在早期,建立计算机系统是很容易的。为什么,你问?因为用户的期望值并不高。正是那些对易用性、高性能、可靠性等抱有期望的可恶用户,导致了所有这些令人头疼的问题。下次你遇到这些电脑用户时,感谢他们造成的所有问题。
13.1 早期系统 Early Systems
从内存的角度来看,早期的机器并没有为用户提供太多的抽象。基本上,该机器的物理内存与图13.1(第2页)中所示类似。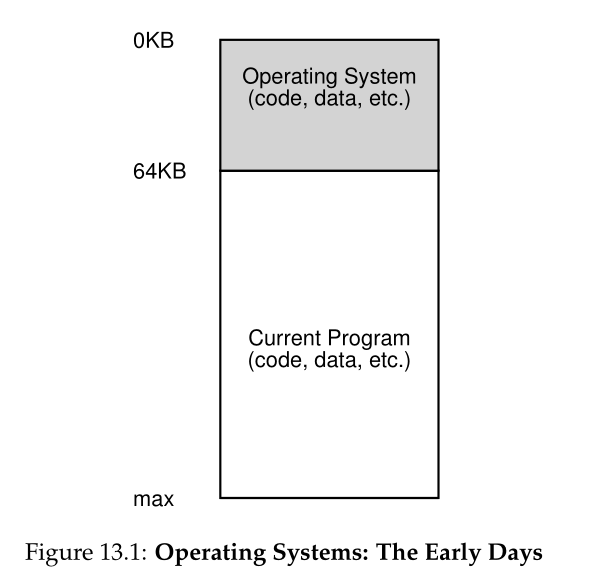
操作系统是一组位于内存中的例程(实际上是一个库)(在本例中从物理地址 0 开始),并且将有一个正在运行的程序(一个进程)当前位于物理内存中(在此示例中从物理地址64k开始 )并使用其余内存。这里几乎没有假象(illusions),用户对操作系统的期望也不高。在那个年代,操作系统开发人员的生活肯定很轻松,不是吗?
13.2 多进程和分时 Multiprogramming and Time Sharing
过了一段时间,因为机器很贵,人们开始更有效地共享机器。因此,多进程设计(multiprogramming)时代[DV66]诞生了,在这个时代,多个进程可以在给定的时间内运行,而操作系统可以在它们之间切换,例如当一个进程决定执行I/O时。这样做可以提高CPU的有效利用率(utilization)。在那些每台电脑都要花费数十万甚至数百万美元的时代,这种效率(efficiency)的提高尤其重要(你会觉得你的Mac电脑很贵!)
然而,很快,人们开始要求更多的机器,分时(time sharing)的时代诞生了[S59, L60, M62, M83]。特别是,许多人意识到批处理计算的局限性,特别是对程序员本身[CV65]的局限性,他们厌倦了冗长的程序调试周期(因此无效)。交互性(interactivity)的概念变得很重要,因为许多用户可能同时使用一台机器,每个用户都在等待(或希望)来自当前正在执行的任务的及时响应。
实现分时的一种方法是运行一个进程一小会儿,让它完全访问所有内存(图 13.1),然后停止它,将其所有状态保存到某种磁盘(包括所有物理内存),加载一些其他进程的状态,运行一段时间,从而实现某种粗略的机器共享[M+63]。
不幸的是,这种方法有一个大问题:它太慢了,特别是当内存增长时。虽然保存和恢复寄存器级状态(PC、通用寄存器等)相对较快,但将内存的全部内容保存到磁盘是非常低效的。因此,我们宁愿把进程留在内存中,同时在它们之间切换,允许操作系统有效地实现分时(如图13.2)。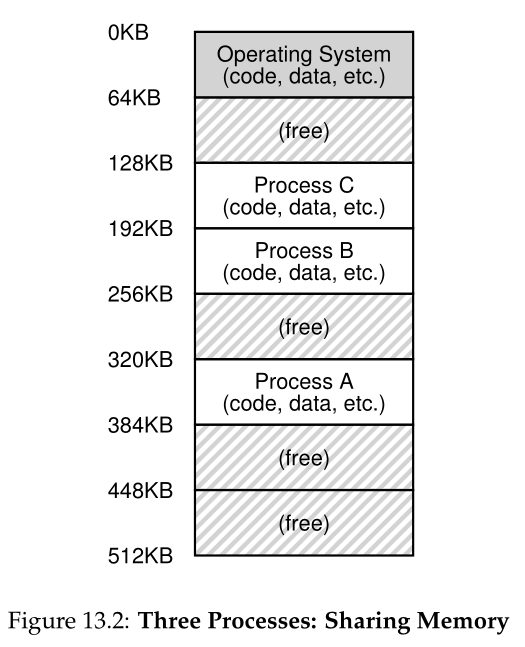
在图中,有三个进程(A、B和C),每个进程都有512KB物理内存的一小部分。假设只有一个CPU,操作系统选择运行其中一个进程(比如a),而其他进程(B和C)则在就绪队列中等待运行。
