
第一题给我整懵了,还是得好好读题!
t1:没按照顺序输出,wrong了一发
t2:没有考虑抢劫的那天与前面和后面的关系,wrong了一次
t3:溢出,wrong了一次
t4:虽然写出来了,但不是很优雅,待后续看看大佬的写法!
5934. 找到和最大的长度为 K 的子序列
给你一个整数数组 nums 和一个整数 k 。你需要找到 nums 中长度为 k 的 子序列 ,且这个子序列的 和最大 。
请你返回 任意 一个长度为 k 的整数子序列。
子序列 定义为从一个数组里删除一些元素后,不改变剩下元素的顺序得到的数组。
示例 1:
输入:nums = [2,1,3,3], k = 2 输出:[3,3] 解释: 子序列有最大和:3 + 3 = 6 。
示例 2:
输入:nums = [-1,-2,3,4], k = 3 输出:[-1,3,4] 解释: 子序列有最大和:-1 + 3 + 4 = 6 。
示例 3:
输入:nums = [3,4,3,3], k = 2 输出:[3,4] 解释: 子序列有最大和:3 + 4 = 7 。 另一个可行的子序列为 [4, 3] 。
提示:
- 1 <= nums.length <= 1000
- -105 <= nums[i] <= 105
- 1 <= k <= nums.length
思路:
暴力
方法1:遍历数组k次,找到最大的k个数,并一次输出
方法2:存储每个数及其对应下标,首选按照数的大小排序,其次将前k个按照下标排序,最后输出
//方法2class Solution {public int[] maxSubsequence(int[] nums, int k) {int n = nums.length;int[][] a = new int[n][2];int[][] b = new int[k][2];for (int i = 0; i < n; i++) {a[i] = new int[]{i, nums[i]};}Arrays.sort(a, (o1, o2) -> (o1[1] == o2[1] ? o1[0] - o2[0] : o2[1] - o1[1]));for (int i = 0; i < k; i++)b[i] = a[i];Arrays.sort(b, (o1, o2) -> (o1[0] - o2[0]));int[] res = new int[k];for (int i = 0; i < k; i++)res[i] = b[i][1];return res;}}
5935. 适合打劫银行的日子
你和一群强盗准备打劫银行。给你一个下标从 0 开始的整数数组 security ,其中 security[i] 是第 i 天执勤警卫的数量。日子从 0 开始编号。同时给你一个整数 time 。
如果第 i 天满足以下所有条件,我们称它为一个适合打劫银行的日子:
- 第 i 天前和后都分别至少有 time 天。
- 第 i 天前连续 time 天警卫数目都是非递增的。
- 第 i 天后连续 time 天警卫数目都是非递减的。
更正式的,第 i 天是一个合适打劫银行的日子当且仅当:security[i - time] >= security[i - time + 1] >= … >= security[i] <= … <= security[i + time - 1] <= security[i + time].
