到目前为止,我们假设地址空间小得不切实际并且适合物理内存。事实上,我们一直假设每个正在运行的进程的每个地址空间都适合内存。我们现在将放宽这些大的假设,并假设我们希望支持许多并发运行的大地址空间。
为此,我们需要在存储层次结构(memory hierarchy)中增加一个级别。到目前为止,我们假设所有页面都驻留在物理内存中。然而,为了支持大地址空间,操作系统需要一个地方来存放当前需求不大的地址空间的一部分。一般来说,这种位置的特点是它的容量应该大于内存;结果,它通常更慢(如果它更快,我们会将其用作内存,不是吗?)。在现代系统中,此角色通常由硬盘驱动器(hard disk drive)提供。因此,在我们的存储层次结构中,大而慢的硬盘位于底部,内存位于上方。因此,我们到达了关键的问题所在:
关键的问题:如何超越物理内存 操作系统如何利用一个更大、更慢的设备来透明地提供一个大虚拟地址空间的假象(illusion)?
您可能会有一个问题:为什么我们要为进程支持单个大地址空间?同样,答案是方便和易于使用。在一个大的地址空间中,你不必担心是否有足够的内存空间来容纳你的程序的数据结构;相反,您只需自然地编写程序,根据需要分配内存。这是操作系统提供的一种强大的假象,它让你的生活变得简单得多。别客气!在使用内存覆盖(memory overlays)的旧系统中发现了一个差异,这需要程序员在需要时手动将代码或数据块移进或移出内存[D97]。试着想象一下这是什么样子:在调用函数或访问一些数据之前,你需要首先安排代码或数据在内存中;讨厌的东西!
Aside:存储技术 我们将在后面更深入地探究I/O设备的实际工作方式(参见关于I/O设备的章节)。所以要有耐心!当然,较慢的设备不一定是硬盘,但可以是更现代的设备,如基于闪存的SSD。我们也会谈到这些事情。现在,假设我们有一个大的、相对较慢的设备,我们可以用它来帮助我们构建一个非常大的虚拟内存的假象,甚至比物理内存本身还要大。
除了单个进程之外,交换空间(swap space)的增加还允许操作系统支持为多个并发运行的进程提供大型虚拟内存的假象。多道程序设计(multiprogramming)的发明(为了更好地利用机器,“一次”运行多个程序)几乎要求能够交换一些页面,因为早期的机器显然不能同时容纳所有进程所需的所有页面。因此,多道编程和易用性的结合使我们希望支持使用比实际可用内存更多的内存。这是所有现代虚拟机系统都在做的事情;现在,我们将更多地了解它。
21.1 交换空间 Swap Space
我们需要做的第一件事是在磁盘上为来回移动页面预留一些空间。在操作系统中,我们通常将这种空间称为交换空间(swap space),因为我们将页面从内存交换到它,并将页面从它交换到内存。因此,我们将简单地假设操作系统可以以页面大小为单位对交换空间进行读写。为此,操作系统需要记住给定页面的磁盘地址(disk address)。
交换空间的大小很重要,因为它最终决定了在给定的时间内系统可以使用的最大内存页数。为了简单起见,让我们假设它现在非常大。
在这个小例子中(图 21.1),你可以看到一个 4 页物理内存和一个 8 页交换空间的小例子。在示例中,三个进程(Proc 0、Proc 1 和 Proc 2)正在主动共享物理内存;然而,这三个中的每一个在内存中都只有一部分有效的页面,其余的位于磁盘的交换空间中。第四个进程 (Proc 3) 将其所有页面都换出到磁盘,因此显然当前没有运行。一块交换空间仍然是空闲的。即使从这个小例子中,也希望你能看到使用交换空间是如何让系统假装内存比实际大的。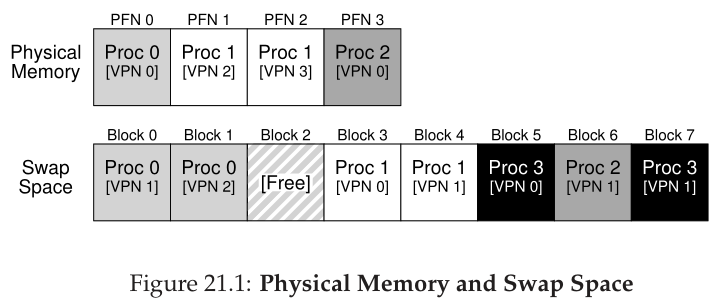
我们应该注意,交换空间并不是磁盘上唯一用于交换流量的位置。例如,假设您正在运行一个程序二进制文件(例如,ls或您自己编译的主程序)。这个二进制文件中的代码页最初是在磁盘上找到的,当程序运行时,它们被加载到内存中(或者在程序开始执行时全部加载,或者像在现代系统中一样,在需要时一次加载一页)。但是,如果系统需要在物理内存中为其他需求腾出空间,它可以安全地重用这些代码页的内存空间,因为它知道以后可以从文件系统中的磁盘上的二进制文件中再次交换它们。
21.2 存在标志位 The Present Bit
