- 19.1 TLB基础算法 TLB Basic Algorithm
- 19.2 例子:访问列表 Example: Accessing An Array
- 19.3 谁处理TLB未命中 Who Handles The TLB Miss
- 19.4 TLB内容:里面有什么? TLB Contents: What’s In There?
- 19.5 TLB问题:上下文切换 TLB Issue: Context Switches
- 19.6 问题:替换策略 Issue: Replacement Policy
- 19.7 一个真实的TLB项 A Real TLB Entry
- 19.8 总结 Summary
- References
- Homework (Measurement)
使用分页作为支持虚拟内存的核心机制可能会导致较高的性能开销。通过将地址空间分割成固定大小的小单元(即页面),分页需要大量的映射信息。由于映射信息通常存储在物理内存中,因此从逻辑上讲,分页需要对程序生成的每个虚拟地址进行额外的内存查找。在每次取指令或显式加载或存储指令之前,要到内存中获取翻译信息是非常慢的。这就是我们的问题:
关键的问题:如何加快地址翻译 我们如何加快地址转换,并通常避免分页似乎需要的额外内存引用?需要哪些硬件支持?哪些需要操作系统参与?
当我们想让事情变得更快时,操作系统通常需要一些帮助。而且,操作系统的老朋友——硬件——也经常提供帮助。为了加速地址转换,我们将添加所谓的(出于历史原因[CP78])转换后备缓冲区(translation-lookaside buffer),或TLB [CG68, C95]。TLB是芯片内存管理单元(MMU)的一部分,它只是流行的虚拟到物理地址转换的硬件缓存;因此,更好的名称应该是地址转换缓存(address-translation cache)。在每个虚拟内存引用时,硬件首先检查TLB,看是否在其中保存了所需的转换;如果是,则无需查询页表(其中包含所有转换)就可以(快速地)执行转换。由于其巨大的性能影响,TLBs在实际意义上使虚拟内存成为可能[C95]。
19.1 TLB基础算法 TLB Basic Algorithm
图19.1显示了硬件如何处理虚拟地址转换的粗略示意图,假设有一个简单的线性页表(linear page table)(即,页表是一个数组)和一个硬件管理的TLB(hardware-managed TLB)(即,硬件处理页表访问的大部分责任;我们将在下面对此做更多的解释)。
硬件遵循的算法是这样工作的:首先,从虚拟地址中提取虚拟页码(VPN)(图 19.1 中的第 1 行),并检查 TLB 是否保存了该 VPN 的转换(第 2 行)。如果是,我们就有一个 TLB 命中(TLB hit),这意味着 TLB 持有翻译。成功!我们现在可以从相关的 TLB 条目中提取物理页帧号 (PFN),将其连接到原始虚拟地址的偏移量上,并形成所需的物理地址 (PA),并访问内存(第 5 - 7 行),假设进行的保护检查没有失败(第 4 行)。
如果 CPU 在 TLB 中找不到转换(TLB 未命中),我们还有一些工作要做。在这个例子中,硬件访问页表以找到转换(第 11 - 12 行),并假设进程生成的虚拟内存引用有效且可访问(第 13、15 行),用转换更新 TLB(第 18 行)。这些操作的开销很大,主要是因为访问页表(第 12 行)需要额外的内存引用。最后,一旦 TLB 更新,硬件重试指令;这次在TLB中找到翻译,快速处理内存引用。
与所有缓存一样,TLB构建的前提是,在常见情况下,可以在缓存中找到转换(即命中)。如果是这样,则开销很小,因为TLB是在处理核心附近找到的,而且设计得非常快。当一个未命中发生时,会产生较高的分页成本;必须访问页表来查找转换和额外的内存引用(使用更复杂的页表或许更多)结果。如果这种情况经常发生,程序很可能会运行得明显更慢;相对于大多数CPU指令来说,内存访问是非常昂贵的,TLB未命中会导致更多的内存访问。因此,我们希望尽可能地避免TLB未命中。
19.2 例子:访问列表 Example: Accessing An Array
为了明确TLB的操作,让我们检查一个简单的虚拟地址跟踪,并看看TLB如何提高其性能。在这个例子中,我们假设内存中有一个由10个4字节整数组成的数组,从虚拟地址100开始。进一步假设我们有一个小的8位虚拟地址空间,有16字节的页面;因此,虚拟地址分解为4位VPN(有16个虚拟页面)和4位偏移量(每个页面有16个字节)。
