可用为止。为了在单个处理器上正确地工作,它需要一个**抢占式调度程序(preemptive scheduler)**(即,为了时不时地运行不同的线程,它会通过计时器中断一个线程)。如果没有抢占,自旋锁在单个CPU上没有多大意义,因为在CPU上自旋的线程永远不会放弃它。
Tip:可以将并发看作是一个恶意的调度程序 从这个例子中,您可能会对理解并发执行所需采取的方法有所了解。你应该尝试做的是假装你是一个恶意的调度器(malicious scheduler),一个在最不合时宜的时候中断线程以阻止他们构建同步原语(synchronization primitives)的微弱尝试。你真是个卑鄙的调度器!尽管中断的确切顺序可能是不可能的,但它是可能的,这就是我们需要证明特定方法不起作用的全部内容。恶意思考可能很有用!(至少,有时)
28.8 评估自旋锁 Evaluating Spin Locks
鉴于我们的基本自旋锁,我们现在可以评估它沿我们之前描述的轴(axes)的有效性。锁最重要的方面是正确性(correctness):它是否提供互斥?答案是肯定的:自旋锁一次只允许一个线程进入临界区。因此,我们有一个正确的锁。
下一个轴(axes)是公平(fairness)。自旋锁对等待线程有多公平?你能保证一个正在等待的线程会进入临界区吗?不幸的是,这里的答案是坏消息:自旋锁不能提供任何公平保证。的确,在竞争中,线程自旋可能永远自旋下去。简单的自旋锁(如前所述)是不公平的,可能导致饥饿(starvation)。
最后一个轴是性能(performance)。使用自旋锁的成本是多少?为了更仔细地分析这一点,我们建议考虑几个不同的案例。在第一种情况中,想象线程在单个处理器上竞争锁;在第二种情况下,考虑线程分布在多个cpu上。
对于自旋锁,在单个CPU的情况下,性能开销可能非常痛苦;设想这样一种情况:持有锁的线程在临界区被抢占。调度程序可能会运行每一个其他线程(假设有N - 1个其他线程),每个线程都试图获取锁。在这种情况下,在放弃CPU之前,每个线程都将在一个时间段内自旋,这是对CPU周期的浪费。
但是,在多个cpu上,自旋锁工作得相当好(如果线程的数量大致等于cpu的数量)。其思路如下:假设CPU 1上的线程A和CPU 2上的线程B都在争锁。如果线程A (CPU 1)获取了锁,然后线程B试图获取锁,B将自旋(对CPU 2)。然而,大概是临界区域是短的, 因此很快锁可用,并被线程B获得. 在这种情况下,旋转以等待另一个处理器上持有的锁不会浪费很多周期,因此是有效的。
28.9 比较并交换 Compare-And-Swap
一些系统提供的另一个硬件原语称为比较并互换指令(compare-and-swap)(例如,在SPARC上调用它),或比较并交换指令(compare-and-exchange)(在x86上调用它)。这条指令的C伪代码见图28.4。
基本思想是通过比较并交换来测试ptr指定地址上的值是否等于expected值;如果是,则用新值更新ptr所指向的内存位置。如果不是,那就什么都不做。在这两种情况下,返回该内存位置的原始值,从而允许调用compare-and-swap的代码知道它是否成功。
使用比较并交换指令,我们可以以与test-and-set非常相似的方式构建锁。例如,我们可以用以下代码替换上面的lock()例程:
代码的其余部分与上面的测试和设置示例相同。这段代码的工作方式非常相似;它只是检查标志是否为0,如果是,则原子地交换1,从而获得锁。当锁被持有时,试图获取锁的线程将被卡住,直到锁最终被释放。
如果您想了解如何真正创建一个c可调用的x86版本的比较和交换,代码序列(来自[S05])可能会有用(https://github.com/remzi-arpacidusseau/ostep-code/tree/master/threads-locks)。
最后,您可能已经感觉到,比较并交换是比测试并设置更强大的指令。将来,当我们简要地研究无锁同步(lock-free synchronization)[H91]等主题时,我们将在一定程度上利用这种能力。然而,如果我们只是用它构建一个简单的自旋锁,它的行为与我们上面分析的自旋锁相同。
28.10 加载链接和存储条件 Load-Linked and Store-Conditional
