


信息图表需要经历无数次推敲,才能更好得传递信息,全文13000字左右,阅读时长30分钟
图表是数据可视化的常用表现形式,是对数据的二次加工,可以帮助我们理解数据、洞悉数据背后的真相,让我们更好地适应这个数据驱动的世界。无论在工作汇报、产品设计、后台设计以及数据大屏中都能看到它的身影。然而,在实际工作中我发现很多初入行的设计师对于图表设计并不是很了解,同时市面上对于这方面的资料相对零散,不成体系。所以我结合了平时工作中的理解,梳理了这篇文章,希望能帮助到大家。
一、图表的组成
1. 图表的构成
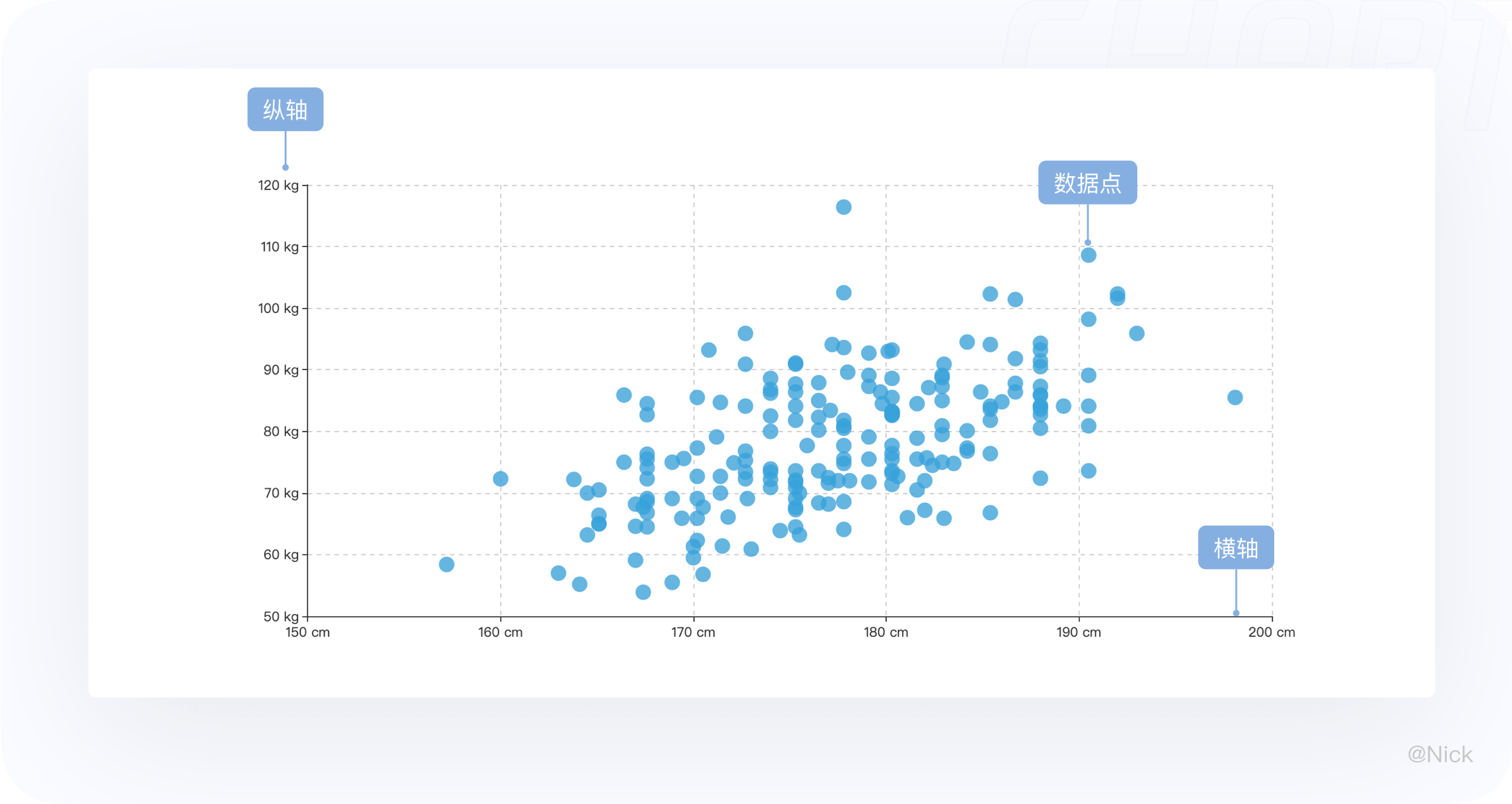
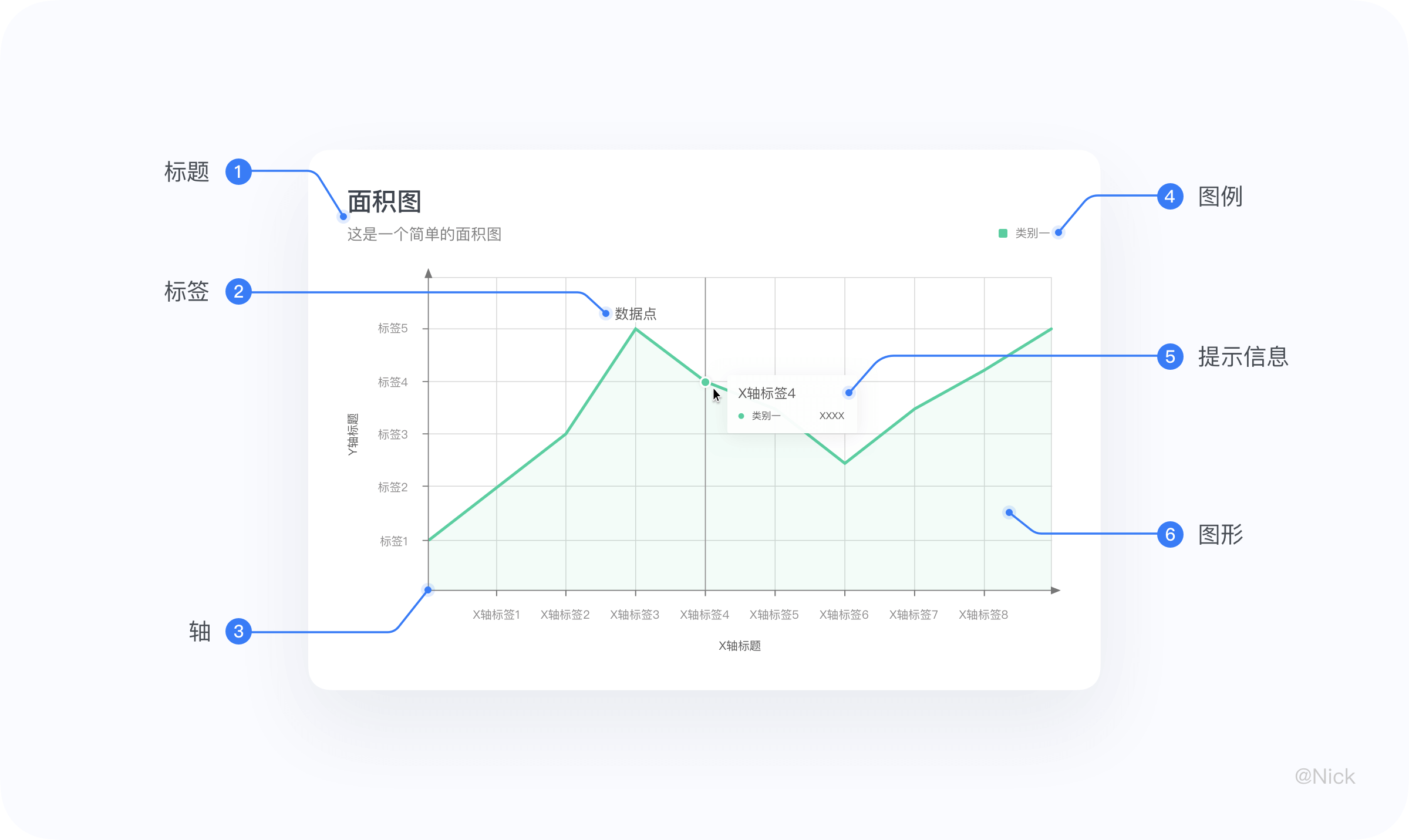
当我们把图表的结构进行拆解后,就会发现一个图表是由很多个细小构件组成的,这些构件有自己的名字和用途,分别是标题、轴、图形、图例、标签、提示信息。在平常使用的过程中,会根据场景去修饰删减一些构件元素,以此来减少冗余信息,用最适量的数据墨水比(Data-ink Ratio),帮助用户快速达成目标,在最少的时间内获取更多的信息。
- 标题 - 描述图表的主题(包含主标题和副标题)
- 标签 - 对当前这一组数据进行的内容标注
- 轴 - 用来定义坐标系中数据在方向和值的映射关系
- 图例 - 对图形本身的概括
- 提示信息 - 当tap或者hover的时候,以交互提示信息的形式展示该点的数据详情
- 图形 - 统计图表的视觉通道在形状上映射的视觉展现
接下来,我会一点一点地为大家讲解它们,方便大家合理的使用它们。但在此之前,我们先来了解一个知识点 - 数据墨水比,以便更好的理解接下来的内容。
2. 数据墨水比
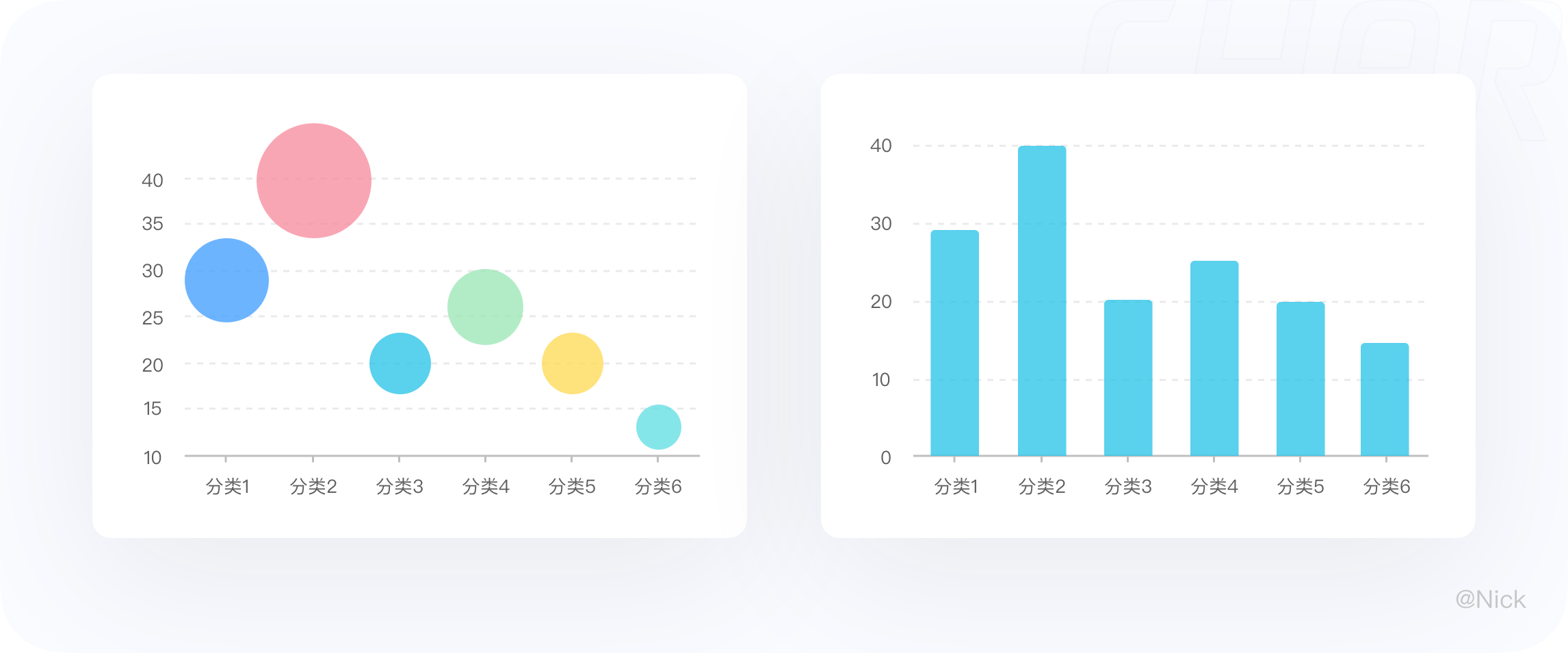
数据墨水比——“data-ink ratio”,是1983年视觉大师爱德华·塔夫特(Edward Tufte)在《The Visual Display of Quantitative Information》中提出的一个概念:一幅图表的绝大部分笔墨应该用于展示数据信息,数据变化则笔墨也变化。他将数据油墨比定义为图表中用于数据的墨水量除以总油墨量。其中数据墨水指的是图表中不可删除的核心内容。比如,我可以删除图例、删除坐标轴、删除网格线,这可能不会影响你从图表中读取相关的信息。但如果我删除柱形图、饼图这些图表的主体元素,那么图表就失去所要表达的内容了。
我个人更喜欢用“信噪比”= 信号/(信号+噪音) 这个概念去理解,因为通过可视化传达的信息不仅仅是数据,还有业务洞察,像观点、结论性的信息往往需要用文字来呈现的也是至关重要。不过无论使用哪个词,最终的目的都是突出传达“信息”部分,去除那些干扰的“噪音”。
因此,图表中的数据墨水占比越多,那么该图表的冗余信息就越少,信息传递效果就越好。所以,在创建图表和图形时,我们的目标应该是在合理范围内最大化数据墨水比。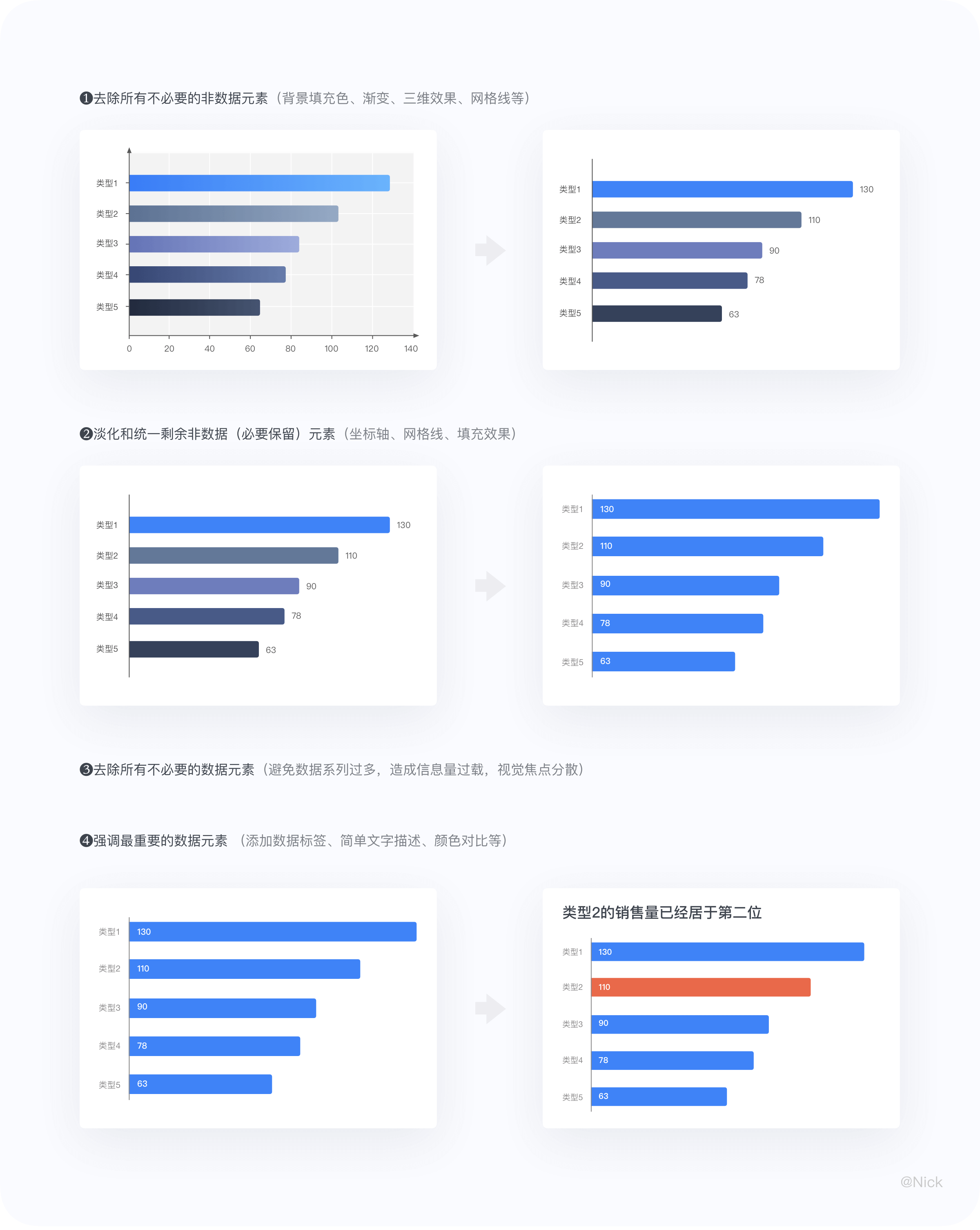
二、图表元素详解
1.标题
一个明确、相符的标题可以迅速让读者理解图表要表达的内容。通常图表的标题是根据图表所需要表达的内容决定的,大多数小伙伴可能认为命名没有太多问题。但当这个图表的结论是单一且唯一的时候,建议在概括图表内容的标题中加入结论性的信息点。这样能减少读者误解你的意图的可能,而且能够确保他们将注意力集中于你想着重强调的数据上 。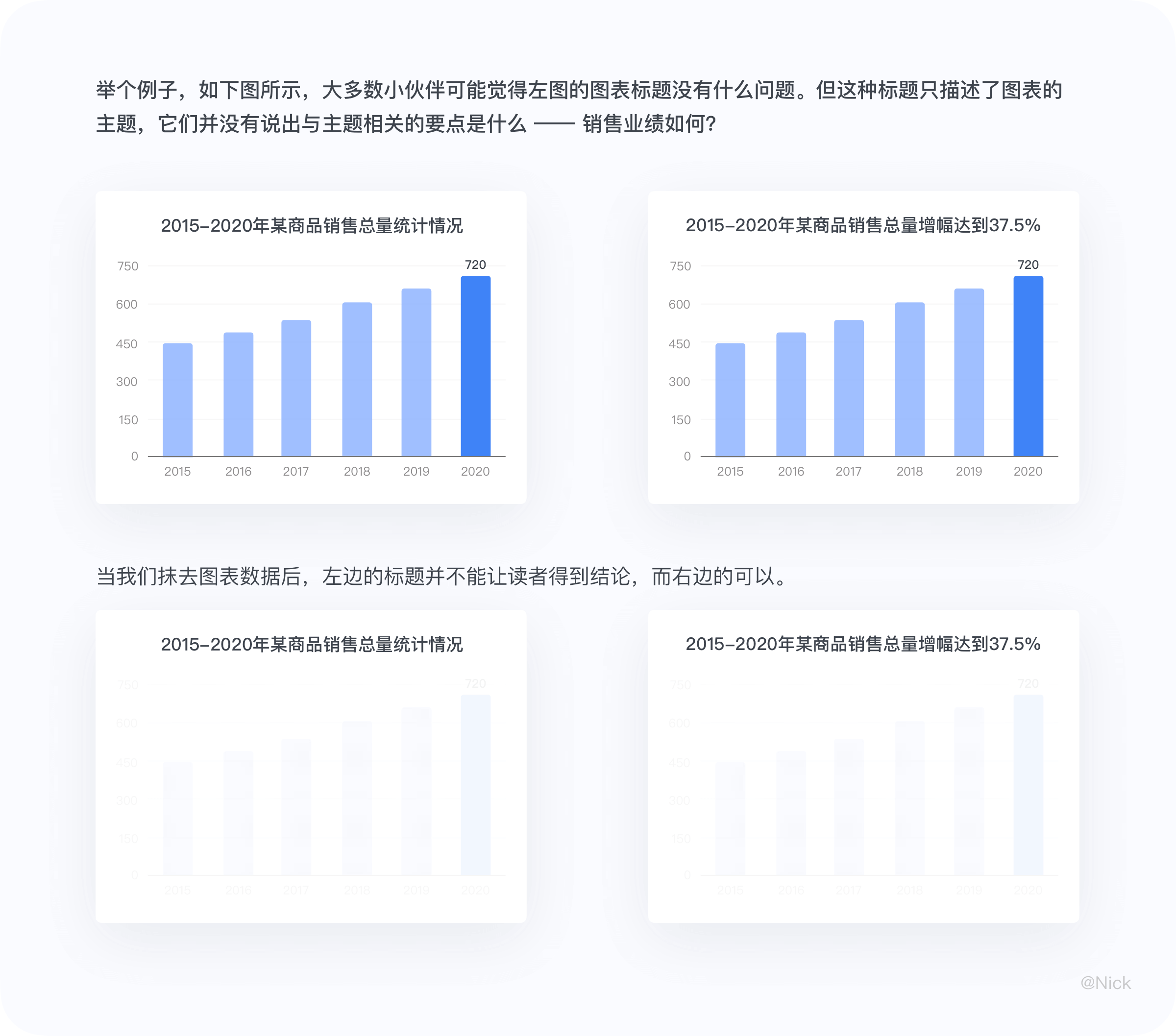
2. 轴(坐标轴)
2.1 定义
轴是能够使每个数组在维度空间内找到映射关系的定位系统,更偏向数学/物理概念。换句话说,轴的功能像是把可视化对象置于共同的基准上,再以标尺进行数值量测。在数据可视化中,一般存在于笛卡尔坐标系(直角坐标系)和极坐标系中。对轴进行「原子」要素的拆分,我们可以得到以下几种元素,分别为:轴线、轴刻度线、轴标签、轴标题(单位)以及网格线。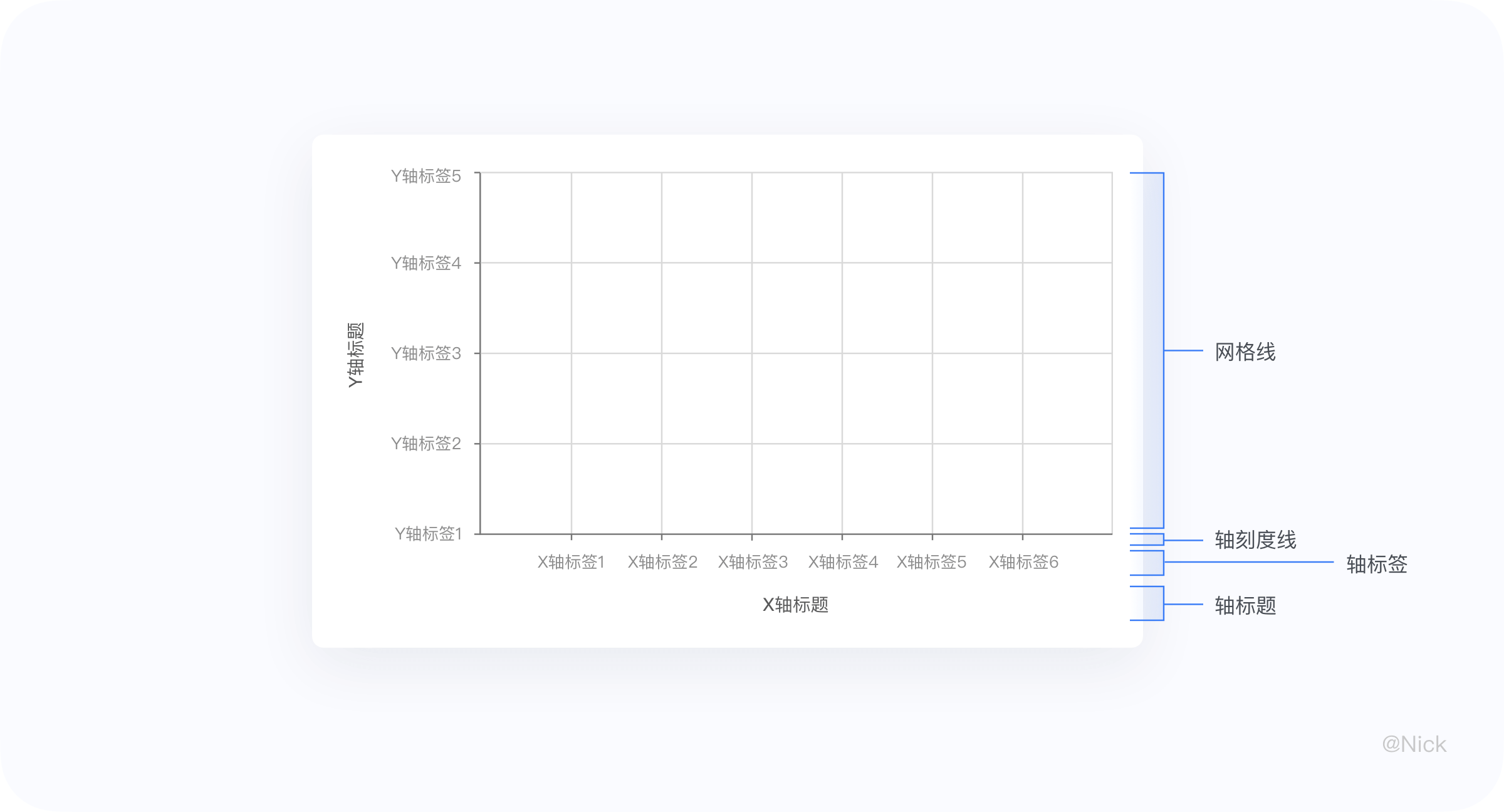
2.2 分类
根据对应变量是连续数据还是离散数据,轴可以分为:分类轴,时间轴,连续轴。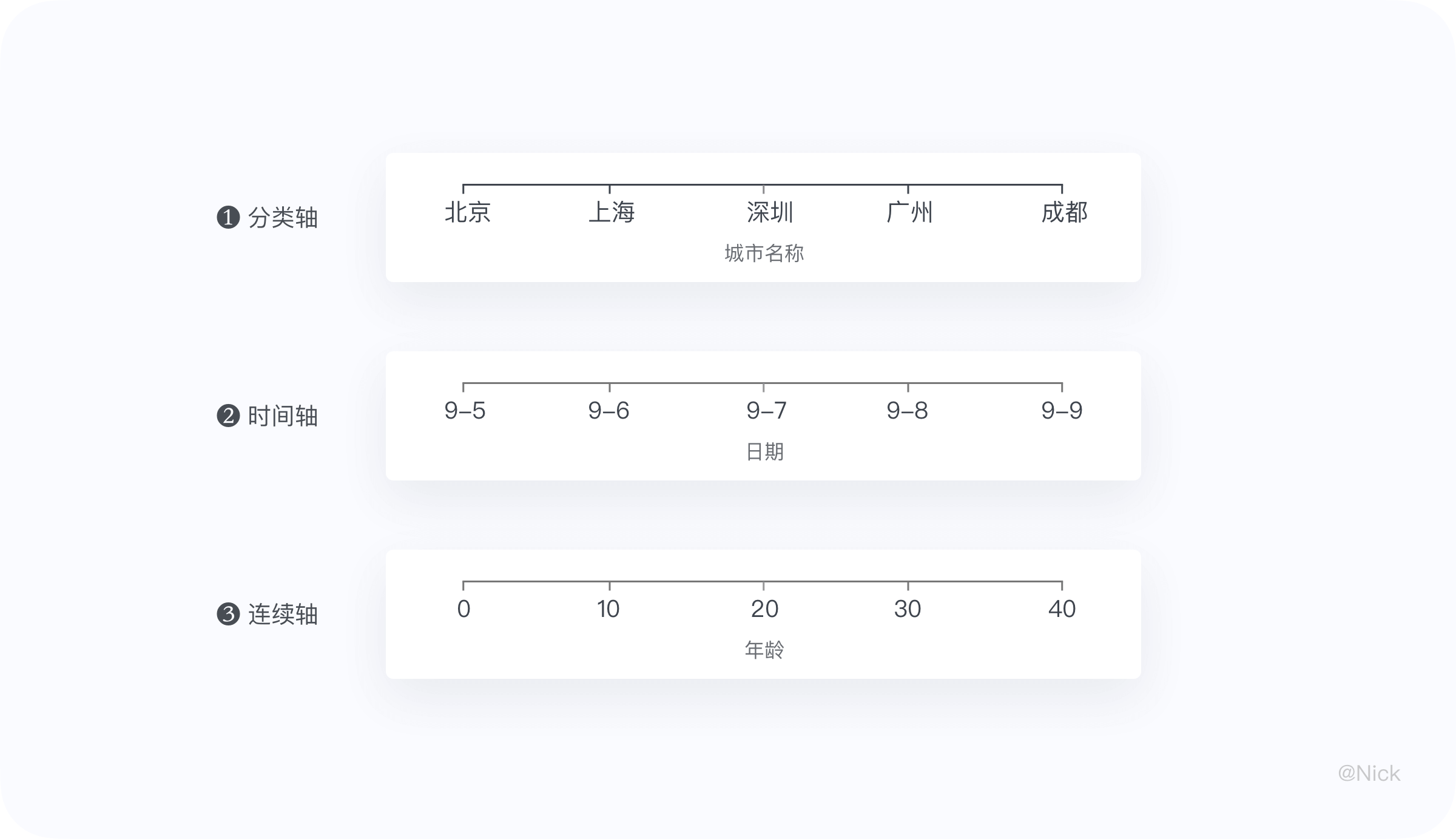
2.3 使用建议
2.3.1 轴线
**
轴线一般只考虑是否显示,结合上面所讲的数据墨水比,在有网格线的情况下,柱状图/折线图会隐藏 y 轴线,条形图则是隐藏 x 轴线,以达到信息降噪,突出视觉重点的目的。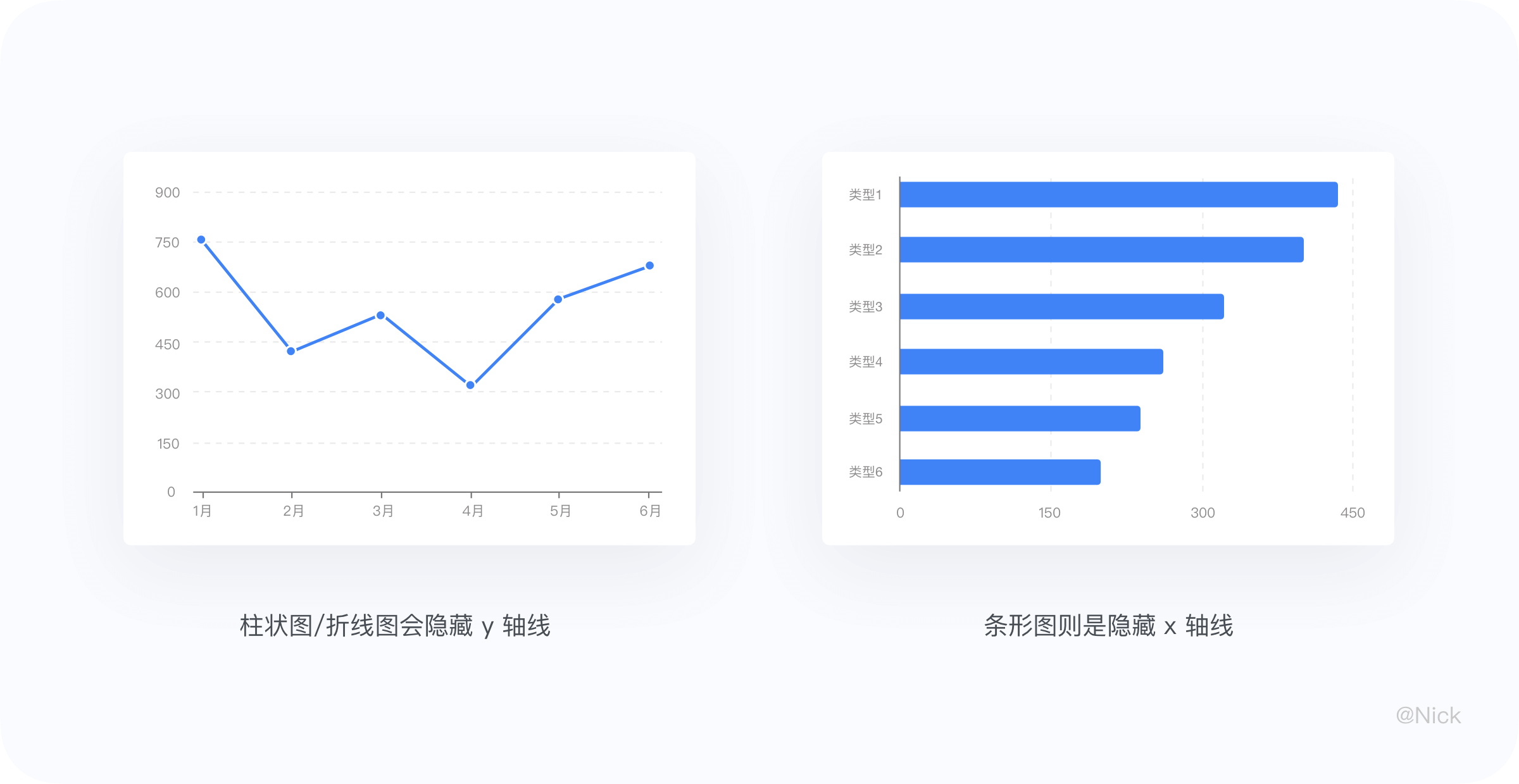
2.3.2 轴刻度线
轴刻度线是轴线上的小线段, 可以提供数值标签在坐标轴上的明确位置。轴刻度线有3种类型,分别为:置内、置中(即交叉方式)、置外。但刻度应置于数值坐标轴外侧, 不建议刻度采用置中或置内方式显示。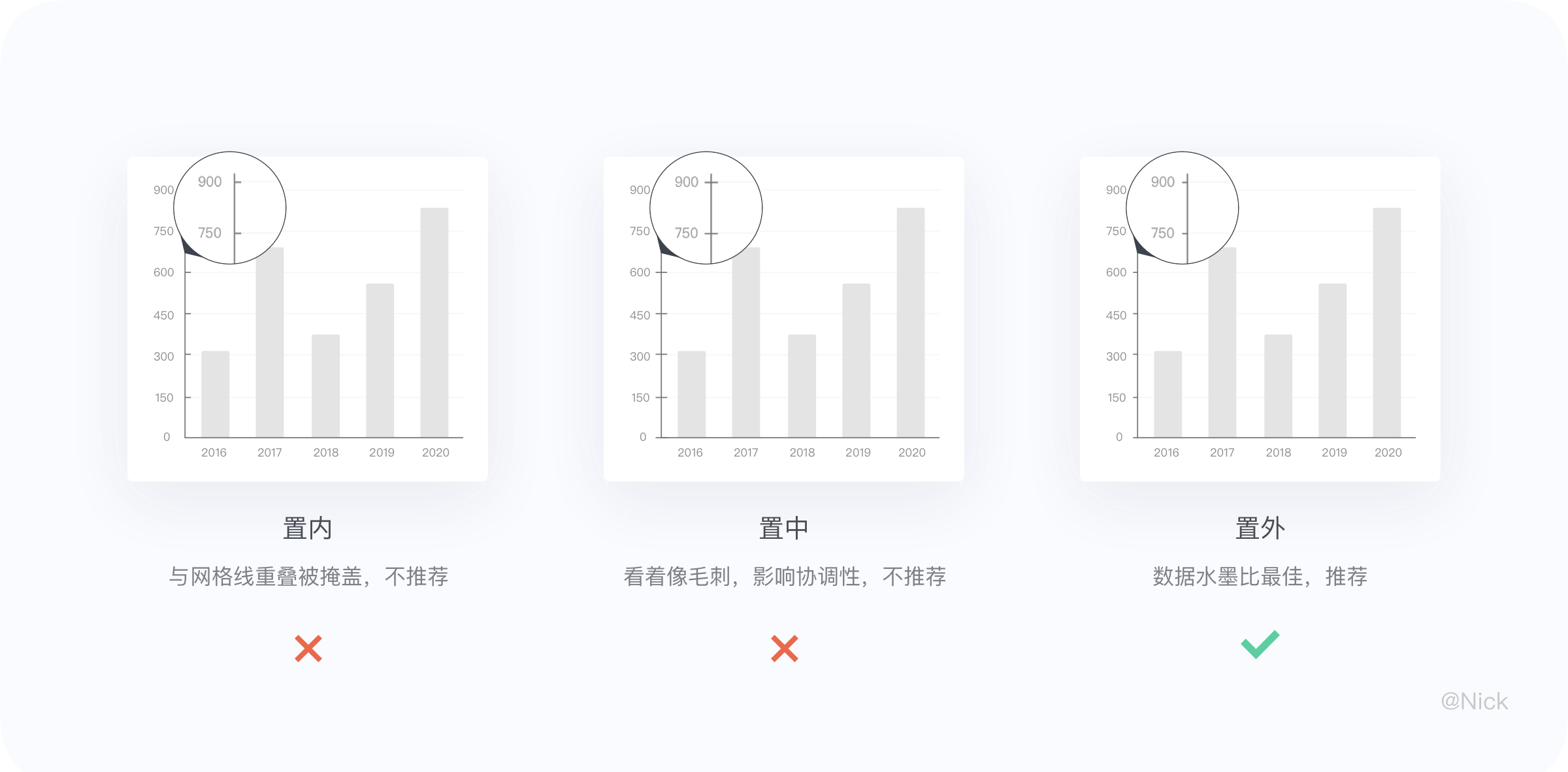
