




https://mp.weixin.qq.com/s/hN2aYWbyBuPy0dqIpw6hKg
🙋🏻♀️ 编者按:本文是蒙娜丽莎平台核心开发申姜在支付宝体验科技沙龙暨数金荟上的演讲内容,欢迎享用~
前言
大家好,我是来自 网商银行-移动渠道部 的申姜(甘文鹏),今天分享的主题是:蒙娜丽莎 —— 一个更加智能的视觉走查解决方案。
为了解决视觉走查这个老大难问题我们最近和设计团队一起做了蒙娜丽莎视觉走查平台。做了很多事,踩了很多坑,当然也有很多收获,今天想借这个机会跟跟大家分享一下。在分享正式开始之前我想先通过一个小视频让大家了解一下蒙娜丽莎是干什么的,这样看后面的分享也不会觉得懵逼。话不多说,直接开始。
,时长00:56
可能有人看懂了,也有人没看懂,但是有一个信息大家应该了解了 —— 蒙娜丽莎是通过算法来做视觉走查的。那么什么是走查?为什么要做走查?怎么来做走查呢?今天的分享都会一一讲到。
一个小案例

这是一个发生在我身上的故事。
刚来网商的时候我是做网商 App iOS 客户端的,标准页面仔。好不容易糊好了一个页面提测了,结果当天就有人找上来了说有问题。我以为是测试,后来才知道是设计。我很诧异,测试都没说啥为啥设计追着我不放?这里的设计师都这么爱“找事”的么?以前的公司也不这样啊。当然,最后我还是乖乖按照设计师的要求改了,但是就这一个页面光调视觉就调了快一天,反复摩擦。
这种经历应该很多前端同学都有遇到过。被设计师反复摩擦苦不苦?太苦了!反反复复修改、部署,烦不烦?太烦了!等后面我跟设计同学熟悉之后我问过他关于走查的态度,原来他也很苦。
页面上的每一个控件、元素在设计过程中都是有特定含义的,需要斟酌、修改很久才能产出一张设计图,然而,最终开发写代码提测的页面跟设计师设计的却很不一样,在主观上设计师就会很难以接受。不仅如此,除了这些主观意识以外还有更深一层的含义。
如果视觉还原度不够的话,统一性、品牌形象、信息传达都没办法按照设计师的设想来进行。最终很有可能会导致用户流失。讲到这里了大家都能够理解视觉走查的必要性,道理我们都懂,但是开发和设计师之间的冲突却并没有任何缓解。这时候我们就会有一个灵魂拷问:难道就没有优雅一点、高效一点的解决方案吗?
带着这个问题我们开始探索新方案。
探索新方案

探索新方案之前我们需要更多的输入,所以做了一些调研。
蚂蚁内部的视觉走查以前都是以「纯人工截图对比」的方案来做的,这里不做赘述。调研外部方案时找到了“他山石”,他更好的解决了让「人工走查更方便」的问题,比我们内部方案好一些,但也没有根本性的开发和设计师的痛点。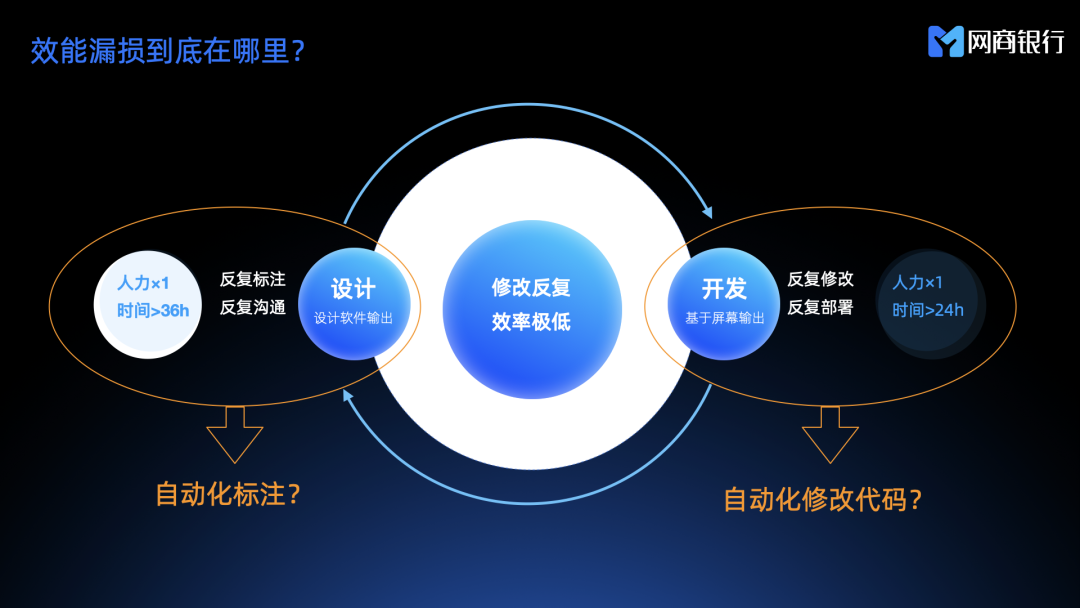
方案调研完了,那么这些方案的效能漏损在哪里?
其实不管是手动标注还是“他山石”都逃不过一个反复标注、反复沟通的问题,这个很费时间。另一个就是开发同学要不断的修改、不断部署的问题,这个同样费时间。那么我们开一下脑洞:如果能够同时实现「自动化标注」、「自动化修改代码」那是不是视觉走查这件事就可以做到完全的无人工干预?理论上是这样的,但是实操很难。作为页面仔其实我们最开始探索的是如何实现自动修改代码,但实际操作起来太难,前端框架太多,业务复杂,而且我们是银行团队,稳定性压倒一切,自动修改代码的风险太高了。综上所述最终我们还是脚踏实地的研究如何实现自动化标注。
基于图像算法的智能走查方案
在自动化标注的方向上我们有很多成果,而这一些列的技术方案统称为“基于图像算法的智能走查方案”
方案一:基于计算机视觉的“像素眼” —— 像素作差

