在我们结束虚拟化内存的研究之前,让我们仔细看看整个虚拟内存系统是如何组合在一起的。我们已经看到了这类系统的关键元素,包括许多页表设计、与TLB的交互(有时,甚至由操作系统本身处理),以及决定哪些页面保留在内存中,哪些页面删除的策略。然而,还有许多其他特性组成了一个完整的虚拟内存系统,包括许多性能、功能和安全性特性。因此,我们的问题是:
关键的问题:如何构建一个完整的虚拟内存系统 要实现一个完整的虚拟内存系统需要具备哪些特性?他们如何提高性能,提高安全性,或者以其他方式改进系统?
我们将通过覆盖两个系统来做这个。第一个是“现代”虚拟内存管理器的最早例子之一,发现于VAX/VMS操作系统[LL82],在20世纪70年代和80年代早期开发;令人惊讶的是,这个系统中有大量的技术和方法至今仍然存在,因此它很值得研究。有些想法,即使是50年前的想法,仍然值得了解,这是大多数其他领域(如物理学)的人都知道的想法,但必须在技术驱动的学科(如计算机科学)中陈述。
其次是Linux,原因应该是显而易见的。Linux是一种被广泛使用的系统,可以在手机这样的小而弱的系统上有效地运行,也可以在现代数据中心中扩展性最强的多核系统上运行。因此,它的VM系统必须足够灵活,才能在所有这些场景中成功运行。我们将讨论每一个系统,以说明在前面几章中提出的概念如何在一个完整的内存管理器中结合在一起。
23.1 VAX/VMS虚拟内存 VAX/VMS Virtual Memory
VAX-11小型机架构是在1970年代末由数字设备公司(Digital Equipment Corporation,DEC)引入的。在微型计算机时代,DEC是计算机行业的重要参与者;不幸的是,一系列糟糕的决定和PC的出现慢慢地(但肯定地)导致了它们的消亡[C03]。该体系结构在许多实施(implementations)中得到了实现(was realized),包括VAX-11/780和功能较弱的VAX-11/750。
该系统的操作系统被称为VAX/VMS(或仅仅是普通的VMS),其主要架构师之一是Dave Cutler,他后来领导了微软的Windows NT [C93]的开发工作。VMS有一个普遍的问题,即它将运行在广泛的机器上,包括非常便宜的VAXen(是的,这是适当的复数),以及同一体系结构家族中非常高端和强大的机器。因此,操作系统必须具有跨这一巨大范围的系统工作(并且工作得很好)的机制和策略。
作为另外一个问题,VMS是软件创新用来隐藏架构的一些固有缺陷的一个很好的例子。尽管操作系统经常依赖于硬件来构建有效的抽象和假象,但有时硬件设计师并不能把所有事情都做好;在VAX硬件中,我们将看到一些这样的例子,以及尽管存在这些硬件缺陷,VMS操作系统如何构建有效的、可工作的系统。
内存管理硬件 Memory Management Hardware
VAX-11为每个进程提供了一个32位的虚拟地址空间,分成512字节的页。因此,一个虚拟地址由一个23位的VPN和一个9位的偏移量组成。此外,使用VPN的上两位来区分页面位于哪个分段内;因此,正如我们前面所看到的,该系统是分页和分段的混合。
地址空间的下半部分称为“进程空间”,对每个进程都是唯一的。在进程空间的前半部分(称为P0)中,会找到用户程序,以及向下增长的堆。在进程空间(P1)的后半部分,我们找到向上增长的栈。地址空间的上半部分被称为系统空间(S),尽管只使用了它的一半。受保护的操作系统代码和数据驻留在这里,并且以这种方式跨进程共享操作系统。
VMS设计人员的一个主要担忧是VAX硬件中页面的大小非常小(512字节)。这种大小是由于历史原因而选择的,其根本问题是使简单的线性页表变得过大。因此,VMS设计者的首要目标之一就是确保VMS不会因页表(过大)压垮内存。
系统通过两种方式减少页表放在内存中的压力。首先,通过将用户地址空间分成两个部分,VAX-11为每个进程的每个区域(P0和P1)提供一个页表,因此,栈和堆之间的地址空间的未使用部分不需要页表空间。基寄存器和边界寄存器的使用与预期一致;基寄存器保存该段的页表地址,边界保存其大小(即页表条目的数量)。
其次,通过在内核虚拟内存中放置用户页表(对于P0和P1,因此每个进程两个),操作系统进一步降低了内存压力。因此,当分配或增长页表时,内核从它自己的虚拟内存中分配空间,即段S。如果内存压力很大,内核可以将这些页表的页交换到磁盘,从而使物理内存可供其他用途使用。
将页表放在内核虚拟内存中意味着地址转换更加复杂。例如,要转换 P0 或 P1 中的虚拟地址,硬件必须首先尝试在其页表(该进程的 P0 或 P1 页表)中查找该页的页表项;但是,在这样做时,硬件可能首先必须查询系统页表(位于物理内存中);转换完成后,硬件可以得知页表的页面地址,然后最终得知所需内存访问的地址。幸运的是,所有这些都通过 VAX 的硬件管理 TLB 变得更快,通常(希望)绕过这种费力的查找。
