python基础:字符串
本节知识结构
字符串其实也算是一种特殊的有序容器,因为比较特别
所以单独分了出来

字符串
定义字符串
# 字符串'Hibari'"Hibari"# 字符串变量s = 'Hibari's2 = "Hibari"
字符元素
 ```python
S[index]
```python
S[index]
参数说明
S 字符串变量
index 整数(表示字符串的下标)
#
返回值
S[] 字符(返回当前元素储存的一个字符)
#
功能说明:
下标从0往大,表示从元素从第一个开始往后数
下标从-1往更小,表示倒着数
#
注意:
虽然单个元素可以单独取出,但并不能修改
```python# ================================# 示例a = "pyt"print(a[0])print(a[1])print(a[2])print(" ")print(a[-1])print(a[-2])print(a[-3])# 输出pyttyp# ================================
字符串格式化
# 通过符号'+'可以将字符串连接起来
# ================================# 示例a = 'py' +'th' +'on'print(a)# 输出python# ================================
%s、%d、%f 字符串格式化符号
# 字符串格式化符号:用法和c语言的一样# %s 整数格式化符号# %d 整数格式化符号# %f 浮点格式化符号## 浮点精度:# %.1f 保留1位小数# %.2f 以此类推保留2位
# ================================# 示例name = 'Hibari'no = 22time = 10.16print("Cname: %s" %name)print("Number: %d" %no)print("Ctime: %f" %time)print("Cname: %s Number: %d Ctime: %.2f" %(name,no,time))#输出Cname: HibariNumber: 22Ctime: 10.160000Cname: Hibari Number: 22 Ctime: 10.16# ================================
format( ) 字符串格式化方法
 ```python
```python
示例1
name = ‘Hibari’ no = 22 time = 10.16 print(“Cname: {} Number: {} Ctime: {:.1f}” .format(name,no,time)) print(“ctime: {:.1f}”.format(time))
输出
Cname: Hibari Number: 22 Ctime: 10.2 ctime: 10.2
```python# 示例2S = "{2} {0} {1:.1f}"print(S.format('Hibari', 3.1415, 'ID:'))# 输出ID: Hibari 3.1
字符串内置方法
find( ):——- 查找字符串
 ```python
```python
示例
s = “this is not the page” a = s.find(“is”) b = s.find(“is”,3,8) c = s.find(“hibari”) print(a) print(b) print(c)
输出
2 # this中从第3个元素开始有is,所以返回下标2 5 # 从第(3+1)个元素开始查找,第(8+1)个元素结束到第6个元素找到, -1 # 没有找到,返回-1
---<a name="JEDrj"></a>#### count( ):----统计相同字符串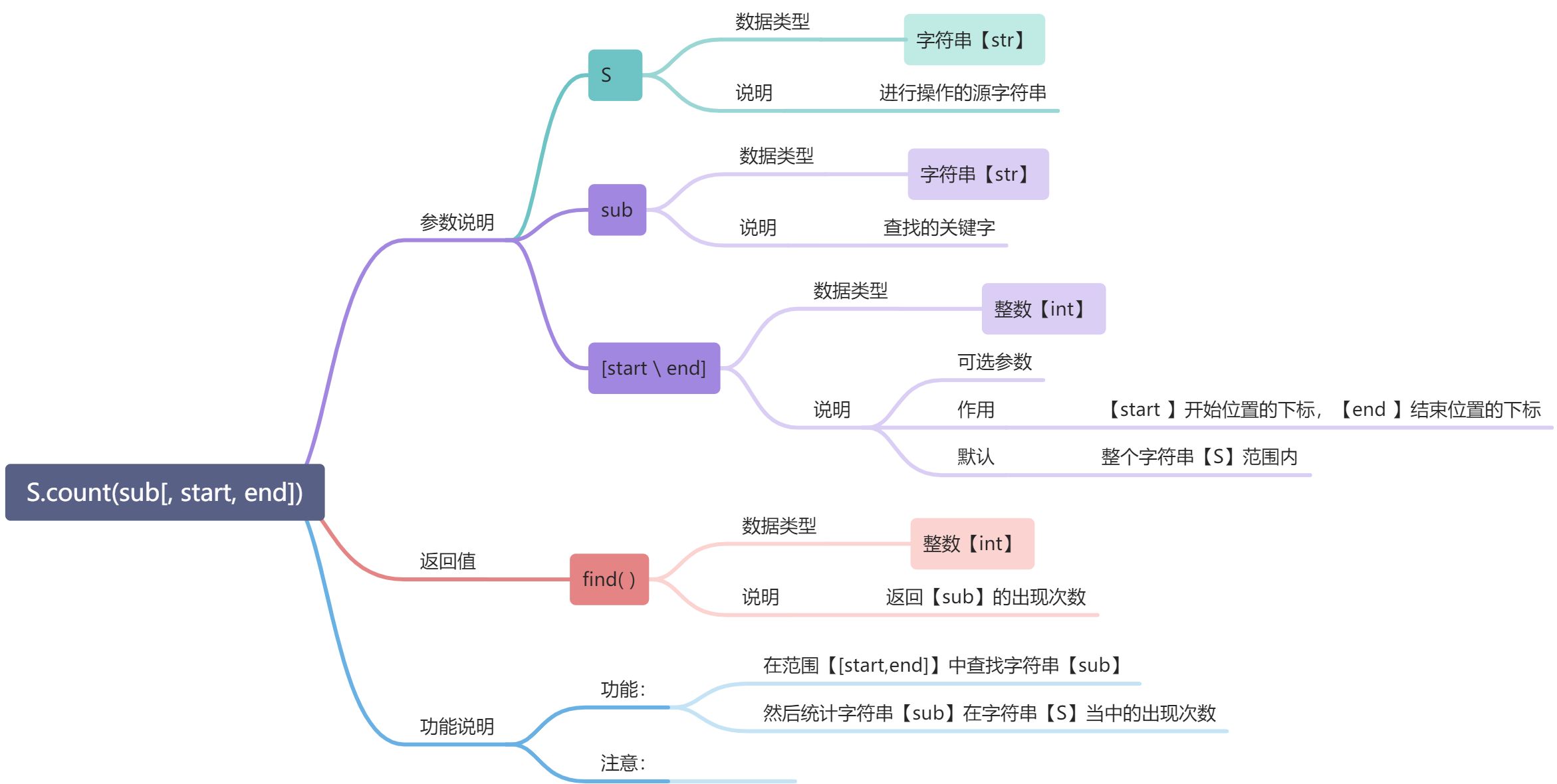```python# 示例s = "this is not the page"a = s.count("is")b = s.count("is",3,8)c = s.count("hibari")print(a)print(b)print(c)# 输出210
