在检查了互联网的边缘之后,让我们现在更深入地研究网络核心——分组交换机和互连互联网终端系统的链路的网格。 图 1.10 用粗阴影线突出显示了网络核心。<br />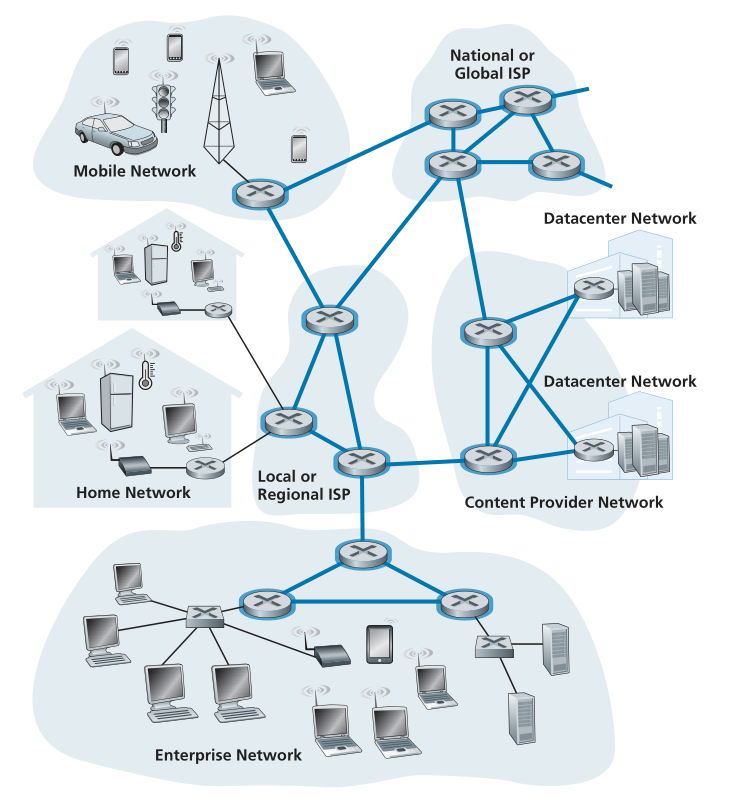<br />**Figure 1.10 ♦ The network core**
1.3.1 数据包交换 Packet Switching
在网络应用中,终端系统彼此交换报文(messages)。报文可以包含应用程序设计者想要的任何内容。 报文可以执行控制功能(例如,图 1.2 中握手示例中的“Hi”消息)或可以包含数据,例如电子邮件消息、JPEG 图像或 MP3 音频文件。 为了将报文从源端系统发送到目标端系统,源将长报文分解为更小的数据块,称为数据包(packets)。 在源和目的地之间,每个数据包都通过通信链路和数据包交换机(packet switches)(有两种主要类型,路由器和链路层交换机(routers and link-layer switches))。 数据包在每条通信链路上以等于链路全传输速率的速率传输。 因此,如果源端系统或分组交换机正在以 R 比特/秒的传输速率通过链路发送 L 比特的数据包,则传输该数据包的时间为 L / R 秒。
存储转发传输 Store-and-Forward Transmission
大多数分组交换机在链路的输入端使用存储转发传输(store-and-forward transmission)。 存储转发传输意味着数据包交换机必须先接收整个数据包,然后才能开始将数据包的第一位传输到出站链路上。 为了更详细地探索存储转发传输,请考虑一个简单的网络,该网络由通过单个路由器连接的两个终端系统组成,如图 1.11 所示。 一个路由器通常会有许多事件链路(incident links),因为它的工作是将传入的数据包切换到传出的链路上; 在这个简单的例子中,路由器有一个相当简单的任务,将一个数据包从一个(输入)链路传输到另一个连接的链路。 在这个例子中,源有三个数据包,每个数据包由 L 位组成,要发送到目的地。在图 1.11 所示的时间快照中,源已经传输了一些数据包 1,并且数据包 1 的前端已经到达路由器。 由于路由器采用存储转发方式,在这个时刻,路由器不能传输它接收到的比特; 相反,它必须首先缓冲(即“存储”)数据包的位。 只有在路由器接收到数据包的所有位后,它才能开始将数据包传输(即“转发”)到出站链路上。 为了深入了解存储转发传输,现在让我们计算从源开始发送数据包到目的地收到整个数据包所经过的时间。(这里我们将忽略传播延迟——比特以接近光速穿过导线所需的时间——这将在 1.4 节中讨论。)源在时间 0 开始传输; 在时间 L/R 秒,源已经传输了整个数据包,并且整个数据包已被接收并存储在路由器上(因为没有传播延迟)。 在时间 L/R 秒,由于路由器刚刚收到整个数据包,它可以开始将数据包传输到出站链路上,前往目的地; 在时间 2L/R,路由器已经传输了整个数据包,并且整个数据包已经被目的地接收到。因此,总延迟为 2L/R。 如果交换机在比特到达时立即转发(而不首先接收整个数据包),那么总延迟将是 L/R,因为比特不会在路由器上保留。但是,正如我们将在第 1.4 节中讨论的,路由器需要在转发之前接收、存储和处理整个数据包。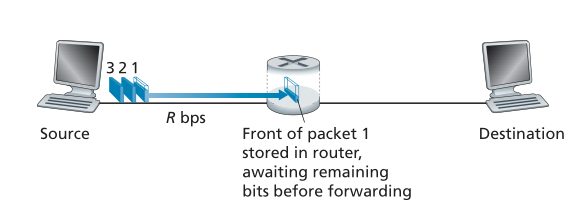
Figure 1.11 ♦ Store-and-forward packet switching
