- 45.1 磁盘故障模式 Disk Failure Modes
- 45.2 处理潜在扇区错误 Handling Latent Sector Errors
- 45.3 检测损坏:校验和 Detecting Corruption: The Checksum
- 45.4 使用校验和 Using Checksums
- 45.5 一个新问题:写定位错误 A New Problem: Misdirected Writes
- 45.6 最后一个问题:写入丢失 One Last Problem: Lost Writes
- 45.7 擦拭 Scrubbing
- 45.8 校验和的开销 Overheads Of Checksumming
- 45.9 总结 Summary
- References
- Homework (Simulation)
除了到目前为止我们所研究的文件系统的基本进展之外,还有一些特性值得研究。在本章中,我们再次关注可靠性(之前在RAID章节中研究过存储系统的可靠性)。具体来说,考虑到现代存储设备的不可靠特性,文件系统或存储系统应该如何确保数据是安全的?<br />该一般领域被称为**数据完整性(data integrity)**或**数据保护(data protection)**。因此,我们现在将研究用于确保您输入存储系统的数据在存储系统返回给您时是相同的技术。
关键的问题:如何确保数据完整性 系统应如何确保写入存储的数据受到保护? 需要哪些技术? 如何使这些技术高效,同时具有低空间和时间开销?
45.1 磁盘故障模式 Disk Failure Modes
正如您在 RAID 一章中了解到的,磁盘并不完美,并且可能会出现故障(有时)。 在早期的 RAID 系统中,故障模型非常简单:要么整个磁盘都在工作,要么完全失效,而这种故障的检测很简单。 这种磁盘故障的故障停止(fail-stop)模型使构建 RAID 变得相对简单 [S90]。
您没有了解现代磁盘所表现出的所有其他类型的故障模式。 具体来说,正如 Bairavasundaram 等人。 详细研究 [B+07, B+08],现代磁盘有时似乎大部分都在工作,但无法成功访问一个或多个块。 具体来说,两种类型的单块故障是常见且值得考虑的:潜在扇区错误 (LSE) 和块损坏(latent-sector errors (LSEs) and block corruption)。 我们现在将更详细地讨论每一个。
当磁盘扇区(或扇区组)以某种方式损坏时,就会出现 LSE。 例如,如果磁头由于某种原因接触表面(磁头碰撞(head crash),在正常操作中不应该发生的事情),它可能会损坏表面,使位无法读取。 宇宙射线(Cosmic rays)还可以翻转位,导致内容不正确。 幸运的是,驱动器使用磁盘纠错码 (error correcting codes,ECC) 来确定块中的磁盘位是否良好,在某些情况下,还可以修复它们; 如果它们不是好的,并且驱动器没有足够的信息来修复错误,则在发出读取它们的请求时,磁盘将返回错误。
在某些情况下,磁盘块以磁盘本身无法检测到的方式损坏(corrupt)。 例如,有问题的磁盘固件可能会将一个块写入错误的位置; 在这种情况下,磁盘 ECC 表明块内容很好,但从客户端的角度来看,随后访问时会返回错误的块。 类似地,当一个块通过有故障的总线从主机传输到磁盘时,它可能会损坏; 由此产生的损坏数据由磁盘存储,但这不是客户想要的。 这些类型的故障特别隐蔽,因为它们是静默故障(silent faults); 返回错误数据时,磁盘没有给出问题的指示。
Prabhakaran 等人。 将这种更现代的磁盘故障观点描述为故障-部分(fail-partial)磁盘故障模型 [P+05]。 在这种情况下,磁盘仍然可能完全失效(就像传统的故障停止模型中的情况一样); 然而,磁盘也可能看起来在工作并且有一个或多个块变得不可访问(即 LSE)或保存错误的内容(即损坏(corruption))。 因此,当访问一个看似正常工作的磁盘时,有时它可能会在尝试读取或写入给定块时返回错误(非静默部分错误),有时它可能只是简单地返回错误数据 (静默部分故障)。
