现在,运行进程的底层机制(mechanisms)(例如,上下文切换)应该很清楚了;如果不是,回到一两章,再读一遍这些东西是如何工作的。然而,我们还不了解操作系统调度器所采用的高级策略。但是,我们还没有了解操作系统调度程序采用的高级策略(policies)。我们现在将做到这一点,介绍多年来各种聪明和勤奋的人制定的一系列调度策略(scheduling policies)(有时称为纪律(disciplines))。
事实上,调度的起源早于计算机系统;早期的方法是从业务管理领域采取的,并应用于计算机。这一现实不足为奇:装配线和许多其他人类活动也需要安排时间,其中也存在许多相同的问题,包括对效率的渴望。因此,我们的问题是:
关键的问题:如何制定调度策略 我们应该如何建立一个思考调度策略的基本框架?关键假设是什么?什么指标是重要的?在最早的计算机系统中使用了哪些基本方法?
7.1
负载假设 Workload Assumptions
在讨论可能的策略之前,让我们首先对系统中运行的进程(有时统称为工作负载(workload))做一些简化的假设。确定工作负载是构建策略的关键部分,您对工作负载了解得越多,您的策略就可以调整得越好。
我们在这里所做的工作量假设大多是不现实的,但这是可以的(就目前而言),因为我们会随着工作的进行而放松它们,最终发展出我们所说的……(戏剧性的停顿)…一种完全可操作的调度纪律(fully-operational scheduling discipline)。
对于在系统中运行的进程(有时称为作业),我们将做出以下假设:
- 每个工作运行的时间相同。
- 所有的工作都在同一时间到达。
- 一旦启动,每个作业就会运行到完成。
- 所有的工作只使用CPU(即,他们不执行I/O) 。
- 每个工作的运行时间是已知的。
我们说过,这些假设中的许多都是不现实的,但就像奥威尔的《动物庄园》[O45]中有些动物比其他动物更平等一样,在本章中,有些假设比其他假设更不现实。特别是,每个工作的运行时间都是已知的,这可能会让您感到困扰:这将使调度程序无所不知,尽管这很好(很可能),但不太可能很快发生。
7.2
调度指标 Scheduling Metrics
除了对工作负载进行假设外,我们还需要一个东西来比较不同的调度策略:调度指标(Scheduling Metrics)。指标只是我们用来衡量某些东西的东西,在调度中有许多不同的指标是有意义的。
现在,让我们通过拥有一个简单的指标来简化我们的生活:周转时间(turnaround time)。工作的周转时间定义为工作完成的时间减去工作到达系统的时间。更正式地说,周转时间是_T_turnaround: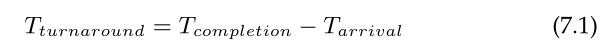
因为我们假设所有的工作都在同一时间到达,现在_T_arrival = 0,因此_T_turnaround = _T_completion。当我们放宽上述假设时,这一事实将会改变。
您应该注意到周转时间是一个性能指标(performance metric),这将是我们这一章的主要重点。另一个利益度量是公平(fairness),例如,由Jain的公平指数(Jain’s Fairness Index)[J91]衡量。在调度上,性能和公平常常是平等的;例如,调度程序可能会优化性能,但代价是阻止一些工作运行,从而降低公平性。这个难题告诉我们,生活并不总是完美的。
7.3
先进先出 First In, First Out (FIFO)
我们可以实现的最基本的算法被称为先进先出(FIFO)调度(First In, First
Out (FIFO)),有时也称为先来先服务(FCFS)调度(First Come, First Served (FCFS))。先进先出有许多积极的性质:它显然是简单的,因此容易实现。考虑到我们的假设,它运行得很好。
让我们一起做一个简单的例子。想象在大致相同的时间(_T_arrival = 0)三份工作到达系统中,A, B和C。因为FIFO把一些工作放在首位, 假设他们几乎同时到达, A只是在B之前一点点到达,B只是在C之前一点点到达。还假设每个作业运行10秒。这些工作的平均周转时间(average turnaround time)是多少?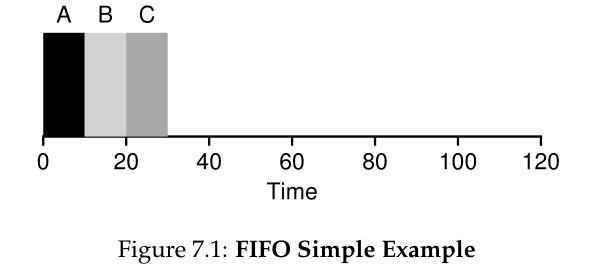
从图7.1中,你可以看到A在10结束,B在20结束,C在30结束。因此,这三个工作的平均周转时间就是(10+20+30)/3 = 20。计算周转时间就这么简单。
现在让我们放松一个假设。特别是,让我们放松假设1,因此不再假设每个作业运行相同的时间。FIFO现在的表现如何?您可以构造什么样的工作负载来使FIFO表现较差?