由于视觉同学常被称为“像素眼”,所以给我们的第一直觉就是用 ImageDiff 来实现,也就是从 Sketch 生成一张视觉稿的切图,再从研发容器中获取到真实运行的页面截图,通过简单的像素做差,配合一定的阈值设定,也可以生成报告。
这种方式能很精准的告诉我们哪里有差异,但究竟是什么差异算法是不知道的。这样的结果明显是没办法满足要求的,因为我们最终要知道的是字体、色值、大小、位置这种具体的差异。
我们继续推导,既然图片上没有这些属性,那哪里有呢?DOM 节点上有。所以我们想到了一个新的探索路径,如果我们可以感知页面的 DOM 树布局结构是不是就可以解决这里遇到的问题?
方案二:基于 DOM 节点的像素级走查
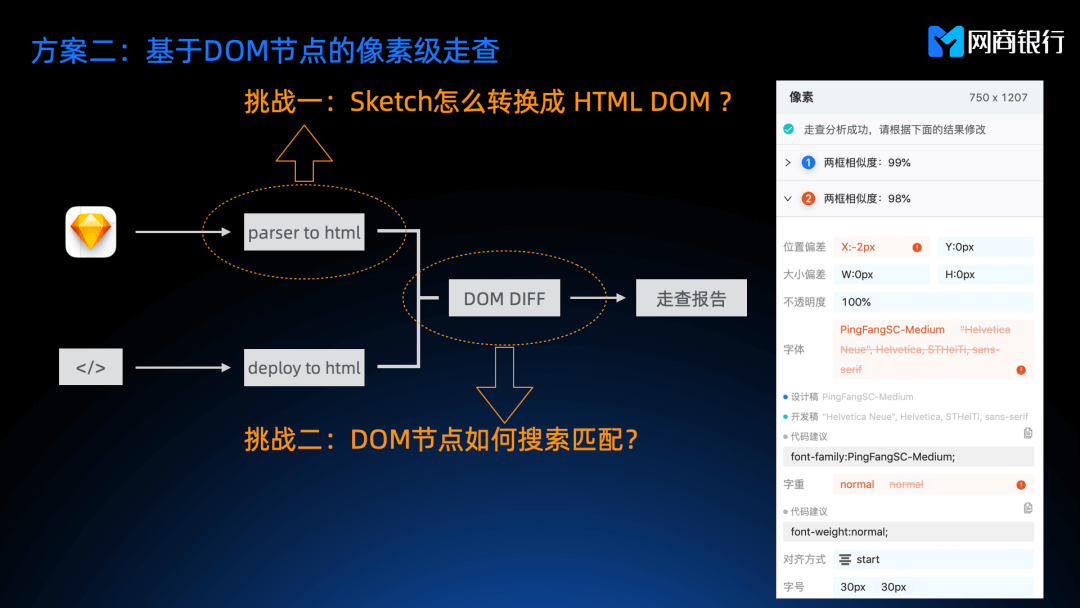
基于 DOM 来做视觉走查是对的,因为我们可以从 DOM 节点上拿到非常丰富的信息,最终方案是:
- 设计稿转成 HTML
- 代码部署得到 HTML
- 这两个 HTML 的 DOM 节点做交叉匹配
- 找到匹配节点之后对比样式。
最终就可以得到我们的走查报告。
但这里面有两个难题,Sketch 怎么准确的转成 HTML ?DOM 节点怎么来做匹配?
视觉稿精准解析方案
基本原理
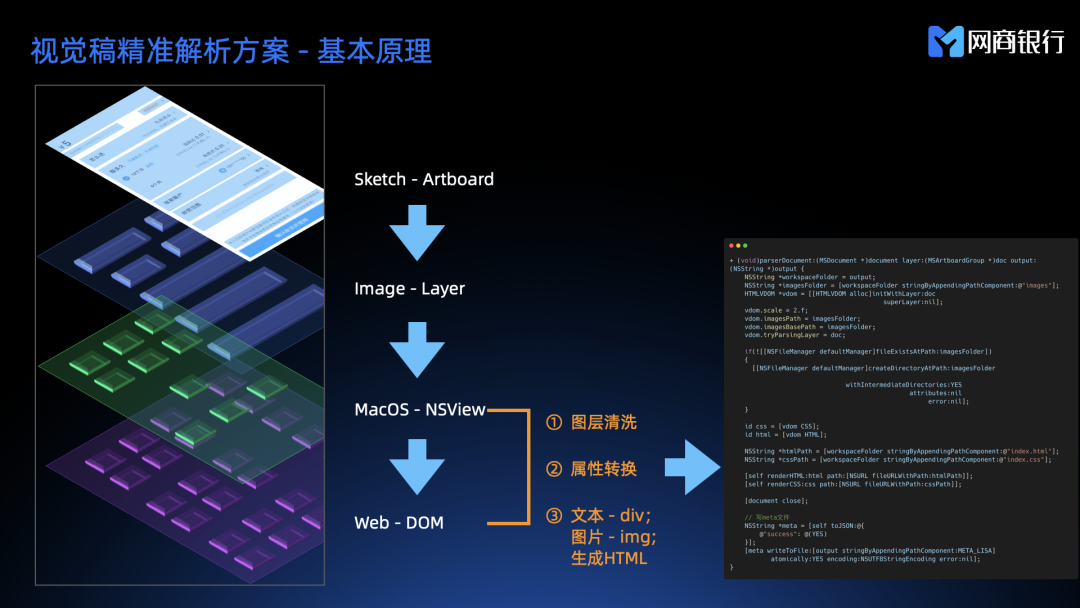
视觉稿解析成 HTML 的方案我们叫做“视觉稿精准解析方案”,原理大致如下:
- 我们每次走查用到的其实只是 sketch 文件中的一个画板;
- 画板其实是由一个个的图层组成;
- 图层在 MacOS 上的表现其实就是 NSView;
- Sketch 转成 HTML 最主要的就是要解决 NSView 到 DOM 的转换,而这一步最主要做三件事:图层清洗、属性转换、HTML 标签生成。
- 设计师的画图思路和开发的编码布局思路是不一样的,sketch 上经常会有空白图层和不可见图层,所以我们要做图层的清洗,把所有这些不可见图层全部删除;
- MacOS 体系的视图属性和 WEB 体系的 DOM 属性其实大部分是重叠的,所以我们可以对属性做一一映射。
- 遍历图层时我们需要做文字和图片的分类,文字统一使用 div 标签,图片统一使用 img 标签,最终组装成一个完整的 HTML。
方案落地