这两种类型的故障都有些罕见,但有多罕见? 图 45.1 总结了两个 Bairavasundaram 研究 [B+07,B+08] 的一些发现。
Figure 45.1: Frequency Of LSEs And Block Corruption
该图显示了在研究过程中出现至少一个 LSE 或块损坏的驱动器的百分比(大约 3 年,超过 150 万个磁盘驱动器)。 该图进一步将结果细分为“廉价”驱动器(通常是 SATA 驱动器)和“昂贵”驱动器(通常是 SCSI 或光纤通道)。 如您所见,虽然购买更好的驱动器可以降低这两类问题的频率(大约降低一个数量级),但它们仍然经常发生,您需要仔细考虑如何在存储系统中处理它们。
关于 LSE 的一些额外发现是:
- 具有多个LSE的高成本驱动器与成本较低的驱动器一样可能产生额外的错误
- 对于大多数驱动器,在第二年之后每年错误率会增加
- LSE的数量随着磁盘大小的增加而增加
- 大多数磁盘的LSE数量小于50
- 带有LSEs的磁盘更有可能出现额外的LSEs
- 存在大量的空间和时间局部性
- 磁盘清理是有用的(大多数LSE都是这样找到的)
关于 corruption(损坏)的一些发现:
- 同一驱动器类别中不同驱动器型号的损坏几率差异很大
- 不同型号的寿命效应不同
- 工作负载和磁盘大小对损坏的影响很小
- 大多数损坏的磁盘只有少数损坏
- 损坏不是独立于磁盘内或 RAID 中的磁盘
- 存在空间局部性和一些时间局部性
- 与 LSE 的相关性较弱
要了解有关这些失败的更多信息,您可能应该阅读原始论文 [B+07,B+08]。 但希望重点应该是清楚的:如果你真的希望构建一个可靠的存储系统,你必须包括检测和恢复 LSE 和块损坏的机制。
45.2 处理潜在扇区错误 Handling Latent Sector Errors
考虑到这两种部分磁盘故障的新模式,我们现在应该尝试看看我们可以对它们做些什么。 让我们首先解决两者中较容易的一个,即潜在扇区错误(latent sector errors)。
关键的问题:如何处理潜在扇区错误 存储系统应该如何处理潜在扇区错误? 需要多少额外的机器来处理这种形式的部分故障?
事实证明,潜在扇区错误相当容易处理,因为它们(根据定义)很容易检测到。 **当存储系统尝试访问一个块,并且磁盘返回错误时,存储系统应该简单地使用它必须使用的任何冗余机制来返回正确的数据。 **例如,在镜像 RAID 中,系统应该访问备用副本; 在基于奇偶校验的 RAID-4 或 RAID-5 系统中,系统应该从奇偶校验组中的其他块重建块。 因此,通过标准冗余机制可以轻松地恢复诸如 LSE 之类的容易检测到的问题。<br />多年来,LSE 的日益流行影响了 RAID 设计。 当全盘故障和 LSE 同时发生时,RAID-4/5 系统中会出现一个特别有趣的问题。 具体来说,当整个磁盘出现故障时,RAID 会尝试通过读取奇偶校验组中的所有其他磁盘并重新计算缺失值来**重建(reconstruct)**磁盘(例如,到热备盘上)。** 如果在重建期间,在任何一个其他磁盘上遇到 LSE,我们就会遇到问题:重建无法成功完成。**<br />为了解决这个问题,**一些系统增加了额外的冗余度**。 例如,NetApp 的 **RAID-DP** **相当于两个奇偶校验磁盘,而不是一个** [C+04]。 当在重建过程中发现 LSE 时,额外的奇偶校验有助于重建丢失的块。 与往常一样,这是有成本的,因为为每个条带维护两个奇偶校验块的成本更高; 然而,NetApp **WAFL** 文件系统的日志结构特性在许多情况下减轻了这种成本 [HLM94]。 剩余的成本是空间,其形式是为第二个奇偶校验块提供额外的磁盘。
45.3 检测损坏:校验和 Detecting Corruption: The Checksum
现在让我们解决更具挑战性的问题,即数据损坏导致的静默故障。 如何防止用户在出现损坏时获取坏数据,从而导致磁盘返回坏数据?
关键的问题:如何在数据损坏的情况下保持数据完整性 鉴于此类故障的静默性质,存储系统可以做什么来检测何时出现损坏(corruption)? 需要哪些技术? 如何有效地实施它们?