一个真实的地址空间 A Real Address Space
研究VMS的一个好处是,我们可以看到真实的地址空间是如何构造的(图23.1)。到目前为止,我们假设了一个简单的地址空间,只包含用户代码、用户数据和用户堆,但正如我们在上面看到的,实际地址空间明显要复杂得多。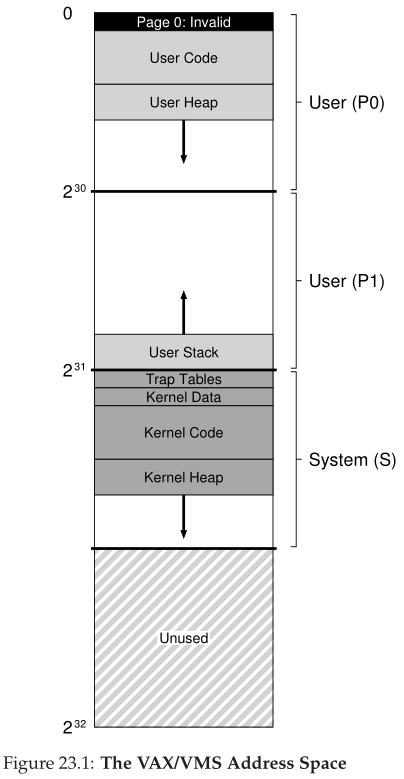
例如,代码段永远不会从第0页开始。相反,这个页面被标记为不可访问,以便为检测空指针(null-pointer)访问提供一些支持。因此,设计地址空间时需要考虑的一个问题是对调试的支持,此处不可访问的零页以某种形式提供了这种支持。
Aside:为什么空指针访问会导致seg错误 现在您应该很好地理解了空指针解引用时会发生什么。进程通过类似这样的操作生成一个虚拟地址0:
硬件尝试在TLB中查找VPN(这里也是0),结果TLB没有找到。查询页表,发现VPN 0的条目被标记为无效。因此,我们有一个无效的访问,它将控制权转移到操作系统,这可能会终止进程(在UNIX系统上,进程被发送一个信号,允许它们对这样的错误作出反应;但是,如果未捕获,进程将被杀死)。
也许更重要的是,内核虚拟地址空间(即它的数据结构和代码)是每个用户地址空间的一部分。在上下文切换时,操作系统改变P0和P1寄存器以指向即将运行的进程的相应页表;但是,它不改变S基寄存器和边界寄存器,因此将“相同的”内核结构映射到每个用户地址空间。
由于许多原因,内核被映射到每个地址空间。这种构造使内核的工作变得更容易;例如,当操作系统从用户程序获得一个指针时(例如,在write()系统调用中),很容易将该指针中的数据复制到它自己的结构中。操作系统是自然编写和编译的,而不用担心它访问的数据来自哪里。相反,如果内核完全位于物理内存中,就很难将页表的页交换到磁盘;如果内核有自己的地址空间,那么在用户应用程序和内核之间移动数据将再次变得复杂和痛苦。使用这种结构(现在广泛使用),内核对应用程序来说几乎是一个库,尽管是受保护的库。
关于这个地址空间的最后一点与保护有关。显然,操作系统不希望用户应用程序读取或写入操作系统数据或代码。因此,硬件必须支持不同的页面保护级别才能实现这一点。VAX通过在页表的保护位中指定CPU访问特定页必须达到的特权级别来实现这一点。因此,系统数据和代码被设置为比用户数据和代码更高的保护级别;尝试从用户代码访问这些信息将在操作系统中生成一个trap,并且(您猜对了)可能会终止有问题的进程。
页面替换 Page Replacement
VAX中的页表项(PTE)包含以下位:一个有效位、一个保护字段(4位)、一个修改(或脏)位、一个保留给OS使用的字段(5位),最后一个物理帧号(PFN),用于在物理内存中存储页的位置。精明的读者可能会注意到:没有引用位!因此,VMS替换算法必须在没有硬件支持的情况下确定哪些页面是活动的。
开发人员还担心内存占用(memory hogs)问题,即占用大量内存并使其他程序难以运行的程序。迄今为止,我们看到的大多数策略都容易受到这种“霸占”的影响;例如,LRU是一种全局策略,它在进程之间不公平地共享内存。
Aside:模拟引用位 事实证明,不需要硬件引用位就可以知道系统中使用了哪些页面。事实上,在1980年代早期,Babaoglu和Joy证明了VAX上的保护位可以用来模拟引用位[BJ81]。基本思想:如果您想了解系统中哪些页面正被积极使用,请将页表中的所有页面标记为不可访问(但保留有关进程真正可访问哪些页面的信息,可能在页表项的“为操作系统保留字段(reserved OS field)”部分)。当一个进程访问一个页面时,它会在操作系统中产生一个trap;然后操作系统将检查该页面是否真的应该可以访问,如果是,则将该页面恢复到其正常保护(例如,只读或读写)。在替换时,操作系统可以检查哪些页面仍然标记为不可访问,从而了解哪些页面最近未被使用。 这种引用位的“模拟”的关键是减少开销,同时还能很好地了解页面使用情况。操作系统不能过于激进地将页面标记为不可访问的,否则开销会太高。操作系统在标记时也不能太被动,否则所有的页面都会被引用;操作系统将再次不知道该驱逐哪个页面。
