- 43.1 连续地写入磁盘 Writing To Disk Sequentially
- 43.2 连续高效地写入 Writing Sequentially And Effectively
- 43.3 要缓冲多少?How Much To Buffer?
- 43.4 问题:查找Inodes Problem: Finding Inodes
- 43.5 通过间接解决:Inode映射 Solution Through Indirection: The Inode Map
- 43.6 完成解决方案:Checkpoint区域 Completing The Solution: The Checkpoint Region
- 43.7 从磁盘读取文件:概述 Reading A File From Disk: A Recap
- 43.8 目录呢? What About Directories?
- 43.9
- 43.10
- 43.11
- 43.12
- 43.13
- References
- Homework (Simulation)
90 年代初,由 John Ousterhout 教授和研究生 Mendel Rosenblum 领导的伯克利小组开发了一种新的文件系统,称为日志结构文件系统 [RO91]。 他们这样做的动机是基于以下观察:
- 系统内存在增长(System memories are growing):随着内存越来越大,可以在内存中缓存更多数据。 随着缓存的数据越来越多,磁盘流量越来越多地由写入组成,因为读取由缓存提供服务。 因此,文件系统性能很大程度上取决于其写入性能。
- 随机 I/O 性能和连续 I/O 性能之间存在很大差距(There is a large gap between random I/O performance and sequential I/O performance):硬盘传输带宽多年来大幅增加 [P98]; 随着更多位被装入驱动器的表面,访问所述位时的带宽增加。 然而,寻道和旋转延迟成本下降缓慢; 制造便宜的小型电机以更快地旋转盘片或更快地移动磁盘臂是具有挑战性的。 因此,如果您能够以顺序方式使用磁盘,与导致查找和旋转的方法相比,您将获得相当大的性能优势。
- 现有文件系统在许多常见工作负载上表现不佳(Existing file systems perform poorly on many common workloads):例如,FFS [MJLF84] 将执行大量写入以创建大小为一个块的新文件:一个用于新的 inode,一个用于更新 inode 位图,一个用于文件所在的目录数据块,一个用于目录 inode 以更新它,一个用于作为新文件一部分的新数据块,一个用于数据位图以将数据块标记为已分配。 因此,尽管 FFS 将所有这些块放置在同一块组中,但 FFS 会导致许多短寻道和随后的旋转延迟,因此性能远低于峰值连续带宽。
文件系统不支持 RAID 意识(File systems are not RAID-aware):例如,RAID-4 和 RAID-5 都存在小型写入问题,即对单个块的逻辑写入会导致 4 个物理 I/O 发生。 现有文件系统不会尝试避免这种最坏情况的 RAID 写入行为。
Tip:细节很重要 所有有趣的系统都由一些一般性的想法和许多细节组成。 有时,当你学习这些系统时,你会想:“哦,我明白了; 剩下的只是细节,”而你使用它只是了解了事情的真正运作方式。 不要这样做! 很多时候,细节很关键。 正如我们将在 LFS 中看到的,总体思路很容易理解,但要真正构建一个有效的系统,您必须考虑所有棘手的情况。
因此,理想的文件系统应关注写入性能,并尝试利用磁盘的连续带宽。 此外,它将在不仅写出数据而且经常更新磁盘元数据结构的常见工作负载上表现良好。 最后,它可以在 RAID 以及单个磁盘上运行良好。
Rosenblum 和 Ousterhout 引入的新型文件系统称为 LFS,是 Log-structured File System 的缩写。 写入磁盘时,LFS 首先在内存段(segment)中缓冲所有更新(包括元数据!); 当该段已满时,它会在一个长的、连续的传输中写入到磁盘的未使用部分。 LFS 永远不会覆盖现有数据,而是始终将段写入空闲位置。 由于segment很大,磁盘(或RAID)使用效率高,文件系统性能接近顶峰。关键的问题:如何使所有写都是连续的(sequential) 文件系统如何将所有写入转换为连续写入? 对于读取,此任务是不可能的,因为要读取的所需块可能位于磁盘上的任何位置。 然而,对于写入,文件系统总是有选择的,而我们希望利用的正是这个选择。
43.1 连续地写入磁盘 Writing To Disk Sequentially
因此,我们面临第一个挑战:我们如何将文件系统状态的所有更新转换为一系列对磁盘的连续写入? 为了更好地理解这一点,让我们举一个简单的例子。 想象一下,我们正在将数据块 D 写入文件。 将数据块写入磁盘可能会导致以下磁盘布局,其中 D 写入磁盘地址 A0:
但是,当用户写入数据块时,写入磁盘的不仅仅是数据; 还有其他元数据(metadata)需要更新。这种情况下,我们也将文件的inode(I)写入磁盘,并使其指向数据块D。写入磁盘时,数据块和inode 看起来像这样(请注意,inode 看起来与数据块一样大,通常情况并非如此;在大多数系统中,数据块的大小为 4 KB,而 inode 小得多,大约 128 字节):
简单地将所有更新(例如数据块、inode 等)连续写入磁盘的基本思想是 LFS 的核心。 如果你理解了这一点,你就会得到基本的概念。 但与所有复杂系统一样,细节决定成败。
43.2 连续高效地写入 Writing Sequentially And Effectively
不幸的是,连续(单独)写入磁盘并不足以保证高效的写入。 例如,假设我们在时间 T 将单个块写入地址 A。然后我们稍等片刻,然后在地址  (连续排列的下一个块地址)写入磁盘,但在时间
(连续排列的下一个块地址)写入磁盘,但在时间  。 不幸的是,在第一次和第二次写入之间,磁盘已经旋转; 当您发出第二次写入时,它将因此在被提交(being committed)之前等待大部分旋转延迟(具体而言,如果旋转需要时间
。 不幸的是,在第一次和第二次写入之间,磁盘已经旋转; 当您发出第二次写入时,它将因此在被提交(being committed)之前等待大部分旋转延迟(具体而言,如果旋转需要时间  ,则磁盘将等待
,则磁盘将等待  才能将第二次写入提交(commit)到磁盘表面)。 因此,您可以看到,仅仅连续写入磁盘并不足以达到最佳性能; 相反,您必须向驱动器发出大量连续写入(或一次大写入)才能获得良好的写入性能。
才能将第二次写入提交(commit)到磁盘表面)。 因此,您可以看到,仅仅连续写入磁盘并不足以达到最佳性能; 相反,您必须向驱动器发出大量连续写入(或一次大写入)才能获得良好的写入性能。
为了达到这个目的,LFS 使用了一种称为写缓冲(write buffering)的古老技术。 在写入磁盘之前,LFS 会跟踪内存中的更新(updates); 当它收到足够数量的更新时,它会立即将它们全部写入磁盘,从而确保磁盘的高效使用。