与潜在扇区错误不同,损坏检测是一个关键问题。客户端如何判断块已损坏? 一旦知道一个特定的块是坏的,恢复就和以前一样:你需要有一些其他的块副本(希望是一个没有损坏的副本!)。 因此,我们在这里专注于检测技术。<br />现代存储系统用于保持数据完整性的主要机制称为**校验和(checksum)**。 校验和只是一个函数的结果,该函数将一大块(chunk)数据(比如一个 4KB 的块)作为输入,并在所述数据上计算一个函数,生成数据内容的一个小摘要(summary,比如 4 或 8 个字节)。 该摘要称为校验和。 **这种计算的目标是通过将校验和与数据一起存储,然后在稍后访问时确认数据的当前校验和与原始存储值匹配,从而使系统能够检测数据是否以某种方式被破坏或更改。**
常见校验和函数 Common Checksum Functions
许多不同的函数用于计算校验和,并且在强度(strength,即它们在保护数据完整性方面的能力)和速度(speed,即它们的计算速度)方面各不相同。 系统中常见的权衡出现在这里:通常,您获得的保护越多,成本就越高。 天下没有免费的午餐(There is no such thing as a free lunch)。
Tip:天下没有免费的午餐(THERE’S NO FREE LUNCH) 没有免费午餐之类的东西,或简称为 TNSTAAFL,是一个古老的美国成语,它暗示当您看似免费获得某样东西时,实际上您可能会为此付出一些代价。 它来自过去,食客会为顾客做免费午餐的广告,希望能吸引他们; 进去之后才知道,要获得“免费”的午餐,必须购买一种或多种酒精饮料。 当然,这实际上可能不是问题,特别是如果您是一个有抱负的酒鬼(或典型的本科生)。
一些使用的一种简单的校验和函数基于异或(XOR)。 对于基于 XOR 的校验和,校验和是通过对要进行校验和的数据块的每个块进行 XOR 运算来计算的,从而产生代表整个块的 XOR 的单个值。<br />为了更具体,假设我们在 16 字节的块上计算 4 字节的校验和(这个块当然太小而不能真正成为磁盘扇区或块,但它可以作为示例)。 十六进制的 16 个数据字节如下所示:<br /><br />如果我们以二进制形式查看它们,我们会得到以下结果:<br /><br />因为我们将数据以每行 4 个字节为一组排列,所以很容易看出校验和结果是什么:对每一列执行 XOR 以获得最终校验和值:<br /><br />结果是十六进制的0x201b9403。<br />XOR 是一个合理的校验和,但有其局限性。 例如,如果每个校验和单元内相同位置的两个位发生变化,校验和将不会检测到损坏。 为此,人们研究了其他校验和函数。<br />另一个基本的校验和函数是加法。 这种方法的优点是速度快; 计算它只需要对每个数据块执行 2 的补码(2's-complement)加法,忽略溢出。 它可以检测数据中的许多变化,但如果数据发生移位,则效果不佳。<br />一种稍微复杂的算法称为 **Fletcher 校验和(Fletcher checksum)**,以发明者 John G. Fletcher [F82] 的名字命名(您可能会猜到)。 计算非常简单,涉及两个校验字节 s1 和 s2 的计算。 具体来说,假设块 D 由字节 d1 ... dn 组成; s1 定义如下: s1 = (s1 + di) mod 255(计算所有 di); s2 依次是:s2 = (s2 + s1) mod 255(再次计算所有 di)[F04]。 Fletcher 校验和几乎与 CRC 一样强(见下文),检测所有单比特、双比特错误和许多突发错误 [F04]。<br />最后一种常用的校验和称为**循环冗余校验 (cyclic redundancy check,CRC)**。 假设您希望计算数据块 D 的校验和。您所做的只是将 D 视为一个大二进制数(毕竟它只是一个位串)并将其除以商定的值 (k)。 该除法的余数是 CRC 的值。 事实证明,**人们可以相当有效地实现这种二进制模运算,因此 CRC 在网络中也很流行**。 有关更多详细信息,请参阅别处 [M13]。<br />无论使用何种方法,显然不存在完美的校验和:**具有不同内容的两个数据块可能具有相同的校验和,这称为冲突(collision)**。 这个事实应该是直观的:毕竟,计算校验和需要一些大的东西(例如,4KB)并生成一个小得多的摘要(例如,4 或 8 个字节)。 在选择一个好的校验和函数时,我们试图找到一个在保持易于计算的同时最小化冲突机会的函数。
校验和布局 Checksum Layout
现在您对如何计算校验和有了一些了解,接下来让我们分析如何在存储系统中使用校验和。 我们必须解决的第一个问题是校验和的布局,即校验和应该如何存储在磁盘上?