轴刻度线的使用就是加强映射关系,快速的对应到数据点。分类轴较多出现在柱状、条形中,对于映射有天然的对应关系,故在分类轴中习惯隐藏轴上的刻度线。
2.3.3 网格线
网格线是用来辅助图表优化映射关系的。使用网格线可以增加数据的可阅读性,网格线提供了两种功能:一是延伸数值刻度至可视化对象中,以便观察数据值之大小;二是增加可视化对象之间的比较基础 ,利于比较。
网格线一般跟随值域轴的位置单向显示,柱状图采用水平网格,条形图采用垂直网格。在使用网格线时,应该注意遵从主次原则,以轴线为主,网格线为辅,样式上可采用实线或者虚线。避免颜色过重,不要使用纯黑或者纯白,在视觉层级上不能抢了图表中的信息。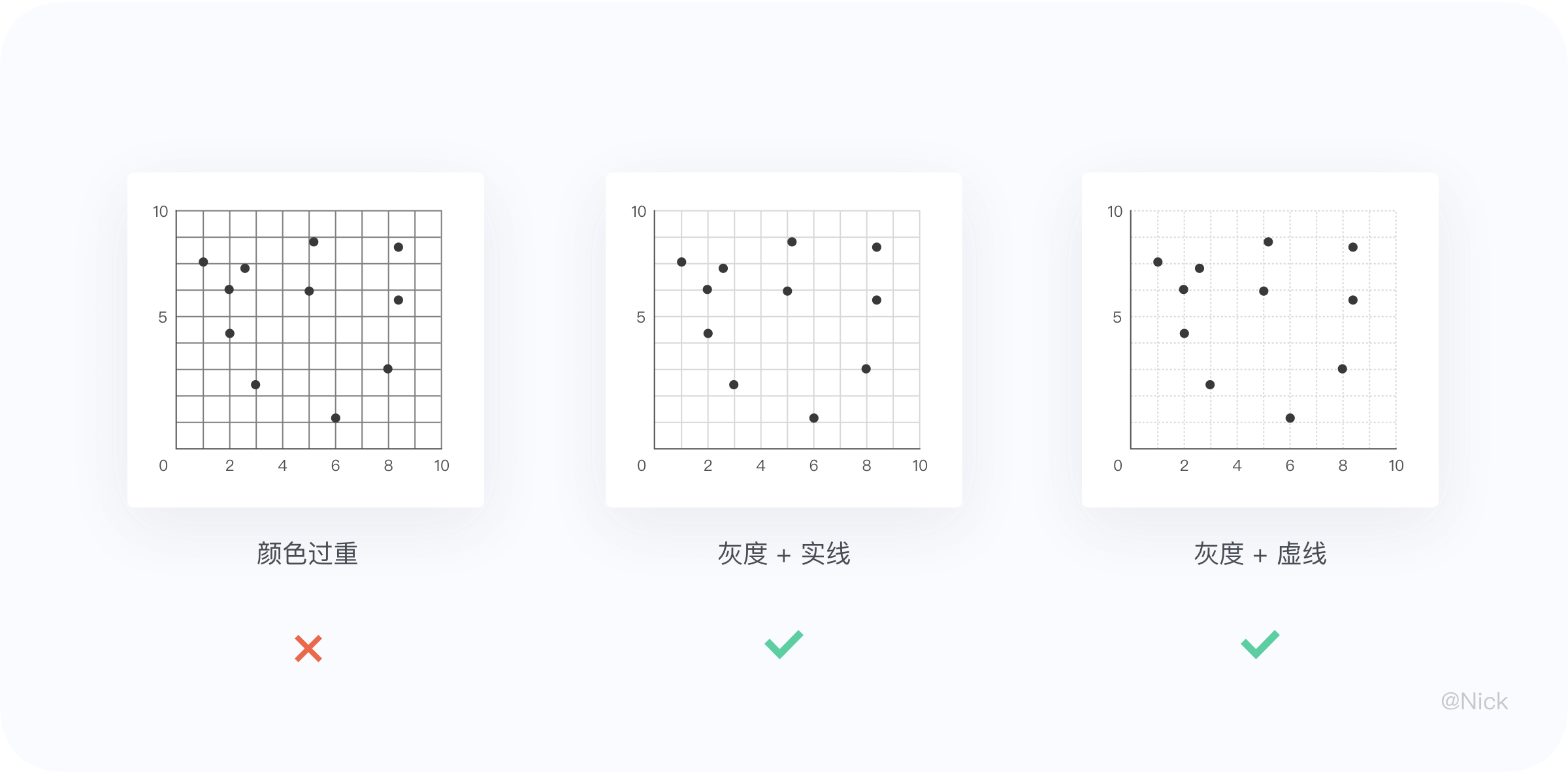
2.3.4 轴标题
轴标题(单位)主要用于说明定义域轴、值域轴的数据含义。当可视化图表的其他部分内容(标题、图例、轴标签等)已经能充分表达数据含义,根据奥卡姆剃刀定律,可以略去轴标题,近一步增大数据油墨比,精简画面元素。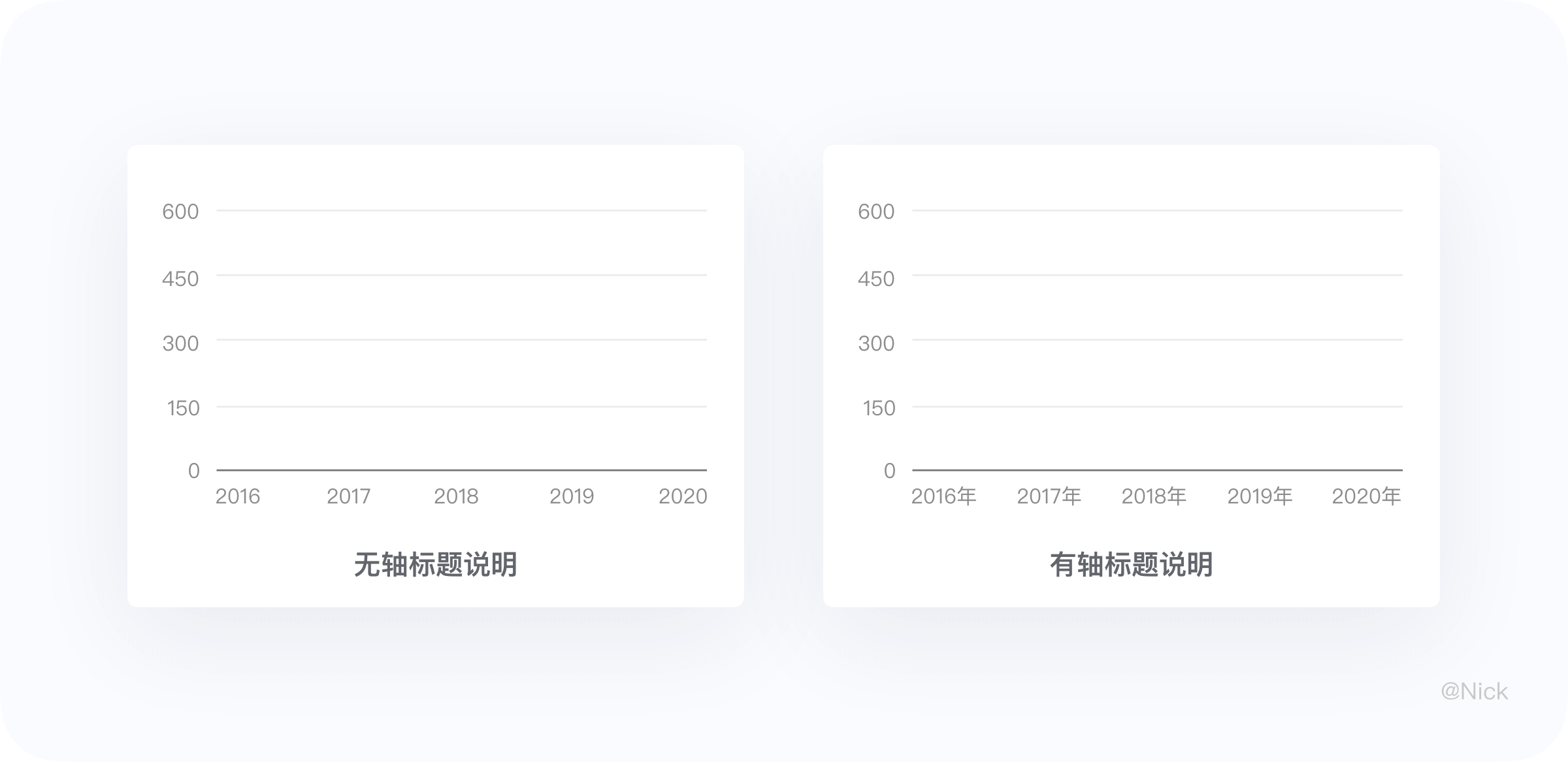
2.3.5 轴标签
轴标签的设计较为复杂,涉及到的细节点比较多。这里将围绕直角坐标系的X轴和Y轴这两个方向进行讨论。
**
X轴标签
**
x 轴标签的设计重点在显示规则上,在可视化图表设计中,我们常常会碰到轴标签内容过长的情况,当空间有限时,轴标签会重叠在一起。如何处理此类问题,这里根据轴的不同类型给了对应的解决方案 。
A. 连续/时间轴标签
**
在连续轴和时间轴中,我们可以利用抽样显示的手段来优化轴标签重叠的问题。这里不推荐使用旋转来缩减宽度。一方面从美观度上,旋转可能会破坏界面整体协调。另一方面,连续/时间轴并不需要显示所有的轴标签,参考格式塔中的[连续性原理],尽管轴标签未能完全展示,但用户会在脑海中把缺失的部分补齐,轴标签仍然会像连续着的一样。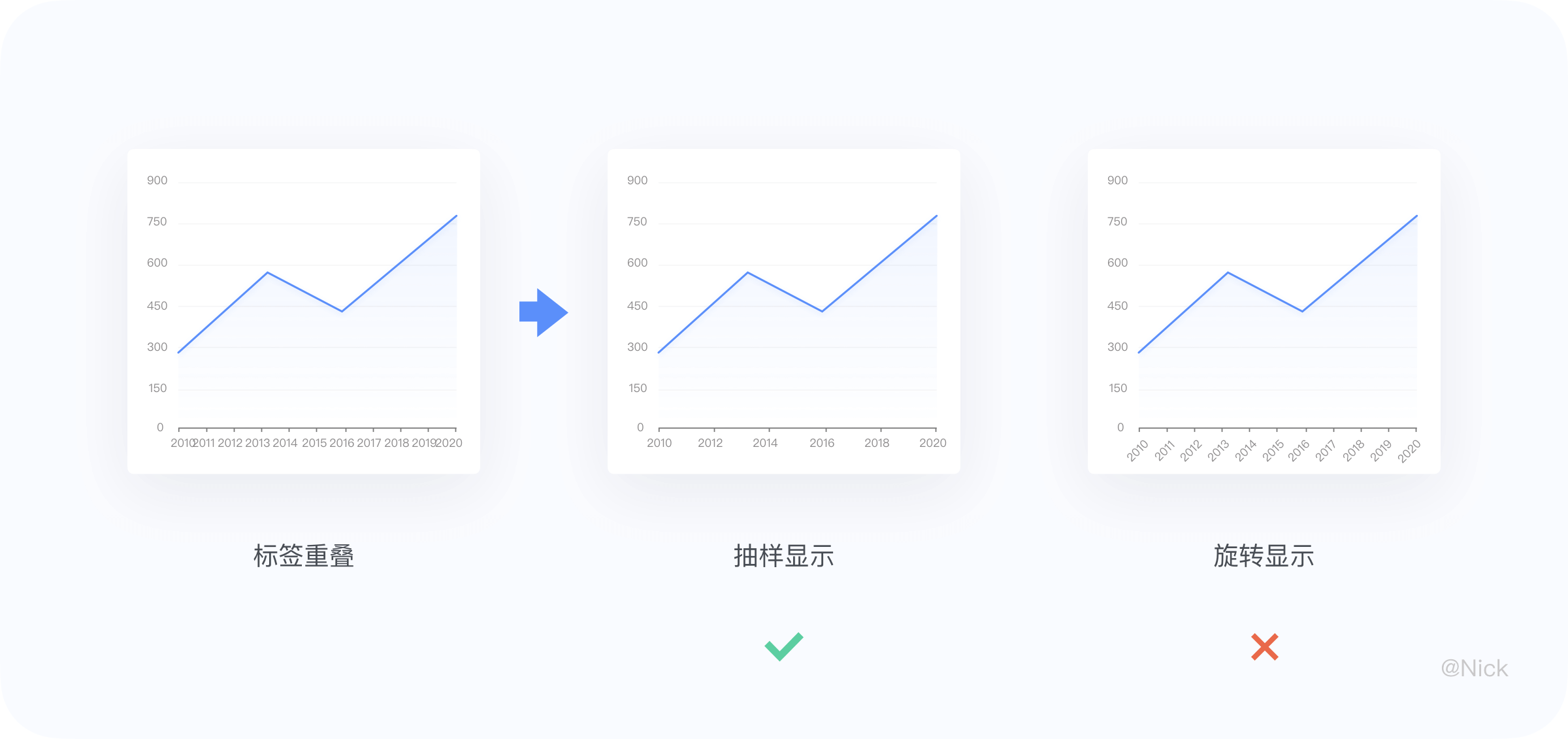
B. 分类轴标签
在分类轴中,由于标签与标签之间并没有紧密的逻辑关联关系。若采用抽样规则,隐藏了一些标签,则加大了用户对图表信息的提取难度,这是我们不想看到的。对于分类轴,这里建议通过标签旋转或转换成其他图表(条形图)来缩减宽度。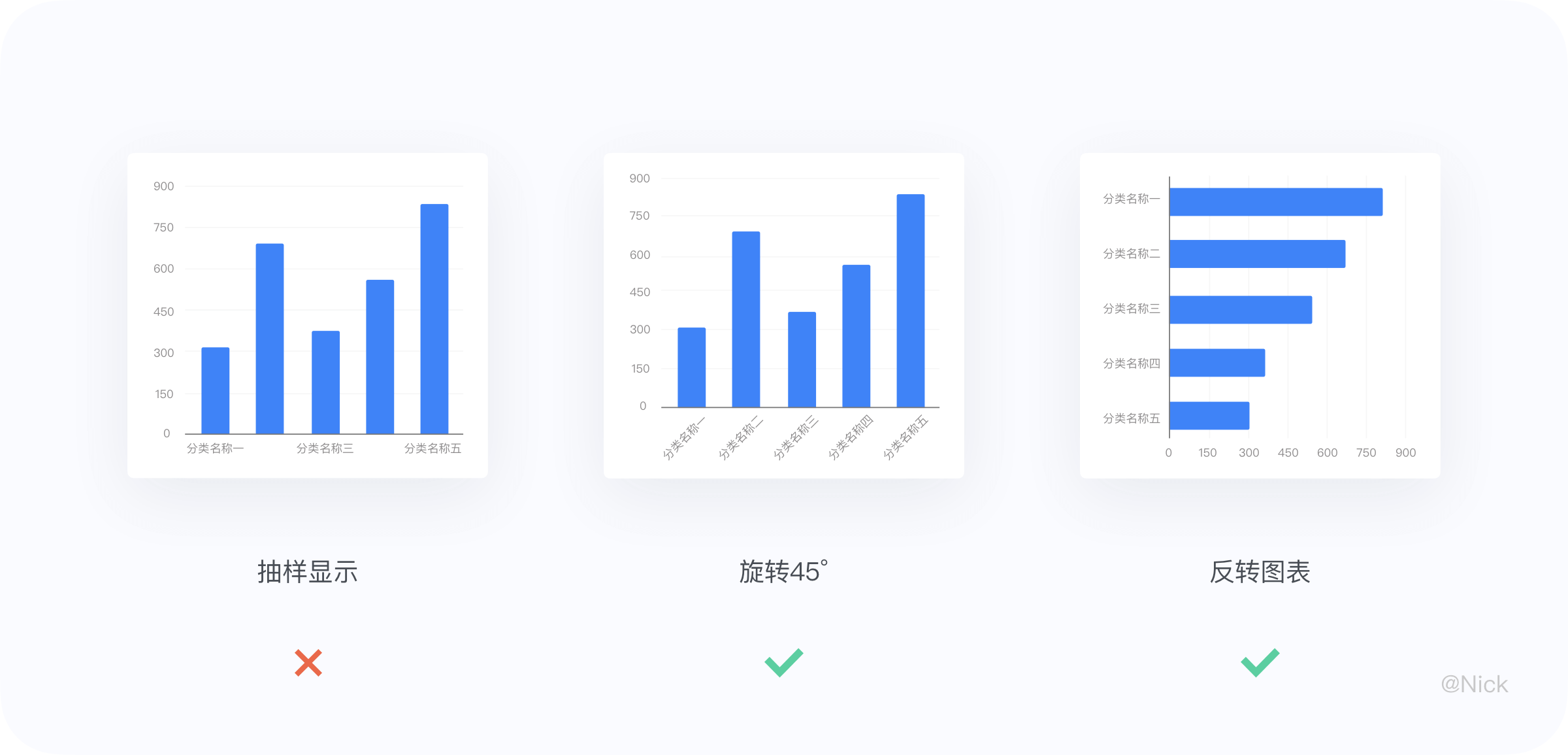
Y轴标签
y 轴标签的设计重点在标签数量、取值范围和数据格式上。标签显示区域一般根据最长标签宽度自适应缩放。如果数组是固定的,就写成固定宽度,节省图表计算量,提高渲染速度。
A. 轴标签的数量
轴标签的数量不建议过多,太多的标签必定导致横向网格线变多,造成元素冗余,干扰图形信息表达。根据 7±2 法则,Y轴标签数量应尽量控制在这个范围内。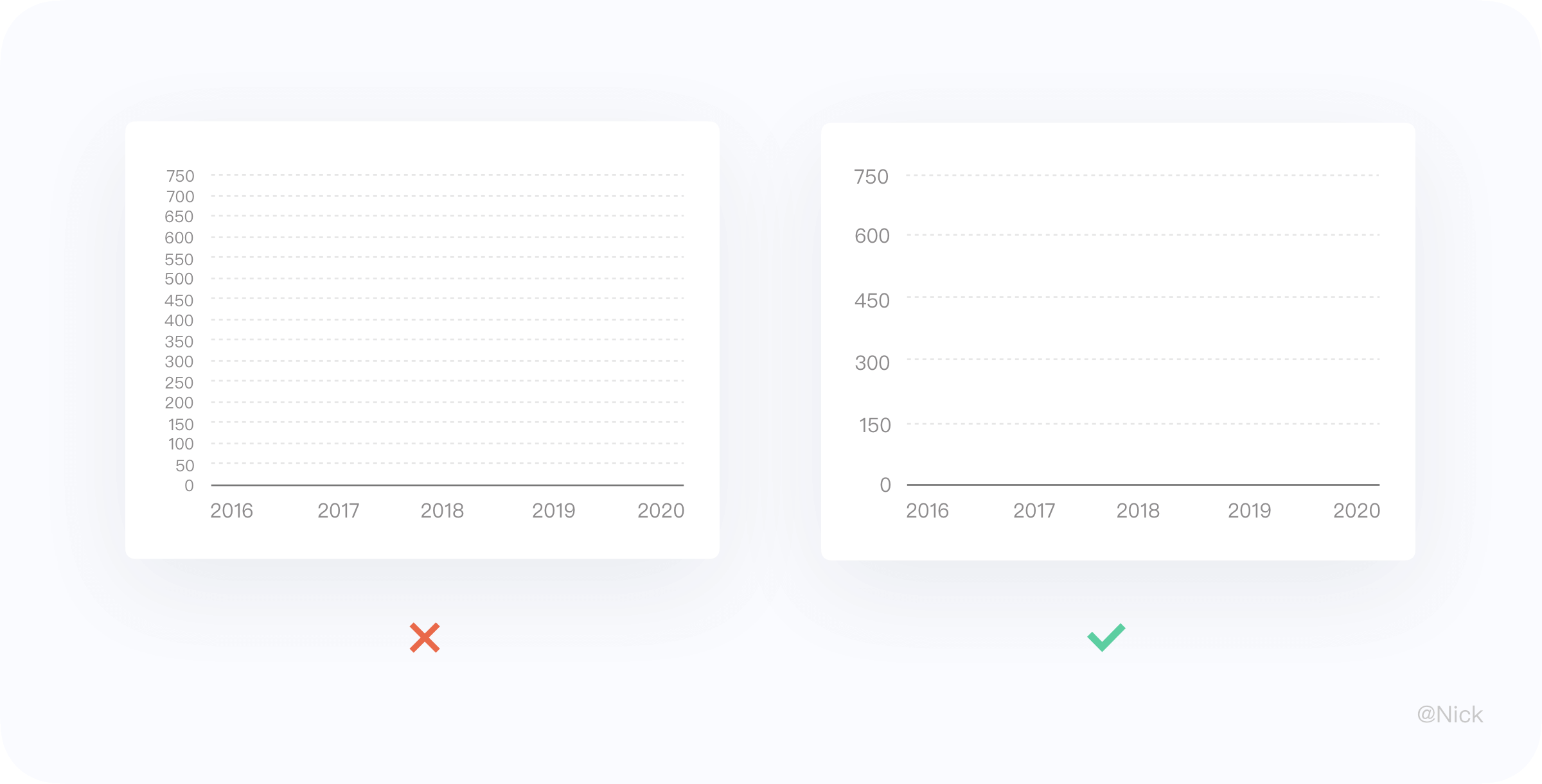
B. 轴标签的取值范围
一般来说,y 轴标签的取值应从 0 基线开始,以恰当反映数值。展示被截断的数据可能会误导用户做出错误的判断。比如数据本身没有那么起伏变化,处理上下限的颗粒度,把刻度拉长,一样能显得“长势喜人”。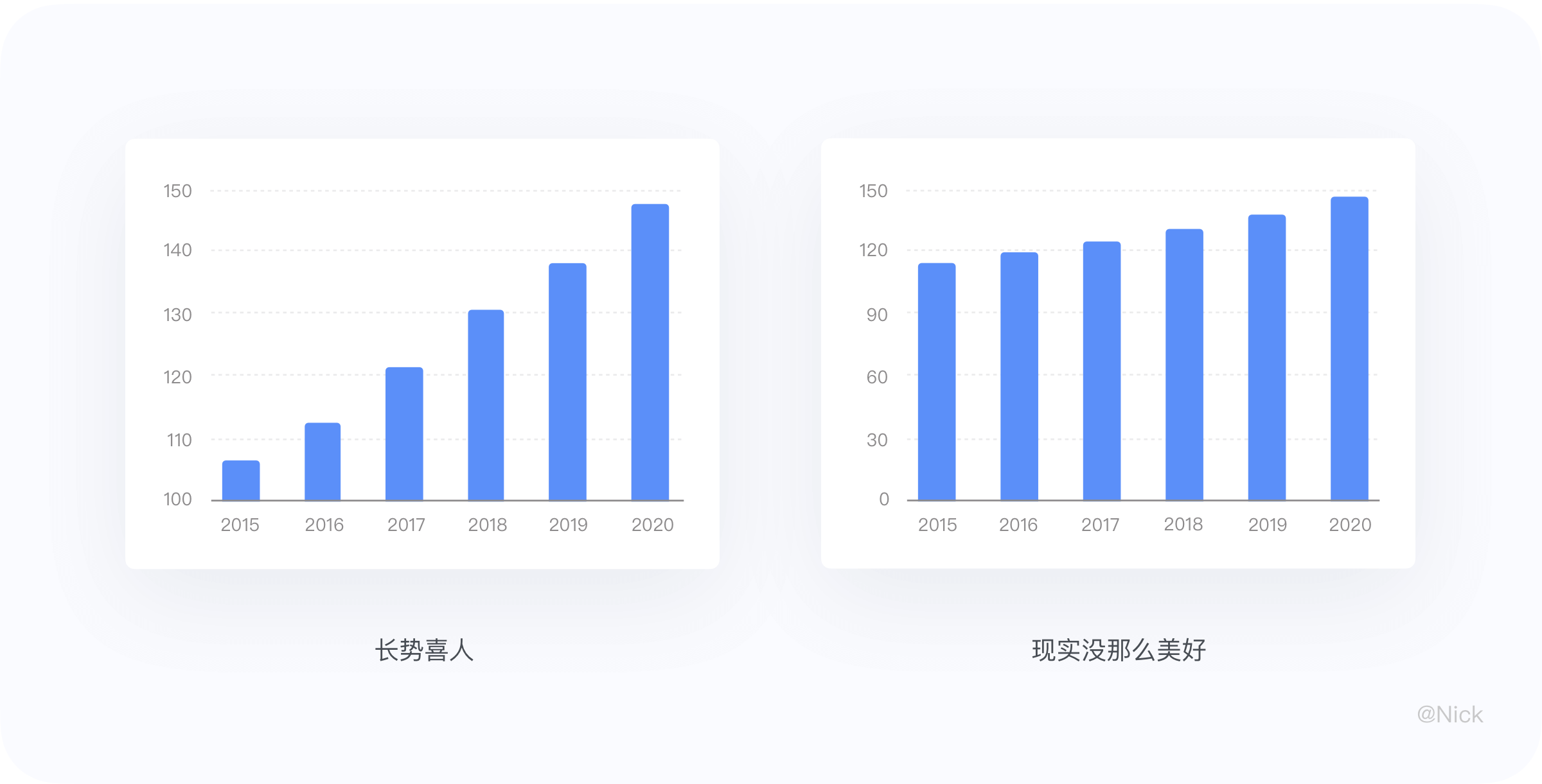
从上面就能明白,在看图表的时候千万不要被表面给欺骗,仅仅观看柱状图的高低趋势往往不能得出正确结论,需要注意坐标轴起始位置有没有被人做过虚假处理。
但存在是有根源的,对于此类的取值方式不做过多评价。这里主要想讲一下我常用的取值方式:对于Y轴的上限即最大值根据实际数据进行动态计算。比如一排数字中最大的为1190,那么轴标签最高位为1200;一排数字中最大的是1210,那么轴标签最高位为1400。其中的1400和2100是根据轴上的分段数决定的。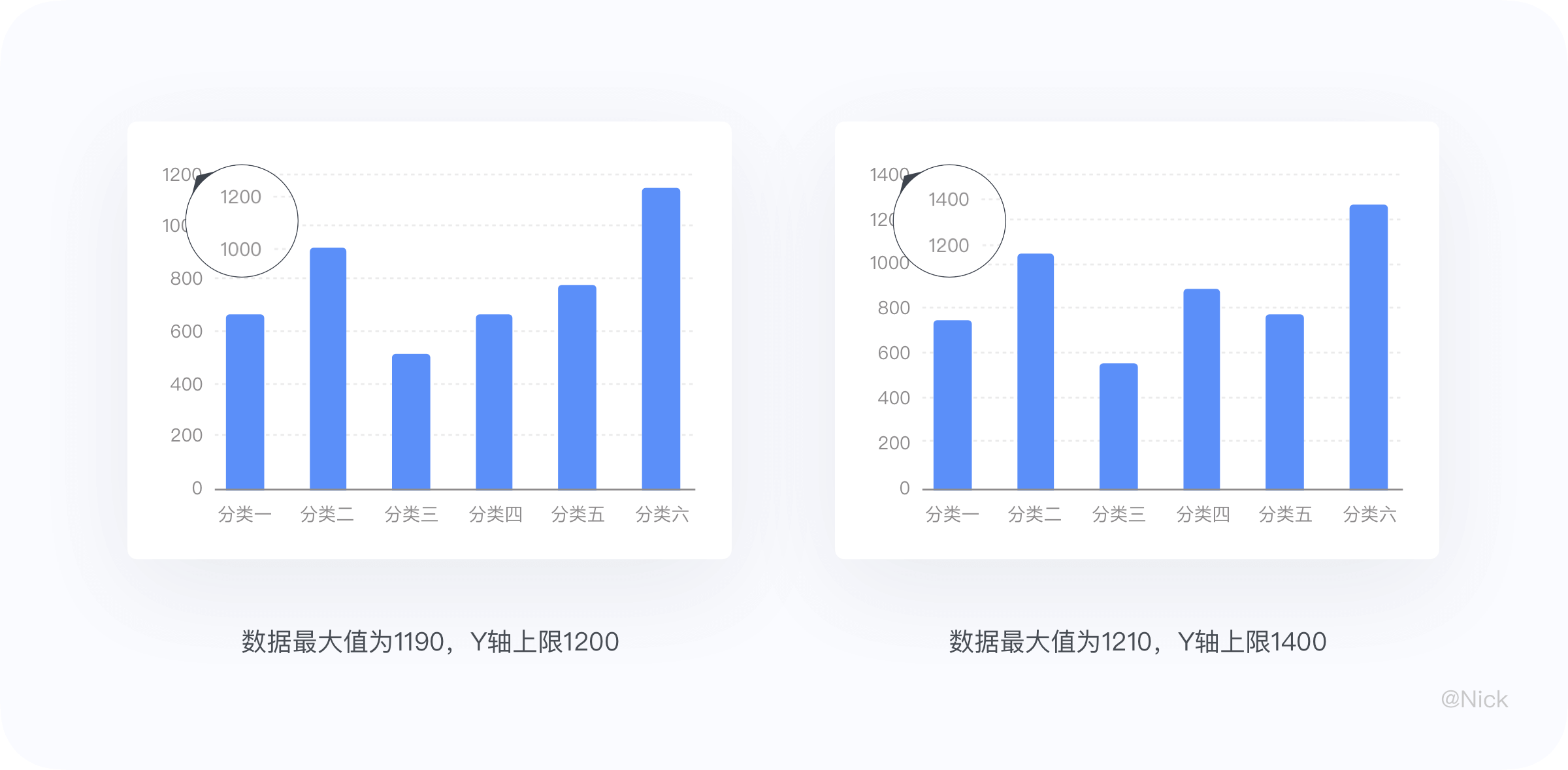 但有些人对Y轴标签的取值给出了如下建议:在折线图中,取值一般保证图形约占绘图区域的2/3,或者将柱状的高度控制在图表高度的85%左右。
但有些人对Y轴标签的取值给出了如下建议:在折线图中,取值一般保证图形约占绘图区域的2/3,或者将柱状的高度控制在图表高度的85%左右。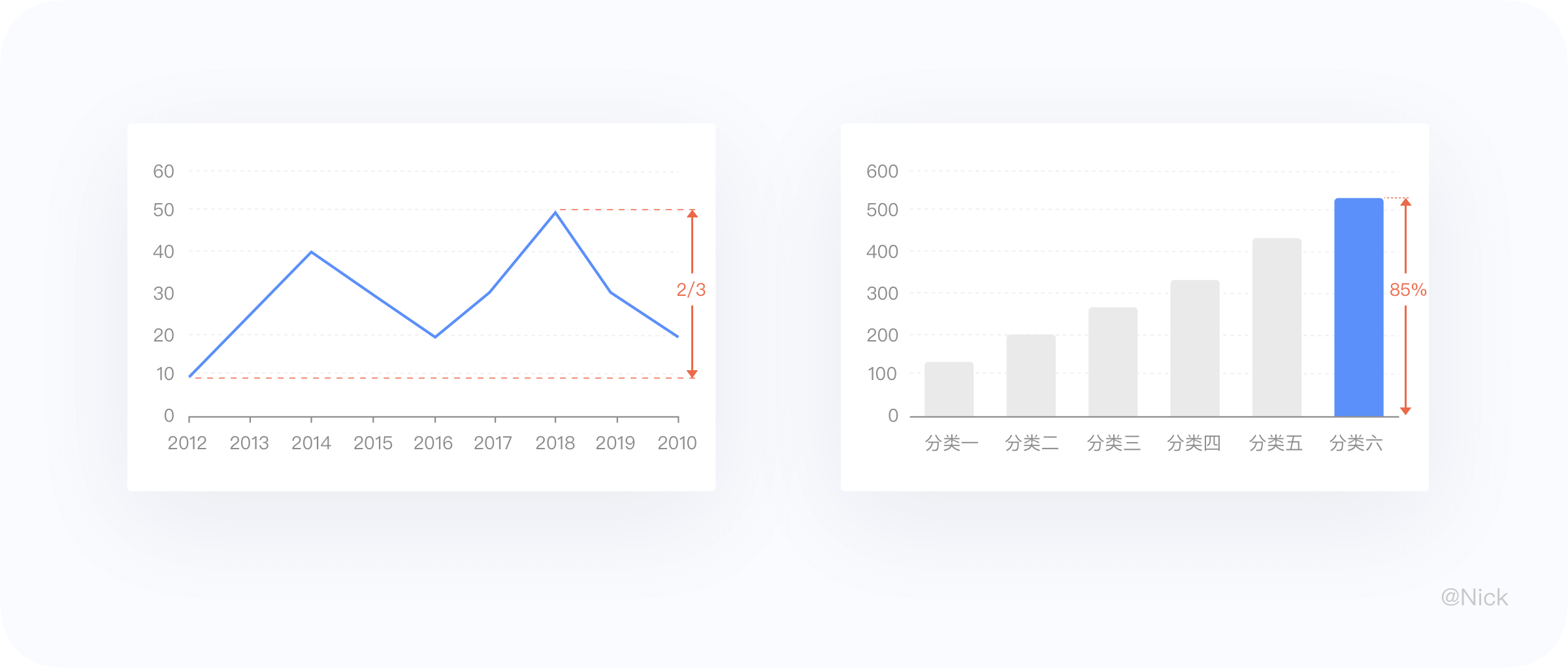
但我认为这种方式太刻意了,并且规则定制的比较细。但是得承认这样子确认会显的好看,做案例可以,做真实数据不行。因为考虑到实际数据有的时候会出现极限情况,比如有些特别大有些特别小,为了保证用户能从图表中准确地获取信息,不应该为了美感而破坏了它的真实性。因此并不推荐用这种方式来取值。
C. 轴标签的数据格式
关于Y轴标签的数据格式,这里重点讲一些比较容易忽视的设计细节。第一,标签保留的小数位数保持统一,不要因为某些轴标签是整数值,就略去小数点。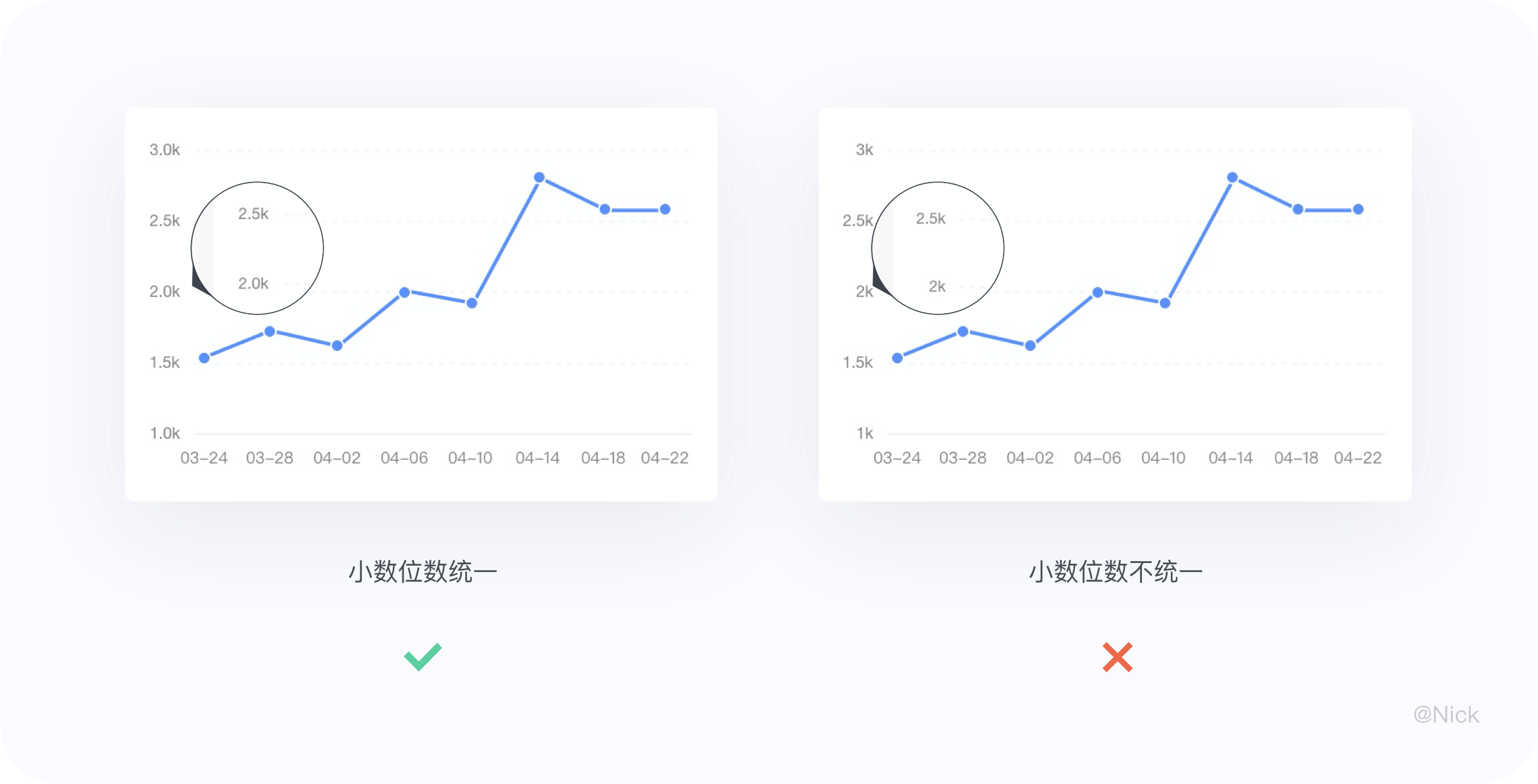