图19.2(第4页)显示了在系统的16个16字节页面上布局的数组。你可以看到,数组的第一个条目([0])从(VPN=06, offset=04)开始;只有3个4字节的整数适合这个页面。该数组继续到下一页(VPN=07),其中接下来的四个条目([3]…[6])。最后,10项数组的最后3项(一个[7]…a[9])位于地址空间的下一页(VPN=08)。
现在让我们考虑一个访问每个数组元素的简单循环,在C语言中是这样的:
为了简单起见,我们假设循环生成的内存只访问数组(忽略变量i和sum,以及指令本身)。当第一个数组元素([0])被访问时,CPU将看到虚拟地址100的加载。硬件从中提取VPN (VPN=06),并使用它来检查TLB是否有有效的转换。假设这是程序第一次访问数组,结果将是TLB未命中。
下一个访问是[1],这里有一些好消息:TLB命中!因为数组的第二个元素紧挨着第一个元素,所以它位于同一页面上;因为我们在访问数组的第一个元素时已经访问了这个页面,所以地址转换已经加载到TLB中了。这也是我们成功的原因。访问[2]遇到了类似的成功(另一个成功),因为它也生活在同一个页面[0]和[1]。
不幸的是,当程序访问[3]时,我们遇到了另一个TLB未命中。然而,再次,下一个条目([4]…a[6])将TLB击中,因为它们都驻留在内存中的同一页面上。
最后,访问[7]会导致最后一次TLB失败。硬件再次查询页表,以确定这个虚拟页在物理内存中的位置,并相应地更新TLB。最后两个访问([8]和[9])从TLB更新中受益;当硬件在TLB中查找它们的转换时,会产生另外两个命中结果。
让我们总结一下对数组的10次访问期间的TLB活动:miss, hit, hit, miss, hit, hit, hit, miss, hit。因此,我们的TLB命中率(命中次数除以总访问次数)是70%。虽然这不是太高(实际上,我们希望命中率接近100%),但它不是零,这可能会让人感到惊讶。即使这是程序第一次访问数组,TLB也会由于空间局部性而提高性能。数组中的元素被紧密地封装在页面中(即,它们在空间中彼此接近),因此只有第一次访问页面上的元素时才会产生TLB未命中。
还要注意页面大小在本例中所起的作用。如果页面大小是原来的两倍(32字节,而不是16字节),那么数组访问所遭遇的失误会更少。由于典型的页面大小更接近4KB,这些密集的、基于数组的访问可以实现出色的TLB性能,每一页访问只遇到一个未命中。
Tip:尽可能使用缓存 缓存是计算机系统中最基本的性能技术之一,它被反复使用以使“普通情况下更快”[HP06]。硬件缓存背后的思想是利用指令和数据引用中的局部性(locality)。局部性通常有两种类型:时间局部性(temporal locality)和空间局部性(spatial locality)。对于时间局部性,其思想是最近访问过的指令或数据项很可能在不久的将来再次访问。想想循环中的循环变量或指令;它们会随着时间的推移被反复访问。对于空间局部性,其思想是,如果一个程序访问地址为x的内存,它很可能很快就会访问地址为x附近的内存。想象一下,在这里通过某种数组,访问一个元素,然后访问下一个元素。当然,这些属性取决于程序的确切性质,因此不是硬性的定律,而更像是经验法则。 硬件缓存,无论是指令、数据还是地址转换(就像我们的TLB),都通过将内存副本保存在小的、快速的片内存储器中来利用局部性。处理器可以先检查附近的副本是否存在于缓存中,而不是去(慢)内存中满足请求;如果是这样,处理器可以快速访问它(即,在几个CPU周期内),避免花费访问内存的昂贵时间(许多纳秒)。 您可能会想:如果缓存(比如TLB)这么棒,为什么我们不创建更大的缓存并将所有数据保存在其中呢?不幸的是,这就是我们遇到更基本的物理定律的地方。如果你想要一个快速缓存,它必须是小的,因为光速和其他物理限制等问题变得相关。从定义上讲,任何大型缓存都是缓慢的,因此无法达到目的。因此,我们只能使用小型、快速的缓存;剩下的问题是如何最好地使用它们来提高性能。
关于TLB性能的最后一点:如果程序在这个循环完成后不久再次访问数组,我们可能会看到更好的结果,假设我们有一个足够大的TLB来缓存所需的转换:hit, hit, hit, hit, hit, hit, hit, hit, hit。在这种情况下,由于时间局部性,即内存项在时间上的快速重新引用,TLB命中率会很高。与任何缓存一样,TLBs的成功依赖于空间和时间局部性,这是程序属性。如果感兴趣的程序显示出这样的局部性(许多程序都是这样),TLB命中率可能会很高。
19.3 谁处理TLB未命中 Who Handles The TLB Miss
