现在我们已经看过了网络层的数据和控制平面,转发和路由的重要区别,以及网络层的服务和功能,让我们把注意力转移到它的转发功能上ーー从路由器的传入链路到该路由器的适当传出链路的数据包的实际传输。
图4.4显示了通用路由器体系结构的高级视图。可以识别四个路由器组件: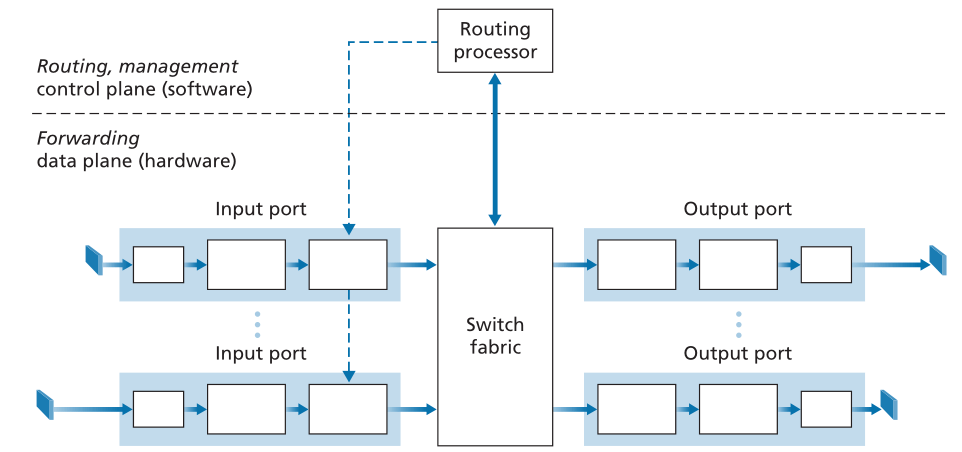
Figure 4.4 ♦ Router architecture
图4.4.♦路由器体系结构
- 输入端口(Input ports)。输入端口执行几个关键功能。它执行在路由器上终止传入物理链路的物理层功能;如图4.4中输入端口最左边的框和输出端口最右边的框所示。输入端口还执行与传入链路另一端的链路层互操作所需的链路层功能;这由输入和输出端口中的中间框表示。也许最关键的是,还在输入端口执行查找功能(lookup function);这将发生在输入端口最右边的框中。在这里,查询转发表以确定到达的数据包将通过交换结构转发到的路由器输出端口。控制数据包(例如,携带路由协议信息的数据包)从输入端口转发到路由处理器。请注意,这里的术语“端口(port)”-指的是物理输入和输出路由器接口-与第2章和第3章中讨论的与网络应用程序和套接字相关的软件端口明显不同。在实践中,路由器支持的端口数量可以从企业路由器中相对较少的数量,到ISP边缘路由器中的数百个10 Gbps端口,在这些端口中,传入线路的数量往往是最多的。例如,Juniper MX2020边缘路由器支持多达800个100 Gbps以太网端口,总体路由器系统容量为800 Tbps[Juniper MX 2020]。
- 交换结构(Switching fabric)。交换结构将路由器的输入端口连接到其输出端口。此交换结构完全包含在路由器中——网络路由器内部的网络!
- 输出端口(Output ports)。输出端口存储从交换结构接收的数据包,并通过执行必要的链路层和物理层功能在传出链路上传输这些数据包。当链路是双向的(即,在两个方向上传输流量)时,输出端口通常会与同一线路卡(same line card)上该链路的输入端口配对。
- 路由处理器(Routing processor)。路由处理器执行控制平面功能。在传统路由器中,它执行路由协议(我们将在5.3和5.4节中学习),维护路由表和附加的链路状态信息,并计算路由器的转发表。在SDN路由器中,路由处理器负责与远程控制器(remote controller)通信,以便(除其他活动外)接收远程控制器计算的转发表条目,并将这些条目安装在路由器的输入端口中。路由处理器还执行我们将在5.7节中学习的网络管理功能。
路由器的输入端口、输出端口和交换结构几乎总是在硬件中实现,如图4.4所示。要理解为什么需要硬件实现,请考虑这样一种情况:对于100 Gbps的输入链路和64字节的IP数据报,在另一个数据报到达之前,输入端口只有5.12 ns来处理该数据报。如果将N个端口组合在一个线卡(line card)上(实际上经常这样做),则数据报处理管道的运行速度必须快N倍-对于软件实施来说太快了。转发硬件可以使用路由器供应商自己的硬件设计实现,也可以使用购买的商用硅芯片(例如,英特尔和Broadcom等公司销售的芯片)构建。
当数据平面以纳秒时间尺度运行时,路由器的控制功能—执行路由协议、响应连接的上下链路、与远程控制器通信(在SDN情况下)以及执行管理功能—以毫秒或秒时间尺度运行。因此,这些控制平面(control plane)功能通常在软件中实现,并在路由处理器(通常为传统CPU)上执行。
在深入研究路由器内部结构的细节之前,让我们回到本章开头的类比,在该类比中,数据包转发被比作进入和离开交换的汽车。让我们假设立交是一个环形交叉路口,当一辆汽车进入环形交叉路口时,需要进行一些处理。让我们考虑一下此处理需要哪些信息:
- 基于目的地的转发(Destination-based forwarding)。假设汽车在一个入口站停了下来,并指出了它的最终目的地(不是在当地的环形交叉路口,而是它旅程的最终目的地)。入口站的服务员查看最终目的地,确定通向该最终目的地的环形交叉路口出口,并告诉司机走哪个环形交叉路口出口。
- 广义转发(Generalized forwarding)。除了目的地之外,服务员还可以根据许多其他因素来确定汽车的出口坡道。例如,选定的出口坡道可能取决于汽车的原产地,例如发放汽车牌照的州。来自某一州的汽车可能会被指示使用一个出口坡道(通过慢路通往目的地),而来自其他州的汽车可能会被指示使用不同的出口坡道(通过高速公路通往目的地)。同样的决定可能会根据车型、品牌和年份做出。或者,一辆不适合在路上行驶的汽车可能会被封锁,不允许通过环形交叉路口。在广义转送的情况下,任何数量的因素都可能影响乘务员对给定汽车的出口坡道的选择。
一旦汽车进入环形交叉口(可能会挤满从其他输入道路进入并前往其他环形交叉口的其他车辆),它最终会在规定的环形交叉口出口匝道离开,在那里它可能会遇到其他车辆在该出口处离开环形交叉口。