为了解决这两个问题,开发人员提出了**分段FIFO(segmented FIFO)**替换策略[RL81]。其思想很简单:每个进程在内存中可以保留的页面的最大数量,称为其**常驻集大小(resident set size,RSS)**。每一页都保存在FIFO列表中;当一个进程超过它的RSS时,“先入”页面就会被移除。FIFO显然不需要硬件的任何支持,因此很容易实现。<br />当然,正如我们之前看到的,纯 FIFO 的性能并不是特别好。**为了提高 FIFO 的性能,VMS 引入了两个二次机会(second-chance)列表,其中页面在从内存中被逐出之前放置在其中,特别是全局的干净页面空闲列表(clean-page free list)和脏页面列表(dirty-page list)。当一个进程 P 超过它的 RSS 时,一个页面从它的每个进程的 FIFO 中删除;如果是干净的(未修改),则将其放在干净页面列表的末尾;如果脏(已修改),则将其放在脏页列表的末尾。**<br />**如果另一个进程Q需要一个空闲页,它会从全局干净列表(clean list)中取出第一个空闲页。但是,如果原始进程P在该页被再利用之前在该页上出现错误(缺页错误),则P将从空闲(或脏)列表中回收该页,从而避免昂贵的磁盘访问。这些全局二次机会列表越大,分段 FIFO 算法的性能就越接近 LRU [RL81]。**<br />VMS中使用的另一个优化也有助于克服VMS中的小页面尺寸。具体来说,**使用这样的小页面,交换期间的磁盘I/O效率可能非常低,因为磁盘在大型传输时效率更高**。为了提高I/O交换效率,VMS增加了许多优化,但最重要的是**聚集(clustering)**。**通过聚集,VMS将全局脏列表中的大量页面分组在一起,并一下子将它们写入磁盘(从而使它们变得干净)**。在大多数现代系统中都使用聚集,因为可以自由地将页面放置在交换空间内的任何位置,从而让操作系统对页面进行分组,执行更少和更大的写入,从而提高性能。
其他优雅的技巧 Other Neat Tricks
VMS 有另外两个现在标准(now-standard)的技巧:按需置零(demand zeroing)和写时复制(copy-on-write)。我们现在描述这些惰性(lazy)优化。VMS(和大多数现代系统)中的一种惰性形式是页面按需置零(demand zeroing of pages)。为了更好地理解这一点,让我们考虑将一个页面添加到您的地址空间的示例,比如在您的堆中。在一个简单的实现中,操作系统通过在物理内存中找到一个页面,并将其置零(安全需要;否则,当其他进程使用该页时,您就可以看到该页上有什么!),然后将它映射到您的地址空间(即,设置页表以根据需要引用该物理页)。但是简单实现的代价可能很高,特别是在进程不使用该页面的情况下。
通过按需置零,当页面被添加到您的地址空间时,操作系统会做很少的工作;它在页表中放置一个条目,标记该页不可访问。如果该进程随后读取或写入页面,则会发生进入操作系统的trap。在处理trap时,操作系统注意到(通常通过页表条目的“为操作系统保留”部分中标记的一些位)这实际上是一个按需置零页;在这一点上,操作系统完成了查找物理页面、将其置零并将其映射到进程地址空间的所需工作。如果进程从不访问页面,则避免所有此类工作,因此就有了按需置零的优点。
VMS中的另一个很酷的优化是写时复制(copy-on-write,简称COW)。这个想法至少可以追溯到TENEX操作系统[BB+72],很简单:当操作系统需要将一个页面从一个地址空间复制到另一个地址空间时,它可以将其映射到目标地址空间,并在两个地址空间中将其标记为只读,而不是复制它。如果两个地址空间都只读取页面,则不采取进一步的操作,因此操作系统实现了快速复制,而不实际移动任何数据。
然而,如果其中一个地址空间确实试图写入页面,它将trap进入操作系统。然后,操作系统会注意到这个页面是一个COW页面,因此(惰性地)分配一个新页面,用数据填充它,并将这个新页面映射到错误进程(产生trap的进程)的地址空间。然后该进行程继续进行,现在拥有自己的页面私有副本。
COW之所以有用有很多原因。当然,任何类型的共享库都可以以写时复制的方式映射到许多进程的地址空间,从而节省宝贵的内存空间。在UNIX系统中,由于fork()和exec()的语义,COW更为关键。您可能还记得,fork()创建了调用者地址空间的精确副本;由于地址空间很大,这样的复制速度很慢,而且数据密集。更糟糕的是,大多数地址空间会立即被exec()的后续调用所覆盖,这将用即将被执行的程序的地址空间覆盖调用进程的地址空间。通过执行“写时复制”fork(),操作系统避免了大量不必要的复制,从而在提高性能的同时保留了正确的语义。
Tip:偷懒(BE LAZY) 无论是在生活中还是在操作系统中,懒惰都是一种美德。懒惰会将工作推迟到以后,这在操作系统中是有好处的,原因有很多。首先,推迟工作可能会减少当前操作的延迟,从而提高响应性;例如,操作系统经常报告对文件的写入立即成功,而只在后台将它们写入磁盘。第二,也是更重要的,懒惰有时使你根本不需要做这项工作;例如,将写操作延迟到文件被删除时,就完全不需要写操作了。懒惰在生活中也是好事:例如,通过推迟你的操作系统项目,你可能会发现项目规范的缺陷是由你的同学解决的;然而,课程项目不太可能被取消,所以太懒惰可能会有问题,导致项目迟到,成绩差,和一个悲伤的教授。不要让教授伤心!
