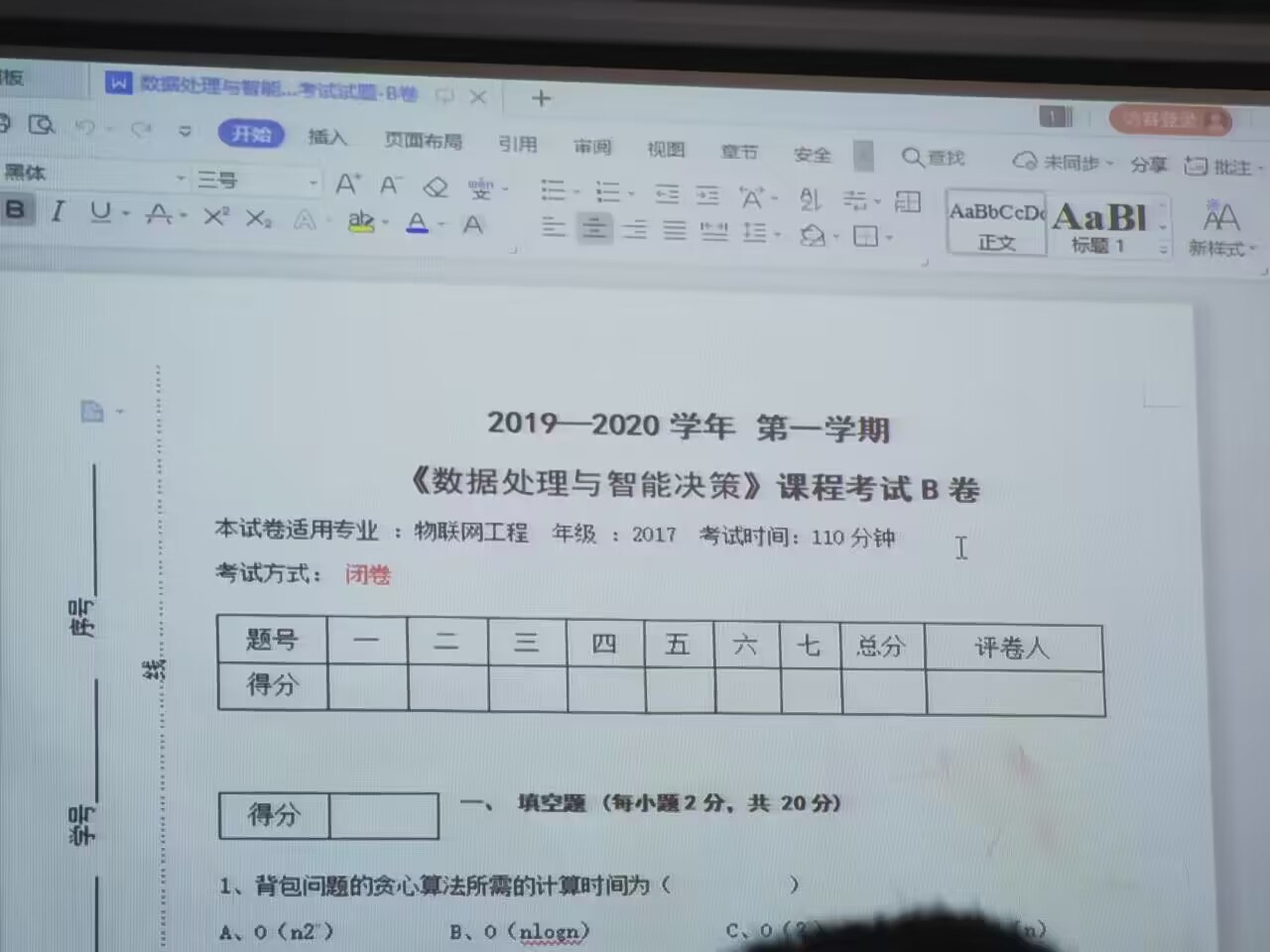
背包问题的贪心算法所需时间为 O(n log n)![7`E`CYK]M48ASNAV](`BH[J_tmb.JPG](https://cdn.nlark.com/yuque/0/2023/jpeg/22782459/1687230671576-f43acffb-6086-4d4f-b072-f5d558e2d855.jpeg#averageHue=%23a7b3bb&clientId=ue3947bbd-0e85-4&from=paste&height=960&id=u2e8b7004&originHeight=960&originWidth=1280&originalType=binary&ratio=1&rotation=0&showTitle=false&size=147772&status=done&style=none&taskId=ubf77680c-6338-4612-b05a-4e02028e37f&title=&width=1280)
- O-1背包问题的回溯算法所需的计算时间为
C、O(2^n)
即选项C。 - 采用最大效益优先搜索方式的算法是
C、贪心法
即选项C。 - 贪心算法与动态规划算法的主要区别是
A、最优子结构
即选项A。 - 实现最大子段和利用的算法是
B、动态规划法
即选项B。 - 优先队列式分支限界法选取扩展结点的原则是
C、结点的优先级
即选项C。 - 背包问题的贪心算法所需的计算时间为
B、O(nlogn)
即选项B。
![0_UMM_~Y5UFPNBVQ5Z]`J]M_tmb.JPG](/uploads/projects/u2304658432@professionalcourses/979a890fe7a12ebb5c15a25b87353074.jpeg)
- 最长公共子序列算法采用的算法是
B、动态规划法
即选项B。 - 实现棋盘覆盖算法利用的算法是
A、分治法
即选项A。 - 下面是贪心算法的基本要素的是
C、贪心选择性质
即选项C。 - 回溯算法的效率不依赖于下列哪些因素
B、计算约束函数的时间