现在让我们计算从源开始发送第一个数据包到目的地收到所有三个数据包所经过的时间。 和以前一样,在 L/R 时刻,路由器开始转发第一个数据包。 但也在 L/R 时刻,源将开始发送第二个数据包,因为它刚刚完成了整个第一个数据包的发送。 因此,在时间 2L/R,目的地已收到第一个数据包,而路由器已收到第二个数据包。 类似地,在时间 3L/R,目的地收到了前两个数据包,路由器收到了第三个数据包。最后,在时间 4L/R,目的地收到了所有三个数据包!
现在让我们考虑这样一个一般的情况:将一个包从源发送到目的地,路径由N条速率为R的链路组成(因此,源和目的地之间有N-1个路由器)。应用上面相同的逻辑,我们可以看到端到端延迟是:
现在,您可能想要尝试确定在一系列的N个链路上发送P个包时的延迟是多少。
排队延迟和丢包 Queuing Delays and Packet Loss
每个分组交换机都有多个连接到它的链路。 对于每个连接的链路,数据包交换机都有一个输出缓冲区(output buffer,也称为输出队列(output queue)),用于存储路由器即将发送到该链路的数据包。 输出缓冲区在数据包交换中起着关键作用。 如果到达的数据包需要传输到链路上,但发现该链路忙于传输另一个数据包,则到达的数据包必须在输出缓冲区中等待。 因此,除了存储和转发延迟之外,数据包还会遭受输出缓冲区排队延迟(queuing delays)。这些延迟是可变的,取决于网络中的拥塞(congestion)程度。 由于缓冲区空间的数量是有限的,因此到达的数据包可能会发现缓冲区已满,而其他数据包正在等待传输。 在这种情况下,将发生数据包丢失——到达的数据包或已经排队的数据包之一将被丢弃。
图 1.12 说明了一个简单的分组交换网络。 如图 1.11 所示,数据包由 3 维平板(slabs)表示。 一个slab的宽度代表数据包中的比特数。 在此图中,所有数据包都具有相同的宽度,因此具有相同的长度。 假设主机 A 和 B 正在向主机 E 发送数据包。主机 A 和 B 首先将它们的数据包沿 100 Mbps 以太网链路发送到第一个路由器。路由器然后将这些数据包定向到 15 Mbps 链路。 如果在很短的时间间隔内,到达路由器的数据包的到达速率(转换为每秒比特数)超过 15 Mbps,则由于数据包在传输到链路上之前在链路的输出缓冲区中排队,路由器将发生拥塞。例如,如果主机 A 和主机 B 各自同时突发地连续(back-to-back)发送 5 个数据包,那么这些数据包中的大多数将花费一些时间在队列中等待。 事实上,这种情况与许多日常情况完全相似——例如,当我们排队等候银行出纳员或在收费站前等候时。 我们将在 1.4 节中更详细地研究这种排队延迟。
转发表和路由协议 Forwarding Tables and Routing Protocols
早些时候,我们说过路由器接收到达其连接的通信链路之一的数据包,然后将该数据包转发到其连接的另一个通信链路。 但是路由器如何确定它应该将数据包转发到哪条链路上呢? 数据包转发实际上在不同类型的计算机网络中以不同的方式完成。 在这里,我们简要描述它是如何在 Internet 上完成的。
在 Internet 中,每个终端系统都有一个地址,称为 IP 地址。 当源端系统想要向目标端系统发送数据包时,源端系统在数据包的报头中包含目的地的 IP 地址。 与邮政地址一样,此地址具有层次结构。 当数据包到达网络中的路由器时,路由器会检查数据包的目标地址的一部分并将数据包转发到相邻的路由器。 更具体地说,每个路由器都有一个转发表(forwarding table),将目标地址(或目标地址的一部分)映射到该路由器的出站链路。 当数据包到达路由器时,路由器会检查地址并使用此目标地址搜索其转发表,以找到适当的出站链路。 然后路由器将数据包定向到此出站链路。