事实上,很难为这个想法找到一个好的引文,因为它很可能是由许多人在计算史上很早就发明的。 有关写缓冲的好处的研究,请参阅 Solworth 和 Orji [SO90]; 要了解其潜在危害,请参阅 Mogul [M94]。
LFS 一次写入更新的组块(chunk)被称为**段(segment)**。 尽管该术语(segment)在计算机系统中被过度使用,但在这里它仅表示 LFS 用于对写入进行分组的组块。 因此,**当写入磁盘时,LFS 会在内存段中缓冲更新,然后将该段全部写入磁盘。 只要段足够大,这些写操作就会很高效。**<br />下面是一个例子,其中 LFS 将两组更新(two sets of updates)缓冲到一个小段中; 实际段更大(几 MB)。 第一次更新是对文件 j 的四块写入; 第二个是一个块被添加到文件 k。 然后 LFS 一次将整个 7 个块的段提交到磁盘。 这些块的最终磁盘布局如下:<br />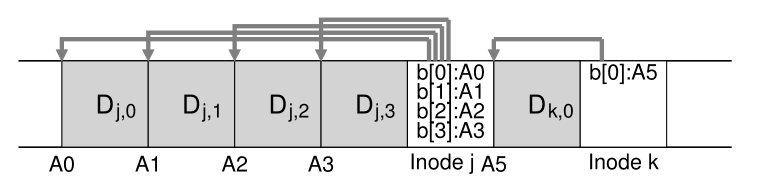
43.3 要缓冲多少?How Much To Buffer?
这就提出了以下问题:在写入磁盘之前,LFS 应该缓冲多少更新? 答案当然取决于磁盘本身,特别是定位开销与传输速率相比有多高; 有关类似分析,请参阅 FFS 章节。
例如,假设每次写入之前的定位(即旋转和寻道开销)大约需要  秒。 进一步假设磁盘传输速率是
秒。 进一步假设磁盘传输速率是  MB/s。 在这样的磁盘上运行时,LFS 在写入之前应该缓冲多少?
MB/s。 在这样的磁盘上运行时,LFS 在写入之前应该缓冲多少?
思考这个问题的办法是,每次写的时候,都要支付固定的定位成本。 因此,您需要写多少才能摊销(amortize)这笔费用? 你写的越多越好(显然),你离达到峰值带宽越近。
为了获得具体的答案,假设我们正在写出 D MB。 写出这块数据的时间 ( ) 是定位时间
) 是定位时间  加上传输时间
加上传输时间  ,或者:
,或者:
因此,有效写入速率 ( ),即写入的数据量除以写入的总时间,为:
),即写入的数据量除以写入的总时间,为:
我们感兴趣的是使有效速率 ( %22%20aria-hidden%3D%22true%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-52%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3Cg%20transform%3D%22translate(759%2C-155)%22%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-65%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-66%22%20x%3D%22466%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-66%22%20x%3D%221017%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-65%22%20x%3D%221567%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-63%22%20x%3D%222034%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-74%22%20x%3D%222467%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-69%22%20x%3D%222828%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-76%22%20x%3D%223174%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-65%22%20x%3D%223659%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3C%2Fsvg%3E#card=math&code=R%7Beffective%7D&id=PmqSE))接近峰值率。 具体来说,我们希望有效速率是峰值速率的某个分数 F,其中 0 < F < 1(典型的 F 可能是峰值速率的 0.9,或 90%)。 在数学形式中,这意味着我们想要 。
%22%20aria-hidden%3D%22true%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-52%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3Cg%20transform%3D%22translate(759%2C-155)%22%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-65%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-66%22%20x%3D%22466%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-66%22%20x%3D%221017%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-65%22%20x%3D%221567%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-63%22%20x%3D%222034%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-74%22%20x%3D%222467%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-69%22%20x%3D%222828%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-76%22%20x%3D%223174%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-65%22%20x%3D%223659%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3C%2Fsvg%3E#card=math&code=R%7Beffective%7D&id=PmqSE))接近峰值率。 具体来说,我们希望有效速率是峰值速率的某个分数 F,其中 0 < F < 1(典型的 F 可能是峰值速率的 0.9,或 90%)。 在数学形式中,这意味着我们想要 。
此时,我们可以求出D:



举个例子,一个磁盘,定位时间为10毫秒,峰值传输速率为100MB/s; 假设我们想要峰值的 90% (F = 0.9) 的有效带宽。 在这种情况下, 。 尝试一些不同的值,看看我们需要缓冲多少才能接近峰值带宽。 需要多少才能达到峰值的 95%? 99%?