即选项B。 - 下面哪种函数是回溯法中为避免无效搜索采取的策略
B、剪枝函数
即选项B。
![4)G}HXTB6{4VGRQS]PW0`WR_tmb.JPG](/uploads/projects/u2304658432@professionalcourses/fc7d3916ea8b59f68ba00d0d7fed460d.jpeg)
- 机器学习算法的可以分为 监督学习和无监督学习 两种。
- 常用的距离度量方式有 欧氏距离、曼哈顿距离和余弦相似度等。
- 任何可用计算机求解的问题所需的时间都与其 复杂度 有关。
- 问题的 最优子结构 是该问题可用动态规划算法或贪心算法求解的关键特征。
- 以深度优先方式系统搜索问题解的算法称为 深度优先搜索
- 回溯法是一种既带有 深度优先搜索 的搜索算法。
- 微比特的思想是从已有的相互依赖的事情序列中推断出 服务领域。
- 倒排索引排序主要应用于 搜索引擎 等。
- 数据推荐算法一般可以分为 基于内容的推荐算法、协同过滤算法和混合推荐算法 等。
- Sunday算法一种基于大数据的 字符串匹配算法。
3、简答题
- SVM的主要思想是通过找到一个最优超平面,将不同类别的样本分割开,以实现分类的目标。它基于统计学习理论中的结构风险最小化原则,通过最大化训练样本集与超平面的最小间隔,寻找到一条能够最好地将样本分割的超平面。SVM通过在高维特征空间中构造一个分离超平面来进行分类任务,使得该超平面能够最大化分类边界与训练样本的距离,从而使得分类的泛化性能更好。同时,SVM还可以通过使用核函数进行非线性分类,将样本映射到更高维的特征空间中,从而处理非线性可分问题。
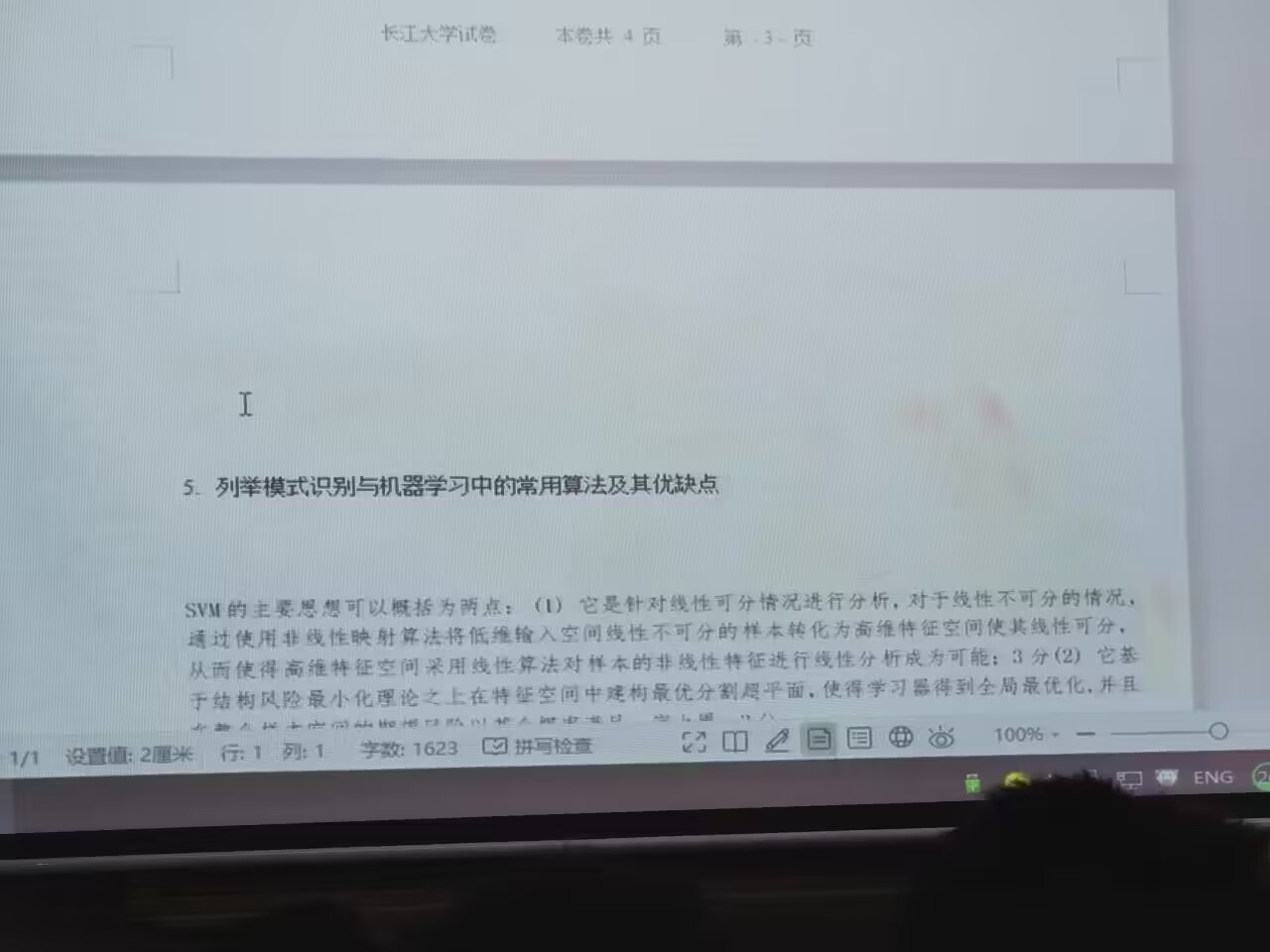
在模式识别与机器学习中,常用的算法及其对应的优缺点如下:
- 支持向量机(Support Vector Machine,SVM):
- 优点:在处理二分类和多分类问题上表现优秀;具有较强的泛化能力;可以通过核函数进行非线性分类。
- 缺点:对大规模数据集的训练和预测速度较慢;对于数据噪声敏感。
- 决策树(Decision Tree):
- 优点:易于理解和解释;可以处理离散和连续特征;能够处理大规模数据集;可用于特征选择。