端到端的路由过程类似于不使用地图而是更喜欢问路的汽车司机。 例如,假设 Joe 从费城开车到佛罗里达州奥兰多的 156 Lakeside Drive。 乔首先开车到他附近的加油站,并询问如何前往佛罗里达州奥兰多的 156 Lakeside Drive。 加油站服务员提取地址的佛罗里达部分,并告诉乔他需要进入州际高速公路 I-95 South,该高速公路的入口就在加油站旁边。 他还告诉乔,一旦他进入佛罗里达,他应该问那里的其他人。 乔然后沿着 I-95 South 行驶,直到他到达佛罗里达州的杰克逊维尔,此时他向另一位加油站服务员询问方向。 服务员提取地址的奥兰多部分并告诉乔他应该继续沿 I-95 前往代托纳海滩,然后再问其他人。在代托纳海滩,另一位加油站服务员也提取了地址的奥兰多部分,并告诉乔他应该直接乘坐 I-4 到奥兰多。 乔乘坐 I-4 州际公路在奥兰多出口下车。 Joe 去找另一个加油站服务员,这次服务员提取了地址的 Lakeside Drive 部分,并告诉 Joe 到达 Lakeside Drive 必须遵循的道路。 乔到达湖滨大道后,他问一个骑自行车的孩子如何到达目的地。 孩子提取地址的 156 部分并指向房子。 乔终于到达了他的最终目的地。 在上面的类比中,加油站服务员和骑自行车的孩子类似于路由器。
我们刚刚了解到路由器使用数据包的目标地址来索引转发表并确定适当的出站链路。 但这句话又引出了另一个问题:如何设置转发表? 它们是在每个路由器中手动配置的,还是 Internet 使用更自动化的程序? 这个问题将在第 5 章深入研究。 但是为了激起你的兴趣,我们现在将注意到 Internet 有许多用于自动设置转发表的特殊路由协议(routing protocols)。 例如,路由协议可以确定从每个路由器到每个目的地的最短路径,并使用最短路径结果来配置路由器中的转发表。
1.3.2 电路交换 Circuit Switching
通过链路和交换机网络移动数据有两种基本方法:电路交换和数据包交换(circuit switching and packet switching)。 在上一小节介绍了分组交换网络之后,我们现在将注意力转向电路交换网络。
在电路交换网络中,沿路径(缓冲区、链路传输速率)提供终端系统之间通信所需的资源在终端系统之间的通信会话期间预留。在分组交换网络中,这些资源是没有预留的; 会话的报文按需使用资源,因此可能必须等待(即排队)以访问通信链路。 作为一个简单的类比,考虑两家餐厅,一家需要预订,另一家既不需要预订也不接受预订。对于需要预约的餐厅,出门前还得经过电话的麻烦。 但是,当我们到达餐厅时,原则上我们可以立即就座并点餐。 对于不需要订位的餐厅,我们也不需要费心订桌。 但是当我们到达餐厅时,我们可能需要等一张桌子才能坐下。
传统电话网络是电路交换网络的例子。考虑一下当一个人想要通过电话网络向另一个人发送信息(语音或传真)时会发生什么。 在发送方可以发送信息之前,网络必须在发送方和接收方之间建立连接。 这是一个真正的连接,发送方和接收方之间路径上的交换机为该连接维护连接状态。 在电话的行话中,这种连接称为电路(circuit)。 当网络建立电路时,它还会在连接期间预留网络链路中的恒定传输速率(代表每条链路传输容量的一小部分)。 由于已为此发送方到接收方连接预留了给定的传输速率,因此发送方可以以保证的恒定速率将数据传输到接收方。
