
问答题
1.短距离无线通信技术
1.Wi-Fi
理论上,用户位于接入点周围的某个区域,但如果被墙遮挡,建筑物内的有效传输距离将小于室外。WiFi技术主要用于SOHO、购物中心、机场、家庭无线网络、机场、酒店、其他公共热点等不方便安装电缆的建筑物和场所,节省了大量电缆铺设费用。
2.蓝牙
无线数据和语音通信的开放全球规范。蓝牙技术应用的技术就是在固定或移动的设备之间的通信环境建立通用的短距离无线接口。其传输频带是世界通用的2.4GHzISM频带。提供1Mbps的传输率和10m的传输距离。缺点:芯片尺寸和价格难以下降,抗干扰性不强,传输距离太短,信息安全问题等。
3.ZigBee
这主要用于短距离内的各种电子设备之间,数据传输速度不高。ZigBee这个名字来源于蜂群用于生存和发展的交流方式。蜜蜂曲折地跳舞,分享新发现的食物的位置、距离和方向。ZigBee可以说是同一个蓝牙家族的兄弟。这个家族使用2.4GHz频带,使用跳频技术。但ZigBee比蓝牙简单低速,功耗和成本低。基本速率为250kb/s,降低到28kb/s时,传输范围可以扩展到134m,可以得到更高的可靠性。它还可以连接到254个节点和网络。比蓝牙更好地支持游戏、家电、设备和家庭自动化应用程序。
4.IrDA
是使用红外线进行点对点通信的技术,是实现无线个人区域网络(PAN)的第一项技术。目前,其软件和硬件技术非常成熟,在PDA、手机、笔记本电脑、打印机和其他产品等小型移动设备上支持IrDA。
优点:不需要申请使用权,低成本红外线通信,体积小,功耗低,连接方便,移动通信所需的简单易用,红外线辐射角小,传输安全性高。
缺点:此技术只能用于两个(非多个)设备之间的连接。蓝牙技术就没有这个限制,所以IrDA现在的研究方向是解决视距传输问题和提高数据传输速度的方法。
5.NFC
像飞利浦、诺基亚和索尼推进的RFID(非接触射频识别)这样的短距离无线通信技术标准。与RFID不同,NFC使用双向识别和连接。动作在13.56MHz的频率范围内,距离为20cm。NFC最初只是远程控制识别和网络技术的组合,但现在逐渐发展成了无线连接技术。
NFC通过在一个设备上组合所有识别应用程序和服务,解决了存储多个密码的故障,确保了数据的安全。使用NFC,可以在多个设备(例如,数字照相机、PDA、机顶盒、计算机、手机等)之间实现无线互连,并相互交换数据和服务。同样,要构建Wi-Fi系列无线网络,需要具有多个计算机、打印机和其他无线卡的设备。还要求一些技术专家完成这项工作。在接入点上设置NFC后,如果其中两个处于关闭状态,则可以进行通信,比设置Wi-Fi连接容易得多。
6.UWB超宽带
无线载波通信技术。因为使用纳秒量级的非正弦波窄脉冲而不是正弦波载波来传输数据,UWB可以以非常宽的带宽传输信号。美国FCC规定,所以占了很大的频谱。UWB在3.1到10.6GHz频带内占有500MHz以上的频带。
UWB近年来发展迅速,因为它可以使用低功耗、低复杂度的收发机实现高速数据传输。使用低功率脉冲,可以以非常宽的频谱传输数据,并利用频谱资源,而不会对传统的窄带无线通信系统造成重大干扰。基于UWB技术的高速数据收发机有广泛的用途。
UWB技术的优点是系统复杂度低,发送信号的功率谱密度低,对信道衰落不敏感,拦截能力低,定位精度高。特别适合在室内等高密度多路径站点进行高速无线访问,以及构建高效的无线LAN和无线个人LAN(wpan)。UWB主要用于墙壁、地面和人体可以透过的狭窄范围、高分辨率雷达和图像系统。
此外,这项新技术也适用于需要非常高的速率(100Mb/s以上)的LAN和PAN,即光纤昂贵的情况。通常,UWB可以在10m内实现高达数百Mbps的传输性能,但远程应用的IEEE802.11b或HomeRF无线PAN的性能比UWB强。UWB不会与流行的IEEE802.11b和家庭RF直接竞争,因为UWB在大约10m外的室内使用得很多。
7.其他
现在,与手机集成的RFID技术主要是NFC(近距离通信)、SIMpass(双接口SIM卡)和RF-SIM(可进行中短距离无线通信的手机智能卡)技术。
SIMpass技术是DI卡技术和SIM卡技术的结合,被称为双接口SIM卡。SIMpass是支持接触式和非接触式工作接口的多功能SIM卡。接触式接口实现SIM功能,非接触式接口实现支付功能。与多个智能卡应用程序规格兼容.。
2.谷歌的三架马车是什么P174
浅谈Google的三驾马车之GFS
谷歌在2003到2006年间发表了三篇论文,《MapReduce: Simplified Data Processing on Large Clusters》,《Bigtable: A Distributed Storage System for Structured Data》和《The Google File System》介绍了Google如何对大规模数据进行存储和分析。这三篇论文开启了工业界的大数据时代,被称为Google的三驾马车。
背景介绍
在21世纪初,互联网上的内容,大多数企业需要存储的数据量并不大。但是Google不同,Google的搜索引擎的数据基于爬虫,而由于网页的大量增加,爬虫得到的数据也随之急速膨胀,单机或简单的分布式方案已经不能满足业务的需求,所以Google必须设计新的数据存储系统,其产物就是Google File System(GFS)。不过,在Google的设计中,为了尽可能的解耦,GFS仅负责数据存储而不提供类似数据库的服务。也就是说,GFS只存数据,而对数据的具体内容一无所知,自然也就不能提供基于内容的检索功能。所以,更进一步,Google开发了Bigtable作为数据库,向上层服务提供基于内容的各种功能。此外,Google 的搜索结果依赖于PageRank算法的排序,而该算法又需要一些额外的数据,比如某网页的被引用次数,所以他们还开发了对于的数据处理工具MapReduce,在读取了Bigtable数据的技术上,根据业务需求,对数据内容进行运算。其总体架构如下,GFS能充分利用多个Linux服务器的磁盘,并向上掩盖分布式系统的细节。Bigtable在GFS的基础上对数据内容进行识别和存储,向上提供类似数据库的各种操作。MapReduce则使用Bigtable中的数据进行运算,再提供给具体的业务使用。
Google File System
GFS是三驾马车中最底层的组件,当然也是最复杂的,因为他直接和分布式的系统接触。在具体探讨实现细节之前,Google给出了一些设计前提和设计目标。
- 由于使用的机器是廉价的商业化机器,那么机器崩溃被认为是一种常态。
- 系统存储以大文件为主,但也支持小文件。文件大小通常在100MB左右并且需要高效的操作几个GB的文件。
- 系统需要支持大规模的连续读取和小规模的随机读取,以及大规模的追加写。
- 高性能稳定的网络带宽比延迟更重要。
- 以及最重要的,能在分布式的系统上运行。
总体架构
首先我们来看看GFS的总体架构。在这个架构中,GFS采用了单Master(Single Master)的设计来简化系统的复杂度。Master负责两点,一是存储和维护Chunk Server和数据块的相关信息,二是处理客户端的请求。也就是说,Master并不存储任何具体的数据,这些数据被存在被称为Chunk Server的数据节点上。其中Chunk就是指数据块,在GFS中被固定为64MB大小,我想着可能跟第二个目标相关。每当数据需要被写入时,就更新GFS中的信息,并把数据封装成Chunk写入到数据库中,具体流程在下面会仔细介绍。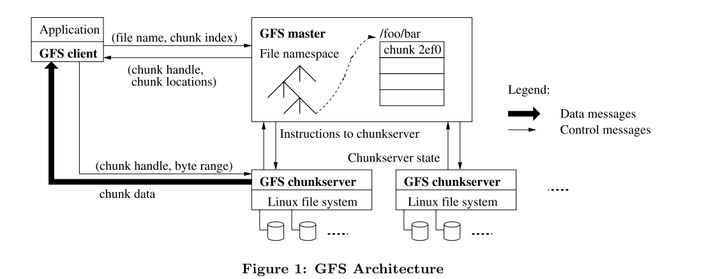
上图演示了应用如何调用GSF进行读操作的具体流程
- 应用调用GFS Client的函数,要求其读取具体的文件/foo/bar,假设大小为50MB。
- GFS Client根据Chunk的固定大小计算出/foo/bar的Chunk的Index,即64/50向上取整,Chunk Index=1。以及其在Chunk内的偏移量Byte Range[0,50],并将File Name和Chunk Index作为参数发送给GFS Master
- Master返回了对应的Chunk Handle(也就是Chunk的ID,上图中的2ef0)和Chunk Locations(Chunk Server和其副本的IP)
- GFS Client根据返回的Chunk Locations找到最近的Chunk Server,然后根据Chunk Handle找到对应的Chunk,最后按照这个文件在Chunk中偏移量Byte Range读取文件。