replace( ):—替换字符串
 ```python
```python
示例
s = “this is not the page” a = s.replace(“is”,”xx”) b = s.replace(“is”,”xx”,1) print(s) print(a) print(b)
输出
this is not the page thxx xx not the page thxx is not the page
---<a name="38Cqr"></a>#### split( ):------分割字符串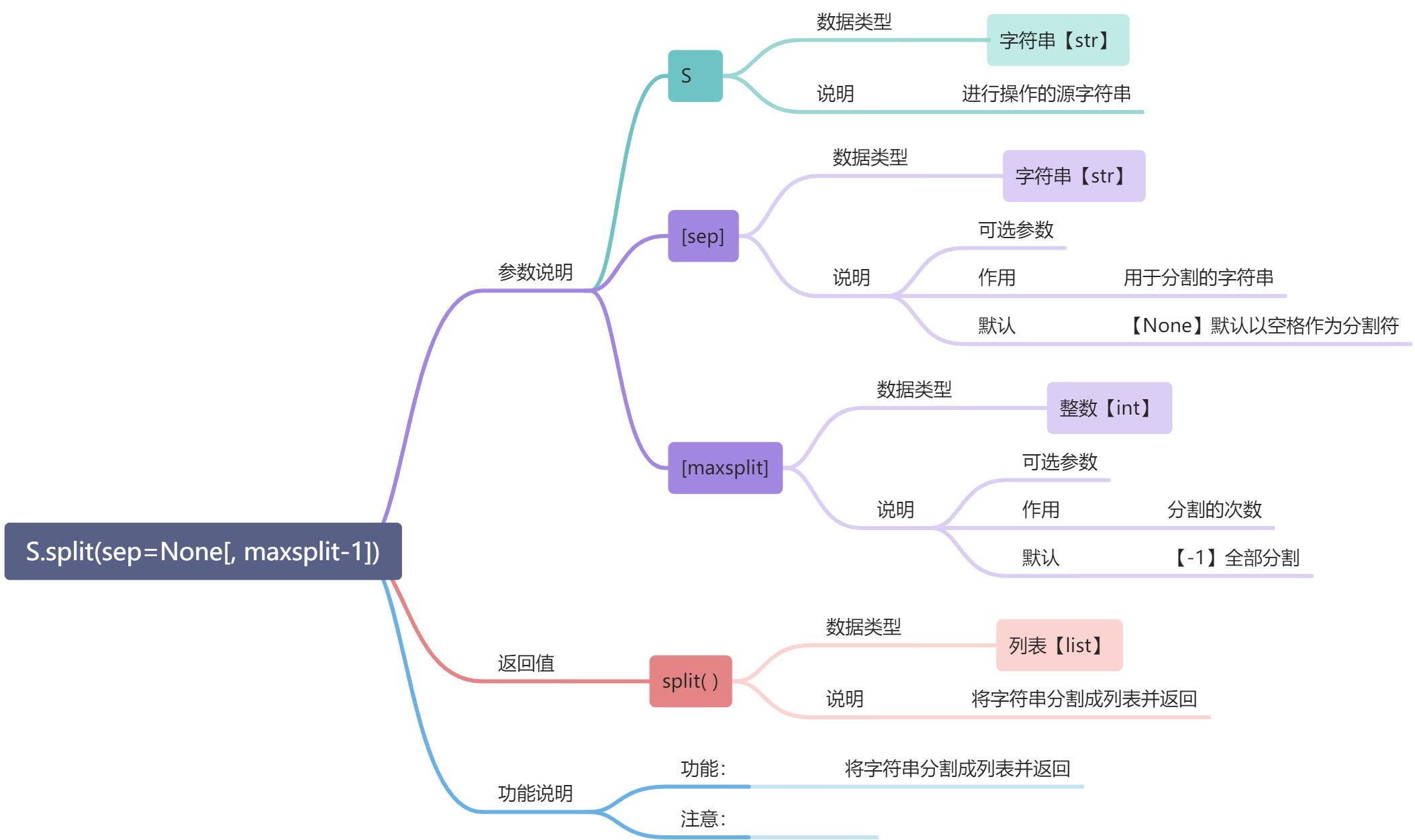```python# 示例s = "this is not the web page pagepagepage"a = s.split()b = s.split("ag", 2)print(a)print(b)# 输出['this', 'is', 'not', 'the', 'web', 'page', 'pagepagepage']['this is not the web p', 'e p', 'epagepage']
————————————-
startswith( ):判断起始字符串
endswith( ):-判断后缀字符串

# 示例s = "this is not the web page you are looling for"print(s.startswith("this"))print(s.startswith("this",5,))print(s.startswith("is",5,))print(s.endswith("for"))# 输出TrueFalseTrueTrue
————————————-
