撰文 | 李瑞风、刘玉婷、侯英萍、淦晶波、吴朋泽
翻译 | 苏嘉昱、付云天、李瑞风
摘 要
在真核生物中,染色质会被折叠成复杂的三维结构并在生命活动中动态调控。最近几年,许多研究染色质三维结构的技术纷纷涌现,包括3C(染色质构象捕获,Chromosome Conformation Capture)技术和基于3C的其他技术(Hi-C,ChIA-PET等),使得人们可以研究三维基因组结构改变对基因调控的影响。越来越多的研究揭示三维基因组结构在基因表达和细胞功能调控中有着重要作用。特别地,许多疾病都与遗传变异相关,而大部分变异位于基因组非编码区,因此传统的测序方法很难确定变异导致疾病的具体机制。借助三维基因组技术,我们可以研究疾病中非编码基因组区域的改变对染色质相互作用和对基因表达的影响。在这篇综述中,我们将介绍目前的三维基因组技术,并聚焦于它们在癌症和其他疾病研究中的应用,同时也展望了三维基因组学在临床疾病领域的发展方向。
1
染色质构象捕获技术
染色质构象捕获技术的出现对研究染色质空间结构至关重要。目前在3C和基于3C的技术上的重大突破,使得我们可以更详细地分析基因组的三维结构。在此,我们回顾了捕获染色质相互作用图谱的关键的技术【表1】。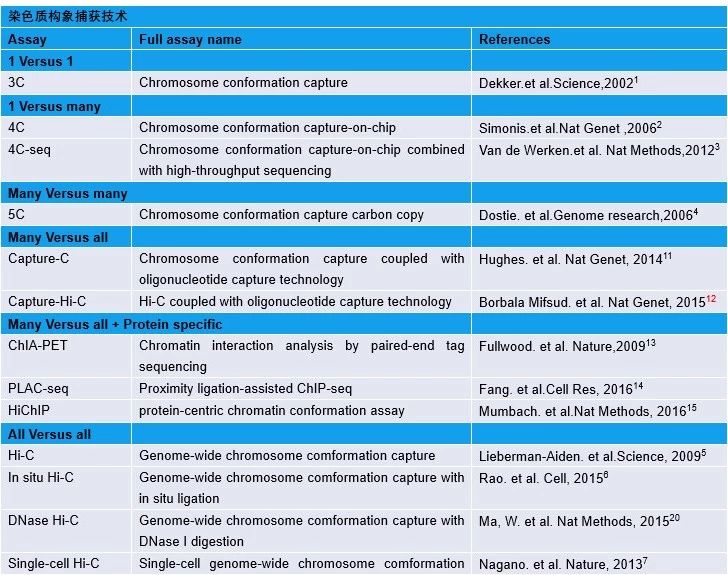
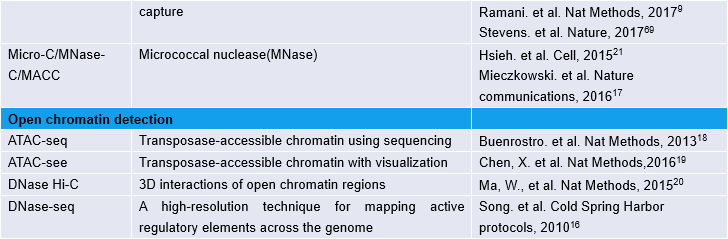
表1:3C和基于3C的技术概览
3C技术1最早由Dekker及其同事于2002年开发。该技术可以捕获两个特定基因组位点之间的长程染色质相互作用。用于3C分析的样品需经历一系列的实验步骤处理(图1),包括甲醛固定以便原位交联(in situ cross-linking)、限制性酶酶切、空间位置接近的DNA末端的连接,最后使用两个目标基因组位点的引物进行PCR来识别相互作用。然而,3C技术也有其限制:它只能用于两个预先设计好的基因组位点之间的染色质相互作用分析。2006年,基于3C改进的4C技术被开发出来,被命名为“芯片上的染色质构象捕获”(Chromosome Conformation Capture on a Chip,4C)2,3。利用4C可以检测一个基因组位点对多个基因组位点之间的相互作用。为了建立并行捕获多对多位点间的相互作用的方法,研究者们开发了一种高通量的3C方法,并命名为3C-Carbon Copy(5C)4,用于检测β-珠蛋白基因位点上的顺式和反式染色质相互作用。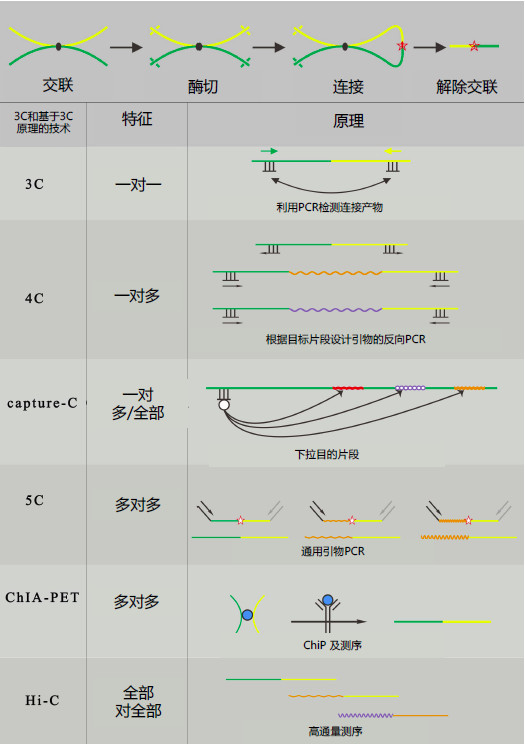
图1:染色质构象捕获技术和三维染色质结构。染色质构象捕获技术(3C)和基于3C的各项技术的实验原理及流程。
为了实现高通量的染色质相互作用分析,Dekker和同事们在2009年又开发了Hi-C,这是一种将DNA酶切连接与大规模测序相结合的方法,用于绘制全基因组水平上染色质互相作用5。2014年,研究人员使用原位Hi-C6技术在9个细胞系中构建了千碱基(kilobase)级别分辨率的染色质相互作用图谱,因而能够检测增强子和启动子之间的染色质环(loops)。最近,单细胞Hi-C的方法7-9揭示了单细胞内的染色质相互作用及这种作用在细胞间的异质性。此外,许多Hi-C分析和可视化的工具已经被开发,以帮助我们分析和解释Hi-C数据【表2】。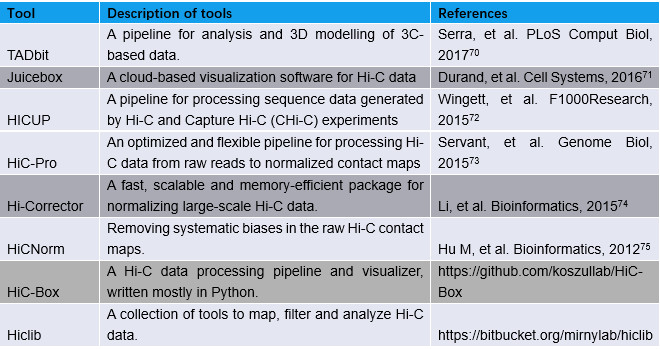
表2:Hi-C数据分析和可视化工具
尽管Hi-C技术是挖掘全基因组水平染色质相互作用信息的强大工具,但由于许多不含染色质相互作用信息的无效测序片段的存在,Hi-C对高通量测序数据的可用率较低 (30%~60%)。靶向染色质捕获技术(T2C)10 和Capture-C技术11将酶切产物和标记有生物素探针杂交,从而富集感兴趣的染色质区域上的染色质互作片段。此外,Capture-Hi-C12技术可实现数百倍的片段富集,极大地提高了对感兴趣染色质区域局部相互作用的检测效率。然而,基于捕获的方法并不能从全基因组水平观察染色质相互作用。
前文所提及的3C,4C,5C到Hi-C,T2C和Capture-Hi-C的技术,并不以捕获由特定蛋白质(如转录因子)所介导的染色质相互作用为目标。为了鉴定这种特定的染色质相互作用,研究者们将3C与染色质免疫沉淀(ChIP)相结合,开发了ChIA-PET13(Chromatin Interaction Analysis by Paired-End Tag)技术。之后为了进一步降低成本、提升方法的灵敏度,研究人员开发了两种策略,PLAC-seq(Proximity Ligation-Assisted ChIP-seq)14 和HiChIP(以蛋白质为中心的染色质构象测定方法,protein-centric chromatin conformation assay)15。相比于ChIA-PET,PLAC-seq显著提高了效率和准确性,而HiChIP则使具有染色质互作信息的reads的产量提高了10倍以上,并使实验所需细胞的数量要求减少了100倍以上。
另一种基于3C的改进方法是,捕获开放区域的染色质间的相互作用。目前,许多核酸酶介导的检测方法,包括DNase-seq16、MNase-seq17、ATAC-seq18和ATAC-see19,正被用于捕获通常为开放染色质的基因调控元件。例如,DNase-seq利用DNase I在开放染色质区域的敏感性来从全基因组中富集这些染色质开放区域,从而获得开放染色质区域的图谱。MNase-seq被用于检测核小体的占有情况(occupancy)和染色质的可接近性(accessibility)。相应地,这些方法被各自改造为能够捕获开放染色质区域之间相互作用的技术。DNase Hi-C20可以用来表征长非编码RNA(lincRNA)的启动子及它们之间的相互作用。Micro-C21方法则使用微球菌核酸酶(MNase)将染色质片段化,并在核小体水平的分辨率下显示染色质构象。