(在继续阅读之前考虑一下……继续思考……明白了吗?!)
假设您现在已经明白了这一点,但为了以防万一,让我们做一个示例来说明不同长度的作业如何导致FIFO调度的问题。特别地,让我们再次假设三个任务(A、B和C),但这次A运行100秒,而B和C各运行10秒。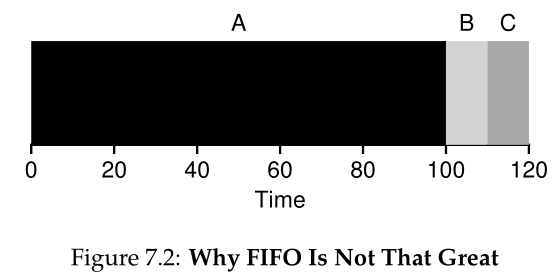
如图7.2所示,在B或C有机会运行之前,工作A会先运行整整100秒。因此,系统的平均周转时间很高:痛苦的110秒((100+110+120)/3 = 110)。
这个问题通常被称为护航效应(convoy effect )[B+79],即大量相对较短的资源潜在消耗者排在重量级资源消耗者之后。这种安排可能会让你想起在杂货店排队的情景,以及当你看到你前面的人提着三辆装满食品和支票簿的购物车时的感觉;还需要一段时间。
那么我们该怎么办呢?我们怎样才能开发出更好的算法来处理运行时间不同的新工作呢?首先考虑一下;然后继续读下去。
Tip:SJF的原理 最短工作优先(Shortest Job First)代表了一个通用的调度原则,它可以应用于任何系统,其中每个客户(或者,在我们的例子中,一个工作)的周转时间很重要。想想你等待的任何队伍:如果有问题的机构关心客户满意度,他们很可能已经考虑了SJF。例如,杂货店通常会有一条“十件或十件以下”的长队,以确保只买几件东西的购物者不会被困在家庭后面,为即将到来的核冬天做准备。
7.4 最短工作优先
Shortest Job First (SJF)
事实证明,有一种非常简单的方法可以解决这个问题;事实上,它是从运筹学[C54,PV56]偷来的想法,并应用于计算机系统的工作调度。这个新的调度规程称为最短作业优先( Shortest Job First)(SJF),这个名称应该很容易记住,因为它非常完整地描述了策略:它先运行最短的作业,然后运行下一个最短的作业,以此类推。
让我们以上面的示例为例,但使用SJF作为调度策略。图7.3显示了运行A、B和C的结果。希望这个图表能够清楚地说明为什么SJF在平均周转时间方面表现得更好。简单地在A之前运行B和C, SJF将平均周转时间从110秒减少到50秒((10+20+120)/3 = 50),提高了两倍以上。
Aside:抢占式调度(PREEMPTIVE SCHEDULERS) 在过去的批处理计算时代,开发了许多不可抢占(non-preemptive)的调度程序;这样的系统将运行每个作业直到完成,然后再考虑是否运行一个新作业。几乎所有的现代调度程序都是抢先的,并且非常愿意为了运行另一个进程而停止一个进程的运行。这意味着调度程序使用了我们之前学习过的机制;特别地,调度器可以执行上下文切换,临时停止一个正在运行的进程并恢复(或启动)另一个进程。
事实上,假设所有工作同时到达,我们可以证明SJF确实是一种最优调度算法。然而,你是学系统的,不是学理论或运筹学;不允许出示证据。
因此,我们找到了使用SJF进行调度的好方法,但是我们的假设仍然是相当不现实的。让我们再放松一下。特别地,我们可以以假设2为目标,现在假设工作可以随时到来,而不是同时到来。这将导致什么问题?