原理搞懂了那么如何落地?
通过调研我们发现 Sketch 官方提供了 Plugin 插件机制,所以我们可以把前面讲到的逻辑全部写到插件里。但是这里有一个坑,Sketch 官方提供的 JavaScript 版本 API 在操作图层时功能有限,建议还是使用 OC 编写,下面两个文档可以参考:
- CocoaScript:https://developer.sketch.com/plugins/cocoascript
- Internal API:https://developer.sketch.com/plugins/internal-api
插件开发完成之后我们并不需要将他安装到 Sketch App 中去。官方提供了 sketchtool 命令,我们可以通过这个命令让 SketchApp 动态加载插件,用完立马释放,如:
/Applications/Sketch.app/Contents/MacOS/sketchtool \ run /monalisa/plugin/bkcodego.sketchplugin \ bkcodego.id.detail-parser \ —without-activat=YES \ —new-instance=YES \ —context=”{\”file\”:\”/data/test.sketch\”, \”output\”:\”/data/output/v1\”}”
解析结果

最终我们解析后得到的就是一个有 HTML、CSS、Image 的完整页面,可以完整的在浏览器渲染。
讲到这里其实视觉稿走查的方案基本就讲完了,但是这个仅仅只是单机版,如果要大规模提供服务肯定是不能满足的,所以我们做了集群化服务
集群化服务

- 云服务做任务调度、回调处理、任务存储;
- 每次有解析任务都会先下发给消息队列。用消息队列的原因有两个:
- 每到饭点和下班之前就会有大量设计稿解析任务、走查任务触发,波峰波谷明显,如果同步调用会需要更多的资源,消息队列的形式可以蓄水,降低一些硬件资源的成本。
- 解决标准机房和非标机房网络通信的问题。
- 我们在非标机房建了一个MacMini的机房,机房的mac机器会订阅消息队列的消息。接受到消息之后做一系列的解析。
基于 OpenCV + MobileNetV2 的节点匹配算法
基本原理

我们的节点匹配是基于 OpenCV+MobilenetV2 神经网络算法来实现的,基本原理是这样:
- 元数据获取
- sketch 转成 HTML ,上传 CDN ,得到一个 URL ;前端代码部署,得到一个 URL ;