总而言之,自2002年3C技术被发明以来,它已经经历了许多改进,包括3C(一对一位点),4C(一对多位点),5C(多对多位点,高通量),全基因组(Hi-C,Micro-C等)和靶向区域(ChIA-PET,Capture-C,Capture Hi-C)的分析技术。这些技术(如表1所示)极大地推动了基因组空间组织结构的研究。
2
染色质空间结构的新发展
利用基于3C的各种技术,研究人员能够在不同细胞、不同组织上获得染色质结构及相互作用的信息。目前染色质不同层级的结构已经被揭示22,23,比如A / B区块(A/B compartments),平均大小为1Mb的拓扑关联结构域(TADs)24-26,以及结构域中位数大小为185kb的染色质环(loops)6(图2)。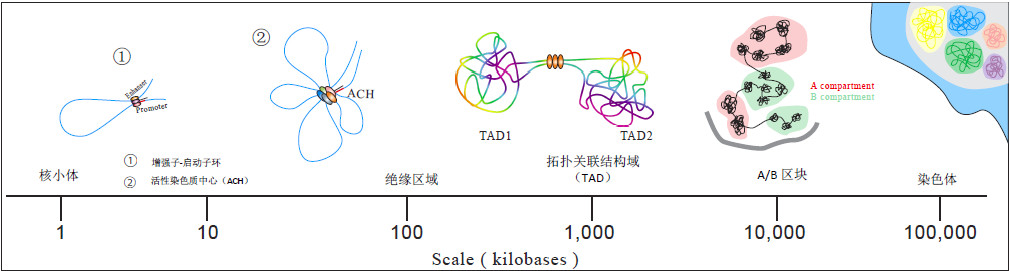
图2:基于3C技术的三维基因组的层次结构。层级结构包括染色质领域(CT),A / B区块(compartment),拓扑关联结构域(TAD)(~100kb-1000kb)。TAD由绝缘区域(Insulated Neighborhood,INs)(平均大小=~200kb)和染色质环(~10kb-500kb)组成。 增强子-启动子相互作用环和活性染色质中心(ACH)被限制在IN内。
一般而言,常染色质和异染色质区域在同一个染色质领域(Chromosome Territory,CT)内往往是空间分离的,染色质被分成A区和B区两个区块(compartment)。A区通常由开放且富含基因的染色质区域组成,而B区则由关闭且缺乏基因的染色质区域组成27。相应地,A区和B区分别对应于更高和更低水平的基因表达。此外,针对高分辨率Hi-C数据的分析还确定了TADs和染色质环(loops)结构。2014年,研究者们报道了多种人类细胞系的全基因组染色质环图谱6。染色质环可以帮助形成增强子-启动子之间的相互作用,并形成由多个增强子及其相互作用的启动子组成的活性染色质中心(active chromatin hub)28。另外,ChIA-PET数据表明了结构蛋白(architectural proteins)在染色质结构形成和调控转录中的重要功能,这些蛋白包括CCCTC结合因子(CTCF)、黏连蛋白和RNA聚合酶II29。染色质空间结构的重要性不仅体现在它们对基因表达的影响上,还体现在这种结构在物种间的保守性上6,30。然而,基因组的结构和功能之间的关系尚未完全了解,需要使用细胞系、组织样本和疾病模型进行进一步的三维基因组学研究。
3
癌症中三维基因组的异常结构
癌症是一类由不受控制的细胞生长和扩散引起的恶性疾病31,它们以基因组中的各种突变,如点突变、小的插入或缺失、染色质重排(Chromosome Rearrangement,CR)和拷贝数变异等为特征。近年来,几项针对癌症基因组的系统研究已经完成31。癌症基因组图谱(TCGA)32描述了许多种癌症中点突变和结构变异的图谱(landscape)33。一些基因能在不同的癌症类型中普遍地发生突变,比如TP53,KRAS和PIK3CA。这些基因与细胞增殖的主要通路有关,包括MAPK信号通路,PI(3)K信号通路等。许多研究也表明,表观遗传学在癌症中同样发生了改变34。尽管在近几十年中我们已经了解了很多关于基因组序列在许多癌症中是如何突变的的信息,但是我们对三维基因组如何参与癌症的发生和发展还是知之甚少。
最近,研究人员已经实现了针对乳腺癌、前列腺癌、神经胶质瘤和多发性骨髓瘤的癌症三维基因组研究35-40。他们发现在癌细胞中,不同结构尺度的三维基因组均会发生改变。Barutcu等人使用Hi-C分析了正常乳腺上皮细胞(MCF-10A)和乳腺癌细胞(MCF-7)35,发现癌细胞的三维基因组与正常细胞不同。相比正常细胞,乳腺癌细胞中约12%的基因组区域发生了A / B 区块的转换。更进一步,从A区到B区的转换与基因表达的下调相关,相反方向的转换则与基因表达的上调相关。在乳腺癌细胞中,小而富含基因的染色体(如16号到22号染色体)之间的相互作用频率低于正常细胞。同时,染色体内相互作用也有不同:端粒和亚端粒区域在正常细胞中相互作用更频繁。此后,Taberlay等人的工作表明在前列腺癌中,三维基因组结构同样是紊乱的40。他们发现前列腺癌细胞比正常细胞具有更多的TADs和更小的TAD长度。他们还在具有拷贝数变异的区域里发现了许多癌症特异性的TAD边界。此外,染色质长程相互作用的变化与表观遗传修饰和基因表达的变化一致。Wu等人通过整合Hi-C,全基因组测序(WGS)和RNA-seq的数据来比较多发性骨髓瘤细胞和正常B细胞38,也报道了类似的发现。