(再停下来想……你在思考吗?来吧,你能做到)
这里我们可以用一个例子再次说明这个问题。这一次,假设A到达t = 0时需要运行100秒,而B和C到达t = 10时需要运行10秒。使用纯SJF,我们将得到如图7.4所示的时间表。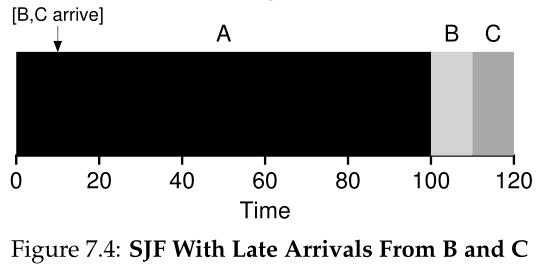
从图中可以看出,即使B和C在A到达后不久,他们仍然被迫等待A完成任务,因此也面临同样的护航问题。这三个作业的平均周转时间是103.33秒((100+(110-10)+(120-10))/3)。调度程序可以做什么?
7.5
最短时间完成优先 Shortest Time-to-Completion First (STCF)
要解决这个问题,我们需要放松假设3(作业必须运行到完成),所以让我们这样做。我们还需要在调度程序内部安装一些机器。正如您可能已经猜到的,根据我们前面关于定时器中断和上下文切换的讨论,当B和C到达时,调度程序当然可以做其他事情:它可以抢占(preempt)作业A并决定运行另一个作业,也许稍后继续运行A。根据我们的定义,SJF是一个不可抢占(non-preemptive )的调度程序,因此存在上述问题。
幸运的是,有一个调度程序可以做到这一点:将抢占添加到SJF,称为最短完成时间优先(Shortest Time-to-Completion First,STCF)或抢占最短作业优先(Preemptive Shortest Job First,PSJF)调度程序[CK68]。每当有新作业进入系统时,STCF调度器就会确定哪些剩余作业(包括新作业)剩下的时间最少,并调度该作业。因此,在我们的例子中,STCF会抢占A并运行B和C来完成;只有完成了,才能安排A的剩余时间。图7.5显示了一个示例。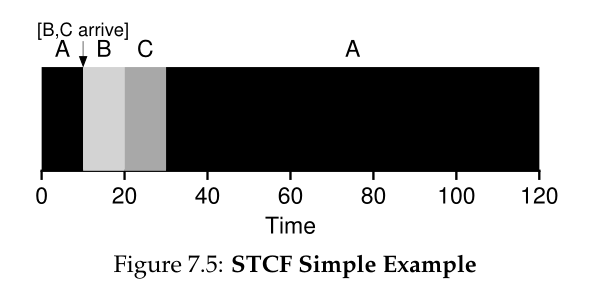
结果是大大提高了平均周转时间:50秒(((120-0)+(20-10)+(30-10))/3)。和之前一样,在我们新的假设下,STCF被证明是最优的;假设如果所有作业同时到达SJF,那么SJF是最优的,那么您应该能够看到STCF最优性背后的直觉。
7.6
一个新的指标:响应时间 A New Metric: Response Time
因此,如果我们知道作业长度,并且作业只使用CPU,而我们唯一的指标是周转时间,那么STCF将是一个很好的策略。事实上,对于许多早期的批处理计算系统,这些类型的调度算法是有意义的。然而,分时机器的出现改变了这一切。现在,用户坐在终端前,也会要求系统提供交互性能。因此,一个新的指标诞生了:响应时间(response time)。
我们将响应时间定义为从作业到达系统到它第一次被调度的时间。更正式: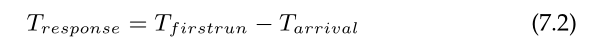
有些人对它的定义略有不同,例如,也包括工作产生某种响应的时间;我们的定义是这个的最佳情况版本,本质上假设任务立即产生响应。
例如,如果我们有图7.5中的时间表(A在时间0到达,B和C在时间10到达),每个作业的响应时间如下:作业A为0,作业B为0,C为10(平均为3.33)。
您可能会想,STCF和相关的规程在响应时间方面不是特别好。例如,如果三个作业同时到达,则第三个作业必须等待前两个作业全部运行,然后才调度一次。虽然这种方法在周转时间方面很好,但在响应时间和交互性方面却相当糟糕。实际上,想象一下,你坐在终端前,输入信息,却要等10秒钟才能看到系统的响应,仅仅因为有其他工作安排在你的面前:这不是很令人愉快。
因此,我们还剩下另一个问题:如何构建对响应时间敏感的调度器?