有些平台提供了一对协同工作的指令,以帮助构建临界区域。例如,在MIPS架构[H93]中,加载链接和存储条件指令( load-linked and store-conditional instructions)可以串联使用,以构建锁和其他并发结构。这些指令的C伪代码如图28.5所示。Alpha、PowerPC和ARM提供了类似的指令[W09]。
load-linked操作与典型的load指令非常相似,只是简单地从内存中取出一个值并将其放入寄存器。关键的区别在于 store-conditional,它只有在没有发生对地址的存储的干预时才会成功(并更新存储在刚刚load-linked的地址中的值)。在成功的情况下,StoreConditional 返回1,并将ptr 处的值更新为value;如果失败,则不会更新 ptr 处的值并返回 0。
作为对您的一个挑战,请尝试考虑如何使用load-linked和store-conditional来构建锁。然后,当您完成时,查看下面的代码,它提供了一个简单的解决方案。做到!解决方案如图28.6所示。
lock()代码是唯一有趣的部分。首先,线程自旋,等待标志被设置为0(因此表明锁没有被持有)。一旦这样,线程就尝试通过store-conditional获取锁;如果成功,则线程自动将标志的值更改为1,从而可以进入临界区。
请注意,store-conditional可能会导致失败。一个线程调用lock()并执行load-linked,当锁未被持有时返回0。在它尝试store-conditional之前,它被中断,另一个线程进入锁代码,同样执行load-linked指令,也获得一个0并继续执行。此时,两个线程都已经执行了load-linked,并且都准备尝试store-conditional。这些指令的关键特征是,只有一个线程能够成功地将标志更新为1,从而获得锁;第二个尝试store-conditional的线程会失败(因为另一个线程在load-linked和store-conditional之间更新了flag的值),因此必须再次尝试获取锁。
在几年前的课堂上,本科生大卫·卡佩尔(David Capel)为喜欢“短路布尔条件句”的同学们提出了一种更简洁的形式。看看你是否能找出为什么它是等价的。它当然更短了!
28.11
取出并增加 Fetch-And-Add
最后一个硬件原语是取加(fetch-and-add)指令,它在返回特定地址的旧值的同时,原子地增加一个值。取加指令的C伪代码是这样的:
Tip:代码越少越好(劳尔定律Lauer’s Law) 程序员喜欢吹嘘他们写了多少代码来做某件事。这样做从根本上是错误的。相反,我们应该吹嘘的是,我们为完成给定的任务而编写的代码是多么的少。简短、简洁的代码总是首选;它可能更容易理解,并且有更少的错误。正如Hugh Lauer在讨论Pilot操作系统的构建时所说:“如果同样的人有两倍的时间,他们可以用一半的代码制作出同样好的系统。”我们把这个叫做劳尔定律(Lauer’s Law),它很值得记住。所以下次当你在吹嘘你写了多少代码来完成任务时,再想想,或者更好的是,回去重写,让代码尽可能的清晰和简洁。
在本例中,我们将使用获取和增加来构建一个更有趣的票据锁(ticket lock),正如Mellor-Crummey和Scott [MS91]所介绍的那样。在图28.7中可以找到锁和解锁代码。<br /><br />这个解决方案不是使用单个值,而是结合使用ticket和turn变量来构建锁。基本操作非常简单:当线程希望获得锁时,它首先对票据值执行原子取加操作;这个值现在被认为是这个线程的“turn”(myturn)。然后使用全局共享lock->turn来确定它是哪个线程的turn; 当(myturn == turn)为给定线程时,该线程将进入临界区。解锁是通过增加turn值来完成的,这样下一个等待的线程(如果有的话)就可以进入临界区。<br />注意这个解决方案与我们之前的尝试的一个重要区别:它确保了所有线程的执行。一旦一个线程被分配了它的票据值,它将在将来的某个时间点被调度(一旦它前面的线程通过了临界区并释放了锁)。在我们以前的尝试中,不存在这样的保证;在test-and-set(例如)上自旋的线程可能永远自旋,即使其他线程获取和释放锁。
28.12 自旋太多:现在呢? Too Much Spinning: What Now?