虽然在乳腺癌和前列腺癌中的研究已经给三维基因组在癌症中发生改变的假说提供了证据,但是这些研究使用的是正常和癌细胞的细胞系,而且并不能证明癌症与三维基因组改变之间存在因果关系。最近的一些研究将3C和CRISPR/Cas9技术相结合,提供了三维基因组紊乱可能导致癌症形成的实验证据36,37。Hnisz等人将黏连蛋白ChIA-PET应用于T细胞急性淋巴细胞白血病(T-ALL)细胞,发现了绝缘区域(insulated neighborhood)37。他们发现基因组小片段的缺失突变会删除绝缘区域间的边界,从而使T-ALL原癌基因,比如TAL1和LMO2,表达失调(图3A)。作者进一步使用CRISPR/Cas9删除了这些原癌基因周围的能与CTCF结合的染色质环锚定域,实现了这些原癌基因表达的激活37。在另一项关于神经胶质瘤的研究中,研究人员证实了三维基因组的重构与绝缘子(CTCF)功能失常及癌症相关36。胶质瘤中最主要的一个亚类涉及IDH基因突变,而这会产生CpG岛甲基化的表型(G-CIMP)并导致CTCF结合位点的超甲基化。进一步,这又使得TAD边界处CTCF发生异常结合,于是PDGFRA(一个神经胶质瘤原癌基因)与其增强子之间形成连续的相互作用,最终激活PDGFRA表达。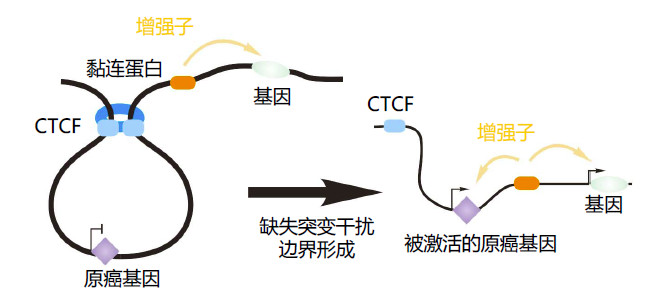
图3:癌症中染色质三维结构的破坏导致基因表达异常。(A)通过破坏绝缘区域激活原癌基因。
4
基因拷贝数变异影响癌症三维基因组
基因突变的积累导致癌症的发生,这些突变包括点突变、小片段插入缺失(indel)和重复、缺失等体细胞基因拷贝数的改变(SCNA)。SCNA在许多癌症中很常见41,在某些特定的癌症中,它们是驱动突变事件(driving mutation events)42。之前的研究通常认为拷贝数变异主要影响编码基因:如果基因发生重复,那么该基因可能成为致癌基因;如果发生缺失,它将起到抑癌基因的作用。然而通过分析多种癌症的SCNAs,发现只有不到四分之一的常见SCNA与已知的致癌基因重叠43。一些研究报道了一种称为增强子劫持(enhancer hijacking)的新机制44来解释SCNA引起癌症的原因。SCNA使得增强子等调控元件重新排列,原先与增强子没有互作的基因现在与增强子并列排布,因而产生了错误表达,最终导致癌症的发生。因此,SCNAs在癌症中可以通过两种方式影响基因的表达:一种是剂量效应,另一种是增强子劫持。结合SCNAs和转录组分析,我们可以很容易地确定癌症中的基因剂量效应45,46,然而确定增强子劫持事件则较为困难,这是因为目前对三维基因组结构和不同癌症中增强子的位置的认识还比较少。
识别增强子劫持需要结合基因组的变化和三维基因组的信息。Weischenfeld等人开发了一种称为CESAM(Cis Expression Structural Alteration Mapping)47的新方法。CESAM整合了基因组序列,表观遗传学和三维基因组的信息,并将它们与TADs重叠来预测SCNA断点的功能。TADs在所有细胞类型中基本保守,且TADs48中的基因表达存在一定程度的相关性。CTCF等绝缘蛋白与TADs边界结合,抑制不同TAD之间基因和调控元件的相互作用。然而,SCNA对TAD边界的破坏可能会改变TAD结构,并导致新TAD的形成49。因此,在改变的TAD内部及其附近的基因和调控元件之间的相互作用可能会改变。根据这一的假设,CESAM通过将SCNA断点映射到TADs来评估SCNA对局部基因组结构的影响(图3B)。为了鉴定可能的增强子劫持事件,CESAM建立了一个线性回归模型,将SCNA事件、TAD边界和基因表达相关联,以确定基因表达是否受到附近被SCNA改变的TAD的影响(图3C)。在这一工作中,作者分析了来自TCGA数据库的7416个癌症样品,并预测了癌症样品中由于SCNA诱导的TADs重组而发生表达上调的18个候选基因,包括IRS4和IGF2。这项工作是应用三维基因组信息来鉴定致癌突变机制的一个很好的例子。
图3:癌症中染色质三维结构的破坏导致基因表达异常。(B)缺失或重复破坏TAD边界,从而导致受影响的TAD内或附近基因的异常表达。图片展示了TCGA中肾上腺皮质癌样品的TERT位点和CNV。
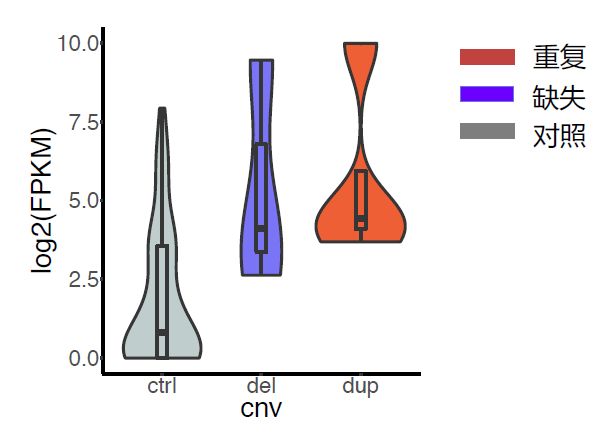
图3:癌症中染色质三维结构的破坏导致基因表达异常。(C)具有不同类型的CNV的样品和没有CNV的样品中的TERT表达水平。与没有CNV的样品(灰色,用于对照)相比,具有重复(红色)的样品和具有缺失(蓝色)的样品有更高的基因表达。
通过整合Hi-C,ChIA-PET,RNA-seq和CRISPR / Cas9等不同技术,可以从三维基因组的角度推断癌症中许多非编码基因突变和结构变异导致的后果。可以乐观地预计,在针对其他癌症类型和临床癌细胞样本的研究中,将可以鉴定出更多的癌细胞中扰乱三维基因组结构的功能性基因变化。
5
与三维基因组异常结构相关的非肿瘤疾病
除了癌症,三维基因组对其他疾病也有很大影响,如先天性肢体畸形(congenital limb malformations)50、自身免疫性疾病(autoimmune diseases)51、烹调综合征(cooks syndrome)和性反转(sex reversal)49等。在这些疾病中,基因组中存在胚系突变(germline mutations),如染色质重排(Chromosomal rearrangements,CR)和单核苷酸变异(SNV)。CR事件(包括删除,重复,插入,倒位,易位)是人类基因组中常见的结构变异,但其影响往往难以捉摸52。它们通常因破坏基因或蛋白质结构而导致疾病,但也可能通过改变染色质三维结构来影响基因表达40,50。最近的一项研究显示,CR可以通过改变三维染色质结构引起多指畸形50。图4展示了CR的致病模型。进一步,作者在小鼠模型中应用CRISPR / Cas9,证实了三维基因组的异常结构与发育性疾病的因果关系。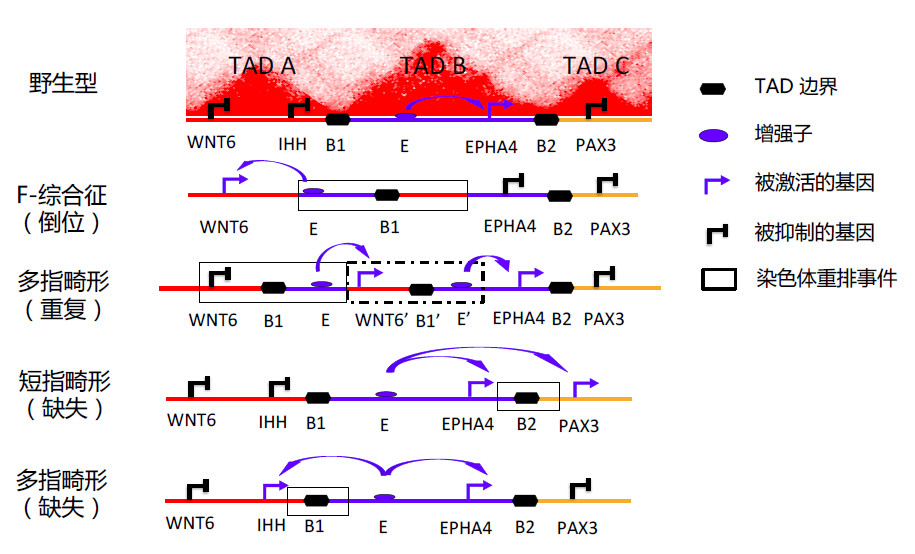