- 缺点:容易出现过拟合;对于不平衡数据集效果不佳。
- 随机森林(Random Forest):
- 优点:由多个决策树组成的集成算法,具有较高的准确性和鲁棒性;能够处理高维数据;能够避免过拟合问题。
- 缺点:对于噪声较大的数据集可能会导致过拟合;需要较多的计算资源。
- 朴素贝叶斯(Naive Bayes):
- 优点:基于贝叶斯定理,计算简单快速;对小规模数据集表现良好;适用于文本分类等应用。
- 缺点:假设特征之间相互独立,可能不符合实际情况;对于特征相关性较强的数据集效果较差。
- K均值聚类(K-means Clustering):
- 优点:一种基于距离的聚类算法,简单易实现;可以快速对数据进行聚类,适用于大规模数据集。
- 缺点:对于不同形状、密度差异较大的数据集效果不佳;对初始中心点的选择较为敏感。
- 线性回归(Linear Regression):
- 优点:适用于预测连续目标变量的算法,计算简单快速;可通过正则化来解决过拟合问题。
- 缺点:对非线性关系的建模能力较弱。
- 神经网络(Neural Networks):
- 优点:能够适应各种复杂的模式和非线性关系;具有较强的拟合能力。
- 缺点:对于小规模数据集容易过拟合;网络结构和参数调整较为困难。
- 深度学习(Deep Learning):
- 优点:利用深度神经网络进行学习和训练;能够处理大规模、高维度的数据;具有较强的特征提取和表示能力。
- 缺点:对于小规模数据集容易过拟合;需要大量的计算资源和数据支持。
这些算法各有优势和限制,选择合适的算法需要根据具体问题、数据集的特点以及任务的需求来综合考虑。![LS{JV68B`CY6@TBX]@GS_LW_tmb.JPG](/uploads/projects/u2304658432@professionalcourses/1d14655c35fbd6b536a708cde6b9298b.jpeg)
- SVM的主要思想是通过找到一个最优超平面,将不同类别的样本尽可能地分开。具体地,SVM寻找一个能够最大化类别间间隔的超平面,这被称为最大间隔分类器。SVM还引入了核函数来将低维特征映射到高维特征空间,以解决线性不可分的问题。