随着分时变得越来越流行,您可能会猜到对操作系统提出了新的要求。特别是,允许多个程序同时驻留在内存中使保护(protection)成为一个重要问题;你不希望一个进程能够读取,或者更糟的是,写入其他进程的内存。
13.3 地址空间 The Address Space
然而,我们必须记住那些讨厌的用户,这样做需要操作系统创建一个易于使用(easy to use)的物理内存抽象。我们称这种抽象为地址空间(address space),它是运行程序在系统中的内存视图。理解这个基本的操作系统对内存的抽象是理解内存是如何虚拟化的关键。
进程的地址空间包含正在运行的程序的所有内存状态。例如,程序的代码(指令)必须存在内存中的某个地方,因此它们在地址空间中。程序在运行时,使用堆栈来跟踪它在函数调用链中的位置,以及分配局部变量、向例程传递参数和返回值。最后,堆用于动态分配、用户管理的内存,例如您可能从C语言中的malloc()调用或c++或Java等面向对象语言中的new中接收到的内存。当然,这里也有其他的东西(例如,静态初始化的变量),但现在让我们假设这三个组件:代码、栈和堆。
在图13.3的示例中,我们有一个很小的地址空间(只有16KB)。程序代码位于地址空间的顶部(在本例中从0开始,并被压缩到地址空间的前1K中)。代码是静态的(因此很容易放在内存中),所以我们可以把它放在地址空间的顶部,并且知道在程序运行时它不需要更多的空间。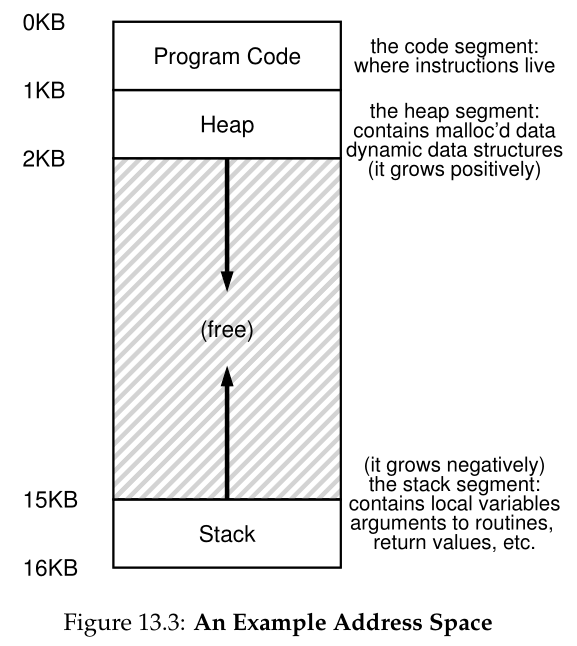
接下来,在程序运行时,地址空间的两个区域可能会增长(和收缩)。这些是堆(在顶部)和堆栈(在底部)。我们这样放置它们是因为它们都希望能够增长,通过将它们放在地址空间的相反两端,我们可以允许这样的增长:它们只需要向相反的方向增长。因此,堆刚好在代码之后开始(1KB),并向下增长(比如当用户通过malloc()请求更多内存时);栈从16KB开始并向上增长(比如当用户调用过程时)。然而,栈和堆的这种布局只是一种约定;如果您愿意,您可以以不同的方式安排地址空间(稍后我们将看到,当多个线程(threads)在一个地址空间中共存时,没有像这样划分地址空间的好方法了,唉)。
当然,当我们描述地址空间时,我们描述的是操作系统提供给正在运行的程序的抽象(abstraction)。该程序实际上不在物理地址 0 到 16KB 的内存中;而是在某个任意物理地址加载。检查图 13.2 中的过程 A、B 和 C;在那里您可以看到每个进程如何加载到不同地址的内存中。因此问题是:
关键的问题:如何虚拟化内存 操作系统如何在单个物理内存之上为多个正在运行的进程(所有共享内存)构建这种私有的、潜在的大地址空间的抽象?