第二,正负向的 y 轴标签,由于负值带“-”符号,整个 y 轴看起来会有视觉偏差,特别是双轴图的右 y 轴更明显。这里建议正负向 y 轴给正值标签带上“+”,以达到视觉平衡的效果。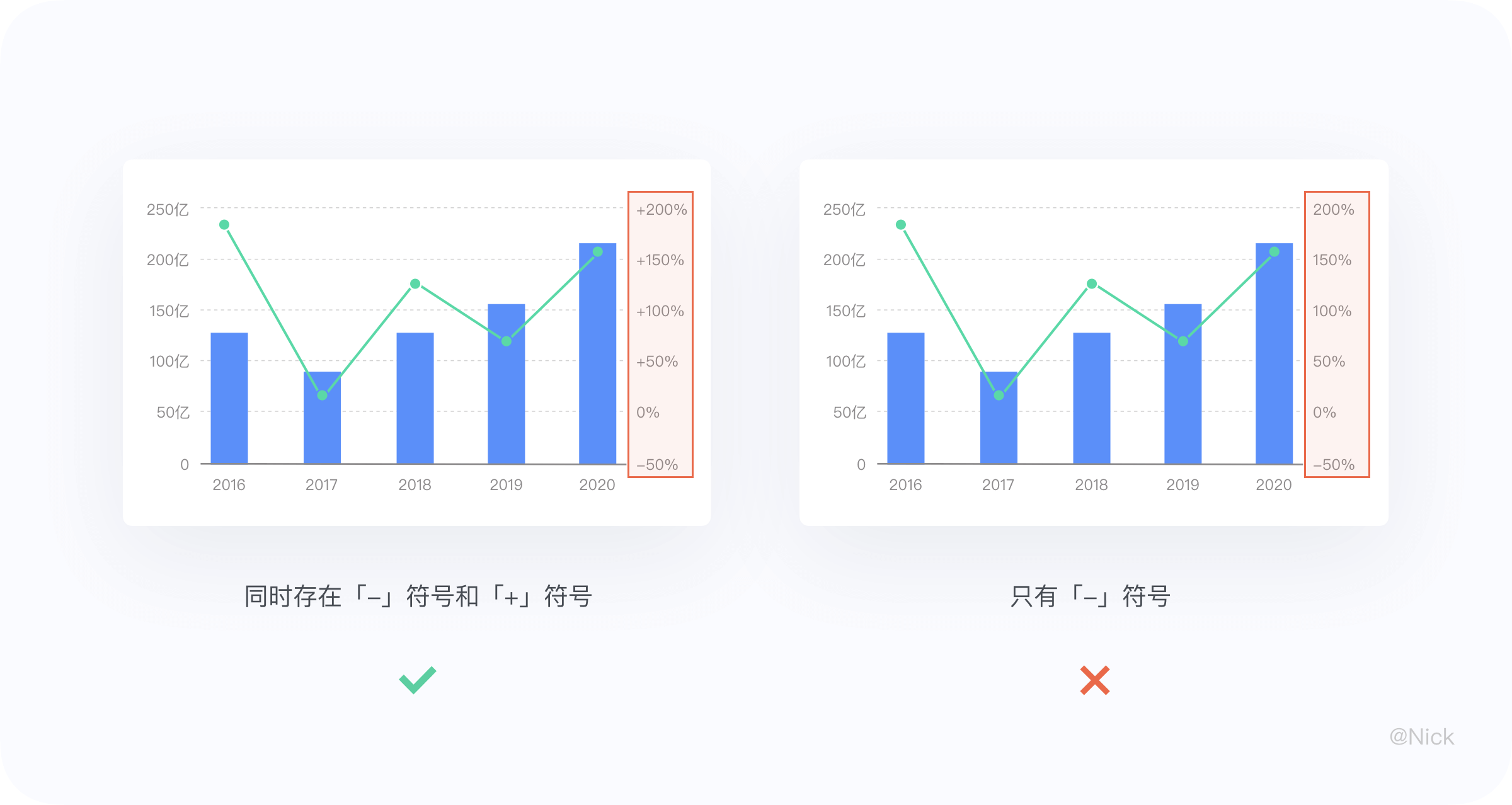
3. 图例
3.1 定义
图例是对图形本身的概括,在图表元素中属于辅助内容。它提供读者以对照的方式来理解可视化对象的项目归类。由映射图形形状和文本组成。
3.2 类型
根据数据类型不同,分为连续型图例和分类型图例;根据状态不同,图例可以被设置为静态或可交互态。
3.3 使用建议
3.3.1 数字文本取整
正如,伦斯勒理工学院的行为经济学家高拉夫杰恩(Gaurav Jain)所说:“数字有一种语言的力量,能给予人一种特殊的感觉。当我们使用具体的整数数字时,人的衡量会减少。这种行为没有明显的原因。”
当人们的大脑在处理不以零结尾的不规则数字时,需要更多的脑力来处理,加大了获取信息的难度。因此在使用数字时,应该考虑这种偏好,倾向于一些取整的数字。同样的,这不仅仅适用于图例中的数字,同样适用于坐标轴上下限的数字。
3.3.2水平图例和垂直图例
带有连续性的倾向于使用水平图例,因为更符合人们的阅读习惯;带有分类属性的倾向于使用竖直图例,图例的右边可放置更长的文本。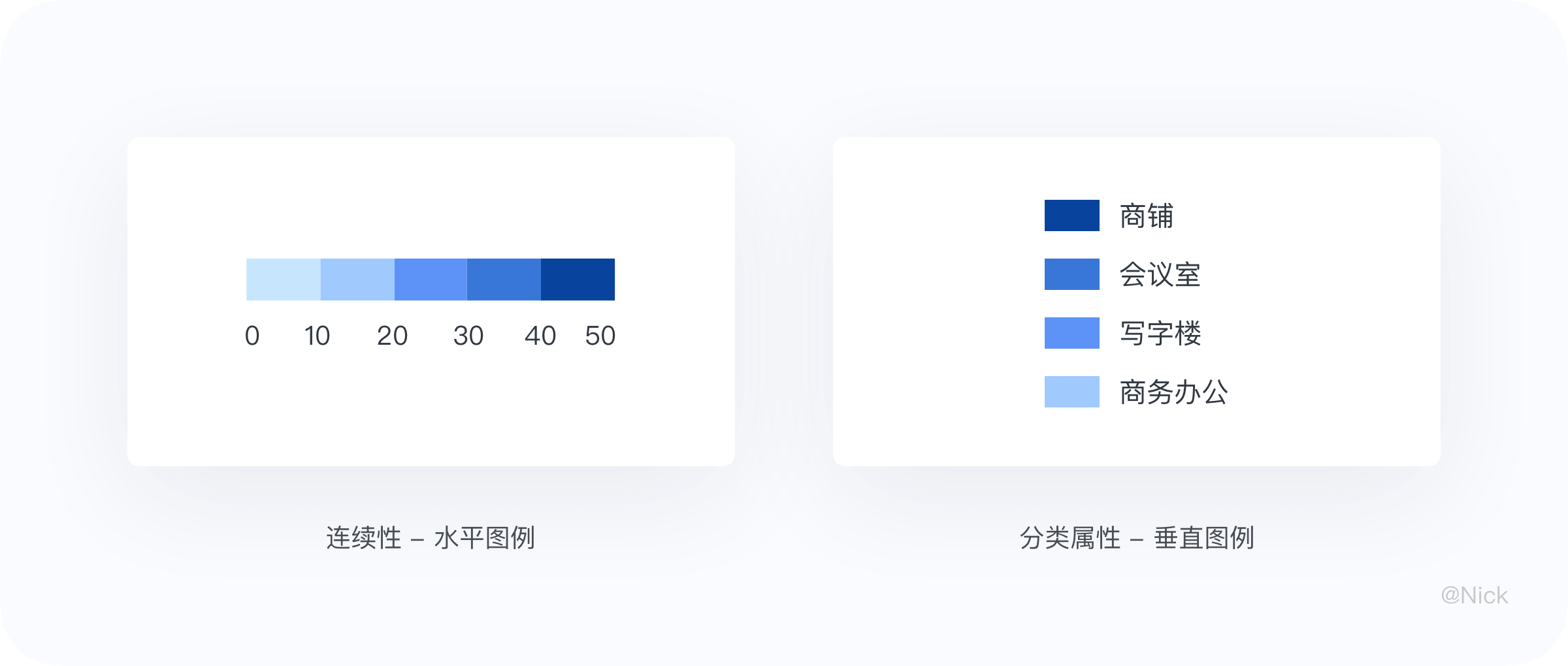
3.3.3 图例的位置
**
默认把图例放在左上角去做一个通用的方案看起来没毛病。但考虑到人的视觉动线是从上至下,从左到右。这里有一个更好的做法:缩短用户对照图例看图形的本能路径,可以提升对信息的获取效率。如下图所示: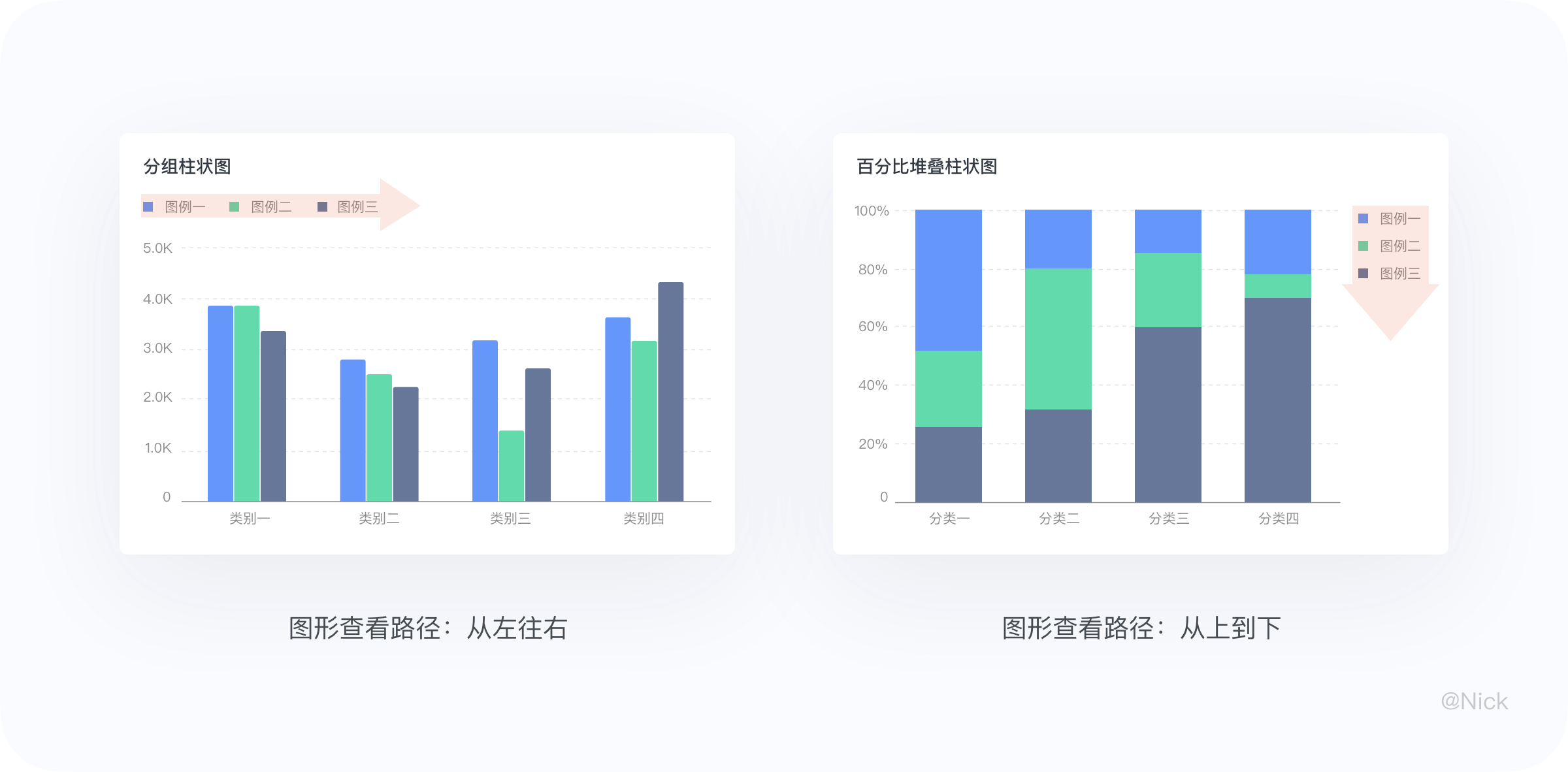
3.3.4 多折线图采用跟随图例
当我们在制作多折线图时,经常会出现个数据系列之间相互交错的情形,并使得各种数据标记与之前的出现顺序不一致,即与图例排列顺序不同。因此用户的眼睛必须在图例与折线之间进行连连看,最佳的做法是采用跟随图例形式,去标识出折线所属于的维值信息,这样会更直观有效。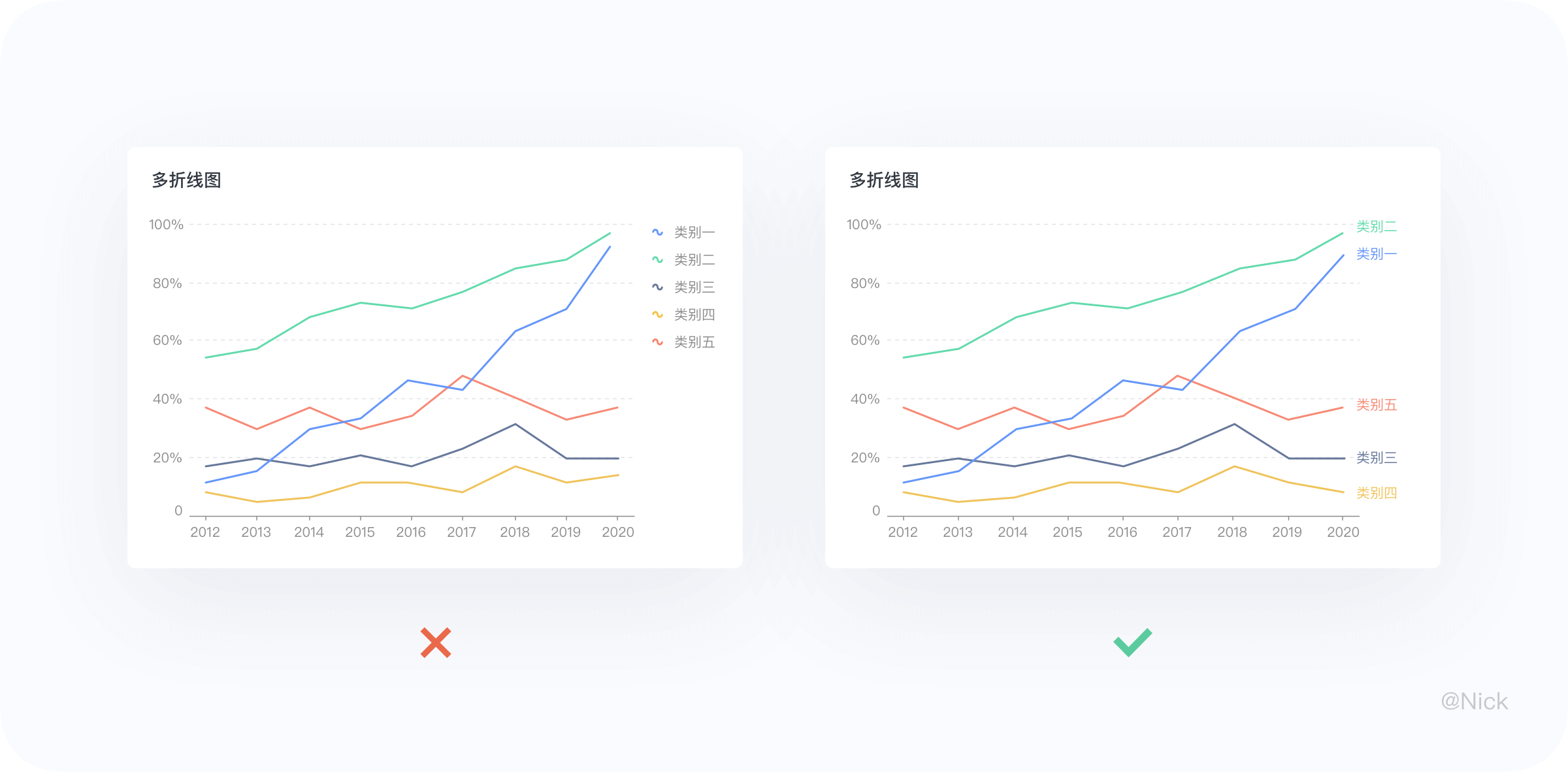
4. 标签
4.1 定义
在图表中,标签是对当前的一组数据进行的内容标注。包括数据点、拉线、文本数值等元素,根据不同的图表类型选择使用。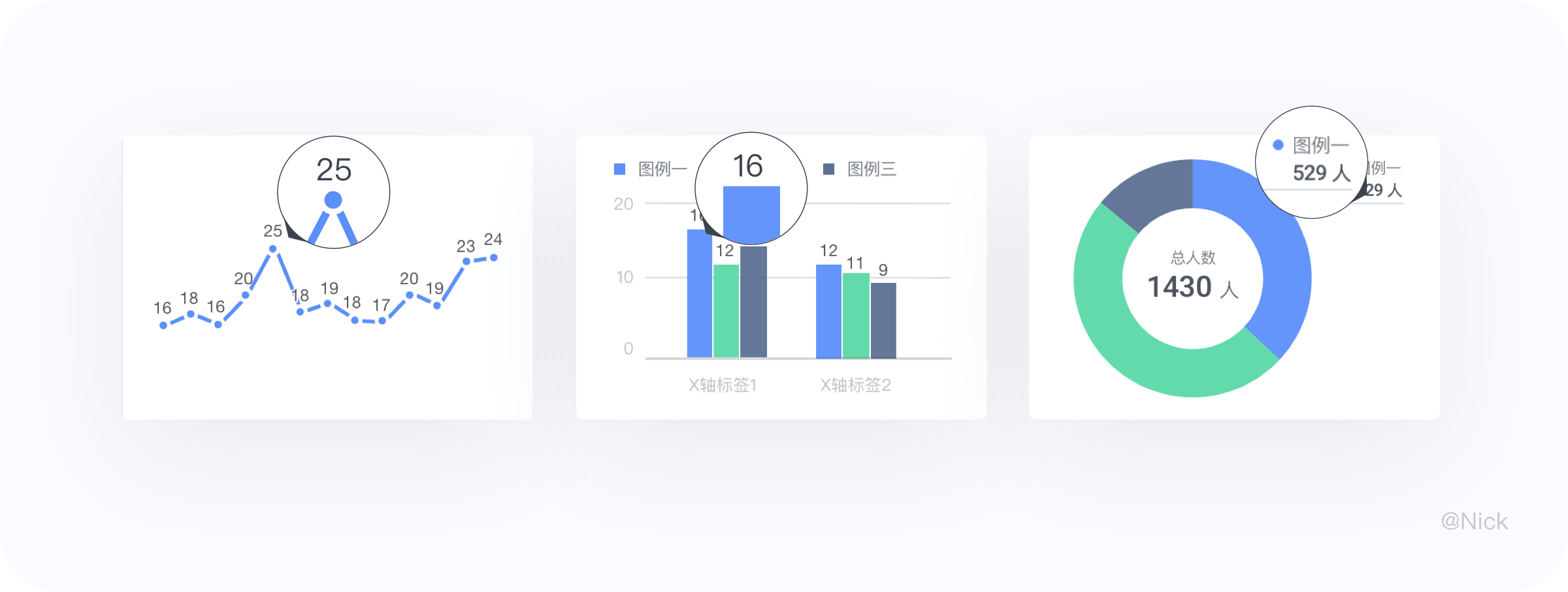
4.2 使用建议
4.2.1 标签的显示策略
在绘制的图表的时候,我们倾向将标签直接打在图形外,但在「堆叠类」图表中,标签会显示在图形内。这样做会有个后果,标签的文本和图形经常需要交叠展示,所以可读性需要足够良好,所以通过对 HS 值的判断,决定文字的颜色是否需要反思。这样对比度就在可控范围内,不会出现可读性的问题。有时,还需要增加描边,让标签更清晰。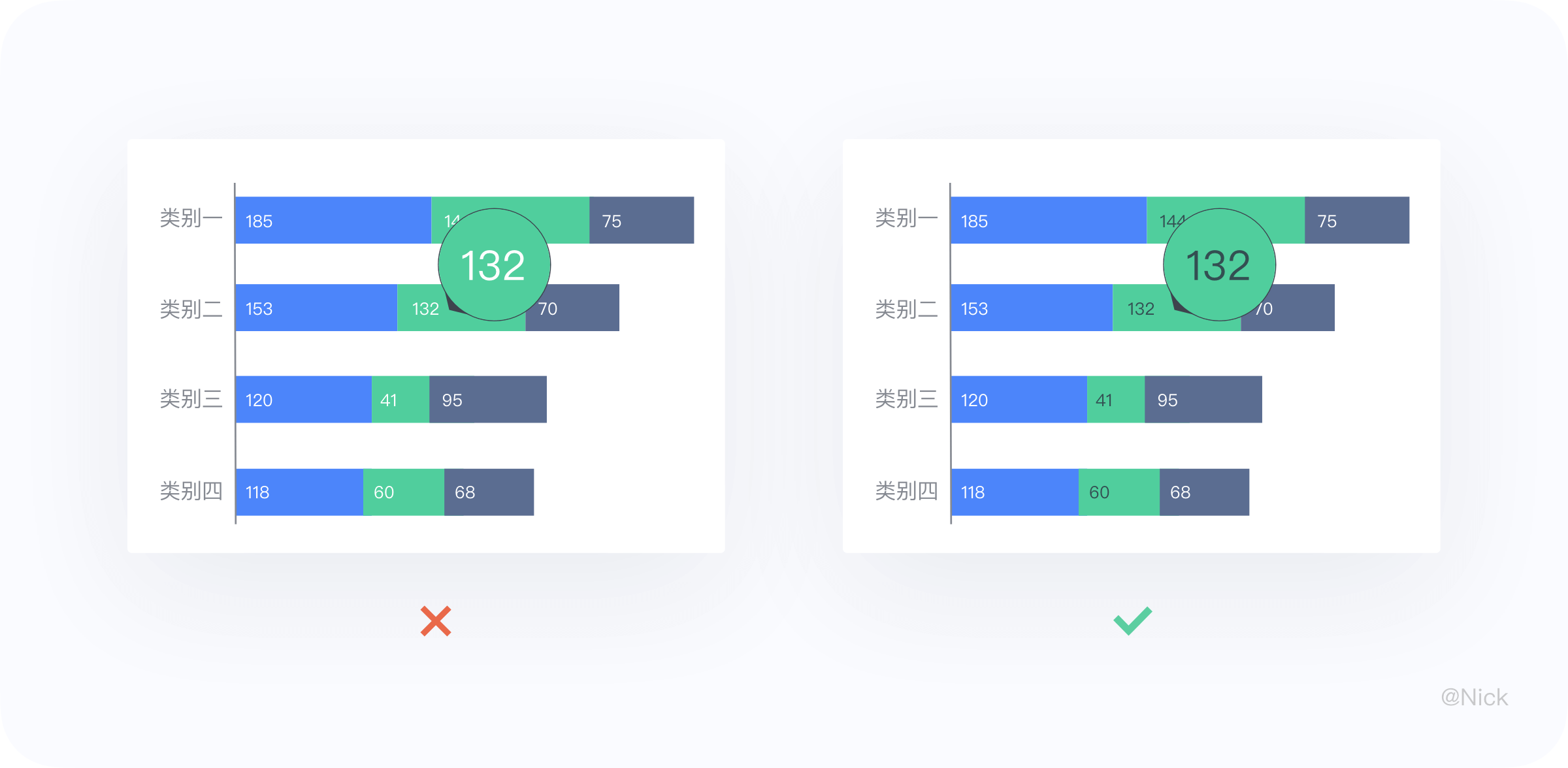
当数据特别多并且密的时候会造成全部标签挤在一起的情况。在标签重叠时,采用动态计算的抽样显示方式,自动隐藏其中一个,同时当 Hover 图表时,显示被隐藏的对应的数据。这样保证了图表的清晰度,也保证了信息的完整性。
5. 提示信息
5.1 定义
提示信息一般是tap或者hover的时候,图表以交互的方式吐出该位置的数据,帮助用户更深入的了解数据。一般由视觉标记图形,文本标签,数值标记这3中元素构成。
5.2 类型
提示信息的展现形式由4种。按不同的图表类型,分为悬浮、固定位置、固定在轴上、固定在图形上。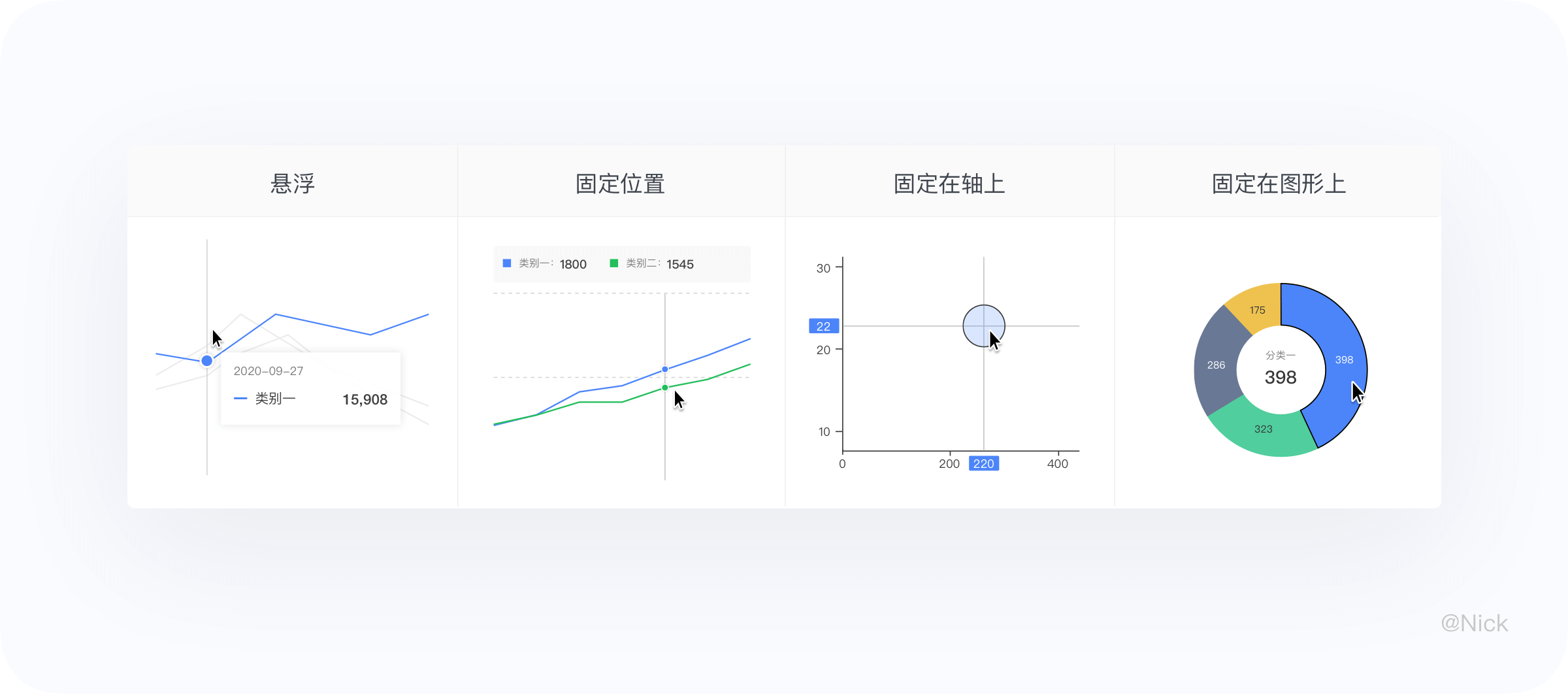
6. 图形
6.1 定义
人类从图形中获取信息的效率远高于文本,可以说如今人类早已进入了读图时代。图形是统计图表的视觉通道在形状上映射的视觉展现,是图表的必备元素,承载着数据背后蕴含的信息。按照组件原子化的思路来定义现在千奇百怪的图表,大致可以分为六种基础样式:折线,面积,散点,气泡,饼/环,柱形,条形。
6.2 使用建议
这里主要想重点讲一下,如何通过设计来强化图表信息的表达,以便简化用户获取信息的成本。关于具体某个图表的制作规范和运用场景,会在之后的文章中提及。
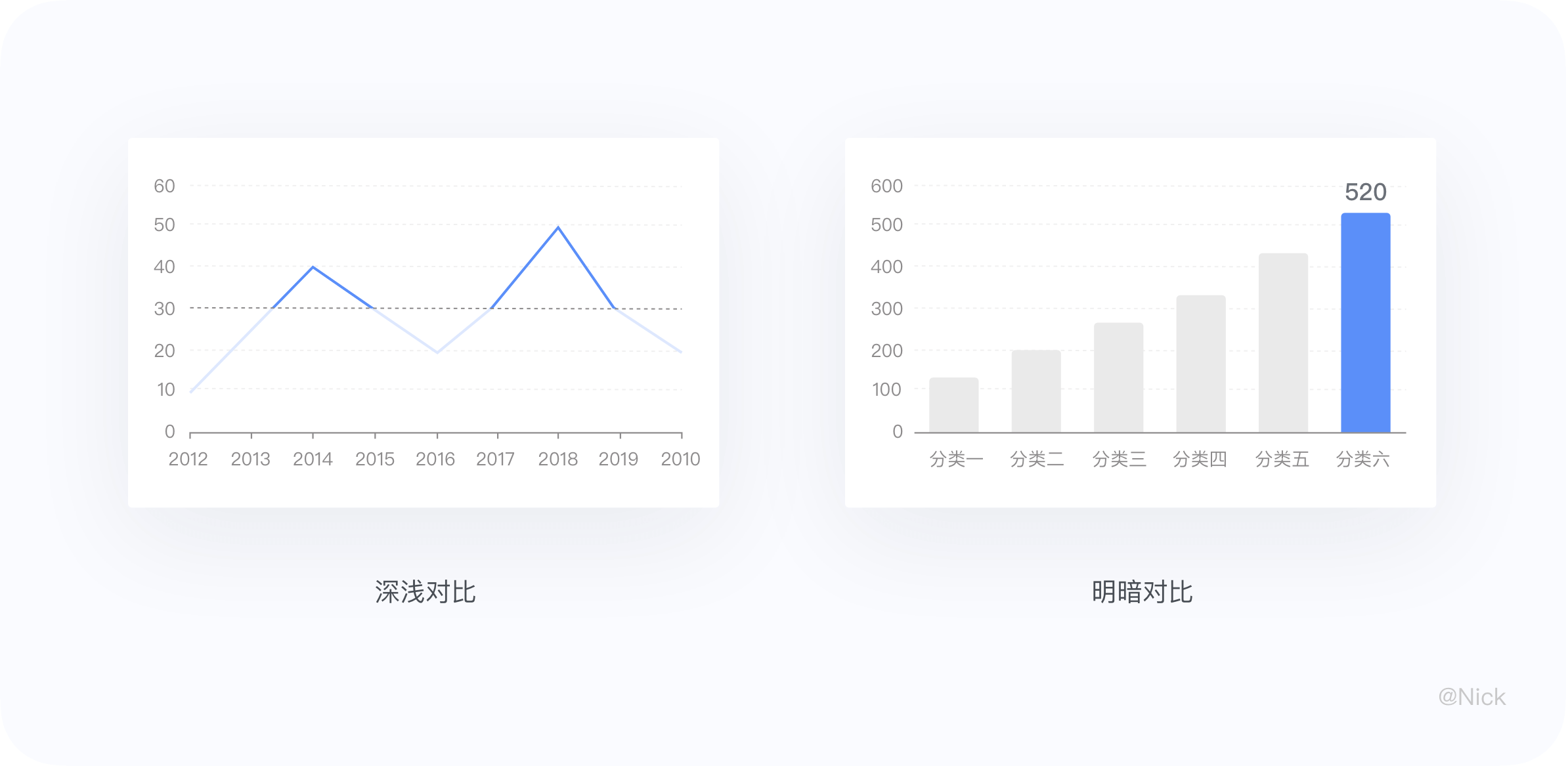
6.2.1 改变颜色 - 明暗/深浅/色彩对比
通过明暗对比、颜色对比以及色彩对比等手段可以有效的区分信息,在视觉层级上也是明显的处理了视觉噪音,便于用户区分信息。
6.2.2 添加标注
通过添加标注,人为去干预信息的表达,多用于一前一后的标识,便于用户识别信息。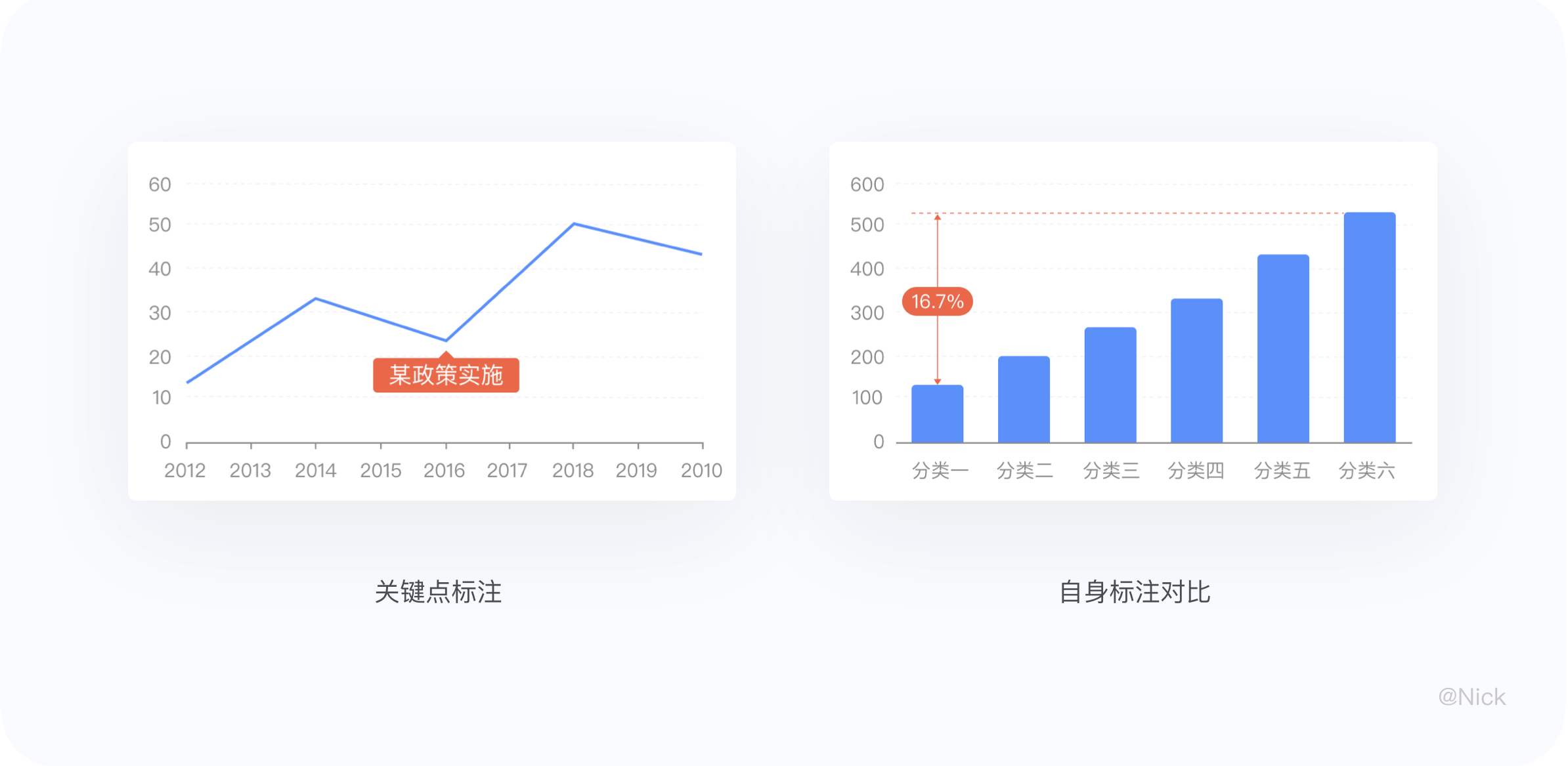
三、选择合适的图表
我们做数据分析的有句话叫“一图胜千言”,图表是展现数据的一种重要展现形式,选对了图表就能帮助我们更加快速、直观的传达数据信息。
那如何挑选合适的图表呢?在我看来大致分为三步:
1. 确定核心内容:明确要用图表传达的核心信息;
2.判断比较关系:判断数据之间的比较类型(如占比、数量、趋势等);
3.选择图表类型:选择对应含义的图表(如饼图、柱状图、折线图等)。
很多朋友在判定和选择图表类型时会不知所措,但其实你只需要记住一句话:决定图表形式的不是数据,而是你要传达的信息。
1. 确定核心内容
同一组数据用不同的角度看,有不同的主题,比如下面这组数据: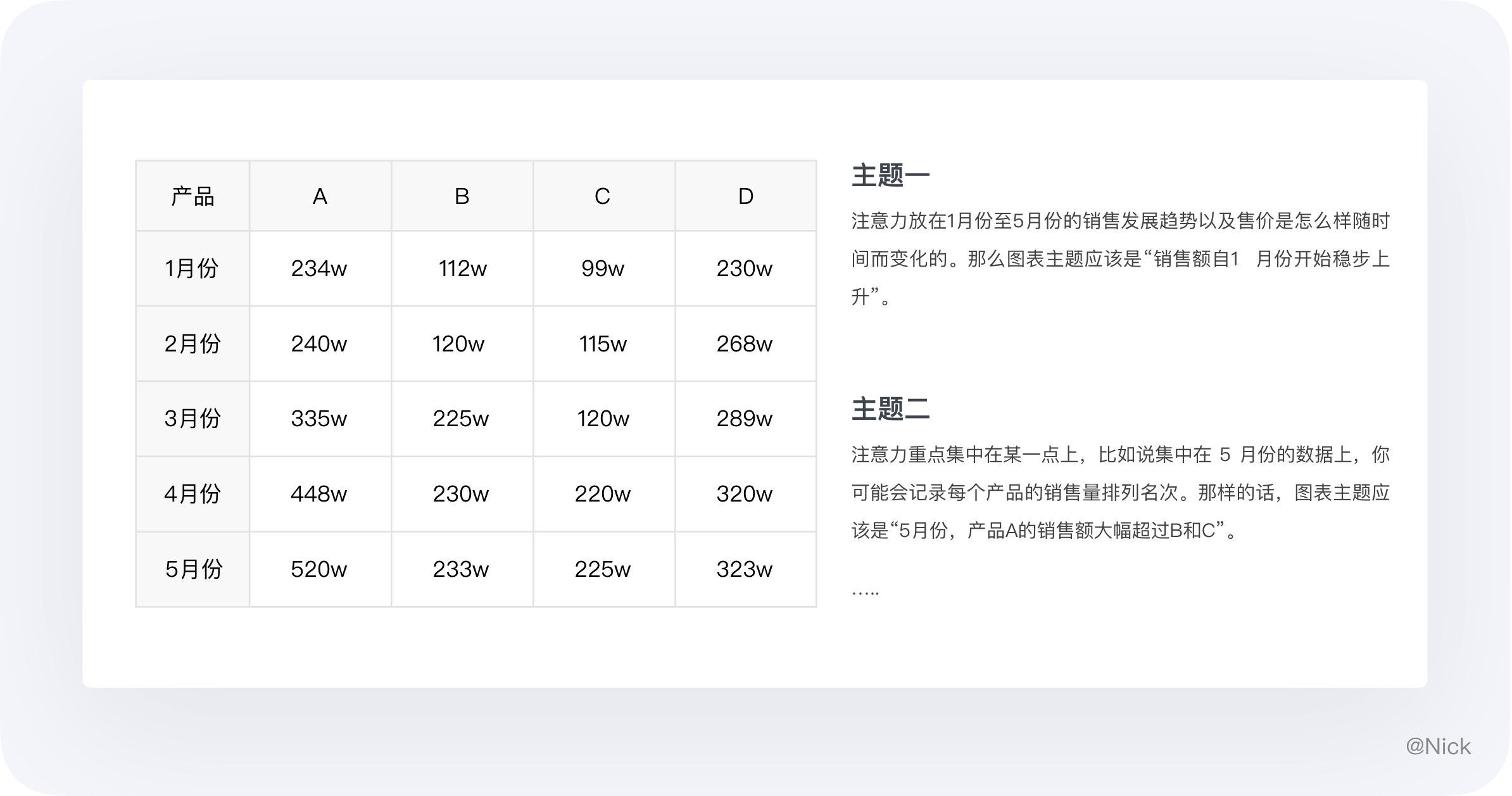
从另一个角度看同样是5月份的数据,你还可能会将侧重点放在每个产品占销售额的百分比上。那你的图表主题应该是“5月份,产品 A 占公司产品总销售额的比例位居首位”。
综上所述,选择合适图表的关键,最初也是最重要的,就是明确要用图表传达的核心信息。
2. 判断比较关系
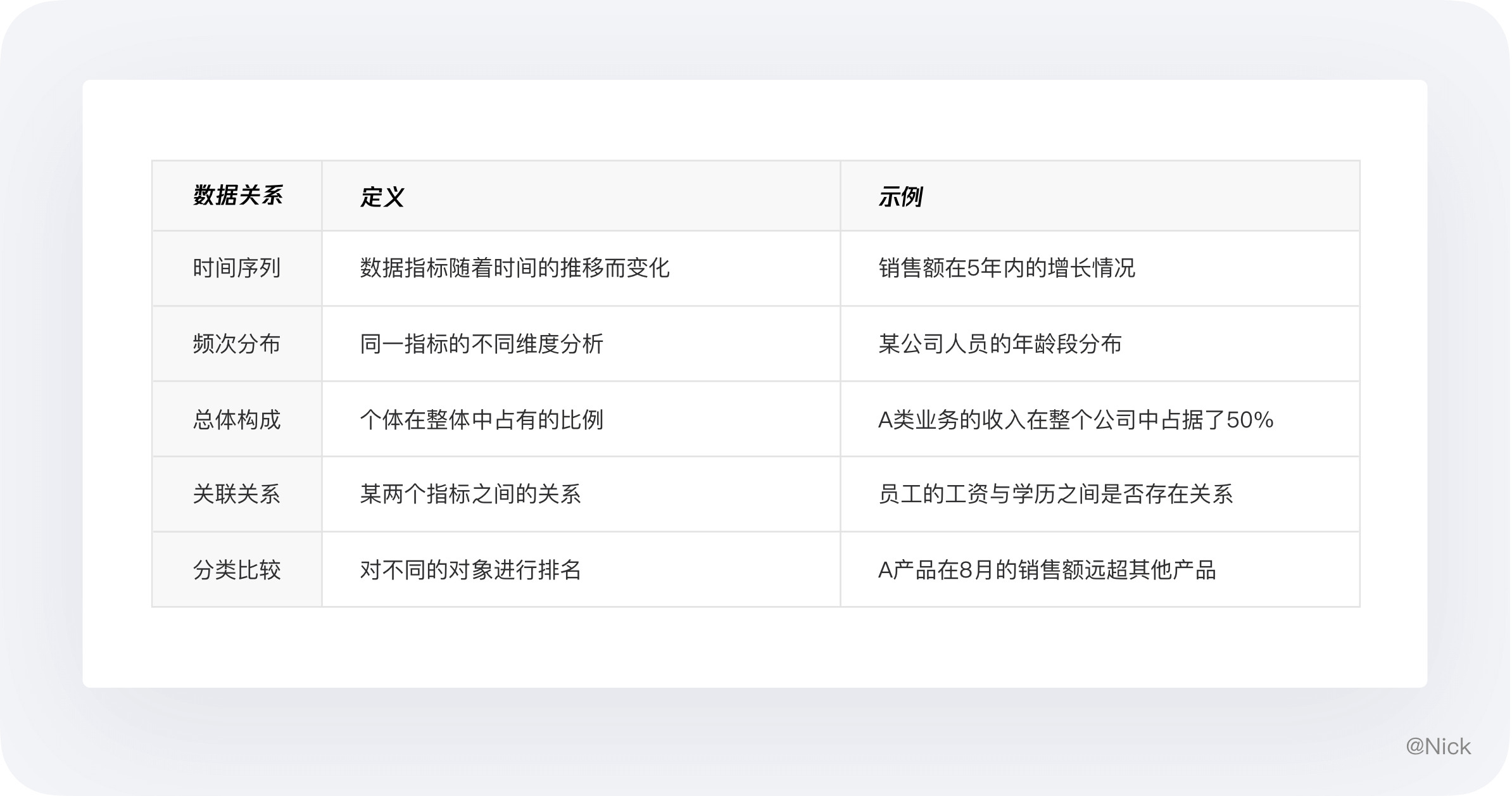
在实际工作中需要用图表反映数据的场景五花八门,但按数据关系分类无非以下几种情况,给大家简单举几个例子:
- “预计在今后 10 年多的时间里,销售额将增长 ”对应的关系为时间趋势;
- “雇员的最高工资额在 30000 到 35000 美元之间 ”对应的关系为频率分布;
- “汽油并不是牌子越响价格越高其性能就越好”对应的关系为相关性;
- “9 月份里,6 个区域的营业额大致相同”对应的关系为排名对比;
- “销售部经理在他的领域内只花费了他 15% 的时间”对应的关系为占比。
3. 选择图表类型
国外专家Andrew Abela曾整理了一份图表类型选择指南图示(如下图),他把数据的关系分成了4种类型,帮助我们去选出合适的图表来呈现。
但其实结合我自己的经验,考虑到日常企业的数据分析场景,图中有些图表使用频率是非常低的。所以我参考了上图的部分内容,对其进行了总结,替换掉了一些图表并对其进行了美化,总体上我认为这是会更适合商务图表展示,而且会更接地气,适合大家参考使用。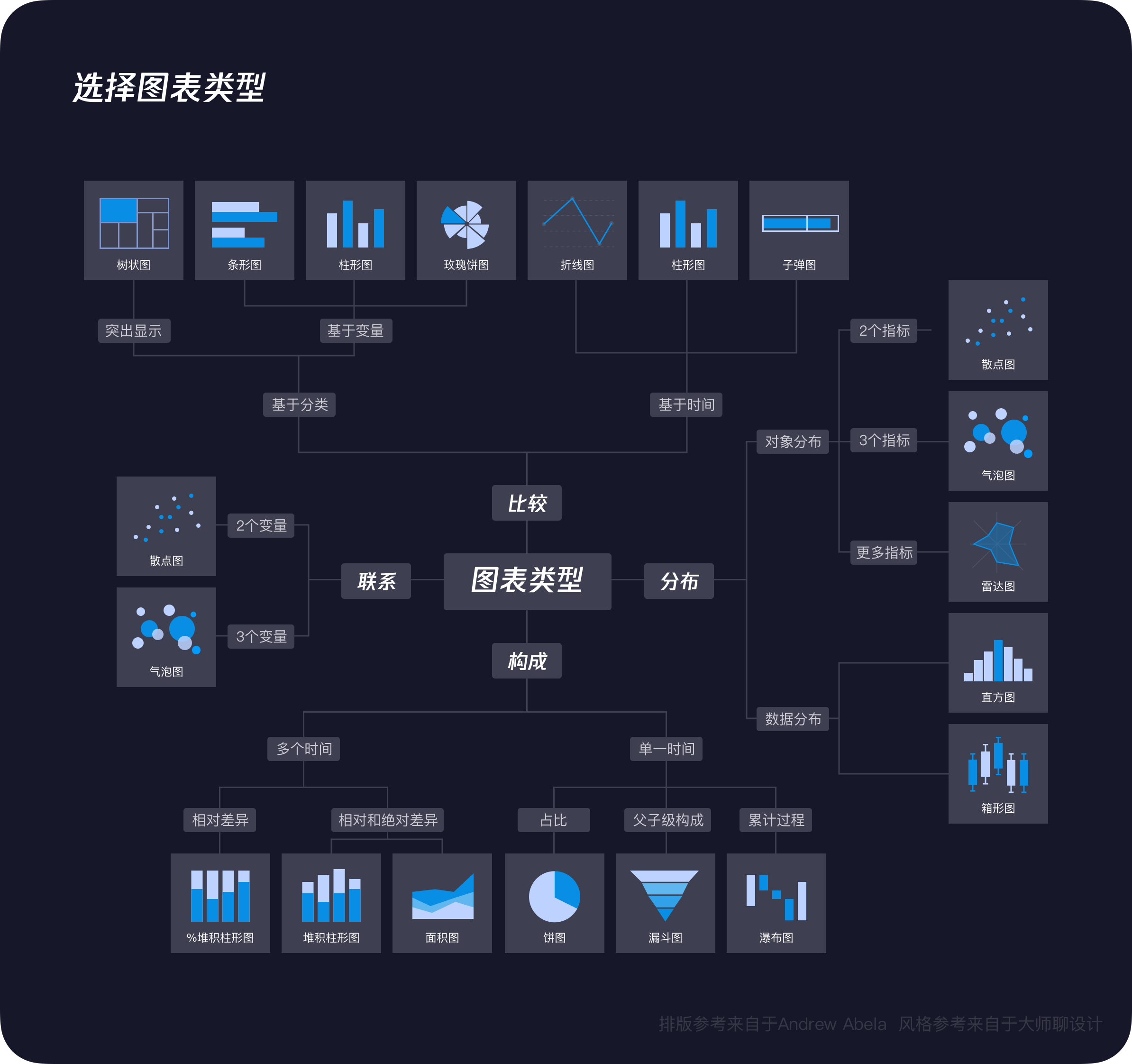
四、常见的可视化图表
1. 折线图
1.1 定义
折线图是通过线条的波动(上升或下降)来显示连续数据随时间或有序类别变化的图表,常用于反映数据随着时间推移而产生的变化趋势。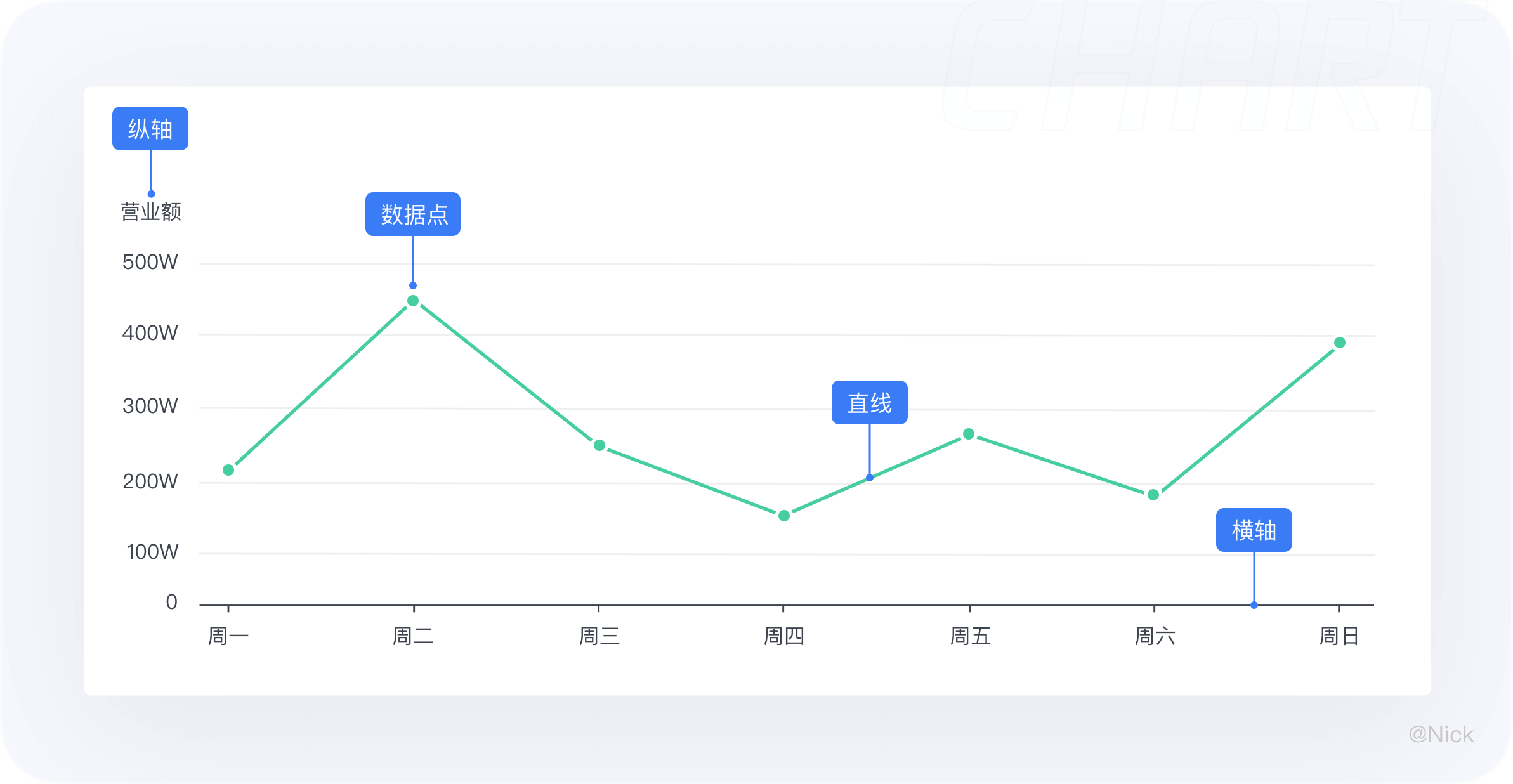
2.2 适用场景
横轴为连续类别(如时间)且注重变化趋势、预测,适用于折线图。
举个例子:比如想看2020年上半年商品的营业额情况,并对走势做一个分析。由于每个月份的商品营业额相关的,它们代表一种数据在不同时间下的数据值,因此我们可以用折线图将它们连接起来。
但如果想看2020年上半年北京、上海、广州、深圳、南京五个省份的营业额情况,由于每个省份的营业额是不相关的,所以我们不能随便用折线图来替代柱状图。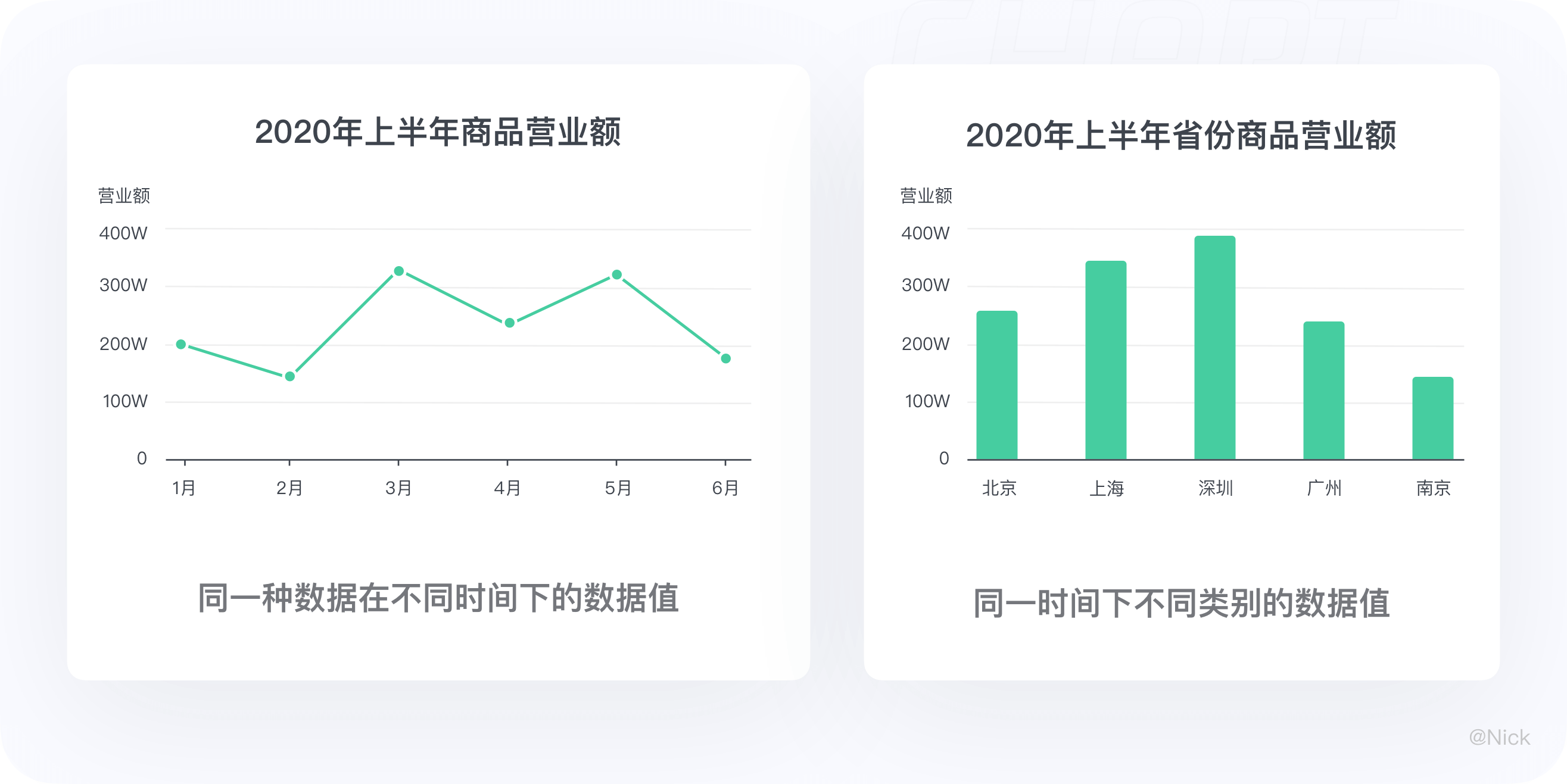
2.3 使用建议
2.3.1 使用合适的时间间隔,使锯齿状的线条平滑
如果折线图上下浮动过于剧烈,那么可以尝试拉长时间间隔,比如不每天采样而以周为单位来采样。用户不太原因去阅读锯齿状的线条,或者说他们不会喜欢这样的图表。
但是如果有强需求说是一定要在某个范围,这条略过。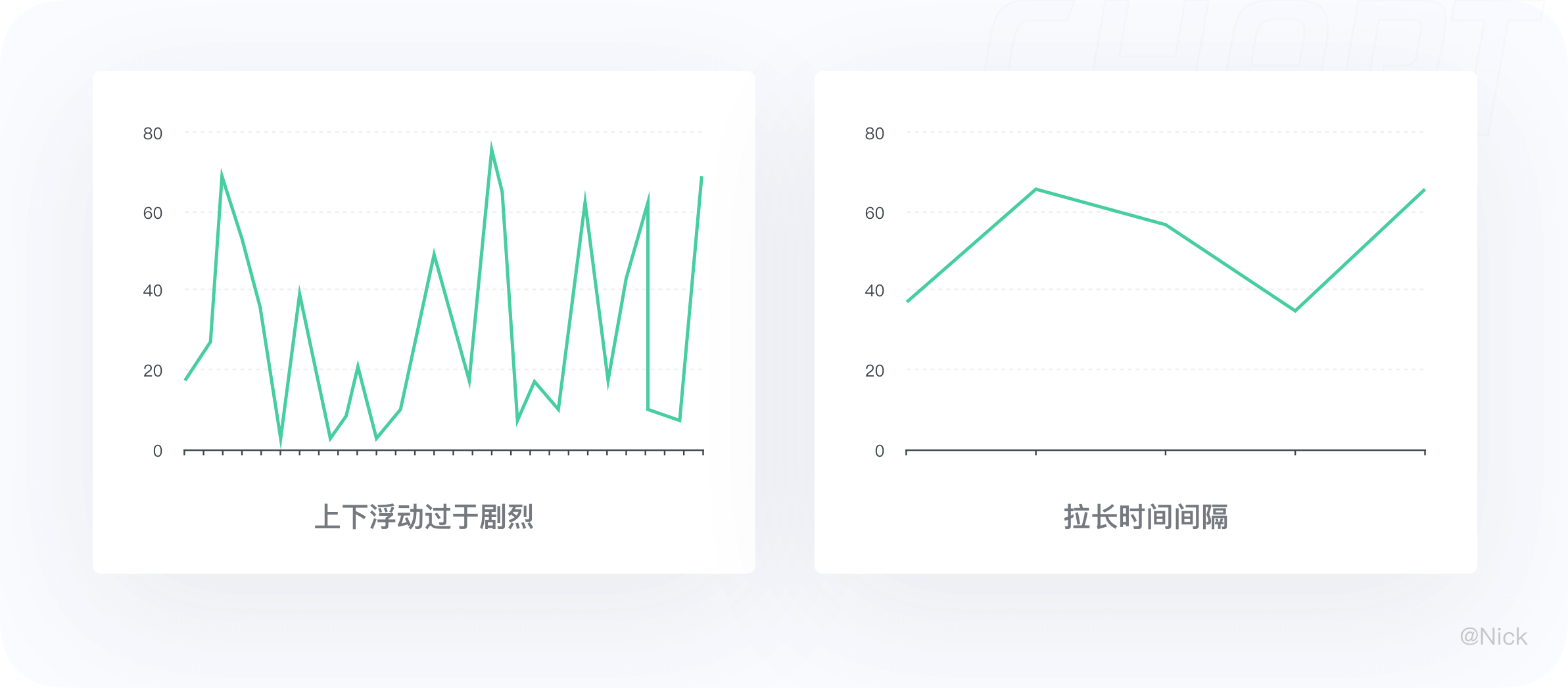
2.3.2 善用数据点标记、特殊标记
当有些特定的数值特别重要时,我们可以在线条上标注出他们,但全部标清数据点在大多数情况下标记出来的意义不大,从视觉上来看会显得非常琐碎。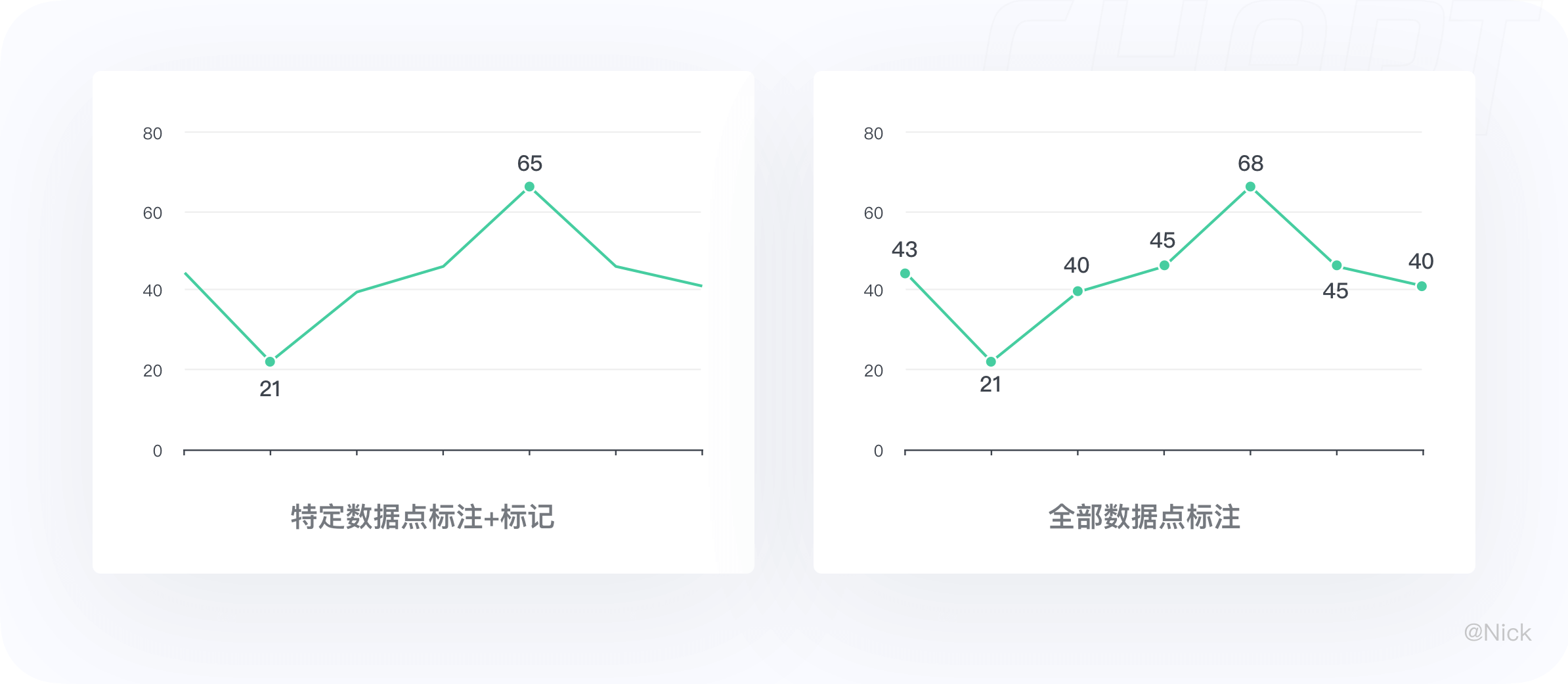
2.3.3 分清主次关系,加强数据感知
若对比数据较多,为了避免信息繁杂。可采用实线的强弱和色彩的对比来区分主次内容,让用户更关注在主折线,获取主数据的波动感知。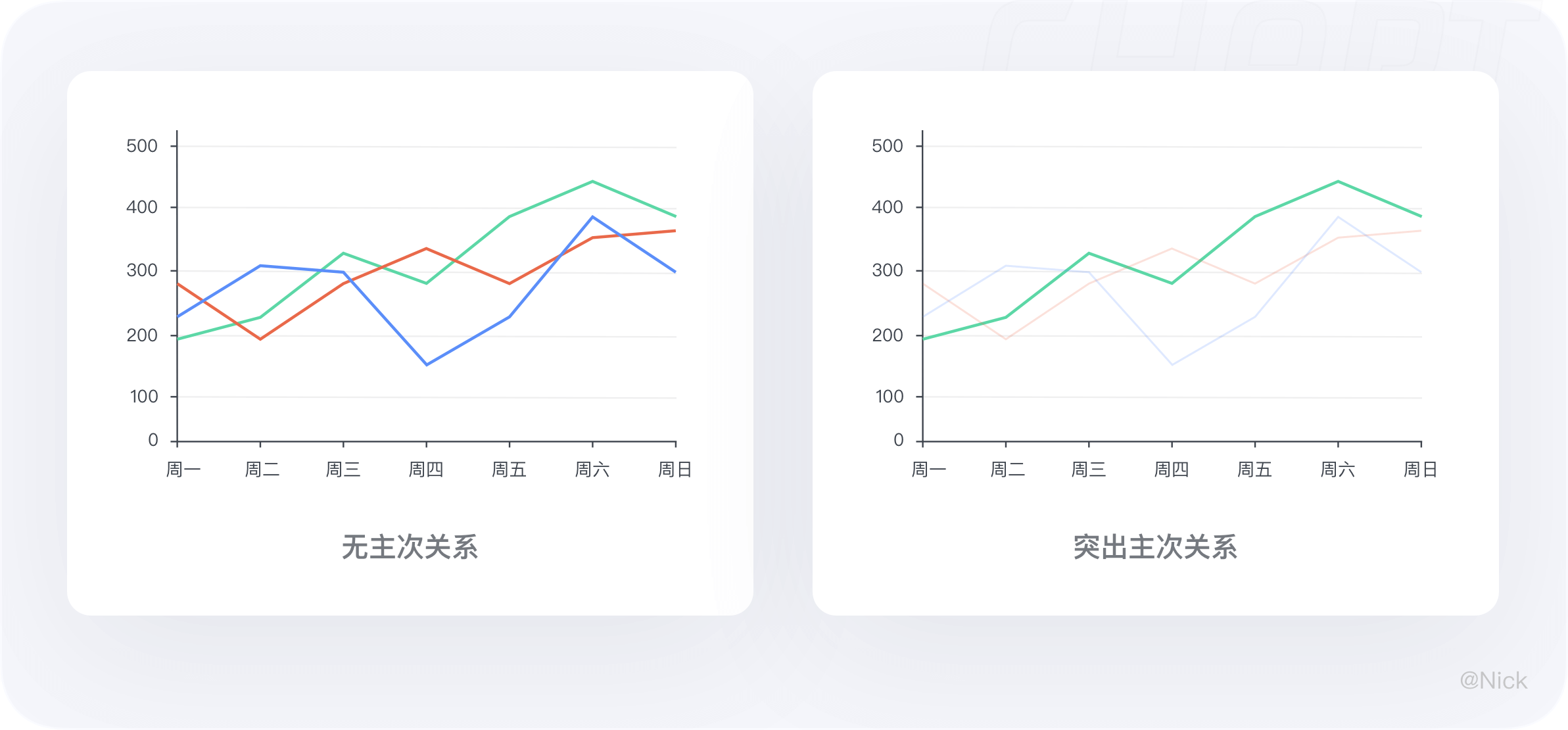
知识扩展:折线图与曲线图的区别
折线图:更关注于点的数据,相对短的一段时间数据随时间变化的趋势;
曲线图:更关注点构成的线点数据,一段时间内整体数据随时间变化的趋势。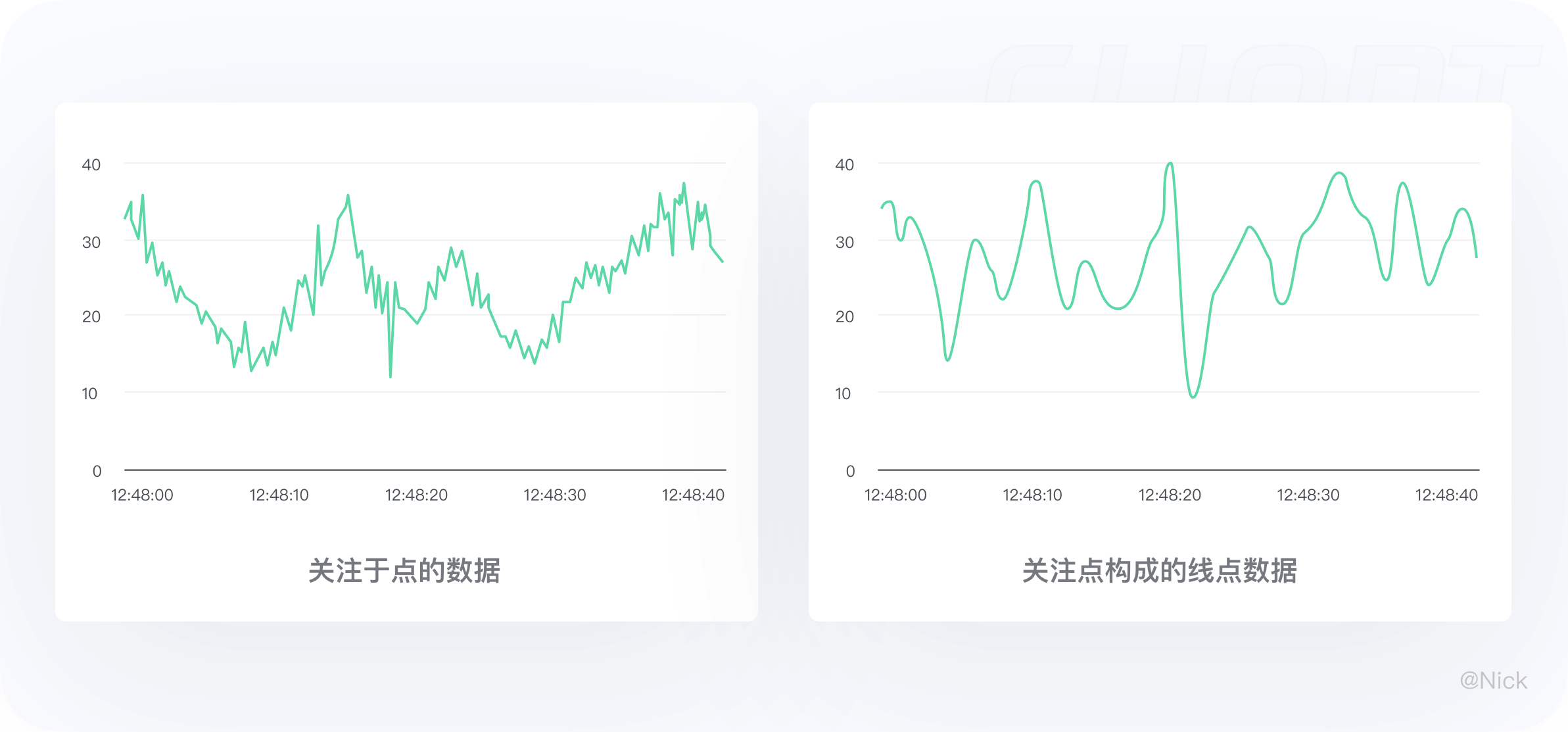
曲线图是折线图中的一种,当图表数据点过于密集时,使用曲线图更能表达数据随时间变化的趋势、周期性。
2. 面积图
2.1 定义
面积图又叫区域图,是一种随有序变量的变化,反映数值变化的统计图表,原理与折线图相似。它在折线图的基础上多了一个面积概念,填充的区域可以表示“累积”的含义(当X轴为连续的数值时)。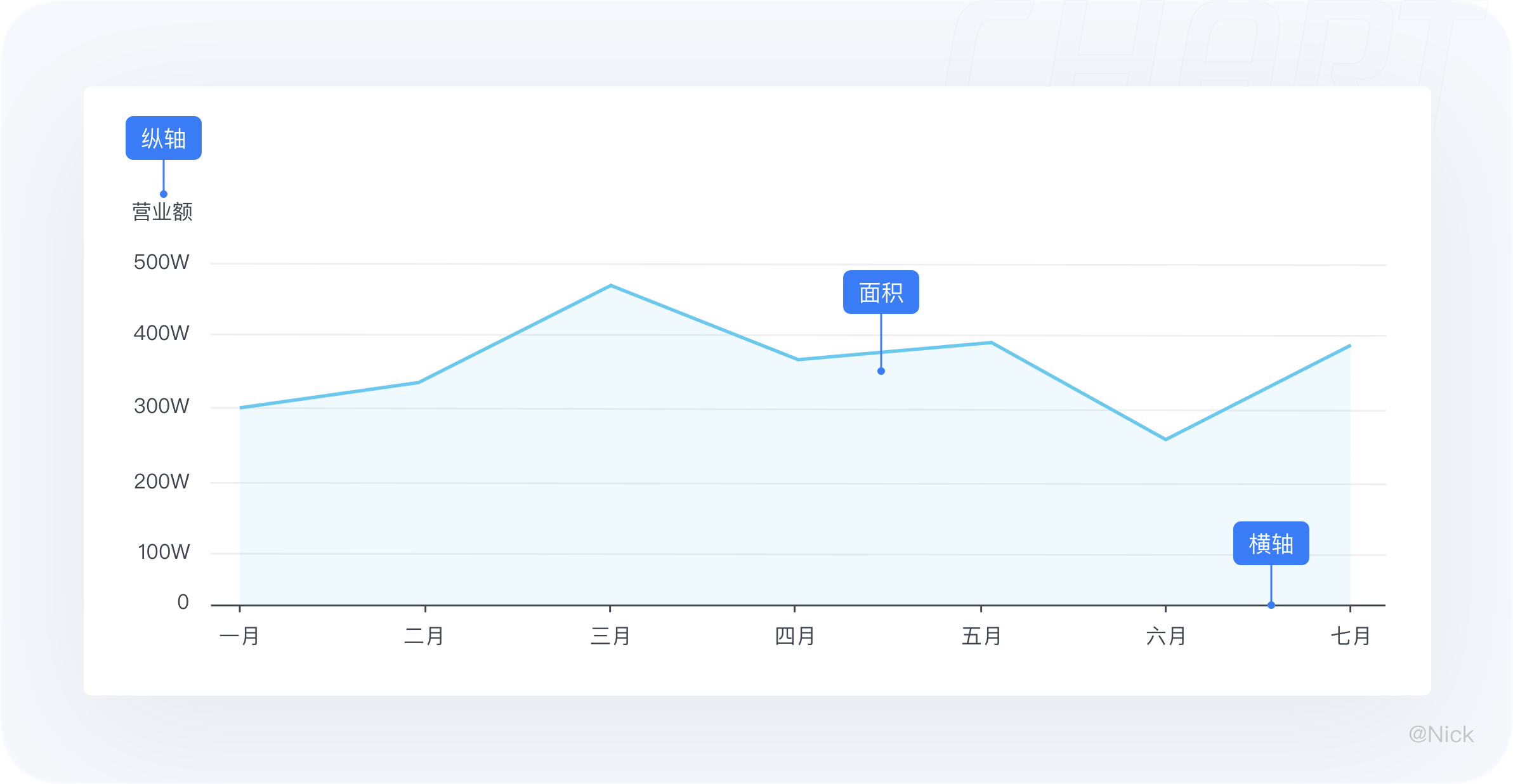
2.2 适用场景
当注重随时间的趋势变化和累计的值时,适用于面积图。
例如:想要查看今年10月和去年10月每日的商品营业额走势,并对整月营业额进行比较,这时就可以采用面积图。但当自变量不是顺序性的变量,则不适合用面积图。