图4:破坏TADs的染色质重排(CR)事件的致病模型。关于短指畸形、多指畸形和F-综合征中WNT6,IHH,EPHA4和PAX3基因位点上CR事件的模型,重排破坏了含有肢体发育增强子的TAD的边界。野生型染色质构象中有三个TADs结构,由边界元件分隔。增强子(E)的增强活性仅限于位于TAD B内部的EPHA4基因。在具有染色质区域倒位的F-综合征中,E被移出TAD B并被置于TAD A中的基因WNT6附近,TAD边界现在位于E的右侧。这导致E和WNT6之间发生相互作用,而E和EPHA4之间的正常相互作用被TAD边界阻断了。在具有复制事件(虚线矩形所示)的多指畸形中,新建立的TAD中的WNT6拷贝位于E旁边,导致二者的相互作用和WNT6的异常表达。在具有缺失事件的短指畸形中,缺失删去了边界B2和TAD B和TAD C的间隔,因此EPHA4和PAX3都能够与E相互作用,导致PAX3的异常表达。以类似的方式,IHH的表达在边界B1缺失的多指畸形中异常。图片改编自Li等56和Lupianez等50的工作。
全基因组关联分析(GWASs)已成功用于鉴定与复杂疾病相关的遗传变异53。但是,这些基因组非编码区的变异影响疾病的机制大多还不明了。很多与疾病有关的SNPs位于染色质非编码区域,并与增强子重叠54,55。这一现象提示,应当鉴定那些与疾病相关GWAS变异的染色质区域存在物理相互作用的基因。Capture Hi-C在这方面起到很大的作用,因为它可以帮助我们低成本并有效地识别这些启动子-增强子的相互作用。例如,最近的一项研究使用这种方法,在四种自身免疫性疾病中鉴定了SNP与它们在B细胞和T细胞中潜在的功能性靶基因之间的相互作用51。Capture Hi-C证明,许多与疾病相关的SNPs常常与数百万碱基之外的基因相互作用,而并非附近的基因。一个具体的例子是,与类风湿性关节炎(RA)相关的SNP区域与位于640kb外的参与NF-κB途径的基因AZI2的启动子具有强相互作用。
为了整合并可视化疾病相关的CRs(Chromosomal rearrangements)与三维染色质结构之间的关系,Li等人开发了一个Web浏览器来查询与疾病相关的CRs和感兴趣的基因(3Disease Browser,http://3dgb.cbi.pku.edu.cn/disease/)**56**。 3Disease浏览器整合了Hi-C数据、注释信息(TADs, 基因等)、染色质三维模型和表观遗传信息。其他三维基因组浏览器也被开发用于整合和可视化多种数据类型(参见表3关于三维基因组浏览器的比较)。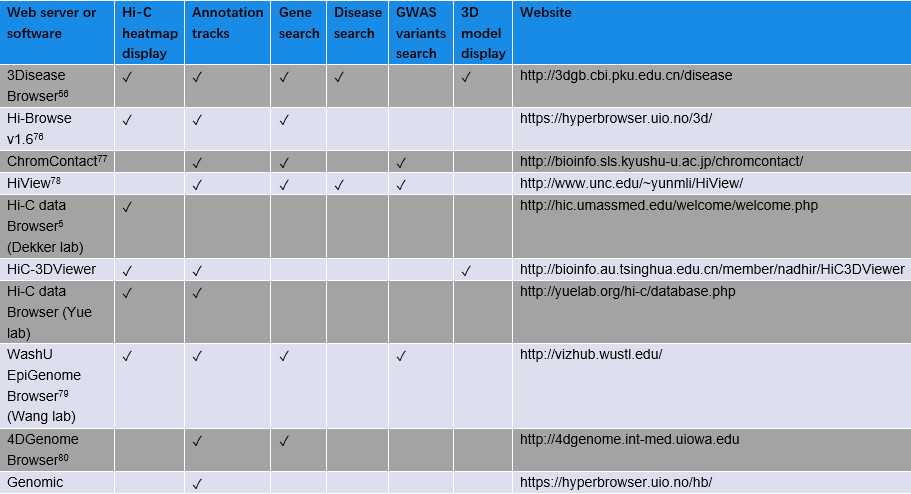

表3:三维基因组浏览器的比较 (改自 Li et al56)
6
三维基因组技术在临床多组学中的应用
现在有许多组学技术可以帮助我们更深入地了解疾病,比如RNA-seq和WGS。Hi-C等三维基因组技术由于能够检测疾病中的三维基因组结构变化并推断其对基因表达的影响,是其他组学技术很好的补充。我们以临床癌症研究为例说明三维基因组技术在临床多组学中的应用(图5)。从癌症患者获得配对的正常和癌症组织样品后,可以进行Hi-C和RNA-seq等组学实验。由于癌症等许多疾病与拷贝数变异(CNV)和易位等染色质结构变异相关,在临床研究中,我们通常使用WGS来检测这种结构变化,但我们和其他研究者都发现,Hi-C数据也可以用来检测并确认结构变异38,57。在最近的一项研究中发现57,与WGS测得的数据相比,Hi-C数据可以准确检测到大规模CNV(> 1 Mb)和易位事件。因此,Hi-C数据不仅可以为我们提供三维结构信息,还可以提供CNV和易位的信息。通过综合的多组学分析(图5),我们期望能确定正常样本和癌症样本之间的显著差异,结合不同组学水平上的变化,推断这些遗传改变产生的原因和功能后果。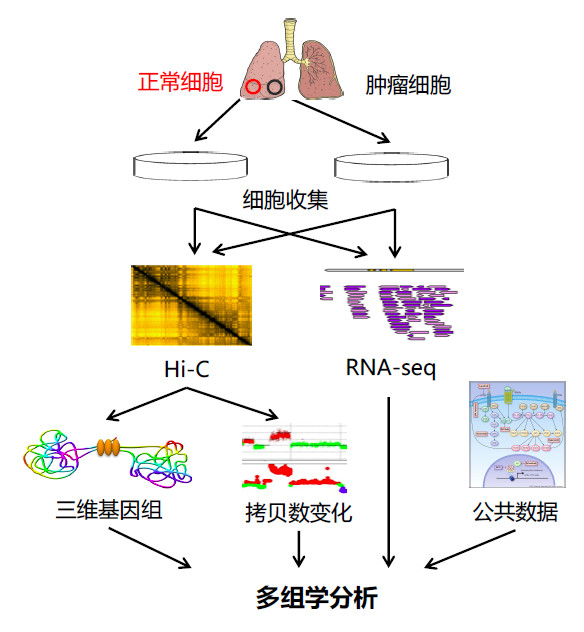
图5:3C技术应用于临床研究的流程示意图。首先从癌症患者中获得配对的正常和癌症组织样品用于多组学实验,随后利用Hi-C和RNA-seq等技术进行整合分析。
随着技术的进步,三维基因组方法有望应用于临床和治疗研究。Almassalha等人使用药物来改变染色质组装密度,防止了癌细胞的进一步恶化,并提高了抗癌治疗的效果58。这项研究表明,修改染色质和基因组的三维结构也可以达到治疗效果。当我们能更好地理解染色质结构和疾病之间的关系时,探索以三维基因组编辑来达到治疗目的的方法是令人激动并充满前途的59,60。
7
单细胞Hi-C技术及未来三维基因组技术的发展
在临床研究中应用三维基因组技术需要面临几个挑战。比如,为了实现原位的Hi-C需要数百万个细胞,然而,临床样本中所能提供的的细胞数要小得多。关于是否能够利用较少的临床样品细胞量来检测染色质相互作用的问题,目前并没有充分的研究。除此之外,还有一些与传统基因组研究中类似的挑战需要在处理临床样品时克服,例如肿瘤和正常细胞需要被足够干净地分离,以及不感兴趣的细胞类型需要被去除。
另一方面, Hi-C等三维基因组技术常常受到低分辨率和偏差(bias)的影响,这可能是由不均匀片段化、PCR扩增偏差、噪音连接(noisy ligation)等因素引起的61。 为了解决这些问题,研究人员们开发了一系列基于Hi-C技术的改进方法。 在桥式连接Hi-C(BL-Hi-C)中,生物素标记的20bp桥式连接物(bridge linker)在DNA被片段化后被加入到溶液中,通过两步连接反应来减少连接噪音62。 线性PCR方法可以用来减少PCR扩增的偏差63。通过提高Hi-C技术的分辨率并降低噪音背景,研究人员们将可以研究各种疾病过程中三维基因组结构的细微变化。