我们简单的基于硬件的锁很简单(只有几行代码),而且它们是有效的(如果您愿意,甚至可以通过编写一些代码来证明),这是任何系统或代码的两个优秀属性。然而,在某些情况下,这些解决方案可能非常低效。假设您在一个处理器上运行两个线程。现在,假设一个线程(线程0)处于临界区,因此持有锁,不幸被中断。第二个线程(线程1)现在试图获取锁,但发现锁被持有。因此,它开始自旋。然后自旋。然后它继续自旋转。最后,定时器中断结束,线程0再次运行,释放锁,最后(下一次它运行时),线程1不必自旋那么多,将能够获得锁。因此,每当线程在这种情况下被捕获时,它就会浪费整个时间片,只为了检查一个不会改变的值!当N个线程争用一个锁时,问题会变得更糟;N - 1个时间片可能以类似的方式被浪费,只是自旋和等待一个线程释放锁。因此,我们的下一个问题:
关键的问题:如何避免自旋 我们如何开发一个锁,而不是不必要地浪费时间在CPU上旋转?
单靠硬件支持并不能解决这个问题。我们也需要操作系统支持!现在我们来看看它是如何工作的。
28.13
一个简单的方法:让出来,宝贝 A Simple Approach: Just Yield, Baby
硬件支持让我们走得更远:有效锁,甚至(就像票据锁的情况)获取锁的公平性。然而,我们仍然有一个问题:当上下文切换发生在临界区,线程开始无休止地自旋,等待被中断(持有锁)的线程再次运行时,该怎么办?
我们的第一个尝试是一种简单而友好的方法:当你要旋转时,把CPU让给另一个线程。就像艾尔·戴维斯可能会说的,“让出来,宝贝!”[D91]。图28.8显示了这种方法。
在这种方法中,我们假设一个操作系统原语yield(),当线程想要放弃CPU并让另一个线程运行时,可以调用它。线程可以处于以下三种状态之一(运行中、就绪或阻塞(running, ready,
or blocked)); yield只是一个系统调用,它将调用者从运行状态移动到就绪状态,从而促进另一个线程运行。因此,让步线程(yielding thread)本质上是对自己进行调度(deschedules)。
考虑一个CPU上有两个线程的例子;在这种情况下,我们基于让步(yielding)的方法非常有效。如果一个线程碰巧调用lock()并发现一个锁被持有,它将简单地放弃CPU,因此另一个线程将运行并完成它的临界区。在这个简单的例子中,让步(yielding)方法工作得很好。
现在让我们考虑这样一种情况:有许多线程(比如100个)重复地争用一个锁。在这种情况下,如果一个线程获得了锁并在释放它之前被抢占,其他99个线程将分别调用lock(),找到被持有的锁,并让出CPU。假设有某种轮询(round-robin)调度程序,在持有锁的线程再次运行之前,这99个线程中的每一个都将执行这种运行-让步(run-and-yield)模式。虽然比旋转方法更好(旋转会浪费99个时间片),但这种方法仍然是昂贵的;上下文切换的成本可能是巨大的,因此存在大量浪费。
更糟糕的是,我们根本没有解决饥饿(starvation)问题。当其他线程反复进入和退出临界区时,一个线程可能会陷入无休止的yield循环。我们显然需要一种直接解决这个问题的方法。
28.14 使用队列:睡眠而不是自旋 Using Queues: Sleeping Instead Of Spinning
我们之前的方法的真正问题是,它们留下了太多的机会。调度程序决定接下来运行哪个线程;如果调度程序做出了错误的选择,线程运行时必须自旋等待锁(我们的第一种方法),或者立即放弃CPU(我们的第二种方法)。无论哪种方式,都有可能造成浪费,也无法预防饥饿(starvation)。
因此,我们必须显式地施加一些控制:在当前持有者释放锁之后,哪个线程将获得锁。要做到这一点,我们需要更多的操作系统支持,以及一个队列来跟踪哪些线程正在等待获取锁。
为了简单起见,我们将使用Solaris提供的支持,即两个调用:park()将调用线程置于睡眠状态,unpark(threadID)将唤醒由threadID指定的特定线程。这两个例程可以串联使用,以构建一个锁,如果调用者试图获取已被持有的锁,该锁将使调用者进入睡眠状态,并在锁空闲时唤醒它。让我们看一看图28.9中的代码,以理解这种原语的一种可能用法。
在这个例子中,我们做了一些有趣的事情。首先,我们将旧的测试和设置思想与显式的等待锁队列结合起来,以生成更有效的锁。其次,我们使用队列来帮助控制谁下一个获得锁,从而避免饥饿(starvation)。