请你返回一个数组,包含 所有 适合打劫银行的日子(下标从 0 开始)。返回的日子可以 任意 顺序排列。
示例 1:
输入:security = [5,3,3,3,5,6,2], time = 2 输出:[2,3] 解释: 第 2 天,我们有 security[0] >= security[1] >= security[2] <= security[3] <= security[4] 。 第 3 天,我们有 security[1] >= security[2] >= security[3] <= security[4] <= security[5] 。 没有其他日子符合这个条件,所以日子 2 和 3 是适合打劫银行的日子。
示例 2:
输入:security = [1,1,1,1,1], time = 0 输出:[0,1,2,3,4] 解释: 因为 time 等于 0 ,所以每一天都是适合打劫银行的日子,所以返回每一天。
示例 3:
输入:security = [1,2,3,4,5,6], time = 2 输出:[] 解释: 没有任何一天的前 2 天警卫数目是非递增的。 所以没有适合打劫银行的日子,返回空数组。
示例 4:
输入:security = [1], time = 5 输出:[] 解释: 没有日子前面和后面有 5 天时间。 所以没有适合打劫银行的日子,返回空数组。
提示:
- 1 <= security.length <= 105
- 0 <= security[i], time <= 105
思路:
贪心,前后各遍历计算一次到当前天为止合法的连续天数,并分别记录
class Solution {public List<Integer> goodDaysToRobBank(int[] s, int time) {int n = s.length;int[] pre = new int[n], last = new int[n];int len = 0;for (int i = 0; i < n; i++) {if (i == 0) {len = 1;pre[i] = len;} else {if (s[i] <= s[i - 1])len++;elselen = 1;pre[i] = len;}}len = 0;for (int i = n - 1; i >= 0; i--) {if (i == n - 1) {len = 1;last[i] = len;}else {if (s[i] <= s[i + 1])len++;elselen = 1;last[i] = len;}}List<Integer> res = new ArrayList<>();for (int i = 0; i < n; i++) {if (pre[i] >= time + 1 && last[i] >= time + 1)res.add(i);}return res;}}
5936. 引爆最多的炸弹
给你一个炸弹列表。一个炸弹的 爆炸范围 定义为以炸弹为圆心的一个圆。
炸弹用一个下标从 0 开始的二维整数数组 bombs 表示,其中 bombs[i] = [xi, yi, ri] 。xi 和 yi 表示第 i 个炸弹的 X 和 Y 坐标,ri 表示爆炸范围的 半径 。
你需要选择引爆 一个 炸弹。当这个炸弹被引爆时,所有 在它爆炸范围内的炸弹都会被引爆,这些炸弹会进一步将它们爆炸范围内的其他炸弹引爆。
给你数组 bombs ,请你返回在引爆 一个 炸弹的前提下,最多 能引爆的炸弹数目。
示例 1:
输入:bombs = [[2,1,3],[6,1,4]] 输出:2 解释: 上图展示了 2 个炸弹的位置和爆炸范围。 如果我们引爆左边的炸弹,右边的炸弹不会被影响。 但如果我们引爆右边的炸弹,两个炸弹都会爆炸。 所以最多能引爆的炸弹数目是 max(1, 2) = 2 。
示例 2:
输入:bombs = [[1,1,5],[10,10,5]] 输出:1 解释: 引爆任意一个炸弹都不会引爆另一个炸弹。所以最多能引爆的炸弹数目为 1 。
示例 3: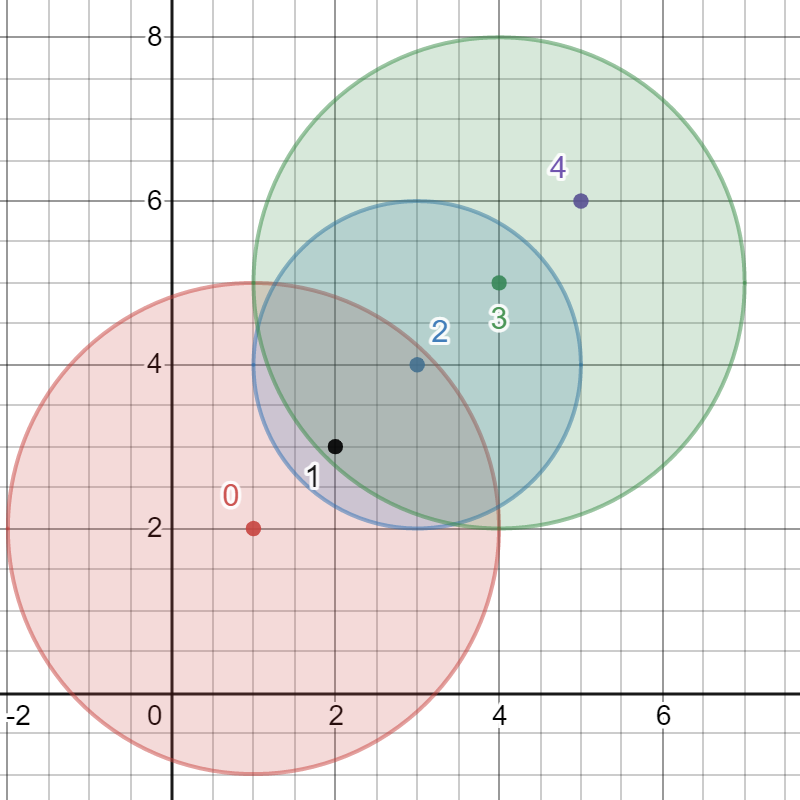
输入:bombs = [[1,2,3],[2,3,1],[3,4,2],[4,5,3],[5,6,4]] 输出:5 解释: 最佳引爆炸弹为炸弹 0 ,因为: - 炸弹 0 引爆炸弹 1 和 2 。红色圆表示炸弹 0 的爆炸范围。 - 炸弹 2 引爆炸弹 3 。蓝色圆表示炸弹 2 的爆炸范围。 - 炸弹 3 引爆炸弹 4 。绿色圆表示炸弹 3 的爆炸范围。 所以总共有 5 个炸弹被引爆。
提示:
- 1 <= bombs.length <= 100
- bombs[i].length == 3
- 1 <= xi, yi, ri <= 105