我们必须回答一个问题:谁处理TLB miss?有两种可能的答案:硬件或软件(操作系统)。在过去,硬件有复杂的指令集(有时被称为CISC,用于复杂指令集计算机),而构建硬件的人并不太信任那些鬼鬼祟祟的操作系统人员。因此,硬件将完全处理TLB miss。为此,硬件必须知道页表在内存中的确切位置(通过页表基寄存器(page-table base register),如图19.1中的第11行所示),以及它们的确切格式;如果没有命中,硬件将“遍历”页表,找到正确的页表项并提取所需的转换,用转换更新TLB,然后重试指令。具有硬件管理TLBs的“老”架构的一个例子是Intel x86架构,它使用固定的多级页表(详见下一章);当前页表由CR3寄存器指向[I09]。
更现代的架构(例如,MIPS R10k [H93]或Sun的SPARC v9 [WG00],都是RISC或精简指令集(reduced-instruction set)计算机)有所谓的软件管理TLB(software-managed TLB)。在TLB未命中时,硬件仅仅引发一个异常(图19.3中的第11行),它暂停当前指令流,将特权级别提升到内核模式,并跳转到一个trap处理程序(trap handler)。正如您可能猜到的那样,这个trap处理程序(trap handler)是操作系统中的代码,其编写目的是处理TLB 未命中。运行时,代码将在页表中查找转换,使用特殊的“特权”指令更新TLB,并从trap返回;此时,硬件会重试指令(导致TLB命中)。
Aside:RISC VS. CISC 在20世纪80年代,计算机体系结构界发生了一场伟大的战斗。一方是CISC阵营,即复杂指令集计算(Complex Instruction Set Computing);另一边是RISC,用于简化指令集计算(Reduced Instruction Set Computing)[PS81]。RISC方面由伯克利的David Patterson和斯坦福的John Hennessy(他们也是一些著名书籍的合著者[HP06])领导,尽管后来John Cocke因为他在RISC方面的早期工作而被授予图灵奖[CM00]。CISC指令集往往包含很多指令,而每一条指令都相对强大。例如,您可能会看到一个字符串复制,它接受两个指针和一个长度,并将字节从源复制到目标。CISC背后的思想是指令应该是高级原语,以使汇编语言本身更容易使用,并使代码更紧凑。 RISC指令集恰恰相反。RISC背后的一个关键观察是,指令集实际上是编译器的目标,而所有编译器真正想要的是一些可以用来生成高性能代码的简单原语。因此,RISC的支持者认为,让我们尽可能地从硬件中剥离(尤其是微码),并使剩下的内容简单、统一和快速。 在早期,RISC芯片产生了巨大的影响,因为它们明显更快[BC91];写了许多论文;一些公司成立了(如MIPS和Sun)。然而,随着时间的推移,CISC制造商,如英特尔,将许多RISC技术纳入其处理器的核心,例如通过添加早期流水线阶段,将复杂指令转换为微指令,然后可以以类似RISC的方式处理。这些创新,加上每个芯片上越来越多的晶体管,使CISC保持了竞争力。最终的结果是争论平息了,今天这两种类型的处理器都可以运行得很快。
让我们讨论几个重要的细节。首先,return-from-trap指令需要与我们之前在服务系统调用时看到的return-from-trap稍有不同。在后一种情况下,在进入操作系统的trap之后,return-from-trap应该在指令处恢复执行,就像从过程调用返回的结果会立即返回到对过程调用之后的指令。在前一种情况下,当从TLB错误处理trap返回时,硬件必须在导致trap的指令上恢复执行;因此,这次重试让指令再次运行,这一次导致TLB命中。因此,取决于trap或异常是如何引起的,当trap进入操作系统时,硬件必须保存不同的PC,以便在时间到来时正确恢复。
其次,在运行TLB未命中处理代码时,操作系统需要格外小心,以免造成无限的TLB未命中链发生。许多解决方案;例如,您可以将TLB miss处理程序保留在物理内存中(在物理内存中它们是未映射的(unmapped),不受地址转换的约束),或者在TLB中保留一些条目用于永久有效的转换,并将其中一些永久转换槽用于处理程序代码本身;这些有线转换总是在TLB中发生。
软件管理方法的主要优点是灵活性:操作系统可以使用任何它想要实现页表的数据结构,而无需更改硬件。另一个优点是简单,如图中的TLB控制流所示(图19.3中的第11行,与图19.1中的第11 - 19行相比)。硬件不会在未命中的情况下做太多事情:只是抛出一个异常,让OS TLB未命中处理程序来做其余的事情。