在此类比中,我们可以很容易地认出图4.4中的主要路由器组件-入口道路和入口站对应于输入端口(具有查找功能以确定本地输出端口);环行交叉口对应于交换结构;环行交叉口出口对应于输出端口。有了这个类比,考虑瓶颈可能出现在哪里是很有启发意义的。如果汽车以惊人的速度到达(例如,环形交叉路口在德国或意大利),会发生什么?但是车站服务员很慢,是吗?服务员必须以多快的速度工作才能确保入口道路上没有后备人员?即使有速度惊人的服务员,如果汽车缓慢地穿过环形交叉路口会发生什么-还会发生备份(backups)吗?如果在所有环形交叉路口入口匝道进入的大多数车辆都想在同一出口匝道离开环形交叉路口,会发生什么?后备车辆可以在出口匝道或其他地方发生吗?如果我们想为不同的车辆分配优先权,或首先阻止某些车辆进入回旋处,回旋处应该如何运作?这些都类似于路由器和交换机设计人员面临的关键问题。
在以下小节中,我们将更详细地了解路由器的功能。[Turner 1988;McKeown 1997a;Partridge 1998;Iyer 2008;Serpanos 2011;Zilberman 2019]提供特定路由器架构的讨论。为具体和简单起见,我们在本节中首先假定转发决策仅基于数据包的目的地址,而不是基于一组通用的数据包首部字段。我们将在第4.4节介绍更一般的数据包转发情况。
4.2.1 输入端口处理和基于目的地址的转发 Input Port Processing and Destination-Based Forwarding
图4.5显示了输入处理的更详细视图。如前所述,输入端口的线路终端功能和链路层处理实现了该单独输入链路的物理层和链路层。在输入端口中执行的查找是路由器操作的核心-路由器正是在这里使用转发表来查找到达的数据包将通过交换结构转发到的输出端口。转发表由路由处理器计算和更新(使用路由协议与其他网络路由器中的路由处理器交互),或者从远程SDN控制器接收。转发表通过图4.4中路由处理器到输入线路卡的虚线指示的单独总线(例如,PCI总线)从路由处理器复制到线路卡。利用每个线路卡上的这种卷影副本(shadow copy),可以在每个输入端口处本地做出转发决定,而无需在每个数据包的基础上调用集中式路由处理器,从而避免集中式处理瓶颈。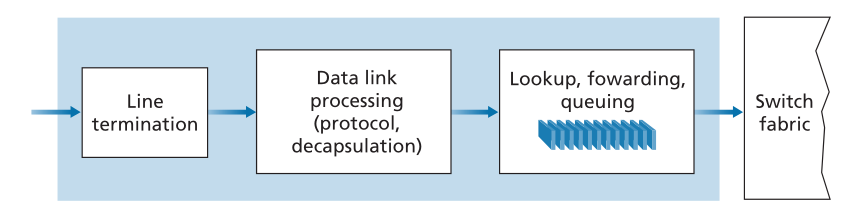
Figure 4.5 ♦ Input port processing
图4.5.♦输入端口处理
现在让我们考虑一种“最简单”的情况,即传入数据包要交换到的输出端口基于数据包的目的地址。在32位IP地址的情况下,转发表的暴力实施将为每个可能的目的地址都有一个条目。由于有40多亿个可能的地址,因此完全不可能选择此选项。
作为如何处理此规模问题的示例,假设我们的路由器有四条链路(编号为0到3),并且数据包将转发到链路接口,如下所示:
| 目的地址范围 | 链路接口 |
|---|---|
| 11001000 00010111 00010000 00000000 到 11001000 00010111 00010111 11111111 |
0 |
| 11001000 00010111 00011000 00000000 到 11001000 00010111 00011000 11111111 |
1 |
| 11001000 00010111 00011001 00000000 到 11001000 00010111 00011111 11111111 |
2 |
| 其他 | 3 |
显然,在本例中,路由器转发表中没有必要包含40亿个条目。例如,我们可以有以下只有四个条目的转发表:
| 前缀 | 链路接口 |
|---|---|
| 11001000 00010111 00010 | 0 |
| 11001000 00010111 00011000 | 1 |
| 11001000 00010111 00011 | 2 |
| 其他 | 3 |
使用这种类型的转发表,路由器会将数据包目的地址的前缀与表中的条目进行匹配;如果匹配,路由器会将数据包转发到与匹配相关联的链路。例如,假设数据包的目的地址是11001000 00010111 00010110 10100001;因为此地址的21位前缀与表中的第一个条目匹配,所以路由器会将数据包转发到链路接口0。如果前缀与前三个条目中的任何一个都不匹配,则路由器会将数据包转发到默认接口3。虽然这听起来很简单,但这里有一个非常重要的微妙之处。您可能已经注意到,目的地址可以匹配多个条目。例如,地址11001000 00010111 00011000 10101010的前24位与表中的第二个条目匹配,地址的前21位与表中的第三个条目匹配。当有多个匹配时,路由器使用**最长前缀匹配规则(longest prefix-matching rule)**;也就是说,它在表中查找最长匹配条目,并将数据包转发到与最长前缀匹配相关联的链路接口。当我们在第4.3节更详细地学习Internet寻址时,我们将确切了解为什么使用最长前缀匹配规则。<br />考虑到转发表的存在,查找在概念上很简单-硬件逻辑只是在转发表中搜索最长的前缀匹配。但在千兆传输速率下,此查找必须在纳秒内执行(回想一下我们前面的10Gbps链路和64字节IP数据报的示例)。**因此,不仅必须在硬件中执行查找,还需要超越通过大表的简单线性搜索的技术**;快速查找算法(fast lookup algorithms)的调查可以在[Gupta 2001,Ruiz-Sanchez 2001]中找到。还必须特别注意存储器访问时间,从而设计出嵌入式片上DRAM和速度更快的SRAM(用作DRAM缓存)存储器。在实践中,三元内容可寻址存储器(Ternary Content Addressable Memories,TCAM)也经常用于查找[Yu 2004]。