思路:本质是有向图的连通性
- 建图,引爆每个炸弹时哪些炸弹会爆得出每个点的所有出边
- bfs,计算引爆每个炸弹时最多有多少个炸弹爆炸
class Solution {public int maximumDetonation(int[][] b) {Map<Integer, List<Integer>> map = new HashMap<>();int n = b.length;for (int i = 0; i < n; i++) {for (int j = 0; j < n; j++) {if (j == i) continue;if (check(b[i], b[j]))map.computeIfAbsent(i, key -> new ArrayList<>()).add(j);}}int max = 0;boolean[] st = new boolean[n];Queue<Integer> q = new LinkedList<>();for (int i = 0; i < n; i++) {Arrays.fill(st, false);int cnt = 1;q.offer(i);st[i] = true;while (!q.isEmpty()) {int cur = q.poll();List<Integer> list = map.get(cur);if (list == null) continue;for (int x : list) {if (st[x]) continue;st[x] = true;q.offer(x);cnt++;}}max = Math.max(cnt, max);}return max;}boolean check(int[] a, int[] b) {double x = a[0] - b[0], y = a[1] - b[1];return 1L * x * x + y * y <= 1L * a[2] * a[2];}}
5937. 序列顺序查询
一个观光景点由它的名字 name 和景点评分 score 组成,其中 name 是所有观光景点中 唯一 的字符串,score 是一个整数。景点按照最好到最坏排序。景点评分 越高 ,这个景点越好。如果有两个景点的评分一样,那么 字典序较小 的景点更好。
你需要搭建一个系统,查询景点的排名。初始时系统里没有任何景点。这个系统支持:
- 添加 景点,每次添加 一个 景点。
- 查询 已经添加景点中第 i 好 的景点,其中 i 是系统目前位置查询的次数(包括当前这一次)。
- 比方说,如果系统正在进行第 4 次查询,那么需要返回所有已经添加景点中第 4 好的。
注意,测试数据保证 任意查询时刻 ,查询次数都 不超过 系统中景点的数目。
请你实现 SORTracker 类:
- SORTracker() 初始化系统。
- void add(string name, int score) 向系统中添加一个名为 name 评分为 score 的景点。
- string get() 查询第 i 好的景点,其中 i 是目前系统查询的次数(包括当前这次查询)。
示例:
输入: [“SORTracker”, “add”, “add”, “get”, “add”, “get”, “add”, “get”, “add”, “get”, “add”, “get”, “get”] [[], [“bradford”, 2], [“branford”, 3], [], [“alps”, 2], [], [“orland”, 2], [], [“orlando”, 3], [], [“alpine”, 2], [], []]
输出: [null, null, null, “branford”, null, “alps”, null, “bradford”, null, “bradford”, null, “bradford”, “orland”]
解释:
SORTracker tracker = new SORTracker(); // 初始化系统
tracker.add(“bradford”, 2); // 添加 name=”bradford” 且 score=2 的景点。
tracker.add(“branford”, 3); // 添加 name=”branford” 且 score=3 的景点。
tracker.get(); // 从好带坏的景点为:branford ,bradford 。 // 注意到 branford 比 bradford 好,因为它的 评分更高 (3 > 2) 。 // 这是第 1 次调用 get() ,所以返回最好的景点:”branford” 。tracker.add(“alps”, 2); // 添加 name=”alps” 且 score=2 的景点。