您可能会注意到这个guard是如何使用的(图28.9),基本上起到了自旋锁的作用,围绕着 flag 和队列操作。因此,这种方法并不能完全避免自旋等待;一个线程在获取或释放锁时可能会被中断,从而导致其他线程自旋等待这个线程再次运行。然而,自旋所花费的时间非常有限(只有锁定和解锁代码中的几条指令,而不是用户定义的临界区),因此这种方法可能是合理的。
您可能还会注意到,在lock()中,当线程无法获得锁(它已经被持有)时,我们会小心地将自己添加到队列中(通过调用gettid()函数来获取当前线程的线程ID),将guard设置为0,并释放CPU。给读者一个问题:如果在park()之后而不是之前释放guard锁,会发生什么?提示:坏事。
您可能会进一步注意到,当另一个线程被唤醒时,flag没有被设置回0。这是为什么呢?好吧,这不是一个错误,而是一种必要!当线程被唤醒时,它就像是从park()返回;然而,它在代码中的那个点上并没有持有guard,因此甚至不能尝试将flag设置为1。因此,我们只需将锁直接从释放锁的线程传递给获取锁的下一个线程; flag在这之间没有被设置为0。(本文译者注:这时flag没必要设置为0,因为队列中的线程被唤醒后会直接进入临界区域,直到队列为空时,最后一个持有锁的线程将锁的flag设置为0,线程们再次竞争锁,并再次产生队列)。
最后,在调用park()之前,您可能会注意到解决方案中感知到的竞争条件。如果时机不正确,线程将会park,假设它应该休眠,直到锁不再被持有。此时切换到另一个线程(例如,持有锁的线程)可能会导致问题,例如,如果那个线程随后释放了锁。然后,第一个线程的后续park将永远休眠(可能),这个问题有时被称为唤醒/等待竞争(wakeup/waiting race)。(本文译者注:由于没有持有锁的线程p2在park前被unpark,并被从队列中删除,而持有锁的线程p1做完这些之后就从unlock返回,而没有持有锁的线程p2会进入park,继而永远park,而后续想要获取锁的线程也只能将自己加入队列并永远park,因为已经没有线程能够将他们唤醒(unpark),参考这个问题https://stackoverflow.com/questions/27908513/wakeup-waiting-race-in-a-lock)。
Solaris通过添加第三个系统调用来解决这个问题:setpark()。通过调用这个例程,线程可以指示它即将park。如果它碰巧被中断,而另一个线程在调用park之前调用了unpark,则随后的park立即返回,而不是休眠。lock()内部的代码修改非常小: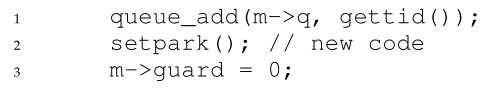
另一种解决方案可以将guard传递到内核。在这种情况下,内核可以采取预防措施,以原子方式释放锁并让正在运行的线程退出队列。
Aside:避免自旋的更多理由:优先级倒置 避免使用自旋锁的一个很好的理由是性能:如正文所述,如果一个线程在持有锁时被中断,其他使用自旋锁的线程将花费大量的CPU时间来等待锁可用。然而,事实证明,在某些系统上避免自旋锁还有另一个有趣的原因:正确性。需要警惕的问题被称为优先级倒置,不幸的是,这是一个星系间的灾难,发生在地球[M15]和火星[R97]! 让我们假设一个系统中有两个线程。线程2 (T2)的优先级高,线程1 (T1)的优先级低。在这个例子中,我们假设CPU调度程序总是在T2上运行T1,如果两者都是可运行的;T1仅在T2无法运行时运行(例如,T2在I/O时阻塞)。 现在,这个问题。假设T2由于某种原因被阻塞。T1运行,抓住自旋锁,进入临界区。T2现在变得不阻塞(可能是因为完成了一个I/O), CPU调度器立即调度它(从而重新调度T1)。T2现在尝试获取锁,因为它不能(T1持有锁),它只能继续自旋。因为锁是自旋锁,T2永远自旋,系统挂起。 不幸的是,仅仅避免使用自旋锁并不能避免优先级倒置问题(唉)。假设有三个线程,T1、T2和T3,其中T3优先级最高,T1最低。现在想象T1获取了一个锁。然后T3启动,因为它的优先级比T1高,所以立即运行(抢占T1)。T3试图获取T1持有的锁,但在等待时卡住了,因为T1仍然持有它。如果T2开始运行,它的优先级将高于T1,因此它将运行。T3的优先级比T2高,它一直在等待T1,现在T2正在运行,T1可能永远不会运行。强大的T3无法运行,而低端的T2控制着CPU,这不是很可悲吗?高优先级已经不像以前那样了。 可以用多种方法来解决优先级反转问题。在自旋锁导致问题的特定情况下,您可以避免使用自旋锁(后面将详细描述)。一般来说,高优先级线程等待低优先级线程可以临时提高低优先级线程的优先级,从而使其能够运行并克服倒置,这种技术称为优先级继承(priority inheritance)。最后一个解决方案是最简单的:确保所有线程具有相同的优先级。