- Chunk Server按照其要求返回文件数据。
整个的流程相当清晰,客户端负责将文件在File Namespace的位置交给Master,Master根据其位置返回对应的Chunk和Chunk Server,然后客户端再根据这些信息去拿数据。但是,这里有很巧妙的设计,就是GFS将所有数据传输的压力都放到Chunk Server上,而不是Master。假设由Master根据Chunk Handle去找数据并返回给客户端,那么这里就有会造成系统带宽压力增大。如果按照假设设计,Chunk Server将数据传回给Master后,Master还要将数据传回给客户端,也就是64MB的流量陡然翻倍成128MB。而实际的GFS不仅降低了Master带宽的压力,还把读取数据的压力均摊到每个Chunk Server上,降低了整个系统的压力。这些设计明显有助于实现目标三。
通过对读取过程的分析,可以发现,GFS已经完全实现目标二中的大规模连续读和小规模随机读的要求。
Single Master
Master中保存三种信息(MATEDATA)
- 文件和chunk的namespace,即文件树形式的命名方式。
- 文件到chunk的映射,即每个文件需要哪几个Chunk来记录。
- 每一个chunk的具体位置。
这些信息都平时都存在内存中,以此提高响应速度。这似乎只能存储很少的信息,但是,Master只需要64byte的空间就能记录64MB的Chunk的相关信息,也就是说,128MB的内存能存储1PB的数据的相关信息。不过,为了保证Master能在崩溃后恢复,在执行改变前两种信息的操作前需要使用WAL的形式定期地保存到磁盘上。这样,在Master恢复的时候,就能通过磁盘上的WAL来重建前两种信息。而Chunk的位置则可以通过Heartbeats的形式查询并更新,这样不仅加速了Master的恢复,也能使GFS的配置更加灵活。
写数据(Write)
由于每个Chunk Server都有备份的副本,所以写操作要比读操作稍微复杂一点。具体的流程如下图所示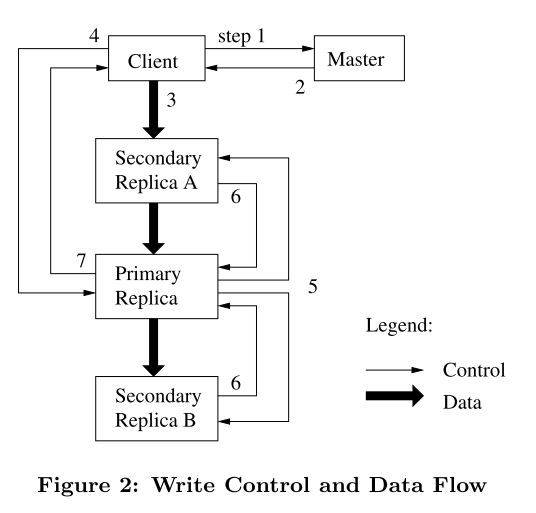
- 客户端向 Master 询问目前哪个Chunk Server持有该Chunk的Lease
- Master 向客户端返回Primary Replica和其他Replica的位置
- 客户端将数据推送到所有的Replica上。Chunk Server会把这些数据保存在缓冲区中,等待所有 Replica 都接收到数据。
- 客户端发送写请求给 Primary,Primary 为来自各个客户端的修改操作选定执行序列号,并按顺序地应用于其本地存储的数据。
- Primary 将写请求转发给其他 Secondary Replica,Replica 们按照相同的顺序应用这些修改
- Secondary Replica 响应 Primary,示意自己已经完成操作。
- Primary 响应客户端,并返回该过程中发生的错误
这里要说明的是,每个Chunk被复制到多个Chunk Server中,以此避免单个节点崩溃可能造成的数据损失。而这些Chunk Server中负责相应写操作的Chunk Server被称为Primary Replica,其余的被称为Secondary Replica,接受来自Primary Replica的请求。而为了保证写入数据的一致性,只能有一个Primary Replica,这里的唯一性就由Lease来实现。当需要写入数据时,Master会将特定的Lease分配给某个Replica,拿到Lease的这个Replica就称为了Primary Replica。
我们再仔细分析整个写的的流程。我们可以注意到为了保证数据的一致性,一次写入只能有一个Primary Replica,同样地,在正式写入数据之前要求所有Secondary Replica缓存数据也是为了一致性。这里的思想类似于WAL,将要执行的操作先保存下来,这样万一崩溃了也能从磁盘读入数据,继续执行未完成的操作。等待所有Secondary Replica完成操作后再相应客户端也是为了保证数据的一致性。
和读操作类似,在写操作中,为了降低Master的压力,所有的数据由客户端发向Chunk Server。
追加(Append)
为了提升性能,GFS提供并推荐使用追加操作修改文件。它与写操作不同之处仅仅在于它向文件尾端添加数据而不是覆盖,它的流程也he 写操作大同小异
- 客户端将数据推送到每个 Replica,然后将请求发往 Primary
- Primary 首先判断将数据追加到该块后是否会令块的大小超过上限:如果是,那么 Primary 会为该块写入填充至其大小达到上限,并通知其他 Replica 执行相同的操作,再响应客户端,通知其应在下一个块上重试该操作
- 如果数据能够被放入到当前块中,那么 Primary 会把数据追加到自己的 Replica 中,拿到追加成功返回的偏移值,然后通知其他 Replica 将数据写入到该偏移位置中
- 最后 Primary 再响应客户端
特别值得一提的是,GFS保证追加操作至少被执行一次(at least once),这意味着追加操作可能被执行多次。当追加操作失败时,为了保证偏移量,GFS会在对应的位置填充重复的数据,然后重试追加。也就是说,GFS不保证在每个副本中的数据完全一致,而仅仅保证数据被写入了。
数据一致性
在GFS中,由于分布式系统的原因,不同节点间处理请求和存储数据速度不一致导致了客户算读取数据时可能出现各种不同的情况。
文件的数据修改则相对复杂。在讲述接下来的内容前,首先我们先明确,在文件的某一部分被修改后,它可能进入以下三种状态的其中之一:
在文件的某一部分被修改后,它可能进入以下三种状态的其中之一:
- 客户端读取不同的 Replica 时可能会读取到不同的内容,那这部分文件是不一致的(Inconsistent)。
- 所有客户端无论读取哪个 Replica 都会读取到相同的内容,那这部分文件就是一致的(Consistent)。
- 所有客户端都能看到上一次修改的所有完整内容,且这部分文件是一致的,那么我们说这部分文件是确定的(Defined)。
也就是说,在一致性和强度上,Defined>Consistent>Inconsistent。
在修改后,一个文件的当前状态将取决于此次修改的类型以及修改是否成功。具体来说:
- 如果一次写入操作成功且没有与其他并发的写入操作发生重叠,那这部分的文件是确定的(同时也是一致的)。
- 如果有若干个写入操作并发地执行成功,那么这部分文件会是一致的但会是不确定的:在这种情况下,客户端所能看到的数据通常不能直接体现出其中的任何一次修改。也就是说,操作成功执行了,但是有的操作的数据改变被覆盖了,客户端看不到被覆盖的数据改变。
- 失败的写入操作会让文件进入不一致的状态。
论文中给出了总结的表格:
至于为什么追加(Append)是Defined但是有可能是不一致是因为:在追加写操作失败时,为了保证数据的偏移,可能为填充重复的数据,此时导致了不一致。但是失败的操作会被再次执行,此时又保证了数据的一致性。而由于使用的是追加,所以任何数据的改动都可以观察到,所以是Defined。
快照(Snapshot)
这里的快照的目的不同于Raft中的压缩,它仅仅驶出为了生成一个新的Replica,可以看做是一个简单的复制操作。
- 在 Master 接收到快照请求后,它首先会撤回相关Chunk Server的 Lease,保证在创建快照的过程中,客户端对不会对相关的Chunk Server进行写操作或者追加操作。
- 当Lease收回后,Master会先将相关的改动写入日志,然后对自己管理的命名空间进行复制操作,复制产生的新记录指向原本的 Chunk。
- 当有客户端尝试对新的Chunk Server进行写入时,Master 会注意到这个 Chunk 的引用计数大于1(可能是一个标记)。此时,Master 会为要读取的Chunk生成一个Handle,然后通知所有持有这些 Chunk 的 Chunk Server 在本地复制并使用出新的 Chunk,然后再返回给客户端
我想GFS提供快照的原因可能是为了在一个副本损坏时,从Primary Replica或者其他副本复制数据,然后用新的节点代替损坏的节点。