图 1.13 说明了一个电路交换网络。 在这个网络中,四个电路交换机通过四个链路互连。 这些链路中的每一个都有四个电路,因此每个链路可以支持四个同时连接。 主机(例如,PC 和工作站)均直接连接到其中一台交换机。 当两台主机想要通信时,网络会在两台主机之间建立专用的端到端连接。 因此,为了使主机 A 与主机 B 通信,网络必须首先在两条链路中的每一条上预留一条电路。在此示例中,专用端到端连接使用第一条链路中的第二条电路和第二条链路中的第四条电路。 因为每条链路有四个电路,对于端到端连接使用的每条链路,该连接在连接期间获得该链路总传输容量的四分之一。 因此,例如,如果相邻交换机之间的每条链路的传输速率为 1 Mbps,则每个端到端电路交换机连接将获得 250 kbps 的专用传输速率。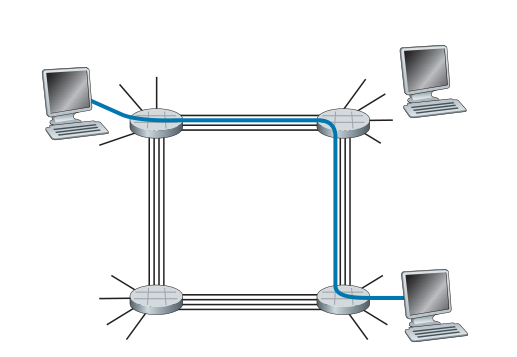
Figure 1.13 ♦ A simple circuit-switched network consisting of four switches
and four links
相比之下,请考虑当一台主机想要通过数据包交换网络(例如 Internet)向另一台主机发送包时会发生什么。 与电路交换一样,数据包通过一系列通信链路传输。 但与电路交换不同的是,数据包被发送到网络中,而不会预留任何链路资源。 如果其中一条链路因为需要同时通过该链路传输其他数据包而拥塞,则该数据包将不得不在传输链路的发送端的缓冲区中等待并遭受延迟。 Internet 尽最大努力及时交付数据包,但它不做任何保证。
电路交换网络中的多路复用 Multiplexing in Circuit-Switched Networks
链路中的电路通过频分复用 (frequency-division multiplexing,FDM) 或时分复用 (time-division multiplexing,TDM) 实现。 使用 FDM,链路的频谱在通过链路建立的连接之间划分。 具体而言,该链路在连接期间将频带专用于每个连接。 在电话网络中,该频带的宽度通常为 4 kHz(即 4,000 赫兹或每秒 4,000 个周期)。 频带的宽度被称为带宽(bandwidth),这并不奇怪。 FM 广播电台也使用 FDM 来共享 88 MHz 和 108 MHz 之间的频谱,每个电台都被分配了一个特定的频段。
对于TDM链路,时间被划分为固定持续时间的帧(frames),每一帧被划分为固定数量的时间片(time slots)。 当网络通过链路建立连接时,网络将每一帧中的一个时间片专用于该连接。这些时间片专供该连接单独使用,有一个时间片可用于(在每一帧中)传输连接的数据。
图 1.14 说明了支持多达四个电路的特定网络链路的 FDM 和 TDM。 对于 FDM,频域被分割为四个频段,每个频段的带宽为 4 kHz。 对于TDM,时域被分割成帧,每帧有四个时间片; 每个电路在循环的 TDM 帧中被分配相同的专用时间片。 对于 TDM,电路的传输速率等于帧速率乘以一个时间片中的比特数。 例如,如果链路每秒传输 8,000 帧,并且每个时间片由 8 位组成,则每个电路的传输速率为 64 kbps。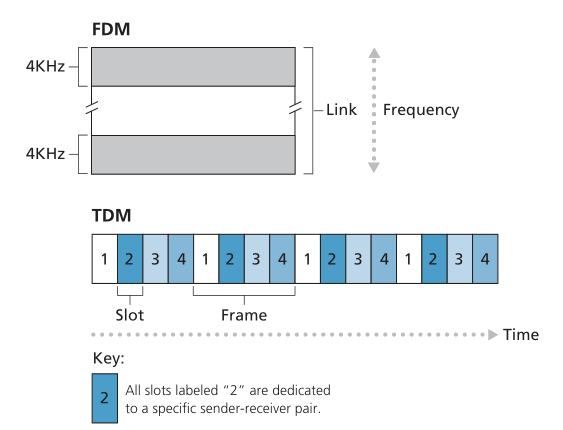
Figure 1.14 ♦ With FDM, each circuit continuously gets a fraction of the
bandwidth. With TDM, each circuit gets all of the bandwidth
periodically during brief intervals of time (that is, during slots)
使用 FDM,每个电路都会连续获得一小部分带宽。 使用 TDM,每个电路在短暂的时间间隔内(即,在时间片期间)定期获得所有带宽