23.2 Linux虚拟内存系统 The Linux Virtual Memory System
现在,我们将讨论Linux VM系统的一些更有趣的方面。Linux开发是由解决实际生产中遇到的实际问题的实际工程师推动的,因此大量特性慢慢地被整合到现在功能完整、功能丰富的虚拟内存系统中。
虽然我们不能讨论Linux VM的每一个方面,但我们将讨论最重要的方面,特别是它已经超越了VAX/VMS等经典VM系统。我们还将着重介绍Linux和旧系统之间的共性。
在这一讨论中,我们将重点讨论适用于Intel x86的Linux。虽然Linux可以并且确实运行在许多不同的处理器体系结构上,但是x86上的Linux是它最主要和最重要的部署,因此是我们关注的焦点。
Linux地址空间 The Linux Address Space
与其他现代操作系统非常相似,也与VAX/VMS非常相似,Linux虚拟地址空间由用户部分(用户程序代码、栈、堆和其他部分驻留的地方)和内核部分(内核代码、栈、堆和其他部分驻留的地方)组成。与其他系统一样,在上下文切换时,当前运行的地址空间的用户部分会发生变化;内核部分在各个进程中是相同的。和其他系统一样,在用户模式下运行的程序不能访问内核虚拟页面;只有通过进入内核并转换到特权模式,才能访问这些内存。
直到最近,由于安全威胁,才发生了变化。阅读下面关于Linux安全性的小节,了解关于此修改的详细信息。
在经典的32位Linux(即带有32位虚拟地址空间的Linux)中,地址空间的用户部分和内核部分的分割发生在地址0xC0000000处,或者地址空间的四分之三处。因此,从0到0xBFFFFFFF的虚拟地址是用户虚拟地址;剩余的虚拟地址(0xC0000000到0xFFFFFFFF)在内核的虚拟地址空间中。64位Linux也有类似的划分,但略有不同。图23.2显示了典型(简化)地址空间的描述。<br />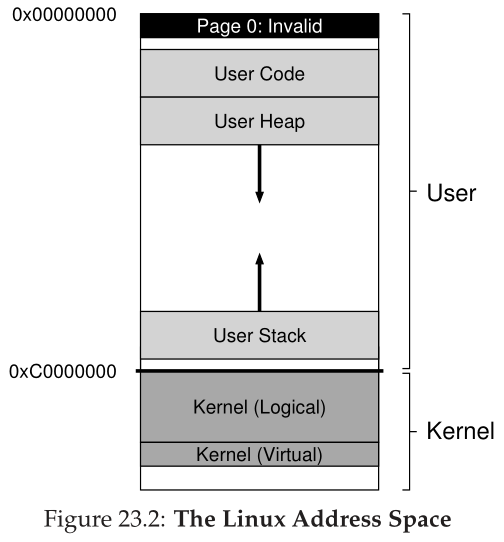<br />Linux的一个稍微有趣的方面是,它包含两种类型的内核虚拟地址。第一个被称为**内核逻辑地址(kernel logical addresses)**[O16]。**这就是内核的普通虚拟地址空间;要获得更多这种类型的内存,内核代码只需要调用kmalloc**。**大多数内核数据结构都在这里,比如页表、每个进程的内核栈等等**。与系统中的大多数其他内存不同,**内核逻辑内存不能交换到磁盘**。<br />内核逻辑地址最有趣的方面是它们与物理内存的连接。具体来说,**内核逻辑地址和物理内存的第一部分之间存在直接映射**。因此,**内核逻辑地址 0xC0000000 转换为物理地址 0x00000000,0xC0000FFF 转换为 0x00000FFF,依此类推。这种直接映射有两个含义。第一个是内核逻辑地址和物理地址之间来回转换很简单;因此,这些地址通常被视为确实是物理地址。第二个是如果一块内存在内核逻辑地址空间中是连续的,那么它在物理内存中也是连续的。这使得在内核地址空间的这一部分分配的内存适合需要连续物理内存才能正常工作的操作,例如通过目录内存访问 (directory memory access,DMA) 与设备之间的 I/O 传输(我们将在本书的第三部分)。**<br />另一种类型的内核地址是**内核虚拟地址(kernel virtual address)**。为了**获得这种类型的内存,内核代码调用一个不同的分配器vmalloc,它返回一个指针,指向一个所需大小的虚拟连续区域**。与内核逻辑内存不同,**内核虚拟内存通常不是连续的**;**每个内核虚拟页都可能映射到不连续的物理页(因此不适合DMA)**。然而,**这样的内存更容易分配,因此用于大型缓冲区,在那里找到连续的大块物理内存将具有挑战性**。<br />在32位Linux中,**存在内核虚拟地址的另一个原因是,它们使内核能够寻址超过(大约)1 GB的内存**。几年前,机器的内存比现在少得多,允许访问超过1 GB的内存不是问题。然而,随着技术的发展,很快就需要允许内核使用更多的内存。内核虚拟地址,以及它们从严格的一对一映射到物理内存的断开,使这成为可能。然而,随着64位Linux的发展,这种需求就不那么迫切了,因为内核不再局限于最后1 GB的虚拟地址空间。
页表结构 Page Table Structure
因为我们关注的是针对x86的Linux,所以我们的讨论将集中在x86提供的页表结构类型上,因为它决定了Linux能做什么,不能做什么。如前所述,x86提供了一种硬件管理的多级页表(multi-level page table)结构,每个进程有一个页表;操作系统简单地在内存中设置映射,在页面目录(page directory)的开始处指向一个特权寄存器(privileged register),其余的由硬件处理。正如预期的那样,在进程创建、删除和上下文切换时,操作系统都会参与进来,确保硬件MMU(内存管理单元)使用了正确的页表来执行转换。
可能近年来最大的变化是从32位x86到64位x86的转变,如上所述。正如在VAX/VMS系统中看到的,32位地址空间已经存在很长时间了,随着技术的变化,它们最终开始成为程序的真正限制。虚拟内存使得对系统进行编程变得很容易,但是对于包含许多GB内存的现代系统来说,32位已经不足以引用每一个内存了。因此,有必要进行下一个飞跃。
