到目前为止,我们一直将每个进程的整个地址空间放在内存中。通过使用基寄存器和边界寄存器,操作系统可以轻松地将进程重新定位到物理内存的不同部分。然而,您可能已经注意到关于我们的这些地址空间的一些有趣的事情:在栈和堆之间的正中央有一大块“空闲”空间。
从图16.1中可以看出,尽管栈和堆之间的空间没有被进程使用,但当我们将整个地址空间重定位到物理内存中的某个位置时,它仍然会占用物理内存;因此,使用基寄存器和边界寄存器对来虚拟化内存的简单方法是很浪费的。当整个地址空间无法装入内存时,它也会使程序很难运行;因此,base and bounds不像我们希望的那样灵活。因此:
关键的问题:如何支持大地址空间 我们如何在栈和堆之间(潜在地)使用大量空闲空间来支持大地址空间?注意,在我们的示例中,使用很小的(假装的)地址空间,这种浪费看起来并不太严重。但是,想象一下,一个32位地址空间(4 GB大小);一个典型的程序将只使用数兆字节的内存,但仍然要求整个地址空间驻留在内存中。
16.1 分段:泛化的基/边界 Segmentation: Generalized Base/Bounds
为了解决这个问题,一个想法诞生了,它被称为分段。这是一个相当古老的想法,至少可以追溯到20世纪60年代早期[H61, G62]。想法很简单:与其在MMU中只有一个基和边界对,为什么不在地址空间的每个逻辑段中都有一个基和边界对呢?段只是地址空间中特定长度的连续部分,在规范地址空间中,我们有三个逻辑上不同的段:代码段、栈段和堆段。分段允许操作系统做的是将这些段中的每一个放在物理内存的不同部分,从而避免用未使用的虚拟地址空间填充物理内存。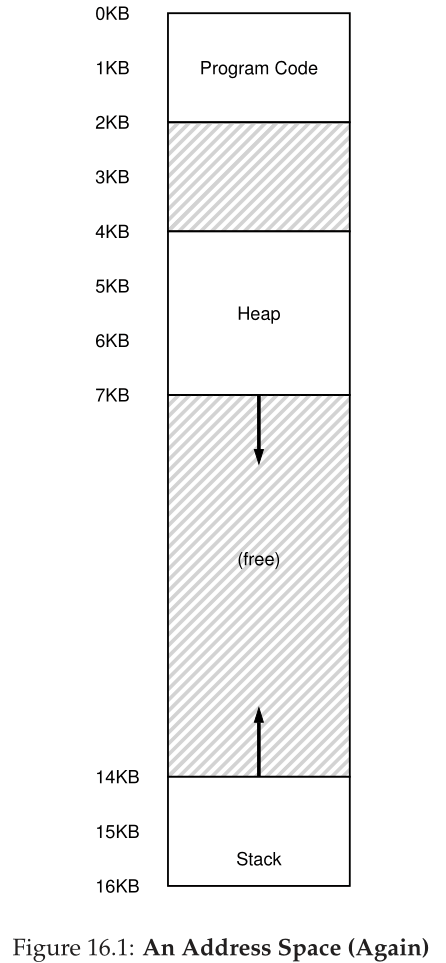
让我们来看一个例子。假设我们希望将图16.1中的地址空间放入物理内存中。使用每个段的基和边界对,我们可以将每个段独立地放在物理内存中。例如,见图16.2;在这里,您可以看到一个64KB的物理内存,其中包含这三个段(16KB预留给操作系统)。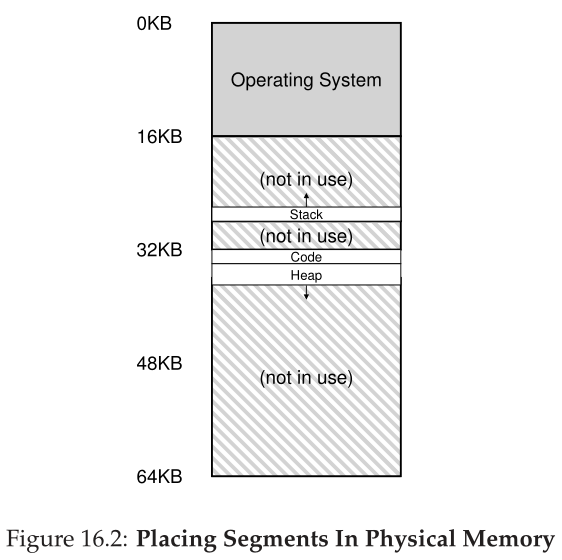
从图中可以看到,物理内存中只分配使用过的内存,因此可以容纳带有大量未使用地址空间的大地址空间(我们有时称之为稀疏地址空间(sparse address spaces))。
MMU中支持分段所需的硬件结构正是你所期望的:在这种情况下,一组三个基和边界寄存器对。下面的图16.3显示了上面示例的寄存器值;每个边界寄存器保存一个段的大小。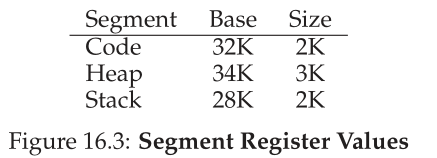
从图中可以看出,代码段放置在物理地址32KB,大小为2KB,堆段放置在34KB,大小为3KB。这里的size部分和前面介绍的bounds 寄存器完全一样;它告诉硬件该段中有多少字节是有效的(从而使硬件能够确定程序何时进行了超出这些范围的非法访问)。
让我们使用图16.1中的地址空间做一个示例转换。假设引用了虚拟地址 100(它在代码段中,您可以在图 16.1 中直观地看到)。当引用发生时(例如,在取指令时),硬件会将基值添加到该段的偏移量(在这种情况下为 100)以到达所需的物理地址:100 + 32KB,或 32868。然后它将检查地址是否在边界内(100小于2KB),发现是,并发出对物理内存地址32868的引用。