7.7
轮循 Round Robin
为了解决这个问题,我们将引入一种新的调度算法,经典的称为Round-Robin (RR)调度[K64]。其基本思想很简单:RR不是运行作业直至完成,而是在一个时间片(time slice)(有时称为调度量(scheduling quantum))中运行一个作业,然后切换到运行队列中的下一个作业。它重复这样做,直到任务完成。因此,RR有时被称为时间切片(time-slicing)。注意,时间片的长度必须是定时器-中断周期的倍数;因此,如果计时器每10毫秒中断一次,则时间片可以是10、20或任何其他10毫秒的倍数。
为了更详细地理解RR,让我们看一个示例。假设三个作业A、B和C同时到达系统,并且每个作业都希望运行5秒。SJF调度程序在运行另一个作业之前运行每个作业直至完成(图7.6)。相比之下,具有1秒tim-slice的RR将快速地遍历作业(图7.7)。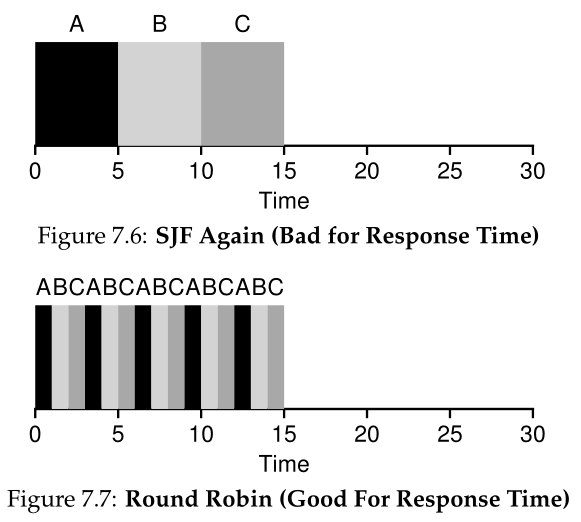
Aside:摊销可以降低成本 摊销(amortization)的一般方法通常用于某些操作有固定成本的系统。通过降低成本的发生频率(即通过减少操作次数),系统的总成本就降低了。例如,如果时间片设置为10毫秒,而上下文切换成本为1毫秒,那么大约10%的时间用于上下文切换,因此是浪费的。如果我们想摊销这个成本,我们可以增加时间片,例如,到100毫秒。在这种情况下,上下文切换花费的时间不到1%,因此时间切片的成本被平摊了。
RR的平均响应时间为:(0+1+2)/3 = 1;对于SJF,平均响应时间为:(0+5+10)/3 = 5。
如您所见,时间片的长度对RR至关重要。越短,RR在响应时间度量下的性能越好。然而,将时间片设置得太短是有问题的:突然之间,上下文切换的成本将主导整体性能。因此,决定时间片的长度对系统设计者来说是一种权衡,既要使时间片足够长,以摊销(amortize)切换成本,又不要使时间片长到系统不再响应。
注意,上下文切换的成本并不仅仅来自于保存和恢复几个寄存器的操作系统操作。当程序运行时,它们在CPU缓存、TLBs、分支预测器和其他片上硬件中构建大量状态。切换到另一个作业会刷新此状态,并引入与当前正在运行的作业相关的新状态,这可能会导致显著的性能成本[MB91]。
因此,如果响应时间是我们唯一的度量标准,具有合理时间片的RR是一个出色的调度器。那我们的老朋友周转时间呢?让我们再看一下上面的例子。运行时间为5秒的A、B和C同时到达,而RR是具有(长)1秒时间片的调度程序。从上图中我们可以看到,A在13分结束,B在14分结束,C在15分结束,平均14分结束。很可怕的!