当操作系统这样做时,我们说操作系统在虚拟化内存(virtualizing memory),因为运行的程序认为它被加载到一个特定地址(比如0)的内存中,并且有一个潜在的非常大的地址空间(比如32位或64位);现实情况却大不相同。
例如,当图 13.2 中的进程 A 尝试在地址 0(我们将其称为虚拟地址(virtual address))执行加载时,操作系统与某些硬件支持一起以某种方式必须确保加载实际上不是转到物理地址 0,而是转到物理地址 320KB(其中 A 加载到内存中)。这是内存虚拟化的关键,它是世界上每个现代计算机系统的基础。
13.4
目标 Goals
因此,我们在这组笔记中谈到了操作系统的工作:虚拟化内存。不过,操作系统不仅会虚拟化内存;它还会有风格。为了确保操作系统能够做到这一点,我们需要一些目标来指导我们。我们以前看到过这些目标(想想引言),我们还会看到它们,但它们确实值得重复。
虚拟内存(VM)系统的一个主要目标是透明(transparency)。操作系统应该以一种对正在运行的程序不可见的方式实现虚拟内存。因此,程序不应该知道内存是虚拟化的;相反,程序的行为就好像它有自己的私有物理内存一样。在幕后,操作系统(和硬件)在许多不同的工作之间进行多路复用内存的所有工作,因此实现了假象(illusion)。
透明度的这种用法有时令人困惑;一些学生认为透明意味着一切都是公开的,也就是说,政府应该是什么样的。在这里,它的意思是相反的:操作系统提供的假象不应该对应用程序可见。因此,通常情况下,一个透明的系统是很难被注意到的,而不是响应《信息自由法》规定的请求的系统。
虚拟内存的另一个目标是效率(efficiency)。操作系统应该努力使虚拟化尽可能高效(efficient),无论是从时间方面(即,不使程序运行得更慢)还是从空间方面(即,不为支持虚拟化所需的结构使用太多内存)。为了实现省时的虚拟化,操作系统将不得不依赖硬件支持,包括TLBs (我们将在适当的时候学习)等硬件特性。
最后,虚拟内存的第三个目标是保护(protection)。操作系统应该确保保护进程不受其他进程的影响,以及保护操作系统本身不受进程的影响。当一个进程执行加载、存储或取指令时,它不应该以任何方式访问或影响任何其他进程或操作系统本身的内存内容(即地址空间之外的任何内容)。因此,保护使我们能够交付进程间隔离(isolation)的特性;每个进程都应该在自己独立的茧中运行,不受其他错误甚至恶意进程的破坏。
Tip:隔离原则 隔离是建立可靠系统的一个关键原则。如果两个实体正确地彼此隔离,这意味着其中一个可以失败而不影响另一个。操作系统努力将进程彼此隔离,并以这种方式防止一个进程伤害另一个进程。通过内存隔离,操作系统进一步确保运行的程序不会影响底层操作系统的运行。一些现代操作系统甚至更进一步地将操作系统的各个部分与其他部分隔离开来。因此,这种微核(microkernels)[BH70, R+89, S+03]可能比典型的单片核设计提供更大的可靠性。
在下一章中,我们将重点探讨虚拟化内存所需的基本机制(mechanisms),包括硬件和操作系统支持。我们还将研究您在操作系统中可能遇到的一些更相关的策略(policies),包括如何管理可用空间,以及在空间不足时应该将哪些页面踢出内存。通过这样做,我们将增进您对现代虚拟内存系统如何真正工作的理解。
13.5
总结 Summary 我们已经看到引入了一个主要的操作系统子系统:虚拟内存(virtual memory)。VM 系统负责为程序提供一个大的、稀疏的、私有的地址空间的假象,程序在其中保存所有指令和数据。操作系统在一些重要的硬件帮助下,将获取每一个虚拟内存的引用,并将它们转换为物理地址,这些地址可以呈现给物理内存以获取所需的信息。操作系统将对多个进程同时进行此操作,以确保保护程序不受其他进程的影响,同时也保护了操作系统。整个方法需要大量机制(许多低级机制)以及一些关键策略才能发挥作用;我们将从底向上开始,首先描述关键机制。就这样我们继续!
Aside:你看到的每个地址都是虚拟的 写过输出指针的C程序吗?您看到的值(一个很大的数字,通常以十六进制方式打印)是一个虚拟地址(virtual address)。有没有想过你的程序代码是在哪里找到的?你也可以把它打印出来,是的,如果你能打印出来,它也是一个虚拟地址。事实上,作为用户级程序的程序员,您可以看到的任何地址都是虚拟地址。只有操作系统,通过其棘手的内存虚拟化技术,知道这些指令和数据值在机器的物理内存中的位置。所以永远不要忘记:如果你在程序中打印出一个地址,它是一个虚拟地址,一个关于内存如何布局的假象;只有操作系统(和硬件)知道真相。 下面是一个小程序(va.c),它输出main()例程的位置(代码所在的位置),malloc()返回的堆分配值的值,以及一个整数在栈上的位置:
当在64位Mac上运行时,我们得到如下输出:
从这里,您可以看到代码首先出现在地址空间,然后是堆,而栈一直在这个大型虚拟空间的另一端。所有这些地址都是虚拟的,将由操作系统和硬件进行转换,以便从它们的真实物理位置获取值。
References
[BH70] “The Nucleus of a Multiprogramming System” by Per Brinch Hansen. Communica-
tions of the ACM, 13:4, April 1970. The first paper to suggest that the OS, or kernel, should be
a minimal and flexible substrate for building customized operating systems; this theme is revisited
throughout OS research history.
[CV65] “Introduction and Overview of the Multics System” by F. J. Corbato, V. A. Vyssotsky.
Fall Joint Computer Conference, 1965. A great early Multics paper. Here is the great quote about
time sharing: “The impetus for time-sharing first arose from professional programmers because of their
constant frustration in debugging programs at batch processing installations. Thus, the original goal
was to time-share computers to allow simultaneous access by several persons while giving to each of
them the illusion of having the whole machine at his disposal.”
[DV66] “Programming Semantics for Multiprogrammed Computations” by Jack B. Dennis,
Earl C. Van Horn. Communications of the ACM, Volume 9, Number 3, March 1966. An early
paper (but not the first) on multiprogramming.
[L60] “Man-Computer Symbiosis” by J. C. R. Licklider. IRE Transactions on Human Factors in
Electronics, HFE-1:1, March 1960. A funky paper about how computers and people are going to enter
into a symbiotic age; clearly well ahead of its time but a fascinating read nonetheless.
[M62] “Time-Sharing Computer Systems” by J. McCarthy. Management and the Computer
of the Future, MIT Press, Cambridge, MA, 1962. Probably McCarthy’s earliest recorded paper
on time sharing. In another paper [M83], he claims to have been thinking of the idea since 1957.