2.3 使用建议
2.3.1 使用透明填充色
透明度可以很好的帮助使用者观察不同序列之间的重叠关系,没有透明度的面积会导致不同序列之间相互遮盖减少可以被观察到的信息。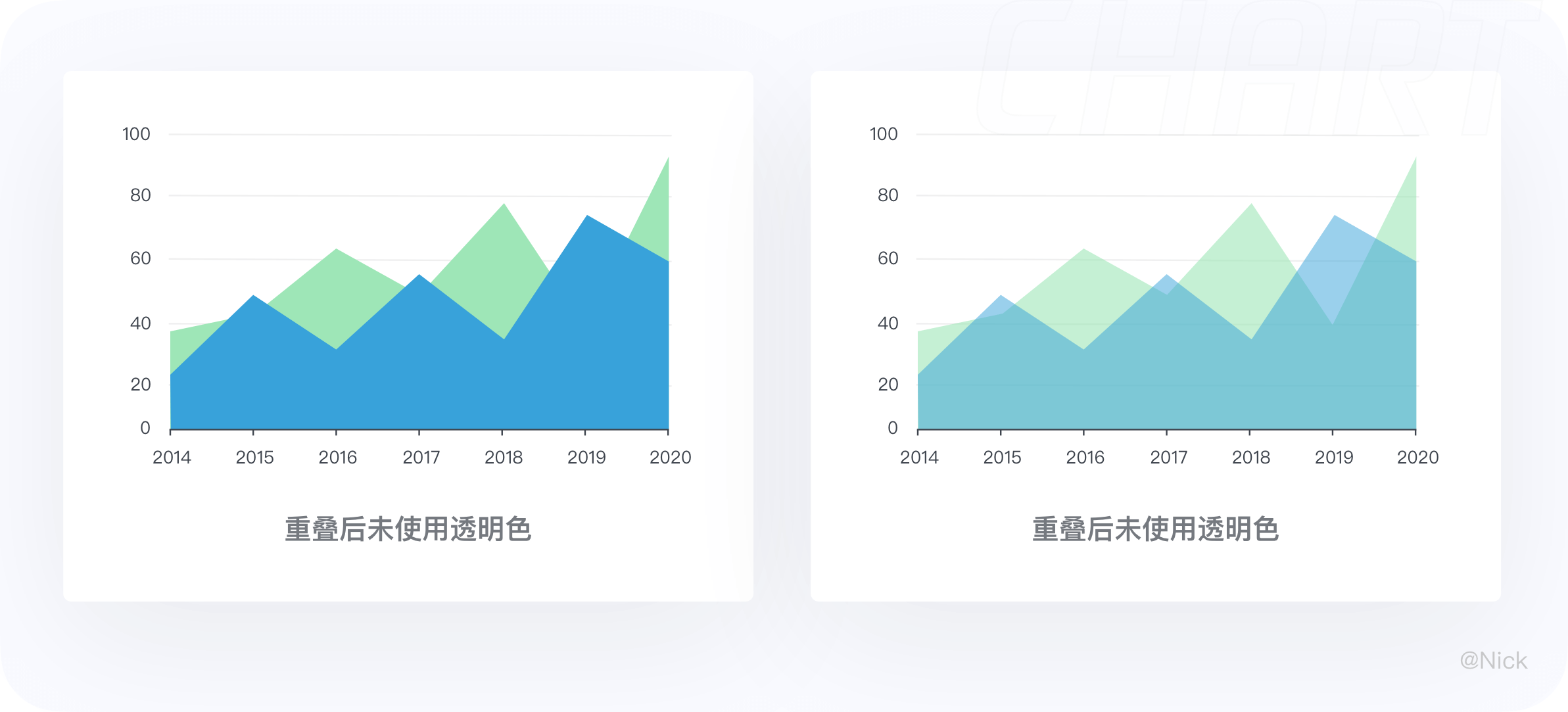
2.3.2 当X轴数据较少,考虑其他图表
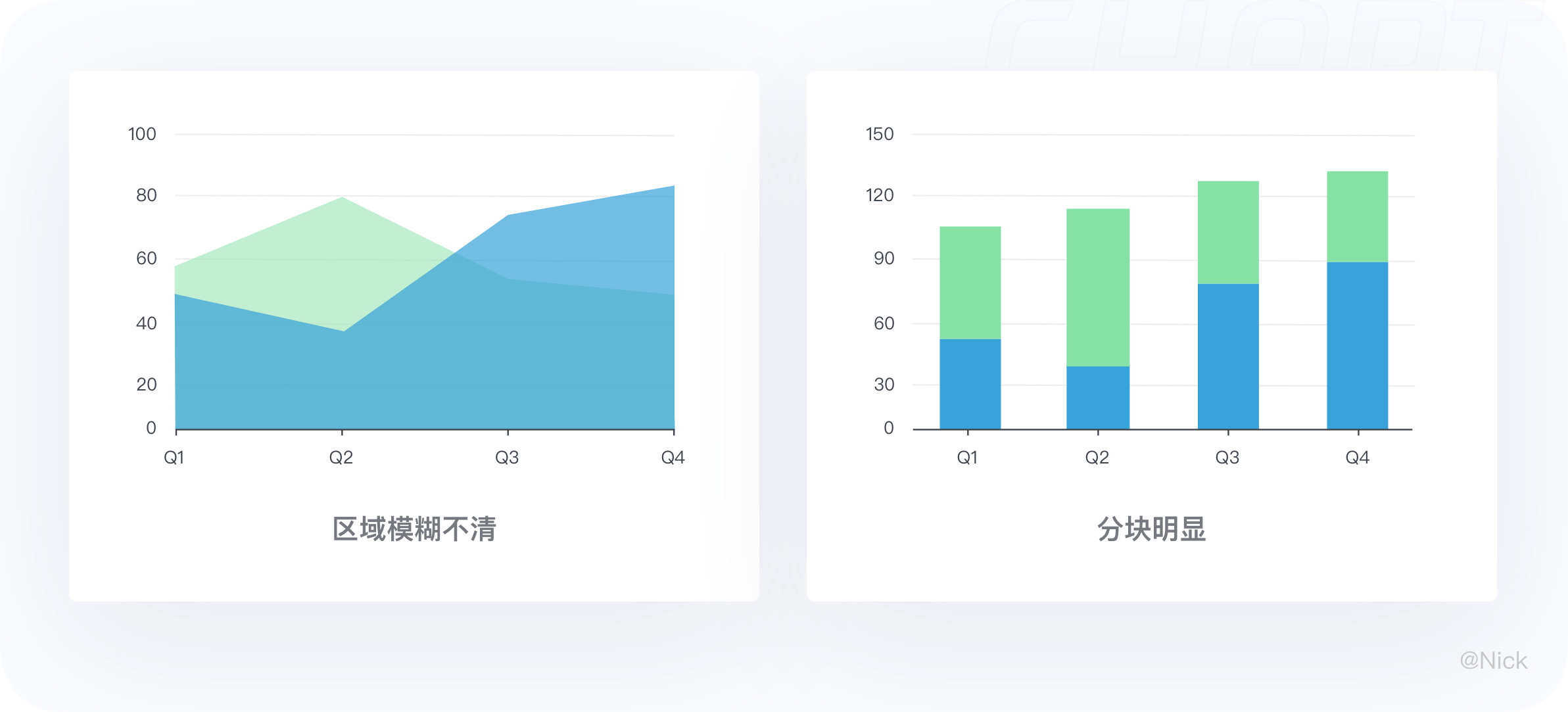
当数据值相距很远时,区域是模糊不清的,此时不太适合使用面积图展示。
如下方示例虽然仔细分析能确定只展示了两个类别,乍一看,很可能会误以为图表上显示三种不同的颜色,但使用分组柱状图就可以很好解决这个问题。
2.3.3 不要超过4个数据系列
面积图只适合展现少量的数据,最多建议不要超过四个类别,否则就会导致非常难以识别。因此在多个类别下,要尽量避免使用面积图,采用相似图表来表示,比如折线图。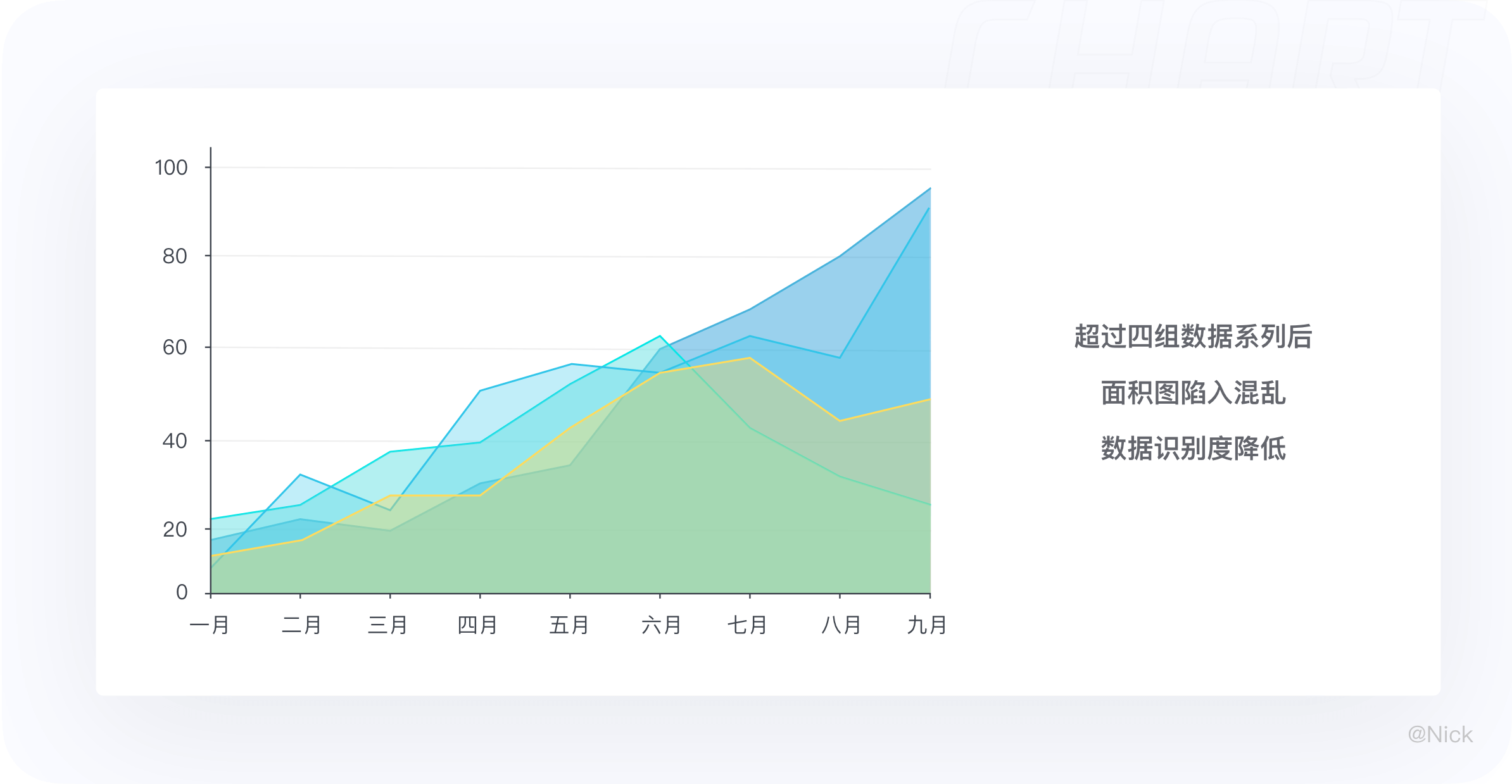
3.堆叠面积图
3.1 定义
堆叠面积图与面积图类似,都是在折线图的基础上,将折线与自变量坐标轴之间区域填充起来的统计图表。
唯一的区别是堆叠面积图有多个数据系列,它们一层层的堆叠起来,每个数据系列的起始点是上一个数据系列的结束点。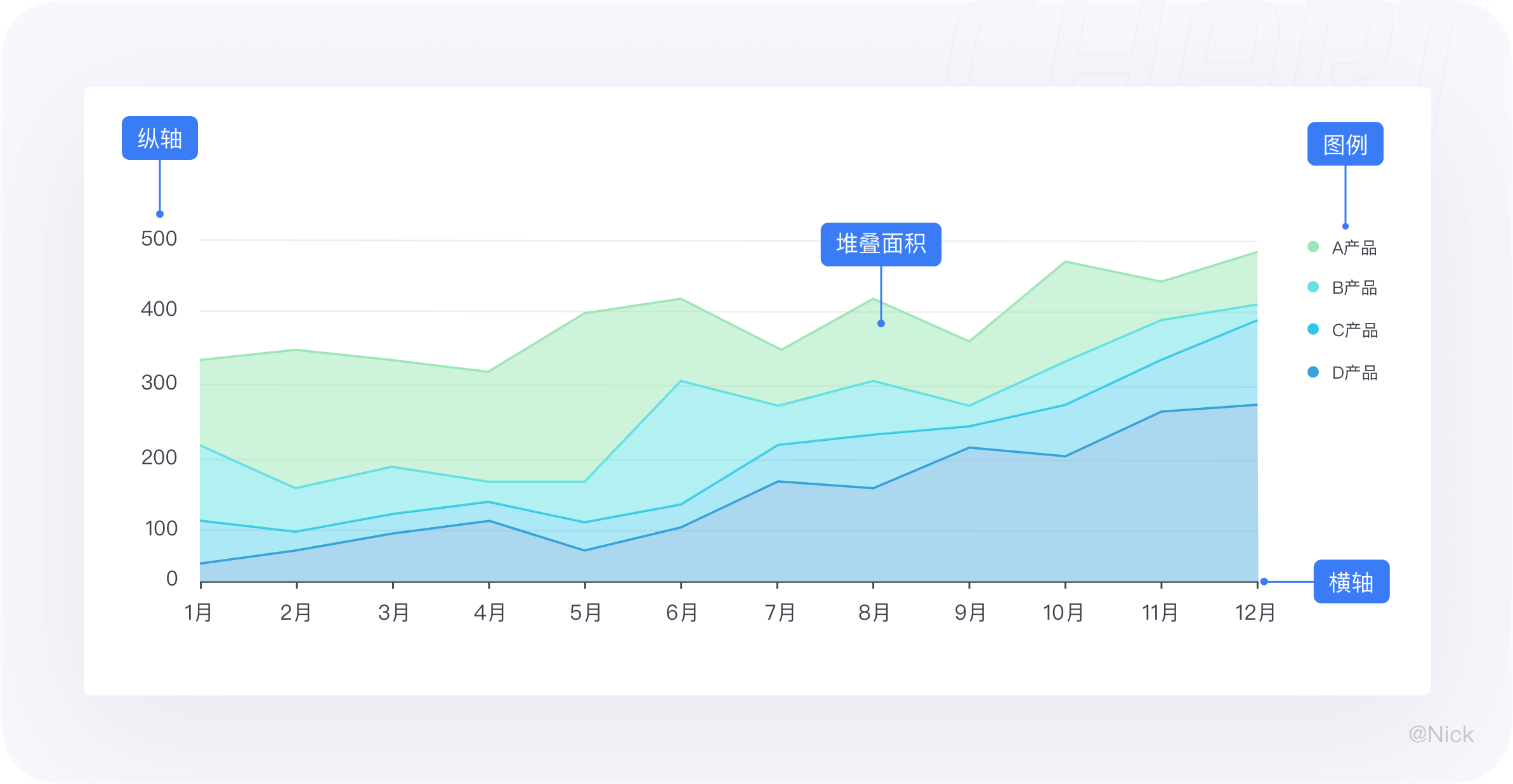
3.2 适用场景
适用于观察多变量随时间的变化情况,且既能看到整体趋势又能看到各变量的构成情况。
3.3 使用建议
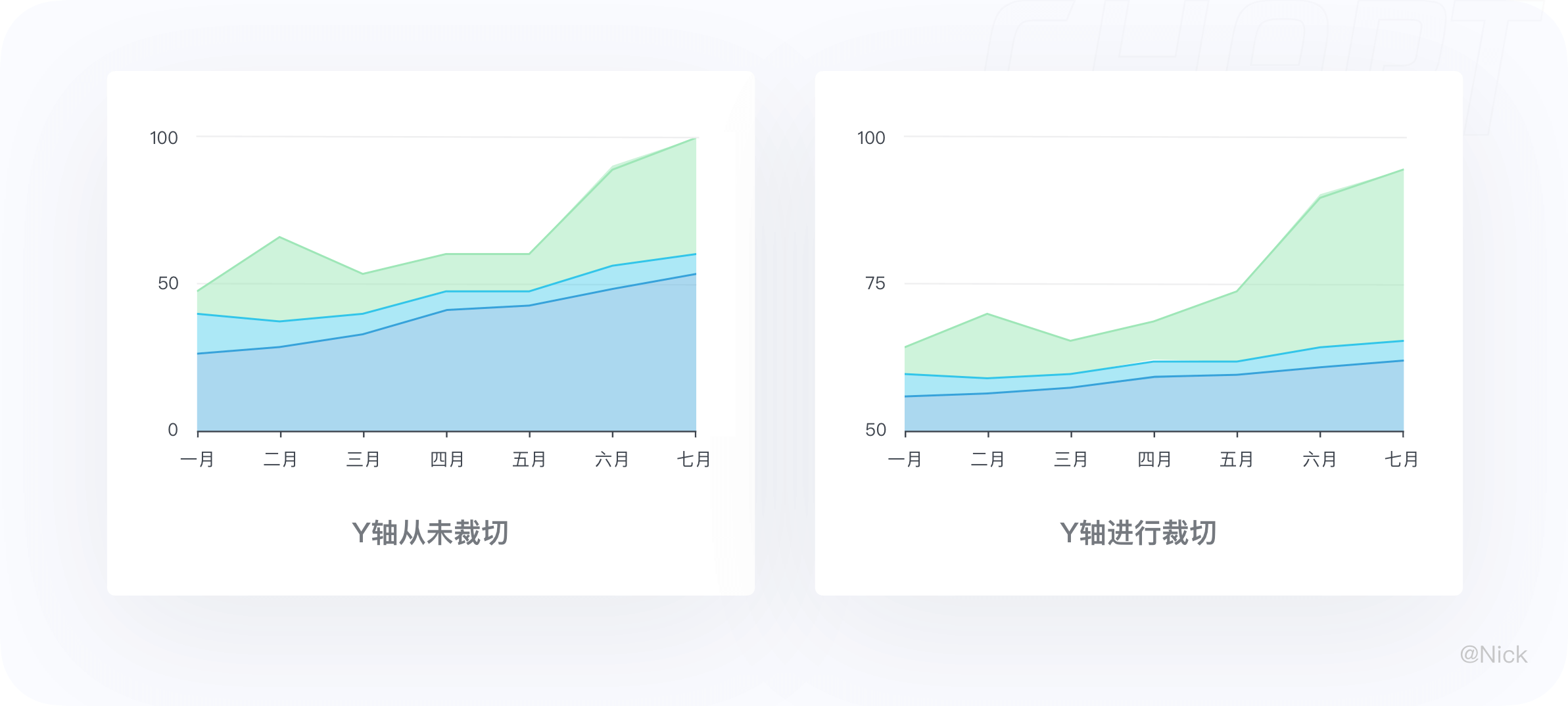
3.3.1 尽量不要对Y轴进行裁切
为了保证数据传递的准确性,在适用堆叠面积图时,尽量不要对Y轴进行裁剪。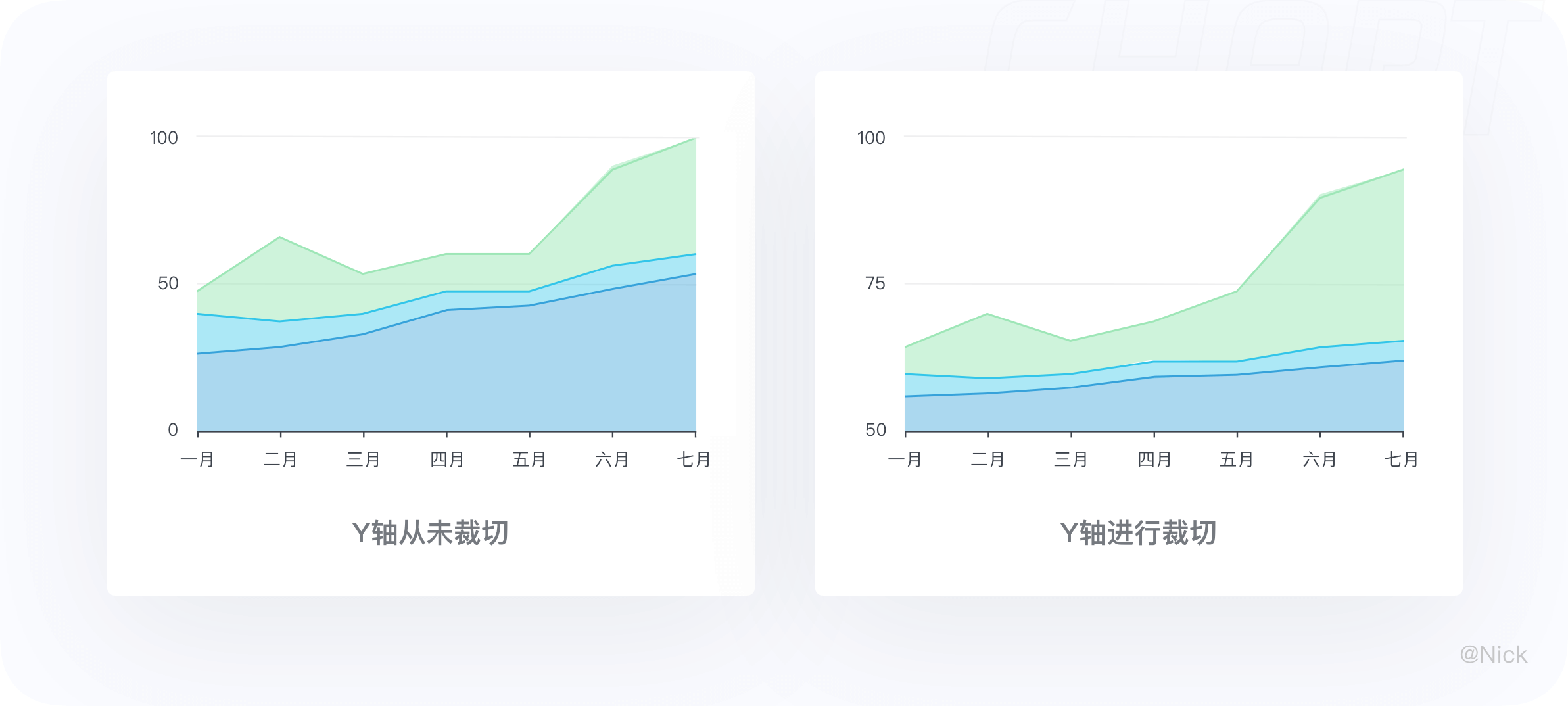
3.3.2 不要超过7个数据系列
当数据系列过多时,往往造成难以观察,所以建议使用堆叠面积图时数据系列最好不要超过7个。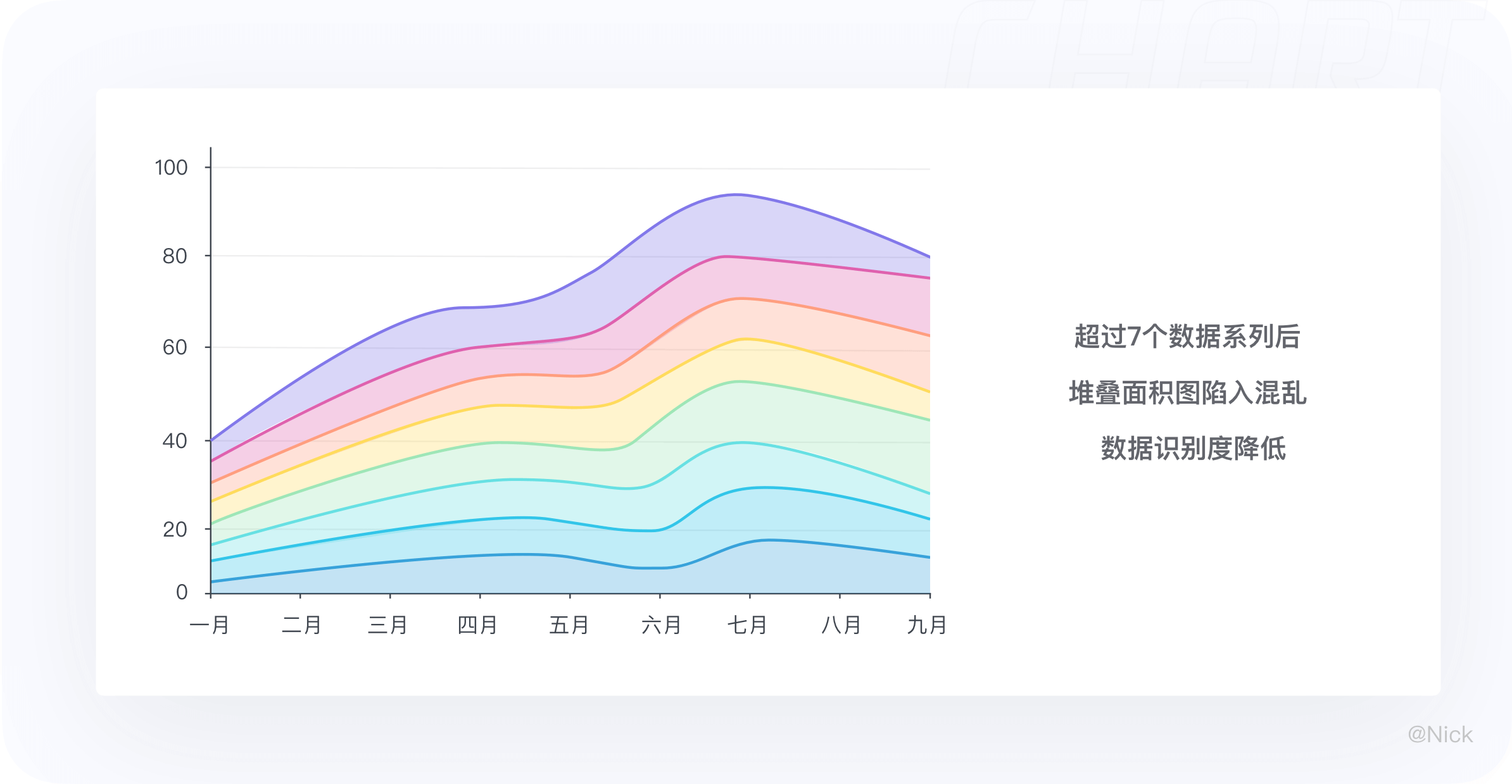
3.3.3 变化量大的数据置于上方
建议堆叠面积图中把变化量较大的数据放在上方,变化量较小的数据放在下方会获得更加的展示效果。
3.3.4 不适合带有负值的数据系列
堆积面积图要展示部分和整体之间的关系,所以不能用于包含负值的数据的展示。
4.柱状图
4.1 定义
柱状图,是一种使用矩形条,对不同类别进行数值比较的统计图表。使用垂直或水平的柱子的长短对比数值大小,其中一个轴表示需要对比的分类维度;另一个轴代表相应的数值。
在柱状图上,分类变量的每个实体都被表示为一个矩形(通俗讲即为“柱子”),而数值则决定了柱子的高度。纵向柱状图的柱是垂直方向的,如图: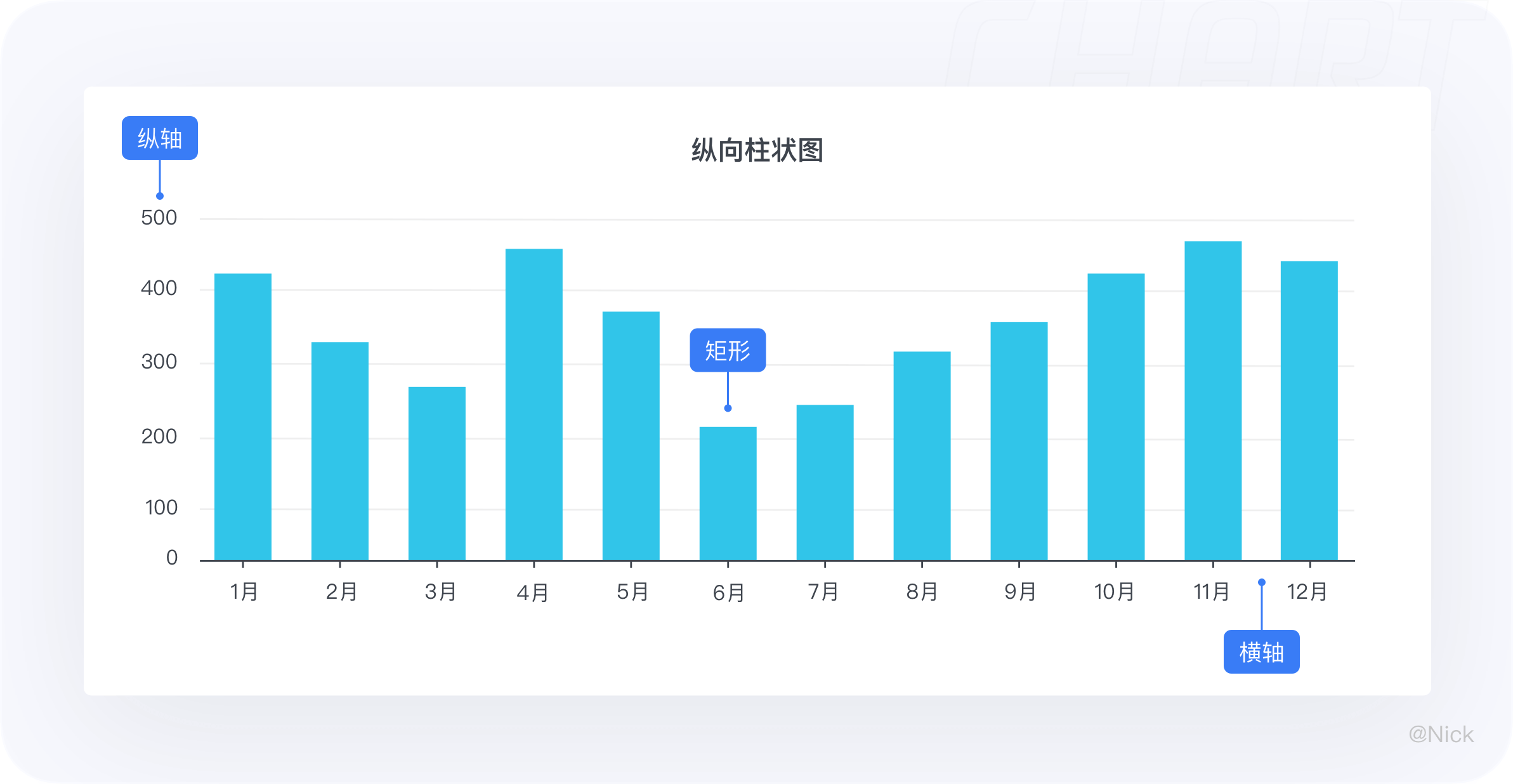
横向柱状图的柱是水平方向的,又称条形图,如图:
4.2 适用场景
柱状图最适合对分类的数据进行比较,尤其是当数值比较接近时,由于人眼对于高度的感知优于其他视觉元素(如面积、角度等),因此使用柱状图更加合适。
如下图所示,5组数据的数值很接近,若采用饼图,这无法直观的进行比较,右边的柱状图则能更好地传递图表信息。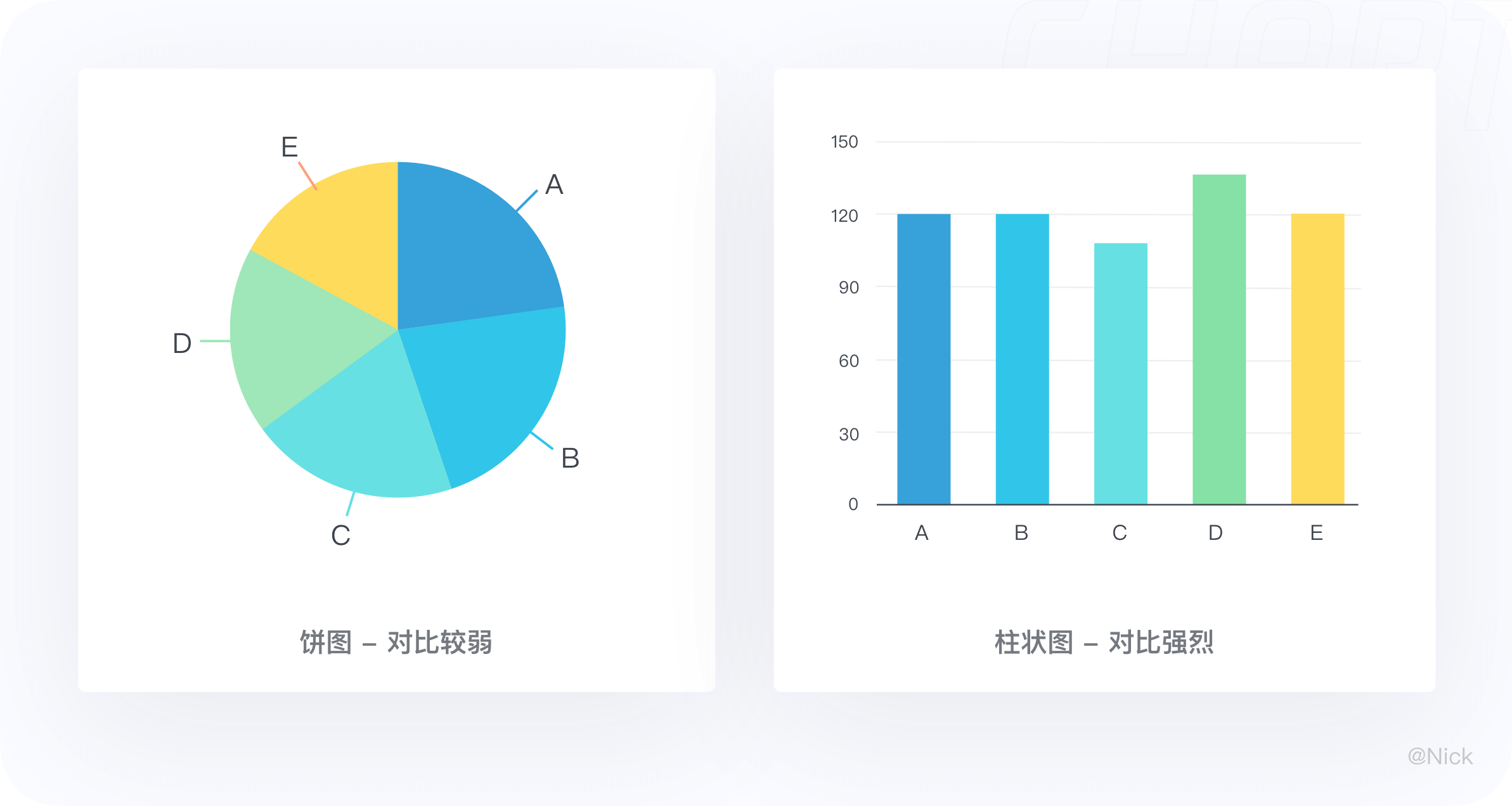
4.3 使用建议
4.3.1 使用合适的宽度去适配柱条的宽度
当柱子太窄时,用户的视觉可能会集中在两个柱中间的负空间,而这里是不承载任何数据的。宽度推荐使用在1/2 柱宽到 1 柱宽之间,但也要视情况而定。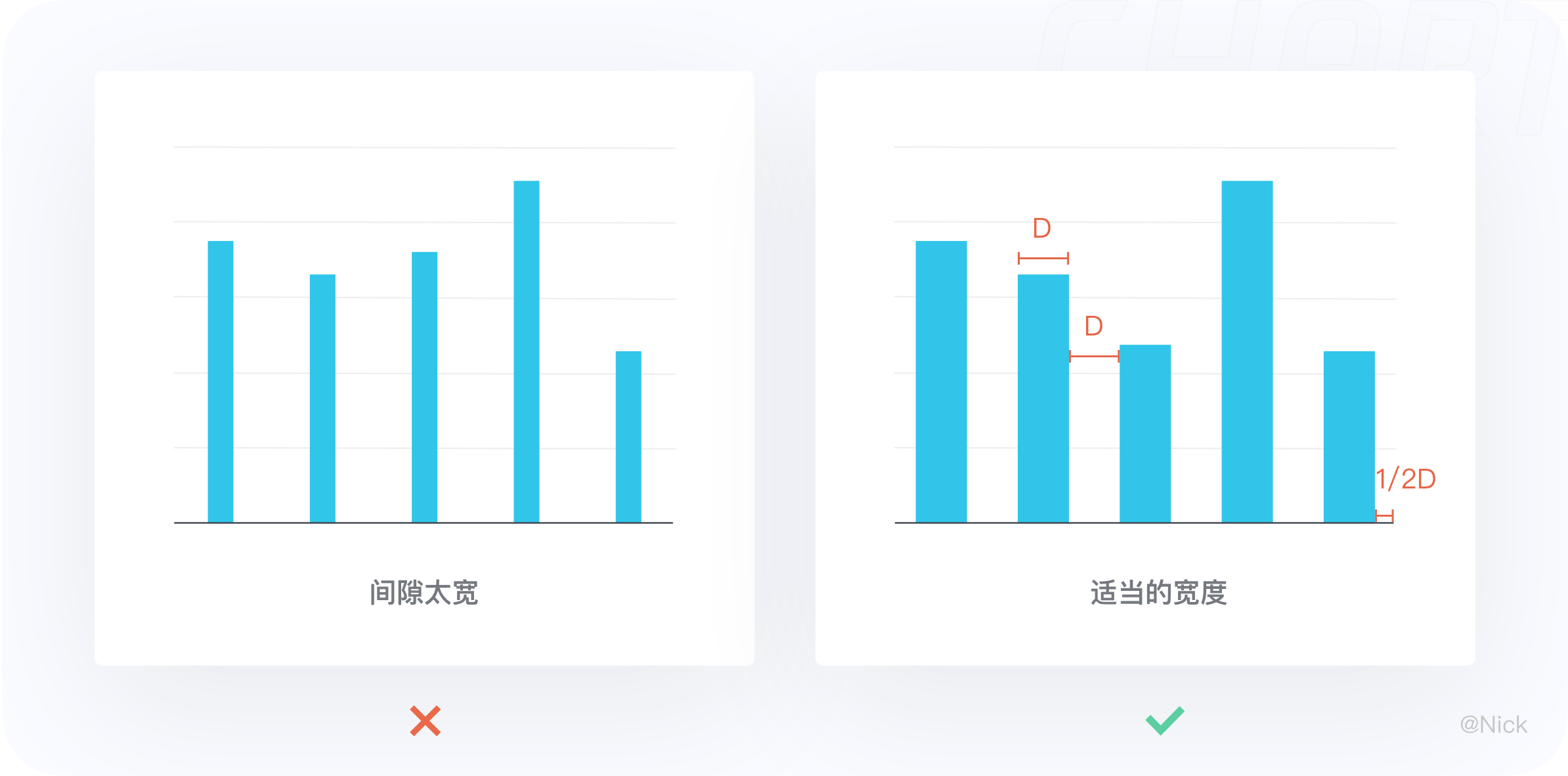
4.3.2 不推荐采用全圆角
保证柱形图有精确的圆角,以确保柱形顶部精确测量柱形的长度;全圆角则有可能歪曲可视化图表的表达。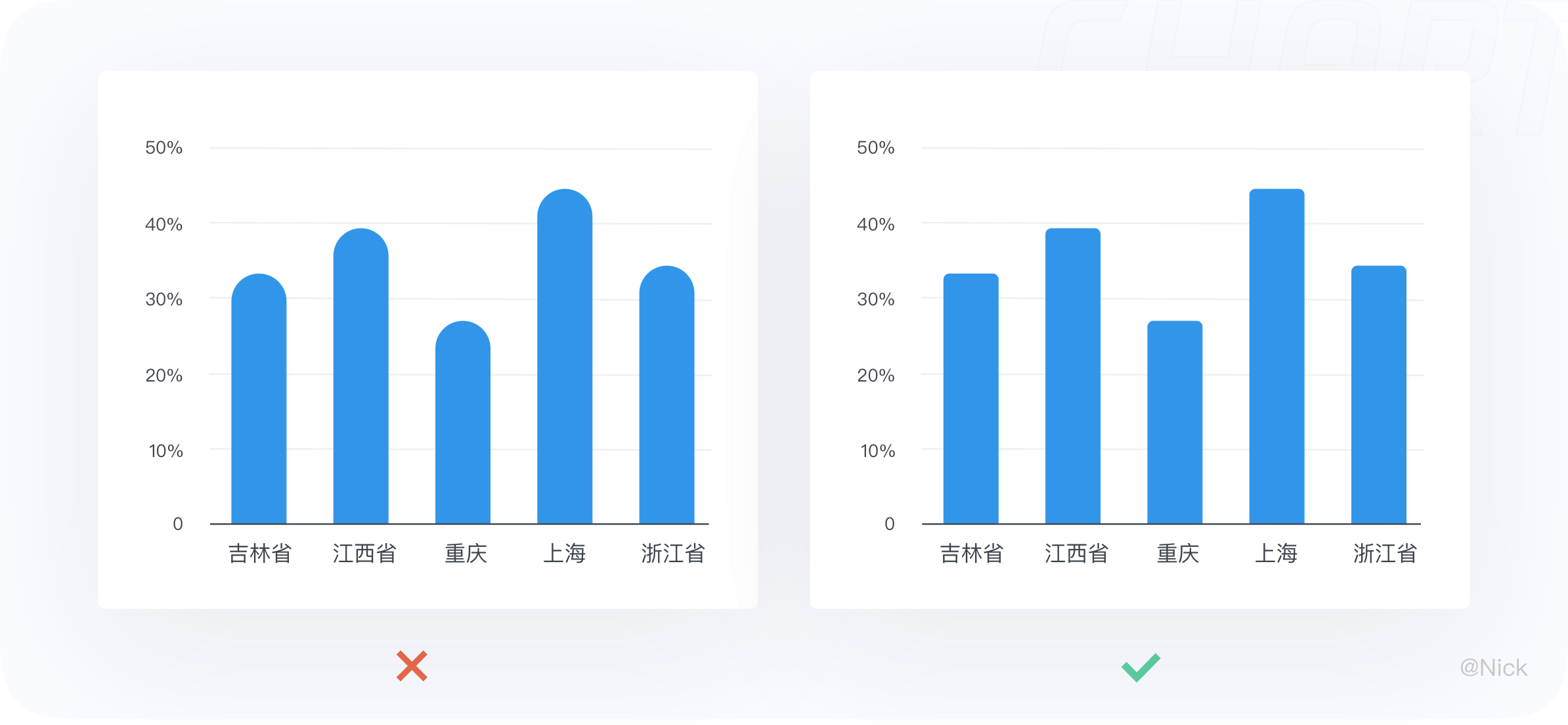
4.3.3 避免适用过多的颜色
柱形图一般比较一组分类数据,柱子的高低已经传递了相关信息,不必通过颜色来区分,所以建议使用相同的颜色或同一颜色的不同色调,过多的颜色会增加理解成本。
如果需要强调某个数据时,可以使用对比色或者变化色调来突出显示有意义的数据点。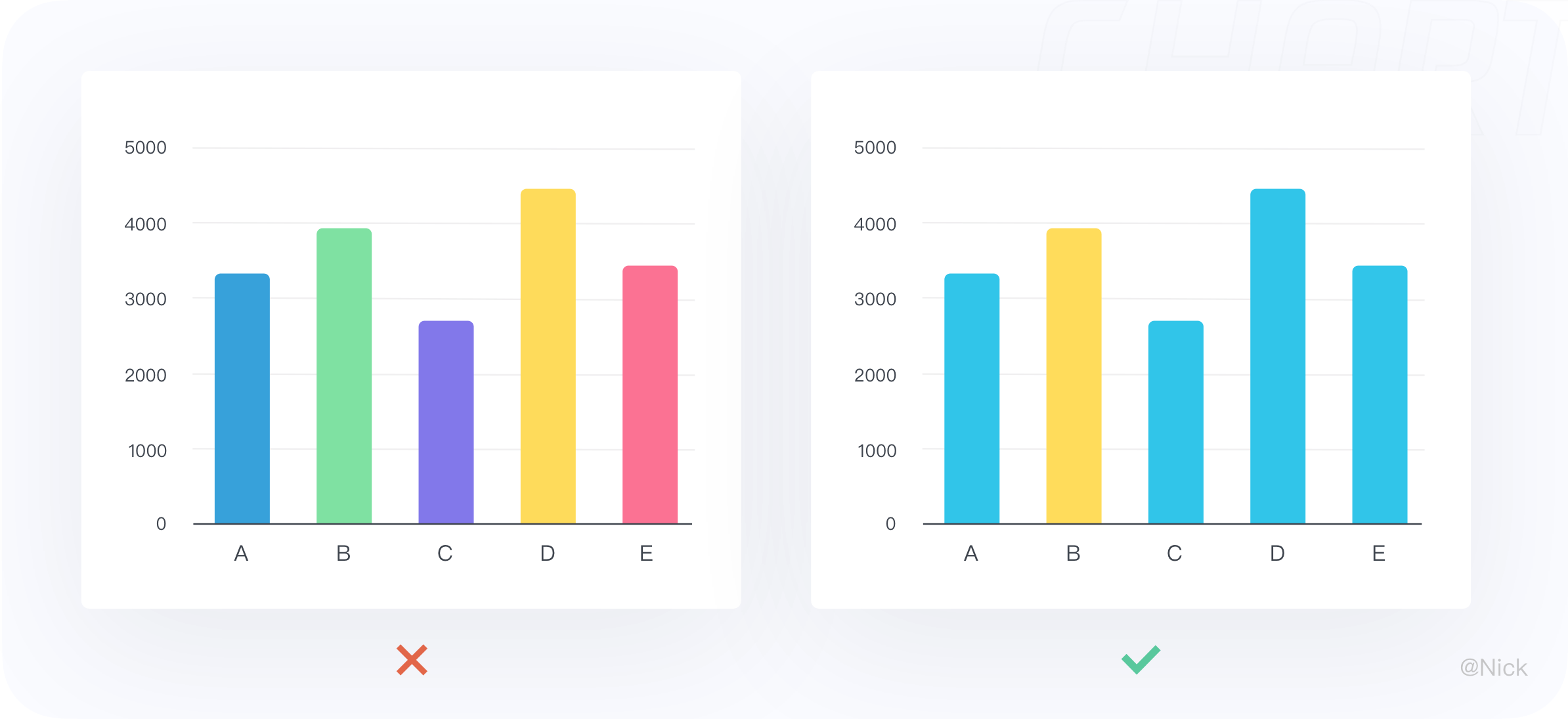
4.3.4 采用有序排列,轴标签右对齐
对多个数据系列排序时,如果不涉及到日期等特定数据,最好能符合一定的逻辑用直观的方式引导用户更好的查看数据。
可以通过升序或降序排布,例如按照数量从多到少来对数据进行排序,也可以按照字母顺序等来排布。总之,按照逻辑排序可以一定程度上引导人们更好地阅读数据。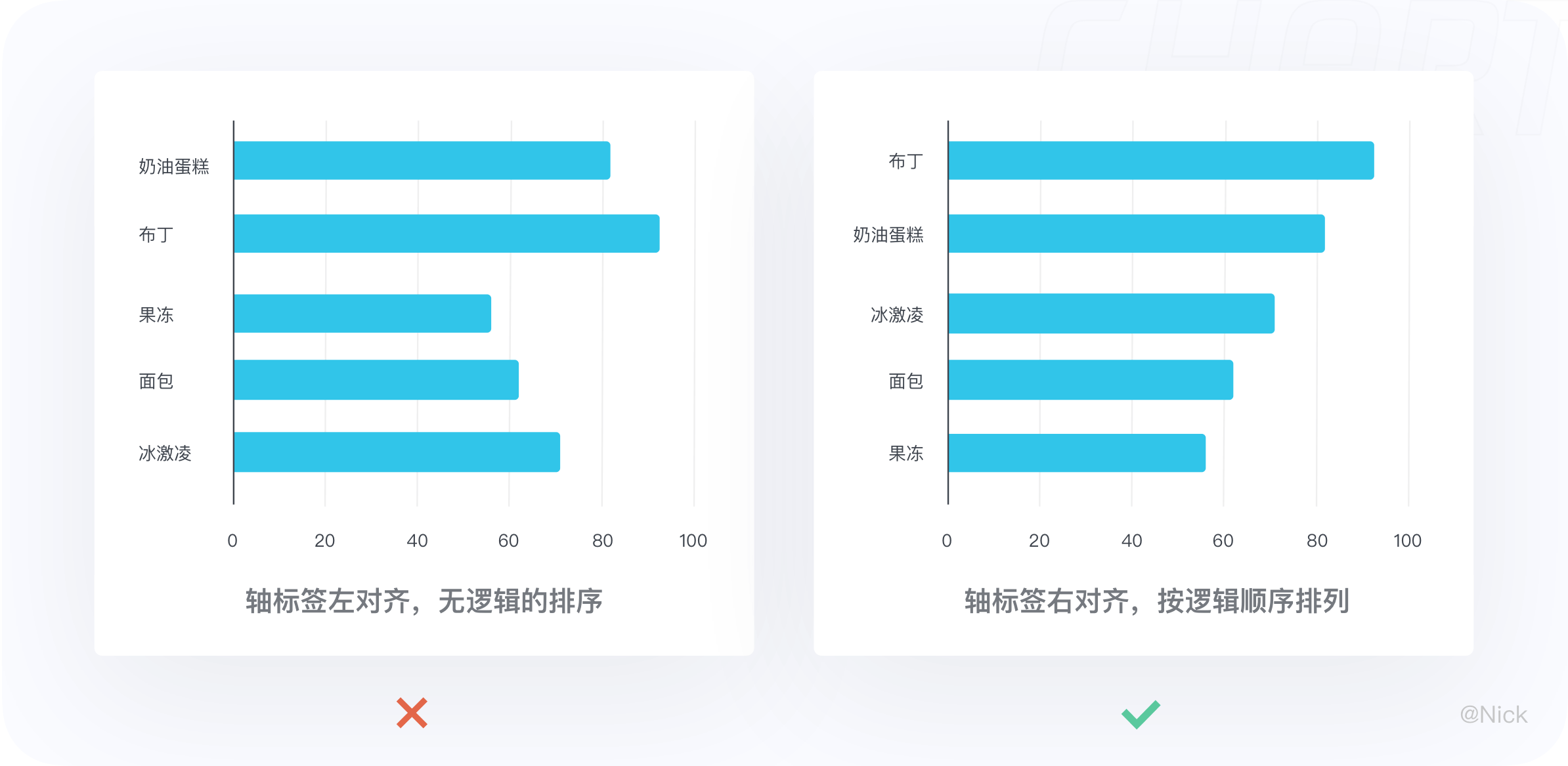
4.3.5 标签直接显示在柱体上
条形图还可以通过省略横轴和纵轴,并直接在柱子上表明数值,来降低数据墨水比,进一步提高信息的获取效率。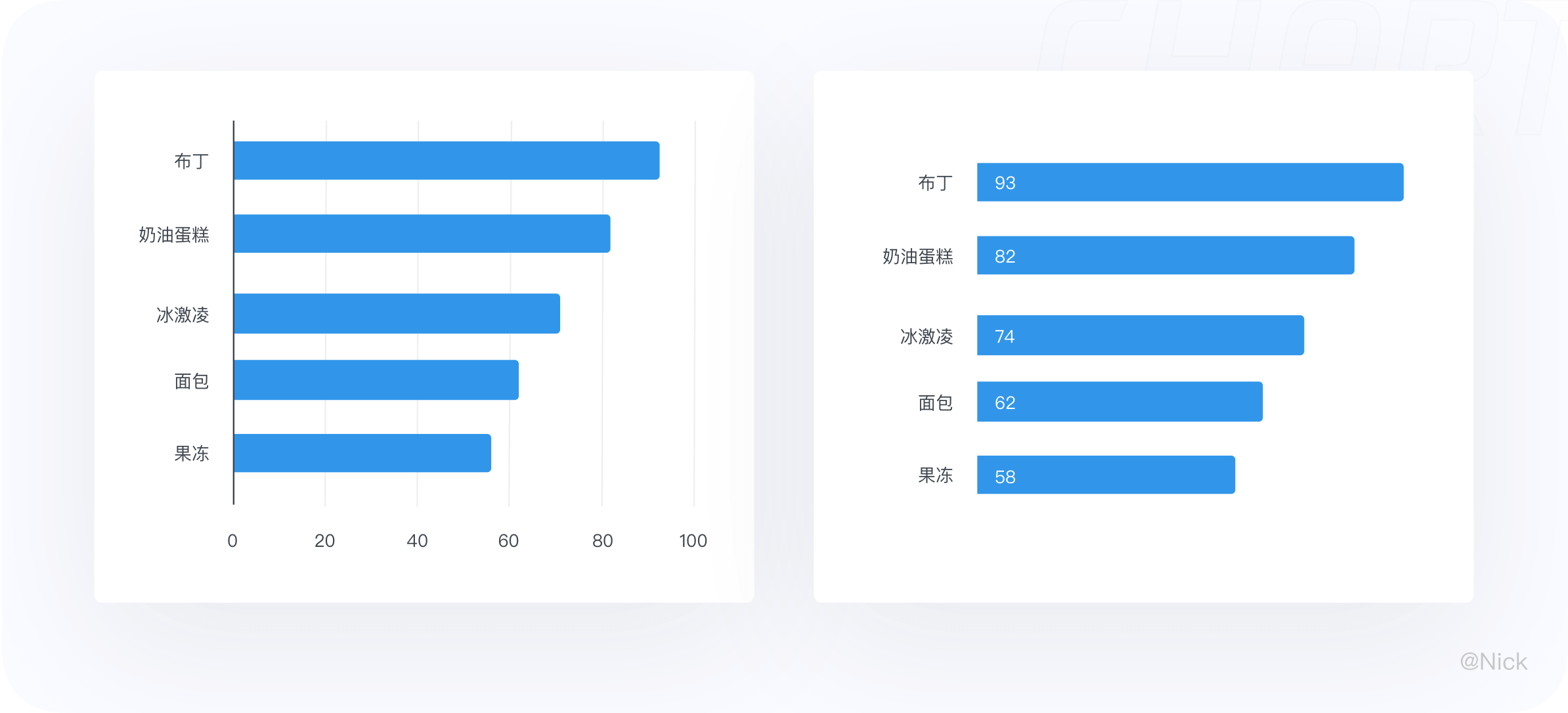