通过TCAM,32位IP地址被呈现给存储器,存储器在基本上恒定的时间内返回该地址的转发表条目的内容。Cisco Catalyst 6500和7600系列路由器和交换机可以容纳多达一百万个TCAM转发表条目[Cisco TCAM 2014]。<br />**一旦通过查找确定了数据包的输出端口,就可以将该数据包发送到交换结构**。**在一些设计中,如果来自其他输入端口的数据包当前正在使用交换结构,则可以临时阻止数据包进入交换结构**。阻塞的数据包将在输入端口排队,然后计划在稍后的时间点穿过交换结构。我们稍后将更详细地介绍数据包(在输入端口和输出端口)的阻塞、排队和调度。**虽然“查找”可以说是输入端口处理中最重要的操作,但必须采取许多其他操作:(1)必须进行物理层和链路层处理,如前所述;(2)必须检查数据包的版本号、校验和和生存时间字段(我们将在第4.3节中研究),并且必须重写后两个字段;以及(3)必须更新用于网络管理的计数器(如接收的IP数据报的数量)。**<br />让我们通过注意以下输入端口步骤来结束对输入端口处理的讨论:查找目的地IP地址(“匹配(match)”),然后将数据包发送到交换结构中到指定的输出端口(“动作(action)”)的输入端口步骤是在许多联网设备(而不仅仅是路由器)中执行的更一般的“匹配加动作(match plus action)”抽象的具体情况。在链路层交换机(第6章介绍)中,查找链路层目的地址,除了向输出端口将帧发送到交换结构之外,还可以采取几项操作。在防火墙(第8章所述)(过滤掉所选传入数据包的设备)中,其首部报头与给定标准(例如,源/目的IP地址和传输层端口号的组合)匹配的传入数据包可以被丢弃(动作)。在网络地址转换器(network address translator,NAT,在第4.3节中介绍)中,传输层端口号与给定值匹配的传入数据包将在转发(动作)之前重写其端口号。事实上,“匹配加动作”抽象[Bosshart 2013]在当今的网络设备中既强大又流行,是我们将在4.4节中学习的广义转发概念的核心。
4.2.2 交换 Switching
交换结构(switching fabric)是路由器的核心,因为数据包实际上是通过此结构从输入端口交换(即转发)到输出端口的。交换可以通过多种方式完成,如图4.6所示: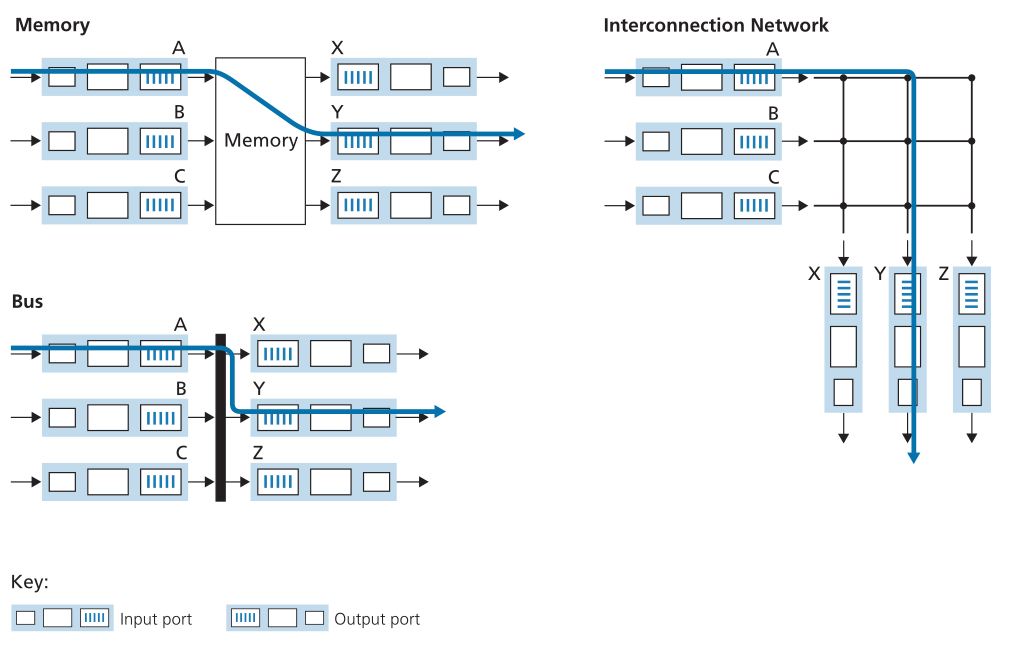
Figure 4.6 ♦ Three switching techniques
图4.6.♦三种交换技术
- 通过内存进行交换(Switching via memory)。最简单、最早的路由器是传统计算机,输入和输出端口之间的切换是在CPU(路由处理器)的直接控制下完成的。在传统操作系统中,输入和输出端口充当传统的I/O设备。具有到达数据包的输入端口首先通过中断向路由处理器发出信号。然后将数据包从输入端口复制到处理器内存中。然后,路由处理器从首部中提取目的地址,在转发表中查找适当的输出端口,并将数据包复制到输出端口的缓冲区。在这种情况下,如果内存带宽是每秒最多可以向内存写入或从内存读取B个数据包,则总体转发吞吐量(数据包从输入端口传输到输出端口的总速率)必须小于B/2。还请注意,不能同时转发两个数据包,即使它们具有不同的目的端口,因为在共享系统总线上一次只能完成一个存储器读/写操作。
一些现代路由器通过内存进行交换。然而,与早期路由器的主要不同之处在于,目的地址的查找和将数据包存储到适当的内存位置都是通过在输入线路卡(input line cards)上进行处理来执行的。在某些方面,通过内存交换的路由器看起来非常像共享内存多处理器,线路卡上的处理将数据包交换(写入)到适当输出端口的内存中。Cisco Catalyst 8500系列交换机[Cisco 8500 2020]通过共享内存在内部交换数据包。 - 通过总线交换(Switching via a bus)。在此方法中,输入端口通过共享总线将数据包直接传输到输出端口,而无需路由处理器的干预。这通常是通过让输入端口将交换机内部标签(首部)预先挂在数据包上来完成的,该数据包指示该数据包正被传输到的本地输出端口,并将该数据包发送到总线上。所有输出端口都会收到数据包,但只有与标签匹配的端口才会保留数据包。然后,该标签在输出端口处被移除,因为该标签仅在交换机内用于穿过总线。如果多个数据包同时到达路由器,且每个数据包都位于不同的输入端口,则除了一个数据包之外,所有数据包都必须等待,因为一次只能有一个数据包通过总线。因为每个数据包都必须通过单个总线,所以路由器的交换速度受到总线速度的限制;在我们的环形交叉口类比中,这就好像环形交叉口一次只能容纳一辆车。尽管如此,对于在小型局域网和企业网络中运行的路由器来说,通过总线进行交换通常就足够了。Cisco 6500路由器[Cisco 6500 2020]通过32 Gbps背板总线内部交换数据包。