垃圾回收
当GFS收到删除文件的请求时,它并不直接删除文件,而是给文件打上删除的时间戳并将其命名为掩藏文件(文件开头加”.”)。在周期性扫描过程中,当发现文件的删除时间超过设定期限后,才真正地将文件删除。Google认为其有以下优点
- 对于大规模的分布式系统来说,这样的机制更为可靠:在 Chunk 创建时,创建操作可能在某些 Chunk Server 上成功了,在其他 Chunk Server 上失败了,这导致某些 Chunk Server 上可能存在 Master 不知道的 Replica。除此以外,删除 Replica 的请求可能会发送失败,Master 会需要记得尝试重发。相比之下,由 Chunk Server 主动地删除 Replica 能够以一种更为统一的方式解决以上的问题
- 这样的删除机制将存储回收过程与 Master 日常的周期扫描过程合并在了一起,这就使得这些操作可以以批的形式进行处理,以减少资源损耗;除外,这样也得以让 Master 选择在相对空闲的时候进行这些操作
- 用户发送删除请求和数据被实际删除之间的延迟也有效避免了用户误操作的问题
高可用
论文中主要探讨了三个方面的高可用,分别是Master,Chunk Server和数据完整性。
当Master崩溃时,有两种情况,一是进程崩溃但是服务器没有,这种情况下,重开一个进程即可。另一种情况是整个机器崩溃了,在GFS还有被称为Shadow Master的机器,复制Master节点的信息。当Master机器崩溃后,Shadow Master会接替Master进行服务,但是仅提供读取操作的服务,不能更改信息。
当Chunk Server崩溃时,Master会安排新的Replica代替它,从其他Replica复制原始数据。而当Chunk Server恢复时,由于数据不同步,不应该提供服务,Master就需要区别新旧Chunk Server。GFS使用版本号来标记这个信息,每分配以此Lease,版本号就会增加并同步给其他Replica,而由于Chunk Server崩溃后不能更新,我们就能从版本号上辨别新旧。
由于写操作和追加操作可能不成功,所以数据可能会损坏。GFS使用检验和检查是否损坏,每次客户端读取数据时,Chunk Server都会检查检验和,一旦发现损坏,就会向Master报告。Master则会将请求发送给其他Replica,并从其他Replica复制数据到该机器。总结
2003年GFS的横空出世具有划时代的意义,它标志着学术上的分布式理论和一些实验性质的尝试在工业界有了大规模商用的案例,尤其还是在Google这样的公司。它的系统设计在后续的系统中被屡次参考复用,而其设计确实有独到之处,比如Master负责控制流而完全将数据流从其剥离,这样的设计不能不说是优雅。这篇论文催生了HDFS,至今仍被许多公司使用,足以可见其影响力之大。哪怕这篇论文距离今天已经有快20年的时间,GFS在Google内部迭代多次,但是其设计仍然值得每一个分布式程序员学习。
浅谈Google的三驾马车之MapReduce及总结
谷歌在2003到2006年间发表了三篇论文,《MapReduce: Simplified Data Processing on Large Clusters》,《Bigtable: A Distributed Storage System for Structured Data》和《The Google File System》介绍了Google如何对大规模数据进行存储和分析。这三篇论文开启了工业界的大数据时代,被称为Google的三驾马车。本文介绍MapReduce的相关内容。
背景介绍
在21世纪初,互联网上的内容,大多数企业需要存储的数据量并不大。但是Google不同,Google的搜索引擎的数据基于爬虫,而由于网页的大量增加,爬虫得到的数据也随之急速膨胀,单机或简单的分布式方案已经不能满足业务的需求,所以Google必须设计新的数据存储系统,其产物就是Google File System(GFS)。不过,在Google的设计中,为了尽可能的解耦,GFS仅负责数据存储而不提供类似数据库的服务。也就是说,GFS只存数据,而对数据的具体内容一无所知,自然也就不能提供基于内容的检索功能。所以,更进一步,Google开发了Bigtable作为数据库,向上层服务提供基于内容的各种功能。此外,Google 的搜索结果依赖于PageRank算法的排序,而该算法又需要一些额外的数据,比如某网页的被引用次数,所以他们还开发了对于的数据处理工具MapReduce,在读取了Bigtable数据的技术上,根据业务需求,对数据内容进行运算。其总体架构如下,GFS能充分利用多个Linux服务器的磁盘,并向上掩盖分布式系统的细节。Bigtable在GFS的基础上对数据内容进行识别和存储,向上提供类似数据库的各种操作。MapReduce则使用Bigtable中的数据进行运算,再提供给具体的业务使用。
MapReduce
MapReduce本来是函数式编程中的两个函数,在尝试解决利用大数据进行计算时,Jeff Dean和Sanjay Ghemawat想到了使用这种思想简化计算模型。
基本思想
MapReduce把所有的计算都拆分成两个基本的计算操作,即Map和Reduce。其中Map函数以一系列键值对作为输入,然后输出一个中间文件(Intermediate)。这个中间态是另一种形式的键值对。然后,Reduce函数将这个中间态作为输入,计算得出结果。其中,Map函数和Reduce函数的逻辑都是由开发人员自行定义的。一种经典的逻辑如下图所示。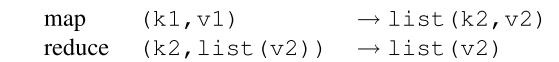
以WordCount为例,准备要统计一本书中所有单词出现的次数。在Map函数中,我们每遇到一个单词W,就往中间文件中写入(W,1)。然后,在Reduce函数中,把所有(W,1)出现的次数相加,就能得到W的出现次数V。
分布式MapReduce流程
上面提到的模型和思想都是单机的,想要在分布式系统中实现,还需要一些改动。在MapReduce中,他们选择将大任务拆分成小任务分配给多台机器,以此充分利用分布式系统的性能。下图是论文中展示的MapReduce的流程图。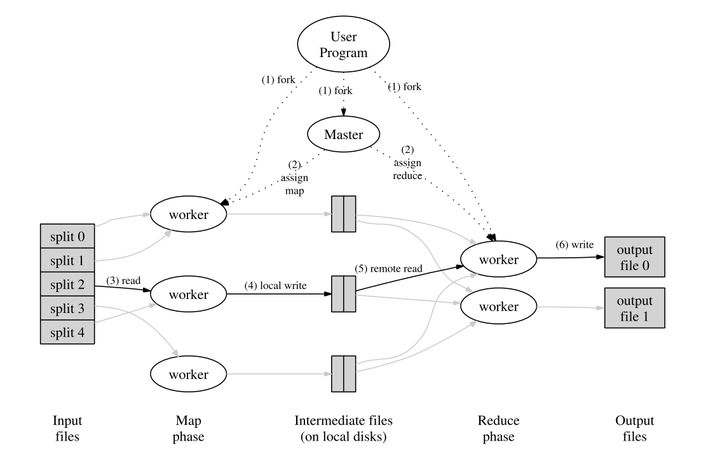
具体的流程如下
- MapReduce客户端会将输入的文件会分为M个片段,每个片段的大小通常在 16~64 MB 之间。然后在多个机器上开始运行MapReduce程序。
- 系统中会有一个机器被选为Master节点,整个 MapReduce 计算包含M个Map 任务和R个 Reduce 任务。Master节点会为空闲的 Worker节点分配Map任务和 Reduce 任务
- 执行Map任务的 Worker开始读入自己对应的片段并将读入的数据解析为输入键值对。然后调用由用户定义的 Map任务。最后,Worker会将Map任务输出的结果存在内存中。
- 在执行Map的同时,Map Worker根据Partition 函数将产生的中间结果分为R个部分,然后定期将内存中的中间文件存入到自己的本地磁盘中。任务完成时,Mapper 便会将中间文件在其本地磁盘上的存放位置报告给 Master。
- Master会将中间文件存放位置通知给Reduce Work。Reduce Worker接收到这些信息后便会通过RPC读取中间文件。在读取完毕后,Reduce Worker会对读取到的数据进行排序,保证拥有相同键的键值对能够连续分布。
- 最后,Reduce Worker会为每个键收集与其关联的值的集合,并调用用户定义的Reduce 函数。Reduce 函数的结果会被放入到对应的结果文件。
- 当所有Map和Reduce都结束后,程序会换新客户端并返回结果。
整个流程非常清晰。首先,将输入文件分割成M个个片段,然后每个Map Worker读取对应的片段并执行Map函数,将结果存入中间文件。Reduce Work则通过Master得知中间文件的位置,然后读取其对应中间文件的内容并运行Reduce函数,最后把结果输出到结果文件中。
这里值得说明的是,无论是输入文件到Map Worker的映射还是中间文件到Reduce Worker的映射都可以通过自定义的哈希函数来确定,论文中默认使用Hash(key) mod R来确定。另外,M和R的值都是由用户指定的,应当比实际的机器数量要多一些,以此实现均衡负载。