迁移到64位地址会以预期的方式影响x86中的页表结构。因为x86使用多级页表,所以当前的64位系统使用4级表。但是,虚拟地址空间的完全64位性质还没有使用,而只是使用底部的48位。因此,虚拟地址可以如下所示: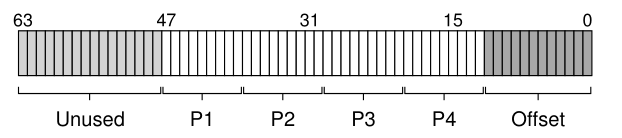
正如你所看到的画面,虚拟地址的前16位未使用(因此在转换中发挥任何作用),底部12位(由于4 kb页面大小)是用作偏移(因此就直接使用,而不是转换),留下中间的36位虚拟地址参加转换。地址的P1部分用于在最顶部的页面目录中建立索引,并从那里开始逐层进行转换,直到P4对页面表的实际页面建立索引,从而产生所需的页表条目。
随着系统内存越来越大,这个庞大的地址空间的更多部分将被启用,从而产生5级,最终是6级页表树结构。想象一下:一个简单的页表查找需要6级转换,只是为了找出某个数据片段驻留在内存中的哪个位置。
大页面支持 Large Page Support
Intel x86 允许使用多种页面大小,而不仅仅是标准的 4 KB 页面。具体来说,最近的设计支持硬件中 2-MB 甚至 1-GB 的页面。因此,随着时间的推移,Linux 已经发展到允许应用程序使用这些大页面(huge pages)(在 Linux 世界中这样称呼它们)。
正如前面所暗示的,使用大页面可以带来许多好处。正如在VAX/VMS中看到的,这样做减少了页表中需要的映射数量;页面越大,映射就越少。然而,页表条目的减少并不是巨大页面背后的驱动力;而是更好的TLB行为和相关的性能增益。
当进程积极地使用大量内存时,它会迅速用转换填充TLB。如果这些转换是针对4-KB的页面,那么在不导致TLB未命中的情况下,只能访问少量的总内存。对于运行在具有许多GBs内存的机器上的现代“大内存”工作负载来说,其结果是显著的性能成本;最近的研究表明,一些应用程序花费10%的周期来处理TLB未命中[B+13]。
通过使用TLB中更少的槽,大页面允许进程访问更大的内存区域,而不会出现TLB未命中,这是它的主要优点。然而,大页面还有其他好处: TLB 未命中路径较短,这意味着当 TLB 未命中确实发生时,它会得到更快的服务。此外,分配可能非常快(在某些情况下),这是一个很小但有时很重要的好处。
Tip:考虑渐进主义(CONSIDER INCREMENTALISM) 生活中很多时候,你被鼓励成为一名革命者。“往大了想!”,他们说。“改变世界!”,他们尖叫。你可以明白为什么它很吸引人;在某些情况下,需要进行大的改变,因此努力推动它们很有意义。而且,如果您以这种方式尝试,至少他们可能会停止对您大喊大叫。 然而,在许多情况下,更慢、更渐进的方法可能是正确的做法。本章中的Linux大页面示例就是工程渐进主义的一个例子; 开发人员没有采取原教旨主义者的立场并坚持大页面是未来的方式,而是采取谨慎的方法,首先为它引入专门的支持,更多地了解它的优缺点,并且只有在有真正的理由时,为所有应用程序添加更多通用支持。 渐进主义虽然有时遭到蔑视,但往往会导致缓慢的、深思熟虑的和明智的进展。在构建系统时,这种方法可能正是您所需要的。事实上,在生活中也是如此。
Linux对大页面的支持有一个有趣的方面,那就是它是如何渐进完成的。起初,Linux开发人员知道这种支持只对少数应用程序很重要,比如具有严格性能要求的大型数据库。因此,决定允许应用程序显式地请求大页面的内存分配(通过mmap()或shmget()调用)。这样,大多数应用程序将不受影响(并且继续只使用4 kb的页面;一些要求很高的应用程序必须改变来使用这些接口,但对它们来说,这是值得的。<br />最近,随着对更好的TLB行为的需求在许多应用程序中越来越普遍,Linux开发人员添加了**透明的(transparent)**大页面支持。**当启用该特性时,操作系统会自动寻找分配大页面的机会(通常是2 MB,但在某些系统上是1 GB),而不需要修改应用程序。**<br />巨大的页面并非没有成本。**最大的潜在成本是内部碎片,也就是说,页面很大,但使用很少的一部分**。这种形式的浪费可以用大但很少使用的页面填充内存。交换(如果启用)也不适用于大页面,有时会大大增加系统执行的 I/O 量。分配的开销也可能很糟糕(在其他一些情况下)。**总的来说,有一点很清楚:多年来一直为系统提供良好服务的 4 KB 页面大小已不再是以前的通用解决方案;不断增长的内存大小要求我们将大页面和其他解决方案视为 VM 系统必要演进的一部分。Linux 对这种基于硬件的技术的缓慢采用证明了即将发生的变化。**
页面缓存 The Page Cache
为了降低访问持久存储的成本(本书第三部分的重点),大多数系统使用主动缓存(caching)子系统来将流行的数据项(popular data items)保存在内存中。在这方面,Linux与传统操作系统没有什么不同。