- 两个 URL 分别用 Chromedriver 无头浏览器渲染,得到 DOM 信息;
- DOM&BOX 修正
- DOM 节点清洗、去重、合并、重建
- 四边留白识别,边框修正
-
元数据获取

无论是 sketch 文件还是前端代码都不能被匹配算法消费,我们需要把这些“源文件”转化成算法能够识别的元数据。元数据获取流程是这样的: 两个链接通过 Chromedriver 渲染,我们可以借助 selenium 做 DOM 遍历
遍历 DOM 之后我们要得到 3 个产物:
- dom 树
- dom 每一个节点的截图
- 全屏截图。
- Chromedriver 在初始化的时候是需要指定屏幕大小的,一旦页面长度超过屏幕高度我们就没法一次性截到完整的全页面图片,这时候就只能不断滚动、不断截图 得到一批页面截图
- 借助 SIFT + OpenCV 实现图像特征提取、特征匹配、图像拼接,最后可以得到一张完整的页面长截图。
DOM & BOX 修正
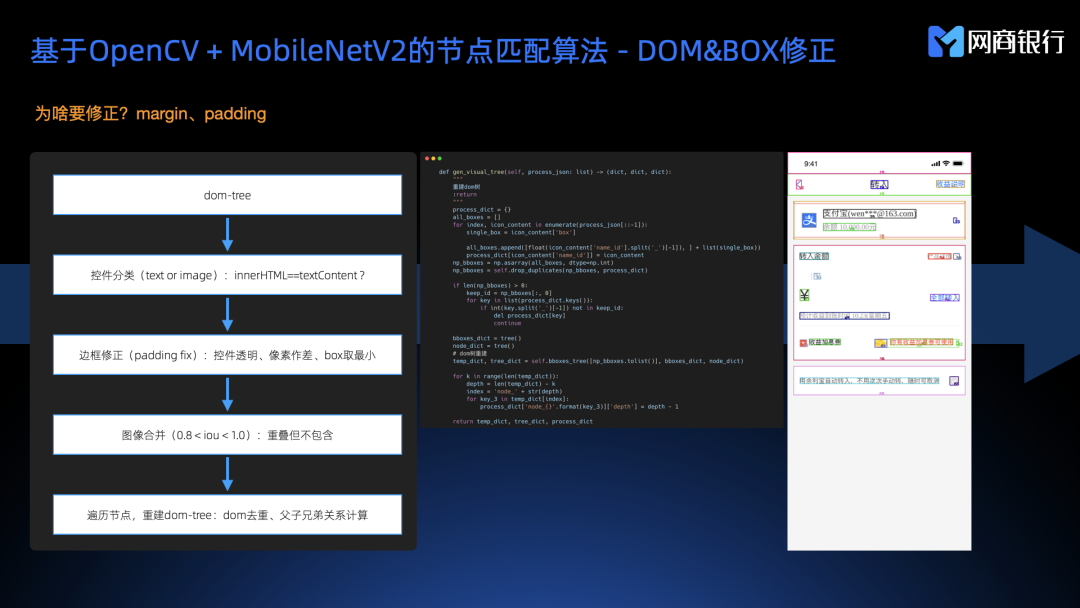
元数据获取完成之后我们就得到了 DOM 树,但是这些 DOM 信息却不能直接用到匹配逻辑里去,为什么呢?主要原因是不管是我们写代码还是设计师画页面,很多时候都会给控件的四周留白,padding、margin ,这种东西没有标准的,只要实现方式不一样他的留白就不一样,这样会对匹配算法带来很多不必要的干扰,所以要对 DOM 树上所有的节点做一次 BOX 的修正。具体流程如下:
DOM 树作为输入,遍历节点,每个节点都作为一个控件;
- 对控件做分类;
- innerHTML==textContent 则判定为文字组件,否则为图片组件;
- 控件边框修正;
- 原始 DOM 截图作为基线A
- 将原始 DOM 中某个控件透明度置为 0 ,然后整个页面截图作为B
- A、B 一起做像素差,得到的差值就是变化的部分,抹掉了留白得到的就是最小的 box
- 图像合并;
- 为什么要做这一步?设计师在做页面设计时经常会使用很多细小图层堆叠出来一个完整控件,sketch 解析成 HTML 之后也会相应的出现很多小控件堆叠,我们需要把这种堆叠在一起的细小控件合并为一个大控件来做处理。
- 计算每个控件与其他控件的 iou,如果 iou>0.8 则判定为重叠
- 计算包含所有重叠小控件集合的最小包围矩形 box,这个 box 作为合并后大控件的 box
经过边框修正和图像合并后我们会得到一个视觉角度的 DOM 树,这个 DOM 就是后面我们给节点匹配算法用的输入。
节点匹配 & 样式对比