分组交换的支持者一直认为电路交换是浪费的,因为专用电路在静默期间(silent periods)是空闲的。 例如,当通话中的一个人停止通话时,空闲的网络资源(连接路径上的链路中的频带或时间片)不能被其他正在进行的连接使用。 作为这些资源如何未被充分利用的另一个示例,请考虑使用电路交换网络远程访问一系列 X 射线的放射科医生。放射科医师建立连接,请求图像,考虑图像,然后请求新图像。 网络资源被分配给连接,但在放射科医生的思考期间没有被使用(即被浪费)。 分组交换的支持者还指出,建立端到端电路和预留端到端传输容量很复杂,需要复杂的信令软件(signaling software)来协调端到端路径上交换机的操作。
在我们结束对电路交换的讨论之前,让我们通过一个数值示例来进一步了解该主题。 让我们考虑通过电路交换网络将 640,000 位的文件从主机 A 发送到主机 B 需要多长时间。 假设网络中的所有链路都使用 24 个时间片的 TDM,比特率为 1.536 Mbps。 还假设在主机 A 可以开始传输文件之前建立端到端电路需要 500 毫秒。 发送文件需要多长时间?每个电路的传输速率为 (1.536 Mbps)/24 = 64 kbps,因此传输文件需要 (640,000 位)/(64 kbps) = 10 秒。 在这 10 秒的基础上我们加上电路建立时间,给 10.5 秒发送文件。 请注意,传输时间与链路数量无关:如果端到端电路通过一条链路或一百条链路,则传输时间将为 10 秒。 (实际的端到端延迟还包括传播延迟;请参阅第 1.4 节。)
数据包交换与电路交换 Packet Switching Versus Circuit Switching
在描述了电路交换和数据包交换之后,让我们比较两者。 数据包交换的批评者经常争辩说数据包交换不适合实时服务(例如,电话呼叫和视频会议呼叫),因为其可变且不可预测的端到端延迟(主要是由于可变和不可预测的排队延迟) )。 分组交换的支持者认为(1)它比电路交换提供更好的传输容量共享;(2)它比电路交换更简单、更高效且实施成本更低。 关于数据包交换与电路交换的有趣讨论是 [Molinero-Fernandez 2002]。 一般来说,不喜欢麻烦预订餐厅的人更喜欢数据包交换而不是电路交换。
为什么分组交换更有效? 我们来看一个简单的例子。 假设用户共享 1 Mbps 链接。 还假设每个用户在活跃期(用户以 100 kbps 的恒定速率生成数据)和非活跃期(用户不生成数据)之间交替。 进一步假设用户只有 10% 的时间是活跃的(并且在剩余的 90% 的时间里空闲地喝咖啡)。 对于电路交换,必须始终为每个用户保留 100 kbps。 例如,对于电路交换 TDM,如果一秒帧被分成 10 个时间片,每个时间片为 100 毫秒,那么每个用户将被分配一个时间片。
因此,电路交换链路只能支持 10 (= 1 Mbps/100 kbps) 同时用户。 对于数据包交换,特定用户处于活跃状态的概率为 0.1(即 10%)。 如果有 35 个用户,则有 11 个或更多同时活跃用户的概率约为 0.0004。 (作业问题 P8 概述了如何获得此概率。)当同时活跃用户数为 10 或更少时(发生概率为 0.9996),数据的总到达速率小于或等于 1 Mbps,即链路的输出速率。因此,当有 10 个或更少的活动用户时,用户的数据包基本上没有延迟地通过链路,就像电路交换的情况一样。 当同时活跃用户超过 10 个时,则数据包的总到达率超过了链路的输出容量,输出队列将开始增长。 (它继续增长,直到总输入速率回落到 1 Mbps 以下,此时队列的长度将开始减少。)因为在此示例中同时活动用户超过 10 个的可能性很小,因此数据包交换基本上提供了具有与电路交换相同的性能,但同时允许超过三倍的用户数量。