。 尝试一些不同的值,看看我们需要缓冲多少才能接近峰值带宽。 需要多少才能达到峰值的 95%? 99%?
43.4 问题:查找Inodes Problem: Finding Inodes
为了理解我们如何在 LFS 中找到一个 inode,让我们简要回顾一下如何在一个典型的 UNIX 文件系统中找到一个 inode。 在典型的文件系统(如 FFS,甚至是旧的 UNIX 文件系统)中,查找 inode 很容易,因为它们被组织在一个数组中并放置在磁盘上的固定位置。
例如,旧的 UNIX 文件系统将所有 inode 保存在磁盘的固定部分。 因此,给定一个 inode 编号和起始地址,要找到一个特定的 inode,您可以简单地通过将 inode 编号乘以 inode 的大小并将其添加到磁盘阵列的起始地址来计算其确切的磁盘地址 ; 给定 inode 编号的基于数组的索引快速而直接。
在 FFS 中查找给定 inode 编号的 inode 稍微复杂一些,因为 FFS 将 inode 表拆分为块并在每个柱面组中放置一组 inode。 因此,必须知道每一块 inode 有多大以及每个块的起始地址。 之后,计算是相似的,也很容易。
在 LFS 中,生活更加艰难。 为什么? 好吧,我们已经设法将 inode 分散到整个磁盘中! 更糟糕的是,我们永远不会就地覆盖,因此最新版本的 inode(即我们想要的那个)一直在移动。
43.5 通过间接解决:Inode映射 Solution Through Indirection: The Inode Map
为了解决这个问题,LFS 的设计者通过称为 inode 映射 (inode map,imap) 的数据结构在 inode 编号和 inode 之间引入了一个间接层级(level of indirection)。 imap 是一种将 inode 编号作为输入并生成最新版本 inode 的磁盘地址的结构。 因此,您可以想象它通常会被实现为一个简单的数组(array),每个条目有 4 个字节(一个磁盘指针)。 任何时候将 inode 写入磁盘,imap 都会更新为新位置。
不幸的是,imap 需要保持持久性(即写入磁盘); 这样做允许 LFS 在崩溃时跟踪 inode 的位置,从而根据需要进行操作。 因此,一个问题:imap 应该驻留在磁盘上的什么位置?
当然,它可以存在于磁盘的固定部分。 不幸的是,由于它经常更新,这将需要更新文件结构,然后写入 imap,因此性能会受到影响(即,在每个更新和 imap 的固定位置之间会有更多的磁盘寻道 )。
相反,LFS 将 inode map 的块放在它正在写入所有其他新信息的位置旁边。 因此,当将数据块追加到文件 k 时,LFS 实际上将新数据块、它的 inode 和一块 inode map一起写入磁盘,如下所示: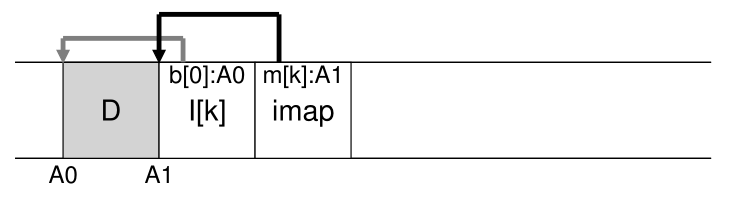
在这张图中,标记为 imap 的块中存储的 imap 数组片段告诉 LFS,inode k 位于磁盘地址 A1; 其次,这个 inode 告诉 LFS 它的数据块 D 位于地址 A0。
43.6 完成解决方案:Checkpoint区域 Completing The Solution: The Checkpoint Region
聪明的读者(就是你,对吧?)可能已经注意到这里的一个问题。 我们如何找到 inode map,既然它的部分现在也分布在磁盘上? 最后,没有什么神奇之处:文件系统必须在磁盘上有一些固定且已知的位置才能开始文件查找。
为此,LFS 在磁盘上有一个固定的位置,称为 checkpoint 区域 (checkpoint region,CR)。 checkpoint 区域包含指向最新的 inode map 片段的指针(即地址),因此可以通过首先读取 CR 找到 inode map 片段。 请注意,checkpoint 区域仅定期更新(例如每 30 秒左右),因此性能不会受到不良影响。 因此,磁盘布局的整体结构包含一个 checkpoint 区域(指向 inode map的最新部分); 每个 inode map 块都包含 inode 的地址; inode 指向文件(和目录),就像典型的 UNIX 文件系统一样。
这是 checkpoint 区域的示例(注意它一直在磁盘的开头,地址 0),以及单个 imap 块、inode 和数据块。 一个真正的文件系统当然会有更大的 CR(实际上,它会有两个,我们稍后会明白)、许多 imap 块,当然还有更多的 inode、数据块等。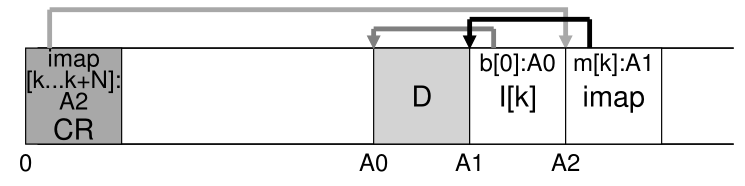