- 优化问题主要分为线性规划和非线性规划两大类。对于线性规划问题,可以使用遗传算法、蚁群优化算法等进行求解;对于非线性规划问题,可以使用粒子群优化算法、模拟退火算法等进行求解。
- 设计动态规划算法的主要步骤包括:
- 定义子问题:将原问题划分为若干个子问题,确定状态和状态转移方程。
- 确定初始条件:确定初始状态的值或条件。
- 递推求解:根据状态转移方程,从初始状态逐步向后递推,求解每个子问题的最优解。
- 建立最优解表格或递归关系:为了避免重复计算,将小规模子问题的最优解存储在表格中,或者使用递归关系表示最优解。
- 依次填表或递归回溯:根据表格或递归关系,按照自底向上或自顶向下的顺序求解各个子问题的最优解。
- 一些常见的相似度计算算法包括:
- 余弦相似度(Cosine Similarity)
- 欧氏距离(Euclidean Distance)
- 曼哈顿距离(Manhattan Distance)
- Jaccard相似系数
以余弦相似度为例,其计算过程如下:
- 首先计算两个向量的点积。
- 然后计算两个向量的模长乘积。
- 最后将点积除以模长乘积,得到余弦相似度。
余弦相似度常用于文本分类、推荐系统等领域的相似度计算。例如,在一个文本分类任务中,可以将文本样本表示成向量,然后使用余弦相似度来衡量不同文本之间的相似程度。相似度越高,说明两个文本样本越相似。 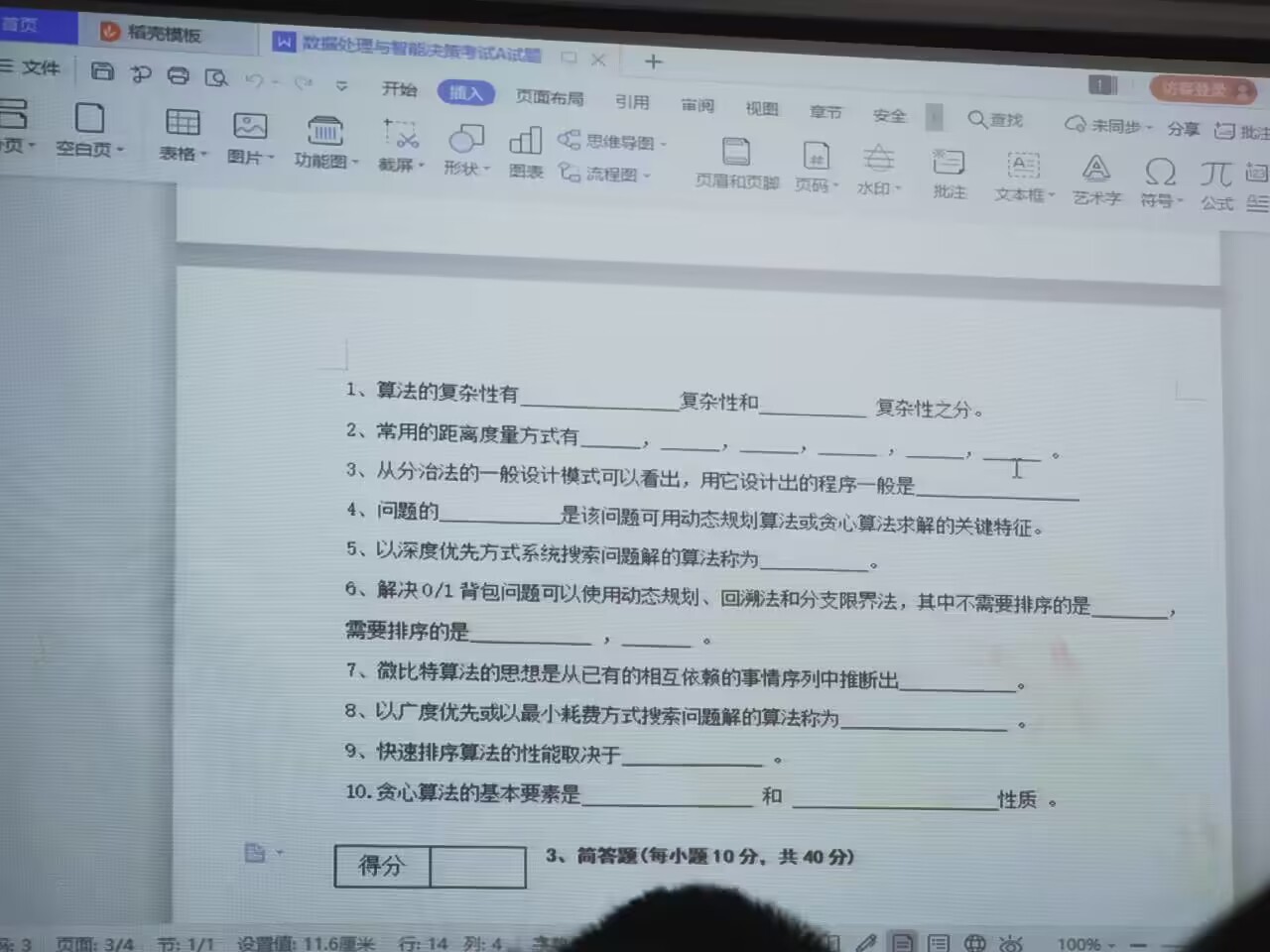
- 算法的复杂性有时间复杂性和空间复杂性之分。
- 常用的距离度量方式有欧几里得距离、曼哈顿距离和闵可夫斯基距离。 所有
- 欧氏距离(Euclidean Distance)
- 曼哈顿距离(Manhattan Distance)
- 切比雪夫距离(Chebyshev Distance)
- 闵可夫斯基距离(Minkowski Distance)
- 马哈拉诺比斯距离(Mahalanobis Distance)
- 汉明距离(Hamming Distance)
- 余弦相似度(Cosine Similarity)
杰卡德相似系数(Jaccard Similarity Coefficient)