5.堆叠柱状图
5.1 定义
堆叠柱状图(Stacked Column Chart),又称堆叠柱形图,是一种用来分解整体、比较各部分的图表。
它是柱状图的扩展,不同的是,柱状图的数据值为并行排列,堆叠柱图则是一个个叠加起来的。它可以展示每一个分类的总量,以及该分类包含的每个小分类的大小及占比,并且这些子类别一般用不同的颜色来指代。
5.2 适用场景
对比不同类别数据的数值大小,同时对比每一类别数据中,子类别的构成及大小。
例如下图显示的是每种化妆品在各个产品的销售情况,通过堆叠柱状图,我们可以很清晰低对比同一种化妆品到底在哪个城市销量更好。
5.3 使用建议
5.3.1 纵向堆叠柱状图 – 最多不要超过6个数据
堆叠柱状图最好的展示效果是每个组只包含两到三个类别,最多不要超过6个,因为太多的数据系列会很容易让人眼花缭乱, 如下图:
5.3.2 数值标签居中对齐
堆叠条状图的数值建议在图形之间,居中对齐,在图形左侧容易产生误解。
5.3.3 避免用堆叠柱状图展示包含负数的数据
由于要分析部分数据在整体中的占比,避免用堆叠柱状图展示包含负数的数据。因为柱子的高度必须为正数,有负数则无法直观显示在图上。
5.3.4 数据标签特别长时,采用水平堆叠柱状图
大多数的堆叠柱状图都是垂直绘制的,但是如果你的数据标签特别长时,考虑更好地展示效果,可以选择使用水平堆叠的方式。
6. 分组柱状图
6.1 定义
分组柱状图,又叫聚集柱状图。跟柱状图类似,使用柱子的长短来映射和对比数据值。每个分组中的柱子使用不同的颜色或者相同颜色不同透明的方式区别各个分类,各个分组之间需要保持间隔。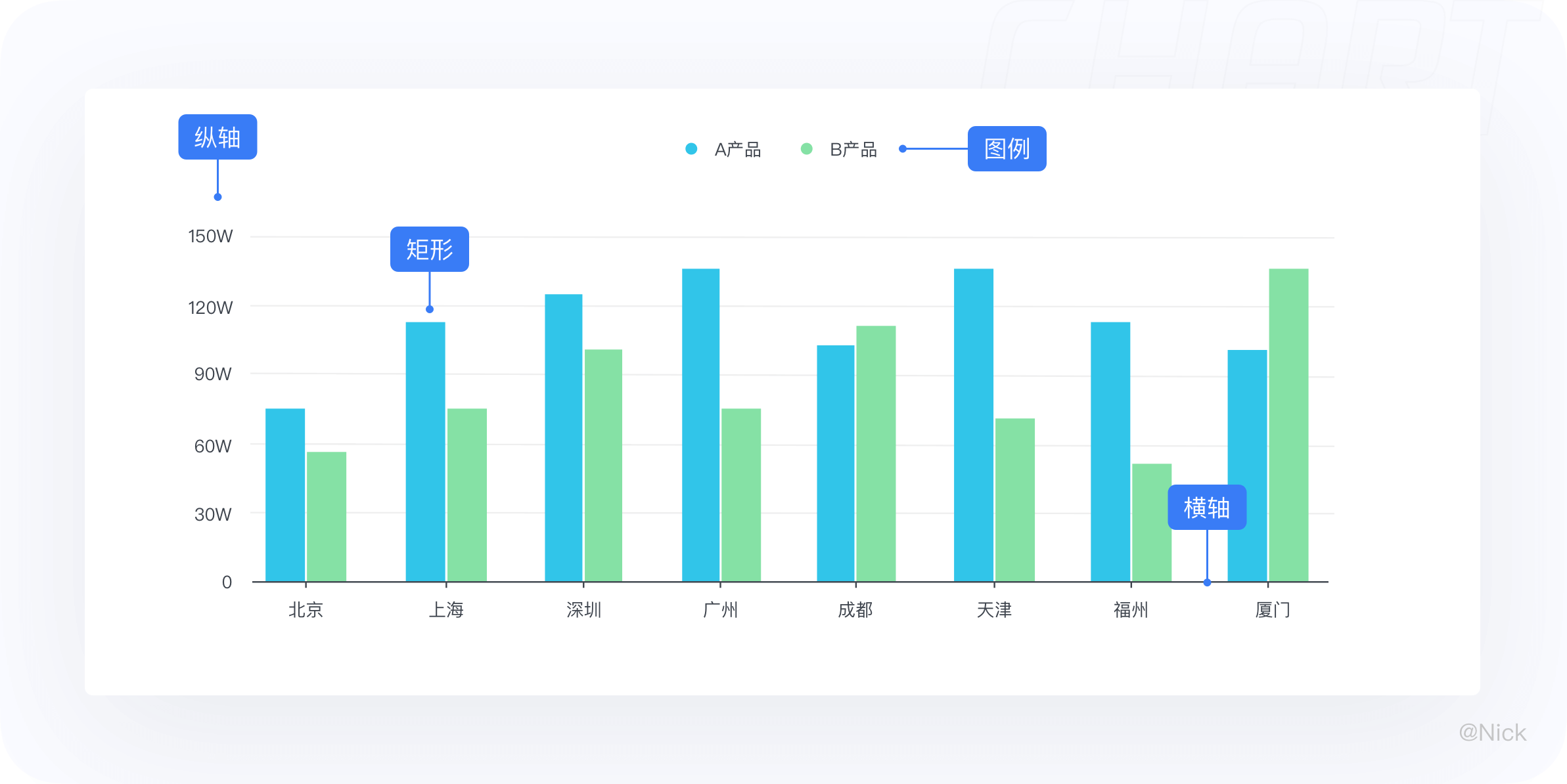
6.2 适用场景
对比不同分组内相同分类的大小,对比相同分组内不同分类的大小。其中,分组个数不要超过 12 个,每个分组下的分类不要超过 6 个。
6.3 使用建议
6.3.1 数据的数值差异大,建议使用双轴
分组柱状图适合比较多组数值差异不大的数据,比如,对于要同时查看一个数值和百分比的时间趋势,双轴图就派上大用场了。
为了浏览起来更直观,建议用柱图来表示数值类数据,用线图来表示百分比。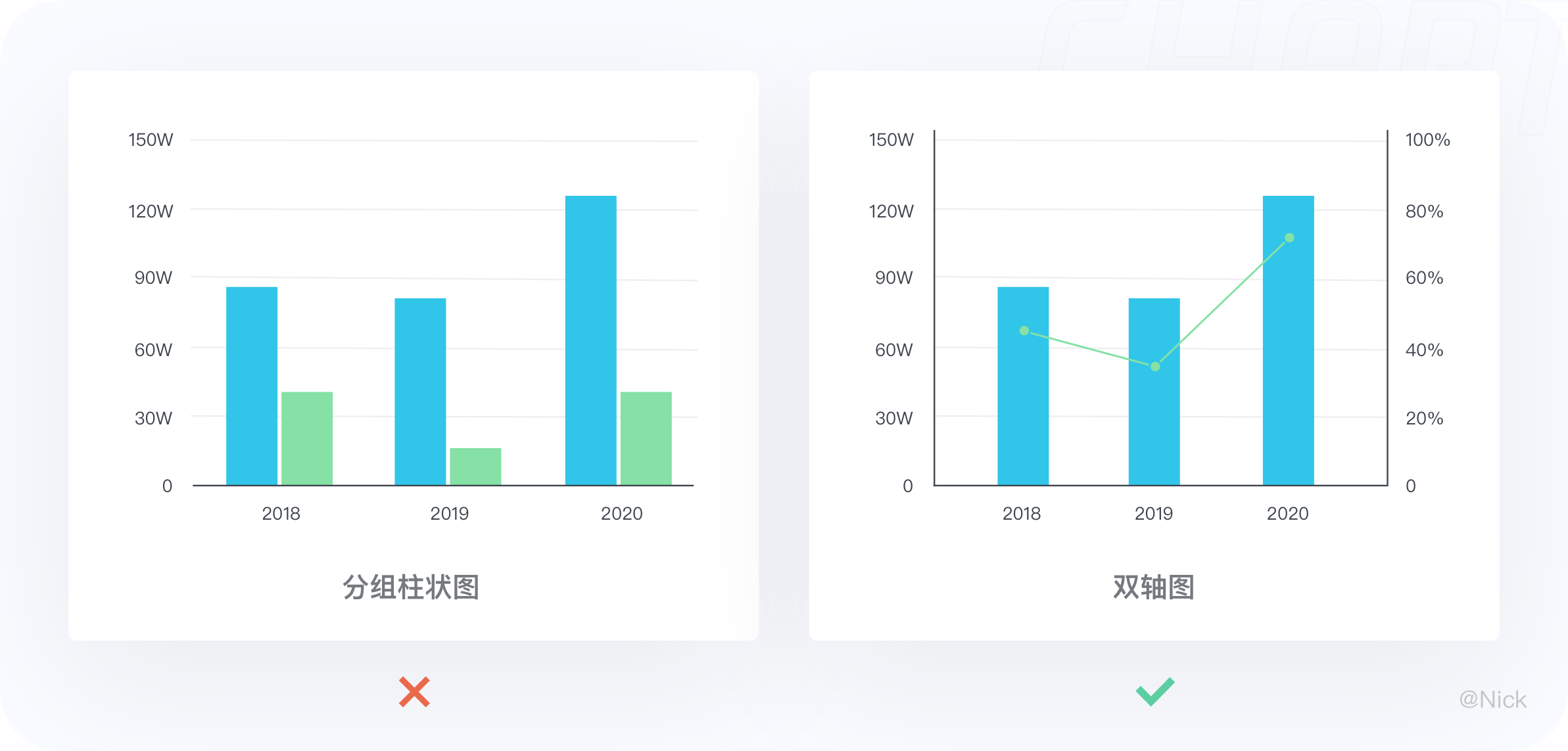
6.3.2 组之间的间距 > 柱子之间的间距
分组柱状图强调组的概念,组是一个个重复单元。按照格式塔原理,每两个分组之间的间距要大于组内不同系列之间的间距,以免造成视觉上错误的归类和区分。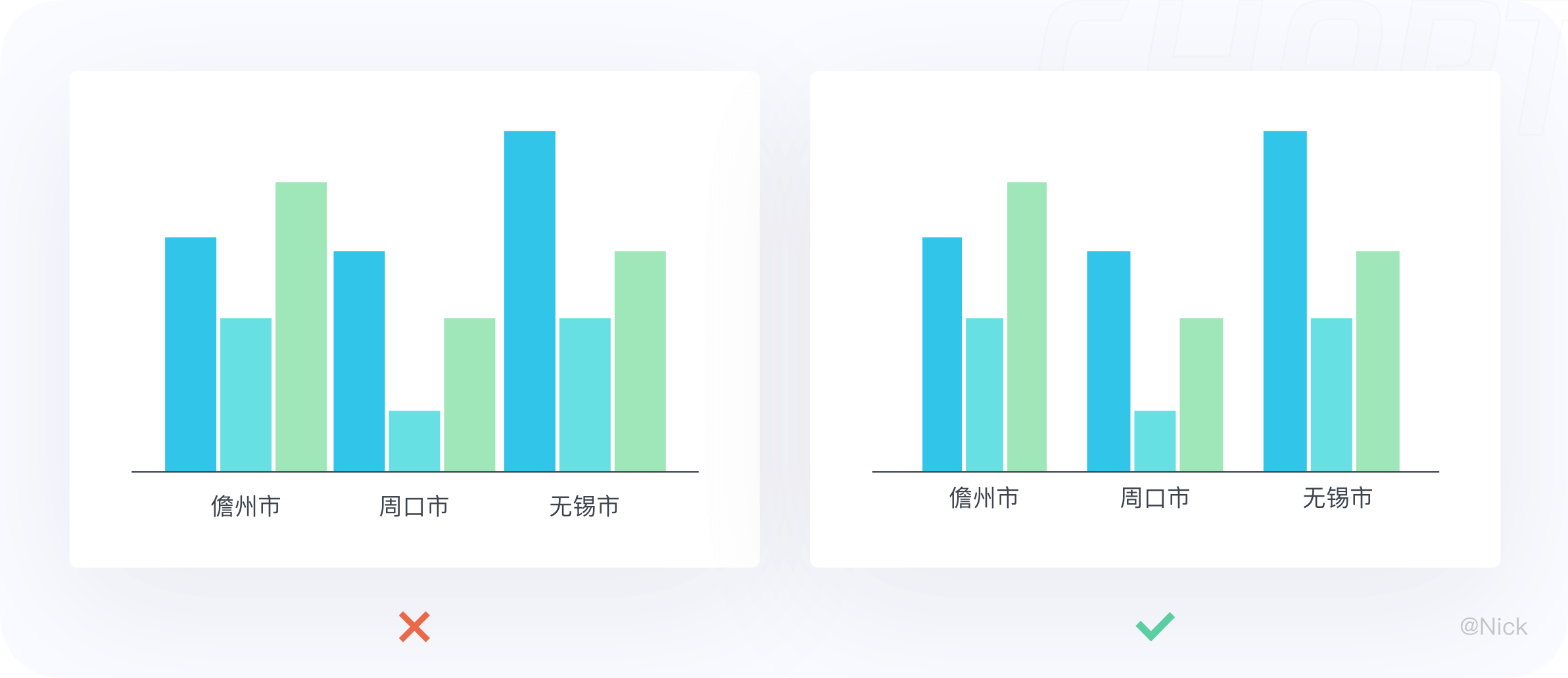
7. 双向柱状图
7.1 定义
双向柱状图是使用正向和反向的柱子显示类别之间的数值比较,其中分类轴表示需要对比的分类维度,连续轴代表相应的数值,分为两种情况,一种是正向刻度值与反向刻度值完全对称;另一种是正向刻度值与反向刻度值反向对称,即互为相反数。
同样的,可分为垂直方和水平两个方向,其中水平双向柱状图又叫正负条形图。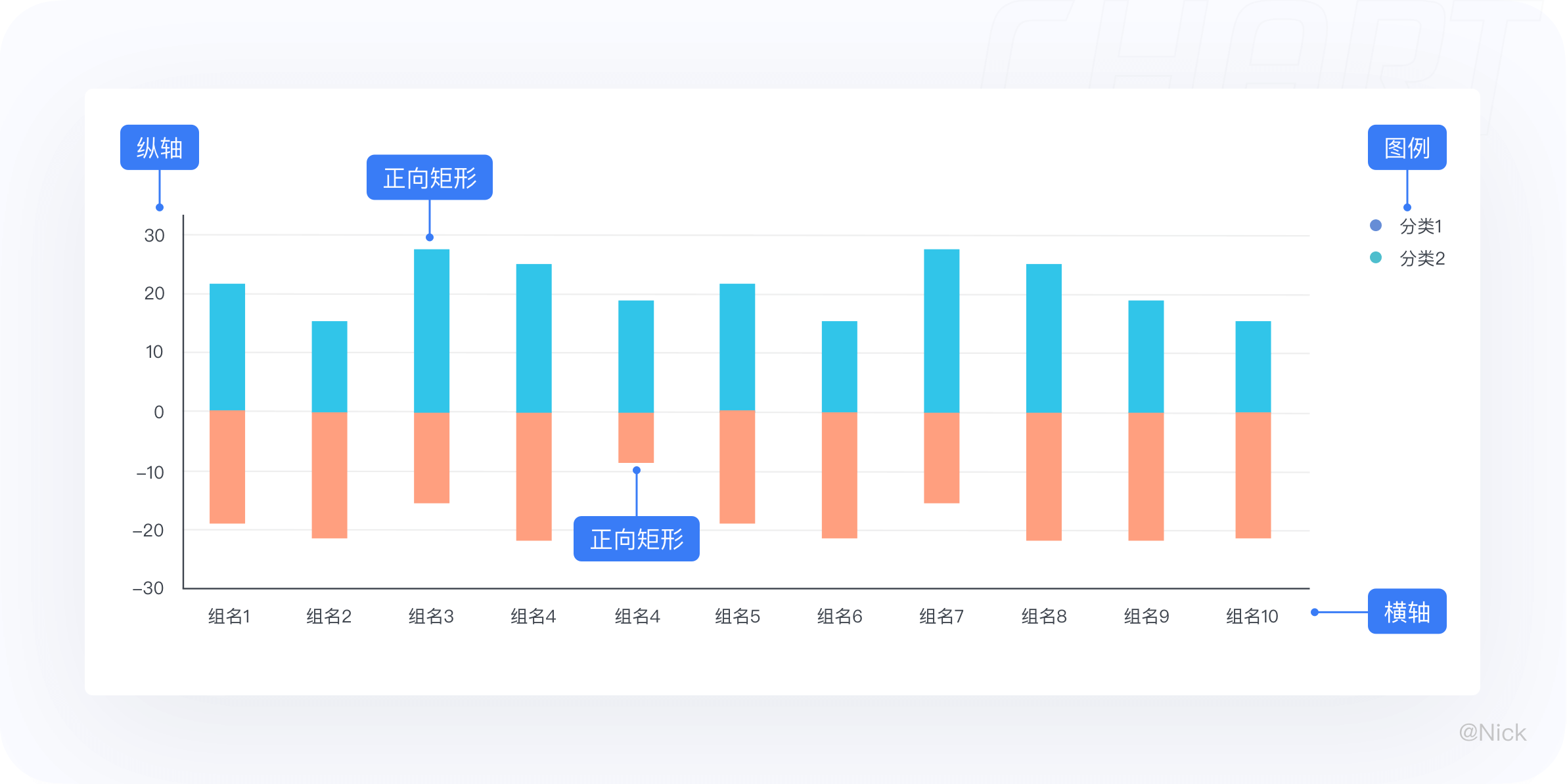
7.2 适用场景
双向柱状图一般用于正负两份相反数据的对比,例如一周内个人收入和支出的统计,其中收入为正数,支出为负数。
使用双向柱状图可以很明确的对收入和支出做出对比,并能从单个系列中分析收入和支出的数值及波动。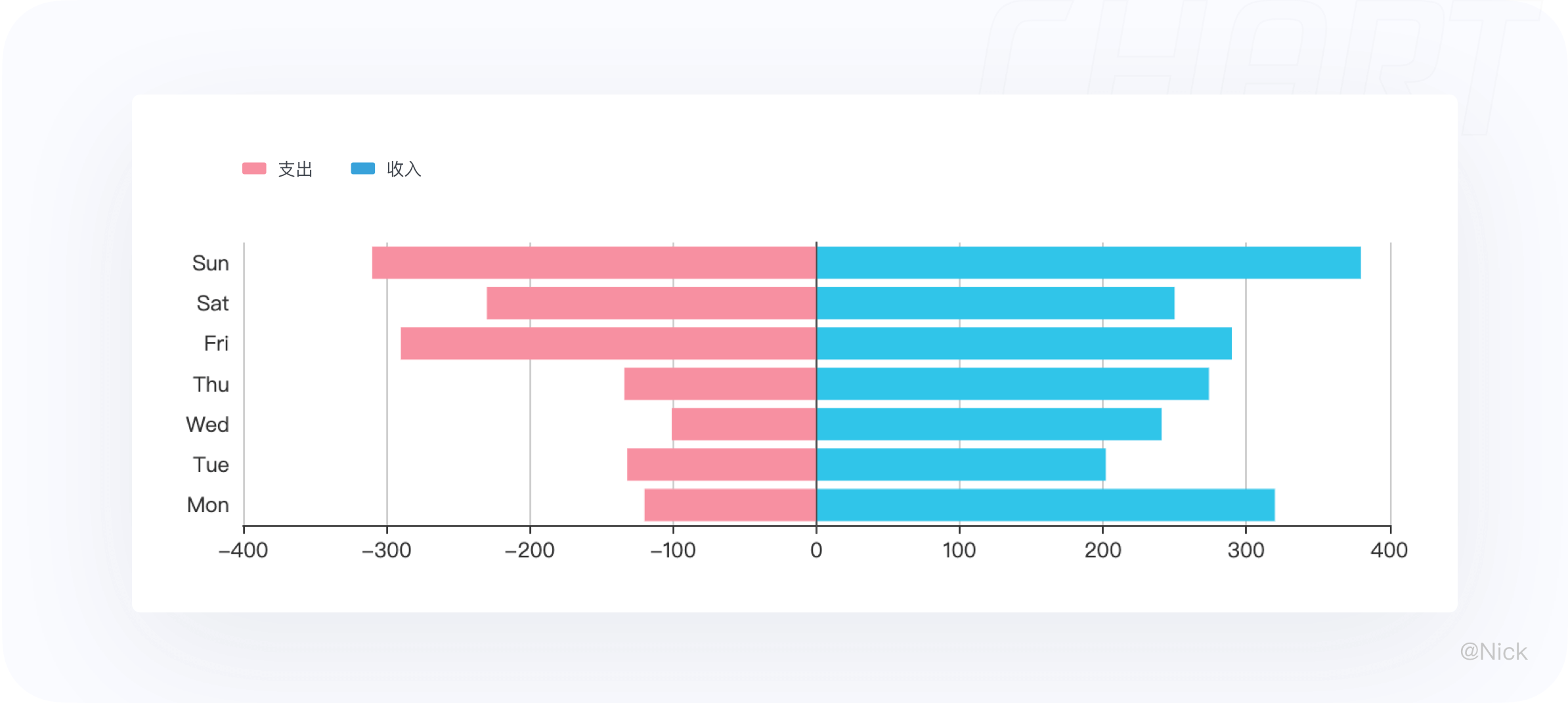
7.3 使用建议
7.3.1 不适合不含相反含义的数据
双向柱状图多用于展示含相反含义的数据,因此要避免不具有正负含义的数据使用而造成的误解。
如下图人口统计图表中使用双向柱状图一边绘制男性一边绘制女性,只是单纯的两类不同数据的对比,并不存在负数。这种情况将两个数据序列绘制成一个分组柱状图是更合适的。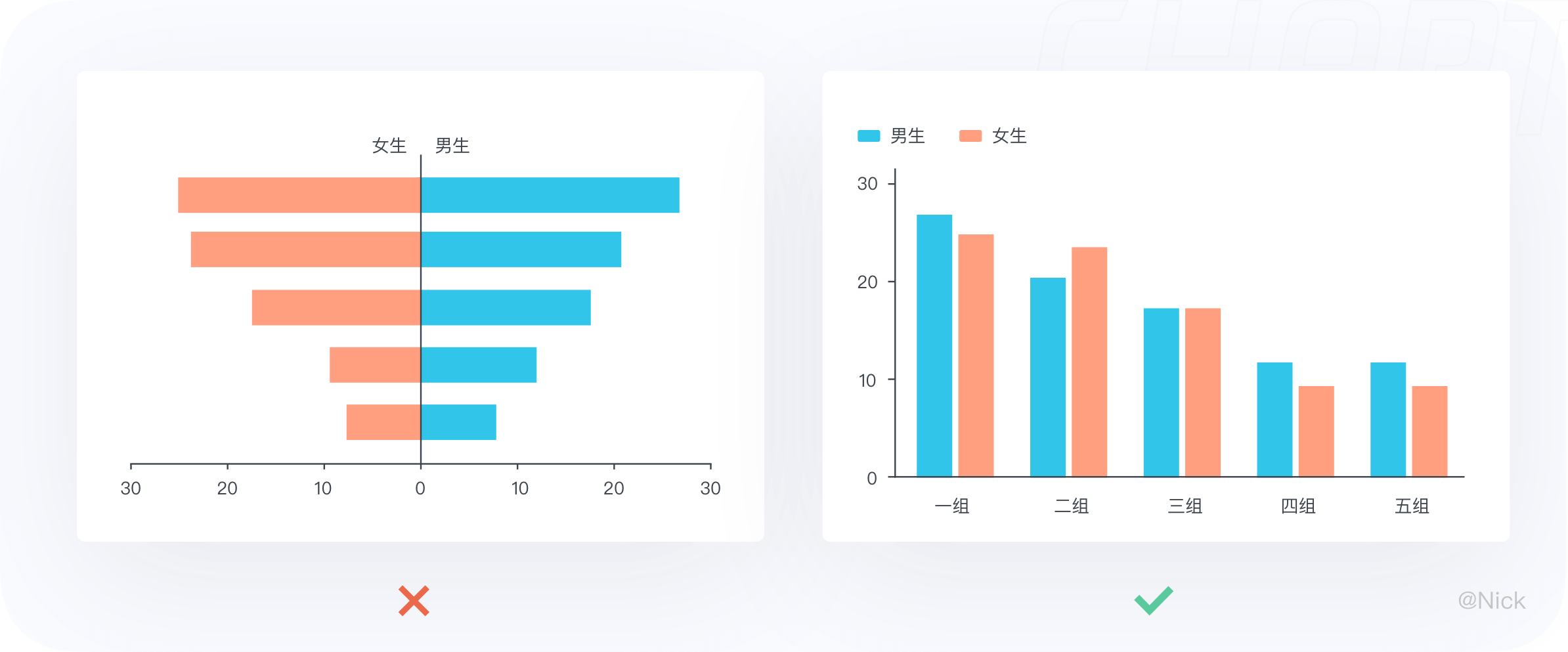
7.3.2 采用色彩差异较大的颜色
向柱状图正向和负向的数据具有对比性,因此一般选用差值较大的具有对比性的颜色,保证高效的获取有效的信息。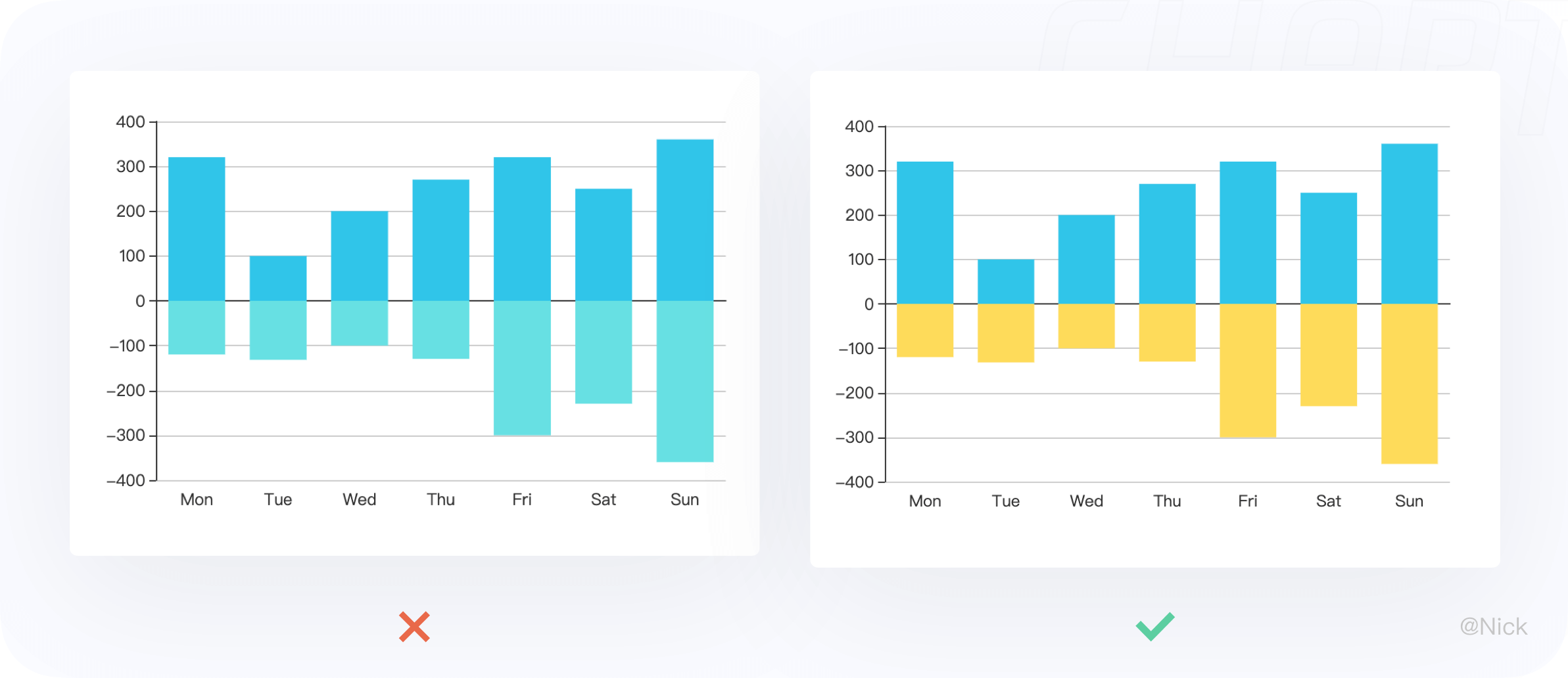
8. 饼图
8.1 定义
饼图,或称饼状图,是一个划分为几个扇形的圆形统计图表。在饼图中,每个扇形的弧长(以及圆心角和面积)大小,表示该种类占总体的比例,且这些扇形合在一起刚好是一个完全的圆形。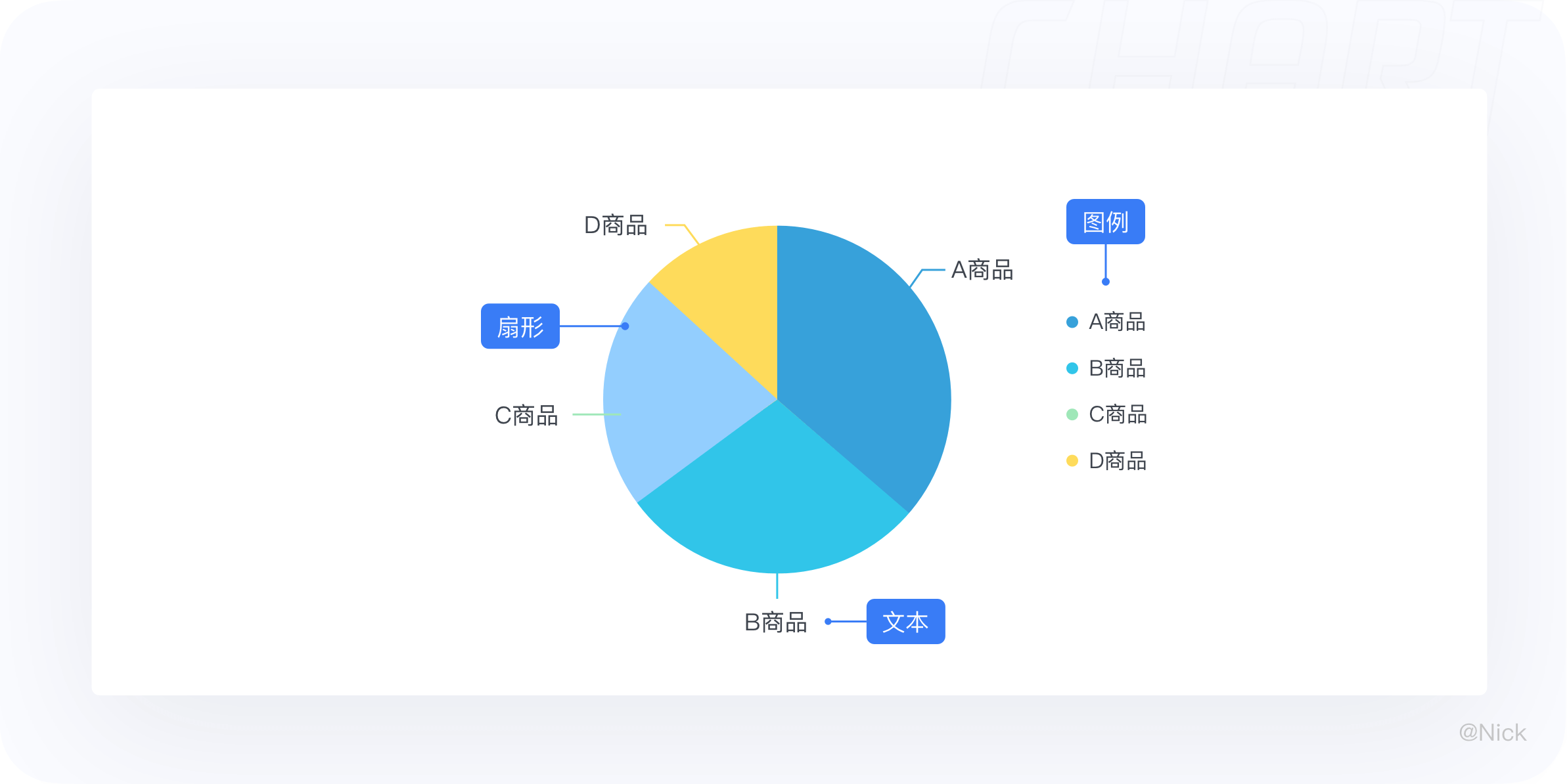
8.2 适用场景
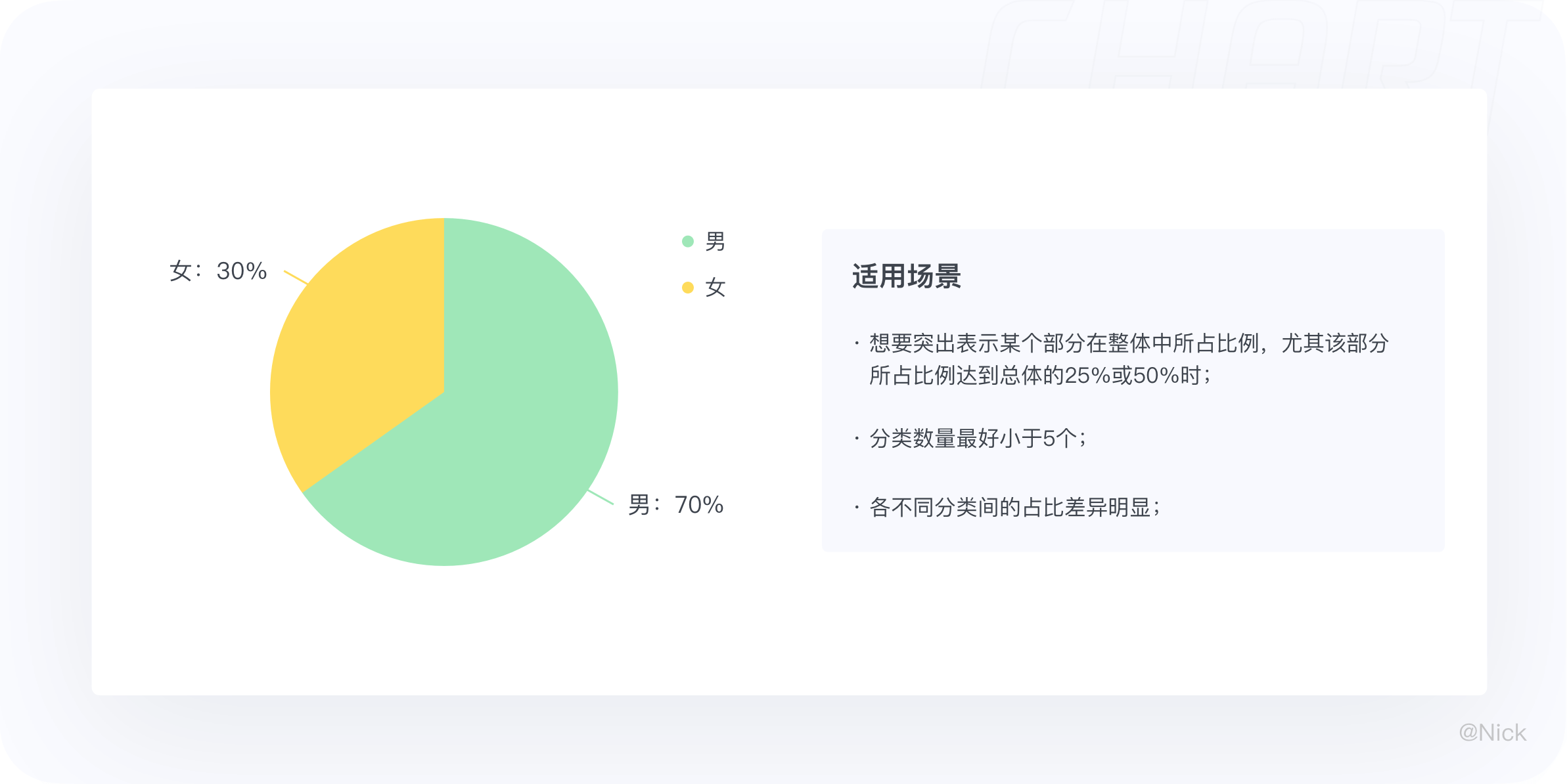
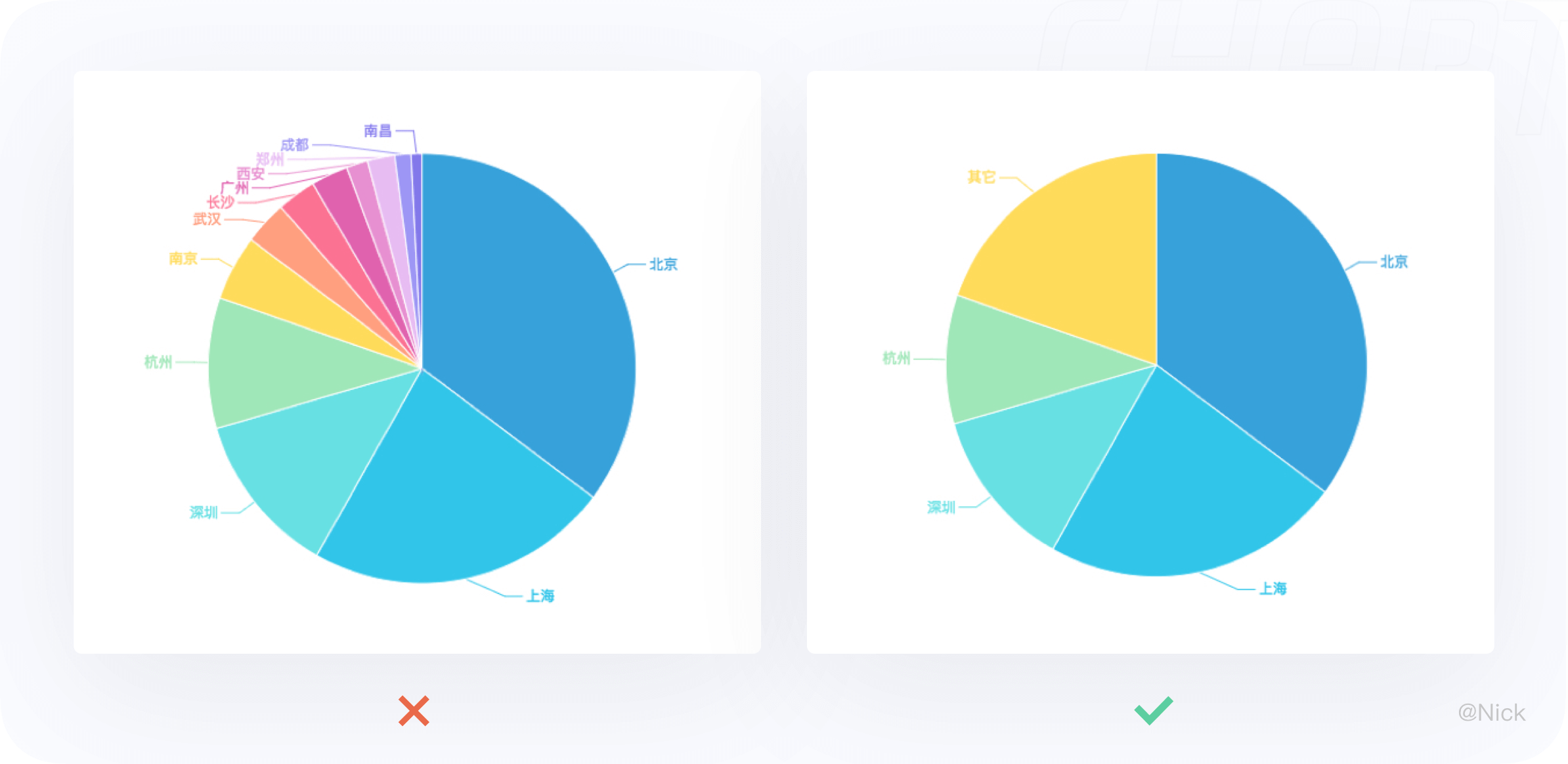
饼图主要用于展现不同类别数值相对于总数的占比情况,尤其是想要突出表示某个部分在整体中所占比例,且该部分所占比例达到总体的25%或50%时,很适合用饼图。
8.3 使用建议
8.3.1 分块数量尽量控制在5个以内,最多不要超过9个