Fault-Tolerance
因为使用了分布式系统,所以不可避免地要考虑容错的问题,在MapReduce中,容错也考虑Master和Work两种情况。
Master节点会定期地将当前运行状态存为快照,当Master节点崩溃,就从最近的快照恢复然后重新执行任务。
Master节点会定期地Ping每个Work节点,一旦发现Work节点不可达,针对其当前执行的是Map还是Reduce任务,会有不同的策略。
如果是Map任务,无论任务已完成或是未完成,都会废除当前节点的任务。。之后,Master会将任务重新分配给其他节点,同时由于已经生成的中间文件不可访问,还会通知还未拿到中间文件的Reduce Worker去新的节点拿数据。
如果是Reduce任务,由于结果文件存在GFS中,文件的可用性和一致性由GFS保证,所以Master仅将未完成的任务重新分配。
优化
如果集群中有某个 Worker 花了特别长的时间来完成最后的几个 Map 或 Reduce 任务,整个 MapReduce 计算任务的耗时就会因此被拖长,这样的 Worker 也就成了落后者。MapReduce 在整个计算完成到一定程度时就会将剩余的任务即同时将其分配给其他空闲 Worker 来执行,并在其中一个 Worker 完成后将该任务视作已完成。
这里论文中还提出了其他一些策略,但是我认为不是十分重要也就不再提及。
总结
MapReduce是一个相当简单的计算模型,它尝试将所有的计算任务都拆分成基础的Map和Reduce,以此降低实现的复杂度。但是,这恰恰提高了编程逻辑的复杂度。我看过使用MapReduce实现Join功能的代码,十分地巧妙灵活。但是看似巧妙的背后,是模型过于简单而导致复杂度转移到了代码逻辑的层面。
另一方面,MapReduce的程序类似于批处理程序,需要完整的输入程序才能开始运算,而且每次运算都要至少写入两次磁盘。这就导致每次运算都要等待很长的时间,完全不能实现需要快速响应的业务场景的需求。
以上两个方面,一个引出了支持类SQL的计算工具,另一个引出了支持流式计算的工具,而这两个特性正是今天流行的计算工具的热点。
总得来说,虽然MapReduce在今天几乎抛弃了,但是在当初那个年代以及谷歌的业务需求看来,是相当合适的。
浅谈Google的三驾马车之Bigtable
谷歌在2003到2006年间发表了三篇论文,《MapReduce: Simplified Data Processing on Large Clusters》,《Bigtable: A Distributed Storage System for Structured Data》和《The Google File System》介绍了Google如何对大规模数据进行存储和分析。这三篇论文开启了工业界的大数据时代,被称为Google的三驾马车。本文介绍Bigtable的相关内容。
背景介绍
在21世纪初,互联网上的内容,大多数企业需要存储的数据量并不大。但是Google不同,Google的搜索引擎的数据基于爬虫,而由于网页的大量增加,爬虫得到的数据也随之急速膨胀,单机或简单的分布式方案已经不能满足业务的需求,所以Google必须设计新的数据存储系统,其产物就是Google File System(GFS)。不过,在Google的设计中,为了尽可能的解耦,GFS仅负责数据存储而不提供类似数据库的服务。也就是说,GFS只存数据,而对数据的具体内容一无所知,自然也就不能提供基于内容的检索功能。所以,更进一步,Google开发了Bigtable作为数据库,向上层服务提供基于内容的各种功能。此外,Google 的搜索结果依赖于PageRank算法的排序,而该算法又需要一些额外的数据,比如某网页的被引用次数,所以他们还开发了对于的数据处理工具MapReduce,在读取了Bigtable数据的技术上,根据业务需求,对数据内容进行运算。其总体架构如下,GFS能充分利用多个Linux服务器的磁盘,并向上掩盖分布式系统的细节。Bigtable在GFS的基础上对数据内容进行识别和存储,向上提供类似数据库的各种操作。MapReduce则使用Bigtable中的数据进行运算,再提供给具体的业务使用。
Bigtable
Bigtable实现在Google File System的基础上,它关心数据的内容,根据的数据的内容建立数据模型,对外提供读写数据的接口。
数据模型
Bigtable基本的数据结构和关系型数据库类似,都是以行列构成的表,但是,它还另外增加了新的维度——时间。也就是说,在行列确定的情况下,一个单元格(Cell)中有多个以事件为版本的数据。Bigtable用(row:string, column:string, time:int64) → string表示映射关系。下图为论文中给出的一个例子。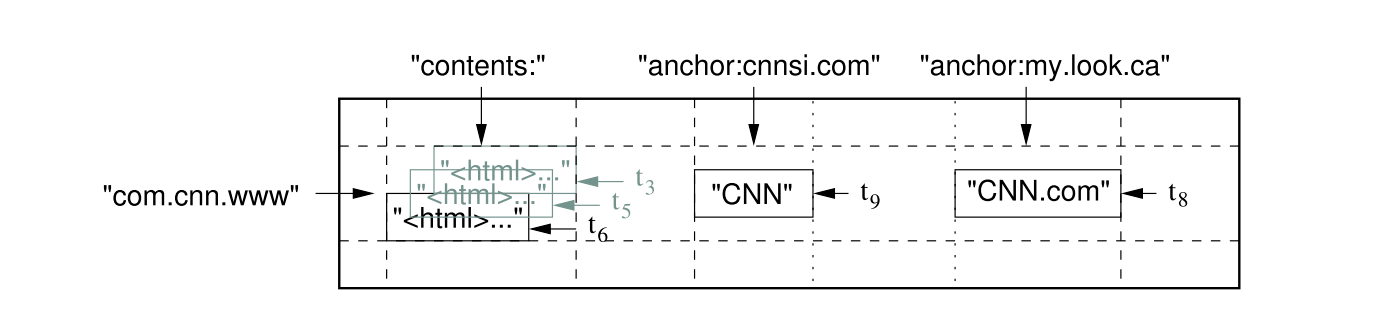
如果想要在表中查询指定版本的内容,我们需要指出行,列,及版本。比如(“com.cnn.www”,“anchor:cnnsi.com”,t9)→ “CNN”。我个人猜想,增加时间这个维度是因为“三驾马车”被设计出来的时候主要是为了支持搜索引擎,搜索引擎可能需要保留多个时间段的网页数据,而GFS也使用追加(Append)作为数据的主要修改方式,所以增加时间戳作为版本既充分利用了GFS的特性,也能满足业务的需求。
另外,Bigtable还把多个Column Keys并入到被称为Column Family的集合中,并将Column Family作为访问控制的基础单元。我认为,这种方案其实是一种事务(Transaction)的实现方案。传统的事务以行为基本操作单位,在读写时对行上锁以实现隔离,而Bigtable则是以Column Family为单位,这里的访问控制其实就是锁的思想。
相关组件
在介绍系统的整体架构之前,我们要对Bigtable用到的两个重要组件有一些了解。由于Bigtable是分布式的数据库,在节点之间的协调上需要额外的处理,这里,Bigtable使用了Google内部的Chubby。我们可以把Chubby看做是Zookeeper,因为Zookeeper本质也就是Chubby的开源版本。另一方面,为了加快数据的查找和存储效率,Bigtable在存储数据之前都进行了排序,而此处用到的存储文件文论称之为SSTable(Sorted String Table)。
在Bigtable中,由于单个表(Table)存储的数据可能相当地多,那么读写的效率就会十分低下,于是Bigtable将Table分割为固定大小的Tablet,将其作为数据存储和查找的基本单位。每当Table增加了这里要说明的是,tablet是数据存储的基本单元,是用户感知不到的。而Column Family则是访问的基本单元,是编程时指定的,两者一前一后,不是一个概念。
Tablet 定位
因为是在分布式系统中,那么每个Tablet所在的机器不同,需要记录相关信息(METADATA)对其进行管理。而存储这些METADATA又需要分布式的系统,所以Bigtable又将这些METADATA的METADATA记录在一个文件中,并将这个文件的位置保存在Chubby中。总结一下,Bigtable有以下三层结构: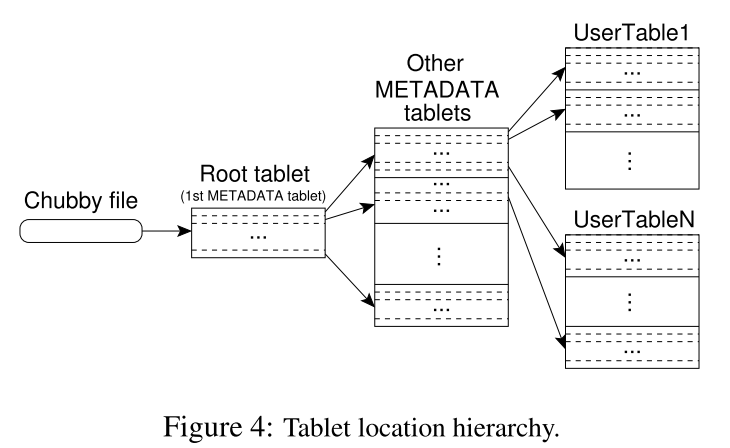
- 在Chubby中保存着Root Tablet的位置
- Root Tablet中保存着METADATA Table中所有 Tablet 的位置
- METADATA Table中保存着所有存储数据的Tablet的位置
这其中有几点值得注意。由于Root Tablet的特殊性,哪怕它的数据量再大,它也不允许被分割。METADATA tables被读取到内存中以加快速度,其中存储的是以开始和结尾的Row Key作为键,tablet位置作为值的映射。
如果客户端希望读取特定的数据,那么它会以此读取Chubby中的文件,Root Tablet,METADATA Tablet,最后读取存储改数据的Tablet。同时,为了加快读取的速度,它会将这些信息缓存到本地,直到信息失效。
Tablet分配
在谈Table分配之前,论文先讨论了怎么处理成员变更的问题。类似于GFS,Bigtable使用Master节点来管理这些相关的事情。