单细胞Hi-C(scHi-C)7-9是Hi-C技术发展的另一个重要方向。一方面,从胚胎发育或某些罕见疾病中能够获得的细胞数量非常有限。另一方面,癌细胞的三维基因组结构可能非常不均一。发展scHi-C技术不仅可以验证大量Hi-C(bulk Hi-C)的结果,还可以揭示癌症等疾病背后的分子异质性,从而帮助研究癌症等疾病。scHi-C所面临的技术挑战是,如何在实验操作中减少DNA损失,同时降低噪音背景。想要在这两个目标之间达到平衡很困难,因为在过滤噪音背景的同时也可能会失去真正的相互作用片段。考虑到实验工作流程中的每一步都可能导致DNA损失,减少损失的一个有效方法便是简化这些流程。最早的scHi-C技术是在2013年建立的7。在当时的方法中,Nagano等人首先用限制酶(Bgl II或Dpn II)切割DNA,然后用生物素在每个核中标记片段。在临近片段被连接后,每一个细胞核都被人工挑选出来,再通过富集生物素来捕获片段。片段经过Alu I切割后使用接头连接PCR(adapter ligation PCR)进行扩增,最后测序7。2017年,Nagano等人又将人工分选细胞核改为流式细胞术分选,并使用Tn5转座酶建立标签,取代了原方法最后的Alu I酶切,末端修复和接头连接等步骤8。这些进展进一步简化了scHi-C的实验工作流程,大大提高了测得序列的DNA reads数【表4】。Flyamer等人开发了另一种scHi-C技术64。他们没有用生物素标记DNA片段,而是在DNA连接和解除交联(reverse cross-linking)后扩增全基因组64,之后使用计算的方法过滤得到有效reads。表4总结了各种scHi-C方案。总体而言,用现有的scHi-C技术获得的有效reads数尚不足以绘制可靠的单个细胞的染色质相互作用图谱。我们期待未来更完善的scHi-C技术能提供足够数量的相互作用reads和更小的噪音。
表4:单细胞Hi-C技术概览
尽管Hi-C可以揭示全基因组染色质的相互作用,但图谱的分辨率取决于测序的深度,一份全基因组、高分辨率的相互作用图谱的测序成本可能是巨大的。对于一些疾病,例如前文涉及的多指畸形,来自包含潜在致病基因的局部染色质区域的互作图谱就能提供足够的信息。在这种情况下,靶向染色质捕获(Targeted Chromosome Capture,T2C)10和Capture-C技术11可以取代Hi-C。这两种技术能够捕获染色质特定区域上的相互作用,并且使研究人员能够以可接受的成本获得具有足够分辨率的互作图谱。
受限于二代测序的特点,高度重复的基因组区域不能准确地比对在参考基因组上,但这些高度重复的区域可能具有重要的功能。比如,端粒就在癌症和衰老中发挥重要作用65。目前我们对高重复区的基因组空间结构几乎没有了解。随着第三代测序技术的不断发展,重复区域将可以准确测序66。结合第三代测序与染色质捕获技术的技术很可能即将被开发出来,以更好地揭示高度重复区域的染色质构象结构。
总之,三维基因组技术极大地促进了对发育相关疾病和复杂疾病的研究。诸如癌症等复杂疾病是由基因与其调控元件之间复杂相互作用的改变而引起的67,68。 研究染色质构象在疾病中的变化可以帮助理解这些相互作用,并为开发新的生物标记、设计靶向治疗位点提供线索。在不远的将来,单细胞、高通量、多组学的三维基因组分析方法将会实现,我们将能够获得更深入的信息来了解在正常和患病条件下基因组的基态和动态结构。
参考文献:
1 Job Dekker, Karsten Rippe, Martijn Dekker & Kleckner, N. Capturing Chromosome Conformation. Science, doi:DOI:10.1126/science.1067799 (2002).
2 Simonis, M. et al. Nuclear organization of active and inactive chromatin domains uncovered by chromosome conformation capture-on-chip (4C). Nat Genet 38, 1348-1354, doi:10.1038/ng1896 (2006).
3 Van de Werken, H. J. et al. Robust 4C-seq data analysis to screen for regulatory DNA interactions. Nat Methods 9, 969-972, doi:10.1038/nmeth.2173 (2012).
4 Dostie, J. et al. Chromosome Conformation Capture Carbon Copy (5C): a massively parallel solution for mapping interactions between genomic elements. Genome research 16, 1299-1309, doi:10.1101/gr.5571506 (2006).
5 Lieberman-Aiden, E. et al. Comprehensive mapping of long-range interactions reveals folding principles of the human genome. Science 326, 289-293, doi:10.1126/science.1181369 (2009).