43.7 从磁盘读取文件:概述 Reading A File From Disk: A Recap
为了确保您了解 LFS 的工作原理,现在让我们来看看从磁盘读取文件必须发生的事情。假设我们内存中没有任何东西可以开始。我们必须读取的第一个磁盘数据结构是 checkpoint 区域。checkpoint 区域包含指向整个 inode map 的指针(即磁盘地址),因此 LFS 然后读入整个 inode map并将其缓存在内存中。此后,当给定文件的 inode 编号时,LFS 只需在 imap 中查找 inode-number 到 inode-disk-address 映射,并读取最新版本的 inode。为了从文件中读取块,此时,LFS 与典型的 UNIX 文件系统完全一样,根据需要使用直接指针或间接指针或双重间接指针等。在一般情况下,LFS 在从磁盘读取文件时应该执行与典型文件系统相同数量的 I/O;整个 imap 被缓存,因此 LFS 在读取期间所做的额外工作是在 imap 中查找 inode 的地址。
43.8 目录呢? What About Directories?
到目前为止,我们只考虑了 inode 和数据块,简化了我们的讨论。 但是,要访问文件系统中的文件(例如 /home/remzi/foo,我们最喜欢的假文件名之一),也必须访问某些目录。 那么 LFS 是如何存储目录数据的呢?
幸运的是,目录结构与经典的 UNIX 文件系统基本相同,因为目录只是(名称、inode 编号)映射的集合。 例如,在磁盘上创建文件时,LFS 必须同时写入一个新的 inode、一些数据,以及引用该文件的目录数据及其 inode。 请记住,LFS 将在磁盘上连续执行此操作(在缓冲更新一段时间后)。 因此,在目录中创建文件 foo 将导致磁盘上的以下新结构: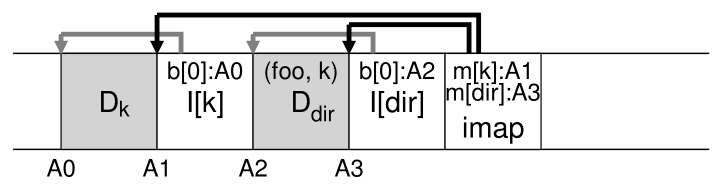
inode map 的一部分包含目录文件 dir 以及新创建的文件 f 的位置信息。 因此,在访问文件 foo(inode 编号为 k)时,首先要查看 inode map(通常缓存在内存中)以找到目录 dir (A3) 的 inode 的位置; 然后您读取目录 inode,它为您提供目录数据的位置 (A2); 读取这个数据块会给你(foo,k)的名称到 inode 编号的映射。 然后您再次查阅 inode map 以找到 inode 编号 k (A1) 的位置,最后在地址 A0 处读取所需的数据块。
在 LFS 中还有一个严重的问题是 inode map 解决的,称为递归更新问题(recursive update problem) [Z+12]。 这个问题出现在任何从不就地更新,而是将更新移动到磁盘上的新位置的文件系统上(如LFS)。
具体来说,每当更新 inode 时,它在磁盘上的位置都会发生变化。 如果我们不小心,这也将需要更新指向该文件的目录,然后将强制更改该目录的父目录,依此类推,一直到文件系统树。
LFS 通过 inode map巧妙地避免了这个问题。 即使 inode 的位置可能会发生变化,但这种变化永远不会反映在目录本身中; 而是更新 imap 结构,同时目录保存相同的名称到 inode 编号的映射。 因此,通过间接,LFS 避免了递归更新问题。
43.9
一个新问题:垃圾回收 A New Problem: Garbage Collection
您可能已经注意到 LFS 的另一个问题; 它反复将文件的最新版本(包括其 inode 和数据)写入磁盘上的新位置。 这个过程在保持写入效率的同时,意味着 LFS 将旧版本的文件结构分散在整个磁盘中。 我们(相当不客气地)称这些旧版本为垃圾(garbage)。
例如,假设我们有一个由 inode 编号 k 引用的现有文件,它指向单个数据块 D0。我们现在更新该块,生成一个新的 inode 和一个新的数据块。 LFS 的最终磁盘布局如下所示(注意,为了简单起见,我们省略了 imap 和其他结构;还必须将新的 imap 块写入磁盘以指向新的 inode):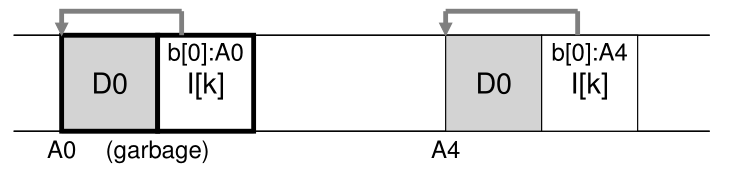
在图中,您可以看到 inode 和数据块在磁盘上都有两个版本,一个是旧的(左边的),另一个是当前的,因此是活动的(live)(右边的)。 通过(逻辑上)更新数据块的简单行为,LFS 必须保留许多新结构,因此在磁盘上留下所述块的旧版本。