28.15
不同的操作系统,不同的支持 Different OS, Different Support
到目前为止,我们已经看到了OS可以提供的一种支持,以便在线程库中构建更有效的锁。其他操作系统也提供类似的支持;细节有所不同。
例如,Linux提供了一个futex,它类似于Solaris接口,但提供了更多的内核内功能。具体来说,每个futex都与它关联一个特定的物理内存位置,以及每个futex在内核中的队列。调用者可以使用futex调用(如下所述)在需要时休眠和唤醒。
具体来说,有两个调用可用。对futex_wait(address, expected)的调用使调用线程进入睡眠状态,假设address处的值等于expected。如果不相等,调用立即返回。对例程futex_wake(address)的调用将唤醒一个正在队列中等待的线程。图28.10显示了这些调用在Linux互斥锁中的用法。
这段来自nptl库(gnu libc库的一部分)[L09]中的lowlevellock.h的代码片段很有趣,原因有几个。首先,它使用一个整数来跟踪锁是否被持有(整数的高位)和锁上等待者的数量(所有其他位)。因此,如果锁是负的,它将被持有(因为设置了高位,该位决定了整数的符号)。
其次,代码片段展示了如何针对常见情况进行优化,特别是在没有争用锁的情况下;在只有一个线程获取和释放锁的情况下,只需要做很少的工作(原子位测试并设置为锁,原子增加来释放锁)。
看看你是否能通过这个“现实世界”锁的其余部分来理解它是如何工作的。做到这一点并成为 Linux 锁定的高手,或者至少是当书告诉你做某事时倾听的人。
比如买一本《OSTEP》的印刷版!即使这本书可以在网上免费获得,你会不会喜欢在书桌上放一本精装本呢?或者,更好的是,十份副本与朋友和家人分享?再多一个副本扔给敌人?(这本书很重,因此扔掉它是非常有效的)。
28.16
两阶段锁 Two-Phase Locks
最后要注意的是:Linux方法具有一种已经断断续续使用了多年的老方法的味道,至少可以追溯到20世纪60年代早期的Dahm Locks [M82],现在被称为两阶段锁。两阶段锁意识到自旋是有用的,特别是当锁即将被释放的时候。所以在第一阶段,锁自旋一段时间,希望它能获得锁。
但是,如果在第一个自旋阶段没有获得锁,就会进入第二个阶段,在这个阶段调用者将处于休眠状态,只有在稍后锁变为空闲时才会唤醒。上面的Linux锁就是这种锁的一种形式,但它只旋转一次;概括地说,在使用futex支持睡眠之前,可以循环固定的时间。
两阶段锁是混合(hybrid)方法的另一个实例,在这种方法中,结合两个好的想法可能会产生一个更好的想法。当然,它是否这样做很大程度上取决于许多因素,包括硬件环境、线程数量和其他工作负载细节。与往常一样,制作一个适用于所有可能用例的通用锁是一个相当大的挑战。
28.17
总结 Summary 上面的方法展示了如今真正的锁是如何构建的:一些硬件支持(以更强大的指令的形式)加上一些操作系统支持(例如,以 Solaris 上的 park() 和 unpark() 原语的形式,或 futex 在 Linux 上)。当然,细节不同,执行这种锁定的确切代码通常是高度调整的。如果您想查看更多详细信息,请查看 Solaris 或 Linux 代码库;它们是一本引人入胜的读物 [L09, S09]。另见David等人在现代多处理器上比较锁定策略的出色工作 [D+13]。
References
[D91] “Just Win, Baby: Al Davis and His Raiders” by Glenn Dickey. Harcourt, 1991. The book
about Al Davis and his famous quote. Or, we suppose, the book is more about Al Davis and the Raiders,
and not so much the quote. To be clear: we are not recommending this book, we just needed a citation.