Aside:分段错误 术语段错误(segmentation fault)或违规产生于在分段机器上对非法地址的内存访问。有趣的是,即使在完全不支持分段的机器上,这个术语仍然存在。或者不那么幽默,如果你不知道为什么你的代码总是出错。
现在让我们看看堆中的一个地址,虚拟地址4200(再次参见图16.1)。如果我们仅仅将虚拟地址4200添加到堆的底部(34KB),我们就会得到一个物理地址39016,这不是正确的物理地址。我们首先需要做的是将偏移量提取到堆中,即,这个地址在这个段中指的是哪个字节。因为堆从虚拟地址4KB(4096)开始,所以4200的偏移量实际上是4200减去4096,即104。然后我们取这个偏移量(104)并将它添加到基寄存器物理地址(34K)中以获得所需的结果:34920。
如果我们试图引用超出堆末端的非法地址(即7KB或更大的虚拟地址),会怎么样?你可以想象会发生什么:硬件检测到地址是越界的,进入操作系统,可能导致违规进程的终止。现在您知道了所有C程序员都害怕的著名术语的起源:段违规或段错误(egmentation violation or segmentation fault)。
16.2 我们指的是哪段? Which Segment Are We Referring To?
硬件在转换过程中使用段寄存器。它如何知道进入一个段的偏移量,以及一个地址指向哪个段?
一种常见的方法,有时被称为显式方法(explicit approach),是基于虚拟地址的前几位将地址空间分割成段;该技术被用于VAX/VMS系统[LL82]。在上面的例子中,我们有三个片段;因此我们需要两个bits来完成我们的任务。如果我们使用14位虚拟地址的前两位来选择段,我们的虚拟地址看起来是这样的。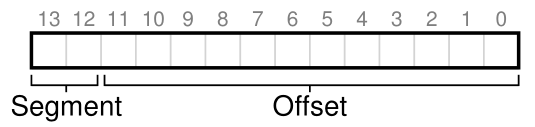
在我们的示例中,如果前两位是00,则硬件知道虚拟地址在代码段中,因此使用代码基和边界来将虚拟地址重定位到正确的物理地址。如果前两位是01,则硬件知道地址在堆中,因此使用堆基和边界。让我们以上面的示例堆虚拟地址(4200)为例,并对其进行转换,以确保这一点介绍得很清楚。虚拟地址4200的二进制形式可以在这里看到: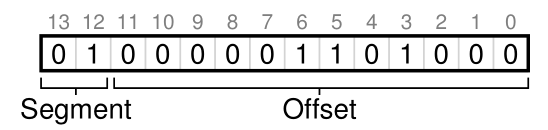
正如你可以从图片中看到的,最高的两位(01)告诉硬件我们指的是哪一部分。低12位是段的偏移量:0000 0110 1000,十六进制0x068,十进制的104。因此,硬件只需取前两位来确定要使用哪个段寄存器,然后取后12位作为进入段的偏移量。通过将基寄存器加到偏移量,硬件到达最终的物理地址。注意,偏移量也简化了边界检查:我们可以简单地检查偏移量是否小于边界;如果没有,地址是非法的。因此,如果基和边界是数组(每个段有一个条目),硬件会像这样做,以获得所需的物理地址:
在我们正在运行的示例中,我们可以为上面的常量填充值。具体来说,SEG MASK设置为0x3000, SEG_SHIFT设置为12,OFFSET_MASK设置为0xFFF。
您可能还注意到,当我们使用前两位时,我们只有三个段(代码、堆、栈),其中一个段地址空间没有使用。为了充分利用虚拟地址空间(并避免未使用的段),一些系统将代码放在与堆相同的段中,因此只使用一位来选择使用哪个段[LL82]。