Linux页面缓存(page cache)是统一的,将来自三个主要来源的页面保存在内存中: 内存映射文件(memory-mapped files)、来自设备的文件数据和元数据(metadata)(通常通过将 read() 和 write() 调用定向到文件系统来访问)以及堆和栈组成每个进程的页面(有时称为匿名内存(anonymous memory),因为它下面没有命名文件,而是交换空间)。这些对象保存在页面缓存哈希表(page cache hash
table)中,以便在需要所述数据时进行快速查找。
如果条目是干净的(clean)(已读但未更新)或脏的(dirty)(即已修改(modified)),页面缓存将进行跟踪。后台线程(称为pdflush)定期将脏数据写入后备存储(即,为文件数据写入特定文件,或为匿名区域交换空间),从而确保修改后的数据最终被写回持久存储。此后台活动要么在特定时间段后发生,要么在太多页面被认为是脏的(都是可配置参数)时发生。
在某些情况下,系统运行时内存不足,Linux必须决定将哪些页面踢出内存以释放空间。为此,Linux使用了一种经过修改的2Q替换[JS94],我们将在这里描述它。
基本思想很简单:标准LRU替换是有效的,但可能会被某些公共访问模式所破坏。例如,如果一个进程重复访问一个大文件(特别是接近内存大小或更大的文件),LRU就会将其他文件踢出内存。更糟糕的是:在内存中保留该文件的部分是没有用的,因为它们在被踢出内存之前从来不会被重新引用。
Linux 版本的 2Q 替换算法通过保留两个列表并在它们之间划分内存来解决这个问题。第一次访问时,将一个页面放在一个队列中(原论文中称为A1,但Linux中为非活动列表(inactive list));当它被重新引用时,该页面被提升到另一个队列(原来称为 Aq,但在 Linux 中称为活动列表(active list))。当需要替换时,替换的候选者从非活动列表中取出。Linux 还定期将页面从活动列表的底部移动到非活动列表,将活动列表保持在总页面缓存大小的三分之二左右 [G04]。
理想情况下,Linux应该以完美的LRU顺序管理这些列表,但是,正如前面章节所讨论的,这样做代价很高。因此,与许多操作系统一样,使用了近似的LRU(类似于时钟(clock)替换)。
这种2Q方法的行为通常与LRU非常相似,但值得注意的是,它通过将循环访问的页面限制在非活动列表中来处理发生循环大文件访问的情况。因为这些页面在被踢出内存之前不会被重新引用,所以它们不会刷新活动列表中发现的其他有用页面。
Aside:无处不在的内存映射 内存映射比Linux早了几年,并且在Linux和其他现代系统的许多地方都使用它。其思想很简单:通过在已经打开的文件描述符上调用 mmap(),进程返回一个指向虚拟内存区域开头的指针,文件内容似乎位于该区域的开头。然后使用该指针,进程可以使用简单的指针解引用访问文件的任何部分。 访问内存映射文件(memory-mapped file)中尚未被带入内存的部分会触发缺页错误(page faults),此时操作系统将会置入相关数据的页面,并相应地更新进程的页表(即请求页面调度(demand paging))使其可访问。 每个常规 Linux 进程都使用内存映射文件,即使 main() 中的代码也不直接调用 mmap(),因为 Linux 将代码从可执行文件和共享库代码加载到内存中。下面是 pmap 命令行工具的(高度简化的)输出,它显示了不同的映射构成了正在运行的程序(shell,在本例中为 tcsh)的虚拟地址空间。输出显示四列:映射的虚拟地址、其大小、区域的保护位和映射的源:
从这个输出可以看到,tcsh二进制文件的代码、libc、libcrypt、libtinfo的代码以及动态链接器本身(ld.so)的代码都映射到地址空间。还有两个匿名区域,堆(第二个条目,标记为anon)和栈(标记为stack)。内存映射文件为操作系统构建现代地址空间提供了一种直接而有效的方法。
安全和缓冲区溢出 Security And Buffer Overflows
现代虚拟内存系统(Linux、Solaris或某个BSD变体)与古代虚拟内存系统(VAX/VMS)之间的最大区别可能是现代对安全的重视。对于操作系统来说,保护一直是一个严重的问题,但随着机器之间的相互联系比以往任何时候都要多,开发人员实施各种防御对策来阻止那些狡猾的黑客控制系统也就不足为奇了。
一个主要的威胁是缓冲区溢出(buffer overflow)攻击,它可以用来攻击普通用户程序,甚至是内核本身。这些攻击的思想是在目标系统中找到一个漏洞,使攻击者将任意数据注入目标的地址空间。这种漏洞有时会出现,因为开发人员(错误地)假设输入不会太长,因此(信任地)将输入复制到缓冲区;因为输入实际上太长了,它会溢出缓冲区,从而覆盖目标的内存。下面的代码可能是问题的根源:
有关这个话题的一些细节和链接,请参见https://en.wikipedia.org/wiki/Buffer_overflow,包括安全黑客Elias Levy的著名文章,也被称为“Aleph One”。