6 Rao, S. S. et al. A 3D map of the human genome at kilobase resolution reveals principles of chromatin looping. Cell 159, 1665-1680, doi:10.1016/j.cell.2014.11.021 (2014).
7 Nagano, T. et al. Single-cell Hi-C reveals cell-to-cell variability in chromosome structure. Nature 502, 59-64, doi:10.1038/nature12593 (2013).
8 Nagano, T. et al. Cell-cycle dynamics of chromosomal organization at single-cell resolution. Nature 547, 61-67, doi:10.1038/nature23001 (2017).
9 Ramani, V. et al. Massively multiplex single-cell Hi-C. Nature methods, doi:10.1038/nmeth.4155 (2017).
10 Kolovos, P. et al. Targeted Chromatin Capture (T2C): a novel high resolution high throughput method to detect genomic interactions and regulatory elements. Epigenetics & chromatin7, 10, doi:10.1186/1756-8935-7-10 (2014).
11 Hughes, J. R. et al. Analysis of hundreds of cis-regulatory landscapes at high resolution in a single, high-throughput experiment. Nat Genet 46, 205-212, doi:10.1038/ng.2871 (2014).
12 Borbala Mifsud, Filipe Tavares-Cadete & Young, A. N. Mapping long-range promoter contacts in human cells with high-resolution capture Hi-C. Nat Genet, doi:0.1038/ng.3286 (2015).
13 Fullwood, M. J. et al. An oestrogen-receptor-alpha-bound human chromatin interactome. Nature 462, 58-64, doi:10.1038/nature08497 (2009).
14 Fang, R. et al. Mapping of long-range chromatin interactions by proximity ligation-assisted ChIP-seq. Cell research 26, 1345-1348, doi:10.1038/cr.2016.137 (2016).
15 Mumbach, M. R. et al. HiChIP: efficient and sensitive analysis of protein-directed genome architecture. Nat Methods, doi:10.1038/nmeth.3999 (2016).
16 Song, L. & Crawford, G. E. DNase-seq: a high-resolution technique for mapping active gene regulatory elements across the genome from mammalian cells. Cold Spring Harbor protocols, pdb prot5384, doi:10.1101/pdb.prot5384 (2010).
17 Mieczkowski, J. et al. MNase titration reveals differences between nucleosome occupancy and chromatin accessibility. Nature communications 7, 11485, doi:10.1038/ncomms11485 (2016).
18 Buenrostro, J. D., Giresi, P. G., Zaba, L. C., Chang, H. Y. & Greenleaf, W. J. Transposition of native chromatin for fast and sensitive epigenomic profiling of open chromatin, DNA-binding proteins and nucleosome position. Nat Methods 10, 1213-1218, doi:10.1038/nmeth.2688 (2013).