再举一个例子,假设我们将一个块附加到原始文件 k。 在这种情况下,会生成新版本的 inode,但旧数据块仍由 inode 指向。 因此,它仍然存在并且是当前文件系统的重要组成部分: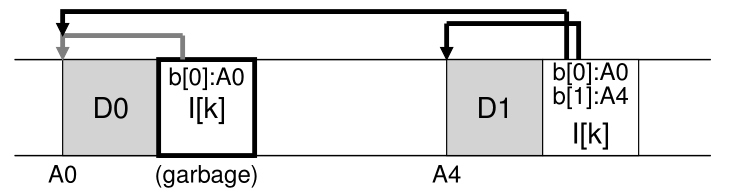
那么我们应该如何处理这些旧版本的 inode、数据块等等呢? 可以保留那些旧版本并允许用户恢复旧文件版本(例如,当他们不小心覆盖或删除文件时,这样做可能非常方便); 这种文件系统被称为版本控制文件系统(versioning file system),因为它跟踪文件的不同版本。
但是,LFS 只保留文件的最新实时版本; 因此(在后台),LFS 必须定期找到这些旧的不再使用的版本的文件数据、inode 和其他结构,并清理(clean)它们; 因此,清理应该使磁盘上的块再次空闲以供后续写入使用。 请注意,清理过程是垃圾回收(garbage collection)的一种形式,这是一种出现在编程语言中的技术,可以自动为程序释放不再使用的内存。
前面我们讨论了段(segments)与在 LFS 中实现对磁盘进行大量写入的机制一样重要。 事实证明,它们也是高效清理不可或缺的一部分。 想象一下,如果 LFS 清理器在清理过程中简单地扫过并释放单个数据块、inode 等会发生什么。 结果:文件系统在磁盘上的分配空间之间混合了一定数量的空闲孔(holes)。 写入性能会大幅下降,因为 LFS 将无法找到一个大的连续区域来顺序写入磁盘并具有高性能。
相反,LFS 清理器在逐段的基础上工作,从而为后续写入清理大块空间。 基本的清理过程如下。LFS清理器定期读取一些旧的(部分使用的)段,确定这些段中哪些块是活动的,然后写出一组新的段,其中只有活动的块,释放旧的段以便写入。具体来说,我们希望清理器读取 M 个现有段,将它们的内容压缩(compact)为 N 个新段(其中 N < M),然后将 N 个段写入磁盘的新位置。 旧的 M 段随后被释放,可供文件系统用于后续写入。
然而,我们现在面临两个问题。 第一个是机制(mechanism):LFS 如何知道段内哪些块是活的,哪些是死的? 第二个是策略(policy):清理器应该多久运行一次,它应该选择哪些部分来清理?
43.10
确定块的活跃度 Determining Block Liveness
我们首先解决机制。 给定磁盘段 S 中的数据块 D,LFS 必须能够确定 D 是否处于活动状态。 为此,LFS 向描述每个块的每个段添加了一些额外的信息。 具体来说,LFS 包括,对于每个数据块 D,它的 inode 号(它属于哪个文件)和它的偏移量(这是文件的哪个块)。 此信息记录在称为 segment summary block(段摘要块)的段开头的结构中。
有了这些信息,就可以直接确定一个区块是活的还是死的。 对于位于磁盘地址 A 处的块 D,查看段摘要块并找到其 inode 编号 N 和偏移量 T。接下来,查看 imap 以找到 N 所在的位置并从磁盘读取 N(可能它已经在内存中,这样更好)。 最后,使用偏移量 T,查看 inode(或某个间接块)以查看 inode 认为此文件的第 T 个块在磁盘上的位置。 如果它正好指向磁盘地址 A,LFS 可以断定块 D 是活动的。 如果它指向其他任何地方,LFS 可以断定 D 没有被使用(即它已经死了),因此知道不再需要这个版本。 下面是一个伪代码摘要:
(N, T) = SegmentSummary[A];inode = Read(imap[N]);if (inode[T] == A)// block D is aliveelse// block D is garbage
这是一个描述机制的图,其中段摘要块(标记为 SS)记录地址 A0 处的数据块实际上是文件 k 偏移量 0 的一部分。 并看到它确实指向那个位置。<br />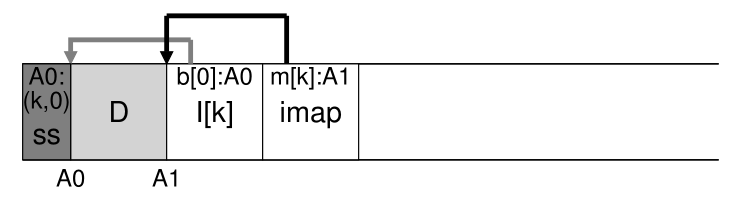<br />**LFS 有一些捷径可以使确定活性的过程更高效。 例如,当一个文件被截断或删除时,LFS 会增加它的版本号(version number)并在 imap 中记录新的版本号。 通过在磁盘段中记录版本号,LFS 可以简单地通过将磁盘版本号与 imap 中的版本号进行比较来缩短上述较长的检查,从而避免额外的读取。**
43.11
一个策略问题:清理哪些块,什么时候清理? A Policy Question: Which Blocks To Clean, And When?