最基本的方法只是简单地存储每个磁盘扇区(或块)的校验和。 给定一个数据块 D,让我们调用该数据的校验和 C(D)。 因此,没有校验和,磁盘布局如下所示:
使用校验和,布局为每个块添加一个校验和:
由于校验和通常很小(例如 8 字节),并且磁盘只能写入扇区大小的块(512 字节)或其倍数,因此出现的一个问题是如何实现上述布局。 驱动器制造商采用的一种解决方案是将驱动器格式化为 520 字节扇区; 每个扇区额外的 8 个字节可用于存储校验和。
在没有这种功能的磁盘中,文件系统必须找到一种方法来存储打包成 512 字节块的校验和。 一种这样的可能性如下:
在该方案中,n 个校验和一起存储在一个扇区中,然后是 n 个数据块,然后是另一个用于接下来 n 个块的校验和扇区,依此类推。 这种方法的好处是可以处理所有磁盘,但效率较低; 例如,如果文件系统要覆盖块 D1,它必须读入包含 C(D1) 的校验和扇区,更新其中的 C(D1),然后写出校验和扇区和新数据块 D1(因此 ,一读两写)。 较早的方法(每个扇区一个校验和)只执行一次写入。
45.4 使用校验和 Using Checksums
确定校验和布局后,我们现在可以继续实际了解如何使用校验和。 在读取块 D 时,客户端(即文件系统或存储控制器)也会从磁盘 Cs(D) 读取其校验和,我们称之为存储校验和(stored checksum,因此称为下标 Cs)。 然后客户端计算检索到的块 D 的校验和,我们称之为计算校验和(computed checksum) Cc(D)。 此时,客户端比较存储和计算的校验和; 如果它们相等(即 Cs(D) == Cc(D),则数据可能没有损坏,因此可以安全地返回给用户。如果它们不匹配(即 Cs(D) != Cc(D)),这意味着数据自存储以来发生了变化(因为存储的校验和反映了当时数据的值)。在这种情况下,我们有一个损坏,我们的校验和帮助我们检测了它。
那么对于损坏(corruption),自然的问题是我们应该怎么做? 如果存储系统有一个冗余副本,答案很简单:尝试用它代替。 如果存储系统没有这样的副本,可能的答案是返回错误。 无论哪种情况,都要意识到损坏检测不是灵丹妙药; 如果没有其他方法可以获取未损坏的数据,那么您就是运气不好。
45.5 一个新问题:写定位错误 A New Problem: Misdirected Writes
上述基本方案在损坏块的一般情况下运行良好。 但是,现代磁盘有几种不寻常的故障模式,需要不同的解决方案。
第一个感兴趣的故障模式称为写定位错误(misdirected write)。 这出现在将数据正确写入磁盘的磁盘和 RAID 控制器中,除了是在错误的位置。 在单磁盘系统中,这意味着磁盘写入块  没有到地址
没有到地址  (根据需要),而是写到了地址
(根据需要),而是写到了地址  (因此“破坏”了
(因此“破坏”了  ); 另外,在多磁盘系统中,控制器也可以不将
); 另外,在多磁盘系统中,控制器也可以不将  写入磁盘
写入磁盘  的地址
的地址  ,而是写入其他磁盘
,而是写入其他磁盘  。 因此我们的问题:
。 因此我们的问题:
关键的问题:如何处理写定位错误 存储系统或磁盘控制器应该如何检测写定位错误? 校验和需要哪些附加功能?