使用这么多位来选择一个段的另一个问题是它限制了虚拟地址空间的使用。具体来说,每个段都限制在最大大小,在我们的示例中是4KB(使用前两位来选择段意味着16KB的地址空间被分割成4个部分,在本例中是4KB)。如果一个正在运行的程序希望将一个段(比如堆或栈)增长到超过这个最大值,那么这个程序就不走运了。
硬件还有其他方法来确定一个特定的地址在哪个段中。在隐式方法(implicit approach)中,硬件通过注意地址是如何形成的来确定段。例如,如果地址是从程序计数器生成的(即,它是一个指令获取),那么地址就在代码段内;如果地址基于栈或基指针,它必须在栈段中;任何其他地址必须在堆中。
16.3 那栈呢? What About The Stack?
到目前为止,我们已经忽略了地址空间的一个重要组成部分:栈。在上图(图16.3)中,栈被重新定位到物理地址28KB,但有一个关键的区别:它是向后增长的(即向较低的地址)。在物理内存中,它从28KB“开始”,然后增长到26KB,对应于虚拟地址从16KB到14KB;翻译必须以不同的方式进行。
虽然为了简单起见,我们说堆栈从28KB“开始”,但这个值实际上是向后增长区域位置下方的字节;第一个有效字节实际上是28KB减1。相反,向前增长区域从段的第一个字节的地址开始。我们采用这种方法是因为它使计算物理地址的数学方法简单明了:物理地址就是底数加上负偏移量。
首先我们需要一点额外的硬件支持。除了基值和边界值,硬件还需要知道段的增长方式(例如,当段向正方向增长时,将bit设置为1,当段向负方向增长时,将bit设置为0)。我们更新的硬件跟踪视图如图16.4所示:
随着硬件理解段可以向负方向增长,硬件现在必须以稍微不同的方式转换这些虚拟地址。让我们以一个栈虚拟地址为例,并对其进行转换以理解该过程。
在本例中,假设我们希望访问虚拟地址15KB,该虚拟地址应该映射到物理地址27KB。我们的二进制虚拟地址看起来像这样:11 1100 0000 0000(十六进制0x3C00)。硬件使用最上面的两位(11)来指定段,但是我们还剩下3KB的偏移量。为了获得正确的负偏移量,我们必须从3KB中减去最大段大小:在本例中,段可以是4KB,因此正确的负偏移量是3KB减去4KB,等于-1KB。只需将负偏移量(-1KB)添加到基(28KB),就可以得到正确的物理地址:27KB。边界检查可以通过确保负偏移量的绝对值小于或等于段的当前大小(在本例中为2KB)来计算。
16.4 支持共享 Support for Sharing
随着对分段支持的增长,系统设计人员很快意识到他们可以通过更多的硬件支持实现新型效率。具体来说,为了节省内存,有时在地址空间之间共享(share)某些内存段很有用。特别是,代码共享(code sharing)很常见,并且仍在今天的系统中使用。
为了支持共享,我们需要一些来自硬件的额外支持,以保护位(protection bits)的形式。基本支持为每个段添加几个位,指示程序是否可以读或写段,或者执行段内的代码。通过将代码段设置为只读,可以在多个进程之间共享相同的代码,而不用担心破坏隔离;当每个进程仍然认为自己正在访问自己的私有内存时,操作系统正在秘密地共享进程无法修改的内存,从而保持了这种假象(illusion)。
硬件(和操作系统)跟踪的附加信息示例如图16.5所示。如您所见,代码段被设置为读取和执行,因此内存中的相同物理段可以映射到多个虚拟地址空间。