在上述机制之上,LFS 必须包含一组策略来确定何时清理以及哪些块值得清理。 确定何时清理更容易; 定期、在空闲时间、或者当您因为磁盘已满而不得不这样做时。
确定要清理的块更具挑战性,并且已成为许多研究论文的主题。 在最初的 LFS 论文 [RO91] 中,作者描述了一种尝试分离热段和冷段(segregate hot and cold segments)的方法。 热段是指内容被频繁覆盖的段; 因此,对于这样的段,最好的策略是在清理它之前等待很长时间,因为越来越多的块被覆盖(在新段中)并因此被释放以供使用。 相比之下,冷段可能有一些死块,但其其余内容相对稳定。 因此,作者得出结论,应该早点清理冷段,晚点清理热段,并开发一种启发式方法来做到这一点。 但是,与大多数策略一样,这项策略并不完美。 后来的方法展示了如何做得更好 [MR+97]。
43.12
崩溃恢复和日志 Crash Recovery And The Log
最后一个问题:如果在 LFS 写入磁盘时系统崩溃会发生什么? 您可能还记得在上一章关于日志的情况,更新期间的崩溃对于文件系统来说很棘手,因此 LFS 也必须考虑一些问题。
在正常操作期间,LFS 将写入缓冲到一个段中,然后(当该段已满或经过一段时间后)将该段写入磁盘。 LFS 将这些写入组织在一个日志(log)中,即 checkpoint 区域指向一个头和尾段,每个段指向下一个要写入的段。 LFS 还会定期更新 checkpoint 区域。 在这些操作中的任何一个(写入段,写入 CR)期间都可能发生崩溃。 那么 LFS 如何处理写入这些结构期间的崩溃呢?
我们先讲第二种情况。 为了确保 CR 更新以原子方式发生,LFS 实际上保留了两个 CR,每个在磁盘的一端,并交替写入它们。 LFS 在用最新的指向 inode map 和其他信息的指针更新 CR 时也实现了一个谨慎的协议; 具体来说,它首先写出一个头部(带有时间戳(timestamp)),然后是 CR 的主体,最后是最后一个块(也带有时间戳)。 如果系统在 CR 更新期间崩溃,LFS 可以通过查看不一致的时间戳对来检测到这一点。 LFS 将始终选择使用具有一致时间戳的最新 CR,从而实现 CR 的一致更新。
现在让我们解决第一种情况。 由于 LFS 每隔 30 秒左右写入一次 CR,因此文件系统的最后一个一致快照可能很旧。 因此,在重新启动时,LFS 可以通过简单地读取checkpoint 区域、它指向的 imap 片段以及后续文件和目录来轻松恢复; 但是,最后几秒的更新将会丢失。
为了改进这一点,LFS 尝试通过数据库社区中称为前滚(roll forward)的技术重建其中的许多段。 基本思想是从最新的一个 checkpoint 区域开始,找到日志的结尾(包含在 CR 中),然后使用它来读取下一段,看看其中是否有任何有效的更新。 如果有,LFS 会相应地更新文件系统,从而恢复自上次 checkpoint 以来写入的大部分数据和元数据。 有关详细信息,请参阅 Rosenblum 的获奖论文 [R92]。
43.13
总结 Summary
LFS 引入了一种更新磁盘的新方法。 LFS 总是写入磁盘的未使用部分,而不是在某些地方覆盖文件,然后通过清理回收旧空间。 这种方法在数据库系统中称为影式分页(shadow paging) [L77],在文件系统中有时称为写时复制(copy-on-write),可以实现高效写入,因为 LFS 可以将所有更新收集到内存段中,然后将它们一起连续写出去。
LFS 生成的大型写入在许多不同设备上的性能非常出色。 在硬盘上,大型写入确保定位时间最小化; 在基于奇偶校验的 RAID 上,例如 RAID-4 和 RAID-5,它们完全避免了小型写入问题。 最近的研究甚至表明,基于闪存的 SSD 需要大型 I/O 才能获得高性能 [H+17]; 因此,也许令人惊讶的是,即使对于这些新媒体,LFS 风格的文件系统也可能是一个很好的选择。
这种方法的缺点是它会产生垃圾; 数据的旧副本分散在整个磁盘中,如果要回收这些空间以供后续使用,则必须定期清理旧段。 清理成为 LFS 中很多争议的焦点,对清理成本的担忧 [SS+95] 可能限制了 LFS 在该领域的初步影响。然而,一些现代商业文件系统,包括
NetApp的WAFL [HLM94]、Sun的ZFS [B07]、Linux的btrfs [R+13],甚至是现代的基于闪存的SSD(flash-based SSDs) [AD14],都采用了类似的写时复制方法写入磁盘,因此LFS的智慧遗产在这些现代文件系统中继续存在。特别是,WAFL 通过将它们转化为功能来解决清理问题; 通过快照(snapshots)提供旧版本的文件系统,用户可以在不小心删除当前文件时访问旧文件。
Tip:化缺点为优点 每当您的系统存在根本性缺陷时,看看您是否可以将其转变为功能或有用的东西。 NetApp 的 WAFL 使用旧文件内容做到了这样; 通过提供旧版本,WAFL 不再需要经常担心清理(尽管它确实删除旧版本,最终,在后台),因此提供了一个很酷的功能,并在一个奇妙的转变中消除了许多 LFS 清理问题。 系统中还有其他例子吗? 毫无疑问,但您必须自己考虑它们,因为本章以大写的“O”结束。 超过。 完毕。 卡普特。 我们出去了。 和平!