19 Chen, X. et al. ATAC-see reveals the accessible genome by transposase-mediated imaging and sequencing. Nature methods 13, 1013-1020, doi:10.1038/nmeth.4031 (2016).
20 Ma, W. et al. Fine-scale chromatin interaction maps reveal the cis-regulatory landscape of human lincRNA genes. Nat Methods 12, 71-78, doi:10.1038/nmeth.3205 (2015).
21 Hsieh, T. H. et al. Mapping Nucleosome Resolution Chromosome Folding in Yeast by Micro-C. Cell 162, 108-119, doi:10.1016/j.cell.2015.05.048 (2015).
22 Gibcus, J. H. & Dekker, J. The hierarchy of the 3D genome. Molecular cell 49, 773-782, doi:10.1016/j.molcel.2013.02.011 (2013).
23 Bonev, B. & Cavalli, G. Organization and function of the 3D genome. Nat Rev Genet 17, 661-678, doi:10.1038/nrg.2016.112 (2016).
24 Dixon, J. R. et al. Topological domains in mammalian genomes identified by analysis of chromatin interactions. Nature 485, 376-380, doi:10.1038/nature11082 (2012).
25 Crane, E. et al. Condensin-driven remodelling of X chromosome topology during dosage compensation. Nature 523, 240-244, doi:10.1038/nature14450 (2015).
26 Nora, E. P. et al. Spatial partitioning of the regulatory landscape of the X-inactivation centre. Nature 485, 381-385, doi:10.1038/nature11049 (2012).
27 Naumova, N. & Dekker, J. Integrating one-dimensional and three-dimensional maps of genomes. J Cell Sci 123, 1979-1988, doi:10.1242/jcs.051631 (2010).
28 Ji, X. et al. 3D Chromosome Regulatory Landscape of Human Pluripotent Cells. Cell stem cell 18, 262-275, doi:10.1016/j.stem.2015.11.007 (2016).
29 Tang, Z. et al. CTCF-Mediated Human 3D Genome Architecture Reveals Chromatin Topology for Transcription. Cell 163, 1611-1627, doi:10.1016/j.cell.2015.11.024 (2015).
30 Rudan, M. et al. Comparative Hi-C Reveals that CTCF Underlies Evolution of Chromosomal Domain Architecture. Cell reports 10, 1297-1309, doi:10.1016/j.celrep.2015.02.004 (2015).
31 Garraway, L. A. & Lander, E. S. Lessons from the cancer genome. Cell 153, 17-37, doi:10.1016/j.cell.2013.03.002 (2013).
32 Tomczak, K., Czerwinska, P. & Wiznerowicz, M. The Cancer Genome Atlas (TCGA): an immeasurable source of knowledge. Contemp Oncol (Pozn) 19, A68-77, doi:10.5114/wo.2014.47136 (2015).
33 Kandoth, C. et al. Mutational landscape and significance across 12 major cancer types. Nature 502, 333-339, doi:10.1038/nature12634 (2013).
34 Kanwal, R., Gupta, K. & Gupta, S. Cancer epigenetics: an introduction. Methods in molecular biology 1238, 3-25, doi:10.1007/978-1-4939-1804-11 (2015).
35 Barutcu, A. R. et al. Chromatin interaction analysis reveals changes in small chromosome and telomere clustering between epithelial and breast cancer cells. _Genome biology 16, 214, doi:10.1186/s13059-015-0768-0 (2015).
36 Flavahan, W. A. et al. Insulator dysfunction and oncogene activation in IDH mutant gliomas. Nature 529, 110-114, doi:10.1038/nature16490 (2016).
37 Hnisz, D. et al. Activation of proto-oncogenes by disruption of chromosome neighborhoods. Science 351, 1454-1458, doi:10.1126/science.aad9024 (2016).
38 Wu, P. et al. 3D genome of multiple myeloma reveals spatial genome disorganization associated with copy number variations. Nat Commun 8, 1937, doi:10.1038/s41467-017-01793-w (2017).
39 Seaman, L. et al. Nucleome Analysis Reveals Structure-Function Relationships for Colon Cancer. Molecular cancer research 15, 821-830, doi:10.1158/1541-7786.MCR-16-0374 (2017).
40 Taberlay, P. C. et al. Three-dimensional disorganisation of the cancer genome occurs coincident with long range genetic and epigenetic alterations. Genome research, doi:10.1101/gr.201517.115 (2016).
41 Beroukhim, R. et al. The landscape of somatic copy-number alteration across human cancers. Nature 463, 899-905, doi:10.1038/nature08822 (2010).
42 Ciriello, G. et al. Emerging landscape of oncogenic signatures across human cancers. Nature genetics45, 1127-1133, doi:10.1038/ng.2762 (2013).
43 Zack, T. I. et al. Pan-cancer patterns of somatic copy number alteration. Nature genetics45, 1134-1140, doi:10.1038/ng.2760 (2013).
44 Northcott, P. A. et al. Enhancer hijacking activates GFI1 family oncogenes in medulloblastoma. Nature 511, 428-434, doi:10.1038/nature13379 (2014).
45 Huang, N., Shah, P. K. & Li, C. Lessons from a decade of integrating cancer copy number alterations with gene expression profiles. Briefings in bioinformatics13, 305-316, doi:10.1093/bib/bbr056 (2012).
46 Samur, M. K. et al. The shaping and functional consequences of the dosage effect landscape in multiple myeloma. BMC genomics14, 672, doi:10.1186/1471-2164-14-672 (2013).
47 Weischenfeldt, J. et al. Pan-cancer analysis of somatic copy-number alterations implicates IRS4 and IGF2 in enhancer hijacking. Nature genetics49, 65-74, doi:10.1038/ng.3722 (2017).
48 Ali, T., Renkawitz, R. & Bartkuhn, M. Insulators and domains of gene expression. Current opinion in genetics & development 37, 17-26, doi:10.1016/j.gde.2015.11.009 (2016).
49 Franke, M. et al. Formation of new chromatin domains determines pathogenicity of genomic duplications. Nature 538, 265-269, doi:10.1038/nature19800 (2016).
50 Lupianez, D. G. et al. Disruptions of topological chromatin domains cause pathogenic rewiring of gene-enhancer interactions. Cell 161, 1012-1025, doi:10.1016/j.cell.2015.04.004 (2015).
51 Martin, P. et al. Capture Hi-C reveals novel candidate genes and complex long-range interactions with related autoimmune risk loci. Nature communications 6, 10069, doi:10.1038/ncomms10069 (2015).
52 Shrivastav, M., De Haro, L. P. & Nickoloff, J. A. Regulation of DNA double-strand break repair pathway choice. Cell research 18, 134-147, doi:10.1038/cr.2007.111 (2008).