现在让我们考虑第二个简单的例子。 假设有 10 个用户,其中一个用户突然生成 1000 个 1,000 比特的数据包,而其他用户保持静止,不生成数据包。 在每帧10个时间片、每个时间片由1,000比特组成的TDM电路交换下,活动用户每帧只能使用其一个时间片传输数据,而每帧中剩余的9个时隙保持空闲。 在传输所有活动用户的 100 万比特数据之前需要 10 秒。 在数据包交换的情况下,活动用户可以以 1 Mbps 的全链路速率连续发送其数据包,因为没有其他用户生成需要与活动用户的数据包复用的数据包。 在这种情况下,所有活动用户的数据将在 1 秒内传输。
以上示例说明了数据包交换性能优于电路交换性能的两种方式。 他们还强调了在多个数据流之间共享链路传输速率的两种形式之间的关键区别。 无论需求如何,电路交换都会预先分配传输链路的使用,分配的但不需要的链路时间将不被使用。 另一方面,数据包交换根据需要分配链路的使用。 链路传输容量将仅在具有需要通过链路传输的数据包的用户之间逐个数据包的基础上共享。
尽管数据包交换和电路交换在当今的电信网络中都很流行,但趋势肯定是朝着数据包交换的方向发展。 甚至今天的许多电路交换电话网络也在慢慢地向数据包交换迁移。 特别是,电话网络经常使用数据包交换来处理昂贵的海外电话呼叫部分。
1.3.3 网络的网络 A Network of Networks
我们之前看到终端系统(PC、智能手机、Web 服务器、邮件服务器等)通过接入 ISP 连接到 Internet。 接入 ISP 可以提供有线或无线连接,使用一系列接入技术,包括 DSL、电缆、FTTH、Wi-Fi 和蜂窝。 请注意,接入 ISP 不必是电信公司或有线电视公司; 例如,它可以是一所大学(为学生、教职员工和教职员工提供 Internet 接入权限)或一家公司(为其员工提供接入权限)。 但是,将终端用户和内容提供者连接到接入(access) ISP 只是解决连接组成 Internet 的数十亿个终端系统这一难题的一小部分。 要完成这个难题,接入 ISP 本身必须互连。 这是通过创建一个网络的网络(network of networks)来完成的——理解这个短语是理解互联网的关键。
多年来,形成互联网的网络的网络已经演变成一个非常复杂的结构。 这种演变在很大程度上是由经济和国家政策驱动的,而不是由绩效考虑驱动的。 为了了解当今的互联网网络结构,让我们逐步构建一系列网络结构,每个新结构都更好地近似于我们今天拥有的复杂互联网。 回想一下,首要目标是互连接入 ISP,以便所有终端系统可以相互发送数据包。 一种朴素的方法是让每个接入 ISP 直接(directly)与其他每个接入 ISP 连接。 当然,这样的网状设计对于接入 ISP 来说成本太高,因为它需要每个接入 ISP 都具有到全世界数十万个其他接入 ISP 中的每一个的单独通信链路。
我们的第一个网络结构,网络结构 1(Network Structure 1),将所有接入 ISP 与单个全球中转(a single global transit) ISP 互连。 我们的(想象中的)全球中转(global transit) ISP 是一个路由器和通信链路网络,它不仅跨越全球,而且在数十万个接入 ISP 的每一个附近都有至少一个路由器。 当然,全球 ISP 建立如此广泛的网络将是非常昂贵的。 为了盈利,它自然会向每个接入 ISP 收取连接费用,定价反映(但不一定成正比)接入 ISP 与全球 ISP 交换的流量。 由于接入 ISP 向全球中转 ISP 付款,因此称接入 ISP 为客户(customer),而称全球中转 ISP 为提供商(provider)。