References
[AD14] “Operating Systems: Three Easy Pieces” (Chapter: Flash-based Solid State Drives) by Remzi Arpaci-Dusseau and Andrea Arpaci-Dusseau. Arpaci-Dusseau Books, 2014.
把你带到这本书的另一章有点笨拙,但我们要判断谁呢?
[B07] “ZFS: The Last Word in File Systems” by Jeff Bonwick and Bill Moore.
ZFS幻灯片;不幸的是,目前还没有好的ZFS论文。也许你会写一个,这样我们可以在这里引用它?
[H+17] “The Unwritten Contract of of Solid State Drives” by Jun He, Sudarsun Kannan, An- drea C. Arpaci-Dusseau, Remzi H. Arpaci-Dusseau. EuroSys ’17, April 2017.
从SSD中提取高性能必须遵循哪些不成文的规则?有趣的是,请求规模(大型或并行请求)和局部性仍然很重要,即使是在SSD上。事情变化越多……
[HLM94] “File System Design for an NFS File Server Appliance” by Dave Hitz, James Lau,
Michael Malcolm. USENIX Spring ’94.
WAFL从LFS和RAID中汲取了许多想法,并将其应用到价值数十亿美元的存储公司NetApp的高速NFS设备中。
[L77] “Physical Integrity in a Large Segmented Database” by R. Lorie. ACM Transactions on
Databases, Volume 2:1, 1977.
这里介绍了影式分页的原始思想。
[MJLF84] “A Fast File System for UNIX” by Marshall K. McKusick, William N. Joy, Sam J.
Leffler, Robert S. Fabry. ACM TOCS, Volume 2:3, August 1984.
原始FFS论文; 有关详细信息,请参阅 FFS 一章。
[MR+97] “Improving the Performance of Log-structured File Systems with Adaptive Methods” by Jeanna Neefe Matthews, Drew Roselli, Adam M. Costello, Randolph Y. Wang, Thomas
E. Anderson. SOSP 1997, pages 238-251, October, Saint Malo, France.
最近的一篇论文详细介绍了LFS中更好的清理策略。
[M94] “A Better Update Policy” by Jeffrey C. Mogul. USENIX ATC ’94, June 1994.
在本文中,Mogul 发现缓冲写入时间过长然后将它们大量发送到磁盘可能会损害读取工作负载。 因此,他建议更频繁地以较小的批次发送写入。
[P98] “Hardware Technology Trends and Database Opportunities” by David A. Patterson.
ACM SIGMOD ’98 Keynote, 1998.
一组关于计算机系统技术趋势的精彩幻灯片。 希望帕特森很快就会创建另一个。
[R+13] “BTRFS: The Linux B-Tree Filesystem” by Ohad Rodeh, Josef Bacik, Chris Mason. ACM
Transactions on Storage, Volume 9 Issue 3, August 2013.
最后,一篇关于 BTRFS 的好论文,对写时复制文件系统的现代研究。
[RO91] “Design and Implementation of the Log-structured File System” by Mendel Rosen- blum and John Ousterhout. SOSP ’91, Pacific Grove, CA, October 1991.
SOSP关于LFS的原始论文,已被数百篇其他论文引用,并启发了许多真实的系统。
[R92] “Design and Implementation of the Log-structured File System” by Mendel Rosenblum.
关于 LFS 的获奖论文,论文中缺少许多细节。
[SS+95] “File system logging versus clustering: a performance comparison” by Margo Seltzer,
Keith A. Smith, Hari Balakrishnan, Jacqueline Chang, Sara McMains, Venkata Padmanabhan.
USENIX 1995 Technical Conference, New Orleans, Louisiana, 1995.
一篇展示 LFS 性能的论文有时会出现问题,特别是对于多次调用 fsync() 的工作负载(例如数据库工作负载)。 这篇论文在当时是有争议的。
[SO90] “Write-Only Disk Caches” by Jon A. Solworth, Cyril U. Orji. SIGMOD ’90, Atlantic
City, New Jersey, May 1990.
对写缓冲及其好处的早期研究。 但是,缓冲时间过长可能有害:有关详细信息,请参阅 Mogul [M94]。
[Z+12] “De-indirection for Flash-based SSDs with Nameless Writes” by Yiying Zhang, Leo
Prasath Arulraj, Andrea C. Arpaci-Dusseau, Remzi H. Arpaci-Dusseau. FAST ’13, San Jose,
California, February 2013.