现在我们在磁盘上有了一些空间,我们需要在系统的更高位置添加一些机制,以便支持在磁盘和磁盘之间交换页面。为了简单起见,让我们假设我们有一个具有硬件管理TLB的系统。
首先回忆一下在内存引用中发生了什么。正在运行的进程生成虚拟内存引用(用于获取指令或数据访问),在这种情况下,硬件在从内存中获取所需数据之前将它们转换为物理地址。
请记住,硬件首先从虚拟地址提取VPN,检查TLB是否匹配(TLB命中),如果命中,生成物理地址并从内存中获取它。希望这是常见的情况,因为它很快(不需要额外的内存访问)。
如果在TLB中没有找到VPN(即TLB未命中TLB miss),硬件将在内存中找到页表(使用页表基寄存器(page table base register)),并使用VPN作为索引查找该页的页表项(page table entry,PTE)。如果页面是有效的,并且存在于物理内存中,硬件从PTE中提取PFN,将其安装到TLB中,并重试指令,这一次生成一个TLB命中;到目前为止,一切顺利。
但是,如果希望将页面交换到磁盘,则必须添加更多的机制。具体来说,当硬件在PTE中查找时,它可能会发现页面不在物理内存中。硬件(或操作系统,在软件管理的TLB方法中)确定这一点的方法是通过每个页表条目中的一条新信息,称为存在位(present bit)。如果当前位被设为1,这意味着页面在物理内存中,一切都按照上面的方式进行;如果将其设置为0,则该页不在内存中,而是在磁盘的某个地方。访问不在物理内存中的页面的行为通常称为缺页错误(page fault)。
当出现缺页错误时,会调用操作系统来处理该缺页错误。正如我们现在所描述的,运行一段特定的代码(称为缺页错误处理程序(page-fault handler)),并必须为缺页错误提供服务。
Aside:交换术语和其他东西 虚拟内存系统中的术语在机器和操作系统之间可能会有点混乱,而且会有所不同。例如,通常情况下,缺页错误(page fault)可以指对生成某种错误的页表的任何引用:这可能包括我们在这里讨论的错误类型,即页不存在错误,但有时可能指非法内存访问。确实,我们将绝对合法的访问(对映射到进程虚拟地址空间的页面的访问,但当时根本不在物理内存中)称为“错误”,这很奇怪;但通常情况下,当人们说一个程序是“页面故障(page faulting)”时,他们的意思是它正在访问操作系统已经交换到磁盘上的虚拟地址空间。 我们怀疑这种行为被称为“错误”的原因与操作系统中处理它的机制有关。当一些不寻常的事情发生时,例如,当一些硬件不知道如何处理的事情发生时,硬件简单地将控制转移到操作系统,希望它能使事情变得更好。在这种情况下,进程想要访问的页面从内存中丢失了;硬件做它唯一能做的事,那就是抛出一个异常,然后操作系统从那里接管。由于这与进程做了非法的事情时所发生的事情是相同的,所以我们将该活动称为“错误”可能并不奇怪。
21.3 缺页错误 The Page Fault
回想一下,如果TLB未命中,我们就会有两种类型的系统:硬件管理的TLB(硬件在页表中查找所需的转换)和软件管理的TLB(操作系统在其中查找)。在这两种类型的系统中,如果页面不存在,则由操作系统负责处理缺页错误。运行命名正确的OS缺页错误处理程序(page-fault handler)来确定要做什么。几乎所有的系统都在软件中处理缺页错误;即使使用硬件管理的TLB,硬件也信任操作系统来管理这一重要职责。
如果页面不存在并且已经被交换到磁盘,那么操作系统将需要将页面交换到内存中,以处理缺页错误。因此,一个问题出现了:操作系统如何知道在哪里找到所需的页面?在许多系统中,页表是存储此类信息的自然位置。因此,操作系统可以使用PTE中通常用于数据的位,例如用于磁盘地址的页面的PFN。当操作系统接收到某个页面的缺页错误时,它会在PTE中查找地址,并向磁盘发出请求,将该页面获取到内存中。
当磁盘I/O完成时,操作系统将更新页表以标记该页为present页,更新页表项(PTE)的PFN字段以记录新获取的页在内存中的位置,然后重试该指令。下一次尝试可能会产生一个TLB未命中,然后会对其进行服务并使用转换更新TLB(可以在服务缺页错误时交替更新TLB以避免这一步)。最后,最后一次重新启动将在TLB中找到转换,从而从已转换物理地址的内存中获取所需的数据或指令。