- 通过互连网络进行交换(Switching via an interconnection network)。克服单个共享总线带宽限制的一种方式是使用更复杂的互连网络,例如过去用于互连多处理器计算机体系结构中的处理器的互连网络。纵横制交换机是由2N条总线组成的互连网络,这些总线将N个输入端口连接到N个输出端口,如图4.6所示。每条垂直总线在交叉点与每条水平总线相交,该交叉点可以随时由交换结构控制器(switch fabric controller,其逻辑是交换结构本身的一部分)打开或关闭。当数据包从端口A到达并需要转发到端口Y时,交换机控制器关闭总线A和Y的交叉点,然后端口A将数据包发送到(仅由总线Y)拾取的总线上。请注意,来自端口B的数据包可以同时转发到端口X,因为A到Y和B到X的数据包使用不同的输入和输出总线。因此,与前两种交换方法不同,纵横制交换机能够并行转发多个数据包。纵横制交换机(crossbar switch)是无阻塞的-只要当前没有其他数据包转发到输出端口,转发到该输出端口的数据包就不会被阻止到达该输出端口。然而,如果来自两个不同输入端口的两个包被送往相同的输出端口,则其中一个包将不得不在输入端等待,因为一次只能通过任何给定的总线发送一个包。思科12000系列交换机[思科12000 2020]使用纵横制交换网络;思科7600系列可以配置为使用总线或纵横制交换机[思科7600 2020]。更复杂的互连网络使用多级交换元件,以允许来自不同输入端口的数据包通过多级交换结构同时流向相同的输出端口。有关交换机体系结构的调查,请参阅[Tobagi 1990]。Cisco CRS采用三阶段无阻塞交换策略。路由器的交换容量也可以通过并行运行多个交换结构来扩展。在此方法中,输入端口和输出端口连接到N个并行运行的交换结构。一个输入端口将一个数据包分成K个更小的块,并将这些块通过这N个交换结构中的K个发送(“喷射(sprays)”)到选定的输出端口,输出端口将K个块重新组装回原始数据包。
4.2.3 输出端口处理 Output Port Processing
输出端口处理(如图4.7所示)获取已存储在输出端口内存中的数据包,并通过输出链路传输它们。这包括选择(即,调度)用于传输的数据包并使其出队列,以及执行所需的链路层和物理层传输功能。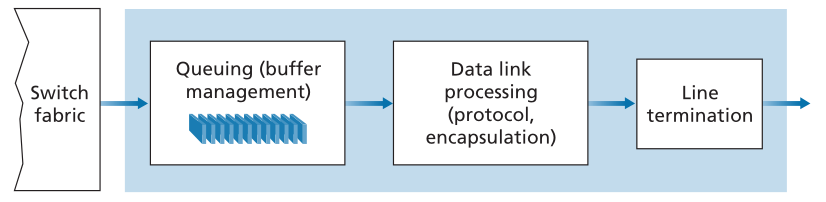
Figure 4.7 ♦ Output port processing
图4.7.♦输出端口处理4.2.4 排队在哪里发生? Where Does Queuing Occur?
如果我们考虑输入和输出端口功能以及图4.6中所示的配置,则很明显,数据包队列可能会同时在输入端口和输出端口形成,就像我们在环形交叉路口类比中确定的汽车可能在交通交叉路口的输入和输出处等待的情况一样。排队的位置和程度(输入端口队列或输出端口队列)将取决于流量负载、交换结构的相对速度和线路速度。现在让我们更详细地考虑这些队列,因为随着这些队列变得越来越大,路由器的内存最终可能会耗尽,当没有内存可用于存储到达的数据包时,将会发生数据包丢失(packet loss)。回想一下,在前面的讨论中,我们说过数据包“在网络中丢失”或“在路由器上丢弃”。正是在这里,在路由器内的这些队列中,这样的数据包实际上被丢弃和丢失。
假设输入和输出线路速度(传输速率)都具有每秒Rline个数据包的相同传输速率,并且存在N个输入端口和N个输出端口。为了进一步简化讨论,让我们假设所有数据包都具有相同的固定长度,并且数据包以同步方式(synchronous manner)到达输入端口。也就是说,在任何链路上发送数据包的时间等于在任何链路上接收数据包的时间,并且在这样的时间间隔内,可以零个或一个数据包到达输入链路。将交换结构传输速率Rswitch定义为数据包可以从输入端口移动到输出端口的速率。如果Rswitch比Rline快N倍,那么在输入端口上只会出现可以忽略不计的排队。这是因为即使在最坏的情况下,其中所有N个输入线路都在接收数据包,并且所有数据包都将被转发到相同的输出端口,每批N个数据包(每个输入端口一个数据包)也可以在下一批数据包到达之前通过交换结构被清除。输入队列 Input Queueing
但是,如果交换结构不够快(相对于输入线路速度),无法毫无延迟地通过交换结构传输所有到达的数据包,会发生什么情况?在这种情况下,数据包排队也可能发生在输入端口,因为数据包必须加入输入端口队列才能等待通过交换结构传输到输出端口。为了说明此排队的重要结果,请考虑纵横制交换结构,并假设(1)所有链路速度都相同,(2)一个数据包可以在与在输入链路上接收数据包相同的时间量内从任何一个输入端口传输到给定输出端口,以及(3)数据包以FCFS方式从给定输入队列移动到它们所需的输出队列。只要多个数据包的输出端口不同,就可以并行传输多个数据包。但是,如果两个输入队列前面的两个数据包要发往同一个输出队列,则其中一个数据包将被阻塞,并且必须在输入队列中等待-交换结构一次只能将一个数据包传输到给定的输出端口。
图4.8显示了一个示例,在该示例中,输入队列前面的两个数据包(带深色阴影)发往相同的右上角输出端口。假设交换结构选择从左上角队列的前面传输数据包。在这种情况下,左下角队列中的深色阴影数据包必须等待。但是,不仅此深色阴影数据包必须等待,在左下角队列中排在该数据包之后的浅阴影数据包也必须等待,即使不存在对右中输出端口(浅阴影数据包的目的地)的争用。这种现象在输入队列交换机中称为队头(head-of-the-line,HOL)阻塞-输入队列中排队的数据包必须等待通过交换矩阵进行传输(即使其输出端口是空闲的),因为它被位于队头的另一个数据包阻塞。[Karol 1987]指出,由于HOL阻塞,一旦输入链路上的数据包到达率仅达到其容量的58%,在某些假设下,输入队列将增长到无限长度(非正式地说,这相当于将发生重大数据包丢失)。在[McKeown 1997]中讨论了许多HOL阻塞的解决方案。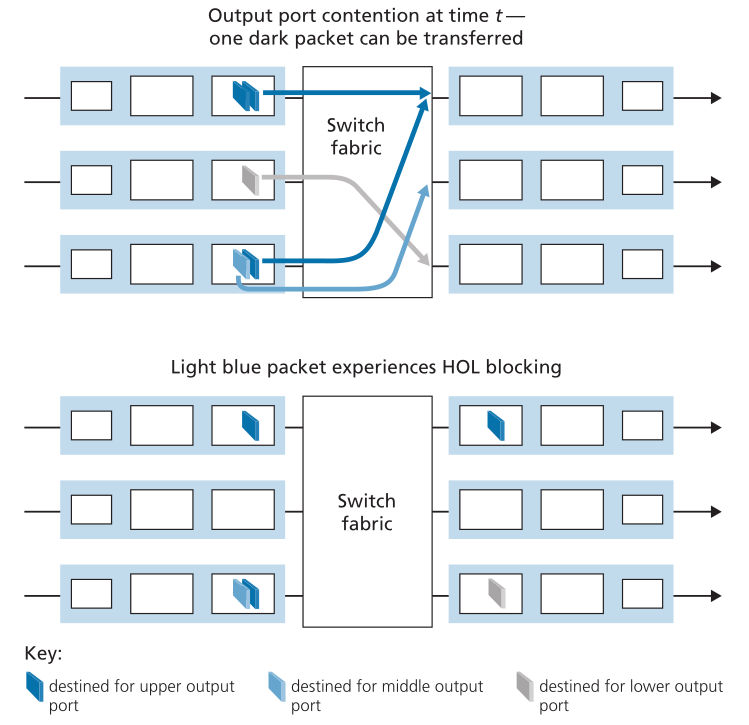