现在,如果某家公司建立并运营盈利的全球中转 ISP,那么其他公司自然会建立自己的全球中转 ISP,并与原来的全球中转 ISP 竞争。 这导致了网络结构 2(Network Structure 2),它由数十万个接入 ISP 和多个全球中转 ISP 组成。 接入 ISP 肯定更喜欢网络结构 2 而非网络结构 1,因为他们现在可以根据其定价和服务在竞争的全球传输提供商中进行选择。 但是请注意,全球中转 ISP 本身必须互连:否则,连接到全球中转提供商之一的接入 ISP 将无法与连接到其他全球中转提供商的接入 ISP 通信。
刚刚描述的网络结构 2 是一个两层层次结构,全球传输提供商位于顶层,接入 ISP 位于底层。这假设全球中转 ISP 不仅能够接近每个接入 ISP,而且还发现这样做在经济上是可取的。实际上,尽管一些 ISP 确实拥有令人印象深刻的全球覆盖范围并与许多接入 ISP 直接连接,但没有一个 ISP 在世界上的每个城市都有存在。相反,在任何给定区域中,都可能有一个区域 ISP(regional ISP),该区域中的接入 ISP 连接到该区域。然后,每个区域 ISP 都连接到第 1 层 ISP(tier-1 ISPs,一级网络提供商)。 Tier-1 ISP 类似于我们的(想象中的)全球中转 ISP;但实际上确实存在的 1 级 ISP 并没有在世界上的每个城市都存在。大约有十几个一级 ISP,包括 Level 3 Communications、AT&T、Sprint 和 NTT。有趣的是,没有任何组织正式制裁一级地位;俗话说——如果你不得不问你是否是一个团体的成员,你可能不是。
回到这个网络的网络,不仅有多个一级 ISP 相互竞争,一个区域内也可能有多个区域 ISP 相互竞争。 在这样的层次结构中,每个接入 ISP 向其连接的区域 ISP 付费,每个区域 ISP 向其连接的第 1 层 ISP 付费。 (接入 ISP 也可以直接连接到一级 ISP,在这种情况下,它向一级 ISP 付费)。 因此,在层次结构的每个级别都存在客户-供应商(customer-provider)关系。 请注意,第 1 层 ISP 不向任何人付费,因为它们位于层次结构的顶部。更复杂的是,在某些地区,可能有一个较大的区域性 ISP(可能跨越整个国家),该区域中较小的区域性 ISP 连接到该 ISP; 然后较大的区域 ISP 连接到第 1 层 ISP。 例如,在中国,每个城市都有接入 ISP,这些接入 ISP 连接到省级 ISP,省级 ISP 又连接到国家 ISP,最终连接到一级 ISP [Tian 2012]。 我们将这种多层层次结构称为网络结构 3,它仍然只是当今互联网的粗略近似。
为了构建更接近当今互联网的网络,我们必须在分层网络结构 3 中添加网络入网点 (points of presence,PoP)、多宿(multi-homing)、对等互连(peering)和互联网交换点 (Internet exchange points,IXP)。PoP 存在于分层结构的所有级别中,除了底层(接入 ISP)级别。 PoP 只是提供商网络中的一组一个或多个路由器(位于同一位置),客户 ISP 可以在其中连接到提供商 ISP。对于要连接到提供商 PoP 的客户网络,它可以从第三方电信提供商处租用高速链路,将其路由器之一直接连接到 PoP 处的路由器。任何 ISP(第 1 层 ISP 除外)都可以选择多宿,即连接到两个或多个提供商 ISP。因此,例如,接入 ISP 可能与两个区域性 ISP 多宿,或者它可能与两个区域 ISP 和第 1 层 ISP 多宿。类似地,区域 ISP 可能与多个第 1 层 ISP 进行多宿。当 ISP 多宿时,即使其提供商之一出现故障,它也可以继续向 Internet 发送和接收数据包。