在许多情况下,这种溢出不是灾难性的,例如,无意中将错误输入提供给用户程序甚至操作系统可能会导致它崩溃,但不会更糟。但是,恶意程序员可以精心制作溢出缓冲区的输入,以便将自己的代码注入目标系统,从而使他们能够接管并按照自己的意愿行事。如果在网络连接的用户程序上成功,攻击者可以在受感染的系统上运行任意计算甚至出租周期;如果在操作系统本身上成功,则攻击可以访问更多资源,这是一种所谓的**特权升级(privilege escalation)**(即用户代码获得内核访问权限)。如果你猜不出来,这些都是坏事。<br />防范缓冲区溢出的第一个也是最简单的方法是**防止在地址空间的某些区域(例如栈内)中发现的任何代码被执行**。AMD在x86版本中引入了**NX位**(用于No-eXecute)(类似的XD位现在可以在英特尔上使用),这就是一种防御; 它只是阻止从在其相应页表条目中设置了此位的任何页面执行。该方法可以防止由攻击者注入目标栈的代码被执行,从而缓解问题。<br />然而,聪明的攻击者……聪明,即使被注入的代码不能被攻击者显式地添加,任意的代码序列也可以被恶意代码执行。这个想法以其最普遍的形式为人所知,即**面向返回的编程(return-oriented programming,ROP) **[S07],它确实非常出色。ROP背后的观察结果是,在任何程序的地址空间中都有大量的代码位(用ROP的术语来说就是**gadget**),特别是链接到大量C库的C程序。因此,攻击者可以覆盖栈,使当前执行函数的返回地址指向一个期望的恶意指令(或一系列指令),然后是一个返回指令。通过将大量gadget串在一起(即,确保每个返回跳转到下一个gadget),攻击者可以执行任意代码。神奇的!<br />为了防御ROP(包括它的早期形式,**返回函数库攻击(return-to-libc attack)**[S+04]), Linux(和其他系统)添加了另一种防御,称为**地址空间布局随机化(address space layout randomization,ASLR)**。**操作系统不是将代码、栈和堆放置在虚拟地址空间中的固定位置,而是将它们的位置随机化**,因此,要实现这类攻击所需的复杂代码序列非常具有挑战性。大多数针对脆弱用户程序的攻击会导致崩溃,但无法控制正在运行的程序。<br />有趣的是,你可以很容易地在实践中观察到这种随机性。下面是在现代Linux系统上演示它的一段代码:<br /><br />这段代码只是打印出堆栈上一个变量的(虚拟)地址。**在旧的非ASLR系统中,这个值每次都是相同的。但是,正如你在下面看到的,值会随着每次运行而改变**:<br /><br />ASLR对于用户级程序来说是一种非常有用的防御,因此它也被整合到内核中,并以一种被称为**内核地址空间布局随机化(kernel address space layout randomization,KASLR)**的特性出现。然而,正如我们接下来讨论的那样,内核可能还有更大的问题要处理。
其他安全问题:熔毁和幽灵 Other Security Problems: Meltdown And Spectre
当我们写下这些话时(2018年8月),系统安全的世界已经被两起新的相关攻击所颠覆。第一个叫熔毁(Meltdown),第二个叫幽灵(Spectre)。大约在同一时间,四个不同的研究人员/工程师小组发现了它们,并引发了对上述计算机硬件和操作系统提供的基本保护的深刻质疑。请参阅meltdownattack.com和spectreattack.com了解详细描述每种攻击的论文。幽灵被认为是两者中问题更大的一个。
这些攻击都利用了一个普遍的弱点,即现代系统中的cpu执行各种疯狂的幕后技巧来提高性能。有一类技术是问题的核心,称为预测执行(speculative execution),在这种技术中,CPU预测哪些指令将在未来很快执行,并提前开始执行它们。如果预测正确,程序就会运行得更快;如果没有,如果没有,CPU 会撤销它们对架构状态(例如,寄存器)的影响,再次尝试,这次是沿着正确的路径前进。
预测的问题在于,它往往会在系统的各个部分(如处理器缓存、分支预测器等)留下执行的痕迹。因此问题就来了:正如攻击的作者所表明的那样,这种状态会使内存内容变得脆弱,甚至是我们认为受到MMU保护的内存。
因此,增加内核保护的一种途径是从每个用户进程中删除尽可能多的内核地址空间,取而代之的是为大多数内核数据使用单独的内核页表(称为内核页表隔离(kernel page-table isolation),或KPTI) [G+17]。因此,不是将内核的代码和数据结构映射到每个进程中,而是只保留最小的最小值;当切换到内核时,现在需要切换到内核页表。这样做可以提高安全性并避免一些攻击媒介,但代价是:性能。切换页表代价高昂。啊,安全成本:便利性和性能。
不幸的是,KPTI并没有解决上面列出的所有安全问题,只是其中的一部分。而简单的解决方案,比如关闭预测,几乎没有意义,因为系统的运行速度会慢数千倍。因此,如果您关注的是系统安全性,那么这是一个有趣的时刻。
要真正理解这些攻击,您(很可能)首先必须了解更多。从理解现代计算机体系结构开始,就像在这个主题的高级书籍中发现的那样,关注于预测和实现它所需的所有机制。一定要在上面提到的网站上读到Meltdown和Spectre攻击;实际上,它们还包括了对预测的有用入门,所以从这里开始或许还不错。并研究操作系统的进一步漏洞。谁知道还有什么问题?