Figure 4.8 ♦ HOL blocking at and input-queued switch
图4.8.♦HOL阻塞和输入队列交换机输出队列 Output Queueing
接下来,让我们考虑交换机的输出端口是否会出现排队。假设Rswitch再次比Rline快N倍,并且到达N个输入端口中的每一个的数据包都去往相同的输出端口。在这种情况下,在将单个数据包发送到传出链路所需的时间内,N个新数据包将到达此输出端口(N个输入端口各一个)。由于输出端口在一个时间单位(数据包传输时间)内只能传输单个数据包,因此N个到达的数据包将不得不排队(等待)通过传出链路传输。则在仅发送先前排队的N个数据包中的一个所需的时间内,可能还会有N个数据包到达。诸若此类。因此,即使交换结构比端口线路速度快N倍,也可以在输出端口处形成数据包队列。最终,排队的数据包数量可能会增长到足以耗尽输出端口的可用内存。
当没有足够的内存来缓冲传入的数据包时,必须决定是丢弃到达的数据包(称为弃尾(drop-tail)的策略),还是删除一个或多个已排队的数据包,以便为新到达的数据包腾出空间。在某些情况下,为了向发送方提供拥塞信号,在缓冲器满之前丢弃数据包(或标记数据包的报头)可能是有利的。此标记可以使用我们在3.7.2节中研究的显式拥塞通知位来完成。已经提出并分析了许多主动数据包丢弃和标记策略(统称为主动队列管理(active queue management,AQM)算法)[Labrador 1999,Hollot 2002]。随机早期检测(Random Early Detection,RED)算法是研究和实现最广泛的AQM算法之一[Christian ansen 2001]。最近的AQM策略包括PIE(增强的比例积分控制器(Proportional Integral controller Enhanced)[RFC 8033])和Codel[Nichols 2012]。
输出端口队列如图4.9所示。在时间t,数据包已经到达每个传入输入端口,每个都去往最上面的传出端口。假设线路速度相同,并且交换机在一个时间单位后以三倍于线路速度的速度运行(即在接收或发送数据包所需的时间内),则所有三个原始数据包都已传输到传出端口,并排队等待传输。在下一个时间单元中,这三个数据包中的一个将通过传出链路传输。在我们的示例中,两个新的数据包已经到达交换机的传入端;其中一个数据包的目的地是最上面的输出端口。这种排队的结果是,输出端口的数据包调度器(packet scheduler)必须从排队的数据包中选择一个数据包进行传输-这是我们将在下一节讨论的主题。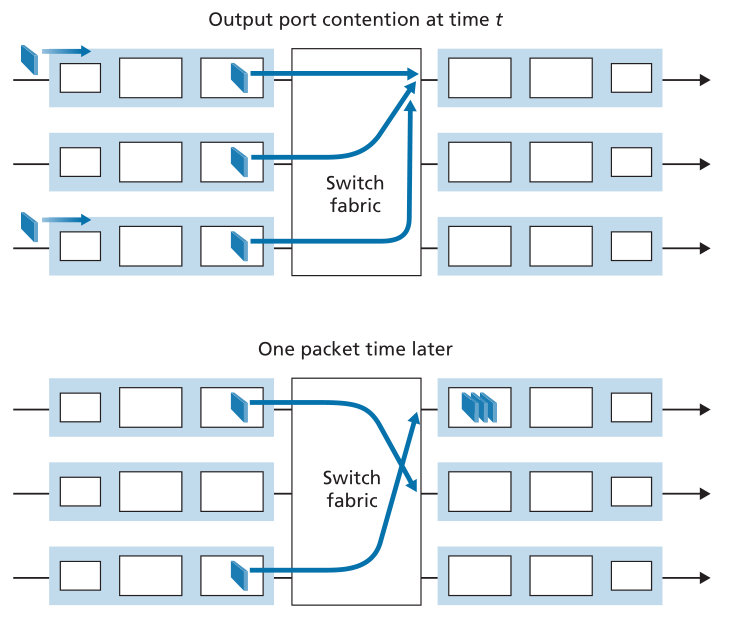
Figure 4.9 ♦ Output port queueing
图4.9.♦输出端口队列多少缓冲才“足够”? How Much Buffering Is “Enough?”
我们上面的研究显示了当数据包突发到达路由器的输入或(更有可能的)输出端口时,数据包队列是如何形成的,并且数据包到达速率暂时超过了数据包可以转发的速率。这种不匹配持续的时间越长,队列增长的时间就越长,直到最终端口的缓冲区变满并丢弃数据包。一个自然的问题是,一个端口应该提供多少缓冲。事实证明,这个问题的答案比人们想象的要复杂得多,它可以教给我们相当多关于网络边缘和网络核心的拥塞感知发送器之间的微妙交互!
多年来,缓冲区大小调整的经验法则[RFC 3439]是缓冲区大小(B)应等于平均往返时间(RTT,比方说250毫秒)乘以链路容量(C)。因此,RTT为250毫秒的10-Gbps链路将需要相当于B=RTT×C=2.5 Gbit缓冲器的缓冲量。这一结果基于对相对较少的TCP流的排队动力学的分析(Villamizar 1994)。然而,最近的理论和实验工作[Appenzeller 2004]表明,当大量独立的TCP流(N)通过链路时,所需的缓冲量为 。在核心网络中,大量TCP流通常通过大型主干路由器链路,N的值可能很大,所需缓冲区大小的减少非常显著。[Appenzeller 2004;Wischik 2005;Behehti 2008]从理论、实现和操作的角度对缓冲区大小问题进行了非常易读的讨论。
。在核心网络中,大量TCP流通常通过大型主干路由器链路,N的值可能很大,所需缓冲区大小的减少非常显著。[Appenzeller 2004;Wischik 2005;Behehti 2008]从理论、实现和操作的角度对缓冲区大小问题进行了非常易读的讨论。
认为缓冲越多越好的想法是暂时的—更大的缓冲可以让路由器吸收更大的数据包到达率波动,从而降低路由器的丢包率。但更大的缓冲区也意味着可能会有更长的排队延迟。对于游戏玩家和交互式电话会议用户来说,几十毫秒很重要。将per-hop缓冲区的数量增加10倍以减少丢包可能会使端到端延迟增加10倍!增加的RTT还会使TCP发送方对初期拥塞和/或数据包丢失的响应变得更慢和更慢。这些基于延迟的考虑表明,缓冲是一把双刃剑-缓冲可以用来吸收流量的短期统计波动,但也可能导致延迟增加和随之而来的担忧。缓冲有点像盐—适量的盐会使食物变得更好,但过多的盐会使食物无法食用!