McCarthy left the systems area and went on to become a giant in Artificial Intelligence at Stanford,
including the creation of the LISP programming language. See McCarthy’s home page for more info:
http://www-formal.stanford.edu/jmc/
[M+63] “A Time-Sharing Debugging System for a Small Computer” by J. McCarthy, S. Boilen,
E. Fredkin, J. C. R. Licklider. AFIPS ’63 (Spring), New York, NY, May 1963. A great early example
of a system that swapped program memory to the “drum” when the program wasn’t running, and then
back into “core” memory when it was about to be run.
[M83] “Reminiscences on the History of Time Sharing” by John McCarthy. 1983. Available:
http://www-formal.stanford.edu/jmc/history/timesharing/timesharing.html. A terrific his-
torical note on where the idea of time-sharing might have come from including some doubts towards
those who cite Strachey’s work [S59] as the pioneering work in this area.
[NS07] “Valgrind: A Framework for Heavyweight Dynamic Binary Instrumentation” by N.
Nethercote, J. Seward. PLDI 2007, San Diego, California, June 2007. Valgrind is a lifesaver of a
program for those who use unsafe languages like C. Read this paper to learn about its very cool binary
instrumentation techniques – it’s really quite impressive.
[R+89] “Mach: A System Software kernel” by R. Rashid, D. Julin, D. Orr, R. Sanzi, R. Baron,
A. Forin, D. Golub, M. Jones. COMPCON ’89, February 1989. Although not the first project on
microkernels per se, the Mach project at CMU was well-known and influential; it still lives today deep
in the bowels of Mac OS X.
[S59] “Time Sharing in Large Fast Computers” by C. Strachey. Proceedings of the International
Conference on Information Processing, UNESCO, June 1959. One of the earliest references on time
sharing.
[S+03] “Improving the Reliability of Commodity Operating Systems” by M. M. Swift, B. N.
Bershad, H. M. Levy. SOSP ’03. The first paper to show how microkernel-like thinking can improve
operating system reliability.
Homework (Code)
在本作业中,我们将学习一些有用的工具,用于检查基于linux的系统上的虚拟内存使用情况。这将只是一个简短的提示,什么是可能的;你必须自己深入研究,才能真正成为专家(一如既往!)。
Questions
- 您应该检查的第一个Linux工具是非常简单的free工具。首先,键入man free,阅读整个手册页;很短,不用担心!
- 现在,运行free,可能使用一些有用的参数(例如,-m,以兆字节为单位显示内存总数)。你的系统中有多少内存?有多少是空闲的?这些数字符合你的直觉吗?
- 接下来,创建一个使用一定数量内存的小程序,称为memory-user.c。这个程序应该接受一个命令行参数:它将使用的内存的兆字节数。当运行时,它应该分配一个数组,并不断地流过数组,接触每个元素。程序应该无限期地这样做,或者,可能在命令行指定的一定时间内这样做。
- 现在,在运行memory-user程序时,也要(在不同的终端窗口,但在同一台机器上)运行free工具。当程序运行时,内存使用总数如何变化?当你杀死memory-user的时候呢?这些数字符合你的预期吗?尝试使用不同的内存使用量。当您使用大量内存时会发生什么?
- 让我们尝试另一个工具,称为pmap。花些时间阅读pmap手册页面的详细内容。
- 要使用pmap,您必须知道您感兴趣的进程的进程ID( process ID)。因此,首先运行ps auxw来查看所有进程的列表;然后,选择一个有趣的,比如浏览器。在这种情况下,您还可以使用memory-user程序(实际上,为了方便,您甚至可以让该程序调用getpid()并打印其PID)。
- 现在,在其中一些进程上运行pmap,使用各种标志(如-X)来显示进程的许多细节。你看到了什么?与代码/栈/堆的简单概念相反,现代地址空间有多少不同的实体?
- 最后,让我们在memory-user程序上运行pmap,使用不同数量的已使用内存。你在这里看到了什么?pmap的输出是否符合您的期望?

若有收获,就点个赞吧
0 人点赞