对于保护位,前面描述的硬件算法也必须改变。除了检查虚拟地址是否在边界内,硬件还必须检查是否允许特定的访问。如果用户进程试图写入只读段,或从非可执行段执行,硬件应该引发异常,从而让操作系统处理出错的进程。
16.5 细粒度分段 vs. 粗粒度分段 Fine-grained vs. Coarse-grained Segmentation
到目前为止,我们的大多数示例都集中在只有几个段的系统上(例如,代码、栈、堆);我们可以将这种分段看作是粗粒度(coarse-grained)的,因为它将地址空间分割成相对较大的粗块。然而,一些早期的系统(如Multics [CV65,DD68])更加灵活,允许地址空间由大量较小的段组成,称为细粒度(fine-grained)分段。
支持许多段甚至需要进一步的硬件支持,在内存中存储某种类型的段表(segment table)。这样的段表通常支持创建大量的段,从而使系统能够以比我们到目前为止讨论的更灵活的方式使用段。例如,像Burroughs B5000这样的早期机器支持数千个段,并希望编译器将代码和数据分割成独立的段,然后由操作系统和硬件支持[RK68]。当时的想法是,通过拥有细粒度的段,操作系统可以更好地了解哪些段正在使用,哪些没有,从而更有效地利用主内存。
16.6 操作系统支持 OS Support
你现在应该有一个分段如何工作的基本想法。当系统运行时,地址空间的一部分被重定位到物理内存中,因此相对于我们对整个地址空间只使用一个基/边界对的简单方法,可以实现大量的物理内存节省。具体来说,栈和堆之间所有未使用的空间都不需要分配到物理内存中,这允许我们在物理内存中容纳更多的地址空间,并支持每个进程的大型和稀疏的虚拟地址空间。
然而,分段为操作系统提出了一些新的问题。第一个是老问题:在上下文切换时,操作系统应该做什么?现在您应该有一个很好的猜测:必须保存和恢复段寄存器。显然,每个进程都有自己的虚拟地址空间,在让进程再次运行之前,操作系统必须确保正确设置这些寄存器。
第二个是当段增长(或萎缩)时的操作系统交互。例如,程序可以调用malloc()来分配对象。在某些情况下,现有堆将能够为请求提供服务,因此malloc()将为对象找到空闲空间,并将指向该对象的指针返回给调用者。然而,在其他情况下,堆段本身可能需要增长。在这种情况下,内存分配库将执行一个系统调用来增加堆(例如,传统的UNIX sbrk()系统调用)。然后,操作系统(通常)将提供更多的空间,将段大小寄存器更新为新的(更大的)大小,并通知库更新成功;然后,标准库可以为新对象分配空间,并成功返回到调用程序。请注意,如果没有更多的物理内存可用,或者如果它认为调用进程已经有太多的内存,操作系统可能会拒绝请求。
最后,可能也是最重要的问题是管理物理内存中的空闲空间。当创建一个新的地址空间时,操作系统必须能够在物理内存中为它的段找到空间。以前,我们假设每个地址空间的大小是相同的,因此物理内存可以被认为是一堆可以容纳进程的槽。现在,每个进程有许多段,每个段的大小可能不同。
出现的一般问题是物理内存很快就会充满可用空间的小孔,从而难以分配新段或增加现有段。我们称这个问题为外部碎片(external frag mentation) [R69];参见图 16.6(左)。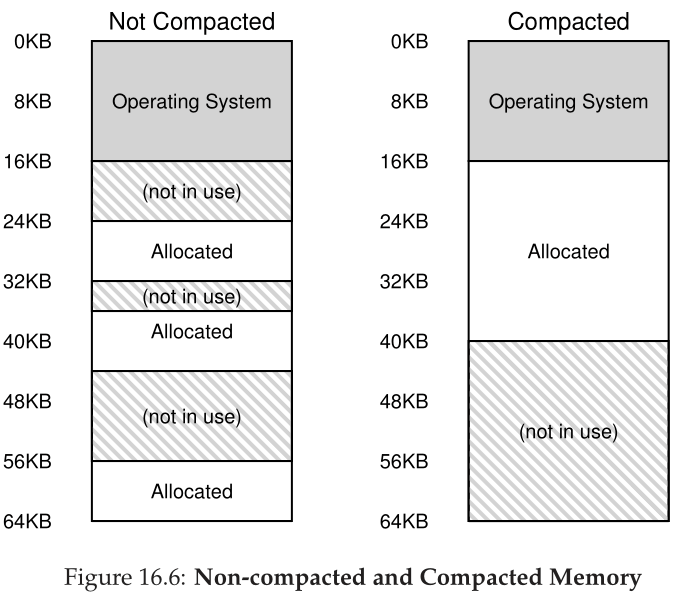