首先,Bigtable使用Chubby来检测Tablet Server的变化。这里的操作和Zookeeper的用法类似,当有新节点加入时,它需要在Chubby中新建一个对应的文件,并获取该文件的锁。由于所有的节点在Chubby中都有对应的文件,那么Master可以通过监听Chubby来获取所有Tablet Server的信息。这里有两种节点失效的情况,一种是仅仅回收了锁但是文件还在,这种情况很可能是节点崩溃了。由于节点不能自己退出,所以在Master节点得到该文件的锁后,它会将文件删除,以此表示节点退出。另一种情况是,文件已经被删除,这种情况说明节点是主动退出系统,那么可以直接重新分配Tablet给其他节点即可。
在正常的情况下,系统中会有大量数据写入,Master需要负责将这些数据分配到合适的Tablet Server。Bigtable并没有明确指出分配所使用的的算法,但是它提出了一个要求。为了保证数据的一致性,同一时间,一个 Tablet只能被分配给一个Tablet Server。Master通过向 Tablet Server 发送载入请求来分配 Tablet。如果该载入请求被Tablet Server接收到前Master仍是有效的,那么就可以认为此次 Tablet 分配操作已成功。
在这里,我们还要考虑Master崩溃的情况,论文中描述了Master恢复的步骤如下:
- 在 Chubby 上获取 Master 独有的锁,确保不会有另一个 Master 同时启动
- 从 Chubby 了解在工作的 Tablet Server
- 从各个 Tablet Server 处获取其所负责的 Tablet 列表,并向其表明自己作为新 Master 的身份,确保 Tablet Server 的后续通信能发往这个新 Master
- Master 确保 Root Tablet 及 METADATA 表的 Tablet 已完成分配
- Master 扫描 METADATA 表获取集群中的所有 Tablet,并对未分配的 Tablet 重新进行分配
读写Tablet
上面我们谈了Bigtable的数据模型,如何寻找和分配Tablet,那么数据是怎么以(row,column,time)的格式被组织成Tablet的呢?论文中给出的流程图如下: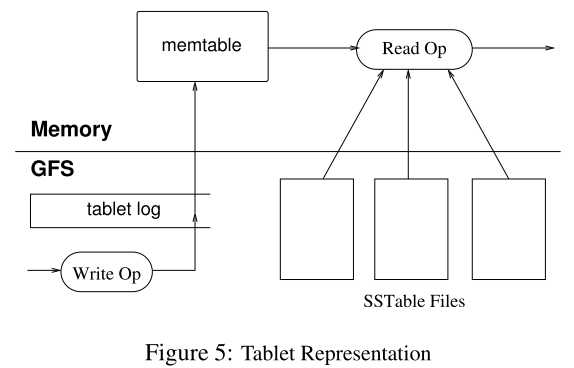
每个Tablet由若干个位于 GFS 上的 SSTable、一个位于内存内的MemTable以及一份Tablet Log组成。
我们来解释一下这张图。为了保证系统可恢复,Google首先使用Table Log(即WAL)将客户端发出的写操作请求记录在磁盘中,那么,一旦系统崩溃,仍然可以从磁盘读取数据,继续执行命令。然后,相关的数据被放入位于内存中的Memtable中,因为内存的速度相当快,那么执行排序等操作就要快得多。当Memtable的大小达到设定的值后,它就会以SSTable的形式被存储到GFS中,这被称为Minor Compaction。
客户端的读操作请求则要综合考虑Memtable和SSTable中的数据,如果Memtable中已经有需要读的数据,就无需读取SSTable。由于Memtable和SSTable都是有序的,所以读取的速度都相当快。
在这里,虽然论文没有明确指出,我认为Memtable和SSTable的大小很可能是64MB。因为GFS将单个Chunk设置为64MB,那么为了最大化地利用磁盘空间,Memtable和SSTable的大小设置为这个值是相当合理的。
由于SSTable中的数据有可能被标记为删除,那么我们需要定期对其进行处理,Bigtable将其称为Major Compaction。在这个过程中,Bigtable会将过期或者被删除的数据删除,并合并多个SSTable。这里似乎和GFS的Garbage Collection有点类似,但是我认为这可能是两个层面的活动。Bigtable清理的是单个Chunk中的数据,而GFS清理的是磁盘中的单个Chunk。
优化
论文中提到,仅靠上述这些方法还不能达到要求的速度,因此,Bigtable还做了一些优化。
第一,为了提高读取的速度,Bigtable使用布隆过滤器判断数据是否在某个SSTable中。
第二,Tablet Server使用Scan Cache缓存SSTable返回的数据,在重复读时提高效率。使用Block Cache缓存从GFS读取的SSTable,这样在读取附近的数据时就无需从磁盘读取。
第三,Bigtable把所有的写入操作都写入到同一个Bigtable Log文件中,而不是每个Server分配一个。同时,因为这个文件相当大,恢复起来很费事。Bigtable会对其进行排序并进行切分,每个Tablet Sever只需读取自己的那部分就可以了。
第四,Bigtable允许针对特定的Column Family生成SSTable,同时进行压缩,以提高读取的效率。
总结
Bigtable重要的贡献是证明了在分布式的系统中,针对超大规模的数据量,使用排序大表的来设计数据库是可行的。这直接带动了LSM Tree的流行,在后来的HBase,LevelDB中都使用了这种方式处理数据。另外,Bigtable系统中Chubby的使用,还告诉工业界分布式协调组件的重要性,这也引导了Zookeeper的设计实现,而其仍然是今天的分布式系统中重要的组件。
3.物联网的数据特点是什么P155
1.数据多态性
2.海量性
3.语义丰富性
4.查询实时性和可靠性
- 数据多态性
物联网支持各种复杂的应用,即使对同一种应用,也会涉及多种多样的数据。从数据本身的属性来分,有描述物体不同特性的数据。例如,一个生态监控环境,既包含温度、湿度和光照度等物理数据,又包括含 O2和 CO2浓度等化学数据,还包括细菌数和植被等生物数据。从数据的基本格式来分,有数据(如数值型、字符型等表达形式)格式、科学文本格式以及可扩展标记语言( Extensible Markup Language,XML)格式等。从数据的结构来分,有结构化数据(如标准的数据记录)和非结构化数据(如视频、音频等多媒体数据)。从数据的语义来分,有采集的底层原始数据,也有经过聚合后的高层概括性数据。
数据多态性必定导致数据的异构性:①描述同一个实体的数据具有不同的格式,例如,名字是全称还是缩写,取值的单位和精度不同;②数据本身不一致,例如,由于观测仪器不同,对于同样的观测目标也会得到不同的观测值。同时,描述实体的数据,可能是不断变化的,具有显著的动态性。物联网中,经常发生设备的加入、删除、移动等情况,因此,由设备采集或者设备间进行交互的数据,也处于不断变化之中。语义上的歧义、数据测量的误差以及数据的动态变化,进一步导致了部分数据存在不确定性。
- 海量性
物联网是由数十亿或数万亿个无线识别的物体彼此连接和整合而成的动态网络,这些数量庞大的智能设备进行实时数据采集和彼此之间信息交互,产生了巨大的数据量。因此,需要存储、处理的数据非常巨大。例如,在一个物联网支持的超市物流系统中,如果需要跟踪1000万件物品的位置、状态等信息,假设每天读取10次,每次100个字节,那么,一天的数据量为10 GB,一年的数据量为3.65 TB。如果考虑一个大型的智能交通或生态监测等实时监控系统,那么每天需要处理的数据量可达到TB级,一年或多年的历史数据,将达到PB 量级。
另外,物联网中物体的状态数据,通常以流(Stream)的形式实时产生,有些情况中,甚至是高速产生的,如应急处理中的实时监控系统。这种系统,会源源不断地产生大量的实时监测数据,由于数据难以全部保存下来,所以需要在计算机内存中立即进行过滤、处理。
- 语义丰富性
物联网所支持的应用,涉及从底层的设备到高层的控制、决策系统,包含大量显式、隐含的应用语义。对于采集到的各种原始数据,需要经过数据集成和语义融合,以获得具有高层语义的信息。例如,为了判断一名患者是否有脑溢血前兆,除了要采集心电信号、血压值和呼吸状态等实时信息,还要结合病历信息等,进行综合信息处理。通常,物联网中的物体具有时空性,因此数据中必须包含时空信息。例如,智能交通系统,必须知道每辆车的行驶时间、行驶地点等时空信息,以预测车辆的运行轨迹和交通流量的变化。
物联网中连接的实体,还具有大量的背景知识。例如,一件由RFID标识的商品,虽然电子标签只记录了该商品的唯一标识字,但是,该商品的制造商、产地、品名、型号和价格等。大量的元信息,都已经保存在后台数据库中。
- 查询实时性和可靠性