注意,当I/O正在运行时,进程将处于阻塞(blocked)状态。因此,在处理缺页错误时,操作系统将可以自由地运行其他就绪进程。由于I/O开销很大,一个进程的I/O(缺页错误)与另一个进程的执行的重叠(overlap)是多程序系统最有效地利用硬件的另一种方式。
21.4 如果内存满了怎么办? What If Memory Is Full?
在上面描述的过程中,您可能会注意到,我们假设有足够的空闲内存可以从交换空间中置入页面(page in)。当然,情况可能并非如此;内存可能已满(或接近)。因此,操作系统可能希望首先移出(page out)一个或多个页面,以便为操作系统即将引入的新页面腾出空间。选择要踢出或替换(replace)的页面的过程称为页面替换策略(page-replacement policy)。
事实证明,创建良好的页面替换策略已经投入了大量的精力,因为删除错误的页面可能会导致程序性能的巨大损失。做出错误的决定可能会导致程序以类似磁盘的速度而不是类似内存的速度运行;在目前的技术中,这意味着程序的运行速度要慢1万到10万倍。因此,这样的策略是我们应该仔细研究的;事实上,这正是我们下一章要做的。就目前而言,了解这种基于这里描述的机制构建的策略的存在就足够了。
21.5 缺页错误控制流 Page Fault Control Flow
有了这些知识,我们现在可以大致描绘出内存访问的完全控制流程。换句话说,当有人问你“当一个程序从内存中取出一些数据时会发生什么?”,你应该对所有不同的可能性有一个很好的想法。更多细节请参见图21.2和21.3中的控制流;第一个图显示了硬件在转换过程中做了什么,第二个图显示了操作系统在缺页错误时做了什么。
从图21.2的硬件控制流程图中,注意现在有三种重要的情况来理解TLB未命中的发生。首先,页面既存在(present)又有效(valid)(第18行和第21行);在这种情况下,TLB 未命中处理程序可以简单地从PTE获取PFN,重试指令(这一次导致TLB命中),从而继续前面描述的(很多次)。在第二种情况下(第22 - 23行),必须运行缺页错误处理程序;尽管这是进程可以访问的合法页面(毕竟它是合法的),但它不在物理内存中。第三(也是最后),访问可能是一个无效的页面,例如由于程序中的错误(第13行和第14行)。在这种情况下,PTE中的其他位并不重要;硬件捕获这种无效访问,操作系统捕获处理程序运行,可能会终止有问题的进程。
从图21.3中的软件控制流程中,我们可以看到为了处理缺页错误,操作系统大概必须做些什么。首先,操作系统必须为即将出现错误的页面找到一个物理帧;如果没有这样的页面,我们将不得不等待替换算法运行,并将一些页面踢出内存,从而将它们释放出来供这里使用。有了物理帧,处理程序就发出I/O请求,从交换空间读取页面。最后,当慢操作完成时,操作系统更新页表并重试指令。重试将导致TLB失败,然后,在另一次重试时,TLB命中,此时硬件将能够访问所需的项。
21.6 当替换真的发生时 When Replacements Really Occur
到目前为止,我们所描述的替换方式假设操作系统一直等到内存完全满了,然后才替换(逐出)一个页面,为其他一些页面腾出空间。可以想象,这有点不现实,操作系统有很多理由更主动地保留一小部分内存。
为了保持少量的空闲内存,大多数操作系统都使用某种高水位(high watermark,HW)和低水位(low watermark,LW)来帮助决定何时开始从内存中清除页面。其工作原理如下:当操作系统注意到可用的页面少于LW页面时,负责释放内存的后台线程就会运行。线程将删除页面,直到有可用的HW页面为止。后台线程(有时称为交换守护进程(swap daemon)或页面守护进程(page daemon))然后进入睡眠状态,因为它释放了一些内存供运行进程和操作系统使用。
单词daemon(通常发音为demon)是一个古老的术语,指的是执行一些有用任务的后台线程或进程。事实证明(再一次!)这个术语的来源是Multics [CS94]。
通过一次执行多个替换,新的性能优化成为可能。例如,许多系统将多个页面聚集(cluster)或分组(group),并将它们一次性写入交换分区,从而提高磁盘的效率[LL82];我们将在后面详细讨论磁盘时看到,这种聚集减少了磁盘的寻道和旋转开销,从而显著提高性能。