DOM 清洗完成之后我们就可以进行真正的节点匹配了。具体流程如下:两组输入:2个 DOM 树,2 个页面完整截图
- hash 相似度过滤
- 两个图片做均值 hash。
- hash 相似度 < 0.5:认为是不相干的两张图,不做后续匹配,页面走查不通过。
- hash 相似度 ≥ 0.99:认为是完全相同的两张图,不做后续匹配,页面走查通过。
- 两个 DOM 树交叉遍历
- DOM 节点两两比对
- 匹配形状、文本、图片相似度
- 节点匹配到之后做样式比对:字体、字号、位置、大小、颜色
- 生成报告
架构图


蒙娜丽莎的平台化建设
讲了这么多都是技术细节,那业务的开发同学怎么用我们的能力呢?总不能所有人都拉过来培训一把,让大家电脑上跑脚本吧。这么一来我们就需要一个平台,把我们实现的自动化能力都通过一个平台来输出给大家,这个平台就是「蒙娜丽莎平台」。由于蒙娜丽莎平台还未商业化所以这里不做过多赘述,还是以一个小视频展示一下平台的能力
,时长00:49
以前我们一个中大型的项目在上线前的走查基本要花两三天时间,用了蒙娜丽莎之后基本可以在一天之内搞定。这个提效其实是比较明显的。

未来展望

FOR 解析
- 目前蒙娜丽莎视觉走查都是依赖 Sketch 文件作为设计资源输入的,但是业内的设计工具其实不是只有 Sketch,还有 Figma ,后续我们也会探索基于 Figma 的解析和走查;
- Sketch 只能运行在 macOS 上,所以目前的设计资产解析服务都是运行在非标的 MacMini 集群。非标服务器运维成本巨大,后续会考虑将解析服务迁移到标准 Linux 集群
FOR 走查
- 视觉走查的能力不止能用于发布前的视觉验收,理论上也可以用于线上的视觉巡检和页面的异常感知等,这也是我们后续的一个方向。
- 涉及卡片多状态的时候设计师一般只会给卡片级的示例而非页面级,这种卡片级的走查目前还无法使用蒙娜丽莎走查,区块走查需要做起来。
- 为了走查需要把页面数据造的和设计稿一致,这样对造账号和 mock 数据的依赖很大,成本不小,这个也需要解决,所以我们也会往泛化样式的方向探索。
FOR 开源
视觉走查是一个老大难的问题,这不是一个业务、一个团队、一家公司的问题,他是一个行业性难题。我们也希望能够通过开源等形式来和大家一起共建,所以后续解析服务、走查服务可能都会开源,大家敬请期待 ~
最后,如果有对「智能视觉走查」感兴趣的朋友可以加群一起探讨。如果群二维码失效可以加管理员的微信,管理员会拉你进群。
-精彩推荐-


若有收获,就点个赞吧
0 人点赞