23.3 总结 Summary
现在,您已经看到了对两个虚拟内存系统的从头到尾的回顾。希望大多数细节都很容易理解,因为您应该已经很好地理解了基本机制和策略。关于VAX/VMS的更多细节可以在Levy和Lipman的优秀(简短)论文中找到[LL82]。我们鼓励你阅读它,因为这是一个了解这些章节背后的原始材料的好方法。
您还了解了一些Linux的知识。虽然它是一个庞大而复杂的系统,但它从过去继承了许多好的想法,其中许多我们没有空间来详细讨论。例如,Linux在fork()上执行延迟的页写时复制,从而通过避免不必要的复制来降低开销。Linux还需要零页(使用/dev/zero设备的内存映射),并且有一个后台交换守护进程(swapd),它将页交换到磁盘以减少内存压力。事实上,虚拟机充满了从过去吸取的好想法,也包括许多自己的创新。
想要了解更多,看看这些合理的(可惜,过时的)书[BC05,G04]。我们鼓励你自己阅读它们,因为我们只能从复杂的海洋中提供最微不足道的一滴。但是,你总得有个开始。没有无数的水滴,还有什么海洋呢?[M04]
References
[B+13] “Efficient Virtual Memory for Big Memory Servers” by A. Basu, J. Gandhi, J. Chang, M. D. Hill, M. M. Swift. ISCA ’13, June 2013, Tel-Aviv, Israel.
A recent work showing that TLBs matter, consuming 10% of cycles for large-memory workloads. The solution: one massive segment to hold large data sets. We go backward, so that we can go forward!
[BB+72] “TENEX, A Paged Time Sharing System for the PDP-10” by D. G. Bobrow, J. D. Burchfiel, D. L. Murphy, R. S. Tomlinson. CACM, Volume 15, March 1972. An early time-sharing OS where a number of good ideas came from. Copy-on-write was just one of those; also an inspiration for other aspects of modern systems, including process management, virtual memory, and file systems.
[BJ81] “Converting a Swap-Based System to do Paging in an Architecture Lacking Page-Reference Bits” by O. Babaoglu, W. N. Joy. SOSP ’81, Pacific Grove, California, December 1981.
How toexploit existing protection machinery to emulate reference bits, from a group at Berkeley working on their own version of UNIX: the Berkeley Systems Distribution (BSD). The group was influential in the development of virtual memory, file systems, and networking.
[BC05] “Understanding the Linux Kernel” by D. P. Bovet, M. Cesati. O’Reilly Media, November 2005.
One of the many books you can find on Linux, which are out of date, but still worthwhile.
[C03] “The Innovator’s Dilemma” by Clayton M. Christenson. Harper Paperbacks, January 2003.
A fantastic book about the disk-drive industry and how new innovations disrupt existing ones. A good read for business majors and computer scientists alike. Provides insight on how large and successful companies completely fail.
[C93] “Inside Windows NT” by H. Custer, D. Solomon. Microsoft Press, 1993.
The book about Windows NT that explains the system top to bottom, in more detail than you might like. But seriously, a pretty good book.
[G04] “Understanding the Linux Virtual Memory Manager” by M. Gorman. Prentice Hall, 2004.
An in-depth look at Linux VM, but alas a little out of date.
[G+17] “KASLR is Dead: Long Live KASLR” by D. Gruss, M. Lipp, M. Schwarz, R. Fellner, C. Maurice, S. Mangard. Engineering Secure Software and Systems, 2017. Available:
https://gruss.cc/files/kaiser.pdf Excellent info on KASLR, KPTI, and beyond.
[JS94] “2Q: A Low Overhead High Performance Buffer Management Replacement Algorithm” by T. Johnson, D. Shasha. VLDB ’94, Santiago, Chile.
A simple but effective approach to building page replacement.
[LL82] “Virtual Memory Management in the VAX/VMS Operating System” by H. Levy, P. Lipman. IEEE Computer, Volume 15:3, March 1982.
Read the original source of most of this material. Particularly important if you wish to go to graduate school, where all you do is read papers, work, read some more papers, work more, eventually write a paper, and then work some more.
[M04] “Cloud Atlas” by D. Mitchell. Random House, 2004.
It’s hard to pick a favorite book. There are too many! Each is great in its own unique way. But it’d be hard for these authors not to pick “Cloud Atlas”, a fantastic, sprawling epic about the human condition, from where the the last quote of this chapter is lifted. If you are smart – and we think you are – you should stop reading obscure commentary in the references and instead read “Cloud Atlas”; you’ll thank us later.
[O16] “Virtual Memory and Linux” by A. Ott. Embedded Linux Conference, April 2016. https://events.static.linuxfound.org/sites/events/files/slides/elc 2016 mem.pdf .
A useful set of slides which gives an overview of the Linux VM.
[RL81] “Segmented FIFO Page Replacement” by R. Turner, H. Levy. SIGMETRICS ’81, Las Vegas, Nevada, September 1981.
A short paper that shows for some workloads, segmented FIFO can approach the performance of LRU.
[S07] “The Geometry of Innocent Flesh on the Bone: Return-into-libc without Function Calls (on the x86)” by H. Shacham. CCS ’07, October 2007.
A generalization of return-to-libc. Dr. Beth Garner said in Basic Instinct, “She’s crazy! She’s brilliant!” We might say the same about ROP.
[S+04] “On the Effectiveness of Address-space Randomization” by H. Shacham, M. Page, B. Pfaff, E. J. Goh, N. Modadugu, D. Boneh. CCS ’04, October 2004.
A description of the return-to-libc attack and its limits. Start reading, but be wary: the rabbit hole of systems security is deep…

若有收获,就点个赞吧
0 人点赞