饼图不适用于多分类的数据,因为随着分类的增多,每个切片的面积变小,视觉区分度随之降低。
当数据类别较多时,我们可以把较小或不重要的数据合并成第五个模块命名为”其它”。如果一定要保证数据的完整性和准确性,此时选择柱状图或堆积柱状图或许更合适。
8.3.2 切片大小相似时,建议采用柱状图或南丁格尔玫瑰图
由于人类对“角度”的感知力并不如“长度”,在需要准确的表达数值(尤其是当数值接近、或数值很多)时,饼图常常不能胜任,因此当各类别数据占比较接近时(如下左图),我们很难对比出每个类别占比的大小。
此时建议选用柱状图或南丁格尔玫瑰图(如下右图)来获取更好的展示效果。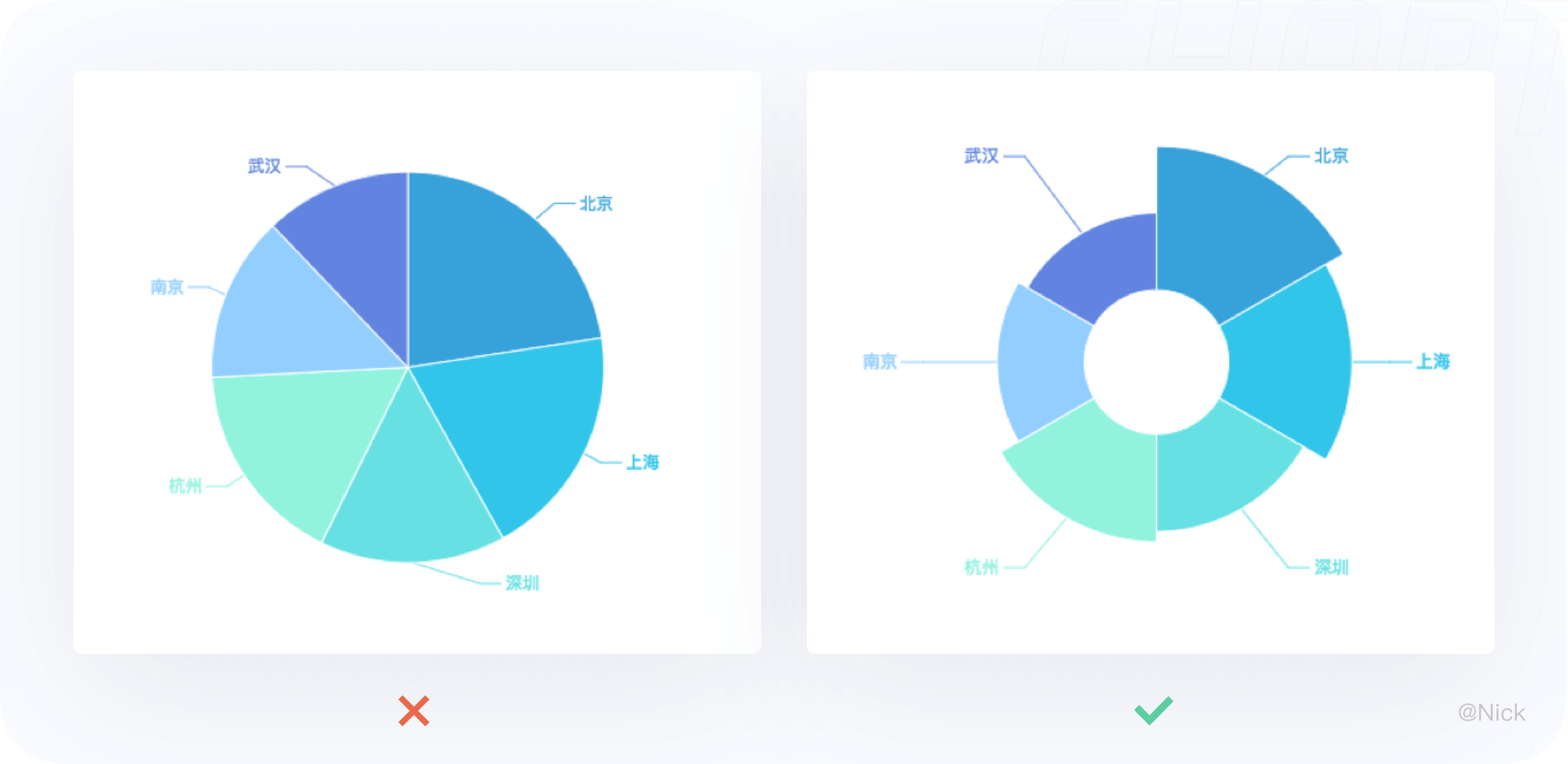
8.3.3 正确放置切片位置,提高图表可读性
大多数人视觉习惯是按照顺时针和自上而下的顺序去观察。因此在绘制饼图时,建议从12点钟开始沿顺时针右边第一个分块绘制饼图最大的数据分块,有效的强调其重要性。
其余的数据分块有两种建议:一种是按照数据大小依次顺时针排列;另一种在12点钟的左边绘制第二大的分块,其余的分块按照逆时针排列,最小的分块放在底部。
让用户的视线焦点集中在上半部分,增强获取信息的速度。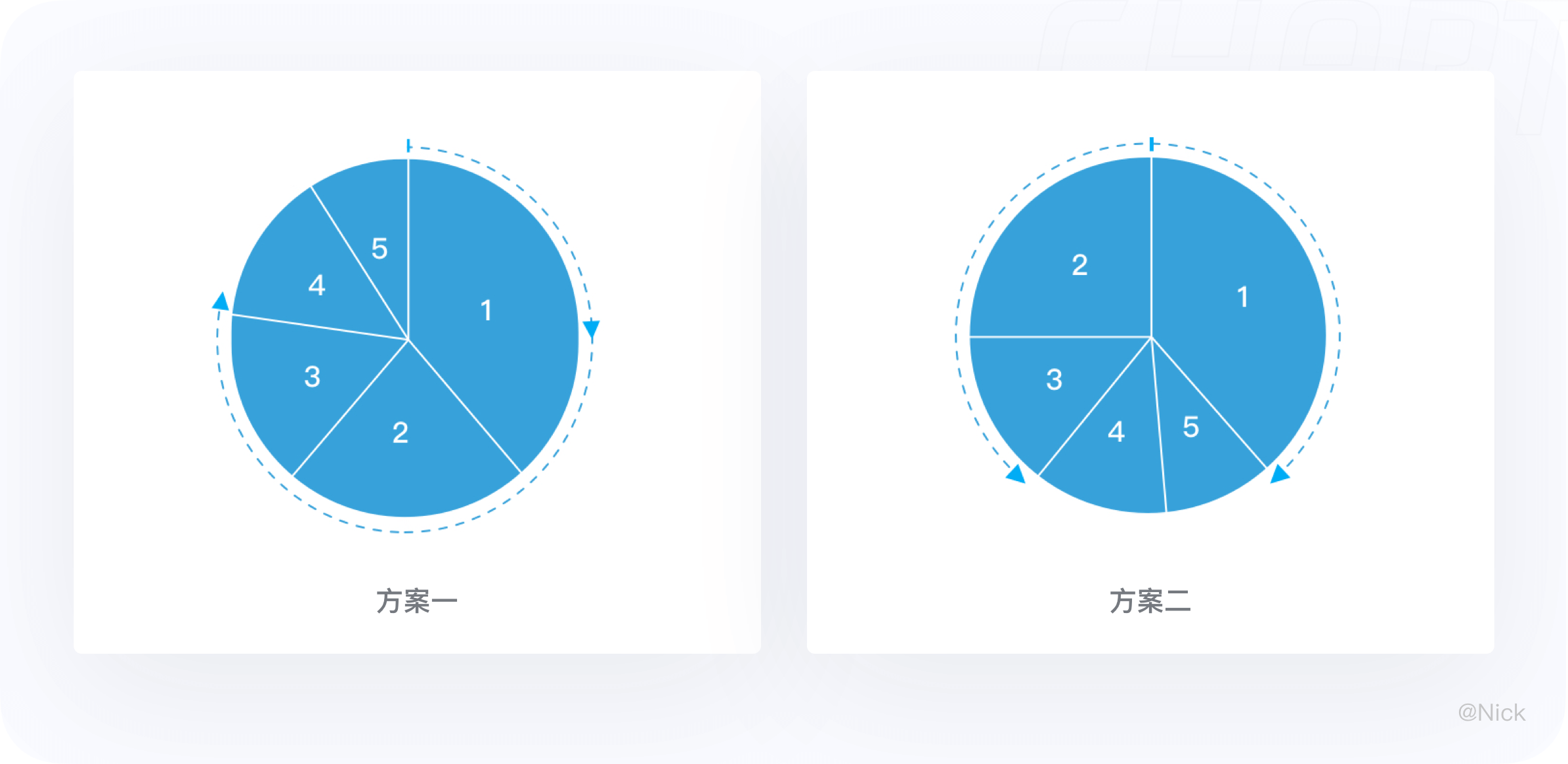
9. 环形图
9.1 定义
环形图,又叫做甜甜圈图,是由两个及两个以上大小不一的饼图叠在一起,挖去中间的部分所构成的图形。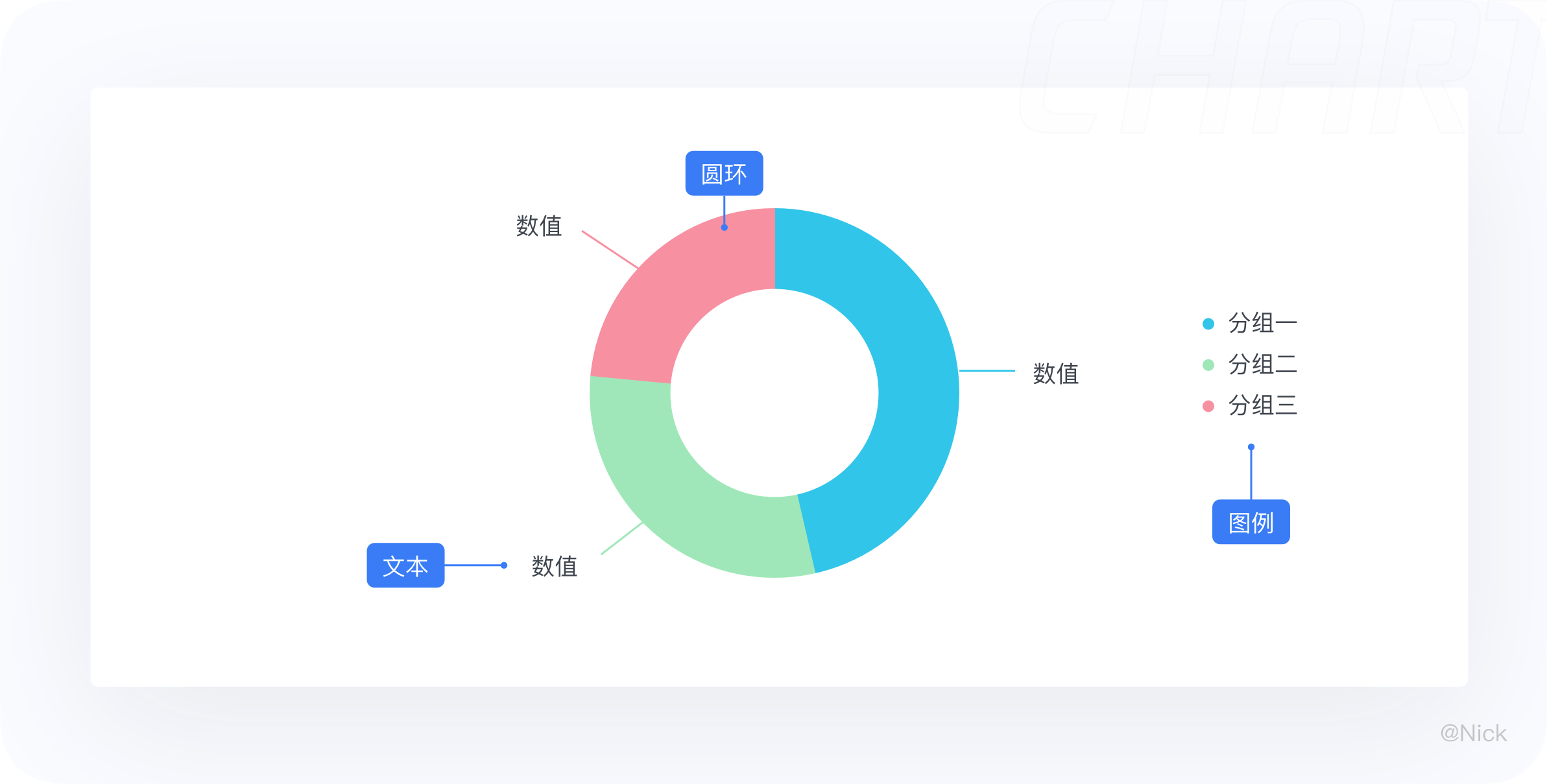
9.2 适用场景
适用于展示分类的占比情况,与饼图用法相似,但环图相对于饼图空间的利用率更高,比如我们可以使用它的空心区域显示文本信息,比如标题等。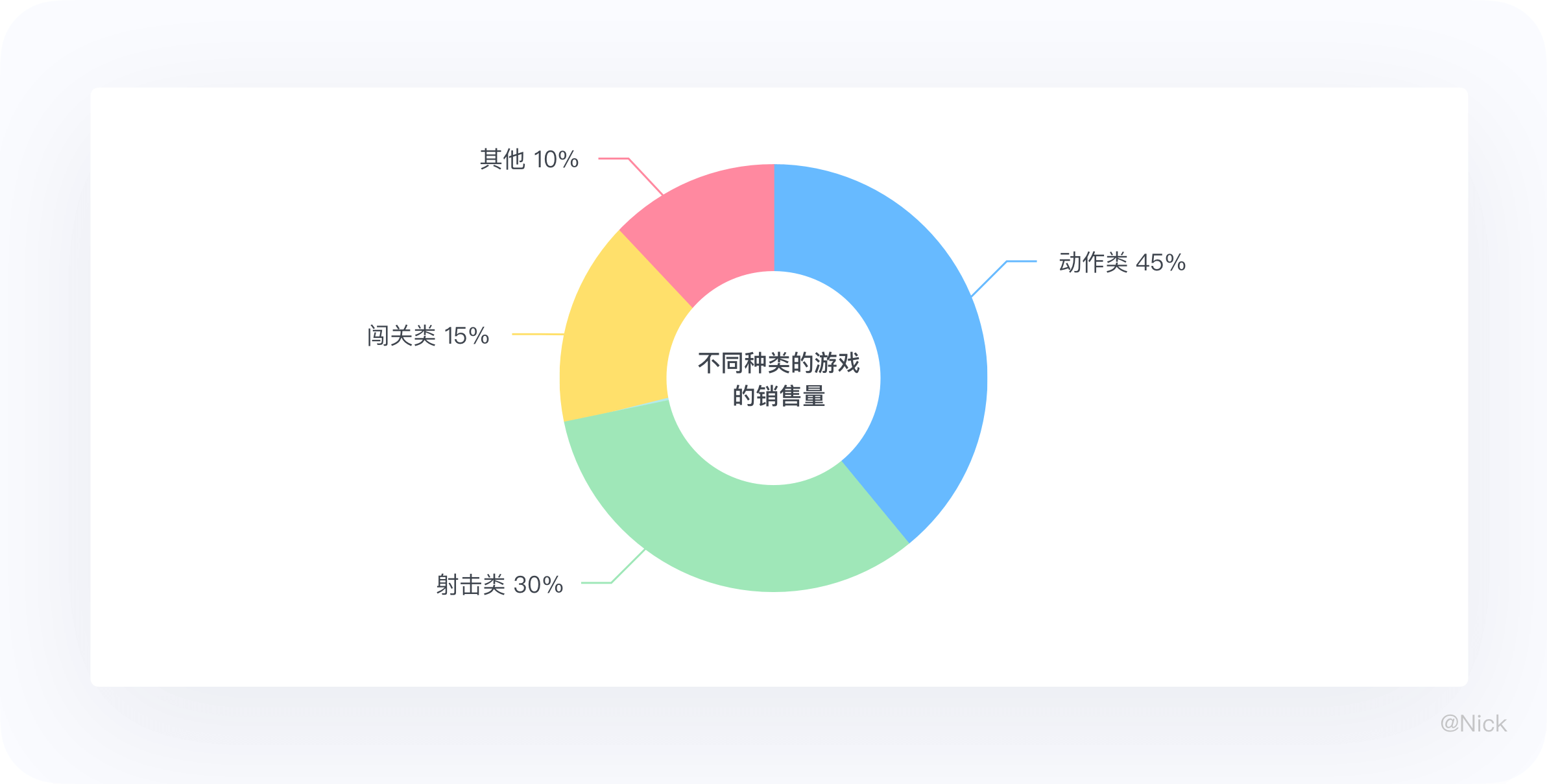
9.3 使用建议
9.3.1 不适用于分类过多的场景
关于环图不适用分类过多的场景,否则阅读会将很差(如下图)。
可行的办法:一是将一些不重要的变量合并为“其他”,避免扇区超过5个;二是改用条形图或者表格。尤其是,如果你想让读者清楚的阅读到每一条数据,选用表格会更加直截了当。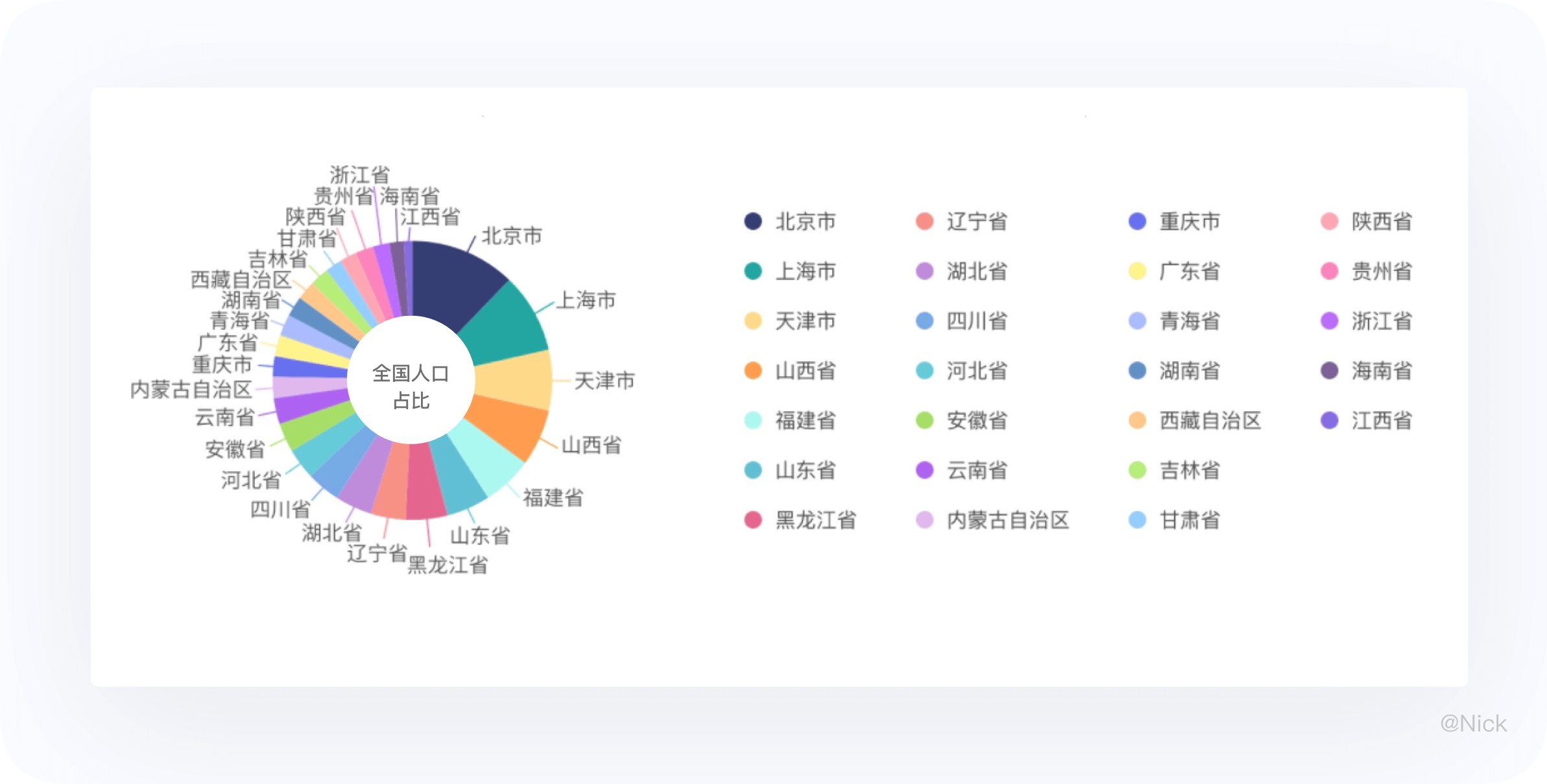
9.3.2 不适用于分类占比差别不明显的场景
下图中游戏公司的不同种类的游戏的销售量相近,所以不太适合使用环图,此时可以使用柱状图。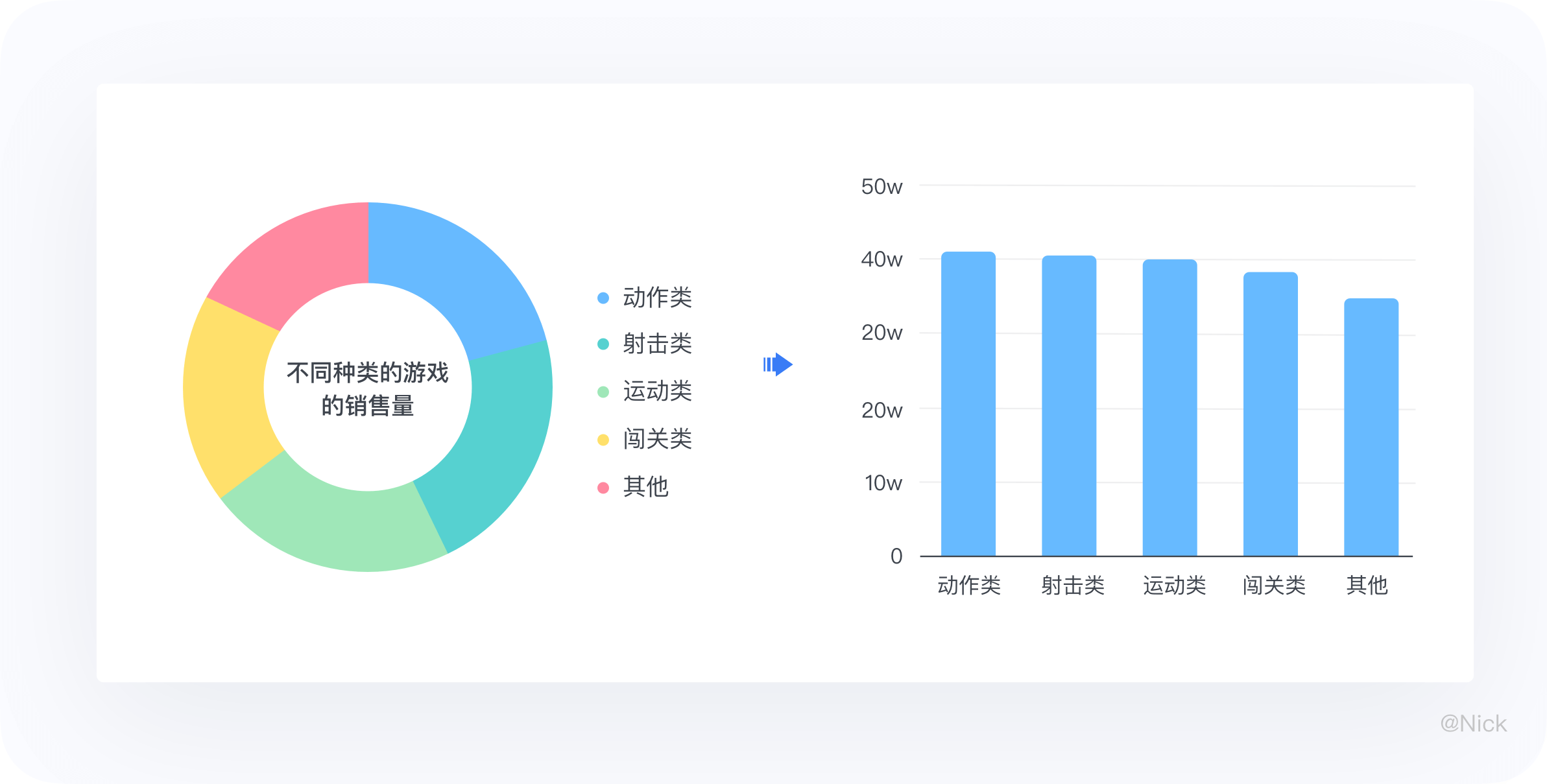
10. 南丁格尔玫瑰图
10.1 定义
南丁格尔玫瑰图又名鸡冠花图、极坐标区域图,尽管外形很像饼图,但它是用半径来反映数值大小的(而饼图是以扇形的弧度来表示数据的)。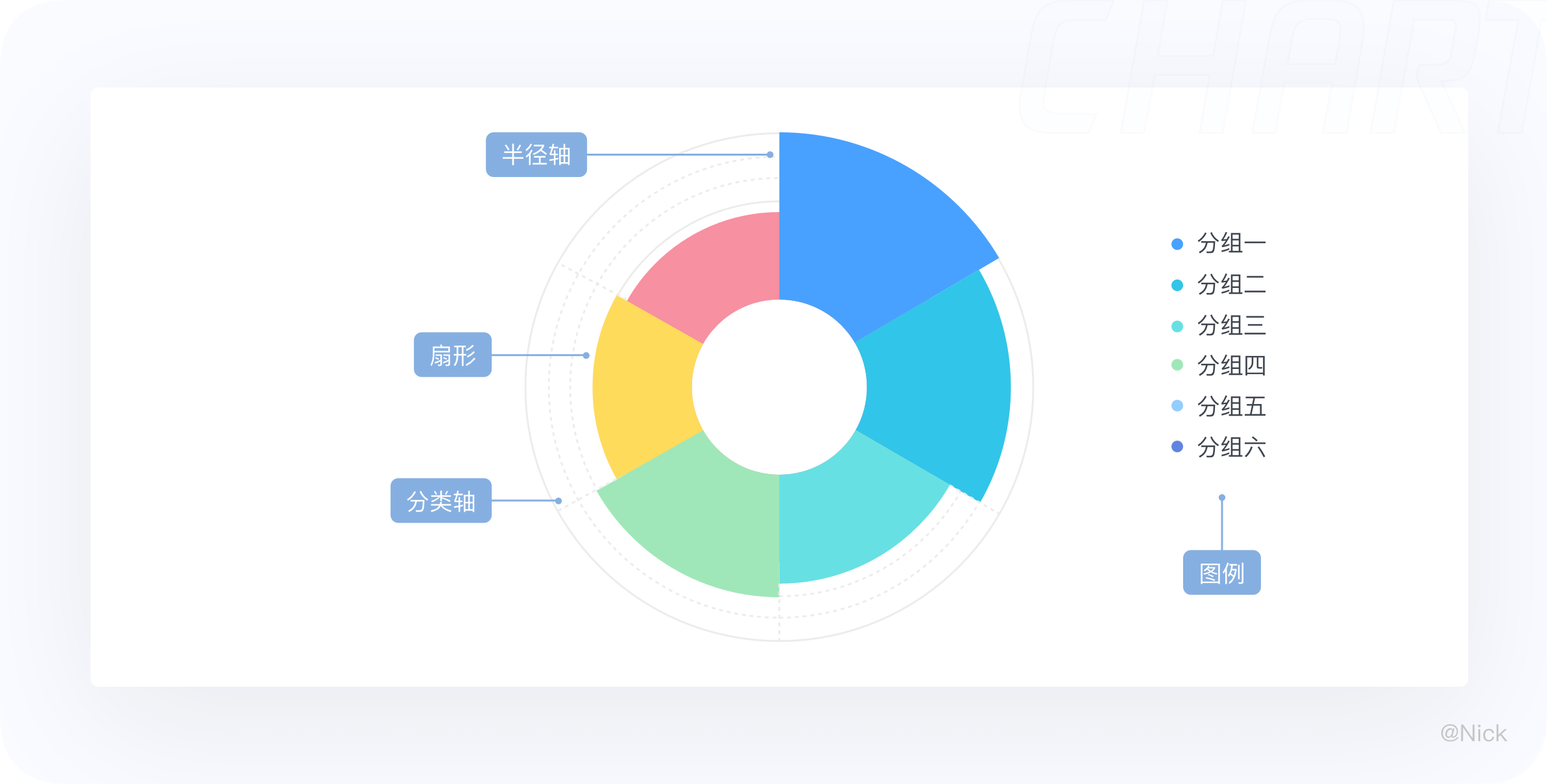
10.2 适用场景
对比不同分类的大小,且各分类值差异不是太大时。由于半径和面积之间是平方的关系,视觉上,南丁格尔玫瑰图会将数据的比例夸大。
10.3 使用建议
10.3.1 分类过少的场景,直接用饼图或者环图来表示
如下图展示一个班级男女同学的个数,这种场景下,使用饼图或者环形图比用南丁格尔玫瑰图更合适。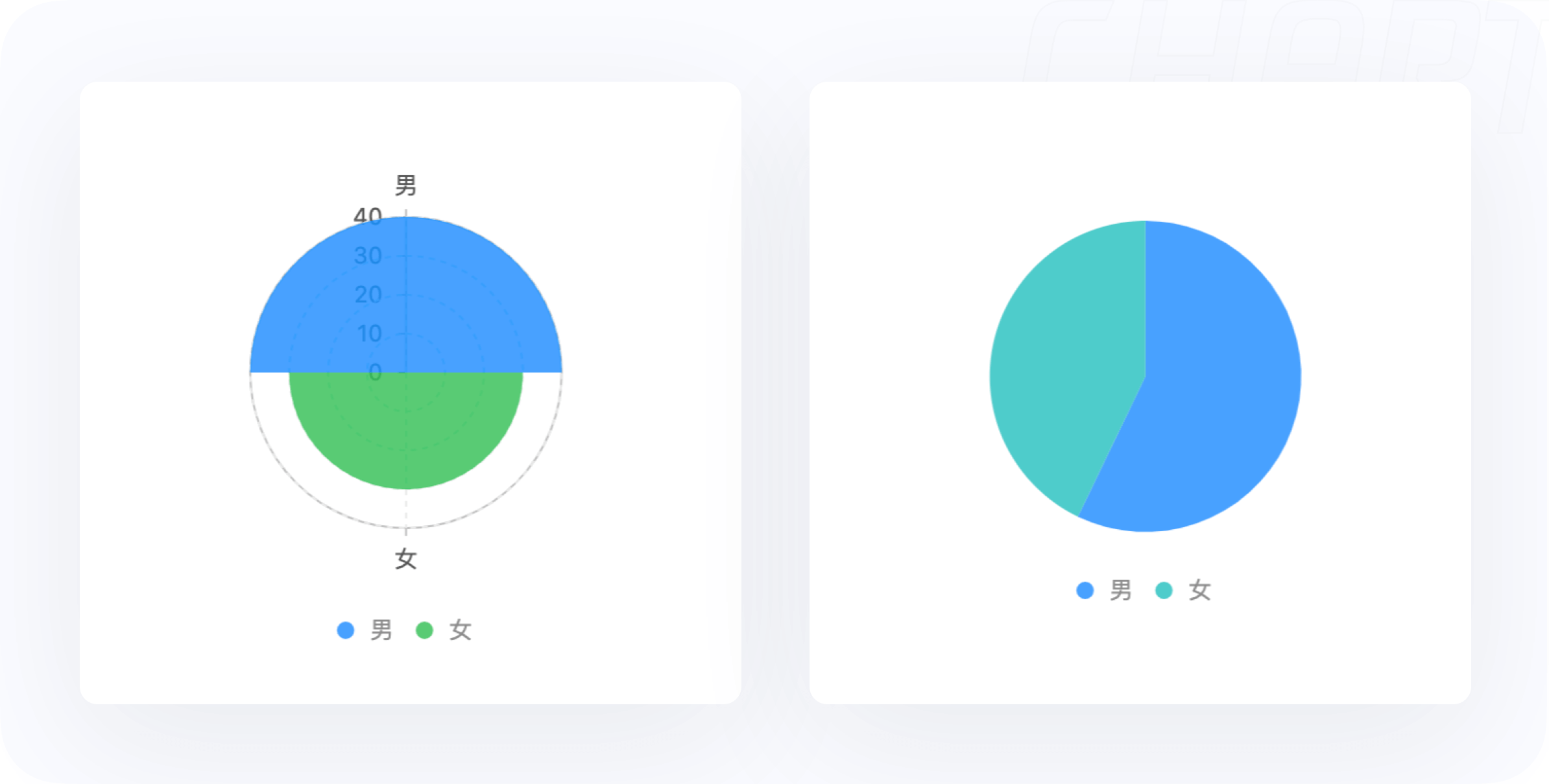
10.3.2 希望精确的比较数值大小时,推荐使用柱状图
南丁格尔玫瑰图是将数值映射到半径上,而扇形的面积和半径是平方关系,因此视觉上看,数值的差异会被扩大。
因此,当数值差异较大、或者希望精确的比较数值大小时,推荐使用柱状图。
下面使用南丁格尔玫瑰图展示各个省份的人口数据,这种场景下使用玫瑰图不合适,原因是在玫瑰图中数值过小的分类会非常难以观察,推荐使用条形图(横向柱状图)。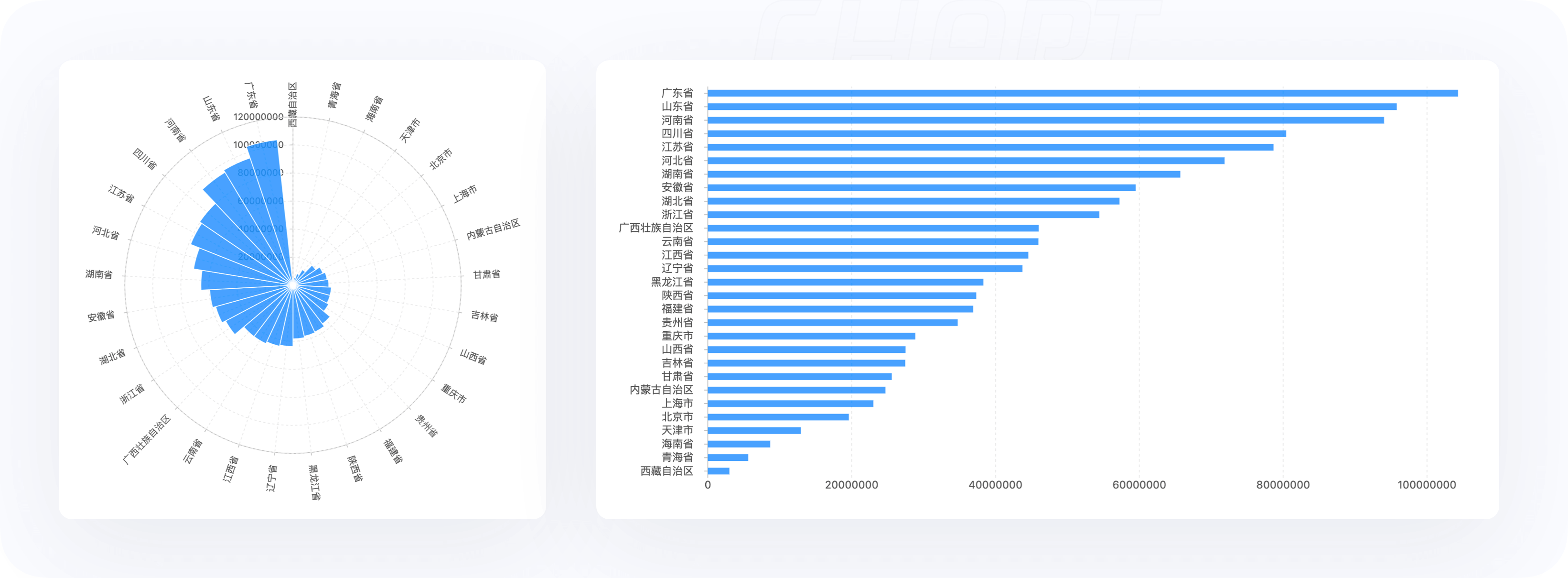
11. 散点图
11.1 定义
散点图,又名点图、散布图、X-Y图,它是将所有的数据以点的形式展现在平面直角坐标系上的统计图表。它至少需要两个不同变量,一个沿x轴绘制,另一个沿y轴绘制,每个点在X、Y轴上都有一个确定的位置。
11.2 适用场景
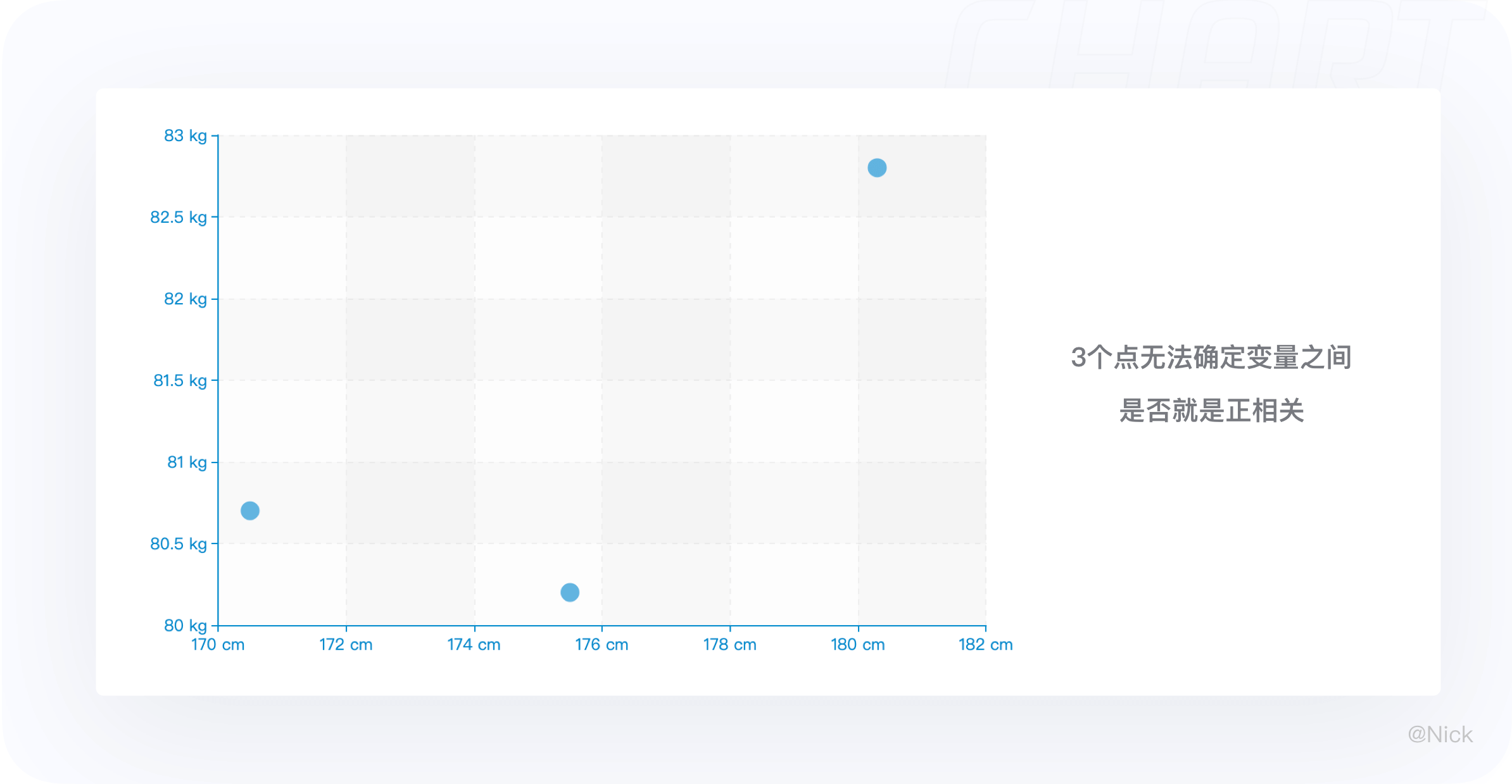
散点图适用于分析变量之间是否存在某种关系或相关性。其中,相关性包含正相关(两个变量值同时增加)、负相关(一个变量值增加另一个变量值下降)、不相关、线性相关、指数相关、U形相关等。
11.3 使用建议
11.3.1 尽量为散点图添加趋势线
在观察两个变量之间的关系时,趋势线是非常有用的,趋势线的形状走向解释了两个变量之间的关系类型,还可以用来预测未来的值。但需要注意的是趋势线最可只能使用两条,以免干扰正常的数据的阅读。
11.3.2 数据量过少时,不推荐使用散点图
散点图只有有足够多的数据点,并且数据之间有相关性时才能呈现很好的结果。如果一份数据只有极少的信息或者数据间没有相关性,那么绘制一个很空的散点图和不相关的散点图都是没有意义的。