19.4 TLB内容:里面有什么? TLB Contents: What’s In There?
让我们更详细地看看硬件TLB的内容。一个典型的TLB可能有32、64或128个条目,这就是所谓的全关联(fully associative)。基本上,这只是意味着任何给定的转换可以在TLB中的任何位置,硬件将并行搜索整个TLB以找到所需的转换。TLB条目可能看起来像这样: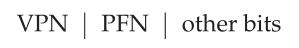
请注意,VPN和PFN都出现在每个条目中,因为转换可以在这些位置中的任何一个结束(在硬件术语中,TLB被称为全关联缓存(fully-associative cache))。硬件并行地搜索条目,看是否有匹配项。
更有趣的是“其他部分”。例如,TLB通常有一个有效位(valid bit),表示条目是否有有效的转换。保护位(protection bits)也很常见,它决定如何访问页面(如在页表中)。例如,代码页可能标记为读和执行,而堆页可能标记为读和写。还可能有其他一些字段,包括地址空间标识符(addres-space identifier)、脏位(dirty bit)等等;请参阅下面的更多信息。
Aside:TLB有效位≠页表有效位 一个常见的错误是将TLB中的有效位与页表中的有效位混淆。在页表中,当一个页表条目(PTE)被标记为无效时,这意味着该页没有被进程分配,并且不能被正常工作的程序访问。当访问无效页面时,通常的响应是trap给操作系统,操作系统将通过终止进程作出响应。 相比之下,TLB有效位仅指TLB项内部是否有有效的转换。例如,当系统启动时,每个TLB项的公共初始状态将被设置为无效,因为那里还没有缓存地址转换。一旦启用了虚拟内存,一旦程序开始运行并访问它们的虚拟地址空间,TLB就会被缓慢地填充,因此有效的项很快就会填满TLB。 TLB有效位在执行上下文切换时也非常有用,我们将在下面进一步讨论。通过将所有TLB项设置为无效,系统可以确保即将运行的进程不会意外地使用前一个进程的虚拟到物理转换。
19.5 TLB问题:上下文切换 TLB Issue: Context Switches
使用TLBs时,在进程之间切换时会出现一些新问题(因此也会出现地址空间)。具体来说,TLB包含仅对当前运行的进程有效的虚拟到物理的转换;这些转换对其他进程没有意义。因此,在从一个进程切换到另一个进程时,硬件或操作系统(或两者)必须小心,以确保即将运行的进程不会意外地使用来自先前运行的某个进程的转换。
为了更好地理解这种情况,让我们看一个示例。当一个进程(P1)运行时,假定TLB可能缓存了对它有效的转换,即来自P1的页表的转换。对于本例,假设P1的第10个虚拟页映射到物理帧100。
在本例中,假设存在另一个进程(P2),并且操作系统可能很快决定执行上下文切换并运行它。假设P2的第10个虚拟页映射到物理帧170。如果两个进程的项都在TLB中,那么TLB的内容将是:
在上面的TLB中,我们显然有一个问题:VPN 10转换为PFN 100 (P1)或PFN 170 (P2),但硬件不能区分哪项是针对哪个进程的。因此,为了让TLB正确而有效地支持跨多个进程的虚拟化,我们需要做更多的工作。这就是问题所在:
关键的问题:怎样管理上下文切换上的TLB内容 在进程之间进行上下文切换时,后一个进程的TLB中的转换对即将运行的进程没有意义。为了解决这个问题,硬件或操作系统应该做什么?