毫不奇怪,答案很简单:为每个校验和添加更多信息。 在这种情况下,添加一个**物理标识符(physical identifier,physical ID)**是很有帮助的。 例如,如果存储的信息现在包含校验和 C(D) 以及块的磁盘号和扇区号,则客户端很容易确定正确的信息是否驻留在特定的位置。 具体来说,如果客户端正在读取磁盘10上的块 4 ,则存储的信息应包括该磁盘号和扇区偏移量,如下所示。 如果信息不匹配,则发生了写定位错误,现在检测到损坏。 以下是此添加信息在两磁盘系统上的外观示例。 请注意,这个数字和之前的其他数字一样,不是按比例缩放的,因为校验和通常很小(例如,8 字节)而块要大得多(例如,4 KB 或更大):<br />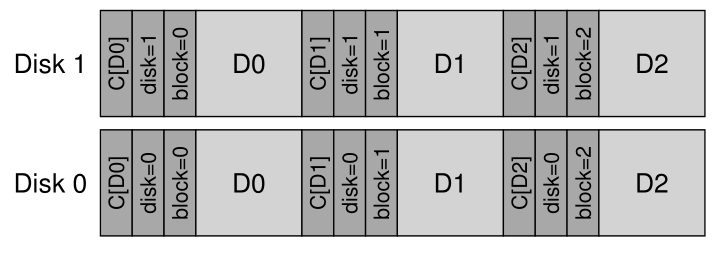<br />从磁盘格式可以看出,现在磁盘上有相当多的冗余:对于每个块,每个块内的磁盘号重复,并且有问题的块的偏移量也保持在块本身旁边 。 不过,冗余信息的存在应该不足为奇。 冗余是错误检测(在这种情况下)和恢复(在其他情况下)的关键。 一些额外的信息,虽然不是完美磁盘所严格需要的,但可以在出现问题时帮助检测问题。
45.6 最后一个问题:写入丢失 One Last Problem: Lost Writes
不幸的是,写定位错误并不是我们要解决的最后一个问题。 具体来说,一些现代存储设备还存在写入丢失(lost write)的问题,当设备通知上层写入已完成但实际上从未持久化时,就会发生这种情况; 因此,留下的是块的旧内容而不是更新的新内容。
这里显而易见的问题是:我们上面的任何校验和策略(例如,基本校验和或物理标识)是否有助于检测丢失的写入? 不幸的是,答案是否定的:旧块可能具有匹配的校验和,并且上面使用的物理 ID(磁盘号和块偏移量)也将是正确的。 因此我们的关键问题是:
关键的问题:如何处理写入丢失 存储系统或磁盘控制器应该如何检测写入丢失? 校验和需要哪些附加功能?
有许多可能的解决方案可以提供帮助 [K+08]。 一种经典方法 [BS04] 是执行**写验证或写后读(write verify or read-after-write)**; 通过在写入后立即读回数据,系统可以确保数据确实到达了磁盘表面。 然而,这种方法很慢,完成写入所需的 I/O 数量增加了一倍。<br />一些系统在系统的其他地方添加校验和来检测写入丢失。 例如,Sun 的 Zettabyte 文件系统 (ZFS) 在每个文件系统 inode 和文件中对于每个块的间接块中包含一个校验和。 因此,即使对数据块本身的写入丢失,inode 内的校验和也不会与旧数据匹配。 **只有当对 inode 和数据的写入同时丢失时,这种方案才会失败**,这是一种不太可能(但不幸的是,可能!)的情况。
45.7 擦拭 Scrubbing
考虑到所有这些讨论,您可能想知道:这些校验和何时真正得到检查? 当然,应用程序访问数据时会进行一些检查,但大多数数据很少访问,因此将保持未检查状态。 对于可靠的存储系统来说,未经检查的数据是有问题的,因为位损坏最终会影响特定数据的所有副本。
为了解决这个问题,许多系统使用了各种形式的磁盘擦拭(disk scrubbing) [K+08]。 通过定期读取系统的每个块,并检查校验和是否仍然有效,磁盘系统可以减少某个数据项的所有副本被损坏的机会。 典型的系统每晚或每周安排一次扫描。
45.8 校验和的开销 Overheads Of Checksumming
在结束之前,我们现在讨论使用校验和进行数据保护的一些开销。 有两种截然不同的开销,这在计算机系统中很常见:空间和时间。
空间开销有两种形式。 第一个是在磁盘(或其他存储介质)本身上; 每个存储的校验和占用磁盘空间,不能再用于用户数据。 一个典型的比率可能是每4 KB数据块8字节校验和,磁盘空间开销为0.19%。
第二种类型的空间开销来自系统的内存。 访问数据时,现在必须在内存中为校验和以及数据本身留出空间。 然而,如果系统只是简单地检查校验和,然后在完成后将其丢弃,那么这种开销是短暂的,并且不会引起太大的关注。 只有当校验和保存在内存中时(为了防止内存损坏 [Z+13]),这个小的开销才会被观察到。
虽然空间开销很小,但校验和引起的时间开销可能非常明显。 至少,CPU 必须在每个块上计算校验和,无论是在存储数据时(以确定存储的校验和的值),还是在访问数据时(再次计算校验和并将其与存储的校验和进行比较)。 许多使用校验和(包括网络栈)的系统采用的一种减少 CPU 开销的方法是将数据复制和校验和合并为一项简化的活动; 因为无论如何都需要复制(例如,将数据从内核页面缓存复制到用户缓冲区),所以组合复制/校验和可能非常有效。