大多数物联网系统的建立,为了支持实时应用,如实时观测、实时监控、实时控制、实时预测,以及时了解物理世界的现况,对物体和环境进行必要的控制和干预。因此,查询处理必须满足实时要求,保证在限定的时间内给出查询结果。另外,由于物联网的复杂性,系统中存在许多不可知因素,更需要保证查询处理的可靠性。对可能出现的错误或系统故障,应具有容错能力,保证查询结果的正确性和可靠性。
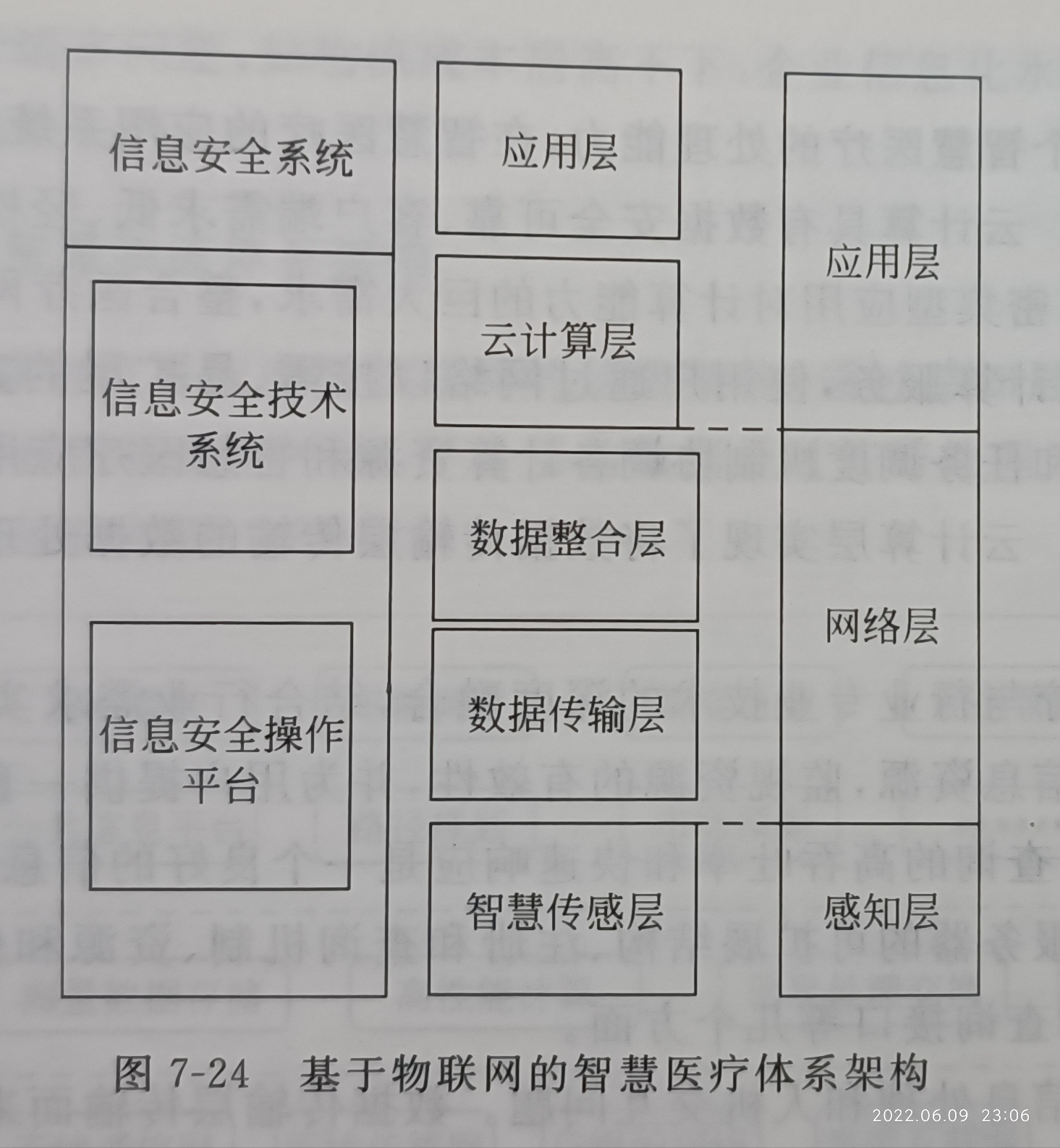
4.感知层有哪些技术P36
1.传感器技术
物联网系统中的海量数据信息来源于终端设备,而终端设备数据来源可归根于传感器,传感器赋予了万物“感官”功能,如人类依靠视觉、听觉、嗅觉、触觉感知周围环境,同样物体通过各种传感器也能感知周围环境。且比人类感知更准确、感知范围更广。例如人类无法通过触觉准确感知某物体具体温度值,也无法感知上千高温,也不能辨别细微的温度变化。
传感器定义为将物理、化学、生物等信息变化按照某些规律转换成电参量(电压、电流、频率、相位、电阻、电容、电感等)变化的一种器件或装置。
传感器一般由敏感元件、转换元件和基本电路组成。敏感元件是直接感知被测量的元件,将被测量变化转换成该敏感材料特性参数的变化。某些敏感元件为无源器件,无法直接输出电压或电流,所以需要通过转换元件特性参数的变化转换成电压或电流。基本电路将转换元件输出的信号进行放大、整形及编码输出。
传感器种类繁多,
按照被测量类型可分为温度传感器、湿度传感器、位移传感器、加速度传感器、压力传感器、流量传感器等。
按照传感器工作原理可分为物理性传感器(基于力、热、声、光、电、磁等效应)、化学性传感器(基于化学反应原理)和生物性传感器(基于霉、抗体、激素等分子识别)。
2.自动识别技术
基本概念
自动识别技术(Automatic Identification and Data Capture)就是应用一定的识别装置,通过被识别物品和识别装置之间的接近活动,自动地获取被识别物品的相关信息,并提供给后台的计算机处理系统来完成相关后续处理的一种技术。自动识别技术将计算机、光、电、通信和网络技术融为一体,与互联网、移动通信等技术相结合,实现了全球范围内物品的跟踪与信息的共享,从而给物体赋予智能,实现人与物体以及物体与物体之间的沟通和对话。 物联网中非常重要的技术就是自动识别技术,自动识别技术融合了物理世界和信息世界,是物联网区别于其他网络(如:电信网,互联网)最独特的部分。自动识别技术可以对每个物品进行标识和识别,并可以将数据实时更新,是构造全球物品信息实时共享的重要组成部分,是物联网的基石。通俗讲,自动识别技术就是能够让物品“开口说话”的一种技术。
技术分类(按照应用领域和具体特征的分类标准,自动识别技术可以分为如下七种)
条码识别技术
一维条码是由平行排列的宽窄不同的线条和间隔组成的二进制编码。比如:这些线条和间隔根据预定的模式进行排列并且表达相应记号系统的数据项。宽窄不同的线条和间隔的排列次序可以解释成数字或者字母。可以通过光学扫描对一维条码进行阅读,即根据黑色线条和白色间隔对激光的不同反射来识别。二维条码技术是在一维条码无法满足实际应用需求的前提下产生的。比如:由于受信息容量的限制,一维条码通常对物品的标示,而不是对物品的描述。二维条码能够在横向和纵向两个方向同时表达信息,因此能在很小的面积内表达大量的信息。
生物识别技术
指通过获取和分析人体的身体和行为特征来实现人的身份的自动鉴别。 生物特征分为物理特征和行为特点两类。指通过获取和分析人体的身体和行为特征来实现人的身份的自动鉴别。
生物特征分为物理特征和行为特点两类。
物理特征:包括指纹、掌形、眼睛(视网膜和虹膜)、人体气味、脸型、皮肤毛孔、手腕、手的血管纹理和DNA等;
行为特点包括:签名、语音、行走的步态、击打键盘的力度等。如:声音识别技术,人脸识别技术,指纹识别技术。
图像识别技术
在人类认知的过程中,图形识别指图形刺激作用于感觉器官,人们进而辨认出该图像是什么的过程,也叫图像再认。在信息化领域,图像识别,是利用计算机对图像进行处理、分析和理解,以识别各种不同模式的目标和对象的技术。例如:地理学中指将遥感图像进行分类的技术。图像识别技术的关键信息,既要有当时进入感官(即输入计算机系统)的信息,也要有系统中存储的信息。只有通过存储的信息与当前的信息进行比较的加工过程,才能实现对图像的再认。
磁卡识别技术
磁卡是一种磁记录介质卡片,由高强度、高耐温的塑料或纸质涂覆塑料制成,能防潮、耐磨且有一定的柔韧性,携带方便、使用较为稳定可靠。磁条记录信息的方法是变化磁的极性,在磁性氧化的地方具有相反的极性,识别器才能够在磁条内分辨到这种磁性变化,这个过程被称作磁变。一部解码器可以识读到磁性变化,并将它们转换回字母或数字的形式,以便由一部计算机来处理。磁卡技术能够在小范围内存储较大数量的信息,在磁条上的信息可以被重写或更改。
IC卡识别技术
IC卡即集成电路卡,是继磁卡之后出现的又一种信息载体。IC卡通过卡里的集成电路存储信息,采用射频技术与支持IC卡的读卡器进行通讯。射频读写器向IC卡发一组固定频率的电磁波,卡片内有一个LC串联谐振电路,其频率与读写器发射的频率相同,这样在电磁波激励下,LC谐振电路产生共振,从而使电容内有了电荷;在这个电容的另一端,接有一个单向导通的电子泵,将电容内的电荷送到另一个电容内存储,当所积累的电荷达到2 V时,此电容可作为电源为其它电路提供工作电压,将卡内数据发射出去或接受读写器的数据。按读取界面将IC卡分为下面两种。接触式IC卡,该类卡通过IC卡读写设备的触点与IC卡的触点接触后进行数据的读写。国际标准ISO7816对此类卡的机械特性、电器特性等进行了严格的规定。非接触式IC卡,该类卡与IC卡读取设备无电路接触,通过非接触式的读写技术进行读写(例如光或无线技术)。卡内所嵌芯片除了CPU、逻辑单元、存储单元外,增加了射频收发电路。国际标准ISO10536系列阐述了对非接触式IC卡的规定。该类卡一般用在使用频繁、信息量相对较少、可靠性要求较高的场合。
光学字符识别技术(OCR)
OCR(Optical Character Recognition),是属于图形识别的一项技术 。其目的就是要让计算机知道它到底看到了什么,尤其是文字资料。针对印刷体字符(比如一本纸质的书),采用光学的方式将文档资料转换成为原始资料黑白点阵的图像文件,然后通过识别软件将图像中的文字转换成文本格式,以便文字处理软件进一步编辑加工的系统技术。一个OCR识别系统,从影像到结果输出,必须经过影像输入、影像预处理、文字特征抽取、比对识别、最后经人工校正将认错的文字更正,最后将结果输出。
射频识别技术(RFID)
射频识别技术是通过无线电波进行数据传递的自动识别技术,是一种非接触式的自动识别技术。它通过射频信号自动识别目标对象并获取相关数据,识别工作无需人工干预,可工作于各种恶劣环境。与条码识别、磁卡识别技术和IC卡识别技术等相比,它以特有的无接触、抗干扰能力强、可同时识别多个物品等优点,逐渐成为自动识别中最优秀的和应用的领域最广泛的技术之一,是最重要的自动识别技术。
3.RFID技术
射频识别技术(RFID),是20世纪80年代发展起来的一种新兴自动识别技术,射频识别技术是一项利用射频信号通过空间耦合(交变磁场或电磁场)实现无接触信息传递并通过所传递的信息达到识别目的的技术。 RFID是一种简单的无线系统,只有两个基本器件,该系统用于控制、检测和跟踪物体。系统由一个询问器(或阅读器)和很多应答器(或标签)组成。
射频识别技术(RFID)
技术
最初在技术领域,应答器是指能够传输信息回复信息的电子模块,近些年,由于射频技术发展迅猛,应答器有了新的说法和含义,又被叫做智能标签或标签。RFID电子电梯合格证的阅读器(读写器)通过天线与RFID电子标签进行无线通信,可以实现对标签识别码和内存数据的读出或写入操作。典型的阅读器包含有高频模块(发送器和接收器)、控制单元以及阅读器天线。 RFID射频识别是一种非接触式的自动识别技术,它通过射频信号自动识别目标对象并获取相关数据,识别工作无需人工干预,可工作于各种恶劣环境。RFID技术可识别高速运动物体并可同时识别多个标签,操作快捷方便。 标签(Tag):由耦合元件及芯片组成,每个标签具有唯一的电子编码,附着在物体上标识目标对象。 阅读器(Reader):读取(有时还可以写入)标签信息的设备,可设计为手持式rfid读写器(如:C5000W)或固定式读写器; 天线(Antenna):在标签和读取器间传递射频信号。
工作原理