为了使用后台分页线程,应该对图21.3中的控制流进行稍微的修改;算法不会直接执行替换,而是简单地检查是否有可用的空闲页面。如果没有,它将通知后台分页线程需要空闲页面;当线程释放一些页面时,它会重新唤醒原始线程,然后该线程可以在所需页面中置入页面(page in)并继续其工作。
Tip:在后台工作 当您有一些工作要做时,通常最好是在后台(background)进行,以提高效率并允许对操作进行分组。操作系统通常在后台工作;例如,许多系统在实际将数据写入磁盘之前将缓冲文件写入内存。这样做有很多可能的好处:提高磁盘效率,因为磁盘现在可以一次接收许多写入,因此能够更好地调度它们;改进了写入延迟(latency of writes),因为应用程序认为写入完成得很快;减少工作的可能性,因为写入可能永远不需要到磁盘(即,如果文件被删除);更好地利用空闲时间(idle time),因为后台工作可能会在系统空闲时完成,从而更好地利用硬件 [G+95]。
21.7 总结 Summary
在这个简短的章节中,我们介绍了访问比系统中实际存在的更多内存的概念。要做到这一点,需要页表结构更加复杂,因为必须包含一个存在位(present bit)(某种类型的)来告诉我们页是否存在于内存中。如果不是,操作系统缺页错误处理程序(page-fault handler)将运行来处理缺页错误(page fault),从而安排将所需页面从磁盘传输到内存,可能首先替换内存中的一些页面,为即将被换入的页面腾出空间。
重要的是(而且令人惊讶的是!),这些行动都是在进程中透明地发生的。就进程而言,它只是在访问自己的私有连续虚拟内存。在后台,页面被放置在物理内存中的任意(非连续)位置,有时它们甚至不在内存中,需要从磁盘获取。虽然我们希望在通常情况下内存访问是快速的,但在某些情况下,它需要多个磁盘操作来服务它;像执行一条指令这样简单的事情,在最坏的情况下,可能需要花费许多毫秒才能完成。
References
[CS94] “Take Our Word For It” by F. Corbato, R. Steinberg. www.takeourword.com/TOW146
(Page 4). Richard Steinberg writes: “Someone has asked me the origin of the word daemon as it applies
to computing. Best I can tell based on my research, the word was first used by people on your team at
Project MAC using the IBM 7094 in 1963.” Professor Corbato replies: “Our use of the word daemon
was inspired by the Maxwell’s daemon of physics and thermodynamics (my background is in physics).
Maxwell’s daemon was an imaginary agent which helped sort molecules of different speeds and worked
tirelessly in the background. We fancifully began to use the word daemon to describe background pro-
cesses which worked tirelessly to perform system chores.”
[D97] “Before Memory Was Virtual” by Peter Denning. In the Beginning: Recollections of
Software Pioneers, Wiley, November 1997. An excellent historical piece by one of the pioneers of
virtual memory and working sets.