53 Li, Z. et al. Genome-wide association analysis identifies 30 new susceptibility loci for schizophrenia. Nature genetics49, 1576-1583, doi:10.1038/ng.3973 (2017).
54 Fairfax, B. P. et al. Innate immune activity conditions the effect of regulatory variants upon monocyte gene expression. Science 343, 1246949, doi:10.1126/science.1246949 (2014).
55 Farh, K. K. et al. Genetic and epigenetic fine mapping of causal autoimmune disease variants. Nature 518, 337-343, doi:10.1038/nature13835 (2015).
56 Li, R., Liu, Y., Li, T. & Li, C. 3Disease Browser: A Web server for integrating 3D genome and disease-associated chromosome rearrangement data. Scientific reports 6, 34651, doi:10.1038/srep34651 (2016).
57 Chakraborty, A. & Ay, F. Identification of copy number variations and translocations in cancer cells from Hi-C data. Bioinformatics, doi:10.1093/bioinformatics/btx664 (2017).
58 Almassalha, L. M. et al. Macrogenomic engineering via modulation of the scaling of chromatin packing density. Nat Biomed Eng 1, 902-913, doi:10.1038/s41551-017-0153-2 (2017).
59 Sachdeva, M. et al. CRISPR/Cas9: molecular tool for gene therapy to target genome and epigenome in the treatment of lung cancer. Cancer Gene Ther 22, 509-517, doi:10.1038/cgt.2015.54 (2015).
60 Huang, H. & Wu, Q. CRISPR Double Cutting through the Labyrinthine Architecture of 3D Genomes. Journal of genetics and genomics 43, 273-288, doi:10.1016/j.jgg.2016.03.006 (2016).
61 Yaffe, E. & Tanay, A. Probabilistic modeling of Hi-C contact maps eliminates systematic biases to characterize global chromosomal architecture. Nature genetics43, 1059-1065, doi:10.1038/ng.947 (2011).
62 Liang, Z. et al. BL-Hi-C is an efficient and sensitive approach for capturing structural and regulatory chromatin interactions. Nature communications 8, 1622, doi:10.1038/s41467-017-01754-3 (2017).
63 Chen, C. et al. Single-cell whole-genome analyses by Linear Amplification via Transposon Insertion (LIANTI). Science 356, 189-194, doi:10.1126/science.aak9787 (2017).
64 Flyamer, I. M. et al. Single-nucleus Hi-C reveals unique chromatin reorganization at oocyte-to-zygote transition. Nature 544, 110-114, doi:10.1038/nature21711 (2017).
65 Gilley, D., Tanaka, H. & Herbert, B. S. Telomere dysfunction in aging and cancer. The international journal of biochemistry & cell biology 37, 1000-1013, doi:10.1016/j.biocel.2004.09.003 (2005).
66 Chin, C. S. et al. Nonhybrid, finished microbial genome assemblies from long-read SMRT sequencing data. Nature methods 10, 563-569, doi:10.1038/nmeth.2474 (2013).
67 Bailey, J. N., Pericak-Vance, M. A. & Haines, J. L. The impact of the human genome project on complex disease. Genes 5, 518-535, doi:10.3390/genes5030518 (2014).
68 Forbes, S. A. et al. COSMIC: exploring the world’s knowledge of somatic mutations in human cancer. Nucleic acids research 43, D805-811, doi:10.1093/nar/gku1075 (2015).
69 Stevens, T. J. et al. 3D structures of individual mammalian genomes studied by single-cell Hi-C. Nature 544, 59-64, doi:10.1038/nature21429 (2017).
70 Serra, F. et al. Automatic analysis and 3D-modelling of Hi-C data using TADbit reveals structural features of the fly chromatin colors. PLoS computational biology 13, e1005665, doi:10.1371/journal.pcbi.1005665 (2017).
71 Durand, N. C. et al. Juicebox Provides a Visualization System for Hi-C Contact Maps with Unlimited Zoom. Cell Syst 3, 99-101, doi:10.1016/j.cels.2015.07.012 (2016).
72 Wingett, S. et al. HiCUP: pipeline for mapping and processing Hi-C data. F1000Research 4, 1310, doi:10.12688/f1000research.7334.1 (2015).
73 Servant, N. et al. HiC-Pro: an optimized and flexible pipeline for Hi-C data processing. Genome biology 16, 259, doi:10.1186/s13059-015-0831-x (2015).
74 Li, W., Gong, K., Li, Q., Alber, F. & Zhou, X. J. Hi-Corrector: a fast, scalable and memory-efficient package for normalizing large-scale Hi-C data. Bioinformatics 31, 960-962, doi:10.1093/bioinformatics/btu747 (2015).
75 Hu, M. et al. HiCNorm: removing biases in Hi-C data via Poisson regression. Bioinformatics 28, 3131-3133, doi:10.1093/bioinformatics/bts570 (2012).
76 Paulsen, J. et al. HiBrowse: multi-purpose statistical analysis of genome-wide chromatin 3D organization. Bioinformatics 30, 1620-1622, doi:10.1093/bioinformatics/btu082 (2014).
77 Sato, T. & Suyama, M. ChromContact: A web tool for analyzing spatial contact of chromosomes from Hi-C data. BMC genomics16, 1060, doi:10.1186/s12864-015-2282-x (2015).
78 Xu, Z. et al. HiView: an integrative genome browser to leverage Hi-C results for the interpretation of GWAS variants. BMC research notes 9, 159, doi:10.1186/s13104-016-1947-0 (2016).
79 Zhou, X. et al. Exploring long-range genome interactions using the WashU Epigenome Browser. Nature methods 10, 375-376, doi:10.1038/nmeth.2440 (2013).
80 Teng, L., He, B., Wang, J. & Tan, K. 4DGenome: a comprehensive database of chromatin interactions. Bioinformatics 31, 2560-2564, doi:10.1093/bioinformatics/btv158 (2015).
81 Sandve, G. K. et al. The Genomic HyperBrowser: inferential genomics at the sequence level. Genome biology 11, R121, doi:10.1186/gb-2010-11-12-r121 (2010).
82 Nowotny, J. et al. GMOL: An Interactive Tool for 3D Genome Structure Visualization. Scientific reports 6, 20802, doi:10.1038/srep20802 (2016).
83 Lewis, T. E. et al. Genome3D: exploiting structure to help users understand their sequences. Nucleic acids research 43, D382-386, doi:10.1093/nar/gku973 (2015).
84 Nagano, T. et al. Single-cell Hi-C for genome-wide detection of chromatin interactions that occur simultaneously in a single cell. Nature protocols 10, 1986-2003, doi:10.1038/nprot.2015.127 (2015).
原文链接:
https://link.springer.com/article/10.1007/s10565-018-9430-4?from=timeline&isappinstalled=0

若有收获,就点个赞吧
0 人点赞