因此,如果周转时间是我们的指标,那么RR确实是最糟糕的政策之一,这就不足为奇了。从直觉上看,这应该是有意义的:RR所做的是尽可能延长每个作业,在移动到下一个作业之前只运行一小段时间。由于周转时间只关心作业何时完成,RR几乎是悲观的,在许多情况下甚至比简单的FIFO更糟糕。
更普遍地说,任何公平的策略(如RR),即在小的时间尺度上均匀地将CPU分配给活动进程,将在诸如周转时间等指标上表现糟糕。事实上,这是一种内在的权衡:如果你愿意不公平,你可以缩短任务完成时间,但以响应时间为代价;如果你重视公平性,响应时间就会降低,但代价是周转时间。这种权衡(trade-off)在系统中很常见;鱼与熊掌不可兼得。
Tip:重叠可以提高利用率 在可能的情况下,重叠(overlap)操作以最大限度地利用系统。重叠在许多不同的领域都很有用,包括执行磁盘I/O或向远程机器发送消息时;无论是哪种情况,启动操作然后切换到其他工作都是一个好主意,提高了系统的整体利用率和效率。
我们开发了两种类型的调度程序。第一种类型(SJF、STCF)优化了周转时间,但对响应时间不利。第二种类型(RR)优化了响应时间,但不利于周转。我们仍然有两个需要放松的假设:假设4(作业不进行I/O)和假设5(每个作业的运行时间是已知的)。下面让我们来解决这些假设。
7.8
合并I/O Incorporating I/O
首先我们放宽假设 4——当然所有程序都执行 I/O。想象一个不接受任何输入的程序:它每次都会产生相同的输出。想象一个没有输出的情况:这就是谚语所说的,森林里的树倒了,却没有人看见;它运行并不重要。
当一个作业发起I/O请求时,调度程序显然要做出决定,因为当前运行的作业在I/O期间不会使用CPU;它被阻塞,等待I/O完成。如果将I/O发送到硬盘驱动器,进程可能会阻塞几毫秒或更长时间,这取决于驱动器当前的I/O负载。因此,调度程序可能会在那个时候在CPU上调度另一个作业。
调度程序还必须在I/O完成时做出决定。当这种情况发生时,将引发中断,操作系统将运行并将发出I/O的进程从阻塞状态移回就绪状态。当然,它甚至可以在那个时候决定运行作业。操作系统应该如何对待每个工作?
为了更好地理解这个问题,让我们假设有两个任务,A和B,每个任务都需要50毫秒的CPU时间。然而,有一个明显的区别:A运行10毫秒,然后发出一个I/O请求(这里假设每个I/O需要10毫秒),而B只使用CPU 50毫秒,不执行I/O。调度程序首先运行A,然后运行B(图7.8)。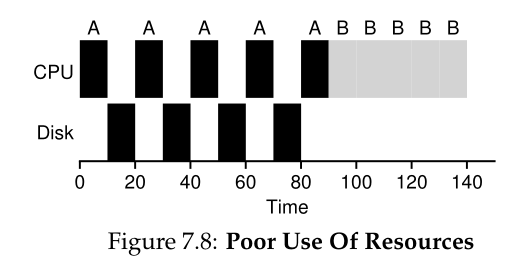
假设我们正在尝试构建一个STCF调度程序。这样的调度器应该如何解释A被分成5个10-ms的子任务,而B只是单个50-ms的CPU需求?显然,只运行一个作业,然后运行另一个作业,而不考虑如何考虑I/O是没有意义的。
一种常见的方法是将A的每一个10毫秒的子工作视为一个独立的工作。因此,当系统启动时,它的选择是调度一个10毫秒的a还是一个50毫秒的B。使用STCF,选择较短的a是很清楚的。然后,当a的第一个子任务完成时,只剩下B,它开始运行。然后提交a的新子作业,它抢占B并运行10毫秒。这样做允许重叠(overlap),CPU被一个进程使用,同时等待另一个进程的I/O完成;因此,系统得到了更好的利用(参见图7.9)。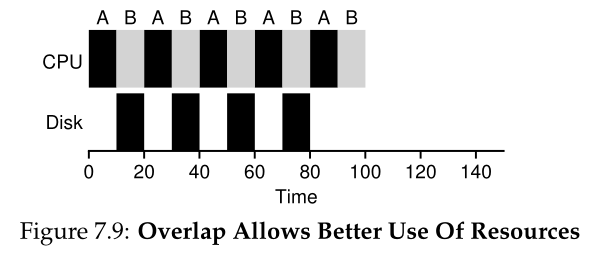
因此,我们看到调度程序如何合并I/O。通过将每次CPU突发作为一个作业处理,调度程序可以确保交互式进程频繁运行。当这些交互作业执行I/O时,会运行其他cpu密集型作业,从而更好地利用处理器。
7.9
No More Oracle 有了基本的I/O方法后,我们就得出了最后的假设:调度程序知道每个作业的长度。正如我们之前所说,这可能是我们能做出的最糟糕的假设。事实上,在通用操作系统中(就像我们所关心的那些),操作系统通常对每个作业的长度知之甚少。因此,在没有这种先验知识的情况下,我们如何构建一个行为类似于SJF/STCF的方法?此外,我们如何将我们看到的一些想法与RR调度器结合起来,使响应时间也相当好?