[G+95] “Idleness is not sloth” by Richard Golding, Peter Bosch, Carl Staelin, Tim Sullivan, John
Wilkes. USENIX ATC ’95, New Orleans, Louisiana. A fun and easy-to-read discussion of how idle
time can be better used in systems, with lots of good examples.
[LL82] “Virtual Memory Management in the VAX/VMS Operating System” by Hank Levy, P.
Lipman. IEEE Computer, Vol. 15, No. 3, March 1982. Not the first place where page clustering was
used, but a clear and simple explanation of how such a mechanism works. We sure cite this paper a lot!
Homework (Measurement)
这个作业向您介绍了一个新工具vmstat,以及如何使用它来理解内存、CPU和I/O使用情况。在继续下面的练习和问题之前,请阅读相关的README并检查mem.c中的代码。
Questions
- 首先,打开两个独立的终端连接到同一台机器,这样您就可以轻松地在一个窗口和另一个窗口中运行一些东西。
现在,在一个窗口中运行vmstat 1,它每秒显示关于计算机使用情况的统计信息。请阅读手册页、相关的README和您需要的任何其他信息,以便您能够理解其输出。让这个窗口运行vmstat,以进行下面的练习。
现在,我们将运行程序mem.c,但使用很少的内存。这可以通过输入./mem 1(只使用1mb内存)来实现。运行mem时,CPU使用率统计如何变化?用户时间栏中的数字有意义吗?当同时运行多个mem实例时,这将如何改变?
- 现在让我们开始查看运行mem时的一些内存统计信息。我们将重点关注两个列:swpd(使用的虚拟内存数量)和free(空闲内存数量)。运行 ./mem 1024(它分配1024mb),观察这些值是如何变化的。然后杀死正在运行的程序(通过输入control-c),再次观察值的变化。关于这些值,你注意到了什么?特别是,当程序退出时,free列如何变化?当mem退出时,可用内存的数量是否按预期增加?
- 接下来,我们将研究交换列(si和so),它们表示与磁盘之间发生了多少交换。当然,要激活这些,您需要运行具有大量内存的mem。首先,检查Linux系统上有多少空闲内存(例如,输入cat /proc/meminfo;请键入man proc以了解/proc文件系统的详细信息以及可以在那里找到的信息类型)。/proc/meminfo中的第一个条目是系统中的内存总量。让我们假设它有8gb的内存;如果是,首先运行mem 4000(大约4 GB)并观察交换入/出列。他们会给出非零值吗?然后,尝试用5000,6000等等。与第一个循环相比,当程序进入第二个循环(以及之后)时,这些值发生了什么?在第二个、第三个循环和随后的循环中,有多少数据(总共)被交换输入和输出?(这些数字有意义吗?)
- 进行与上面相同的实验,但是现在观察其他统计数据(如CPU利用率和阻塞I/O统计数据)。当mem执行的时候,他们是如何改变的?
- 现在让我们来检查性能。为mem选择一个适合内存的输入(如果系统上的内存为8gb,则为4000)。循环0需要多长时间(以及随后的循环1、2等等)?现在选择一个舒适的内存大小之外的大小(假设是12000,假设是8gb内存)。在这里循环要多久?带宽(bandwidth)数如何比较?不断交换与在内存中舒适地适合所有内容时的性能有何不同?你能做一个图表,x轴是mem使用的内存大小,y轴是访问所述内存的带宽吗?最后,第一个循环的性能与后续循环的性能相比如何,对于所有内容都适合内存和不适合的情况?
- 交换空间不是无限的。您可以使用带有-s标志的工具swap来查看有多少交换空间可用。如果您试图用越来越大的值运行mem,超出swap中似乎可用的值,会发生什么?在什么时候内存分配会失败?
- 最后,如果您是高级用户,您可以使用swapon和swapoff配置您的系统以使用不同的交换设备。详细信息请阅读手册页。如果您可以访问不同的硬件,请查看在切换到经典硬盘驱动器、基于闪存的SSD甚至是RAID阵列时,交换性能的变化。更新的设备能在多大程度上提高交换性能?您能有多接近内存中的性能?

若有收获,就点个赞吧
0 人点赞