从分治法的一般设计模式可以看出,用它设计出的程序一般是递归的。
- 问题的最优子结构是该问题可用动态规划算法或贪心算法求解的关键特征。
- 以深度优先方式系统搜索问题解的算法称为回溯算法。
- 解决0/1背包问题可以使用动态规划、回溯法和分支限界法,其中不需要排序的是动态规划,需要排序的是分支限界法。
- 拓扑排序算法的思想是从已有的相互依赖的事物序列中推断出一个有序的序列。
- 以广度优先或以最小耗费方式搜索问题解的算法称为最优优先搜索算法。
- 快速排序算法的性能取决于划分的选择。
- 贪心算法的基本要素是贪心选择性质和最优子结构性质。
![37}G13I{AYI4332JM14W7F_tmb.JPG
K-means算法和KNN算法都是常用的机器学习算法,但在问题类型、特点和应用方面存在一些差异。
K-means算法:
特点:
- 是一种无监督学习算法,用于聚类问题。
- 通过将数据点划分为k个簇来寻找数据的分布及簇的中心点。
- 采用迭代的方式,通过最小化每个数据点与其所属簇的中心点之间的距离来优化簇的分布。
- 算法的收敛性较好,易于理解和实现。
- 对数据具有假设,即假设数据点在样本空间中的分布具有类似于球状或高斯分布。
异同:
- 相同点:K-means算法与KNN算法都包含“K”这一参数,用于指定簇的数量或邻居的数量。
- 不同点:K-means算法是一种聚类算法,通过数据点之间的距离来寻找簇的中心点;而KNN算法是一种分类或回归算法,通过找到最近的K个邻居来进行预测。
KNN算法:
特点:
- 是一种有监督学习算法,用于分类和回归问题。
- 通过找到最近的K个邻居来进行预测,基于邻居的标签或数值属性。
- 可以适用于多类别分类和回归问题。
- 对数据没有假设,能够适应不同类型的分布和数据特征。
异同:
- 相同点:KNN算法与K-means算法都可以通过距离度量来衡量数据之间的相似性。
- 不同点:KNN算法是一种有监督算法,用于分类和回归问题,通过找到最近的K个邻居来进行预测;而K-means算法是一种无监督学习算法,用于聚类问题,通过生成簇的中心点来划分数据。
![WY{~_2P%I%HZUMVNTV5}39_tmb.JPG