标签进入磁场后,接收解读器发出的射频信号,凭借感应电流所获得的能量发送出存储在芯片中的产品信息(Passive Tag,无源标签或被动标签),或者由标签主动发送某一频率的信号(Active Tag,有源标签或主动标签),解读器读取信息并解码后,送至中央信息系统进行有关数据处理。 一套完整的RFID系统, 是由阅读器(Reader)与电子标签(TAG)也就是所谓的应答器(Transponder)及应用软件系统三个部份所组成,其工作原理是Reader发射一特定频率的无线电波能量给Transponder,用以驱动Transponder电路将内部的数据送出,此时 Reader便依序接收解读数据, 送给应用程序做相应的处理。 以RFID 卡片阅读器及电子标签之间的通讯及能量感应方式来看大致上可以分成:感应耦合(Inductive Coupling) 及后向散射耦合(BackscatterCoupling)两种。一般低频的RFID大都采用第一种式,而较高频大多采用第二种方式。 阅读器根据使用的结构和技术不同可以是读或读/写装置,是RFID系统信息控制和处理中心。阅读器通常由耦合模块、收发模块、控制模块和接口单元组成。阅读器和应答器之间一般采用半双工通信方式进行信息交换,同时阅读器通过耦合给无源应答器提供能量和时序。在实际应用中,可进一步通过Ethernet或WLAN等实现对物体识别信息的采集、处理及远程传送等管理功能。应答器是RFID系统的信息载体,目前应答器大多是由耦合原件(线圈、微带天线等)和微芯片组成无源单元。
系统优势
RFID是一项易于操控,简单实用且特别适合用于自动化控制的灵活性应用技术,识别工作无须人工干预,它既可支持只读工作模式也可支持读写工作模式,且无需接触或瞄准;可自由工作在各种恶劣环境下:短距离射频产品不怕油渍、灰尘污染等恶劣的环境,可以替代条码,例如用在工厂的流水线上跟踪物体;长距射频产品多用于交通上,识别距离可达几十米,如自动收费或识别车辆身份等。射频识别系统主要有以下几个方面系统优势: 读取方便快捷:数据的读取无需光源,甚至可以透过外包装来进行。有效识别距离更大,采用自带电池的主动标签时,有效识别距离可达到30米以上; 识别速度快:标签一进入磁场,解读器就可以即时读取其中的信息,而且能够同时处理多个标签,实现批量识别; 数据容量大:数据容量最大的二维条形码(PDF417),最多也只能存储2725个数字;若包含字母,存储量则会更少;RFID标签则可以根据用户的需要扩充到数十K; 使用寿命长,应用范围广:其无线电通信方式,使其可以应用于粉尘、油污等高污染环境和放射性环境,而且其封闭式包装使得其寿命大大超过印刷的条形码; 标签数据可动态更改:利用编程器可以向写入数据,从而赋予RFID标签交互式便携数据文件的功能,而且写入时间相比打印条形码更少; 更好的安全性:不仅可以嵌入或附着在不同形状、类型的产品上,而且可以为标签数据的读写设置密码保护,从而具有更高的安全性; 动态实时通信:标签以与每秒50~100次的频率与解读器进行通信,所以只要RFID标签所附着的物体出现在解读器的有效识别范围内,就可以对其位置进行动态的追踪和监控。
主要应用:
1.图书管理系统的应用 2.瓦斯钢瓶的管理应用 3.服装生产线和物流系统的管理和应用 4.三表预收费系统 5.酒店门锁的管理和应用 6.大型会议人员通道系统 7.固定资产的管理系统 8.医药物流系统的管理和应用 9.智能货架的管理 10.珠宝盘点管理。
4.条形码技术
条形码技术是在计算机应用和实践中产生并发展起来的广泛应用于商业、邮政、图书管理、仓储、工业生产过程控制、交通等领域的一种自动识别技术,具有输入速度快、准确度高、成本低、可靠性强等优点,在当今的自动识别技术中占有重要的地位。
条形码的概念
条形码是由一组规则排列的条、空以及对应的字符组成的标记,“条”指对光线反射率较低的部分,“空”指对光线反射率较高的部分,这些条和空组成的数据表达一定的信息,并能够用特定的设备识读,转换成与计算机兼容的二进制和十进制信息。通常对于每一种物品,它的编码是唯一的,对于普通的一维条形码来说,还要通过数据库建立条形码与商品信息的对应关系,当条形码的数据传到计算机上时,由计算机上的应用程序对数据进行操作和处理。因此,普通的一维条形码在使用过程中仅作为识别信息,它的意义是通过在计算机系统的数据库中提取相应的信息而实现的。
条形码的码制
码制即指条形码条和空的排列规则,常用的一维码的码制包括:EAN码、39码、交叉25码、UPC码、128码、93码,及Codabar(库德巴码)等。
不同的码制有它们各自的应用领域:
EAN 码:是国际通用的符号体系,是一种长度固定、无含意的条形码,所表达的信息全部为数字,主要应用于商品标识
39码和128码:为目前国内企业内部自定义码制,可以根据需要确定条形码的长度和信息,它编码的信息可以是数字,也可以包含字母,主要应用于工业生产线领域、图书管理等
93码:是一种类似于39码的条形码,它的密度较高,能够替代39码
25码:只要应用于包装、运输以及国际航空系统的机票顺序编号等
Codabar码:应用于血库、图书馆、包裹等的跟踪管理
条形码符号的组成
一个完整的条形码的组成次序依次为:静区(前)、起始符、数据符、(中间分割符,主要用于EAN码)、(校验符)、终止符、静区(后),如图: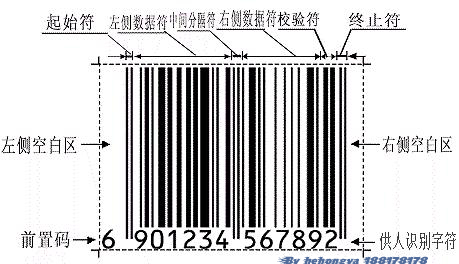
5.射频技术和条形码技术的优缺点
近年来,科技在飞速的发展,RFID电子标签构建智能生活,以独特的优势让生活、工作发生了质的改变,在各个行业中扮演中重要的角色,并且被大量的应用在物流、仓储、图书馆、酒类、高级奢侈品、高档服装、护照以及各类证件等这些领域。
RFID射频技术可以远距离快速识别、读取、并且准确无误,储存容量大,能大量满足各个企业提高货物,提高信息管理的效率,还可以让经销商和制造商快速的信息互联,及时接收和反应信息。而传统的条形码虽然成本低,但是无法识别多个标签、信息容量小、安全性不强等很多的不足之处,我们一起来以下对比图。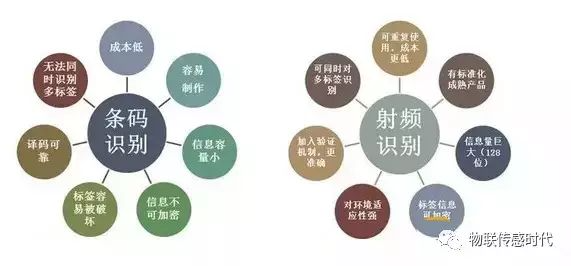
由上图我们可以得出明显的对比: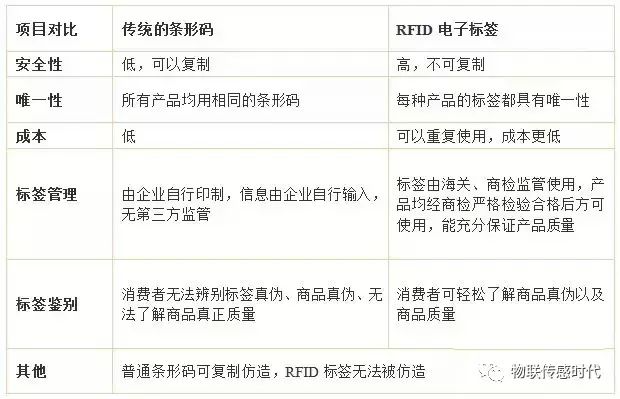
传统的条形码具有一定的局限性,安全性不高、载体是纸张容易受损、储存容量小,相比传统条形码,RFID电子标签具有以下6大优势。
RFID电子标签的6大优势:
1.实现快速扫描
RFID电子标签识别准确无误,识别距离具有灵活性,可同时识别读取多个标签,在没有任何物体覆盖的情况下,RFID标签可以进行穿透性通信和无屏障阅读。
2、数据的记忆容量大
RFID电子标签最大的容量则有数MegaBytes。未来物体所需要携带的资料信息量会不断增多,记忆载体数据容量发展根据市场的相应需求,也正在不断的扩大,目前处于稳居向上的趋势。前景是很可观的。
3.抗污染能力和耐久性
RFID电子标签对水、油和化学制品等物质具有很强抵抗性。另外、RFID标签是将数据储存在芯片中,因此能有效的避免损坏而造成数据流失。
4.可以重复使用
RFID电子标签具有重复新增、修改、删除RFID卷标内储存数据的功能,方便信息的替换和更新。
5.体积小型化、形状多样化
RFID电子标签不受形状或尺寸大小的限制,所以不需要为了读取精确度而配合纸张的固定和印刷品质。此外,RFID标签也正在往小型化和多样化的发展,以适用于更多不同的产品。
6.安全性
RFID电子标签承载的是电子式信息,其数据内容是经由密码保护,安全性极强,该内容不易被伪造及变造、盗取等。
RFID电子标签以独特的优势备受瞩目,被各个行业广泛的应用。
常用自动识别技术的属性比较
| 系统参数 | 条形码 | 光学字符 | 生物识别 | 磁卡 | 接触式IC卡 | 射频识别 |
|---|---|---|---|---|---|---|
| 信息载体 | 纸、塑料薄膜、金 属表面 |
物质表面 | | | 磁性物质(磁卡) | EEPROM | EEPROM |
| 典型的字节长度 | 1~100 | 1~100 | | | 16~64K | 16~64K | 16~64K |
| 机器识别效果 | 好 | 好 | 费时间 | 好 | 好 | 好 |
| 读取方式 | CCD/激光束扫描 | 光电转换 | 机器识别 | 电磁转换 | 电擦写 | 无线通信 |
| 读写性能 | 读 | 读 | 读 | 读/写 | 读/写 | 读/写 |