7.10
Summary 我们介绍了调度背后的基本思想并开发了两种方法。第一个运行剩余的最短作业,从而优化周转时间;第二个在所有作业之间交替,从而优化响应时间。两者都不好,而另一个是好的,唉,这是系统中常见的固有权衡。我们也看到了如何将 I/O 合并到画面中,但仍然没有解决操作系统根本无法预见未来的问题。很快,我们将看到如何通过构建一个使用最近的过去来预测未来的调度程序来克服这个问题。这个调度器被称为多级反馈队列,它是下一章的主题。
References
[B+79] “The Convoy Phenomenon” by M. Blasgen, J. Gray, M. Mitoma, T. Price. ACM Op-
erating Systems Review, 13:2, April 1979. Perhaps the first reference to convoys, which occurs in
databases as well as the OS.
[C54] “Priority Assignment in Waiting Line Problems” by A. Cobham. Journal of Operations
Research, 2:70, pages 70–76, 1954. The pioneering paper on using an SJF approach in scheduling the
repair of machines.
[K64] “Analysis of a Time-Shared Processor” by Leonard Kleinrock. Naval Research Logistics
Quarterly, 11:1, pages 59–73, March 1964. May be the first reference to the round-robin scheduling
algorithm; certainly one of the first analyses of said approach to scheduling a time-shared system.
[CK68] “Computer Scheduling Methods and their Countermeasures” by Edward G. Coffman
and Leonard Kleinrock. AFIPS ’68 (Spring), April 1968. An excellent early introduction to and
analysis of a number of basic scheduling disciplines.
[J91] “The Art of Computer Systems Performance Analysis: Techniques for Experimental De-
sign, Measurement, Simulation, and Modeling” by R. Jain. Interscience, New York, April 1991.
The standard text on computer systems measurement. A great reference for your library, for sure.
[O45] “Animal Farm” by George Orwell. Secker and Warburg (London), 1945. A great but
depressing allegorical book about power and its corruptions. Some say it is a critique of Stalin and the
pre-WWII Stalin era in the U.S.S.R; we say it’s a critique of pigs.
[PV56] “Machine Repair as a Priority Waiting-Line Problem” by Thomas E. Phipps Jr., W. R.
Van Voorhis. Operations Research, 4:1, pages 76–86, February 1956. Follow-on work that gen-
eralizes the SJF approach to machine repair from Cobham’s original work; also postulates the utility of
an STCF approach in such an environment. Specifically, “There are certain types of repair work, …
involving much dismantling and covering the floor with nuts and bolts, which certainly should not be
interrupted once undertaken; in other cases it would be inadvisable to continue work on a long job if one
or more short ones became available (p.81).”
[MB91] “The effect of context switches on cache performance” by Jeffrey C. Mogul, Anita Borg.
ASPLOS, 1991. A nice study on how cache performance can be affected by context switching; less of an
issue in today’s systems where processors issue billions of instructions per second but context-switches
still happen in the millisecond time range.
[W15] “You can’t have your cake and eat it” by Authors: Unknown.. Wikipedia (as of Decem-
ber 2015). http://en.wikipedia.org/wiki/You can’t have your cake and eat it.
The best part of this page is reading all the similar idioms from other languages. In Tamil, you can’t
“have both the moustache and drink the soup.”
Homework (Simulation)
此程序scheduler.py允许您查看不同的调度程序在响应时间、周转时间和总等待时间等调度指标下的执行情况。有关详细信息,请参阅README。
Questions
- 计算使用SJF和FIFO调度程序运行三个长度为200的作业时的响应时间和周转时间。
- 现在做同样的工作,但不同的工作长度:100、200和300。
- 现在执行同样的操作,但还要使用RR调度器和时间片1。
- 对于哪种类型的工作负载,SJF提供与FIFO相同的周转时间?
- 对于哪些类型的工作负载和量子长度,SJF提供与RR相同的响应时间?
- 随着工作长度的增加,SJF的响应时间会发生什么变化?你能用模拟器来演示趋势吗?
- 随着量子(quantum)长度的增加,RR 的响应时间会发生什么变化?给定 N 个作业,你能写出给出最坏情况响应时间的方程式吗?

若有收获,就点个赞吧
0 人点赞