在上面的讨论中,我们隐含地假设许多独立发送者在拥塞的链路上竞争带宽和缓冲区。虽然对于网络核心内的路由器来说,这可能是一个很好的假设,但在网络边缘,这一假设可能不成立。图4.10(A)显示了一台家庭路由器将TCP数据段发送到远程游戏服务器。根据[Nichols 2012],假设传输一个数据包(包含玩家的TCP段)需要20毫秒,在通往游戏服务器的路径上其他地方的排队延迟可以忽略不计,并且RTT为200毫秒。如图4.10(B)所示,假设在时间t=0,25个数据包的突发到达队列。这些排队的数据包中的一个然后每20ms发送一次,从而在t=200毫秒时,第一个ACK到达,就像第21个数据包正在被发送一样。此ACK到达会导致TCP发送器发送另一个数据包,该数据包在家庭路由器的传出链路上排队。在t=220处,下一个ACK到达,并且当第22个数据包被发送时,另一个TCP数据段由玩家释放并排队,依此类推。您应该说服自己,在这种情况下,每次发送排队的数据包时,ACK时钟都会导致新的数据包到达队列,从而导致家庭路由器的传出链路上的队列大小始终为5个数据包!也就是说,端-端流水线已满(以每20毫秒一个包的路径瓶颈速率向目的地传送包),但排队延迟量是恒定且持久的。结果,游戏玩家对延迟感到不满,家长(甚至知道Wireshark!)也很困惑,因为他或她不明白为什么延迟会持续很长时间,即使在家庭网络上没有其他流量的情况下也是如此。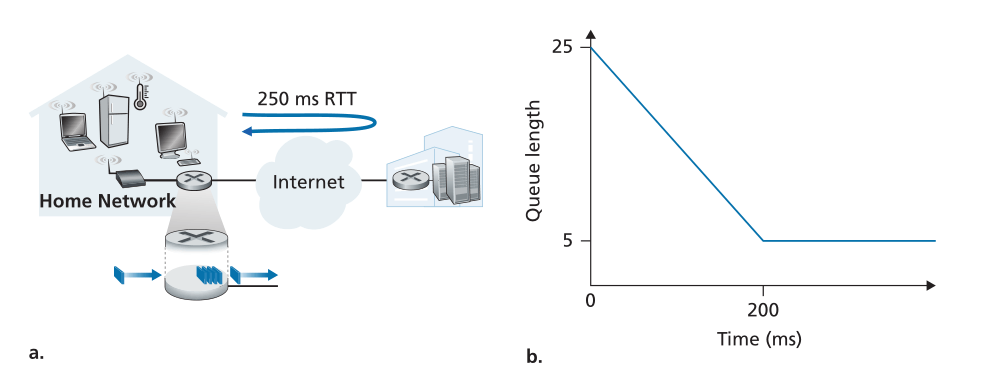
Figure 4.10 ♦ Bufferbloat: persistent queues
图4.10♦缓冲膨胀:持久队列
上述由于持久缓冲而导致长延迟的情况称为缓冲膨胀(bufferbloat),说明不仅吞吐量很重要,而且最小延迟也很重要[Kleinrock 2018],并且网络边缘的发送方和网络内的队列之间的交互确实可能是复杂和微妙的。我们将在第6章中研究的有线网络DOCSIS 3.1标准最近添加了一种特定的AQM机制[RFC 8033,RFC 8034]来对抗缓冲区膨胀,同时保持批量吞吐量性能。4.2.5 数据包调度 Packet Scheduling
现在让我们回到确定排队的数据包在传出链路上传输的顺序的问题。由于您自己无疑已经在许多场合排过长队,并观察过等待的客户是如何得到服务的,因此您无疑熟悉路由器中常用的许多排队规则。有先到先得(first-come-first-served,FCFS,也称为先进先出,first-in-first-out,FIFO)。英国人以耐心有序地在公交车站和市场排队(“哦,你在排队吗?”)而闻名。其他国家的服务是优先的,有一类等待的客户优先于其他等待的客户。还有轮询排队,客户也被分成几类(就像优先级排队一样),但每一类客户都会被轮流提供服务。先进先出 First-in-First-Out (FIFO)
图4.11显示了FIFO链路调度规程的排队模型抽象。如果链路当前忙于传输另一个数据包,则到达链路输出队列的数据包将等待传输。如果没有足够的缓冲空间来容纳到达的数据包,则队列的数据包丢弃策略随后确定数据包是否将被丢弃(丢失),或者是否将从队列中移除其他数据包以便为到达的数据包腾出空间,如上所述。在下面的讨论中,我们将忽略数据包丢弃。当包在传出链路上完全传输(即,接收服务)时,它将从队列中移除。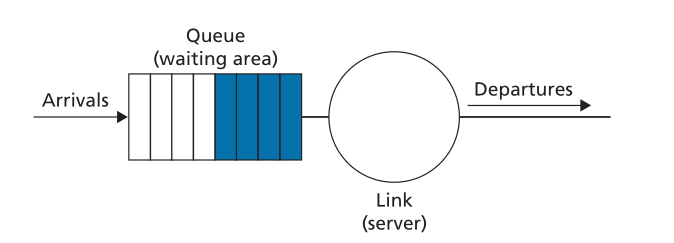
Figure 4.11 ♦ FIFO queueing abstraction
图4.11♦先进先出队列抽象
FIFO(也称为先到先服务或FCFS)调度规则按照数据包到达输出链路队列的相同顺序选择用于链路传输的数据包。我们都熟悉服务中心的先进先出(FIFO)排队,在那里,到达的顾客排在单一等待队伍的后面,保持秩序,当他们到达队伍的前部时,他们会得到服务。图4.12显示了运行中的FIFO队列。数据包到达由时间线上方的数字箭头表示,数字表示数据包到达的顺序。各个数据包的离开时间显示在较低的时间线下方。包在服务中花费的时间(被传输)由两个时间线之间的阴影矩形表示。在我们的示例中,让我们假设每个数据包需要三个单位的时间来传输。在FIFO规则下,数据包按照到达的顺序离开。请注意,在数据包4离开后,链路保持空闲(因为数据包1到4已被传输并从队列中移除),直到数据包5到达。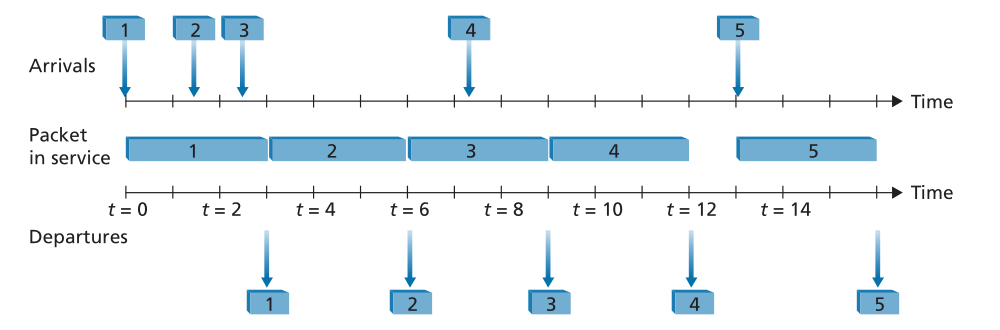