这个问题有很多可能的解决方案。一种方法是简单地在上下文切换时刷新(flush)TLB,从而在运行下一个进程之前清空它。在基于软件的系统上,这可以通过显式的(和有特权的)硬件指令来实现;对于硬件管理的TLB,刷新可以在页表基寄存器发生更改时执行(注意,无论如何,操作系统必须在上下文切换时更改PTBR)。在这两种情况下,flush操作只是将所有有效位设置为0,本质上清除TLB的内容。
通过在每个上下文切换上刷新TLB,我们现在有了一个有效的解决方案,因为进程永远不会意外地在TLB中遇到错误的转换。然而,这是有代价的:每次进程运行时,它必须在接触其数据和代码页时导致TLB未命中。如果操作系统在各个进程间切换频繁,则该代价可能较高。
为了减少这种开销,一些系统添加了硬件支持以支持跨上下文切换共享TLB。特别是,一些硬件系统在TLB中提供了一个地址空间标识符(address space identifier,ASID)字段。你可以把ASID看作是一个进程标识符(process identifier,PID),但通常它有更少的位(例如,ASID是8位,而PID是32位)。
如果我们从上面的示例TLB中添加ASID,很明显进程可以很容易地共享TLB:只需要ASID字段来区分其他相同的翻译。下面是一个带有ASID字段的TLB的描述: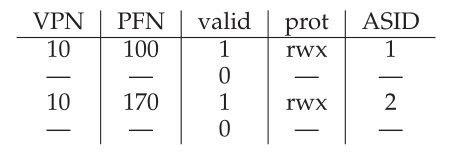
因此,使用地址空间标识符,TLB可以同时保存来自不同进程的转换,而不会产生任何混淆。当然,为了执行转换,硬件还需要知道当前运行的是哪个进程,因此操作系统必须在上下文切换时为当前进程的ASID设置一些特权寄存器(privileged register)。
顺便提一下,您可能还想到了另一种情况,即TLB的两个项非常相似。在本例中,两个不同的进程有两个项,它们具有两个不同的VPNs,指向相同的物理页:
例如,当两个进程共享一个页面(例如,一个代码页面)时,可能会出现这种情况。在上面的例子中,进程1与进程2共享物理页101;P1将该页映射到其地址空间的第10页,而P2将该页映射到其地址空间的第50页。共享代码页(以二进制文件或共享库的形式)非常有用,因为它减少了使用中的物理页的数量,从而减少了内存开销。
19.6 问题:替换策略 Issue: Replacement Policy
对于任何缓存,以及TLB,我们必须考虑的另一个问题是缓存替换(cache replacement)。具体来说,当我们在TLB中安装一个新项时,我们必须替换(replace)一个旧项,因此问题是:替换哪一个?