11.3.3 用颜色、形状来区分不同的数据类别
如果数据包含不同系列,可以给不同系列使用不同的颜色,例如蓝色代表男性,红色代表女性,并增加图例标注出蓝色代表的含义。
帮助用户快速获取相关信息。但要注意,要避免数据分类过多的情况,过多的数据分类,会导致无法快速识别,失去可视化的意义和价值。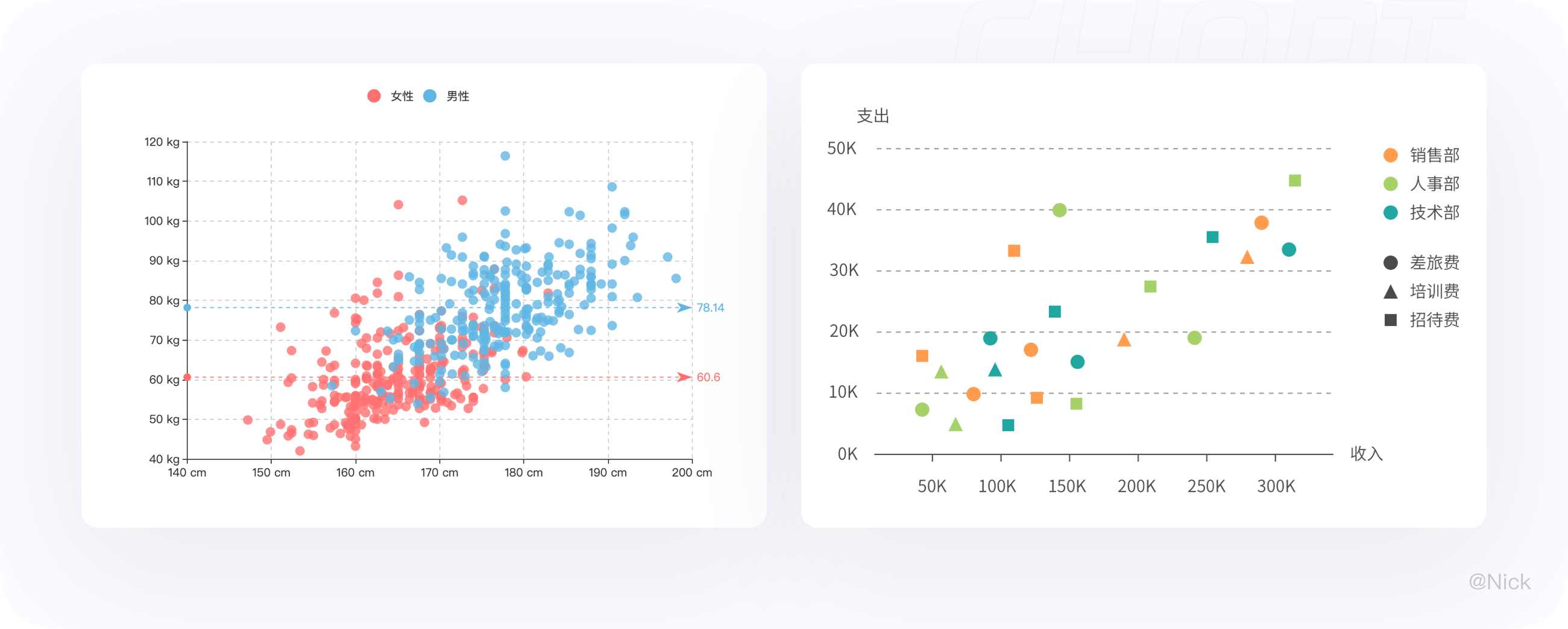
12. 气泡图
12.1 定义
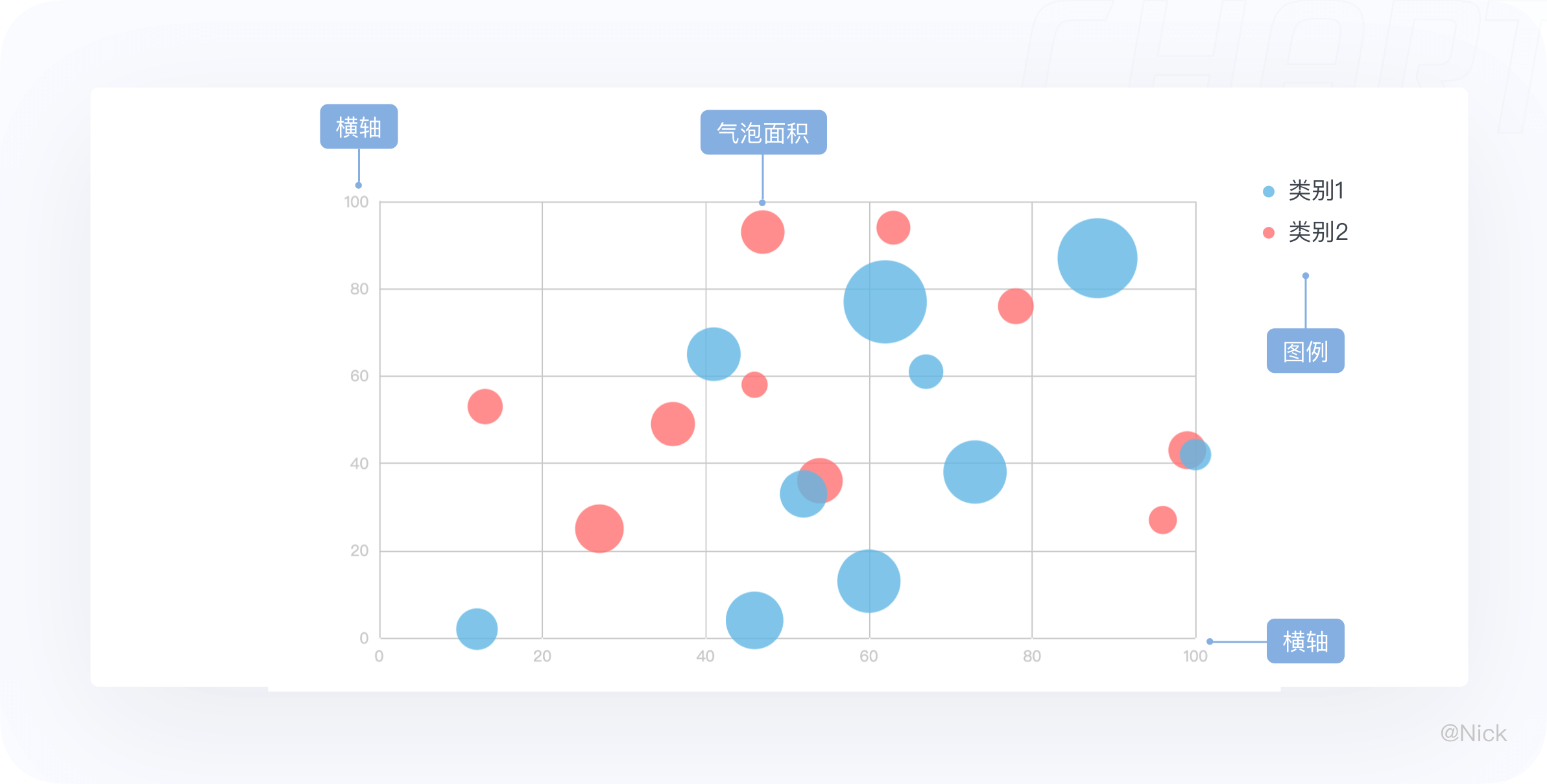
气泡图是显示变量之间相关性的一种图表,由笛卡尔坐标系(直角坐标系)和大小不一的圆组成,可以看作是散点图的变形。
与散点图不同的是,气泡图是一个多变量图,它增加了第三个数值即气泡大小的变量,在气泡图中,较大的气泡表示较大的值。可以通过气泡的位置分布和大小比例,来分析数据的规律。
12.2 适用场景
一般而言,气泡图需要3个变量,其中2个决定了气泡在笛卡尔坐标系中的位置(即x,y轴上的值),另外一个则通过气泡的大小来表示。
当然,气泡图也可以容纳更多维的数据,例如用第4个变量决定气泡的颜色、透明度等。
特殊地,气泡图也可以用于二维数据,即y轴和气泡大小使用同一维度的数据(y轴和气泡大小的双视觉编码)。
这种情况下,相比于柱状图它能达到更美观的目的。例如,下图表示了2014年每个季度的销售额。x轴代表时间,y轴和气泡大小代表了销售业绩。
12.3 使用建议
12.3.1 气泡的大小应体现为面积,而非半径
绘制气泡图时,需注意气泡的大小是映射到面积而不是半径或者直径绘制的。
以下图为例,如果两个数值是1:2的关系,如果按照半径1:2来绘制,那么实际的圆面积,将会是1:4的比例,这就夸大了数据之间的差异。
13. 雷达图
13.1 定义
雷达又叫戴布拉图、蜘蛛网图。它是一种显示多变量数据的图形方法。通常从同一中心点开始等角度间隔地射出三个以上的轴,每个轴代表一个定量变量,各轴上的点依次连接成线或几何图形。
每个变量都有一个从中心向外发射的轴线,所有的轴之间的夹角相等,同时每个轴有相同的刻度,将轴到轴的刻度用网格线链接作为辅助元素,连接每个变量在其各自的轴线的数据点成一条多边形。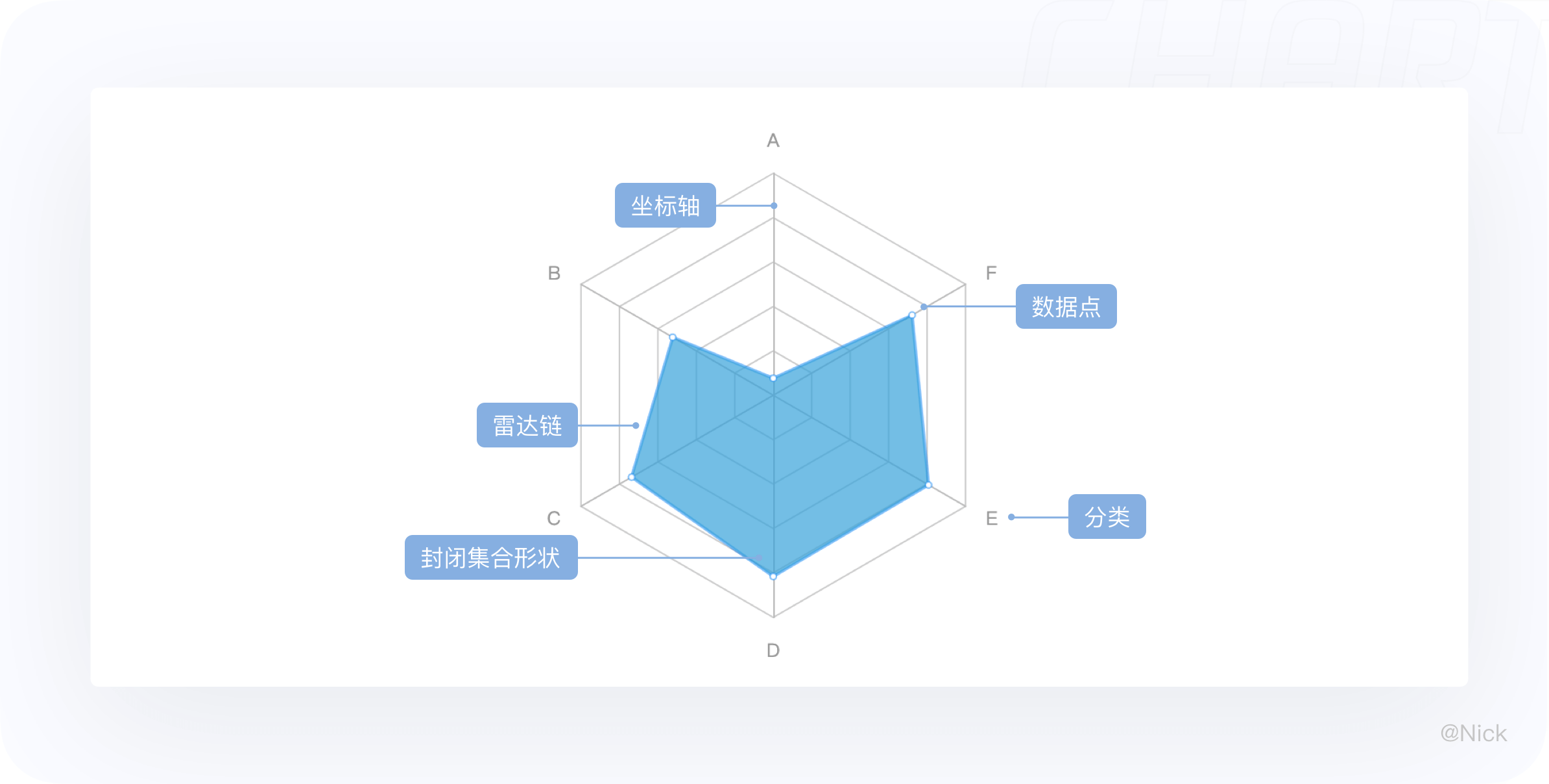
13.2 适用场景
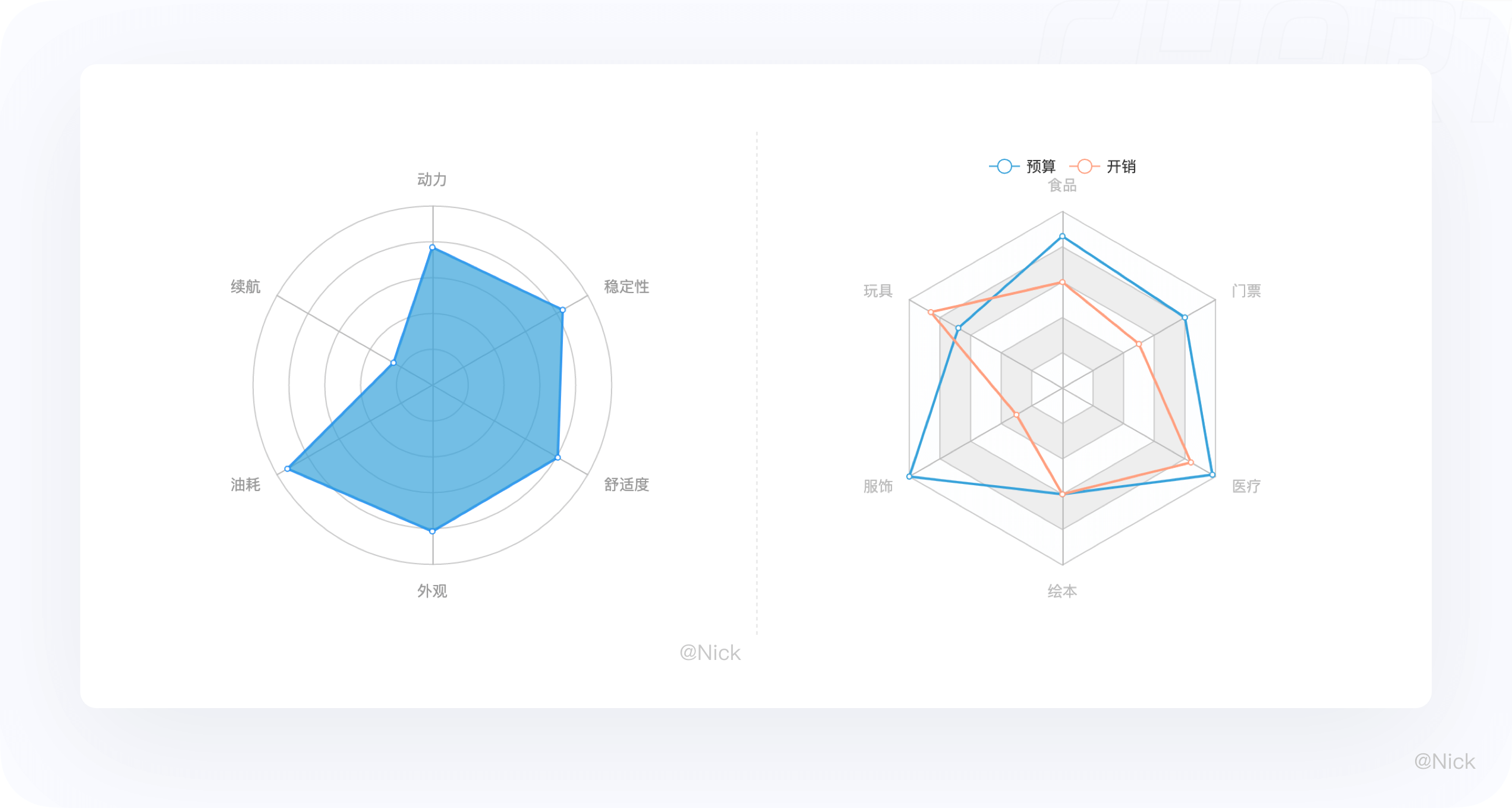
雷达图对于查看哪些变量具有相似的值、变量之间是否有异常值都很有用。雷达图表也可用于查看哪些变量在数据集内得分较高或较低,因此非常适合显示性能(见下图)。
13.3 使用建议
13.3.1 多边形数量控制在五个左右
一个雷达图包含的多边形数量是有限的,如果有五个以上要评估的事物,无论是轮廓还是填充区域,都会产生覆盖和混乱,使得数据难以阅读。
13.3.2 控制变量的数量
如果变量过多,也会造成可读性下降,因为一个变量对应一个坐标轴,这样会使坐标轴过于密集,使图表给人感觉很复杂,所以最佳实践就是尽可能控制变量的数量使雷达图保持简单清晰。
14. 漏斗图
14.1 定义
漏斗图,形如“漏斗”,在开始和结束之间由N个流程环节组成。
漏斗图总是起始于100%的数量,并在各个环节依次减少,每个环节用一个梯形来表示,整体形如漏斗。与饼图一样,漏斗图呈现的也不是具体的数据,而是该数据相对于总数的占比、漏斗图不需要使用任何数据轴。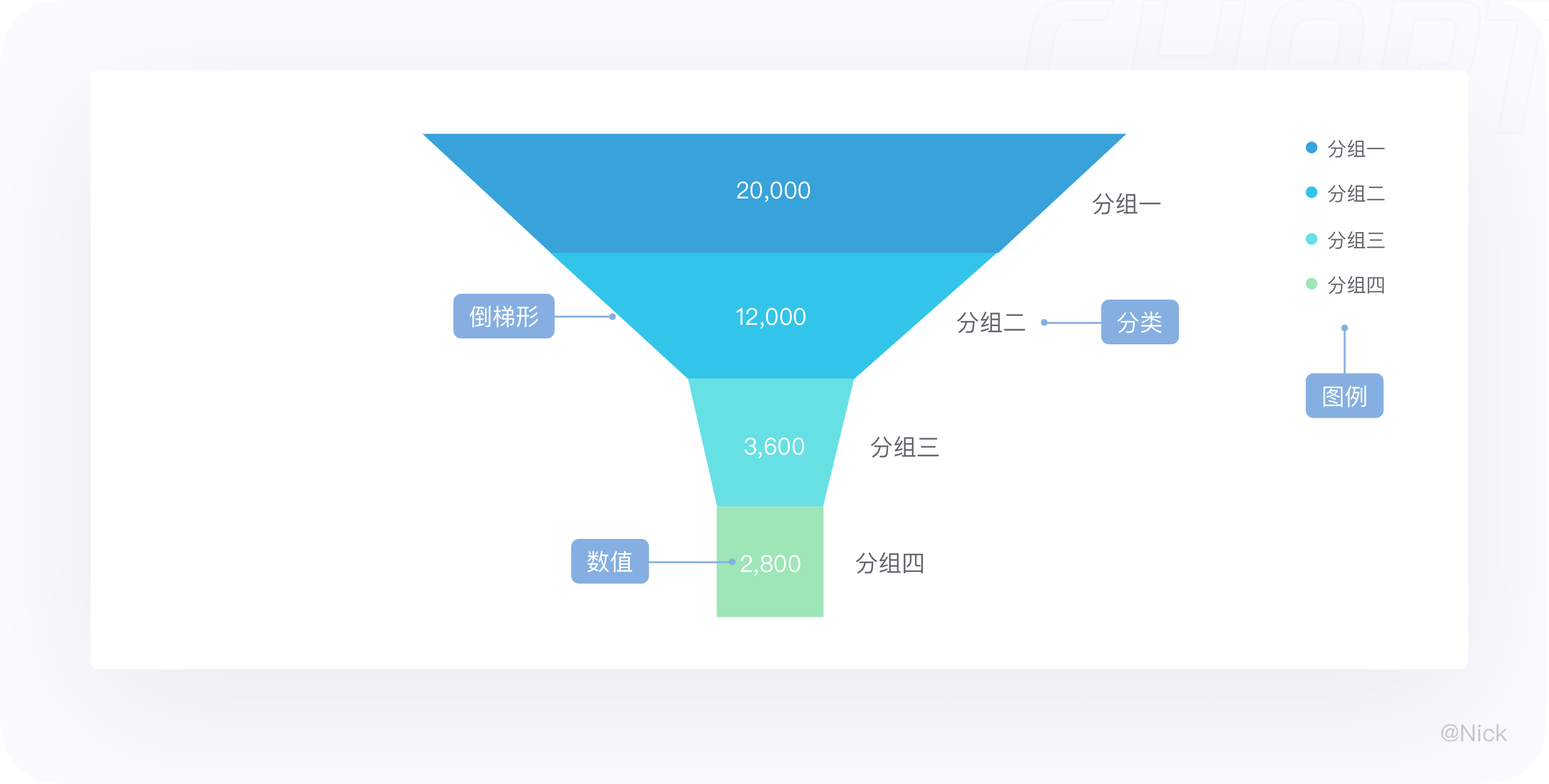
14.2 适用场景
漏斗图适用于业务流程比较规范、周期长、环节多的单流程单向分析,通过漏斗各环节业务数据的比较能够直观地发现和说明问题所在的环节,进而做出决策。
其中,数据是要有序的,彼此之间有逻辑上的顺序关系,阶段最好大于3个。
14.3 使用建议
14.3.1 数据要逻辑上的顺序关系
漏斗图不适合没有逻辑关系的数据,换句话说,如果数据不构成“流程”,那么不能使用漏斗图。例如,想要展示不同游戏类型的销量对比,用漏斗图就是不合适的。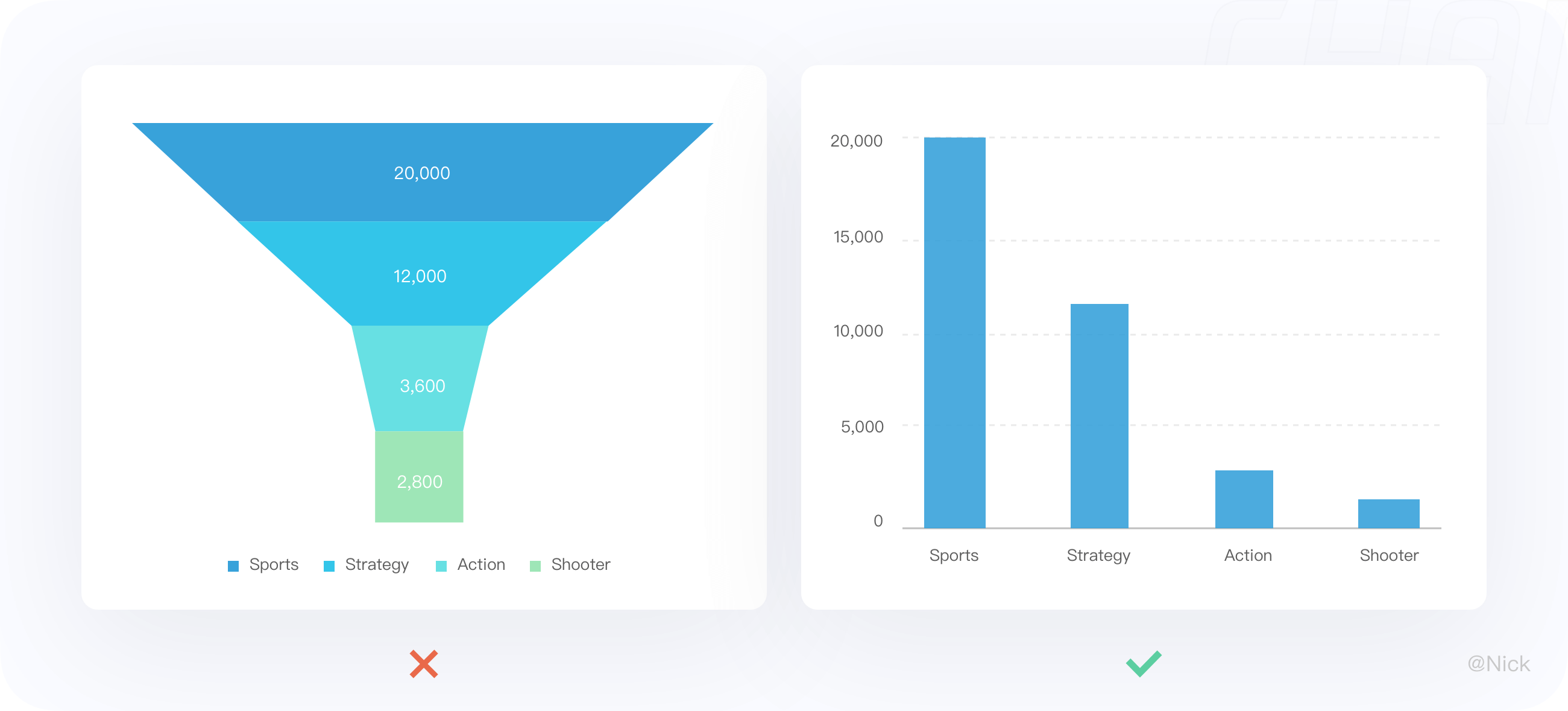
14.3.2 梯形的高度、面积都是有意义的,不应想当然的篡改
漏斗图作为一种统计图表,漏斗图的“长相”,本质上是由数据决定的。在传达数据时,漏斗图是通过“面积”表示的,对于人眼来说,面积的识别本来就不太容易。
如果我们在制作漏斗图时,再人为的改变漏斗中每一个梯形的高度,那么识别起来就十分困难。以下图为例,抹掉数字后,你几乎不可能知道第一层是第二层的三倍。
五、后记
以上就是本篇文章的全部内容,关于可视化相关的知识还有很多没有涉及到,例如可视化图表的配色、商务仪表盘、以及其他的图表运用场景等等都还未讲到。以后有时间慢慢整理分享给大家,谢谢阅读!

参考文献:
蚂蚁数据可视化
设计师要了解的数据可视化 —— 基础篇
数据可视化指南:那些高手才懂的坐标轴设计细节
ECharts数据可视化

若有收获,就点个赞吧
0 人点赞