[D+13] “Everything You Always Wanted to Know about Synchronization but Were Afraid to
Ask” by Tudor David, Rachid Guerraoui, Vasileios Trigonakis. SOSP ’13, Nemacolin Wood-
lands Resort, Pennsylvania, November 2013. An excellent paper comparing many different ways to
build locks using hardware primitives. Great to see how many ideas work on modern hardware.
[D68] “Cooperating sequential processes” by Edsger W. Dijkstra. 1968. Available online here:
http://www.cs.utexas.edu/users/EWD/ewd01xx/EWD123.PDF. One of the early semi-
nal papers. Discusses how Dijkstra posed the original concurrency problem, and Dekker’s solution.
[H93] “MIPS R4000 Microprocessor User’s Manual” by Joe Heinrich. Prentice-Hall, June 1993.
Available: http://cag.csail.mit.edu/raw/documents/R4400 Uman book Ed2.pdf. The old MIPS
user’s manual. Download it while it still exists.
[H91] “Wait-free Synchronization” by Maurice Herlihy. ACM TOPLAS, Volume 13: 1, January
1991. A landmark paper introducing a different approach to building concurrent data structures. Be-
cause of the complexity involved, some of these ideas have been slow to gain acceptance in deployment.
[L81] “Observations on the Development of an Operating System” by Hugh Lauer. SOSP ’81,
Pacific Grove, California, December 1981. A must-read retrospective about the development of the
Pilot OS, an early PC operating system. Fun and full of insights.
[L09] “glibc 2.9 (include Linux pthreads implementation)” by Many authors.. Available here:
http://ftp.gnu.org/gnu/glibc. In particular, take a look at the nptl subdirectory where you
will find most of the pthread support in Linux today.
[M82] “The Architecture of the Burroughs B5000: 20 Years Later and Still Ahead of the Times?”
by A. Mayer. 1982. Available: www.ajwm.net/amayer/papers/B5000.html. “It (RDLK)
is an indivisible operation which reads from and writes into a memory location.” RDLK is thus test-
and-set! Dave Dahm created spin locks (“Buzz Locks”) and a two-phase lock called “Dahm Locks.”
[M15] “OSSpinLock Is Unsafe” by J. McCall. mjtsai.com/blog/2015/12/16/osspinlock
-is-unsafe. Calling OSSpinLock on a Mac is unsafe when using threads of different priorities – you
might spin forever! So be careful, Mac fanatics, even your mighty system can be less than perfect…
[MS91] “Algorithms for Scalable Synchronization on Shared-Memory Multiprocessors” by
John M. Mellor-Crummey and M. L. Scott. ACM TOCS, Volume 9, Issue 1, February 1991.
An excellent and thorough survey on different locking algorithms. However, no operating systems
support is used, just fancy hardware instructions.
[P81] “Myths About the Mutual Exclusion Problem” by G.L. Peterson. Information Processing
Letters, 12(3), pages 115–116, 1981. Peterson’s algorithm introduced here.
[R97] “What Really Happened on Mars?” by Glenn E. Reeves. research.microsoft.com/
en-us/um/people/mbj/Mars Pathfinder/Authoritative Account.html. A descrip-
tion of priority inversion on Mars Pathfinder. Concurrent code correctness matters, especially in space!