upper( ):——-字符串转大写
lower( ):——-字符串转小写
 ```python
```python
示例
s = “Hello World” print(s.upper()) print(“Hello World”.upper()) print(s.lower)
输出
HELLO WORLD HELLO WORLD hello world
<a name="m8Bgs"></a>#### <br /><a name="zvCyU"></a>#### ----------------------------<a name="LZijA"></a>#### join( ):-------序列 转 字符串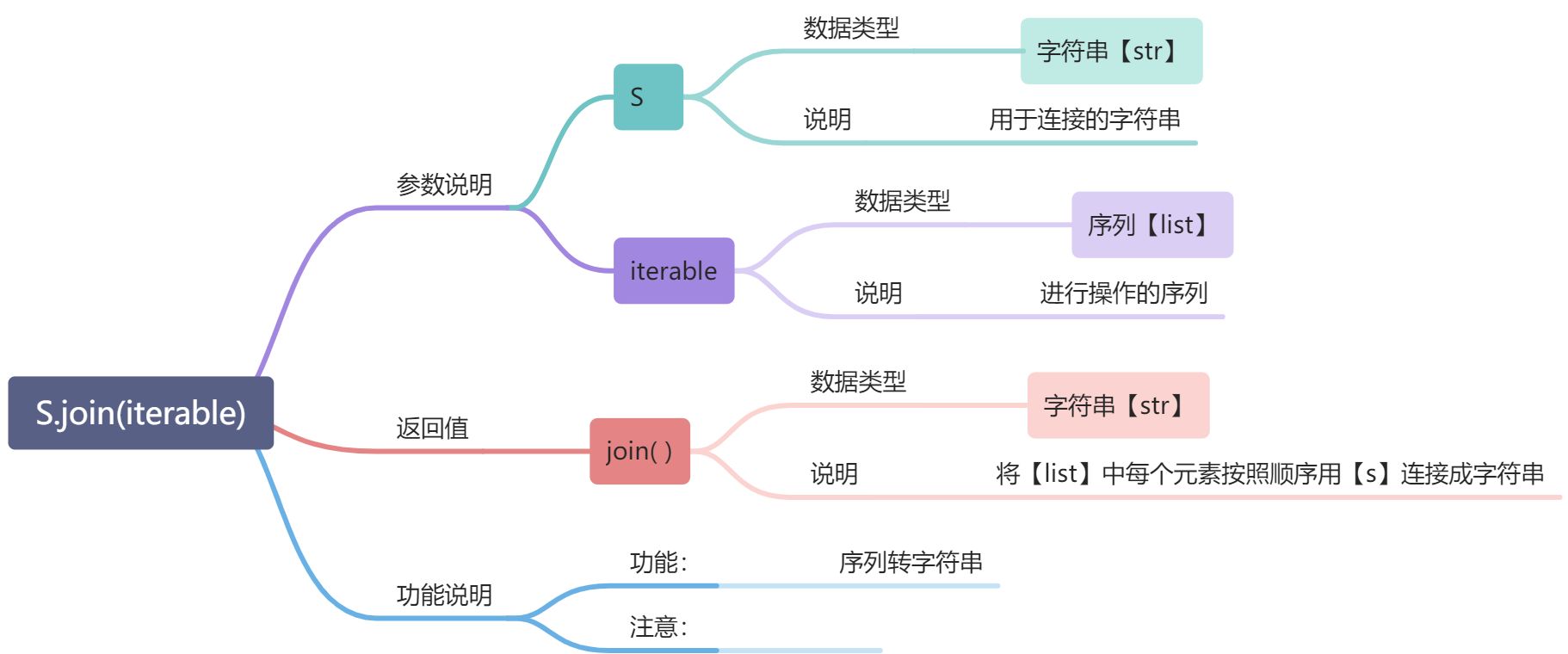```python# 示例s = "/////"a = ["Hello", "World", "And", "Python"]print (s.join(a))# 输出Hello/////World/////And/////Python
strip( ):———去除开头和结尾的指定字符
 ```python
```python
示例
a = “/////Python.py” b = a.strip(“.py”) c = a.strip(“/“) print(b) print(c) print( (a.strip(“/“)).strip(“.py”) )
输出
/////Python Python.py Python
---<a name="3JHaz"></a>#### len( ):--------长度查询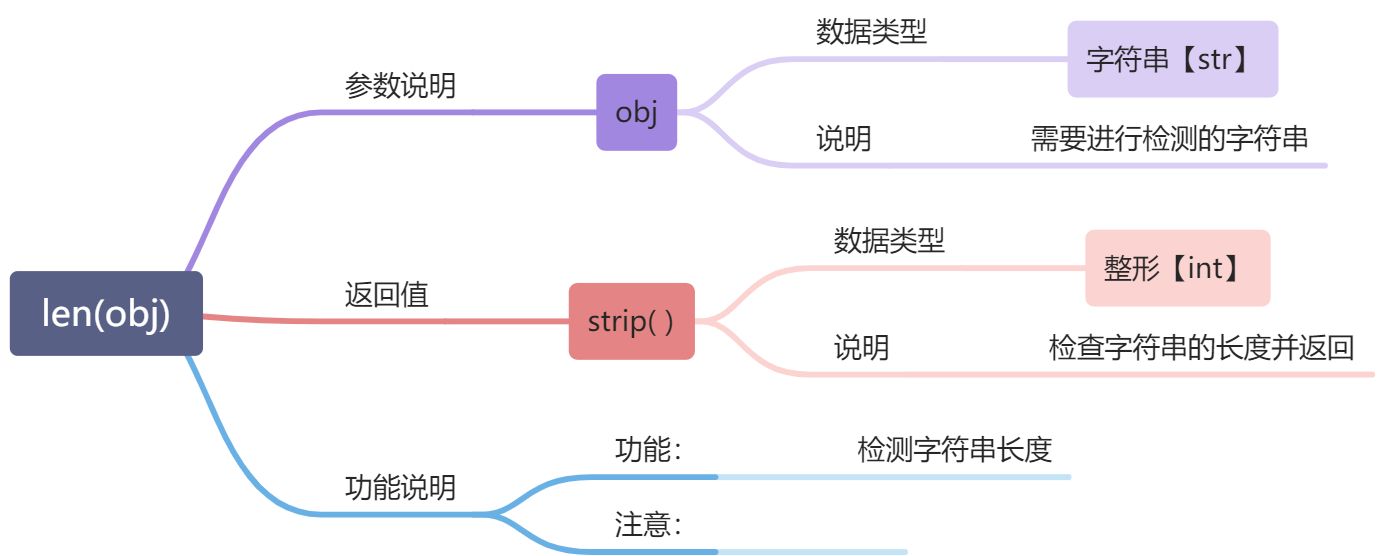```python# 示例a = (1, "pythong", 3.14)s = "Hello World"print(len(a))print(len(s))# 输出311

若有收获,就点个赞吧
0 人点赞