tracker.get(); // 从好到坏的景点为:branford, alps, bradford 。 // 注意 alps 比 bradford 好,虽然它们评分相同,都为 2 。 // 这是因为 “alps” 字典序 比 “bradford” 小。 // 返回第 2 好的地点 “alps” ,因为当前为第 2 次调用 get() 。
tracker.add(“orland”, 2); // 添加 name=”orland” 且 score=2 的景点。 tracker.get(); // 从好到坏的景点为:branford, alps, bradford, orland 。 // 返回 “bradford” ,因为当前为第 3 次调用 get() 。 tracker.add(“orlando”, 3); // 添加 name=”orlando” 且 score=3 的景点。 tracker.get(); // 从好到坏的景点为:branford, orlando, alps, bradford, orland 。 // 返回 “bradford”. tracker.add(“alpine”, 2); // 添加 name=”alpine” 且 score=2 的景点。
tracker.get(); // 从好到坏的景点为:branford, orlando, alpine, alps, bradford, orland 。 // 返回 “bradford” 。 tracker.get(); // 从好到坏的景点为:branford, orlando, alpine, alps, bradford, orland 。 // 返回 “orland” 。
提示:
- name 只包含小写英文字母,且每个景点名字互不相同。
- 1 <= name.length <= 10
- 1 <= score <= 105
- 任意时刻,调用 get 的次数都不超过调用 add 的次数。
- 总共 调用 add 和 get 不超过 4 * 104
思路:
比赛时的做法太烂了,就不写了
方法一:使用两个优先队列,一个从好到差pd,另一个从差到好pg
1. 每次插入一个元素都将其放入`pg`中,比较两堆的堆顶元素,若pd的堆顶元素比pg差,就交换他们2. 每次调用get()函数都相当于返回pg的堆顶元素,故将其弹出,插入到`pd`中,方便下一轮查询。
class SORTracker {class Node {String name;int score;Node(String name, int score) {this.name = name;this.score = score;}}//降序Comparator<Node> comp =(o1, o2) -> {if (o1.score != o2.score)return -(o1.score - o2.score);elsereturn o1.name.compareTo(o2.name);};PriorityQueue<Node> pd;PriorityQueue<Node> pg;public SORTracker() {pd = new PriorityQueue<>((o1, o2) -> {if (o1.score != o2.score)return o1.score - o2.score;elsereturn -o1.name.compareTo(o2.name);});pg = new PriorityQueue<>((o1, o2) -> {if (o1.score != o2.score)return -(o1.score - o2.score);elsereturn o1.name.compareTo(o2.name);});}public void add(String name, int score) {pg.add(new Node(name, score));while (!pd.isEmpty() && comp.compare(pg.peek(), pd.peek()) < 0) {Node a = pg.poll();Node b = pd.poll();pg.offer(b);pd.offer(a);}}public String get() {Node t = pg.poll();pd.offer(t);return t.name;}}/*** Your SORTracker object will be instantiated and called as such:* SORTracker obj = new SORTracker();* obj.add(name,score);* String param_2 = obj.get();*/

若有收获,就点个赞吧
0 人点赞