[S05] “Guide to porting from Solaris to Linux on x86” by Ajay Sood, April 29, 2005. Available:
http://www.ibm.com/developerworks/linux/library/l-solar/.
[S09] “OpenSolaris Thread Library” by Sun.. Code: src.opensolaris.org/source/xref/
onnv/onnv-gate/usr/src/lib/libc/port/threads/synch.c. Pretty interesting, al-
though who knows what will happen now that Oracle owns Sun. Thanks to Mike Swift for the pointer.
[W09] “Load-Link, Store-Conditional” by Many authors.. en.wikipedia.org/wiki/Load-
Link/Store-Conditional. Can you believe we referenced Wikipedia? But, we found the infor-
mation there and it felt wrong not to. Further, it was useful, listing the instructions for the different ar-
chitectures: ldl l/stl c and ldq l/stq c (Alpha), lwarx/stwcx (PowerPC), ll/sc (MIPS),
and ldrex/strex (ARM). Actually Wikipedia is pretty amazing, so don’t be so harsh, OK?
[WG00] “The SPARC Architecture Manual: Version 9” by D. Weaver, T. Germond. SPARC In-
ternational, 2000. http://www.sparc.org/standards/SPARCV9.pdf. See developers.
sun.com/solaris/articles/atomic sparc/ for more on atomics.
Homework (Simulation)
这个程序x86.py允许您查看不同的线程交错是如何导致或避免竞争条件的。有关程序如何工作的详细信息,请参阅README并回答下面的问题。
Questions
- 检查flag.s。这段代码使用单个内存标志实现锁定。你能理解这个汇编吗?
- 当您使用默认值运行时,flag.s 是否有效?使用 -M 和 -R 标志来跟踪变量和寄存器(并打开 -c 以查看它们的值)。你能预测 flag 最终会得到什么值吗?
- 使用 -a 标志更改寄存器 %bx 的值(例如,如果您只运行两个线程,则使用 -a bx=2,bx=2)。代码有什么作用?它如何改变你对上述问题的回答?
- 为每个线程设置bx为高值,然后使用-i标志产生不同的中断频率;什么值会导致不好的结果?哪些会带来好的结果?
- 现在让我们看看程序 test-and-set.s。首先,尝试理解使用 xchg 指令构建简单锁定原语的代码。锁获取是怎么写的?锁释放呢?
- 现在运行代码,再次更改中断间隔 (-i) 的值,并确保循环多次。代码是否总是按预期工作?它有时会导致 CPU 使用效率低下吗?你怎么能量化呢?
- 使用 -P 标志生成锁定代码的特定测试。例如,运行一个调度程序,在第一个线程中获取锁,然后在第二个线程中尝试获取它。正确的事情发生了吗?你还应该测试什么?
- 现在让我们看一下 peterson.s 中的代码,它实现了 Peterson 算法(在文本的Aside栏中提到)。研究代码,看看你是否能理解它。
- 现在使用不同的 -i 值运行代码。你看到了哪些不同的行为?确保正确设置线程 ID(例如使用 -a bx=0,bx=1),因为代码假定它。
- 你能控制调度(使用 -P 标志)来“证明”代码有效吗?您应该展示哪些不同的情况?考虑互斥和避免死锁。
- 现在研究ticket.s中的ticket lock的代码。是否与章节中的代码相符?然后使用以下标志运行:-a bx=1000,bx=1000(导致每个线程在临界区循环 1000 次)。观察会发生什么;线程是否花很多时间自旋等待锁?
- 当您添加更多线程时,代码的表现如何?
- 现在检查 yield.s,其中 yield 指令使一个线程能够让出对 CPU 的控制(实际上,这将是一个 OS 原语,但为简单起见,我们假设一条指令完成任务)。找到一个场景,其中 test-and-set.s 会浪费循环自旋,而 yield.s 不会。节约了多少指令?在什么情况下会产生这些节省?
- 最后,检查 test-and-test-and-set.s。这个锁有什么作用?与 test-and-set.s 相比,它带来了什么样的节省?

若有收获,就点个赞吧
0 人点赞