在这个示例中,一个进程希望分配一个20KB的段。在该示例中,有24KB空闲,但不是在一个连续的段中(而是在三个非连续的块中)。因此,操作系统无法满足20KB的请求。类似的问题也可能发生在增大段的请求到达时;如果接下来这么多字节的物理空间不可用,那么操作系统将不得不拒绝请求,即使在物理内存的其他地方可能有可用的空闲字节。
这个问题的一个解决方案是通过重新安排现有的段来压缩(compact)物理内存。例如,操作系统可以停止任何正在运行的进程,将它们的数据复制到一个连续的内存区域,将它们的段寄存器值更改为指向新的物理位置,从而有很大的可用内存范围来工作。通过这样做,操作系统允许新的分配请求成功。但是,压缩是昂贵的,因为复制段是内存密集型的,通常会占用相当多的处理器时间;参见图16.6(右)以获得压缩物理内存的图。压缩(具有讽刺意味的是)还会使增长现有段的请求难以服务,从而可能导致进一步重新安排以适应此类请求。
一种更简单的方法可能是使用空闲链表管理算法,它试图保持大范围的可用内存用于分配。人们已经采用了数百种方法,包括经典算法,如best-fit(保留一个空闲空间链表,并返回一个大小最接近、满足请求者所需分配的空间)、worst-fit、first-fit,以及更复杂的方案,如buddy algorithm [K68]。如果你想了解更多关于这类算法[W+95]的知识,Wilson等人的一份出色的调查是一个很好的开始,或者你可以等到我们在后面的章节中介绍一些基础知识时再开始。然而,不幸的是,无论算法多么聪明,外部碎片仍将存在;因此,一个好的算法只是尝试最小化它。
Tip:如果存在 1000 种解决方案,则没有最好的解决方案 存在这么多不同的算法来尝试最小化外部碎片的事实表明了一个更强大的潜在事实:没有一种“最佳”方法可以解决问题。因此,我们满足于一些合理的东西,并希望它足够好。唯一真正的解决方案(我们将在接下来的章节中看到)是完全避免这个问题,永远不要在可变大小的块中分配内存。
16.7
总结 Summary
分段解决了许多问题,并帮助我们构建更有效的内存虚拟化。除了动态重定位,分段还可以通过避免地址空间的逻辑段之间巨大的潜在内存浪费,更好地支持稀疏地址空间。它也是快速的,因为做算术分段要求是简单的和非常适合硬件;翻译地址的开销是最小的。还有一个附加的好处:代码共享。如果代码被放置在一个单独的段中,那么这个段可能会被多个正在运行的程序共享。
然而,正如我们所了解的,在内存中分配可变大小的段会导致一些我们想要克服的问题。第一个,如上所述,是外部碎片。因为段的大小是可变的,所以空闲内存被分割成各种大小的段,因此满足内存分配请求可能很困难。人们可以尝试使用智能算法[W+95]或周期性压缩内存,但问题是根本性的,难以避免。
第二个可能更重要的问题是,分段仍然不够灵活,无法支持我们的完全泛化稀疏地址空间。例如,如果我们在一个逻辑段中有一个大的但很少使用的堆,那么整个堆必须仍然驻留在内存中才能被访问。换句话说,如果我们关于如何使用地址空间的模型与底层分段设计支持它的方式不完全匹配,分段就不能很好地工作。因此,我们需要找到一些新的解决方案。准备好找到他们了吗?
References
[CV65] “Introduction and Overview of the Multics System” by F. J. Corbato, V. A. Vyssotsky.