Figure 4.12 ♦ The FIFO queue in operation
图4.12♦运行中的先进先出队列优先级队列 Priority Queuing
在优先级队列下,到达输出链路的数据包在到达队列时被以优先级分类,如图4.13所示。在实践中,网络运营商可以配置队列,使得携带网络管理信息(例如,由源或目的地TCP/UDP端口号指示)的数据包接收比用户业务更高的优先级;另外,实时IP语音数据包可能比非实时业务(如电子邮件数据包)接收优先级。每个优先级类别通常都有自己的队列。在选择要传输的数据包时,优先级排队规则将传输具有非空队列(即具有等待传输的数据包)的最高优先级类别的数据包。在相同优先级的数据包之间的选择通常以FIFO方式完成。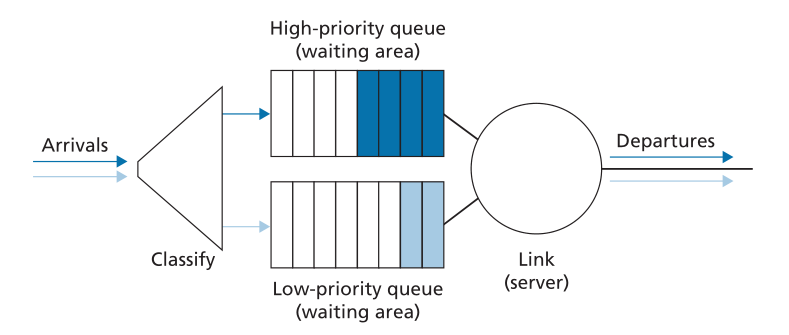
Figure 4.13 ♦ The priority queueing model
图4.13♦优先级队列模型
图4.14说明了具有两个优先级类别的优先级队列的操作。数据包1、3和4属于高优先级类别,而数据包2和5属于低优先级类别。数据包1到达后,发现链路空闲,便开始传输。在数据包1的传输过程中,数据包2和3到达并分别在低优先级和高优先级队列中排队。在数据包1传输之后,选择数据包3(高优先级数据包)通过数据包2(即使它较早到达,也是低优先级数据包)进行传输。在数据包3的传输结束时,数据包2开始传输。数据包4(高优先级数据包)在数据包2(低优先级数据包)的传输期间到达。在非抢占式优先级队列(non-preemptive priority queuing)规则下,数据包的传输一旦开始就不会中断。在这种情况下,数据包4排队等待传输,并在数据包2的传输完成后开始传输。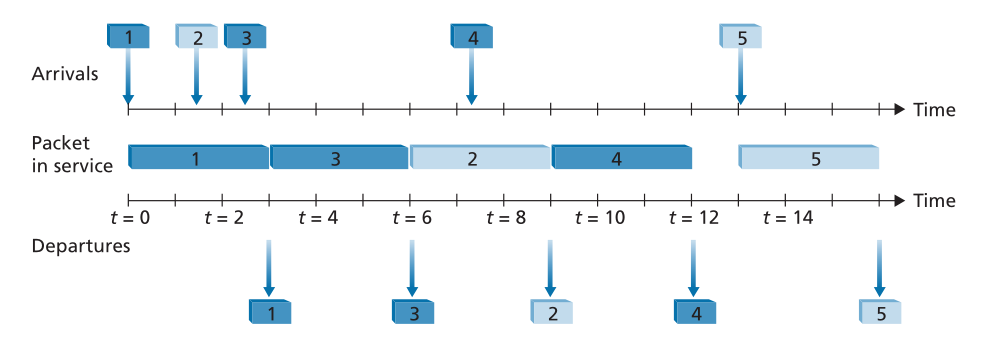
Figure 4.14 ♦ The priority queue in operation
图4.14♦运行中的优先级队列PRINCIPLES IN PRACTICE 实践中的原则 NET NEUTRALITY 网络中立性 我们已经看到,数据包调度机制(例如,优先级业务调度规则,如严格的优先级和WFQ)可以用于向不同的业务“类”提供不同级别的服务。确切地说,什么构成业务的“类”是由ISP决定的,但是可以潜在地基于IP数据报头中的任何一组字段。例如,IP数据报头中的端口字段可用于根据与该端口相关联的“公知服务”对数据报进行分类:SNMP网络管理数据报(端口161)可被分配给比IMAP电子邮件协议(端口143或993)数据报更高的优先级,并因此接收更好的服务。ISP还可能使用数据报的源IP地址为某些公司发送的数据报提供优先级(这些公司可能已经为此特权向ISP支付了费用),而不是其他公司(尚未付费)发送的数据报;ISP甚至可以拦截具有给定公司或国家/地区的源IP地址的流量。有许多机制可以让ISP为不同类别的流量提供不同级别的服务。真正的问题是什么政策和法律决定了ISP实际能做什么。当然,这些法律会因国家不同而有所不同;参见[史密森2017]中的简要调查。在这里,我们将简要考虑美国对所谓的“网络中立”的政策。 “网络中立(net neutrality)”一词没有一个确切的定义,但美国联邦通信委员会2015年3月发布的关于保护和促进开放互联网的命令[FCC 2015]提供了三条“清晰、清晰的界线(clear, bright line)”规则,这些规则现在经常与网络中立联系在一起:
- “不能阻挡。。。。从事提供宽频互联网接入服务的人士。。。不得屏蔽合法内容、应用程序、服务或无害设备,并接受合理的网络管理。“
- “不能节流。。。。从事提供宽频互联网接入服务的人士。。。不得因互联网内容、应用程序或服务或使用无害设备而损害或降低合法的互联网流量,但必须经过合理的网络管理。“
- “没有付费优先顺序。。。。从事提供宽频互联网接入服务的人士。。。不得进行有偿优先排序。“付费优先化”指的是对宽带提供商的网络的管理,以直接或间接地偏爱某些业务而不是其他业务,包括通过使用诸如业务整形、优先化、资源预留或其他形式的优先业务管理等技术。。“