除了 CPU 开销之外,一些校验和方案可能会导致额外的 I/O 开销,特别是当校验和与数据分开存储时(因此需要额外的 I/O 来访问它们),以及后台擦拭(scrubbing)所需的任何额外 I/O。 前者可以通过设计减少; 后者可以调整,从而限制其影响,也许通过控制何时发生这种擦拭活动。 半夜,当大多数(不是全部!)生产工人上床睡觉时,可能是执行此类擦拭活动并提高存储系统稳健性的好时机。
45.9 总结 Summary
我们已经讨论了现代存储系统中的数据保护,重点是校验和的实现和使用。 不同的校验和针对不同类型的故障提供保护; 随着存储设备的发展,新的故障模式无疑会出现。 也许这种变化将迫使研究界和行业重新审视其中一些基本方法,或者完全发明全新的方法。 时间会告诉我们的。 或者它不会。时间就是这样有趣。
References
[B+07] “An Analysis of Latent Sector Errors in Disk Drives” by L. Bairavasundaram, G. Good- son, S. Pasupathy, J. Schindler. SIGMETRICS ’07, San Diego, CA.
第一篇详细研究潜在扇区错误的论文。 该论文还获得了 Kenneth C. Sevcik 杰出学生论文奖,该奖以一位过早去世的杰出研究人员和杰出人物的名字命名。 为了向 OSTEP 作者展示从美国搬到加拿大是可能的,肯曾经为我们唱了加拿大国歌,他站在一家餐馆的中间这样做。 我们选择了美国,但得到了这个记忆。
[B+08] “An Analysis of Data Corruption in the Storage Stack” by Lakshmi N. Bairavasun-daram, Garth R. Goodson, Bianca Schroeder, Andrea C. Arpaci-Dusseau, Remzi H. Arpaci-Dusseau. FAST ’08, San Jose, CA, February 2008.
这是第一篇真正详细研究磁盘损坏的论文,重点关注在超过150万个驱动器中,这种损坏在三年内发生的频率。
[BS04] “Commercial Fault Tolerance: A Tale of Two Systems” by Wendy Bartlett, Lisa Spainhower. IEEE Transactions on Dependable and Secure Computing, Vol. 1:1, January 2004.
这个构建容错系统的经典是对 IBM 和 Tandem 最先进技术的一个很好的概述。 对于那些对该领域感兴趣的人来说,另一个必须阅读。
[C+04] “Row-Diagonal Parity for Double Disk Failure Correction” by P. Corbett, B. English, A. Goel, T. Grcanac, S. Kleiman, J. Leong, S. Sankar. FAST ’04, San Jose, CA, February 2004.
一篇关于额外冗余如何帮助解决全磁盘故障/部分磁盘故障组合问题的早期论文。 也是如何将更多理论工作与实践相结合的一个很好的例子。
[F04] “Checksums and Error Control” by Peter M. Fenwick.
一个很棒的简单的校验和教程,免费提供给您。
[F82] “An Arithmetic Checksum for Serial Transmissions” by John G. Fletcher. IEEE Trans-actions on Communication, Vol. 30:1, January 1982.
弗莱彻关于他的同名校验和的原始工作。 他并没有将其称为 Fletcher 校验和,而是什么都不称其为; 后来,其他人以他的名字命名了它。 所以不要因为这种看似吹嘘的行为而责怪老弗莱奇。 这个轶事可能会让你想起魔方; 魔方从未称其为“魔方(Rubik’s cube)”; 相反,他只是称它为“我的立方体”。
[HLM94] “File System Design for an NFS File Server Appliance” by Dave Hitz, James Lau, Michael Malcolm. USENIX Spring ’94.