Fall Joint Computer Conference, 1965. One of five papers presented on Multics at the Fall Joint
Computer Conference; oh to be a fly on the wall in that room that day!
[DD68] “Virtual Memory, Processes, and Sharing in Multics” by Robert C. Daley and Jack B.
Dennis. Communications of the ACM, Volume 11:5, May 1968. An early paper on how to perform
dynamic linking in Multics, which was way ahead of its time. Dynamic linking finally found its way
back into systems about 20 years later, as the large X-windows libraries demanded it. Some say that
these large X11 libraries were MIT’s revenge for removing support for dynamic linking in early versions
of UNIX!
[G62] “Fact Segmentation” by M. N. Greenfield. Proceedings of the SJCC, Volume 21, May
1962. Another early paper on segmentation; so early that it has no references to other work.
[H61] “Program Organization and Record Keeping for Dynamic Storage” by A. W. Holt. Com-
munications of the ACM, Volume 4:10, October 1961. An incredibly early and difficult to read paper
about segmentation and some of its uses.
[I09] “Intel 64 and IA-32 Architectures Software Developer’s Manuals” by Intel. 2009. Avail-
able: http://www.intel.com/products/processor/manuals. Try reading about segmentation in
here (Chapter 3 in Volume 3a); it’ll hurt your head, at least a little bit.
[K68] “The Art of Computer Programming: Volume I” by Donald Knuth. Addison-Wesley,
1968. Knuth is famous not only for his early books on the Art of Computer Programming but for his
typesetting system TeX which is still a powerhouse typesetting tool used by professionals today, and
indeed to typeset this very book. His tomes on algorithms are a great early reference to many of the
algorithms that underly computing systems today.
[L83] “Hints for Computer Systems Design” by Butler Lampson. ACM Operating Systems
Review, 15:5, October 1983. A treasure-trove of sage advice on how to build systems. Hard to read in
one sitting; take it in a little at a time, like a fine wine, or a reference manual.
[LL82] “Virtual Memory Management in the VAX/VMS Operating System” by Henry M. Levy,
Peter H. Lipman. IEEE Computer, Volume 15:3, March 1982. A classic memory management
system, with lots of common sense in its design. We’ll study it in more detail in a later chapter.
[RK68] “Dynamic Storage Allocation Systems” by B. Randell and C.J. Kuehner. Communica-
tions of the ACM, Volume 11:5, May 1968. A nice overview of the differences between paging and
segmentation, with some historical discussion of various machines.
[R69] “A note on storage fragmentation and program segmentation” by Brian Randell. Com-
munications of the ACM, Volume 12:7, July 1969. One of the earliest papers to discuss fragmenta-
tion.
[W+95] “Dynamic Storage Allocation: A Survey and Critical Review” by Paul R. Wilson, Mark
S. Johnstone, Michael Neely, David Boles. International Workshop on Memory Management,
Scotland, UK, September 1995. A great survey paper on memory allocators.
Homework (Simulation)
这个程序可以让你看到地址翻译是如何在一个分段系统执行的。有关详细信息,请参阅README。
Questions
- 首先,让我们使用一个很小的地址空间来转换一些地址。这是一组简单的参数,有一些不同的随机种子;你能翻译这些地址吗?

- 现在,让我们看看我们是否理解我们构建的这个微小的地址空间(使用上述问题中的参数)。段 0 中最高的合法虚拟地址是多少?段 1 中最低的合法虚拟地址怎么样?整个地址空间中最低和最高的非法地址分别是什么?最后,您将如何使用 -A 标志运行 segment.py 来测试您是否正确?
- 假设在128字节的物理内存中有一个很小的16字节地址空间。您将设置什么基和边界以使模拟器为指定的地址流生成以下转换结果:valid, valid, violation, … , violation, valid, valid?假设以下参数:
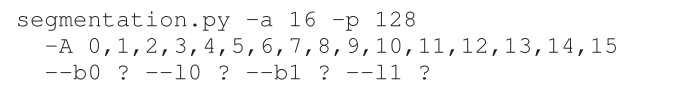
- 假设我们想要产生一个问题,其中大约90%的随机生成的虚拟地址是有效的(不是分段违规)。您应该如何配置模拟器来做到这一点?哪些参数对得到这个结果很重要?
- 您是否可以运行模拟器以使没有虚拟地址是有效的?如何做?

若有收获,就点个赞吧
0 人点赞