非常有趣的是,在下达命令之前,已经观察到ISP违反前两条规则的行为[Faulhaber 2012]。2005年,北卡罗来纳州的一家ISP同意停止阻止其客户使用Vonage的做法,Vonage是一种IP语音服务,与其自己的电话服务竞争。2007年,Comcast被判定为干扰BitTorrent P2P流量,在内部创建并向BitTorrent发送方和接收方发送TCP RST数据包,导致它们关闭其BitTorrent连接[FCC 2008]。 网络中立性辩论的双方都进行了激烈的辩论,主要集中在网络中立性在多大程度上为客户提供了好处,同时又促进了创新。见[Peha 2006,Faulhaber 2012,Economides 2017,MadhyDisa 2017]。 2015年FCC关于保护和促进开放互联网的命令,禁止ISP阻止、限制或提供付费优先顺序,被2017年FCC恢复互联网自由命令所取代,[FCC 2017]撤销了这些禁令,转而关注ISP的透明度。有了如此多的兴趣和如此多的变化,我们可能可以肯定地说,我们还没有接近于在美国或其他地方看到关于网络中立的最后一章。
轮询和加权公平队列 Round Robin and Weighted Fair Queuing (WFQ)
在轮询队列规则下,数据包与优先级排队一样被分类。然而,轮询调度器在类之间交替服务,而不是在类之间有严格的服务优先级。在最简单的循环调度形式中,先传输1类数据包,然后是2类数据包,然后是1类数据包,然后是2类数据包,依此类推。所谓的节省工作队列(work-conserving queuing)规则永远不会允许链路在有(任何类别的)数据包排队等待传输时保持空闲。一种节约循环规则,如果查找给定类的数据包,但没有找到,则会立即检查循环序列中的下一个类。
图4.15说明了两类循环队列的操作。在本例中,数据包1、2和4属于类1,数据包3和5属于第二类。数据包1到达输出队列后立即开始传输。数据包2和3在数据包1的传输期间到达,因此排队等待传输。在传输数据包1之后,链路调度器查找2类数据包,从而传输数据包3。在传输数据包3之后,调度器查找1类数据包,从而传输数据包2。在传输数据包2之后,数据包4是唯一排队的数据包;因此,它紧跟在数据包2之后传输。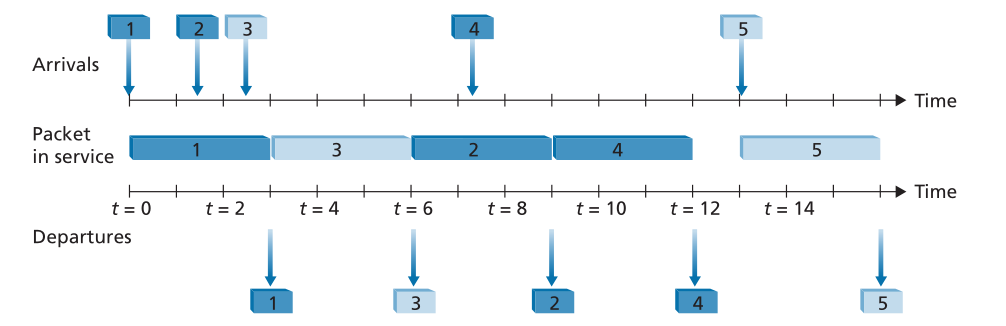
Figure 4.15 ♦ The two-class robin queue in operation
图4.15♦运行中的两级轮询队列
在路由器中广泛实现的轮询排队的一般形式是所谓的加权公平排队(weighted fair queuing,WFQ)规则[Demers 1990;Parekh 1993]。WFQ如图4.16所示。在这里,到达的数据包被分类并在适当的每个类别的等待区域中排队。正如在循环调度中一样,WFQ调度器将以循环方式服务类-首先服务类1,然后服务类2,然后服务类3,然后(假设有三个类)重复服务模式。WFQ也是一种节省工作的排队规则,因此当它发现一个空的类队列时,它会立即转移到服务序列中的下一个类。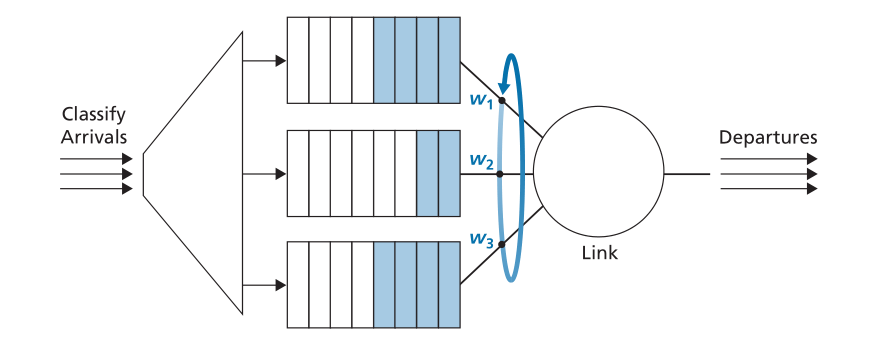
Figure 4.16 ♦ Weighted fair queueing
图4.16♦加权公平队列
WFQ与轮询的不同之处在于,每个类别可以在任何时间间隔内接收不同数量的服务。具体地说,每个类 都被分配了一个权重
都被分配了一个权重 。在WFQ下,在有
。在WFQ下,在有 类数据包要发送的任何时间间隔期间,
类数据包要发送的任何时间间隔期间, 类将被保证接收等于
类将被保证接收等于 的服务的一小部分,其中分母的和取自所有同样有包排队等待传输的类。在最坏的情况下,即使所有类别都已排队数据包,类别
的服务的一小部分,其中分母的和取自所有同样有包排队等待传输的类。在最坏的情况下,即使所有类别都已排队数据包,类别 仍将被保证接收带宽的一部分
仍将被保证接收带宽的一部分 ,其中在这种最坏情况下分母的总和在所有类别上。因此,对于具有传输速率
,其中在这种最坏情况下分母的总和在所有类别上。因此,对于具有传输速率 的链路,类别
的链路,类别 将始终实现至少
将始终实现至少 的吞吐量。我们对WFQ的描述已经理想化了,因为我们没有考虑这样一个事实,即数据包是离散的,并且数据包的传输不会被中断来开始另一个数据包的传输;[Demers 1990;Parekh 1993]讨论了这个数据包化问题。
的吞吐量。我们对WFQ的描述已经理想化了,因为我们没有考虑这样一个事实,即数据包是离散的,并且数据包的传输不会被中断来开始另一个数据包的传输;[Demers 1990;Parekh 1993]讨论了这个数据包化问题。

若有收获,就点个赞吧
0 人点赞