我们的论文是关于构建基于闪存的存储设备的新方法,以避免文件系统和 FTL 中的冗余映射。 这个想法是让设备选择写入的物理位置,并将地址返回到存储映射的文件系统。
Homework (Simulation)
本节介绍 lfs.py,这是一个简单的 LFS 模拟器,可用于更好地了解基于 LFS 的文件系统的工作原理。 有关如何运行模拟器的详细信息,请阅读README文件。
Questions
- 运行 ./lfs.py -n 3,也许改变种子 (-s)。 你能弄清楚运行了哪些命令来生成最终的文件系统内容吗? 你能说出这些命令是按什么顺序发出的吗?最后,你能确定每个块在最终文件系统状态下的活跃度吗? 使用 -o 显示运行了哪些命令,使用 -c 显示最终文件系统状态的活跃度。 当您增加发出的命令数量(即,将 -n 3 更改为 -n 5)时,任务对您来说变得有多困难?
- 如果您发现上述问题很痛苦,您可以通过显示由每个特定命令引起的更新集来帮助自己。 为此,请运行 ./lfs.py -n 3 -i。 现在看看是否更容易理解每个命令必须是什么。 更改随机种子以获得不同的命令来解释(例如,-s 1、-s 2、-s 3 等)。
- 要进一步测试您确定每个命令对磁盘进行哪些更新的能力,请运行以下命令:./lfs.py -o -F -s 100(可能还有其他一些随机种子)。 这仅显示一组命令,并没有显示文件系统的最终状态。 你能推断出文件系统的最终状态必须是什么吗?
- 现在看看您是否可以在多次文件和目录操作后确定哪些文件和目录是活动的。 运行 tt ./lfs.py -n 20 -s 1 然后检查最终的文件系统状态。 你能找出哪些路径名是有效的吗? 运行 tt ./lfs.py -n 20 -s 1 -c -v 以查看结果。 使用 -o 运行以查看您的答案是否与给定的一系列随机命令匹配。 使用不同的随机种子来获得更多的问题。
- 现在让我们发出一些特定的命令。 首先,让我们创建一个文件并重复写入。 为此,请使用 -L 标志,它允许您指定要执行的特定命令。 让我们创建文件“/foo”并写入四次: -L c,/foo:w,/foo,0,1:w,/foo,1,1:w,/foo,2,1:w ,/foo,3,1 -o. 看看是否可以确定最终文件系统状态的活跃度; 使用 -c 检查您的答案。
- 现在,让我们做同样的事情,但使用单个写入操作而不是四个。 运行 ./lfs.py -o -L c,/foo:w,/foo,0,4 以创建文件“/foo”并通过一次写入操作写入 4 个块。 再次计算活性,并检查 -c 是否正确。 一次写入一个文件(就像我们在这里所做的那样)与一次写入一个块(如上所述)之间的主要区别是什么? 这告诉你在主内存中缓冲更新的重要性,就像真正的 LFS 一样?
- 我们再做一个具体的例子。 首先,运行以下命令:./lfs.py -L c,/foo:w,/foo,0,1. 这组命令有什么作用? 现在,运行 ./lfs.py -L c,/foo:w,/foo,7,1。 这组命令有什么作用? 两者有何不同? 从这两组命令中你能看出 inode 中的 size 字段是什么?
- 现在让我们明确地看看文件创建与目录创建。 运行模拟 ./lfs.py -L c,/foo 和 ./lfs.py -L d,/foo 以创建一个文件,然后创建一个目录。 这些运行有什么相似之处,有什么不同?
- LFS 模拟器也支持硬链接。 运行以下命令来研究它们是如何工作的:./lfs.py -L c,/foo:l,/foo,/bar:l,/foo,/goo -o -i。 创建硬链接时写出哪些块? 这与仅创建一个新文件有何相似之处,有何不同? 创建链接时,引用计数字段如何更改?
- LFS 做出许多不同的策略决定。 我们不会在这里探索其中的很多——也许还有一些留待未来——但这里有一个我们确实探索的简单问题:inode 编号的选择。 首先,运行 ./lfs.py -p c100 -n 10 -o -a s 以显示“顺序”分配策略的通常行为,该策略尝试使用最接近于零的空闲 inode 编号。 然后,通过运行 ./lfs.py -p c100 -n 10 -o -a r 更改为“随机”策略(-p c100 标志确保 100% 的随机操作是文件创建)。 随机策略与顺序策略会导致哪些磁盘差异? 这说明在真实 LFS 中选择 inode 编号的重要性是什么?
- 我们一直假设的最后一件事是 LFS 模拟器总是在每次更新后更新 checkpoint 区域。 在真正的 LFS 中,情况并非如此:它会定期更新以避免长时间搜索。 运行 ./lfs.py -N -i -o -s 1000 以查看 checkpoint 区域未强制写入磁盘时的一些操作以及文件系统的中间和最终状态。 如果 checkpoint 区域从未更新会发生什么? 如果定期更新会怎样? 你能弄清楚如何通过在日志中前滚来将文件系统恢复到最新状态吗?

若有收获,就点个赞吧
0 人点赞

{kind=link}
{kind=link}
{kind=link}