贝叶斯算法是基于贝叶斯定理的统计学算法,用于处理分类问题。它将先验知识和数据进行结合,通过计算后验概率来进行分类预测。
贝叶斯算法的原理:
- 先验概率: 根据已知的先验知识和经验,对类别进行概率上的假设。
- 条件概率: 根据已有的特征和类别标签的数据,计算特征在给定类别下的条件概率。
- 贝叶斯定理: 利用先验概率和条件概率来计算后验概率,即给定特征下某一类别的概率。
在垃圾邮件判断中的应用:
贝叶斯算法可以应用于垃圾邮件判断,即将收到的邮件划分为“垃圾邮件”和“非垃圾邮件”两个类别。下面是一个简单的示例:
假设我们拥有一个已经标记好的邮件数据集,其中包括了邮件的特征(如关键词、发件人等)和对应的标签(垃圾邮件/非垃圾邮件)。现在我们收到了一封新的邮件,要判断它是垃圾邮件还是非垃圾邮件。
首先,我们计算出先验概率:垃圾邮件的概率和非垃圾邮件的概率。假设我们的数据集中有90封垃圾邮件和110封非垃圾邮件,则垃圾邮件的先验概率为P(垃圾邮件) = 90/200,非垃圾邮件的先验概率为P(非垃圾邮件) = 110/200。
然后,我们计算条件概率。对于每个特征,我们计算在某一类别下的条件概率。例如,我们可以计算“垃圾邮件”类别下包含特定关键词的条件概率P(关键词|垃圾邮件),以及“非垃圾邮件”类别下的条件概率P(关键词|非垃圾邮件)。
最后,根据贝叶斯定理,我们可以计算出后验概率。对于新的邮件,分别计算它属于垃圾邮件和非垃圾邮件的后验概率,然后选择具有更高后验概率的类别作为预测结果。
例如,假设我们已经计算出了新邮件属于垃圾邮件的后验概率为0.8,属于非垃圾邮件的后验概率为0.2,则我们可以预测这封邮件是垃圾邮件。
贝叶斯算法在垃圾邮件判断中的应用,通过考虑先验知识和条件概率,能够对新接收的邮件进行分类判断,提高了邮件过滤的准确性。
相似度计算是一种用于比较两个对象之间相似程度的计算方法。以下是几种常用的相似度计算算法:
- 欧氏距离:衡量两个向量之间的距离,计算方法为两个向量对应元素差的平方和的开方。应用于机器学习领域中的聚类算法、特征选择等。
- 余弦相似度:衡量两个向量之间的夹角(余弦值),计算方法为两个向量点积除以两个向量的模的乘积。应用于文本分类、推荐系统等。