正如我们刚刚了解到的,客户 ISP 向其提供商 ISP 付费以获得全球互联网互连。客户 ISP 支付给提供商 ISP 的金额反映了它与提供商交换的流量。为了降低这些成本,层次结构相同级别的一对附近 ISP 可以对等互连(peer),也就是说,它们可以直接将它们的网络连接在一起,以便它们之间的所有流量都通过直接连接而不是通过上游中介。当两个 ISP 对等时,通常是免结算的,即两个 ISP 都不向另一个付费。如前所述,一级 ISP 也可以相互对等,无需结算。有关对等互连和客户-提供商关系的可读讨论,请参阅 [Van der Berg 2008]。按照同样的思路,第三方公司可以创建 Internet 交换点 (IXP),这是多个 ISP 可以对等互连的交汇点。 IXP 通常位于具有自己的交换机的独立建筑物中 [Ager 2012]。今天互联网上有超过 600 个 IXP [PeeringDB 2020]。我们将这个由接入 ISP、区域 ISP、一级 ISP、PoP、多宿主、对等互连和 IXP 组成的生态系统称为网络结构 4(Network Structure 4)。
我们现在终于到了网络结构 5(Network Structure 5),它描述了今天的 Internet。网络结构 5,如图 1.15 所示,通过添加内容提供商网络(content-provider networks)建立在网络结构 4 之上。 Google 目前是此类内容提供商网络的主要示例之一。 在撰写本文时,Google 拥有 19 个主要数据中心,分布在北美、欧洲、亚洲、南美和澳大利亚,每个数据中心拥有数万或数十万台服务器。 此外,谷歌拥有较小的数据中心,每个数据中心都有几百台服务器; 这些较小的数据中心通常位于 IXP 内。 Google 数据中心都通过 Google 的私有 TCP/IP 网络互连,该网络覆盖全球,但与公共 Internet 分开。 重要的是,Google 专用网络仅传输进出 Google 服务器的流量。如图 1.15 所示,Google 专用网络试图通过与较低层 ISP 的对等互连(免结算)来“绕过”互联网的上层,方法是直接与它们连接或通过 IXP 与它们连接 [Labovitz 2010]。 但是,由于许多接入 ISP 仍然只能通过一级网络中转才能到达,因此 Google 网络也连接到一级 ISP,并为与它们交换的流量向这些 ISP 付费。 通过创建自己的网络,内容提供商不仅可以减少对上层 ISP 的付款,而且还可以更好地控制其服务最终如何交付给最终用户。 第 2.6 节更详细地描述了 Google 的网络基础设施。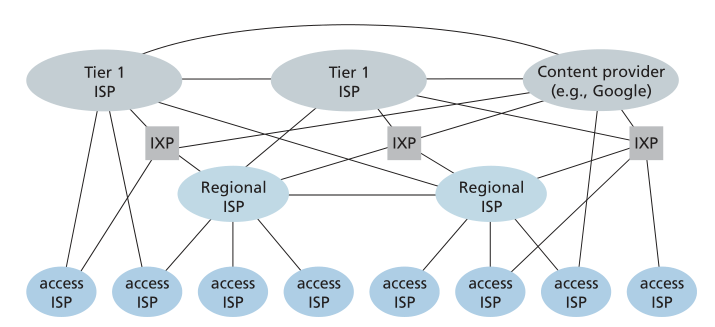
Figure 1.15 ♦ Interconnection of ISPs
总而言之,当今的互联网——一个由网络组成的网络——是复杂的,由十几个一级 ISP 和数十万个低级 ISP 组成。 ISP 的覆盖范围多种多样,有的跨越多个大陆和海洋,有的则仅限于狭窄的地理区域。 低层 ISP 连接到高层 ISP,高层 ISP 相互互连。 用户和内容提供者是低层 ISP 的客户,低层 ISP 是高层 ISP 的客户。 近年来,主要内容提供商也创建了自己的网络,并在可能的情况下直接连接到较低级别的 ISP。

若有收获,就点个赞吧
0 人点赞