关键的问题:如何设计TLB替换政策 当我们添加一个新的TLB项时,应该替换哪个TLB项?当然,目标是最小化未命中率(miss rate)(或增加命中率(hit rate)),从而提高性能。
我们将在处理将页面交换到磁盘的问题时详细研究这些策略;在这里,我们将重点介绍一些典型的策略。一种常见的方法是收回最近使用最少的(least-recently-used,LRU)项。LRU试图利用内存引用流中的局部性,假设最近没有被使用的条目很可能是一个很好的收回候选项。另一种典型的方法是使用随机(random)策略,它随机地收回TLB映射。这种策略是有用的,因为它的简单性和避免极端情况行为的能力;例如,当程序在TLB大小为n的n + 1个页面上循环时,合理的策略(如LRU)的行为非常不合理;在这种情况下,LRU每次访问都会失败,而random则做得更好。
19.7 一个真实的TLB项 A Real TLB Entry
最后,让我们简单地看看一个真实的TLB。这个例子来自MIPS R4000 [H93],这是一个使用软件管理TLBs的现代系统;一个稍微简化的MIPS TLB项如图19.4所示。
MIPS R4000支持32位地址空间和4KB页面。因此,我们期望在我们的典型虚拟地址中有一个20位的VPN和12位的偏移。然而,正如您在TLB中看到的,VPN只有19位;事实证明,用户地址只来自一半的地址空间(剩下的留给内核),因此只需要19位VPN。VPN转换为最多24位物理帧号(PFN),因此可以支持最多64GB(物理)主内存(2**24** 4KB页)的系统。
在MIPS TLB中还有一些其他有趣的位。我们看到一个全局位(G),它用于进程间全局共享的页面。因此,如果设置了全局位,则忽略ASID。我们还看到了8位ASID,操作系统可以使用它来区分地址空间(如前文所述)。有一个问题:如果同时运行的进程超过256个(2**8**个),操作系统应该怎么做?最后,我们看到3个Coherence (C)位,这决定了一个页面是如何被硬件缓存的(有点超出了本文内容的范围);当页面被写入时标记的脏位(我们将在后面看到它的用法);一个有效的位,它告诉硬件条目中是否存在有效的转换。还有一个页面掩码字段(未显示),它支持多种页面大小;稍后我们将看到为什么使用更大的页面可能是有用的。最后,64位中有些是未使用的(图中用灰色表示)。
MIPS TLBs通常有32或64个这样的项,其中大多数是在用户进程运行时使用的。但是,有一些是为操作系统保留的。一个被监听(wired)寄存器可以由操作系统设置,以告诉硬件有多少TLB插槽预留给操作系统;操作系统将这些保留映射用于它想要在关键时刻访问的代码和数据,其中TLB 未命中将是有问题的(例如,在TLB 未命中处理程序中)。
因为 MIPS TLB 是软件管理的,所以需要有更新 TLB 的指令。MIPS 提供了四个这样的指令: TLBP,它探测 TLB 以查看其中是否存在特定的转换;TLBR,将 TLB 项的内容读入寄存器;TLBWI,替换特定的 TLB 项;和 TLBWR,它替换了一个随机的 TLB 项。操作系统使用这些指令来管理 TLB 的内容。这些指令具有特权(privileged)当然是至关重要的;想象一下如果用户进程可以修改 TLB 的内容,它会做什么(提示:几乎任何事情,包括接管机器,运行自己的恶意“OS”,甚至让太阳(Sun)消失)。
19.8 总结 Summary
我们已经看到硬件如何帮助我们使地址转换更快。通过提供一个小型的、专用的片上TLB作为地址转换缓存,大多数内存引用有望在不访问主内存中的页表的情况下得到处理。因此,在通常情况下,程序的性能几乎就像内存根本没有被虚拟化一样,这对于操作系统来说是一个出色的成就,而且对于现代系统中分页的使用无疑是必不可少的。
然而,TLBs并没有让每个存在的程序都变得美好。特别是,如果程序在短时间内访问的页面数量超过了TLB所能容纳的页面数量,则程序将产生大量的TLB失败,从而运行得相当慢。我们将这种现象称为超出TLB覆盖范围(TLB coverage),对于某些程序来说,这可能是一个相当大的问题。一种解决方案,我们将在下一章中讨论,就是支持更大的页面大小;通过将关键数据结构映射到由较大页面映射的程序地址空间区域,可以增加TLB的有效覆盖率。数据库管理系统(database management system,DBMS)等程序经常利用对大页面的支持,这些程序具有一些大的和随机访问的数据结构。
另一个值得一提的TLB问题是:TLB访问很容易成为CPU管道(pipeline)中的瓶颈,特别是所谓的物理索引缓存(physically-indexed cache)。使用这样的缓存,地址转换必须在访问缓存之前进行,这可能会大大降低速度。由于这个潜在的问题,人们研究了各种使用虚拟地址访问缓存的聪明方法,从而避免了缓存命中时昂贵的转换步骤。这种虚拟索引缓存(virtually-
indexed cache)解决了一些性能问题,但也给硬件设计带来了新的问题。详见Wiggins的详细调查[W03]。
References
[BC91] “Performance from Architecture: Comparing a RISC and a CISC with Similar Hard-
ware Organization” by D. Bhandarkar and Douglas W. Clark. Communications of the ACM,
September 1991. A great and fair comparison between RISC and CISC. The bottom line: on similar
hardware, RISC was about a factor of three better in performance.