| 人工识别性 | 受约束 | 简单 | 不可 | 不可 | 不可 | 不可 |
| 系统参数 | 条形码 | 光学字符 | 生物识别 | 磁卡 | 接触式IC卡 | 射频识别 |
|---|---|---|---|---|---|---|
| 信息载体 | 纸、塑料薄膜、金 属表面 |
物质表面 | | | 磁性物质(磁卡) | EEPROM | EEPROM |
| 典型的字节长度 | 1~100 | 1~100 | | | 16~64K | 16~64K | 16~64K |
| 机器识别效果 | 好 | 好 | 费时间 | 好 | 好 | 好 |
| 读取方式 | CCD/激光束扫描 | 光电转换 | 机器识别 | 电磁转换 | 电擦写 | 无线通信 |
| 读写性能 | 读 | 读 | 读 | 读/写 | 读/写 | 读/写 |
| 人工识别性 | 受约束 | 简单 | 不可 | 不可 | 不可 | 不可 |
| 系统参数 | 条形码 | 光学字符 | 生物识别 | 磁卡 | 接触式IC卡 | 射频识别 |
| 信息载体 | 纸、塑料薄膜、金 属表面 |
物质表面 | | | 磁性物质(磁卡) | EEPROM | EEPROM |
| 典型的字节长度 | 1~100 | 1~100 | | | 16~64K | 16~64K | 16~64K |
| 机器识别效果 | 好 | 好 | 费时间 | 好 | 好 | 好 |
| 读取方式 | CCD/激光束扫描 | 光电转换 | 机器识别 | 电磁转换 | 电擦写 | 无线通信 |
| 读写性能 | 读 | 读 | 读 | 读/写 | 读/写 | 读/写 |
| 人工识别性 | 受约束 | 简单 | 不可 | 不可 | 不可 | 不可 |
设计题
P225
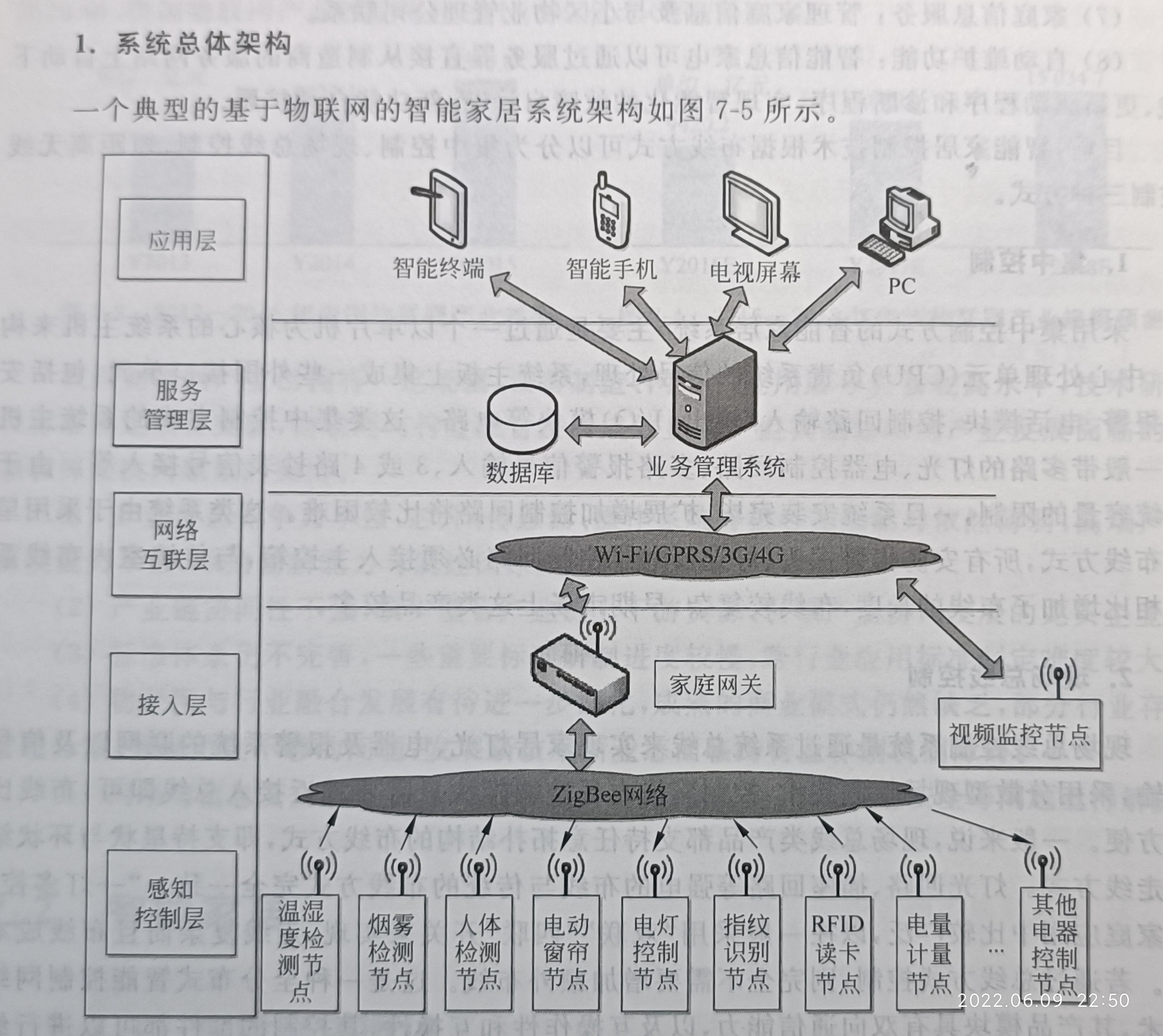
P231
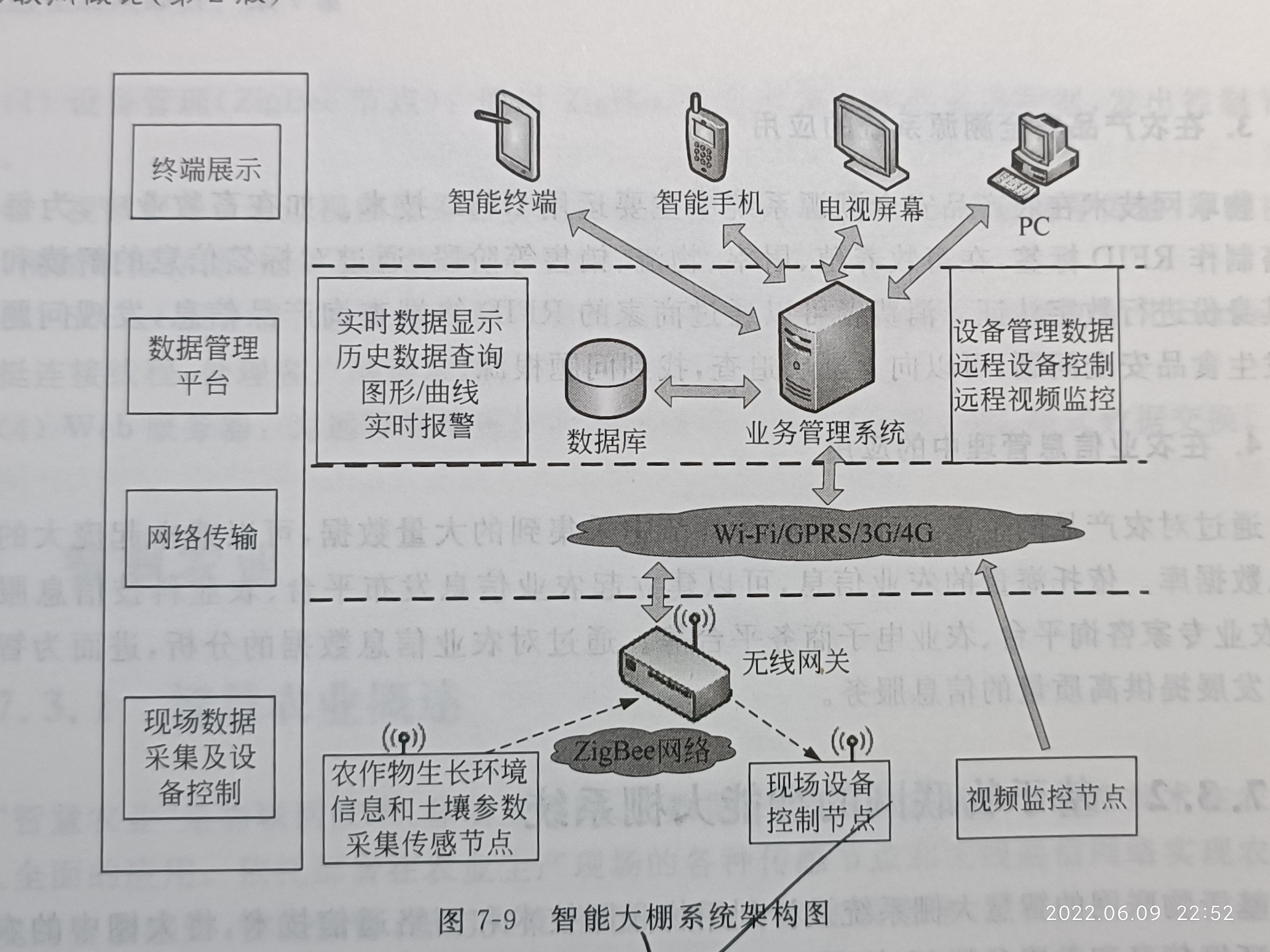
P233
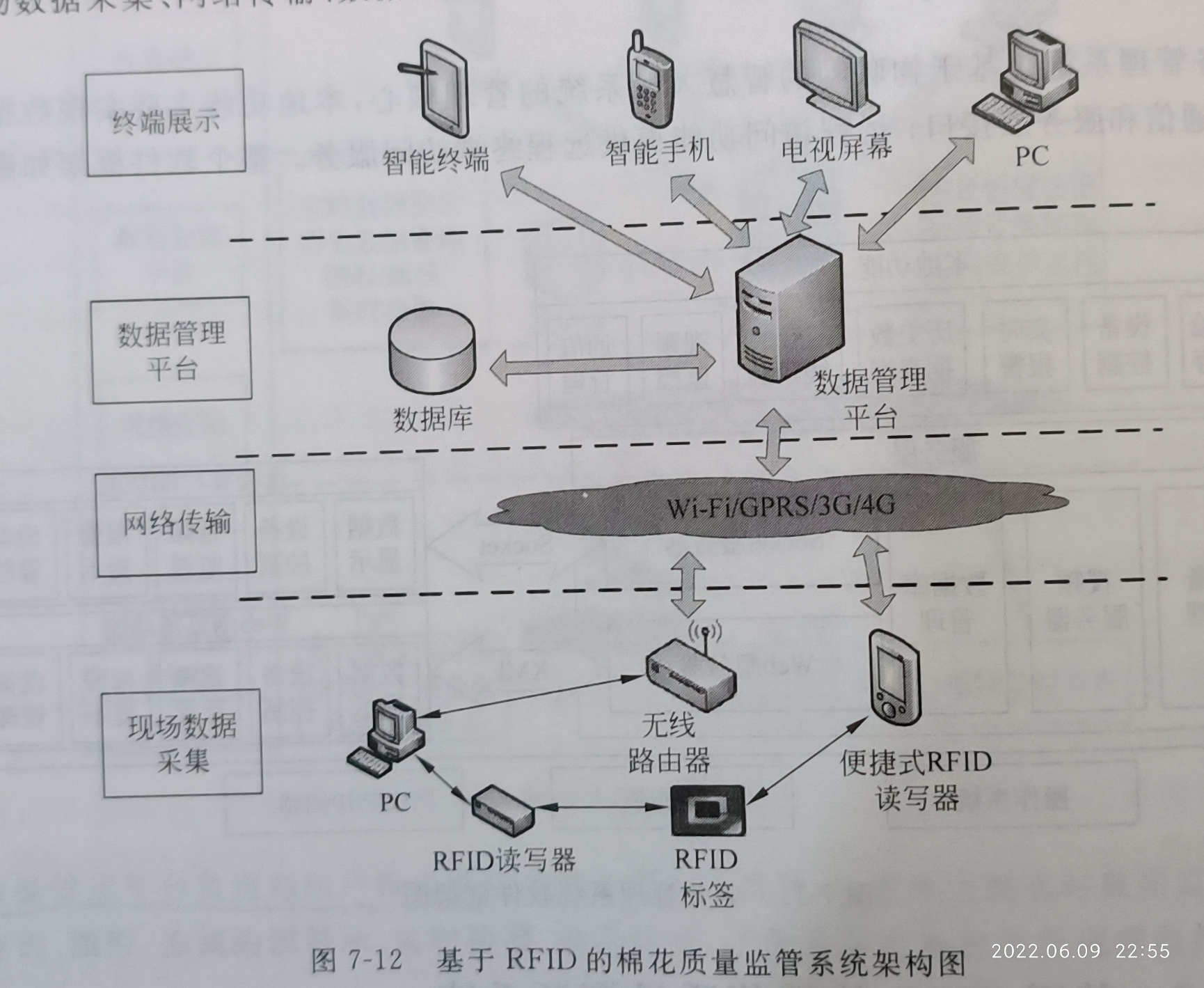
P237
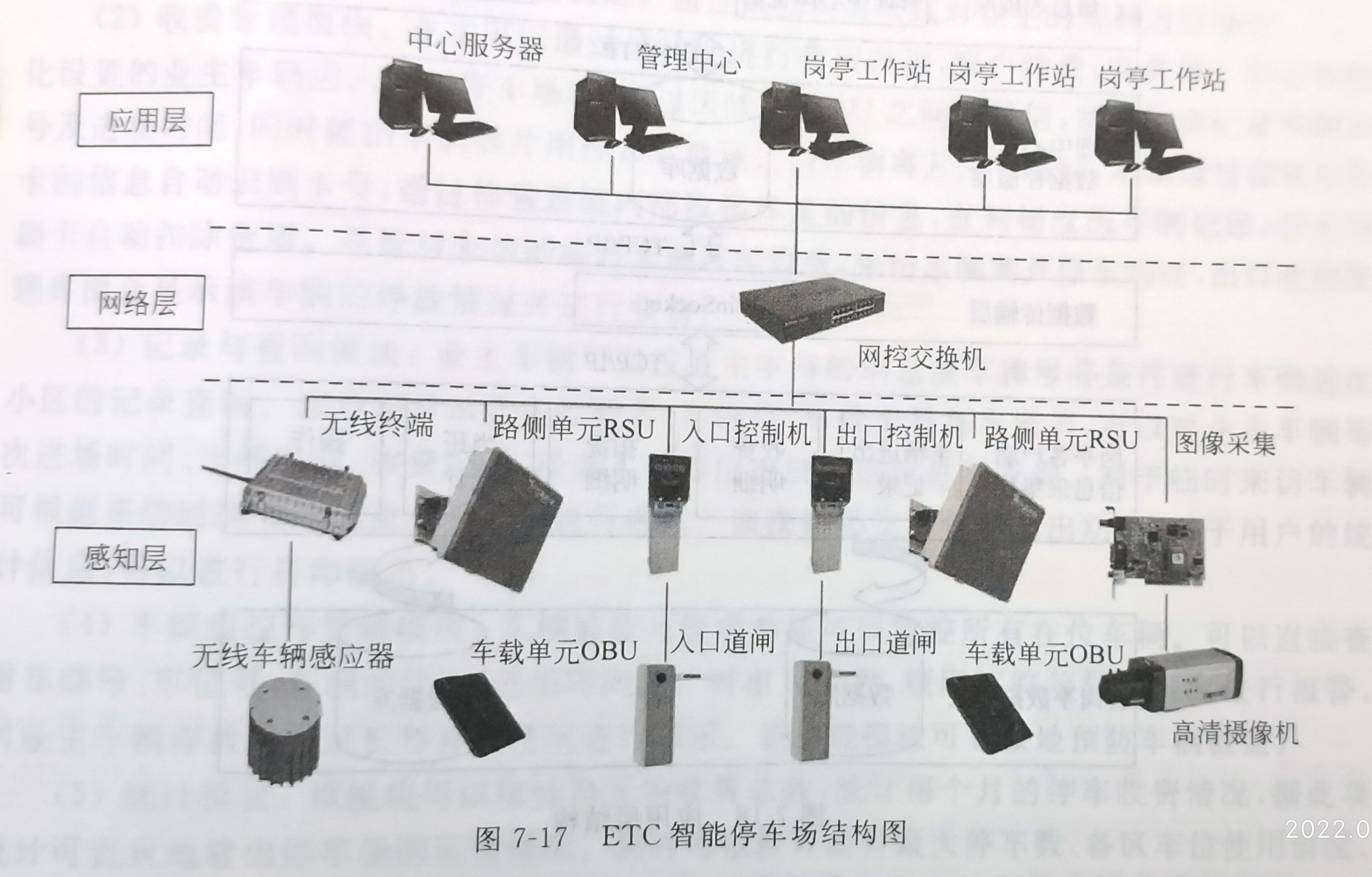
P241
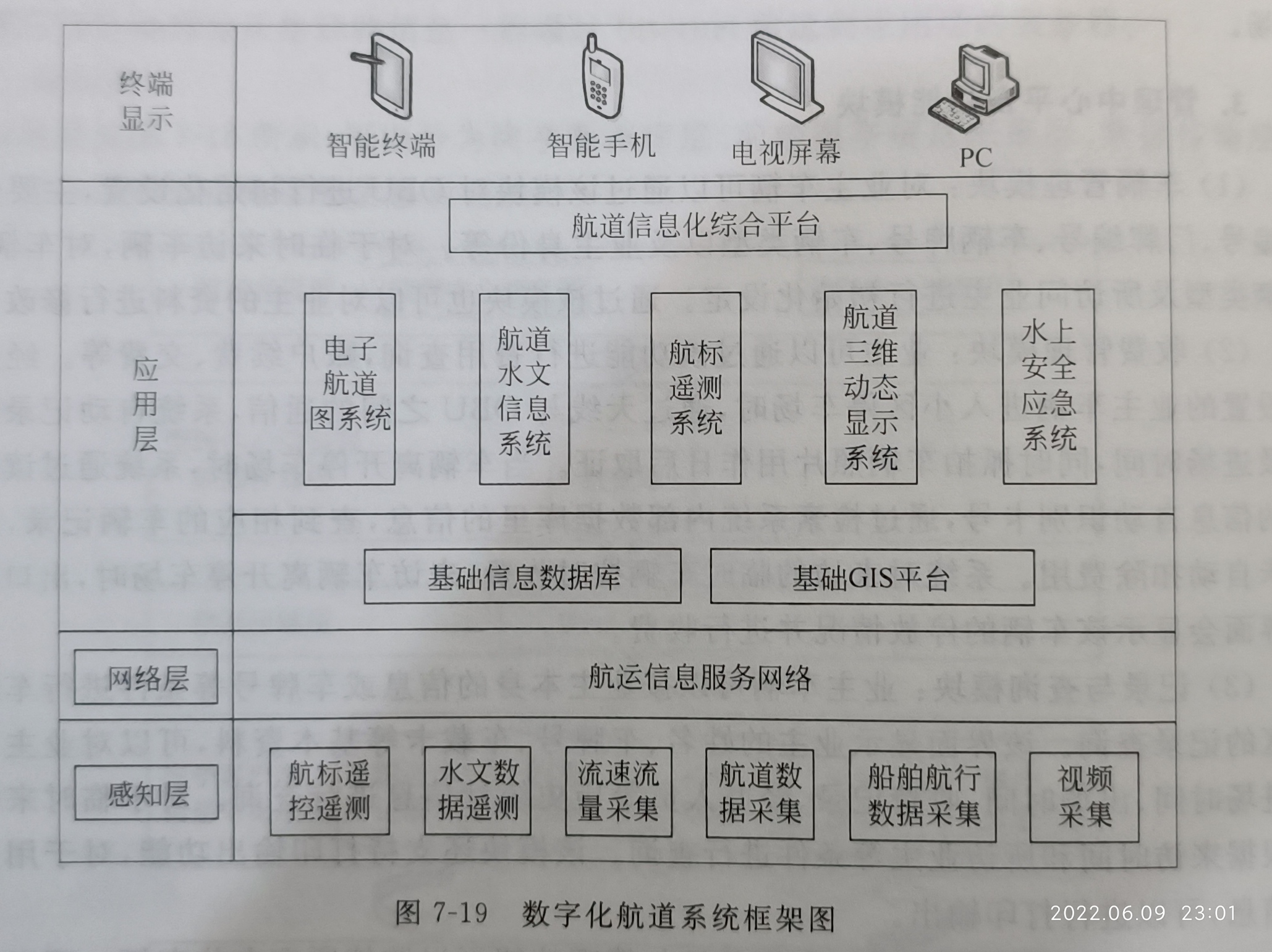
P247
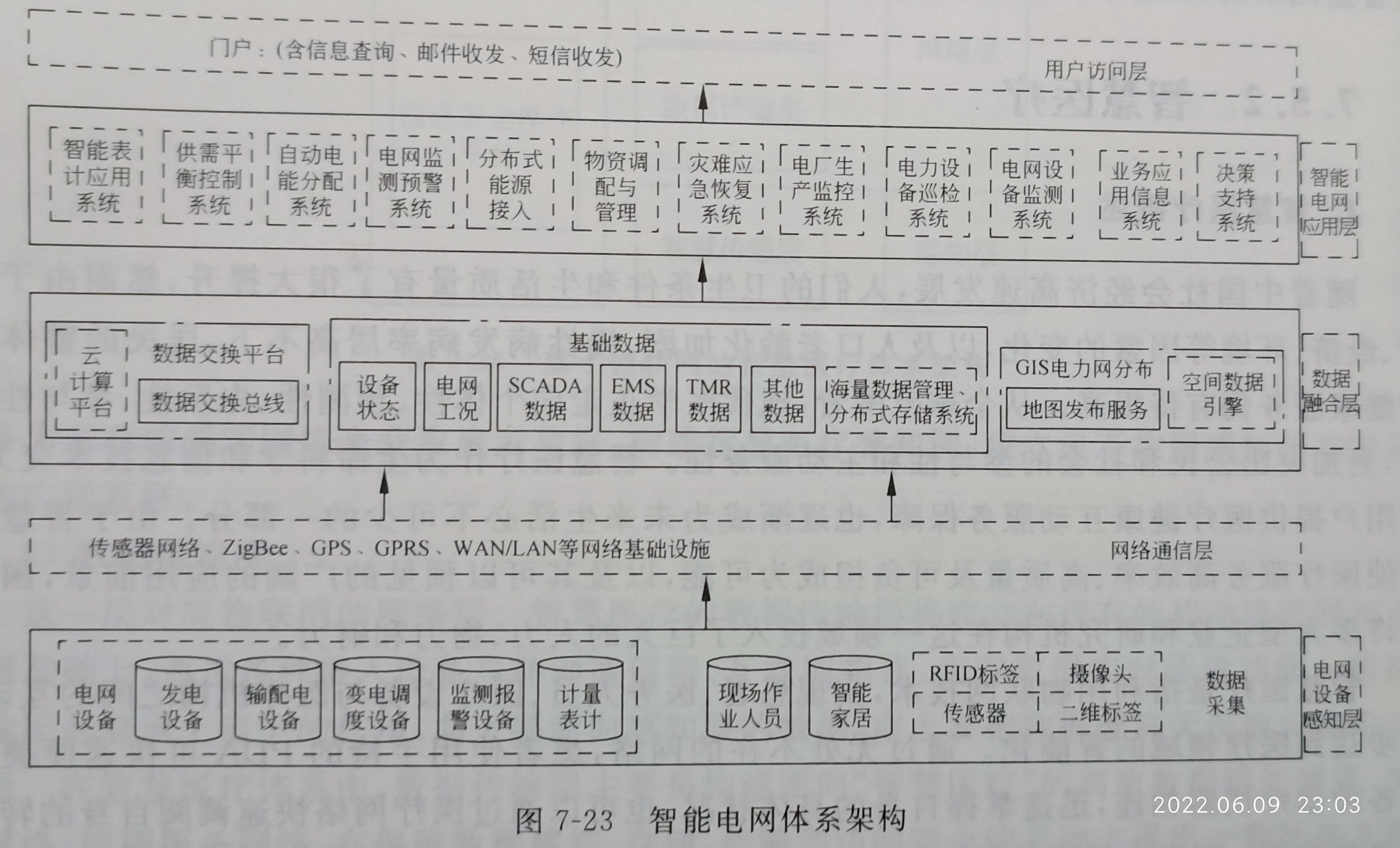
P249
P251

zigbee细节
Zigbee是一种新兴的短距离、低速率无线网络技术,它是一种介于无线标记技术和蓝牙之间的技术方案。它有自己的无线电标准,在数千个微小的传感器之间相互协调实现通信。这些传感器只需要很少的能量以接力的方式通过无线电波将数据从个传感器传到另一个传感器,所以它们的通信效率非常高。
Zigbee的基础是IEEE802.15.4这是EEE无线个人局域网(PAN, Personal area network)工作组的一项标准,被称作IEEE802.15.4( Zigbee)技术标准。
ZigBee技术优点
1、低功耗:工作模式下,ZigBee技术的传输速率低,传输数据量很小,因此信号的收发时间很短。其次,在非工作模式情况下,ZigBee的节点处于休眠状态。设备搜索延迟一般为30ms,休眠激活时延为15ms,活动设备接入信道时延为15 ms。由于工作时间较短,收发信息功耗较低且采用了休眠模式,使得ZigBee节点非常省电。ZigBee节点的电池工作时间可以长达6个月到2年左右,对于某些占空比(工作时间/(工作时间+休眠时间))小于1%的应用,电池的寿命甚至可以超过十年。相比较蓝牙仅能工作数周,WIFI仅可工作数小时。
2、低成本:通过大幅简化协议,降低了对节点存储和计算能力的要求,。根据研究以8051的8位微控制器测算,全功能设备需要32K的代码,精简功能只需要4KB的代码,而且ZigBee协议专利免费。
3、低速率:ZigBee工作在20-250kbit/s的较低速率,分别提供250kbit/s(2.4GHz)、40kbit/s(915MHz)和20kbit/s(868MHz)的原始数据吞吐率,能够满足低速率传输数据的应用要求。
4、近距离:ZigBe设备点对点的传输范围一般介于10-100米之间。在增加射频发射功率后,传输范围可增加到1-3km。如果通过路由和节点间的转发,传输距离可以更远。
5、短时延:ZigBee响应速度较快,一般从睡眠转入工作状态只需要15ms。节点连接进入网络只需30ms,进一步节省了电能。相比较蓝牙需要3-10秒,WIFI需要3秒。
6、网络容量大:ZigBee低速率、低功耗和短距离传输的特点使得它非常适宜支持简单器件。ZigBee定义了两种器件:全功能器件(FFD)和简化功能器件(RFD)。对于全功能器件,要求它支持所有的49个参数。而对于简化功能器件,在最小配置时只要求他支持38个参数。一个全功能器件可以与简化功能器件和其他全功能器件通话, 可以按3种方式工作,分别是个域网协调器、协调器或器件。而简化功能器件只能与全功能器件通话,仅用于非常简单的应用。一个ZigBee的网络节点最多包括有255个ZigBee网络节点,其中有一个是主控(Master)设备,其余则是从属(Slove)设备。若是通过网络协调器(Network Coordinator),整个网络可以支持超过64000个ZigBee网络节点,再加上各个网络协调器可以相互连接,整个ZigBee的网络节点的数目将是十分可观。
7、高安全:ZigBee提供了数据完整性检查和鉴权功能。在数据传输过程中提供了三级安全性。第一级实际是无安全方式,对于某种应用,如果安全并不重要或者上层已经提供了足够的安全保护,器件就可以选择这种方式来转移数据。对于第二级的安全级别,器件可以使用接入控制清单(ACL)来防止非法器件来获取数据,在这一级不采取加密措施。第三级安全级别在数据传输过程中,采用AES的对称密码。AES可以用来保护数据净荷和防止攻击者冒充合法用户。
8、免执照频段:ZigBee设备物理层采用工业、科学、医疗(ISM)频段。
9、数据传输可靠:ZigBee的媒质传入控制层(MAC层)采用talk-when-ready的碰撞避免机制。在这种完全确认的数据传输机制下,当有数据传送需求时则立刻发送,发送的每个数据分组都必须等待接收方的确认消息,并进行确认信息回复。若没有得到确认信息的回复就表示发生了冲突,将重传一次。采用这种方法可以提高系统信息传送的可靠性。ZigBee为需要固定带宽的通信业务预留了专用时隙,避免了发送数据时竞争和冲突。同时,ZigBee针对时延敏感的应用做了优化,通信时延和休眠状态激活的时延都非常短。
ZigBee技术缺点
1、成本:目前ZIGBEE芯片出货量比较大的TI公司,芯片其成本均在2~3美金左右,再考虑到其他外围器件和相关2.4G射频器件,成本难以低于10美金,针对智能家居这种成本敏感而有需要大量节点的家用设备,其成本颇为尴尬。
2、通信稳定性:目前国内Zigbee技术主要采用ISM频段中的2.5G频率,其衍射能力弱,穿墙能力弱。家居环境中,即使是一扇门,一扇窗,一堵非承重墙,也会让信号大打折扣。当然,有些厂家会使用射频功放,对2.5G信号进行放大,但是这样会造成额外的辐射污染,同时也和ZIGBEE低功耗,节能的初衷背道而驰。
3、自组网能力:Zigbee技术的主要特点是支持自组网能力强,自恢复能力强,因此,对于井下定位,停车场车位定位,室外温湿度采集,污染采集等应用非常具有吸引力。然而,对于智能家居的应用场景中,开关,插座,窗帘的位置一旦固定,一直不变,自组网的优点也就不复存在,但是自组网所耗费的时间和资源却依旧高昂。
总结
Zigbee是一种新兴的专为低速率无线个域网(LR-WPAN)而设计的低成本、低功耗的短距离无线通信协议,能够广泛的应用于军事、工业、智能家居等领域。但由于Zigbee技术出现较晚,其规范及应用仍在不断的完善和发展之中。
北斗
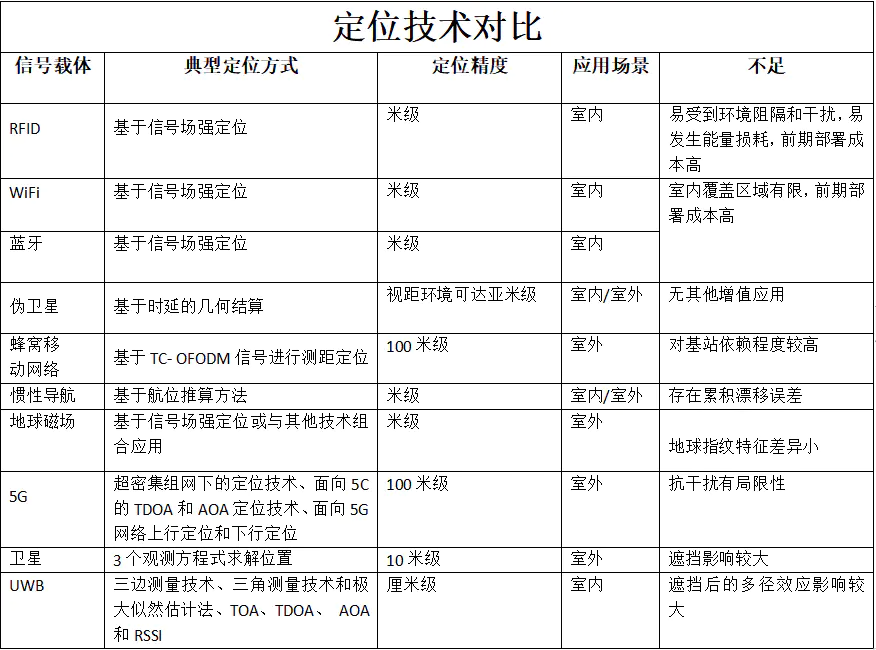
RFID
IEEE 802.11
其他知识
物联网概念
国际电信联盟ITU互联网报告,对物联网做了如下定义:是通过二维码识读设备,射频识别设备,红外遥感器,全球定位系统和激光扫描器等信息传感设备,按照约定的协议,把任何物品与互联网相连接,进行信息交换和通信,以实现智能化识别,定位,跟踪,监控和管理的一种网络。
物联网三大特色

若有收获,就点个赞吧
0 人点赞