- 杰卡德相似系数:用于衡量集合之间的相似性,计算方法为两个集合的交集元素个数除以两个集合的并集元素个数。应用于用户群体相似度分析、社交网络分析等。
- 皮尔逊相关系数:衡量两个变量之间的线性相关程度,计算方法为两个变量的协方差除以两个变量的标准差的乘积。应用于数据分析、推荐系统等。
其中,我将详细描述余弦相似度的过程和应用实例:
余弦相似度是一种常用的相似度计算方法,它通过计算两个向量的夹角(余弦值)来衡量它们的相似程度。具体的计算过程如下:
- 将两个向量表示为向量空间中的向量:将待比较的两个对象(如文本、用户等)表示为特征向量,其中每个特征代表对象的某个属性。
- 计算两个向量的点积:将两个向量的对应元素相乘,并将结果求和,得到两个向量的点积。
- 计算两个向量的模的乘积:分别计算两个向量的模的乘积,即将每个向量的每个元素平方后求和,并对两个向量都进行开放。
- 计算余弦相似度:将步骤2得到的点积除以步骤3得到的模的乘积,得到最终的余弦相似度。
应用实例:假设我们要进行文本分类。我们有一组已标记好的文本数据集,以及一个未标记的待分类的新文本。我们可以将每个文本表示为一个特征向量,其中每个特征代表词汇表中每个词在文本中的出现频率。
例如,我们有两个已标记的文本向量A和B。根据词汇表,向量A为 [1, 2, 0, 1, 0],向量B为 [2, 1, 1, 0, 2]。我们想知道这两个文本向量的相似程度。
首先,计算向量A和向量B的点积为:1_2 + 2_1 + 0_1 + 1_0 + 0*2 = 4。
然后,计算向量A和向量B的模的乘积为:sqrt((1^2 + 2^2 + 0^2 + 1^2 + 0^2) (2^2 + 1^2 + 1^2 + 0^2 + 2^2)) = sqrt(22 10) ≈ 14.83。
最后,计算余弦相似度为:4 / 14.83 ≈ 0.27。
这样,我们就得到了向量A和向量B的余弦相似度为0.27。根据相似度的大小,可以判断它们在某种意义上是相似的或者不相似的。通过比较待分类文本和已标记文本的相似度,可以将其分类到与之相似的类别中,实现文本分类的任务。

若有收获,就点个赞吧
0 人点赞

{kind=link}
{kind=link}