[CM00] “The evolution of RISC technology at IBM” by John Cocke, V. Markstein. IBM Journal
of Research and Development, 44:1/2. A summary of the ideas and work behind the IBM 801, which
many consider the first true RISC microprocessor.
[C95] “The Core of the Black Canyon Computer Corporation” by John Couleur. IEEE Annals
of History of Computing, 17:4, 1995. In this fascinating historical note, Couleur talks about how he
invented the TLB in 1964 while working for GE, and the fortuitous collaboration that thus ensued with
the Project MAC folks at MIT.
[CG68] “Shared-access Data Processing System” by John F. Couleur, Edward L. Glaser. Patent
3412382, November 1968. The patent that contains the idea for an associative memory to store address
translations. The idea, according to Couleur, came in 1964.
[CP78] “The architecture of the IBM System/370” by R.P. Case, A. Padegs. Communications of
the ACM. 21:1, 73-96, January 1978. Perhaps the first paper to use the term translation lookaside
buffer. The name arises from the historical name for a cache, which was a lookaside buffer as called by
those developing the Atlas system at the University of Manchester; a cache of address translations thus
became a translation lookaside buffer. Even though the term lookaside buffer fell out of favor, TLB
seems to have stuck, for whatever reason.
[H93] “MIPS R4000 Microprocessor User’s Manual”. by Joe Heinrich. Prentice-Hall, June 1993.
Available: http://cag.csail.mit.edu/raw/ . documents/R4400 Uman book Ed2.pdf A manual,
one that is surprisingly readable. Or is it?
[HP06] “Computer Architecture: A Quantitative Approach” by John Hennessy and David Pat-
terson. Morgan-Kaufmann, 2006. A great book about computer architecture. We have a particular
attachment to the classic first edition.
[I09] “Intel 64 and IA-32 Architectures Software Developer’s Manuals” by Intel, 2009. Avail-
able: http://www.intel.com/products/processor/manuals. In particular, pay attention to “Vol-
ume 3A: System Programming Guide” Part 1 and “Volume 3B: System Programming Guide Part
2”.
[PS81] “RISC-I: A Reduced Instruction Set VLSI Computer” by D.A. Patterson and C.H. Se-
quin. ISCA ’81, Minneapolis, May 1981. The paper that introduced the term RISC, and started the
avalanche of research into simplifying computer chips for performance.
[SB92] “CPU Performance Evaluation and Execution Time Prediction Using Narrow Spectrum
Benchmarking” by Rafael H. Saavedra-Barrera. EECS Department, University of California,
Berkeley. Technical Report No. UCB/CSD-92-684, February 1992.. A great dissertation about how
to predict execution time of applications by breaking them down into constituent pieces and knowing the
cost of each piece. Probably the most interesting part that comes out of this work is the tool to measure
details of the cache hierarchy (described in Chapter 5). Make sure to check out the wonderful diagrams
therein.
[W03] “A Survey on the Interaction Between Caching, Translation and Protection” by Adam
Wiggins. University of New South Wales TR UNSW-CSE-TR-0321, August, 2003. An excellent
survey of how TLBs interact with other parts of the CPU pipeline, namely hardware caches.
[WG00] “The SPARC Architecture Manual: Version 9” by David L. Weaver and Tom Germond.
SPARC International, San Jose, California, September 2000. Available: www.sparc.org/
standards/SPARCV9.pdf. Another manual. I bet you were hoping for a more fun citation to
end this chapter.