描述 NetApp 核心理念和产品的开创性论文。 基于此系统,NetApp 已成长为一家价值数十亿美元的存储公司。 要了解有关 NetApp 的更多信息,请阅读 Hitz 的自传“How to Castrate a Bull”(这是真正的标题,不是开玩笑)。 你认为你可以通过进入 CS 来避免公牛阉割。
[K+08] “Parity Lost and Parity Regained” by Andrew Krioukov, Lakshmi N. Bairavasun-daram, Garth R. Goodson, Kiran Srinivasan, Randy Thelen, Andrea C. Arpaci-Dusseau, Remzi H. Arpaci-Dusseau. FAST ’08, San Jose, CA, February 2008.
这项工作探讨了不同的校验和方案如何在保护数据方面起作用(或不起作用)。 我们揭示了当前保护策略中的许多有趣缺陷。
[M13] “Cyclic Redundancy Checks” by unknown.
CRC 的超级清晰简洁的描述。 事实证明,互联网上充满了信息。
[P+05] “IRON File Systems” by V. Prabhakaran, L. Bairavasundaram, N. Agrawal, H. Gunawi, A. Arpaci-Dusseau, R. Arpaci-Dusseau. SOSP ’05, Brighton, England.
我们关于磁盘如何具有部分故障模式的论文,以及对现代文件系统如何对此类故障做出反应的详细研究。 事实证明,相当糟糕! 我们在这项工作中发现了许多错误、设计缺陷和其他奇怪之处。 其中一些已经反馈到 Linux 社区,从而提高了文件系统的可靠性。 别客气!
[RO91] “Design and Implementation of the Log-structured File System” by Mendel Rosen-blum and John Ousterhout. SOSP ’91, Pacific Grove, CA, October 1991.
很酷,我们再次引用它。
[S90] “Implementing Fault-Tolerant Services Using The State Machine Approach: A Tutorial” by Fred B. Schneider. ACM Surveys, Vol. 22, No. 4, December 1990.
如何构建容错服务。对于那些构建分布式系统的人来说,这是必读的。
[Z+13] “Zettabyte Reliability with Flexible End-to-end Data Integrity” by Y. Zhang, D. Myers, A. Arpaci-Dusseau, R. Arpaci-Dusseau. MSST ’13, Long Beach, California, May 2013.
如何为系统页面缓存添加数据保护。没有空间,否则我们会写一些东西…
Homework (Simulation)
在本作业中,您将使用checksum.py来研究校验和的各个方面。
Questions
- 首先只运行 checksum.py 不带参数。 计算可加的、基于 XOR 的和 Fletcher 校验和。 使用 -c 检查您的答案。
- 现在执行相同的操作,但将种子 (-s) 更改为不同的值。
- 有时,加法和基于 XOR 的校验和会产生相同的校验和(例如,如果数据值全为零)。 您能否传入一个 4 字节的数据值(使用 -D 标志,例如,-D a,b,c,d),该值不仅包含零并且导致附加和基于 XOR 的校验和具有相同的值? 一般来说,什么时候会出现这种情况? 使用 -c 标志检查您是否正确。
- 现在传入一个 4 字节值,您知道该值将为加法和 XOR 生成不同的校验和值。 一般来说,什么时候会出现这种情况?
- 使用模拟器计算校验和两次(对一组不同的数字各计算一次)。 两个数字字符串应该不同(例如,第一次是 -D a1,b1,c1,d1,第二次是 -D a2,b2,c2,d2),但应该产生相同的附加校验和。 一般来说,即使数据值不同,附加校验和何时会相同? 使用 -c 标志检查您的具体答案。
- 现在对XOR校验和执行同样的操作。
- 现在让我们看看一组特定的数据值。 第一个是:-D 1,2,3,4。 这些数据的不同校验和(加法、异或、弗莱彻)是什么? 现在将其与通过 -D 4,3,2,1 计算这些校验和进行比较。 关于这三个校验和,您注意到什么? 弗莱彻与其他两个相比如何? Fletcher 通常比简单的加法校验和之类的东西“更好”吗?
- 没有校验和是完美的。 给定您选择的特定输入,您能否找到导致相同 Fletcher 校验和的其他数据值? 一般什么时候会出现这种情况? 从一个简单的数据字符串(例如,-D 0,1,2,3)开始,看看是否可以替换这些数字之一,但最终会得到相同的 Fletcher 校验和。 与往常一样,使用 -c 来检查您的答案。

若有收获,就点个赞吧
0 人点赞