Homework (Measurement)
在本作业中,您将测量访问TLB的大小和成本。这个想法是基于Saavedra-Barrera [SB92]的工作,他开发了一种简单而漂亮的方法来测量缓存层次结构的许多方面,所有这些都用一个非常简单的用户级程序。阅读他的作品了解更多细节。
其基本思想是访问大型数据结构(例如数组)中的某些页面,并对这些访问进行计时。例如,假设一台机器的TLB大小恰好是4(这可能非常小,但对于本文的讨论很有用)。如果您编写的程序只访问4个或更少的页面,那么每次访问都应该是TLB命中,因此相对较快。然而,一旦在循环中重复接触5个或更多页面,每次访问的成本就会突然上升到TLB 未命中的成本。
对数组进行一次循环的基本代码应该是这样的: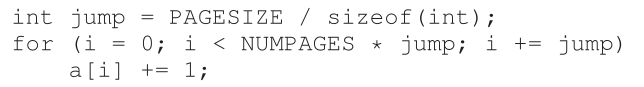
在这个循环中,数组a的每页更新一个整数,直到NUMPAGES指定的页数为止。通过重复计时这样一个循环(比如,在另一个循环中围绕这个循环运行数亿次,或者运行几秒钟需要多少次循环),可以计算每次访问所需的时间(平均)。通过查找随着NUMPAGES增加而增加的成本,您可以大致确定第一级TLB有多大,确定是否存在第二级TLB(如果存在,它有多大),并大致了解TLB命中和未命中会如何影响性能。
图19.5显示了随着循环中访问的页面数量的增加,每次访问的平均时间。从图中可以看到,当只访问几个页面(8个或更少)时,平均访问时间大约为5纳秒。当访问16个或更多页时,每次访问会突然跳到20纳秒左右。成本的最后一次飞跃发生在1024页左右,此时每次访问大约需要70纳秒。从这些数据中,我们可以得出这样的结论:存在一个两级TLB层次结构;第一个非常小(可能只有8到16项);第二个更大但更慢(大约有512项)。在第一级TLB中,命中和未命中之间的总体差异是相当大的,大约是14倍。TLB性能很重要!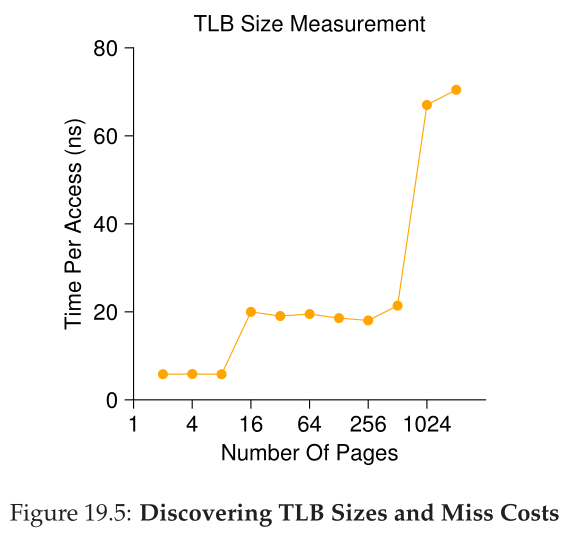
Questions
- 为了计时,你需要使用一个计时器(例如,gettimeofday())。这样的计时器有多精确?操作需要多长时间才能准确计时?(这将有助于确定在循环中您必须重复访问页面多少次才能成功计时)
- 编写一个名为tlb.c的程序,它可以粗略地衡量访问每个页面的成本。程序的输入应该是:要触摸的页数和试验的次数。
- 现在,用您最喜欢的脚本语言(bash?)编写一个脚本来运行这个程序,同时将访问的页面数量从1更改为几千,可能每次迭代增加2倍。在不同的机器上运行脚本并收集一些数据。需要多少试验才能得到可靠的测量结果?
- 接下来,将结果绘制成与上面类似的图。使用ploticus甚至zplot这样的好工具。可视化通常会使数据更容易消化;你认为这是为什么?
- 需要注意的一件事是编译器优化。编译器会做各种聪明的事情,包括删除循环,这些循环会使程序的其他部分随后不使用的值递增。如何确保编译器不会从TLB大小估计器中删除上面的主循环?
- 另一件需要注意的事情是,当今大多数系统都配备多个 CPU,当然,每个 CPU 都有自己的 TLB 层次结构。要真正获得良好的测量结果,您必须仅在一个 CPU 上运行代码,而不是让调度程序将其从一个 CPU 跳到下一个 CPU。你怎么能这样做?(提示:在 Google 上查找“固定线程pinning a thread”以获得一些线索)如果您不这样做,并且代码从一个 CPU 移动到另一个 CPU 会发生什么?
- 可能出现的另一个问题与初始化有关。如果你在访问数组a之前没有初始化它,你第一次访问它将是非常昂贵的,因为初始访问成本,如要求归零。这会影响您的代码及其时间吗?你能做些什么来平衡这些潜在的成本?

若有收获,就点个赞吧
0 人点赞
